4. Results
The State of California is located on the west coast of the US that stretches northward from the US–Mexico border along the Pacific Ocean for roughly 1450 km. As shown in
Table 1, it encompasses a total land area of 402,887 km
2 and comprises 58 counties. With a steady population growth from about 33.9 million people to about 39.3 million people during the first two decades of the twenty-first century (i.e., a 1.16-fold increase), the number of census tracts also increased from 7049 in 2000 to 8037 in 2010 (i.e., a 0.88-fold increase). Within the State of California,
Table 1 shows that its seven most populous MSAs also experienced a steady population growth (which ranges from a 1.07-fold increase in the Los Angeles–Long Beach–Anaheim MSA to a 1.40-fold increase in the Riverside–San Bernardino–Ontario MSA) and their number of census tracts also increased in a corresponding manner (which ranges from a 0.71-fold increase in the Riverside–San Bernardino–Ontario MSA to a 0.96-fold increase in the San Diego–Chula Vista–Carlsbad MSA). All in all, approximately 79.2 percent of Californias lived in these seven MSAs: about 34.9 percent in Los Angeles–Long Beach–Anaheim MSA, about 11.9 percent in San Francisco–Oakland–Berkeley MSA, about 10.9 percent in Riverside–San Bernardino–Ontario MSA, about 8.3 percent in San Diego–Chula Vista–Carlsbad MSA, about 5.7 percent in Sacramento–Roseville–Folsom MSA, about 5.0 percent in San Jose–Sunnyvale–Santa Clara MSA, and about 2.5 percent in Fresno MSA.
Table 1.
Descriptions of the study areas.
Table 1.
Descriptions of the study areas.
| | Total Land Area (km2) a | Census Tracts (#) | Counties(#) |
| | 2000 | 2010 |
| State of California | 402,887 | 7049 | 8037 | 58 |
| Los Angeles–Long Beach–Anaheim MSA | 12,572 | 2631 | 2924 | 2 |
| San Francisco–Oakland–Berkeley MSA | 6396 | 871 | 976 | 5 |
| Riverside–San Bernardino–Ontario MSA | 70,476 | 587 | 822 | 2 |
| San Diego–Chula Vista–Carlsbad MSA | 10,897 | 605 | 627 | 1 |
| Sacramento–Roseville–Folsom MSA | 13,191 | 403 | 484 | 4 |
| San Jose–Sunnyvale–Santa Clara MSA | 6930 | 349 | 383 | 2 |
| Fresno MSA | 15,447 | 158 | 199 | 1 |
| | Total Population (#) b |
| | 2000 | 2005–2009 | 2010–2014 | 2015–2019 |
| State of California | 33,871,648 | 36,308,527 | 38,061,951 | 39,278,430 |
| Los Angeles–Long Beach–Anaheim MSA | 12,365,627 | 12,762,126 | 13,055,565 | 13,244,547 |
| San Francisco–Oakland–Berkeley MSA | 4,123,740 | 4,218,534 | 4,466,251 | 4,701,332 |
| Riverside–San Bernardino–Ontario MSA | 3,254,821 | 4,022,939 | 4,345,485 | 4,560,470 |
| San Diego–Chula Vista–Carlsbad MSA | 2,813,833 | 2,987,543 | 3,183,143 | 3,316,073 |
| Sacramento–Roseville–Folsom MSA | 1,796,857 | 2,076,579 | 2,197,422 | 2,315,980 |
| San Jose–Sunnyvale–Santa Clara MSA | 1,735,819 | 1,784,130 | 1,898,457 | 1,987,846 |
| Fresno MSA | 799,407 | 890,750 | 948,844 | 984,521 |
The overall percentages of socioeconomic groups shown in
Table 2a correspond to a representative description of Californians during the first two decades of the twenty-first century. Among the five mutually exclusive socioeconomic groups considered in this study, the overall percentages of populations who held a bachelor’s degree or higher increased by 7.31% (i.e., an increase from 26.62% to 33.93%) and those who had no high school diploma decreased by 6.51% (i.e., a decrease from 23.21% to 16.69%). In a similar manner, the overall percentages of populations who earned an annual household income of greater than or equal to USD 100,000 increased by 20.45% (i.e., an increase from 17.26% to 37.72%) and those who earned an annual household income of less than USD 25,000 decreased by 9.09% (i.e., a decrease from 25.49% to 16.40%). Otherwise, the overall percentages of other socioeconomic groups slightly increased or decreased during the four time periods, but their temporal changes were negligible.
Below the socioeconomic makeup of Californians at four different time periods (
Table 2a),
Table 2b shows the component loadings of five spatial high-SES indicators and their respective low-SES counterparts. Among them, composite proportions of residents who held a bachelor’s degree or higher (≥BD) and those who earned an annual household income of greater than or equal to USD 100,000 (≥
$100K) were two spatial high-SES indicators that strongly and positively contributed to the spatial composite measures of HIGH-SES (i.e., the first principal component). On the other hand, composite proportions of residents who had no high school diploma (NoHSD) and those who earned an annual household income of less than USD 25,000 (<
$25K) were two spatial low-SES indicators that strongly and positively contributed to the spatial composite measures of LOW-SES (i.e., the first principal component). While the values of component loadings during the four time periods fluctuated to a certain degree, their degrees of fluctuations were negligible.
Table 2.
Overall percentages of high and low socioeconomic groups and component loadings of spatial high- and low-SES indicators in the State of California.
Table 2.
Overall percentages of high and low socioeconomic groups and component loadings of spatial high- and low-SES indicators in the State of California.
| | | Overall Percentages |
| a | | 2000 | 2005–2009 | 2010–2014 | 2015–2019 |
| High Socioeconomic Groups | | | | |
| | Above Poverty | 85.78% | 86.79% | 83.62% | 86.64% |
| | Employed | 92.99% | 92.14% | 89.01% | 93.94% |
| | Bachelor’s Degree or Higher | 26.62% | 29.74% | 31.00% | 33.93% |
| | No Public Assistance Income | 95.11% | 96.75% | 96.01% | 96.77% |
| | Household Income ≥ USD 100,000 | 17.26% | 27.41% | 29.41% | 37.72% |
| Low Socioeconomic Groups | | | | |
| | Below Poverty | 14.22% | 13.21% | 16.38% | 13.36% |
| | Unemployed | 7.01% | 7.86% | 10.99% | 6.06% |
| | No High School Diploma | 23.21% | 19.54% | 18.51% | 16.69% |
| | With Public Assistance Income | 4.89% | 3.25% | 3.99% | 3.23% |
| | Household Income < USD 25,000 | 25.49% | 19.94% | 20.45% | 16.40% |
| | | Component Loadings |
| b | | 2000 | 2005–2009 | 2010–2014 | 2015–2019 |
| Spatial High-SES Indicators | | | | |
| | Above Poverty (AP) | 0.33227 | 0.27138 | 0.31181 | 0.23316 |
| | Employed (EMP) | 0.14588 | 0.08975 | 0.12012 | 0.06990 |
| | Bachelor’s Degree or Higher (≥BD) | 0.74843 | 0.74009 | 0.72347 | 0.74147 |
| | No Public Assistance Income (NoPAI) | 0.15417 | 0.09063 | 0.09899 | 0.07344 |
| | Household Income ≥ USD 100,000 (≥$100K) | 0.53329 | 0.60196 | 0.59593 | 0.62095 |
| Spatial Low-SES Indicators | | | | |
| | Below Poverty (BP) | 0.40014 | 0.41652 | 0.48369 | 0.44621 |
| | Unemployed (UNE) | 0.15693 | 0.11056 | 0.14363 | 0.11129 |
| | No High School Diploma (NoHSD) | 0.71325 | 0.75329 | 0.70724 | 0.76245 |
| | With Public Assistance Income (WithPAI) | 0.16989 | 0.12364 | 0.14063 | 0.12426 |
| | Household Income < USD 25,000 (<$25K) | 0.52694 | 0.48120 | 0.47481 | 0.43789 |
Partly reflecting the differences of population sizes (
Table 1), the overall percentages of socioeconomic groups in seven MSAs (
Table 3a,
Table 4a,
Table 5a,
Table 6a,
Table 7a,
Table 8a and
Table 9a) were somewhat different from those in the State of California (
Table 2a) during the first two decades of the twenty-first century. In addition, the socioeconomic makeup of seven MSAs were also slightly different from one another (
Table 3a,
Table 4a,
Table 5a,
Table 6a,
Table 7a,
Table 8a and
Table 9a). In accord with the temporal changes seen in the entire state of California (
Table 2a), however, similar trends were also evident across seven MSAs (
Table 3a,
Table 4a,
Table 5a,
Table 6a,
Table 7a,
Table 8a and
Table 9a): the overall percentages of populations who held a bachelor’s degree or higher, on average, increased by 7.50% (ranging between 3.63% and 11.64%) and those who had no high school diploma, on average, decreased by 5.96% (ranging between 4.75% and 8.49%); and the overall percentages of populations who earned an annual household income of greater than or equal to USD 100,000, on average, increased by 20.98% (ranging between 15.42% and 26.32%), and those who earned an annual household income of less than USD 25,000, on average, decreased by 8.19% (ranging between 3.77% and 12.11%). Otherwise, the overall percentages of other socioeconomic groups slightly increased or decreased during the four time periods, but their temporal changes were negligible in these seven MSAs.
Table 3.
Overall percentages of high and low socioeconomic groups and component loadings of spatial high- and low-SES indicators in the Los Angeles–Long Beach–Anaheim Metropolitan Statistical Area (MSA).
Table 3.
Overall percentages of high and low socioeconomic groups and component loadings of spatial high- and low-SES indicators in the Los Angeles–Long Beach–Anaheim Metropolitan Statistical Area (MSA).
| | | Overall Percentages |
| a | | 2000 | 2005–2009 | 2010–2014 | 2015–2019 |
| High Socioeconomic Groups | | | | |
| | Above Poverty | 83.84% | 85.92% | 82.92% | 86.06% |
| | Employed | 92.56% | 92.64% | 89.50% | 94.27% |
| | Bachelor’s Degree or Higher | 26.26% | 30.00% | 31.67% | 34.47% |
| | No Public Assistance Income | 94.48% | 96.79% | 96.15% | 96.96% |
| | Household Income ≥ USD 100,000 | 17.03% | 26.89% | 28.92% | 36.52% |
| Low Socioeconomic Groups | | | | |
| | Below Poverty | 16.16% | 14.08% | 17.08% | 13.94% |
| | Unemployed | 7.44% | 7.36% | 10.50% | 5.73% |
| | No High School Diploma | 27.84% | 22.73% | 21.47% | 19.35% |
| | With Public Assistance Income | 5.52% | 3.21% | 3.85% | 3.04% |
| | Household Income < USD 25,000 | 26.89% | 20.76% | 21.16% | 17.26% |
| | | Component Loadings |
| b | | 2000 | 2005–2009 | 2010–2014 | 2015–2019 |
| Spatial High-SES Indicators | | | | |
| | Above Poverty (AP) | 0.38517 | 0.30351 | 0.33079 | 0.24166 |
| | Employed (EMP) | 0.13618 | 0.07071 | 0.09129 | 0.04360 |
| | Bachelor’s Degree or Higher (≥BD) | 0.72895 | 0.72732 | 0.72756 | 0.76130 |
| | No Public Assistance Income (NoPAI) | 0.17881 | 0.09349 | 0.10087 | 0.07655 |
| | Household Income ≥ USD 100,000 (≥$100K) | 0.51938 | 0.60428 | 0.58542 | 0.59520 |
| Spatial Low-SES Indicators | | | | |
| | Below Poverty (BP) | 0.38275 | 0.40067 | 0.44959 | 0.39812 |
| | Unemployed (UNE) | 0.12716 | 0.07741 | 0.10289 | 0.06587 |
| | No High School Diploma (NoHSD) | 0.75233 | 0.78089 | 0.75714 | 0.82523 |
| | With Public Assistance Income (WithPAI) | 0.16521 | 0.11149 | 0.12467 | 0.11249 |
| | Household Income < USD 25,000 (<$25K) | 0.49400 | 0.45962 | 0.44551 | 0.37883 |
Closely resembling the component loadings of five spatial high-SES indicators and their respective low-SES counterparts in the State of California (
Table 2b), the same two spatial high-SES indicators strongly and positively contributed to the spatial composite measures of HIGH-SES and the same two low-SES indicators strongly and positively contributed to the spatial composite measures of LOW-SES in seven MSAs (
Table 3b,
Table 4b,
Table 5b,
Table 6b,
Table 7b,
Table 8b and
Table 9b), although their amount of contributions were larger or smaller depending on the MSAs. However, composite proportions of residents who were below poverty (BP) also strongly and positively contributed to the spatial composite measures of LOW-SES in the Sacramento–Roseville–Folsom MSA (
Table 7b). Moreover, composite proportions of residents who were above poverty (AP) strongly and positively contributed to the spatial composite measures of HIGH-SES as well as composite proportions of residents who were below poverty (BP) also strongly and positively contributed to the spatial composite measures of LOW-SES in the Fresno MSA (
Table 9b). While the values of component loadings at four different time periods fluctuated to a certain degree, their degrees of fluctuations were also negligible in these seven MSAs.
Table 4.
Overall percentages of high and low socioeconomic groups and component loadings of spatial high- and low-SES indicators in the San Francisco–Oakland–Berkeley Metropolitan Statistical Area (MSA).
Table 4.
Overall percentages of high and low socioeconomic groups and component loadings of spatial high- and low-SES indicators in the San Francisco–Oakland–Berkeley Metropolitan Statistical Area (MSA).
| | | Overall Percentages |
| a | | 2000 | 2005–2009 | 2010–2014 | 2015–2019 |
| High Socioeconomic Groups | | | | |
| | Above Poverty | 90.85% | 90.38% | 88.70% | 90.98% |
| | Employed | 95.38% | 93.09% | 91.28% | 95.50% |
| | Bachelor’s Degree or Higher | 38.80% | 43.21% | 44.95% | 49.68% |
| | No Public Assistance Income | 96.75% | 97.67% | 97.10% | 97.49% |
| | Household Income ≥ USD 100,000 | 26.22% | 37.03% | 40.82% | 52.53% |
| Low Socioeconomic Groups | | | | |
| | Below Poverty | 9.15% | 9.62% | 11.30% | 9.02% |
| | Unemployed | 4.62% | 6.91% | 8.72% | 4.50% |
| | No High School Diploma | 15.81% | 12.95% | 12.13% | 10.86% |
| | With Public Assistance Income | 3.25% | 2.33% | 2.90% | 2.51% |
| | Household Income < USD 25,000 | 18.85% | 16.61% | 16.37% | 12.38% |
| | | Component Loadings |
| b | | 2000 | 2005–2009 | 2010–2014 | 2015–2019 |
| Spatial High-SES Indicators | | | | |
| | Above Poverty (AP) | 0.20294 | 0.19386 | 0.22787 | 0.16614 |
| | Employed (EMP) | 0.09892 | 0.09995 | 0.11009 | 0.04946 |
| | Bachelor’s Degree or Higher (≥BD) | 0.79338 | 0.77643 | 0.76419 | 0.79761 |
| | No Public Assistance Income (NoPAI) | 0.11607 | 0.07459 | 0.07849 | 0.06346 |
| | Household Income ≥ USD 100,000 (≥$100K) | 0.55326 | 0.58654 | 0.58806 | 0.57423 |
| Spatial Low-SES Indicators | | | | |
| | Below Poverty (BP) | 0.42001 | 0.44284 | 0.51196 | 0.49836 |
| | Unemployed (UNE) | 0.15855 | 0.16275 | 0.16641 | 0.10486 |
| | No High School Diploma (NoHSD) | 0.59300 | 0.58646 | 0.54605 | 0.64330 |
| | With Public Assistance Income (WithAPI) | 0.18552 | 0.12855 | 0.13931 | 0.11175 |
| | Household Income < USD 25,000 (<$25K) | 0.64218 | 0.64571 | 0.62660 | 0.56064 |
Despite noticeable differences in the overall proportions of socioeconomic groups (
Table 2a,
Table 3a,
Table 4a,
Table 5a,
Table 6a,
Table 7a,
Table 8a and
Table 9a) and the component loadings of five spatial high-SES indicators and their respective low-SES counterparts (
Table 2b,
Table 3b,
Table 4b,
Table 5b,
Table 6b,
Table 7b,
Table 8b and
Table 9b) across the study areas, the forms and strengths of relationships between sixteen spatial measures in the State of California (
Figure 1 and
Figures S1–S3) were very similar to those in the six largest MSAs (
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6 and
Figure 7,
Figures S4–S21), except in the Fresno MSA (
Figure 8 and
Figures S22–S24). Based on a sequence of correlation analyses, the main similarities and differences are summarized as follows.
As shown in
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6 and
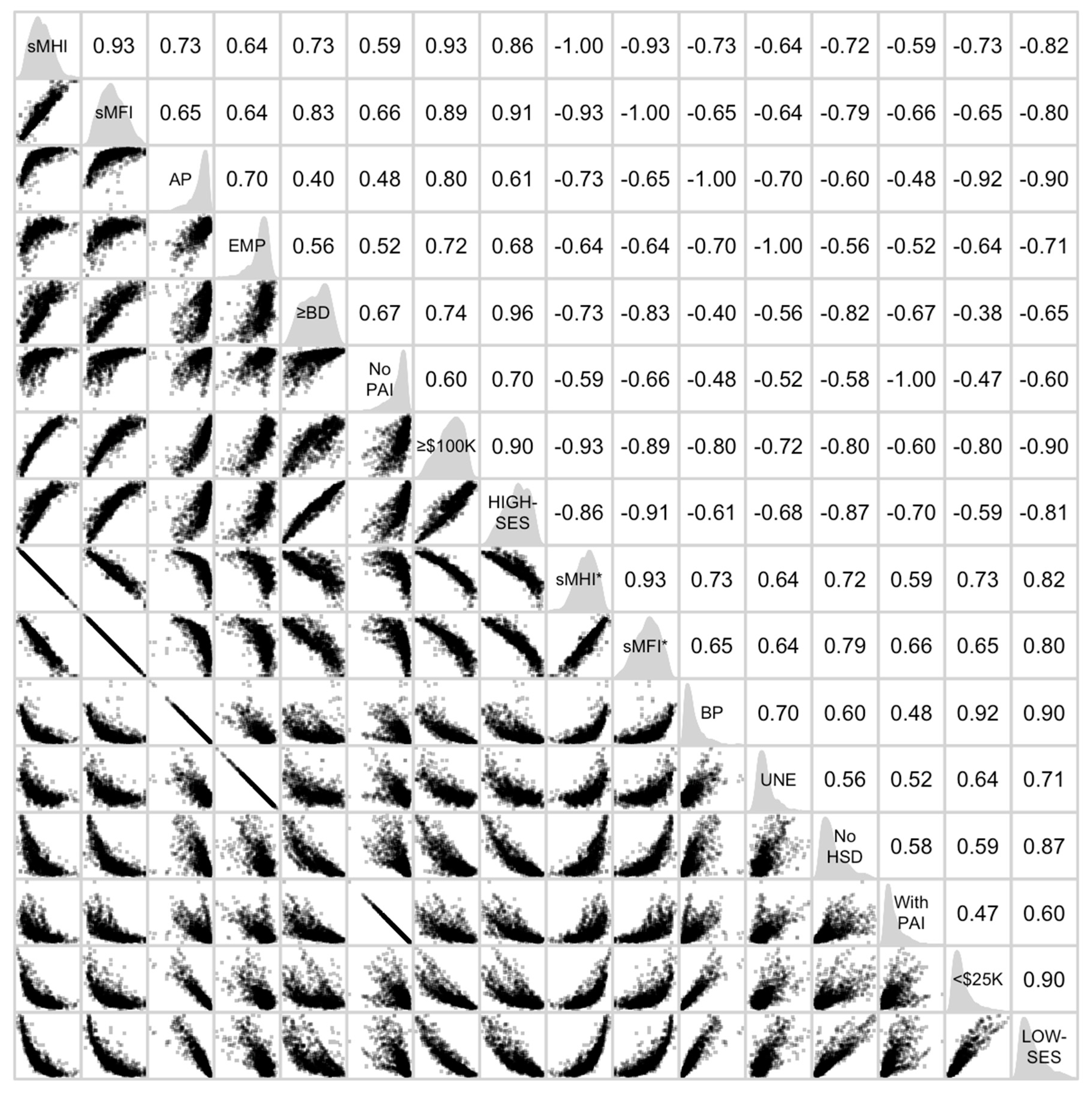
Figure 7, sMHI and sMFI were very strongly and positively correlated with each other following a linear pattern with a small dispersion (0.91 ≤
r ≤ 0.96) and sMHI* and sMFI* were very strongly and positively correlated with each other following a linear pattern with a small dispersion (0.91 ≤
r ≤ 0.96). Since two reference measures were divided or multiplied by −1 to obtain their reversed form, sMHI and sMHI* as well as sMFI and sMFI* were perfectly and negatively correlated with each other (
r = −1.00). Between five spatial high-SES indicators and their respective low-SES counterparts, perfect negative correlations (
r = −1.00) were also evident between AP (above poverty) and BP (below poverty), EMP (employed) and UNE (unemployed), and NoPAI (no public assistance income) and WithPAI (with public assistance income). However, ≥BD (bachelor’s degree or higher) and NoHSD (no high school diploma) as well as ≥
$100K (household income greater than or equal to USD 100,000) and <
$25K (household income less than USD 25,000) were strongly, but negatively correlated with each other following a curvilinear pattern with a moderate dispersion (−0.80 ≤
r ≤ −0.85). While the forms and strengths of these relationships somewhat varied at four different time periods, very similar relationships were observed in correlation matrices based on the 2000 Census data as well as the 2005–2009 and 2010–2014 ACS data (
Figures S1–S21).
Table 5.
Overall percentages of high and low socioeconomic groups and component loadings of spatial high- and low-SES indicators in the Riverside–San Bernardino–Ontario Metropolitan Statistical Area (MSA).
Table 5.
Overall percentages of high and low socioeconomic groups and component loadings of spatial high- and low-SES indicators in the Riverside–San Bernardino–Ontario Metropolitan Statistical Area (MSA).
| | | Overall Percentages |
| a | | 2000 | 2005–2009 | 2010–2014 | 2015–2019 |
| High Socioeconomic Groups | | | | |
| | Above Poverty | 84.95% | 86.72% | 82.03% | 85.24% |
| | Employed | 92.06% | 90.69% | 85.87% | 92.44% |
| | Bachelor’s Degree or Higher | 16.27% | 19.31% | 19.82% | 21.69% |
| | No Public Assistance Income | 94.58% | 96.45% | 95.17% | 96.14% |
| | Household Income ≥ USD 100,000 | 11.54% | 22.89% | 23.13% | 30.26% |
| Low Socioeconomic Groups | | | | |
| | Below Poverty | 15.05% | 13.28% | 17.97% | 14.76% |
| | Unemployed | 7.94% | 9.31% | 14.13% | 7.56% |
| | No High School Diploma | 25.43% | 21.83% | 20.91% | 18.91% |
| | With Public Assistance Income | 5.42% | 3.55% | 4.83% | 3.86% |
| | Household Income < USD 25,000 | 28.42% | 20.04% | 21.78% | 17.99% |
| | | Component Loadings |
| b | | 2000 | 2005–2009 | 2010–2014 | 2015–2019 |
| Spatial High-SES Indicators | | | | |
| | Above Poverty (AP) | 0.50390 | 0.38845 | 0.44687 | 0.35073 |
| | Employed (EMP) | 0.19125 | 0.12161 | 0.17112 | 0.10936 |
| | Bachelor’s Degree or Higher (≥BD) | 0.62245 | 0.54135 | 0.54816 | 0.55131 |
| | No Public Assistance Income (NoPAI) | 0.21893 | 0.12265 | 0.14252 | 0.09325 |
| | Household Income ≥ USD 100,000 (≥$100K) | 0.52358 | 0.72541 | 0.67099 | 0.74323 |
| Spatial Low-SES Indicators | | | | |
| | Below Poverty (BP) | 0.44414 | 0.46381 | 0.52371 | 0.49592 |
| | Unemployed (UNE) | 0.15221 | 0.13453 | 0.18541 | 0.14188 |
| | No High School Diploma (NoHSD) | 0.62145 | 0.68256 | 0.65206 | 0.65365 |
| | With Public Assistance Income (WithPAI) | 0.17360 | 0.14020 | 0.16269 | 0.12088 |
| | Household Income < USD 25,000 (<$25K) | 0.60270 | 0.53031 | 0.48960 | 0.54043 |
Table 6.
Overall percentages of high and low socioeconomic groups and component loadings of spatial high- and low-SES indicators in the San Diego–Chula Vista–Carlsbad Metropolitan Statistical Area (MSA).
Table 6.
Overall percentages of high and low socioeconomic groups and component loadings of spatial high- and low-SES indicators in the San Diego–Chula Vista–Carlsbad Metropolitan Statistical Area (MSA).
| | | Overall Percentages |
| a | | 2000 | 2005–2009 | 2010–2014 | 2015–2019 |
| High Socioeconomic Groups | | | | |
| | Above Poverty | 87.57% | 88.46% | 85.31% | 88.41% |
| | Employed | 94.07% | 93.27% | 90.41% | 94.00% |
| | Bachelor’s Degree or Higher | 29.52% | 34.01% | 35.10% | 38.81% |
| | No Public Assistance Income | 96.43% | 97.80% | 97.24% | 97.59% |
| | Household Income ≥ USD 100,000 | 15.71% | 28.41% | 30.22% | 39.17% |
| Low Socioeconomic Groups | | | | |
| | Below Poverty | 12.43% | 11.54% | 14.69% | 11.59% |
| | Unemployed | 5.93% | 6.73% | 9.59% | 6.00% |
| | No High School Diploma | 17.42% | 14.82% | 14.24% | 12.55% |
| | With Public Assistance Income | 3.57% | 2.20% | 2.76% | 2.41% |
| | Household Income < USD 25,000 | 24.32% | 17.86% | 18.85% | 14.18% |
| | | Component Loadings |
| b | | 2000 | 2005–2009 | 2010–2014 | 2015–2019 |
| Spatial High-SES Indicators | | | | |
| | Above Poverty (AP) | 0.28967 | 0.23747 | 0.25431 | 0.17429 |
| | Employed (EMP) | 0.10155 | 0.06750 | 0.11308 | 0.06666 |
| | Bachelor’s Degree or Higher (≥BD) | 0.79960 | 0.76909 | 0.77673 | 0.79620 |
| | No Public Assistance Income (NoPAI) | 0.13180 | 0.06906 | 0.07284 | 0.05807 |
| | Household Income ≥ USD 100,000 (≥$100K) | 0.49905 | 0.58548 | 0.56029 | 0.57260 |
| Spatial Low-SES Indicators | | | | |
| | Below Poverty (BP) | 0.41969 | 0.43987 | 0.49195 | 0.43498 |
| | Unemployed (UNE) | 0.12432 | 0.09383 | 0.16508 | 0.12344 |
| | No High School Diploma (NoHSD) | 0.65083 | 0.71110 | 0.68123 | 0.76661 |
| | With Public Assistance Income (WithPAI) | 0.16188 | 0.10879 | 0.11474 | 0.10915 |
| | Household Income < USD 25,000 (<$25K) | 0.59885 | 0.52935 | 0.50347 | 0.44266 |
By focusing on the scatterplots of pairwise relationships,
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6 and
Figure 7 also show that the relationships between five spatial high-SES indicators followed positive curvilinear or nonlinear patterns with a large dispersion, although these mostly indicated moderate or strong correlations (0.23 ≤
r ≤ 0.86). On the other hand, the relationships between five spatial low-SES indicators mostly followed funnel patterns (and occasionally followed linear patterns) with a large dispersion (0.42 ≤
r ≤ 0.93). Among these indicators, ≥
$100K was strongly or very strongly and positively correlated with sMHI and sMFI in a linear, but slightly curved fashion (0.86 ≤
r ≤ 0.95) and <
$25K was moderately or strongly and positively correlated with sMHI* and sMFI* in a slightly curvilinear fashion (0.61 ≤
r ≤ 0.86). Since the relationships of five spatial high-SES indicators were somewhat different from those of five spatial low-SES indicators, the relationships between spatial composite measures of HIGH-SES and LOW-SES followed a strong negative curvilinear pattern with a moderate dispersion (−0.75 ≤
r ≤ −0.93). Therefore, HIGH-SES was strongly or very strongly and positively correlated with sMHI and sMFI in a linear, but slightly curved fashion (0.84 ≤
r ≤ 0.94) and LOW-SES was moderately or strongly and positively correlated with sMHI* and sMFI* in a slightly curvilinear fashion (0.75 ≤
r ≤ 0.87). While the forms and strengths of these relationships somewhat varied at four different time periods, very similar patterns were observed in correlation matrices based on the 2000 Census data as well as the 2005–2009 and 2010–2014 ACS data (
Figures S1–S21).
Table 7.
Overall percentages of high and low socioeconomic groups and component loadings of spatial high- and low-SES indicators in the Sacramento–Roseville–Folsom Metropolitan Statistical Area (MSA).
Table 7.
Overall percentages of high and low socioeconomic groups and component loadings of spatial high- and low-SES indicators in the Sacramento–Roseville–Folsom Metropolitan Statistical Area (MSA).
| | | Overall Percentages |
| a | | 2000 | 2005–2009 | 2010–2014 | 2015–2019 |
| High Socioeconomic Groups | | | | |
| | Above Poverty | 87.25% | 88.05% | 83.91% | 86.60% |
| | Employed | 93.78% | 91.94% | 87.99% | 93.97% |
| | Bachelor’s Degree or Higher | 26.55% | 29.81% | 30.70% | 33.55% |
| | No Public Assistance Income | 94.54% | 95.97% | 95.22% | 96.23% |
| | Household Income ≥ USD 100,000 | 13.98% | 25.57% | 26.96% | 35.28% |
| Low Socioeconomic Groups | | | | |
| | Below Poverty | 12.75% | 11.95% | 16.09% | 13.40% |
| | Unemployed | 6.22% | 8.06% | 12.01% | 6.03% |
| | No High School Diploma | 15.44% | 13.15% | 12.02% | 10.70% |
| | With Public Assistance Income | 5.46% | 4.03% | 4.78% | 3.77% |
| | Household Income < USD 25,000 | 24.94% | 18.72% | 20.60% | 16.73% |
| | | Component Loadings |
| b | | 2000 | 2005–2009 | 2010–2014 | 2015–2019 |
| Spatial High-SES Indicators | | | | |
| | Above Poverty (AP) | 0.30102 | 0.27132 | 0.34610 | 0.23915 |
| | Employed (EMP) | 0.12662 | 0.12474 | 0.16396 | 0.08385 |
| | Bachelor’s Degree or Higher (≥BD) | 0.80229 | 0.70715 | 0.67399 | 0.70999 |
| | No Public Assistance Income (NoPAI) | 0.22740 | 0.15721 | 0.14747 | 0.10983 |
| | Household Income ≥ USD 100,000 (≥$100K) | 0.44494 | 0.62134 | 0.61426 | 0.64779 |
| Spatial Low-SES Indicators | | | | |
| | Below Poverty (BP) | 0.48477 | 0.49715 | 0.59170 | 0.62193 |
| | Unemployed (UNE) | 0.15954 | 0.16282 | 0.19644 | 0.15564 |
| | No High School Diploma (NoHSD) | 0.50145 | 0.55552 | 0.47355 | 0.44779 |
| | With Public Assistance Income (WithPAI) | 0.22940 | 0.19616 | 0.19689 | 0.16399 |
| | Household Income < USD 25,000 (<$25K) | 0.65989 | 0.61583 | 0.59016 | 0.60130 |
Unlike the linear or curvilinear patterns coupled with a moderate or large dispersion in the State of California and its six largest MSAs at four different time periods (
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figures S1–S21), linear patterns were more tightly scattered and curvilinear patterns were also more tightly scattered with a less steep curvature in the Fresno MSA (
Figure 8 and
Figures S22–S24). In other words, the strengths of correlations were stronger or much stronger across the board. To highlight the uniqueness of Fresno MSA, the relationships between sixteen spatial measures in the Fresno MSA (
Figure 8 and
Figures S22–S24) are summarized as follows.
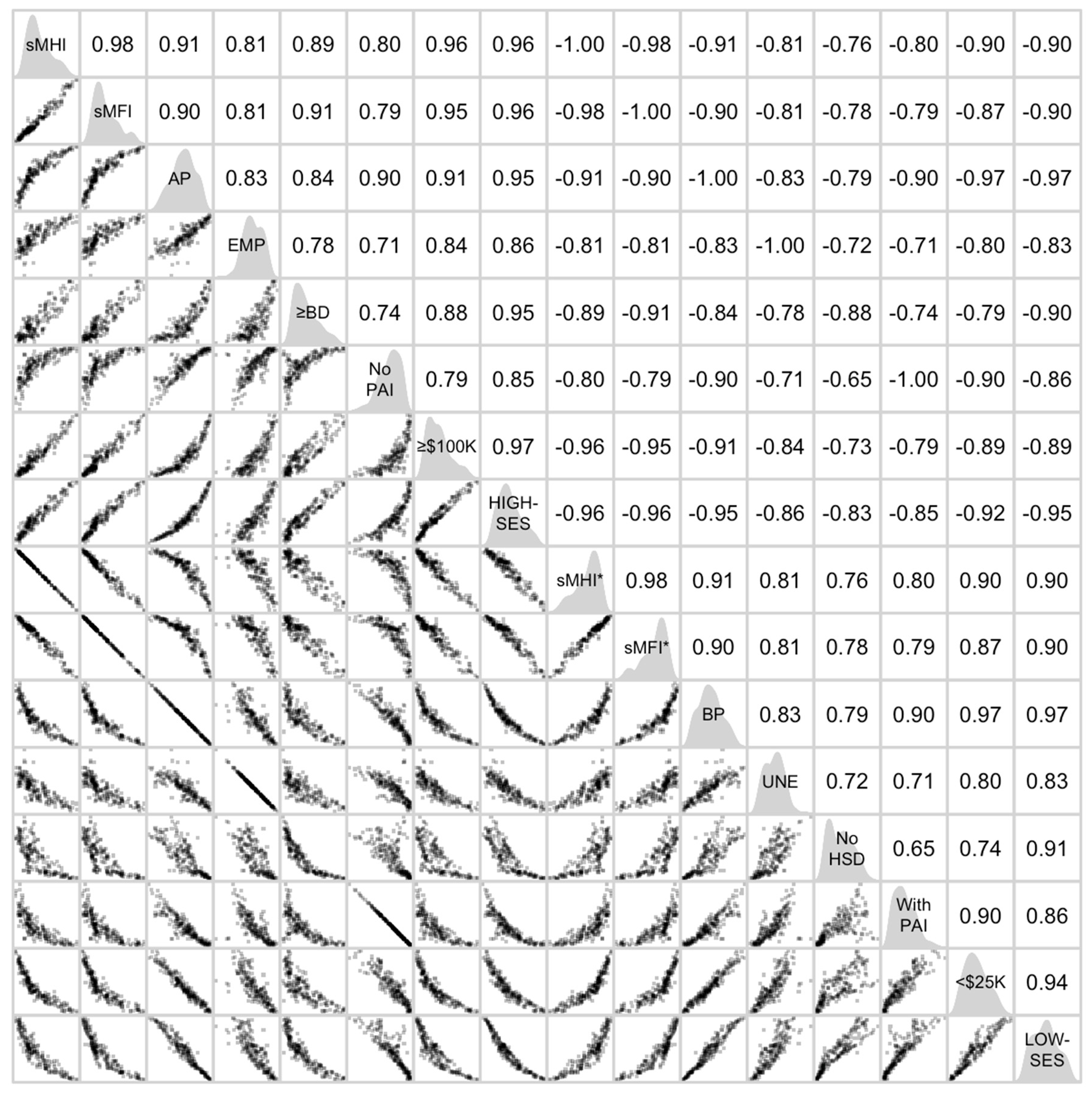
As shown in
Figure 8, sMHI and sMFI (
r = 0.98) as well as sMHI* and sMFI* (
r = 0.98) were very strongly and positively correlated with each other following linear patterns with a very small dispersion. In addition, perfect negative correlations between sMHI and sMHI* (
r = −1.00), sMFI and sMFI* (
r = −1.00), AP and BP (
r = −1.00), EMP and UNE (
r = −1.00), and NoPAI and WithPAI (
r = −1.00) remained unchanged. Moreover, ≥BD and NoHSD (
r = −0.88) as well as ≥
$100K and <
$25K (
r = −0.89) were strongly, but negatively correlated with each other following slightly curvilinear patterns with a small dispersion. Closely reflecting the tightly scattered patterns in
Figure 8, almost exactly the same forms and strengths of relationships were observed in correlation matrices based on the 2000 Census data as well as the 2005–2009 and 2010–2014 ACS data (
Figures S22–S24).
Table 8.
Overall percentages of high and low socioeconomic groups and component loadings of spatial high- and low-SES indicators in the San Jose–Sunnyvale–Santa Clara Metropolitan Statistical Area (MSA).
Table 8.
Overall percentages of high and low socioeconomic groups and component loadings of spatial high- and low-SES indicators in the San Jose–Sunnyvale–Santa Clara Metropolitan Statistical Area (MSA).
| | | Overall Percentages |
| a | | 2000 | 2005–2009 | 2010–2014 | 2015–2019 |
| High Socioeconomic Groups | | | | |
| | Above Poverty | 92.40% | 91.35% | 90.00% | 92.46% |
| | Employed | 96.03% | 92.95% | 91.03% | 95.65% |
| | Bachelor’s Degree or Higher | 39.84% | 43.16% | 46.53% | 51.47% |
| | No Public Assistance Income | 97.26% | 97.85% | 97.50% | 98.20% |
| | Household Income ≥ USD 100,000 | 34.21% | 42.58% | 46.89% | 58.39% |
| Low Socioeconomic Groups | | | | |
| | Below Poverty | 7.60% | 8.65% | 10.00% | 7.54% |
| | Unemployed | 3.97% | 7.05% | 8.97% | 4.35% |
| | No High School Diploma | 16.84% | 14.54% | 13.45% | 11.85% |
| | With Public Assistance Income | 2.74% | 2.15% | 2.50% | 1.80% |
| | Household Income < USD 25,000 | 13.52% | 13.61% | 12.96% | 9.75% |
| | | Component Loadings |
| b | | 2000 | 2005–2009 | 2010–2014 | 2015–2019 |
| Spatial High-SES Indicators | | | | |
| | Above Poverty (AP) | 0.14408 | 0.16464 | 0.19713 | 0.11253 |
| | Employed (EMP) | 0.05896 | 0.06725 | 0.09337 | 0.03751 |
| | Bachelor’s Degree or Higher (≥BD) | 0.83869 | 0.82431 | 0.81372 | 0.86535 |
| | No Public Assistance Income (NoPAI) | 0.08128 | 0.05422 | 0.05012 | 0.04476 |
| | Household Income ≥ USD 100,000 (≥$100K) | 0.51553 | 0.53473 | 0.53644 | 0.48487 |
| Spatial Low-SES Indicators | | | | |
| | Below Poverty (BP) | 0.27501 | 0.34245 | 0.41806 | 0.29676 |
| | Unemployed (UNE) | 0.09646 | 0.11879 | 0.17148 | 0.08429 |
| | No High School Diploma (NoHSD) | 0.89104 | 0.84374 | 0.78909 | 0.90068 |
| | With Public Assistance Income (WithPAI) | 0.13646 | 0.10768 | 0.09239 | 0.09983 |
| | Household Income < USD 25,000 (<$25K) | 0.32015 | 0.38095 | 0.40574 | 0.28920 |
Fairly different from the State of California (
Figure 1) and its six largest MSAs (
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6 and
Figure 7), five spatial high-SES indicators in Fresno MSA (
Figure 8) were strongly and positively correlated with one another following linear or slightly curvilinear patterns with a small dispersion (0.71 ≤
r ≤ 0.91). Also, five spatial low-SES indicators in Fresno MSA (
Figure 8) were strongly and positively correlated with one another following linear or slightly funnel patterns with a small dispersion (0.65 ≤
r ≤ 0.97). By and large, five spatial high-SES indicators were strongly and positively correlated with sMHI and sMFI in linear or slightly curvilinear fashions (0.79 ≤
r ≤ 0.96) and five spatial low-SES indicators were strongly and positively correlated with sMHI* and sMFI* in curvilinear fashions (0.76 ≤
r ≤ 0.91). While the relationships of five spatial high-SES indicators were somewhat different from those of five spatial low-SES indicators, spatial composite measures of HIGH-SES and LOW-SES were very strongly, but negatively correlated with each other following a slightly curvilinear pattern with a small dispersion (
r ≤ −0.95). Moreover, HIGH-SES was very strongly and positively correlated with sMHI and sMFI in a linear fashion (
r ≤ 0.96) and LOW-SES was very strongly and positively correlated with sMHI* and sMFI* in a slightly curvilinear fashion (
r ≤ 0.90). Closely reflecting the tightly scattered patterns in
Figure 8, almost exactly the same forms and strengths of relationships were observed in correlation matrices based on the 2000 Census data as well as the 2005–2009 and 2010–2014 ACS data (
Figures S22–S24).
Table 9.
Overall percentages of high and low socioeconomic groups and component loadings of spatial high- and low-SES indicators in the Fresno Metropolitan Statistical Area (MSA).
Table 9.
Overall percentages of high and low socioeconomic groups and component loadings of spatial high- and low-SES indicators in the Fresno Metropolitan Statistical Area (MSA).
| | | Overall Percentages |
| a | | 2000 | 2005–2009 | 2010–2014 | 2015–2019 |
| High Socioeconomic Groups | | | | |
| | Above Poverty | 77.11% | 79.08% | 72.64% | 77.45% |
| | Employed | 88.19% | 90.01% | 85.68% | 91.29% |
| | Bachelor’s Degree or Higher | 17.55% | 19.39% | 19.48% | 21.17% |
| | No Public Assistance Income | 91.48% | 93.57% | 91.80% | 92.59% |
| | Household Income ≥ USD 100,000 | 8.60% | 17.36% | 18.04% | 24.02% |
| Low Socioeconomic Groups | | | | |
| | Below Poverty | 22.89% | 20.92% | 27.36% | 22.55% |
| | Unemployed | 11.81% | 9.99% | 14.32% | 8.71% |
| | No High School Diploma | 32.48% | 27.38% | 26.78% | 24.04% |
| | With Public Assistance Income | 8.52% | 6.43% | 8.20% | 7.41% |
| | Household Income < USD 25,000 | 35.96% | 27.38% | 28.44% | 23.85% |
| | | Component Loadings |
| b | | 2000 | 2005–2009 | 2010–2014 | 2015–2019 |
| Spatial High-SES Indicators | | | | |
| | Above Poverty (AP) | 0.62481 | 0.53058 | 0.59134 | 0.50281 |
| | Employed (EMP) | 0.27542 | 0.17498 | 0.15434 | 0.12718 |
| | Bachelor’s Degree or Higher (≥BD) | 0.59784 | 0.58857 | 0.52824 | 0.56584 |
| | No Public Assistance Income (NoPAI) | 0.29804 | 0.19907 | 0.21205 | 0.17348 |
| | Household Income ≥ USD 100,000 (≥$100K) | 0.29583 | 0.54938 | 0.54999 | 0.61704 |
| Spatial Low-SES Indicators | | | | |
| | Below Poverty (BP) | 0.47337 | 0.47461 | 0.56499 | 0.52519 |
| | Unemployed (UNE) | 0.21327 | 0.15859 | 0.13860 | 0.12739 |
| | No High School Diploma (NoHSD) | 0.64991 | 0.67650 | 0.59774 | 0.62326 |
| | With Public Assistance Income (WithPAI) | 0.22522 | 0.17784 | 0.20246 | 0.18120 |
| | Household Income < USD 25,000 (<$25K) | 0.50728 | 0.51021 | 0.51312 | 0.53540 |
Regardless of the subtle differences across the study areas at four different time periods (
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8 and
Figures S1–S24), consistent relationships were evident from a sequence of data analyses: sMHI and sMFI showed strong positive linear or slightly curvilinear correlations with HIGH-SES (0.73 ≤
r ≤ 0.97), sMHI* and sMFI* showed strong positive curvilinear or slightly curvilinear correlations with LOW-SES (0.72 ≤
r ≤ 0.92), and HIGH-SES and LOW-SES showed strong negative curvilinear or slightly curvilinear correlations (−0.74 ≤
r ≤ −0.98). While two spatial composite measures are conceptually inverses of each other, their relationships did not show a perfect negative linear correlation in any of the study areas at any time periods.
Figure 1.
Correlation matrix of sixteen spatial measures in the State of California based on the 2015–2019 American Community Survey data. Abbreviations: SES, Socioeconomic Status; sMHI, a spatial median of median household income; sMFI, a spatial median of median family income; AP, a composite proportion of residents who were above poverty; EMP, a composite proportion of residents who were employed; ≥BD, a composite proportion of residents who held a Bachelor’s degree or higher; NoPAI, a composite proportion of residents who received no public assistance income; ≥$100K, a composite proportion of residents who earned an annual household income of greater than or equal to USD 100,000; HIGH-SES, a spatial composite measure of five spatial high-SES indicators derived from a principal component analysis; sMHI*, a spatial median of median household income divided or multiplied by −1; sMFI*, a spatial median of median family income divided or multiplied by −1; BP, a composite proportion of residents who were below poverty; UNE, a composite proportion of residents who were unemployed; NoHSD, a composite proportion of residents who had no high school diploma; WithPAI, a composite proportion of residents who were supported with public assistance income; <$25K, a composite proportion of residents who earned an annual household income of less than USD 25,000; and LOW-SES, a spatial composite measure of five spatial low-SES indicators derived from a principal component analysis.
Figure 1.
Correlation matrix of sixteen spatial measures in the State of California based on the 2015–2019 American Community Survey data. Abbreviations: SES, Socioeconomic Status; sMHI, a spatial median of median household income; sMFI, a spatial median of median family income; AP, a composite proportion of residents who were above poverty; EMP, a composite proportion of residents who were employed; ≥BD, a composite proportion of residents who held a Bachelor’s degree or higher; NoPAI, a composite proportion of residents who received no public assistance income; ≥$100K, a composite proportion of residents who earned an annual household income of greater than or equal to USD 100,000; HIGH-SES, a spatial composite measure of five spatial high-SES indicators derived from a principal component analysis; sMHI*, a spatial median of median household income divided or multiplied by −1; sMFI*, a spatial median of median family income divided or multiplied by −1; BP, a composite proportion of residents who were below poverty; UNE, a composite proportion of residents who were unemployed; NoHSD, a composite proportion of residents who had no high school diploma; WithPAI, a composite proportion of residents who were supported with public assistance income; <$25K, a composite proportion of residents who earned an annual household income of less than USD 25,000; and LOW-SES, a spatial composite measure of five spatial low-SES indicators derived from a principal component analysis.
![Socsci 13 00693 g001]()
Figure 2.
Correlation matrix of sixteen spatial measures in the Los Angeles–Long Beach–Anaheim Metropolitan Statistical Area based on the 2015–2019 American Community Survey data. Abbreviations: SES, Socioeconomic Status; sMHI, a spatial median of median household income; sMFI, a spatial median of median family income; AP, a composite proportion of residents who were above poverty; EMP, a composite proportion of residents who were employed; ≥BD, a composite proportion of residents who held a Bachelor’s degree or higher; NoPAI, a composite proportion of residents who received no public assistance income; ≥$100K, a composite proportion of residents who earned an annual household income of greater than or equal to USD 100,000; HIGH-SES, a spatial composite measure of five spatial high-SES indicators derived from a principal component analysis; sMHI*, a spatial median of median household income divided or multiplied by −1; sMFI*, a spatial median of median family income divided or multiplied by −1; BP, a composite proportion of residents who were below poverty; UNE, a composite proportion of residents who were unemployed; NoHSD, a composite proportion of residents who had no high school diploma; WithPAI, a composite proportion of residents who were supported with public assistance income; <$25K, a composite proportion of residents who earned an annual household income of less than USD 25,000; and LOW-SES, a spatial composite measure of five spatial low-SES indicators derived from a principal component analysis.
Figure 2.
Correlation matrix of sixteen spatial measures in the Los Angeles–Long Beach–Anaheim Metropolitan Statistical Area based on the 2015–2019 American Community Survey data. Abbreviations: SES, Socioeconomic Status; sMHI, a spatial median of median household income; sMFI, a spatial median of median family income; AP, a composite proportion of residents who were above poverty; EMP, a composite proportion of residents who were employed; ≥BD, a composite proportion of residents who held a Bachelor’s degree or higher; NoPAI, a composite proportion of residents who received no public assistance income; ≥$100K, a composite proportion of residents who earned an annual household income of greater than or equal to USD 100,000; HIGH-SES, a spatial composite measure of five spatial high-SES indicators derived from a principal component analysis; sMHI*, a spatial median of median household income divided or multiplied by −1; sMFI*, a spatial median of median family income divided or multiplied by −1; BP, a composite proportion of residents who were below poverty; UNE, a composite proportion of residents who were unemployed; NoHSD, a composite proportion of residents who had no high school diploma; WithPAI, a composite proportion of residents who were supported with public assistance income; <$25K, a composite proportion of residents who earned an annual household income of less than USD 25,000; and LOW-SES, a spatial composite measure of five spatial low-SES indicators derived from a principal component analysis.
![Socsci 13 00693 g002]()
Figure 3.
Correlation matrix of sixteen spatial measures in the San Francisco–Oakland–Berkeley Metropolitan Statistical Area based on the 2015–2019 American Community Survey data. Abbreviations: SES, Socioeconomic Status; sMHI, a spatial median of median household income; sMFI, a spatial median of median family income; AP, a composite proportion of residents who were above poverty; EMP, a composite proportion of residents who were employed; ≥BD, a composite proportion of residents who held a Bachelor’s degree or higher; NoPAI, a composite proportion of residents who received no public assistance income; ≥$100K, a composite proportion of residents who earned an annual household income of greater than or equal to USD 100,000; HIGH-SES, a spatial composite measure of five spatial high-SES indicators derived from a principal component analysis; sMHI*, a spatial median of median household income divided or multiplied by −1; sMFI*, a spatial median of median family income divided or multiplied by −1; BP, a composite proportion of residents who were below poverty; UNE, a composite proportion of residents who were unemployed; NoHSD, a composite proportion of residents who had no high school diploma; WithPAI, a composite proportion of residents who were supported with public assistance income; <$25K, a composite proportion of residents who earned an annual household income of less than USD 25,000; and LOW-SES, a spatial composite measure of five spatial low-SES indicators derived from a principal component analysis.
Figure 3.
Correlation matrix of sixteen spatial measures in the San Francisco–Oakland–Berkeley Metropolitan Statistical Area based on the 2015–2019 American Community Survey data. Abbreviations: SES, Socioeconomic Status; sMHI, a spatial median of median household income; sMFI, a spatial median of median family income; AP, a composite proportion of residents who were above poverty; EMP, a composite proportion of residents who were employed; ≥BD, a composite proportion of residents who held a Bachelor’s degree or higher; NoPAI, a composite proportion of residents who received no public assistance income; ≥$100K, a composite proportion of residents who earned an annual household income of greater than or equal to USD 100,000; HIGH-SES, a spatial composite measure of five spatial high-SES indicators derived from a principal component analysis; sMHI*, a spatial median of median household income divided or multiplied by −1; sMFI*, a spatial median of median family income divided or multiplied by −1; BP, a composite proportion of residents who were below poverty; UNE, a composite proportion of residents who were unemployed; NoHSD, a composite proportion of residents who had no high school diploma; WithPAI, a composite proportion of residents who were supported with public assistance income; <$25K, a composite proportion of residents who earned an annual household income of less than USD 25,000; and LOW-SES, a spatial composite measure of five spatial low-SES indicators derived from a principal component analysis.
![Socsci 13 00693 g003]()
Figure 4.
Correlation matrix of sixteen spatial measures in the Riverside–San Bernardino–Ontario Metropolitan Statistical Area based on the 2015–2019 American Community Survey data. Abbreviations: SES, Socioeconomic Status; sMHI, a spatial median of median household income; sMFI, a spatial median of median family income; AP, a composite proportion of residents who were above poverty; EMP, a composite proportion of residents who were employed; ≥BD, a composite proportion of residents who held a Bachelor’s degree or higher; NoPAI, a composite proportion of residents who received no public assistance income; ≥$100K, a composite proportion of residents who earned an annual household income of greater than or equal to USD 100,000; HIGH-SES, a spatial composite measure of five spatial high-SES indicators derived from a principal component analysis; sMHI*, a spatial median of median household income divided or multiplied by −1; sMFI*, a spatial median of median family income divided or multiplied by −1; BP, a composite proportion of residents who were below poverty; UNE, a composite proportion of residents who were unemployed; NoHSD, a composite proportion of residents who had no high school diploma; WithPAI, a composite proportion of residents who were supported with public assistance income; <$25K, a composite proportion of residents who earned an annual household income of less than USD 25,000; and LOW-SES, a spatial composite measure of five spatial low-SES indicators derived from a principal component analysis.
Figure 4.
Correlation matrix of sixteen spatial measures in the Riverside–San Bernardino–Ontario Metropolitan Statistical Area based on the 2015–2019 American Community Survey data. Abbreviations: SES, Socioeconomic Status; sMHI, a spatial median of median household income; sMFI, a spatial median of median family income; AP, a composite proportion of residents who were above poverty; EMP, a composite proportion of residents who were employed; ≥BD, a composite proportion of residents who held a Bachelor’s degree or higher; NoPAI, a composite proportion of residents who received no public assistance income; ≥$100K, a composite proportion of residents who earned an annual household income of greater than or equal to USD 100,000; HIGH-SES, a spatial composite measure of five spatial high-SES indicators derived from a principal component analysis; sMHI*, a spatial median of median household income divided or multiplied by −1; sMFI*, a spatial median of median family income divided or multiplied by −1; BP, a composite proportion of residents who were below poverty; UNE, a composite proportion of residents who were unemployed; NoHSD, a composite proportion of residents who had no high school diploma; WithPAI, a composite proportion of residents who were supported with public assistance income; <$25K, a composite proportion of residents who earned an annual household income of less than USD 25,000; and LOW-SES, a spatial composite measure of five spatial low-SES indicators derived from a principal component analysis.
![Socsci 13 00693 g004]()
Figure 5.
Correlation matrix of sixteen spatial measures in the San Diego–Chula Vista–Carlsbad Metropolitan Statistical Area based on the 2015–2019 American Community Survey data. Abbreviations: SES, Socioeconomic Status; sMHI, a spatial median of median household income; sMFI, a spatial median of median family income; AP, a composite proportion of residents who were above poverty; EMP, a composite proportion of residents who were employed; ≥BD, a composite proportion of residents who held a Bachelor’s degree or higher; NoPAI, a composite proportion of residents who received no public assistance income; ≥$100K, a composite proportion of residents who earned an annual household income of greater than or equal to USD 100,000; HIGH-SES, a spatial composite measure of five spatial high-SES indicators derived from a principal component analysis; sMHI*, a spatial median of median household income divided or multiplied by −1; sMFI*, a spatial median of median family income divided or multiplied by −1; BP, a composite proportion of residents who were below poverty; UNE, a composite proportion of residents who were unemployed; NoHSD, a composite proportion of residents who had no high school diploma; WithPAI, a composite proportion of residents who were supported with public assistance income; <$25K, a composite proportion of residents who earned an annual household income of less than USD 25,000; and LOW-SES, a spatial composite measure of five spatial low-SES indicators derived from a principal component analysis.
Figure 5.
Correlation matrix of sixteen spatial measures in the San Diego–Chula Vista–Carlsbad Metropolitan Statistical Area based on the 2015–2019 American Community Survey data. Abbreviations: SES, Socioeconomic Status; sMHI, a spatial median of median household income; sMFI, a spatial median of median family income; AP, a composite proportion of residents who were above poverty; EMP, a composite proportion of residents who were employed; ≥BD, a composite proportion of residents who held a Bachelor’s degree or higher; NoPAI, a composite proportion of residents who received no public assistance income; ≥$100K, a composite proportion of residents who earned an annual household income of greater than or equal to USD 100,000; HIGH-SES, a spatial composite measure of five spatial high-SES indicators derived from a principal component analysis; sMHI*, a spatial median of median household income divided or multiplied by −1; sMFI*, a spatial median of median family income divided or multiplied by −1; BP, a composite proportion of residents who were below poverty; UNE, a composite proportion of residents who were unemployed; NoHSD, a composite proportion of residents who had no high school diploma; WithPAI, a composite proportion of residents who were supported with public assistance income; <$25K, a composite proportion of residents who earned an annual household income of less than USD 25,000; and LOW-SES, a spatial composite measure of five spatial low-SES indicators derived from a principal component analysis.
![Socsci 13 00693 g005]()
Figure 6.
Correlation matrix of sixteen spatial measures in the Sacramento–Roseville–Folsom Metropolitan Statistical Area based on the 2015–2019 American Community Survey data. Abbreviations: SES, Socioeconomic Status; sMHI, a spatial median of median household income; sMFI, a spatial median of median family income; AP, a composite proportion of residents who were above poverty; EMP, a composite proportion of residents who were employed; ≥BD, a composite proportion of residents who held a Bachelor’s degree or higher; NoPAI, a composite proportion of residents who received no public assistance income; ≥$100K, a composite proportion of residents who earned an annual household income of greater than or equal to USD 100,000; HIGH-SES, a spatial composite measure of five spatial high-SES indicators derived from a principal component analysis; sMHI*, a spatial median of median household income divided or multiplied by −1; sMFI*, a spatial median of median family income divided or multiplied by −1; BP, a composite proportion of residents who were below poverty; UNE, a composite proportion of residents who were unemployed; NoHSD, a composite proportion of residents who had no high school diploma; WithPAI, a composite proportion of residents who were supported with public assistance income; <$25K, a composite proportion of residents who earned an annual household income of less than USD 25,000; and LOW-SES, a spatial composite measure of five spatial low-SES indicators derived from a principal component analysis.
Figure 6.
Correlation matrix of sixteen spatial measures in the Sacramento–Roseville–Folsom Metropolitan Statistical Area based on the 2015–2019 American Community Survey data. Abbreviations: SES, Socioeconomic Status; sMHI, a spatial median of median household income; sMFI, a spatial median of median family income; AP, a composite proportion of residents who were above poverty; EMP, a composite proportion of residents who were employed; ≥BD, a composite proportion of residents who held a Bachelor’s degree or higher; NoPAI, a composite proportion of residents who received no public assistance income; ≥$100K, a composite proportion of residents who earned an annual household income of greater than or equal to USD 100,000; HIGH-SES, a spatial composite measure of five spatial high-SES indicators derived from a principal component analysis; sMHI*, a spatial median of median household income divided or multiplied by −1; sMFI*, a spatial median of median family income divided or multiplied by −1; BP, a composite proportion of residents who were below poverty; UNE, a composite proportion of residents who were unemployed; NoHSD, a composite proportion of residents who had no high school diploma; WithPAI, a composite proportion of residents who were supported with public assistance income; <$25K, a composite proportion of residents who earned an annual household income of less than USD 25,000; and LOW-SES, a spatial composite measure of five spatial low-SES indicators derived from a principal component analysis.
![Socsci 13 00693 g006]()
Figure 7.
Correlation matrix of sixteen spatial measures in the San Jose–Sunnyvale–Santa Clara Metropolitan Statistical Area based on the 2015–2019 American Community Survey data. Abbreviations: SES, Socioeconomic Status; sMHI, a spatial median of median household income; sMFI, a spatial median of median family income; AP, a composite proportion of residents who were above poverty; EMP, a composite proportion of residents who were employed; ≥BD, a composite proportion of residents who held a Bachelor’s degree or higher; NoPAI, a composite proportion of residents who received no public assistance income; ≥$100K, a composite proportion of residents who earned an annual household income of greater than or equal to USD 100,000; HIGH-SES, a spatial composite measure of five spatial high-SES indicators derived from a principal component analysis; sMHI*, a spatial median of median household income divided or multiplied by −1; sMFI*, a spatial median of median family income divided or multiplied by −1; BP, a composite proportion of residents who were below poverty; UNE, a composite proportion of residents who were unemployed; NoHSD, a composite proportion of residents who had no high school diploma; WithPAI, a composite proportion of residents who were supported with public assistance income; <$25K, a composite proportion of residents who earned an annual household income of less than USD 25,000; and LOW-SES, a spatial composite measure of five spatial low-SES indicators derived from a principal component analysis.
Figure 7.
Correlation matrix of sixteen spatial measures in the San Jose–Sunnyvale–Santa Clara Metropolitan Statistical Area based on the 2015–2019 American Community Survey data. Abbreviations: SES, Socioeconomic Status; sMHI, a spatial median of median household income; sMFI, a spatial median of median family income; AP, a composite proportion of residents who were above poverty; EMP, a composite proportion of residents who were employed; ≥BD, a composite proportion of residents who held a Bachelor’s degree or higher; NoPAI, a composite proportion of residents who received no public assistance income; ≥$100K, a composite proportion of residents who earned an annual household income of greater than or equal to USD 100,000; HIGH-SES, a spatial composite measure of five spatial high-SES indicators derived from a principal component analysis; sMHI*, a spatial median of median household income divided or multiplied by −1; sMFI*, a spatial median of median family income divided or multiplied by −1; BP, a composite proportion of residents who were below poverty; UNE, a composite proportion of residents who were unemployed; NoHSD, a composite proportion of residents who had no high school diploma; WithPAI, a composite proportion of residents who were supported with public assistance income; <$25K, a composite proportion of residents who earned an annual household income of less than USD 25,000; and LOW-SES, a spatial composite measure of five spatial low-SES indicators derived from a principal component analysis.
![Socsci 13 00693 g007]()
Figure 8.
Correlation matrix of sixteen spatial measures in the Fresno Metropolitan Statistical Area based on the 2015–2019 American Community Survey data. Abbreviations: SES, Socioeconomic Status; sMHI, a spatial median of median household income; sMFI, a spatial median of median family income; AP, a composite proportion of residents who were above poverty; EMP, a composite proportion of residents who were employed; ≥BD, a composite proportion of residents who held a Bachelor’s degree or higher; NoPAI, a composite proportion of residents who received no public assistance income; ≥$100K, a composite proportion of residents who earned an annual household income of greater than or equal to USD 100,000; HIGH-SES, a spatial composite measure of five spatial high-SES indicators derived from a principal component analysis; sMHI*, a spatial median of median household income divided or multiplied by −1; sMFI*, a spatial median of median family income divided or multiplied by −1; BP, a composite proportion of residents who were below poverty; UNE, a composite proportion of residents who were unemployed; NoHSD, a composite proportion of residents who had no high school diploma; WithPAI, a composite proportion of residents who were supported with public assistance income; <$25K, a composite proportion of residents who earned an annual household income of less than USD 25,000; and LOW-SES, a spatial composite measure of five spatial low-SES indicators derived from a principal component analysis.
Figure 8.
Correlation matrix of sixteen spatial measures in the Fresno Metropolitan Statistical Area based on the 2015–2019 American Community Survey data. Abbreviations: SES, Socioeconomic Status; sMHI, a spatial median of median household income; sMFI, a spatial median of median family income; AP, a composite proportion of residents who were above poverty; EMP, a composite proportion of residents who were employed; ≥BD, a composite proportion of residents who held a Bachelor’s degree or higher; NoPAI, a composite proportion of residents who received no public assistance income; ≥$100K, a composite proportion of residents who earned an annual household income of greater than or equal to USD 100,000; HIGH-SES, a spatial composite measure of five spatial high-SES indicators derived from a principal component analysis; sMHI*, a spatial median of median household income divided or multiplied by −1; sMFI*, a spatial median of median family income divided or multiplied by −1; BP, a composite proportion of residents who were below poverty; UNE, a composite proportion of residents who were unemployed; NoHSD, a composite proportion of residents who had no high school diploma; WithPAI, a composite proportion of residents who were supported with public assistance income; <$25K, a composite proportion of residents who earned an annual household income of less than USD 25,000; and LOW-SES, a spatial composite measure of five spatial low-SES indicators derived from a principal component analysis.
![Socsci 13 00693 g008]()
5. Discussion
The results of this study (
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8 and
Figures S1–S24) did not support a general notion of exchangeability between two sets of mutually opposite census-tract-level SES indicators. Because such a notion plays an essential role in the development of an area-based index and thus the measurement of neighborhood-level SES, a convoluted manifestation of curvilinear, funnel, and nonlinear patterns, in turn, calls for a thorough assessment on the measurement validity of existing area-based indices used in the US (and other countries). In addition, two spatial approaches (
Oka and Wong 2016;
Wong 1998) implemented in this study suggest that the measurement uncertainty of existing area-based indices may be attributed largely to the shape of their multivariate distribution and partly to their aspatial nature. From a measurement perspective, a sequence of correlation analyses conducted in an array of geographic ranges and their demographic changes at four different time periods (
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8 and
Figures S1–S24) provide a reasonable basis to untangle a few underlying sources of measurement uncertainty overlooked by
Allik et al. (
2020) and
Sorice et al. (
2022).
Whether misled or obscured by the dearth of analytical transparency in the literature, the complexities of human geography (
O’Sullivan 2004) and geographies of uncertainty (
Senanayake and King 2021) have been largely overlooked during the development process of existing area-based indices in the US (and in other countries). In all likelihood, an oversight of such complexities may give rise to measurement error in different geographic settings. For instance, a sequence of correlation analyses in the State of California (
Figure 1 and
Figures S1–S3) and its six largest MSAs (
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6 and
Figure 7 and
Figures S4–S21) suggest that a set of census-tract-level SES indicators may not intercorrelate with one another and thus a conceptualization of high-SES neighborhoods may not invert to a conceptualization of low-SES neighborhoods (or vice versa). The only exception was the Fresno MSA (
Figure 8 and
Figures S22–S24), which comprised about 800,000 to about 985,000 people and 158 or 199 census tracts (
Table 1). While the population size of one million and/or the sample size of 200 census tracts may not be considered as a differential threshold, the measurement uncertainty (
Allik et al. 2020;
Sorice et al. 2022) may be greater in large geographic ranges (e.g., large MSAs and states) and lesser in small geographic ranges (e.g., cities and small MSAs). Therefore, the measurement uncertainty (
Allik et al. 2020;
Sorice et al. 2022) may arise from a difference in the size of human settlements that vary in geographic space.
Since the generalizability of existing area-based indices has not been elucidated in a clear and straightforward manner, further efforts are needed to assess their measurement validity by ensuring an exchangeability between two sets of mutually opposite census-tract-level SES indicators in a wide array of geographic ranges (e.g., from a city to a MSA to a combination of nearby MSAs and its peripheral counties to an entire state and then to the entire conterminous US). Otherwise, an area-based index may not capture what it is intended to capture (i.e., a change from highest to lowest SES neighborhoods or vice versa). In doing so, however, it is important to recognize that distributional patterns of socioeconomic groups tend to be complex and dynamic thereby exhibiting noticeable differences between urban, suburban, and rural areas in the US (
Parker et al. 2018). By and large, these differences reflect local and regional variations in the economic growth and decline of the US (
Cromartie 2018;
Johnson 2012). While conceptual and methodological approaches to the measurement of neighborhood-level SES have long been centered around a multifactorial construct of multiple census-tract-level SES indicators (
Allik et al. 2020;
Sorice et al. 2022), such a construct may be applicable to certain geographic settings, but may not be generalizable to other geographic settings. Therefore, the measurement uncertainty (
Allik et al. 2020;
Sorice et al. 2022) may arise from an intertwined interplay of residential preferences (
Parker et al. 2018) and economic opportunities (
Cromartie 2018;
Johnson 2012) that vary in geographic space.
In conjunction with urban–suburban–rural variations in the size of human settlements and the socioeconomic makeup of neighborhoods, the quality of population estimates (
United States Census Bureau 2020) and the outlier-prone nature of multivariate techniques (
Chesher 1991) cast additional layers of uncertainty over a conventional multivariate approach to the measurement of neighborhood-level SES. On the whole, population estimates at the census tract level (but more so at the block group level) tend to be less accurate (with relatively large margins of error) in sparsely populated areas relative to those in densely populated areas (
Bazuin and Fraser 2013;
Folch et al. 2016;
Spielman et al. 2014). Independent from the accuracy of population estimates, one or more multivariate outliers may emerge from any multivariate technique even in the absence of a univariate outlier (
Hair et al. 2009) and addressing this computational problem may not be a trivial task (
Aggarwal 2013) depending on the dataset being analyzed. While these have been widely regarded as unavoidable sources of measurement error, a comparative study of two similar aspatial composite measures of neighborhood-level SES (
Boscoe et al. 2021) showed substantial dissimilarities between the two in different parts of the US, particularly in local areas with missing data and multivariate outliers. Therefore, the measurement uncertainty (
Allik et al. 2020;
Sorice et al. 2022) may arise from the presence of missing data and/or multivariate outlier(s) that vary in geographic space.
Given the complexities of human geography (
O’Sullivan 2004) and geographies of uncertainty (
Senanayake and King 2021), only a few underlying sources of measurement uncertainty overlooked by
Allik et al. (
2020) and
Sorice et al. (
2022) were described in this study. However, these closely coincide with a couple of common oversights masked by the lack of analytical transparency on the exploratory data analysis of existing area-based indices in the US (and in other countries). As a consequence of such oversights, for example, the curvilinear relationships between HIGH-SES and LOW-SES with a moderate or large dispersion in the State of California and its six largest MSAs at four different time periods (
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figures S1–S21) suggest high degrees of measurement uncertainty, whereas the slightly curvilinear relationships between HIGH-SES and LOW-SES with a small dispersion in the Fresno MSA at four different time periods (
Figure 8 and
Figures S22–S24) suggest low degrees of measurement uncertainty. While
Allik et al. (
2020) and
Sorice et al. (
2022) emphasized the importance of reaching a consensus on the conceptual and methodological approach to the measurement of neighborhood-level SES, the complexities of human geography (
O’Sullivan 2004) and geographies of uncertainty (
Senanayake and King 2021) may pose unprecedented challenges for such research endeavors. Taken together, further efforts on the development of a reliable area-based index in the US (and in other countries) may require a refined conceptualization of neighborhood-level SES and a more sophisticated method to measure it.
By virtue of the study design, a detailed assessment on the measurement validity (
Bannigan and Watson 2009;
Bartlett and Frost 2008;
Heale and Twycross 2015) was beyond the scope of this study. However, a combination of Pearson’s correlation coefficients and scatterplots shown in
Figure 1,
Figure 2,
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8 and
Figures S1–S24 reconfirms the usefulness of explanatory data analysis in understanding the aptness of a hypothetical area-based index used in this study. Notwithstanding the descriptive nature of a correlogram (
Friendly 2002), conducting research on analytical transparency in this way may prevent, reduce, or mitigate the inconsistency of research findings (
Allik et al. 2020;
Sorice et al. 2022) in different geographic settings. Whether modifying an existing area-based index or developing a new one, therefore, further efforts on the development of a reliable area-based index needs to demonstrate its reliability by capturing a change from highest to lowest SES neighborhoods and a change from lowest to highest SES neighborhoods in an inverse manner (at least, equivalent to the relationships between HIGH-SES and LOW-SES shown in
Figure 8 and
Figures S22–S24). Since the lack of analytical transparency may have been responsible for some aspects of the measurement uncertainty (
Allik et al. 2020;
Sorice et al. 2022), further efforts need to pay utmost attention to detail for avoiding ambiguity, confusion, and misunderstandings.
The preceding discussions on a few underlying sources of measurement uncertainty inherent in existing area-based indices and on further efforts in developing a reliable area-based index are not only relevant to the State of California, but also to other states and to the entire US. Since the study of neighborhoods and health has been conducted mostly in industrialized countries, the same notion of analogy applies to non-US countries. Even if the size of small enumeration units were to be slightly smaller or larger than that of census tracts in the US, the concepts of composite population (
Wong 1998) and areal median filtering (
Oka and Wong 2016) can be implemented in other countries. However, the design of census questionnaires differs considerably from one country to another and thus a set of spatial high-SES indicators and their respective low-SES counterparts may be restricted to the availability of census data in their own country. In view of the unavoidable reality of such inter-country differences, a consensus on the optimal number and types of census-tract-level SES indicators incorporated into an area-based index (
Allik et al. 2020;
Sorice et al. 2022) is of importance only within a country, but not between or across countries. Hence, further efforts need to focus on the development of a reliable area-based index based on the available census data at hand and to ensure its measurement validity across a wide array of geographic ranges and their demographic changes at different time periods in their own country.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}