
Deep Learning-Based Understanding of Defects in Continuous Casting Product



 ,
,  ,
, 

Abstract
:1. Introduction
2. Methodology
2.1. Evaluation Method
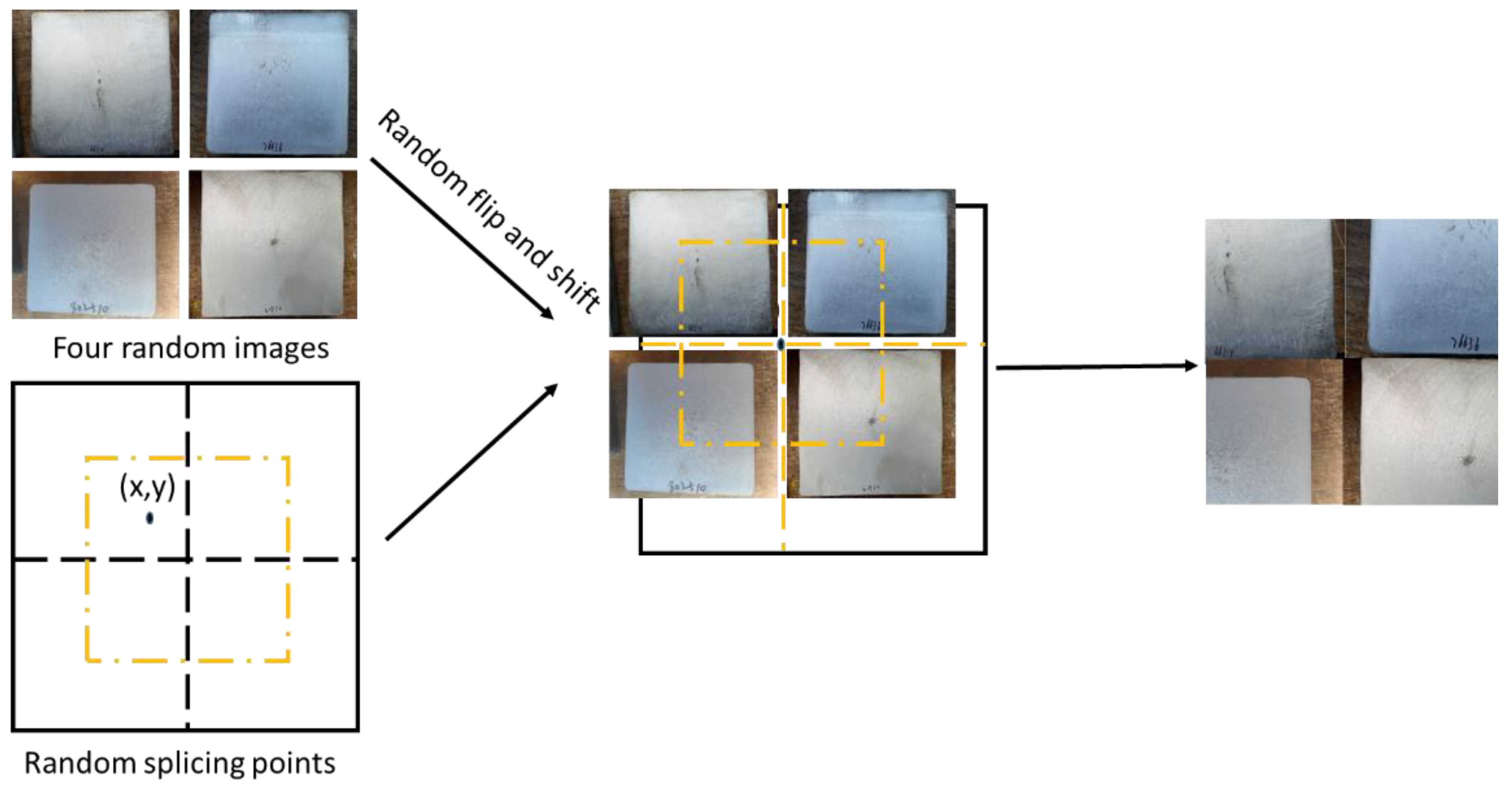
2.2. Data Set of Continuous Cast Billets
2.3. The YOLOv5 Algorithm
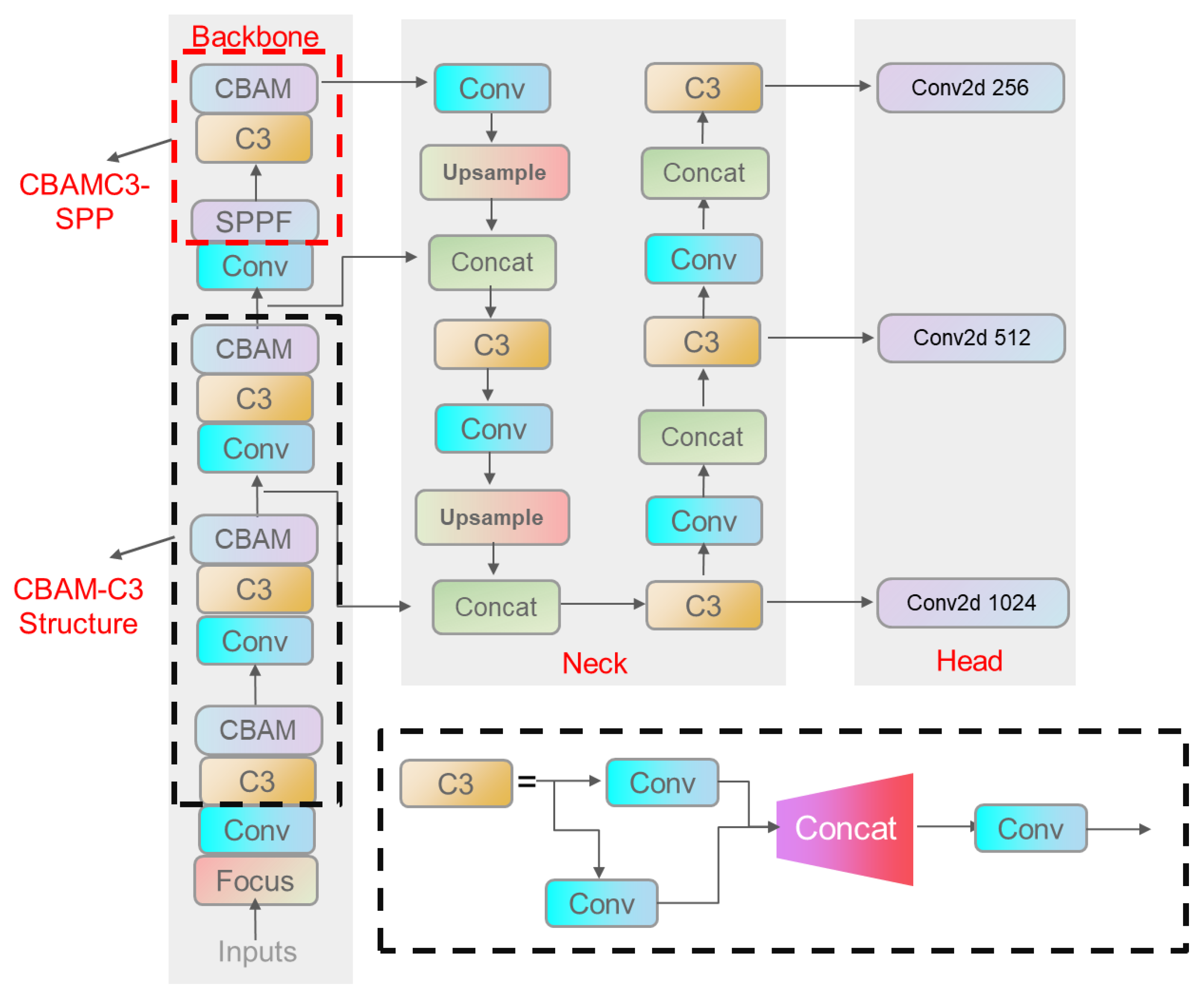
2.4. Convolutional Block Attention Module
2.5. Loss Function
3. Results and Discussion
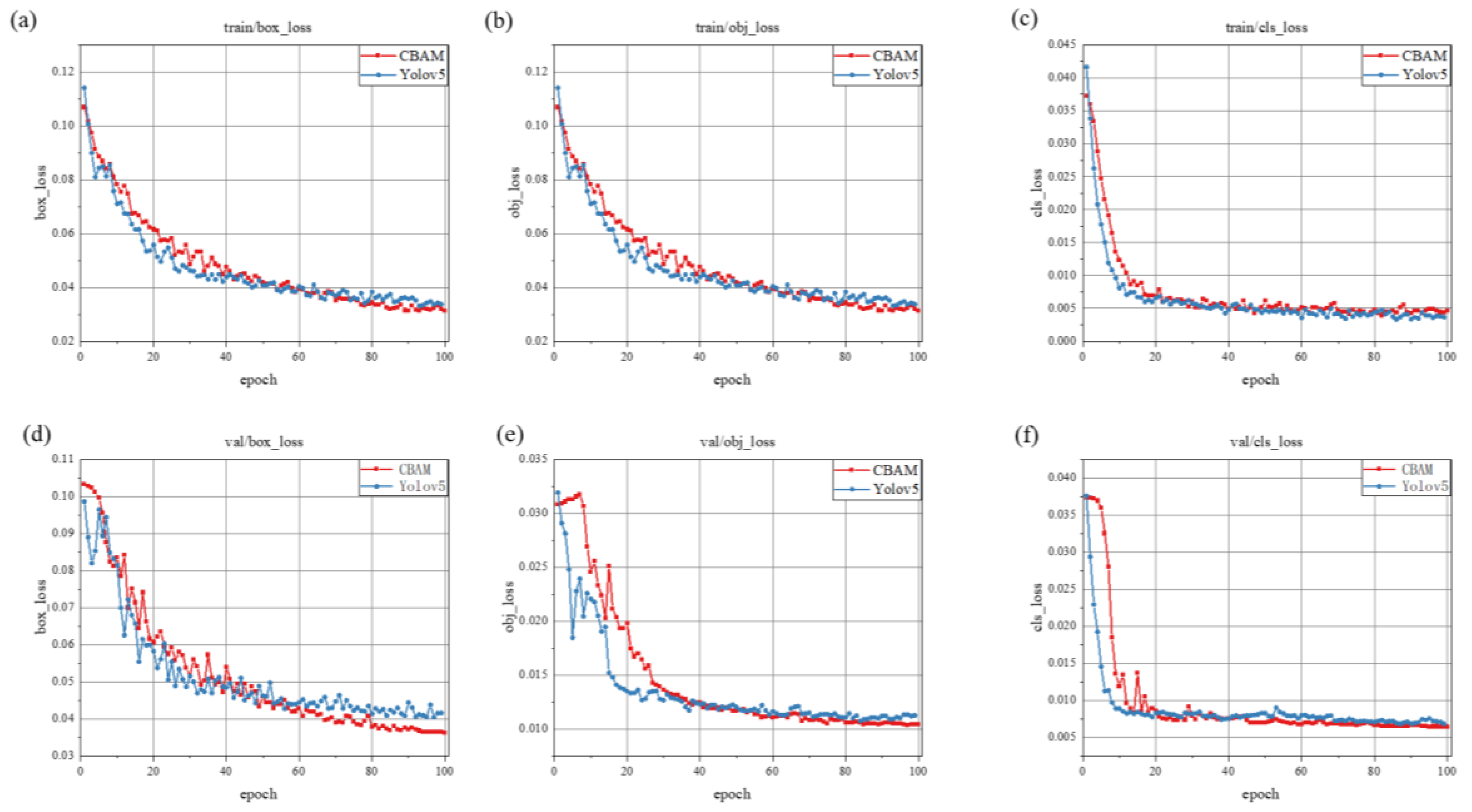
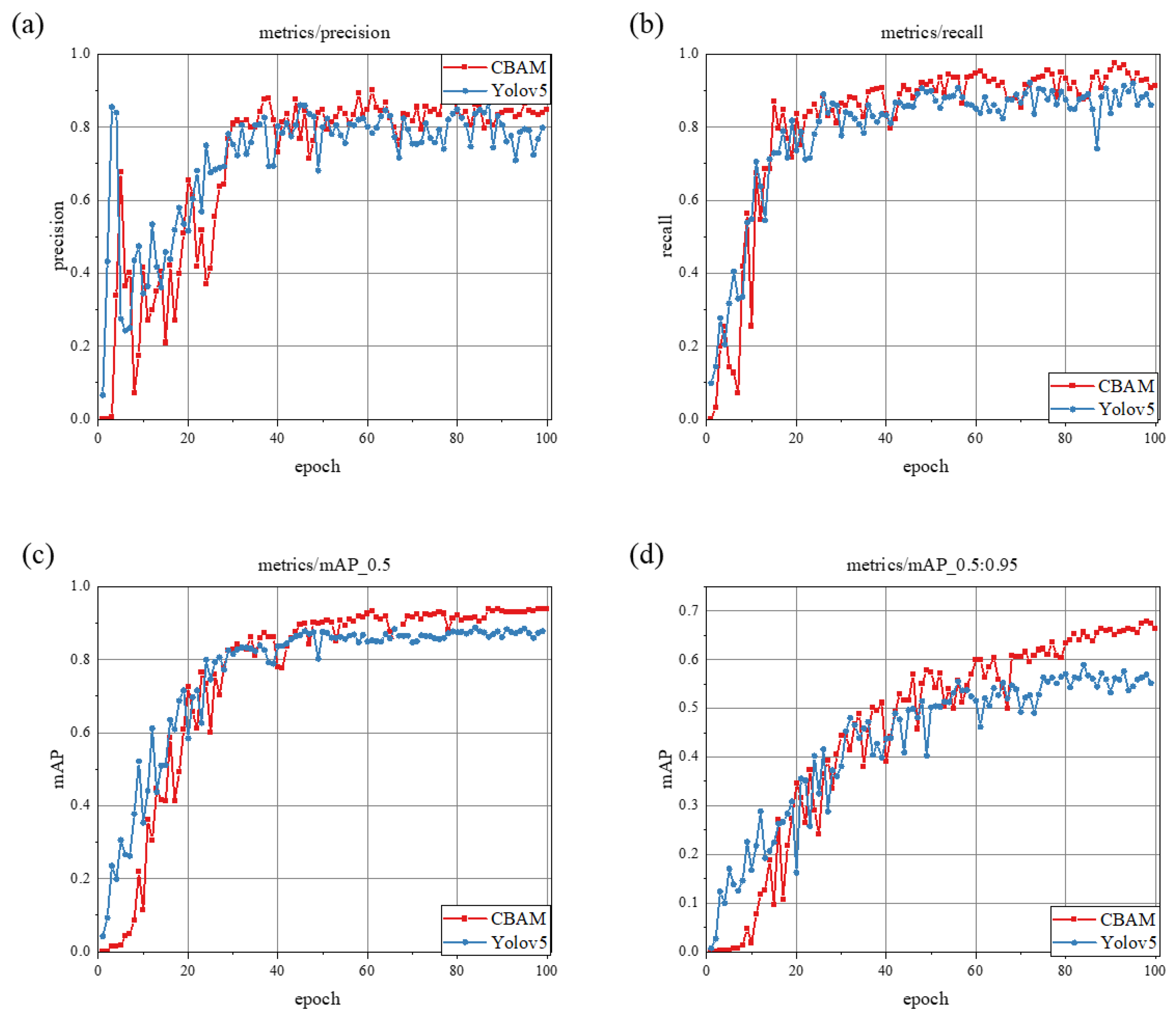
3.1. Comparison Results of Different Attention Modules
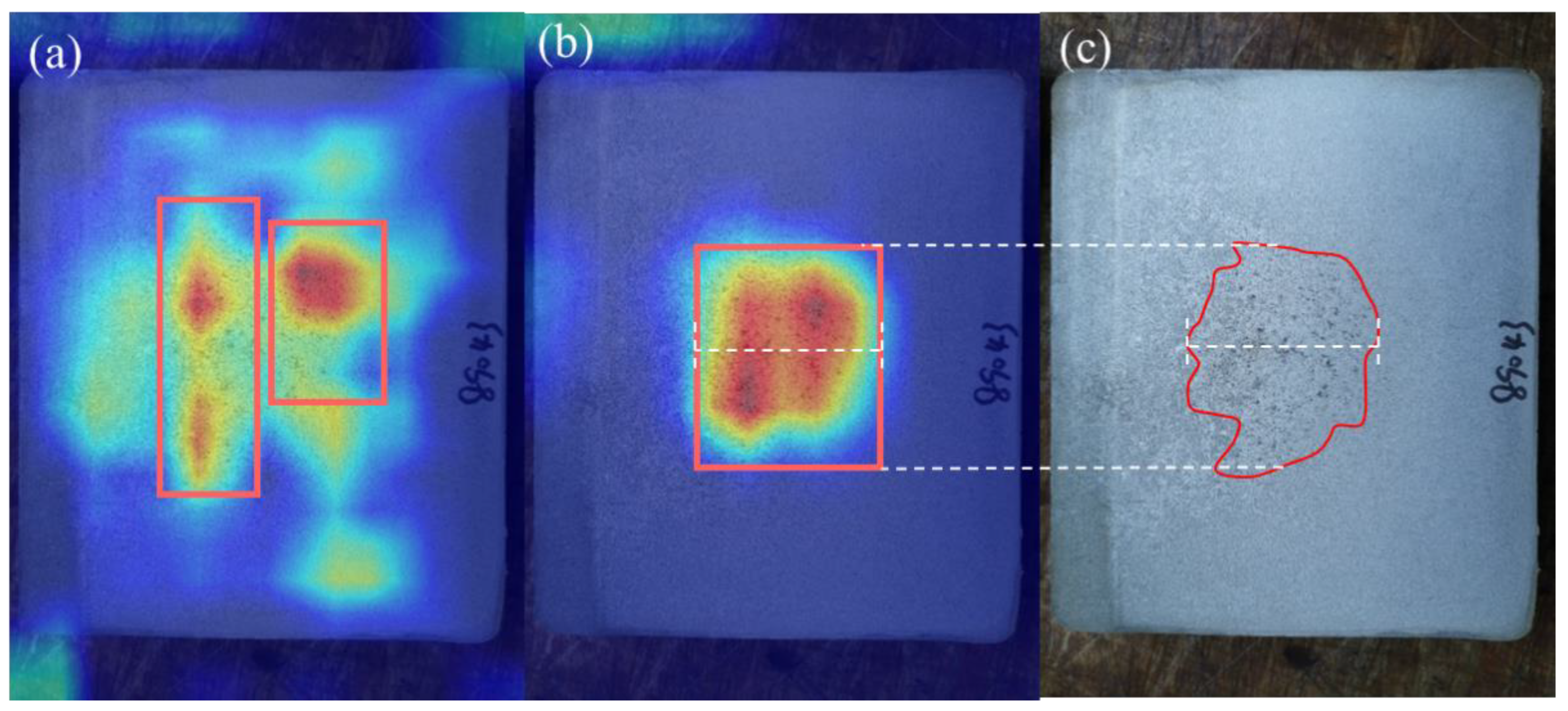
3.2. Visualizing Knowledge of CNNs via Grad-CAM
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Flemings, M.C. Our Understanding of Macrosegregation: Past and Present. ISIJ Int. 2000, 40, 833–841. [Google Scholar] [CrossRef]
- Ning, H.; Li, X.; Meng, L.; Jiang, A.; Ya, B.; Ji, S.; Zhang, W.; Du, J.; Zhang, X. Effect of Ni and Mo on microstructure and mechanical properties of grey cast iron. Mater. Technol. 2023, 38, 2172991. [Google Scholar] [CrossRef]
- Guo, L.; Su, X.; Dai, L.; Wang, L.; Sun, Q.; Fan, C.; Wang, Y.; Li, X. Strain ageing embrittlement behaviour of X80 self-shielded flux-cored girth weld metal. Mater. Technol. 2023, 38, 2164978. [Google Scholar] [CrossRef]
- Yang, C.; Xu, H.; Wang, Y.; Li, F.; Mao, H.; Liu, S. Hot Tearing analysis and process optimisation of the fire face of Al-Cu alloy cylinder head based on MAGMA numerical simulation. Mater. Technol. 2023, 38, 2165245. [Google Scholar] [CrossRef]
- Li, Q.; Zuo, H.; Feng, J.; Sun, Y.; Li, Z.; He, L.; Li, H. Strain rate and temperature sensitivity on the flow behaviour of a duplex stainless steel during hot deformation. Mater. Technol. 2023, 38, 2166216. [Google Scholar] [CrossRef]
- Misra, R.D.K. Strong and ductile texture-free ultrafine-grained magnesium alloy via three-axial forging. Mater. Lett. 2023, 331, 133443. [Google Scholar] [CrossRef]
- Misra, R.D.K. Enabling manufacturing of multi-axial forging-induced ultrafine-grained strong and ductile magnesium alloys: A perspective of process-structure-property paradigm. Mater. Technol. 2023, 38, 2189769. [Google Scholar] [CrossRef]
- Wang, L.; Li, J.; Liu, Z.Q.; Li, S.; Yang, Y.; Misra, R.; Tian, Z. Towards strength-ductility synergy in nanosheets strengthened titanium matrix composites through laser power bed fusion of MXene/Ti composite powder. Mater. Technol. 2023, 38, 2181680. [Google Scholar] [CrossRef]
- Niu, G.; Zurob, H.S.; Misra, R.D.K.; Tang, Q.; Zhang, Z.; Nguyen, M.-T.; Wang, L.; Wu, H.; Zou, Y. Superior fracture toughness in a high-strength austenitic steel with heterogeneous lamellar microstructure. Acta Mater. 2022, 226, 117642. [Google Scholar] [CrossRef]
- Misra, R.D.K.; Challa, V.S.A.; Injeti, V.S.Y. Phase reversion-induced nanostructured austenitic alloys: An overview. Mater. Technol. 2022, 37, 437–449. [Google Scholar] [CrossRef]
- Liu, Z.; Xie, Z.; Luo, D.; Zhou, W.; Guo, H.; Shang, C. Influence of central segregation on the welding microstructure and properties of FH40 cryogenic steel. Chin. J. Eng. 2023, 45, 1335–1341. [Google Scholar] [CrossRef]
- YB/T 4002-2016; Standard Diagrams for Macrostructure and Defect in Continuous Casting Slab. National Steel Standardization Technical Committee of the People’s Republic of China: Beijing, China, 2016.
- SN 960: 2009; Classification of Defects in Materials-Standard Charts and Sample Guide. SMS Demag AG Mannesmann: Düsseldorf, Germany, 2009.
- Abraham, S.; Cottrel, J.; Raines, J.; Wang, Y.; Bodnar, R.; Wilder, S.; Peters, J. Development of an Image Analysis Technique for Quantitative Evaluation of Centerline Segregation in As-Cast Products. In Proceedings of the 2016 AISTech Conference Proceedings, Pittsburgh, PA, USA, 16–19 May 2016. [Google Scholar]
- Rapp, S. Requirements of the MAOP Rule and Its Implications to Pipe Procurement. In Proceedings of the INGAA Foundation Best Practices in Line Pipe Procurement and Manufacturing Workshop, Houston, TX, USA, 9 June 2010. [Google Scholar]
- Xi, J.; Shentu, L.; Hu, J.; Li, M. Automated surface inspection for steel products using computer vision approach. Appl. Opt. 2017, 56, 184–192. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Peng, Y.; Yan, Y. Steel Surface Defect Classification Based on Discriminant Manifold Regularized Local Descriptor. IEEE Access 2018, 6, 71719–71731. [Google Scholar] [CrossRef]
- Choi, D.C.; Jeon, Y.J.; Kim, S.H.; Moon, S.; Yun, J.P.; Kim, S.W. Detection of pinholes in steel billets using Gabor Filter combination and morphological Features. ISIJ Int. 2017, 57, 1045–1053. [Google Scholar] [CrossRef]
- Tao, X.; Zhang, D.; Ma, W.; Liu, X.; Xu, D. Automatic metallic surface defect detection and recognition with convolutional neural networks. Appl. Sci. 2018, 8, 1575. [Google Scholar] [CrossRef]
- Lin, W.Y.; Lin, C.Y.; Chen, G.S.; Hsu, C.Y. Steel surface defects detection based on deep learning. In International Conference on Applied Human Factors and Ergonomics; Springer: Berlin/Heidelberg, Germany, 2018; pp. 141–149. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Chen, Y.; Hong, Z.; Liao, Y.; Zhu, M.; Han, T.; Shen, Q. Automatic Detection of Display Defects for Smart Meters Based on Deep Learning; Faculty of Electrical Engineering and Computing, University of Zagreb: Zagreb, Croatia, 2021. [Google Scholar]
- Li, J.Y.; Su, Z.F.; Geng, J.H.; Yin, Y. Real-Time Detection of Steel Strip Surface Defects Based on Improved YOLO Detection Network. IFAC-PapersOnLine 2018, 51, 76–81. [Google Scholar] [CrossRef]
- Yao, J.; Qi, J.; Zhang, J.; Shao, H.; Yang, J.; Li, X. A Real-Time Detection Algorithm for Kiwifruit Defects Based on YOLOv5. Electronics 2021, 10, 1711. [Google Scholar] [CrossRef]
- Yang, D.; Cui, Y.; Yu, Z.; Yuan, H. Deep Learning Based Steel Pipe Weld Defect Detection. Appl. Artif. Intell. 2021, 35, 1237–1249. [Google Scholar] [CrossRef]
- Zheng, D.; Li, L.; Zheng, S.; Chai, X.; Zhao, S.; Tong, Q.; Guo, L. Comput Intel Neurosci, 2021. Computational Intel a Defect Detection Method for Rail Surface and Fasteners Based on Deep Convolutional Neural Network. Ligence Neurosci. 2021, 2021, 2565500. [Google Scholar]
- YB/T 4002-2013; Standard Diagrams for Macrostructure and Defects in Continuous Casting Billets. National Steel Standardization Technical Committee of the People’s Republic of China: Beijing, China, 2013.
- Kou, X.P.; Liu, S.J.; Cheng, K.Q.; Qian, Y. Development of a YOLO-V3-based model for detecting defects on steel strip surface. Measurement 2021, 182, 109454. [Google Scholar] [CrossRef]
- Yun, S.; Han, D.; Chun, S.; Choe, J.; Yoo, Y. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the International Conference on Computer Vision, Chongqing, China, 10–12 July 2020. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond Empirical Risk Minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Zhao, Z.; Yang, X.; Zhou, Y.; Sun, Q.; Ge, Z.; Liu, D. Real-time detection of particleboard surface defects based on improved YOLOV5 target detection. Sci. Rep. 2021, 11, 21777. [Google Scholar] [CrossRef] [PubMed]
- Clausen, H.; Grov, G.; Aspinall, D. CBAM: A Contextual Model for Network Anomaly Detection. Computers 2021, 10, 79. [Google Scholar] [CrossRef]
- Li, J.; Yang, Y. HM-YOLOv5: A fast and accurate network for defect detection of hot-pressed light guide plates. Eng. Appl. Artif. Intell. 2023, 117, 105529. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-Cam: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Defect Level | Defect Detection Box Length Ratio/% |
|---|---|
| 0 | 0 |
| 0.5 | 0 < L ≤ 13.45 |
| 1 | 13.45 < L ≤ 19.73 |
| 1.5 | 19.73 < L ≤ 23.21 |
| 2 | 23.21 < L ≤ 26.67 |
| 2.5 | 26.67 < L ≤ 31.35 |
| 3 | 31.35 < L ≤ 36.90 |
| 3.5 | 36.90 < L ≤ 39.42 |
| 4 | 39.42 < L |
| Model | Attention Mechanisms | mAP/% |
|---|---|---|
| YOLOv5 | None | 84.1 |
| ECA | 86.5 | |
| SE | 90.1 | |
| CA | 87.8 | |
| CBAM | 91.0 |
| Model | Attention Mechanisms | mAP/% |
|---|---|---|
| YOLOv5 | YOLOv5 | 84.1 |
| YOLOv5 + Neck CBAM | CBAM behind C3 layer | 91.0 |
| YOLOv5 + SPP CBAM | C3CBAM after SPP | 92.3 |
| CBAM-YOLOv5 | Combined with the above | 93.7 |
| Num | Learning Rate | Optimizer | IoU | mAP/% |
|---|---|---|---|---|
| Exp1 | 0.1 | SGD | 0.4 | 93.1 |
| Exp2 | 0.1 | SGD | 0.5 | 92.6 |
| Exp3 | 0.1 | SGD | 0.6 | 92.4 |
| Exp4 | 0.1 | Adam | 0.5 | 92.2 |
| Exp5 | 0.01 | SGD | 0.4 | 93.7 |
| Exp6 | 0.01 | SGD | 0.5 | 93.0 |
| Exp7 | 0.01 | SGD | 0.6 | 92.7 |
| Exp8 | 0.01 | Adam | 0.5 | 92.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, Z.; Zhao, J.; Misra, R.D.K.; Guo, F.; Xie, Z.; Wang, X.; Li, X.; Wang, J.; Shang, C. Deep Learning-Based Understanding of Defects in Continuous Casting Product. Metals 2023, 13, 1809. https://doi.org/10.3390/met13111809
Ding Z, Zhao J, Misra RDK, Guo F, Xie Z, Wang X, Li X, Wang J, Shang C. Deep Learning-Based Understanding of Defects in Continuous Casting Product. Metals. 2023; 13(11):1809. https://doi.org/10.3390/met13111809
Chicago/Turabian StyleDing, Zeyuan, Jingxiao Zhao, Raja Devesh Kuma Misra, Fujian Guo, Zhenjia Xie, Xuelin Wang, Xiucheng Li, Jingliang Wang, and Chengjia Shang. 2023. "Deep Learning-Based Understanding of Defects in Continuous Casting Product" Metals 13, no. 11: 1809. https://doi.org/10.3390/met13111809
APA StyleDing, Z., Zhao, J., Misra, R. D. K., Guo, F., Xie, Z., Wang, X., Li, X., Wang, J., & Shang, C. (2023). Deep Learning-Based Understanding of Defects in Continuous Casting Product. Metals, 13(11), 1809. https://doi.org/10.3390/met13111809