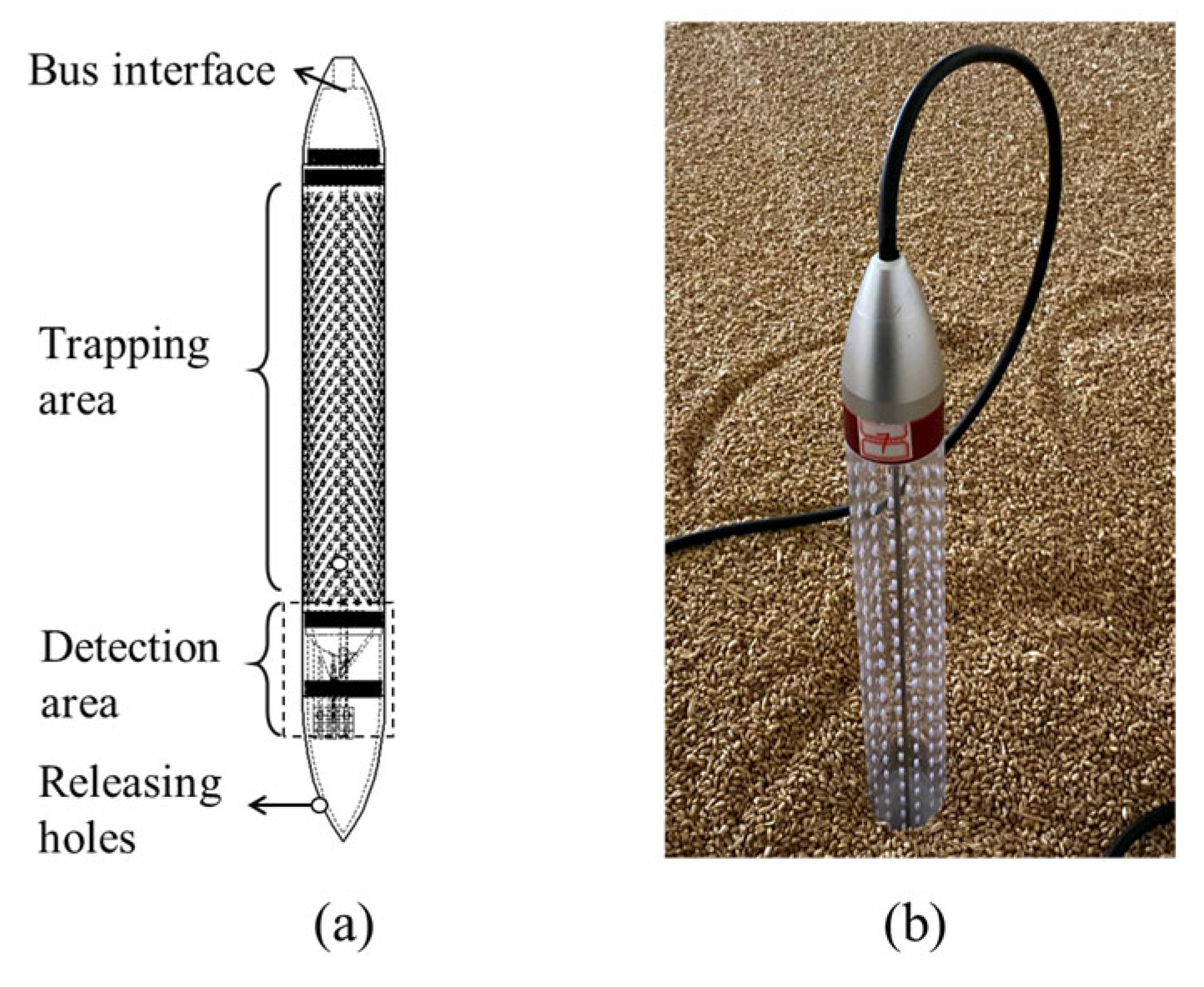
2.5. Data Analysis
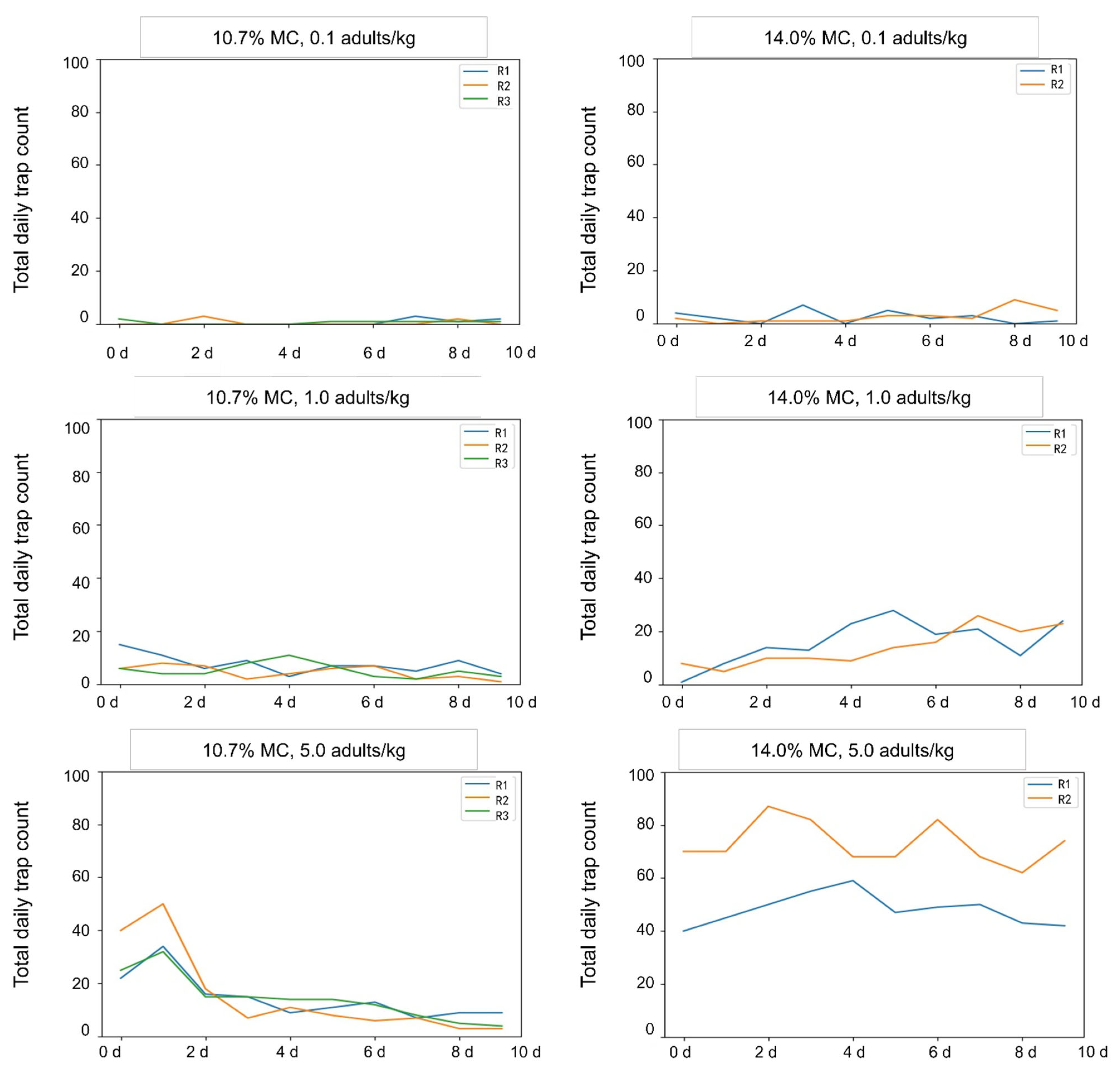
We evaluated detection success of the electronic probe trap by calculating the average number of traps that detected beetles each day and the average total daily trap counts in each bin. We evaluated detection success of manual sampling by counting the number of samples in which beetles were detected and the number of detected beetles in each bin. For each replicate, we took 15 samples according to the manual sampling method. We drew the curves of the total daily trap counts for each replicate under different insect densities to demonstrate the time distribution characteristics of trap counts.
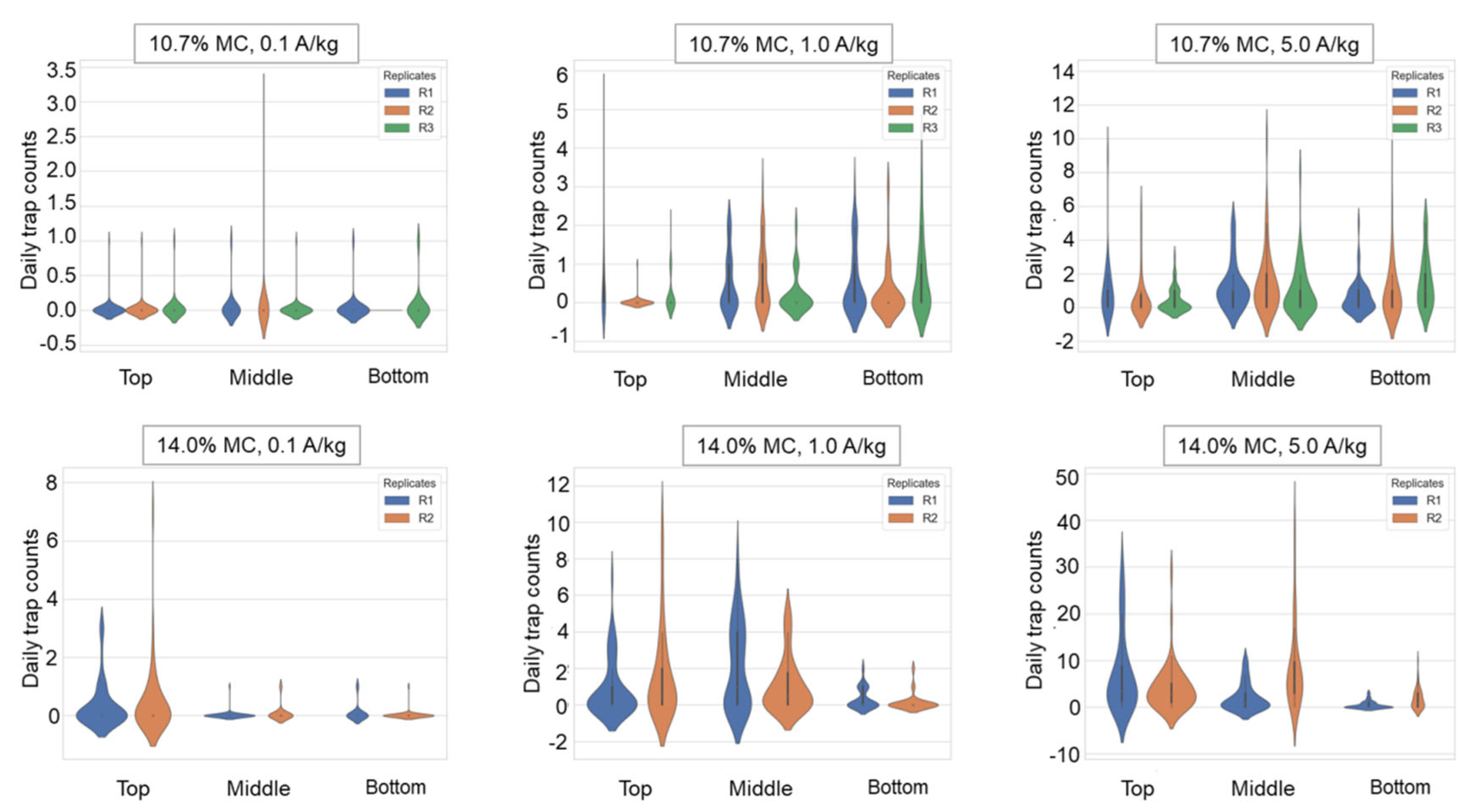
To determine where the beetles had been captured inside the bin, we calculated the percentage of capture at different layers (CP
L) for each replicate, as follows:
where CP
L is the capture percentage at the specified layer (%), CL is the total trap counts in the 10-day trapping period from all of the traps in the specified layer L, and T is the total trap counts from all of the traps in the bin. For each replicate, we individually calculated the CP
L at the top, middle, and bottom layers.
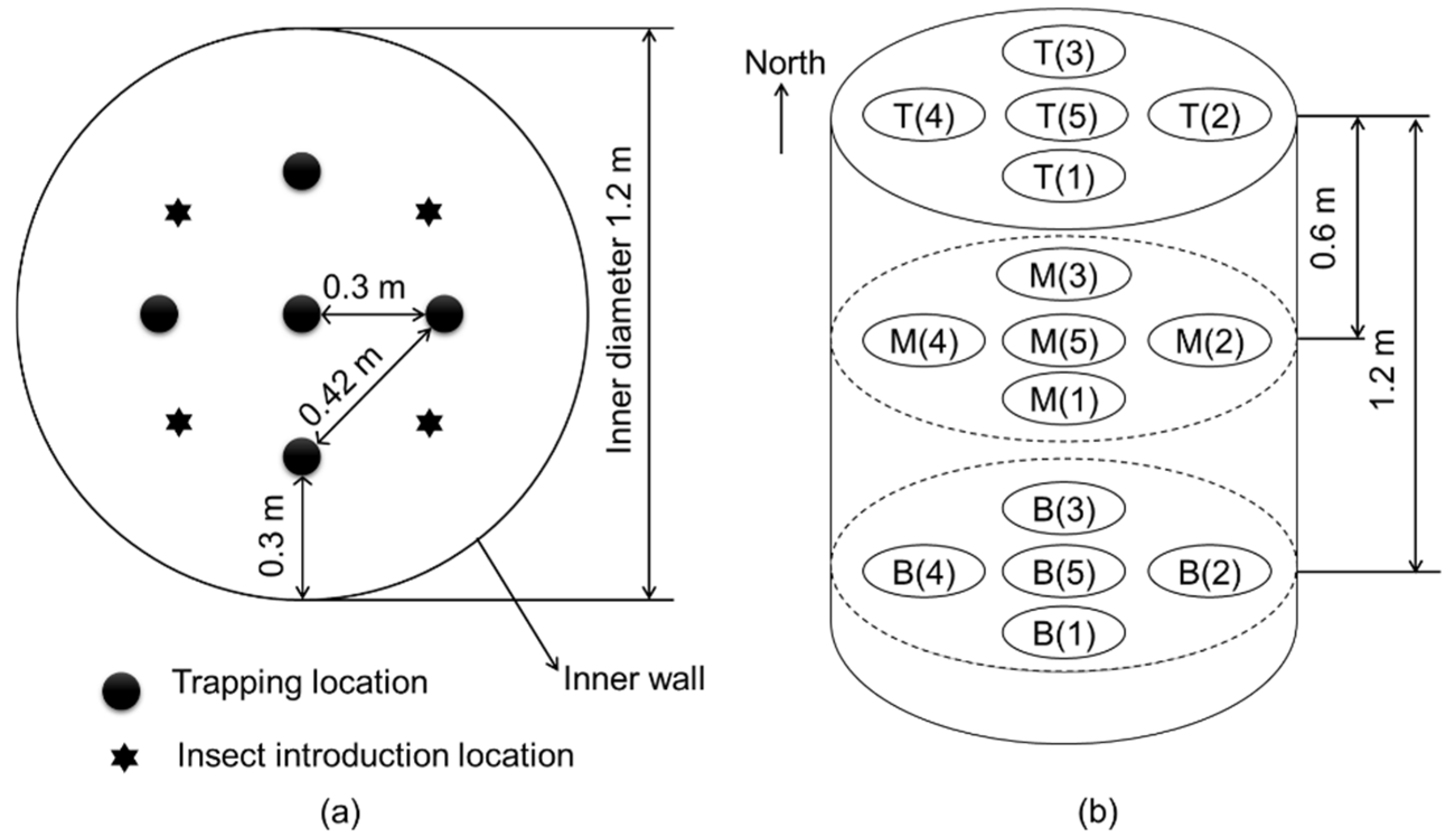
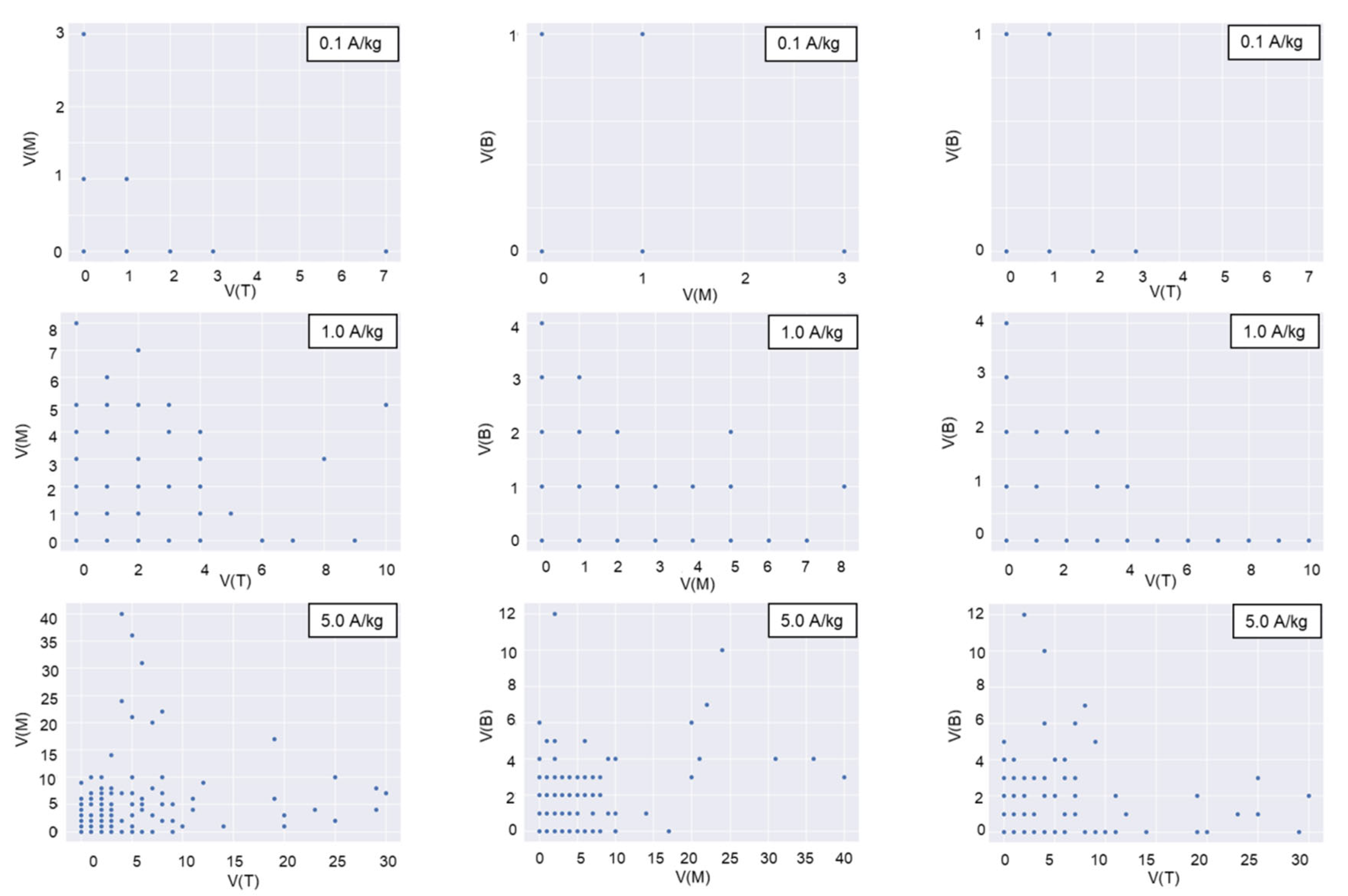
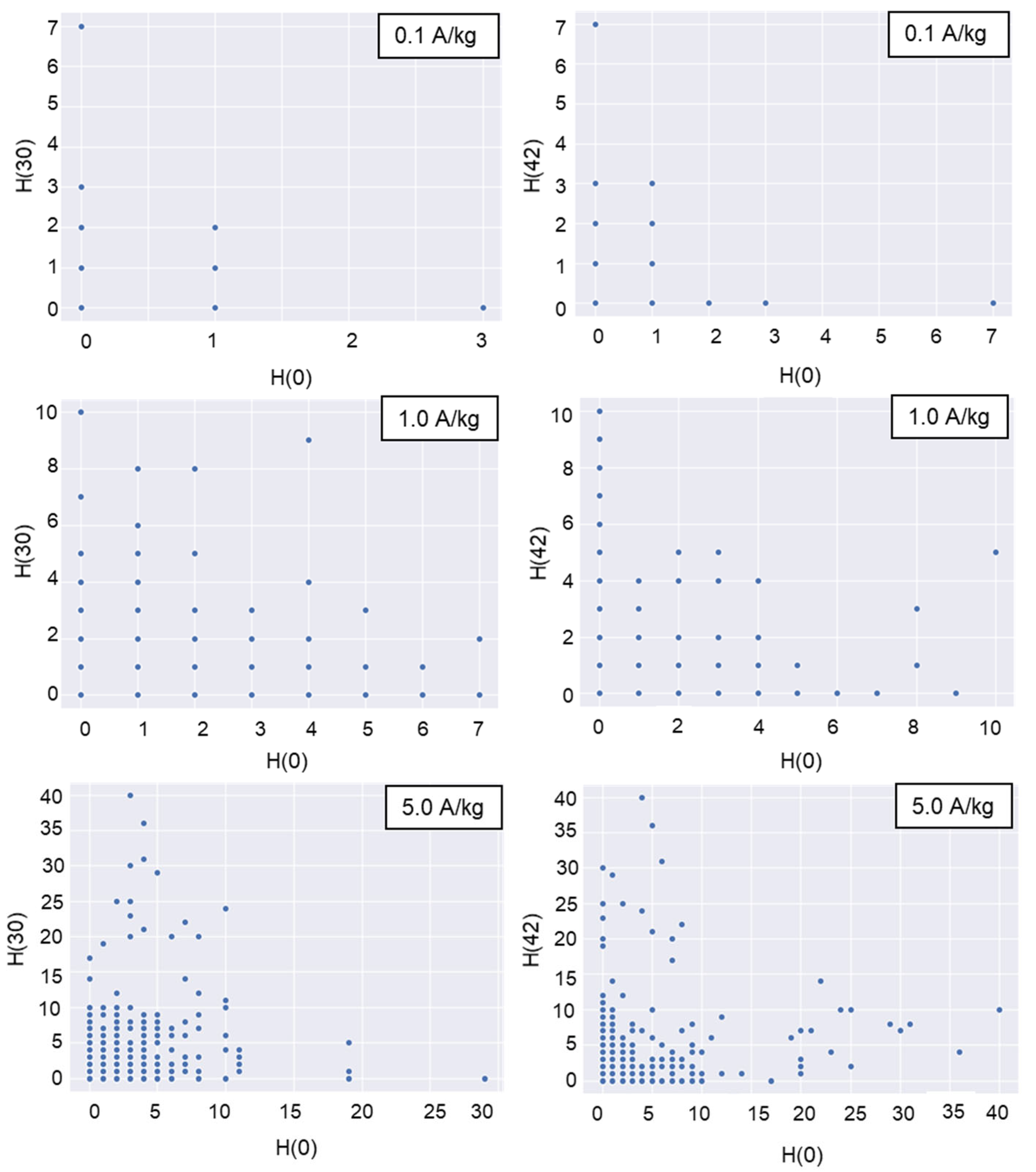
Violin plots were drawn for the daily trap counts from each trap deployed in the top, middle, and bottom layers to analyze the spatial distribution of daily trap counts. The geostatistical method of Jian et al. (2011) [
3] was used. The correlation coefficient for the following pairs of daily trap counts was calculated as follows: [H(0), H(30)], [H(0), H(42)], [V(T), V(M)], [V(M), V(B)], [V(T), V(B)], [V(0), V(60)], and [V(0), V(120)]. H is the number of daily trap counts in the horizontal direction, and V is the number of daily trap counts in the vertical direction at the trap location. The first bracket denotes the number of the start location, and the second bracket specifies the distance between the start trap and the second trap location in the indicated direction [
3]. For instance, [H(0), H(30)] indicates that data at location H(0) were joined with data 30 cm away in the horizontal direction. A 30 cm distance horizontal direction existed between the center and the half-radius. In this pair, H(0) indicated the trap count for that day at the center. A 42 cm distance in the horizontal direction existed between the two adjacent half-radii locations (
Figure 2). The top, middle, and bottom layers are indicated in the brackets by T, M, and B, respectively. For instance, [V(M), V(B)] compares the middle and bottom layer trap counts for the day in the vertical direction.
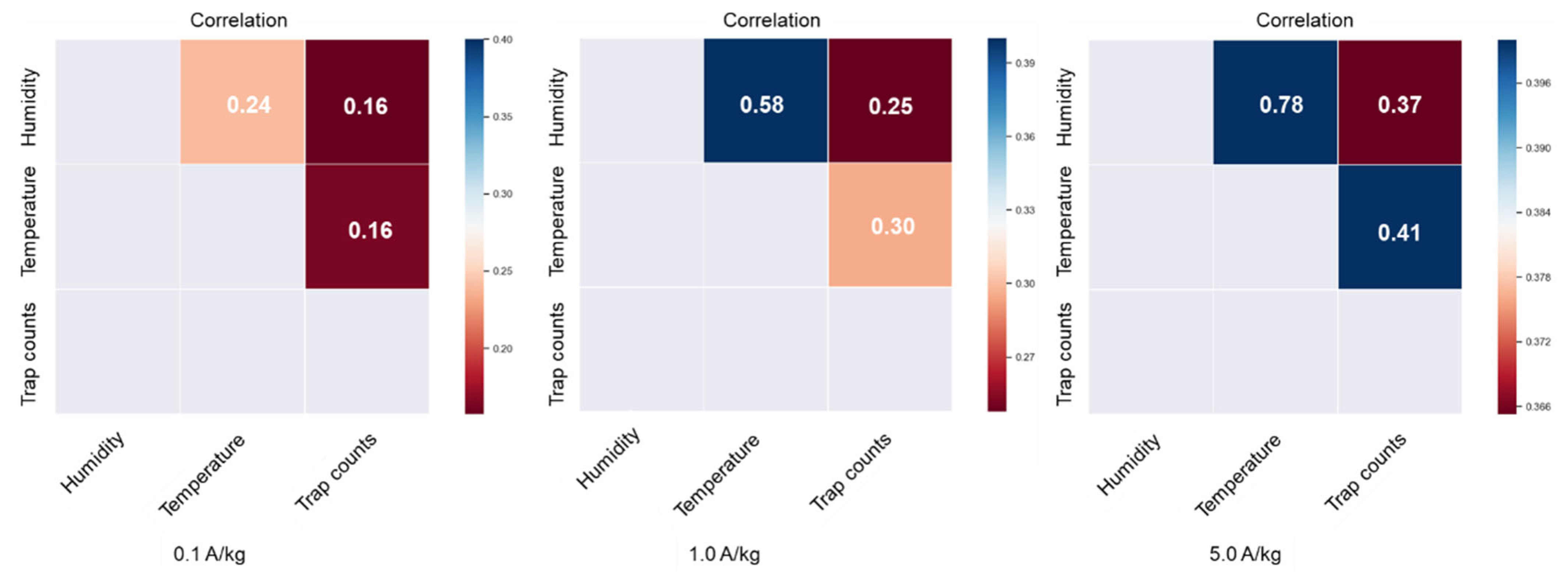
The significance of factors affecting trap counts was analyzed. A factorial test to analyze the effect of the following factors on daily trap counts was undertaken: insect density, grain temperature, MC, and humidity. Grain temperatures were grouped according to temperature intervals of 0–20 °C, 20–25 °C, 25–30 °C, and 30–40 °C, and according to humidity intervals of 0–50%, 50–60%, 60–70%, and 70–80% to examine whether the grain temperature and humidity had a significant effect on trap counts. Heat maps of the Pearson correlation coefficient between daily trap counts, grain temperature, and humidity obtained from each trap under different insect densities further illustrated correlations.
To characterize the aggregation distribution pattern of
C. pusillus adults in paddy bulks, we calculated Lloyd’s index of mean crowding [
17] and Taylor’s power law [
18] using trap counts. Trap count data from the 15 traps in each bin were used as the sample set for the calculation on sampling days. For each sample set, Lloyd’s index of mean crowding was calculated as follows:
where I
L is Lloyd’s index of mean crowding,
is the mean of the trap counts of the sample set, and s
2 is the variance. Then, we adopted the Iwao linear regression method [
19] to determine the index of basic contagion (b
0) (i.e., mean crowding of individuals) and the density–contagiousness coefficients (b
1), i.e., patchiness of clusters, from the regression models:
where b
0 denotes the size of the individual clumps that make up the basic unit of the spatial pattern. A value of b
0 = 0 indicates that an individual is the basic component, b
0 > 0 indicates that a colony is the basic component, and b
0 < 0 indicates the tendency for individual repulsion. A value of b
1 > 1 denotes a series of aggregated distributions, a value of b
1 = 1 denotes random distribution, and a value of b
1 < 1 denotes uniform distribution.
Taylor’s power law expressed in the logarithmic form [
3,
8] was used to fit the data, as follows:
where lna is the intercept and b is the slope or specific aggregation index. We used the value of b to categorize uniform, random, and aggregated spatial patterns of insect distribution based on b being <1, =1, and >1, respectively [
20].
The Pearson correlation coefficient was associated with insect densities. Frequencies of trap counts were calculated to find the relationship between insect densities and the frequencies (TF
D) at each location under different MC levels, as follows:
where TF
D is the average value of trap counts in the specified trapping period (A/day). We tested the trapping periods in the past 3, 5, 7, or 10 days to find the highest relationship between the insect densities and frequencies of trap counts. We also calculated the average values of the Pearson correlation coefficient associated with the introduced insect density and the TF
D at each location in the past 3, 5, 7, and 10 d. Then, we calculated the Pearson correlation coefficient between the TF
D with the highest coefficient and the insect density at each location.
A paired
t-test was adopted for the following data analysis. Data were analyzed with custom Python scripts (Version 3.5.2), primarily using Statsmodels (
https://github.com/statsmodels/statsmodels/, Version 0.13.3, accessed on 2 November 2022), Scipy (
https://scipy.org/, Version 1.8.0, accessed on 4 February 2022), Pandas (
https://pandas.pydata.org/, Version1.5.0, accessed on 3 October 2022), and Seaborn (
http://seaborn.pydata.org/, Version 0.12.0, accessed on 19 September 2022) packages.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}