
Enabling Artificial Intelligence Adoption through Assurance


Abstract
:1. Introduction
What Is AI Assurance?
2. Motivation
- Mission Alignment—each of these agencies emphasizes how AI will contribute to the agency’s core mission.
- Informed by scientific understanding—using terms like domain aware, informed by science and technology, these documents highlight that AI algorithms should incorporate existing knowledge.
- Explainability—using terms like interpretability, transparency, and accountability, these documents highlight how important it is to explain AI decisions and predictions Samek et al. (2019).
- Fairness—terms such as objective, accurate, and equitable highlight how we need to understand any biases resident in AI algorithms, even if they are capturing and reflecting existing biases in society Pearl (2009); Coeckelbergh (2020).
- Reliability, Robustness—highlight the need to understand the consistency of algorithm prediction across varying domains and understand when they may fail Cantero Gamito and Ebers (2021).
- Ethical—as AI scales solutions, it also scales mistakes, discrimination, and potential non-ethical outcomes. Algorithms ought to be assured to ensure ethical standards (within the context it is applied) are met Coeckelbergh (2020).
- Trustworthiness—concepts such as integrity, human-centered development and use, respect the law, convey that humans must be able to trust the AI algorithms for wide-scale (agency level) adoption Banks and Ashmore (2019).
3. AI Assurance Definitions and Main Terms
- The difference between validation and verification: In the software testing world, testing could be categorized into two groups: validation and verification (often referred to as V&V). In simple terms, validation means providing the desired system to the user, it is building the right system, while verification is building the system right (i.e., without any errors, bugs, or technical issues). A conventional software system however, doesn’t learn, it is based on predefined and preexisting sets of commands and instructions. AI assurance requires V&V, but it certainly expands beyond those limits. One of AI assurance’s aspects that is fairly novel is Explainable AI (AI) Samek et al. (2019); Batarseh et al. (2021).
- Test and Evaluation: Chapter 8 of the Defense Acquisition Guidebook defines the purpose of a Test and Evaluation (T&E) program is to provide “engineers and design-makers with knowledge to assist in managing risks, measure technical progress, and characterize operational effectiveness, operational suitability, and survivability (including cybersecurity), or lethality of the system in the intended operational environment.” To achieve this goal, a T&E programs should use a structured sequence of tests across the development life-cycle of a system coupled with statistical analyses of the data. Traditionally, T&E programs have ended at system fielding. However, the increase in software defined systems has pushed the need for ongoing T&E on fielded systems, the incorporation of AI software will further exacerbate this need. In this paper, we will look at T&E as the data collection process for achieving system validation for AI Assurance.
- Explainable AI (XAI): References the concept of explainability Samek et al. (2019) at the intersection of multiple areas of active research. We discuss the following aspects of XAI:
- (a)
- Transparency: users of AI systems “have a right” to have outputs and decisions affecting them explained in understandable (and preferably domain-specific) terms and formats. That allows them to inspect its safety and clear goals.
- (b)
- (c)
- Bias: bias has two forms in the context of AI model building. It can be statistical, and could be detected through overfitting and underfitting measure (which is opposite to variance). Bias can be also due to issues such as skew or data incompleteness in “the environment”; this aspect could be investigated and mitigated through data collection best practices, and the analysis of contextual awareness Nelson (2019).
- (d)
- Fairness: If decisions are made based on an AI system, they need to be verified that they are “fair”. The infamous story of Google’s racist bot is an example of what should be avoided Pearl (2009); Cantero Gamito and Ebers (2021).
- Data democracy and context: The results of data science endeavors are majorly driven by data quality Santhanam (2020); Hossin and Sulaiman (2015). Throughout these deployments, serious show-stopper problems are still generally unresolved by the field, those include: data collection ambiguities, data imbalance and availability, the lack of domain information, and data incompleteness. All those aspects are at the heart of AI assurance. Moreover, context plays a pivotal role in data collection and decision making as it can change the meaning of concepts present in a dataset. The availability of data at an organization to the data collector is an example of democratization. However, the scope of data required to create the desired outputs is refereed to as the context of the data collection (i.e., how much data is enough?).
- AI subareas: In this document, we aim to establish subareas of AI clearly. As stated, different areas require different assurance aspects, and so we aim to capture those categories: a. Machine Learning (including supervised and unsupervised learning), b. Computer Vision, c. Reinforcement Learning, d. Deep Learning (including neural networks), e. Agent-Based Systems f. Natural Language Processing (including text mining), g. Knowledge-Based Systems (including expert systems).
4. Factors Influencing AI Assurance
4.1. Data Democracy and Quality
4.2. Notion of an Operating Envelope
4.3. Hardware Design Model Integration
4.4. Statistical Considerations
5. Proposed Framework for Assuring AI
5.1. Define
- AI Domain—what is the broad organization mission that is acquiring the AI enabled system (e.g., government, energy sector, defense, healthcare, etc.)?; What context does that bring to the challenge of assuring AI? Gunning et al. (2019)
- Mission context—what is the problem that the organization is trying to solve with an AI system(s)? How does the AI support the organizational mission? Gunning et al. (2019)
- AI Area—what is the type of AI needed (e.g., deep learning, reinforcement learning, etc.); How does the AI contribute in ways that previous methods failed?
- Scientific/Engineering Alignment—What are the scientific and/or engineering needs that the AI can solve?; How does it integrate with know constraints?; How does it incorporate prior knowledge (solely through data or other mechanisms)?
- AI Goal—What are the primary directives for the AI, how does this stem from the AI domain? Must it be ethical, explainable, fair, etc.? Pearl (2009); Cantero Gamito and Ebers (2021)
5.2. Measure
- Algorithm Performance Cantero Gamito and Ebers (2021)
- Security Banks and Ashmore (2019)
- Trustworthiness Cantero Gamito and Ebers (2021)
- Explainability Samek et al. (2019)
- Ethicality Coeckelbergh (2020)
5.3. Characterize & Add Context
5.4. Plan Strategy
5.5. Execute & Analyze
5.6. Monitor & Improve
6. Challenges in Assuring AI
- Model Quality. in Siebert et al. (2020) discuss the importance of quality metrics in reference to AI and ML. The primary driver of their work was to motivate the need to develop good quantitative measures of quality to connect context to function in an operational setting. A critical arena for this correlation is in the consideration of what is called the ground truth of the model. Existence of ground truth can occur in three modes: full, partial, or not at all. In each of the three scenarios, its existence can directly determine the ability to effectively determine quality measures. In the case of full ground truth being known, the ability to characterize quality can be done in direct measure with the known ground truth. In the case of partial ground truth awareness, considerations of data quality must be examined meticulously. Finally, if no ground truth is known the training and test splits are based on assumptions that require delicate evaluation as it pertains to the quality of model predictions. In all three cases, it becomes clear that metrics associated with the characterization of model performance should be used to proffer connections to the quality of model outputs (i.e., predictions) Hossin and Sulaiman (2015).
- Usage of Model Metrics. Model metrics differ based on the types of models being developed. Classification models utilize accuracy, precision, f-score, and others while clustering methods Emmons et al. (2016) utilize others such as Silhouette and Elbow Diagrams. In evaluating the quality of models, the treatment of these metrics as it pertains to determination of false positives (FP) and false negatives (FN) may be weighted differently as its applied to the specific model. Compatibility considerations for FP and FN have also been shown to play a part in forming deeper understandings of quality and assurance practices Banks and Ashmore (2019); Samek et al. (2019).
- Model Dependency. Furthermore, while supervised ML models have pre-labeled outcomes (i.e., predictions) that could be verified against actual numbers, unsupervised models don’t have the same labels as the outcomes are dependent on the patterns found in the data, therefore, AI assurance is model-dependent Batarseh et al. (2021).
- Domain Dependence. Additionally, different domains have different “expectations”, for instance, a 0.1 variance in revenue predictions for decision making at a company has much more benign consequences than a 0.1 variance in an open heart surgery robot or a mission-critical bomber aircraft. Therefore, AI assurance measures are domain-dependent Gunning et al. (2019).
- Geography. Besides the “domain” challenge, there is a global (geographical) issue based on environmental, geographic, and geospatial (and even cultural) factors that contribute to (re)-training, (re)-testing, and (cross)-validation of models. For example, as weather patterns may alter due to seasons or other factors, ML performance may vary likewise. Understanding the impacts of these changes are critical to model stability.
- Operating Envelopes. Minimization of factors contributing to operating envelope change is important. The observations and measurements (i.e., the data) gathered prior to building a model should be stable over time. Challenges related to maintaining this stability can drastically impact model performance and operation Batarseh et al. (2021).
7. Conclusions, Summaries, and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Allen, Gregory C. 2019. Understanding China’s Ai Strategy. Available online: https://www.cnas.org/publications/reports/ (accessed on 30 April 2021).
- Amodei, Dario, Sundaram Ananthanarayanan, Rishita Anubhai, Jingliang Bai, Eric Battenberg, Carl Case, Jared Casper, Bryan Catanzaro, Qiang Cheng, Guoliang Chen, and et al. 2016. Deep speech 2: End-to-end speech recognition in english and mandarin. Paper presented at the International Conference on Machine Learning, New York, NY, USA, June 19–24; pp. 173–82. [Google Scholar]
- Banks, Alec, and Rob Ashmore. 2019. Requirements assurance in machine learning. Paper presented at the AAAI Workshop on Artificial Intelligence Safety 2019, Honolulu, HI, USA, January 27; pp. 14–21. [Google Scholar]
- Batarseh, Feras A., and Ruixin Yang. 2020. Data Democracy: At the Nexus of Artificial Intelligence, Software Development, and Knowledge Systems. Cambridge: Academic Press. [Google Scholar]
- Batarseh, Feras A., Laura Freeman, and Chih-Hao Huang. 2021. A survey on artificial intelligence assurance. Journal of Big Data 8: 1–30. [Google Scholar] [CrossRef]
- Bloomfield, Robin, and John Rushby. 2020. Assurance 2.0: A manifesto. arXiv arXiv:2004.10474. [Google Scholar]
- Cantero Gamito, Marta, and Martin Ebers. 2021. Algorithmic Governance and Governance of Algorithms: An Introduction. Cham: Springer International Publishing, pp. 1–22. [Google Scholar]
- Coeckelbergh, Mark. 2020. AI Ethics. MIT Press Essential Knowledge Series; Cambridge: MIT Press. [Google Scholar]
- Department of Defense. 2018. Summary of the 2018 Department of Defense Artificial Intelligence Strategy; Report. Washington, DC: Department of Defense.
- Dodge, Samuel, and Lina Karam. 2019. Human and dnn classification performance on images with quality distortions: A comparative study. ACM Transactions on Applied Perception (TAP) 16: 1–17. [Google Scholar] [CrossRef]
- Emmons, Scott, Stephen Kobourov, Mike Gallant, and Katy Börner. 2016. Analysis of network clustering algorithms and cluster quality metrics at scale. PLoS ONE 11: e0159161. [Google Scholar] [CrossRef] [PubMed]
- Executive Order 13859: American Artificial Intelligence Initiative; 2019. Washington, DC: Executive Order, Executive Office of the President of the United States of America.
- Gama, João, Pedro Medas, Gladys Castillo, and Pedro Rodrigues. 2004. Learning with drift detection. In Advances in Artificial Intelligence—SBIA 2004. Lecture Notes in Computer Science. Berlin and Heidelberg: Springer, vol. 3171. [Google Scholar]
- Gama, João, Indrundefined Žliobaitundefined, Albert Bifet, Mykola Pechenizkiy, and Abdelhamid Bouchachia. 2014. A survey on concept drift adaptation. ACM Computing Surveys (CSUR) 46: 1–37. [Google Scholar] [CrossRef]
- Gunning, David, Mark Stefik, Jaesik Choi, Timothy Miller, Simone Stumpf, and Guang-Zhong Yang. 2019. Xai—Explainable artificial intelligence. Science Robotics 4. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2015. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. Paper presented at IEEE International Conference on Computer Vision, Santiago, Chile, December 7–13; pp. 1026–34. [Google Scholar]
- Hoerl, Roger W., and Ronald D. Snee. 2020. Statistical Thinking: Improving Business Performance. Hoboken: John Wiley & Sons. [Google Scholar]
- Hossin, Mohammad, and Md Nasir Sulaiman. 2015. A review on evaluation metrics for data classification evaluations. International Journal of Data Mining & Knowledge Management Process 5: 1–11. [Google Scholar]
- Jha, Susmit, John Rushby, and Natarajan Shankar. 2020. Model-centered assurance for autonomous systems. In Computer Safety, Reliability, and Security. SAFECOMP 2020. Lecture Notes in Computer Science. Cham: Springer, vol. 12234. [Google Scholar]
- Kläs, Michael, and Anna Maria Vollmer. 2018. Uncertainty in machine learning applications: A practice-driven classification of uncertainty. In Computer Safety, Reliability, and Security. SAFECOMP 2018. Lecture Notes in Computer Science. Cham: Springer, vol. 11094. [Google Scholar]
- Lanus, Erin, Ivan Hernandez, Adam Dachowicz, Laura Freeman, Melanie Grande, Andrew Lang, Jitesh H. Panchal, Anthony Patrick, and Scott Welch. 2021. Test and evaluation framework for multi-agent systems of autonomous intelligent agents. arXiv arXiv:2101.10430. [Google Scholar]
- Launchbury, John. 2017. A Darpa Perspective on Artifical Intelligence. Available online: https://https://www.darpa.mil/attachments/AIFull.pdf (accessed on 30 April 2021).
- National Defense Authorization Act (NDAA) for Fy 2013. 2013. Bill Passed, United States. Congress. House. Washington, DC: Committee on Armed Services.
- National Institute for Standards and Technology (NIST). 2020. Security and Privacy Controls for Information Systems and Organizations; NIST Special Publication 800-53, Rev. 5; Gaithersburg: National Institute for Standards and Technology (NIST).
- Nelson, Gregory S. 2019. Bias in artificial intelligence. North Carolina Medical Journal 80: 220–22. [Google Scholar] [CrossRef] [PubMed]
- Office for the Director of National Intelligence. 2019. The Aim Initiative: A Strategy for Augmenting Intelligence Using Machines; Technical Report. McLean: Office for the Director of National Intelligence.
- Pearl, Judea. 2009. Causality, 2nd ed. Cambridge: Cambridge University Press. [Google Scholar]
- Pei, Kexin, Yinzhi Cao, Junfeng Yang, and Suman Jana. 2017. Deepxplore: Automated whitebox testing of deep learning systems. Paper presented at 26th Symposium on Operating Systems Principles, Shanghai, China, October 28; pp. 1–18. [Google Scholar]
- Rushby, John. 1988. Quality Measures and Assurance for Ai Software. NASA Contractor Report 4187. Menlo Park: SRI International. [Google Scholar]
- Samek, Wojciech, Grégoire Montavon, Andrea Vedaldi, Lars Kai Hansen, and Klaus-Robert Müllerüller. 2019. Explainable AI: Interpreting, Explaining and Visualizing Deep Learning. Lecture Notes in Computer Science. Berlin: Springer International Publishing. [Google Scholar]
- Santhanam, P. 2020. Quality management of machine learning systems. In Engineering Dependable and Secure Machine Learning Systems. Cham: Springer International Publishing, pp. 1–13. [Google Scholar]
- Shankar, Rama. 2009. Process Improvement Using Six Sigma: A DMAIC Guide. Milwaukee: Quality Press. [Google Scholar]
- Siebert, Julien, Lisa Joeckel, Jens Heidrich, Koji Nakamichi, Kyoko Ohashi, Isao Namba, Rieko Yamamoto, and Mikio Aoyama. 2020. Towards guidelines for assessing qualities of machine learning systems. In Quality of Information and Communications Technology. QUATIC 2020. Communications in Computer and Information Science. Cham: Springer, vol. 1266. [Google Scholar]
- Silver, David, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, and et al. 2016. Mastering the game of go with deep neural networks and tree search. Nature 529: 484–89. [Google Scholar] [CrossRef] [PubMed]
- The National Artificial Intelligence Research and Development Strategic Plan: 2019 Update. 2019, Report by the Select Committee on Artificial Intelligence of The National Science and Technology Council, Executive Office of the President of the United States of America. Available online: https://www.nitrd.gov/pubs/National-AI-RD-Strategy-2019.pdf (accessed on 30 April 2021).
- Tsymbal, Alexey. 2004. The Problem of Concept Drift: Definitions and Related Work. Technical Report. Dublin: Department of Computer Science, Trinity College. [Google Scholar]
- Tsymbal, Alexey, Mykola Pechenizkiy, Padraig Cunningham, and Seppo Puuronen. 2006. Handling local concept drift with dynamic integration of classifiers: Domain of antibiotic resistance in nosocomial infections. Paper presented at 19th IEEE Symposium on Computer-Based Medical Systems (CBMS ’06), Salt Lake City, UT, USA, June 22–23; pp. 679–84. [Google Scholar]
- Žliobaitė, Indrė. 2009. Learning under concept drift: An overview. arXiv arXiv:1010.4784. [Google Scholar]

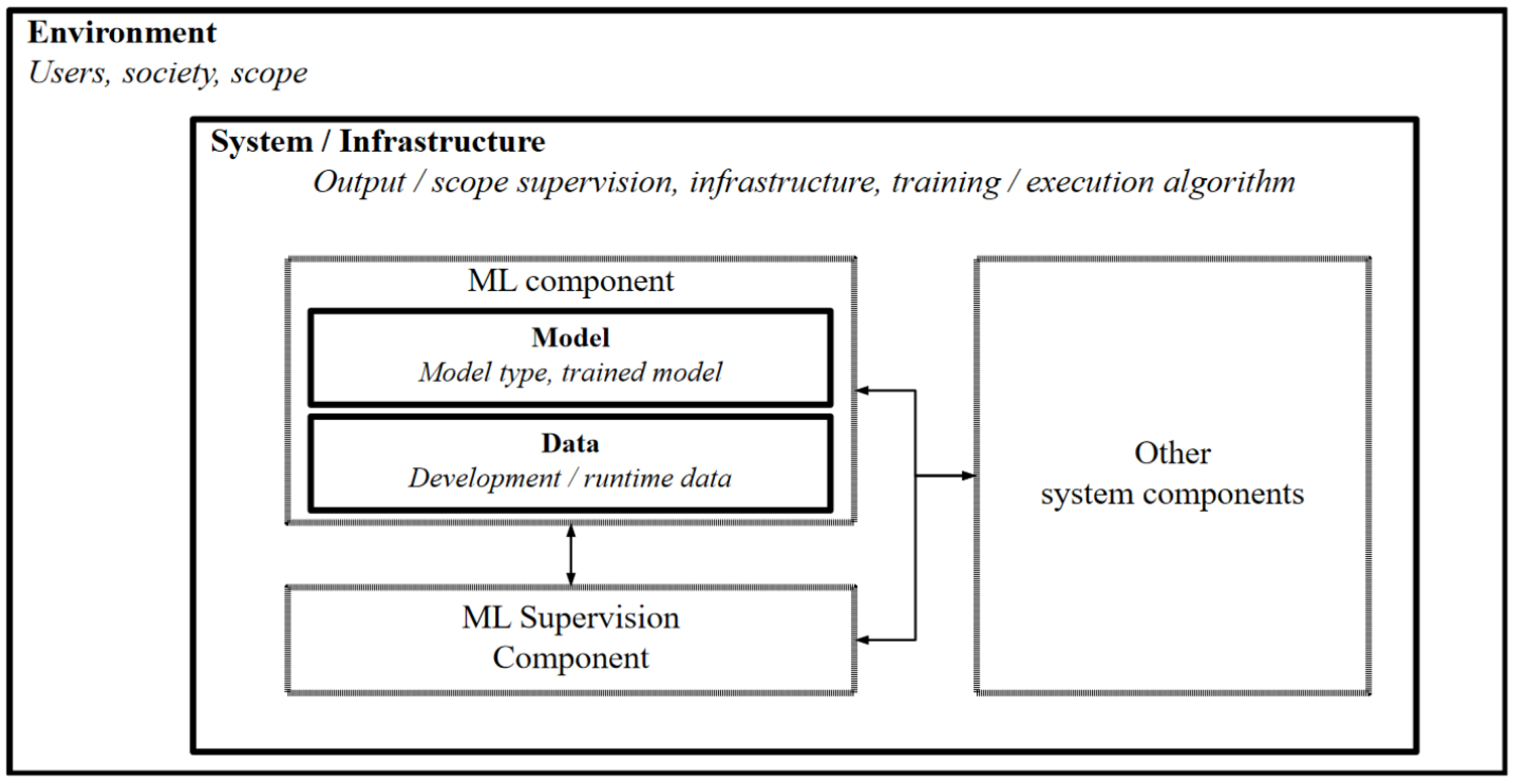
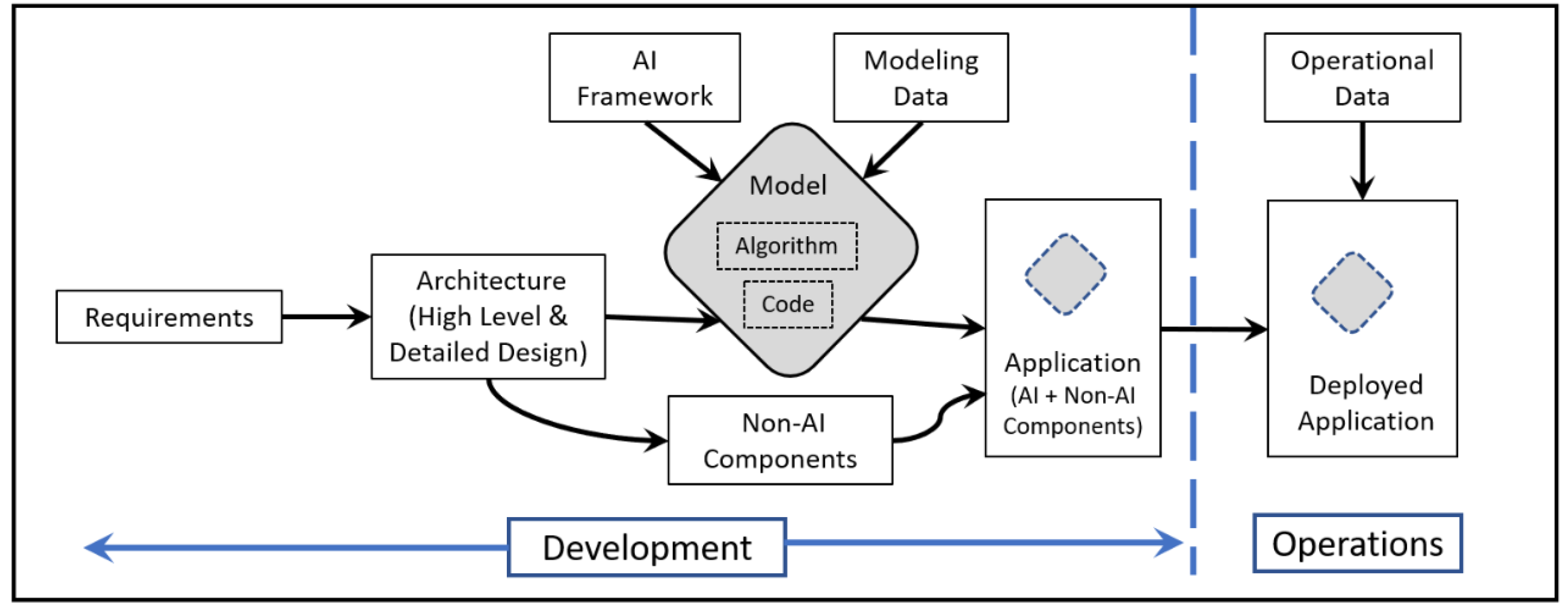


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Term | Definition | Reference |
|---|---|---|
| AI Assurance | A process that is applied at all stages of the AI engineering lifecycle ensuring that any intelligent system is producing outcomes that are valid, verified, data-driven, trustworthy and explainable to a layman, ethical in the context of its deployment, unbiased in its learning, and fair to its users. | Batarseh et al. (2021) |
| AI Domain | The organizational mission, domain (such as healthcare, economics, and energy), and associated systems/requirements pertaining to the AI enabled system. | Gunning et al. (2019) |
| Bias | The case when an algorithm produces results that are systemically prejudiced due to erroneous assumptions or inputs. | Nelson (2019) |
| Causality | The underlying web of causes of a behavior or event and furnishes critical insights that predictive models fail to provide | Pearl (2009); Cantero Gamito and Ebers (2021) |
| Data Democracy | Making digital information (i.e., data) accessible to the average non-technical user of information systems, without having to require the involvement of IT | Batarseh and Yang (2020) |
| Domain Dependence | Aligning an AI algorithm’s utility with technical capabilities, industry-specific systems, and related requirements | Gunning et al. (2019) |
| Ethicality | An AI algorithm’s ability to incorporate moral judgements based on right vs. wrong, morality, and social responsibility | Coeckelbergh (2020) |
| Explainability (XAI) | An AI system that is developed with high transparency and in a manner that promotes laymen level understanding of its algorithm and rationale. | Gunning et al. (2019) |
| Fairness | An AI algorithm’s ability to ensure that an outpu reflects the whole population and its demographics. | Pearl (2009); Cantero Gamito and Ebers (2021) |
| Model Quality | (Re)-Training and (Re)-Testing of a model to optimize model metrics like accuracy and precision to iteratively and continuously improve a model’s predictive power. | Hossin and Sulaiman (2015); Santhanam (2020); Rushby (1988) |
| Model Dependency | Set of libraries, code, and capabilities necessary for an algorithm to run. | Pearl (2009); Batarseh and Yang (2020); Cantero Gamito and Ebers (2021) |
| Operating Envelope | Envelopes are directly connected to the environment in which models run. They concern the external factors that impact data acquisition that affect model operation, training, testing, and execution through direct or indirect interactions. | Batarseh et al. (2021); Cantero Gamito and Ebers (2021) |
| Reliability | The removal of bugs, faults, and intrinsic errors in a model to enable its predictions to be consistent over time. | Cantero Gamito and Ebers (2021); Batarseh et al. (2021) |
| Robustness | The efficacy of a model to scale to other similar but different data sets and produce consistent results. | Cantero Gamito and Ebers (2021); Batarseh et al. (2021) |
| Transparency | Stating outputs and decisions of AI in a manner that can be explained in understandable (and preferably domain-specific) terms and formats to facilitate improved understanding of safety and compliance goals | Samek et al. (2019); Coeckelbergh (2020) |
| Trustworthiness | Confidence that a decision provided by an AI algorithm is reliable and would pass the Turing test in that it could be the same outcome created by a human user; which leads to trust. | Batarseh et al. (2021); Banks and Ashmore (2019) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Freeman, L.; Rahman, A.; Batarseh, F.A. Enabling Artificial Intelligence Adoption through Assurance. Soc. Sci. 2021, 10, 322. https://doi.org/10.3390/socsci10090322
Freeman L, Rahman A, Batarseh FA. Enabling Artificial Intelligence Adoption through Assurance. Social Sciences. 2021; 10(9):322. https://doi.org/10.3390/socsci10090322
Chicago/Turabian StyleFreeman, Laura, Abdul Rahman, and Feras A. Batarseh. 2021. "Enabling Artificial Intelligence Adoption through Assurance" Social Sciences 10, no. 9: 322. https://doi.org/10.3390/socsci10090322
APA StyleFreeman, L., Rahman, A., & Batarseh, F. A. (2021). Enabling Artificial Intelligence Adoption through Assurance. Social Sciences, 10(9), 322. https://doi.org/10.3390/socsci10090322