

Best Practices for Comprehensive Annotation of Neuropeptides of Gryllus bimaculatus
 , , , ,
, , , ,
Simple Summary
Abstract
1. Introduction
2. Materials and Methods
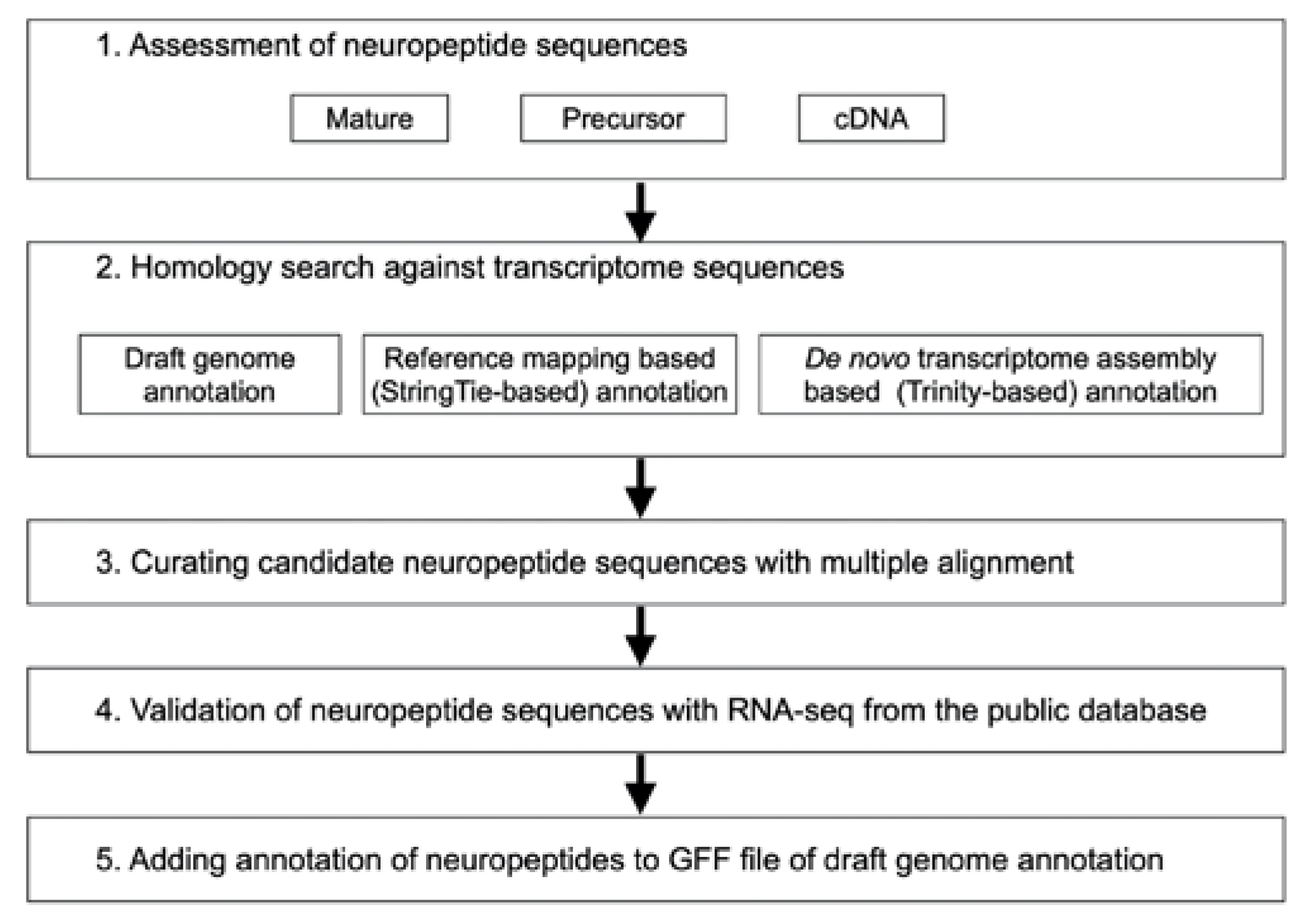
2.1. Overview of Identification Method for Neuropeptides
2.2. Identification of Seed Neuropeptide Sequences
2.3. RNA Sequencing Data
2.4. Construction of Transcript Datasets
2.5. Search for Neuropeptide-Related Loci
2.6. Validation of Neuropeptide Genomic Loci
2.7. Preparation for Data Release of New Neuropeptide Annotation
3. Results
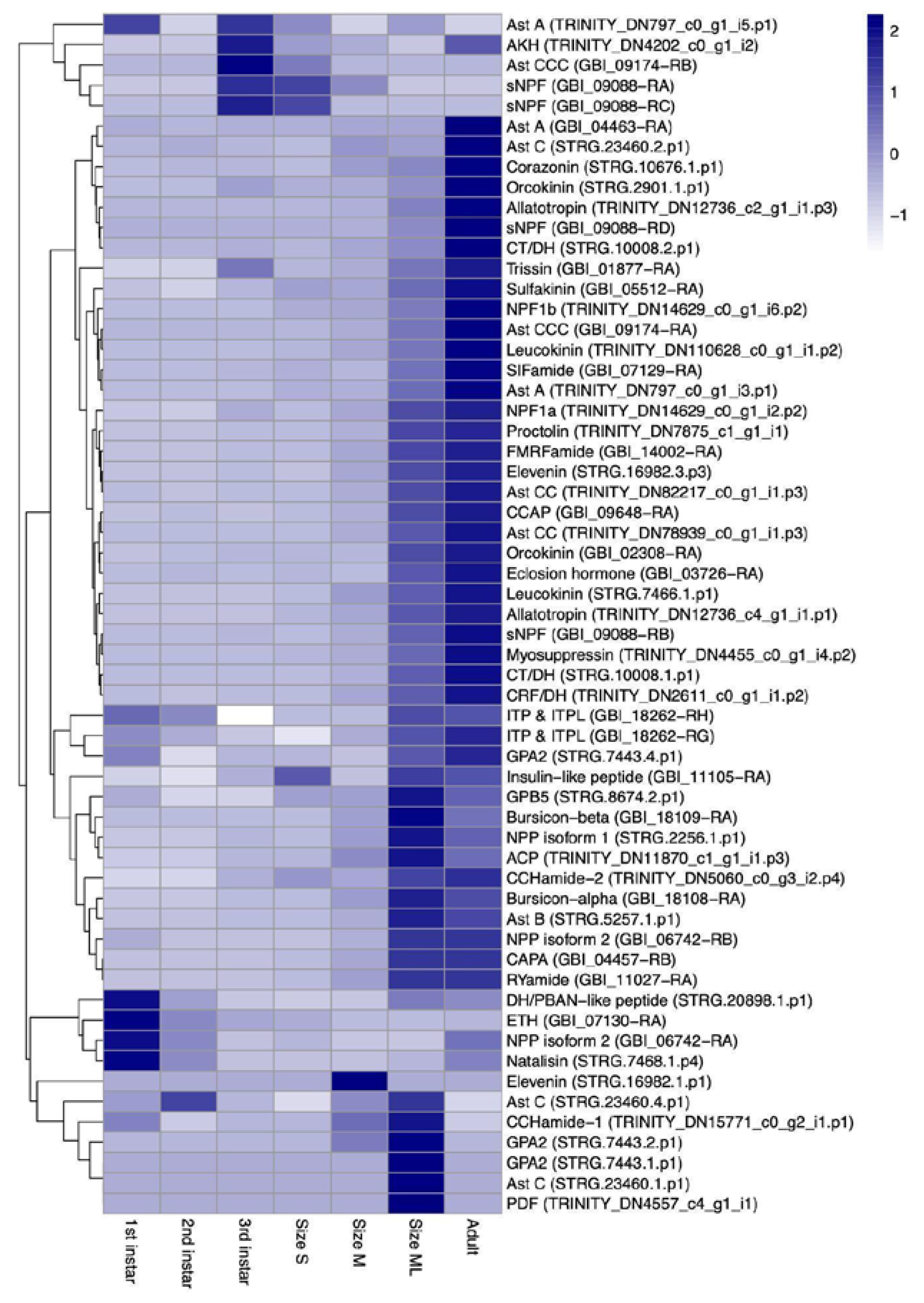
3.1. Neuropeptides Identification
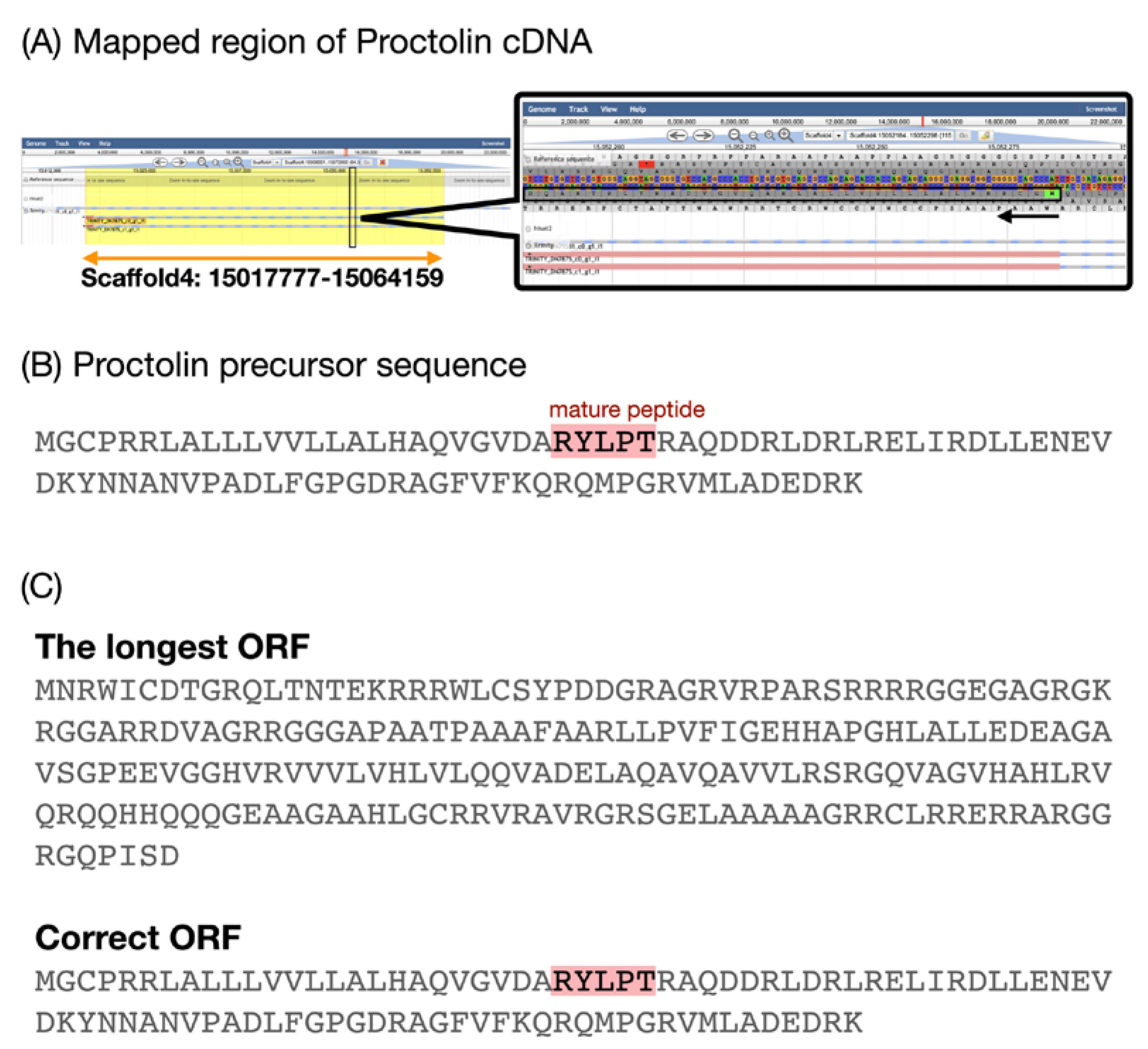
3.2. Validation of Curated Neuropeptides
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, J.-J.; Shi, Y.; Lin, G.-L.; Yang, C.-H.; Liu, T.-X. Genome-Wide Identification of Neuropeptides and Their Receptor Genes in Bemisia Tabaci and Their Transcript Accumulation Change in Response to Temperature Stresses. Insect Sci. 2021, 28, 35–46. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wang, M.; Yin, S.; Jang, R.; Wang, J.; Xue, Z.; Xu, T. NeuroPep: A Comprehensive Resource of Neuropeptides. Database 2015, 2015, bav038. [Google Scholar] [CrossRef]
- Xu, G.; Gu, G.-X.; Teng, Z.-W.; Wu, S.-F.; Huang, J.; Song, Q.-S.; Ye, G.-Y.; Fang, Q. Identification and Expression Profiles of Neuropeptides and Their G Protein-Coupled Receptors in the Rice Stem Borer Chilo Suppressalis. Sci. Rep. 2016, 6, 28976. [Google Scholar] [CrossRef] [PubMed]
- Hoyer, D.; Bartfai, T. Neuropeptides and Neuropeptide Receptors: Drug Targets, and Peptide and Non-Peptide Ligands: A Tribute to Prof. Dieter Seebach. Chem. Biodivers. 2012, 9, 2367–2387. [Google Scholar] [CrossRef] [PubMed]
- Fukumura, K.; Konuma, T.; Tsukamoto, Y.; Nagata, S. Adipokinetic Hormone Signaling Determines Dietary Fatty Acid Preference through Maintenance of Hemolymph Fatty Acid Composition in the Cricket Gryllus bimaculatus. Sci. Rep. 2018, 8, 4737. [Google Scholar] [CrossRef]
- Seike, H.; Nagata, S. Different Transcriptional Levels of Corazonin, Elevenin, and PDF According to the Body Color of the Two-Spotted Cricket Gryllus Bimaculatus. Biosci. Biotechnol. Biochem. 2021, 86, 23–30. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.J.; Fukumura, K.; Nagata, S. Effects of Adipokinetic Hormone and Its Related Peptide on Maintaining Hemolymph Carbohydrate and Lipid Levels in the Two-Spotted Cricket, Gryllus bimaculatus. Biosci. Biotechnol. Biochem. 2018, 82, 274–284. [Google Scholar] [CrossRef]
- Zhu, Z.; Tsuchimoto, M.; Nagata, S. CCHamide-2 Signaling Regulates Food Intake and Metabolism in Gryllus bimaculatus. Insects 2022, 13, 324. [Google Scholar] [CrossRef]
- Ylla, G.; Nakamura, T.; Itoh, T.; Kajitani, R.; Toyoda, A.; Tomonari, S.; Bando, T.; Ishimaru, Y.; Watanabe, T.; Fuketa, M.; et al. Insights into the Genomic Evolution of Insects from Cricket Genomes. Commun. Biol. 2021, 4, 733. [Google Scholar] [CrossRef]
- Meyering-Vos, M.; Wu, X.; Huang, J.; Jindra, M.; Hoffmann, K.H.; Sehnal, F. The Allatostatin Gene of the Cricket Gryllus bimaculatus (Ensifera, Gryllidae). Mol. Cell. Endocrinol. 2001, 184, 103–114. [Google Scholar] [CrossRef]
- Wang, J.; Meyering-Vos, M.; Hoffmann, K.H. Cloning and Tissue-Specific Localization of Cricket-Type Allatostatins from Gryllus bimaculatus. Mol. Cell. Endocrinol. 2004, 227, 41–51. [Google Scholar] [CrossRef] [PubMed]
- Tsukamoto, Y.; Nagata, S. Newly Identified Allatostatin Bs and Their Receptor in the Two-Spotted Cricket, Gryllus bimaculatus. Peptides 2016, 80, 25–31. [Google Scholar] [CrossRef]
- Zhou, Y.J.; Seike, H.; Nagata, S. Function of Myosuppressin in Regulating Digestive Function in the Two-Spotted Cricket, Gryllus bimaculatus. Gen. Comp. Endocrinol. 2019, 280, 185–191. [Google Scholar] [CrossRef] [PubMed]
- Chuman, Y.; Matsushima, A.; Sato, S.; Tomioka, K.; Tominaga, Y.; Meinertzhagen, I.A.; Shimohigashi, Y.; Shimohigashi, M. CDNA Cloning and Nuclear Localization of the Circadian Neuropeptide Designated as Pigment-Dispersing Factor PDF in the Cricket Gryllus bimaculatus. J. Biochem. 2002, 131, 895–903. [Google Scholar] [CrossRef]
- Meyering-Vos, M.; Müller, A. Structure of the Sulfakinin CDNA and Gene Expression from the Mediterranean Field Cricket Gryllus bimaculatus. Insect Mol. Biol. 2007, 16, 445–454. [Google Scholar] [CrossRef] [PubMed]
- Veenstra, J.A. Two Lys-Vasopressin-like Peptides, EFLamide, and Other Phasmid Neuropeptides. Gen. Comp. Endocrinol. 2019, 278, 3–11. [Google Scholar] [CrossRef]
- Hou, L.; Jiang, F.; Yang, P.; Wang, X.; Kang, L. Molecular Characterization and Expression Profiles of Neuropeptide Precursors in the Migratory Locust. Insect Biochem. Mol. Biol. 2015, 63, 63–71. [Google Scholar] [CrossRef]
- Clynen, E.; Huybrechts, J.; Verleyen, P.; De Loof, A.; Schoofs, L. Annotation of Novel Neuropeptide Precursors in the Migratory Locust Based on Transcript Screening of a Public EST Database and Mass Spectrometry. BMC Genom. 2006, 7, 201. [Google Scholar] [CrossRef] [PubMed]
- Lagueux, M.; Kromer, E.; Girardie, J. Cloning of a Locusta cDNA Encoding Neuroparsin A. Insect Biochem. Mol. Biol. 1992, 22, 511–516. [Google Scholar] [CrossRef]
- Pauls, D.; Chen, J.; Reiher, W.; Vanselow, J.T.; Schlosser, A.; Kahnt, J.; Wegener, C. Peptidomics and Processing of Regulatory Peptides in the Fruit Fly Drosophila. EuPA Open Proteom. 2014, 3, 114–127. [Google Scholar] [CrossRef]
- Baggerman, G.; Boonen, K.; Verleyen, P.; De Loof, A.; Schoofs, L. Peptidomic Analysis of the Larval Drosophila melanogaster Central Nervous System by Two-Dimensional Capillary Liquid Chromatography Quadrupole Time-of-Flight Mass Spectrometry. J. Mass Spectrom. 2005, 40, 250–260. [Google Scholar] [CrossRef] [PubMed]
- Simonet, G.; Claeys, I.; Vanderperren, H.; November, T.; De Loof, A.; Vanden Broeck, J. cDNA Cloning of Two Different Serine Protease Inhibitor Precursors in the Migratory Locust, Locusta migratoria. Insect Mol. Biol. 2002, 11, 249–256. [Google Scholar] [CrossRef] [PubMed]
- Roller, L.; Yamanaka, N.; Watanabe, K.; Daubnerová, I.; Zitnan, D.; Kataoka, H.; Tanaka, Y. The Unique Evolution of Neuropeptide Genes in the Silkworm Bombyx mori. Insect Biochem. Mol. Biol. 2008, 38, 1147–1157. [Google Scholar] [CrossRef]
- Camacho, C.; Coulouris, G.; Avagyan, V.; Ma, N.; Papadopoulos, J.; Bealer, K.; Madden, T.L. BLAST+: Architecture and Applications. BMC Bioinform. 2009, 10, 421. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Zhou, Y.; Chen, Y.; Gu, J. Fastp: An Ultra-Fast All-in-One FASTQ Preprocessor. Bioinformatics 2018, 34, i884–i890. [Google Scholar] [CrossRef] [PubMed]
- Kim, D.; Langmead, B.; Salzberg, S.L. HISAT: A Fast Spliced Aligner with Low Memory Requirements. Nat. Methods 2015, 12, 357–360. [Google Scholar] [CrossRef] [PubMed]
- Pertea, M.; Pertea, G.M.; Antonescu, C.M.; Chang, T.-C.; Mendell, J.T.; Salzberg, S.L. StringTie Enables Improved Reconstruction of a Transcriptome from RNA-Seq Reads. Nat. Biotechnol. 2015, 33, 290–295. [Google Scholar] [CrossRef]
- Haas, B.J.; Papanicolaou, A.; Yassour, M.; Grabherr, M.; Blood, P.D.; Bowden, J.; Couger, M.B.; Eccles, D.; Li, B.; Lieber, M.; et al. De Novo Transcript Sequence Reconstruction from RNA-Seq Using the Trinity Platform for Reference Generation and Analysis. Nat. Protoc. 2013, 8, 1494–1512. [Google Scholar] [CrossRef]
- Mistry, J.; Chuguransky, S.; Williams, L.; Qureshi, M.; Salazar, G.A.; Sonnhammer, E.L.L.; Tosatto, S.C.E.; Paladin, L.; Raj, S.; Richardson, L.J.; et al. Pfam: The Protein Families Database in 2021. Nucleic Acids Res. 2021, 49, D412–D419. [Google Scholar] [CrossRef] [PubMed]
- Grabherr, M.G.; Haas, B.J.; Yassour, M.; Levin, J.Z.; Thompson, D.A.; Amit, I.; Adiconis, X.; Fan, L.; Raychowdhury, R.; Zeng, Q.; et al. Full-Length Transcriptome Assembly from RNA-Seq Data without a Reference Genome. Nat. Biotechnol. 2011, 29, 644–652. [Google Scholar] [CrossRef]
- Danecek, P.; Bonfield, J.K.; Liddle, J.; Marshall, J.; Ohan, V.; Pollard, M.O.; Whitwham, A.; Keane, T.; McCarthy, S.A.; Davies, R.M.; et al. Twelve Years of SAMtools and BCFtools. Gigascience 2021, 10, giab008. [Google Scholar] [CrossRef]
- Pertea, G.; Pertea, M. GFF Utilities: GffRead and GFFCompare. F1000Research 2020, 9, 304. [Google Scholar] [CrossRef]
- Matsumoto, S.; Kutsuna, N.; Daubnerová, I.; Roller, L.; Žitňan, D.; Nagasawa, H.; Nagata, S. Enteroendocrine Peptides Regulate Feeding Behavior via Controlling Intestinal Contraction of the Silkworm Bombyx mori. PLoS One 2019, 14, e0219050. [Google Scholar] [CrossRef] [PubMed]
- Katoh, K.; Standley, D.M. MAFFT Multiple Sequence Alignment Software Version 7: Improvements in Performance and Usability. Mol. Biol. Evol. 2013, 30, 772–780. [Google Scholar] [CrossRef] [PubMed]
- Shen, W.; Le, S.; Li, Y.; Hu, F. SeqKit: A Cross-Platform and Ultrafast Toolkit for FASTA/Q File Manipulation. PLoS One 2016, 11, e0163962. [Google Scholar] [CrossRef]
- Buels, R.; Yao, E.; Diesh, C.M.; Hayes, R.D.; Munoz-Torres, M.; Helt, G.; Goodstein, D.M.; Elsik, C.G.; Lewis, S.E.; Stein, L.; et al. JBrowse: A Dynamic Web Platform for Genome Visualization and Analysis. Genome Biol. 2016, 17, 66. [Google Scholar] [CrossRef]
- Kono, N.; Nakamura, H.; Ohtoshi, R.; Arakawa, K. Transcriptomic Data during Development of a Two-Spotted Cricket Gryllus Bimaculatus. Data Brief 2021, 38, 107388. [Google Scholar] [CrossRef]
- Bray, N.L.; Pimentel, H.; Melsted, P.; Pachter, L. Near-Optimal Probabilistic RNA-Seq Quantification. Nat. Biotechnol. 2016, 34, 525–527. [Google Scholar] [CrossRef]
- Gentleman, R.; Carey, V.; Huber, W.; Hahne, F. Genefilter: Methods for Filtering Genes from High-Throughput Experiments, Version 1.64.0; R Package, 2018.
- Kolde, R. Pheatmap: Pretty Heatmaps, R Package Version 1.0.12; 2019. Available online: https://CRAN.R-project.org/package=pheatmap (accessed on 4 January 2019).
- Wu, T.D.; Reeder, J.; Lawrence, M.; Becker, G.; Brauer, M.J. GMAP and GSNAP for Genomic Sequence Alignment: Enhancements to Speed, Accuracy, and Functionality. Methods Mol. Biol. 2016, 1418, 283–334. [Google Scholar]
- Tanaka, Y.; Suetsugu, Y.; Yamamoto, K.; Noda, H.; Shinoda, T. Transcriptome Analysis of Neuropeptides and G-Protein Coupled Receptors (GPCRs) for Neuropeptides in the Brown Planthopper Nilaparvata Lugens. Pept. 2014, 53, 125–133. [Google Scholar] [CrossRef]
- Hewes, R.S.; Taghert, P.H. Neuropeptides and Neuropeptide Receptors in the Drosophila melanogaster Genome. Genome Res. 2001, 11, 1126–1142. [Google Scholar] [CrossRef] [PubMed]
- Vanden Broeck, J. Neuropeptides and Their Precursors in the Fruitfly, Drosophila melanogaster. Peptides 2001, 22, 241–254. [Google Scholar] [CrossRef] [PubMed]
- Dircksen, H. Insect Ion Transport Peptides Are Derived from Alternatively Spliced Genes and Differentially Expressed in the Central and Peripheral Nervous System. J. Exp. Biol. 2009, 212, 401–412. [Google Scholar] [CrossRef]
- Elphick, M.R.; Mirabeau, O.; Larhammar, D. Evolution of Neuropeptide Signalling Systems. J. Exp. Biol. 2018, 221, jeb151092. [Google Scholar] [CrossRef]
- Veenstra, J.A.; Šimo, L. The TRH-Ortholog EFLamide in the Migratory Locust. Insect Biochem. Mol. Biol. 2020, 116, 103281. [Google Scholar] [CrossRef] [PubMed]
- Nagai-Okatani, C.; Nagasawa, H.; Nagata, S. Tachykinin-Related Peptides Share a G Protein-Coupled Receptor with Ion Transport Peptide-Like in the Silkworm Bombyx mori. PLoS One 2016, 11, e0156501. [Google Scholar] [CrossRef]
- Kotwica-Rolinska, J.; Krištofová, L.; Chvalová, D.; Pauchová, L.; Provazník, J.; Hejníková, M.; Sehadová, H.; Lichý, M.; Vaněčková, H.; Doležel, D. Functional Analysis and Localisation of a Thyrotropin-Releasing Hormone-Type Neuropeptide (EFLa) in Hemipteran Insects. Insect Biochem. Mol. Biol. 2020, 122, 103376. [Google Scholar] [CrossRef]
- Zandawala, M.; Paluzzi, J.-P.; Orchard, I. Isolation and Characterization of the CDNA Encoding DH31 in the Kissing Bug, Rhodnius prolixus. Mol. Cell. Endocrinol. 2011, 331, 79–88. [Google Scholar] [CrossRef] [PubMed]
- Horodyski, F.M.; Bhatt, S.R.; Lee, K.-Y. Alternative Splicing of Transcripts Expressed by the Manduca Sexta Allatotropin (Mas-AT) Gene Is Regulated in a Tissue-Specific Manner. Peptides 2001, 22, 263–269. [Google Scholar] [CrossRef] [PubMed]
- Nagata, S.; Matsumoto, S.; Mizoguchi, A.; Nagasawa, H. Identification of CDNAs Encoding Allatotropin and Allatotropin-like Peptides from the Silkworm, Bombyx mori. Peptides 2012, 34, 98–105. [Google Scholar] [CrossRef]
- Yeoh, J.G.C.; Pandit, A.A.; Zandawala, M.; Nässel, D.R.; Davies, S.-A.; Dow, J.A.T. DINeR: Database for Insect Neuropeptide Research. Insect Biochem. Mol. Biol. 2017, 86, 9–19. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Neuropeptides | ID | Locus | D. melanogaster | B. mori | Method (1) |
|---|---|---|---|---|---|
| Adipokinetic hormone (AKH) | GBI_30800-RA (TRINITY_DN4202_c0_g1_i2) | Scaffold206: 697999…707834 (+) | + | + | T |
| AKH/Corazonin-related peptide (ACP) | GBI_32000-RA (TRINITY_DN11870_c1_g1_i1.p3) | − | − | + | T |
| Allatostatin A (Ast A) | GBI_32100-RA (TRINITY_DN797_c0_g1_i3.p1), GBI_32200-RA (TRINITY_DN797_c0_g1_i5.p1) GBI_04463-RA | GBI_04463-RA (2) Scaffold20: 11377336…11377923 (−) | + | + | D,T |
| Allatostatin B (Ast B) | GBI_04462-RB (STRG.5257.1.p1) | Scaffold20: 10912781…10975738 (−) | + | + | S |
| Allatostatin C (Ast C) | GBI_31000-RA (STRG.23460.1.p1), GBI_31000-RB (STRG.23460.2.p1), GBI_31000-RC (STRG.23460.4.p1) | Scaffold437: 197807…241684 (−) | + | + | S |
| Allatostatin CC (Ast CC) | GBI_32300-RA (TRINITY_DN78939_c0_g1_i1.p3), GBI_32400-RA (TRINITY_DN82217_c0_g1_i1.p3) | − | + | + | T |
| Allatostatin CCC (Ast CCC) | GBI_09174-RA, GBI_09174-RB | Scaffold60: 395418…593331 (+) | − | − | D |
| Allatotropin | GBI_32500-RA (TRINITY_DN12736_c4_g1_i1.p1), GBI_32600-RA (TRINITY_DN12736_c2_g1_i1.p3) | − | − | + | T |
| Bursicon-alpha | GBI_18108-RA | Scaffold254: 577937…579923 (−) | + | + | D |
| Bursicon-beta | GBI_18109-RA | Scaffold254: 587165…588284 (+) | + | + | D |
| CAPA | GBI_04457-RB | Scaffold20: 9936553…9977407 (+) | + | + | D |
| Corazonin | GBI_30500-RA (STRG.10676.1.p1) | Scaffold62: 3436728…3448223 (−) | + | + | S |
| Crustacean cardioactive peptide (CCAP) | GBI_09648-RA | Scaffold65: 3361094…3402145 (+) | + | + | D |
| CCHamide-1 | GBI_32700-RA (TRINITY_DN15771_c0_g2_i1.p1) | − | + | + | T |
| CCHamide-2 | GBI_32800-RA (TRINITY_DN5060_c0_g3_i2.p4) | − | + | + | T |
| Diapause hormone (DH/PBAN-like peptide) | GBI_30900-RA (STRG.20898.1.p1) | Scaffold262: 1299901…1301218 (+) | + | + | S |
| Diuretic hormone 31 (CT/DH) | GBI_08745-RB (STRG.10008.1.p1), GBI_08745-RC (STRG.10008.2.p1) | Scaffold56: 1634530…1842684 (+) | + | + | S |
| Corticotropin releasing factor-like diuretic hormone (CRF/DH) | GBI_32900-RA (TRINITY_DN2611_c0_g1_i1.p2) | − | + | + | T |
| Ecdysis triggering hormone (ETH) | GBI_07130-RA | Scaffold39: 4483375…4511070 (+) | + | + | D |
| Eclosion hormone | GBI_03726-RA | Scaffold15: 14005275…14019193 (+) | + | + | D |
| Elevenin | GBI_30700-RA (STRG.16982.1.p1), GBI_30700-RB (STRG.16982.2.p3), GBI_30700-RC (STRG.16982.3.p3) | Scaffold153: 2142142…2267228 (+) | − | + | S |
| EFLamide | − | − | − | − | |
| FMRFamide | GBI_14002-RA | Scaffold134: 2784690…2789881 (−) | + | + | D |
| Glycoprotein hormone A2 (GPA2) | GBI_30100-RA (STRG.7443.1.p1), GBI_30100-RB (STRG.7443.2.p1), GBI_30100-RC (STRG.7443.4.p1) | Scaffold34: 5739999…5757709 (−) | + | + | S |
| Glycoprotein hormone B5 (GPB5) | GBI_30400-RA (STRG.8674.2.p1) | Scaffold43: 6774211…6779917 (−) | + | + | S |
| Insulin-like peptide | GBI_11105-RA | Scaffold84: 3089694…3140894 (−) | + | + | D |
| Ion transport peptide and ion transport peptide-like (ITP and ITPL) | GBI_18262-RG, GBI_18262-RH | Scaffold259: 893509…930810 (−) | + | + | D |
| Kinin (Leucokinin) | GBI_30200-RA (STRG.7466.1.p1), GBI_33200-RA (TRINITY_DN110628_c0_g1_i1.p2) | GBI_30200-RA) (3) Scaffold34: 8543640…8544062 (−) | + | + | S,T |
| Myosuppressin | GBI_33000-RA (TRINITY_DN4455_c0_g1_i4.p2) | − | + | + | T |
| Natalisin | GBI_30300-RA (STRG.7468.1.p4) | Scaffold34: 8647546…8652008 (−) | + | + | T |
| Neuropeptide F1a (NPF1a) | GBI_33300-RA (TRINITY_DN14629_c0_g1_i2.p2) | − | + | + | − |
| Neuropeptide F1b (NPF1b) | GBI_33100-RA (TRINITY_DN14629_c0_g1_i6.p2) | − | + | + | T |
| Neuroparsin precursor (NPP) isoform 1 | GBI_01783-RB (STRG.2256.1.p1) | Scaffold7: 15634784…15638238 (+) | − | + | S |
| Neuroparsin precursor (NPP) isoform 2 | GBI_06742-RA, GBI_06742-RB | Scaffold35: 7759086…7774792 (+) | − | + | D |
| Orcokinin | GBI_02308-RA, GBI_02308-RB (STRG.2901.1.p1) | Scaffold9: 16015120…16184531 (−) | + | + | D, S |
| Pigment dispersing factor (PDF) | GBI_30600-RA (TRINITY_DN4557_c4_g1_i1) | Scaffold130: 1613008…1616041 (−) | + | + | T |
| Proctolin | GBI_30000-RA (TRINITY_DN7875_c1_g1_i1) | Scaffold4: 15016980…15064115 (−) | + | + | T |
| RYamide | GBI_11027-RA | Scaffold83: 5210571…5235250 (−) | + | + | D |
| Short neuropeptide F (sNPF) | GBI_09088-RA, GBI_09088-RB, GBI_09088-RC, GBI_09088-RD | Scaffold59: 3780407…4100907 (+) | + | + | D |
| SIFamide | GBI_07129-RA | Scaffold39: 4382305…4384876 (+) | + | + | D |
| Sulfakinin | GBI_05512-RA | Scaffold28: 3070275…3081238 (−) | + | + | D |
| Tachykinin | − | − | + | + | − |
| Trissin | GBI_01877-RA, GBI_01877-RB | Scaffold8: 2096488…2133885 (−) | + | + | D |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mochizuki, T.; Sakamoto, M.; Tanizawa, Y.; Seike, H.; Zhu, Z.; Zhou, Y.J.; Fukumura, K.; Nagata, S.; Nakamura, Y. Best Practices for Comprehensive Annotation of Neuropeptides of Gryllus bimaculatus. Insects 2023, 14, 121. https://doi.org/10.3390/insects14020121
Mochizuki T, Sakamoto M, Tanizawa Y, Seike H, Zhu Z, Zhou YJ, Fukumura K, Nagata S, Nakamura Y. Best Practices for Comprehensive Annotation of Neuropeptides of Gryllus bimaculatus. Insects. 2023; 14(2):121. https://doi.org/10.3390/insects14020121
Chicago/Turabian StyleMochizuki, Takako, Mika Sakamoto, Yasuhiro Tanizawa, Hitomi Seike, Zhen Zhu, Yi Jun Zhou, Keisuke Fukumura, Shinji Nagata, and Yasukazu Nakamura. 2023. "Best Practices for Comprehensive Annotation of Neuropeptides of Gryllus bimaculatus" Insects 14, no. 2: 121. https://doi.org/10.3390/insects14020121
APA StyleMochizuki, T., Sakamoto, M., Tanizawa, Y., Seike, H., Zhu, Z., Zhou, Y. J., Fukumura, K., Nagata, S., & Nakamura, Y. (2023). Best Practices for Comprehensive Annotation of Neuropeptides of Gryllus bimaculatus. Insects, 14(2), 121. https://doi.org/10.3390/insects14020121