
Point-of-Care Disease Screening in Primary Care Using Saliva: A Biospectroscopy Approach for Lung Cancer and Prostate Cancer

 , ,
, ,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Lung Cancer Screening Programme and Participant Recruitment
2.2. Saliva Collection and Swab Analysis
2.3. ATR-FTIR Spectral Analyses of Swabs
2.4. Computational Analysis: Preprocessing and Chemometrics
2.5. Model Validation
3. Results
3.1. Lung Cancer
3.2. Prostate Cancer
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
References
- Pastorino, U.; Silva, M.; Sestini, S.; Sabia, F.; Boeri, M.; Cantarutti, A.; Sverzellati, N.; Sozzi, G.; Corrao, G.; Marchianô, A. Prolonged lung cancer screening reduced 10-year mortality in the MILD trial: New confirmation of lung cancer screening efficacy. Ann. Oncol. 2019, 30, 1162–1169. [Google Scholar] [CrossRef]
- Sasieni, P.; Smittenaar, R.; Hubbell, E.; Broggio, J.; Neal, R.D.; Swanton, C. Modelled mortality benefits of multi-cancer early detection screening in England. Br. J. Cancer 2023, 129, 72–80. [Google Scholar] [CrossRef]
- Barauna, V.G.; Singh, M.N.; Barbosa, L.L.; Marcarini, W.D.; Vassallo, P.F.; Mill, J.G.; Ribeiro-Rodrigues, R.; Campos, L.C.G.; Warnke, P.H.; Martin, F.L. Ultrarapid on-site detection of SARS-CoV-2 infection using simple ATR-FTIR spectroscopy and an analysis algorithm: High sensitivity and specificity. Anal. Chem. 2021, 93, 2950–2958. [Google Scholar] [CrossRef]
- Martin, F.L.; Dickinson, A.W.; Saba, T.; Bongers, T.; Singh, M.N.; Bury, D. ATR-FTIR spectroscopy with chemometrics for analysis of saliva samples obtained in a lung-canceer-screening programme: Application of swabs as a paradigm for high throughput in a clinical setting. J. Pers. Med. 2023, 13, 1039. [Google Scholar] [CrossRef]
- Nonaka, T.; Wong, D.T.W. Saliva diagnostics: Salivaomics, saliva exosomics, and saliva liquid biopsy. JADA 2023, 154, 696–704. [Google Scholar]
- Bandhakavi, S.; Stone, M.D.; Onsongo, G.; Van Riper, S.K.; Griffin, T.J. A dynamic range compression and three-dimensional peptide fractionation analysis platform expands proteome coverage and the diagnostic potential of whole saliva. J. Proteome Res. 2009, 8, 5590–5600. [Google Scholar] [CrossRef]
- Yan, W.; Apweiler, R.; Balgley, B.M.; Boontheung, P.; Bundy, J.L.; Cargile, B.J.; Cole, S.; Fang, X.; Gonzalez-Begne, M.; Griffin, T.J.; et al. Systematic comparison of the human saliva and plasma proteomes. Proteom. Clin. Appl. 2009, 3, 116–134. [Google Scholar] [CrossRef]
- Denny, P.; Hagen, F.K.; Hardt, M.; Liao, L.; Yan, W.; Arellanno, M.; Bassilian, S.; Bedi, G.S.; Boonheung, P.; Cociorva, D.; et al. The proteomes of human parotid and submandibular/sublingual gland salivas collected as ductal secretions. J. Proteome Res. 2008, 7, 1994–2006. [Google Scholar] [CrossRef]
- Stendelyte, L.; Malinauskas, M.; Grinkeviciute, D.E.; Jankauskaite, L. Exploring non-invasive salivary biomarkers for acute pain diagnostics: A comprehensive review. Diagnostics 2023, 13, 1929. [Google Scholar] [CrossRef]
- Available online: http://www.blackpooljsna.org.uk/Living-and-Working-Well/Health-Conditions/Cancer/Lung-Cancer.aspx (accessed on 16 October 2023).
- Guo, S.; Wei, G.; Chen, W.; Lei, C.; Xu, C.; Guan, Y.; Ji, T.; Wang, F.; Liu, H. Fast and deep diagnosis using blood-based ATR-FTIR spectroscopy for digestive tract cancers. Biomolecules 2022, 12, 1815. [Google Scholar] [CrossRef]
- Martin, F.L.; Kelly, J.G.; Llabjani, V.; Martin-Hirsch, P.L.; Patel, I.I.; Trevisan, J.; Fullwood, N.J.; Walsh, M.J. Distinguishing cell types or populations based on the computational analysis of their infrared spectra. Nat. Protoc. 2010, 5, 1748–1760. [Google Scholar] [CrossRef]
- Schiemer, R.; Furniss, D.; Phang, S.; Seddon, A.B.; Atiomo, W.; Gajjar, K.B. Vibrational biospectroscopy: An alternative approach to endometrial cancer diagnosis and screening. Int. J. Mol. Sci. 2022, 23, 4859. [Google Scholar] [CrossRef]
- Giamougiannis, P.; Morais, C.L.M.; Rodriguez, B.; Wood, N.J.; Martin-Hirsch, P.L.; Martin, F.L. Detection of ovarian cancer (±neo-adjuvant chemotherapy effects) via ATR-FTIR spectroscopy: Comparative analysis of blood and urine biofluids in a large patient cohort. Anal. Bioanal. Chem. 2021, 413, 5095–5107. [Google Scholar] [CrossRef]
- Maitra, I.; Morais, C.L.M.; Lima, K.M.G.; Ashton, K.M.; Date, R.S.; Martin, F.L. Attenuated total reflection Fourier-transform infrared spectral discrimination in human bodily fluids of oesophageal transformation to adenocarcinoma. Analyst 2019, 144, 7447–7456. [Google Scholar] [CrossRef]
- McCall, J. Genetic algorithms for modelling and optimisation. J. Comput. Appl. Math. 2005, 184, 205–222. [Google Scholar] [CrossRef]
- Morais, C.L.M.; Lima, K.M.G.; Singh, M.; Martin, F.L. Tutorial: Multivariate classification for vibrational spectroscopy in biological samples. Nat. Protoc. 2020, 15, 2143–2162. [Google Scholar] [CrossRef]
- Brereton, R.G.; Lloyd, G.R. Partial least squares discriminant analysis: Taking the magic away. J. Chemom. 2014, 28, 213–225. [Google Scholar] [CrossRef]
- Dixon, S.J.; Brereton, R.G. Comparison of performance of five common classifiers represented as boundary methods: Euclidean Distance to Centroids, Linear Discriminant Analysis, Quadratic Discriminant Analysis, Learning Vector Quantization and Support Vector Machines, as dependent on data structure. Chemometr. Intell. Lab. Syst. 2009, 95, 1–17. [Google Scholar]
- Morais, C.L.M.; Lima, K.M.G. Principal component analysis with linear and quadratic discriminant analysis for identification of cancer samples based on mass spectrometry. J. Braz. Chem. Soc. 2018, 29, 472–481. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Kennard, R.W.; Stone, L.A. Computer aided design of experiments. Technometrics 1969, 11, 137–148. [Google Scholar] [CrossRef]
- Morais, C.L.M.; Lima, K.M.G.; Martin, F.L. Uncertainty estimation and misclassification probability for classification models based on discriminant analysis and support vector machines. Anal. Chim. Acta 2019, 1063, 40–46. [Google Scholar] [CrossRef] [PubMed]
- Movasaghi, Z.; Rehman, S.; ur Rehman, D.I. Fourier transform infrared (FTIR) spectroscopy of biological tissues. Appl. Spectrosc. Rev. 2008, 43, 134–179. [Google Scholar] [CrossRef]
- O’Rourke, K. Lung cancer screening associated with earlier diagnosis and improved survival. Cancer 2022, 128, 3011–3012. [Google Scholar] [CrossRef]
- Gasparri, R.; Guaglio, A.; Spaggiari, L. Early diagnosis of lung cancer: The urgent need of a clinical test. J. Clin. Med. 2022, 11, 4398. [Google Scholar] [CrossRef]
- Takahashi, K.; Nakamura, S.; Watanabe, K.; Sakaguchi, M.; Narimatsu, H. Availability of financial and medical resources for screening providers and its impact on cancer screening uptake and intervention programs. Int. J. Environ. Res. Public Health 2022, 19, 11477. [Google Scholar] [CrossRef]
- Hands, J.R.; Clemens, G.; Stables, R.; Ashton, K.; Brodbelt, A.; Davis, C.; Dawson, T.P.; Jenkinson, M.D.; Lea, R.W.; Walker, C.; et al. Brain tumour differentiation: Rapid stratified serum diagnostics via attenuated total reflection Fourier-transform infrared spectroscopy. J. Neurooncol. 2016, 127, 463–472. [Google Scholar] [CrossRef]
- Steiner, G.; Galli, R.; Preusse, G.; Michen, S.; Meinhardt, M.; Temme, A.; Sobottka, S.B.; Juratli, T.A.; Koch, E.; Schackert, G.; et al. A new approach for clinical translation of infrared spectroscopy: Exploitation of the signature of glioblastoma for general brain tumour recognition. J. Neurooncol. 2022, 161, 57–66. [Google Scholar] [CrossRef]
- Mokari, A.; Guo, S.; Bocklitz, T. Exploring the steps of infrared (IR) spectral analysis: Pre-processing, (classical) data modelling, and deep learning. Molecules 2023, 28, 6886. [Google Scholar] [CrossRef]
- Zupančič, B.; Umek, N.; Ugwoke, C.K.; Cvetko, E.; Horvat, S.; Grdadolnik, J. Application of FTIR spectroscopy to detect changes in skeletal muscle composition due to obesity with insulin resistance or STZ-induced diabetes. Int. J. Mol. Sci. 2022, 23, 12498. [Google Scholar] [CrossRef]
- Theakstone, A.G.; Brennan, P.M.; Jenkinson, M.D.; Goodacre, R.; Baker, M.J. Investigating centrifugal filtration of serum-based FTIR spectroscopy for stratification of brain tumours. PLoS ONE 2023, 18, e0279669. [Google Scholar] [CrossRef] [PubMed]
- Morais, C.L.M.; Paraskevaidi, M.; Cui, L.; Fullwood, N.J.; Isabelle, M.; Lima, K.M.G.; Martin-Hirsch, P.L.; Sreedhar, H.; Trevisan, J.; Walsh, M.J.; et al. Standardisation of complex biologically derived spectrochemical datasets. Nat. Protoc. 2019, 14, 1546–1577. [Google Scholar] [CrossRef] [PubMed]
- Cui, L.; Butler, H.J.; Martin-Hirsch, P.L.; Martin, F.L. Aluminium foil as a potential substrate for ATR-FTIR, transflection FTIR or Raman spectrochemical analysis of biological specimens. Anal. Methods 2016, 8, 481–487. [Google Scholar] [CrossRef]
- Bassan, P.; Sachdeva, A.; Lee, J.; Gardner, P. Substrate contributions in micro-ATR of thin samples: Implications for analysis of cells, tissue and biological fluids. Analyst 2013, 138, 4139–4146. [Google Scholar] [CrossRef] [PubMed]
- Bel’skaya, V.; Sarf, E.A.; Gundyrev, I.A. Study of the IR spectra of the saliva of cancer patients. J. Appl. Spectrosc. 2019, 85, 1076–1084. [Google Scholar] [CrossRef]
- Moura, P.C.; Raposo, M.; Vassilenko, V. Breath volatile organic compounds (VOCs) as biomarkers for the diagnosis of pathological conditions: A review. Biomed. J. 2023, 46, 100623. [Google Scholar] [CrossRef]
- Filianoti, A.; Costantini, M.; Bove, A.M.; Anceschi, U.; Brassetti, A.; Ferriero, M.; Mastroianni, R.; Misuraca, L.; Tuderti, G.; Ciliberto, G.; et al. Volatilome analysis in prostate cancer by electronic nose: A pilot monocentric study. Cancers 2022, 14, 2927. [Google Scholar] [CrossRef]
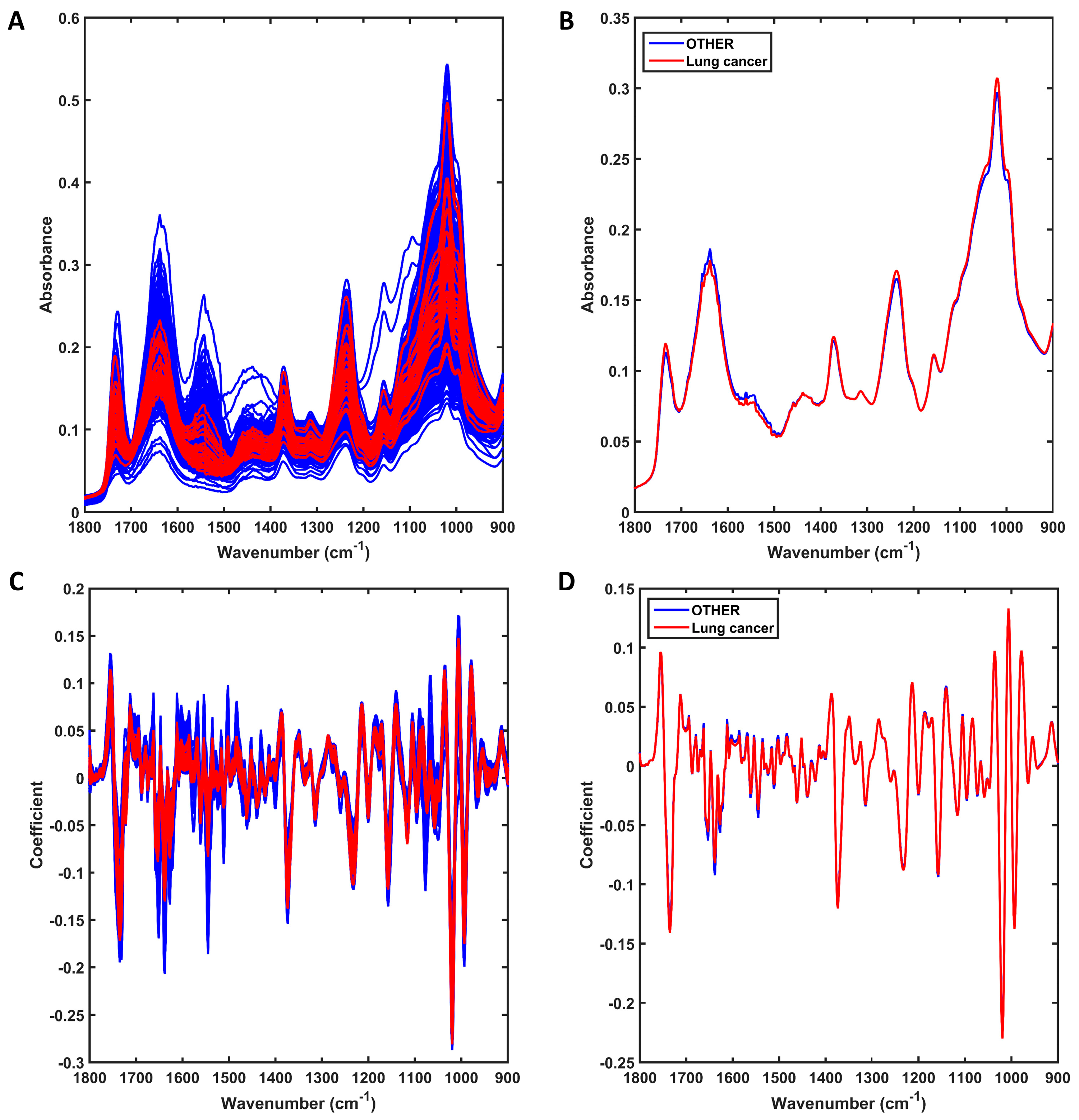


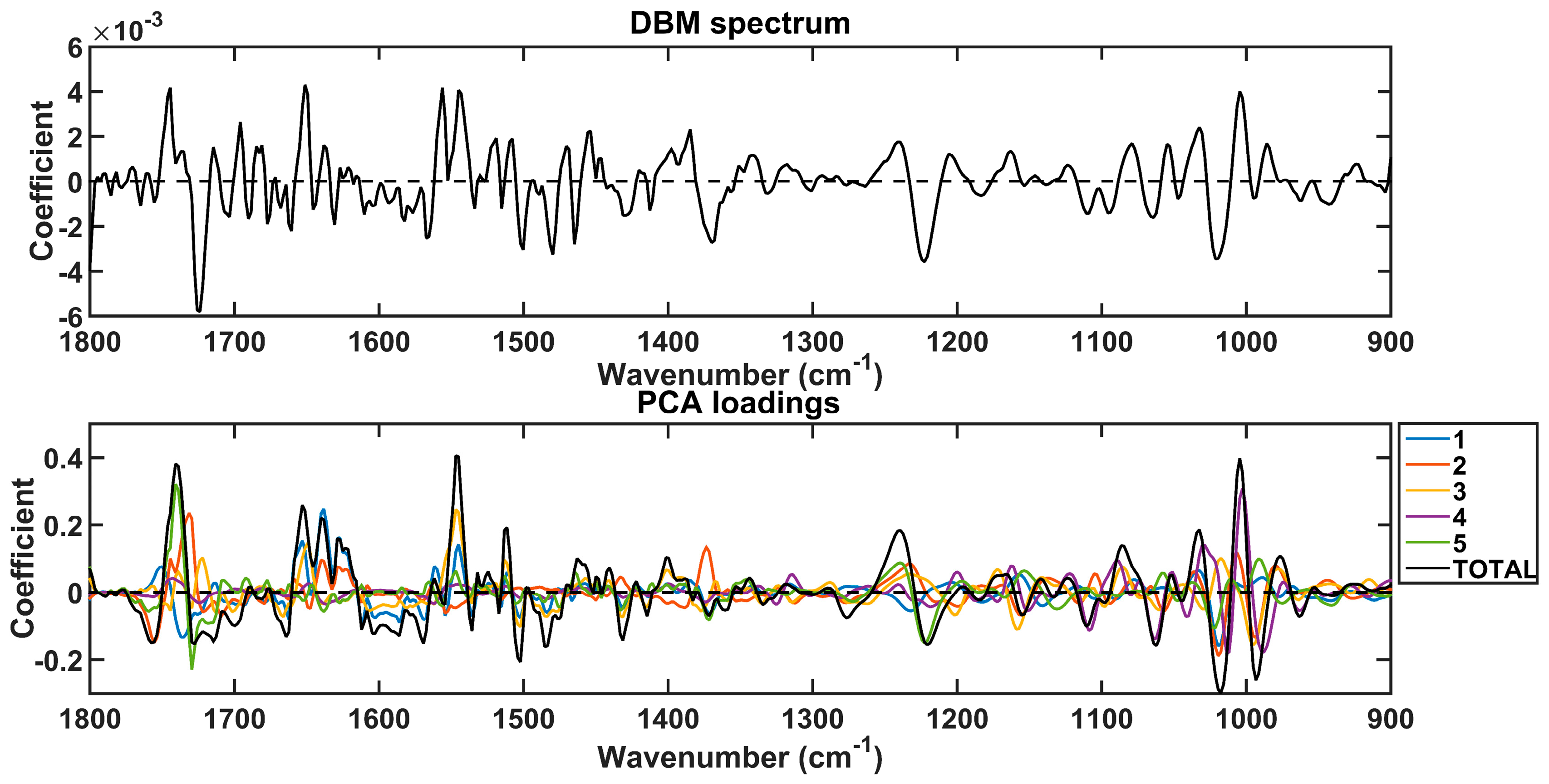

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy | Sensitivity | Specificity | F-Score | G-Score | |
|---|---|---|---|---|---|
| Training | 0.93 | 0.73 | 0.93 | 0.82 | 0.82 |
| Testing | 0.91 | 1.00 | 0.91 | 0.95 | 0.95 |
| Confusion matrix (real vs. predicted class) | |||||
| Training | Other conditions | LG | Total | ||
| Other conditions | 620 | 44 | 664 | ||
| Lung cancer | 6 | 16 | 22 | ||
| Testing | Other conditions | LG | Total | ||
| Other conditions | 258 | 26 | 284 | ||
| Lung cancer | 0 | 9 | 9 | ||
| Wavenumbers (cm−1) | Absorbance | Tentative Assignment |
|---|---|---|
| 1740 | ↑ | C=O stretching (lipids); ester C=O stretching vibration in phospholipids |
| 1722 | ↑ | C=O stretching vibration |
| 1704 | ↑ | C=O stretching vibration |
| 1660 | ↓ | Amide I band |
| 1649 | ↓ | Unordered random coils and turns of Amide I; C=O, C=N, N-H of adenine, thymine, guanine, cytosine |
| 1633 | ↓ | C=C stretching uracyl, C=O stretching |
| 1620 | ↓ | Peak of nucleic acids due to the base carbonyl stretching and ring breathing mode |
| 1565 | ↓ | C-C stretching (ring base) |
| 1554 | ↓ | C-O stretching; predominantly α-sheet of Amide II (Amide II band mainly stems from the C-N stretching and C-N-H bending vibrations weakly coupled to the C=O stretching mode) |
| 1544 | ↓ | Amide II band |
| 1480 | ↓ | Polyethylene methylene deformation modes; Amide II band |
| 1240 | ↑ | Asymmetric PO2− stretching; phosphate band (phosphate stretching modes originate from the phosphodiester groups of nucleic acids); Amide III (C-N stretching mode of proteins, indicating mainly α-helix conformation) |
| 1222 | ↑ | Phosphate stretching bands from phosphodiester groups of cellular nucleic acids |
| 1094 | ↑ | Symmetric PO2− stretching |
| 1078 | ↑ | Symmetric PO2− stretching; glycogen absorption due to C-O and C-C stretching and C-O-H deformation motions |
| 1066 | ↑ | C-O stretching of phosphodiester and ribose |
| 1020 | ↑ | C-O stretching associated with glycogen |
| 1005 | ↑ | Ring stretching vibrations mixed strongly with CH in-plane bending |
| Accuracy | Sensitivity | Specificity | F-Score | G-Score | |
|---|---|---|---|---|---|
| Training | 0.97 | 1.00 | 0.97 | 0.98 | 0.98 |
| Testing | 0.93 | 1.00 | 0.92 | 0.96 | 0.96 |
| Confusion matrix (real vs. predicted class) | |||||
| Training | Other conditions | P-CA | Total | ||
| Other conditions | 388 | 11 | 399 | ||
| P-CA | 0 | 12 | 12 | ||
| Testing | Other conditions | P-CA | Total | ||
| Other conditions | 158 | 13 | 171 | ||
| P-CA | 0 | 5 | 5 | ||
| Wavenumbers (cm−1) | Absorbance | Tentative Assignment |
|---|---|---|
| 1740 | ↓ | C=O stretching (lipids); ester C=O stretching vibration in phospholipids |
| 1729 | ↓ | C=O stretching |
| 1715 | ↓ | C=O stretching in thymine |
| 1653 | ↓ | Amide I band |
| 1640 | ↓ | Amide I band |
| 1628 | ↓ | Amide I band |
| 1622 | ↓ | Peak of nucleic acids due to the base carbonyl stretching and ring breathing mode |
| 1570 | ↓ | Amide II band |
| 1546 | ↓ | Amide II band |
| 1512 | ↓ | In-plane CH bending vibration from the phenyl rings |
| 1503 | ↓ | In-plane CH bending vibration from the phenyl rings |
| 1485 | ↓ | C8-H coupled with a ring vibration of guanine; CH deformation |
| 1240 | ↓ | Asymmetric PO2− stretching; phosphate band (phosphate stretching modes originate from the phosphodiester groups of nucleic acids); amide III (C-N stretching mode of proteins, indicating mainly α-helix conformation) |
| 1220 | ↓ | PO2− asymmetric stretching vibrations of nucleic acids when it is highly hydrogen-bonded; asymmetric hydrogen-bonded phosphate stretching mode; phosphate II (PO2− asymmetric stretching) in B-form DNA |
| 1086 | ↓ | Symmetric phosphate stretching modes of PO2− |
| 1062 | ↓ | C-O stretching in deoxyribose |
| 1033 | ↓ | C-C stretching in skeletal cis conformation, CH2OH stretching, C-O stretching coupled with C-O bending |
| 1018 | ↓ | C-O stretching, C-C stretching, OCH bending in ring |
| 1005 | ↓ | Ring stretching vibrations mixed strongly with CH in-plane bending |
| 993 | ↓ | C-O stretching in ribose, C-C stretching |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martin, F.L.; Morais, C.L.M.; Dickinson, A.W.; Saba, T.; Bongers, T.; Singh, M.N.; Bury, D. Point-of-Care Disease Screening in Primary Care Using Saliva: A Biospectroscopy Approach for Lung Cancer and Prostate Cancer. J. Pers. Med. 2023, 13, 1533. https://doi.org/10.3390/jpm13111533
Martin FL, Morais CLM, Dickinson AW, Saba T, Bongers T, Singh MN, Bury D. Point-of-Care Disease Screening in Primary Care Using Saliva: A Biospectroscopy Approach for Lung Cancer and Prostate Cancer. Journal of Personalized Medicine. 2023; 13(11):1533. https://doi.org/10.3390/jpm13111533
Chicago/Turabian StyleMartin, Francis L., Camilo L. M. Morais, Andrew W. Dickinson, Tarek Saba, Thomas Bongers, Maneesh N. Singh, and Danielle Bury. 2023. "Point-of-Care Disease Screening in Primary Care Using Saliva: A Biospectroscopy Approach for Lung Cancer and Prostate Cancer" Journal of Personalized Medicine 13, no. 11: 1533. https://doi.org/10.3390/jpm13111533
APA StyleMartin, F. L., Morais, C. L. M., Dickinson, A. W., Saba, T., Bongers, T., Singh, M. N., & Bury, D. (2023). Point-of-Care Disease Screening in Primary Care Using Saliva: A Biospectroscopy Approach for Lung Cancer and Prostate Cancer. Journal of Personalized Medicine, 13(11), 1533. https://doi.org/10.3390/jpm13111533