
Application and Evaluation of Mathematical Models for Prediction of the Electric Energy Demand Using Plant Data of Five Industrial-Size EAFs



Abstract
:1. Introduction
2. Materials and Methods
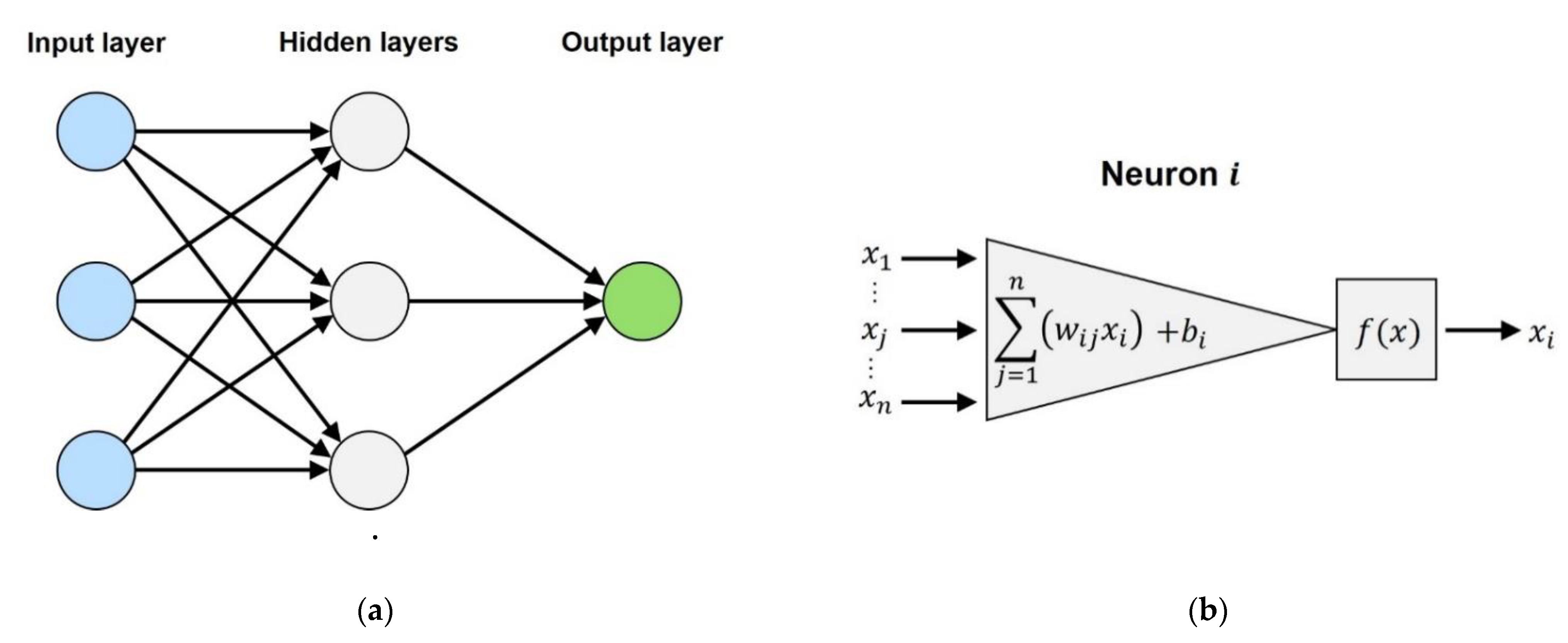
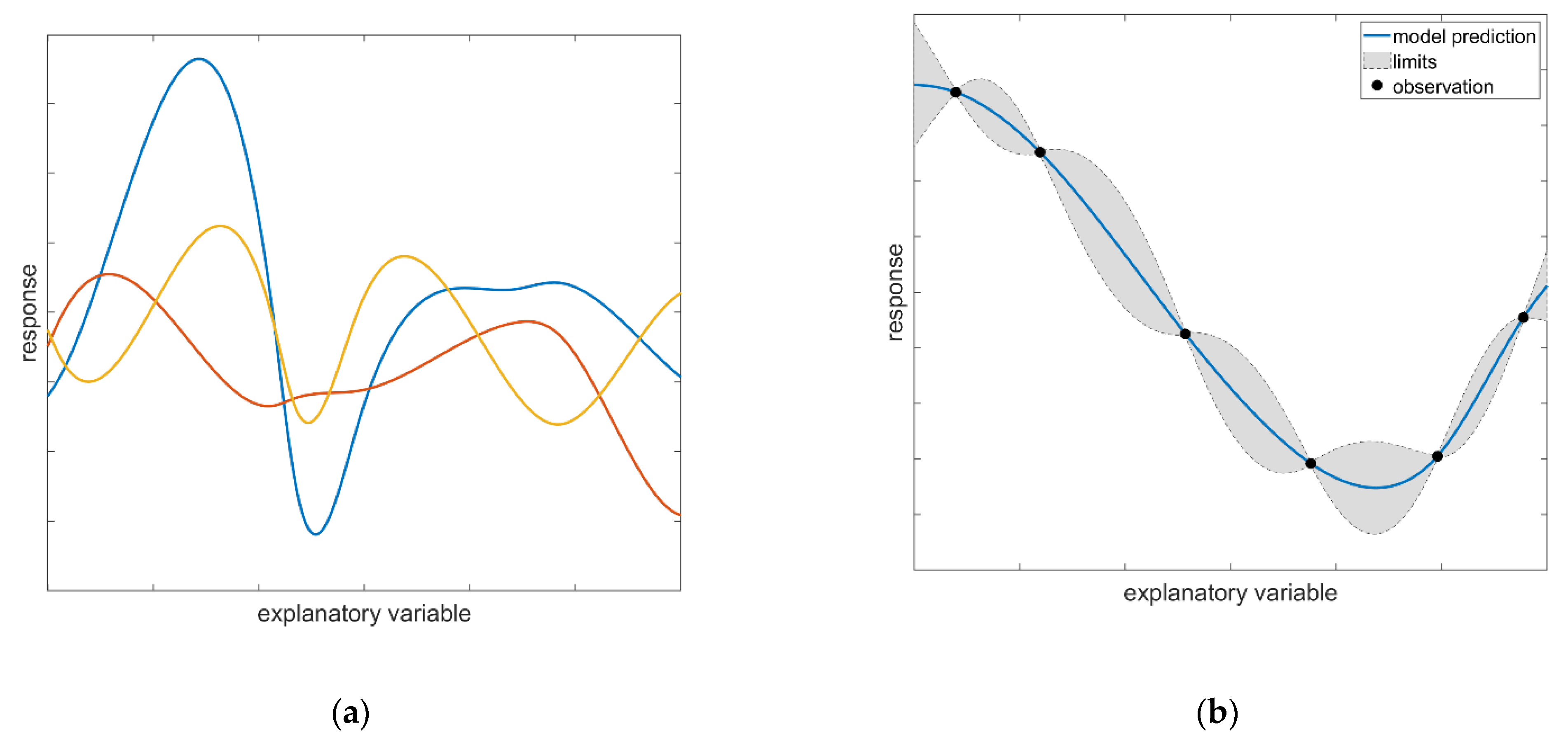
2.1. Modelling Approach
2.2. Datasets of EAF Heats Used in This Study
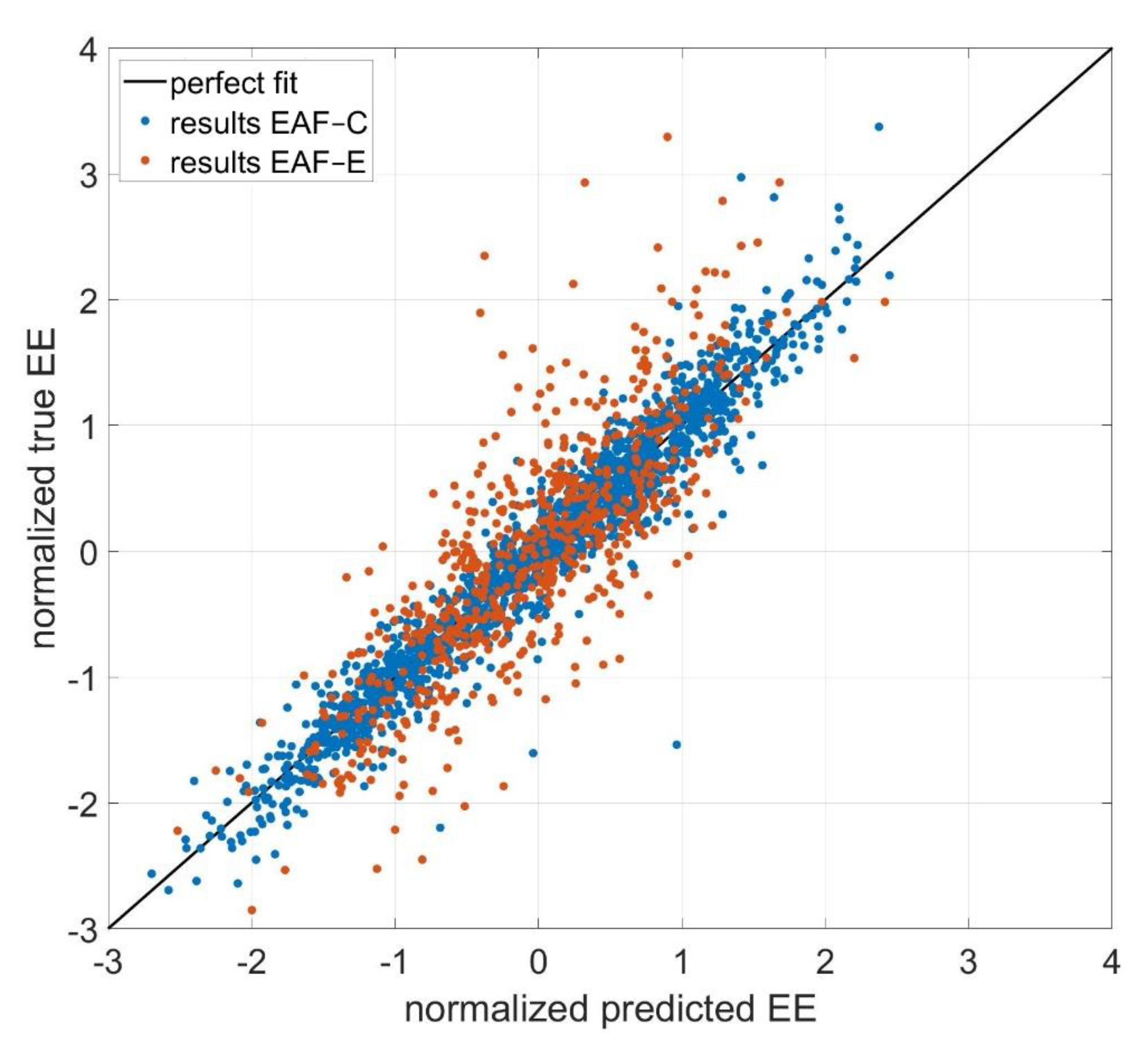
3. Results
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Steel Association. Steel Statistical Yearbook 2019: Concise Version; World Steel Association: Brussels, Belgium, 2019. [Google Scholar]
- Wirtschaftsvereinigung Stahl. Statistisches Jahrbuch der Stahlindustrie: 2020|2021; Wirtschaftsvereinigung Stahl: Berlin, Germany, 2021. [Google Scholar]
- European Commission. Climate Strategies & Targets. Available online: https://ec.europa.eu/clima/policies/strategies_en (accessed on 29 June 2021).
- Carlsson, L.S.; Samuelsson, P.B.; Jönsson, P.G. Predicting the Electrical Energy Consumption of Electric Arc Furnaces Using Statistical Modeling. Metals 2019, 9, 959. [Google Scholar] [CrossRef] [Green Version]
- Hay, T.; Visuri, V.-V.; Aula, M.; Echterhof, T. A Review of Mathematical Process Models for the Electric Arc Furnace Process. Steel Res. Int. 2021, 92, 2000395. [Google Scholar] [CrossRef]
- Bekker, J.G.; Craig, I.K.; Pistorius, P. Modeling and Simulation of an Electric Arc Furnace Process. ISIJ Int. 1999, 39, 23–32. [Google Scholar] [CrossRef] [Green Version]
- Logar, V.; Dovžan, D.; Škrjanc, I. Modeling and Validation of an Electric Arc Furnace: Part 1, Heat and Mass Transfer. ISIJ Int. 2012, 52, 402–412. [Google Scholar] [CrossRef] [Green Version]
- Logar, V.; Dovzan, D.; Škrjanc, I. Modeling and Validation of an Electric Arc Furnace: Part 2, Thermo-chemistry. ISIJ Int. 2012, 52, 413–423. [Google Scholar] [CrossRef] [Green Version]
- MacRosty, R.D.M.; Swartz, C.L.E. Dynamic Modeling of an Industrial Electric Arc Furnace. Ind. Eng. Chem. Res. 2005, 44, 8067–8083. [Google Scholar] [CrossRef]
- Cameron, I.T.; Hango, K. Process Modelling and Model Analysis; Academic Press: London, UK, 2001; ISBN 978-0121569310. [Google Scholar]
- Kleimt, B.; Köhle, S.; Kühn, R.; Zisser, S. Application of models for electrical energy consumption to improve EAF operation and dynamic control. In Proceedings of the 8th European Electric Steelmaking Conference, proceedings. European Electric Steelmaking Conference, Birmingham, UK, 9–12 May 2005. [Google Scholar]
- Pfeifer, H.; Kirschen, M.; Simoes, J.-P. Thermodynamic analysis of electrical energy demand. In Proceedings of the 7th European Electric Steelmaking Conference, Venice, Italy, 26–29 May 2002; pp. 1.413–1.428, ISBN 88-85298-44-3. [Google Scholar]
- Kirschen, M.; Zettl, K.-M.; Echterhof, T.; Pfeifer, H.; Models for EAF Energy Efficiency. Steel Times International [Online], 6 April 2017. Available online: https://www.steeltimesint.com/features/models-for-eaf-energy-efficiency (accessed on 25 July 2021).
- Kleimt, B.; Pierre, R.; Kordel, T.; Rekersdrees, T.; Schlinge, L.; Hellermann, O.; Elsabagh, S.; Haverkamp, V.; Gogolin, S. Adaptive EAF Online Control Based on Innovative Sensors and Comprehensive Models for Improved Yield and Energy Efficiency; European Commission: Brussels, Belgium, 2019; ISBN 978-92-79-98359-7. [Google Scholar]
- Malfa, E.; Nyssen, P.; Filippini, E.; Dettmer, B.; Unamuno, I.; Gustafsson, A.; Sandberg, E.; Kleimt, B. Cost and Energy Effective Management of EAF with Flexible Charge Material Mix. BHM Berg-und Hüttenmännische Mon. 2013, 158, 3–12. [Google Scholar] [CrossRef]
- Conejo, A.N.; Cárdenas, J. Energy Consumption in the EAF with 100% DRI. In Proceedings of the AISTech 2006 Conference, Cleveland, OH, USA, 1–4 May 2006; pp. 529–535. [Google Scholar]
- Carlsson, L.S.; Samuelsson, P.B.; Jönsson, P.G. Using Statistical Modeling to Predict the Electrical Energy Consumption of an Electric Arc Furnace Producing Stainless Steel. Metals 2019, 10, 36. [Google Scholar] [CrossRef] [Green Version]
- Gajic, D.; Gajic, I.S.; Savic, I.; Georgieva, O.; Di Gennaro, S. Modelling of electrical energy consumption in an electric arc furnace using artificial neural networks. Energy 2016, 108, 132–139. [Google Scholar] [CrossRef]
- Baumert, J.-C.; Engel, R.; Weiler, C. Dynamic modelling of the electric arc furnace process using artificial neural networks. Revue de Métallurgie 2002, 99, 839–849. [Google Scholar] [CrossRef]
- Chen, C.; Liu, Y.; Kumar, M.; Qin, J. Energy Consumption Modelling Using Deep Learning Technique—A Case Study of EAF. Procedia CIRP 2018, 72, 1063–1068. [Google Scholar] [CrossRef]
- Bowman, B.; Krüger, K. Arc Furnace Physics; Verlag Stahleisen: Düsseldorf, Germany, 2009; ISBN 9783514007680. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016; ISBN 0262035618. [Google Scholar]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning, 1st ed.; The MIT Press: Cambridge, MA, USA, 2016; pp. 33–77. [Google Scholar]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2013; ISBN 978-0262018029. [Google Scholar]
- Stein, M.L. Interpolation of Spatial Data: Some Theory for Kriging, 1st ed.; Springer: New York, NY, USA, 1999; ISBN 978-0-387-98629-6. [Google Scholar]
- Hartung, J.; Elpelt, B.; Klösener, K.-H. Statistik: Lehrund Handbuch der Angewandten Statistik; Oldenbourg Wissenschaftsverlag: Munich, Germany, 2012; ISBN 978-3-486-71054-0. [Google Scholar]
- Toulouevski, Y.; Zinurov, I. Innovation in Electric Arc Furnaces: Scientific Basis for Selection; Springer: Berlin, Germany, 2010; ISBN 978-3-642-03800-6. [Google Scholar]
- Kovačič, M.; Stopar, K.; Vertnik, R.; Šarler, B. Comprehensive Electric Arc Furnace Electric Energy Consumption Modeling: A Pilot Study. Energies 2019, 12, 2142. [Google Scholar] [CrossRef] [Green Version]
- Wooldridge, J.M. Introductory Econometrics: A Modern Approach, 5th ed.; South Western Educ Pub: Mason, OH, USA, 2012; ISBN 978-1-111-53104-1. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Name | Unit | Parameter | Name | Unit |
|---|---|---|---|---|---|
| Tap weight | t | Power-on time | min | ||
| Weight of ferrous material | t | Power-off time | min | ||
| Weight of DRI | t | Specific burner gas | |||
| Weight of HBI | t | Specific lance oxygen | |||
| Weight of hot metal | t | Specific post-combustion oxygen | |||
| Weight of slag formers | t | Furnace specific factor | - | ||
| Tapping temperature | °C | Energy losses |
| Furnace | EAF-A | EAF-B | EAF-C | EAF-D | EAF-E |
|---|---|---|---|---|---|
| Average tap weight [t] | 81 | 153 | 142 | 142 | 123 |
| Average tap-to-tap time [min] | 45 | 62 | 69 | 61 | 57 |
| Average specific electric energy demand [kWh/t] | 325 | 467 | 535 | 422 | 345 |
| Ferrous Material | Scrap | DRI | DRI/Scrap Mix | Scrap | Scrap |
| Number of overall heats | 5220 | 1046 | 6139 | 8088 | 2341 |
| Number of excluded heats | 150 | 32 | 791 | 785 | 163 |
| Percentage of removed heats | 2.9 | 3.1 | 12.8 | 9.7 | 7.0 |
| Furnace | EAF-A | EAF-B | EAF-C | EAF-D | EAF-E |
|---|---|---|---|---|---|
| Electric energy demand [kWh] | x | x | x | x | x |
| Mass of charged scrap grades [t] | x | x | x | x1 | x1 |
| Mass of slag formers [t] | x | x | x | x1 | x1 |
| Charged or injected Coal [t] | x | x | x | x | x |
| Bath height [m] | - | - | - | - | x |
| Oxygen consumption [m3] | (x) | (x) | (x) | x | x |
| Natural gas consumption [m3] | x2 | - | x | x | x |
| Power-on time [min] | x | x | x | x | x |
| Tap-to-tap time [min] | x | x | x | x | x |
| Sub-process times [min] | x | - | - | - | x |
| Tap weight [t] | x | x | x | x | x |
| Melt temperature [°C] | x | x | x | x | x |
| Mass of hot heel [t] | - | x | - | - | x |
| Steel composition [kg/kg] | - | - | - | x | (x) |
| Slag composition [kg/kg] | - | - | - | (x) | - |
| Model Performance | EAF-A | EAF-B | EAF-C | EAF-D | EAF-E |
|---|---|---|---|---|---|
| MAE [kWh/t] | 25.1 | 14.8 | 31.6 | 21.1 | 40.0 |
| SD [kWh/t] | 36.0 | 19.0 | 41.6 | 27.3 | 53.1 |
| RSD [%] | 11.1 | 4.1 | 7.8 | 6.5 | 15.4 |
| Furnace | Model Performance | Linear Regression | ANN | GPR |
|---|---|---|---|---|
| EAF-A | 0.842 | 0.847 | 0.859 | |
| MAE [kWh/t] | 7.9 | 7.6 | 7.1 | |
| SD [kWh/t] | 11.2 | 10.5 | 10.6 | |
| RSD [%] | 3.4 | 3.2 | 3.3 | |
| EAF-B | 0.899 | 0.871 | 0.943 | |
| MAE [kWh/t] | 11.7 | 12.7 | 8.3 | |
| SD [kWh/t] | 15.4 | 16.4 | 11.1 | |
| RSD [%] | 3.3 | 3.5 | 2.4 | |
| EAF-C | 0.881 | 0.923 | 0.941 | |
| MAE [kWh/t] | 14.9 | 12.3 | 10.3 | |
| SD [kWh/t] | 20.8 | 16.4 | 14.4 | |
| RSD [%] | 3.9 | 3.1 | 2.7 | |
| EAF-D | 0.754 | 0.755 | 0.769 | |
| MAE [kWh/t] | 9.9 | 9.9 | 9.6 | |
| SD [kWh/t] | 12.8 | 12.8 | 12.4 | |
| RSD [%] | 3.0 | 3.0 | 2.9 | |
| EAF-E | 0.519 | 0.587 | 0.651 | |
| MAE [kWh/t] | 6.3 | 5.8 | 5.3 | |
| SD [kWh/t] | 8.4 | 7.8 | 7.2 | |
| RSD [%] | 2.4 | 2.3 | 2.1 |
| Furnace | Model Performance | Linear Regression | ANN | GPR |
|---|---|---|---|---|
| EAF-A | 0.185 | 0.183 | 0.227 | |
| MAE [kWh/t] | 17.4 | 17.4 | 17 | |
| SD [kWh/t] | 24.4 | 24.5 | 23.7 | |
| RSD [%] | 7.5 | 7.5 | 7.3 | |
| EAF-B | 0.71 | 0.748 | 0.821 | |
| MAE [kWh/t] | 20.3 | 17.0 | 13.4 | |
| SD [kWh/t] | 24.7 | 23.0 | 19.4 | |
| RSD [%] | 5.3 | 4.9 | 4.2 | |
| EAF-C | 0.742 | 0.755 | 0.853 | |
| MAE [kWh/t] | 24.3 | 21.9 | 17.0 | |
| SD [kWh/t] | 30.6 | 29.8 | 23.1 | |
| RSD [%] | 5.7 | 5.6 | 4.3 | |
| EAF-D | 0.244 | 0.242 | 0.228 | |
| MAE [kWh/t] | 17.3 | 17.3 | 17.2 | |
| SD [kWh/t] | 22.5 | 22.5 | 22.7 | |
| RSD [%] | 5.3 | 5.3 | 5.4 | |
| EAF-E | 0.245 | 0.299 | 0.360 | |
| MAE [kWh/t] | 8.0 | 7.5 | 7.3 | |
| SD [kWh/t] | 10.5 | 10.1 | 9.7 | |
| RSD [%] | 3.0 | 2.9 | 2.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Reimann, A.; Hay, T.; Echterhof, T.; Kirschen, M.; Pfeifer, H. Application and Evaluation of Mathematical Models for Prediction of the Electric Energy Demand Using Plant Data of Five Industrial-Size EAFs. Metals 2021, 11, 1348. https://doi.org/10.3390/met11091348
Reimann A, Hay T, Echterhof T, Kirschen M, Pfeifer H. Application and Evaluation of Mathematical Models for Prediction of the Electric Energy Demand Using Plant Data of Five Industrial-Size EAFs. Metals. 2021; 11(9):1348. https://doi.org/10.3390/met11091348
Chicago/Turabian StyleReimann, Alexander, Thomas Hay, Thomas Echterhof, Marcus Kirschen, and Herbert Pfeifer. 2021. "Application and Evaluation of Mathematical Models for Prediction of the Electric Energy Demand Using Plant Data of Five Industrial-Size EAFs" Metals 11, no. 9: 1348. https://doi.org/10.3390/met11091348
APA StyleReimann, A., Hay, T., Echterhof, T., Kirschen, M., & Pfeifer, H. (2021). Application and Evaluation of Mathematical Models for Prediction of the Electric Energy Demand Using Plant Data of Five Industrial-Size EAFs. Metals, 11(9), 1348. https://doi.org/10.3390/met11091348