2.1. Maximum Likelihood Estimation of Distribution Parameters
Maximum likelihood estimation (MLE) is foundational to the data-driven parameterization of probability distributions [
18,
21] and precedes each of the goodness-of-fit (GOF) methods described in the following section (
Figure 3). Supposing that a given set of numerical measurements,
x1,
x2, …
xn, follow a probability distribution, having density distribution
f, MLE determines the parametrization of
f that would have been the most likely to have produced said measurements.
Using standard notation, the probability density function (pdf) can be expressed as a function
f(
x) in which
x is a possible value; by definition,
dx = 1. To explicitly cite the distribution parameters, we may write
f(
x|
θ), in which
θ is a tuple containing the list of parameters of the distribution. For example, a Gaussian distribution (also known as Normal distribution) can be expressed as
f(
x|μ,σ
2), in which the parameters
θ = (μ,σ
2) are the mean and variance. MLE applies the principles of mathematical optimization and calculus to determine appropriate formulas (also known as “estimators”) for estimating parameter values, as a function of the observed values. In the case of a Gaussian distribution, the parameter values are commonly taken to be μ ≈ (Σ
xi/
n) =
and σ
2 ≈ (Σ (
xi −
)
2/(
n − 1)); however, industrial measurements of head grade and other process variables do not follow a Gaussian distribution, hence requiring the broader concepts of MLE and goodness-of-fit testing [
18,
22,
23,
24]. Especially for gold head grades, it is advised that the
distribution of the grade be represented, rather than using averages to define a deterministically constant grade since the variation effects process decisions and outcomes. Moreover, it is important to implement a truly
representative distribution since the erroneous usage of a Gaussian process can again effect process decisions and outcomes.
Anecdotally, professionals within the mining and metallurgical industries are reluctant to consider distributions other than the familiar Gaussian; they are often unfamiliar with the concepts of MLE and goodness-of-fit testing, unless they have had particular training in continuous improvement methodologies, such as Six-Sigma or related statistics or industrial engineering. The current treatment is intended to be adequately brief but self-contained. Alternatively, many practitioners are prone to using group averages to represent the plant behavior, which does not represent lost productivity from a sudden departure away from the operating tolerances or, in the case of gold processing, spikes in cyanide consumption.
Consider a series of random measurements:
X1,
X2, …,
Xn, which are made and are found to have values of
x1,
x2, …
xn, and have some degree of precision: δ > 0. More explicitly, it has been found that
X1 ∈ [
x1 − ½δ,
x1 + ½δ] and
X2 ∈ [
x2 − ½δ,
x2 + ½δ], etc., and finally, that
Xn ∈ [
xn − ½δ,
xn + ½δ] for a small value δ > 0. Supposing that these measurements follow a hypothetical distribution described by
f, the probability that
X1 would have landed within the interval [
x1 − ½δ,
x1 + ½δ] is estimated by the area of a rectangle of width δ and height
f(
x1), and similarly for the other measurements; hence, P(
X1 ∈ [
x1 − ½δ,
x1 + ½δ]) ≈ δ⋅
f(
x1), P(
X2 ∈ [
x2 − ½δ,
x2 + ½δ]) ≈ δ⋅
f(
x2), …, P(
Xn ∈ [
xn − ½δ,
xn + ½δ]) ≈ δ⋅
f(
xn). Assuming that the
n samples are independent, the joint probability is given by the product:
MLE maximizes this joint probability by adjusting the parameters of f, asking the question: which parameter values would have maximized the probability of having measured X1 ≈ x1 and X2 ≈ x2 and … and Xn ≈ xn?
Assuming that the degree of precision, δ, is sufficiently small, then it does not affect the maximization and can be ignored. Thus, as a proxy for the joint probability (Equation (1)), we define the likelihood
L(
x), in which
x = (
x1,
x2,…
xn) is the tuple of measured values:
To explicitly cite the distribution parameters
θ = (
θ1,
θ2, …
θp), we write:
It is common to maximize the natural logarithm of
L, rather than
L itself, which converts the product of Equation (3) into a summation. The log-likeliness function is thus given by:
and indeed, the maximization of
l = ln (
L), rather than
L, does not change the result, considering that ln is a strictly increasing function. This transformation slightly simplifies the calculus to parameterize common distributions, such as the Gaussian and exponential [
21].
Moreover, it is standard to use a “hat” to denote the MLE estimates, i.e., the are the particular values of θ = (θ1, θ2, … θp) that maximize the joint probability (or equivalently the likelihood or log-likelihood) of having measured X1 ≈ x1 and X2 ≈ x2 and … and Xn ≈ xn. The MLE-parametrized density function is also denoted with a ”hat”, as in , and similarly for the cumulative distribution function ; the MLE-parameterization is expressed as .
Depending on the distribution, there may be constraints on certain parameter values, e.g., only positive σ
2 values are allowed in the case of a Gaussian distribution. Therefore, the exercise of MLE is in general a
constrained optimization:
in which Θ is the feasible parameter space, Θ ⊂ ℝ
p, yet there are many practical cases in which the constraints do not affect the optimization. In practice, Θ can be taken as ℝ
p to apply unconstrained optimization techniques (calculus), and only if the resulting parametrization is infeasible is it necessary to consider a specialized constrained approach.
If
L(
x|
θ) varies continuously with
θ, then elementary differential calculus can be applied. For distributions with only one parameter,
is determined by setting ∂
L/∂
θ to zero and solving for
θ. Nearly all of the distributions under consideration, regarding the Minera Florida data, consist of two parameters, in which case
is determined by setting ∂
L/∂
θ1 = 0 and ∂
L/∂
θ2 = 0 and solving for two unknowns:
θ1 and
θ2. More generally, for
p-parameter distributions, the calculus consists of solving
p equations to obtain
p unknowns [
21]. As will be described in
Section 3.1, the gold head grades are best represented by a log-normal distribution, for which the MLE estimation formulas (also known as “estimators”) have been found to be:
Both expressed as a function of the observed measurement values, x, to emphasize that the parametrization is data-driven. Furthermore, it is data-driven in a dependable (rigorous) sense, i.e., the sense of maximum likeliness. Alternatively, for example, log-normal could be erroneously fitted with the logarithm of the mean, rather than the mean of the logarithm; the MLE formulation resolves these potential pitfalls.
However, prior to selecting a particular standard distribution to represent a particular variable (e.g., log-normal to represent the head grade), a litany of other potential distributions are also considered, which are each parameterized according to Equation (5), leading to distribution-specific estimation formulas (e.g., Equations (6) and (7) for the case of log-normal). The idea is to compare the
best log-normal distribution to the
best Gaussian distribution, and to the
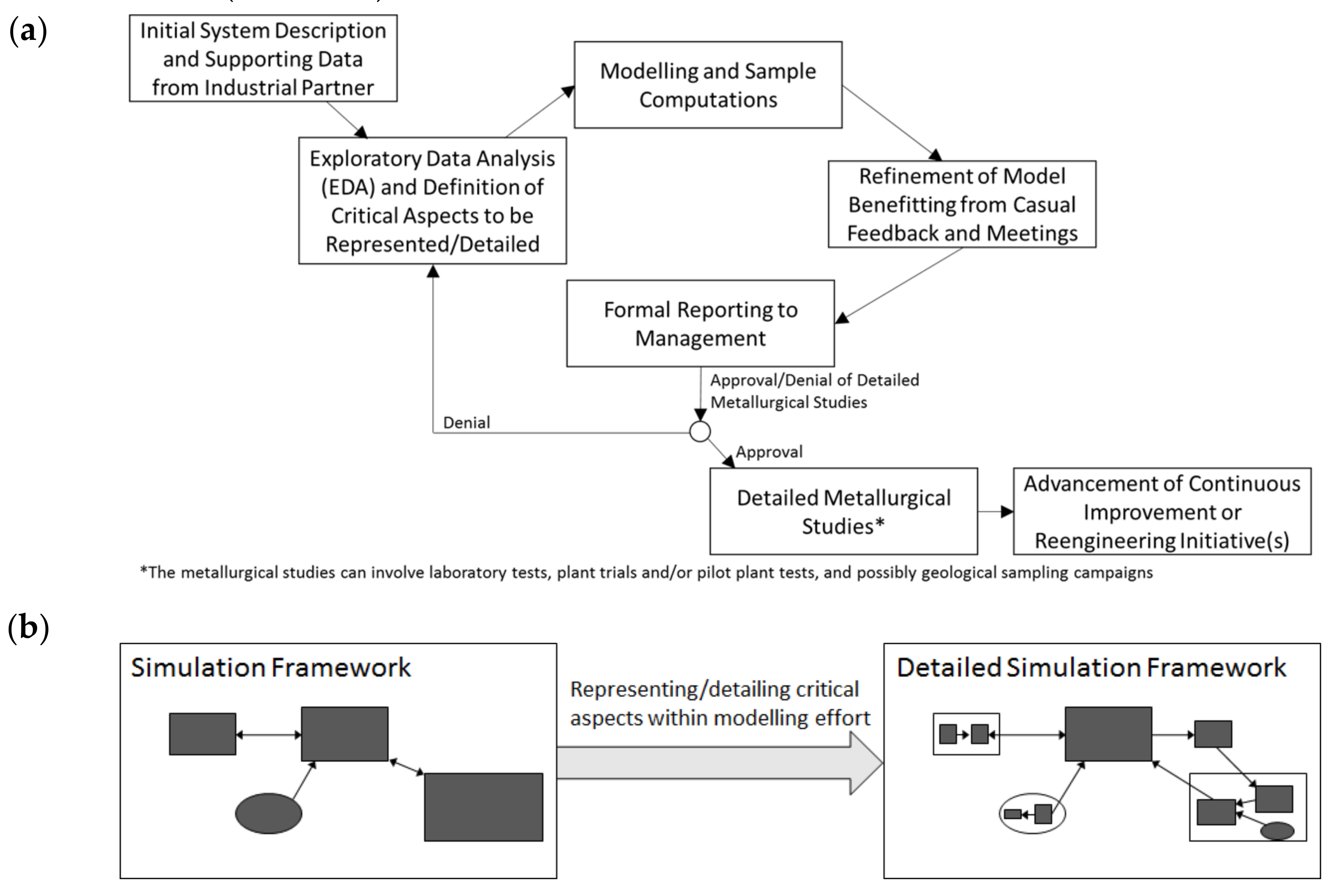
best Gamma distribution, and so on. In this case, “best” means optimally parametrized in the sense of MLE. The distribution-specific estimators are usually programmed within software such as the input analyzer that is available with Rockwell Arena or the commonly used easy fit by Math Wave Technologies. In typical applications, it may not be necessary to derive or to work directly with the distribution-specific estimation formulas, relying instead on the software; however, the detailing of the DES/DRS framework has required that we directly program these estimators as an essential part of the data processing (
Figure 4). It is prudent (and strongly recommended) to derive the formulas for any of the MLE estimators that are programmed into such a framework to be precisely sure of what the parameters represent. These calculus exercises are fairly basic and avoid errors that would later be very difficult to detect. As an example, once again, Equation (5) demands the mean of the logarithm rather than the logarithm of the mean. Consider further that an unapologetically deterministic simulation may be preferred over such an ill-conceived probabilistic model that gives
false confidence.
In summary, MLE is the rigorous mathematical basis for data-driven parameterization. It provides the formulas to channel industrial measurements into the DES/DRS framework of Órdenes et al. [
2]. The approach and experience that we have gained in the context of Minera Florida can be adapted to other mining contexts.
2.2. Chi-Squared, Kolmogorov–Smirnov, and Anderson–Darling Statistics
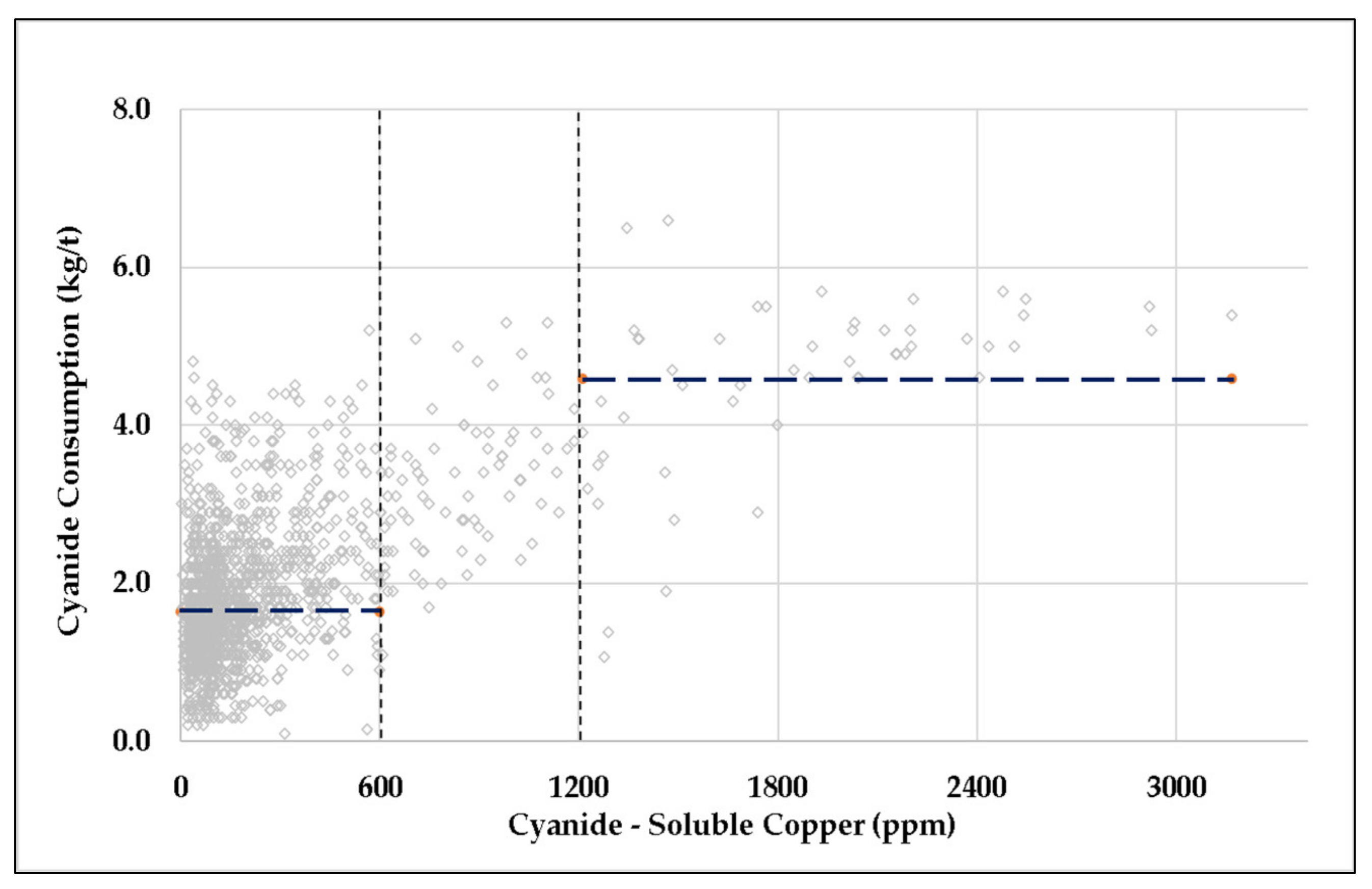
Critical process variables, such as gold head grade, can be observed with histograms and clearly do not follow Gaussian distributions. Yet, statistical concepts that are erroneously adapted to the Gaussian distributions are still commonly used. Even when metallurgical operators and engineers recognize this “non-Gaussianity”, they are left with the task of selecting other standard distributions which might be more appropriate, but without knowledge of a rigorous approach, the Gaussian distribution is nonetheless retained. This erroneous application of the Gaussian process makes it difficult to justify a budget for detailed metallurgical studies (
Figure 2) and has hindered the progress at Mineral Florida. Particularly, in responding to critical variation, such as with gold head grade, any deterministic approach is inadequate, but an ill-adjusted probabilistic approach may be even less desirable since it provides false confidence.
In other industrial contexts, the typical approach is to rank the MLE parametrization for a list of candidate distributions according to goodness-of-fit (GOF) statistics (
Figure 3). Given several hundred gold head grade measurements, for example, the preference to model these data as log-normal rather than as Gaussian involves a comparison of GOF metrics from the MLE-parameterized log-normal together with the GOF metrics of the MLE-parameterized Gaussian, with both parameterized with respect to the same given data. More broadly, software such as the Rockwell input analyzer and easy fit (of Math Wave Technologies) tabulate the GOF metrics for an extensive list of candidate distributions. The user of the software may then select the best-ranked distribution but, alternatively, may select another highly ranked distribution if it has fewer parameters and/or can be more effectively implemented or studied in computational experiments. This shall be further discussed below.
The chi-squared (
χ2) is the most widely known statistic that is used for GOF. Indeed, the
χ2 is described in elementary statistics textbooks such as [
20]. Anecdotally, practitioners of extractive metallurgy may have a vague familiarity with
χ2, possibly for the construction of variance intervals of Gaussian-distributed variables or embedded within ANOVA tables in the evaluation of the F statistics (that compares variances of Gaussian-distributed variables [
25]). In its classic use as a GOF statistic (dating to 1900, [
26]), it is evaluated as a weighted sum of squares over
k categories:
in which
is the number of observed measurements that fall within category
j, and
is the number of measurements predicted by the MLE-parametrized hypothetical distribution, noting that the
factors act as weighting; alterations of the classic
χ2 may consider different weightings. In general, according to Equation (8), distributions whose MLE-parametrization have smaller differences (
) over the
k categories will give smaller
values and are hence, a better fit.
One drawback of this use of chi-squared is the ambiguity in the definition of the
k categories. Ad hoc approaches for evaluating discrete distributions are described in [
22], including mergers of smaller categories resulting in larger categories that are adequately sampled and (ideally) are equiprobable. For continuous distributions such as Gaussian, log-normal, etc., the
k categories correspond to a set of intervals, {(
aj−1,
aj]|
j = 1…
k}, and the equiprobable condition (
) is strictly enforced by setting:
in which
is the inverse of the MLE-parameterized cumulative distribution function. Thus, for continuous distributions,
is expressed in terms of the number of samples
n:
Yet, even for continuous distributions, there is generally no optimal approach for fixing
k since the optimal number of categories depends on the (unknown) distribution that underlies the data. A commonly used formula is
which is applied in
Section 3.1 for gold head grades.
Alternatives to the
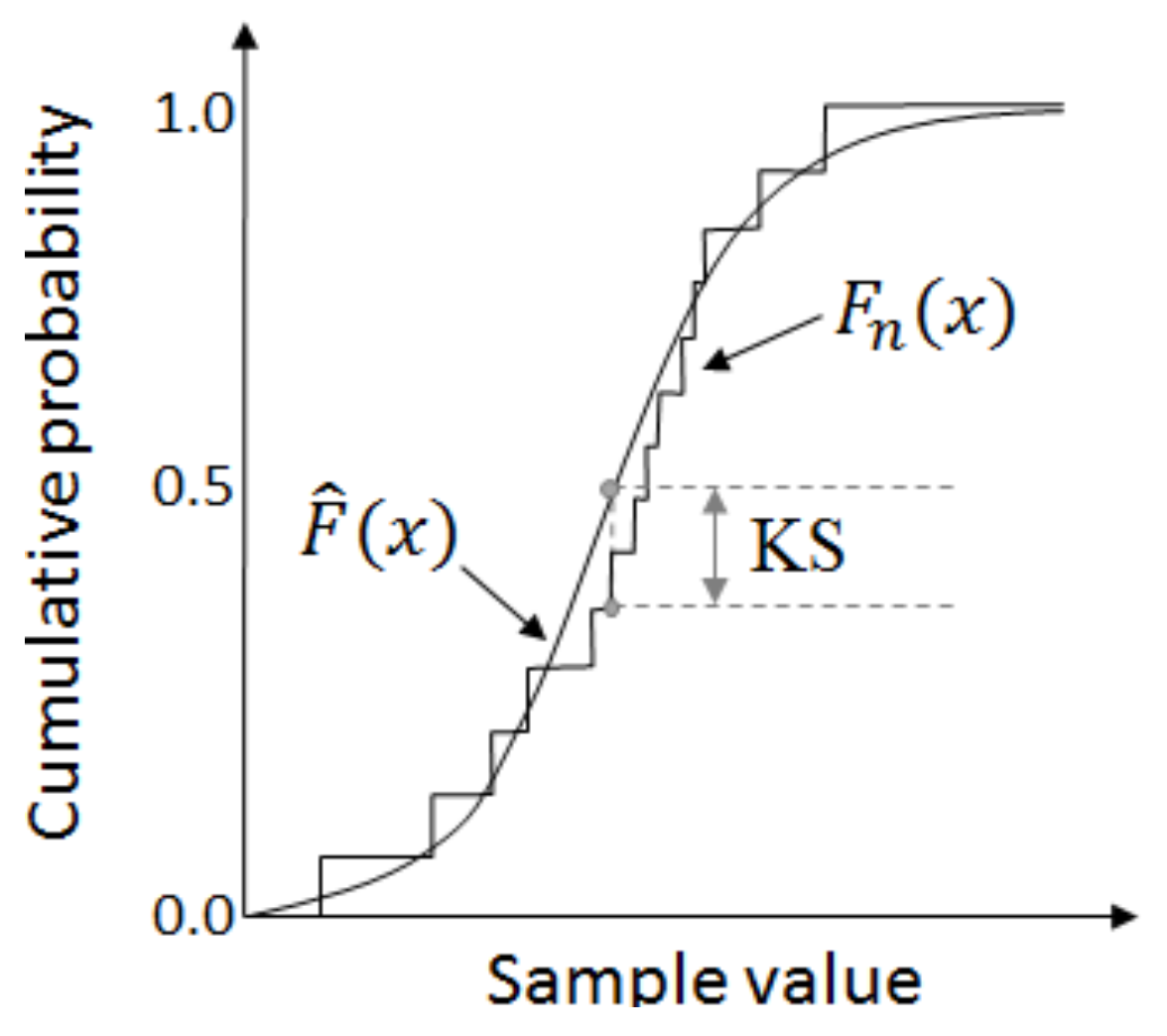
χ2 include Kolmogorov–Smirnov (KS) and Anderson–Darling (AD) statistics, both of which avoid the artificial construction of categories. KS and AD both make use of the empirical cumulative distribution,
Fn(
x) is thus the portion of observed measurements whose value is smaller or equal to
x, which forms a step function graph as illustrated in
Figure 5. Herein the KS statistic is the largest absolute distance between
and
. Formally:
KS is an unweighted metric, i.e., there is no weighting
w(
x) that multiplies the absolute difference. A supremum operation (sup) is more appropriate than a maximum (max) to ensure the largest interpretation of
when evaluating the distance at the sample points
xi, i.e.,
is taken to be the larger of either the left limit
or the right limit
[
23].
The Anderson–Darling statistic is conceived as a weighted integral of the squared difference of
and
,
in which the weighting
preferentially penalizes the deviations in the tails; in practice, AD is indeed more sensitive to tail deviations than either the χ
2 or the KS. Through a partial fraction decomposition of the integrand and the articulation of
as piecewise constant intervals, and a change of the integrating domain such that
, Equation (14) is resolved as:
in which {
x(1),
x(2), …
x(n)} is the sorting of the sample data {
x1,
x2, …
xn} in ascending order, i.e.,
x(1) ≤
x(2) ≤ … ≤
x(n).
In developing data-driven industrial simulations, the χ
2, KS, and AD statistics are used to rank the MLE-parametrized distributions, indicating which distributions are representative of the various process variables. However, they often provide conflicting results, including the χ
2 rankings, which can change depending on how the categories are constructed. Moreover, common software such as easy fit and the Rockwell input analyzer consider an extensive list of distributions, many of which are obscure. For example, the top-ranked distribution according to KS may be a Johnson S
U, which is a four-parameter transformation of the standard Gaussian; if a more commonly used distribution is nearly as good in KS ranking, and is also favorable in the χ
2 and AD rankings, then the more common distribution is a better choice. Firstly, the more common distributions are prolific in published studies across many disciplines, allowing for cross-disciplinary comparisons. More importantly, the common distributions are better received in preparation for detailed studies (
Figure 2a) that would ultimately allow more detailed modelling; the fitted distributions that are most impactful to the simulation may (or should) ultimately be replaced by mechanistic models (
Figure 2b). The application of an obscure multiparameter distribution may be counter-productive since either (1) the process variable is critical and should genuinely be represented through a submodel rather than an obscure distribution, or (2) the variable is not so critical and should rather be represented by a common distribution instead of being a point of unnecessary scrutiny for management.
An existing nuance is that the χ
2, KS, and AD rankings of MLE-parameterized distributions are
descriptive in the sense of
descriptive statistics; this is in contrast to
inferential statistics, which relies on hypothesis testing to infer the properties of an underlying process, given a set of sample data. In the current context, it is understood that the process variables
do not actually follow any of the idealized distributions listed by the fitting software; the task is to decide which of these distributions are
best suited to argue for the next phase of simulation modelling, with the objective of efficiently directing the resources for further study (
Figure 2) and ultimately for process improvement.
In a different context, whereby a systematic sweep of numerous candidate distributions is not involved, a GOF hypothesis test is applied when there is a hypothetical distribution that is specifically observed to be a possible description of the underlying process. For χ2, KS, and AD tests, a null hypothesis is formulated as:
H0. The measured sample data {x1, x2… xn} follows a distribution whose cumulative probability function is described by F0(x|θ) having parameters θ.
The observed χ
2, KS, and AD can then be computed by applying Equations (8), (13), or (15), respectively, to the MLE-parametrized hypothetical cumulative probability function
. For a significance level α ∈ (0, 1], the null hypothesis is rejected if the observed statistics exceed a critical value; such a rejection indicates a minimal confidence (1−α) level in which the underlying process does not follow the hypothetical distribution. For the χ
2 test, the test is formulated as:
in which the critical value is
can be obtained from textbooks or from software (Excel, Minitab, etc.) considering (
k−
p) degrees of freedom;
p is the number of parameters within the hypothetical distribution, e.g.,
p = 2 for Gaussian and log-normal. The critical KS
1−α and AD
1−α are both distribution-specific [
23,
24] and consider multiplicative adjustment factors that depend on the number of samples
n.
For a hypothetical Gaussian distribution, the adjustment factors are
and
. For certain distributions, such as the exponential, the
n-dependent adjustment includes an additive shift as well as a multiplicative factor [
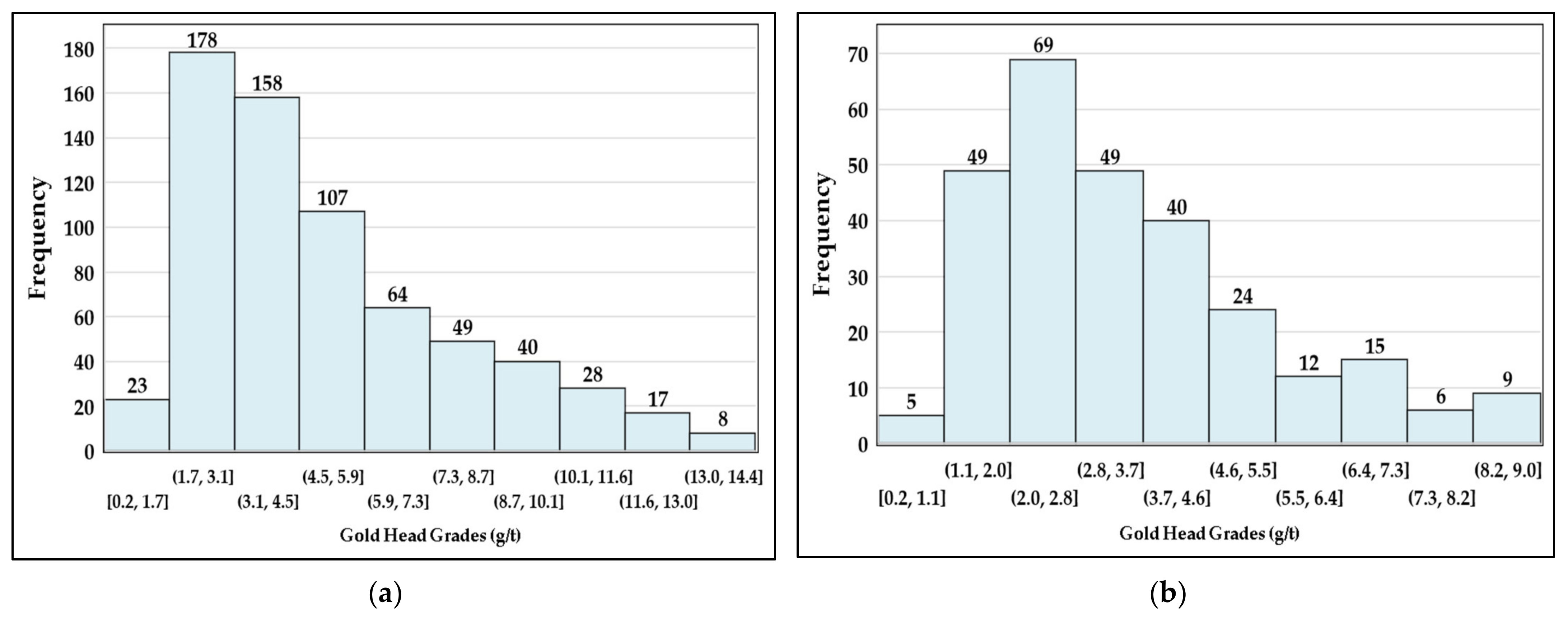
23]. Importantly for the gold head grades, the normality tests can be adapted to the log-normal simply by taking the logarithm of the sample data,
yi = ln (
xi), and then applying Equations (17) and (18) to {
y1,
y2, …
yn}.
Section 3.1 applies the tests of Equations (16)–(18), with α = 0.05 to test log-normality.
It is indeed customary to apply the tests of Equations (16)–(18) for the selected distribution, which incidentally may not be the top-ranked of all GOF metrics. But particular caution is required when interpreting the rejection of these hypotheses, especially when communicating to management (
Figure 2). In the
descriptive statistical context of GOF ranking to support simulation modelling, the null hypothesis,
H0, is moot
a priori unless there is a genuine expectation that the underlying process could follow the proposed distribution. The ultimate decision to accept a distribution-based representation of a process variable, or to replace it with a more detailed submodel (i.e., to truly reject the distribution), must depend on how significant the process variable is to the engineering decision-making. Otherwise, the tendency is to focus erroneously on irrelevant aspects of the model that justifiably have a large statistical deviation from the observed data; in practice, it is typical that the unimpactful aspects (as determined by the approach in
Figure 2) of the model remain less developed in favor of the more impactful aspects that should indeed be more developed. Therefore, simulation modelers must understand the notion of inferential
statistical significance, especially to distinguish it from engineering
decision-making significance. It is likely that all distribution-based representations should ideally be replaced by submodels, “subsubmodels”, etc. (
Figure 2b) from a statistical point-of-view with α ≈ 0. Yet,
in practice, the budgetary and human resource limitations cause the modelling effort to prioritize those aspects which are truly critical to the advancement of the project (
Figure 2a). This engineering-oriented prioritization is not reflected within the weightings of Equations (8), (13), and (14).
2.3. Supporting of Monte Carlo and DES/DRS Frameworks with Exploratory Data Analysis
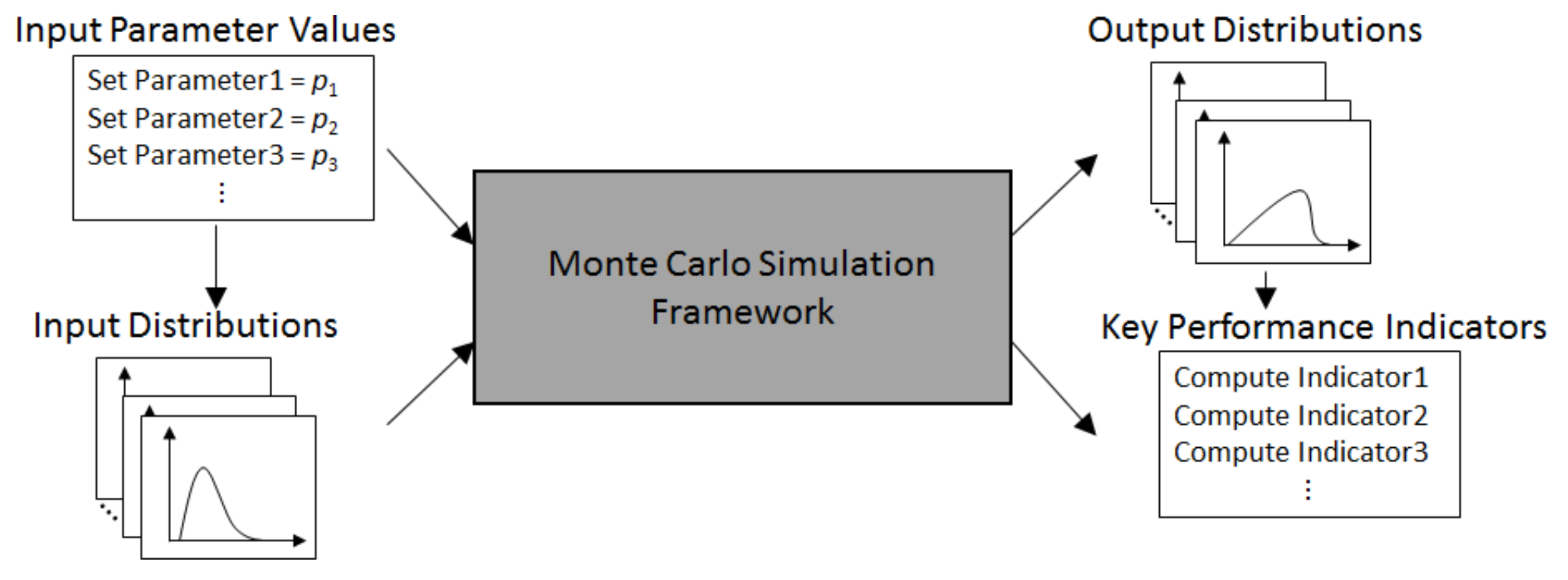
In broad terms, a Monte Carlo simulation framework considers:
A set of input parameters that configure the system that is to be simulated;
That one or more of the inputs are to be represented by probability distributions rather than deterministic values;
That the execution of the simulation consists of numerous replicas, each based on an independent generation of random numbers following the input probability distributions;
That the collection of outputs from the replicas approximate the distribution of possible system behaviors;
Typically, the overall system performance can be assessed through the output distributions and quantified by so-called key performance indicators (KPIs).
Essentially, a Monte Carlo simulation uses random number generation (RNG) to convert input parameters and distributions into output distributions and KPIs. As illustrated in
Figure 6, some of the input parameters can be used to parametrize the input distributions as well as for configuring the internal aspects of the framework. Similarly, certain KPIs can be drawn as summative evaluations of the output distributions, while others may be directly computed by the framework.
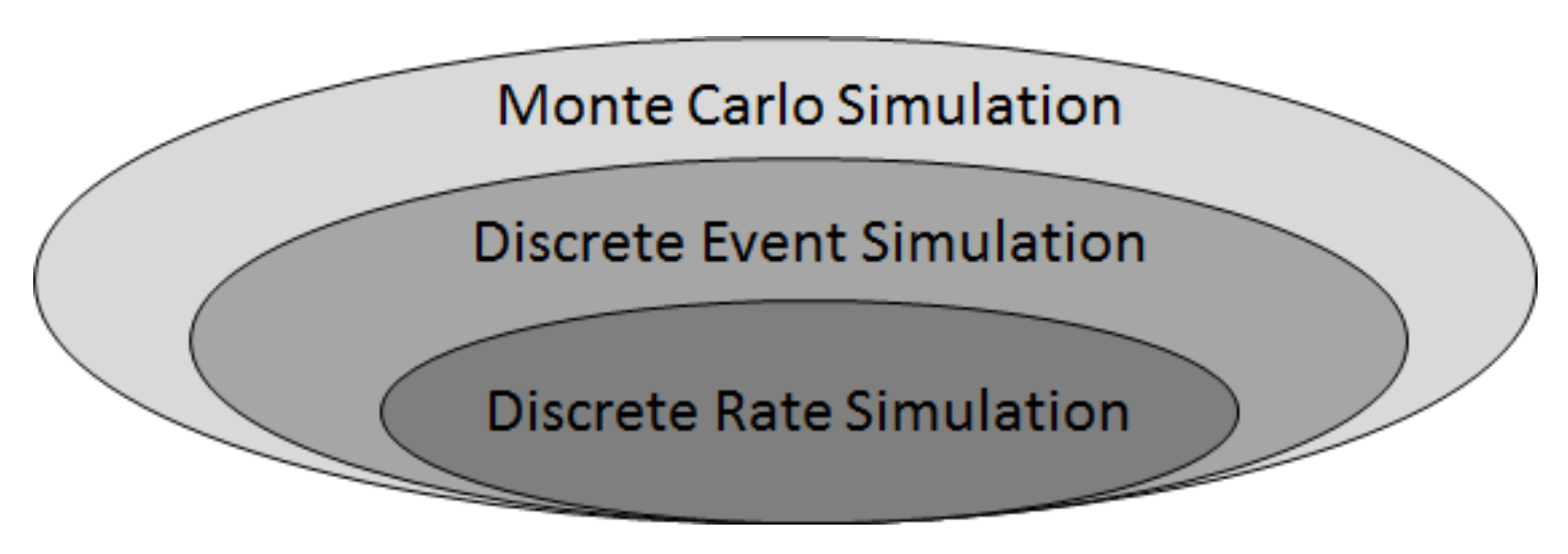
Moreover, a discrete event simulation (DES) framework represents a dynamic system via input parameters and distributions as well as a collection of state variables that are updated at discrete points along a simulated timeline, hence, discrete events. Indeed, it is the simulated clock jumps from one discrete event to the next without explicitly representing the behavior between the events. An activity or condition that extends over a duration is represented by a discrete event that signals its beginning and a later discrete event that signals its end; within this duration, there may be a series of discrete events, and possibly sub-activities, “sub-sub-activities”, etc. depending on the level of detail. DES models can therefore be developed in iterative phases that incorporate hierarchical complexity, as per
Figure 2, which define additional state variables and incrementally detail the system’s activities, conditions, processes, etc. There are cases in which a purely deterministic DES may be of interest (e.g., for initial conception or later verification), but in practice, DES is seen as a type of Monte Carlo simulation (
Figure 7), considering that the time
between events can be the result of RNG and that the updating of state variables that occur
at the events are generally the result of RNG.
Furthermore, a discrete rate simulation (DRS) is a particular kind of DES in which the state variables consist of pairs of levels and rates (
lj,
rj), and the discrete events consist of threshold crossings. Each level-rate pair represents a continuous variable that follows piecewise linear dynamics. The occurrence that such a
continuous variable crosses a threshold is, itself, a
discrete event (e.g., an ore stockpile level crossing below a critical value). When the
ith threshold crossing event occurs at time
ti, the levels
lj are updated as per
and, subsequently, the corresponding rates,
rj, are updated by model-specific formulas for
j ∈ {1,2…,
nCSV}, in which
nCSV is the number of continuous state variables. The model-specific updating of
rj can incorporate RNG, particularly in a mineral processing and extractive metallurgical context, when representing geological variation [
1,
2,
6,
7,
8]. These rate updates can also be the result of an operational policy that depends on the current configuration of the plant, as well as current and forecasted stockpile levels. Also, depending on the particular event, there can also be discrete jumps in
lj as well as in
rj, for example, a corrective action can include an immediate injection of a certain reagent, as well as a change in the continuous feeding rate.
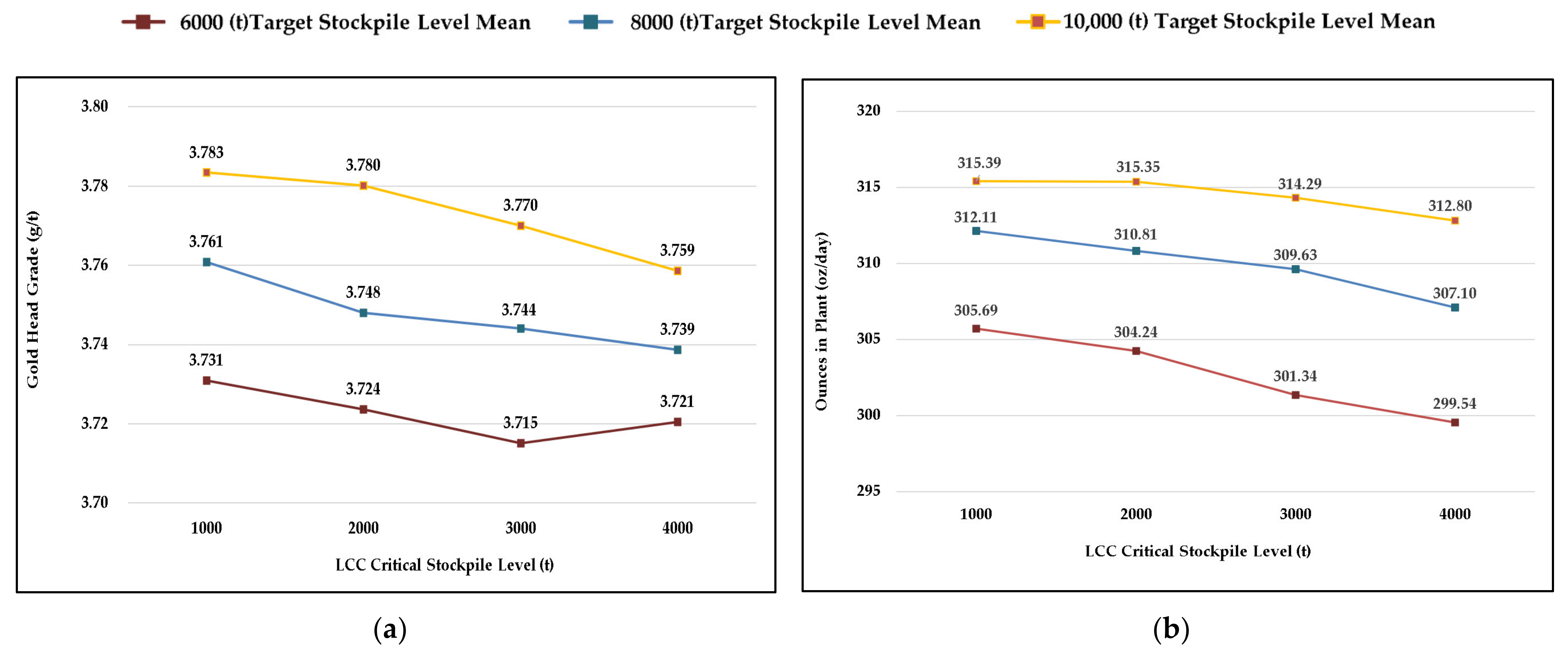
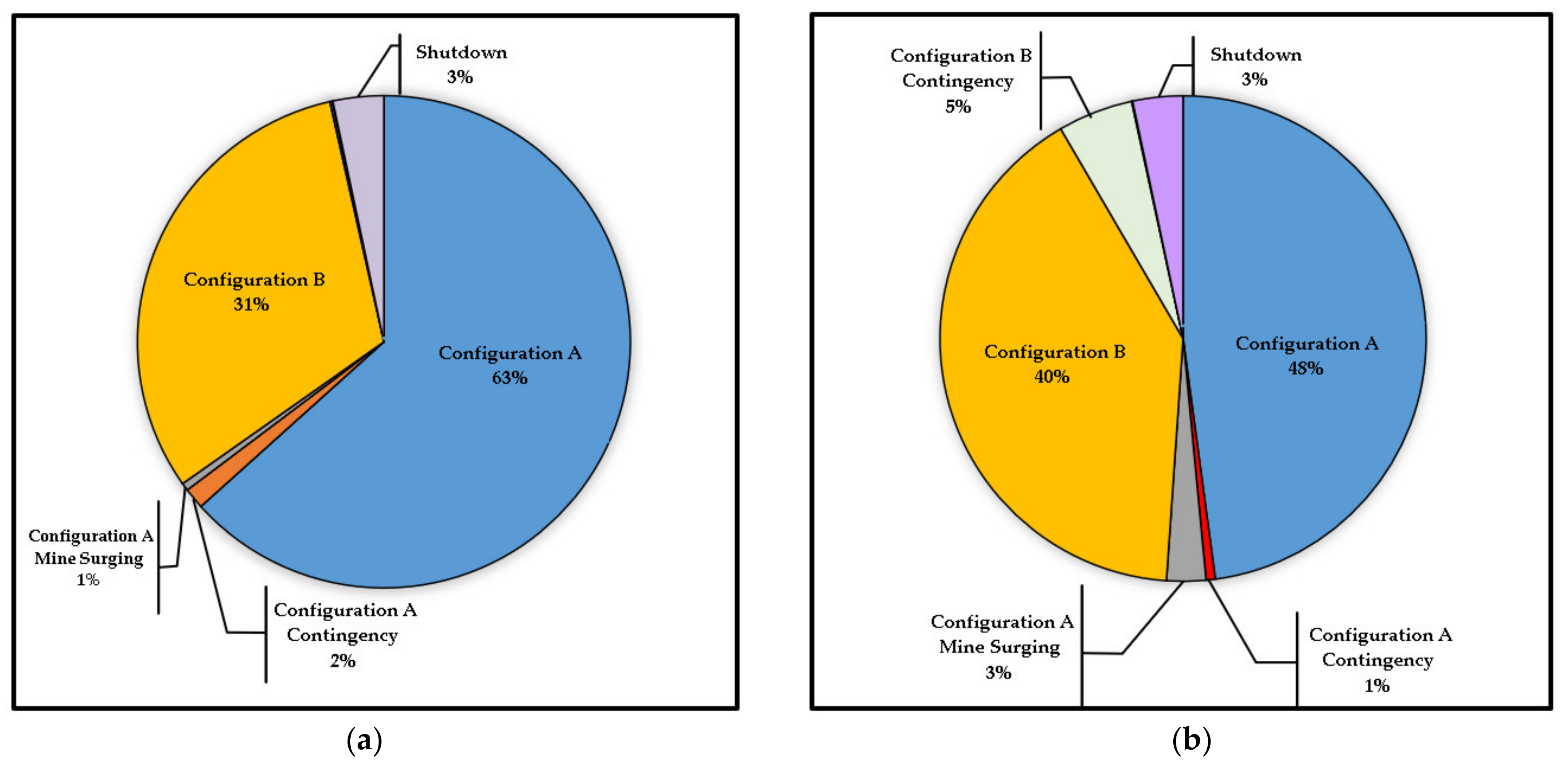
The DES/DRS framework of Navarra et al. [
1] was successfully adapted to represent spikes in cyanide consumption at Minera Florida [
2], considering the following threshold-crossing events:
As will be described in
Section 3.2, stockouts trigger contingency processing modes. The notion of a “geological parcel” is described in [
6] and provides a basic representation of geostatistical variation; each parcel contains a balance of HCC and LCC ore, which is the result of RNG. When detailed geospatial data (i.e., drill core samples) are available, the balance of HCC/LCC can be the result of a sequential Gaussian simulation [
27], which is the subject of ongoing work [
28]. For the current study, it is sufficient to consider:
In the event that the parcel, k − 1, is completely excavated, a following parcel, k, is generated that will contain the next mk tonnes of ore to be excavated;
There is a 70% chance that parcel k is within the same facies as k − 1; if so, then the weight fraction of LCC in parcel k, denoted as , is generated according to a Gaussian distribution centered at , with the small standard deviation, σinterfacies;
Otherwise, if parcel k is in a new facies, then is generated independently of the previous parcel, according to a Gaussian distribution centered on the orebody average and with a comparatively large standard deviation σorebody > σinterfacies.
This basic representation considers only two ore classes (also known as geometallurgical units), such that the weight fraction of HCC is given by . The DES/DRS framework can consider a higher number of ore classes, depending on the context, but these two classes have been sufficient to represent the Minera Florida context. Moreover, the mass mk of parcel k is generated according to a uniform distribution; other distributions have been tested for this purpose, but they have no significant effect.
Arguably, a logical continuation of the work by Órdenes et al. [
2] could include a detailed drill core sampling campaign to replace the parcel-based geological representation [
6] and thus link the DRS system dynamics to ongoing efforts in geospatial orebody modelling [
27,
28]. However, prior to such a costly effort, numerous process variables should be explored and represented within the framework, including gold head grade. From a managerial point-of-view (
Figure 2a), this detailing shows how the data which would result from such a campaign would contribute to continuous improvement efforts and upcoming plant upgrades. Indeed, the previous effort successfully captures the phenomenon of cyanide consumption within the simulation framework [
2], yet the management at Minera Florida were surprised that only a small amount of the extensive data that they had provided had been utilized.
Following the approaches for the DES of manufacturing systems [
18], the parameterization of process-variable distributions is an extension of standard exploratory data analysis (EDA). Depending on the context, standard EDA usually includes a listing of descriptive statistics such as mean, standard deviation, extreme observations (maxima and minima), and quartile data, as well as histograms and possibly other graphical constructions [
29]. The quartile data are often used to establish criteria for outlier filtering.
Figure 4 illustrates the use of maximum likelihood estimation (MLE) and goodness-of-fit statistics (GOF) in order to enhance a DES/DRS model; this type of detailing can be situated within the improvement cycle of
Figure 2 if we consider that a data-driven probability distribution of a process variable is itself a submodel that replaces the deterministic representation.
The conversations that followed the first collaboration with Minera Florida [
2] have emphasized the practical relevance of the data-driven parametrization of probabilistic distributions within gold extractive metallurgy (and ostensibly in other areas of mining and metallurgy). Without developing a convincing connection to the available plant data, the simulations may be rightly criticized for lacking a connection to production metrics, even if the most critical phenomena are well represented. Yet there seems to be an underrepresentation of journal articles detailing the contextualized application of MLE and GOF techniques within extractive metallurgical simulations. With the exception of the current work, we have failed to find such a paper.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}