
Monitoring the Epidemiology of Otitis Using Free-Text Pediatric Medical Notes: A Deep Learning Approach

 ,
,  ,
,  , , ,
, , , 
Abstract
:1. Introduction
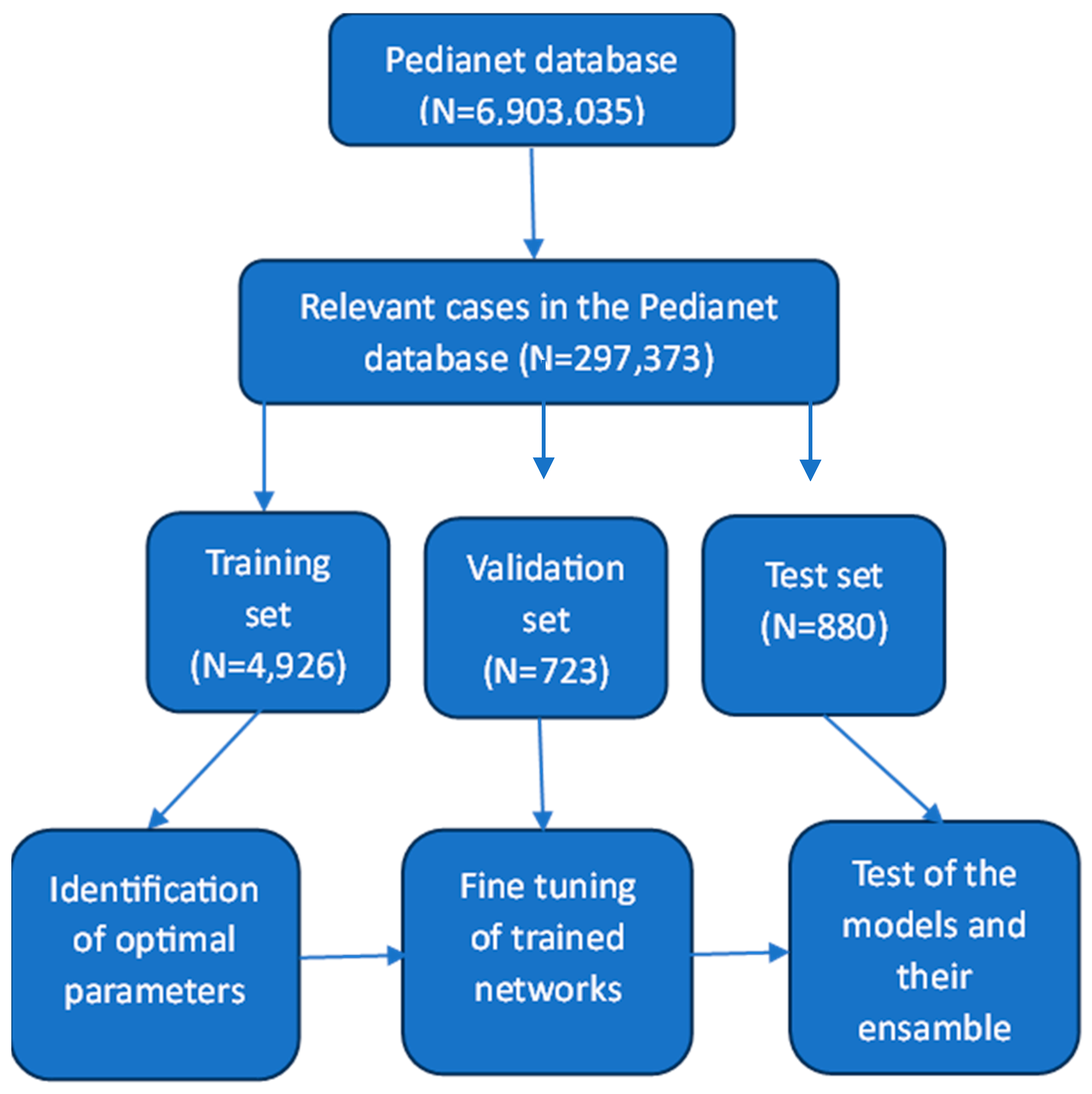
2. Materials and Methods
2.1. Gold Standard
2.2. Data Pre-Processing
2.3. Model Development
2.4. Architectures Employed for Model Development
- 0.
- Simple embedding: The only hidden layer was the embedding layer.
- 1.
- Single kernel convolutional neural network (CNN): After the embedding layer, we attached a single convolutional layer.
- 2.
- Sequential single kernel CNN: After the embedding layer, we attached a sequence of two convolutional layers.
- 3.
- Multiple parallel kernel CNN: After the embedding layer, we attached a single concatenation of multiple convolutional layers.
- 4.
- Deep multiple parallel kernel CNN: After the embedding layer, we attached a sequence of two distinct concatenations of multiple convolutional layers.
3. Results
Model Performance
4. Discussion
Exploiting Free-Text Information in Biomedical Research: Practical Implications
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jamal, A.; Alsabea, A.; Tarakmeh, M.; Safar, A. Etiology, Diagnosis, Complications, and Management of Acute Otitis Media in Children. Cureus 2022, 14, e28019. [Google Scholar] [CrossRef] [PubMed]
- Barbieri, E.; Donà, D.; Cantarutti, A.; Lundin, R.; Scamarcia, A.; Corrao, G.; Cantarutti, L.; Giaquinto, C. Antibiotic Prescriptions in Acute Otitis Media and Pharyngitis in Italian Pediatric Outpatients. Ital. J. Pediatr. 2019, 45, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Kaur, R.; Morris, M.; Pichichero, M.E. Epidemiology of Acute Otitis Media in the Postpneumococcal Conjugate Vaccine Era. Pediatrics 2017, 140, e20170181. [Google Scholar] [CrossRef] [PubMed]
- de Sévaux, J.L.; Venekamp, R.P.; Lutje, V.; Hak, E.; Schilder, A.G.; Sanders, E.A.; Damoiseaux, R.A. Pneumococcal Conjugate Vaccines for Preventing Acute Otitis Media in Children. Cochrane Database Syst. Rev. 2020, 11, CD001480. [Google Scholar] [PubMed]
- Monasta, L.; Ronfani, L.; Marchetti, F.; Montico, M.; Vecchi Brumatti, L.; Bavcar, A.; Grasso, D.; Barbiero, C.; Tamburlini, G. Burden of Disease Caused by Otitis Media: Systematic Review and Global Estimates. PLoS ONE 2012, 7, e36226. [Google Scholar] [CrossRef] [PubMed]
- Kim, M.O.; Coiera, E.; Magrabi, F. Problems with Health Information Technology and Their Effects on Care Delivery and Patient Outcomes: A Systematic Review. J. Am. Med. Inform. Assoc. 2017, 24, 246–250. [Google Scholar] [CrossRef] [PubMed]
- DeLisle, S.; South, B.; Anthony, J.A.; Kalp, E.; Gundlapallli, A.; Curriero, F.C.; Glass, G.E.; Samore, M.; Perl, T.M. Combining Free Text and Structured Electronic Medical Record Entries to Detect Acute Respiratory Infections. PLoS ONE 2010, 5, e13377. [Google Scholar] [CrossRef] [PubMed]
- Qian, K.; Burdick, D.; Gurajada, S.; Popa, L. Learning Explainable Entity Resolution Algorithms for Small Business Data Using SystemER. In Proceedings of the 5th Workshop on Data Science for Macro-Modeling with Financial and Economic Datasets, Amsterdam, The Netherlands, 30 June 2019; pp. 1–6. [Google Scholar]
- Chakraborty, C.; Bhattacharya, M.; Pal, S.; Lee, S.-S. From Machine Learning to Deep Learning: An Advances of the Recent Data-Driven Paradigm Shift in Medicine and Healthcare. Curr. Res. Biotechnol. 2023, 100164. [Google Scholar] [CrossRef]
- Yousefinaghani, S.; Dara, R.; Poljak, Z.; Bernardo, T.M.; Sharif, S. The Assessment of Twitter’s Potential for Outbreak Detection: Avian Influenza Case Study. Sci. Rep. 2019, 9, 18147. [Google Scholar] [CrossRef]
- Pedianet. Available online: http://Pedianet.It/En (accessed on 15 December 2023).
- Goycoolea, M.V.; Hueb, M.M.; Ruah, C. Definitions and Terminology. Otolaryngol. Clin. N. Am. 1991, 24, 757–761. [Google Scholar] [CrossRef]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Lanera, C. Development and Application of Machine Learning Techniques for Text Analyses and Classification in Clinical Research; University of Padova: Padua, Italy, 2023. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving Neural Networks by Preventing Co-Adaptation of Feature Detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Keskar, N.S.; Mudigere, D.; Nocedal, J.; Smelyanskiy, M.; Tang, P.T.P. On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima. arXiv 2016, arXiv:1609.04836. [Google Scholar]
- Topol, E.J. High-Performance Medicine: The Convergence of Human and Artificial Intelligence. Nat. Med. 2019, 25, 44–56. [Google Scholar] [CrossRef] [PubMed]
- Keane, P.A.; Topol, E.J. With an Eye to AI and Autonomous Diagnosis. NPJ Digit. Med. 2018, 1, 40. [Google Scholar] [CrossRef]
- Lorenzoni, G.; Bressan, S.; Lanera, C.; Azzolina, D.; Da Dalt, L.; Gregori, D. Analysis of Unstructured Text-Based Data Using Machine Learning Techniques: The Case of Pediatric Emergency Department Records in Nicaragua. Med. Care Res. Rev. 2021, 78, 138–145. [Google Scholar] [CrossRef]
- Lanera, C.; Berchialla, P.; Baldi, I.; Lorenzoni, G.; Tramontan, L.; Scamarcia, A.; Cantarutti, L.; Giaquinto, C.; Gregori, D. Use of Machine Learning Techniques for Case-Detection of Varicella Zoster Using Routinely Collected Textual Ambulatory Records: Pilot Observational Study. JMIR Med. Inform. 2020, 8, e14330. [Google Scholar] [CrossRef]
- Lanera, C.; Baldi, I.; Francavilla, A.; Barbieri, E.; Tramontan, L.; Scamarcia, A.; Cantarutti, L.; Giaquinto, C.; Gregori, D. A Deep Learning Approach to Estimate the Incidence of Infectious Disease Cases for Routinely Collected Ambulatory Records: The Example of Varicella-Zoster. Int. J. Environ. Res. Public Health 2022, 19, 5959. [Google Scholar] [CrossRef]
- Liang, H.; Tsui, B.Y.; Ni, H.; Valentim, C.C.; Baxter, S.L.; Liu, G.; Cai, W.; Kermany, D.S.; Sun, X.; Chen, J. Evaluation and Accurate Diagnoses of Pediatric Diseases Using Artificial Intelligence. Nat. Med. 2019, 25, 433–438. [Google Scholar] [CrossRef]
- Dahl, G.E.; Yu, D.; Deng, L.; Acero, A. Context-Dependent Pre-Trained Deep Neural Networks for Large-Vocabulary Speech Recognition. IEEE Trans. Audio Speech Lang. Process. 2011, 20, 30–42. [Google Scholar] [CrossRef]
- Xue, V.W.; Lei, P.; Cho, W.C. The Potential Impact of ChatGPT in Clinical and Translational Medicine. Clin. Transl. Med. 2023, 13. [Google Scholar] [CrossRef] [PubMed]
- Zhang, P.; Kamel Boulos, M.N. Generative AI in Medicine and Healthcare: Promises, Opportunities and Challenges. Future Internet 2023, 15, 286. [Google Scholar] [CrossRef]
- Takagi, S.; Watari, T.; Erabi, A.; Sakaguchi, K. Performance of GPT-3.5 and GPT-4 on the Japanese Medical Licensing Examination: Comparison Study. JMIR Med. Educ. 2023, 9, e48002. [Google Scholar] [CrossRef]
- Brin, D.; Sorin, V.; Vaid, A.; Soroush, A.; Glicksberg, B.S.; Charney, A.W.; Nadkarni, G.; Klang, E. Comparing ChatGPT and GPT-4 Performance in USMLE Soft Skill Assessments. Sci. Rep. 2023, 13, 16492. [Google Scholar] [CrossRef]
- Li, H.; Moon, J.T.; Purkayastha, S.; Celi, L.A.; Trivedi, H.; Gichoya, J.W. Ethics of Large Language Models in Medicine and Medical Research. Lancet Digit. Health 2023, 5, e333–e335. [Google Scholar] [CrossRef]
- Scheurwegs, E.; Luyckx, K.; Luyten, L.; Daelemans, W.; Van den Bulcke, T. Data Integration of Structured and Unstructured Sources for Assigning Clinical Codes to Patient Stays. J. Am. Med. Inform. Assoc. 2016, 23, e11–e19. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
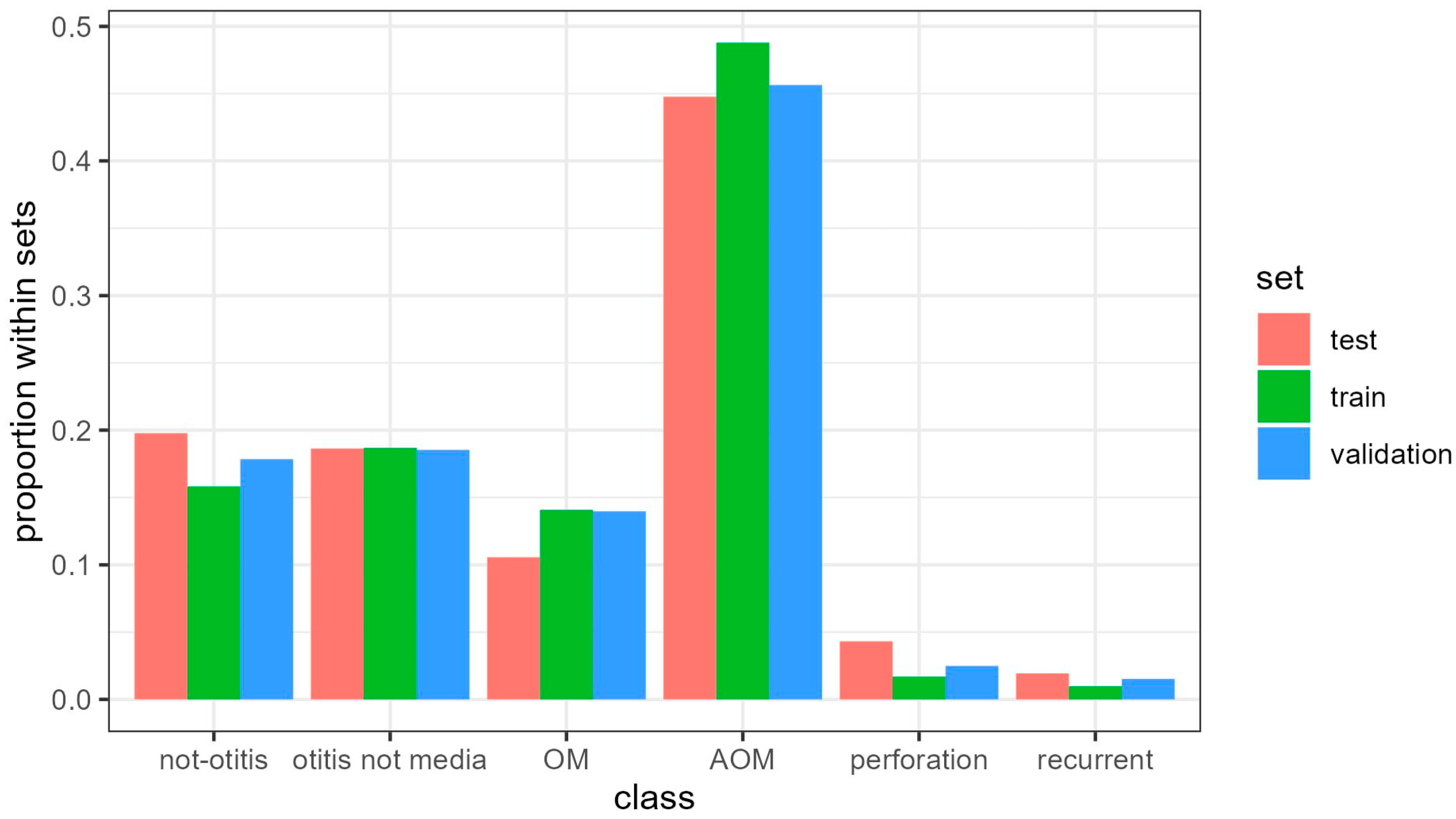
| Training Set | Validation Set | Test Set | |
|---|---|---|---|
| Visits | 4926 | 723 | 880 |
| Pediatricians | 138 | 142 | 142 |
| Children | 4475 | 718 | 873 |
| Gender: Male | 2349 (52.5%) | 377 (52.5%) | 463 (53.0%) |
| Females | 2078 (46.4%) | 341 (47.5%) | 410 (47.0%) |
| Predicted\Gold | No Otitis | Otitis Not Media | OM | AOM | Perforation | Recurrent | Sum |
|---|---|---|---|---|---|---|---|
| No otitis | 155 | 0 | 2 | 0 | 0 | 0 | 157 |
| Otitis not media | 7 | 168 | 7 | 0 | 0 | 0 | 182 |
| OM | 1 | 0 | 101 | 1 | 1 | 0 | 104 |
| AOM | 2 | 1 | 1 | 389 | 6 | 0 | 399 |
| Perforation | 0 | 0 | 0 | 1 | 28 | 0 | 29 |
| Recurrent | 0 | 0 | 0 | 0 | 0 | 9 | 9 |
| Sum | 165 | 169 | 111 | 391 | 35 | 9 | 880 |
| Selected Network | Balanced Precision | Balanced Recall | Accuracy | Balanced F1 |
|---|---|---|---|---|
| Simple embedding | 84.51 | 68.63 | 81.70 | 75.75 |
| Single kernel | 92.60 | 91.87 | 94.66 | 92.23 |
| Sequential CNN | 95.94 | 81.26 | 93.64 | 87.99 |
| Parallel CNN | 96.95 | 94.78 | 96.59 | 95.86 |
| Deep CNN | 96.38 | 93.36 | 96.25 | 94.85 |
| Ensemble (w/o simple embeddings) | 97.03 | 93.97 | 96.59 | 95.48 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lanera, C.; Lorenzoni, G.; Barbieri, E.; Piras, G.; Magge, A.; Weissenbacher, D.; Donà, D.; Cantarutti, L.; Gonzalez-Hernandez, G.; Giaquinto, C.; et al. Monitoring the Epidemiology of Otitis Using Free-Text Pediatric Medical Notes: A Deep Learning Approach. J. Pers. Med. 2024, 14, 28. https://doi.org/10.3390/jpm14010028
Lanera C, Lorenzoni G, Barbieri E, Piras G, Magge A, Weissenbacher D, Donà D, Cantarutti L, Gonzalez-Hernandez G, Giaquinto C, et al. Monitoring the Epidemiology of Otitis Using Free-Text Pediatric Medical Notes: A Deep Learning Approach. Journal of Personalized Medicine. 2024; 14(1):28. https://doi.org/10.3390/jpm14010028
Chicago/Turabian StyleLanera, Corrado, Giulia Lorenzoni, Elisa Barbieri, Gianluca Piras, Arjun Magge, Davy Weissenbacher, Daniele Donà, Luigi Cantarutti, Graciela Gonzalez-Hernandez, Carlo Giaquinto, and et al. 2024. "Monitoring the Epidemiology of Otitis Using Free-Text Pediatric Medical Notes: A Deep Learning Approach" Journal of Personalized Medicine 14, no. 1: 28. https://doi.org/10.3390/jpm14010028
APA StyleLanera, C., Lorenzoni, G., Barbieri, E., Piras, G., Magge, A., Weissenbacher, D., Donà, D., Cantarutti, L., Gonzalez-Hernandez, G., Giaquinto, C., & Gregori, D. (2024). Monitoring the Epidemiology of Otitis Using Free-Text Pediatric Medical Notes: A Deep Learning Approach. Journal of Personalized Medicine, 14(1), 28. https://doi.org/10.3390/jpm14010028