1. Introduction
Big data is an increasingly intrinsic part of how societies operate, requiring a paradigm shift in the way that we conceptualise “traditional” approaches to tasks [
1]. Our understandings are perhaps becoming “data-driven” rather than “knowledge-driven”. The place of individuals within a digital society requires a consideration of transparency, and the “voice” of diverse individuals [
2]. This paper considers the digital revolution in relation to “sharp end” child welfare work undertaken by social workers and courts on behalf of society to protect children from abuse. The focus of this article is on England, although the issues are comparable in “westernised” societies, and increasingly elsewhere in the world.
When applied to high-stake decisions for vulnerable groups, big data technology, which may be accepted elsewhere, can engender suspicion and controversy. For instance, the Allegheny Family Screening Tool (AFST) [
3] uses an algorithmic score to determine risk to children and need for services. Although it has delivered promise, the AFST and a comparable UK pilot that was withdrawn [
4] have also encountered concerns surrounding bias, opaque commercial software, and data privacy.
For proponents of big data, these issues need to be evaluated against the “status quo”. An ethical assessment of the AFST concluded:
“there [would be] significant ethical issues in not using the most accurate risk prediction measure…decisions are already being made daily that are equally subject to any of these imperfections” [
5] (p. 1).
A large part of this paper will focus on understanding these “imperfections” of traditional practice upon which it is argued technology can improve.
Given extensive and expanding efforts to address the undeniable challenges big data poses [
6,
7,
8,
9], it may be a case of when, not if, big data will more routinely shape social work assessments and decisions. Debates are needed now as to how it may do so. It is argued here that to understand the potential contribution of big data to child protection decisions, it is first necessary to consider what can be learned from a long-standing debate surrounding structured approaches to social work assessment. Although research spanning eight decades shows statistically calculated predictions usually outperform unaided judgment, social work has not matched gains made in comparable professions through statistical methods. Where implemented, actuarial or other structured tools can invoke disquiet, resistance, or unintended consequences. The reasons need to be understood.
Drawing on available research and examples from other domains, we introduce a conceptual framework to understand the nature and components of decision-aids and how they exert effect. We later examine how practitioners may use such tools in practice, potential pitfalls, and the deep-rooted psychological forces explaining why probabilistic predictions, for most humans, may be counterintuitive. Finally, we examine the potential for big data technology to address the highlighted difficulties.
2. Context: Care Proceedings in England
Since 2007, the rate of care applications in England has doubled [
10,
11]. The peak year, 2016, saw local authorities deem more than 24,000 children in need of legal state protection, in most cases meaning permanent removal from parents [
10]. Although the 2007 death of Peter Connelly, and media storm that followed, was widely viewed as triggering the rise [
12,
13], by 2016, Lord Justice Munby, then President of the Family Division, described the increase that had continued year on year as a “looming crisis” [
14]
Although the overall increase in cases reaching the courts is clear, local and regional variations have been noted over decades [
15,
16,
17], both in terms of application rates and numbers of looked after children. In 2008, for every 10,000 children, 20 children were in care in Wokingham compared to 151 in Manchester [
18]. Even in areas of comparable socio-economic deprivation, wide inequities are evident. Although “Baby Peter” was a Haringey child, care applications in that authority declined by a third between 2009 and 2017, a period when they rose more than fivefold in Sunderland [
10]. Furthermore, the courts’ treatment of care applications also diverges across the nation in terms of the proportions of children returned to parents, placed with relatives, or made subject to full care orders [
19].
Family court proceedings change the lives of children or parents profoundly [
20]. Within Europe, the UK is seen as an outlier in its willingness to override parental consent to adoption [
21], a practice reinforced by the government policy [
22]. In relation to adoption decisions, the recent judgment of Re B-S [
23] (para 22) was seen by many as “raising the bar” [
24]. LJ Munby emphasised that social workers must weigh and balance the strengths and deficits of each available option “side by side” [
23] (para 44), using a “balance sheet” approach [
23] (para 74.iv). In other words, parents may not be up to the task, but the state can also fail some children.
Effectively, this judgment tasked social workers more explicitly with an actuarial role within their assessment activities [
25,
26]. Required to predict the behaviour of parents, as well as the impact of their actions on each child, social workers must also re-adjust those predictions across a range of scenarios. Clearly, this is no straightforward prospect for workers who come to a profession to communicate, investigate, assess, record, intervene and advise but not to perform statistical probability calculations [
27,
28]. It will be contended that this forecasting task does not flow readily from the social work skillset [
29]. Framing accurate predictions is a task that all humans, not just social workers, frequently get wrong despite feelings of confidence [
30,
31,
32,
33,
34].
Arising from this analysis, it is proposed that a comprehensive actuarial framework with which to assess case factors and quantify their severity is a prerequisite for three purposes: firstly, ensuring consistency between courts and professionals to promote fairness and equitable resource allocation; secondly, achieving best outcomes for children and families by focusing proceedings on the fewest more important factors, thereby serving to minimise errors; thirdly, creating a simpler, more transparent approach to guide practitioners and support parental engagement.
4. Understanding the Nature and Components of Decision-Aids
Statistical tools operate at different stages and incorporate varying levels of structure within the assessment process. Their scientific underpinning also differs. Before determining that tools “work” or how practitioners use them, it is necessary to define their key components and how they carry out their job. In doing so, this helps to conceptualise decision-aids in terms of automation, i.e., the extent to which they relieve practitioners of effort and restrict autonomy. Structure should be viewed broadly, not just in terms of schedules or checklists, but rules and policies that also constrain discretion. This analysis draws on the work and model advanced by Parasuraman et al. [
44].
4.1. Stage of Use
Tools and rules may be used to (a) collect information, (b) analyse that information, or (c) determine a course of action. For instance, alcohol use questionnaires guide collection of data with which to evaluate substance misuse difficulties to a consistent standard, perhaps assigning a graded severity score that might also predict membership of a diagnostic category. Such a device alone, however, cannot specify the relative weight to attach to that factor, alongside others, in determining the overall likelihood of a future event, for instance a child coming to harm.
To achieve this, other tools steer the analysis of all information collected, at this point assigning weights to relevant factors, whether through manually calculated or computer-generated scores that typically assign cases to risk levels. It is important to recognise that good decisions require the best data, but although information collection tools serve to optimise data quality, good information alone does not automatically produce better decisions.
Finally, further tools, or more often, agency policies, determine the ultimate decision. Is the practitioner free to modify a risk score with which they disagree, and if so upwards or downwards, in special circumstances or for certain groups, with or without management approval?
4.2. Level of Structure
The second component to consider is the balance of automation vs. autonomy that different tools strike. For example, a structured questionnaire evaluating alcohol use still requires practitioners to conduct interviews and interpret verbal responses and their veracity. Such devices thus offer low structure, demanding a high level of human input. A highly structured tool, on the other hand, might require the results of a hair strand test and the number of alcohol-related incidents reaching police attention over a five-year period; thus, removing all practitioner discretion. At the analysis stage, a tool may simply advise a practitioner of the factors to consider when reaching their judgment (low structure) or deliver a fully automated risk score (high structure).
4.3. Scientific Base
Thirdly, tools are built on different principles. True actuarial aids are derived from mathematical associations between case factors and known outcomes in a large sample and validated within the population that the tool is to be applied. As large datasets are required, and associations must also be verified by testing their generalisability in separate samples, such tools depend on fewer factors. Consensus aids are those drawn up by experts or professional bodies rather than mathematical relationships. These may therefore be more complex and comprehensive, typically designed to steer the collection of information to ensure that critical aspects are not overlooked. Consensus frameworks may involve scoring mechanisms that render them indistinguishable to practitioners from their actuarial equivalent.
4.4. Evaluating Consensus and Actuarial Decision-Aids
Weighing the merits of the two approaches, consensus tools are not mathematically validated but are therefore easier to develop and implement according to the best current knowledge and recognised professional principles. Although lacking an empirical base, they may still provide a benchmark to promote consistency. When considering predictive accuracy, however, consensus tools have been found to be less reliable in direct comparison [
45,
46], whilst a comprehensive evaluation of a UK version (Safeguarding Children Assessment and Analysis Framework) could not demonstrate improvements in assessment quality, outcomes for children or reduction in re-referrals [
47].
A further drawback highlighted is that consensus tools may be found unwieldy by busy practitioners, and therefore subject to cursory use, completion after the event, or not being used at all [
47,
48]. Actuarial tools, such as the California Family Risk Assessment [
49], must be briefer, because links between variables and outcomes that are generalisable are powerful, but few. That said, acquiring the data to inform an actuarial prediction, as in the case of the Oasys, can also be time consuming, and practitioner shortcuts within that process will undermine the tool’s predictive accuracy. In relation to many actuarial devices, accuracy is all that they have to offer. This underscores the importance of getting that component right, or as near as possible, particularly when a result may be intuitively unconvincing. Unfortunately, due to the time and demands of obtaining sufficient relevant reliable data, this must remain the greatest current challenge for actuarial tool development within social work.
5. Decision-Aids in Practice
The starting point for this analysis is a modified version of the model drawn up by Parasuraman et al. [
44], illustrated in
Figure 1 below, whereby the Qrisk and Oasys tools described above may be visually represented in terms of stage and structure.
This model shows that QRISK3 data collection is highly structured, requiring either static factors or those measured by machine, and also that the analysis by which the variables are converted into an overall risk score requires no professional input for the calculation. Decision selection, i.e., treatment offered, is harder to place on a continuum because it depends not only on the level of prescriptiveness of government guidance, but whether doctors follow it in practice, and the consequences or penalties contingent upon not doing so. The framework, however, helps to identify these important considerations.
The Oasys might be visualised as bringing moderate structure to data collection because factors and scoring criteria are tightly specified but input and judgment is also required from at least two humans. The analysis component is highly structured, i.e., fully automated, but decision-selection structure is low, with only some checks and balances to practitioner discretion provided by agency policy for serious cases.
Viewing tools through such a lens is important because available evidence shows them to exert most influence on outcomes when operating at the analysis but particularly the decision selection stages of assessment. Tools that target information collection alone, i.e., shape the information available but leave the final decision to professional discretion, do the least to steer practitioners on the right course. This is a crucial point because structured decision-making models, including most trialled within UK social work, embrace this approach.
The evidence for this assertion starts with the early work of Sawyer [
50], who published a review of studies where it was possible to examine the accuracy of predictions made when tools were used either at the data collection, or data analysis stages, or both. He concluded that tools used only for information gathering added little to predictive accuracy (26%, as opposed to 20% when not used at all). The most accurate predictions (75%) were achieved when tools guided both processes and indeed when a range of methods was used to collect the data. Significantly, however, this was when professionals did not ultimately modify the algorithmic predictive score. Where they did so, predictive accuracy dropped back to 50%.
Recent research has supported Sawyer’s earlier conclusion by examining what happens when practitioners disagree with automated algorithmic predictions. A professional who modifies a statistical risk score is exercising a “clinical override”, a concept first introduced by Meehl [
36] who described how the probability of any given person going to the cinema would be affected if it was learned that this individual had broken his leg. Meehl correctly reasoned that no algorithm can incorporate rare exceptions and that an element of judgment will be necessary. In practice, however, Dawes later noted:
“When operating freely, clinicians apparently identify too many ‘exceptions’, that is the actuarial conclusions correctly modified are outnumbered by those incorrectly modified” [
37] (p. 1671).
Looking at recidivism risk, Guay and Parent [
51] found predictive accuracy diminished when practitioners chose to modify the Level of Service Inventory classification of risk, and that they usually chose to “uprate” it, doing so more often in relation to sexual offenders. Johnson found that where practitioners modified the actuarial prediction produced by the California Family Risk Assessment model, predictive accuracy fell to that of chance, “a complete absence of predictive validity” [
49] (p. 27). Only one study [
52] shows an instance where overrides improved predictions, and this happened when practitioners “downrated” the risk posed by certain sexual offenders. The same authors found that where sexual offence risk was “uprated” (more commonly), the same rule of loss of predictive accuracy arose.
These observations can be understood in terms of risk aversion, “erring on the side of caution”, exercised by practitioners and agencies when stakes are high:
Practitioners face the mutually exclusive targets of high accuracy and high throughput and exist in a climate where failings in practice will be hunted for if an offender commits a serious offence whilst on supervision. [
53] (p. 14).
It is possible that those “brave” enough to “downrate” a sex offender’s risk, do so in the light of the genuine exceptions, for instance terminal illness, for which the override facility was intended. These observations become critically important when viewed in the context of child protection, also an arena that demands high stake decisions. It is foreseeable that in a risk averse climate, algorithmic predictions of significant harm to children would more often be liable to uprating overrides, resulting in recommendations to place more children in care than necessary.
Something also unsettling is the potential for certain groups to be affected disproportionately. Agencies, as well as practitioners, may exercise overrides. Chappell et al. [
54] found black offenders were 33% more likely to receive practitioner “uprating” overrides that held them in custody longer, with female offenders less likely to be “uprated” in cases where the agency required it.
Despite the intended objectivity of risk assessment instruments,
overrides create avenues through which discretion, subjectivity, and bias may be reincorporated into the detention decision [
54] (p. 333).
A picture emerges where professionals given discretion rarely follow an algorithmic score that does not match their independent prior judgments. Although fears are often expressed that automation may create unthinking “rubber stamping” by practitioners, the opposite is consistently found [
3]. Resistance to statistical guidance can indeed be so strong that where adherence is mandatory, practitioners have acknowledged deliberately manipulating the algorithm by adjusting the data input to achieve the desired outcome [
55,
56,
57]. These observations can be understood in terms of confirmation bias, which shows that humans are not only prone to select and interpret evidence according to pre-existing beliefs, but even strengthen those views in the face of disconfirming evidence [
58]. In other words, practitioners change the tool, not their beliefs, when an algorithm challenges their thinking. Moreover, in doing so, beliefs are strengthened whilst trust in statistical devices diminishes. This creates a danger of discretionary judgments that are masquerading as evidence-based.
A recurrent theme in the social work literature surrounds managerialism and over-bureaucratisation arising from organisational responses to high profile incidents. Although tragic events often stem from systemic weaknesses, practitioners become the target for tools and rules aimed to standardise practice. Not only may such efforts be misdirected, but they often prove counterproductive, not least in terms of the additional burden placed on an overstretched workforce [
56,
57,
58,
59]. The present analysis adds a further route by which organisational attempts to apply structure and uniformity may backfire. It cannot be assumed that tools will be used in practice exactly as intended by policy makers [
56].
6. The Limits of Prediction
Real progress requires addressing this fundamental impasse. To do so, however, it is necessary to dig deeper into the human condition. How and why do organisations attribute responsibility and blame when things go wrong? Why are people prone to “false beliefs” [
37] that may prove so tenacious?
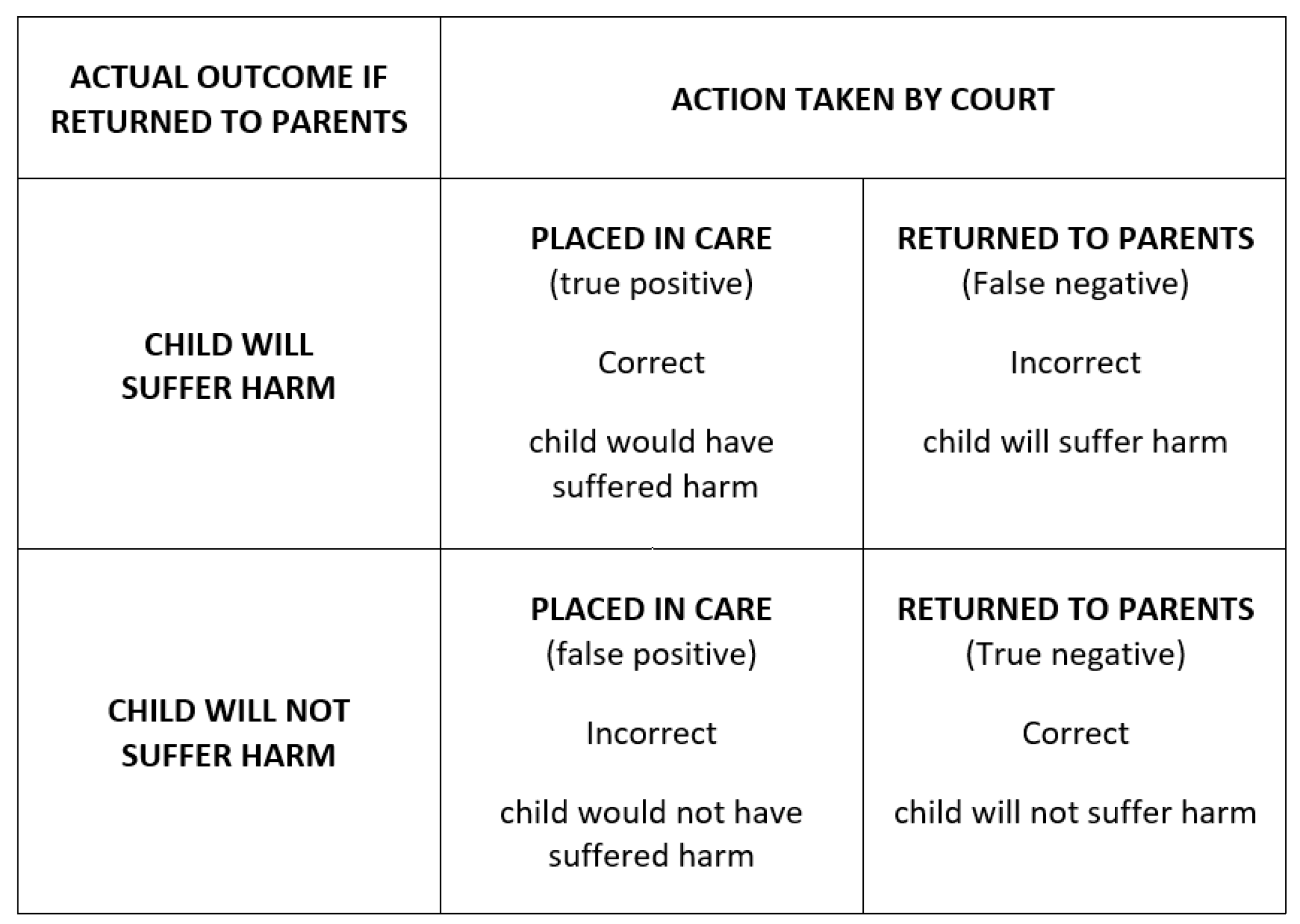
The table below (
Figure 2) shows a decision matrix with only two avenues open to a court that must determine whether the 1989 Children Act threshold has been reached, i.e., that a child is suffering or likely to suffer significant harm, attributable to the care received. Care proceedings are complex, and it cannot be known with certainty what the actual outcome would have been. Where a binary decision is required according to a threshold cut-off, however, we must assume successes and errors fall into the four categories shown in the grid. Errors in prediction are inevitable, but this framework is a basis for measuring and reducing them.
In care proceedings, the Children Act requires two core predictions: future parental behaviour and the child’s response to it. Human actions are only partly driven by internal forces, such as hormonal status or propensity for violence, but also by life circumstances that are dynamically changing, as well as random events and accidents [
60]. All these forces interrelate to create a phenomenon that is notoriously difficult to predict. Estimating harm that may ensue is rendered ever more complex considering the array of personal characteristics and circumstances of those that our behaviour affects. Often it is only in hindsight, therefore, that the chain of events leading to a harmful action is revealed. “Outcome” or “hindsight” bias [
61] can make events appear more predictable afterwards than realistically possible beforehand. Looking back, causal patterns may be registered from an unrepresentative sample that falsely inform further, more generalised predictions [
62]. By analogy, we might predict that every man alive today will father a son, because this reflects his heritage over millions of generations.
In some fields, these limits to prediction are well understood, accepted, and managed. Car insurers simply adjust premiums to reflect the systematic factors statistically associated with accidents, whilst allowing a wide margin for random, unforeseeable events. In fields where harm may be severe, however, particularly when involving vulnerable groups, our capacity to recognise and tolerate the unpredictable appears to break down. Whilst all of us understand and state that we cannot predict the future, when stakes are high, we feel compelled nonetheless to pursue an illusory and unachievable level of future certainty [
60]. In consequence, when an outcome is not the one predicted, we assume responsibility for “getting it wrong”, even when no human or organisational omission occurred. Society has arrived at this point because the alternative seems intolerable; to accept error acknowledges that children must suffer harm or unnecessary disruption through our decisions, and we can do nothing to change that fact. However, the greater problem—and one largely unrecognized—is that when we do not accept some harm as inevitable, we can
increase that harm [
60].
To best illustrate this counterintuitive phenomenon, a series of experiments, replicated across decades and a range of conditions, show humans engage in “a striking violation of rational choice” [
63]. In a typical experimental paradigm, subjects are offered rewards for correctly predicting whether a light will flash red, or green. The light is programmed to flash according to a proportion of 80% red and 20% green in a randomised order [
64]. To maximise gain, subjects must predict the most frequently occurring event every time. This “maximising” strategy is not just the rational, statistical approach that an algorithm would incorporate, but also one that animals quickly learn in equivalent experiments. Human subjects did not take this approach, however. Although they quickly recognised the ratio of red to green flashes, and their guesses fell in proportion, they chose to predict each flash individually, to the effect that only 80% of the 80% red lights were correctly predicted, and 20% of the 20% that were green. Their overall accuracy was thus reduced from 80% to 68%. This behaviour has been termed “probability matching” rather than “maximising” and continues to be observed for many subjects even when the experimental parameters and effective strategy are fully explained to them [
63].
The explanation for this uniquely human approach to prediction is twofold. First, “maximising” involves consciously accepting inevitable loss, and where stakes are involved, people will go to great lengths to avoid it [
65]. Secondly and crucially, the subjects in this experiment reported detecting patterns in the random sequence of flashes that led them to feel they could beat the laws of probability. This observation falls in line with research describing several human biases that hamper our ability to estimate odds accurately. These include ignorance of base rates or regression to the mean, survivorship bias, illusions of validity, clustering or correlation, representativeness, and availability [
66]. Such biases can broadly be understood as conclusions reached upon either unrepresentative samples of data, limited personal experience, and inability to distinguish random from systematic events, i.e., perceiving patterns and connections where they do not exist. In social work, a further human tendency, the “fundamental attribution error” [
67], can lead us to overestimate the influence of core personality traits on the behaviour we observe in other people whilst downplaying situational and random factors; whereas I might put my bad behaviour down to a “bad patch”, an assessor may judge me a “bad person” who will always, and predictably therefore, behave badly. Consider the following hypothetical example:
Ten final hearings are scheduled involving babies recommended for adoption. Inputting all that is known about the parents’ relevant difficulties into a reliable algorithm yields an 80% probability that each child would suffer significant harm if returned to parental care. The judge recognises that granting placement orders for all babies would separate two permanently from their birth family unnecessarily. Unprepared to accept this, she is impressed by the verbal testimony of two mothers who agree to engage with treatment programmes and agrees to reunification for those cases. Unfortunately, statements of intent under courtroom pressure have turned out to be a poor indicator of future outcomes. The algorithm had incorporated all that could possibly be known about the risk to these children, which was equivalent for them all. Only by sending all babies home and looking back twenty years in the future would it be possible to see how turns of unpredictable events had provided two with a stable upbringing.
This hypothetical judge in fact could not know that in trying to avoid two errors—two unnecessary adoptions—she had not only failed in that attempt but had sent a further two children home where they would experience abuse. In this hypothetical instance of irreducible uncertainty, the odds of the “correct” decision, i.e., no predictive errors, were only 1 in 45, whilst there was a 60% chance of doubling the error by trying to avoid it. In fact, to achieve a better than even likelihood that no child would be adopted unnecessarily, no fewer than eight would need to return home, six of whom would experience abuse.
Although professionals do not operate to a “forced choice quota”, probability matching theory raises the possibility they unconsciously develop one. A judge who challenges 30% of care applications may, over time, build a bias that authorities are sending approximately that proportion of cases to court unnecessarily. Research from the criminal courts may support this hypothesis. Kleinberg et al. compared judicial bail decisions with algorithmic predictions and were able to rank judges in terms of leniency, i.e., statistical propensity to grant bail to defendants randomly assigned to them. Apparently, the judges were operating to a personal leniency threshold, but the defendants released or detained by all judges were represented across all risk levels, as determined by the algorithm and actual outcomes [
68].
We do know for certain that resources and energies are finite, so where professionals focus effort on the wrong cases, they take their eye off one or more that are more deserving, and error is increased. Algorithmic predictions are unlikely to provide the level of certainty with which we are intuitively comfortable, and which society incentivises us to achieve. Rather than accept uncertainty, courts tend to seek greater but illusory assurances from experts, or substitute an easier problem to focus on, such as adherence to a written agreement, rather than the disputed issues that necessitated the agreement. Accepting uncertainty instead might lead us to find different ways of managing cases that do not present a clear choice:
“An awareness of the modest results that are often achieved by even the best available methods can help to counter unrealistic faith in our predictive powers and our understanding of human behaviour. It may well be worth exchanging inflated beliefs for an unsettling sobriety, if the result is an openness to new approaches and variables that ultimately increase our explanatory and predictive powers.” [
37] (p. 1673)
7. Is There a Role for Big Data?
7.1. Volume, Variety and Velocity
Although size is relative, whether within the Google infrastructure or social work databases, exponentially increasing stores of digital data are common to both. The almost limitless range of data types includes administrative and personal details, text documents, social media posts, images, sound files, and even digital representations of household odours, or blood-alcohol levels monitored by wearable devices. Data accumulating at high speed may be processed in real time to deliver insights subject to instantaneous update and revision.
Usually, this is achieved through “predictive analytics” or “predictive risk-modelling”, colloquially termed “data mining”. Powerful, machine learning software can be trained to test and recognise complex patterns within the data with minimal human input. By assigning relative weights to the factors associated with known outcomes, models can be developed and their capacity to predict outcomes then tested on a portion of the data that was not used to create the model.
Linking multiple datasets through unique personal identifiers expands available data and insights gained. The Nuffield Family Justice Observatory Project (FJO) [
69] exemplifies a relevant data linkage project, aiming to support research by linking datasets held by the Children and Family Court Advisory and Support Service (Cafcass), the courts, and Department for Education, with others scheduled to follow. Third party organisations now exist throughout the UK dedicated to ensuring adherence to legal, ethical and privacy standards [
9].
7.2. The Future of Big Data?
To consider the full potential of big data in this context, we might examine one of the most challenging areas facing social workers and the family courts. Child protection registrations for neglect have risen ten-fold over the last thirty years [
70]. Three quarters of care applications today [
11,
71] involve neglectful parenting, concerns which are insidious, hard to evidence, and disproportionately related to poverty and deprivation. These difficulties lead to delays in children receiving adequate care [
72], and to complex legal arguments surrounding whether fine lines of distinction exist between neglectful parenting and that which is merely “inconsistent” or “barely adequate” [
73]. Broadhurst et al. state that neglect cases “resist a rationalist risk paradigm” [
74] (p. 1050) and that practitioners must rely on their relationships and interactions with service users.
Does it always have to be this way? In addition to more accurate risk estimation, big data technology might offer benefits to social workers, court decision-makers and service users. Take the example of a first referral describing poor housing conditions. At the earliest point and before a visit takes place, a social worker may know the extent of several related concerns, for instance a record of poor school attendance, missed health appointments, or parental criminal history. These data can be drawn from many datasets, visually presented by an automated process requiring no work for the practitioner and combined into an algorithmic score that guides investigation and intervention.
From an evidence-gathering perspective in this scenario, consider technological innovation. Rather than many professionals visiting a home over time to assess highly changeable conditions according to their personal standards, photographs could be uploaded to a national database, to be graded by an image classifier. Not only would this provide an objective benchmark to monitor progress, but it would also allow comparisons across the general population, and making allowances for local deprivation, with evidence retained for human examination. Combined with data from many other sources, a more concrete evidence base can be built, both to place before courts and decision-makers, and to refine algorithmic predictions.
Ethically, two possibilities could prove revolutionary in time. The first is the potential to take account of population base rates that are entirely unknown at present. For instance, how many parents also consume alcohol at this level without causing harm to their children? The second answers the call of Re B-S [
23] to employ a “balance sheet”. In addition to estimating the continuing risks to any child remaining in parental care, these concerns might be evaluated against typical outcomes for a child of certain characteristics placed in long-term state care.
Finally, the service user’s perspective is often overlooked. Could technology support face to face interventions and parental engagement through greater transparency? Foreseeably, using today’s app-based smartphone software, parents could themselves upload household images, validated by global positioning (GPS), to receive fewer professional visits. They might receive notifications and customised reminders of medical appointments, or motivational messaging for a perfect week of getting children to school on time, shared with family and friends. Following the medical analogy of the Qrisk tool, could a parent check their own dynamically-changing risk score, and see where it sits relative to the line at which professionals may step in?
7.3. Practical Applications of Big Data Technology
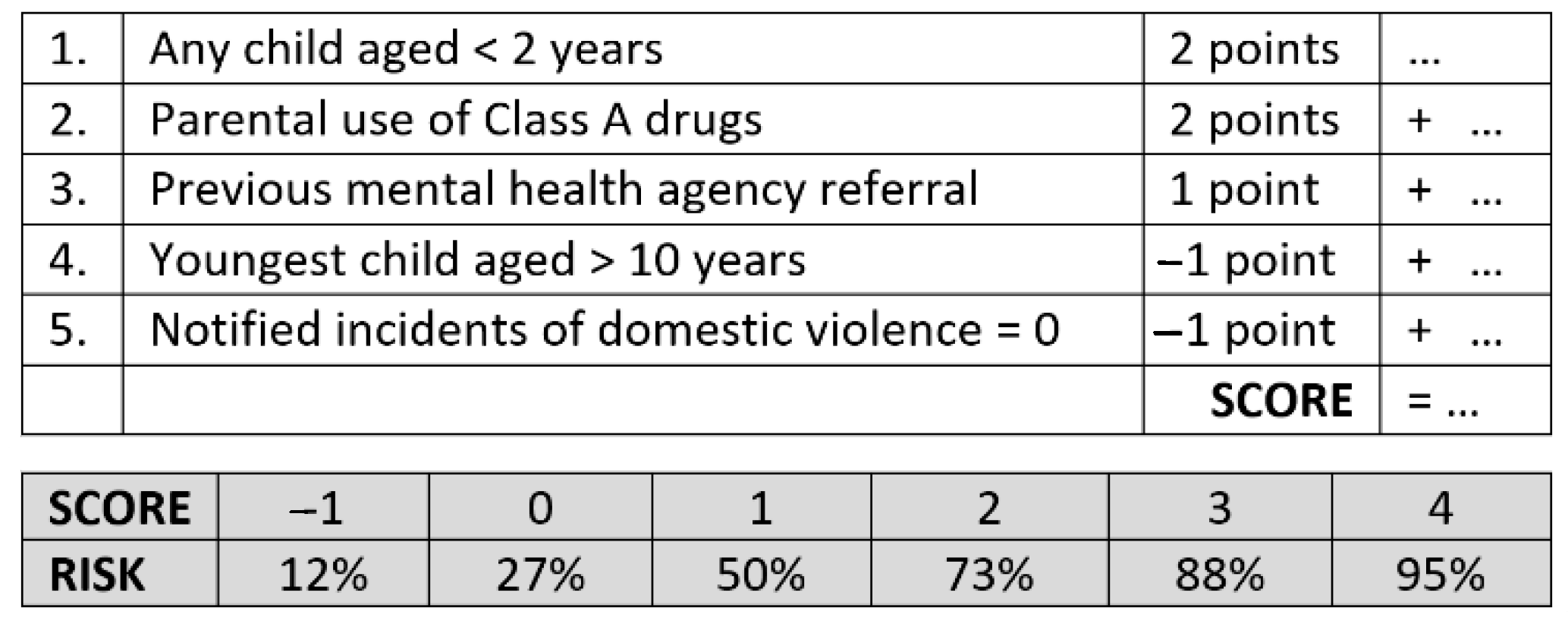
Figure 3 below illustrates how an algorithmic tool might look to professionals and service users. The factors and figures displayed here are used to exemplify a concept, and importantly do not represent actual research. The example is, however, based on real predictive devices created by Rudun and Ustin [
75] for use in related disciplines, each designed to minimise complexity by using the least and most powerful predictors to offer intuitive simplicity to users. Crucially, the tools championed by the authors leverage the power of big data but use models that are fully interpretable as opposed to their “black box” equivalents, i.e., where the workings of the algorithm cannot be known by humans. Such tools demonstrate transparency on two levels: the scientific basis for the score can be explained by experts (essential where legal decisions are concerned), whilst the interface can be understood by all. As this example incorporates referral history [
76], there is a potential for bias, but also for its sources to be more explicitly identified.
Applied to the field of child protection, this kind of device may represent a viable means of guiding both prediction and intervention planning. The tool offers a binary prediction when the score exceeds one point, but also risk banded scores (shown in the grey cells). These classifications indicate the more clear-cut cases that invite decisive action, but also those with a less certain prognosis, where monitoring and support may be warranted and most effective. Such a tool would not replace professional judgement but introduces three vital perspectives. First, discussions may be steered and focused on the issues that are demonstrably most relevant to the protection and welfare of children. Secondly, the energies of the social worker and/or guardian may be concentrated where research indicates them to be most effective, i.e., the collection, verification, and refinement of high-quality information from a range of sources, without which no algorithmic device can function. Thirdly, the inherent simplicity of the device enables override decisions to be shared and scrutinized by all parties of diverse perspectives; thus, reducing the potential for bias or risk averse decisions by any one professional or body.
8. Conclusions
The foregoing presents a bold vision of the future. Some will view it as Orwellian, whilst others will see an opening of processes to scrutiny and service users that are currently restricted to government bodies. As the technology to support such innovation already exists, it is vital that debates start now surrounding the ethical, legal, and practical challenges [
77].
Effective use of structured tools to reach better decisions for children remains an elusive goal. Fundamental obstacles have been identified in this paper. The first relates to the tools themselves, the second to the way practitioners use them, and a third to appreciating the limits of prediction in an uncertain world. To date, only actuarial tools based on mathematically confirmed associations have been shown to enhance predictions; however, even in relation to these devices, practitioners prefer their own beliefs. This implies no lack of integrity, experience, or training, but an understandably deep human desire to spare the vulnerable from harm. Researchers also face challenges collecting sufficient data from relevant populations to build levels of accuracy upon which professionals can depend.
Big data technology operating within UK social work remains in its infancy, with recent reports of disappointing predictive accuracy [
78]. Two points, often overlooked, deserve emphasis, however. Even inaccurate predictions should be compared against those created by our existing methods—usually unaided human judgments [
5]. Moreover, as this paper has illustrated, events that involve human behaviour are inherently less predictable than society wants them to be. Although it has much ground to cover, big data technology can theoretically maximise predictive accuracy, whilst also minimising demands on practitioners by automatically making the best sense of data drawn from multiple sources.
Big data cannot, however, persuade practitioners to accept and embrace statistical prediction in the manner intended by the creators of actuarial tools. This issue may be addressed in part through educating professionals and the public alike of the benefits and limitations, whilst also ensuring algorithms offer not just a score, but an intelligible analysis of the factors and weights that contributed to it. However, real progress demands more.
Human discretion in the use of algorithms will always be required, but the most important point of all may be that this should not be the preserve of one practitioner or professional body—an arrangement that appears to be the only one addressed in research to date. Genuine overrides will always be required, but whether they would be used as often in relation to black prisoners who fully understood, and could also challenge, the processes and scores that led to their incarceration, demands research. A world in which referrers know risk scores before talking to call handlers could introduce a very different landscape and fruitful discussions. Care proceedings are conducted within an adversarial arena in the UK in which all parties enjoy representation from lawyers, and children from independent guardians. The use of a tool is as important as evidence itself. Understanding the information that feeds it will be essential to challenge deficiencies or biases in the information that created it, whilst decisions to modify or discard scientific relationships should be scrutinised, shared, and independently adjudicated if necessary. Such a vision of the future requires accurate devices that are inherently simple, shared and widely understood. Despite societal fears, transparency of judicial decisions may be the greatest contribution big data can make.


{kind=link}
{kind=link}
{kind=link}


