1. Introduction
The Event Horizon Telescope (EHT) is a globe-spanning Very Long Baseline Interferometry (VLBI) array that has captured images of the shadow region of black holes at the center of the galaxy M87 and the Milky Way [
1,
2], attracting worldwide attention. The next-generation EHT (ngEHT)
1 will push this scientific frontier even further, building ∼10 more stations and doubling the observation bandwidth to improve the imaging capabilities and capture the first black hole movies.
The future EHT + ngEHT array will include ∼21 stations. For each station, the sideband bandwidth will increase from the current 4 GHz to 8 GHz. Dual polarization, two sidebands, and simultaneous dual-frequency (230 GHz and 345 GHz) observations correspond to a bandwidth of 64 GHz and recording data rate of 256 Gbps for two-bit recording and Nyquist sampling [
3]. Current EHT observations are 7 days per year, while ngEHT observations are expected to run 60 days per year. Thus, compared with the current EHT, the future array will have more stations, a wider bandwidth, and more observation days each year. The amount of observation data is anticipated to be tens of petabytes in size, which brings great challenges to the correlation. This is the motivation to build a dedicated high-performance correlator
2.
The Submillimeter Array (SMA) is a standalone radio interferometer consisting of eight antennas. A digital correlator-beamformer called SWARM [
6] functions as two distinct instruments: an FX correlator that computes fringe visibilities across frequencies for every pair of antennas, and a beamformer that forms the coherent phased array sum of the eight antennas, aggregating the SMA collecting area to an equivalent single large-aperture telescope. The beamformer mode was designed in SWARM to enable its participation in EHT observations.
In order to match the observational capabilities of the ngEHT and the Wideband SMA Project (wSMA), it is desirable to upgrade the correlator-beamformer of the SMA. Likewise, the VLBI correlator now supporting EHT is limited in bandwidth, which can be processed in a reasonable computing time scale, and also the number of stations that it can handle. We propose a common GPU Tensor Core-based architecture for both of these wideband applications.
This paper reports on the prospects for a correlator-beamformer system having common features that can potentially benefit wSMA and ngEHT. The primary focus of the work described here is the design of an X-engine prototype based on an open-source Tensor Core library [
7]. We note that we have already built a small prototype two-server four-GPU system, on which we have micro-benchmarked and tuned some of the codes and subsystems described in this work. We have made extensive use of the NVIDIA profiling tool Nsight to optimize subsystem performance. We have not yet built the full system described in this paper; however, we continue to actively develop the experimental counterpart to this work.
2. Related Work
The correlator-beamformer (CBF) is a key data processing system for radio interferometers and VLBI arrays. The correlator cross-correlates the baseband data of each antenna/station pair and outputs visibility data for imaging, while the beamformer aggregates the collecting area of the array for VLBI operations.
The correlator function of the CBF is divided into two broad classes. The XF type computes a direct cross-correlation between time series data from pairs of telescopes before transforming to frequency with Fast Fourier Transforms (FFT). The FX type computes the Fourier transform of time series data from each station first, followed by a cross-correlation. The two processing stages are called F-engine and X-engine, respectively. In the F-engine, data from each antenna/station are divided into multiple frequency channels. In the X-engine, a subset of frequency channels from all antenna/station pairs are bin-wise multiplied and the result integrated.
The trade-off between the XF and FX correlation architectures is multidimensional. For high spectral resolutions, the use of FFTs reduces the number of required multiplications in aggregate, although, because of bit growth in the FFTs, these multipliers need to be wider. There are other trade-offs in respect to memory utilization and the number of baselines. Reference [
6] discusses multiplier utilization quantitatively and recommends the FX approach. Whereas XF correlators had been favored historically because wide multipliers were expensive, we observe that almost all new correlator designs (in the last decade, for example) use the FX architecture. We attribute this to the wider availability and lower resource cost of wide multipliers. In addition, FX correlators naturally provide more parallelism through early spectral decomposition. Modern correlator platforms mainly use Field-Programmable Gate Arrays (FPGAs), Graphics Processing Units (GPUs), or CPUs, which are both well equipped with sufficiently wide or even floating point multiplication and are designed at the root for a very high degree of parallelism.
FPGAs have the advantage of hardware programmability. Almost all of the existing hardware correlators are developed with FPGAs. Among them, the Collaboration for Astronomy Signal Processing and Electronics Research (CASPER)
3 open-source FPGA platform is the most popular solution; for example, the SWARM correlator for the SMA [
6], the correlator for MeerKAT [
8], and the correlator for the Arcminute Microkelvin Imager (AMI) array [
9] are all developed with CASPER FPGA boards.
The powerful parallel computing resources of GPUs present an opportunity, and correlators are increasingly adopting GPUs for accelerated computing, especially in X-engines. Hybrid FPGA+GPU architectures have become a very popular solution for correlators. For example, the Canadian Hydrogen Intensity Mapping Experiment (CHIME) [
10], the Large Aperture Experiment to Detect the Dark Ages (LEDA) project of the Long Wavelength Array (LWA) [
11,
12], the Donald C. Backer Precision Array for Probing the Epoch of Reionization (PAPER) [
13], and the Murchison Widefield Array (MWA) [
14] all adopt the hybrid FPGA+GPU architecture for their correlators, where FPGA boards (including ADCs) are used for data acquisition and channelization (F-engines), and GPU boards are used for cross-correlation computing (X-engines). There are also some correlators developed with pure GPUs, such as the early MWA 32-antenna prototype correlator [
15] and the Cobalt correlator of the Low-Frequency Array (LOFAR) [
16]. In these systems, the GPUs are used for the fine channelization of F-engines and cross-correlation of X-engines. ADCs and FPGAs are still required for data acquisition and coarse channelization.
For VLBI arrays, data acquisition and correlation are separated due to the remote station locations. Raw station data are recorded and shipped to a central location for correlation. VLBI correlators are typically CPU-based (software-based). Many VLBI institutions have developed a variety of software correlators. Among them, DiFX [
4,
5] is the most widely used one. Facilities such as the VLBI Global Observing System (VGOS), the Very Long Baseline Array (VLBA), the Australian Long Baseline Array (LBA), and the EHT [
17] all use DiFX to correlate data. Recently, the EHT has been investigating a Cloud-based correlation scheme [
18], which is also based on DiFX.
For VLBI and ngEHT, we sometimes use the term “near-real-time” to describe the desired performance of a wideband correlator. VLBI correlators use recorded data and therefore need not be strictly real-time. “Near-real-time” under these conditions signals that it is desirable to improve the efficiency of media recycling, reducing media costs, which can be very high for the wide bandwidths, high cadences, and increased number of stations of the ngEHT. As a side benefit, faster correlation reduces the time to science and improves fringe search iteration times and efficiency, and feedback on prior campaign results can improve the planning of future ones.
While various architectures have been introduced above, in this paper, we propose a GPU Tensor Core-based correlator for the wSMA and the ngEHT for the following reasons.
(1) GPUs have powerful computing resources, which are far more efficient than CPUs for parallel computing. In particular, the newly embedded Tensor Cores in NVIDIA GPUs are much more efficient than regular CUDA cores as well as FPGAs in terms of matrix multiplication [
7].
(2) There is a wealth of open-source software libraries (both GPU-based and CPU-based) available for radio astronomical instruments. Although CASPER also has various open-source libraries, users still sometimes need to develop new firmware modules with the hardware description languages (HDL). Compared with CASPER libraries and HDL, the GPU source code is easier to upgrade and modify. The GPU development ecosystem includes sophisticated debugging and optimization tools and uses standard languages familiar to a wide swath of software engineers.
(3) The architecture of GPU-based correlators is flexible, maintainable, and scalable. High-performance hardware such as CPUs, GPUs, network interface cards (NICs), etc., can be integrated together easily.
3. System Design and Selection of Open-Source Libraries
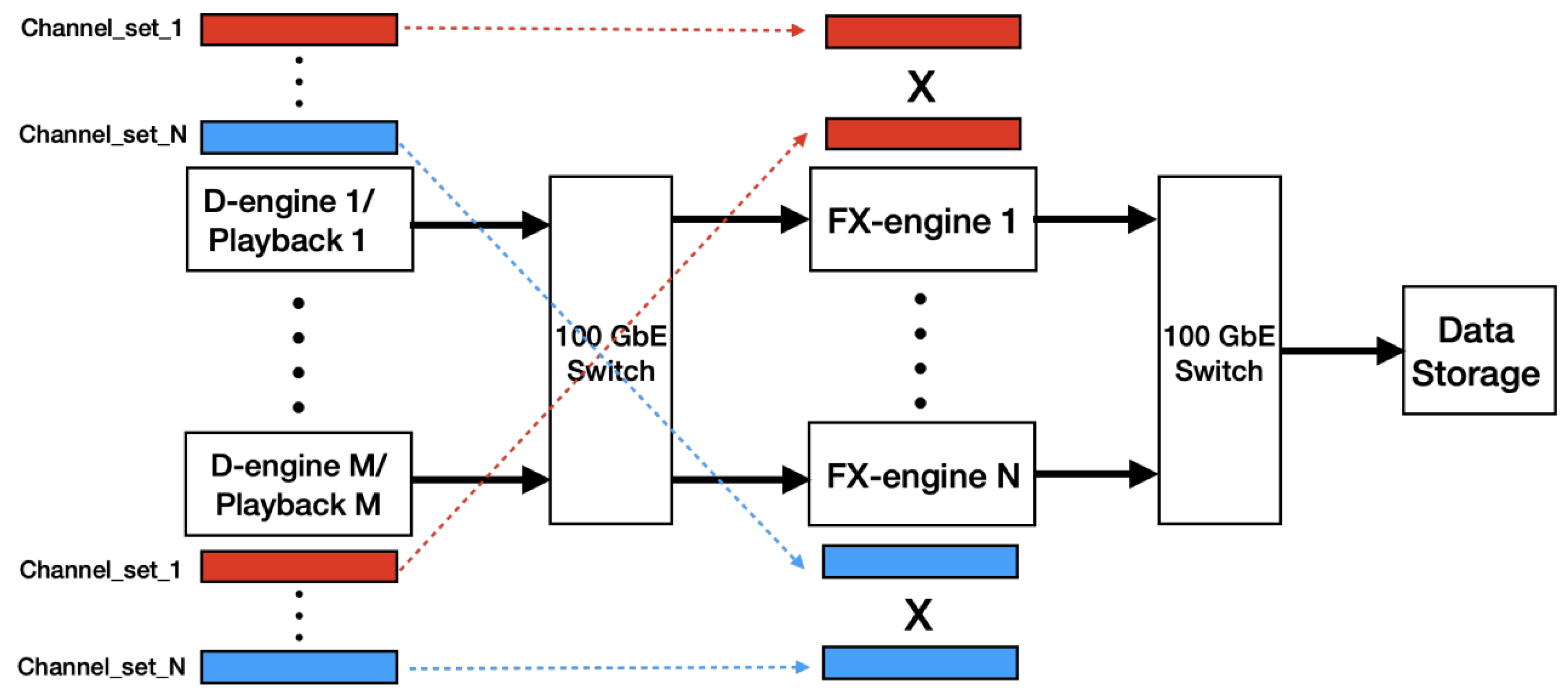
We propose two schemes for the architecture of the correlator. In the first “expanded” scheme, the F-engines and X-engines are implemented in different GPU servers, which is shown in
Figure 1. The corner-turner transpose between the two types of engines is implemented through the network switch. Each network packet from the F-engines contains data containing a subset of frequency channels. Different subsets of packets have different destination IP addresses and are transmitted to different X-engines through the switch. Thus, each X-engine processes a subset of frequency channels from all of the F-engines to form all of the array baselines.
In the second “compact” scheme, the core functions of the F-engine and the X-engine are arranged to execute in the same GPU server. This compact scheme reduces hardware resources such as GPUs, NICs, and CPUs. Thus, it is the preferred architecture for scaled deployment for smaller arrays. Since both wSMA and ngEHT have relatively few antennas and baselines, the compact scheme is potentially attractive. The expanded first scheme is simpler to build and debug, is the better starting point for development and laboratory debug, and is preferred for larger wideband arrays, such as ALMA.
We discuss the compact scheme in more detail in
Section 7.
The main difference between the wSMA real-time correlator and the ngEHT VLBI correlator is that the former uses D-engines to generate data, while the latter uses playback servers. A D-engine is a hardware system with ADCs and FPGAs to digitize the analog signals from each antenna, and it then transmits the data to the corresponding F-engine. The D-engine FPGA firmware optionally includes data processing modules that implement coarse channelization, slope and ripple equalization, and requantization
4.
Based on this same ADC-FPGA hardware, we are developing a wideband digital backend for the ngEHT, as shown in
Figure 2, which includes a Xilinx VCU128 FPGA evaluation motherboard and a sub-board with
Gsps ADCs. This backend can be used as D-engines for the wSMA correlator with only slight modifications of the FPGA firmware. For the ngEHT correlator, the playback servers play back the recorded data from the digital backends to the corresponding F-engines.
For the F-engine, a GPU-based library called katgpucbf
5 developed by the MeerKAT team is being considered. We have installed and tested the F-engine of the library on our experimental server. The next step is to modify it according to the specific requirements. A geometric delay model is required by both applications. The ngEHT VLBI correlator will have much more rapid fringe (or delay rate) correction. It also needs fringe search features, an across delay and delay rate using a geographic model of station placement, and a VLBI Data Interchange Format (VDIF) deformatter. The present focus of this work is on the correlation engine with delay and fringe correction development, and VLBI fringe search features, planned for future development.
Another library under consideration is the new cuFFTDx library developed by NVIDIA. As it generates FFTs that are GPU-callable, it is possible to merge FIR filters, FFTs, and phase corrections in a single GPU kernel instead of three. As a result, only one pass over the data is made, and as each of these functions is limited by the GPU memory bandwidth, one can expect an almost three-fold speedup.
For the X-engine, we developed a pipeline based on open-source libraries. Key components include a network transmission/receiving module, a format conversion module, a GPU-based correlation module, a long-term accumulation (LTA) module, and a pipeline framework to manage the above modules. We review and evaluate the existing open-source libraries and select the appropriate ones in the following sections.
The open-source libraries for network transmission/receiving that were under consideration include PF_ring
6, jive5ab
7, and SPEAD2
8. PF_ring has been adopted by Mark6 equipments to capture network packets from VLBI digital backends. jive5ab is mainly used for data transfer and recording in e-VLBI systems, which has been used in Mark5/Mark6 and FlexBuffer by the European VLBI network. SPEAD is a data format for radio astronomy. SPEAD2 is a python/C++ library with the functions of the SPEAD formatter/deformatter and the network system. It supports both the traditional networking stack and the verbs API [
19]. In order to match the MeerKAT katgpucbf F-engines, we select SPEAD2 as the basic library for the network transmission/receiving module.
The original and most popular GPU correlation library is xGPU [
20], which has been adopted by many radio arrays, such as the LWA, MWA, PAPER, etc. When xGPU was developed 10 years ago, Tensor Cores had not appeared yet, so regular CUDA cores were used for correlation computing, which are not as efficient as Tensor Cores. The CHIME team developed a correlation library based on the AMD GPU. The AMD offerings feature higher computational throughput per unit cost than the comparable NVIDIA GPUs [
21]; however, the former is more difficult to program than the latter. The recently developed Tensor Core Correlator (TCC) library adopts Tensor Cores as computing resources; the library resolves the complexity of using Tensor Cores and addresses several optimization challenges, such as the missing hardware support for complex numbers [
7], which makes it much more efficient than xGPU. Considering the computational efficiency and development threshold, we select TCC as the correlation library.
The format conversion module is used to implement data conversion between F-engines and X-engines. For the implementation platform, we have two options, CPU-based and GPU-based. The input data of the xGPU library must be in the host memory, so the format conversion module must be implemented on the CPU. TCC does not have this restriction, so we implement this module on the GPU, which is much faster than on the CPU. Some observations require long-time integration, and the GPU memory may not be able to cache the pre-integrated data for such a long time. Thus, the TCC library is only used for short-term integration, and an LTA module is required after TCC, which can also be executed on the CPU or GPU. Currently, we implement this module on the CPU.
In order to improve the throughput, each of the above modules should be executed on an individual CPU thread under a framework
9. Some open-source frameworks for radio astronomy include kotekan [
22], PSRDADA
10, bifrost [
23], and HASHPIPE
11. Among them, kotekan, PSRDADA, and bifrost already include the network function inside; kotekan even includes the GPU correlation function. Our computing and network requirements are different from these functions. If we use them in our X-engine, these extra functions will need to be removed, which adds difficulty to the development. The HASHPIPE framework is a very general and convenient multi-thread management pipeline, which does not contain any specific function other than a framework. Since we have already selected modules with specific functions, HASHPIPE is an ideal management framework.
5. Introduction of the Katgpucbf F-Engine
As mentioned previously, we are considering to use and modify the F-engine of the katgpucbf library, so we describe it briefly here. A detailed description can be found in the online documentation of
https://katgpucbf.readthedocs.io/en/latest/index.html, accessed on 20 December 2022. The framework of the F-engine is developed in Python and mainly includes three functions: the
function, which receives network packets from a D-engine or a playback server; the
function, which calls the GPU to process the received network packets; and the
function, which transmits the processed data to the X-engines through the network. The three functions run in parallel with the framework of Asyncio, which is an asynchronous programming framework of Python.
The function is the core of this library. After a chunk of data is received, coarse delay compensation is first performed, and then the GPU kernel functions process the data to achieve channelization. The main signal processing algorithm is the polyphase filter bank (PFB), which consists of an FIR filter and an FFT. The FIR filter has branches equal to the FFT size, and each branch is executed on an individual GPU thread. The output of PFB is a frequency-domain spectrum. However, the X-engines expect time-domain samples of each channel. Thus, a transpose operation is required to convert the data from the frequency domain to time domain. Other functions, such as fine delay compensation, fringe rotation, and quantization, are also required; these functions are integrated into one GPU kernel function called the PostProc function. All of the above kernel functions (FIR Filter, FFT, and PostProc) are implemented with floating point arithmetic.
6. The GPU Tensor Core X-Engine
6.1. The X-Engine Pipeline and Key Modules
The diagram of the proposed X-engine pipeline is shown in
Figure 4, which includes 4 main modules working in parallel (each module is an independent thread) within the framework of HASHPIPE.
The first module of the pipeline is called
&
, which is based on the SPEAD2 library. The network packets output from the F-engines are captured and reconstructed into heaps by the SPEAD2 library. A heap consists of a header containing a timestamp and an array of time-domain samples of one F-engine. Timestamps of multiple heaps may be out of order and thus reordered. Then, heaps with the same timestamp from different F-engines are synchronized into a heap array. Some heaps may be lost due to various reasons. If this happens, the software replaces them with zero values. After synchronization, all
K13 heap arrays are assembled into one large data block, which will be transmitted to the subsequent
module.
The throughput of the entire X-engine pipeline depends on the module that consumes the longest time—that is, the module. This module includes 4 processes: memory copy from CPU to GPU, the format conversion (FC) kernel function, the TCC kernel function, and memory copy from GPU to CPU. In order to improve the throughput of this module, the four processes are executed with 3 streams to form a pipeline; that is, the two kernel functions use a common stream, and each memory copy uses an individual stream. Through profiling with the software of Nsight, the throughput of the pipeline is around 140 Gbps, and the main time is spent on the memory copy from CPU to GPU. After TCC operation, the data have been integrated greatly, so the time consumption of the memory copy from GPU to CPU is not significant.
The input data format of TCC and output data format of katgpucbf F-engines are as follows:
The dimensions from left to right of the above equation change from slow to fast. The format conversion (FC) kernel function is used to rearrange the high-dimensional matrices between these two formats.
Before using the WMMA API to implement the matrix-multiply-and-accumulate operation () for correlation, TCC will construct two matrices of A and B at first. For matrix A, the first axis represents time-domain samples of each channel for integration, and the second axis represents antennas/stations. Matrix B is the transpose of matrix A. Values of matrix C should be set to be all zero. After the multiplication of A and B, we can obtain the visibility data of each channel between any two antennas/stations.
After TCC, the data rate has been greatly reduced, and the LTA module will further reduce the rate by integrating the data over a long period of time. The module is also based on the SPEAD2 library to transmit the visibility data to the data storage servers. Since the visibility data have been integrated by the TCC kernel function and the LTA module, the pressure of data transmission is far less than the & module.
6.2. Hardware Requirements
As mentioned previously, the key hardware of the proposed correlator includes GPUs, NICs, and CPUs. For the F-engines, the required hardware resources depend on the number of antennas/stations. For the X-engines, the required hardware resources depend on the computing capability and IO bandwidth. We analyze the hardware requirements and try to find the bottleneck in the following content.
For the correlation computing of X-engines, the required performance of multiply-and-accumulate operations per second (OPS) can be calculated with the following equation:
where
B is the bandwidth of each sideband, which is 8 GHz.
N is the number of antennas/stations, which is 8/21 for the wSMA/ngEHT. We consider full-stokes correlation with dual polarization—for each antenna pair, the vertical polarization and horizontal polarization must be correlated [
25]. Auto-correlation of each antenna/station per polarization is also considered, so the number of correlation operations is
. The factor 8 arises from the complex-valued multiply–accumulate operation [
20]. The result of Equation (
2) is 9.216/59.136 TOPS for the wSMA/ngEHT correlator. We evaluated the the performance of TCC on an A5000 GPU at different bit widths; the results are shown in
Figure 5. For the 4-bit situation, when the number of antennas is 8, the performance is approximately 6.52 TOPS, which means that two A5000 GPUs can meet the computing requirements of all X-engines of the wSMA correlator. When the number of stations is 21, the performance is approximately 31.36 TOPS, which means that two A5000 GPUs are also sufficient for the computing requirements of all X-engines of the ngEHT correlator. Through the above analysis, we can see that due to the extremely high performance of Tensor Cores, the correlation computation is no longer a bottleneck in the correlator.
For the IO bandwidth, the total data rate between the F-engines and X-engines can be calculated with the following equation:
The result of the above equation is 1024/2688 Gbps for the wSMA/ngEHT correlator. The A5000 GPU uses
with an actual throughput of around 200 Gbps as the data path. As mentioned previously, the throughput of the
module is around 140 Gbps, and the main time is spent on memory copying, so the utilization of
effective bandwidth is approximately 70%. Therefore, due to the bandwidth limitation, theoretically, the number of GPUs required by the X-engines of the wSMA correlator and ngEHT correlator is
= 8 and
= 20, respectively. The NVIDIA ConnectX-5 NIC also uses
to connect to the host server, and the throughput of the network interface is 200 Gbps, which is almost the same as the throughput of PCIe, so the required number of NVIDIA ConnectX-5 NICs is the same as the number of GPUs.
Although we use GPUs to implement correlation computing, CPU resources are also required. The reason is that the HASHPIPE framework and the multiple modules in
Figure 4 require multiple CPU cores. The specific number required cannot be calculated theoretically, but depends on the actual situation during the development and testing stage. Currently, each server has 2 powerful Intel Xeon Silver 4314 CPUs with a total of 32 cores, which are sufficient for our proof-of-concept.
7. The Full Compact Architecture
The full compact architecture is shown as
Figure 6. Compared with the previous architecture in
Figure 1, the changes are as follows. First, the D-engines of the wSMA correlator need to support the functions of coarse channelization and corner turning. For the ngEHT correlator, since the recorded data have been coarsely channelized into sub-bands by the digital backends, the playback servers simply need to corner turn these sub-bands to different GPU servers for further processing. Second, the
&
module needs to perform coarse delay compensation for each sub-band. Third, the main functions of the F-engine and X-engine are integrated into the same GPU to form a new engine called the FX-engine.
The pipeline of the FX-engine is shown in
Figure 7, which is based on the previous X-engine pipeline in
Figure 4, but with the addition of new kernel functions of FIR filters (FIR_Pol0/FIR_Pol1
14), FFTs (FFT_Pol0/FFT_Pol1), and PostProc to achieve fine channelization. These new kernel functions are very similar to that of the katgpucbf F-engine library, but the difference is that the latter only processes data from one antenna/station, while the former needs to process data from all antennas/stations. The other two kernel functions, Format Conversion (FC) and TCC, are the same as in
Figure 7. At present, we have developed an initial design with a throughput of around 86 Gbps for the whole pipeline, but there is still much room for optimization in the future.
8. Acceleration with New Hardware
The data path from the NIC to the GPU in
Figure 4 and
Figure 7 can be divided into 3 steps. At first, data are transmitted from the NIC to the host server’s memory via PCIe. Then, the host server caches and synchronizes these data. Finally, the synchronized data are sent to the GPU via PCIe for correlation. Multiple passes over bandwidth-limited PCIe are very inefficient and represent the bottleneck of the entire pipeline.
The NVIDIA ConnectX NIC that we are using can accelerate the first step through bypassing the kernel’s networking stack. Going a step further, NVIDIA’s new product of BlueField Data Processing Units (DPUs) can provide an acceleration of the first and second steps of the data path. By combining a ConnectX NIC with an array of ARM CPU cores, BlueField DPUs can be fully software-programmable [
26], which can improve the performance of the
&
module in
Figure 4 and
Figure 7. The embedded NIC captures network packets at first, and then forwards them to the subsequent embedded ARM CPUs, which can replace the host’s CPUs to maintain network connections and execute data crossover and time synchronization operations in parallel multi-threads. Since the data receiving, caching, and synchronization are combined and implemented on the same DPU, the whole system can be more efficient and has a lower cost due to the reduced demand on the host CPUs [
27].
The NVIDIA converged accelerator is an upcoming product, which integrates a Bluefiled DPU and a GPU on one board
15. If the X-engine is equipped with this board, the entire data path from the NIC to the GPU no longer needs to go through the host server’s memory. Data can be sent from the DPU to the GPU directly, so all three steps can be accelerated, and the end-to-end throughput can be further improved.
9. Conclusions
We have reviewed the architectures of existing correlator-beamformers. With the benefit of this context, and using codes shared by collaborating institutions including SARAO and ASTRON, we built a proof-of-concept GPU Tensor Core-based correlator for the ngEHT and the wSMA. The requirement is to provide a solution to the transmission and computing challenges brought about by the massive data rates required by wideband instruments.
It is notable that this architecture is a purely software- as opposed to firmware-driven design. Compared to the currently favored approach using FPGAs, the development and ongoing maintenance of a software machine is much easier compared to the very difficult hardware description language (HDL) FPGA firmware design. The GPU’s floating point arithmetic yields improved digital efficiency with lower quantization and clipping losses.
16 In summary, GPUs are an order of magnitude faster to code for complex applications, while being both flexible and maintainable after deployment.
To start the proof-of-concept, we evaluated open-source libraries and selected the appropriate ones according to the requirements. Then, we described the proposed X-engine pipeline and analyzed the hardware resource requirements. We also introduced a full compact architecture, which integrates the main functions of the F-engine and X-engine into one GPU. Finally, we discussed how new hardware can accelerate future correlator-beamformers.
The paper presents proof-of-concept design work and associated benchmarks, which lead us to an optimistic assessment of the prospects for true- or near-real-time computation for connected and VLBI interferometry. We anticipate that this new development will support the improved imaging capability of the ngEHT and wSMA upgrades, thus allowing both instruments to achieve their respective transformative scientific goals.


 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






