Abstract
The sulfur content of hot metal in a blast furnace is an important index that reflects the production effects and quality of the hot metal. Establishing an accurate prediction model for hot metal sulfur content can guide the production process. In the present study, the blast furnace production data were collected and then preprocessed using box plotting. Cross-validation was used in the training process of the model to improve the generalization performance and robustness of the model. Two models for predicting the sulfur content in hot metal were established based on extreme gradient boosting (XGBoost) and multilayer perceptron (MLP) algorithms. The results show that coal consumption (CC), coal ratio (CLR), and sinter consumption (SC) are all positively correlated with hot metal sulfur content. The oxygen enrichment rate (OER) was negatively related to hot metal sulfur content. Both the extreme gradient boosting (XGBoost) and multilayer perceptron (MLP) models predicted hot metal sulfur content effectively; however, the extreme gradient boosting (XGBoost) model had a higher hit rate, accuracy, and stability, with the hit rate achieving 95.07%.
1. Introduction
Blast furnace smelting is a traditional ironmaking process. Due to its high levels of efficiency, it is still the leading technology in steel production [1]. In recent years, prediction technology for hot metal composition has become very popular in large iron and steel enterprises. The quality of hot metal directly affects the quality of steel products, and the sulfur content in hot metal directly reflects the quality level of hot metal; therefore, to improve the quality and production effects of hot metal, it is necessary to control the sulfur content in the hot metal itself [2,3]. Due to the complexity of the hot metal production process in a blast furnace, there is a non-linear relationship between the factors that affect the desulfurization effect during actual production. It is difficult to improve the desulfurization efficiency and endpoint hit rate using empirical data statistical results alone [4]; therefore, establishing a model capable of predicting the hot metal sulfur content for the process of blast furnace ironmaking would be useful for the operation of the blast furnace in terms of reducing the hot metal sulfur content, and promoting high-quality, high-yield, and low-consumption production [5]. It is of great significance to realize intelligent production in the ironmaking industry.
The prediction of hot metal sulfur content is of great concern to blast furnace workers, but traditional mathematical statistics and regression analysis methods are not able to produce high-precision models [4,6]. With the rapid development of big data technology, related technologies are now widely used in the industrial field. At present, there are many prediction methods for hot metal content based on data-driven methods, such as partial least squares [7], neural networks [8], fuzzy mathematics [9], nonlinear time series [10], support vector machines [11,12], and extreme learning machines [13]. For example, Zhang et al. [14] and Wang et al. [15] established prediction models for hot metal sulfur content in blast furnaces based on neural networks. Their hit rates reached 84.69% and 90%, respectively, which showed the effectiveness of the models. Wang et al. [5] established a sulfide capacity prediction model based on the congregated electron phase (CEPM). The predicted sulfide capacity C(S2−) predicted had a good linear relationship with the measured sulfide capacity C(S2−) measured, showing that the congregated electron phase (CEPM) can be used to reliably predict the ironmaking slag sulfide capacity below a certain temperature. Zhou et al. [16] combined statistical analysis, Deng’s relevancy, and back propagation (BP) neural networks to predict the sulfur content in hot metal. The time series process method was adopted to update the training samples in real time and optimize the model. When the prediction error of the improved model was ± 0.1%, the hit rate increased to 96.7%. Jiang et al. [17] established predictive modeling of the hot metal silicon content in a blast furnace based on the ensemble method. The performance of the random forest regression model and extreme gradient enhancement model was comprehensively evaluated; however, due to the different raw materials, production processes, blast furnace size, and operating conditions of different enterprises, their production data are also quite different; therefore, the prediction results of different models will have great differences. It may only guide the production of this enterprise and has no guiding significance for other enterprises. In addition, information on the prediction of hot metal sulfur content in blast furnaces through the extreme gradient boosting (XGBoost) and multilayer perceptron algorithm (MLP) is rare and few researchers have reported applying such huge data from hot metal sulfur content to machine learning methods.
Ensemble learning combines several machine learning technologies into the meta-algorithm of a prediction model. It can reduce variance, and enhance and improve prediction [17]. In this paper, the collected data were first preprocessed, and, then, two sulfur content prediction models based on extreme gradient boosting (XGBoost) and multilayer perceptron algorithm (MLP) integration methods were established. The model with lower computational complexity reduced the training difficulty and computation time, while greatly improving the prediction hit rate (which represents the proportion of positive cases in the sample that are correctly predicted). This prediction model can help operators adjust their operations in time to ensure the smooth and efficient operation of the blast furnace; therefore, this work will promote intelligent production in the blast furnace and it has certain guiding significance.
2. Blast Furnace Production Process
The blast furnace is a complex large-scale countercurrent reactor, which has the advantages of large-scale production and high levels of production efficiency. At present, blast furnace ironmaking is still the mainstream method of the ironmaking process. In the smelting process of the blast furnace, various physical and chemical reactions are completed during the stages of gas upflow and furnace burden falling, with hot metal being obtained through iron–slag separation. The hot metal is then used as raw material for the steelmaking process. The main production process is shown in Figure 1.
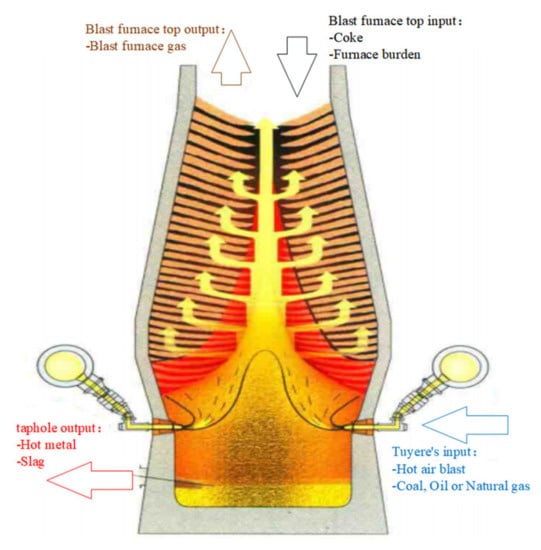
Figure 1.
Overview of blast furnace production.
- The iron-containing raw materials (sinter, pellet, or lump ore), fuel (coke), and slag-making flux (limestone, dolomite, and manganese ore) are loaded into the blast furnace from the furnace top in specific proportions;
- Hot air (oxygen enrichment) is blown into the blast furnace tuyere from the hot air stove (some blast furnaces also inject auxiliary fuels such as coal powder, heavy oil, and natural gas); carbon monoxide and hydrogen are then generated by coke burning with oxygen (from hot air) at high temperature;
- Raw materials and fuels descend during the process of smelting in the furnace; the hot metal is then produced by heat transfer reaction, reduction reaction, melting reaction, and deoxidation with the rising gas, successively; slag is produced by gangue material in iron-containing raw materials and flux;
- The gas produced is discharged from the furnace top; after being dedusted, this gas is used as fuel for the hot stoves, heating furnace, coke oven, boiler, etc. Finally, it enables the recycling of resources and improves the comprehensive utilization efficiency of C resources;
- Hot metal is obtained through iron–slag separation and is used as the raw material for steelmaking. Blast furnace slag can be used as raw material for the production of cement and building materials.
3. Brief Review of XGBoost and MLP
3.1. Extreme Gradient Boosting (XGBoost)
Extreme gradient boosting (XGBoost) is also known as an extreme gradient-lifting tree. It is a scalable machine learning system associated with tree boosting, proposed by Dr. Chen Tianqi of the University of Washington. The algorithm in this system produces the advantages of excellent effects, simple use, fast speed, and improved accuracy. In recent years, the XGBoost has been widely used in the engineering field, and has achieved excellent performance.
The central idea of XGBoost is that it builds decision trees one by one so that each subsequent model (tree) is trained using the residuals of the previous tree, i.e., the new tree corrects the errors made by the previously trained tree. Similar to the random forest model, XGBoost involves several hyperparameters for controlling itself and controlling the decision tree structure [18]. For decision tree theory, please refer to [17]. XGBoost algorithm flow is shown in Figure 2.
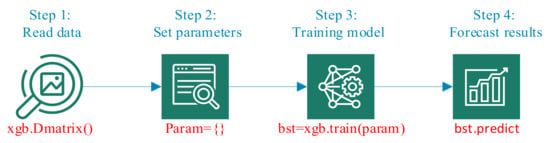
Figure 2.
XGBoost algorithm flow chart.
3.2. Multilayer Perceptron Algorithm (MLP)
The multilayer perceptron algorithm (MLP) is also called an artificial neural network. Its essence is a fully connected feed-forward neural network with one or more hidden layers. An MLP takes the eigenmatrix xm and obtains a predictive variable ŷm by combining linear and nonlinear combinations for the sample set D={(xm, ym)}. The multilayer perceptron not only has input and output layers, but also multiple hidden layers. The simplest MLP requires only an input layer, a single hidden layer, and an output layer. MLP algorithm flow is shown in Figure 3.
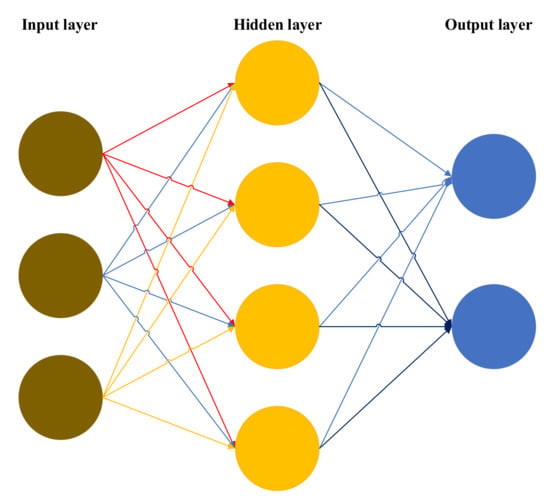
Figure 3.
MLP algorithm flow chart.
For a dataset (xi, li) containing M samples, the mathematical model of the single-layer feed-forward neural network is as follows:
where xi=[xi1, xi2........xim] which represents the M-dimensional features of the ith sample; li=[li1, li2........lim] and the corresponding target vector, βi, is the output weight matrix for connecting the ith hidden and output nodes; g(wi, bi, xk) is a nonlinear segmented continuous function (wi and bi are determined to model parameters). Every single neuron in the hidden layer is composed of the linear combination of input features, x.
The mathematical model of the multi-layer feed-forward neural network is as follows [19]:
where xi is the input of i characteristics of a given sample; wjp is the connection weight of the hidden layer and the input layer; wij is the connection weight of the input layer and the hidden layer; φo is the activation function of the output layer; and φH is the activation function of the hidden layer.
3.3. The Process of Modeling
In order to produce the two predictive models of hot metal sulfur content, the following steps were performed.
Step 1. Preprocessing of original data, including the treatment of extreme outliers and missing values. Research showed [20] that pre-processing of original data followed by correlation modeling leads to more effective prediction than directly using original data for prediction modeling. This step is crucial for building the prediction model.
Step 2. Feature selection. The input parameters of the XGBoost and MLP models were determined by recursive feature elimination. Taking into consideration the hysteresis of the smelting process in the blast furnace, this paper selected the sulfur content of hot metal after one day as a predictive model parameter.
Step 3. Completion of the above steps to obtain the initial dataset. The optimal hyperparameters for the XGBoost and MLP models were obtained by grid searches. A total of 75% of the dataset was used for model training, and the remaining data were used for model testing.
4. Preprocessing of Data and Feature Selection
The blast furnace ironmaking process is the most critical step in the manufacture of steel [21]. The quality of the hot metal is directly influenced by the smelting conditions of the blast furnace [22]; however, the limitations in measurement imposed by the severe operation conditions result in outliers and missing values in the original data. The use of the original dataset requires treatment to ensure quality and reliability [17]. This section presents the challenges of obtaining data, as well as the preparation, preprocessing treatments, and feature selection. This is the key to building a high-precision prediction model.
4.1. Collection of Data
The original (experimental) data were obtained from the blast furnace of a steel plant in Hebei Province, China. Nine years’ worth of detailed blast furnace operational data were used. There were 3406 samples in total. The sampling time was once a day (due to the limitation of data storage, the historical production data was in the form of daily average). The operators recorded the daily production and operation data of the blast furnace for nine years; the production data were not modified or adjusted. These daily averages of every parameter were able to truly reflect the production situation of the blast furnace. The original data collected covered the various operating systems in the smelting process (including the energy consumption conditions, operational conditions, blast furnace burden conditions, and hot metal conditions). Table 1 lists the corresponding relationship between actual physical meaning and parameter name. All parameters in Table 1 can refer to [23,24].

Table 1.
The parameters and abbreviations collected in this study.
4.2. Preprocessing of Data
4.2.1. Significance
In general, original data tends to be incomplete, noisy, and inconsistent. Data preprocessing is the preparation stage prior to data analysis or data mining, and is, therefore, essential. Preprocessing of data involves a series of methods to manage data that would normally be available, extract data accurately, and adjust the data format, thereby obtaining a set of high-quality data that meets the standards of accuracy, integrity, and simplicity; moreover, preprocessing the data ensures that they are more usable for the purposes of data analysis or data mining. In general, preprocessing includes two steps: 1. Filling of missing samples; and 2. Modifying outliers in the data set. These steps are critical to ensure consistency and accuracy when building a model.
4.2.2. Processing of Extreme Outliers
The term “outliers” refers to a group of measured values whose deviation from the average value exceeds twice the standard deviation, also known as abnormal data. The term “extreme outlier” refers to a measured value whose deviation from the average value exceeds three times the standard deviation, which should generally be eliminated. Outliers are usually caused by equipment failure, and directly reflect the abnormal operation of a blast furnace. Box plots can be used to label data beyond the range of (Q1-3IQR, Q3+3IQR) as extreme outliers, and the abnormal data can be processed. Where Q1 and Q3 represent each feature parameter of the first quartile and the third quartile, respectively, IQR is the extreme of the quartile. Null values replace extreme outliers in this paper.
4.2.3. Handling of Missing Value
Blast furnace smelting is a continuous production process. The whole process is completed through mutual contact between furnace charge from top to bottom and gas from bottom to top. To ensure the continuity of time, missing values are usually filled, rather than completely deleted. As shown in Figure 4, almost all parameters have missing values and extreme outliers, which should be corrected. The linear interpolation method was used to correct the data, constructing a straight line to replace the corresponding null and missing values.
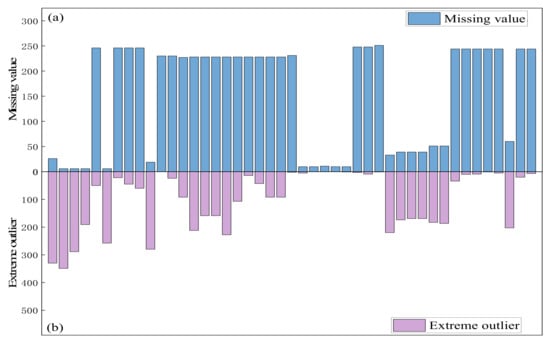
Figure 4.
Number of extreme outliers (a) and missing values (b).
4.3. Feature Selection
In the process of model construction, selecting reasonable input parameters can improve the efficiency of the prediction model, shorten the operation time, and improve the accuracy of the prediction model. It is crucial to the construction of the model.
4.3.1. Correlation Analysis
The Pearson correlation coefficient is widely used to measure the degree of correlation between two variables; it is a linear correlation coefficient. The range of correlation coefficient is from –1 to 1, where greater than 0 represents a positive correlation, and less than 0 represents a negative correlation. The Pearson correlation coefficient can be expressed by the absolute value of R, where |R| < 0.3 represents a weak correlation, 0.3 < |R| < 0.5 represents a low correlation, 0.5 < |R| < 0.8 represents a moderate correlation, and 0.8 < |R| <1 represents a high correlation.
The lighter the color of the heatmap, the higher the negative correlation, and the darker the color of the heatmap, the higher the positive correlation. As seen in Figure 5, the Pearson correlation coefficients among 45 parameters were highly correlated, and the information redundancy between the parameters was also high (due to the limitation of drawing, the order of the 45 parameters in Figure 5 is the same as that in Table 1). In addition, coal consumption (CC), coal ratio (CLR), and sinter consumption (SC) were all positively correlated with hot metal sulfur content. This shows that the increase in sulfur-containing items, of which the main sources are sinter and coal, increased the sulfur content during the production process in the blast furnace. This finally led to the increase in sulfur content in hot metal. The oxygen enrichment rate (OER) was negatively related to the sulfur content in the hot metal; this shows that when the oxygen concentration was increased appropriately, the sulfur content in the hot metal was reduced. An Xiu-we [25] found that the content of sulfur in the dripping iron of an oxygen blast furnace was much lower than that of a conventional blast furnace. This was due to the desulfurization capacity of the oxygen blast furnace slag being improved, thus reducing the sulfur content in the hot metal.
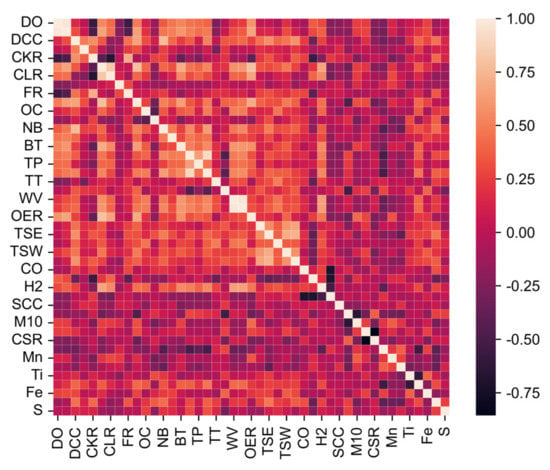
Figure 5.
Heatmap of the Pearson correlation coefficient between each parameter.
4.3.2. Feature Determination
Importance analysis is a method of directly selecting parameters through the internal algorithm of the model; it calculates the contribution degree of each parameter to the target parameter according to the algorithm and sorts the parameters according to score [26]. In other words, we can obtain the sensitivity relationship between each parameter and the target value in this way.
By using the gradient-lifting algorithm based on the decision tree, we obtained a feature importance-ranking graph. As shown in Figure 6, the three features with the highest importance scores were sulfur content in metal (S), differential pressure (DP), and sulfur content in coke (SCC). The three features with the lowest importance score were CRS, CO content (CO), and temperatures in the southwest (TSW).
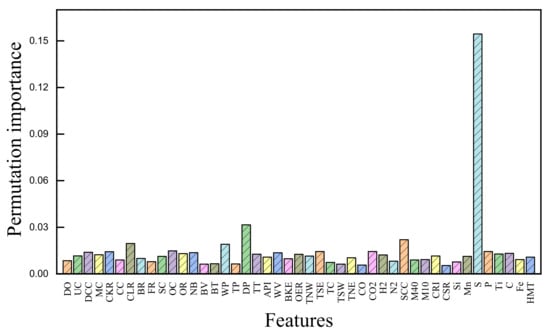
Figure 6.
Importance of each parameter in the model.
Using pre-experiment calculations, we comprehensively considered calculation complexity and prediction accuracy. Finally, characteristic parameters with a critical value of 0.01 were selected for model fitting, and redundant characteristic parameters with a low correlation were deleted. The selected parameters are shown in Table 2.
Table 2.
Input parameters for the two models.
5. Model Comparison
In this study, MLP and XGBoost were used as baseline models to predict hot metal sulfur content. This work uses a dataset size of (3406, 46). The optimal super parameters for both the MLP and XGBoost models were determined by grid search. One grid search was used to optimize three parameters involved in the performance of the MLP model, including activation setting relu, hidden_layer_sizes setting 300, and solver setting adam. A second grid search was used to optimize three parameters involved in the performance of the XGBoost model, including learning_rate setting 0.01, max_depth setting 6, and n_estimators setting 400.
5.1. Comparison of the Predictions of the Two Models
As shown in Figure 7a,b, the comparison curves between the actual values and the predicted values are based on the XGBoost and MLP models, respectively. It is observed that, compared with Figure 7b, the curve coincidence between the predicted values and actual values in Figure 7a is higher; in addition, the two curves in Figure 7a are shorter than those in Figure 7b at some peaks. This phenomenon demonstrates that the prediction effect of the XGBoost model was better than that of the MLP model.
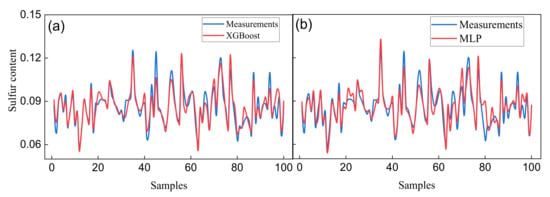
Figure 7.
Forecast results of the XGBoost model (a) and MLP model (b).
Figure 8 shows the degree of fitting for the XGBoost model (a) and MLP model (b). It is observed that, compared with Figure 8b, the points in Figure 8a have fewer fluctuations near the diagonal, a smaller dispersion range, and higher compactness; therefore, compared with the MLP model, the XGBoost model had a better fitting degree and was a more accurate fitting model.
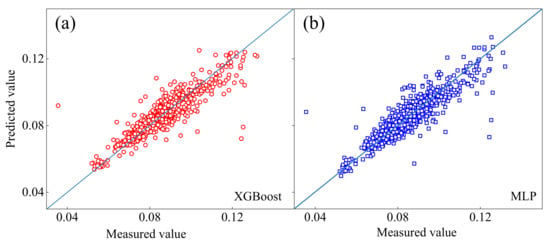
Figure 8.
The fitting of the XGBoost (a) model and MLP model (b).
Figure 9 presents the distribution of prediction errors for the XGBoost model (a) and MLP model (b). It is observed that the dispersion of the XGBoost model prediction error distribution is smaller than that of the MLP model, indicating that the XGBoost model prediction error distribution was much smaller than that of MLP, so the accuracy of the XGBoost prediction model was higher. It can be seen from Figure 7, Figure 8, Figure 9 that the prediction results for the XGBoost model are more accurate than those of the MLP model. Not only could it predict the trends of sulfur content in molten hot metal, but it could also capture data points with large fluctuations.
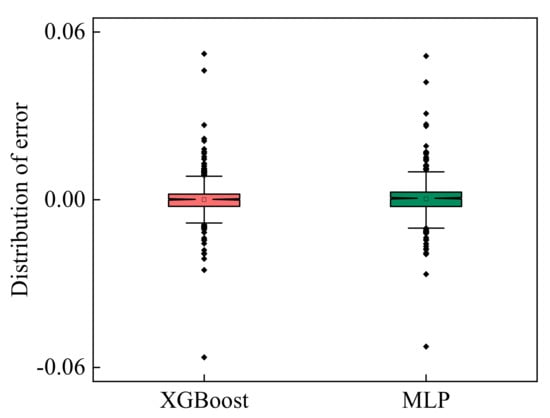
Figure 9.
Distribution of prediction errors of the XGBoost model and MLP model.
5.2. Model Evaluation
Based on the XGBoost and MLP algorithms, this study established two prediction models for sulfur content in hot metal, respectively. The absolute average percentage error (MAPE), root mean square error (RMSE), and prediction hit rate (HR) for the two models were analyzed and compared, and the prediction effects of the two models were comprehensively evaluated. The evaluation indicators were defined as follows:
where n represents the total number of samples, l(xi) is the predicted value, yi is the measured value, and c is the boundary value of the hit rate (c = 0.01, in this paper).
When the allowable prediction error was 0.01, as shown in Table 3, in the training set, the hit rates of the two prediction models were 94.3% and 92.14%, respectively. In the testing set, the hit rates of the two prediction models were 95.07% and 94.13%, respectively. In addition, the average percentage error (MAPE) and root mean square error (RMSE) values of the two models were very low, but the XGBoost model had a smaller value. In summary, the XGBoost and MLP models were both effective predictors and had a high hit rate in predicting hot metal sulfur content, but the XGBoost model had excellent comprehensive evaluation indicators. The XGBoost model was more suitable for predicting hot metal sulfur content than the MLP model.
Table 3.
Assessment of the predicted results of the two models.
6. Conclusions
The sulfur content of hot metal in a blast furnace is an important index, reflecting the production effects and the quality of hot metal; it is crucial to the steel quality produced by steel plants. In this paper, we established two prediction models for hot metal sulfur content based on the XGBoost and MLP algorithms, comprehensively analyzing and comparing the average percentage error (MAPE), root mean square error (RMSE), and hit rate (HR) indicators of both models. The results demonstrate that coal consumption (CC), coal ratio (CLR), and sinter consumption (SC) were all positively correlated with the hot metal sulfur content. The oxygen enrichment rate (OER) was negatively related to the hot metal sulfur content. The XGBoost and MLP models both predicted the hot metal sulfur content effectively; however, the XGBoost model had a higher hit rate, and better accuracy and stability. The XGBoost model was, therefore, more stable and accurate than the MLP model in predicting the sulfur content of hot metal on the following day.
Author Contributions
Conceptualization, S.Z. (Song Zhang), Z.W., F.W. and J.Z.; Methodology, S.Z. (Song Zhang) and Z.W.; Software, D.J.; Formal analysis, Z.W. and J.Z.; Investigation, Z.W. and F.W.; Resources, J.Z and Y.Z.; Data curation, D.J., Y.Z. and S.Z. (Shuigen Zeng); Writing—original draft, S.Z. (Song Zhang); Writing—review & editing, S.Z. (Song Zhang); Supervision, J.Z. and Y.Z.; Funding acquisition, Z.W. and J.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the China Postdoctoral Science Foundation [Project No.: 2021M690370] and the Interdisciplinary Research Project for Young Teachers of USTB (Fundamental Research Funds for the Central Universities) [Project No.: FRF-IDRY-21-004].
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wang, L.; Wu, S.; Kou, M.; Liu, X.; Wang, Y.; Zhuang, W. Influence of Operation Parameters on Mass Fraction of Sulfur in the Hot Metal in Corex Process. In Proceedings of the 7th International Symposium on High-Temperature Metallurgical Processing; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2016; pp. 327–334. [Google Scholar]
- Bhattacharya, T. Prediction of Silicon Content in Blast Furnace Hot Metal Using Partial Least Squares (PLS). ISIJ Int. 2005, 45, 1943–1945. [Google Scholar] [CrossRef]
- Jiao, K.-X.; Zhang, J.-L.; Liu, Z.-J.; Liu, F.; Liang, L.-S. Formation mechanism of the graphite-rich protective layer in blast furnace hearths. Int. J. Miner. Met. Mater. 2016, 23, 16–24. [Google Scholar] [CrossRef]
- Wang, Y.K.; Zhang, Y. Final Sulfur Content Prediction Model in Hot Metal Desulphurization Process Based on IEA-SVM. In Proceedings of the 2011 Chinese Control and Decision Conference (CCDC), Mianyang, China, 23–25 May 2011; pp. 1684–1687. [Google Scholar]
- Zhenyang, W.; Jianliang, Z.; Gang, A.; Zhengjian, L.; Zhengming, C.; Junjie, H.; Jingwei, Z. Analysis on the Oversize Blast Furnace Desulfurization and a Sulfide Capacity Prediction Model Based on Congregated Electron Phase. Met. Mater. Trans. B 2015, 47, 127–134. [Google Scholar] [CrossRef]
- Zhang, H.S.; Zhan, D.P.; Jiang, Z.H. Application of Improved BP Neural Network to Final Sulfur Content Prediction of Hot Metal Pre-desulfurization. J. Northeast. Univ. (Nat. Sci.) 2007, 28, 1140–1142. [Google Scholar]
- Shi, L.; Li, Z.-L.; Yu, T.; Li, J.-P. Model of Hot Metal Silicon Content in Blast Furnace Based on Principal Component Analysis Application and Partial Least Square. J. Iron Steel Res. Int. 2011, 18, 13–16. [Google Scholar] [CrossRef]
- Chen, Y.; Wu, J.; Zhang, Y.; Fu, L.; Luo, Y.; Liu, Y.; Li, L. Research on Hyperparameter Optimization of Concrete Slump Prediction Model Based on Response Surface Method. Materials 2022, 15, 4721. [Google Scholar] [CrossRef]
- Li, J.; Hua, C.; Yang, Y.; Guan, X. A Novel MIMO T–S Fuzzy Modeling for Prediction of Blast Furnace Molten Iron Quality With Missing Outputs. IEEE Trans. Fuzzy Syst. 2020, 29, 1654–1666. [Google Scholar] [CrossRef]
- Gao, C.; Zhou, Z.; Chen, J. Assessing the Predictability for Blast Furnace System through Nonlinear Time Series Analysis. Ind. Eng. Chem. Res. 2008, 47, 3037–3045. [Google Scholar] [CrossRef]
- Jian, L.; Gao, C.; Xia, Z. A Sliding-window Smooth Support Vector Regression Model for Nonlinear Blast Furnace System. Steel Res. Int. 2010, 82, 169–179. [Google Scholar] [CrossRef]
- Xu, X.; Hua, C.; Tang, Y.; Guan, X. Modeling of the hot metal silicon content in blast furnace using support vector machine optimized by an improved particle swarm optimizer. Neural Comput. Appl. 2015, 27, 1451–1461. [Google Scholar] [CrossRef]
- Yan, C.; Qi, J.; Ma, J.; Tang, H.; Zhang, T.; Li, H. Determination of carbon and sulfur content in coal by laser induced breakdown spectroscopy combined with kernel-based extreme learning machine. Chemom. Intell. Lab. Syst. 2017, 167, 226–231. [Google Scholar] [CrossRef]
- Zhang, J.H.; Xie, G.A.; Shen, F.M. Optimization and Analysis of Sulfur Content in Hot Metal Based on Neural Network. J. Mater. Metall. 2006, 5, 86–89. [Google Scholar]
- Wang, W.; Chen, W.; Ye, Y.; Xu, Z.; Jia, F. Application of neural network in prediction of sulfur content in molten iron of blast furnace. Iron Steel 2006, 10, 19–22. [Google Scholar] [CrossRef]
- Zhou, H.; Tang, Z.; Wen, B.; Wang, S.; Yang, J.; Kou, M.; Wu, S.; Dianyu, E. Application of statistical analysis, Deng’s relevancy and BP neural network for predicting molten iron sulfur in COREX process. Int. J. Chem. React. Eng. 2020, 18, 20200122. [Google Scholar] [CrossRef]
- Jiang, D.; Zhou, X.; Wang, Z.; Li, K.; Zhang, J. Predictive modeling of the hot metal silicon content in blast furnace based on ensemble method. Met. Res. Technol. 2022, 119, 515. [Google Scholar] [CrossRef]
- Manojlović, V.; Kamberović, Z.; Korać, M.; Dotlić, M. Machine learning analysis of electric arc furnace process for the evaluation of energy efficiency parameters. Appl. Energy 2022, 307. [Google Scholar] [CrossRef]
- He, T.; Dong, Z.; Meng, K.; Wang, H.; Oh, Y.T. Accelerating multi-layer perceptron based short term demand forecasting using graphics processing units. In Proceedings of the 2009 Transmission & Distribution Conference & Exposition: Asia and Pacific, Seoul, Republic of Korea, 26–30 October 2009. [Google Scholar]
- Jiang, D.; Wang, Z.; Zhang, J.; Jiang, D.; Li, K.; Liu, F. Machine Learning Modeling of Gas Utilization Rate in Blast Furnace. Jom 2022, 74, 1633–1640. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, S.; Yin, Y.; Chen, X. Prediction of the hot metal silicon content in blast furnace based on extreme learning machine. Int. J. Mach. Learn. Cybern. 2017, 9, 1697–1706. [Google Scholar] [CrossRef]
- Zhou, P.; Song, H.; Wang, H.; Chai, T. Data-Driven Nonlinear Subspace Modeling for Prediction and Control of Molten Iron Quality Indices in Blast Furnace Ironmaking. IEEE Trans. Control Syst. Technol. 2016, 25, 1761–1774. [Google Scholar] [CrossRef]
- Wang, X. Iron and Steel Metallurgy (Iron-Making Part); Metallurgical Industry Press: Beijing, China, 2000. [Google Scholar]
- Geerdes, M.; Chaigneau, R.; Kurunov, I.; Lingiardi, O.; Rieketts, J. Modern Blast Furnace lronmaking, 3rd ed.; IOS Press under the Imprint Delft University Press: Amsterdam, The Netherlands, 2015. [Google Scholar]
- An, X.-W.; Wang, J.-S.; Lan, R.-Z.; Han, Y.-H.; Xue, Q.-G. Softening and Melting Behavior of Mixed Burden for Oxygen Blast Furnace. J. Iron Steel Res. Int. 2013, 20, 11–16. [Google Scholar] [CrossRef]
- Liu, S.; Lyu, Q.; Liu, X.; Sun, Y.; Zhang, X. A Prediction System of Burn through Point Based on Gradient Boosting Decision Tree and Decision Rules. ISIJ Int. 2019, 59, 2156–2164. [Google Scholar] [CrossRef]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).