Abstract
This paper presents a systematic literature review focusing on the application of machine learning techniques for deriving observational constraints in cosmology. The goal is to evaluate and synthesize existing research to identify effective methodologies, highlight gaps, and propose future research directions. Our review identifies several key findings: (1) Various machine learning techniques, including Bayesian neural networks, Gaussian processes, and deep learning models, have been applied to cosmological data analysis, improving parameter estimation and handling large datasets. However, models achieving significant computational speedups often exhibit worse confidence regions compared to traditional methods, emphasizing the need for future research to enhance both efficiency and measurement precision. (2) Traditional cosmological methods, such as those using Type Ia Supernovae, baryon acoustic oscillations, and cosmic microwave background data, remain fundamental, but most studies focus narrowly on specific datasets. We recommend broader dataset usage to fully validate alternative cosmological models. (3) The reviewed studies mainly address the tension, leaving other cosmological challenges—such as the cosmological constant problem, warm dark matter, phantom dark energy, and others—unexplored. (4) Hybrid methodologies combining machine learning with Markov chain Monte Carlo offer promising results, particularly when machine learning techniques are used to solve differential equations, such as Einstein Boltzmann solvers, prior to Markov chain Monte Carlo models, accelerating computations while maintaining precision. (5) There is a significant need for standardized evaluation criteria and methodologies, as variability in training processes and experimental setups complicates result comparability and reproducibility. (6) Our findings confirm that deep learning models outperform traditional machine learning methods for complex, high-dimensional datasets, underscoring the importance of clear guidelines to determine when the added complexity of learning models is warranted.
1. Introduction
The field of cosmology has experienced significant growth thanks to advances in observational data collection, enabling a deeper understanding of the Universe’s structure and evolution. However, traditional techniques for analyzing these data, such as Markov chain Monte Carlo (MCMC) or other methods for Bayesian inference, face challenges when applied to increasing volumes of complex data [1,2]. In response, machine learning (ML) techniques have emerged as promising tools to enhance the efficiency and accuracy of cosmological parameter estimation [3].
While systematic literature reviews (SLRs) are widely employed in fields such as medicine, computing, and education to critically evaluate the state of the art and guide future research, they remain relatively unexplored in cosmology. For instance, SLRs have been used in medicine to assess the effectiveness of new treatments and technologies [4], in computing to analyze methodologies for applying ML techniques in electrical power forecasting [5], and in education to synthesize pedagogical strategies [6]. The relevance of an SLR in cosmology lies in its ability to synthesize multiple research efforts applying ML to cosmological problems, identifying patterns, gaps, and promising directions for future investigations. These reviews can accelerate innovation by providing a comprehensive and critical view of accumulated knowledge, as seen in other scientific domains.
The aim of this paper is to contribute with a novel perspective by addressing the intersection between ML techniques and cosmological data constraints through a systematic review of the literature. Unlike previous surveys on ML in cosmology, which often focus on specific applications such as supernova detection [7] or galaxy classification [8], our work systematically categorizes and evaluates the diverse ML methodologies applied across a range of cosmological problems. We not only review the effectiveness of these techniques in improving parameter estimation but also highlight the limitations and propose future research directions. Our primary objectives are as follows: (1) to systematically review and categorize ML techniques applied to cosmological parameter estimation, (2) to assess the effectiveness and limitations of these techniques, and (3) to identify gaps in the literature and suggest new research directions. This is the first comprehensive review to address the broad application of ML techniques for improving Bayesian inference and parameter constraints in cosmology, making it an important resource for researchers in both fields.
This paper is organized as follows: In Section 2, we present the theoretical background that underpins the methods and techniques analyzed in this SLR, whereas in Section 2.1, we briefly describe some important theoretical aspect on cosmology, observational datasets, and the standard procedure for deriving cosmological constraints, and in Section 2.2, we briefly describe some important theoretical aspects for ML and their changes when it is implemented to the Bayesian inference. In Section 3, we discuss some previous SLRs related to our study. In Section 4, we describe the research methodology used to carry out our SLR, whereas in Section 4.1, we present the research questions and objectives that will steer this review. In Section 4.2, we discuss the identification and selection of pertinent studies, along with the application of filters to ensure data quality and relevance, and in Section 4.3, the findings amassed throughout the review process are synthesized and presented cohesively. In Section 5, we present the main results of our SLR according to the following structure: Section 5.1 is devoted to presenting the thematic interconnection of the selected articles. In Section 5.2, we focus our analysis on the samples used according to the datasets considered in the reviewed papers. In Section 5.3, we discuss the models of ML and deep learning (DL) considered in the reviewed papers. In Section 5.4, we present the main objectives that the reviewed papers aim to tackle with the ML techniques. In Section 5.5, we discuss the metadata of the papers selected in our SLR. On the other hand, in Section 6, we discuss the main findings obtained in the results of our review, whereas in Section 6.1, we present the main results, and in Section 6.2, we discuss the works and problems that can be addressed in the future. Section 6.3 provides a concise technique-level comparison and explains why cross-paper benchmarking is not methodologically sound. In Section 7, we discuss the threats to the validity of our SLR, which is composed of the following subsections: Section 7.1 focuses on the applicability of the results to domains outside of cosmology, Section 7.2 addresses how variations in the implementation of models can affect the outcomes of our SLR, Section 7.3 explores whether the conclusions drawn from the SLR accurately reflect the methods implemented in the reviewed papers, and Section 7.4 presents the arguments supporting the validity of our conclusions. Finally, in Section 8, we present some conclusions and a final discussion.
2. Theoretical Background
2.1. Cosmology
In cosmology, the Universe is ruled by the cosmological principle, which establishes homogeneity and isotropy at large scales (>100 Mpc [9]), and it is dominated, in principle, by radiation and baryonic matter during their cosmic evolution. However, observations of some phenomena give us insights into two additional hypotheses to consider, namely, dark matter and dark energy. The first is responsible for the formation of large-scale structure, with initial evidence coming from galaxy rotation curves [10,11], and the second accounts for the late-time accelerated expansion of the Universe [12,13]. These ingredients give us the standard cosmological model (also known as the CDM model), described by Friedmann’s equations [14]:
where G is the Newtonian constant of gravitation, c is the speed of light in a vacuum, k is the curvature of the Universe, dot () accounts for the derivative with respect to the cosmic time t, a is the scale factor (a quantity that describes the evolutionary/expansion history of the Universe), H is the Hubble parameter (the expansion rate of the Universe), and is the cosmological constant. The energy density and pressure of the Universe are and , where the subscripts r and m account for radiation and matter, respectively. At the current time, the radiation component can be neglected and the matter density is composed of baryonic matter and cold dark matter (CDM), which represent approximately and of the total energy budget of the Universe, respectively. The remaining corresponds to dark energy [15], which is described in the model by the cosmological constant.
It is convenient to write the Hubble parameter in terms of the density parameter of each matter component [16]:
where the redshift z is related to the scale factor through the expression , the subscript 0 accounts for the values at the current time, and the subscript i accounts for the radiation and matter components with values and , respectively. For the cosmological constant, the density parameter reads . Considering a flat Universe () [17], the current values of the density parameters are constrained through the Equation (1) as
Therefore, the Hubble parameter for the CDM model can be written in terms of the redshift as follows:
The CDM model is, to date, the most successful cosmological model to describe the background cosmological data, from which we can highlight the following:
- Type Ia Supernovae (SNe Ia): Supernovae (SNe) are highly energetic explosions of some stars and play an important role in the fields of astrophysics and cosmology because they have been used as cosmic distance indicators. In particular, SNe Ia are considered standard candles for measuring the geometry and late-time dynamics of the Universe [18]. In fact, between 1998 and 1999, the independent projects High-z Supernova Search Team [12] and Supernova Cosmology Project [13] showed results that suggested an acceleration in the Universe expansion using SNe Ia data. This behavior is now confirmed by several cosmological observations, establishing that the Universe is currently facing an accelerated expansion, which began recently in cosmic terms at a redshift of [19]; SNe Ia data are widely used to test the capability of alternative models to CDM in describing the cosmological background. The sample used by the Supernova Search team consisted of 50 SNe Ia data points between , while the sample of the Supernova Cosmology Project consisted of 60 SNe Ia data points between . Nowadays, the samples of SNe Ia observations have grown in data points and redshift range, with the most recent being the Pantheon sample [20], consisting of 1048 SNe Ia data points between , and the Pantheon+ sample [21], with 1701 SNe Ia data points between .
- Observational Hubble Parameter Data (OHD): Even though SNe Ia data provide consistent evidence about the existence of a transition epoch in cosmic history where the expansion rate of the Universe changes, it is important to highlight that this conclusion is obtained in a model-dependent way [19]. The study of the expansion rate of the Universe in a model-independent way can be carried out through observations of the Hubble parameter. Up to date, the most complete OHD sample was compiled by Magaña et al. [22], which consists of 51 data points in the redshift range of . In this sample, 31 data points are obtained using the Differential Age method [23], while the remaining 20 data points come from baryon acoustic oscillations measurements [22].
- Baryon Acoustic Oscillations (BAOs): BAOs are the footprints of the interactions between baryons and the relativistic plasma in the epoch before recombination (the epoch in the early Universe when electrons and protons combined to form neutral hydrogen) [24]. There is a significant fraction of baryons in the Universe, and the cosmological theory predicts acoustic oscillations in the plasma that left “imprints” at the current time in the power spectrum of non-relativistic matter [25,26]. Many collaborations have provided BAO measurements, like 6dFGS [27], SDSS-MGS [28], BOSS-DR12 [29], and the Dark Energy Spectroscopic Instrument (DESI) [30] to mention a few.
- Cosmic Microwave Background (CMB): Since the discovery of the CMB in 1965 by Penzias and Wilson [31], the different acoustic peaks in the anisotropy power spectrum have become the most robust observational evidence for testing cosmological models. In this sense, the different acoustic peaks provide information about the matter content and curvature of the Universe [32,33], and they have been measured by different satellites like the Wilkinson Microwave Anisotropy Probe (WMAP) [34] and Planck [35].
- Large-Scale Structure (LSS): The LSS is the study of the distribution of the galaxies in the Universe at large scales (larger than the scale of a galaxies group) [36]. At small scales, gravity concentrates particles to give form to gas, then to stars, and finally to galaxies. At large scales, the galaxies also group in different patterns called “the cosmic web”, which is caused by fluctuations in the early Universe. This distribution has been quantified by various surveys, such as the 2-degree Field Galaxy Redshift Survey (2dFGRS) [37] and the Sloan Digital Sky Survey (SDSS) [38].
- Gravitational Lensing (GL): When a background object (the source) is lensed due to the gravitational force of an intervening massive body (the lens), it generates multiple images. Therefore, the light rays emitted from the source will take different paths through space–time at different image positions, arriving at the observer at different times. This time delay depends on the mass distribution in the lensing and along the line of sight, and also on the cosmological parameters. For this data, we can highlight the strong lensing measurements of the lenses in COSMOGRAIL’s Wellspring (H0LiCOW) collaboration [39], which consist of six gravitationally lensed quasars with measured time delays.
Although CDM is the most robust cosmological model until now, some issues cannot be explained in this theory, such as the nature of dark matter and dark energy, the asymmetry in baryons (the observed imbalance between matter and antimatter), the hierarchy problem (the large difference between the weak force and gravity), and the neutrino mass (the small but nonzero mass of the neutrino), among others [40,41]. Furthermore, as we enter the so-called “era of precision cosmology”, some observational tensions arise and become more problematic with the inclusion of new data. For example, local measurements of Cepheid for the Hubble constant (model-independent) present a discrepancy of with the value inferred by Planck CMB assuming the CDM model [42]. This tension is also supported by the H0LiCOW collaboration with a discrepancy of concerning the value inferred from the Planck CMB [39].
The shortcomings exhibited by the CDM model due to the inclusion of more observational data accentuate the importance of parameter estimation (the best-fit values of the free parameter space of a certain cosmological model) not only for testing the capability of the standard model to describe these new data but also for testing the capability of alternative cosmological scenarios in the description of the cosmological background. To this end, Bayesian inference is commonly used in cosmology for parameter estimation (also referred to as cosmological constraints), which considers Bayes’ theorem of the form
where is the posterior distribution and corresponds to the probability of obtaining the parameter space for a given observational data D, is the likelihood and corresponds to the probability of obtaining the observational data D for a given parameter space , is the prior distribution and corresponds to the previous physical evidence about the parameter space, and is the prior predictive probability, which is extremely hard to calculate [43]. To overcome this last problem, is approximated using Monte Carlo methods, being one of the most used in cosmology the affine-invariant MCMC [44], which is implemented in algorithms like the pure-Python code emcee [45]. Nevertheless, this method is highly dependent on the initial conditions, requires exploring all the parameter space to obtain the best fits, and has problems in the presence of multi-modal likelihoods, and the computing time grows exponentially for big datasets and free parameters [46].
Nowadays, in cosmology, there are new surveys such as the Legacy Survey of Space and Time (LSST) [47], Euclid [48], the Spectro-Photometer for the History of the Universe, Epoch of Reionization, and Ices Explorer (SPHEREx) [49], the Nancy G. Roman Space Telescope (NGRST) [50], the Dark Energy Spectroscopic Instrument (DESI) [30], and the Prime Focus Spectrograph (PFS6) [51]. These surveys will provide new data that, in addition to previous cosmological data, will increase the efficiency and solve the computing time problems of the MCMC method, raising ML as a powerful alternative for improving cosmological constraints.
2.2. Machine Learning
It is often challenging for humans to explicitly define the logical rules underlying very complex tasks, such as image recognition or natural language understanding. In general, it can be said that ML is a paradigm shift in which rules can be defined by delivering the inputs and outputs of a particular task repeatedly to a model. In this way, the model “learns” the patterns present in the inputs that result in certain outputs using some performance measure that ensures the validity of those patterns [52].
Deep learning (DL) is a subset of machine learning (ML) that uses neural networks with many layers. Neural networks are a component of ML, and when they consist of multiple layers, they are referred to as deep learning. The difference between ML and DL is that, in the latter, the models are capable of automatically learning representations of input data, such as text, images, or videos, in much greater detail than ML models. This is due to the use of successive layers of data representation (hence the name Deep) [52]. NNs are one of the main and most popular DL techniques today. Their development has been going on for quite some time, having its origins in 1957 with the perceptron by Frank Rosenblatt (see Figure 1) [53]. Despite their innovation, further research slowed down for a while due to several factors, including a criticism from Minsky and Papert in 1969 [54], as well as limitations in hardware and the availability of sufficient data. It was not until the 1980s, with work such as that of Paul Werbos and David E. Rumelhart, who popularized the use of the Backpropagation algorithm in recurrent neural networks (RNNs), that interest in the area renewed. Since then, several advances have been made, as well as modifications and additions that allow the use of NNs for specific tasks, particularly those related to the ML techniques applied for cosmological constraints.

Figure 1.
Example of basic structure of the perceptron.
The construction of NNs varies depending on the use case, but their operation can be generalized through a structure called layers. The last one carries information from the input to the output of the network, transforming it in the process and obtaining convenient representations for the task to be performed, commonly classifying or analyzing data. These layers receive as input the output of the previous layers or, failing that, the initial data input. The simplest form of these structures is the single-layer perceptron, which is one of the earliest examples of an NN [53]. For example, for binary classification, as shown in Figure 1, we have that contains the n feature values to be classified, and is the resulting value. The model’s output is calculated by applying an activation function f to the weighted linear combination of the inputs:
where denotes the weights associated with each feature , b is the bias, and is the activation function. As an example, the step function can be used:
This function determines the output class based on whether the weighted sum of the inputs surpasses a threshold; in this example, the threshold is 0.
In a multi-layer neural network (see Figure 2), the outputs of each neuron are fed into the subsequent neurons, allowing them to solve problems that are not linearly separable. This is achieved by a weighted sum of the inputs followed by an activation function f, such as the sigmoid, which introduces non-linearity. Thus, the output of a neuron in a layer is as follows:
where is the output of the neuron, denotes the weights, denotes the inputs, is the bias, and f is the activation function, like the sigmoid. In this way, they are transformed into what is now known as an NN.
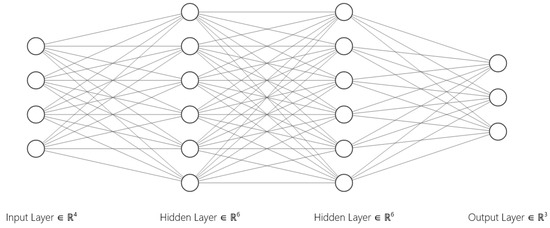
Figure 2.
Example of multi-layer NN inspired by Figure 1.5 of Ref. [55].
In general, the output values of each neuron are calculated based on the weights. In simple words, the layers of an NN are parameterized by the weights, allowing one to obtain different values depending on the context. Finding the “ideal” weights is fundamental to obtaining effective estimates. On the other hand, the activation function works as a filter or limiter that transforms the output values of each neuron. These transformations are usually nonlinear functions, which allow the NN to solve increasingly complex problems. Among the most relevant activation functions is the linear function defined by
which does not limit the output of the neuron and is widely used in regression tasks. There is also the sigmoidal function
which limits the output of the network to a value between 0 and 1 and is often used as the activation function of the last neuron of a binary classification NN. Finally, one of the most commonly used functions is the ReLU function
which only allows the output of positive values of each neuron, suppressing negative values to zero, and it is mainly used to address the vanishing gradient problem in NNs, which results in faster convergence as a secondary effect. Finally, an optimizer is used to adjust the parameters. In general terms, the optimizer uses the loss function of the NN model to determine how much the weights should change to reduce the loss as much as possible. For this, some variant of gradient descent is usually used, with the logic of finding the parameters with which the derivative of the loss function finds convergence.
In summary, an artificial NN makes calculations on input data, which can be numbers, text, images, or other types of data. These calculations are propagated from the input to output neurons using intermediate parameters called weights to adjust subsequent calculations. Learning occurs when, given an input and the subsequent processing of the weights, the NN model can associate the input with an output, which is also called a label or prediction. It can be said that the model recognizes an input because it has learned patterns and generalizations from the data it was trained on. The goal is for the network to capture fundamental features of the data, enabling it to generalize to new, similar datasets. There are many types of artificial NNs, oriented to different types of tasks, but they all maintain a similar structure and way of working [56].
On the other hand, Bayesian machine learning (BML), although similar in operation to classical ML models, also includes techniques that use Bayesian principles to make predictions, allowing, for example, the calculation of the uncertainty of these predictions [57]. Among these models are the Gaussian processes (GPs) that are often used in complex ML problems due to their flexible and non-parametric nature [58] and the Bayesian decision trees (BDTs) that add Bayesian techniques to the classical decision trees, such as, for example, the uncertainty in the decisions of division of parent nodes to children [59,60]. In the context of NNs, Bayesian inference can be used to estimate the uncertainty of model predictions. This fusion is often referred to as Bayesian neural networks (BNNs), and it replaces the classical network weights with fixed values by probability distributions, allowing the model to estimate uncertainty and fit the model with that approach [61].
3. Related Works
While there has been extensive research on the application of ML techniques in cosmology, most existing studies focus on specific applications rather than providing a comprehensive account of how these techniques are used to derive observational constraints, given that ML is still a relatively new and rapidly evolving field. For instance, ML methods have been widely used in classifying astronomical transients, such as supernovae, and in parameter estimation from large-scale structure surveys [62,63,64]. These studies typically highlight the performance of ML models like convolutional neural networks (CNNs) and random forests in handling large and complex datasets.
Recent advances underscore the role of ML in large-scale surveys such as the LSST, which generates millions of transient alerts every night. These alerts far surpass the available spectroscopic resources for follow-up, making ML techniques indispensable for real-time classification and anomaly detection [62,63,65]. ML has also been applied to challenges like photometric redshift estimation and galaxy clustering, with hybrid models combining NNs and support vector machines showing performance improvements [66]. However, these efforts are often fragmented and focus on specific ML techniques or isolated aspects of observational constraints, without offering a comprehensive synthesis of methodologies specifically applied to observational data in cosmology. As of now, no systematic review has compiled and evaluated the full range of ML techniques applied to cosmological problems, such as those dealing with SNe Ia, BAO, and CMB data, among others [62,64]. This lack of synthesis reveals a critical gap in the literature.
Beyond application-specific studies, recent community-level and methodological advances further motivate our focus on observational constraints. The CosmoVerse White Paper synthesizes current observational tensions and the role of systematics, outlining a forward-looking agenda for robust inference pipelines [67]. Methodologically, neural emulators such as CosmoPower accelerate likelihood-based inference by replacing expensive Boltzmann solvers [68], while normalizing-flow approaches (e.g., emuflow) enable efficient joint posteriors across heterogeneous datasets [69].
The present work aims to fill this gap by conducting an SLR that not only categorizes and evaluates the effectiveness of diverse ML techniques but also explores their integration with traditional cosmological methods. This study represents a novel contribution to the field, offering a valuable resource for researchers seeking to leverage ML for cosmological data analysis. The absence of similar reviews highlights the innovative nature of this work, positioning it as a critical step toward advancing ML applications in observational cosmology.
4. Research Methodology
Our SLR is based on the principles for this kind of work in the area of software engineering [70], in combination with the methodologies outlined in Ref. [71]. Broadly, this approach encompasses three key phases:
- 1.
- Planning the Review: This initial stage involves defining the research questions and objectives that will steer the review. This sets a clear framework for the study.
- 2.
- Executing the Review: Here, the identification and selection of pertinent studies occur, along with the application of filters to ensure data quality and relevance. Information extraction is also pivotal during this phase.
- 3.
- Reporting the Review: Finally, the findings amassed throughout this review process are synthesized and presented cohesively. This phase culminates in the succinct and organized presentation of research outcomes.
4.1. Planning the Review
In this subsection, a detailed overview of the key components comprising this review is provided. This includes outlining the research questions guiding the process, the selection of search engines, and the establishment of inclusion and exclusion criteria guiding the selection of materials.
The main objective of this study is to explore the current state of research related to the utilization of ML in assessing the feasibility of fitting observational data with cosmological models, focusing on the constraint of the free parameters of a certain cosmological model. The aim is to examine how ML approaches are being applied in cosmology to enhance the efficiency of Bayesian inference algorithms and other techniques used in model fitting, particularly the MCMC method. For this purpose, the following research questions have been formulated:
- RQ1: What ML approaches are most frequently used in the field of cosmology to adjust the free parameters of cosmological models to observational data?
- RQ2: To what extent does ML contribute to the field of fitting cosmological models to observational data, particularly in enhancing the efficiency of Bayesian inference algorithms and other fitting techniques?
- RQ3: What are the existing research gaps in the utilization of ML for fitting cosmological models, and what are the opportunities for future research to address these gaps and enhance our understanding of observational cosmology?
- RQ4: What types of training data are commonly used in ML approaches applied to fitting cosmological models to observational data, and what methods are employed to obtain and process this data?
In terms of the research search, notable preprint repositories and digital databases such as arXiv, ScienceDirect, ACM Digital Library, Scopus, and Inspirehep were queried. Each search string was tailored to fit the specific formats of each database. These selections were made based on the reputable nature of these databases and their user-friendly search interfaces, which facilitate result filtering and exportation in convenient formats. arXiv was included because it is the primary repository for physics research, where all relevant studies, including those indexed in Web of Science (WoS), are conventionally shared, as well as works not published in journals. To ensure consistency in the selected articles, limit the amount of information under consideration, and maintain a clear focus on the main research themes, inclusion and exclusion criteria were established.
Inclusion Criteria:
- IC1: Research articles written in the English language, but may consider articles in other languages if relevant (with access to translation resources).
- IC2: Research works published from 2014 to 2024, selected based on relevance to the research topic.
- IC3: Articles published in conference/workshop proceedings, academic journals, and as thesis dissertations to encompass diverse scholarly sources.
- IC4: Complete (full-text) research articles to ensure comprehensive review.
Exclusion Criteria:
- EC1: Exclude duplicate articles, ensuring data integrity.
- EC2: Exclude articles that are not focused on ML techniques applied to improve parameter estimation in cosmology.
- EC3: Exclude articles that are not aligned with the goals of the SLR, such as those describing ML techniques that do not improve Bayesian inference for parameter estimation.
Protocol and reporting:
- This SLR followed a pre-specified protocol aligned with PRISMA 2020; the full protocol is publicly archived on Zenodo [72].
4.2. Executing the Review
This section outlines the methodology employed for conducting the review, including the processes of searching, filtering, and selecting the ultimate collection of research articles from which the necessary data were extracted. Subsequently, the data were synthesized and analyzed in preparation for the subsequent phase. This phase extended over a period of approximately eight months, from March 2024 to October 2024. In essence, this phase of the SLR encompasses the initial search and selection of review papers, the definition of the strategy for data extraction, and the conduct of data synthesis and analysis.
4.2.1. Exploration and Concluding Selection of Reviewed Materials
Initially, a thorough and comprehensive search was conducted across specified scholarly databases and the Google search engine. Various search strings were employed to retrieve research articles from diverse digital databases. Boolean operators, specifically AND and OR, were utilized in search syntax to refine the search results. Additionally, a wild card character (*) was incorporated into certain search queries to broaden the scope and capture matching results with one or more characters. Keywords were explored in different combinations within the title, abstract, and keywords sections of each article, as outlined in the search syntax format across various sources. The search string finally used for each source (digital database/library) is presented in Table 1. This systematic review was conducted according to the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines. In Figure 3, we present a PRISMA flow diagram that visually illustrates the detailed process involved in selecting the final set of review materials. The articles finally selected for this review are presented in detail in Appendix A.

Table 1.
Search string used in this review for each digital database/library source.
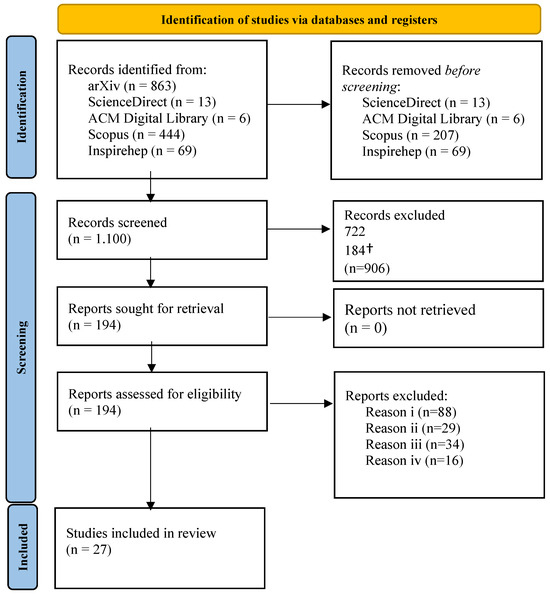
Figure 3.
PRISMA flow diagram illustrating the detailed process involved in selecting the final set of review materials. The reasons to exclude reports are: (i) Lack of focus on cosmological parameter estimation. (ii) Use of synthetic or simulated data without reference to observational constraints. (iii) Applications of ML unrelated to model fitting (e.g., image classification or anomaly detection) and, (iv) Insufficient methodological detail for inclusion. A Python filter assisted tittle/abstract screening and cross-checked the manual review. The † points to 184 articles automatically excluded because the retrieved arXiv entries did not contain the query terms in title/abstract/keywords (a known peculiarity of the arXiv search interface); the remaining 722 were excluded through standard manual screening against the IC/EC.
4.2.2. Data Extraction Strategy
A meticulous strategy is paramount for extracting data and conducting a structured literature review. This strategy is guided by five key themes, as illustrated in Figure 4. These themes have been expanded with specific attributes to structure data extraction effectively, ensuring alignment with the review’s objectives. Below, each theme is described, supplemented by questions that elucidate the type of data extracted from the selected research articles.
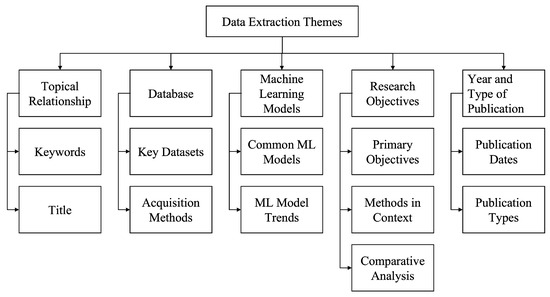
Figure 4.
Data extraction themes.
- Topical Relationship: This theme explores the thematic coherence among the reviewed articles. It is evaluated by the recurrence and relevance of keywords and the thematic correlation of titles, reflecting their collective contribution to the field of cosmology. This theme encompasses the following questions: (i) How often do keywords appear across different articles? (ii) Are the titles indicative of a common thematic focus?
- Databases: This theme investigates the datasets utilized in ML for cosmological model fitting. It examines the types of training data, the methodologies for data collection, and the techniques for processing these data to enhance model accuracy and reliability. This theme encompasses the following questions: (i) What training datasets are prevalent in ML studies for cosmology? (ii) What are the common methods for data acquisition and preprocessing?
- Machine Learning Models: This section delves into the specific models and approaches that the field currently prioritizes, looking for patterns or trends in model selection and application. This theme encompasses the following questions: (i) Which ML models are most commonly referenced in the literature? (ii) Can we identify trends or preferences in the use of certain ML models for cosmological studies?
- Research Objectives: The focus here is on understanding the primary goals of the research articles and how these align with the broader objectives of the field. It also assesses the structure and clarity with which these objectives are presented. This theme encompasses the following questions: (i) What are the primary objectives outlined in the articles? (ii) How are the articles’ methods and results situated within the broader context of cosmological research? (iii) Is there a comparative analysis between the presented research and other studies within the field?
- Year and Type of Publication: This theme catalogs the articles based on their publication year and the medium of publication, which provides insight into the evolution of the field and the dissemination of findings. This theme encompasses the following questions: (i) When were the key articles in the domain published? (ii) Are the articles predominantly from journals, conferences, workshops, or academic theses?
4.3. Reporting the Review
Data were extracted along five predefined themes and analyzed using both qualitative and quantitative approaches. The qualitative analysis is a narrative/thematic synthesis of methods, tasks, validation practices, and reported challenges, while the quantitative analysis consists of descriptive statistics (e.g., counts, proportions) of model families, cosmological probes, datasets, reported speedups, and uncertainty performance. The results are summarized and visualized in Section 4.
5. Results
In this section, we present the details of data synthesis and analysis of the reviewed articles concerning the five themes stated above.
5.1. Topical Relationship
To visually illustrate the thematic interconnection of the selected articles in this SLR, we have adopted an approach akin to a “word cloud”. This graphical representation highlights the frequency of specific terms used in both the titles and keywords of the reviewed articles, reflecting their relevance and thematic focus. The word clouds for the titles and keywords of the articles are displayed in Figure 5 and Figure 6, respectively.

Figure 5.
Word cloud for the titles of the twenty-seven reviewed articles.

Figure 6.
Word cloud for the keywords of the twenty-seven reviewed articles.
In Figure 5, it can be seen that some of the most frequent terms used in the titles include “cosmological”, “neural”, “networks”, “bayesian”, and “learning”. These terms are indicative of the convergence of the disciplines of ML and cosmology, reflecting the primary focus of this research on the effectiveness of ML techniques in fitting cosmological models with observational data.
On the other hand, in Figure 6, the most prominent keywords include “cosmology,” “astrophysics,” “nongalactic,” “analysis,” and “parameters.” The dominance of these terms highlights the strong thematic focus of the reviewed studies on cosmological and astrophysical domains, with particular attention to the analysis of nongalactic data and the estimation of cosmological parameters. Notably, other relevant keywords such as “neural,” “statistical,” “Bayesian,” and “machine” also emerge, reflecting the growing integration of machine learning techniques in addressing cosmological problems.
5.2. Databases
In this section, we focus our analysis on the samples used according to the datasets considered in the reviewed papers. In particular, the main datasets are SNe Ia, OHD, BAO, CMB, LSS, GL, and galaxy clustering data (GCD). Some details about these are presented in Section 2.1. From the twenty-seven reviewed papers, we identify the data samples shown in Figure 7, where we depict a frequency plot of the sample for each cosmological data considered. In the figure, N/S and N/A stand for non-specified and not apply, respectively; simulated refers to a sample that comes from a particular database but is obtained through an ML technique; generated corresponds to a sample that is obtained from an ML technique that does not have a specific database as a source. It is important to clarify that OHD is the name of the database and also of the data sample. In fact, cosmic chronometers are included in the OHD sample. In this sense, the N/S sample can be some specific points of the OHD database.
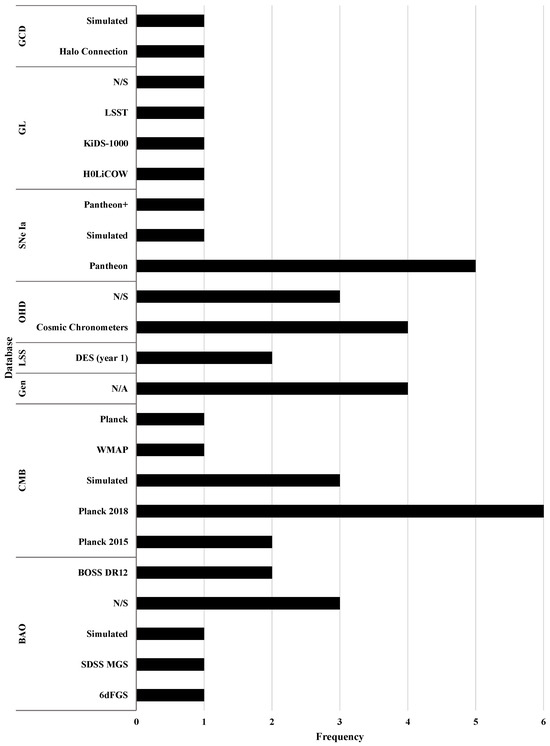
Figure 7.
Frequency plot of the sample for each cosmological datum considered for a total of twenty-seven reviewed papers. In the figure, N/S and N/A stand for non-specified and not apply, respectively, simulated refers to a sample that comes from a particular database but is obtained through a ML technique, and generated corresponds to a sample that is obtained from an ML technique that does not have a specific database as a source.
From Figure 7, we can see that, for the total of twenty-seven reviewed articles, the CMB database is considered in twelve papers, one of which uses two catalogs from the same database, resulting in thirteen uses (). BAO is used in six papers, and as in the previous case, one of them uses three different catalogs, resulting in eight uses (). SNe Ia and OHD are each considered in seven papers (), GL is considered in four papers (), and LSS and GCD are each considered in two papers (). Also, four papers () use a generated data sample from an ML technique without the use of a specific database as a source. The sum of the percentages presented above is not more than because, in general, the reviewed papers used more than one dataset in their studies. From the latter, we can see that nearly of the twenty-seven reviewed papers use CMB data, which is an expected result considering that these are the most expensive data at the computational level. This is because CMB data can add more than twenty free parameters to the constraint (the computational time of the standard MCMC method increases with the number of free parameters), where most of them are nuisance parameters and do not correspond to the free parameters of the cosmological model under study. Additionally, when deriving parameter constraints from observational data, the repeated evaluation of Einstein–Boltzmann solvers (e.g., CAMB/CLASS) is typically the principal computational bottleneck in the inference pipeline.
Focusing on the data samples presented in Figure 7, we can see that one paper () uses Halo Connection measurements [73] and one paper () uses a simulated sample [74] for the GCD; in contrast, for GL data, we have the H0LiCOW [75], KiDS-1000 [76], and LSST [77] samples, each used in one paper (), and one paper () does not specify the sample used [78]. In the case of SNe Ia data, five papers () use the Pantheon sample [79,80,81,82,83], one paper () uses the Pantheon+ sample [84], and one paper () uses a simulated sample from the future Wide-Field Infrared Survey Telescope (WFIRST) experiment using ML techniques [85]. On the other hand, for the OHD, we have four papers () that use cosmic chronometer compilation [75,79,81,84], and three papers () do not specify the sample used [80,86,87]. For LSS data, two papers () use DES (year 1) [88,89]. The following samples are used for CMB data: Six papers () use the Planck 2018 release [76,78,82,89,90,91], two papers () use the Planck 2015 release [83,92], one paper () uses the WMAP sample without specifying the release year [93], one paper () uses the Planck sample without specify the release year [93], and three papers () use a simulated sample from CMB sky images using ML techniques [85,94,95]. The BAO database is considered in two papers () through the BOSS DR12 release [82,89], the SDSS-MGS and 6dFGS [82] releases are each used in one paper (), three papers () do not specify the sample [78,79,81], and one paper () uses a simulated sample from the future measurements of the SKA2 survey using ML techniques [85]. Finally, five papers use a generated database [96,97,98,99].
5.3. Machine Learning Models
For our SLR, the main ML models encountered were GP, BML, BDT, NN, and BNN. 1 Some details about these models are explained in Section 2.2. All of these models can be classified into two major fields: ML (including GP, BML, and BDT) and DL (comprising NN and BNN). The frequency of usage of each of these models is presented in Figure 8. Only models used specifically for analyzing cosmological data are considered in the count, i.e., models used solely for data generation or other tasks are excluded.
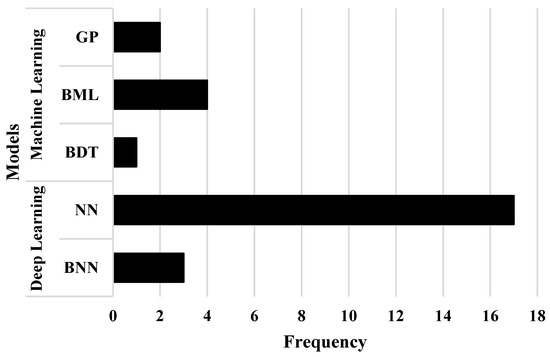
Figure 8.
Frequency plot of the ML models used in the twenty-seven reviewed papers. The main models identified in the SLR are GP, BML, BDT, NN, and BNN. These models can also be classified into two major fields: ML and DL. There is an observable trend toward using DL models for the treatment of cosmological data.
In detail, it can be observed that for a total of twenty-seven reviewed articles, the least-used ML model is BDT, mentioned in only one article () [93], followed by the GP model, which is used in two articles () [82,86]. Next, the BNN model is employed in three articles () [75,94,95]. The BML model was also observed to be in use in four articles () [96,97,98,99]. Interestingly, there appears to be a limited usage of the BDT, BNN, and BML models, which are variations of classical models (like decision trees, NN, and other ML variants) used for Bayesian inference tasks. Finally, the most widely used model is NN, which appears in seventeen articles () [73,74,76,77,78,79,80,81,83,84,85,87,88,89,90,91,92].
Overall, in twenty articles (), the models used can be classified as DL, while in the remaining seven articles (), the models used can be considered as ML models. This information clearly indicates a strong preference for DL models in handling the cosmological data mentioned in Section 5.2.
In the context of deriving observational constraints, the three most frequent families in our corpus offer complementary trade-offs: (i) Deterministic neural networks (NNs) scale well to high-dimensional inputs and deliver the largest computational speedups for repeated forward evaluations, but they require external uncertainty handling (e.g., ensembling/MC dropout) and careful calibration; (ii) Bayesian neural networks (BNNs) provide principled predictive uncertainty and can yield better-calibrated intervals at the cost of higher training/inference complexity; (iii) Gaussian processes (GPs) are sample-efficient with analytic uncertainty and strong calibration in low–moderate dimensional settings, but they suffer from scaling and reduced effectiveness as dimensionality grows. Given heterogeneous datasets and metrics across the included studies, we refrain from aggregate rankings and report these family-level trade-offs to contextualize the preferences observed in Figure 8. Consistent with these frequencies, the predominance of NN reflects pragmatic scaling: Once trained, NN surrogates amortize repeated forward evaluations and leverage modern hardware/toolchains, whereas GP training scales as and is kernel-sensitive in higher dimensions, and BNNs incur additional inference cost and implementation complexity—factors that limit their routine use on large, high-dimensional data.
5.4. Research Objectives
From the twenty-seven reviewed papers, we can conclude that it is possible to identify two main goals: (1) the enhancement of parameter estimation using ML techniques (hereafter referred to as “improvement”) and (2) the application of such improved estimation methods to address cosmological problems (hereafter referred to as “application”). In the first goal, the papers focus on the drawbacks of parameter estimation, mainly focused on the problems associated with the MCMC analysis related to the computing time for big datasets and free parameters, as we mentioned in Section 1. For the second goal, the papers use a previously improved parameter estimation through a certain ML technique to tackle some specific physical cosmological problems, taking advantage of the improvement in the computing time (or other improvements) of the new parameter estimation technique.
In Figure 9, we depict the number of papers and the year of availability online for the twenty-seven reviewed papers. From the Figure, we can see that from 2014 to 2024, twenty-one papers () are focused on the improvement of parameter estimation; meanwhile, six papers () are aimed at application, giving us insights that the main aim of these works is the improvement of cosmological constraints. Considering the years of publication, we do not have reviewed papers from the years 2014, 2016, 2017, and 2018. In 2015, one paper () focused on improvement [93] and one paper () focused on application [99]. On the other hand, from 2019, three papers () are focused on the improvement of parameter estimation [78,92,95]. In 2020, two papers () were focused on improvement [85,94], and two papers () were focused on application [96,98]; in contrast, in 2021, two papers () focused their study on the improvement of cosmological constraints [76,80], and one paper () focused on application [97]. In 2022, five papers () focused their aim on the improvement of parameter estimation [74,77,79,88,90], and only one paper () focused their aim on the application of improved parameter estimation [75]. Similarly, in 2023, seven papers () were focused on improvement [73,81,83,84,87,89,91], while only one paper was focused on application [82]. Finally, in 2024, there was only one reviewed paper (), and it focused on improvement [86]. Note that in the last three years, thirteen of the twenty-seven reviewed papers () are focused on improvement, i.e., nearly half of the reviewed papers. This gives us insights into the growing relevance, in recent years, of achieving more efficient parameter estimation for handling incoming observational cosmological data. The most remarkable results for both improvement and application aims are listed below.
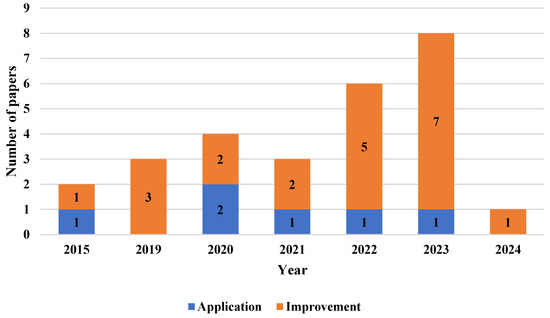
Figure 9.
Number of papers and the year of online availability of the twenty-seven reviewed papers. The articles are divided into two classifications based on their research aim: (1) the improvement of parameter estimation through ML techniques (improvement) and (2) the application of an improved parameter estimation analysis based on an ML technique to face cosmological problems (application).
Improvement Aim:
- 1.
- Some improvements for cosmological parameter estimation are studied in [77], with a 20-times faster enhancement in reproducing the correct contours compared to the MCMC case. Regarding the DL model, a densely connected neural network with three hidden layers, each consisting of 1024 neurons and using ReLU activation functions, was used. This architecture results in a number of trainable parameters on the order of millions due to the full connectivity between layers.
- 2.
- In Ref. [94], an enhancement of times is reported in the computing time in comparison with classical methods for parameter estimation, which accelerates performance, but this is less precise in comparison with the standard MCMC method. In the study, a BNN with the Visual Geometry Group (VGG) architecture was used with a customized calibration method.
- 3.
- A similar result as the above point was obtained in [95], but a BNN with different weight sampling methods is used to provide tighter constraints for the cosmological parameters. The findings of this paper serve as a guide for the models used in [94].
- 4.
- In Ref. [85], the authors show a reduction in computing times, producing excellent performance in parameter estimation compared with the MCMC for the CDM model. Also, a detailed explanation of the hyperparameters and the steps used to train the model is given. In particular, an NN with three hidden layers (reducing the number of neurons in each layer), together with the ReLU activation function, is used.
- 5.
- The number of executions in the Einstein–Boltzmann solvers for the CMB data is reduced in Ref. [78] in comparison with the standard procedure, which saves computational resources, translating into faster computations and avoiding the bottleneck in the solvers for the CDM model with a massive neutrino model. From an ML point of view, three NNs are used, which are made up of a combination of densely connected layers and convolutional layers. These layers are generally used in image classification tasks, but in this particular case, they are used to reduce the number of neurons instead of densely connecting the whole network. Along with this, the ReLU activation function is used together with Leaky ReLU, a version of ReLU that allows a small amount of negative data to be output.
- 6.
- The authors of Ref. [79] report that the estimation of parameters from the MCMC is more efficient with the solutions provided by an ANN, improving numerical integration in the CDM model; the Chevallier–Polarski–Linder parametric dark energy model; a quintessence model with exponential potential; and the Hu-Sawicki model, estimating that the error is 1% in the region of the parameter space corresponding to 95% confidence for all models.
- 7.
- A new method for parameter estimation that is up to 8 times faster than the standard procedure is presented in Ref. [84].
- 8.
- In Ref. [76], using NN techniques, the authors accelerate the estimation of cosmological parameters, taking 10 h compared with the 5 months required by the standard Boltzmann codes. Interestingly, the values of are similar to the standard computation of the CDM model.
- 9.
- In a similar way as in the above point, in Ref. [91], the authors achieve high precision in the criteria, with a difference of compared with the results obtained by the Cosmic Linear Anisotropy Solving System (CLASS), being up to 2 times faster than this standard procedure.
- 10.
- Finally, in Ref. [83], the authors show deviations for the parameters , , , , , and of , , , , , and , respectively, between the MCMC method and the ML technique for the CDM and CDM models.
Application Aim:
- 1.
- Improved parameter estimation with ML techniques was applied to solve the tension in Ref. [96]. In particular, through a BML method, the authors studied a Universe dominated by one fluid with a generalized equation of state.
- 2.
- In a similar way as in the above point, the authors of Ref. [97] apply a BML method in a model with a cosmological constant, baryonic matter, and barotropic dark matter and a model with barotropic dark energy, baryonic matter, and barotropic dark matter.
- 3.
- In Ref. [75], the authors show that the tension can be alleviated using BNN in -modified gravity, specifically in an exponential model.
- 4.
- Finally, in Ref. [98], the authors prove the opacity of the Universe through BNN in the CDM and xCDM models, showing that the Universe is not completely transparent, which also impacts the tension. Regarding the implementation of ML techniques, all scenarios use PyMC3, a probabilistic Python framework that has the necessary tools for applying the ML approach to probabilistic tasks.
In the upper part of Figure 10, we present the data sample considered for each cosmological dataset used in the twenty-seven reviewed papers according to the two main classifications of their research aim mentioned above, namely, improvement and application. As we can see, BAO was used in five papers (), for which their objective was to improve parameter estimation [78,79,81,85,89], and one paper () considered this data in the application of improved parameter estimation through an ML technique [82]. On the other hand, eleven papers () used CMB data in their improvement aim [76,78,83,85,89,90,91,92,93,94,95], while only one paper () considered this data in their application aim [82]. This is an expected result and is a consequence of the conclusion obtained in Section 5.2, i.e., CMB data is the most expensive data at the computational level. Interestingly, two papers () use GCD [73,74] and LSS [77,78] data in the improvement of cosmological constraints, while four papers () use generated data in the application of improved parameter estimation techniques [96,97,98,99]. For GL data, three papers () aimed to improve parameter estimation [76,77,78], and one paper () aimed to apply improved parameter estimation [75]. Finally, six papers () considered improvements aimed at OHD [79,80,81,84,86,87] and SNe Ia [79,80,81,83,84,85] data, and one paper () considered the application of OHD [75] and SNe Ia [82] data.
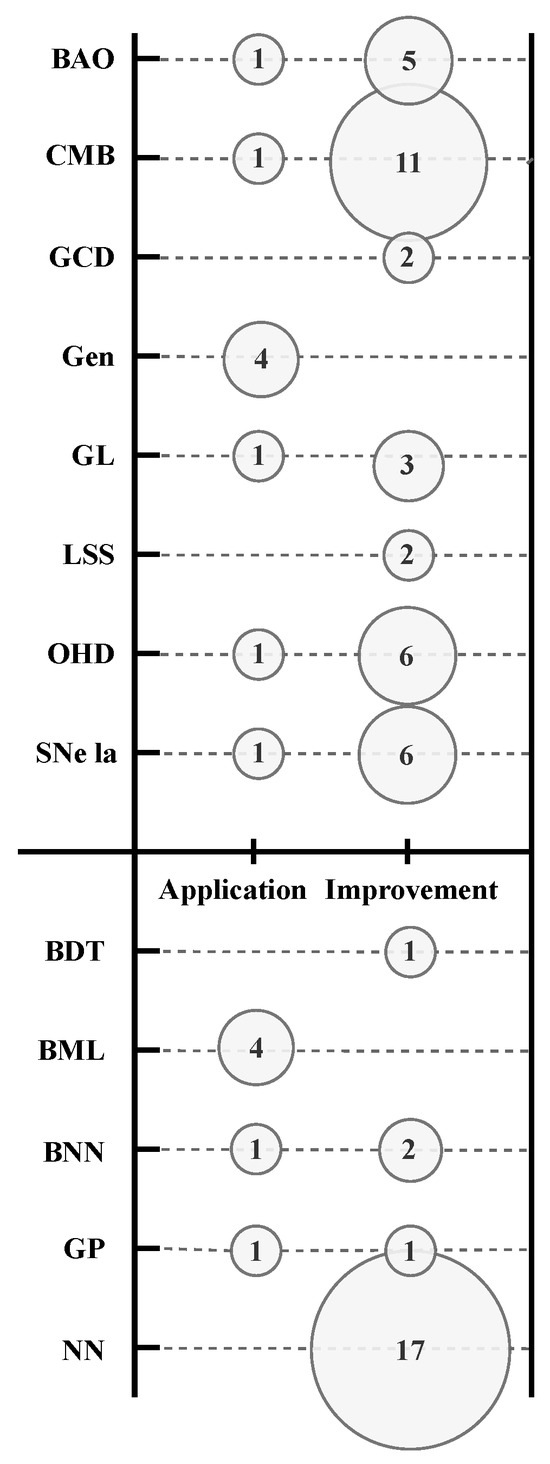
Figure 10.
Data sample for each cosmological dataset (upper) and ML model (lower) used in the twenty-seven reviewed papers according to their research aim: (1) the improvement of parameter estimation through ML techniques (improvement) and (2) the application of an improved parameter estimation analysis based on an ML technique to face cosmological problems (application).
In the lower part of Figure 10, we can observe the frequency of ML and DL model usage based on whether the paper’s objective is application or improvement. Specifically, the BDT model, used once, appears in an article [93] () aiming to enhance parameter estimation. The BML model is exclusively used in papers where the goal is to improve cosmological constraints, specifically in four papers [96,97,98,99] (). The BNN model is used once [75] () in an application article and twice (66.7%) [94,95] in improvement-focused papers. The GP model is used twice: once in an improvement paper () [86] and once in an application paper () [82]. Finally, the NN model is exclusively used in improvement-focused articles, particularly in seventeen cases () [73,74,76,77,78,79,80,81,83,84,85,87,88,89,90,91,92]. As mentioned in the previous section, NN models offer higher representational capacities due to their deep architecture layers, making them particularly useful when dealing with large datasets.
In Figure 11, we present a frequency plot of the usage of databases employed in the twenty-seven reviewed papers, specifying which ML/DL model was used for each database. Note that this plot is slightly different from Figure 10 because, in the latter, we present the number of papers that uses a specific database while, in Figure 11, we present the ML/DL model used in each database, which could be more than one. Following this line, for the BAO database, the GP ML model is considered three times (), and the NN DL model is considered five times (). In this case, Ref. [82] uses three different catalogs of BAO for the GP ML model. On the other hand, for the CMB database, the GP ML model is considered one time (), the BDT ML and BNN DL models are considered two times (), and the NN DL model is considered eight () times. As was the case before, Ref. [93] uses the Planck and WMAP catalogs for the BDT ML model. For the GCD and LSS databases, the NN DL model () is only considered, while for the GL database, the BNN DL model is considered once (), and the NN DL model () is considered three times. Following this, in the OHD database, the BNN DL and GP ML models are considered once (), and the NN DL model is considered five times (); in contrast, for the SNe Ia database, the GP ML model is considered once (), and the NN DL model is considered six times (). Finally, in the generated database, the BML model () is only considered. It is important to highlight that NN is the most used DL model, either to improve parameter estimation or apply an improved cosmological constraint. In particular, for the CMB database, NN is considered eight times (), which is an expected result, again due to the fact that CMB data is the most expensive data at the computational level, justifying the use of NNs because they can obtain deeper representations of the input data. Also, for the generated database, all articles are focused on solving the same problem, which is the tension. For this purpose, the authors improve the ML techniques applied throughout the papers.

Figure 11.
Frequency plot of the usage of databases employed in the twenty-seven reviewed papers. Additionally, the plot specifies which ML/DL model was used for each database.
5.5. Year and Type of Publication
In Figure 9, we can see the number of articles per year selected in our SLR. As a reminder, we focus our review between the years 2014 to 2024. From a total of twenty-seven reviewed papers, two of them became available in 2015 [93,99], three of them () in 2019 [78,92,95], four () in 2020 [85,94,96,98], and three of them () in 2021 [76,80,97]. Interestingly, in 2022, a higher proportion of six of the selected papers () became available online [74,75,77,79,88,90], while eight papers () became available in 2023 [81,82,83,84,87,89,91]. Finally, one of the selected papers () became available online in 2024 [86]. In general, the number of publications has increased in the last few years, especially in 2022 and 2023, amassing of the selected papers, with 2023 being the year with the highest number of selected publications. This indicates a trend in the area of cosmology to search for new methods—in this case, artificial intelligence—for determining Bayesian inference.
On the other hand, in Table 2, the journals in which the selected articles were published are displayed. As it is possible to see, six papers () were published in the Journal of Cosmology and Astroparticle Physics (JCAP), five papers () in Physical Review D (PRD), five papers ( in Monthly Notices of the Royal Astronomical Society (MNRAS), three papers () in The Astrophysical Journal Supplement Series (ApJS), and one paper () in Galaxies, Symmetry, The European Physical Journal C (EPJC) and Science Direct (SD). Four papers () became available in the preprint repository arXiv. This means that these papers are accessible online and can be cited, but they have not undergone a peer review process. It is important to mention that all the journals in which the selected papers were published are Q1 and Q2 journals within the area of physics, with no presence of journals in the area of computational science.
Table 2.
Journals in which the articles were published.
The preprint online repository arXiv is of interest not only because nine of the selected papers are available in that repository and were not published in a journal but also because of the twenty-seven selected papers in our SLR are available in that repository. This highlights the importance of the arXiv preprint repository in the area of cosmology (and other physics areas). However, this leads to confusion in the years of publication in this SLR because we have a year in which a paper is available online in the arXiv repository and another year during which the paper was published in a journal after undergoing the peer review process. Following this line, in Figure 12, we present the number of months in which the reviewed papers were available in the online repository arXiv until their publication in a journal (if this is the case). As we can see, the selected papers published in MNRA exhibit a mean of months since their availability in arXiv until their publication in the journal, with a maximum of 14 months and a minimum of 1 month. On the other hand, PRD exhibits a mean of months to be published since their availability in arXiv exhibits a maximum of 11 and a minimum of 4 months. In the same line, for JCAP, the mean time of publication is months from their availability in arXiv until their date of publication, with a maximum of 11 and a minimum of 2 months. In the case of ApJS, it has the same range as MNRAS but with a mean of months, a maximum of 12, and a minimum of 2 months. Finally, for EPJC and Galaxies, the time of publication was 7 and 5 months, respectively. Something out of the ordinary is the case of a paper published in Symmetry, which took up to 6 years from its first appearance on arXiv to its publication in the journal. This appears to be a singular case and does not seem to reflect an issue with the journal itself. The long delay between the arXiv submission (2015) and the final publication in Symmetry (2021) may be due to substantial updates made to the manuscript over time, including the integration of the ML topic. However, as this is based on a single paper, no general conclusions should be drawn.
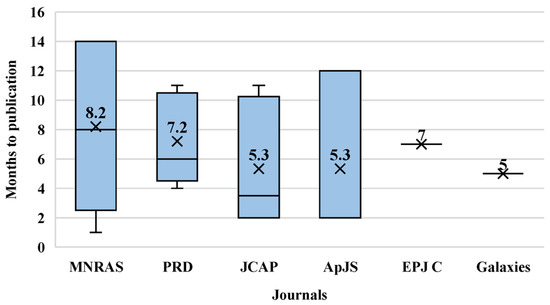
Figure 12.
Number of months in which the reviewed papers were available in the online repository arXiv until their publication in a journal.
This metric contextualizes method adoption and prevents the conflation of preprint and peer-reviewed timelines in our year-based analysis.
6. Review Findings and Future Research Directions
This section presents an in-depth discussion of the review findings derived from the synthesis and analysis of the data. Additionally, it offers practical recommendations for addressing key research gaps, which could lead to potential future research opportunities. Finally, Section 6.3 provides a concise technique-level comparison and benchmarking considerations, clarifying why cross-paper benchmarking is not methodologically sound given heterogeneous tasks/datasets/metrics and linking these points to the expanded performance summaries in Appendix A.
6.1. Main Outcomes
The findings are organized around five main themes presented in Section 4.2, with an overview of the review findings illustrated in Figure 13:
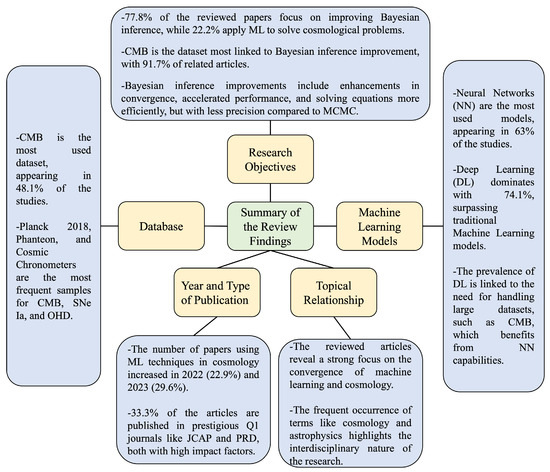
Figure 13.
Summary of the review findings.
- Topical Relationship: As was presented in Section 5.1, the analysis of titles and keywords confirms a clear thematic alignment across the selected studies. The recurring presence of terms such as “cosmology,” “astrophysics,” “parameters,” “neural,” and “Bayesian” illustrates the strong focus on applying machine learning techniques to fundamental cosmological challenges. These challenges predominantly involve the estimation of free parameters and the analysis of nongalactic observational data. Rather than revealing broad interdisciplinary diffusion, the thematic patterns suggest that the application of ML in cosmology remains largely grounded in the physics and astrophysics domains. This concentration highlights both the relevance and the early stage of this interdisciplinary field, where ML methods are still being explored and adapted to address domain-specific problems. The prominence of terms related to data analysis and inference further reinforces the conclusion that ML is primarily being employed to enhance the efficiency and accuracy of traditional model-fitting techniques within established cosmological frameworks.
- Databases: Following Section 5.2, the main datasets used in the reviewed articles are as follows: SNe Ia, OHD, BAO, CMB, LSS, GL, and GCD. For the twenty-seven articles considered in the revision, it can be noted that the most used databases are CMB at , BAO at , and SNe Ia and OHD at . Meanwhile, GL, LSS, and GCD are used less than . It is interesting to note that CMB is the most used dataset since it contains the most expensive data at the computational level. From the data samples, it can be seen that Planck 2018 (), Pantheon (), and Cosmic Chronometers () are the most used in CMB, SNe Ia, and OHD, respectively.
- Machine Learning Models: In general, for both ML and DL models, it was found in Section 5.3 that the majority of the reviewed articles uses NN (). The other encountered models do not exceed usage. Moreover, when considering the technique type alone, DL significantly surpasses ML ( DL compared to ML). This trend is probably due to the large amount of data and the number of parameters to be processed, where DL techniques are often better suited due to their capacity to learn patterns at greater depth. This observation is further reinforced by the discovery that CMB, a rather large and complex database, is primarily handled using NNs.
- Research Objectives: A remarkable result of our SLR is presented in Section 5.4, in which of the papers are focused on improving parameter estimation and are focused on the applications of improved cosmological constraints through ML techniques to solve cosmological problems. In this line, the most studied problem is the tension in different cosmological models. On the other hand, in the improvements, there are more varied results, such as enhancements in convergence, accelerations in the performance of inferences, and the more efficient solutions of equations using ML techniques, but these always occur with less precision compared to the MCMC method. Lower values of precision are achieved for [91] in CDM, and small deviations were observed in for some cosmological parameters [83]. In CDM and CDM, concerning the focus on different databases, it is important to consider that, from CMB, of the articles are related to the improvement of parameter estimation, which is expected as CMB is the most expensive data at the computational level. In the case of OHD and SNe IA, with both exhibiting , they are focused on improvement, and this was also the case for BAO in of the papers. On the other hand, it is interesting that NN is only used in the improvement of cosmological constraints, and BML is only used in applications. In this line, NN is widely used in the reviewed papers for all databases exhibiting for the CMB, for BAO, for OHD, and for GCD and LSS, which results in the use of different catalogs 31 times for the databases mentioned before. Meanwhile, the second most used technique is GP, which was only applied 6 times for all databases.
- Year and Type of Publication: Finally, from Section 5.5, we can see that recent years show an increase in the number of available articles citing the use of ML techniques to improve parameter estimation in cosmology or citing applications to cosmological problems, such as of the reviewed papers published in 2022 and in 2023. On the other hand, of the articles are published in prestigious journals such as JCAP and PRD, which are Q1 journals in the area of physics with a high impact factor. In this line, it is important to note that of the reviewed papers are available in the online arXiv repository, giving insights into the usefulness of this repository in the area of cosmology. We also report the time (in months) between first availability on arXiv and publication in a peer-reviewed venue as a proxy for the pace at which the results are vetted; this helps contextualize the corpus’s reliance on preprints, the maturity of the literature, and the appropriate level of caution when interpreting findings. The updated analysis shows that the mean time is months for JCAP months for PRD, and months for MNRAS. Other journals such as ApJS show a comparable mean time to JCAP, which is also months, while EPJC and Galaxies take 7 and 5 months, respectively. An outlier in the dataset is Symmetry, where one article took 6 years to transition from arXiv to formal publication—likely due to substantial post-submission modifications and topic shifts rather than delays inherent to the journal itself.
6.2. Research Gaps and Recommendations
According to the main findings of our SLR, we organize the gaps and recommendations into three themes—Methodological, Application, and Data-related—summarized in Figure 14.
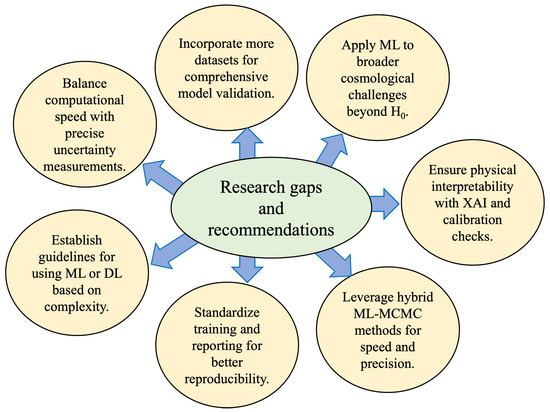
Figure 14.
Summary of the research gaps and recommendations identified in the SLR.
Methodological Gaps and Recommendations
- (M1)
- Improvement vs. Precision for ML TechniquesVarious ML techniques, including BNN, GP, and DL models, have been applied to cosmological data analysis, showing their potential to improve parameter estimation and to handle large complex datasets. However, a central tension emerges between computational acceleration and the fidelity/calibration of the resulting constraints. In our corpus, methods that deliver the largest speedups sometimes exhibit wider credible regions or miscalibrated posteriors relative to classical baselines, highlighting that efficiency gains do not automatically guarantee precision. The cosmological consequences of using faster but less precise surrogates are concrete: posteriors may be biased, credible regions are under-/over-estimated, and thus, key scientific claims can be distorted—e.g., tensions (such as ) artificially inflated or masked, Bayes factors and model selection misreported, and cross-probe consistency (CMB/BAO/SNe/LSS) mischaracterized.There are, nevertheless, regimes where prioritizing speed is justified: when repeated forward evaluations dominate wall-time (e.g., emulating Einstein–Boltzmann pipelines inside MCMC), during rapid exploratory scans in high-dimensional spaces, or for triage/operational tasks. By contrast, precision must take precedence for final parameter estimations intended for publication, tension quantification across probes, and model comparison—settings where coverage and bias directly affect scientific validity. In practice, speed-first surrogates (often NN-based) are valuable for amortizing computation, provided that they are accompanied by explicit uncertainty calibration and validation against classical pipelines. BNN/GP approaches, while costlier, tend to offer stronger uncertainty calibration when their assumptions hold.Recommendations: We recommend reporting both efficiency (speedup ×, wall-time, ESS/s) and calibration/accuracy (coverage, bias, posterior width, and posterior predictive checks/PIT) to make the trade-off explicit; validating surrogates against Einstein–Boltzmann solvers or exact likelihoods at checkpoints; adopting physics-aware inductive biases where possible (e.g., spherical/equivariant layers, operator-learning surrogates); and using hybrid pipelines that combine speed-first emulation with precision-first verification (e.g., periodic exact re-evaluation, proposal preconditioning, stress tests under distribution shift). These practices mitigate the risk that acceleration comes at the expense of reliable cosmological constraints.
- (M2)
- Hybrid Approaches: Combining Machine Learning and MCMC MethodsHybrid methodologies emerge from the reviewed papers that combine ML techniques with the traditional MCMC method. One combination is the use of ML techniques to solve differential equations. For example, in Refs. [79,84], NNs are employed to solve the cosmological background equations, while in Ref. [89], NNs are used to solve the Einstein–Boltzmann equations. In both cases, the solutions are used as input for the MCMC method, accelerating the computation time and maintaining precision. These examples demonstrate the versatility of neural networks in efficiently handling the computationally expensive components of cosmological modeling, paving the way for their integration into traditional inference workflows. This highlights the importance of not only focusing on improving the MCMC method but also on investing resources in optimizing the most time-consuming aspects of the procedure involving CMB data, i.e., the development of more efficient Einstein–Boltzmann solvers.Another combination is using the results of ML techniques as a prior as in Refs. [94,95]. In these works, the results obtained from BNNs are used as prior information/input for the MCMC method, accelerating the computations with similar precision as in the classical implementation of MCMC. This approach is particularly effective in reducing the dimensionality of the parameter space, allowing MCMC methods to focus on fine-tuning within a more constrained region. Such integration not only reduces computational overhead but also enhances the stability of the inference process in high-dimensional scenarios.Despite these advances, the adoption of hybrid methodologies is not without challenges. Ensuring compatibility between ML-generated outputs and MCMC implementations requires careful validation, especially when physical constraints must be preserved. Additionally, the interpretability of ML-based priors remains an area of concern, as it can obscure the underlying assumptions driving the parameter inference. Addressing these challenges will be critical to ensuring the robustness and reliability of hybrid approaches.Based on the above, a recommendation is to explore these hybrid methodologies since they accelerate the computations and give us uncertainties similar to the traditional MCMC method. Future research should focus on standardizing frameworks for integrating ML techniques with MCMC, establishing benchmarks to compare hybrid and traditional methods, and exploring the potential of emerging ML techniques such as physics-informed neural networks (PINNs) to further optimize cosmological computations. These efforts will help realize the full potential of hybrid methods in advancing precision cosmology.Hybrid methodologies that combine ML techniques with MCMC have demonstrated their potential to enhance cosmological computations by balancing precision and efficiency. For instance, NNs can be used to solve cosmological equations or reduce the dimensionality of parameter spaces before applying MCMC, as described in (M2). These approaches leverage the strengths of DL, as discussed in (M4), particularly in handling high-dimensional data and learning intricate patterns in cosmological datasets. By integrating the scalability and adaptability of DL models into hybrid methodologies, researchers could achieve significant gains in both computational performance and accuracy. These efforts will help realize the full potential of hybrid methods in advancing precision cosmology.These hybrid methods, which balance precision and efficiency, complement the strengths of DL discussed in (M4), particularly in analyzing high-dimensional datasets and addressing complex cosmological problems.
- (M3)
- Inconsistent Reporting Standards in Model TrainingThe evidence gathered from the training phases of different models lacks a consistent standard across studies, leading to variability in reporting. Some papers focus on the theoretical aspects, detailing architectural choices and modifications [81,82,83,90], while others provide comprehensive descriptions of experimental setups, such as the libraries used, programming languages, and environmental contexts [94,96,97,98,99]. A subset of studies presents detailed visualizations of model architectures, including layer interconnections and input–output flows [77,78,88,92], whereas others offer step-by-step guidelines for training procedures [85].Despite these contributions, there remains a notable absence of unified guidelines for documenting the training process, leading to substantial heterogeneity in the level of detail provided. For instance, while some studies excel in presenting architectural visualizations or procedural guidelines, critical aspects such as dataset distribution and preprocessing techniques are often underreported. Without these details, it is difficult to evaluate the representativeness and generalizability of the models. Moreover, studies rarely specify training duration, making it challenging to assess computational efficiency or scalability.However, significant gaps remain in the reporting of critical elements such as dataset distribution (how data is divided into subsets for training, validation, and testing), training duration (the total time spent training a model), computing environments (e.g., the hardware or cloud infrastructure used), and hyperparameters (configurations that control the training process, such as the learning rate, which determines how much the model adjusts its parameters in each iteration, and activation functions, which define how signals are passed between layers in neural networks). Equally crucial are other factors that enhance comparability, such as the precise evaluation metrics used, a thorough description of the training pipeline, and the rationale behind specific parameter choices. The absence of these elements creates significant obstacles for meta-analysis, as variability in reporting undermines the comparability of results across studies. These omissions hinder the comparability of results and the identification of optimal configurations, complicating efforts to determine the most effective models or hyperparameter settings.Furthermore, the lack of comprehensive context makes it challenging to replicate experiments under identical conditions. For example, some studies fail to describe the computing hardware used (e.g., GPUs, CPUs, cloud infrastructure), which significantly impacts training performance and cost-effectiveness. In fields like cosmology, where data sizes and computational demands are substantial, these details are critical for assessing the feasibility of deploying similar models in real-world scenarios. This variability raises questions about the reliability and reproducibility of findings, ultimately limiting their utility in advancing the field.As a result, this lack of standardization highlights the urgent need for a more structured approach to documenting the training phases of machine learning models. Developing and adopting reporting frameworks that ensure transparency and completeness, akin to PRISMA guidelines for systematic reviews, would greatly enhance reproducibility, reliability, and the cumulative progress of machine learning in cosmology.
- (M4)
- Deep Learning vs. Traditional Machine Learning in Cosmological ApplicationsOur review confirms that DL models generally outperform traditional ML methods, particularly when processing large datasets with numerous variables. NNs excel in learning intricate patterns through their deep architectures, offering extensive customization to suit various cosmological applications. The findings reveal a marked preference for DL algorithms across the reviewed studies, suggesting that ML models, while useful for preliminary analysis or feature selection, may struggle with the complexities of cosmological data. Specifically, DL methods such as CNNs and RNNs demonstrate superior performance in tasks requiring spatial and temporal pattern recognition, such as analyzing sky surveys and time-series data from telescopes. These strengths make DL particularly advantageous for applications like detecting gravitational waves, mapping dark matter distributions, and estimating cosmological parameters.Additionally, the flexibility of NNs facilitates essential adaptations for cosmological inference, enabling precise parameter estimation and more effective handling of high-dimensional observational data. For example, custom loss functions tailored to cosmological objectives (e.g., minimizing deviations in parameter estimation) and the integration of physical constraints within NN architectures allow for more accurate modeling of astrophysical phenomena. Moreover, the scalability of DL models enables them to handle the exponential growth of data from next-generation surveys, such as the Vera Rubin Observatory and the Euclid mission, where traditional ML methods often falter.Across the surveyed studies, architectural choices are largely adapted from computer science (e.g., CNN/U-Net variants for map-like data, MLPs for emulators), with only limited explicit encoding of cosmological inductive biases. Notable exceptions include spherical/equivariant convolutions for CMB/weak-lensing maps and operator-learning surrogates for Einstein–Boltzmann pipelines. This pattern helps explain why the largest speedups sometimes coexist with calibration issues: Acceleration is prioritized, while symmetry constraints and uncertainty modeling are not always built in. A practical direction is to combine physics-aware architectures with explicit calibration checks (coverage/PIT) and comparisons to classical baselines so that efficiency gains do not compromise constraint reliability.However, the increased computational demands and the risk of overfitting in DL models highlight the importance of establishing clear evaluation metrics and benchmarks to assess their efficiency and reliability in cosmological contexts. Studies should also explore hybrid approaches that combine the strengths of ML and DL—for instance, using ML for feature extraction and DL for parameter inference—to optimize resource utilization while maintaining accuracy.Future research could benefit from clearly defined guidelines for when ML methods are appropriate versus when the added complexity of DL is justified. These guidelines should consider not only the size and complexity of the datasets but also factors such as computational resources, interpretability needs, and the specific objectives of the study. Developing such a framework would enable researchers to make informed decisions, maximizing the scientific impact of their analyses while minimizing resource expenditure.
- (M5)
- Interpretability and Physical Faithfulness (XAI)A recurring concern in precision cosmology is trust in “black-box” models. Beyond aggregate performance, we need evidence that models learn physics-relevant structure rather than survey- or instrument-specific artifacts. In the reviewed literature, XAI is unevenly reported. Useful practices include the following: (i) attribution and saliency analyses on map-like inputs (e.g., integrated gradients, Grad-CAM) with checks that highlighted regions align with physically meaningful features; (ii) stability tests of explanations under small input perturbations and across instruments/surveys to detect spurious correlations; (iii) counterfactual “injection” and ablation tests using simulations (turning on/off specific effects) to verify causal sensitivity to the intended signal; (iv) enforcing inductive biases via symmetry-aware architectures (e.g., spherical/equivariant layers) and operator-learning surrogates; and (v) posterior diagnostics (coverage, posterior predictive checks, and simulation-based calibration) to ensure that uncertainty is not only reported but also calibrated.Recommendations: Report at least one attribution method with stability checks; include cross-survey/domain-shift tests; provide physics “unit tests” via controlled simulation injections; prefer architectures that encode known symmetries; and release code to reproduce explanations and diagnostics alongside classical-baseline comparisons.
Application Gaps
- (A1)
- ML Technique Applied to Cosmological ProblemsThe reviewed papers considered two scenarios: the improvement in the algorithm and the application to a cosmological problem. In the first case, an exploration of the algorithm was focused on refining the parameter estimation processes through ML techniques. In the second case, the ML technique was directly applied toward addressing the tension. This tension refers to the discrepancy between the observational technique (such as CMB) and the local measurements of the Hubble constant . The study of this problem was in the context of different cosmological scenarios relative to CDM, such as a Universe dominated by only one fluid with a general barotropic equation [96] or a Universe with barotropic dark energy and dark matter [97]. In the same line, the problem was studied to probe the opacity of the Universe with an xCDM cosmological model, resulting in impacts in the tension problem [98].While the reviewed papers focus primarily on this specific problem, there exists a significant gap in exploring different cosmological issues that could benefit from these ML techniques. For instance, other cosmological problems could be treated with the ML techniques used in the reviewed articles, such as the cosmological constant problem [100] concerning the large discrepancy between the theoretical value of the cosmological constant and the observed value (which is related to dark energy). The ML techniques explored in the reviewed articles could help to test alternative models to CDM that might solve this problem. On the other hand, the coincidence problem [16], related to the fact that energy densities for dark matter and dark energy are of the same order of magnitude at the current time, which can be seen as a fine-tuning problem, could also be explored with ML techniques to test alternative models to explain this issue.Another cosmological issue is the possibility of a warm dark matter component in the Universe [101], an alternative to the cold dark matter considered in CDM; this could leave imprints in the LSS and CMB background that could be analyzed with the ML techniques and be tested in different cosmological scenarios. Finally, to mention a few, phantom dark energy [102], which accelerates the expansion of the Universe and has an unknown origin, could also be tested in different cosmological scenarios with the use of ML techniques.It is important to emphasize that all the aforementioned problems benefit from the use of ML techniques for parameter estimation, thereby helping to alleviate the tensions within the CDM model. Likewise, other problems may also benefit from these parameter estimation results.
Data-Related Gaps
- (D1)
- Cosmological Data Used in ML TechniquesTraditional cosmological methods, such as those using SNe Ia, BAO, and CMB data, continue to be fundamental tools in cosmology. These provide insights into the expansion, the energy densities, and the parameters of a specific cosmological model. The incorporation of ML techniques enhanced their robustness and efficiency through their abilities to analyze a large and complex dataset, having the potential to optimize the parameter estimation of alternative cosmological models to CDM. Nevertheless, we identify that a large number of the reviewed works do not use the majority of the available databases and focus their studies on a relatively narrow subset of the available dataset. For instance, several studies use particular datasets, like only CMB, or combine SNe Ia with other datasets such as OHD without incorporating the total available dataset.The use of some of the datasets mentioned before brings some valuable results to cosmology but limits the scope of the analysis and estimation of the cosmological parameters for certain cosmological models. Moreover, this could may cause biases because each dataset has its own uncertainties and observational limitations. In this sense, we identify a gap because any alternative cosmological model, to be considered viable, must be able to describe the total background cosmological data in the same or better way as the CDM model. In the case of CDM, it has been extensively tested and validated with a wide range of observational data, and any alternative model must be consistent, at least at the same level, with the current observational data. This includes not only using a single dataset but also accounting to join all of them for a full analysis. Therefore, we recommend that future studies focus on using larger numbers of datasets such as gravitational waves, CMB, LSS, OHD, and SNe Ia, among others, in order to be fully consistent in the analysis of alternative cosmological models. Nevertheless, we would like to emphasize that this is not a straightforward task due to the complexity of the cosmological model and the specificities of its analysis.
6.3. Technique-Level Comparison and Benchmarking Considerations
6.3.1. Why Cross-Paper Benchmarking Is Not Methodologically Sound
The 27 papers in our corpus differ substantially in (i) task framing (e.g., emulation of Boltzmann solvers, likelihood-free simulation-based inference, or direct regression), (ii) cosmological probes and datasets (CMB, BAO, SNe Ia, OHD, LSS, and gravitational lensing), (iii) pipelines (likelihoods, priors, simulators, samplers, and train/validation splits), and—crucially—(iv) reported metrics and reporting conventions. Because there is no common baseline across data, simulators, priors, calibration diagnostics, or compute budgets, constructing an “apples-to-apples” ranking of NN, BNN, and GP from published results would be misleading. A genuinely comparable benchmark would require re-executing all methods under a harmonized protocol (shared datasets/splits, identical likelihoods or simulators, agreed-upon diagnostics, and fixed compute budgets), which lies beyond the scope of a systematic review and is closer to a dedicated community benchmarking effort.
6.3.2. When Each Family of Techniques Tends to Be Preferable
Our synthesis reveals a consistent trade-off between efficiency and uncertainty quality:
- NN-based accelerators (emulators/surrogates, accelerated profile-likelihood computations) are preferable when wall-time and throughput dominate (e.g., repeated model evaluations), provided that calibration is checked against standard pipelines.
- BNN/GP approaches tend to be preferable when calibrated posteriors and well-characterized uncertainty are the priority, accepting higher computational cost when their assumptions hold.
- Hybrid schemes (e.g., NN emulators within MCMC, or normalizing flows in simulation-based inference) are attractive when both speed and calibration matter, using ML to accelerate expensive steps while retaining principled posterior checks.
6.3.3. Minimal Conditions for a Future Community Benchmark
To enable fair, objective comparisons, we encourage convergence on the following: (i) common public datasets/simulators with predefined splits; (ii) standard efficiency metrics (e.g., speedup against a reference pipeline, wall-time per effective sample); (iii) calibration diagnostics (credible-interval coverage, PIT/SBC, posterior-width ratios); (iv) accuracy criteria (NLL/ on held-out data; parameter bias); (v) transparent compute-budget reporting (hardware, runtime caps, seeds); and (vi) out-of-domain tests to quantify robustness under domain shift.
6.3.4. Practical Implication for This Review
Until such conditions are met, cross-paper “performance tables” should be interpreted as as-reported summaries rather than direct rankings. Consistent with this principle, Appendix A also includes a Performance column that consolidates, for each study, the outcomes reported by the authors and explicitly flags their non-comparability across heterogeneous setups.
7. Threats to Validity
In the course of conducting this SLR on the application of ML techniques for observational constraints in cosmology, several potential threats to validity have been identified. These threats may impact the generalizability, reliability, and interpretation of the findings. The following section categorizes and discusses these threats.
7.1. External Validity
This review focuses on the use of machine learning (ML) techniques in cosmology, particularly in improving parameter estimation through Bayesian inference and related methods. While the findings may offer valuable insights, their applicability to other domains, or even different contexts within cosmology itself, is limited. The cosmological datasets reviewed, such as SNe Ia data, CMB measurements, and LSS surveys, have unique characteristics that may not generalize well to other fields. For example, ML models trained on cosmological data often deal with high-dimensional and noisy datasets, which may behave differently in non-cosmological domains. In fact, it is usually the opposite, as it is cosmologists who apply ML techniques developed in other fields (such as computer science) to adapt them to the specific needs of cosmological data. Therefore, researchers applying these techniques outside of cosmology should be cautious when attempting to extrapolate conclusions directly.
On the other hand, the generalization across different cosmological datasets can be challenging. Data from diverse cosmological surveys, such as the LSST or Euclid, may have varying levels of noise, resolution, and biases. These differences can impact the performance of ML models in ways that limit their generalizability. The findings in this review, which focus on specific datasets, may not hold across all future surveys.
In addition, the clear thematic alignment we highlight may partly reflect our inclusion criteria (which prioritize works that explicitly derive observational constraints) together with the modest size of the corpus (27 papers, 2014–2024). This naturally limits thematic diversity at present; accordingly, this survey should be regarded as an initial baseline to be updated as the literature expands and reporting standards mature.
Finally, the results are highly time-specific. The ML techniques reviewed in this paper rely on the data and methods currently available. As new cosmological data emerge and ML models evolve, the conclusions drawn from the present review may become outdated or require significant adjustment.
7.2. Construct Validity
Construct validity refers to how well the ML techniques and evaluation methods used in the studies reviewed actually measure the intended cosmological parameters. One potential threat to construct validity in this review is the diversity of evaluation metrics used across different studies. Some studies may focus on metrics such as accuracy or mean squared error, while others emphasize Bayesian inference performance or uncertainty estimation. This variability in evaluation criteria complicates efforts to compare and synthesize results across studies, potentially leading to inconsistent conclusions about the effectiveness of ML techniques in cosmology.
Another concern is the complexity and uniqueness of cosmological data. Cosmological datasets often involve high noise levels, incomplete information, and non-linear relationships between variables. In some cases, ML models may overfit these unique characteristics rather than generalize to broader cosmological phenomena. This could create an illusion of strong model performance on the training data, but such models might underperform when applied to new or unseen cosmological observations.
7.3. Internal Validity
Internal validity concerns whether the conclusions drawn in the reviewed studies are truly reflective of the methods used, rather than external biases or influences. One prominent threat to internal validity in this review is the possibility of publication bias. Studies that report positive or statistically significant results may be more likely to be published, leading to a potential overestimation of the effectiveness of ML techniques in cosmology. Negative or inconclusive findings might remain unpublished, thus skewing the overall picture of the field.
Additionally, there is a risk of researcher bias during the review process. Although rigorous inclusion and exclusion criteria were employed, the subjective interpretation of the relevance and quality of the studies reviewed may introduce biases. The decisions made regarding which studies to include in this review could influence the overall findings, particularly if certain datasets or methods were preferentially selected.
Finally, the variability in the quality and characteristics of the cosmological datasets used in the reviewed studies also poses a risk to internal validity. Some datasets may be more amenable to ML techniques due to higher data quality or fewer inherent biases, leading to potentially skewed conclusions regarding the effectiveness of the techniques across the field.
7.4. Conclusion Validity
Conclusion validity refers to the strength and reliability of the conclusions drawn from the reviewed studies. A key threat to conclusion validity in this review lies in the interpretation of the findings. Different researchers may prioritize different aspects of ML applications, such as computational efficiency, accuracy, or interpretability. This variation in emphasis can affect the conclusions drawn from the review, as certain aspects of the findings may be given more weight than others depending on the researcher’s focus.
Moreover, inconsistency in the results across studies presents another challenge. Some ML techniques may perform well under certain cosmological conditions but fail to generalize to others. This inconsistency makes it difficult to draw broad, definitive conclusions about the overall utility of ML for cosmological parameter estimation. It is essential to recognize that while certain methods may show promise, the overall effectiveness of ML in cosmology remains context-dependent, with substantial variability in performance depending on the dataset and problem at hand.
8. Conclusions
This study presents a systematic review exploring ML techniques applied to derive observational constraints in cosmology, offering a comprehensive synthesis of the most relevant methodologies at this interdisciplinary intersection. Through the analysis of twenty-seven articles, we identified that NNs and DL approaches dominate the field due to their ability to handle large datasets and extract complex patterns efficiently.
The results of this review indicate that, while ML techniques have shown significant improvements compared to traditional methods such as MCMC, particularly in efficiency (with precision maintained when surrogate models are properly validated), challenges remain regarding their full integration into conventional cosmological practices. The observed preference for hybrid models and the use of simulated data also suggest that the scientific community is in a transitional phase, experimenting with approaches that combine the robustness of classical methods with the flexibility of ML. Specifically, we highlight the potential of DL to address computational bottlenecks in processing CMB data and free cosmological parameters. However, the lack of standardization in evaluation criteria and the limited adoption of certain models, such as BNNs, reveal areas for improvement and the need for future research.
On the applied side, progress has been made in resolving critical issues such as the Hubble constant () tension using Bayesian techniques, but further studies are needed to consolidate these methodologies in broader scenarios. The increasing availability of data through upcoming projects, such as LSST and Euclid, positions ML as an essential tool to tackle emerging challenges in precision cosmology.
In alignment with our objectives (RQ1–RQ4), we state the following: NNs are most frequently used, with BNN and GP being less common (RQ1); NN surrogates typically provide the largest speedups for repeated forward evaluations—enabling practical MCMC—while maintaining precision when validated against Einstein–Boltzmann solvers, whereas BNN and GP generally offer stronger uncertainty calibration under their assumptions (RQ2); head-to-head comparisons are scarce, and reporting remains heterogeneous, with limited cross-survey validation (RQ3); the common mix of observational and simulated data calls for explicit calibration checks and stress tests (RQ4). In practice, we recommend NN for high-dimensional, speed-critical emulation (with uncertainty calibration checks), BNN when well-calibrated posteriors are paramount and data are moderate, and GP for small/medium datasets in low–moderate dimensional settings.
Finally, we propose that future research focus on developing methodological frameworks that integrate common standards for model validation and on creating interpretable approaches to foster trust within the cosmological community. Interdisciplinary collaboration between cosmologists and ML experts will be crucial to maximizing the impact of these techniques and ensuring their sustainable adoption in scientific practice.
Author Contributions
Conceptualization, L.R. and E.G.; methodology, L.R., S.E., E.G., C.M., and F.L.; software, L.R. and S.E.; validation, L.R., S.E., E.G., C.M., and F.L.; formal analysis, L.R., S.E., E.G., C.M., and F.L.; investigation, L.R., S.E., E.G., and C.M.; data curation, L.R. and S.E.; writing—original draft preparation, L.R. and E.G.; writing—review and editing, L.R., S.E., E.G., C.M., and F.L.; visualization, L.R., S.E., E.G., and C.M.; supervision, L.R. and E.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
No new data were created for this work.
Acknowledgments
E.G. acknowledges the scientific support of Núcleo de Investigación No. 7 UCN-VRIDT 076/2020, Núcleo de Modelación y Simulación Científica (NMSC).
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MCMC | Markov chain Monte Carlo; |
| ML | Machine Learning; |
| SLR | Systematic Literature Review; |
| DL | Deep Learning; |
| CDM | Cold Dark Matter; |
| SNe Ia | Type Ia Supernovae; |
| SNe | Supernovae; |
| OHD | Observational Hubble Parameter Data; |
| BAOs | Baryon Acoustic Oscillations; |
| CMB | Cosmic Microwave Background; |
| WMAP | Wilkinson Microwave Anisotropy Probe; |
| LSS | Large Scale Structure; |
| 2dFGRS | 2-degree Field Galaxy Redshift Survey; |
| SDSS | Sloan Digital Sky Survey; |
| GL | Gravitational Lensing; |
| H0LiCOW | Lenses in COSMOGRAIL’s Wellspring; |
| LSST | Legacy Survey of Space and Time; |
| SPHEREx | Spectro-Photometer for the History of the Universe, Epoch of Reionization, and Ices Explorer; |
| NGRST | Nancy G. Roman Space Telescope; |
| DESI | Dark Energy Spectroscopic Instrument; |
| PFS6 | Prime Focus Spectrograph; |
| NN | Neural Network; |
| RNN | Recurrent Neural Network; |
| BML | Bayesian Machine Learning; |
| GP | Gaussian Processes; |
| BDTs | Bayesian Decision Trees; |
| BNN | Bayesian Neural Network; |
| CNN | Convolutional Neural Network; |
| GCD | Galaxy Clustering Data; |
| WFIRST | Wide Field Infrared Survey Telescope; |
| JACP | Journal of Cosmology and Astroparticle Physics; |
| PRD | Physical Review D; |
| MNRAS | Monthly Notices of the Royal Astronomical Society; |
| ApJS | The Astrophysical Journal Supplement Series; |
| EPJC | The European Physical Journal C; |
| PINN | Physics-Informed Neural Network. |
Appendix A. List of Selected Papers for Review and Extracted Data
| Title 1 | Author(s) | Databases | Catalogs | ML Models | Research Aim | Ref. | Year |
| Accelerated Bayesian inference using deep learning | Moss, Adam | CMB | Planck 2015 | NN | Improvement | [92] | 2020 |
| Accelerating cosmological inference with Gaussian processes and neural networks—an application to LSST Y1 weak lensing and galaxy clustering | Boruah, Supranta S; Eifler, Tim; Miranda, Vivian; Krishanth, P M Sai | Weak Lensing | LSST | NN | Improvement | [77] | 2022 |
| Accelerating MCMC algorithms through Bayesian Deep Networks | Hortua, Hector J.; Volpi, Riccardo; Marinelli, Dimitri; Malago, Luigi | CMB | Simulated | BNN | Improvement | [94] | 2020 |
| An analysis of the H 0 tension problem in the Universe with viscous dark fluid | Elizalde, Emilio; Khurshudyan, Martiros; Odintsov, Sergei D.; Myrzakulov, Ratbay | Generated | — | BML | Application | [96] | 2020 |
| An approach to cold dark matter deviation and the tension problem by using machine learning | Elizalde, Emilio; Gluza, Janusz; Khurshudyan, Martiros | Generated | — | BML | Application | [97] | 2021 |
| Faster Bayesian inference with neural network bundles and new results for models | Chantada, Augusto T. and Landau, Susana J. and Protopapas, Pavlos and Scóccola, Claudia G. and Garraffo, Cecilia | SNe Ia, OHD | WMAP, N/S, N/S, SDSS, 2dF survey | NN | Improvement | [84] | 2023 |
| CONNECT: a neural network based framework for emulating cosmological observables and cosmological parameter inference | Nygaard, Andreas; Holm, Emil Brinch; Hannestad, Steen; Tram, Thomas | CMB | Planck 2018 | NN | Improvement | [90] | 2023 |
| Constraints on Cosmic Opacity from Bayesian Machine Learning: The hidden side of the tension problem | Elizalde, Emilio; Khurshudyan, Martiros | Generated | — | BML | Application | [98] | 2020 |
| CosmicNet. Part I. Physics-driven implementation of neural networks within Einstein-Boltzmann Solvers | Albers, Jasper; Fidler, Christian; Lesgourgues, Julien; Schöneberg, Nils; Torrado, Jesus | CMB, Lensing, BAO | Planck 2018, N/S, N/S | NN | Improvement | [78] | 2019 |
| Cosmology-informed neural networks to solve the background dynamics of the Universe | Chantada, Augusto T.; Landau, Susana J.; Protopapas, Pavlos; Scóccola, Claudia G.; Garraffo, Cecilia | SNe Ia, OHD, BAO | Pantheon, Cosmic Chronometers, N/S | NN | Improvement | [79] | 2022 |
| Constraints on prospective deviations from the cold dark matter model using a Gaussian process | Khurshudyan, Martiros; Elizalde, Emilio | OHD | WMAP, SDSS, 2dF survey | GP | Improvement | [86] | 2024 |
| ECoPANN: A Framework for Estimating Cosmological Parameters Using Artificial Neural Networks | Wang, Guo-Jian; Li, Si-Yao; Xia, Jun-Qing | CMB, SNe Ia, BAO | Simulated, Simulated, Simulated | NN | Improvement | [85] | 2020 |
| KiDS-1000 cosmology: machine learning—accelerated constraints on interacting dark energy with CosmoPower | Spurio Mancini, A; Pourtsidou, A | CMB, Weak Lensing | Planck 2018, KiDS-1000 | NN | Improvement | [76] | 2022 |
| Late Time Attractors of Some Varying Chaplygin Gas Cosmological Models | Khurshudyan, Martiros; Myrzakulov, Ratbay | Generated | — | BML | Application | [99] | 2021 |
| Learn-as-you-go acceleration of cosmological parameter estimates | Aslanyan, Grigor; Easther, Richard; Price, Layne C. | CMB | Planck, WMAP | BDT | Improvement | [93] | 2015 |
| Likelihood-free Cosmological Constraints with Artificial Neural Networks: An Application on Hubble Parameters and SNe Ia | Wang, Yu-Chen; Xie, Yuan-Bo; Zhang, Tong-Jie; Huang, Hui-Chao; Zhang, Tingting; Liu, Kun | SNe Ia, OHD | Pantheon, N/S | NN | Improvement | [80] | 2021 |
| LINNA: Likelihood Inference Neural Network Accelerator | To, Chun-Hao; Rozo, Eduardo; Krause, Elisabeth; Wu, Hao-Yi; Wechsler, Risa H.; Salcedo, Andrés N. | Dark Energy Survey (DES) | DES (year 1) | NN | Improvement | [88] | 2023 |
| Parameter estimation for the cosmic microwave background with Bayesian neural networks | Hortúa, Héctor J.; Volpi, Riccardo; Marinelli, Dimitri; Malagò, Luigi | CMB | Simulated | BNN | Improvement | [95] | 2020 |
| Solving the tension in f(T) gravity through Bayesian machine learning | Aljaf, Muhsin; Elizalde, Emilio; Khurshudyan, Martiros; Myrzakulov, Kairat; Zhadyranova, Aliya | Strong Lensing, OHD | H0LiCOW, Cosmic Chronometers | BNN | Application | [75] | 2022 |
| A semi-model-independent approach to describe a cosmological database | Mehrabi, Ahmad | SNe Ia, OHD, BAO | Pantheon, Cosmic Chronometers, N/S | NN | Improvement | [81] | 2023 |
| A thorough investigation of the prospects of eLISA in addressing the Hubble tension: Fisher forecast, MCMC and Machine Learning | Shah, Rahul; Bhaumik, Arko; Mukherjee, Purba; Pal, Supratik | CMB, BAO, SNe Ia | Planck 2018, 6dFGS, SDSS MGS, BOSS DR12, Pantheon | GP | Application | [82] | 2023 |
| CoLFI: Cosmological Likelihood-free Inference with Neural Density Estimators | Wang, Guo-Jian; Cheng, Cheng; Ma, Yin-Zhe; Xia, Jun-Qing; Abebe, Amare; Beesham, Aroonkumar | CMB, SNe Ia | Planck 2015, Pantheon | NN | Improvement | [83] | 2023 |
| Fast and effortless computation of profile likelihoods using CONNECT | Nygaard, Andreas; Holm, Emil Brinch; Hannestad, Steen; Tram, Thomas | CMB | Planck 2018 | NN | Improvement | [91] | 2023 |
| High-accuracy emulators for observables in CDM, , , and w cosmologies | Bolliet, Boris; Mancini, Alessio Spurio; Hill, J. Colin; Madhavacheril, Mathew; Jense, Hidde T.; Calabrese, Erminia; Dunkley, Jo | CMB, LSS, BAO | Planck 2018, DES (year 1), BOSS DR12 | NN | Improvement | [89] | 2023 |
| NAUTILUS: boosting Bayesian importance nested sampling with deep learning | Lange, Johannes U. | Galaxy Clustering data | Halo Connection | NN | Improvement | [73] | 2023 |
| Test of artificial neural networks in likelihood-free cosmological constraints: A comparison of information maximizing neural networks and denoising autoencoder | Chen, Jie-Feng; Wang, Yu-Chen; Zhang, Tingting; Zhang, Tong-Jie | OHD | N/S | NN | Improvement | [87] | 2023 |
| Estimating Cosmological Constraints from Galaxy Cluster Abundance using Simulation-Based Inference | Reza, Moonzarin; Zhang, Yuanyuan; Nord, Brian; Poh, Jason; Ciprijanovic, Aleksandra; Strigari, Louis | Galaxy Clustering data | Pantheon+, Cosmic Chronometers | NN | Improvement | [74] | 2022 |
| 1 All studies included in this review adhered to the predefined inclusion criteria. | |||||||
| Title | Performance 1 |
| Accelerated Bayesian inference using deep learning | The model accelerates MCMC convergence, achieving independent samples in just likelihood evaluations. |
| Accelerating cosmological inference with Gaussian processes and neural networks—an application to LSST Y1 weak lensing and galaxy clustering | The emulator achieves full MCMC-level accuracy while reducing inference time by over two orders of magnitude. |
| Accelerating MCMC algorithms through Bayesian Deep Networks | The Bayesian neural network accelerates MCMC inference by at the cost of slightly increased uncertainties. |
| An analysis of the H0 tension problem in the Universe with viscous dark fluid | The Bayesian model puts very tight constraints on the parameters () and successfully resolves the cosmological H0 tension. |
| An approach to cold dark matter deviation and the tension problem by using machine learning | Bayesian ML achieved precision on estimates and detected dark matter deviations with significance. |
| Faster Bayesian inference with neural network bundles and new results for models | The neural network bundle delivers under error while accelerating Bayesian inference by up to . |
| CONNECT: a neural network based framework for emulating cosmological observables and cosmological parameter inference | CONNECT emulates CLASS with neural networks, achieving model evaluations in milliseconds and parameter deviations below . |
| Constraints on Cosmic Opacity from Bayesian Machine Learning: The hidden side of the tension problem | Bayesian ML analysis yields tight cosmic opacity constraints—with uncertainties as low as for —shedding light on the tension. |
| CosmicNet. Part I. Physics-driven implementation of neural networks within Einstein-Boltzmann Solvers | The neural-network-accelerated perturbation module in CLASS achieves comparable cosmological accuracy while speeding up computations by nearly . |
| Cosmology-informed neural networks to solve the background dynamics of the Universe | The cosmology-informed neural network achieves sub-percent error () across the parameter space with high evaluation speeds. |
| Constraints on prospective deviations from the cold dark matter model using a Gaussian process | The GP model estimates the Hubble constant at with about uncertainty. |
| ECoPANN: A Framework for Estimating Cosmological Parameters Using Artificial Neural Networks | ECoPANN delivers cosmological parameter estimates as accurately as MCMC but in seconds instead of hours. |
| KiDS-1000 cosmology: machine learning—accelerated constraints on interacting dark energy with CosmoPower | The CosmoPower neural emulator delivers CLASS-level accuracy while running faster. |
| Late Time Attractors of Some Varying Chaplygin Gas Cosmological Models | The Bayesian machine learning model infers cosmological parameters with uncertainty in but fails to resolve the tension or fit high-redshift data. |
| Learn-as-you-go acceleration of cosmological parameter estimates | Learn-as-you-go emulation speeds up cosmological parameter estimation by about without sacrificing accuracy. |
| Likelihood-free Cosmological Constraints with Artificial Neural Networks: An Application on Hubble Parameters and SNe Ia | The likelihood-free DAE+MAF method estimates cosmological parameters as accurately as traditional MCMC without needing an explicit likelihood. |
| LINNA: Likelihood Inference Neural Network Accelerator | LINNA achieves cosmological parameter inference with bias and speedup over brute-force methods. |
| Parameter estimation for the cosmic microwave background with Bayesian neural networks | VGG with Flipout delivers the most accurate and fastest CMB parameter estimation. |
| Solving the tension in gravity through Bayesian machine learning | Bayesian machine learning precisely constrained cosmological parameters and demonstrated that exponential models resolve the tension. |
| A semi-model-independent approach to describe a cosmological database | Reduce el estadístico en puntos para datos de y en puntos para el conjunto Pantheon de SNIa. |
| A thorough investigation of the prospects of eLISA in addressing the Hubble tension: Fisher forecast, MCMC and Machine Learning | The machine learning approach (GP) significantly outperforms Fisher and MCMC methods, reducing the Hubble tension by an additional down to . |
| CoLFI: Cosmological Likelihood-free Inference with Neural Density Estimators | CoLFI’s Mixture Neural Network matches MCMC precision with fewer simulations. |
| Fast and effortless computation of profile likelihoods using CONNECT | CONNECT achieves sub- error in emulation and speeds up profile likelihood computations by –. |
| High-accuracy emulators for observables in CDM, , , and w cosmologies | The emulators deliver sub-percent accuracy across cosmological observables with a speedup over traditional Boltzmann codes. |
| NAUTILUS: boosting Bayesian importance nested sampling with deep learning | Nautilus cuts likelihood evaluations by up to while maintaining over accuracy in Bayesian evidence estimates. |
| Test of artificial neural networks in likelihood-free cosmological constraints: A comparison of information maximizing neural networks and denoising autoencoder | MAF-DAE yields tighter cosmological constraints with minimal information loss compared to MAF-IMNN. |
| Estimating Cosmological Constraints from Galaxy Cluster Abundance using Simulation-Based Inference | The SBI inference accurately recovers cosmological parameters with uncertainties comparable to MCMC. |
| 1 The “Performance” values reported in this table are drawn solely from the conclusions and results presented in each paper. Since each study employs different metrics, evaluation methodologies, and experimental conditions, these figures should not be interpreted as directly comparable; they merely reflect what each author was able to quantify and emphasize in their work. | |
Note
| 1 | Taxonomy Note: Rather than a normative “traditional ML vs. deep learning” dichotomy, we report results via the model family (GP, BML, BDT, NN, and BNN) and—where relevant—via uncertainty handling (deterministic vs. probabilistic), which aligns with our corpus and the speed–calibration comparisons. |
References
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Rubin, D.B. Bayesian Data Analysis; Chapman and Hall/CRC: Boca Raton, FL, USA, 1995. [Google Scholar]
- Lewis, A.; Bridle, S. Cosmological parameters from CMB and other data: A Monte Carlo approach. Phys. Rev. D 2002, 66, 103511. [Google Scholar] [CrossRef]
- Ntampaka, M.; Trac, H.; Sutherland, D.J.; Battaglia, N.; Póczos, B.; Schneider, J. A machine learning approach for dynamical mass measurements of galaxy clusters. Astrophys. J. 2015, 803, 50. [Google Scholar] [CrossRef]
- Jpt, H. Cochrane Handbook for Systematic Reviews of Interventions. 2008. Available online: http://www.cochrane-handbook.org (accessed on 10 March 2025).
- López-Sánchez, M.; Hernández-Ocaña, B.; Chávez-Bosquez, O.; Hernández-Torruco, J. Supervised Deep Learning Techniques for Image Description: A Systematic Review. Entropy 2023, 25, 553. [Google Scholar] [CrossRef]
- Bozkurt, A.; Sharma, R.C. Emergency remote teaching in a time of global crisis due to CoronaVirus pandemic. Asian J. Distance Educ. 2020, 15, i–vi. [Google Scholar]
- Lochner, M.; McEwen, J.D.; Peiris, H.V.; Lahav, O.; Winter, M.K. Photometric supernova classification with machine learning. Astrophys. J. Suppl. Ser. 2016, 225, 31. [Google Scholar] [CrossRef]
- Dieleman, S.; Willett, K.W.; Dambre, J. Rotation-invariant convolutional neural networks for galaxy morphology prediction. Mon. Not. R. Astron. Soc. 2015, 450, 1441–1459. [Google Scholar] [CrossRef]
- Mukhanov, V. Physical Foundations of Cosmology; Cambridge University Press: Oxford, UK, 2005. [Google Scholar] [CrossRef]
- Bertone, G.; Hooper, D. History of dark matter. Rev. Mod. Phys. 2018, 90, 045002. [Google Scholar] [CrossRef]
- Salucci, P. Dark Matter in Galaxies: Evidences and challenges. Found. Phys. 2018, 48, 1517–1537. [Google Scholar] [CrossRef]
- Riess, A.G.; Filippenko, A.V.; Challis, P.; Clocchiatti, A.; Diercks, A.; Garnavich, P.M. Observational evidence from supernovae for an accelerating universe and a cosmological constant. Astron. J. 1998, 116, 1009–1038. [Google Scholar] [CrossRef]
- Perlmutter, S.; Aldering, G.; Goldhaber, G.; Knop, R.A.; Nugent, P.; Castro, P.G.; Deustua, S.; Fabbro, S.; Goobar, A.; Groom, D.E.; et al. Measurements of Ω and Λ from 42 High Redshift Supernovae. Astrophys. J. 1999, 517, 565–586. [Google Scholar] [CrossRef]
- Fischer, A.E. Friedmann’s equation and the creation of the universe. Int. J. Mod. Phys. D 2018, 27, 1847013. [Google Scholar] [CrossRef]
- Workman, R.L.; Burkert, V.D.; Crede, V.; Klempt, E.; Thoma, U.; Tiator, L.; Rabbertz, K. Review of Particle Physics. PTEP 2022, 2022, 083C01. [Google Scholar] [CrossRef]
- Velten, H.E.S.; vom Marttens, R.F.; Zimdahl, W. Aspects of the cosmological “coincidence problem”. Eur. Phys. J. C 2014, 74, 3160. [Google Scholar] [CrossRef]
- Aghanim, N. Planck 2018 results. VI. Cosmological parameters. Astron. Astrophys. 2020, 641, A6, Erratum in Astron. Astrophys. 2021, 652, C4. [Google Scholar] [CrossRef]
- Liu, Z.W.; Roepke, F.K.; Han, Z. Type Ia Supernova Explosions in Binary Systems: A Review. Res. Astron. Astrophys. 2023, 23, 082001. [Google Scholar] [CrossRef]
- Moresco, M.; Pozzetti, L.; Cimatti, A.; Jimenez, R.; Maraston, C.; Verde, L.; Thomas, D.; Citro, A.; Tojeiro, R.; Wilkinson, D. A 6% measurement of the Hubble parameter at z∼0.45: Direct evidence of the epoch of cosmic re-acceleration. JCAP 2016, 05, 014. [Google Scholar] [CrossRef]
- Scolnic, D.M.; Jones, D.O.; Rest, A.; Pan, Y.C.; Chornock, R.; Foley, R.J.; Huber, M.E.; Kessler, R.; Narayan, G.; Riess, A.G.; et al. The Complete Light-curve Sample of Spectroscopically Confirmed SNe Ia from Pan-STARRS1 and Cosmological Constraints from the Combined Pantheon Sample. Astrophys. J. 2018, 859, 101. [Google Scholar] [CrossRef]
- Brout, D.; Scolnic, D.; Popovic, B.; Riess, A.G.; Carr, A.; Zuntz, J.; Wiseman, P. The Pantheon+ Analysis: Cosmological Constraints. Astrophys. J. 2022, 938, 110. [Google Scholar] [CrossRef]
- Magana, J.; Amante, M.H.; Garcia-Aspeitia, M.A.; Motta, V. The Cardassian expansion revisited: Constraints from updated Hubble parameter measurements and type Ia supernova data. Mon. Not. Roy. Astron. Soc. 2018, 476, 1036–1049. [Google Scholar] [CrossRef]
- Jimenez, R.; Loeb, A. Constraining cosmological parameters based on relative galaxy ages. Astrophys. J. 2002, 573, 37–42. [Google Scholar] [CrossRef]
- DESI Collaboration; Abdul-Karim, M.; Aguilar, J.; Ahlen, S.; Alam, S.; Allen, L.; Allende Prieto, C.; Alves, O.; An, A.; Andrade, U.; et al. DESI DR2 Results II: Measurements of Baryon Acoustic Oscillations and Cosmological Constraints. arXiv 2025, arXiv:2503.14738. [Google Scholar] [CrossRef]
- Peebles, P.J.E.; Yu, J.T. Primeval adiabatic perturbation in an expanding universe. Astrophys. J. 1970, 162, 815–836. [Google Scholar] [CrossRef]
- Eisenstein, D.J.; Hu, W. Baryonic features in the matter transfer function. Astrophys. J. 1998, 496, 605. [Google Scholar] [CrossRef]
- Beutler, F.; Blake, C.; Colless, M.; Jones, D.H.; Staveley-Smith, L.; Campbell, L.; Parker, Q.; Saunders, W.; Watson, F. The 6dF Galaxy Survey: Baryon acoustic oscillations and the local Hubble constant: 6dFGS: BAOs and the local Hubble constant. Mon. Not. Roy. Astron. Soc. 2011, 416, 3017–3032. [Google Scholar] [CrossRef]
- Ross, A.J.; Samushia, L.; Howlett, C.; Percival, W.J.; Burden, A.; Manera, M. The clustering of the SDSS DR7 main Galaxy sample—I. A 4 per cent distance measure at z = 0.15. Mon. Not. Roy. Astron. Soc. 2015, 449, 835–847. [Google Scholar] [CrossRef]
- Alam, S.; Ata, M.; Bailey, S.; Beutler, F.; Bizyaev, D.; Blazek, J.A.; Bolton, A.S.; Brownstein, J.R.; Burden, A.; Chuang, C.; et al. The clustering of galaxies in the completed SDSS-III Baryon Oscillation Spectroscopic Survey: Cosmological analysis of the DR12 galaxy sample. Mon. Not. Roy. Astron. Soc. 2017, 470, 2617–2652. [Google Scholar] [CrossRef]
- Aghamousa, A.; Aguilar, J.; Ahlen, S.; Alam, S.; Allen, L.E.; Prieto, C.A.; Lang, D. The DESI Experiment Part I: Science, Targeting, and Survey Design. arXiv 2016, arXiv:1611.00036. [Google Scholar] [CrossRef]
- Penzias, A.A.; Wilson, R.W. A Measurement of Excess Antenna Temperature at 4080 Mc/s. Astrophys. J. 1965, 142, 419–421. [Google Scholar] [CrossRef]
- Tegmark, M.; Strauss, M.A.; Blanton, M.R.; Abazajian, K.; Dodelson, S.; Sandvik, H. Cosmological parameters from SDSS and WMAP. Phys. Rev. D 2004, 69, 103501. [Google Scholar] [CrossRef]
- Wang, Y.; Mukherjee, P. Robust dark energy constraints from supernovae, galaxy clustering, and three-year wilkinson microwave anisotropy probe observations. Astrophys. J. 2006, 650, 1–6. [Google Scholar] [CrossRef]
- Hinshaw, G.; Larson, D.; Komatsu, E.; Spergel, D.N.; Bennett, C.; Dunkley, J.; Nolta, M.R.; Halpern, M.; Hill, R.S.; Odegard, N.; et al. Nine-year Wilkinson Microwave Anisotropy Probe (WMAP) Observations: Cosmological Parameter Results. Astrophys. J. Suppl. Ser. 2013, 208, 19. [Google Scholar] [CrossRef]
- Aghanim, N.; Akrami, Y.; Arroja, F.; Ashdown, M.; Aumont, J.; Baccigalupi, C.; Pettorino, V. Planck 2018 results. I. Overview and the cosmological legacy of Planck. Astron. Astrophys. 2020, 641, A1. [Google Scholar] [CrossRef]
- Springel, V.; Frenk, C.S.; White, S.D.M. The large-scale structure of the Universe. Nature 2006, 440, 1137. [Google Scholar] [CrossRef] [PubMed]
- Colless, M.; Dalton, G.; Maddox, S.; Sutherl, W.; Norberg, P.; Cole, S.; Taylor, K. The 2dF Galaxy Redshift Survey: Spectra and redshifts. Mon. Not. Roy. Astron. Soc. 2001, 328, 1039. [Google Scholar] [CrossRef]
- York, D.G.; Adelman, J.; Anderson, J.E., Jr.; Anderson, S.F.; Annis, J.; Bahcall, N.A.; Bakken, J.A.; Barkhouser, R.; Bastian, S.; Berman, E.; et al. The Sloan Digital Sky Survey: Technical Summary. Astron. J. 2000, 120, 1579–1587. [Google Scholar] [CrossRef]
- Wong, K.C.; Suyu, S.H.; Chen, G.C.-F.; Rusu, C.E.; Millon, M.; Sluse, D.; Bonvin, V.; Fassnacht, C.D.; Taubenberger, S.; Auger, M.W.; et al. H0LiCOW – XIII. A 2.4 per cent measurement of H0 from lensed quasars: 5.3σ tension between early- and late-Universe probes. Mon. Not. Roy. Astron. Soc. 2020, 498, 1420–1439. [Google Scholar] [CrossRef]
- Turner, M.S. The Road to Precision Cosmology. Annu. Rev. Nucl. Part. Sci. 2022, 72, 1–35. [Google Scholar] [CrossRef]
- Abdalla, E.; Abellán, G.F.; Aboubrahim, A.; Agnello, A.; Akarsu, Ö.; Akrami, Y.; Pettorino, V. Cosmology intertwined: A review of the particle physics, astrophysics, and cosmology associated with the cosmological tensions and anomalies. J. High Energy Astrophys. 2022, 34, 49–211. [Google Scholar] [CrossRef]
- Riess, A.G.; Yuan, W.; Macri, L.M.; Scolnic, D.; Brout, D.; Casertano, S.; Zheng, W. A Comprehensive Measurement of the Local Value of the Hubble Constant with 1 km s−1 Mpc−1 Uncertainty from the Hubble Space Telescope and the SH0ES Team. Astrophys. J. Lett. 2022, 934, L7. [Google Scholar] [CrossRef]
- Hogg, D.W.; Foreman-Mackey, D. Data analysis recipes: Using Markov Chain Monte Carlo. Astrophys. J. Suppl. 2018, 236, 11. [Google Scholar] [CrossRef]
- Goodman, J.; Weare, J. Ensemble samplers with affine invariance. Commun. Appl. Math. Comput. Sci. 2010, 5, 65–80. [Google Scholar] [CrossRef]
- Foreman-Mackey, D.; Hogg, D.W.; Lang, D.; Goodman, J. emcee: The MCMC Hammer. Publ. Astron. Soc. Pac. 2013, 125, 306–312. [Google Scholar] [CrossRef]
- Hajian, A. Efficient Cosmological Parameter Estimation with Hamiltonian Monte Carlo. Phys. Rev. D 2007, 75, 083525. [Google Scholar] [CrossRef]
- Ivezić, v.; Kahn, S.M.; Tyson, J.A.; Abel, B.; Acosta, E.; Allsman, R.; Johnson, M.W. LSST: From Science Drivers to Reference Design and Anticipated Data Products. Astrophys. J. 2019, 873, 111. [Google Scholar] [CrossRef]
- Laureijs, R.; Amiaux, J.; Arduini, S.; Auguères, J.-L.; Brinchmann, J.; Cole, R.; Cropper, M.; Dabin, C.; Duvet, L.; Ealet, A.; et al. Euclid Definition Study Report. arXiv 2011, arXiv:1110.3193. [Google Scholar] [CrossRef]
- Doré, O.; Bock, J.; Ashby, M.; Capak, P.; Cooray, A.; de Putter, R.; Eifler, T.; Flagey, N.; Gong, Y.; Habib, S.; et al. Cosmology with the SPHEREX All-Sky Spectral Survey. arXiv 2014, arXiv:1412.4872. [Google Scholar]
- Spergel, D.; Gehrels, N.; Baltay, C.; Bennett, D.; Breckinridge, J.; Donahue, M.; Dressler, A.; Gaudi, B.S.; Greene, T.; Guyon, O.; et al. Wide-Field InfrarRed Survey Telescope-Astrophysics Focused Telescope Assets WFIRST-AFTA 2015 Report. arXiv 2015, arXiv:1503.03757. [Google Scholar]
- Takada, M.; Ellis, R.S.; Chiba, M.; Greene, J.E.; Aihara, H.; Arimoto, N.; Wyse, R. Extragalactic science, cosmology, and Galactic archaeology with the Subaru Prime Focus Spectrograph. Publ. Astron. Soc. Jpn. 2014, 66, R1. [Google Scholar] [CrossRef]
- Janiesch, C.; Zschech, P.; Heinrich, K. Machine learning and deep learning. Electron. Mark. 2021, 31, 685–695. [Google Scholar] [CrossRef]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386. [Google Scholar] [CrossRef] [PubMed]
- Minsky, M.; Papert, S. An introduction to computational geometry. Camb. Tiass. Hit 1969, 479, 480. [Google Scholar]
- Chollet, F. Deep Learning with Python; Simon and Schuster: New York, NY, USA, 2021. [Google Scholar]
- Aggarwal, C.C. An Introduction to Neural Networks. In Neural Networks and Deep Learning: A Textbook; Springer International Publishing: Berlin/Heidelberg, Germany, 2018. [Google Scholar] [CrossRef]
- Bharadiya, J.P. A Review of Bayesian Machine Learning Principles, Methods, and Applications. Int. J. Innov. Sci. Res. Technol. 2023, 8, 2033–2038. [Google Scholar]
- Seeger, M. Gaussian processes for machine learning. Int. J. Neural Syst. 2004, 14, 69–106. [Google Scholar] [CrossRef] [PubMed]
- Nuti, G.; Rugama, L.A.J.; Cross, A.I. A Bayesian Decision Tree Algorithm. arXiv 2019, arXiv:1901.03214. [Google Scholar] [CrossRef]
- Dension, D. A Bayesian CART algorithm. Biometrika 1998, 85, 363–377. [Google Scholar] [CrossRef]
- Blundell, C.; Cornebise, J.; Kavukcuoglu, K.; Wierstra, D. Weight Uncertainty in Neural Networks. arXiv 2015, arXiv:1505.05424. [Google Scholar] [CrossRef]
- de Dios Rojas Olvera, J.; Gómez-Vargas, I.; Vázquez, J.A. Observational cosmology with artificial neural networks. Universe 2022, 8, 120. [Google Scholar] [CrossRef]
- Moriwaki, K.; Nishimichi, T.; Yoshida, N. Machine learning for observational cosmology. Rep. Prog. Phys. 2023, 86, 076901. [Google Scholar] [CrossRef]
- Lahav, O. Deep Machine Learning in Cosmology: Evolution or Revolution? arXiv 2023, arXiv:2302.04324. [Google Scholar] [CrossRef]
- Dvorkin, C.; Mishra-Sharma, S.; Nord, B.; Villar, V.A.; Avestruz, C.; Bechtol, K.; Ćiprijanović, A.; Connolly, A.J.; Garrison, L.H.; Narayan, G.; et al. Machine learning and cosmology. arXiv 2022, arXiv:2203.08056. [Google Scholar] [CrossRef]
- Han, B.; Ding, H.; Zhang, Y.; Zhao, Y. Improving accuracy of Quasars’ photometric redshift estimation by integration of KNN and SVM. Proc. Int. Astron. Union 2015, 11, 209. [Google Scholar] [CrossRef]
- Di Valentino, E.; Levi Said, J.; Riess, A.G.; Pollo, A.; Poulin, V.; CosmoVerse Network. The CosmoVerse White Paper: Addressing observational tensions in cosmology with systematics and fundamental physics. Phys. Dark Universe 2025, 49, 101965. [Google Scholar] [CrossRef]
- Spurio Mancini, A.; Piras, D.; Alsing, J.; Joachimi, B.; Hobson, M.P. CosmoPower: Emulating cosmological power spectra for accelerated Bayesian inference from next-generation surveys. Mon. Not. R. Astron. Soc. 2022, 511, 1771–1788. [Google Scholar] [CrossRef]
- Mootoovaloo, A.; García-García, C.; Alonso, D.; Ruiz-Zapatero, J. emuflow: Normalizing flows for joint cosmological analysis. Mon. Not. R. Astron. Soc. 2025, 536, 190–202. [Google Scholar] [CrossRef]
- Kitchenham, B.; Charters, S. Guidelines for Performing Systematic Literature Reviews in Software Engineering; 2007; Available online: https://docs.opendeved.net/lib/7RP54LK8 (accessed on 10 March 2025).
- Kitchenham, B. Procedures for performing systematic reviews. Keele UK Keele Univ. 2004, 33, 1–26. [Google Scholar]
- Rojas, L.; Espinoza, S.; González, E.; Maldonado, C.; Luo, F. Protocol for the Systematic Literature Review (PRISMA 2020): ML for Observational Constraints in Cosmology. 2025. Available online: https://zenodo.org/records/16899506 (accessed on 10 March 2025). [CrossRef]
- Lange, J.U. Nautilus: Boosting Bayesian importance nested sampling with deep learning. Mon. Not. Roy. Astron. Soc. 2023, 525, 3181–3194. [Google Scholar] [CrossRef]
- Reza, M.; Zhang, Y.; Nord, B.; Poh, J.; Ciprijanovic, A.; Strigari, L. Estimating Cosmological Constraints from Galaxy Cluster Abundance using Simulation-Based Inference. arXiv 2022, arXiv:2208.00134. [Google Scholar] [CrossRef]
- Aljaf, M.; Elizalde, E.; Khurshudyan, M.; Myrzakulov, K.; Zhadyranova, A. Solving the H0 tension in f(T) gravity through Bayesian machine learning. Eur. Phys. J. C 2022, 82, 1130. [Google Scholar] [CrossRef]
- Mancini Spurio, A.; Pourtsidou, A. KiDS-1000 cosmology: Machine learning – accelerated constraints on interacting dark energy with CosmoPower. Mon. Not. Roy. Astron. Soc. 2022, 512, L44–L48. [Google Scholar] [CrossRef]
- Boruah, S.S.; Eifler, T.; Miranda, V.; Sai Krishanth, P.M. Accelerating cosmological inference with Gaussian processes and neural networks – an application to LSST Y1 weak lensing and galaxy clustering. Mon. Not. Roy. Astron. Soc. 2022, 518, 4818–4831. [Google Scholar] [CrossRef]
- Albers, J.; Fidler, C.; Lesgourgues, J.; Schöneberg, N.; Torrado, J. CosmicNet. Part I. Physics-driven implementation of neural networks within Einstein-Boltzmann Solvers. JCAP 2019, 09, 028. [Google Scholar] [CrossRef]
- Chantada, A.T.; Landau, S.J.; Protopapas, P.; Scóccola, C.G.; Garraffo, C. Cosmology-informed neural networks to solve the background dynamics of the Universe. Phys. Rev. D 2023, 107, 063523. [Google Scholar] [CrossRef]
- Wang, Y.C.; Xie, Y.B.; Zhang, T.J.; Huang, H.C.; Zhang, T.; Liu, K. Likelihood-free Cosmological Constraints with Artificial Neural Networks: An Application on Hubble Parameters and SNe Ia. Astrophys. J. Supp. 2021, 254, 43. [Google Scholar] [CrossRef]
- Mehrabi, A. A semi-model-independent approach to describe a cosmological database. arXiv 2023, arXiv:2301.07369. [Google Scholar]
- Shah, R.; Bhaumik, A.; Mukherjee, P.; Pal, S. A thorough investigation of the prospects of eLISA in addressing the Hubble tension: Fisher forecast, MCMC and Machine Learning. JCAP 2023, 06, 038. [Google Scholar] [CrossRef]
- Wang, G.J.; Cheng, C.; Ma, Y.Z.; Xia, J.Q.; Abebe, A.; Beesham, A. CoLFI: Cosmological Likelihood-free Inference with Neural Density Estimators. Astrophys. J. Suppl. 2023, 268, 7. [Google Scholar] [CrossRef]
- Chantada, A.T.; Landau, S.J.; Protopapas, P.; Scóccola, C.G.; Garraffo, C. Faster Bayesian inference with neural network bundles and new results for f(R) models. Phys. Rev. D 2024, 109, 123514. [Google Scholar] [CrossRef]
- Wang, G.J.; Li, S.Y.; Xia, J.Q. ECoPANN: A Framework for Estimating Cosmological Parameters using Artificial Neural Networks. Astrophys. J. Suppl. 2020, 249, 25. [Google Scholar] [CrossRef]
- Khurshudyan, M.; Elizalde, E. Constraints on Prospective Deviations from the Cold Dark Matter Model Using a Gaussian Process. Galaxies 2024, 12, 31. [Google Scholar] [CrossRef]
- Chen, J.F.; Chen, J.; Wang, Y.C.; Wang, Y.; Zhang, T.; Zhang, T.J.; Zhang, T. Test of artificial neural networks in likelihood-free cosmological constraints: A comparison of information maximizing neural networks and denoising autoencoder. Phys. Rev. D 2023, 107, 063517. [Google Scholar] [CrossRef]
- To, C.H.; Rozo, E.; Krause, E.; Wu, H.Y.; Wechsler, R.H.; Salcedo, A.N. LINNA: Likelihood Inference Neural Network Accelerator. JCAP 2023, 01, 016. [Google Scholar] [CrossRef]
- Bolliet, B.; Spurio Mancini, A.; Hill, J.C.; Madhavacheril, M.; Jense, H.T.; Calabrese, E.; Dunkley, J. High-accuracy emulators for observables in ΛCDM, Neff, Σmν, and w cosmologies. Mon. Not. Roy. Astron. Soc. 2024, 531, 1351–1370. [Google Scholar] [CrossRef]
- Nygaard, A.; Holm, E.B.; Hannestad, S.; Tram, T. CONNECT: A neural network based framework for emulating cosmological observables and cosmological parameter inference. JCAP 2023, 05, 025. [Google Scholar] [CrossRef]
- Nygaard, A.; Holm, E.B.; Hannestad, S.; Tram, T. Fast and effortless computation of profile likelihoods using CONNECT. JCAP 2023, 11, 064. [Google Scholar] [CrossRef]
- Moss, A. Accelerated Bayesian inference using deep learning. Mon. Not. Roy. Astron. Soc. 2020, 496, 328–338. [Google Scholar] [CrossRef]
- Aslanyan, G.; Easther, R.; Price, L.C. Learn-as-you-go acceleration of cosmological parameter estimates. J. Cosmol. Astropart. Phys. 2015, 2015, 005. [Google Scholar] [CrossRef][Green Version]
- Hortua, H.J.; Volpi, R.; Marinelli, D.; Malago, L. Accelerating MCMC algorithms through Bayesian Deep Networks. arXiv 2020, arXiv:2011.14276. [Google Scholar] [CrossRef]
- Hortua, H.J.; Volpi, R.; Marinelli, D.; Malagò, L. Parameter estimation for the cosmic microwave background with Bayesian neural networks. Phys. Rev. D 2020, 102, 103509. [Google Scholar] [CrossRef]
- Elizalde, E.; Khurshudyan, M.; Odintsov, S.D.; Myrzakulov, R. Analysis of the H0 tension problem in the Universe with viscous dark fluid. Phys. Rev. D 2020, 102, 123501. [Google Scholar] [CrossRef]
- Elizalde, E.; Gluza, J.; Khurshudyan, M. An approach to cold dark matter deviation and the H0 tension problem by using machine learning. arXiv 2021, arXiv:2104.01077. [Google Scholar]
- Elizalde, E.; Khurshudyan, M. Constraints on cosmic opacity from Bayesian machine learning: The hidden side of the H0 tension problem. Phys. Dark Univ. 2022, 37, 101114. [Google Scholar] [CrossRef]
- Khurshudyan, M.; Myrzakulov, R. Late time attractors of some varying Chaplygin gas cosmological models. Symmetry 2021, 13, 769. [Google Scholar] [CrossRef]
- Weinberg, S. The Cosmological Constant Problem. Rev. Mod. Phys. 1989, 61, 1–23. [Google Scholar] [CrossRef]
- Newton, O.; Leo, M.; Cautun, M.; Jenkins, A.; Frenk, C.S.; Lovell, M.R.; Helly, J.C.; Benson, A.J.; Cole, S. Constraints on the properties of warm dark matter using the satellite galaxies of the Milky Way. JCAP 2021, 08, 062. [Google Scholar] [CrossRef]
- Rest, A.; Scolnic, D.; Foley, R.J.; Huber, M.E.; Chornock, R.; Narayan, G.; Tonry, J.L.; Berger, E.; Soderberg, A.M.; Stubb, C.W.; et al. Cosmological Constraints from Measurements of Type Ia Supernovae discovered during the first 1.5 yr of the Pan-STARRS1 Survey. Astrophys. J. 2014, 795, 44. [Google Scholar] [CrossRef]














Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).