1. Introduction
A collaborative effort between researchers and industry experts is actively involved in improving the characteristics of vegetable-based lubricants to make them sustainable cutting fluids. Additive technology and the chemical modification of vegetable oils are some methods being explored to enhance their tribological properties and overall performance. With ongoing research and development, vegetable-based lubricants will likely improve performance and eventually replace mineral-based cutting fluids in various applications [
1,
2]. Cutting fluid dissipates the heat generated in the metal cutting process and also minimizes friction between the tool–work interface, allowing smoother and more efficient cutting. Mineral-based metal cutting fluids have less lubricity compared to vegetable oils. However, they are toxic, non-biodegradable, and detrimental to human beings [
2,
3,
4,
5].
Researchers are exploring trimethylolpropane trioleate (TMPTO) as a potential environmentally friendly lubricant additive and its efficacy under different working conditions. TMPTO is likely being evaluated as a potential bio-lubricant due to its low toxicity and excellent biodegradability, which are important properties for reducing the environmental impact of lubricants [
6,
7]. Adding chemically sulfurized vegetable oil-based additives enhances the lubricating properties of TMPTO base oil [
8]. Sulfurized vegetable oil-based additives are known to have excellent antiwear and extreme pressure (EP) properties. They can form a protective film on metal surfaces, reducing friction and wear under high-pressure conditions. This protective film is a barrier between the moving surfaces, preventing direct metal-to-metal contact and reducing frictional losses [
9]. Bio-lubricants derived from vegetable oils through chemical modification with TMP provide a sustainable and environmentally friendly alternative to mineral-based lubricating oils. They offer similar performance characteristics and can be applied across diverse fields and industries while reducing the overall environmental impact and promoting a more sustainable approach to lubrication.
María et al. (2021) experimentally proved that adding graphene nanoparticles improves the lubricating properties of TMPTO, leading to a thicker and more effective lubricating film between moving surfaces. A thicker film can help reduce friction and wear, enhancing overall lubrication performance. On the other hand, adding boron hexagonal nitride nanoparticles seems to have the opposite effect, causing a reduction in film thickness. This suggests that the presence of boron hexagonal nitride nanoparticles in TMPTO may hinder the formation of a thick lubricating film, potentially resulting in less effective lubrication between the surfaces. As a result, film thickness decreases, which can harm lubrication performance.
Furthermore, their experimental results also indicate slightly lower friction coefficient values with the influence of nanoparticles. This suggests that both the graphene nanoplatelets and boron hexagonal nitride nanoparticles can positively reduce friction between the surfaces [
10,
11]. Wu et al. (2015) tried to optimize the synthesis process of trimethylolpropane trioleate (TMPTO) utilizing oleic acid (OA) and trimethylolpropane (TMP) [
12].
José et al. (2019) studied nano-lubricants composed of an ester base oil primarily consisting of trimethylolpropane trioleate, utilizing dispersions of hexagonal boron nitride (h-BN) nanoparticles at mass concentrations of 0.50, 0.75, and 1.0 wt.%. Their findings suggest that h-BN nanoparticles in the nano-lubricant formulation created physical protective tribofilms between the rubbing surfaces. These tribofilms are considered to have a vital role in reducing friction and minimizing wear, thus enhancing the overall tribological performance of the nano-lubricant system [
13]. Similar trends in antifriction and antiwear performance were obtained for graphene nanoplatelets at a mass concentration of 0.25% of graphene nanoplatelets (GnP) [
14]. The wear prevention properties of a trimethylolpropane (TMP) ester obtained from palm oil were assessed using a four-ball machine under different lubrication regimes. The results indicate that adding 3% of this palm oil-based TMP ester to any regular base oil significantly reduces the coefficient of friction and wear scar by up to 30% [
15].
Polyol ester-based vegetable oils have shown promising properties compared to those of mineral-based lubricants during the high-speed drilling of aluminum and stainless-steel material [
16,
17,
18]. Using graphene-based nanofluid leads to a substantial reduction in drilling torque, which is approximately 25% lower compared to that of a typical emulsion lubricant. Consequently, employing the nanofluid results in a significant expansion of tool life, of up to 20 times longer, compared to that when using a conventional emulsion lubricant [
19].
In the context of drilling fluid applications, trimethylolpropane ester (TMPE) was investigated as an additive, specifically as a nonionic surfactant. It was studied alongside other potential polyol esters, including neopentyl glycol ester (NPGE) and pentaerythritol ester. The purpose of this examination was likely to assess the suitability and effectiveness of TMPE, NPGE, and pentaerythritol ester as additives in drilling fluids, potentially evaluating their impact on various properties such as viscosity, lubricity, stability, or other relevant performance factors [
7,
20,
21].
Machine learning (ML) has found numerous applications in machining processes across various contexts, such as roughness quality prediction, tool condition monitoring, process optimization, quality control, etc. [
21,
22]. The versatility and adaptability of machine learning make it a powerful tool for optimizing and enhancing various aspects of machining operations and cutting tools [
23,
24]. Various techniques are used for the prediction of cutting forces and torque in drilling, such as artificial neural networks [
25,
26], the response surface methodology [
27,
28], and the use of different machine learning algorithms [
29,
30,
31] under dry as well as lubricated conditions.
The predictions developed using advanced machine learning techniques are more accurate in optimizing machining operations and reducing production costs. It is worth noting that publicly accessible research on machine learning models specifically developed for machining with cutting fluids may be relatively limited compared to that for dry machining. Moreover, there is very limited information available regarding the prediction of thrust force and torque under biodegradable lubrication conditions in order to be able to make accurate predictions. Cutting fluids can affect temperature distribution, chip disposal, friction, and tool life, influencing the forces involved in cutting operations and torque. Including cutting fluid-related parameters in the model can help capture these effects and improve the accuracy of the predictions.
Investigating the impact of TMPTO-based lubricant on thrust force and torque during the high-speed drilling of Al-6061 is essential to enhancing machining performance and prolong tool life, improving surface quality, boosting energy efficiency, and ensuring overall process sustainability. The objective of this study was to investigate the drilling process of Al 6061 using a TMPTO-based bio-lubricant as the drilling fluid. The main focus was on understanding and predicting the cutting forces and torque involved in high-speed drilling operations. In addition, the current study presents four regression-based machine learning techniques (linear regression, decision Trees, random forest and support vector machine) to construct predictive models that determine how machining forces develop during turning. An optimization problem was developed to find the exact combination of parameters so that maximum accuracy could be achieved with the fewest resources possible. This would ensure that the model was efficient and effective in its predictions.
3. Experimental Design
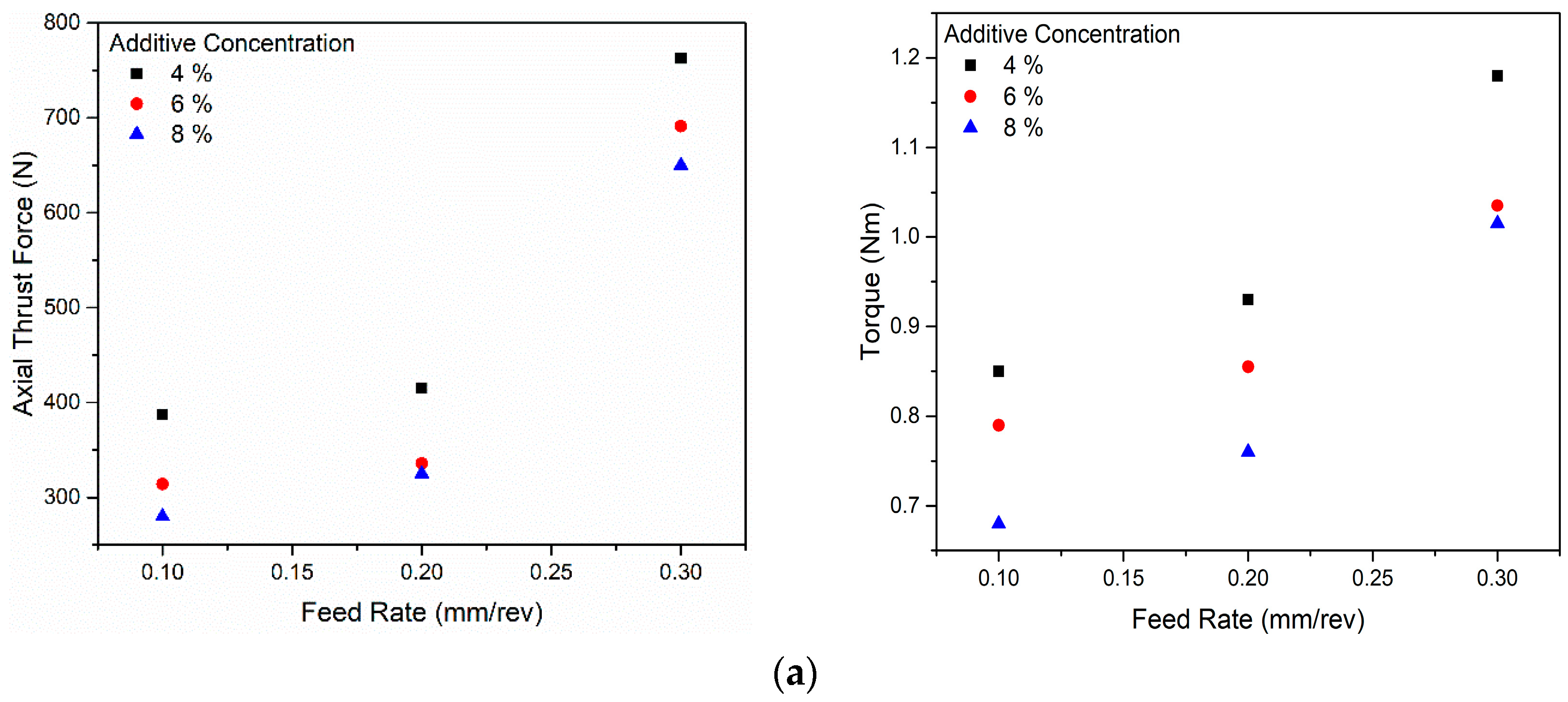
This study aimed to investigate the influence of additive concentration, spindle speed, and feed rate on thrust force and torque. The chosen parameters directly impact the lubrication conditions between contacting surfaces, affecting film thickness, friction, and tool wear. Understanding the relationship between these parameters and thrust force and torque is essential to optimizing lubrication performance and enhancing the efficiency and reliability of the tribological system under actual contact conditions. A Taguchi L9 orthogonal array that systematically varies these parameters while measuring thrust force and torque can provide valuable insights into their interaction and effects in a practical setting. The data obtained from such experiments can be used to develop predictive models and optimize lubrication strategies for specific applications.
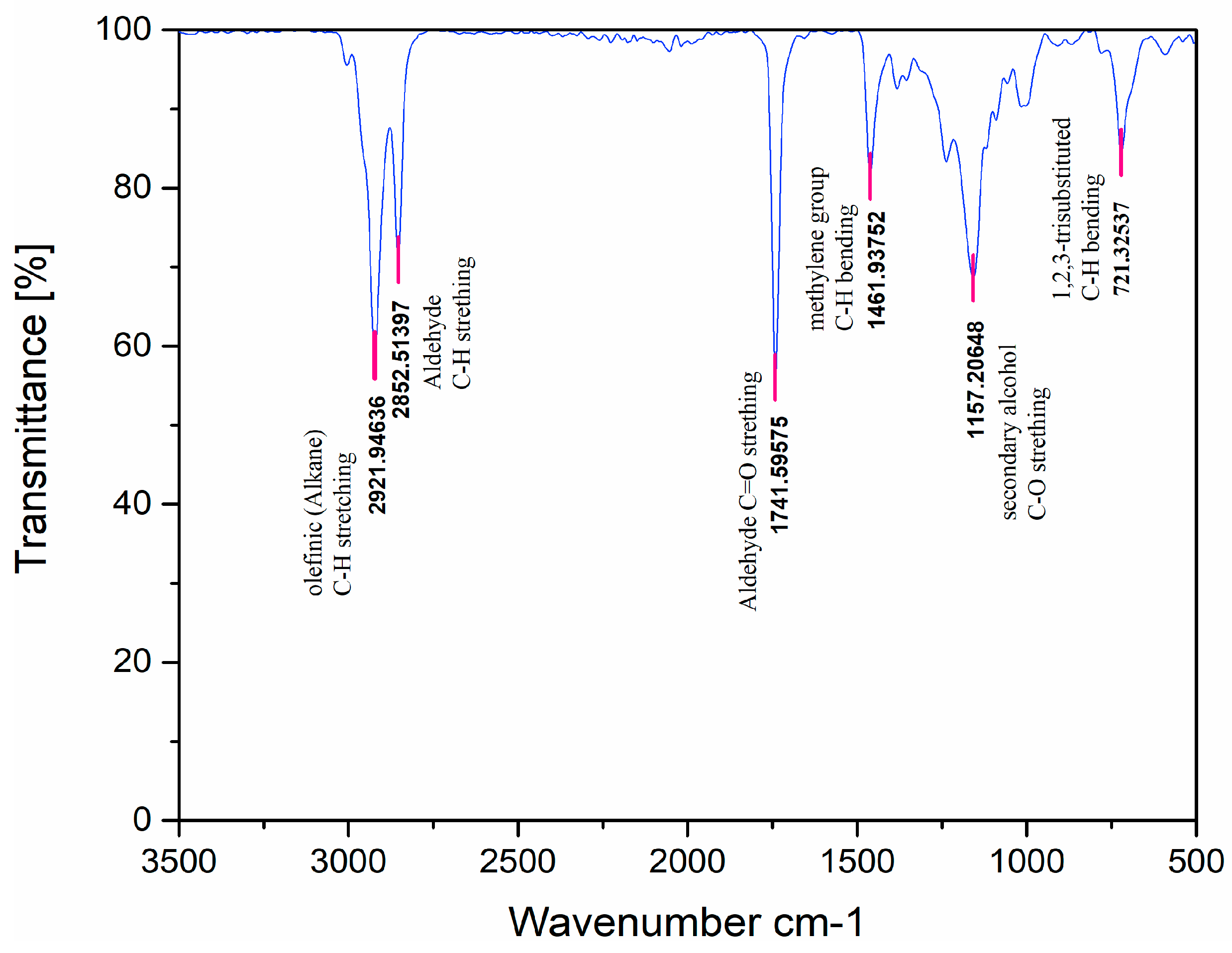
A preliminary screening result of AW/EP was used to select the blend for this investigation. Three levels, as well as three key control factors, were considered in this investigation. For the most effective type of lube oil, the control factors and corresponding levels were additive concentrations, with a 4%, 6% and 8%, spindle speed; 3053 RPM, 4580 RPM and 6107 RPM; and a feed rate of 0.1 mm; 0.2 mm, and 0.3 mm. The level of control factor determines values taken for the experiment. The experiment was conducted using the L27 orthogonal array. Under Taguchi’s orthogonal array, the proposed investigation entails the conduction of 27 experiments. In order to analyze the variance and single-to-noise ratios of the results, each response parameter was replicated twice, leading to a total of 54 observations. Upon completion of the experiment, the response parameters are transformed into a signal-to-noise (S/N) ratio. Calculated S/N ratio values are compared to the obtained results to see if they deviate from or are close to them. In the present study, the objective function follows a “smaller is better” approach, as indicated by Equation (1). This is because all the response parameters are anticipated to have smaller values for improved performance.
3.1. Machine Learning Models for Predicting Responses
3.1.1. Multiple Linear Regression
The multiple linear regression algorithm (MLR) is a linear regression algorithm used in datasets where the dependent variable is a single one, and the independent variables are multivariate [
23]. Linear regression is a type of regression analysis that demonstrates a linear relationship between one or more independent variables and a dependent variable. By using multiple linear regression, the dependent variable (y) is modeled via the independent variables (
x1,
x2,
x3…
xn) as shown in Equation (2),
where,
x1, x2, x3, …, xn are the independent variables;
y is the dependent variable;
n is a positive integer;
b is the bias or the intercept;
w1, w2, w3, …, wn are the weights.
3.1.2. Random Forest Regression
The random forest regression algorithm is a class of machine learning algorithms that combines multiple random decision trees, each of which is trained on a subset of the data set to generate a model [
36]. As a result of using multiple trees, the algorithm becomes more stable, and the variance is reduced. Random forest regression is a popular model in the field of regression analysis due to its ability to work well with large and diverse data sets.
The algorithm creates each tree based on a different sample of input data, which are used as input information. The features are randomly selected for splitting at each node, and the trees are run in parallel at each node without any interaction. In order to produce a single prediction, the predictions from all of the trees are then averaged to produce a single result that can be referred to as the prediction of the random forest. A visual representation of a random forest is shown in
Figure 3.
3.1.3. Support Vector Machines
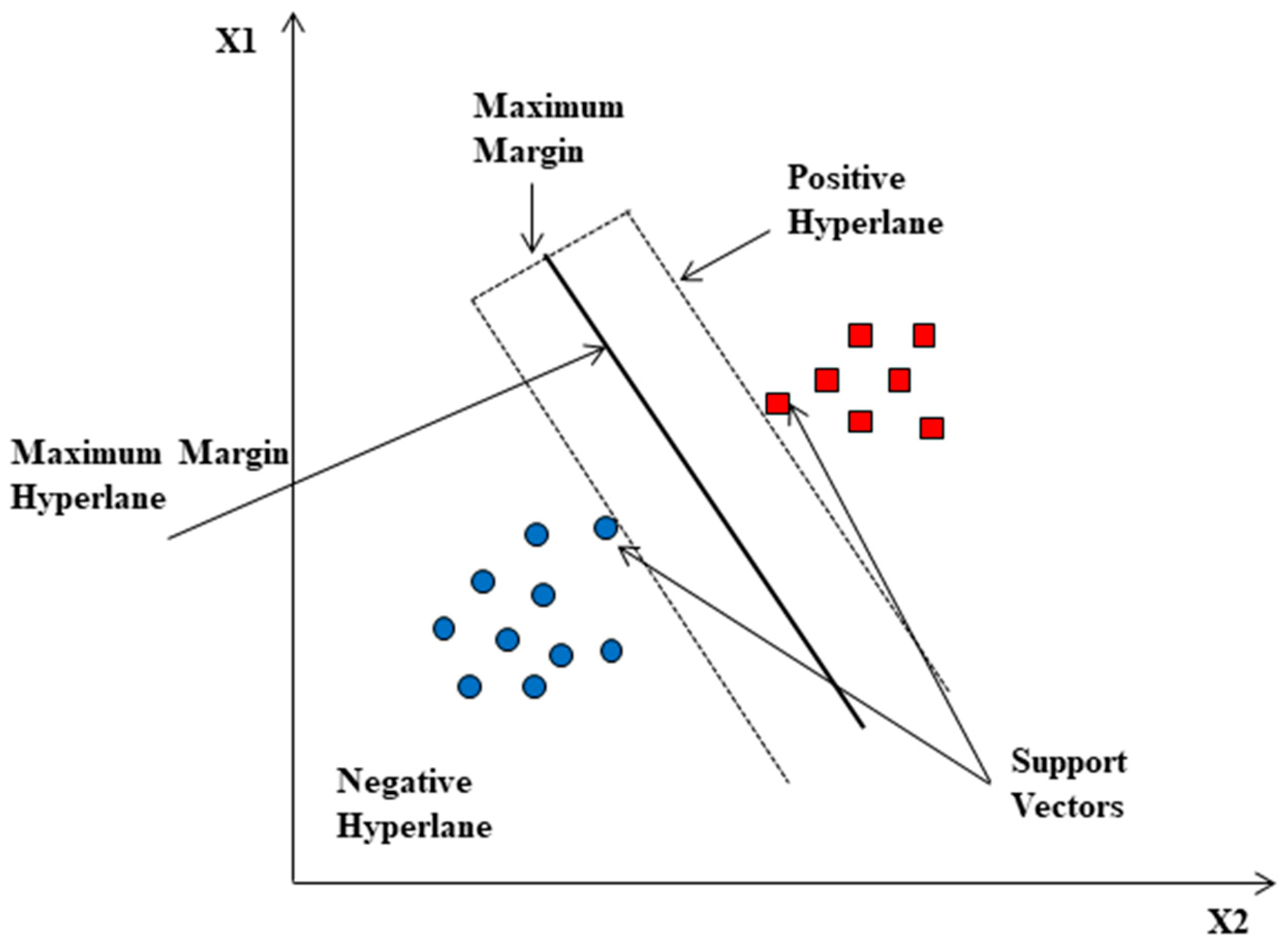
Support vector machines are used to classify data points based on a hyperplane in N-dimensional space (N-number of features), as shown in
Figure 4. As a result, several possible hyperplanes can be used to separate the two data points [
36]. The objective is to find a plane with the maximum margin, representing the maximum distance between two data points. By increasing the margin’s distance, future data points can be classified with greater confidence because they will be reinforced with some reinforcement. Data points are classified using hyperplanes, which are decision boundaries. Depending on which side of the hyperplane the data points fall on, they can be classified into different categories.
Furthermore, in the context of feature space, the dimensionality of the hyperplane is determined by the number of input features. When two input features exist, the hyperplane reduces to a line in the feature space. Three input features convert the hyperplane into a two-dimensional plane. As the number of features increases, visualizing the data and the relationships among the features becomes more challenging.
3.1.4. Decision Tree
In its most basic form, a decision tree can be explained as a flowchart showing the clear path that leads to a decision.
Figure 5 shows a graphical representation of the decision tree.
In data analytics, decision tree is an algorithm used to determine whether data can be classified based on a condition. Initially, a decision tree starts at a point called a node, then branches away from it in two or more directions. Generally, each branch has many possible outcomes, and it is a combination of various decisions and chance events that lead to the outcome.
3.2. Model Performance Evaluation
Training and testing subsets were divided in 80:20 ratios, widely accepted and well-established. Three statistical indices were used to assess the accuracy of the proposed model: mean square error (MSE), mean absolute per cent error (MAPE), and coefficient of determination (R2). These indices provide quantitative measures to assess the performance and predictive capability of the model. The MSE quantifies the average squared difference between predicted and actual values, the MAPD measures the average percentage deviation between predicted and actual values, and the R2 indicates the proportion of variance in the dependent variable explained by the model. The accuracy of any data-driven modeling technique is commonly measured by using all of these indices [
31]. The coefficient of determination (R2) value is calculated by using Equation (3).
To determine the performance of a model, the mean squared error (MSE) is usually used per Equation (4).
yP represents the predicted values,
yA represents the actual values, and n is the number of samples. It is also possible to evaluate the reliability of the neural network model’s result using the mean absolute percentage error (MAPE). MAPE is calculated by using Equation (5):
However, MSE and MAPE are both measures of the accuracy of a model, but they differ in how they handle outliers. R-squared is a measure of how well the model accounts for the variance in the data and is not affected by outliers. MSE is more affected by outliers because it squares all errors, while MAPE is more robust since it takes the absolute value of the error. R-squared is not affected by outliers since it is a measure of the variance explained by the model, not the accuracy of the model itself.
In studies involving animals or humans and other research requiring ethical approval, it is crucial to provide details regarding the authority that granted approval and the corresponding ethical approval code. This information ensures transparency and demonstrates compliance with ethical standards.

 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}