
Statistical Classification and an Optimized Red-Sequence Technique for the Determination of Galaxy Clusters

 ,
,  , and
, and 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Materials and Methods
2.1. Statistical Tools
2.2. Parameter Estimation via the Expectation-Maximization Algorithm
- Expectation (E-step): Compute the posterior probabilities representing the likelihood that observation belongs to component i, conditional on the current parameter estimates .
- Maximization (M-step): Update by maximizing the expected complete-data log-likelihood derived in the E-step.
2.3. Mahalanobis Distance for Multivariate Discrimination
- Cluster Boundary Definition: Delimiting regions in color–magnitude-redshift space where cluster members are statistically concentrated.
- Outlier Rejection: Identifying galaxies with a low probability of membership based on their distance from the cluster centroid.
2.4. Data Sources and Sample Characteristics
2.5. Algorithm Design and Workflow
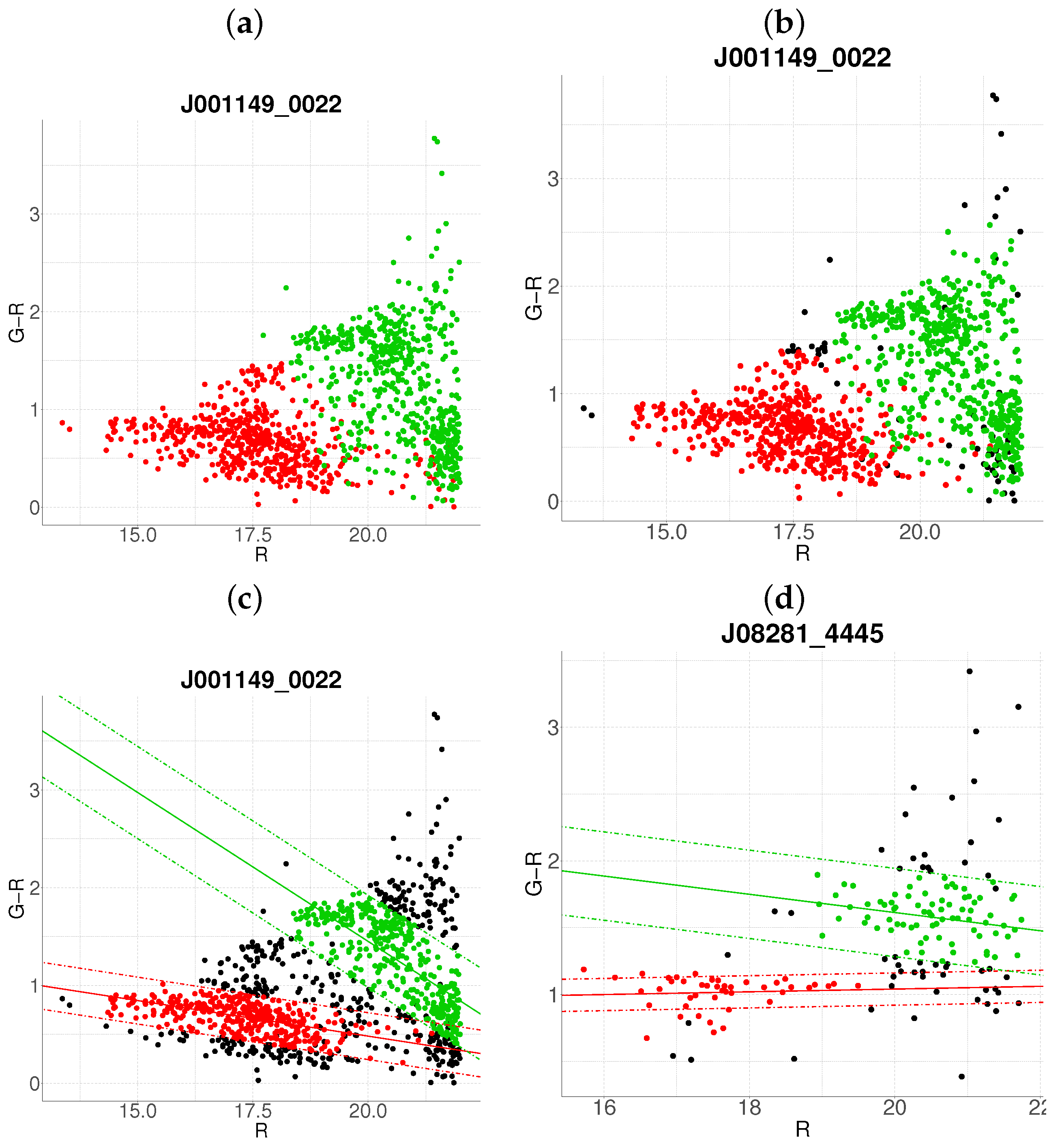
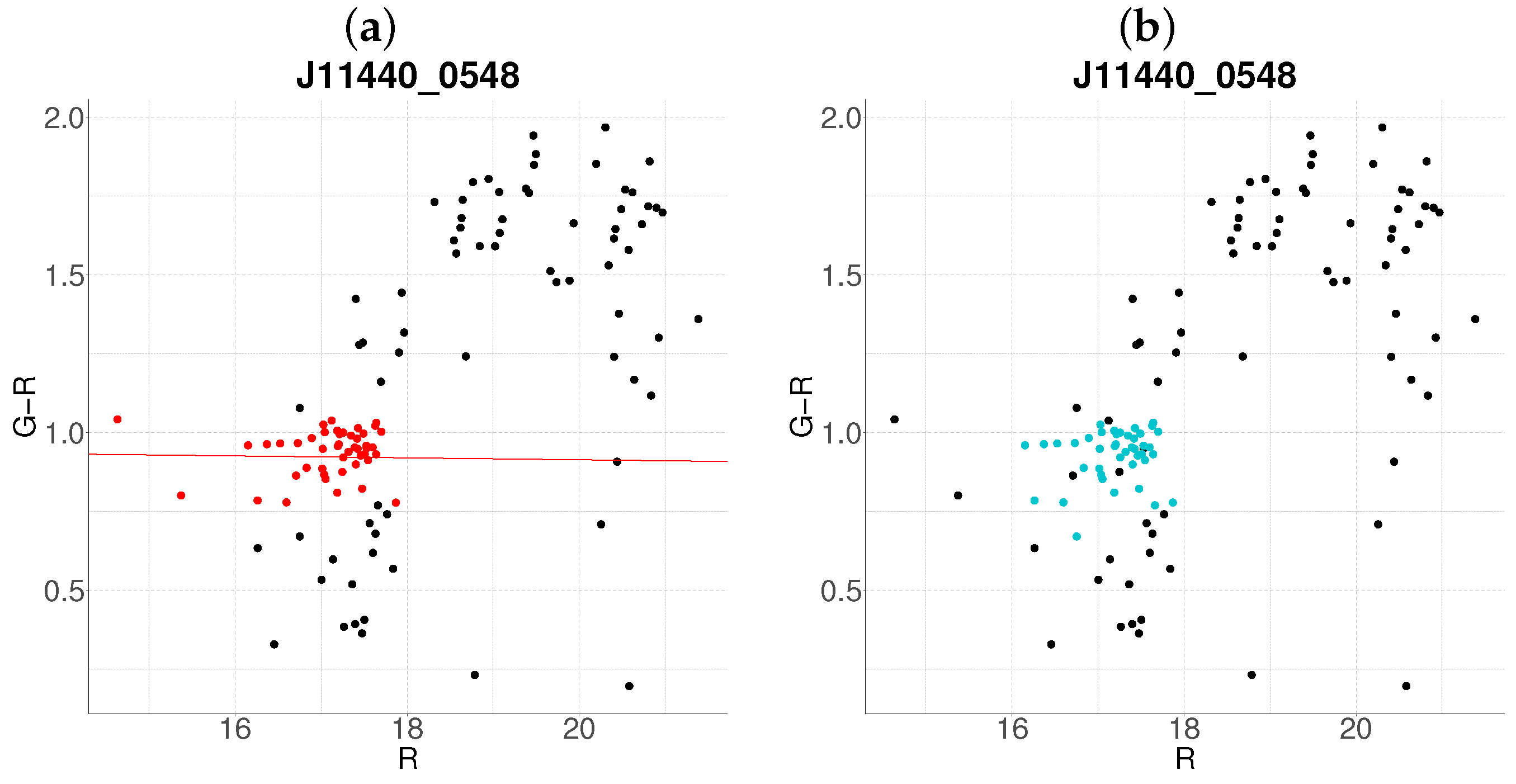
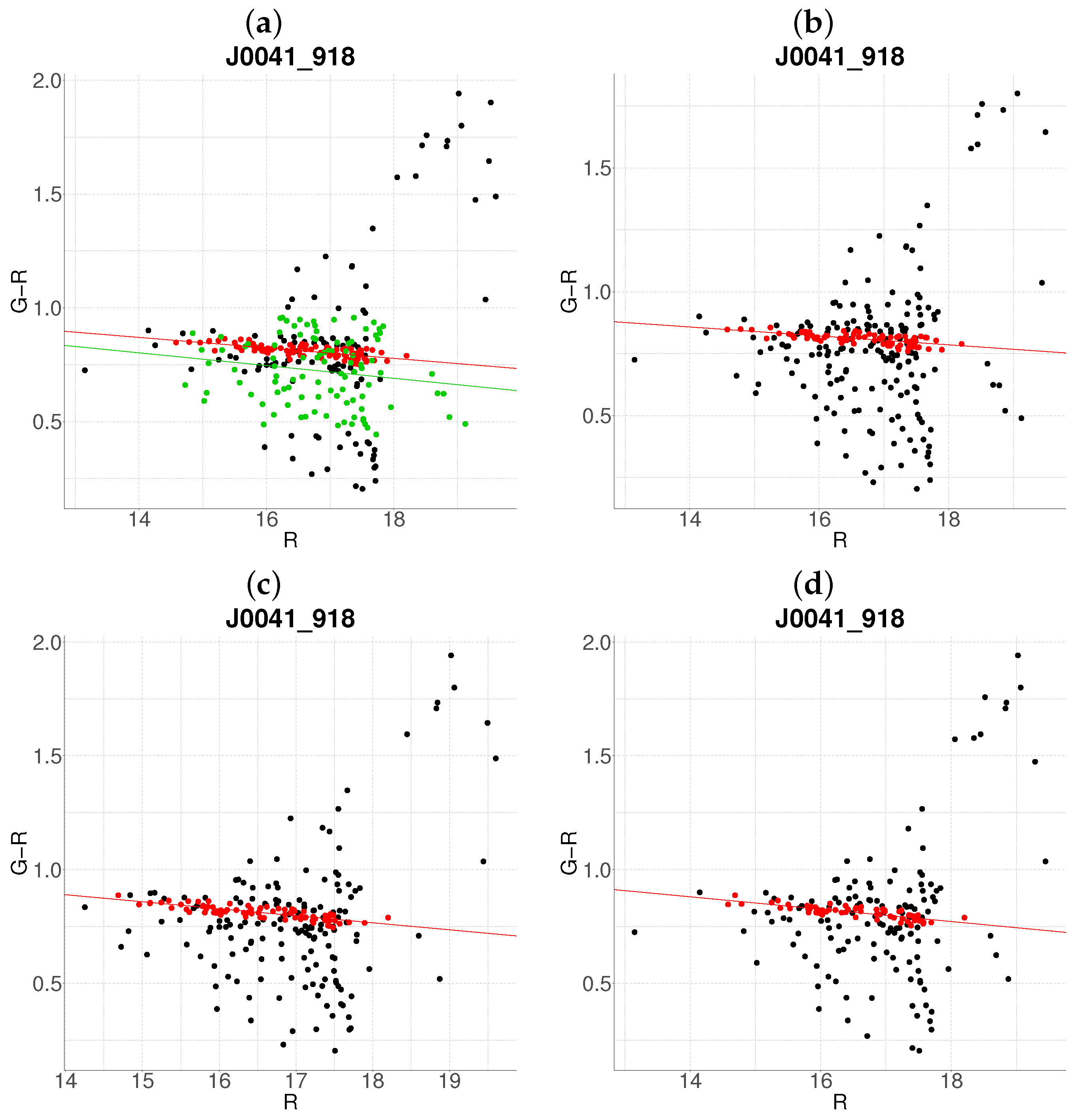
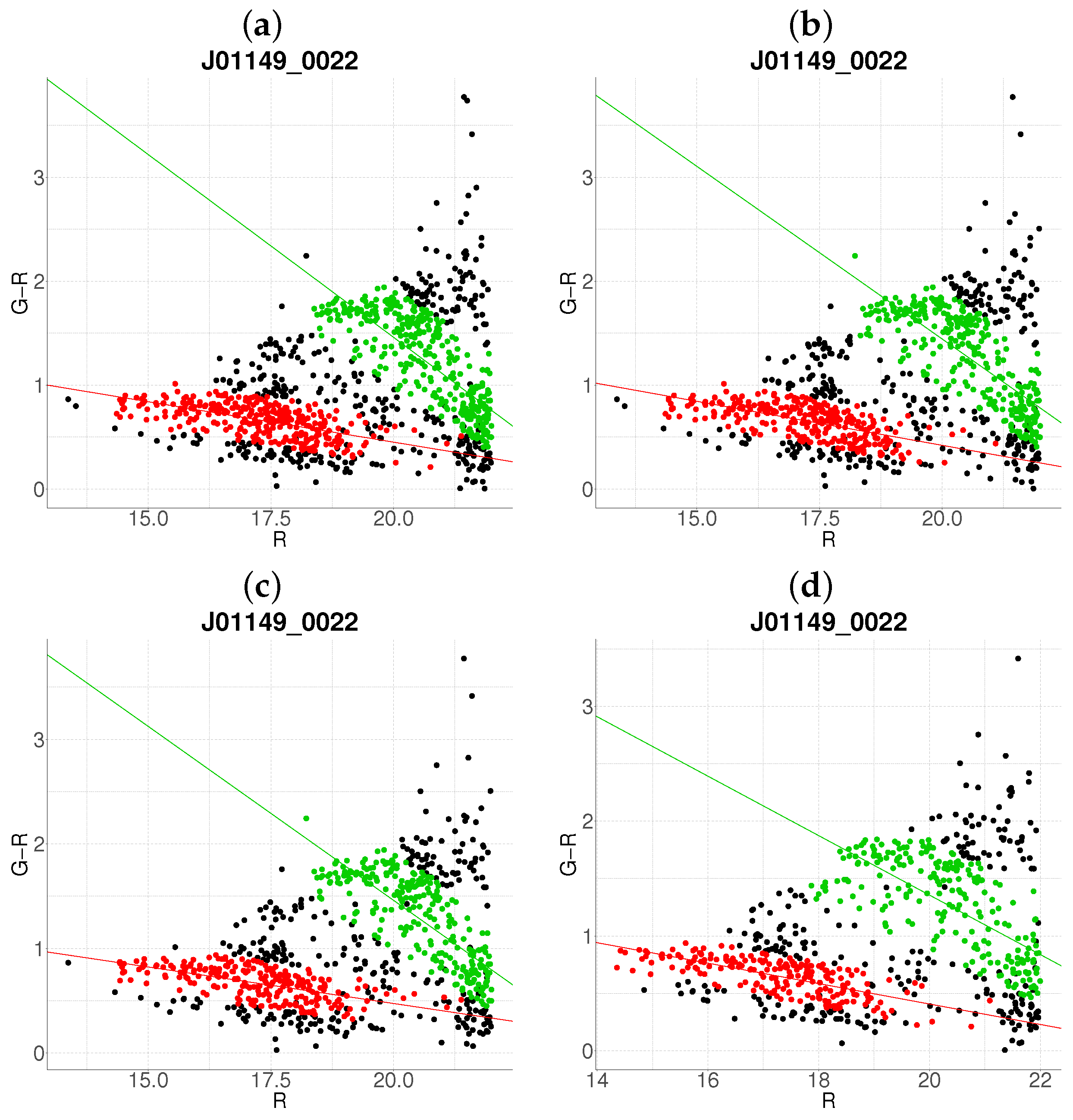
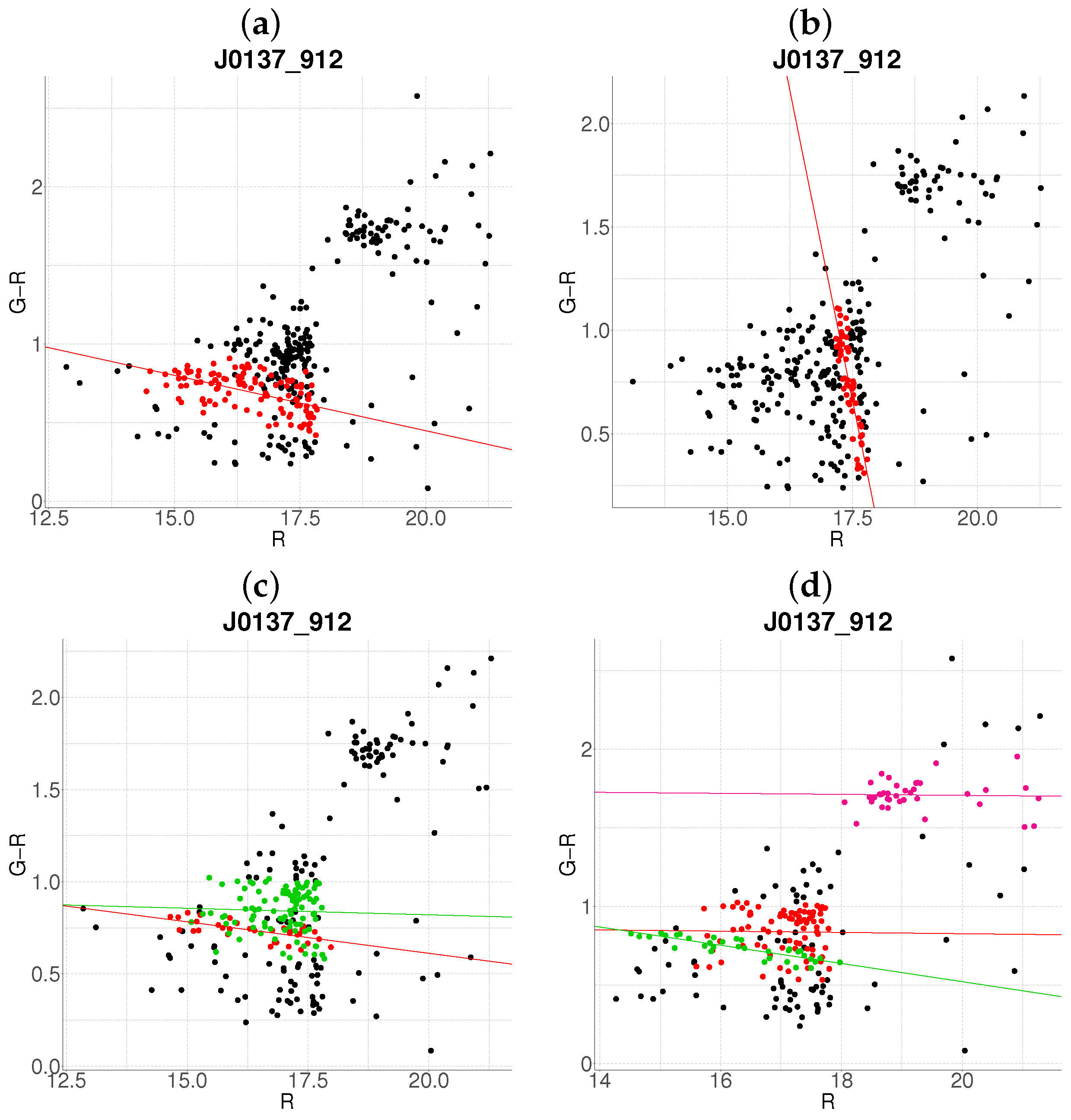
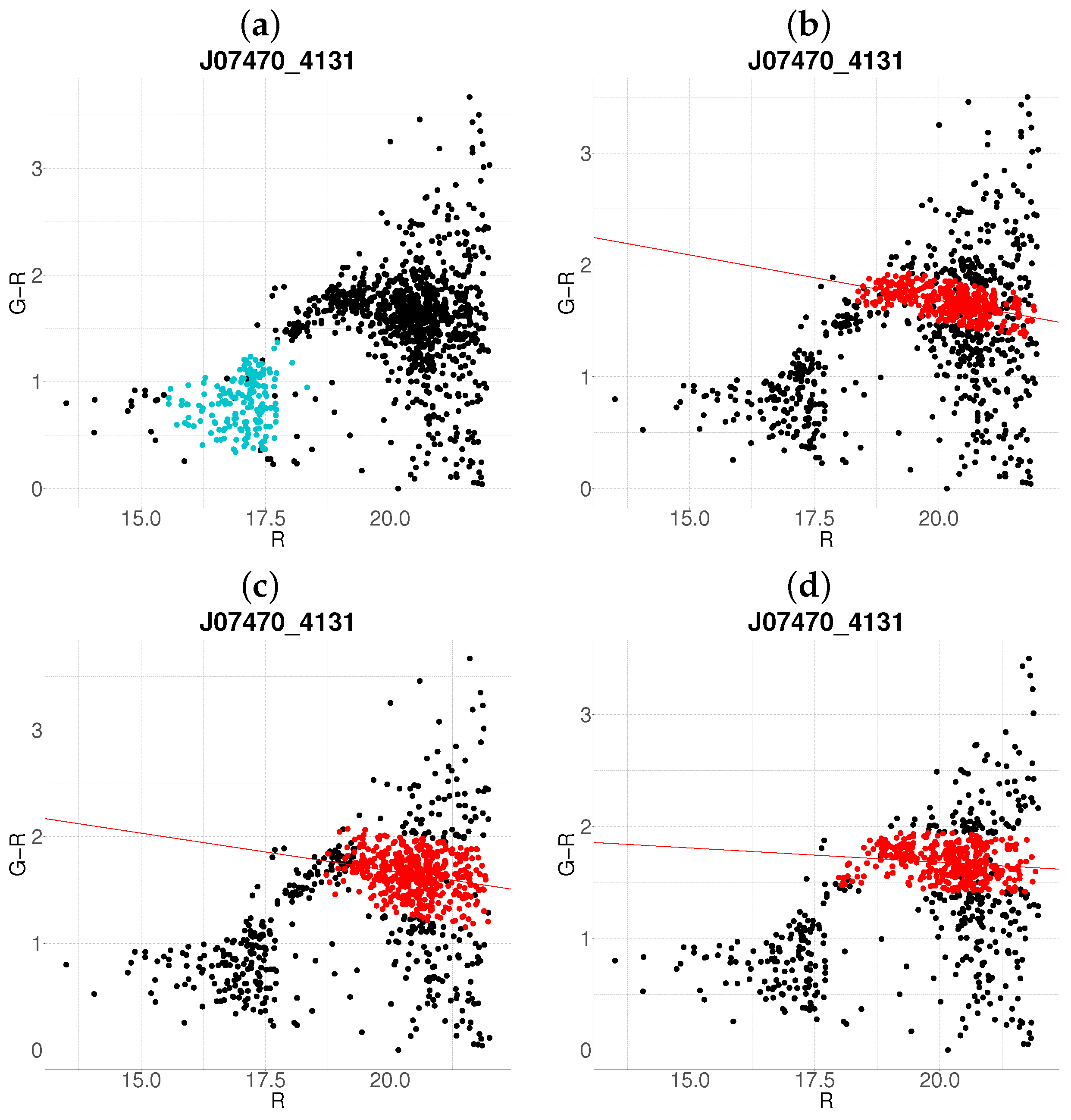
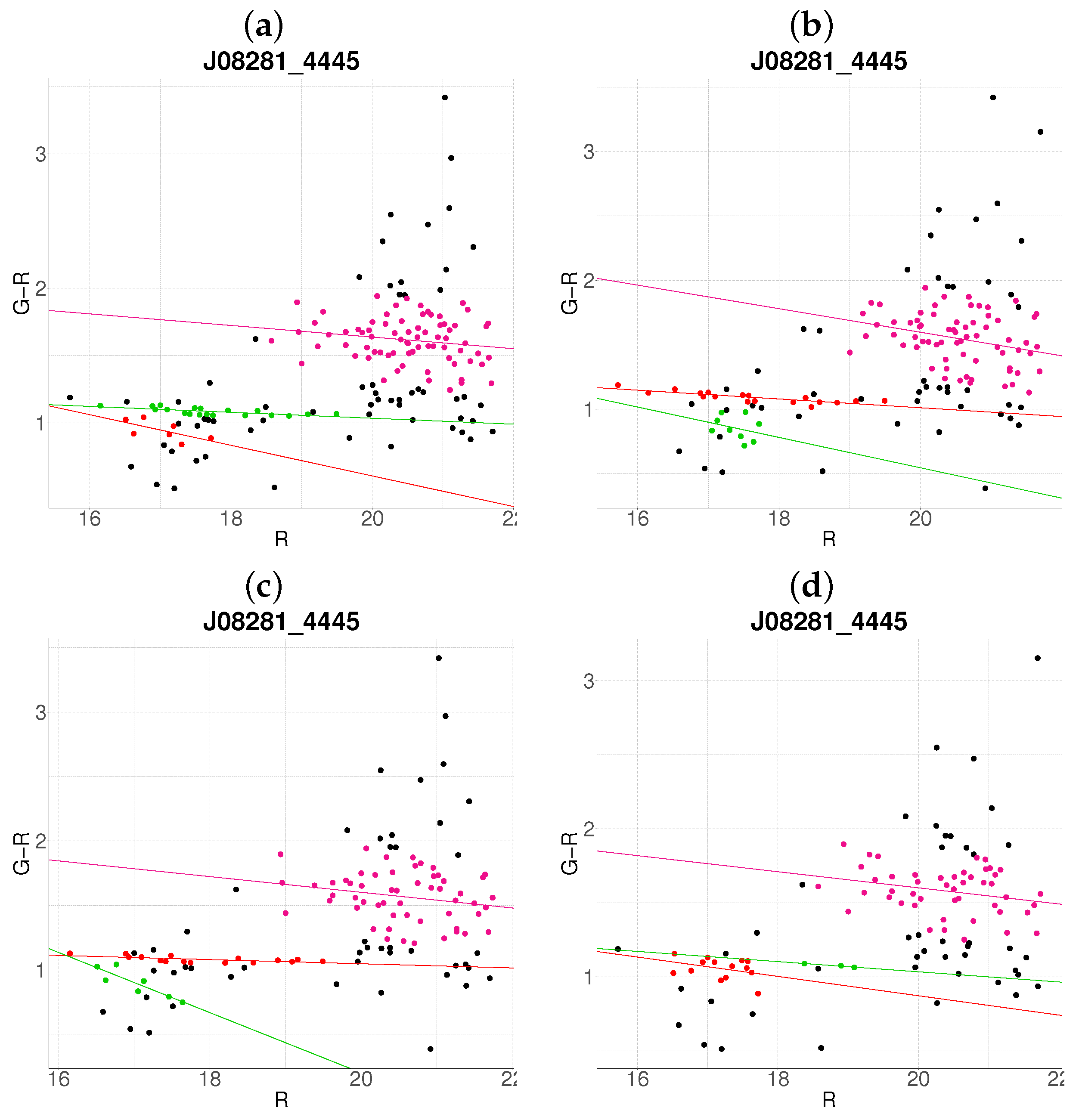
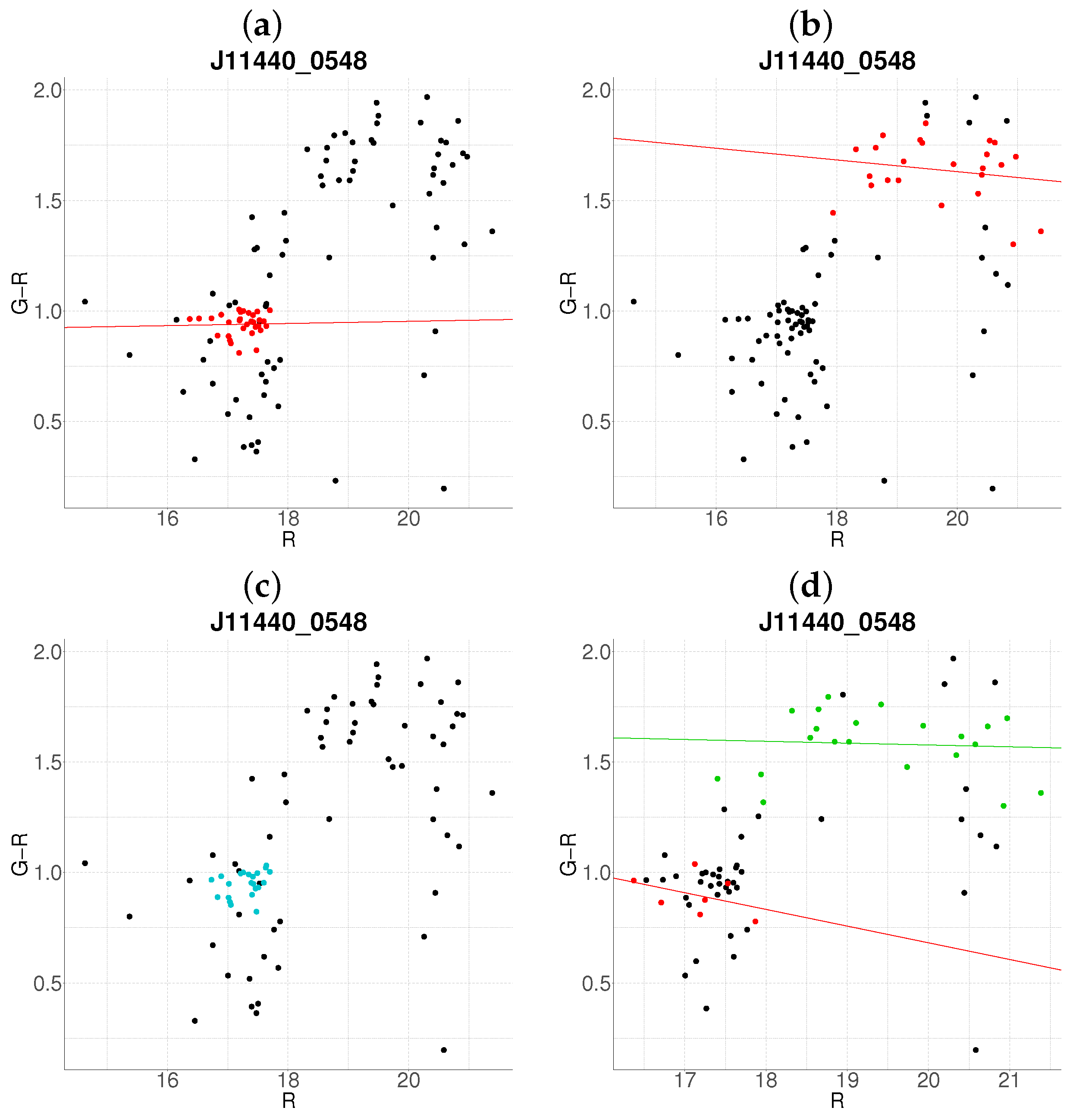
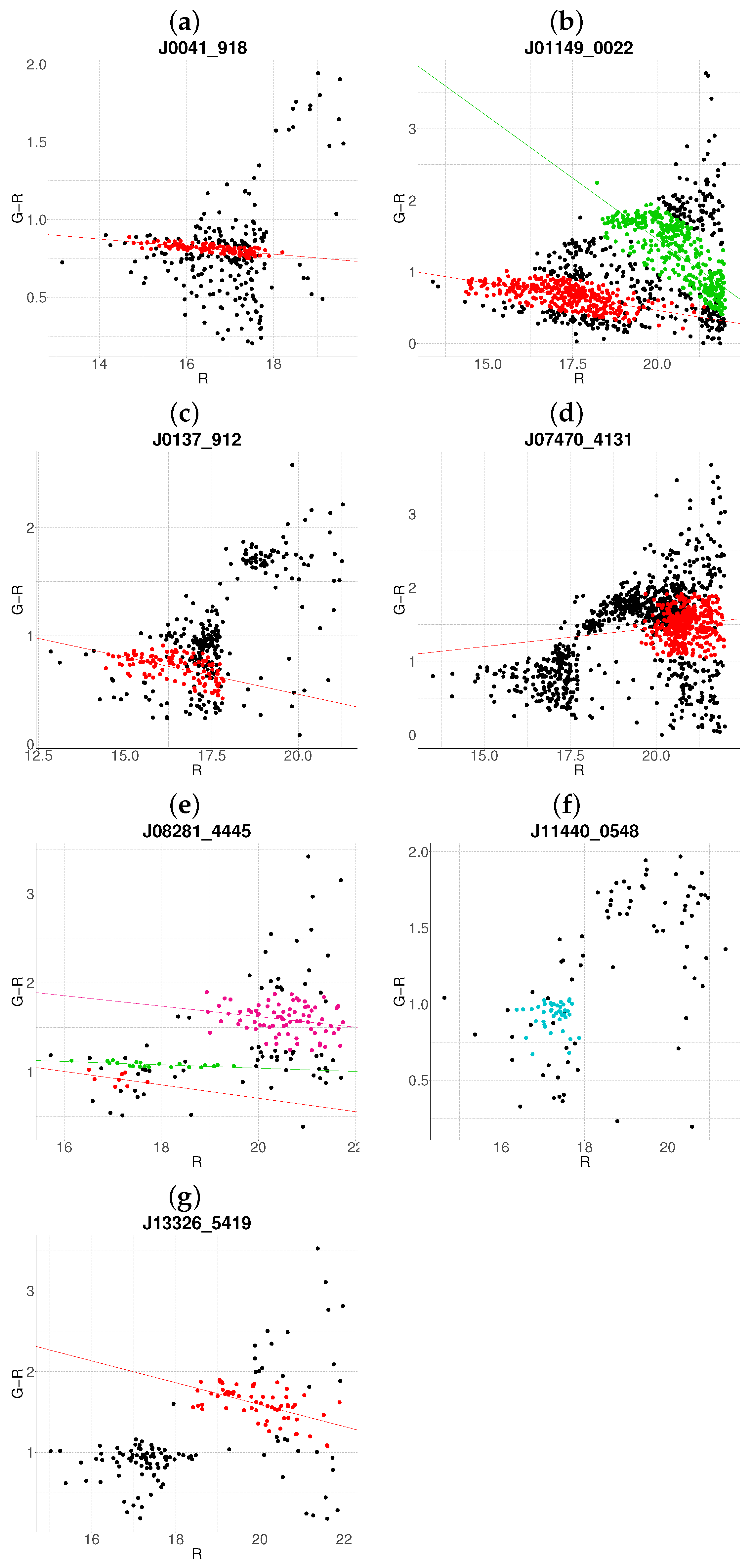
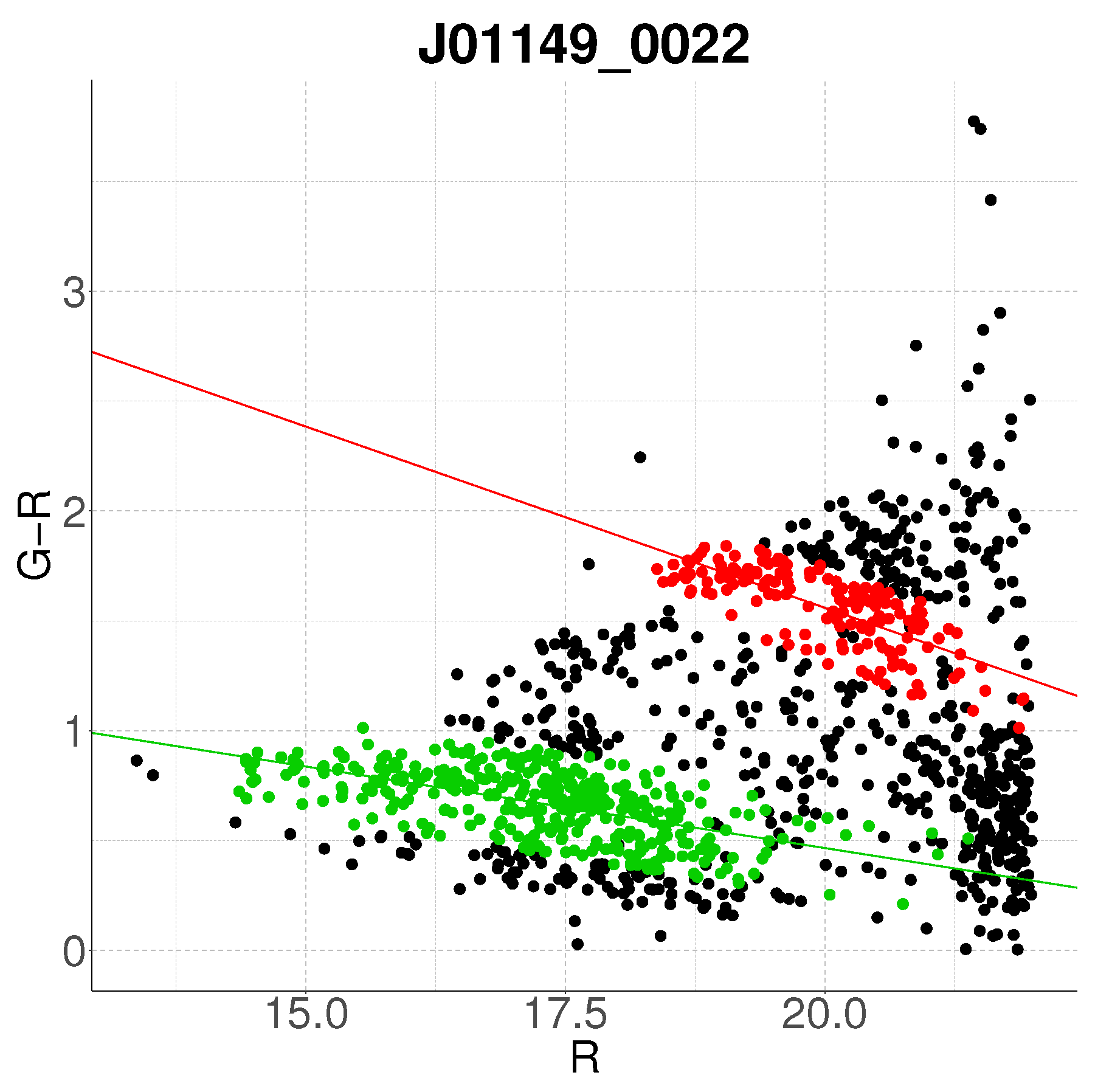
- Step 1: Gaussian mixture modeling via EM algorithmThe EM algorithm is applied to partition the dataset into two candidate subpopulations (cluster vs. background/foreground), modeling their multivariate distributions using Gaussian mixture models (GMMs). Parameters—including component means (), covariance matrices , and mixture weights —are optimized to maximize the likelihood of the observed data. Figure 1a illustrates this step for the cluster J001149-0022, where the initial classification assigns galaxies to two candidate components (red and green).
- Step 2: Outlier rejection via Mahalanobis distanceTo mitigate contamination from interlopers, cluster membership is refined using a statistical threshold based on the Mahalanobis distance. A conservative cutoff is defined as the 95th percentile (0.95 quantile) of the distribution with degrees of freedom equal to the dimensionality of the data (here, 3: ). Observations exceeding this threshold (black points in Figure 1b) are flagged as outliers and excluded from subsequent analysis.
- Step 3: Projection and slope-based acceptanceFor each candidate cluster, the covariance matrix is decomposed into its principal eigenvectors. The first eigenvector defines the dominant orientation (“slope”) of the cluster, while the second eigenvector quantifies intrinsic scatter perpendicular to this axis. Both eigenvectors define a plane in the 3D working enviroment, which we prioritize to capture maximal data variance. Two scenarios arise:
- Negative slope (Red sequence compliance): A negative slope (characteristic of the red sequence) triggers the construction of an acceptance region. This region is bounded by lines offset from the principal axis by , where is the second eigenvalue of (Figure 1c). Galaxies within these bounds are retained as high-confidence cluster members.
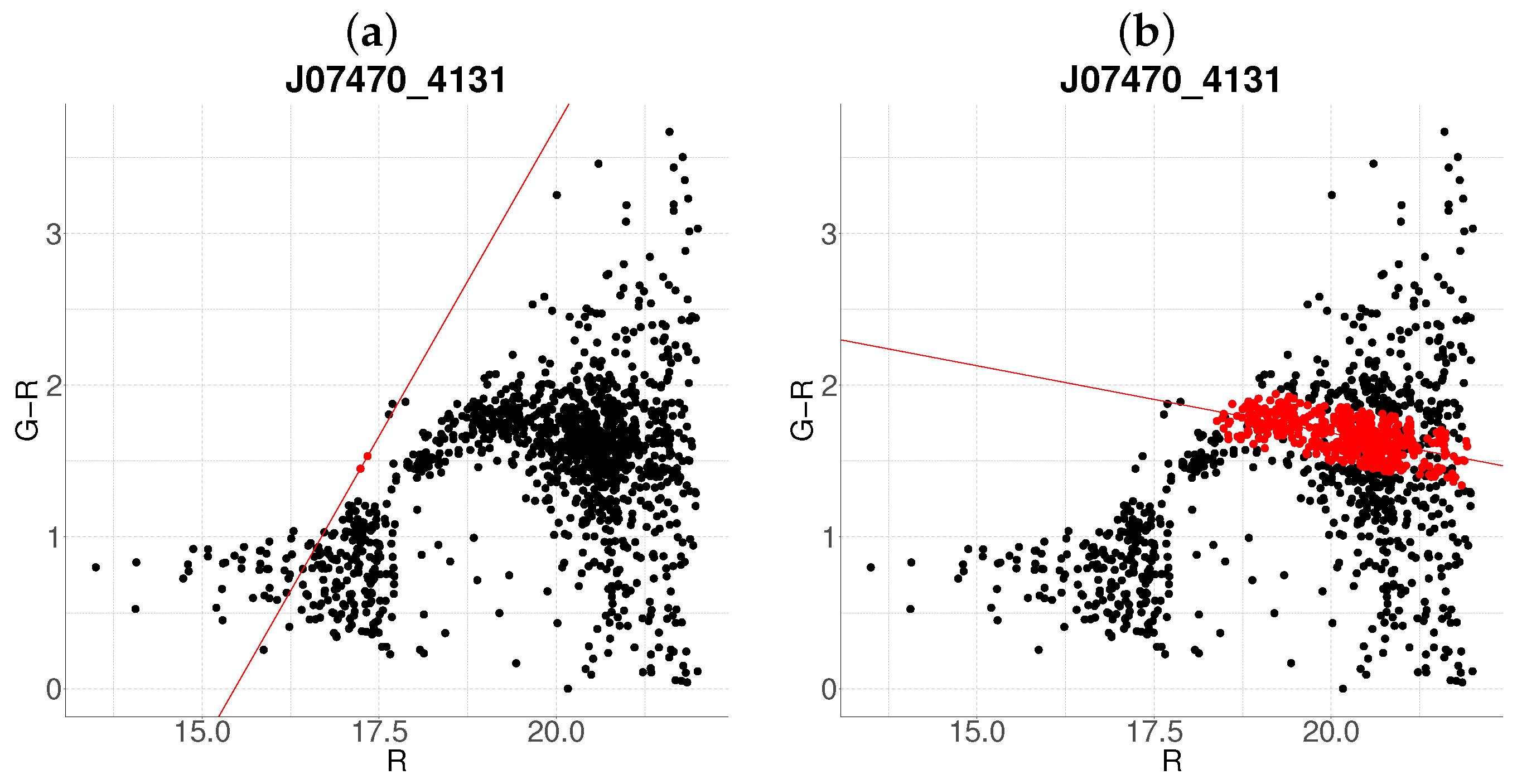
- Non-negative slope (Iterative reassessment): A non-negative slope suggests spurious structure (e.g., projection effects). In such cases, the candidate with the smaller mean r-magnitude undergoes a second iteration (Steps 1–4). Persistent non-negative slopes after iteration lead to candidate rejection (e.g., red group in Figure 1d).
- Step 4: Step control and qualitative comparison of resultsThe algorithm terminates if at the first step, an acceptance region has been built, in another case, at the end of the second step. Final candidates are qualitatively compared against the results obtained with the base algorithm.
3. Results
3.1. Cluster Detection and Membership Refinement
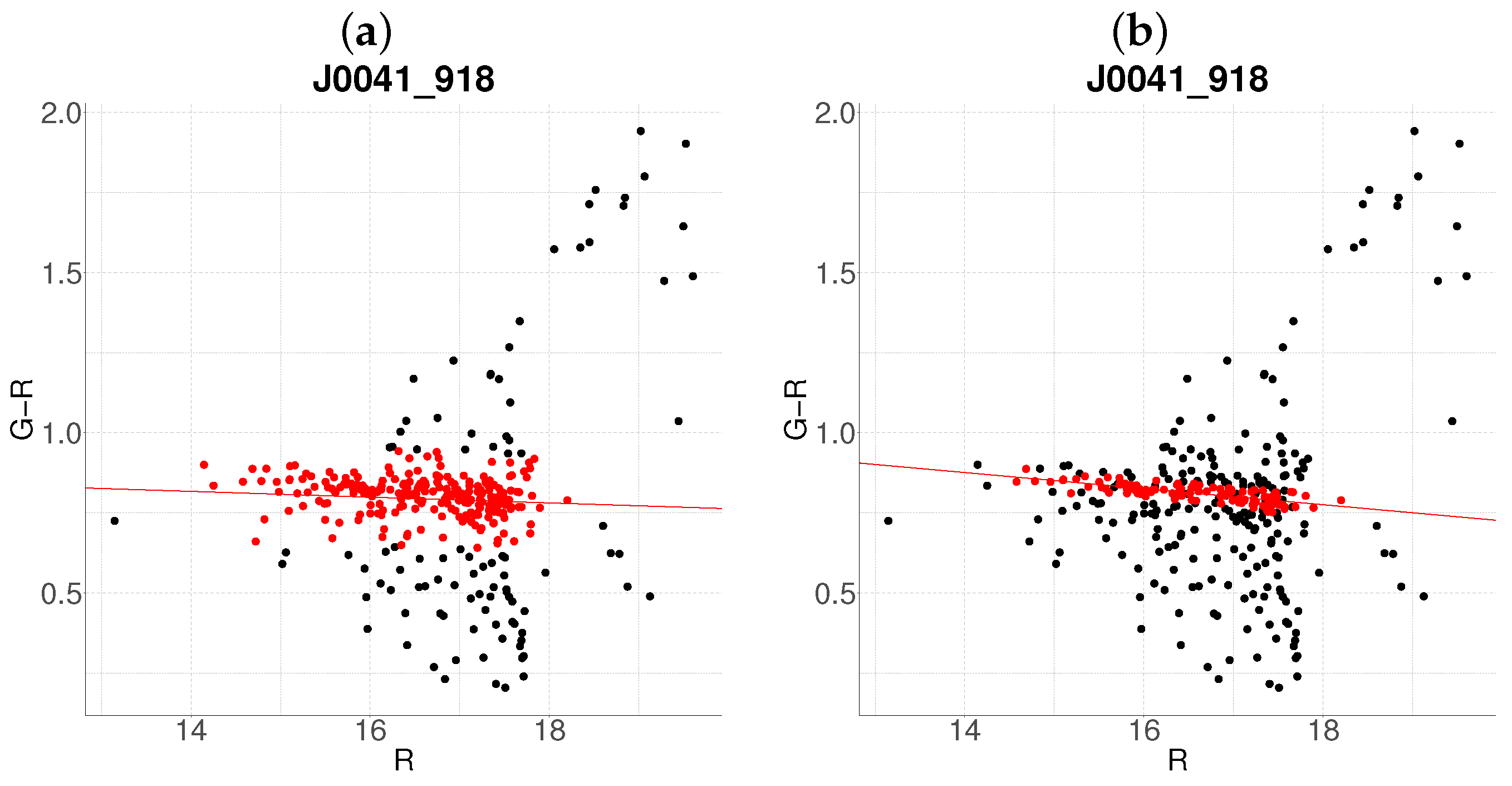
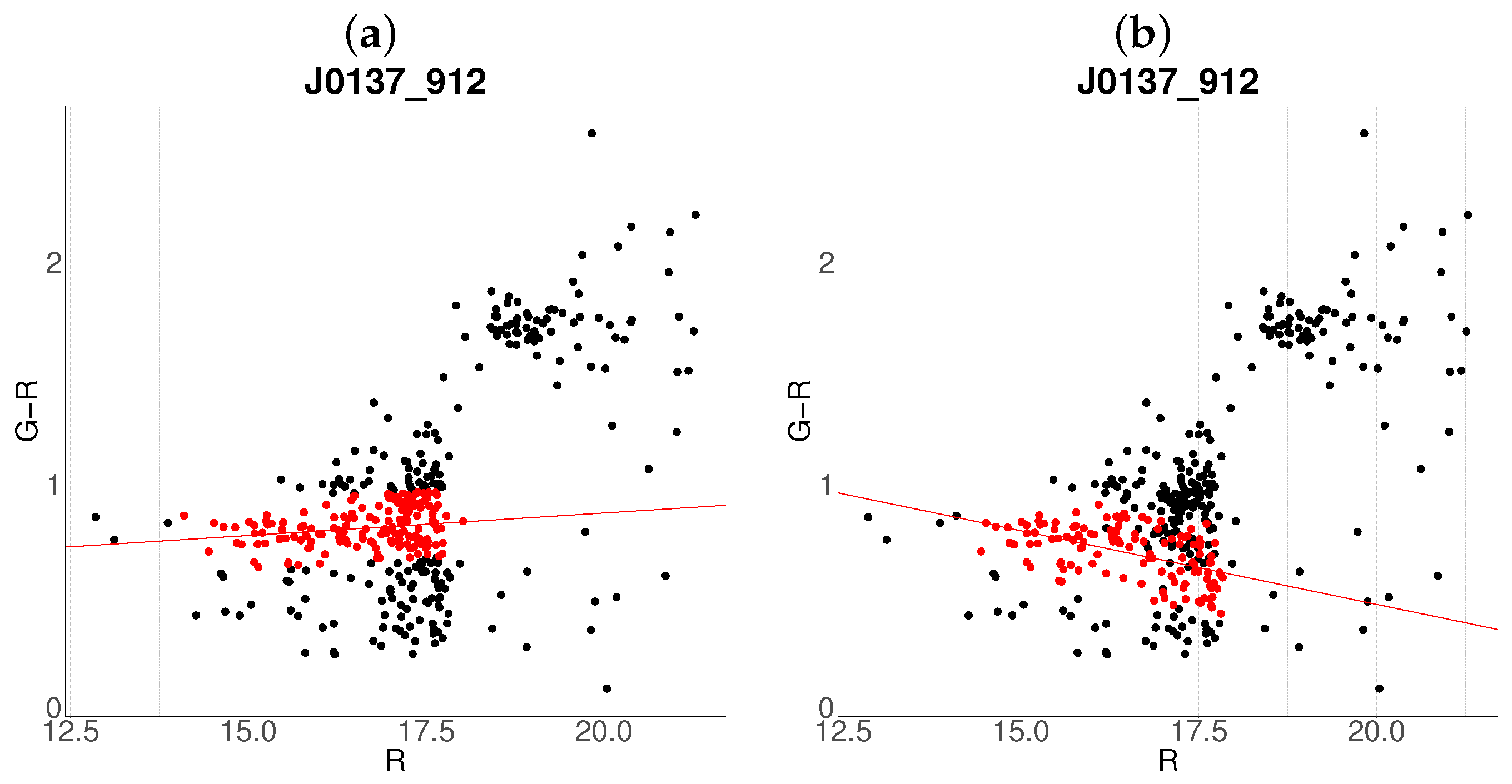
3.2. Resolution of Substructure and Multi-Cluster Detection
Edge Cases and Algorithm Limitations
3.3. Robustness Test Against Data Loss and Photometric Redshift Noise
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Computer Code



References
- Rines, K.; Geller, M.J.; Diaferio, A.; Kurtz, M.J. Measuring the ultimate halo mass of galaxy clusters: Redshifts and mass profiles from the hectospec cluster survey (hecs). Astrophys. J. 2013, 767, 15. [Google Scholar] [CrossRef]
- Baum, W.A. Population Inferences from Star Counts, Surface Brightness and Colors. Publ. Astron. Soc. Pac. 1959, 71, 106–117. [Google Scholar] [CrossRef]
- Faber, S.M.; Jackson, R.E. Velocity dispersions and mass-to-light ratios for elliptical galaxies. Astrophys. J. 1976, 204, 668–683. [Google Scholar] [CrossRef]
- Dressler, A.; Lynden-Bell, D.; Burstein, D.; Davies, R.L.; Faber, S.M.; Terlevich, R.; Wegner, G. Spectroscopy and Photometry of Elliptical Galaxies. I. New Distance Estimator. Astrophys. J. 1987, 313, 42–58. [Google Scholar] [CrossRef]
- Blanton, M.R.; Hogg, D.W.; Bahcall, N.A.; Baldry, I.K.; Brinkmann, J.; Csabai, I.; Eisenstein, D.; Fukugita, M.; Gunn, J.E.; Ivezić, V.; et al. The Broadband Optical Properties of Galaxies with Redshifts 0.02<z<0.22. Astrophys. J. 2003, 594, 186–207. [Google Scholar]
- López-Cruz, O.; Barkhouse, W.A.; Yee, H. The color-magnitude effect in early-type cluster galaxies. Astrophys. J. 2004, 614, 679. [Google Scholar] [CrossRef]
- Hogg, D.W.; Blanton, M.R.; Brinchmann, J.; Eisenstein, D.J.; Schlegel, D.J.; Gunn, J.E.; McKay, T.A.; Rix, H.W.; Bahcall, N.A.; Brinkmann, J.; et al. The Dependence on Environment of the Color-Magnitude Relation of Galaxies. Astrophys. J. Lett. 2004, 601, L29–L32. [Google Scholar] [CrossRef]
- Cerulo, P.; Orellana, G.A.; Covone, G. The evolution of brightest cluster galaxies in the nearby Universe – I. Colours and stellar masses from the Sloan Digital Sky Survey and Wide Infrared Survey Explorer. Mon. Not. R. Astron. Soc. 2019, 487, 3759–3775. [Google Scholar] [CrossRef]
- Khanday, S.A.; Saha, K.; Iqbal, N.; Dhiwar, S.; Pahwa, I. Morphology, colour–magnitude, and scaling relations of galaxies in Abell 426. Mon. Not. R. Astron. Soc. 2022, 515, 5043–5061. [Google Scholar] [CrossRef]
- Hahn, C.; Bottrell, C.; Lee, K.G. HaloFlow. I. Neural Inference of Halo Mass from Galaxy Photometry and Morphology. Astrophys. J. 2024, 968, 968–990. [Google Scholar] [CrossRef]
- Yantovski-Barth, M.J.; Newman, J.A.; Dey, B.; Andrews, B.H.; Eracleous, M.; Golden-Marx, J.; Zhou, R. The CluMPR galaxy cluster-finding algorithm and DESI legacy survey galaxy cluster catalogue. Mon. Not. R. Astron. Soc. 2024, 531, 2285–2303. [Google Scholar] [CrossRef]
- Gladders, M.D.; Yee, H. A new method for galaxy cluster detection. I. The algorithm. Astron. J. 2000, 120, 2148. [Google Scholar] [CrossRef]
- Trejo-Alonso, J.; Caretta, C.; Laganá, T.F.; Sodré Jr, L.; Cypriano, E.S.; Lima Neto, G.; Mendes de Oliveira, C. Red sequence of Abell X-ray underluminous clusters. Mon. Not. R. Astron. Soc. 2014, 441, 776–783. [Google Scholar] [CrossRef]
- Mares, D.; Trejo, J.; Díaz, A. Determinación de Membresía por las Técnicas de Secuencia Roja y Cáusticas; Technical report, 25 Verano de la Ciencia Región Centro; Academia Mexicana de Ciencia: Queretaro, Mexico, 2023. [Google Scholar]
- McLachlan, G.J.; Lee, S.X.; Rathnayake, S.I. Finite Mixture Models. Annu. Rev. Stat. Appl. 2019, 6, 355–378. [Google Scholar] [CrossRef]
- Sarria, M.; Castellanos, G. Entrenamiento discriminativo por distancia de Mahalanobis para detección de patologías de voz. Dyna 2010, 77, 220–228. [Google Scholar]
- Pearson, K. Contributions to the Mathematical Theory of Evolution. Philos. Trans. R. Soc. Lond. A 1894, 185, 71–110. [Google Scholar]
- Rao, C.R. The Utilization of Multiple Measurements in Problems of Biological Classification. J. R. Stat. Soc. Ser. (Methodol.) 1948, 10, 159–203. [Google Scholar] [CrossRef]
- Hasselblad, V. Estimation of Parameters for a Mixture of Normal Distributions. Technometrics 1966, 8, 431–444. [Google Scholar] [CrossRef]
- Gensler, S. Finite Mixture Models. In Handbook of Market Research; Homburg, C., Klarmann, M., Vomberg, A., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 251–264. [Google Scholar] [CrossRef]
- Burgett, W.S.; Vick, M.M.; Davis, D.S.; Colless, M.; De Propris, R.; Baldry, I.; Baugh, C.; Bland-Hawthorn, J.; Bridges, T.; Cannon, R.; et al. Substructure analysis of selected low-richness 2dFGRS clusters of galaxies. Mon. Not. R. Astron. Soc. 2004, 352, 605–654. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum Likelihood from Incomplete Data Via the EM Algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1977, 39, 1–22. [Google Scholar] [CrossRef]
- Portillo, M.T.E.; Plata, J.A.S. P. Ch. Mahalanobis y las aplicaciones de su distancia estadística. CULCyT: Cult. Cient. Tecnol. 2008, 5, 13–20. [Google Scholar]
- Gómez Silva, M.J.; Armingol, J.M.; Escalera, A.d.l. Re-identificación de personas mediante la distancia de Mahalanobis. In Proceedings of the XXXIX Jornadas de Automática, Área de Ingeniería de Sistemas y Automática, Universidad de Extremadura, Badajoz, Spain, 5–7 September 2018; pp. 967–974. [Google Scholar]
- Popesso, P.; Böhringer, H.; Brinkmann, J.; Voges, W.; York, D.G. RASS-SDSS Galaxy clusters survey-I. The catalog and the correlation of X-ray and optical properties. Astron. Astrophys. 2004, 423, 449–467. [Google Scholar] [CrossRef]
- Aihara, H.; Prieto, C.; An, D.; Anderson, S.; Aubourg, E.; Balbinot, E.; Beers, T.; Berlind, A.A.; Bickerton, S.; Bizyaev, D.; et al. The eighth data release of the Sloan Digital Sky Survey: First data from SDSS-III. Astrophys. J. Suppl. Ser. 2011, 193, 29. [Google Scholar] [CrossRef]
- Alam, S.; Albareti, F.; Prieto, C.; Anders, F.; Anderson, S.; Anderton, T.; Andrews, B.; Armengaud, E.; Aubourg, É.; Bailey, S.; et al. The eleventh and twelfth data releases of the Sloan Digital Sky Survey: Final data from SDSS-III. Astrophys. J. Suppl. Ser. 2015, 219, 12. [Google Scholar] [CrossRef]
- Strauss, M.; Weinberg, D.; Lupton, R.; Narayanan, V.; Annis, J.; Bernardi, M.; Blanton, M.; Burles, S.; Connolly, A.; Dalcanton, J.; et al. Spectroscopic target selection in the Sloan Digital Sky Survey: The main galaxy sample. Astron. J. 2002, 124, 1810. [Google Scholar] [CrossRef]
- Stoughton, C.; Lupton, R.; Bernardi, M.; Blanton, M.; Burles, S.; Castander, F.; Connolly, A.; Eisenstein, D.; Frieman, J.; Hennessy, G.; et al. Sloan digital sky survey: Early data release. Astron. J. 2002, 123, 485. [Google Scholar] [CrossRef]
- Koester, B.P.; McKay, T.A.; Annis, J.; Wechsler, R.H.; Evrard, A.; Bleem, L.; Becker, M.; Johnston, D.; Sheldon, E.; Nichol, R.; et al. A MaxBCG catalog of 13,823 galaxy clusters from the sloan digital sky survey. Astrophys. J. 2007, 660, 239. [Google Scholar] [CrossRef]
- Venables, W.; Ripley, B.; Venables, W.; Ripley, B. Linear statistical models. In Modern Applied Statistics with S; Series Statistics and Computing; Springer: New York, NY, USA, 2002; pp. 139–181. [Google Scholar]
- Li, H.; Vogelsberger, M.; Bryan, G.L.; Marinacci, F.; Sales, L.V.; Torrey, P. Formation and evolution of young massive clusters in galaxy mergers: The SMUGGLE view. Mon. Not. R. Astron. Soc. 2022, 514, 265–279. [Google Scholar] [CrossRef]
- Murray, C.; Bartlett, J.G.; Artis, E.; Melin, J.B. Measuring weak lensing masses on individual clusters. Mon. Not. R. Astron. Soc. 2022, 512, 4785–4791. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mares-Rincón, D.R.; Trejo-Alonso, J.J.; Guerrero-Díaz-de-León, J.A.; Macías-Díaz, J.E. Statistical Classification and an Optimized Red-Sequence Technique for the Determination of Galaxy Clusters. Galaxies 2025, 13, 52. https://doi.org/10.3390/galaxies13030052
Mares-Rincón DR, Trejo-Alonso JJ, Guerrero-Díaz-de-León JA, Macías-Díaz JE. Statistical Classification and an Optimized Red-Sequence Technique for the Determination of Galaxy Clusters. Galaxies. 2025; 13(3):52. https://doi.org/10.3390/galaxies13030052
Chicago/Turabian StyleMares-Rincón, Dagoberto R., Josué J. Trejo-Alonso, José A. Guerrero-Díaz-de-León, and Jorge E. Macías-Díaz. 2025. "Statistical Classification and an Optimized Red-Sequence Technique for the Determination of Galaxy Clusters" Galaxies 13, no. 3: 52. https://doi.org/10.3390/galaxies13030052
APA StyleMares-Rincón, D. R., Trejo-Alonso, J. J., Guerrero-Díaz-de-León, J. A., & Macías-Díaz, J. E. (2025). Statistical Classification and an Optimized Red-Sequence Technique for the Determination of Galaxy Clusters. Galaxies, 13(3), 52. https://doi.org/10.3390/galaxies13030052