Automatic BIM Reconstruction for Existing Building MEP Systems from Drawing Recognition


Abstract
1. Introduction
- The components of MEP systems must work in coordination and have strong interdependence, which imposes strict requirements on coordinate accuracy in modeling. However, the coordinate detection accuracy in current studies often fails to meet the requirements of construction specifications;
- MEP components come in various classes, each containing types of different sizes. BIM models generated from semantic segmentation masks in recent studies have met the requirements for planar geometric shapes. But their dimensions overlook the equipment specifications provided in the drawings and design modulus, as well as the height of the components along the Z-axis.
- Semantic segmentation is used to identify MEP components in the drawings and extract their semantic information, with a custom-made MEP dataset used to train the neural network beforehand;
- Key coordinates and dimensions of MEP components are extracted through contour detection and bounding box detection. For duct components, OCR-based annotation recognition is specifically used to identify the height on the Z-axis;
- All model types in Revit are predefined, and an MEP component dictionary is built, ensuring that all generated BIM models comply with the specifications.
2. Methods
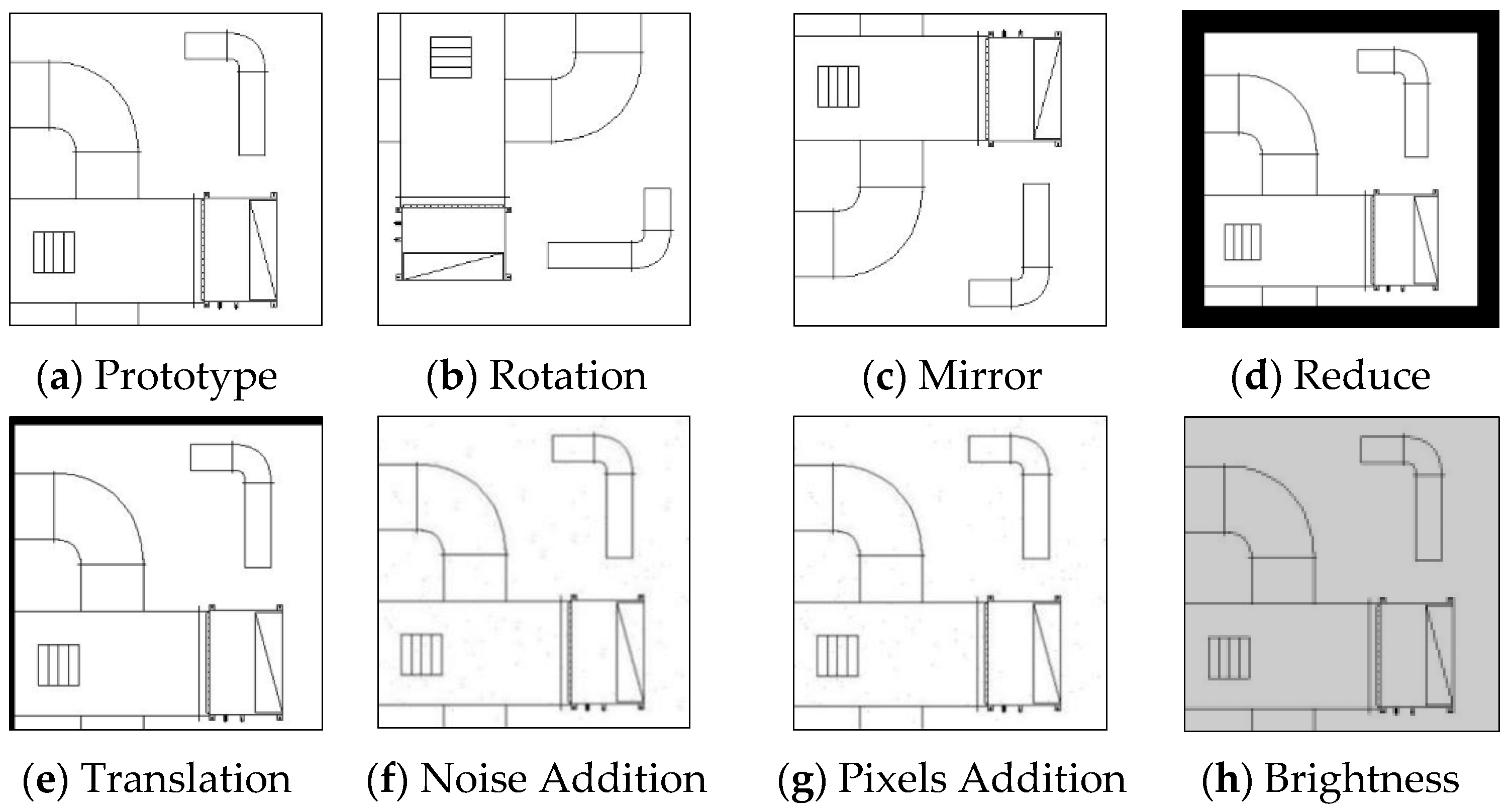
- Creation of the MEP Dataset: First, identify the classes of components that need to be recognized and collect data images. Subsequently, use a sliding window to crop the data images, annotate the images using Labelme, and perform data augmentation. This step ensures that the dataset is diverse and robust, enhancing the training process for the recognition network. The augmented data is then ready for use in training the deep learning network, ensuring better generalization and accuracy when applied to real-world MEP 2D drawings;
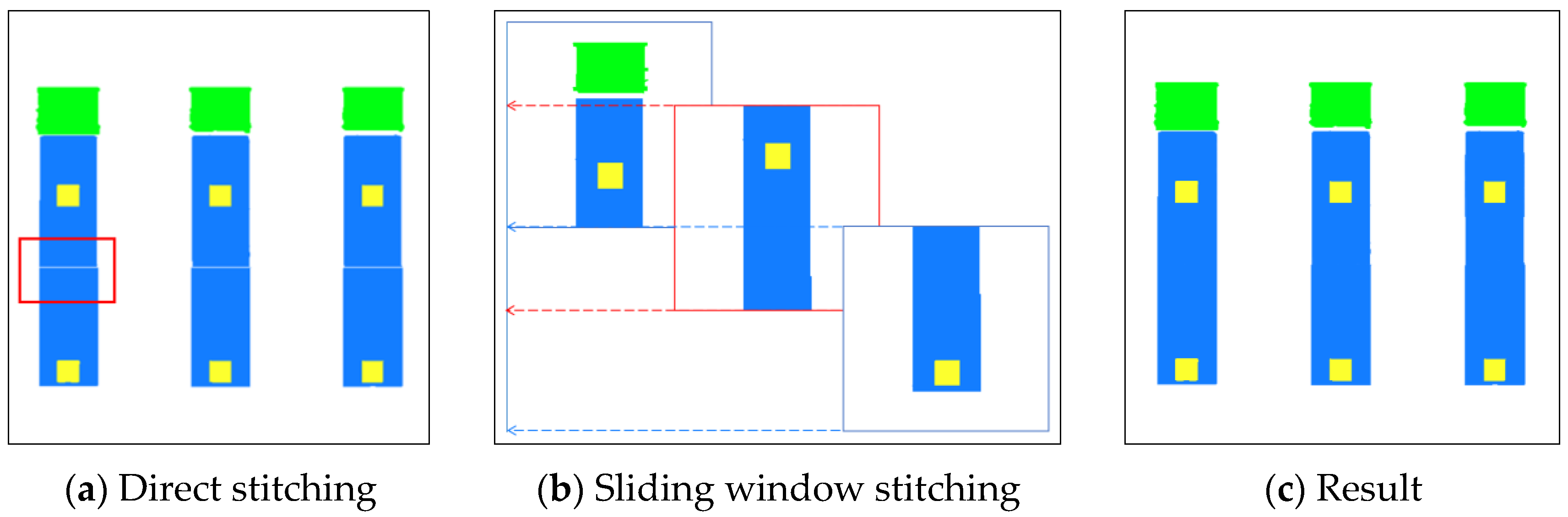
- Semantic Segmentation Training and Prediction: Use MMSegmentation to train several neural networks on the MEP dataset. The best network which achieves the highest evaluating indicator (mIoU) is then utilized to predict images. Next, apply sliding window cropping to break the MEP drawing of a certain floor into smaller cropped images and predict them. Finally, use sliding window stitching to combine the predicted masks from the cropped images into a complete mask image of the entire floor;
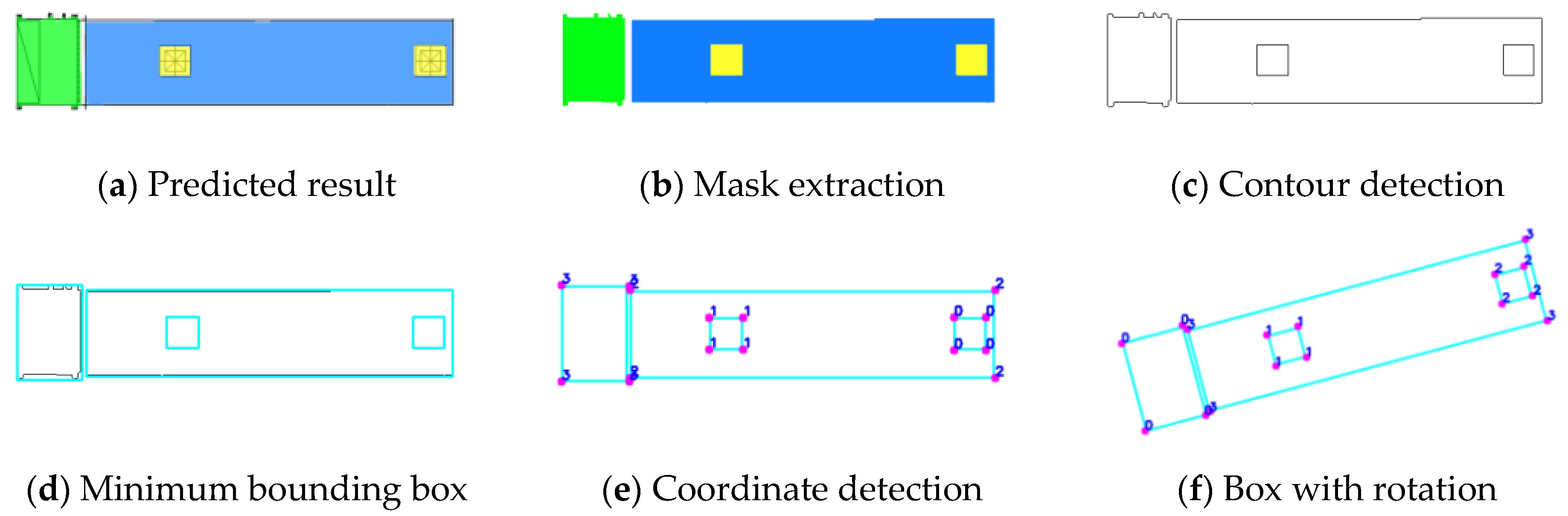
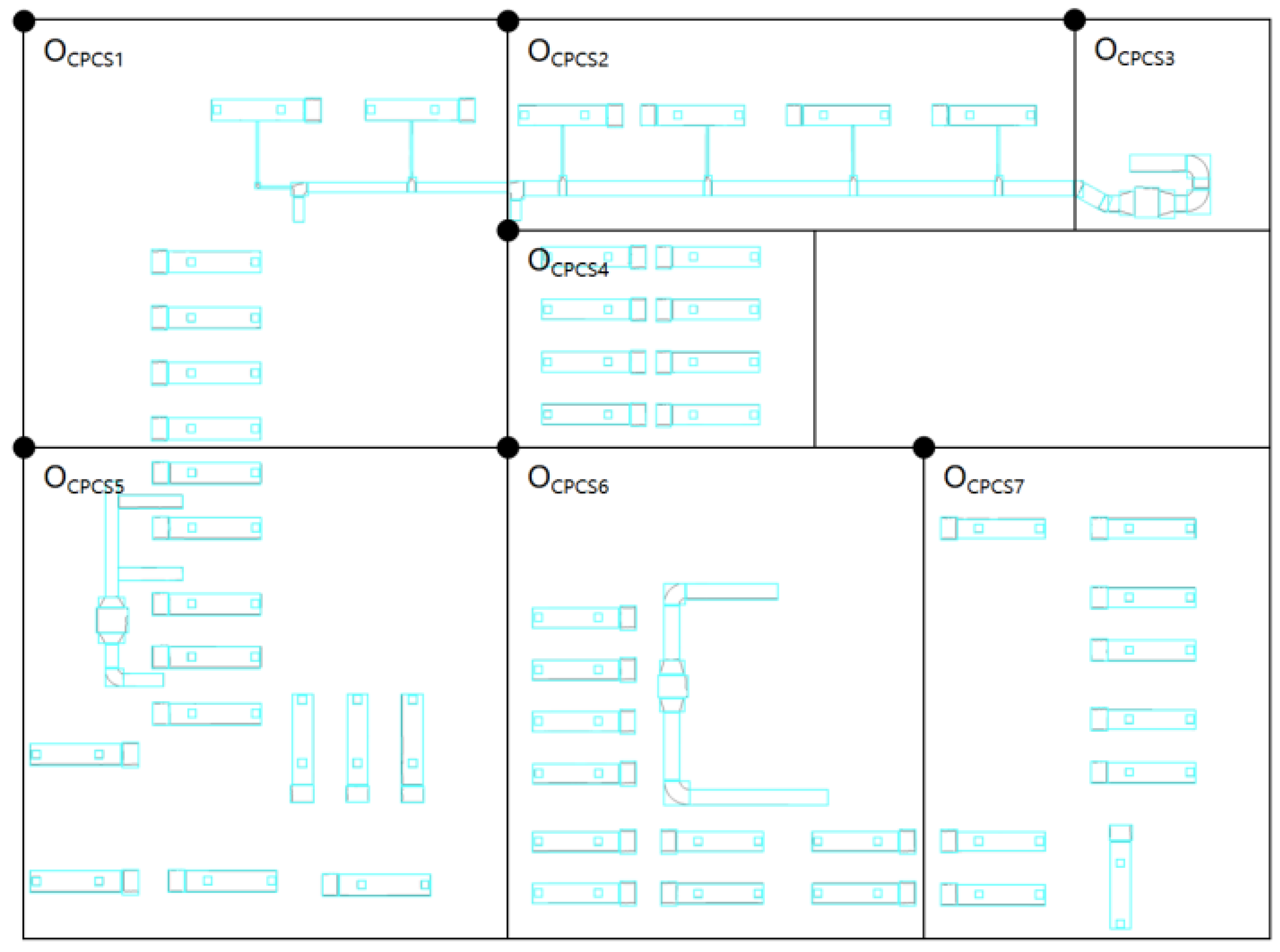
- Contour and Bounding Box Detection: Perform contour detection on the complete mask image to obtain the contours of each component and generate an overall contour image. Then, separate the overall contour image into several individual images. For each component contour in each separated image, generate the minimum bounding rectangular box with a rotation angle;
- Coordinate Transformation and Type Matching: In terms of coordinate transformation, the key point coordinates for modeling, such as the center point and rotation angle for equipment or the two endpoints for ducts, are obtained based on the four corner coordinates extracted from the bounding box. In terms of type matching, an MEP component dictionary is used to match the extracted dimensions with the specifications. For the equipment component, the coordinates of the bounding box are applied to the mask image, and the number of pixels within the component mask inside the bounding box is counted. The pixel count is then converted to the actual size to match the specific model in the dictionary. For the ducts component, OCR is utilized to recognize annotation. Firstly, the annotation is matched with the component based on coordinates, and then the specific model in the dictionary is matched based on the text content;
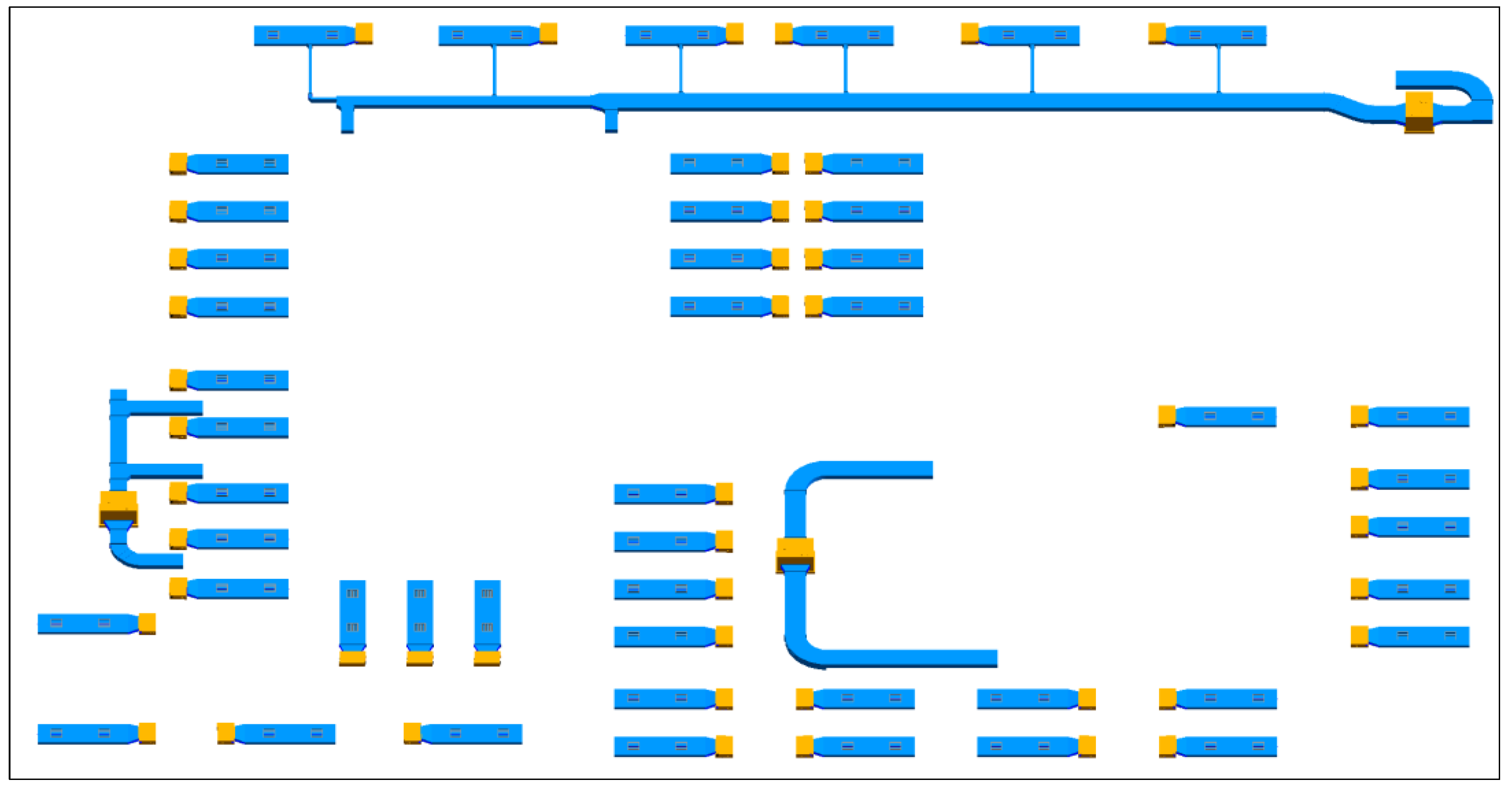
- Automatic BIM Generation: Write the coordinates and dimensions required for modeling into Excel and use Dynamo to generate 3D models.
2.1. Semantic Segmentation of 2D Drawings
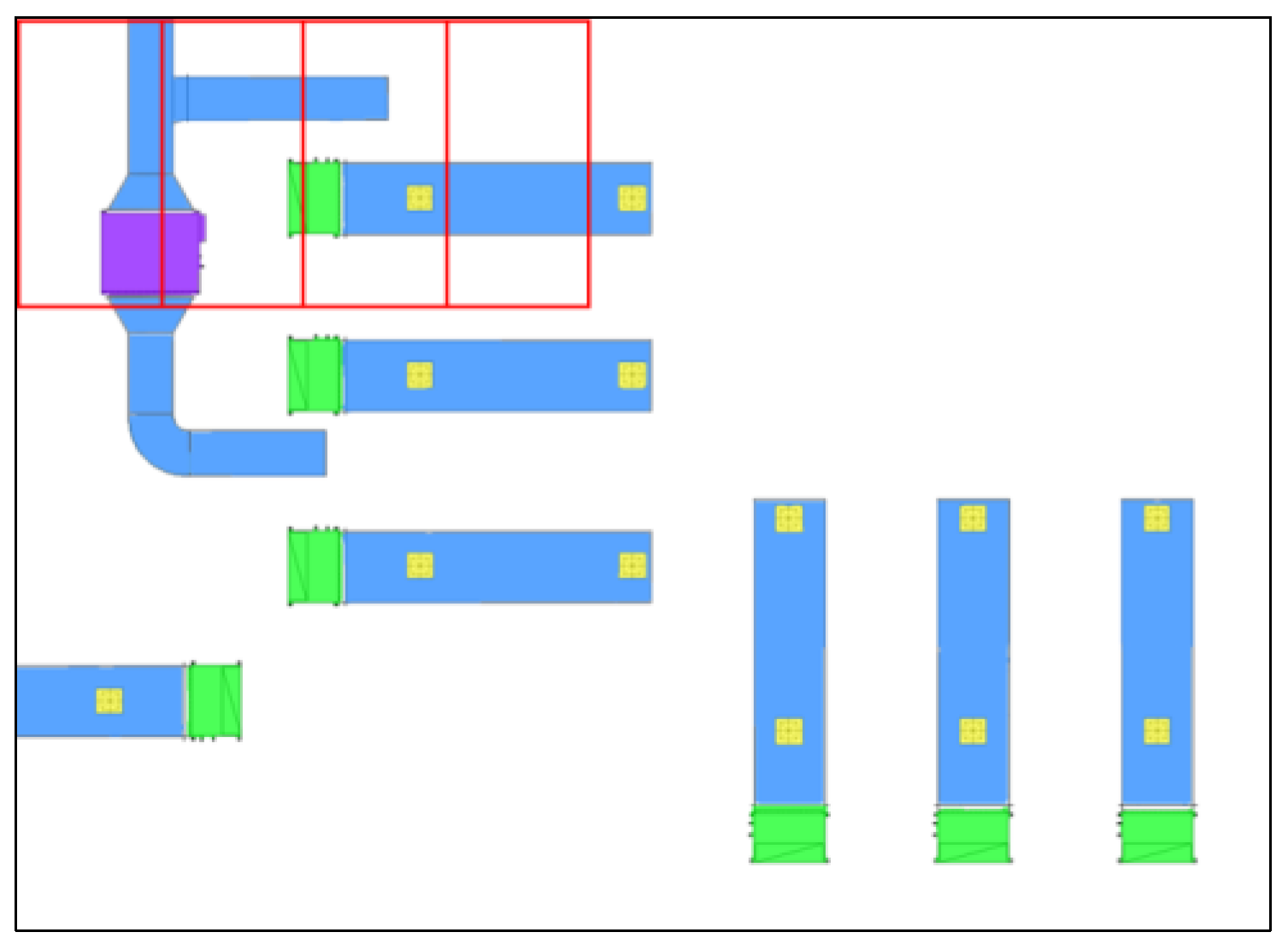
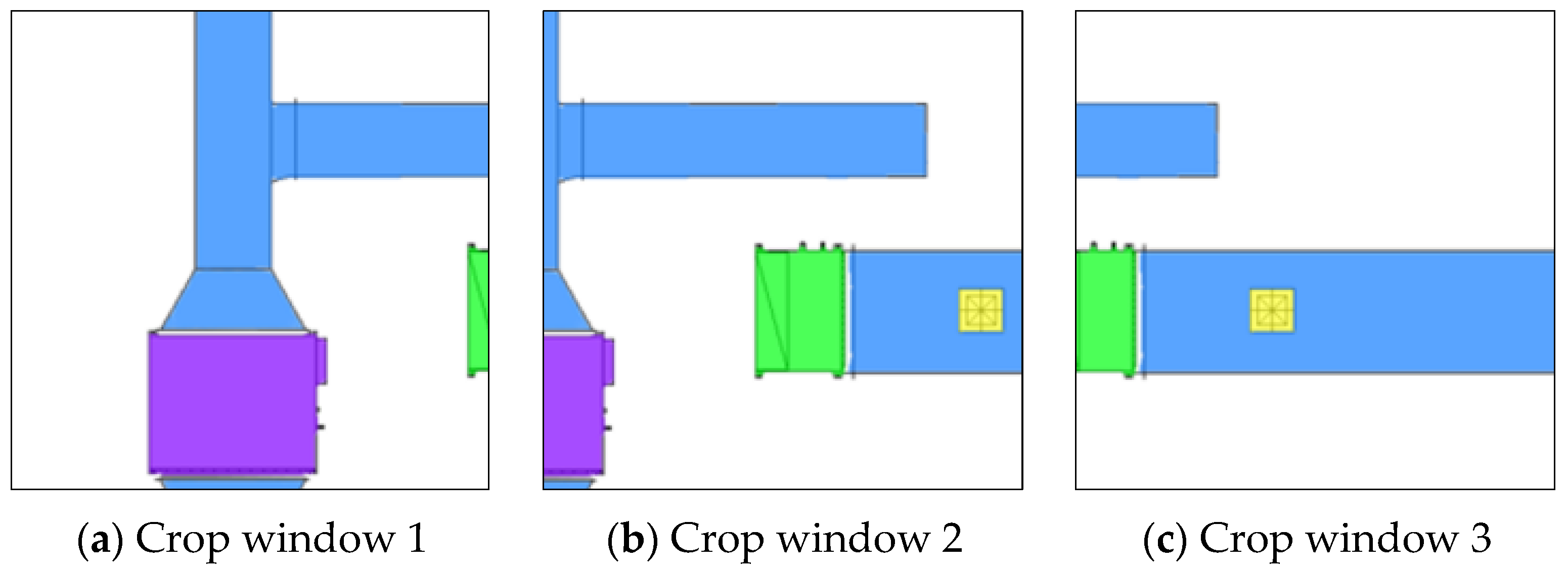
2.1.1. Sliding Window Cropping for Multi-Scale Component Recognition
2.1.2. MMSegmentation for Semantic Segmentation
2.1.3. Sliding Window Stitching for a Overall Mask Image
2.2. Extraction and Transformation of Coordinates
2.2.1. Coordinate Extraction
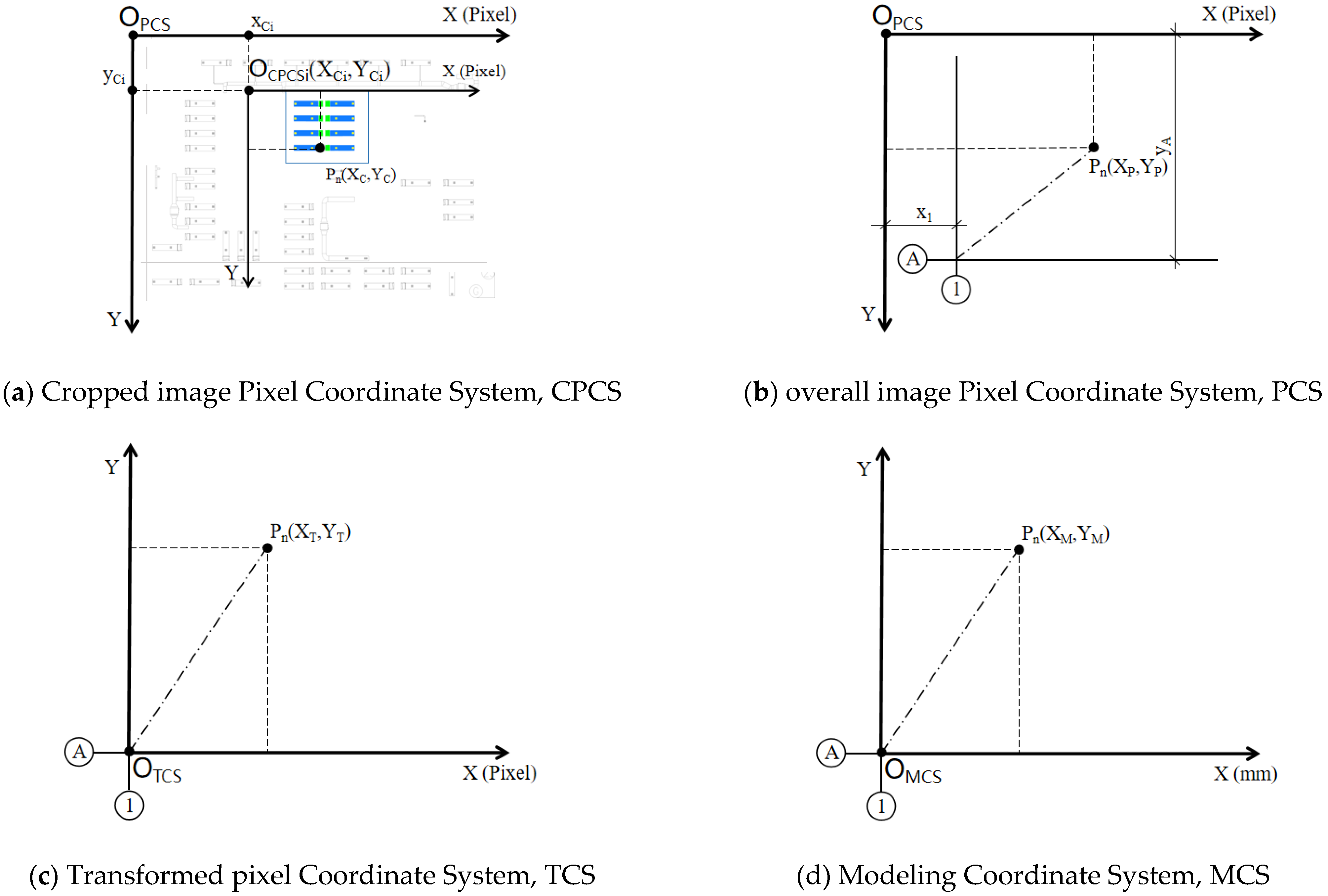
2.2.2. Image Cropping and Coordinate Transformation
- Establish the CPCS (Cropped image Pixel Coordinate System) and the PCS (overall image Pixel Coordinate System). Record the coordinate of the cropped image origin (OCPCSi) in the PCS. Extract the Pn(XC, YC) in the CPCS and transform it to (XP, YP) in PCS, as in Equation (3).
- In the PCS, identify and extract the pixel length of x1 of the leftmost vertical axis line and the pixel length of yA for the ordinate of the bottommost horizontal axis line (x1, yA are shown in Figure 9b).
- Establish the TCS (Transformed pixel Coordinate System). Transform the pixel abscissa and ordinate to obtain Pn(XT, YT). Perform translation transformation on the abscissa and inversion transformation on the ordinate, as in Equation (4).
- Establish the MCS (Modeling Coordinate System). Perform proportional transformation to obtain the modeling coordinates Pn(XM, YM). When an image is input during the prediction stage, an image’s pixel length represents an actual engineering length in millimeters. Therefore, it is necessary to divide the pixel coordinate values by the scale to obtain the coordinates with the unit of millimeter, as in Equation (5).
2.3. Matching Component Types
2.3.1. MEP Component Dictionary
2.3.2. Equipment Type Matching Using Semantic Information
2.3.3. Duct Type Matching Using OCR-Based Annotations
- The coordinate distance is the shortest;
- The slopes of the text rectangle frame and the component rectangle frame are consistent;
- The text content is not composed entirely of numbers.
3. Experiment
3.1. MEP Dataset
3.1.1. Classes of Components
3.1.2. Annotation and Augmentation
3.2. Training Results
3.2.1. Evaluation Metrics
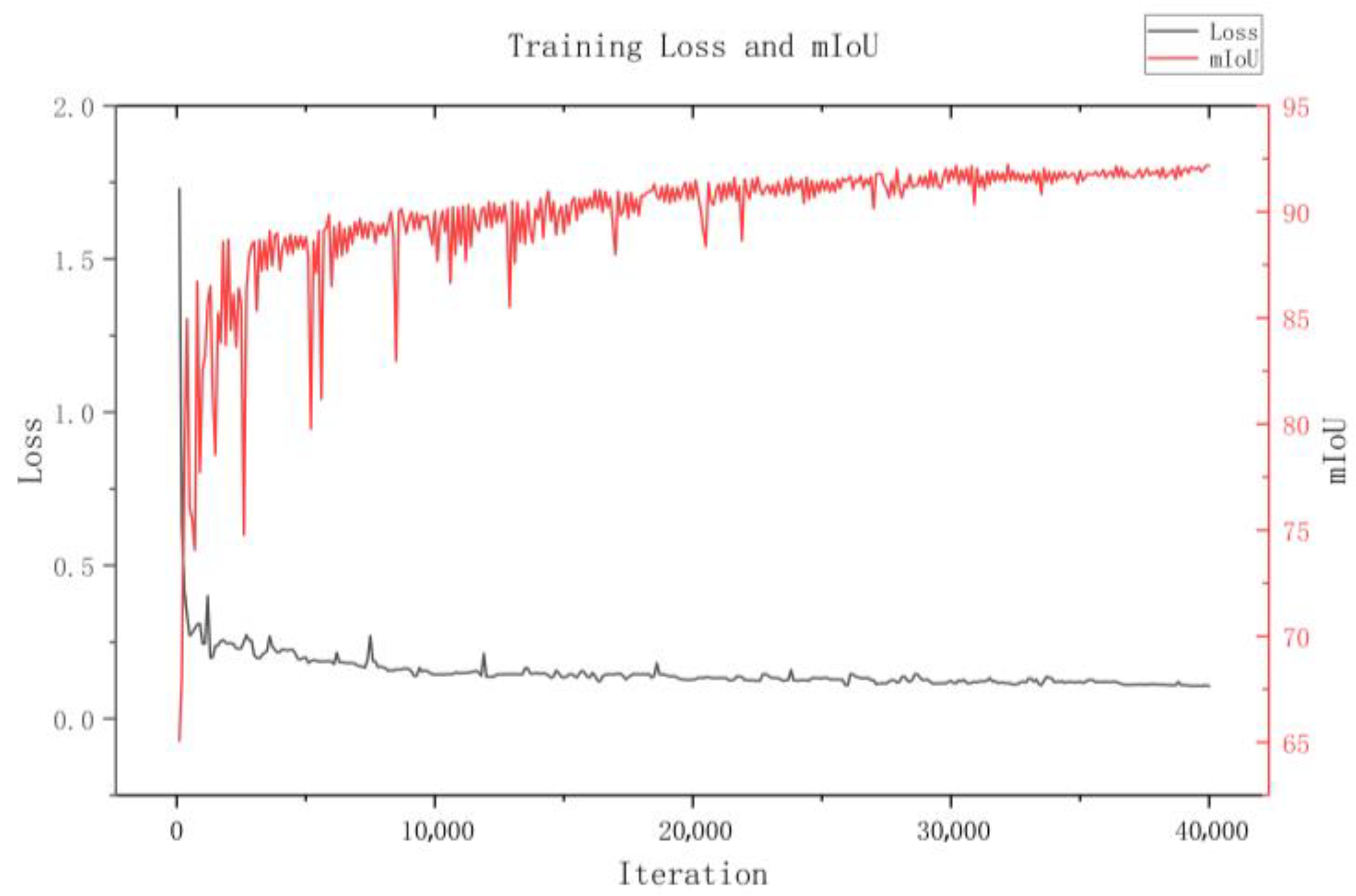
3.2.2. Comparison of Performance Between Different Neural Networks
3.2.3. Analysis of the Best Performed Network, K-Net
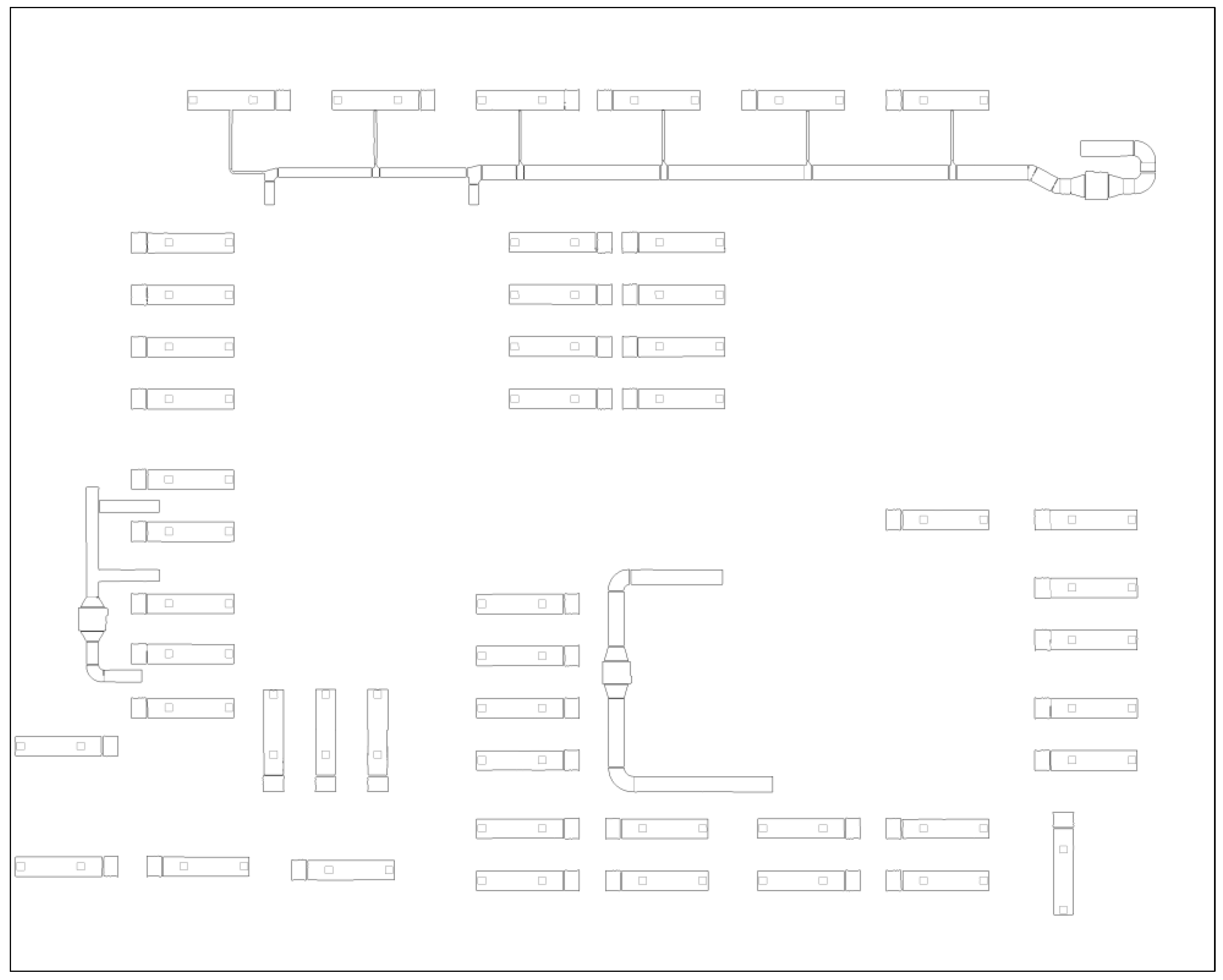
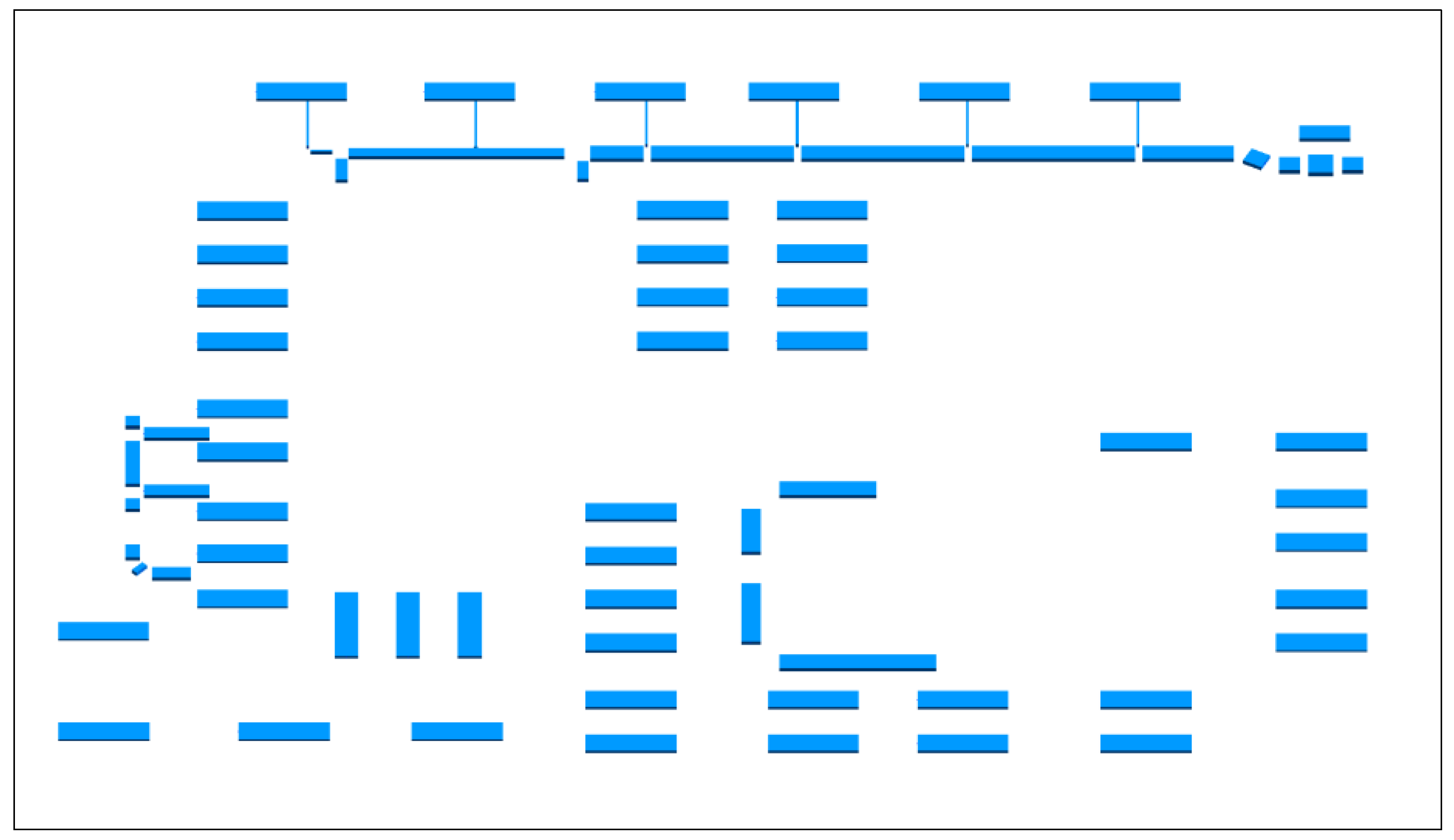
3.3. Generated BIM Results
4. Discussion
4.1. Cases of Prediction Errors in Semantic Segmentation
4.1.1. Incorrect Classification
4.1.2. Missed Recognition
4.2. Factors Affecting Coordinate Extraction Accuracy
4.2.1. Pixel Errors in Mask Boundaries
4.2.2. Image Scale
5. Conclusions
- The MMSegmentation was utilized to call different neural networks to train on the same dataset and conduct a fair performance comparison. Among them, K-Net achieved results with an mIoU of 92.18% and an aAcc of 98.46% during training, verifying the feasibility of using semantic segmentation for MEP drawing recognition. Among other networks, even the lightweight networks have an mIoU exceeding 80%, which validates the rationality of the dataset.
- Gaussian–Laplacian contour detection and minimum bounding box detection are utilized to accurately obtain the coordinates of the components. This process achieved lightweight coordinate detection by simplifying non-essential information in the image. It effectively reduced interfering factors, significantly enhancing the accuracy and reliability of coordinate detection.
- The dimensions of the equipment components are obtained by counting the number of pixels in the bounding box and converting them proportionally. The dimensions of the duct components are obtained through OCR recognition of annotations, which are then associated with the corresponding components.
- The concept of a component dictionary is introduced in this research, which matches extracted component dimensions with preset values in the dictionary and generates the specified model in Revit based on the predefined model type. This method is particularly suitable for MEP components, where the design follows strict standardization and modularization.
- Expanding the classes in the dataset and model types in the component dictionary.
- Enhancing the neural network’s ability to recognize components against complex backgrounds in drawings.
- Optimizing the program to automatically detect collisions or disconnections between components and make adjustments accordingly.
- The generated BIM provides data support for VR (Virtual Reality) and AR (Augmented Reality) applications, advancing research on VR and AR-based inspection.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nachtigall, F.; Milojevic-Dupont, N.; Wagner, F.C. Predicting building age from urban form at large scale. Comput. Environ. Urban Syst. 2023, 105, 102010. [Google Scholar] [CrossRef]
- Ramirez, J.P.D.; Nagarsheth, S.H.; Ramirez, C.E.D.; Henao, N.; Agbossou, K. Synthetic dataset generation of energy consumption for residential apartment building in cold weather considering the building’s aging. Data Brief. 2024, 54, 110445. [Google Scholar] [CrossRef] [PubMed]
- Lee, D.; Cheng, C.C.R. Energy savings by energy management systems: A review. Renew. Sustain. Energy Rev. 2016, 56, 760–777. [Google Scholar] [CrossRef]
- De Wilde, P. Ten questions concerning building performance analysis. Build. Environ. 2019, 153, 110–117. [Google Scholar] [CrossRef]
- Utkucu, D.; Szer, H. Interoperability and data exchange within BIM platform to evaluate building energy performance and indoor comfort. Autom. Constr. 2020, 116, 103225. [Google Scholar] [CrossRef]
- Xiang, Y.; Mahamadu, A.-M.; Florez-Perez, L. Engineering information format utilisation across building design stages: An exploration of BIM applicability in China. J. Build. Eng. 2024, 95, 110030. [Google Scholar] [CrossRef]
- Kang, T.W.; Choi, H.S. BIM perspective definition metadata for interworking facility management data. Adv. Eng. Inform. 2015, 29, 958–970. [Google Scholar] [CrossRef]
- Uggla, G.; Horemuz, M. Towards synthesized training data for semantic segmentation of mobile laser scanning point clouds: Generating level crossings from real and synthetic point cloud samples. Autom. Constr. 2021, 130, 103839. [Google Scholar] [CrossRef]
- Dimitrov, A.; Golparvar-Fard, M. Segmentation of building point cloud models including detailed architectural/structural features and MEP systems. Autom. Constr. 2015, 51, 32–45. [Google Scholar] [CrossRef]
- Wang, B.; Chen, Z.; Li, M.; Wang, Q.; Yin, C.; Cheng, J.C.P. Omni-Scan2BIM: A ready-to-use Scan2BIM approach based on vision foundation models for MEP scenes. Autom. Constr. 2024, 162, 105384. [Google Scholar] [CrossRef]
- Wang, J.; Wang, X.; Shou, W.; Chong, H.-Y.; Guo, J. Building information modeling-based integration of MEP layout designs and constructability. Autom. Constr. 2016, 61, 134–146. [Google Scholar] [CrossRef]
- Park, S.; Shin, M.; Jang, J.Y.; Koo, B.; Kim, T.W. Automated process for generating an air conditioning duct model using the CAD-to-BIM approach. J. Build. Eng. 2024, 91, 109529. [Google Scholar] [CrossRef]
- Cho, C.Y.; Liu, X.S. An Automated Reconstruction Approach of Mechanical Systems in Building Information Modeling (BIM) Using 2D Drawings. In Proceedings of the IWCCE, Seattle, WA, USA, 25–27 June 2017; pp. 236–244. [Google Scholar]
- Zou, Q.; Wu, Y.; Liu, Z.; Xu, W.; Gao, S. Intelligent CAD 2.0. Vis. Inform. 2024, 8, 1–12. [Google Scholar] [CrossRef]
- Jiang, T.; Guo, J.; Xing, W.; Yu, M.; Li, Y.; Zhang, B.; Dong, Y.; Ta, D. A prior segmentation knowledge enhanced deep learning system for the classification of tumors in ultrasound image. Eng. Appl. Artif. Intell. 2025, 142, 109926. [Google Scholar] [CrossRef]
- Safdar, M.; Li, Y.F.; El Haddad, R.; Zimmermann, M.; Wood, G.; Lamouche, G.; Wanjara, P.; Zhao, Y.F. Accelerated semantic segmentation of additively manufactured metal matrix composites: Generating datasets, evaluating convolutional and transformer models, and developing the MicroSegQ+ Tool. Expert Syst. Appl. 2024, 251, 123974. [Google Scholar] [CrossRef]
- Zhang, P.; Zhang, S.; Wang, J.; Sun, X. Identifying rice lodging based on semantic segmentation architecture optimization with UAV remote sensing imaging. Comput. Electron. Agric. 2024, 227, 109570. [Google Scholar] [CrossRef]
- Zhao, Y.; Deng, X.; Lai, H. Reconstructing BIM from 2D structural drawings for existing buildings. Autom. Constr. 2021, 128, 103750. [Google Scholar] [CrossRef]
- Pan, Z.; Yu, Y.; Xiao, F.; Zhang, J. Recovering building information model from 2D drawings for mechanical, electrical and plumbing systems of ageing buildings. Autom. Constr. 2023, 152, 104914. [Google Scholar] [CrossRef]
- Zhang, D.; Pu, H.; Li, F.; Ding, X.; Sheng, V.S. Few-Shot Object Detection Based on the Transformer and High-Resolution Network. CMC-Comput. Mater. Contin. 2022, 74, 3439–3454. [Google Scholar] [CrossRef]
- Wang, C.; Wang, C.; Li, W.; Wang, H. A brief survey on RGB-D semantic segmentation using deep learning. Displays 2021, 70, 102080. [Google Scholar] [CrossRef]
- Zhao, Z.; Hicks, Y.; Sun, X.; Luo, C. Peach ripeness classification based on a new one-stage instance segmentation model. Comput. Electron. Agric. 2023, 214, 108369. [Google Scholar] [CrossRef]
- Futakami, N.; Nemoto, T.; Kunieda, E.; Matsumoto, Y.; Sugawara, A. PO-1688 Automatic Detection of Circular Contour Errors Using Convolutional Neural Networks. Radiother. Oncol. 2021, 161, 1414–1415. [Google Scholar] [CrossRef]
- Gimenez, L.; Robert, S.; Suard, F.; Zreik, K. Automatic reconstruction of 3D building models from scanned 2D floor plans. Autom. Constr. 2016, 63, 48–56. [Google Scholar] [CrossRef]
- Lu, Q.; Chen, L.; Li, S.; Pitt, M. Semi-automatic geometric digital twinning for existing buildings based on images and CAD drawings. Autom. Constr. 2020, 115, 103183. [Google Scholar] [CrossRef]
- Sultana, F.; Sufian, A.; Dutta, P. Evolution of Image Segmentation using Deep Convolutional Neural Network: A Survey. Knowl.-Based Syst. 2020, 201–202, 106062. [Google Scholar] [CrossRef]
- Wang, Y.; Xiao, B.; Bouferguene, A.; Al-Hussein, M.; Li, H. Vision-based method for semantic information extraction in construction by integrating deep learning object detection and image captioning. Adv. Eng. Inform. 2022, 53, 101699. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, W.; Ding, J.; Wang, Y.; Pei, L.; Tian, A. Crack instance segmentation using splittable transformer and position coordinates. Autom. Constr. 2024, 168, 105838. [Google Scholar] [CrossRef]
- Chen, J.; Zhuo, L.; Wei, Z.; Zhang, H.; Fu, H.; Jiang, Y.-G. Knowledge driven weights estimation for large-scale few-shot image recognition. Pattern Recogn. 2023, 142, 109668. [Google Scholar] [CrossRef]
- Kabolizadeh, M.; Rangzan, K.; Habashi, K. Improving classification accuracy for separation of area under crops based on feature selection from multi-temporal images and machine learning algorithms. Adv. Space Res. 2023, 72, 4809–4824. [Google Scholar] [CrossRef]
- Aimin, Y.; Shanshan, L.; Honglei, L.; Donghao, J. Edge extraction of mineralogical phase based on fractal theory. Chaos Solitons Fractals 2018, 117, 215–221. [Google Scholar] [CrossRef]
- Mu, K.; Hui, F.; Zhao, X.; Prehofer, C. Multiscale edge fusion for vehicle detection based on difference of Gaussian. Optik 2016, 127, 4794–4798. [Google Scholar] [CrossRef]
- Tao, X.; Gao, H.; Yang, K.; Wu, Q. Expanding the defect image dataset of composite material coating with enhanced image-to-image translation. Eng. Appl. Artif. Intell. 2024, 133, 108590. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Quantity | Percentage of Quantity | Number of Pixels | Percentage of Pixels | Area (m2) |
|---|---|---|---|---|---|
| Duct | 112 | 60% | 17,627,820 | 30.02% | 110.17 |
| AHX | 4 | 2% | 5,190,870 | 8.84% | 32.44 |
| LXF | 4 | 2% | 4,603,668 | 7.84% | 28.77 |
| OVRF | 4 | 2% | 4,734,921 | 8.01% | 29.40 |
| VRFS | 13 | 7% | 6,975,966 | 11.88% | 43.60 |
| EXF | 50 | 27% | 3,670,016 | 6.25% | 22.94 |
| SUM | 187 | 100% | 42,803,261 | 72.84% | 267.32 |
| Step | Function | Parameter | Probability | Aug Times | Sum Aug Times |
|---|---|---|---|---|---|
| 1 | Rotation | 90° | 1.0 | 1 | 2 |
| 2 | Mirror | vertical | 1.0 | 1 | 4 |
| 3 | Reduce | 0.7–1 | 0.3 | 4 | 20 |
| Translation | 0–100 | 0.3 | |||
| Noise Addition | 55 | 0.05 | |||
| Pixels Addition | 0–255 | 0.03 | |||
| Brightness | 0.8–1 | 0.5 |
| Model | DeepLabV3+ | Segformer | K-Net | PSPNet | Fast-SCNN |
|---|---|---|---|---|---|
| Training Time | 53 h 13 min | 65 h 31 min | 63 h 18 min | 54 h 59 min | 6 h 12 min |
| mIoU | 89.3943 | 90.7642 | 92.1814 | 89.0822 | 80.1886 |
| aAcc | 97.6051 | 97.8156 | 98.4652 | 97.3100 | 94.3571 |
| mAcc | 92.5554 | 93.6786 | 93.6314 | 92.0193 | 84.4205 |
| mDice | 90.7176 | 92.4877 | 93.8986 | 91.3957 | 85.1050 |
| mFscore | 90.7176 | 92.4877 | 93.8986 | 91.3957 | 85.1050 |
| mPrecision | 92.5648 | 95.2566 | 94.4857 | 93.1000 | 85.9161 |
| mRecall | 92.5554 | 93.6786 | 93.6314 | 92.0193 | 84.4205 |
| Class | Duct | AHX | LXF | OVRF | VRFS | EXF | Ground |
|---|---|---|---|---|---|---|---|
| Duct | 0.998 | ||||||
| AHX | 0.999 | 0.001 | |||||
| LXF | 0.999 | 0.001 | |||||
| OVRF | 1 | ||||||
| VRFS | 0.999 | 0.001 | |||||
| EXF | 1 | ||||||
| ground | 0.002 | 0.001 | 0.001 | 0.001 | 0.997 |
| Class | Mask and Information Extraction | MEP Component Dictionary | Matched Type | Reconstruction | |||
|---|---|---|---|---|---|---|---|
| Certain Mask | Pixels Count | Area (mm2) | Type List | Defined Area (mm2) | |||
| VRF |  | 118,152 | 738,450 | VRF45S VRF56S VRF63S VRF71S | 523,480 523,480 670,480 740,480 | VRF71S |  |
| AHX |  | 257,645 | 1,610,281 | AHX1680 AHX2100 | 1,628,400 2,215,525 | AHX1680 |  |
| LXF |  | 80,344 | 502,150 | EF-01 EF-02 | 602,132 502,232 | EF-01 |  |
| OVRF |  | 114,793 | 717,456 | OVRF-01 | 717,565 | OVRF-01 |  |
 | 152,836 | 955,225 | OVRF-02 | 955,831 | OVRF-02 |  | |
| EXF |  | 6375 | 39,844 | EXF-01 EXF-02 EXF-03 | 40,068 91,192 135,505 | EXF-01 |  |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, D.; Fang, Y. Automatic BIM Reconstruction for Existing Building MEP Systems from Drawing Recognition. Buildings 2025, 15, 924. https://doi.org/10.3390/buildings15060924
Wang D, Fang Y. Automatic BIM Reconstruction for Existing Building MEP Systems from Drawing Recognition. Buildings. 2025; 15(6):924. https://doi.org/10.3390/buildings15060924
Chicago/Turabian StyleWang, Dejiang, and Yuanhao Fang. 2025. "Automatic BIM Reconstruction for Existing Building MEP Systems from Drawing Recognition" Buildings 15, no. 6: 924. https://doi.org/10.3390/buildings15060924
APA StyleWang, D., & Fang, Y. (2025). Automatic BIM Reconstruction for Existing Building MEP Systems from Drawing Recognition. Buildings, 15(6), 924. https://doi.org/10.3390/buildings15060924