1. Introduction
As an important civil infrastructure, dams have made great contributions to regional social and economic development by continuously providing seasonal water sources or generating renewable energy. There are approximately 58,000 such large dams (more than 15 m high) worldwide with an estimated cumulative storage capacity of between 7000 and 8300 km
3 [
1]. Dams, especially high dams, provide many benefits, including flood control, water supply, and power generation. However, if a dam breaks, unfortunately, it will also bring a devastating blow to people’s lives and property safety [
2]. Dam safety prediction and early warning are the core links to ensure the safe operation of dams. With the continuous development of computer technology, advanced machine learning algorithms have shown more and more advantages in dam safety prediction analysis. However, the accuracy of traditional dam deformation prediction models is low, which will seriously affect the assessment of dam safety states. Therefore, new methods and technologies are needed to improve the accuracy and generalization ability of dam deformation prediction and overcome the challenges from many external extreme natural conditions, dam body defects, and potential risks in safe operation [
3,
4,
5]. At present, there is a contradiction between the demand and the reality of dam safety monitoring and risk analysis ability. How to understand and solve these contradictions needs to be explored from the source of philosophical thinking. In the understanding and practice of dam safety monitoring, we should consciously take the theory of practice, epistemology, and contradiction as guidance and explore the philosophical roots of dam safety monitoring and risk analysis practice from the perspectives of connection and development. This is of great significance for us to establish a dam safety monitoring system that is compatible with the level of economic development and to construct a reasonable dam safety monitoring risk evaluation index system (
Figure 1).
2. Theory and Method
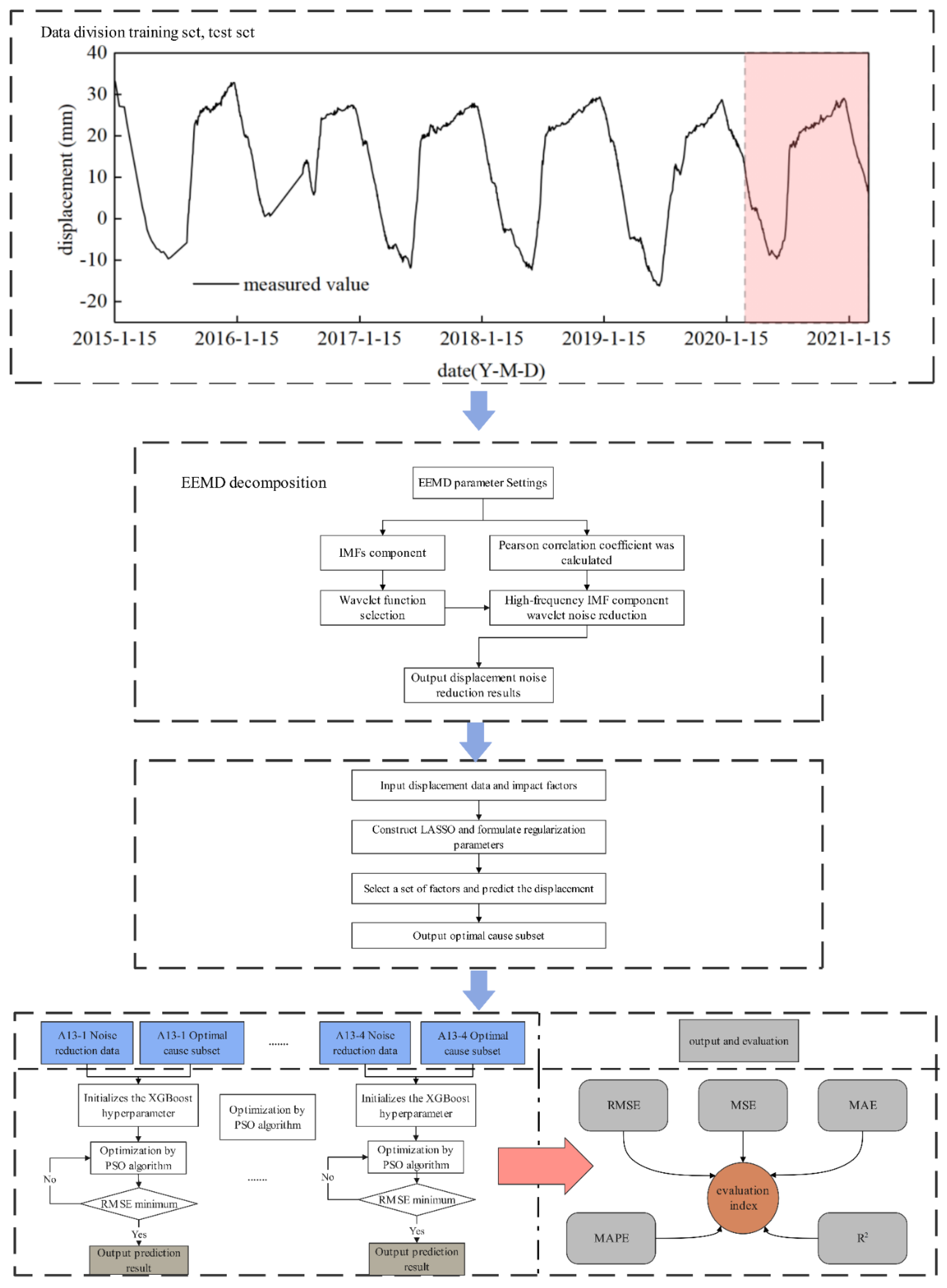
As an important water retaining structure in water conservancy projects, a dam has the characteristic of raising the water level. By 2020, China will have 4872 large- and medium-sized reservoirs with a total storage capacity of 858.9 billion cubic meters. Dam displacement can effectively reflect their operating state and is an important index of dam safety structure health monitoring. It is of great significance to establish an accurate and reliable displacement prediction model for dam health monitoring. Based on the above-mentioned philosophical thinking on contradiction theory, practice theory, epistemology, and system theory and aiming at problems such as the low prediction accuracy of the current analysis model and the insufficient depth of data mining, this paper proposes a dam displacement analysis and prediction model. By using variational mode decomposition of the original deformation sequence data to obtain the components in different frequency domains, an EEMD–wavelet data denoising model was established, and a nonlinear intelligent optimization algorithm was adopted considering the spatio-temporal correlation of multiple measurement points. A spatio-temporal prediction model based on the EEMD–wavelet model was proposed. The accuracy and precision of the prediction model are improved under this prediction model.
Some scholars, including Xu Ren, used the more common LSTM model and intelligent optimization algorithm, and they fully considered the temporal correlation of measurement point data but did not consider the characteristics of the spatial distribution of dam measurement points. Referring to the spatial model proposed by Wu ZhongRu [
2], there is a large number of factors involved in his model, in which the subsets of factors affecting the displacement of dams are fully considered. However, the establishment of a dam displacement prediction model faces a problem of balance. If too many influencing factors are considered, the model may perform well in one case but fail to adapt to others, called “overfitting”. On the contrary, when processing long time-series data, the model needs to maintain computational efficiency and accuracy while ensuring appropriate generalization ability [
3,
4,
5].
In recent years, artificial intelligence algorithms have been widely used in the field of dam displacement prediction, which is mainly divided into traditional regression models and machine learning algorithms [
6,
7]. The predictive methods include the multivariate linear model and generalized linear model, but in these methods, some problems remain to be solved. Neural network algorithms, including BP (back propagation), RBF (radial basis function) neural networks, and GBDTs (gradient lifting decision trees), can better mine the nonlinear relationship in the dam displacement data and make predictions. These algorithms can be combined with intelligent algorithms and optimization algorithms to optimize the hyperparameters of deep learning algorithms for faster and more accurate predictions.
Xu [
8] studied and discussed the application of XGBoost in the displacement prediction of concrete dams and achieved good prediction results based on the data of a single measurement point. Zhou et al. [
9] adopted the LSTM neural network prediction algorithm based on SSA to pre-process the original data into trend terms and periodic terms and then used them in LSTM and GF algorithms to make full use of the timing of the data. Qi [
10] screened the subsets of influence factors of dam deformation and built a dam deformation analysis model based on LSTM. Wu et al. [
11] clustered the original data, combined with the WOA of whale behavior habits in nature to optimize LSSVM’s hyperparameter selection, and achieved a good prediction effect. Dong Yong [
12] extracted the effective information of dam deformation through empirical mode decomposition in signal processing and, finally, adopted LSTM as the prediction model.
Although the above models take into account the temporal and spatial correlations of the measuring points, which can improve the prediction effect to a certain extent, most of them are multi-measuring point models based on statistics, and there are still the following problems: (1) In the regression analysis, the determination of a large number of constants may lead to infinite or no solutions to linear equations, so factor screening is required to reduce the impact of low model generalization [
13,
14]. (2) There is a nonlinear relationship between the environmental factors of a dam, and there is a nonlinear mapping between the environmental quantity and the displacement data. (3) Affected by various factors, noise exists in dam displacement, environment, and temperature data [
15,
16], which affects the prediction accuracy. To solve the problem, a nonlinear intelligent optimization algorithm based on EEMD–wavelet data denoising was established, and a spatio-temporal prediction model based on the EEMD–wavelet model was proposed. A concrete arch dam in the lower Yalong River was taken as an example to verify the accuracy of the model.
2.1. Basic Principle of Statistical Model for Dam Deformation Prediction
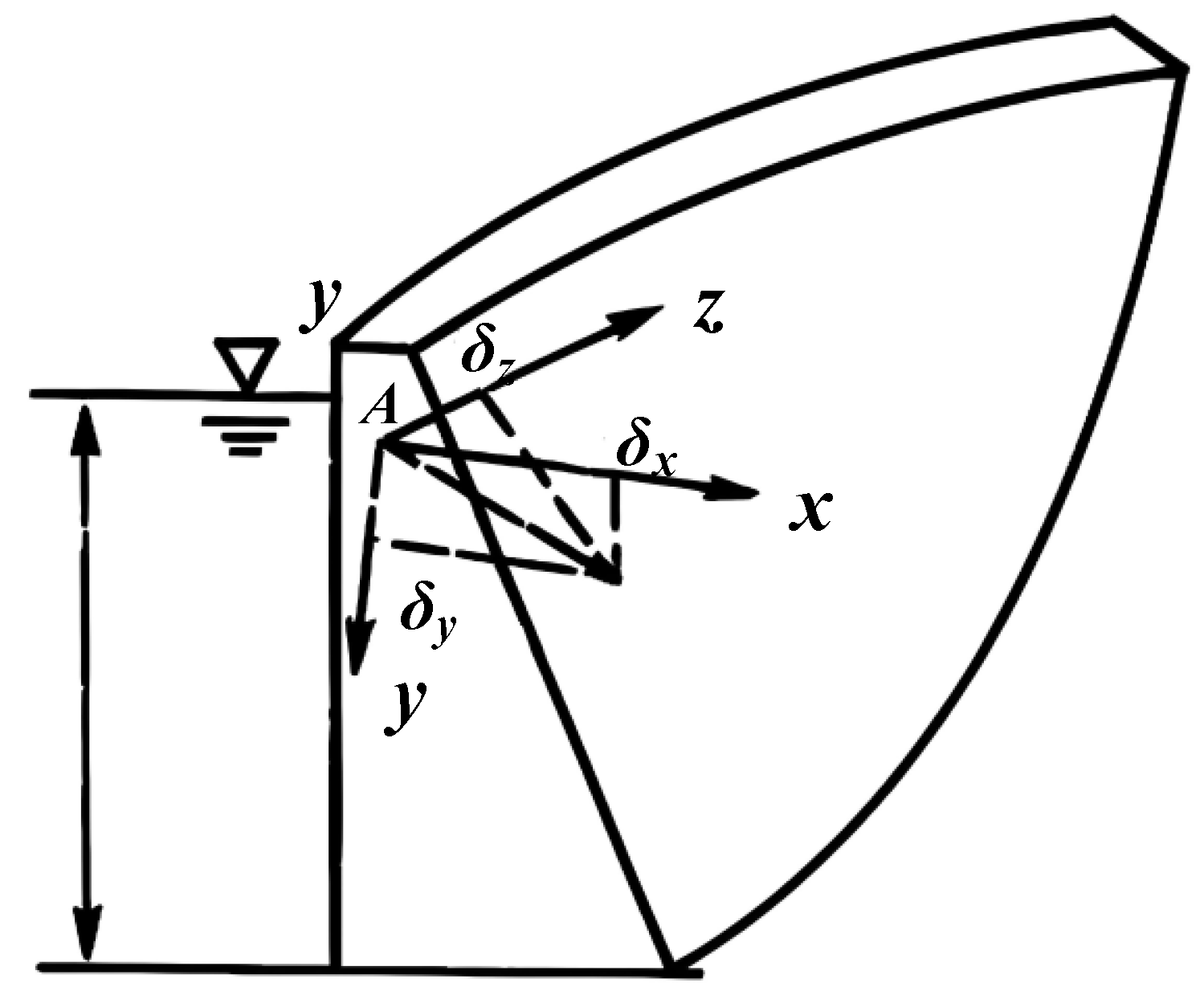
According to the existing dam safety monitoring theory and the calculation of material mechanics and structural mechanics (
Figure 2), the displacement at any point of a concrete dam under the influence of hydrostatic pressure, lifting pressure, temperature, aging, etc., can be expressed as the following equation [
17]:
where
,
, and
, respectively, refer to the displacement in
xyz directions of the dam body; according to its cause, the displacement can be divided into three parts: water pressure component (
), temperature component (
), and aging component (
).
Under the action of water pressure, the horizontal displacement produced by any observation point of the dam is composed of three parts: the displacement caused by the internal force of the reservoir water pressure acting on the dam body; the displacement caused by the deformation of the foundation caused by the internal force on the foundation; and the displacement caused by the rotation of foundation surface due to the heavy action of reservoir water. Through the calculation of water pressure and water pressure components using the mechanical method, it can be concluded that the water pressure component
and the water depth
(
i = 1, 2, …
n power degree) form a linear relationship, that is:
where
is the coefficient;
is the water depth in front of the dam; and
is the highest degree of the polynomial, where the gravity dam
takes a value of 3.
The temperature component is mainly due to the displacement caused by the temperature change in the concrete and bedrock of the dam body. When enough thermometer data are accurately recorded, the temperature component can be calculated using the measured temperature, and the prediction model established is the Hydrostatic-Thermal-Time model, referred to as the HTT [
18] model, as follows:
where
b is the statistical coefficient,
m is the effective temperature count, and
T is the measured temperature.
However, when the temperature monitoring data in the dam are insufficient, the Hydrostatic-Seasonal-Time model (HST model for short) can be used:
where
b is the regression coefficient, and
t is the cumulative number of days from the monitoring date to the first measurement date.
The aging factor is the synthesis of many nonlinear factors, and its influence on the response eventually manifests in the development of a certain direction with the continuous extension of time. As a material entity, the dam’s movement changes in time and space. Time signifies the continuity and sequence of material movement, characterized by one dimension, while space is the extensiveness of material movement, characterized by three dimensions. The time and space of material movement are inseparable, which requires us to do things according to a specific time and place and conditions.
The generation of dam aging components is caused by many complicated factors. It comprehensively reflects the creep and plastic deformation of concrete and bedrock and the compressive deformation of the geological structure of bedrock. Generally speaking, the aging displacement of dams in normal operation changes rapidly in the initial stage and slows down gradually in the later stage. The aging component can be modeled using a variety of mathematical models. For the aging component of concrete dam during its service life, the linear combination form of
and
is used, that is
where
is
;
the number of days from the monitoring date to the beginning of the measurement date; and
and
are the coefficients.
In summary, the HST model can be obtained from the analysis of displacement components at any point of the dam:
The meaning of each symbol in Formula (6) is the same as that of Formulas (1)–(5).
Dam deformation monitoring is inseparable from time- and space-influencing factors. The above equation describes the deformation law of a concrete dam with a single measuring point and only considers the time factor, so it is difficult to describe the spatial correlation of multiple measuring points. On the basis of the above formula, space coordinates are introduced. Each term is expanded according to multiple power series, and with reference to the beam deflection line equation of engineering mechanics, the following results are obtained:
2.2. PSO (Particle Swarm) Algorithm
The PSO algorithm is derived from the research on the foraging behaviors of birds [
19] and is a swarm intelligence algorithm for solving optimization problems. In the algorithm, each particle has two basic properties: position and velocity. The position represents the potential solution of the optimization problem and corresponds to the fitness value of each particle after the fitness function is calculated. The speed of the particle will be dynamically adjusted and updated in each iteration along with the extreme value of the particle itself and the global particle, so as to determine the movement direction and distance of the particle in the next iteration step. The specific updated formula is as follows:
where
,
, and
are, respectively, the velocity, position, and individual extremum of particle
i after the KTH iteration in the D-dimensional search space;
is the global extreme value of the population after the KTH iteration in the D-dimensional search space;
and
are non-negative acceleration factors;
and
are random numbers between [0, 1]; and
is the inertia weight. After several iterations, parameter optimization in the solvable space can be realized (
Figure 3).
The PSO algorithm has a simple principle [
20], fast convergence speed, and strong versatility. However, when the data re more complex, the dimension is higher, and the parameters are not set properly, problems such as premature convergence, low search accuracy, and low late iteration efficiency easily occur. With the progress of iteration, the algorithm gradually shifts from the global search stage to the local search stage. Different stages have different requirements for the algorithm optimization ability. In the early stage, the search scope is large, and it is necessary to pay attention to diversity while improving the search efficiency. And in the later stage, more attention should be paid to the convergence ability of the algorithm. Meanwhile, the loss of diversity should also be reduced to avoid premature convergence of the algorithm. The dynamic adjustment of
can make the PSO algorithm achieve better optimization results at each stage. In this paper, linear decreasing inertia weights are selected to better balance the global search and local search capabilities of the algorithm. The expression is as follows:
where
k is the number of current iterations;
kmax is the maximum number of iterations;
is the inertia weight for the K iteration time; and
and
are the initial and end values of the inertia weights, respectively.
In the iterative process, the PSO algorithm [
21,
22] may fall into the local extreme value due to the fast convergence speed and, thus, converge prematurely. In order to solve the problem of premature convergence, the mutation operation of the genetic algorithm is introduced; that is, the particle position is initialized with a certain probability during each iteration, so that some particles jump out of the local optimal position previously searched and re-search in a larger range.
2.3. EEMD and Wavelet Noise Reduction Principle
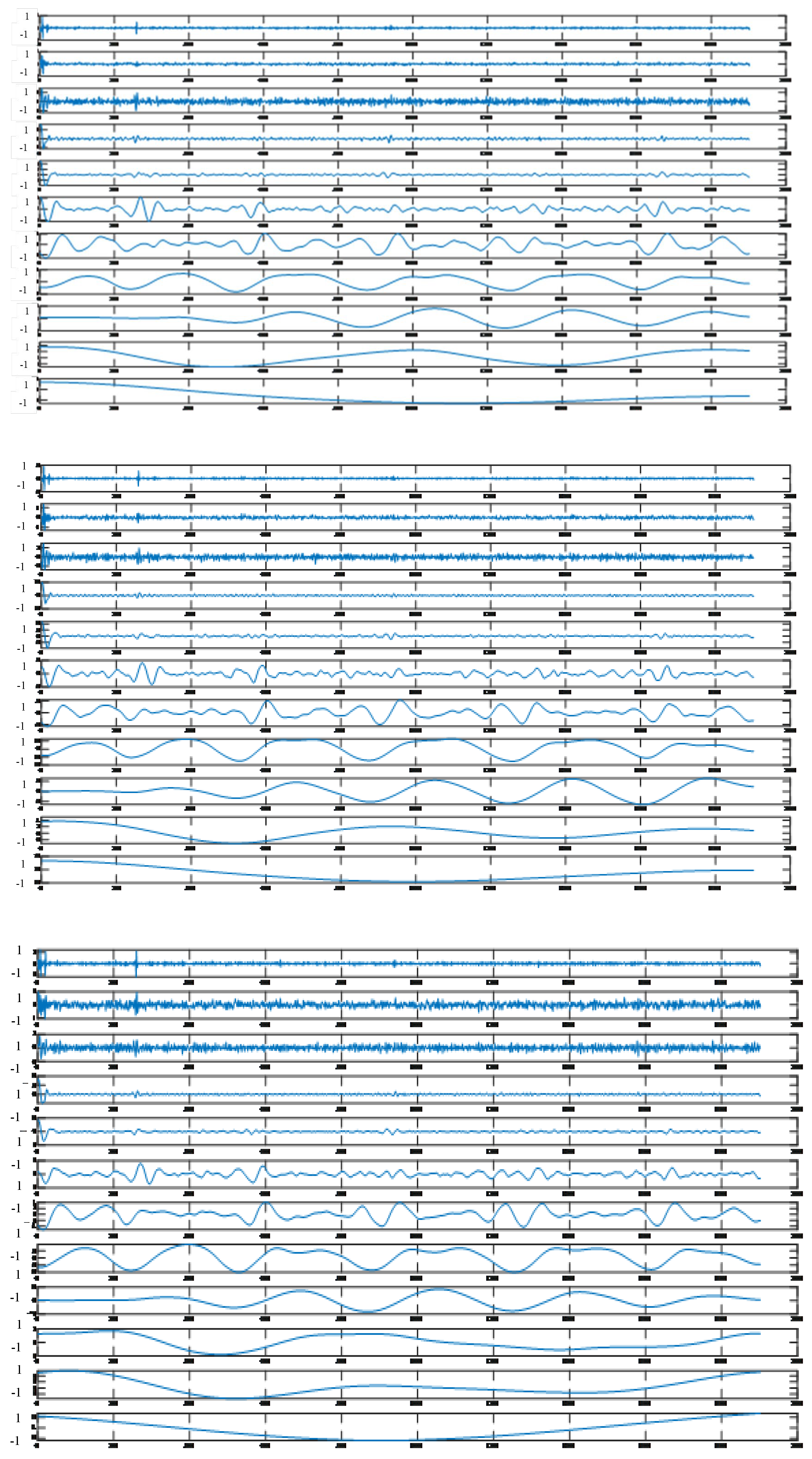
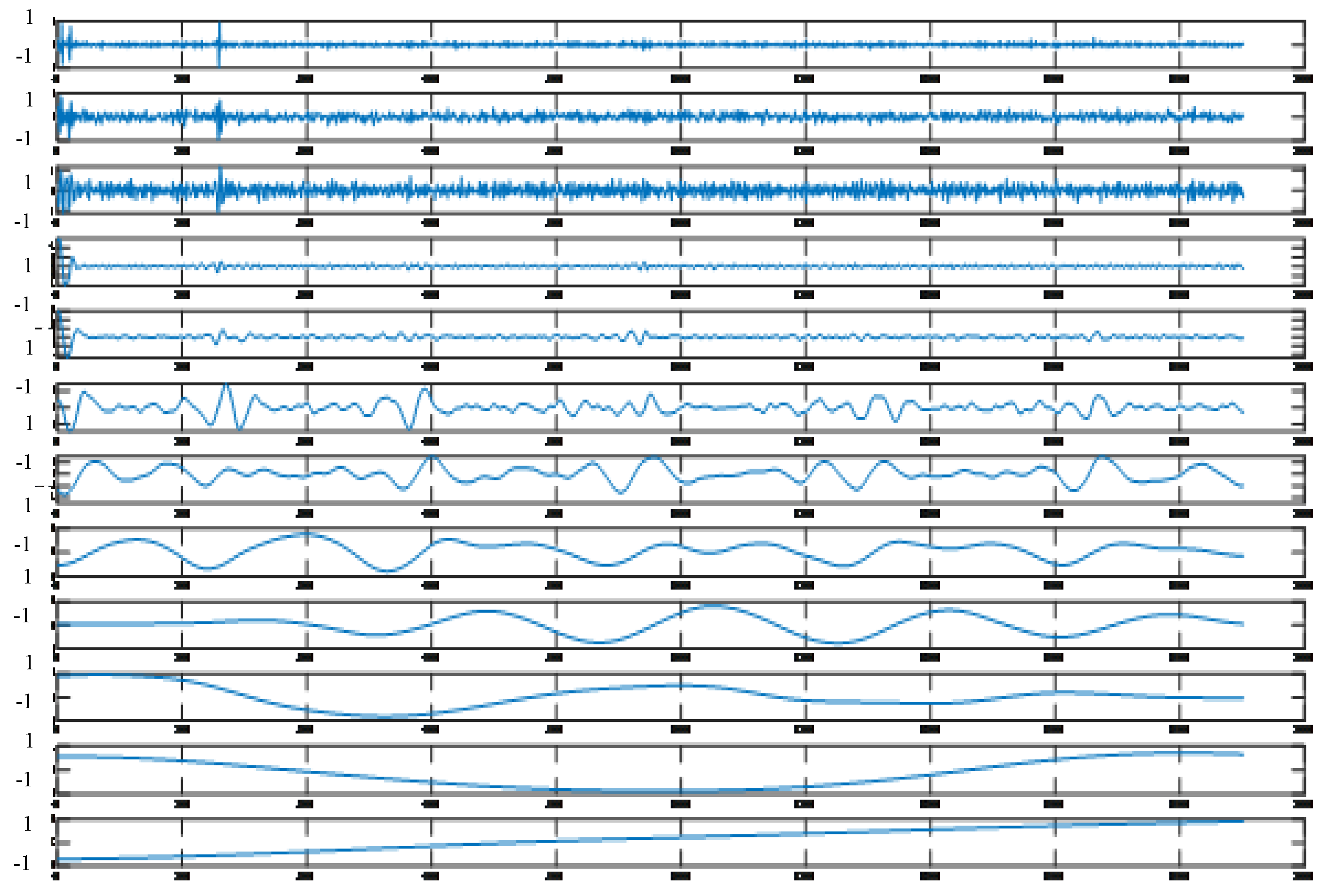
2.3.1. Principles of EEMD
EEMD is an improved model of empirical mode decomposition (EMD) [
23]. Huang et al. believe that any original signal is composed of several overlapping eigenmode functions. In essence, EMD stabilizes the signal to obtain a series of IMFs with a gradually stable frequency and a margin B. However, when the time scale of the signal has a jump change, IMFs will contain different time-scale feature components, and EMD itself has the disadvantage of being prone to modal confusion. For these situations, Huang and Wu proposed the EEMD model. By adding white noise to the signal to be decomposed, EEMD utilizes the uniform distribution of the white noise spectrum to make the original signal spread over the white noise background with a uniform distribution in the entire time–frequency space, and the signals of different time scales will be automatically distributed on the appropriate reference scale, making the signals have continuity at different scales, thus achieving the purpose of suppressing mode confusion. Since the mean value of white noise is zero, after adding white noise several times and obtaining the average value, the additional noise is eliminated, and the result is the signal itself.
The EEMD steps are as follows (
Figure 4):
Step 1: The noise series
is added to the time series
of the dam observation data to obtain the time series
of adding noise:
where
is the amplitude
.
Step 2: The time series obtained in step 1 is decomposed using EEMD into a series of IMFs and a margin B.
Step 3: Step 1 and Step 2 are repeated n times. The jth-order IMF after the ith EMD is represented by IMFij, and the margin B after the ith EMD is represented by Bi.
Step 4: All IMFs of the same order and all allowances
B are averaged to obtain the final
IMFj of each order and allowance
B:
where
j is the order of the partition, and
i is the number of EMDs performed on the time series.
When performing EEMD, the added white noise, amplitude, and repetition times need to be determined after several experiments. The value pointed out by Chen Zhong is usually 0.01~0.5, and the value of repetition times is usually 100~200 times.
2.3.2. High-Frequency Signal Test
After the original signal is decomposed via EEMD [
24], it is necessary to calculate the correlation between the generated components IMF and the original data in order to carry out wavelet packet noise reduction. The correlation coefficient
Ck formula is as follows:
where
is a certain
IMF component,
is the original data, and
and
are the average values. When the calculated value
Ck is above 0.3, the correlation can be considered high. Otherwise, the component
IMF has poor correlation with the original data.
2.3.3. Wavelet Noise Reduction
Dam deformation monitoring data can be regarded as a kind of signal, which is usually disturbed by noise caused by random factors and observation errors from complex environments. In order to extract useful information from these signals to characterize the detected object and improve the accuracy of the data, it is necessary to process the data by denoising them. Wavelet analysis is a method for time–frequency analysis of signals, which gradually developed from the field of signals in the late 1980s. Compared with the single resolution of Fourier transform, wavelet analysis has the characteristics of multi-resolution analysis, so it is widely used in the signal denoising [
25] field. For the dam deformation observation signal
s(
n) containing noise, it can be expressed as follows:
where
is the signal containing noise; and
is a useful signal. The essence of wavelet denoising is that an approximation signal
obtained from a noisy signal
is the optimal approximation to
under a certain error; that is, the actual signal is separated from the noisy signal to the maximum extent, the real signal is retained, and the noise signal is removed so as to achieve the purpose of denoising. Nowadays, there are two kinds of wavelet denoising methods commonly used: hard threshold denoising and soft threshold denoising. Because hard threshold denoising will eliminate some useful signals that are not noise and cause signal distortion, this paper adopts soft threshold denoising (
Figure 5).
2.3.4. Noise Reduction Evaluation Indicators
In signal processing, noise reduction evaluation indexes are mainly measured by smoothness () and the noise reduction error ratio (). The larger the noise reduction error ratio, the smaller the smoothness, indicating that the algorithm has better noise reduction effect, and the noise reduction effect directly affects the prediction accuracy of the prediction model.
The smoothness of the curve
after noise reduction is as follows:
The calculation formula of the noise reduction error ratio is as follows:
In the above formula, is the original data, is the data after noise reduction, is the noise signal power, is the noise reduction signal power, and indicates the time, where the unit is day.
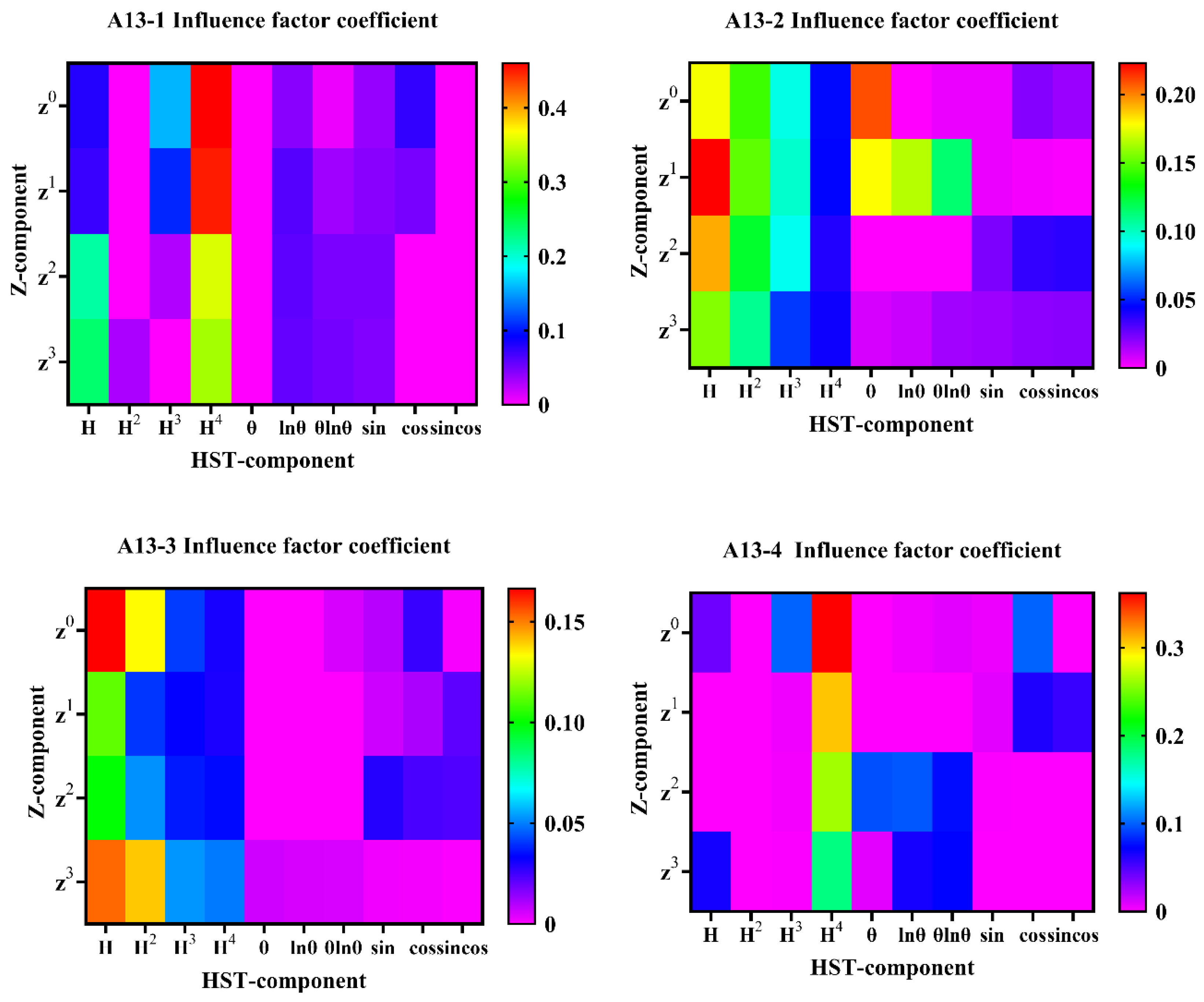
2.4. Optimal Factor Selection Principle Based on LASSO Regression
The complexity of the prediction model is directly related to the number of input variables. As the number of variables entering the model increases, the model becomes more complex. To combat this problem, the LASSO algorithm takes the ingenious approach of constructing a penalty function to refine the model. By increasing the coefficient of the penalty function, LASSO makes the coefficient of some variables in the model gradually shrink to 0. In this way, the LASSO [
26] algorithm can quickly select important variables, thus reducing the complexity of the model and effectively avoiding the phenomenon of overfitting in the model. Its optimization objective function is:
where
is the dependent variable;
is the regression coefficient;
is an independent variable;
is the regression coefficient;
is the number of regression groups; and
is the number of independent variables.
By substituting the constraints into the above formula, we can get:
where
is the penalty function coefficient.
The LASSO algorithm will automatically obtain an optimal value . In the process of model iterative training, the regression coefficients of some influence factors will gradually shrink and tend to zero. At this time, these variables tending to zero can be eliminated.
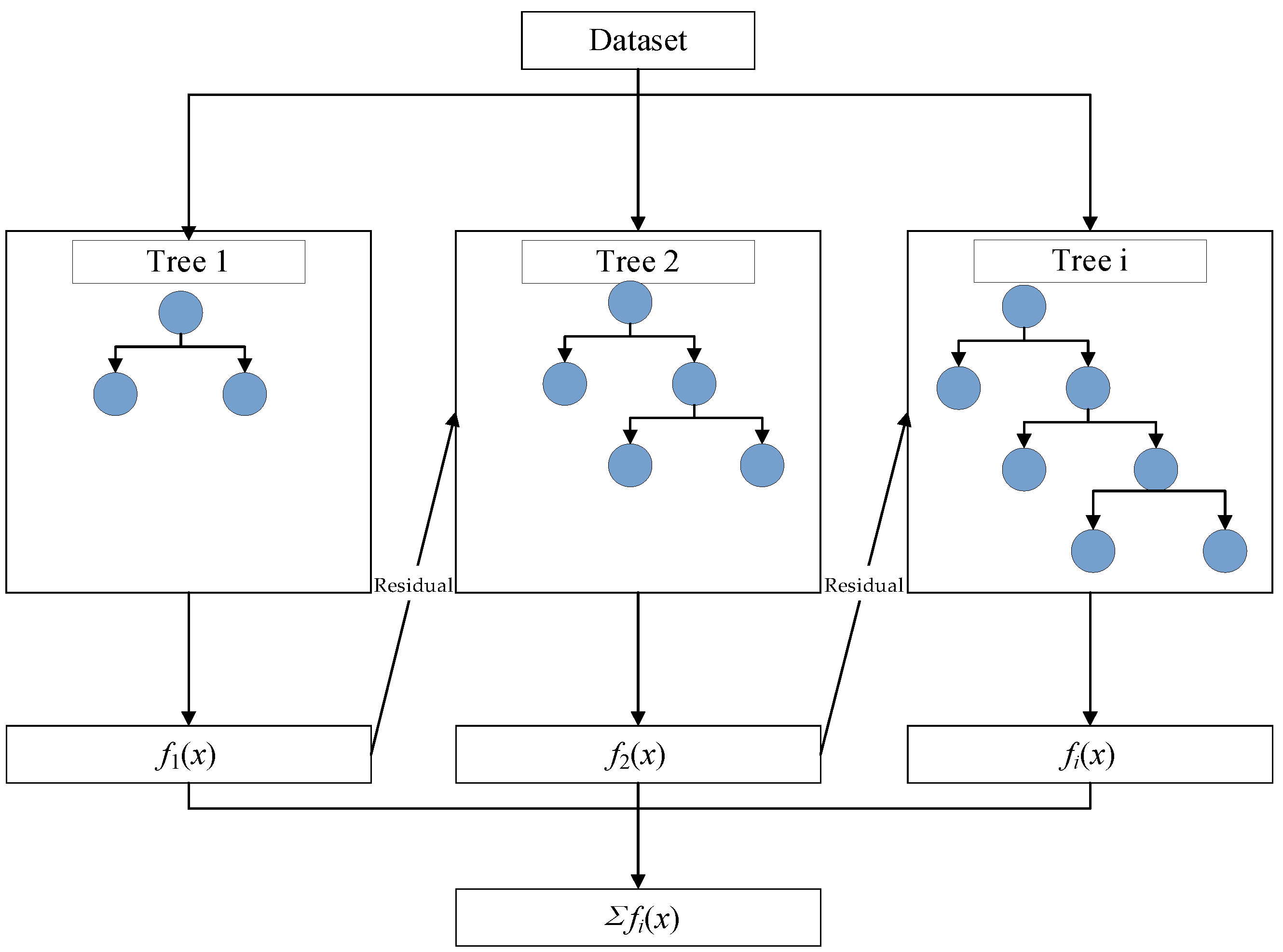
2.5. XGBoost Algorithm Principle
XGBoost [
27,
28] is an extension of the GBM algorithm and a prediction model with both linear regression and regression tree characteristics. In the XGBoost algorithm, there are multiple tree structures, each of which contains multiple branches (decision trees). The generation of each decision tree is adjusted according to the prediction results of the previous decision tree. Taking into account the prediction bias of the previous decision tree, we can gradually correct the prediction results. Each decision tree is generated by taking into account the entire dataset to optimize the model on the largest scale (
Figure 6).
XGBoost corrects residuals from the last prediction by constantly adding new decision trees to the model and avoids overfitting problems through introducing regularization parameters [
29]. Finally, XGBoost adds the weighted sum of the predictions from multiple decision trees to obtain the final prediction result. When building the dam deformation prediction model, the XGBoost algorithm can make use of the dam displacement data and constantly introduce temperature, aging, water pressure, and other factors into the model, as well as comprehensively consider and evaluate the influence of these factors on the dam deformation by approximating the actual displacement value. With XGBoost’s optimization and weighted summation method, the deformation of the dam can be predicted more accurately, and the importance of different factors can be assessed. This makes XGBoost a powerful and flexible tool for dam deformation prediction.
Here,
is the number of predicted rounds;
is the predicted value of dam displacement in the
th round; and
is a tree function of temperature, aging, and water pressure factors. The objective function of the XGBoost algorithm is as follows:
where
is the number of predicted rounds; and
is the loss function of the relevant
,
, where
is the actual value of deformation displacement. The model training is completed when the objective function is found to be at the minimum through iteration.
2.6. Dam Deformation Prediction Model
The construction process and input of the dam deformation prediction model are as follows:
- (1)
EEMD decomposition is performed on the measured value of dam displacement monitoring to obtain several components——using the Pearson correlation coefficient between and . When is less than the threshold, it is considered to be a noise-containing component. The noise-containing component is denoised by using the wavelet packet, and the noise reduction effect is verified by the comparison of curve smoothness and noise reduction error, and then the measured value of a certain measurement point after noise reduction is reconstructed.
- (2)
Based on environmental variables such as the installation elevation and upstream water level of a measuring point, three types of factors, such as water pressure, temperature, and aging, of the measuring point were calculated as input variables, and the measured displacement history data of the measuring point after noise reduction was used as output variables to establish the LASSO model. The optimal factor was selected using the LASSO feature.
- (3)
The root mean square error (RMSE), mean absolute percentage error (MAPE), coefficient of determination (
R2), mean square error (MSE), and mean absolute error (MAE) were used to comprehensively compare the prediction models.
In the above formula, is the th measured displacement value; is the th predicted displacement value; and indicates the data length.
As important statistical indicators, the RMSE and MAE are used to evaluate the performance of predictive models. The RMSE is the root of the mean value of the squared error, and the smaller the value, the better the prediction effect is. However, since the expression equation contains the square error, it is more sensitive to the poorly predicted points and can be used as an indicator to measure the local prediction ability of the model. The MAE assesses the closeness between the predicted and measured values, and it reflects the overall forecasting error state. It is insensitive to outliers and can, therefore, be used to assess the overall prediction accuracy of the model.
The correlation coefficient
R2, also known as the Pearson correlation coefficient, reflects the degree of correlation between two variables, namely the correlation between the predicted value and the actual value. The closer the
R2 value is close to 1, the stronger the correlation between the two variables is and the better the model performance is (
Figure 7).




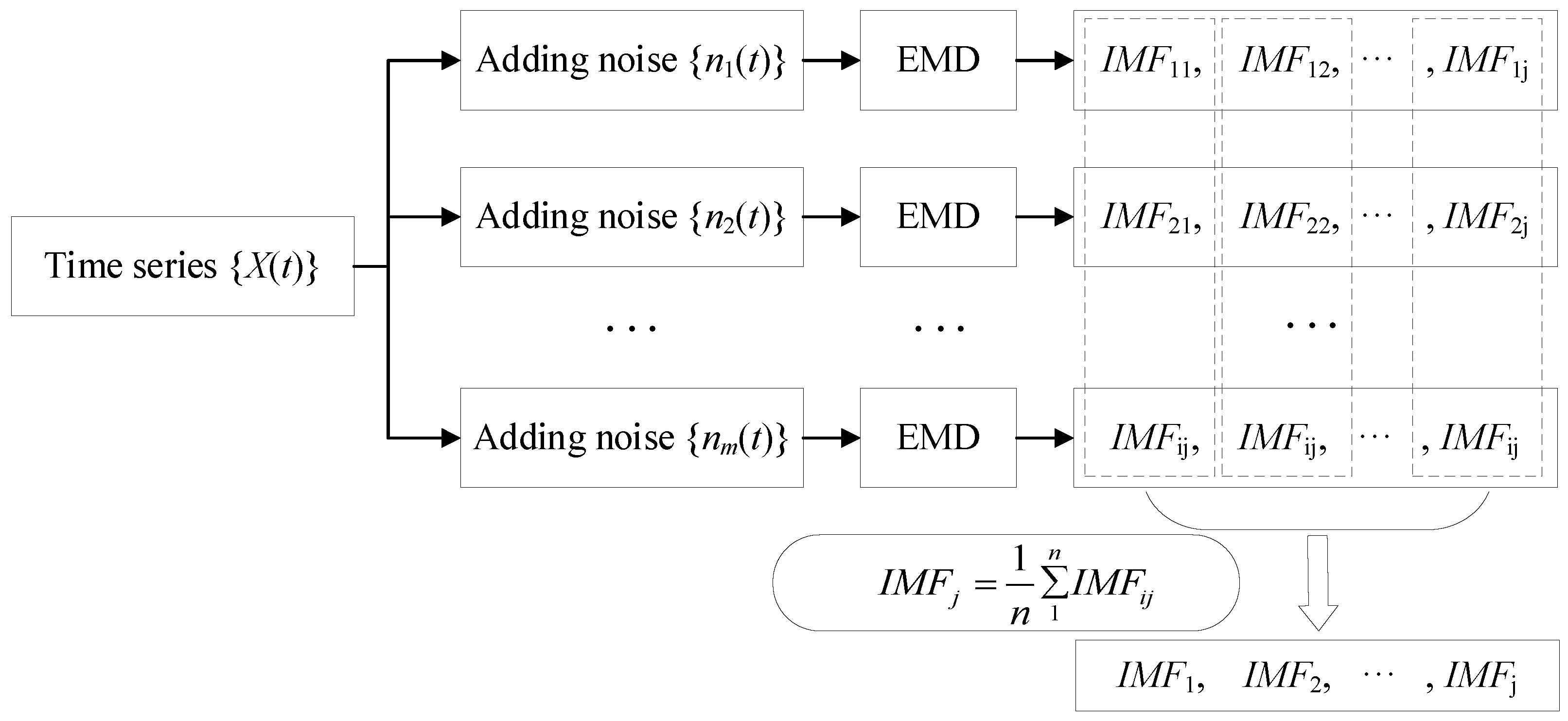




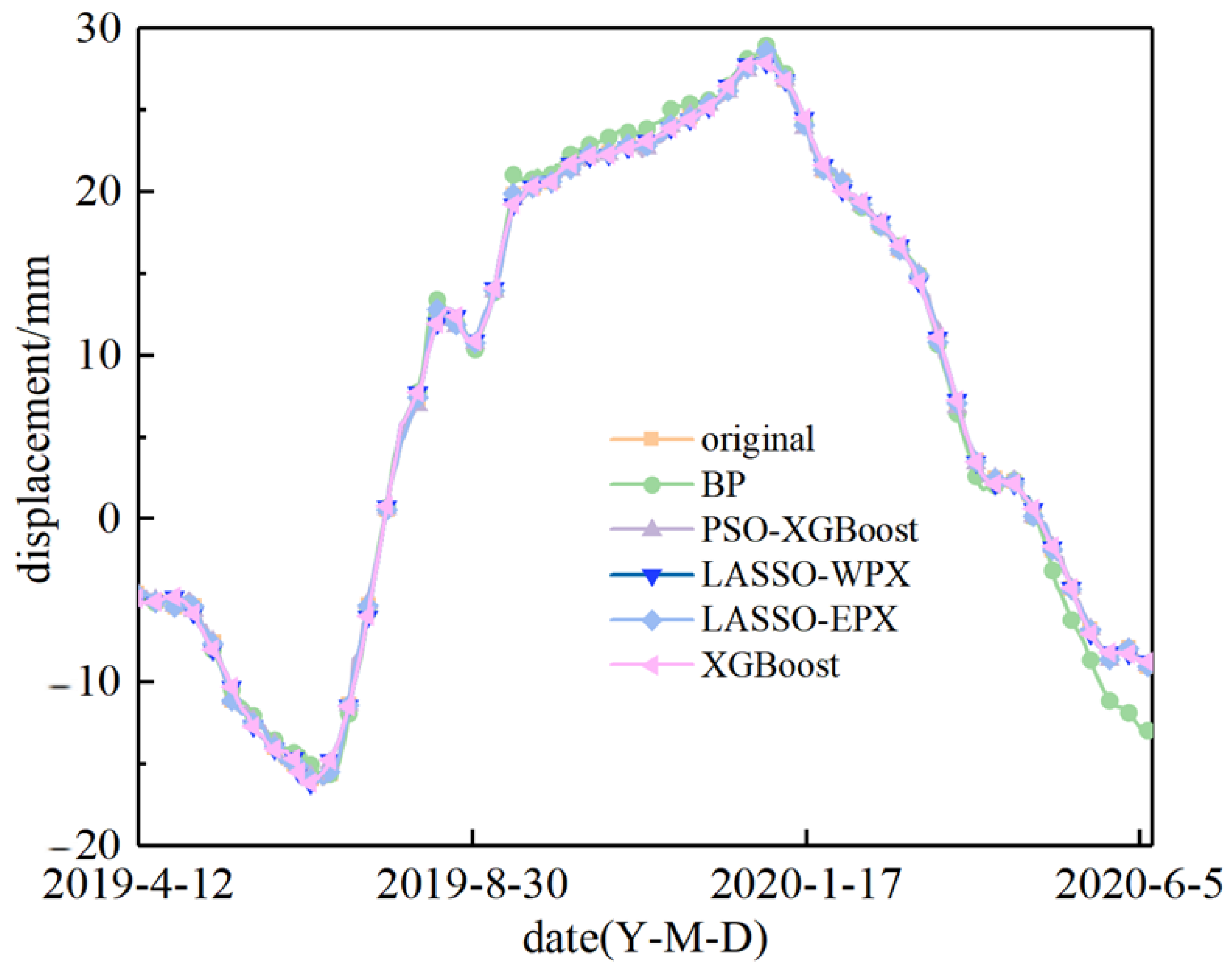
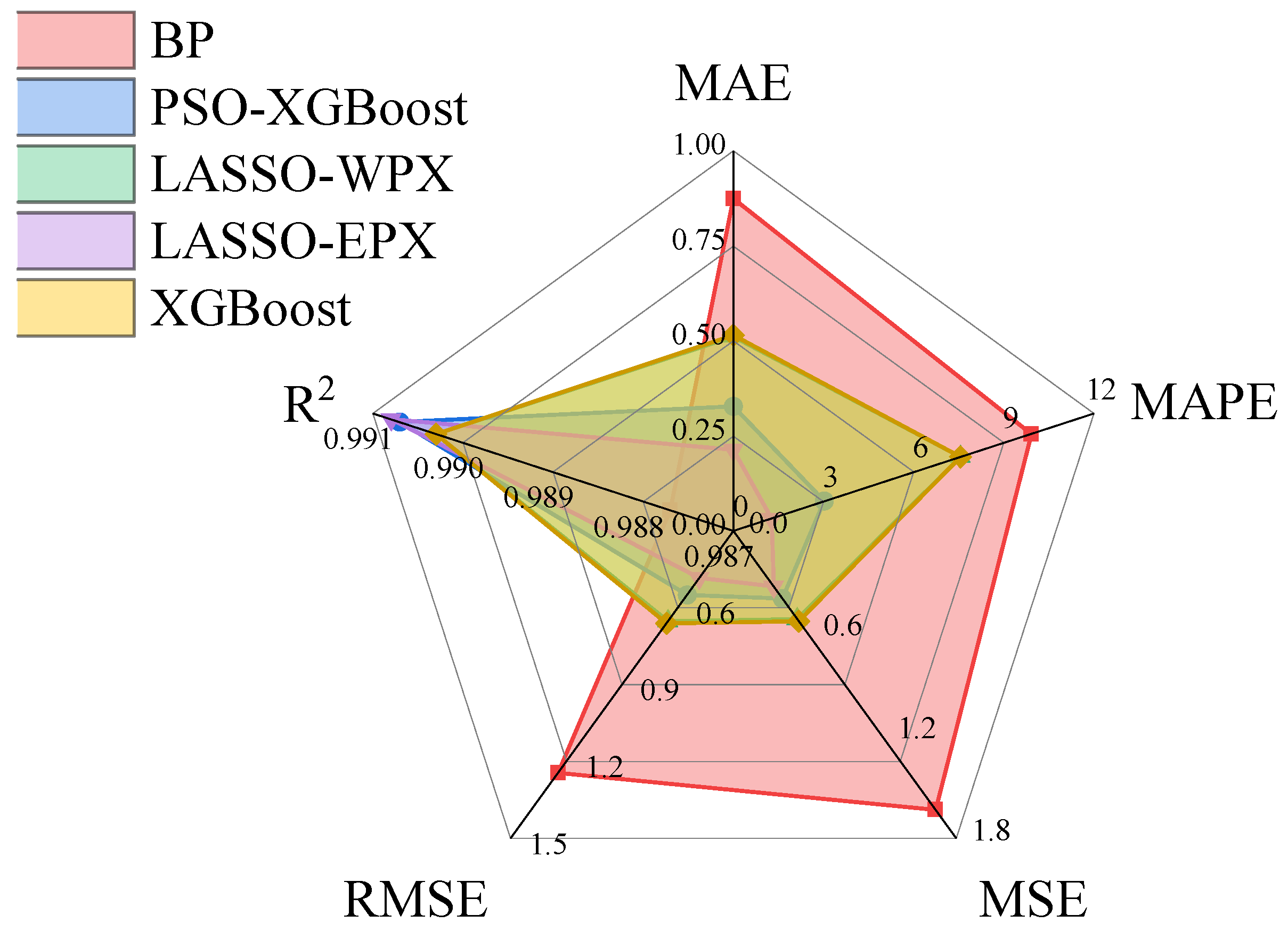

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}