

A Multi-Task Convolutional Neural Network for Semantic Segmentation and Event Detection in Laparoscopic Surgery

 ,
,  ,
,  , and
, and 
Abstract
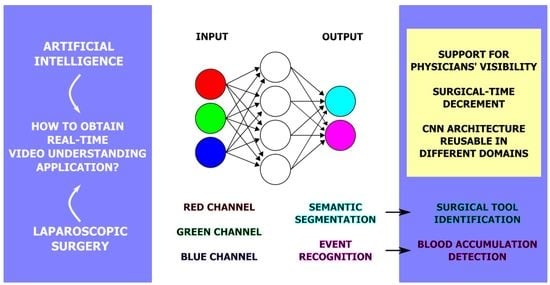
1. Introduction
2. Materials and Methods
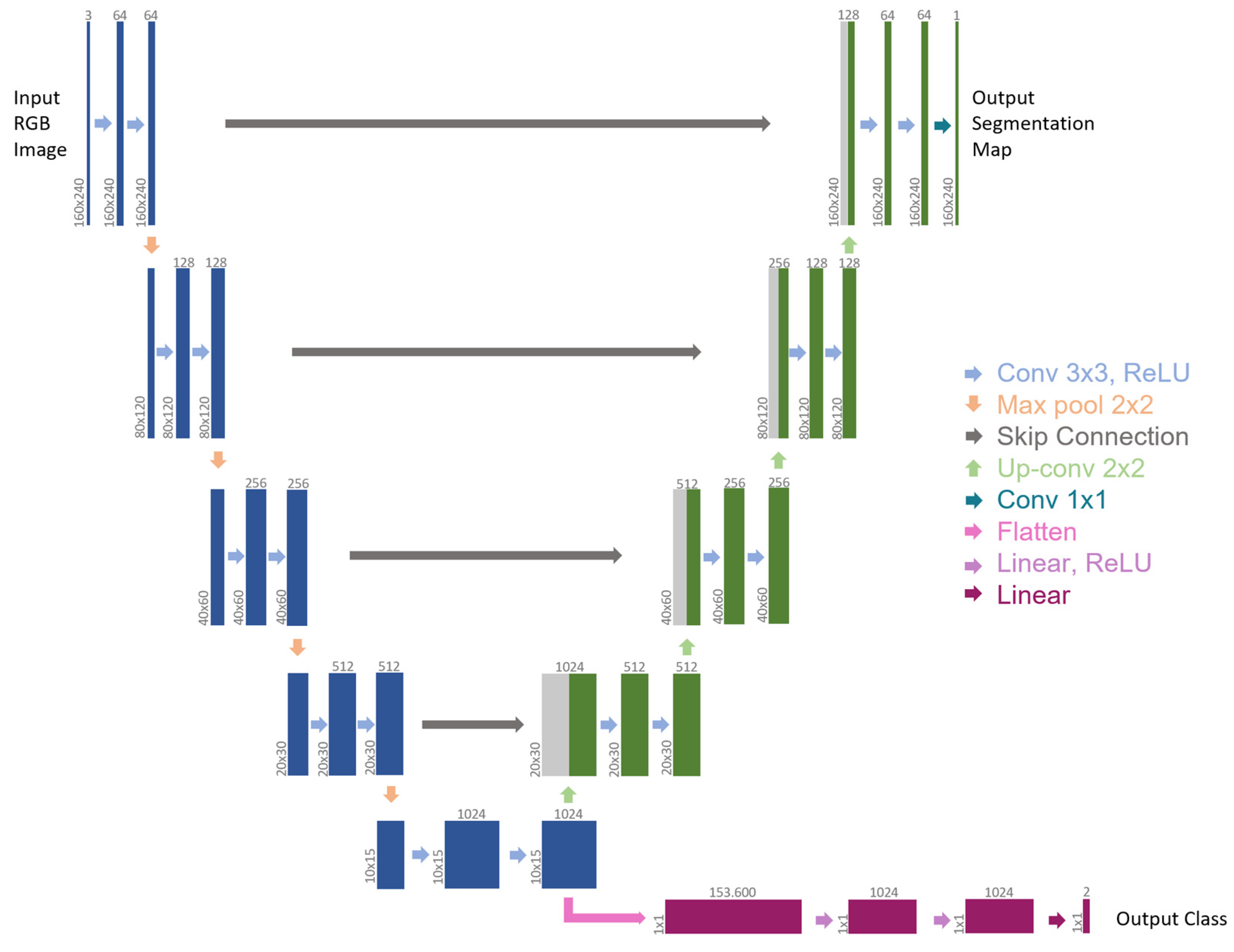
2.1. Neural Network Architecture
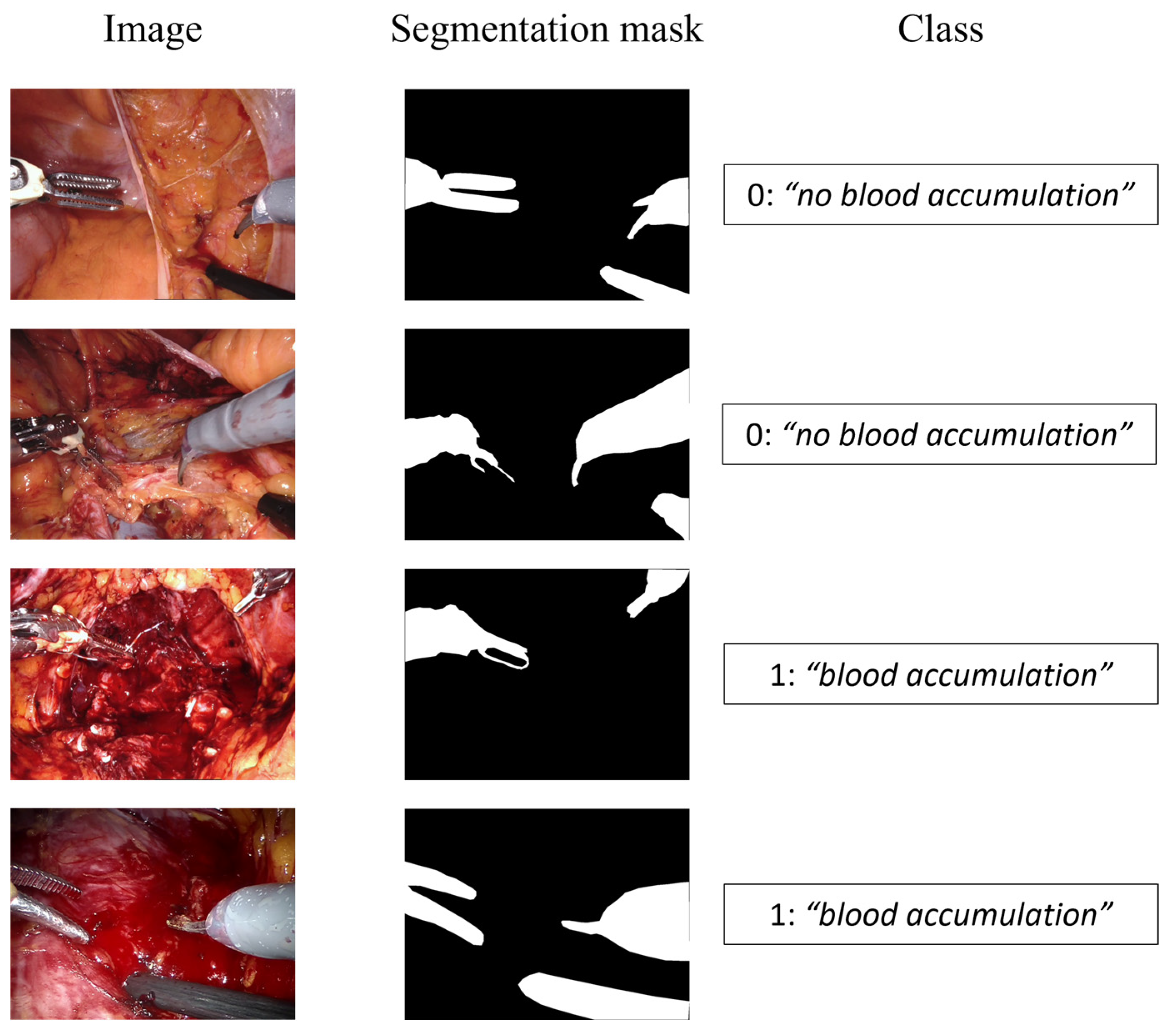
2.2. Dataset
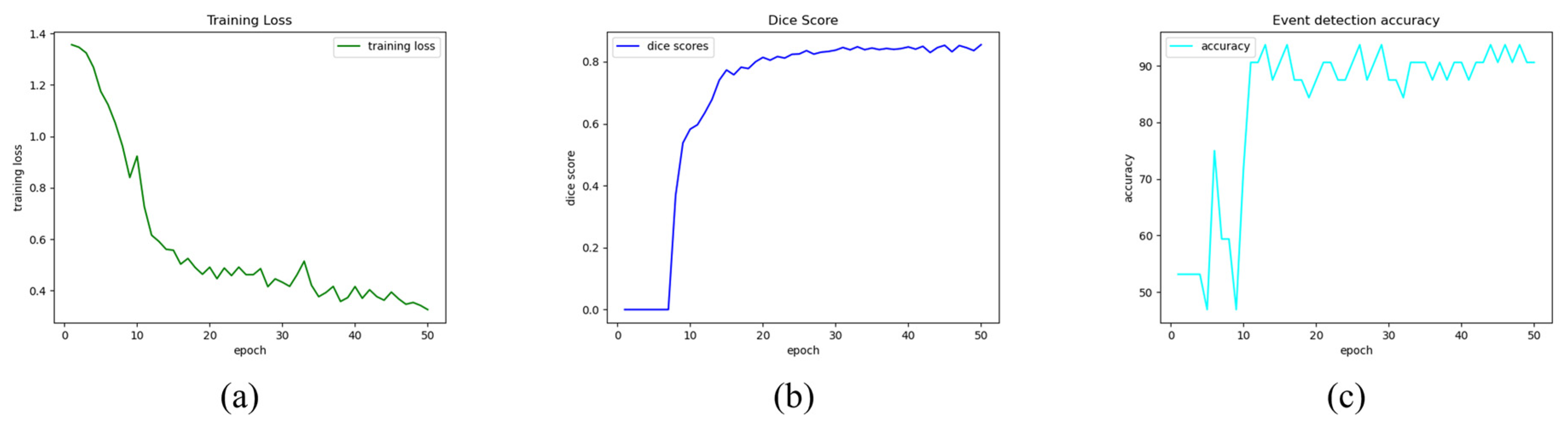
2.3. Training and Metrics
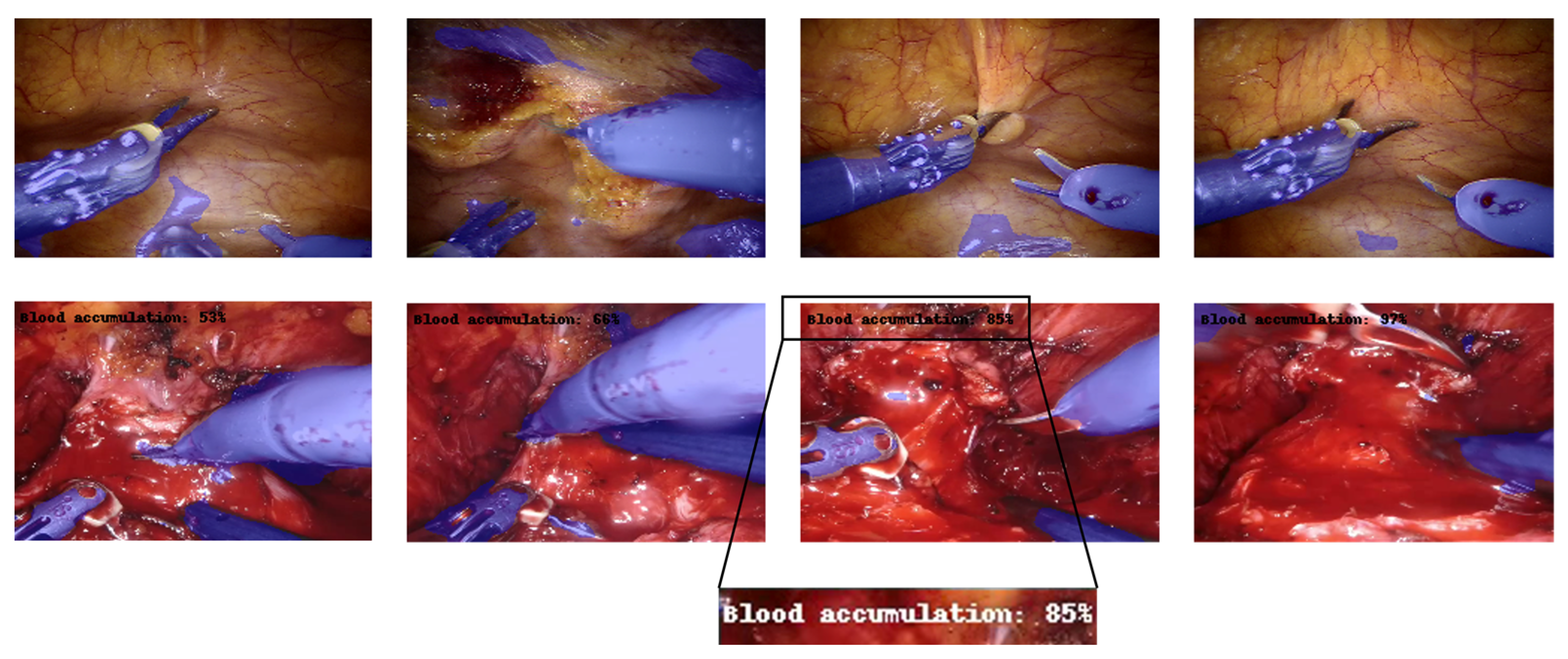
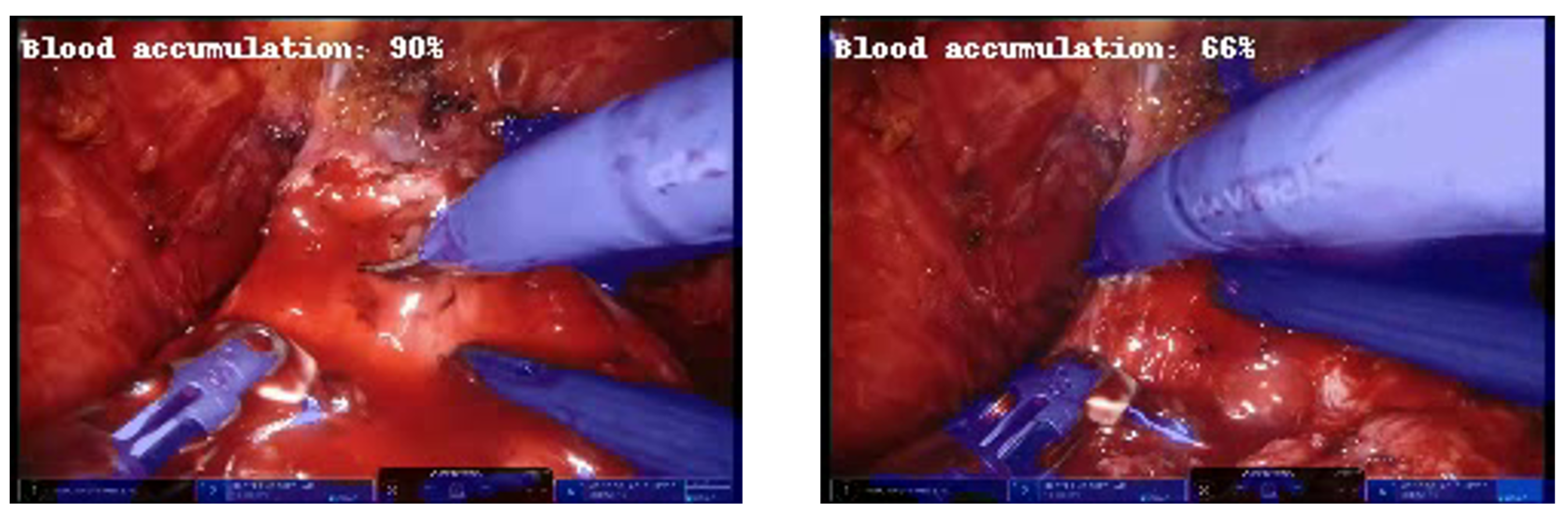
3. Results and Discussion
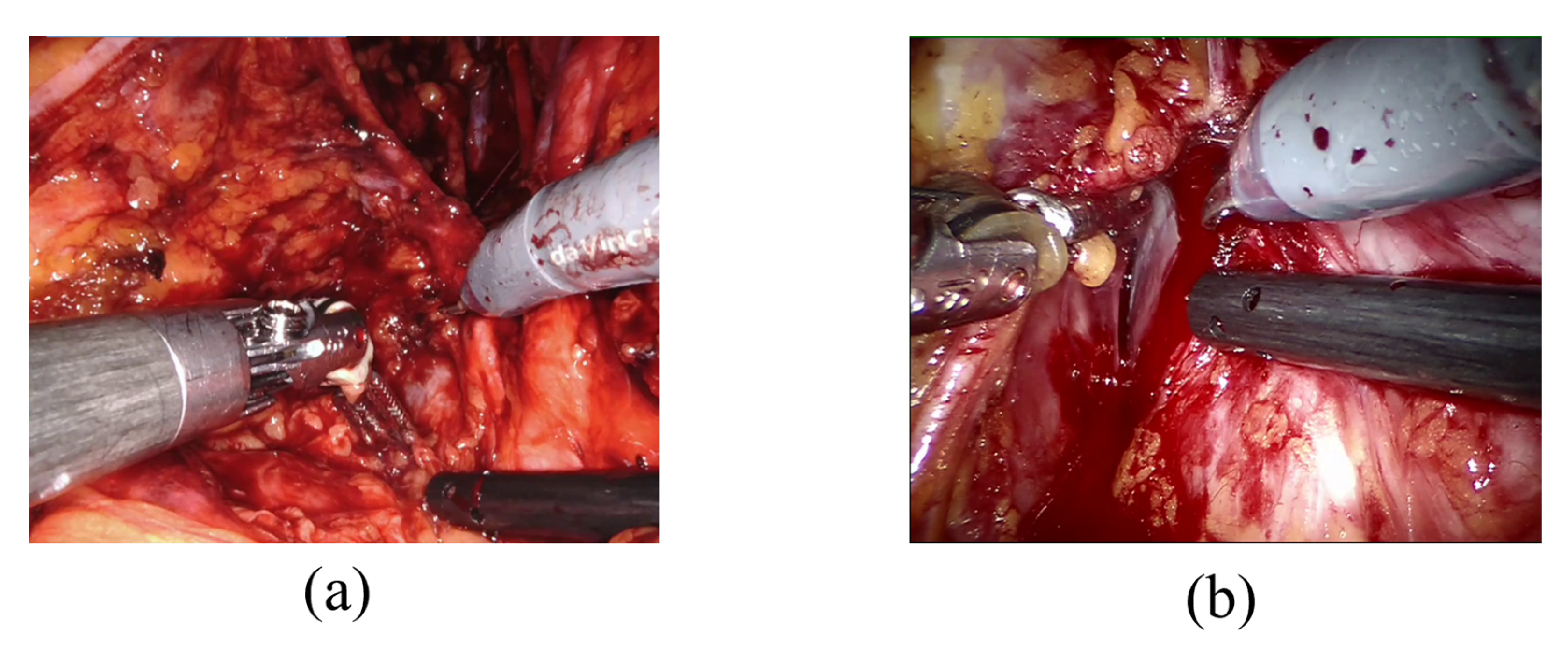
- Neural Network Architecture. The architecture of the network should be extended to consider temporal information extracted from sequential images. This improvement will likely enhance the branch related to event detection in terms of accuracy and reliability. In this research context, for example, it may be easier to distinguish passive bleeding, namely, blood residue on tissues, and active bleeding, which is the surgeons’ object of interest. Moreover, the semantic segmentation task should distinguish tools with different labels to improve the prediction, while the detection task should be extended by adding the localization of the origin of bleeding, which may provide remarkable clinical advantages when the human eye cannot instantly catch it [35].
- Dataset. An improved dataset in terms of numerosity and variance could be beneficial to increase the accuracy of prediction. Furthermore, the sequences of images that do not contain any structure of interest (for instance, the external view of the operating room, and the images inside the trocar) in a limited-size dataset might improve the knowledge of the network about the studied environment [35]. Alternatively, from an algorithmic perspective, it could be advantageous to provide depth information as well as RGB information, to improve the tools’ tracking accuracy. To accomplish this advancement, 3D acquisition cameras should be integrated with the RGB cameras employed during surgical interventions.
- Testing. The model should be evaluated in the operating room to determine its practical limitations in the setting of a real-time application and then enhanced accordingly by adding new features.
- Research field. Extending the algorithm into different domains would be of interest, to perform further analysis both in terms of actor segmentation and tracking and from the point of view of event detection and classification.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Laparoscopy (Keyhole Surgery). 2018. Available online: https://www.nhs.uk/conditions/laparoscopy/ (accessed on 30 September 2022).
- Kaping’a, F. Deep learning for action and event detection in endoscopic videos for robotic assisted laparoscopy. Comput. Sci. 2018, 1–6. [Google Scholar]
- Shah, A.; Palmer, A.J.R.; Klein, A.A. Strategies to minimize intraoperative blood loss during major surgery. Br. J. Surg. 2020, 107, e26–e38. [Google Scholar] [CrossRef] [PubMed]
- Kurian, E.; Kizhakethottam, J.J.; Mathew, J. Deep learning based Surgical Workflow Recognition from Laparoscopic Videos. In Proceedings of the 2020 5th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 10–12 June 2020; pp. 928–931. [Google Scholar]
- Kimmig, R.; Buderath, P.; Heubner, M.; Aktas, B. Robot-assisted hysterectomy: A critical evaluation. Robot. Surg. Res. Rev. 2015, 2, 51–58. [Google Scholar] [CrossRef]
- Basunbul, L.I.; Alhazmi, L.S.S.; Almughamisi, S.A.; Aljuaid, N.M.; Rizk, H.; Moshref, R.; Basunbul, L.I.; Alhazmi, L.; Almughamisi, S.A.; Aljuaid, N.M.; et al. Recent Technical Developments in the Field of Laparoscopic Surgery: A Literature Review. Cureus 2022, 14, e22246. [Google Scholar] [CrossRef] [PubMed]
- Casella, A.; Moccia, S.; Carlini, C.; Frontoni, E.; De Momi, E.; Mattos, L.S. NephCNN: A deep-learning framework for vessel segmentation in nephrectomy laparoscopic videos. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 6144–6149. [Google Scholar]
- Kaushik, R. Bleeding complications in laparoscopic cholecystectomy: Incidence, mechanisms, prevention and management. J. Minimal Access Surg. 2010, 6, 59. [Google Scholar] [CrossRef] [PubMed]
- Smith, J.A.; Herrell, S.D. Robotic-Assisted Laparoscopic Prostatectomy: Do Minimally Invasive Approaches Offer Significant Advantages? J. Clin. Oncol. 2005, 23, 8170–8175. [Google Scholar] [CrossRef] [PubMed]
- Tomimaru, Y.; Noguchi, K.; Morita, S.; Imamura, H.; Iwazawa, T.; Dono, K. Is Intraoperative Blood Loss Underestimated in Patients Undergoing Laparoscopic Hepatectomy? World J. Surg. 2018, 42, 3685–3691. [Google Scholar] [CrossRef]
- Guillonneau, B.; Vallancien, G. Laparoscopic radical prostatectomy: The montsouris technique. J. Urol. 2000, 163, 1643–1649. [Google Scholar] [CrossRef]
- Fuchs, H.; Livingston, M.A.; Raskar, R.; Colucci, D.; Keller, K.; State, A.; Crawford, J.R.; Rademacher, P.; Drake, S.H.; Meyer, A.A. Augmented reality visualization for laparoscopic surgery. In Medical Image Computing and Computer-Assisted Intervention—MICCAI’98; Wells, W.M., Colchester, A., Delp, S., Eds.; Springer: Berlin/Heidelberg, Germany, 1998; pp. 934–943. [Google Scholar]
- Hua, S.; Gao, J.; Wang, Z.; Yeerkenbieke, P.; Li, J.; Wang, J.; He, G.; Jiang, J.; Lu, Y.; Yu, Q.; et al. Automatic bleeding detection in laparoscopic surgery based on a faster region-based convolutional neural network. Ann. Transl. Med. 2022, 10, 546. [Google Scholar] [CrossRef]
- Rawlings, A.L.; Woodland, J.H.; Vegunta, R.K.; Crawford, D.L. Robotic versus laparoscopic colectomy. Surg. Endosc. 2007, 21, 1701–1708. [Google Scholar] [CrossRef]
- Schroeck, F.R.; Jacobs, B.L.; Bhayani, S.B.; Nguyen, P.L.; Penson, D.; Hu, J. Cost of New Technologies in Prostate Cancer Treatment: Systematic Review of Costs and Cost Effectiveness of Robotic-assisted Laparoscopic Prostatectomy, Intensity-modulated Radiotherapy, and Proton Beam Therapy. Eur. Urol. 2017, 72, 712–735. [Google Scholar] [CrossRef] [PubMed]
- Rabbani, N.; Seve, C.; Bourdel, N.; Bartoli, A. Video-Based Computer-Aided Laparoscopic Bleeding Management: A Space-Time Memory Neural Network with Positional Encoding and Adversarial Domain Adaptation. In Proceedings of the 5th International Conference on Medical Imaging with Deep Learning, Zurich, Switzerland, 6–8 July 2022. [Google Scholar]
- Zegers, M.; de Bruijne, M.C.; de Keizer, B.; Merten, H.; Groenewegen, P.P.; van der Wal, G.; Wagner, C. The incidence, root-causes, and outcomes of adverse events in surgical units: Implication for potential prevention strategies. Patient Saf. Surg. 2011, 5, 13. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Martinez, A.; Vicente-Samper, J.M.; Sabater-Navarro, J.M. Automatic detection of surgical haemorrhage using computer vision. Artif. Intell. Med. 2017, 78, 55–60. [Google Scholar] [CrossRef] [PubMed]
- Fu, Y.; Mandal, M.; Guo, G. Bleeding region detection in WCE images based on color features and neural network. In Proceedings of the 2011 IEEE 54th International Midwest Symposium on Circuits and Systems (MWSCAS), Seoul, Republic of Korea, 7–10 August 2011; pp. 1–4. [Google Scholar]
- Fu, Y.; Zhang, W.; Mandal, M.; Meng, M.Q.-H. Computer-Aided Bleeding Detection in WCE Video. IEEE J. Biomed. Health Inform. 2014, 18, 636–642. [Google Scholar] [CrossRef] [PubMed]
- Okamoto, T.; Ohnishi, T.; Kawahira, H.; Dergachyava, O.; Jannin, P.; Haneishi, H. Real-time identification of blood regions for hemostasis support in laparoscopic surgery. Signal Image Video Process. 2019, 13, 405–412. [Google Scholar] [CrossRef]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Wei, H.; Rudzicz, F.; Fleet, D.; Grantcharov, T.; Taati, B. Intraoperative Adverse Event Detection in Laparoscopic Surgery: Stabilized Multi-Stage Temporal Convolutional Network with Focal-Uncertainty Loss. In Proceedings of the 6th Machine Learning for Healthcare Conference, Virtual, 6–7 August 2021; pp. 283–307. [Google Scholar]
- Jia, X.; Meng, M.Q.-H. A deep convolutional neural network for bleeding detection in Wireless Capsule Endoscopy images. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 639–642. [Google Scholar]
- Richter, F.; Shen, S.; Liu, F.; Huang, J.; Funk, E.K.; Orosco, R.K.; Yip, M.C. Autonomous Robotic Suction to Clear the Surgical Field for Hemostasis Using Image-Based Blood Flow Detection. IEEE Robot. Autom. Lett. 2021, 6, 1383–1390. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6999–7019. [Google Scholar] [CrossRef]
- Crawshaw, M. Multi-Task Learning with Deep Neural Networks: A Survey 2020. arXiv 2021. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, Q. A Survey on Multi-Task Learning. IEEE Trans. Knowl. Data Eng. 2021, 34, 5586–5609. [Google Scholar] [CrossRef]
- Ji, J.; Buch, S.; Soto, A.; Niebles, J.C. End-to-End Joint Semantic Segmentation of Actors and Actions in Video. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 734–749. [Google Scholar]
- Hou, R.; Chen, C.; Shah, M. An End-to-end 3D Convolutional Neural Network for Action Detection and Segmentation in Videos 2017. arXiv 2017. [Google Scholar] [CrossRef]
- Goodman, E.D.; Patel, K.K.; Zhang, Y.; Locke, W.; Kennedy, C.J.; Mehrotra, R.; Ren, S.; Guan, M.Y.; Downing, M.; Chen, H.W.; et al. A real-time spatiotemporal AI model analyzes skill in open surgical videos. arXiv 2021, arXiv:2112.07219. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Madad Zadeh, S.; Francois, T.; Calvet, L.; Chauvet, P.; Canis, M.; Bartoli, A.; Bourdel, N. SurgAI: Deep learning for computerized laparoscopic image understanding in gynaecology. Surg. Endosc. 2020, 34, 5377–5383. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
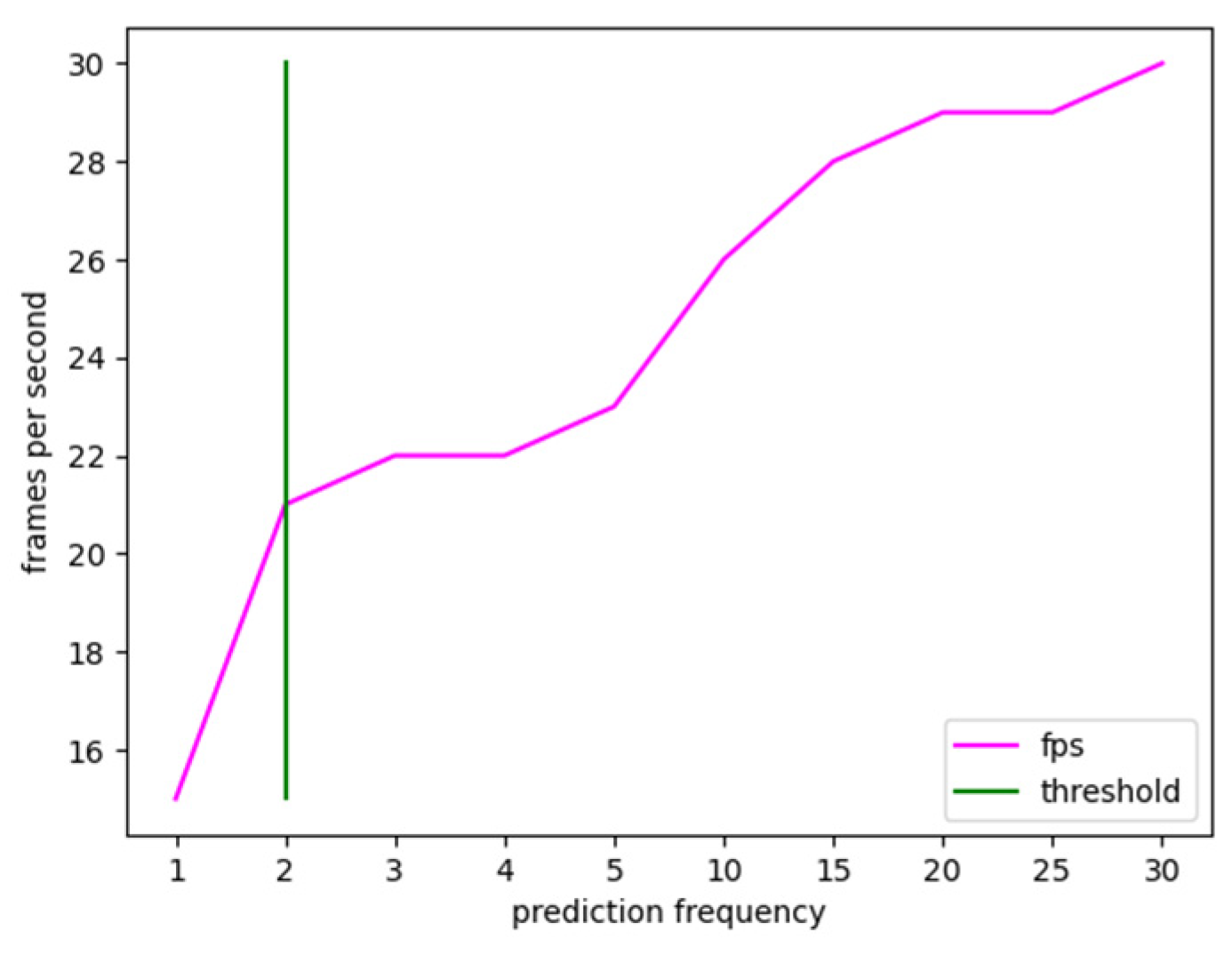
| Prediction Frequency | Frames-per-Second |
|---|---|
| 1 | 15 |
| 2 | 21 |
| 3 | 22 |
| 4 | 22 |
| 5 | 23 |
| 10 | 26 |
| 15 | 28 |
| 20 | 29 |
| 25 | 29 |
| 30 | 30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marullo, G.; Tanzi, L.; Ulrich, L.; Porpiglia, F.; Vezzetti, E. A Multi-Task Convolutional Neural Network for Semantic Segmentation and Event Detection in Laparoscopic Surgery. J. Pers. Med. 2023, 13, 413. https://doi.org/10.3390/jpm13030413
Marullo G, Tanzi L, Ulrich L, Porpiglia F, Vezzetti E. A Multi-Task Convolutional Neural Network for Semantic Segmentation and Event Detection in Laparoscopic Surgery. Journal of Personalized Medicine. 2023; 13(3):413. https://doi.org/10.3390/jpm13030413
Chicago/Turabian StyleMarullo, Giorgia, Leonardo Tanzi, Luca Ulrich, Francesco Porpiglia, and Enrico Vezzetti. 2023. "A Multi-Task Convolutional Neural Network for Semantic Segmentation and Event Detection in Laparoscopic Surgery" Journal of Personalized Medicine 13, no. 3: 413. https://doi.org/10.3390/jpm13030413
APA StyleMarullo, G., Tanzi, L., Ulrich, L., Porpiglia, F., & Vezzetti, E. (2023). A Multi-Task Convolutional Neural Network for Semantic Segmentation and Event Detection in Laparoscopic Surgery. Journal of Personalized Medicine, 13(3), 413. https://doi.org/10.3390/jpm13030413