
Reducing Mesh Dependency in Dataset Generation for Machine Learning Prediction of Constitutive Parameters in Sheet Metal Forming



Abstract
1. Introduction
2. Methodology
2.1. Inverse Approach in Parameter Identification
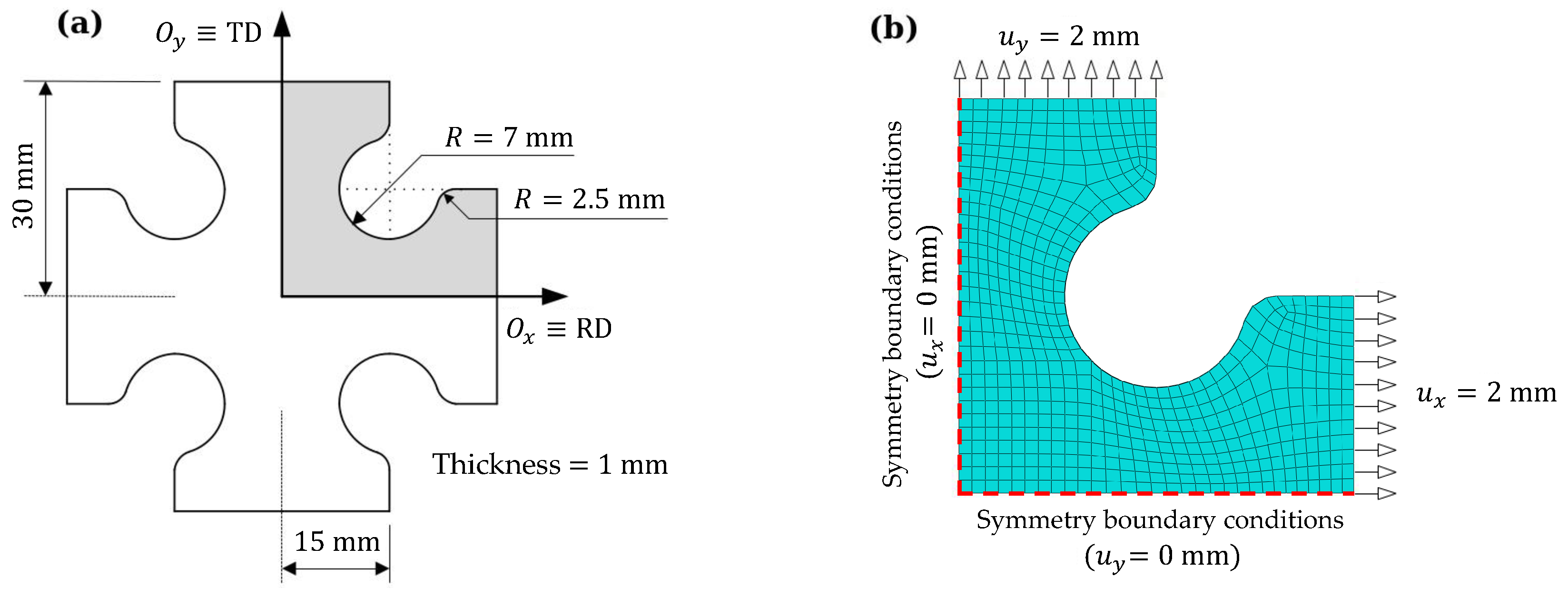
2.2. Numerical Model for the Training Stage
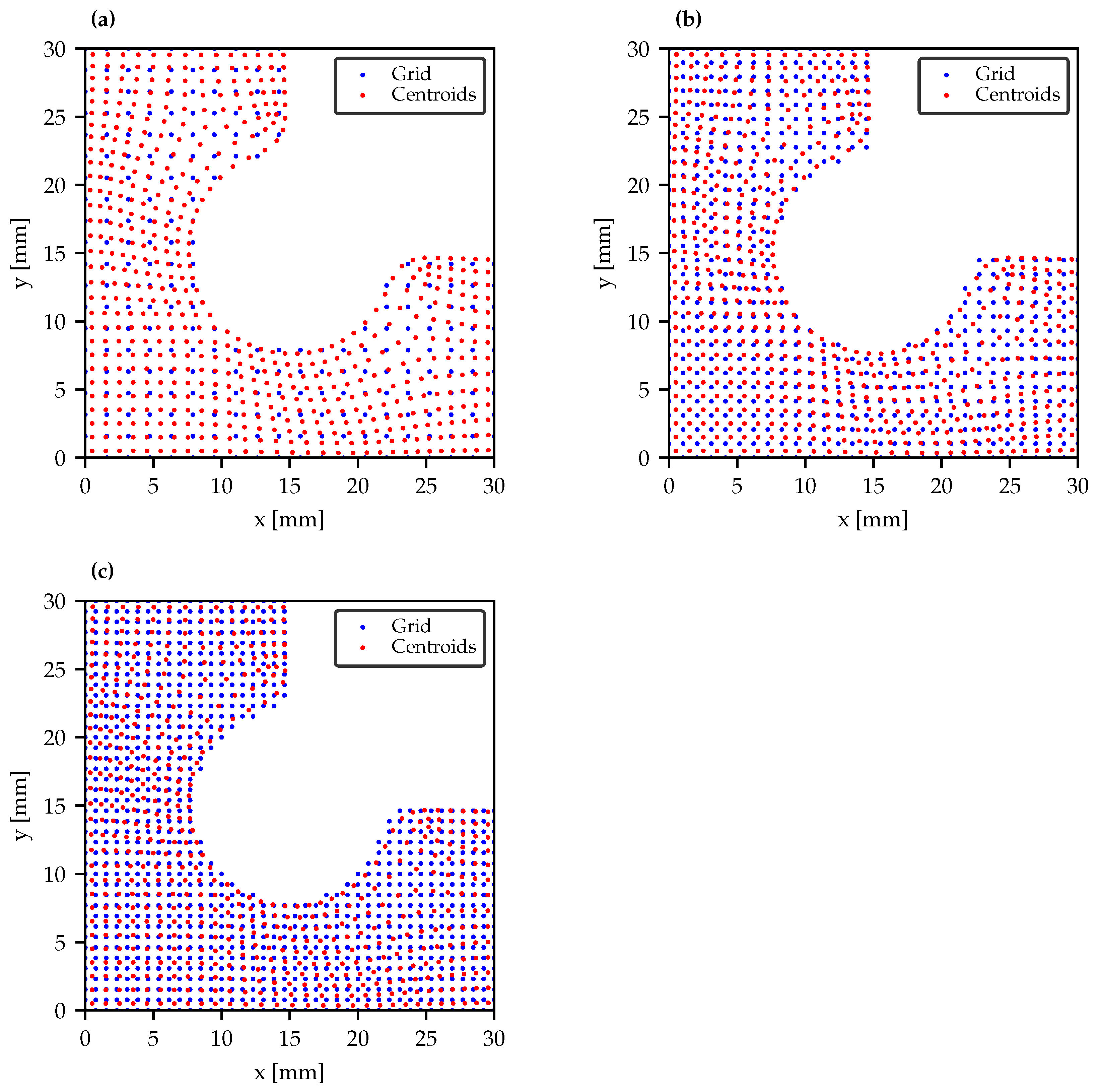
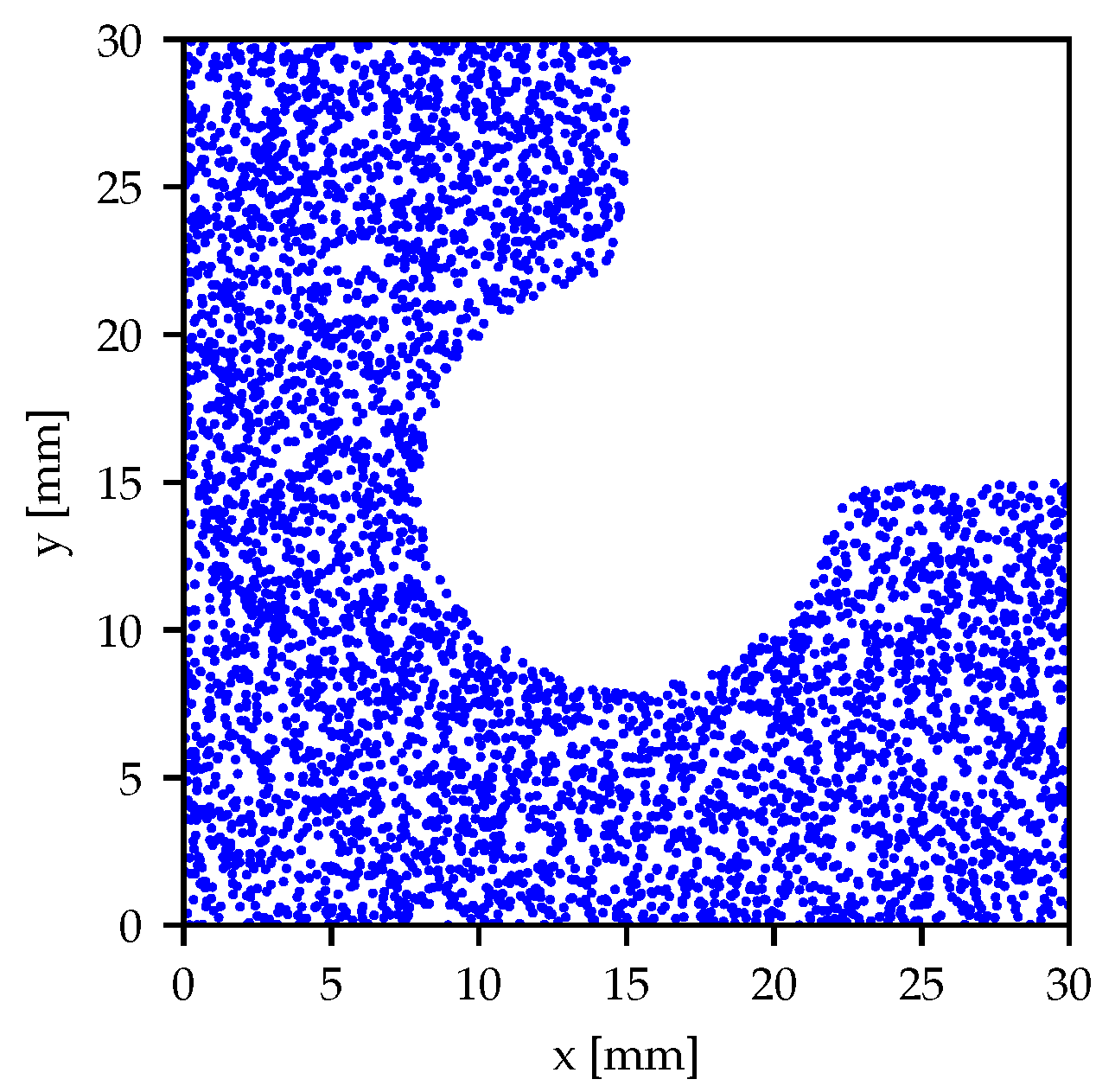
2.3. Dataset Generation
2.4. Interpolation Approach
2.5. Training and Evaluation
2.6. Case Study
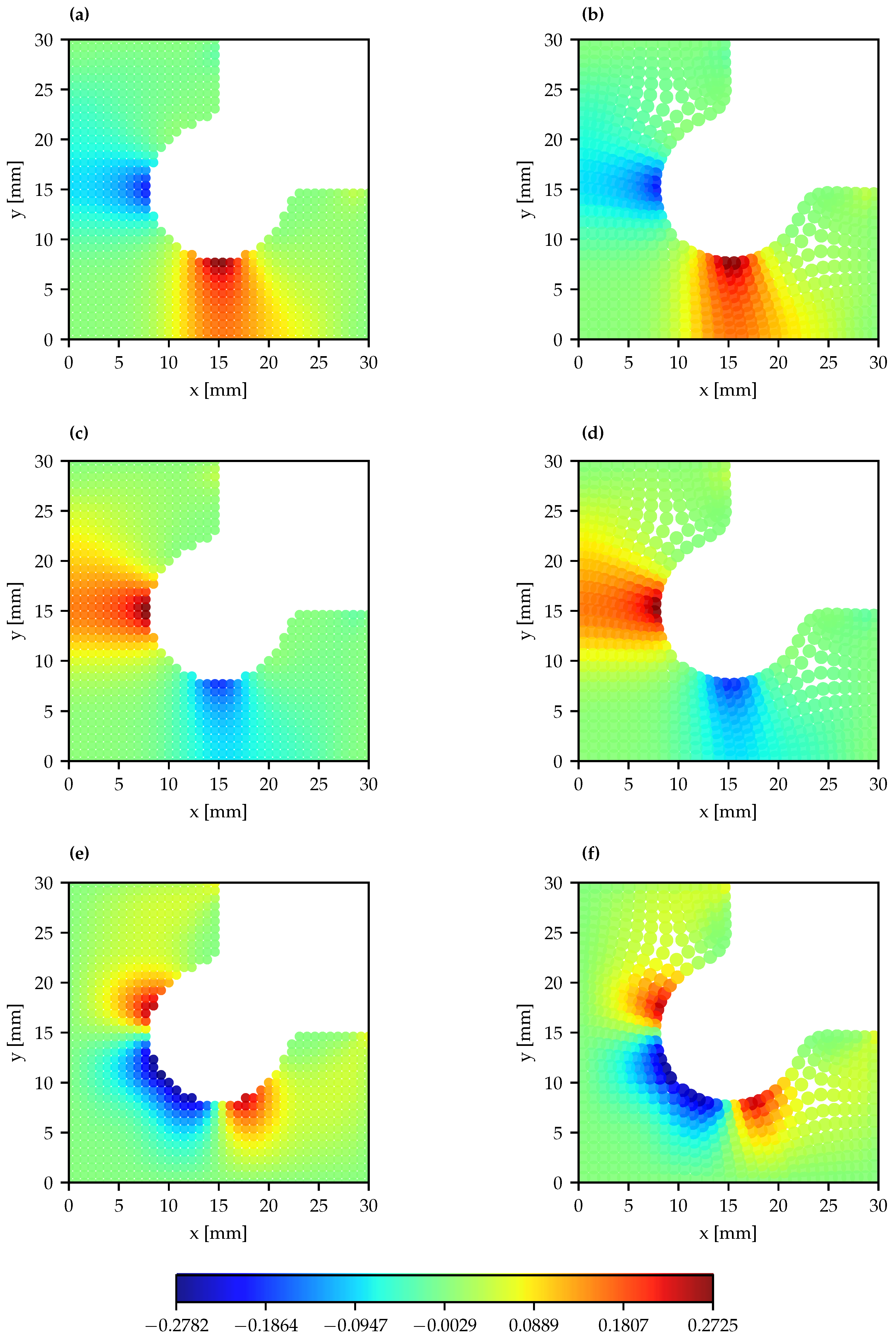
3. Results and Discussion
4. Conclusions
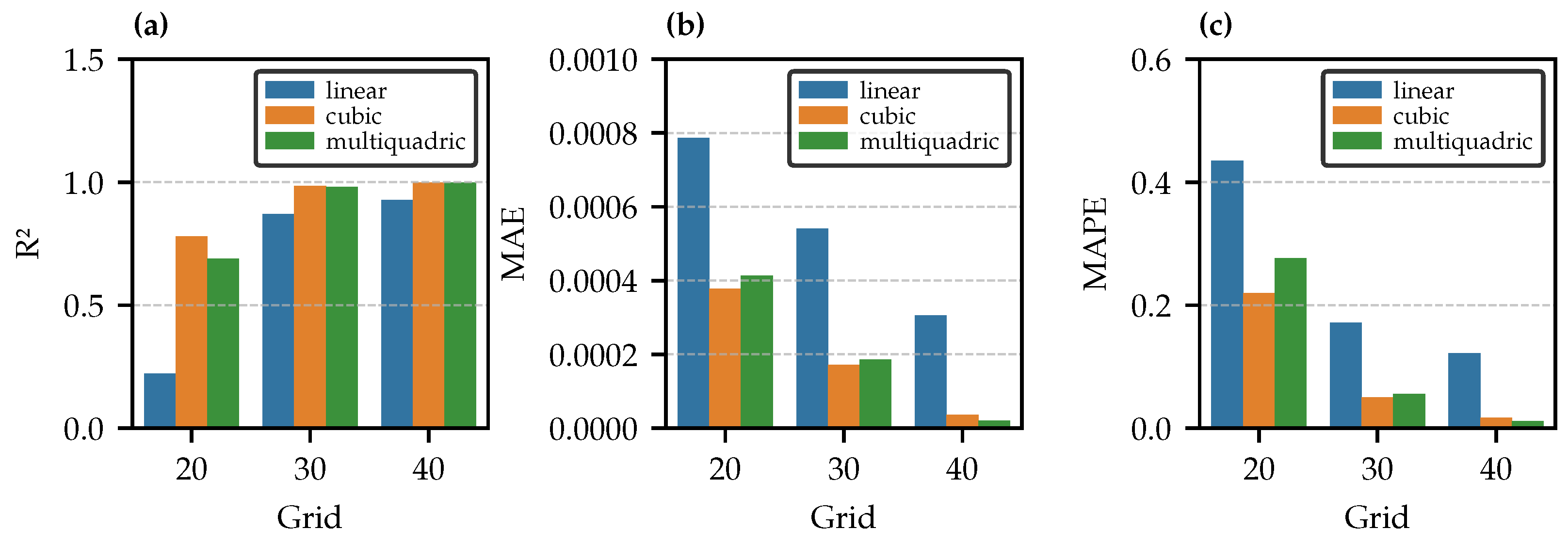
- Interpolation accuracy improves with grid size, with cubic and multiquadric methods outperforming the linear method;
- In reverse interpolation, choosing a grid with at least as many points as the number of mesh centroids improves strain field reconstruction accuracy. However, this increase in grid density has negligible effect on the predictive performance of the ML models;
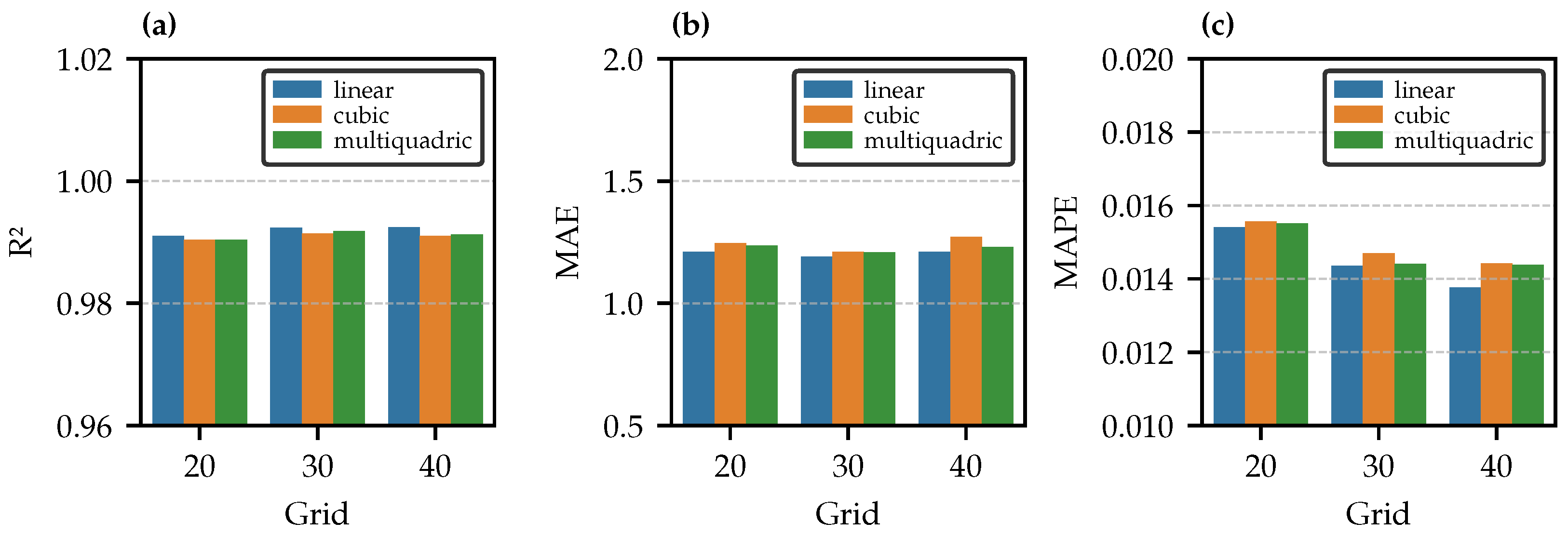
- ML models exhibit strong predictive performance, with the choice of interpolation method or grid having minimal impact on overall model accuracy;
- Similar R2 values between models trained on interpolated vs. original data suggest that interpolation does not degrade predictive performance;
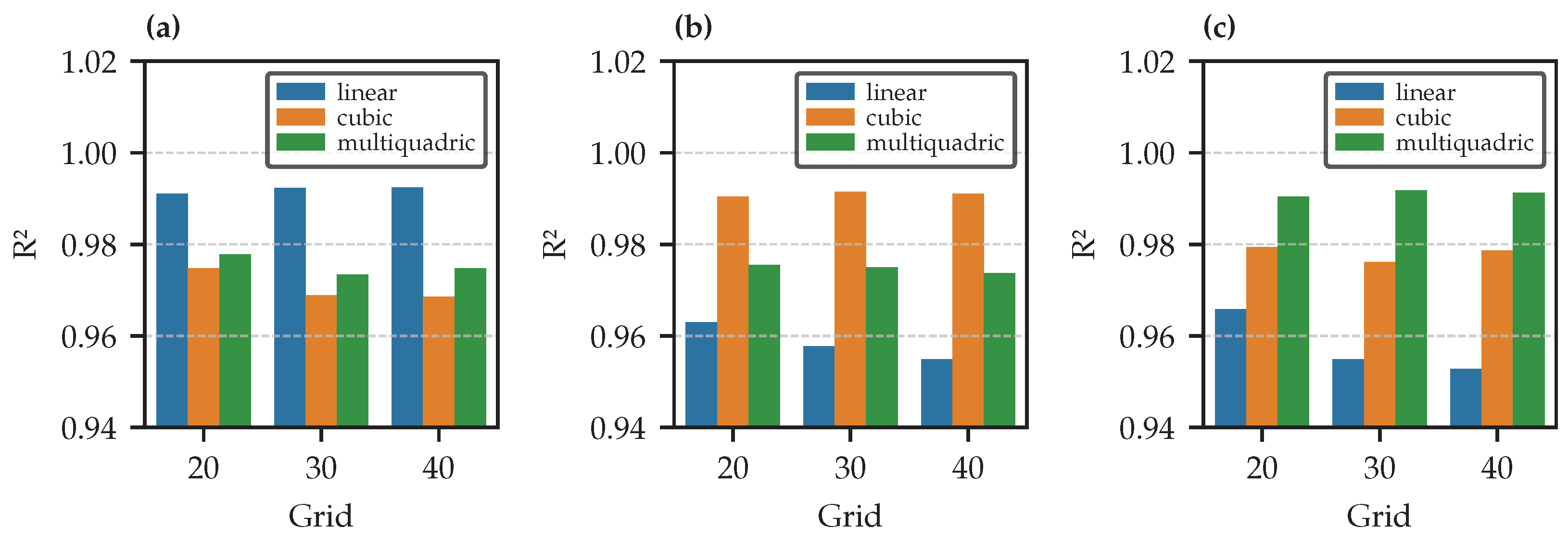
- Models demonstrate high robustness when handling data interpolated by different methods, with cubic and multiquadric models proving the most reliable;
- Cubic and multiquadric models are less compatible with linear-interpolated test data, and vice versa, but perform best when tested with each other’s interpolation methods;
- Better performance is achieved when the model and test data share the same interpolation method;
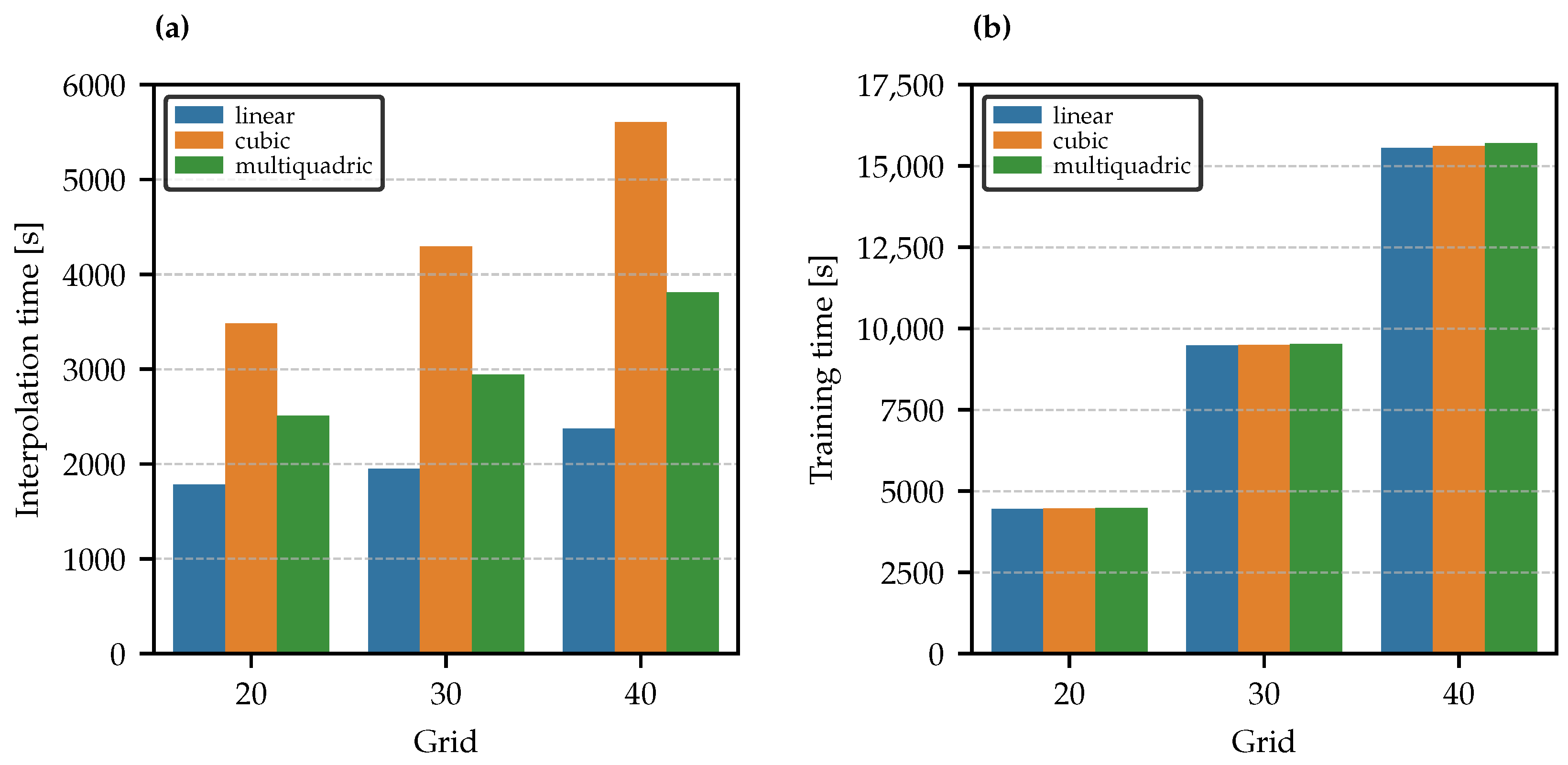
- In terms of computational efficiency, the linear method is the fastest for interpolation, while the cubic method is the most demanding. However, the interpolation method does not affect training time;
- As expected, computational time increases with grid size for both interpolation and training;
- Balancing accuracy, performance, and computational cost, the optimal choice in the present study is the 30 × 30 grid with the multiquadric method. However, this conclusion is specific to the considered setup and should not be generalised without further validation under different constitutive models or testing conditions;
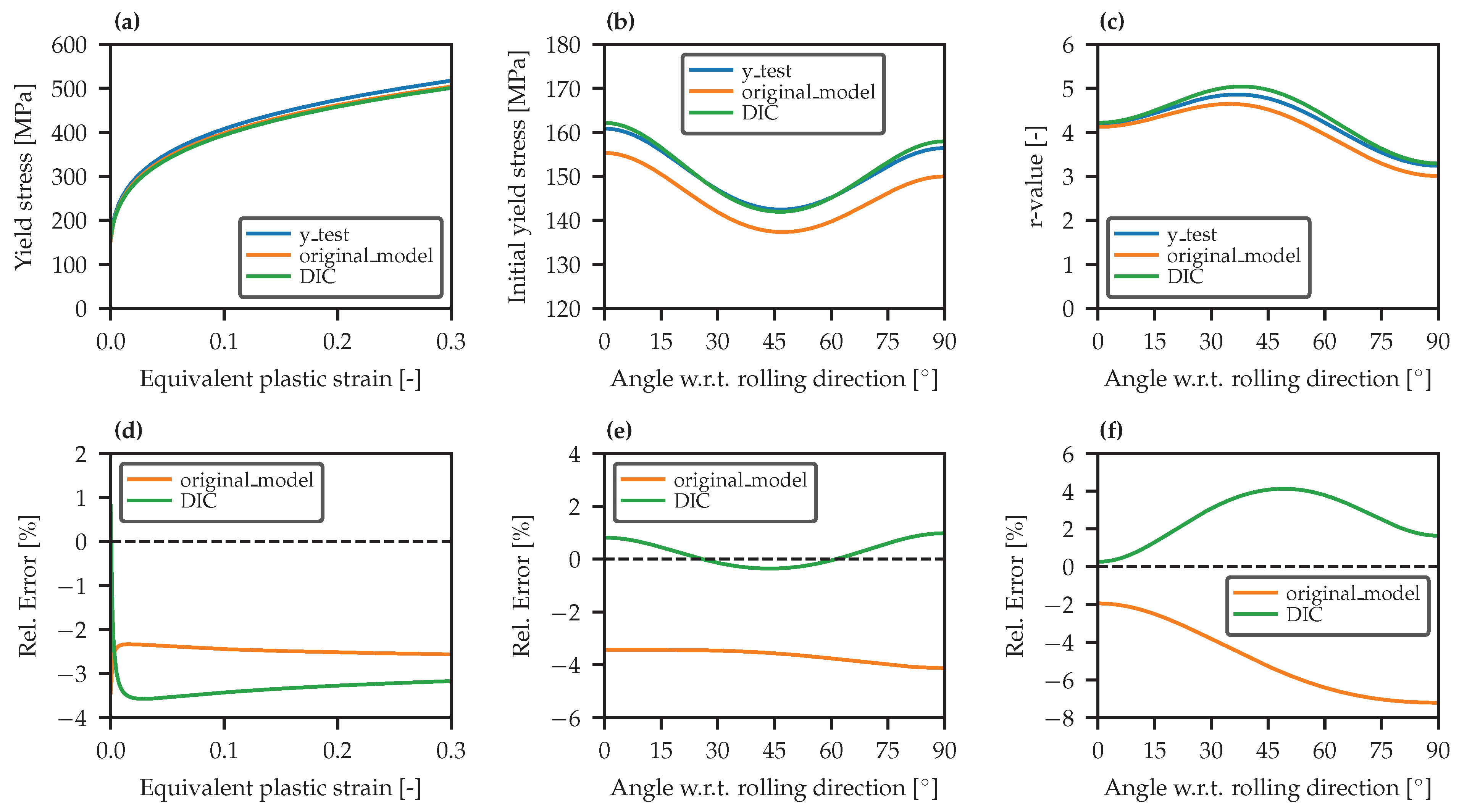
- Synthetic DIC sample predicted parameters closely match those obtained by the original model and the chosen parameters, which not only confirms the strong predictive capability of the model trained with the 30 × 30 grid and multiquadric method, but also demonstrates the effectiveness of the interpolation-based approach when applied to a denser group of points, simulating DIC speckle pattern subsets;
- This study focuses on the pre-failure regime, where strain distributions are relatively smooth. While this condition reduces the severity of mesh dependence, the proposed approach still plays a critical role in enabling compatibility between FEM simulations and full-field experimental data (e.g., DIC), which are often collected with non-matching spatial resolutions.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- do Nascimento Cruz, M.; Nikhare, C.; Filho, R.; Marcondes, P. Sheet metal formability analysis by accessible and reliable digital image correlation system. Int. J. Adv. Manuf. Technol. 2025, 137, 2307–2317. [Google Scholar] [CrossRef]
- Parreira, T.G.; Marques, A.E.; Sakharova, N.A.; Prates, P.A.; Pereira, A.F.G. Identification of Sheet Metal Constitutive Parameters Using Metamodeling of the Biaxial Tensile Test on a Cruciform Specimen. Metals 2024, 14, 212. [Google Scholar] [CrossRef]
- Diller, M.; Thomas, W.; Ahmetoglu, M.A.; Akgerman, N.; Altan, T.; Diller, M.; Thomas, W.; Ahmetoglu, M.A.; Akgerman, N.; Altan, T. Applications of Computer Simulations for Part and Process Design for Automotive Stampings; SAE International: Warrendale, PA, USA, 1997. [Google Scholar] [CrossRef]
- Yoshida, F.; Hamasaki, H.; Uemori, T. A user-friendly 3D yield function to describe anisotropy of steel sheets. Int. J. Plast. 2013, 45, 119–139. [Google Scholar] [CrossRef]
- Chaparro, B.M.; Thuillier, S.; Menezes, L.F.; Manach, P.Y.; Fernandes, J.V. Material parameters identification: Gradient-based, genetic and hybrid optimization algorithms. Comput. Mater. Sci. 2008, 44, 339–346. [Google Scholar] [CrossRef]
- Fu, J.; Cai, Y.; Zhang, B.; Qi, Z.; Liu, F.; Qi, L. A VFM-based identification method for anisotropic thermal-mechanical properties of sheet metals using the digital image correlation and infrared thermography assisted heterogeneous test. J. Mater. Process. Technol. 2024, 330, 118490. [Google Scholar] [CrossRef]
- Rabahallah, M.; Balan, T.; Bouvier, S.; Bacroix, B.; Barlat, F.; Chung, K.; Teodosiu, C. Parameter identification of advanced plastic strain rate potentials and impact on plastic anisotropy prediction. Int. J. Plast. 2009, 25, 491–512. [Google Scholar] [CrossRef]
- Avril, S.; Bonnet, M.; Bretelle, A.S.; Grédiac, M.; Hild, F.; Ienny, P.; Latourte, F.; Lemosse, D.; Pagano, S.; Pagnacco, E.; et al. Overview of Identification Methods of Mechanical Parameters Based on Full-field Measurements. Exp. Mech. 2008, 48, 381–402. [Google Scholar] [CrossRef]
- Rossi, M.; Lattanzi, A.; Amodio, D. A hybrid VFM-FEMU approach to calibrate 3D anisotropic plasticity models for sheet metal forming. Mater. Res. Proc. 2023, 28, 1203–1210. [Google Scholar] [CrossRef]
- Zhang, Y.; Yamanaka, A.; Cooreman, S.; Kuwabara, T.; Coppieters, S. Inverse identification of plastic anisotropy through multiple non-conventional mechanical experiments. Int. J. Solids Struct. 2023, 285, 112534. [Google Scholar] [CrossRef]
- Chen, B.; Starman, B.; Halilovič, M.; Berglund, L.A.; Coppieters, S. Finite Element Model Updating for Material Model Calibration: A Review and Guide to Practice. Arch. Comput. Methods Eng. 2024. [Google Scholar] [CrossRef]
- Fu, J.; Xie, W.; Qi, L. An Identification Method for Anisotropic Plastic Constitutive Parameters of Sheet Metals. Procedia Manuf. 2020, 47, 812–815. [Google Scholar] [CrossRef]
- Fu, J.; Yang, Z.; Nie, X.; Tang, Y.; Cai, Y.; Yin, W.; Qi, L. A VFM-based identification method for the dynamic anisotropic plasticity of sheet metals. Int. J. Mech. Sci. 2022, 230, 107550. [Google Scholar] [CrossRef]
- Lattanzi, A.; Barlat, F.; Pierron, F.; Marek, A.; Rossi, M. Inverse identification strategies for the characterization of transformation-based anisotropic plasticity models with the non-linear VFM. Int. J. Mech. Sci. 2020, 173, 105422. [Google Scholar] [CrossRef]
- Florentin, E.; Lubineau, G. Identification of the parameters of an elastic material model using the constitutive equation gap method. Comput. Mech. 2010, 46, 521–531. [Google Scholar] [CrossRef]
- Latourte, F.; Chrysochoos, A.; Pagano, S.; Wattrisse, B. Elastoplastic Behavior Identification for Heterogeneous Loadings and Materials. Exp. Mech. 2008, 48, 435–449. [Google Scholar] [CrossRef]
- Claire, D.; Hild, F.; Roux, S. A finite element formulation to identify damage fields: The equilibrium gap method. Int. J. Numer. Methods Eng. 2004, 61, 189–208. [Google Scholar] [CrossRef]
- Périé, J.N.; Leclerc, H.; Roux, S.; Hild, F. Digital image correlation and biaxial test on composite material for anisotropic damage law identification. Int. J. Solids Struct. 2009, 46, 2388–2396. [Google Scholar] [CrossRef]
- Cruz, D.J.; Barbosa, M.R.; Santos, A.D.; Amaral, R.L.; de Sa, J.C.; Fernandes, J.V. Recurrent Neural Networks and Three-Point Bending Test on the Identification of Material Hardening Parameters. Metals 2024, 14, 84. [Google Scholar] [CrossRef]
- Kim, J.; Ebrahim, A.S.; Kinsey, B.L.; Ha, J. Identification of Yld2000–2d anisotropic yield function parameters from single hole expansion test using machine learning. CIRP Ann. 2024, 73, 233–236. [Google Scholar] [CrossRef]
- Böhringer, P.; Sommer, D.; Haase, T.; Barteczko, M.; Sprave, J.; Stoll, M.; Karadogan, C.; Koch, D.; Middendorf, P.; Liewald, M. A strategy to train machine learning material models for finite element simulations on data acquirable from physical experiments. Comput. Methods Appl. Mech. Eng. 2023, 406, 115894. [Google Scholar] [CrossRef]
- Chamekh, A.; BelHadjSalah, H.; Hambli, R.; Gahbiche, A. Inverse identification using the bulge test and artificial neural networks. J. Mater. Process. Technol. 2006, 177, 307–310. [Google Scholar] [CrossRef]
- Chamekh, A.; Bel Hadj Salah, H.; Hambli, R. Inverse technique identification of material parameters using finite element and neural network computation. Int. J. Adv. Manuf. Technol. 2009, 44, 173–179. [Google Scholar] [CrossRef]
- Jang, D.P.; Fazily, P.; Yoon, J.W. Machine learning-based constitutive model for J2- plasticity. Int. J. Plast. 2021, 138, 102919. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, C.; Han, S.; Kosec, G.; Zhou, Y.; Wang, L.; Abdel Wahab, M. A deep neural network model for parameter identification in deep drawing metal forming process. J. Manuf. Process. 2025, 133, 380–394. [Google Scholar] [CrossRef]
- Stefanovska, E.; Pepelnjak, T. Optimising predictive accuracy in sheet metal stamping with advanced machine learning: A LightGBM and neural network ensemble approach. Adv. Eng. Inform. 2025, 65, 103103. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; KDD ’16; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Andrade-Campos, A.; Bastos, N.; Conde, M.; Gonçalves, M.; Henriques, J.; Lourenço, R.; Martins, J.M.P.; Oliveira, M.G.; Prates, P.; Rumor, L. On the inverse identification methods for forming plasticity models using full-field measurements. IOP Conf. Ser. Mater. Sci. Eng. 2022, 1238, 012059. [Google Scholar] [CrossRef]
- Bastos, N.; Prates, P.A.; Andrade-Campos, A. Material Parameter Identification of Elastoplastic Constitutive Models Using Machine Learning Approaches. Key Eng. Mater. 2022, 926, 2193–2200. [Google Scholar] [CrossRef]
- Prates, P.; Pinto, J.; Marques, J.; Henriques, J.; Pereira, A.; Andrade-Campos, A. Influence of data filtering and noise on the calibration of constitutive models using machine learning techniques. Mater. Form. 2024, 41, 1807–1816. [Google Scholar] [CrossRef]
- Xia, J.; Won, C.; Kim, H.; Lee, W.; Yoon, J. Artificial Neural Networks for Predicting Plastic Anisotropy of Sheet Metals Based on Indentation Test. Materials 2022, 15, 1714. [Google Scholar] [CrossRef]
- Reu, P.L.; Blaysat, B.; Andó, E.; Bhattacharya, K.; Couture, C.; Couty, V.; Deb, D.; Fayad, S.S.; Iadicola, M.A.; Jaminion, S.; et al. DIC Challenge 2.0: Developing Images and Guidelines for Evaluating Accuracy and Resolution of 2D Analyses. Exp. Mech. 2022, 62, 639–654. [Google Scholar] [CrossRef]
- Chen, B.; Coppieters, S. Unified digital image correlation under meshfree framework. Strain 2024, 60, e12461. [Google Scholar] [CrossRef]
- Prates, P.A.; Pereira, A.F.G.; Sakharova, N.A.; Oliveira, M.C.; Fernandes, J.V. Inverse Strategies for Identifying the Parameters of Constitutive Laws of Metal Sheets. Adv. Mater. Sci. Eng. 2016, 2016, 4152963. [Google Scholar] [CrossRef]
- Martins, J.M.P.; Andrade-Campos, A.; Thuillier, S. Calibration of anisotropic plasticity models using a biaxial test and the virtual fields method. Int. J. Solids Struct. 2019, 172–173, 21–37. [Google Scholar] [CrossRef]
- Prates, P. Coupling machine learning and synthetic image DIC-based techniques for the calibration of elastoplastic constitutive models. Mater. Form. 2023, 28, 1193–1202. [Google Scholar] [CrossRef]
- Dassault Systèmes. Abaqus 2016 Analysis User’s Guide; Dassault Systèmes Simulia Corp.: Providence, RI, USA, 2016; Volume 1–5. [Google Scholar]
- Hill, R.; Orowan, E. A theory of the yielding and plastic flow of anisotropic metals. Proc. R. Soc. London. Ser. A Math. Phys. Sci. 1948, 193, 281–297. [Google Scholar] [CrossRef]
- Swift, H.W. Plastic instability under plane stress. J. Mech. Phys. Solids 1952, 1, 1–18. [Google Scholar] [CrossRef]
- Randomized Designs—pyDOE3 1.0.4.dev3 Documentation. Available online: https://pydoe3.readthedocs.io/en/latest/randomized.html#latin-hypercube (accessed on 7 March 2025).
- Interpolation (scipy.interpolate)—SciPy v1.15.2 Manual. Available online: https://docs.scipy.org/doc/scipy/reference/interpolate.html (accessed on 4 March 2025).
- Griddata—SciPy v1.15.2 Manual. Available online: https://docs.scipy.org/doc/scipy/reference/generated/scipy.interpolate.griddata.html#scipy.interpolate.griddata (accessed on 4 March 2025).
- RBFInterpolator—SciPy v1.15.2 Manual. Available online: https://docs.scipy.org/doc/scipy/reference/generated/scipy.interpolate.RBFInterpolator.html#scipy.interpolate.RBFInterpolator (accessed on 4 March 2025).
- Metrics and Scoring: Quantifying the Quality of Predictions. Available online: https://scikit-learn.org/stable/modules/model_evaluation.html (accessed on 9 March 2025).
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef]
- Lava, P.; Jones, E.M.C.; Wittevrongel, L.; Pierron, F. Validation of finite-element models using full-field experimental data: Levelling finite-element analysis data through a digital image correlation engine. Strain 2020, 56, e12350. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Material Parameters | Input Space | Step Size |
|---|---|---|
| K [MPa] | 280–700 | 0.01 |
| [MPa] | 120–300 | 0.01 |
| n | 0.1–0.3 | 0.001 |
| 0.6–6.0 | 0.001 | |
| 0.6–6.0 | 0.001 | |
| 0.6–6.0 | 0.001 |
| Training | Test | ||
|---|---|---|---|
| Feature | Target | Feature | Target |
| 2000 × 33,880 | 2000 × 6 | 260 × 33,880 | 260 × 6 |
| Grid Size | Total Points | Domain Points | Relative Density |
|---|---|---|---|
| 20 × 20 | 400 | 253 | ≈0.45 |
| 30 × 30 | 900 | 564 | 1.00 |
| 40 × 40 | 1600 | 1006 | ≈1.78 |
| Training Interpolation Method | Grid Size | Test Interpolation Method | ||
|---|---|---|---|---|
| Linear | Cubic | Multiquadric | ||
| Linear | 20 × 20 | s | c | c |
| 30 × 30 | s | c | c | |
| 40 × 40 | s | c | c | |
| Cubic | 20 × 20 | c | s | c |
| 30 × 30 | c | s | c | |
| 40 × 40 | c | s | c | |
| Multiquadric | 20 × 20 | c | c | s |
| 30 × 30 | c | c | s | |
| 40 × 40 | c | c | s | |
| Data | Parameter | |||||
|---|---|---|---|---|---|---|
| [MPa] | [MPa] | |||||
| y_test | 0.2495 | 0.1922 | 2.3281 | 160.84 | 671.78 | 0.218 |
| original_model | 0.2679 | 0.1953 | 2.3245 | 155.32 | 653.63 | 0.217 |
| DIC | 0.2456 | 0.1918 | 2.3906 | 162.15 | 652.62 | 0.221 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mitreiro, D.; Prates, P.A.; Andrade-Campos, A. Reducing Mesh Dependency in Dataset Generation for Machine Learning Prediction of Constitutive Parameters in Sheet Metal Forming. Metals 2025, 15, 534. https://doi.org/10.3390/met15050534
Mitreiro D, Prates PA, Andrade-Campos A. Reducing Mesh Dependency in Dataset Generation for Machine Learning Prediction of Constitutive Parameters in Sheet Metal Forming. Metals. 2025; 15(5):534. https://doi.org/10.3390/met15050534
Chicago/Turabian StyleMitreiro, Dário, Pedro A. Prates, and António Andrade-Campos. 2025. "Reducing Mesh Dependency in Dataset Generation for Machine Learning Prediction of Constitutive Parameters in Sheet Metal Forming" Metals 15, no. 5: 534. https://doi.org/10.3390/met15050534
APA StyleMitreiro, D., Prates, P. A., & Andrade-Campos, A. (2025). Reducing Mesh Dependency in Dataset Generation for Machine Learning Prediction of Constitutive Parameters in Sheet Metal Forming. Metals, 15(5), 534. https://doi.org/10.3390/met15050534