
Early-Stage Detection of Ovarian Cancer Based on Clinical Data Using Machine Learning Approaches

 , , , , ,
, , , , ,  , , and
, , and 
Abstract
:1. Introduction
- Early-stage detection of ovarian cancer using biomarkers;
- Find the significant and associative biomarkers using statistical methods as well as machine learning models;
- Apply machine learning models on a comprehensive dataset including blood samples, general chemistry medical tests, and OC markers and perform robust and statistically sound analytical experiments.
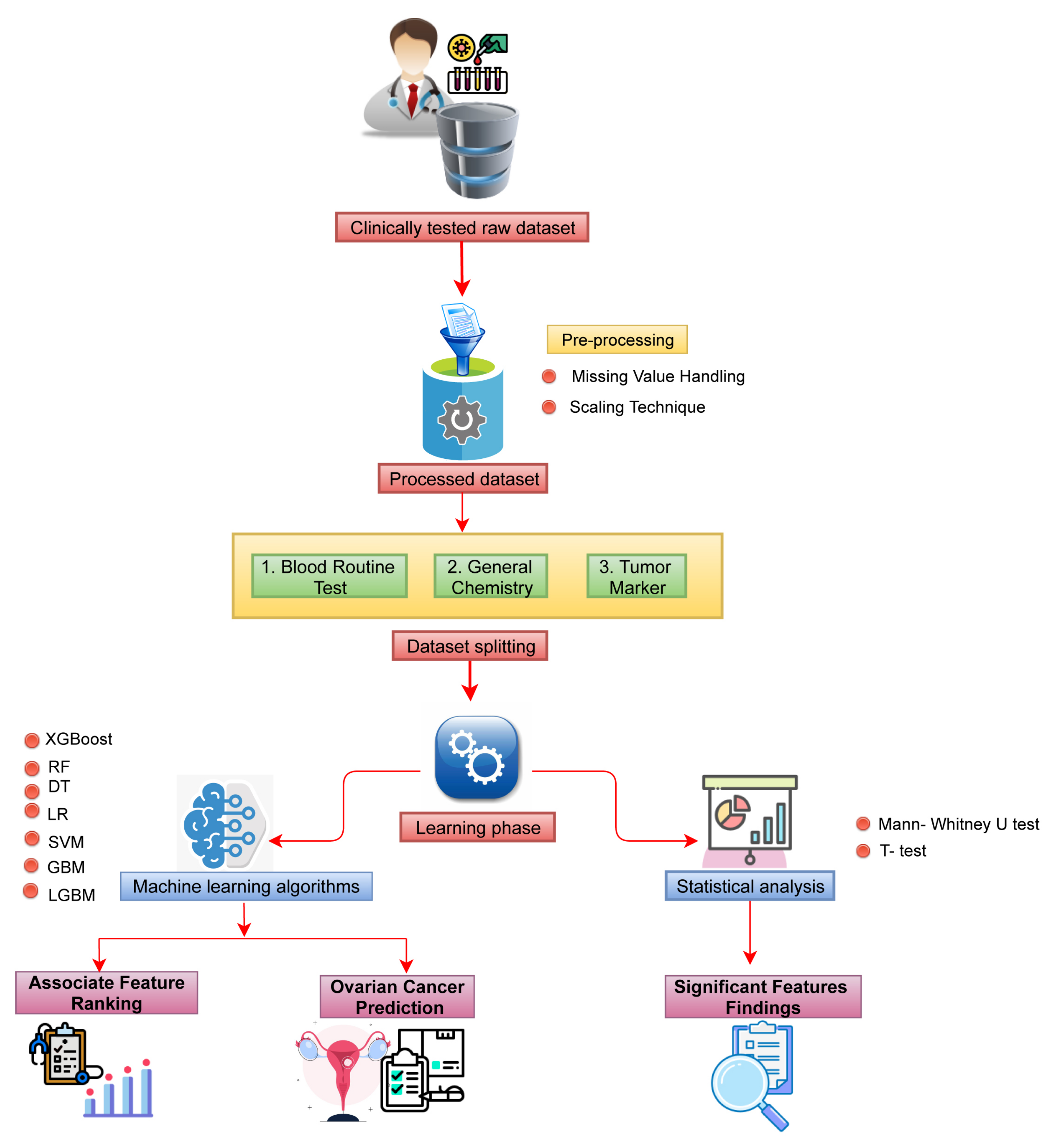
2. Materials and Methods
2.1. Data Collection
2.2. Data Processing
2.3. Association and Impacts of the Features to the Patients
2.4. Machine Learning Models
2.5. Evaluation Metrics
- Accuracy: Accuracy represents the correctness of a model [21], and it can be expressed as follows:
- Precision: Precision states the percentage of appropriately identified samples (positive) inside all identified samples (positive) [22], which can be stated as follows:
- Recall: Recall expresses the capacity of the classifier to properly classify samples within a given class, which is as follows: [23]
- F1-score: F1-score is used for the case when there is class imbalance in data by harmonizing Precision and Recall [22], which is as follows:
- ROC-AUC: ROC-AUC denotes the discrimination capability of the model, and it shows the relationship between specificity and sensitivity [22].The Area Under the Curve (AUC) is the area under the curve.
- Log-loss: Log-loss calculates the ambiguity of the probability of a method by analyzing them to the exact labels. A lesser log-loss value indicates improved predictions [24].Log loss is calculated as follows: , where y is the level of the target variable, is the projected probability of the point given the target value, and q is the actual value of the log loss.
3. Results
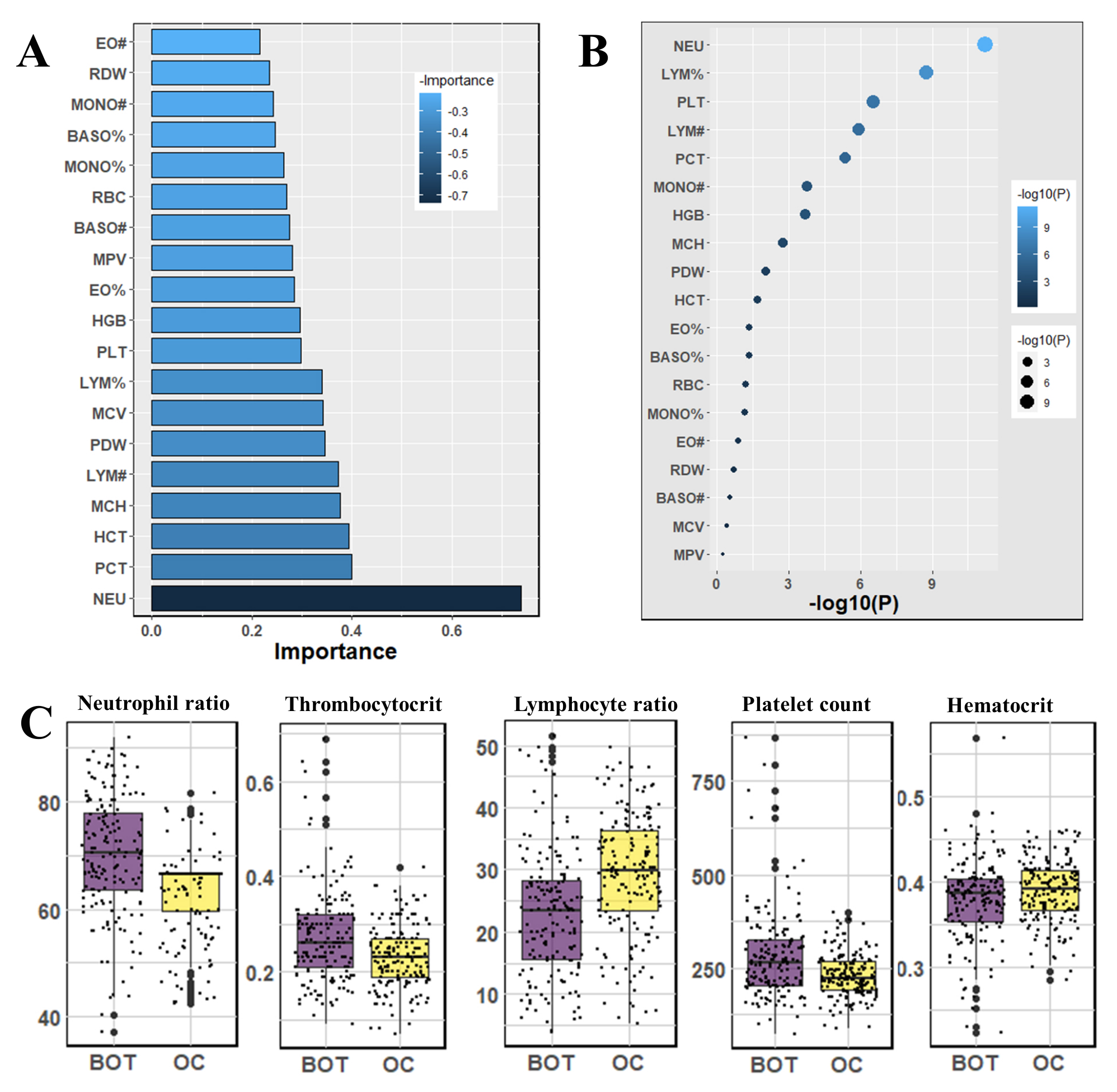
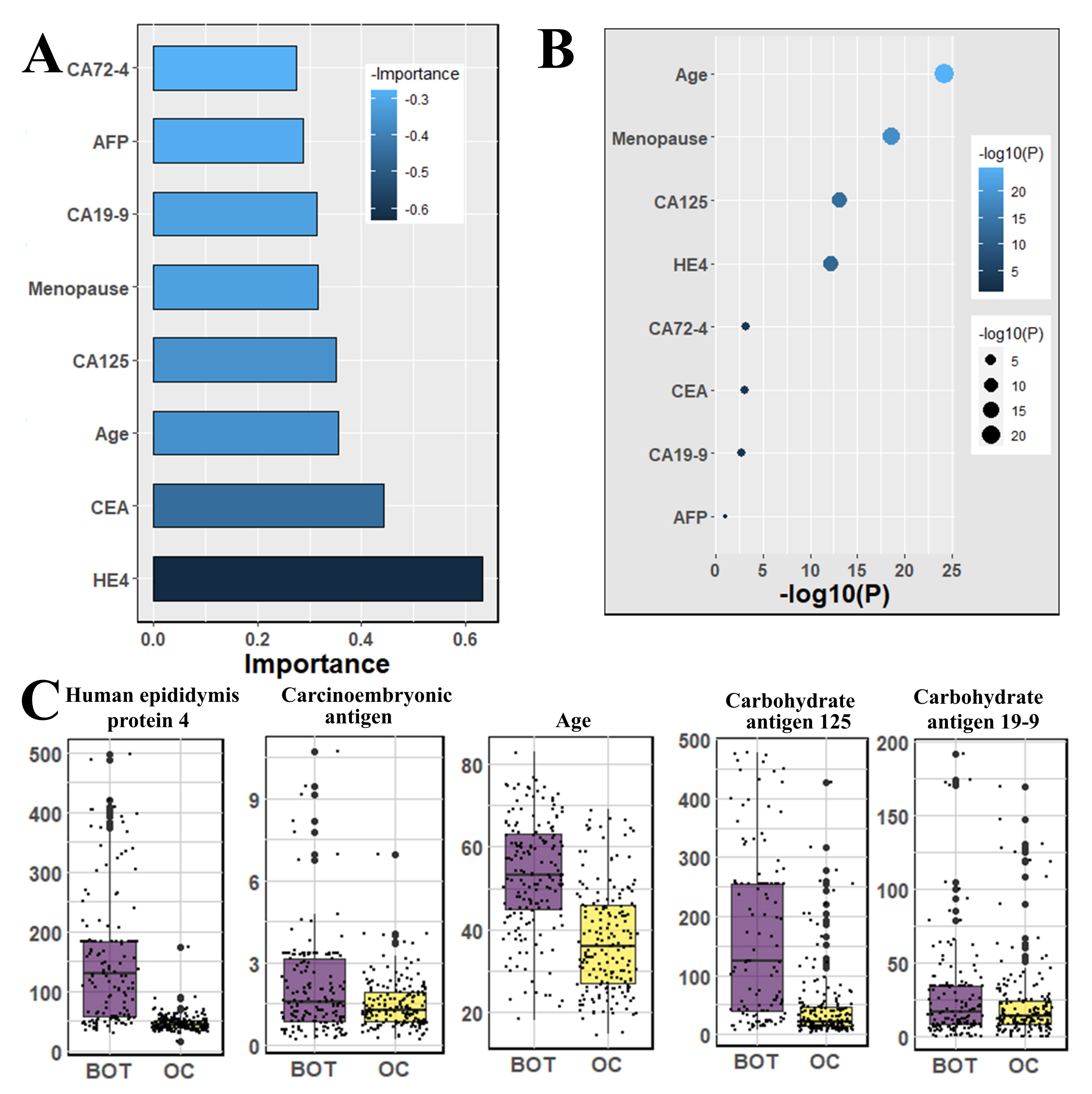
3.1. Finding Significantly Associative Biomarkers Using Statistical Methods
3.2. Classification of Ovarian Cancer Using Machine Learning Algorithms
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MPV | Mean platelet volume |
| BASO# | Basophil cell count |
| PHOS | Phosphorus |
| GLU. | Glucose |
| CA72-4 | Carbohydrate antigen 72-4 |
| K | Kalium |
| AST | Aspartate aminotransferase |
| BASO% | Basophil cell ratio |
| Mg | Magnesium |
| CL | Chlorine |
| CEA | Carcinoembryonic antigen |
| EO# | Eosinophil count |
| CA19-9 | Carbohydrate antigen 19-9 |
| ALB | Albumin |
| IBIL | Indirect bilirubin |
| GGT | Gama glutamyltransferasey |
| MCH | Mean corpuscular hemoglubin |
| GLO | Globulin |
| ALT | Alanine aminotransferase |
| DBIL | Direct bilirubin |
| RDW | Red blood cell distribution width |
| PDW | Platelet distribution width |
| CREA | Creatinine |
| AFP | Alpha-fetoprotein |
| HGB | Hemoglobin |
| Na | Natrium |
| HE4 | Human epididymis protein 4 |
| LYM# | Lymphocyte count |
| CA125 | Carbohydrate antigen 125 |
| BUN | Blood urea nitrogen |
| LYM% | Lymphocyte ratio |
| Ca | Calcium |
| AG | Anion gap |
| MONO# | Mononuclear cell count |
| PLT | Platelet count |
| NEU | Neutrophil ratio |
| EO% | Eosinophil ratio |
| TP | Total protein |
| UA | Uric acid |
| RBC | Red blood cell count |
| PCT | Thrombocytocrit |
| Carban dioxide-combining power | |
| TBIL | Total bilirubin |
| HCT | Hematocrit |
| MONO% | Monocyte ratio |
| MCV | Mean corpuscular volume |
| ALP | Alkaline phosphatase |
References
- Bray, F.; Ferlay, J.; Soerjomataram, I.; Siegel, R.L.; Torre, L.A.; Jemal, A. Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J Clin. 2018, 68, 394–424. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Torre, L.A.; Trabert, B.; DeSantis, C.E.; Miller, K.D.; Samimi, G.; Runowicz, C.D.; Siegel, R.L. Ovarian cancer statistics, 2018. CA Cancer J. Clin. 2018, 68, 284–296. [Google Scholar] [CrossRef] [PubMed]
- Marchetti, C.; Pisano, C.; Facchini, G.; Bruni, G.S.; Magazzino, F.P.; Losito, S.; Pignata, S. First-line treatment of advanced ovarian cancer: Current research and perspectives. Expert Rev. Anticancer Ther. 2010, 10, 47–60. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Gao, J.; Yao, H.; Wu, Z.; Wang, M.; Qi, J. Diagnostic accuracy of serum HE4, CA125 and ROMA in patients with ovarian cancer: A meta-analysis. Tumor Biol. 2014, 35, 6127–6138. [Google Scholar] [CrossRef]
- Lu, M.; Fan, Z.; Xu, B.; Chen, L.; Zheng, X.; Li, J.; Znati, T.; Mi, Q.; Jiang, J. Using machine learning to predict ovarian cancer. Int. J. Med. Inform. 2020, 141, 104195. [Google Scholar] [CrossRef]
- Moore, R.G.; Jabre-Raughley, M.; Brown, A.K.; Robison, K.M.; Miller, M.C.; Allard, W.J.; Kurman, R.J.; Bast, R.C.; Skates, S.J. Comparison of a novel multiple marker assay vs the Risk of Malignancy Index for the prediction of epithelial ovarian cancer in patients with a pelvic mass. Am. J. Obstet. Gynecol. 2010, 203, 228.e221–228.e226. [Google Scholar] [CrossRef] [Green Version]
- Anton, C.; Carvalho, F.M.; Oliveira, E.I.; Maciel, G.A.R.; Baracat, E.C.; Carvalho, J.P. A comparison of CA125, HE4, risk ovarian malignancy algorithm (ROMA), and risk malignancy index (RMI) for the classification of ovarian masses. Clinics 2012, 67, 437–441. [Google Scholar] [CrossRef]
- Lukanova, A.; Kaaks, R. Endogenous hormones and ovarian cancer: Epidemiology and current hypotheses. Cancer Epidemiol. Biomarkers Prev. 2005, 14, 98–107. [Google Scholar] [CrossRef]
- Alqudah, A.M. Ovarian cancer classification using serum proteomic profiling and wavelet features a comparison of machine learning and features selection algorithms. J. Clin. Eng. 2019, 44, 165–173. [Google Scholar] [CrossRef]
- Kawakami, E.; Tabata, J.; Yanaihara, N.; Ishikawa, T.; Koseki, K.; Iida, Y.; Saito, M.; Komazaki, H.; Shapiro, J.S.; Goto, K.; et al. Application of artificial intelligence FOR Preoperative diagnostic And PROGNOSTIC prediction in Epithelial ovarian cancer based on BLOOD BIOMARKERS. Clin. Cancer Res. 2019, 25, 3006–3015. [Google Scholar] [CrossRef] [Green Version]
- Paik, E.S.; Lee, J.W.; Park, J.Y.; Kim, J.H.; Kim, M.; Kim, T.J.; Choi, C.H.; Kim, B.G.; Bae, D.S.; Seo, S.W. Prediction of survival outcomes in patients with epithelial ovarian cancer using machine learning methods. J. Gynecol. Oncol. 2019, 30, e65. [Google Scholar] [CrossRef]
- Akazawa, M.; Hashimoto, K. Artificial Intelligence in Ovarian Cancer Diagnosis. Anticancer Res. 2020, 40, 4795–4800. [Google Scholar] [CrossRef]
- Krithikadatta, J. Normal distribution. J. Conserv. Dent. 2014, 17, 96–97. [Google Scholar] [CrossRef]
- Kim, T.K. T-test as a parametric statistic. Korean J. Anesthesiol. 2015, 68, 540. [Google Scholar] [CrossRef] [Green Version]
- Verma, C.; Illes, Z.; Stoffova, V.; Bakonyi, V.H. Comparative Study of Technology With Student’s Perceptions in Indian and Hungarian Universities for Real-Time: Preliminary Results. IEEE Access 2021, 9, 22824–22843. [Google Scholar] [CrossRef]
- Sur, P.; Candès, E.J. A modern maximum-likelihood theory for high-dimensional logistic regression. Proc. Natl. Acad. Sci. USA 2019, 116, 14516–14525. [Google Scholar] [CrossRef] [Green Version]
- Loey, M.; Manogaran, G.; Taha, M.H.; Khalifa, N.E. A hybrid deep transfer learning model with machine learning methods for face mask detection in the era of the COVID-19 pandemic. Measurement 2021, 167, 108288. [Google Scholar] [CrossRef]
- Awal, M.A.; Masud, M.; Hossain, M.S.; Bulbul, A.A.-M.; Mahmud, S.M.; Bairagi, A.K. A Novel Bayesian Optimization-Based Machine Learning Framework for COVID-19 Detection From Inpatient Facility Data. IEEE Access 2021, 9, 10263–10281. [Google Scholar] [CrossRef]
- Yeşilkanat, C.M. Spatio-temporal estimation of the daily cases of COVID-19 in worldwide using random forest machine learning algorithm. Chaos Solitons Fractals 2020, 140, 110210. [Google Scholar] [CrossRef]
- Meidan, Y.; Sachidananda, V.; Peng, H.; Sagron, R.; Elovici, Y.; Shabtai, A. A novel approach for detecting vulnerable IoT devices connected behind a home NAT. Comput. Secur. 2020, 97, 101968. [Google Scholar] [CrossRef]
- Alazab, M.; Khan, S.; Krishnan, S.S.; Pham, Q.-V.; Reddy, M.P.; Gadekallu, T.R. A Multidirectional LSTM Model for Predicting the Stability of a Smart Grid. IEEE Access 2020, 8, 85454–85463. [Google Scholar] [CrossRef]
- Ahamad, M.M.; Aktar, S.; Rashed-Al-Mahfuz, S.; Uddin, S.; Lio, P.; Xu, H.; Summers, M.A.; Quinn, J.M.W.; Moni, M.A. A machine learning model to identify early stage symptoms of sars-cov-2 infected patients. Expert Syst. Appl. 2020, 160, 113661. [Google Scholar] [CrossRef]
- Braga, A.R.; Gomes, D.G.; Rogers, R.; Hassler, E.E.; Freitas, B.M.; Cazier, J.A. A method for mining combined data from in-hive sensors, weather and apiary inspections to forecast the health status of honey bee colonies. Comput. Electron. Agric. 2020, 169, 105161. [Google Scholar] [CrossRef]
- Akter, T.; Satu, M.S.; Khan, M.I.; Ali, M.H.; Uddin, S.; Lio, P.; Quinn, J.M.W.; Moni, M.A. Machine Learning-Based Models for Early Stage Detection of Autism Spectrum Disorders. IEEE Access 2019, 7, 166509–166527. [Google Scholar] [CrossRef]
- Uddin, S.; Khan, A.; Hossain, M.E.; Moni, M.A. Comparing different supervised machine learning algorithms for disease prediction. BMC Med. Inform. Decis. Making 2019, 19, 281. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine Learning: Algorithms, Real-World Applications and Research Directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef]
- Rauh-Hain, J.A.; Krivak, T.C.; Del Carmen, M.G.; Olawaiye, A.B. Ovarian cancer screening and early detection in the general population. Rev. Obstet. Gynecol. 2011, 4, 15–21. [Google Scholar]
- Gorski, J.W.; Quattrone, M.; Van Nagell, J.R.; Pavlik, E.J. Assessing the costs of screening for ovarian cancer in the United states: An evolving analysis. Diagnostics 2020, 10, 67. [Google Scholar] [CrossRef] [Green Version]
- Martínez-Más, J.; Bueno-Crespo, A.; Khazendar, S.; Remezal-Solano, M.; Martínez-Cendán, J.P.; Jassim, S.; Al Assam, H.; Bourne, T.; Timmerman, D. Evaluation of machine learning methods with Fourier Transform features for CLASSIFYING OVARIAN tumors based on ultrasound images. PLoS ONE 2019, 14, e0219388. [Google Scholar] [CrossRef] [Green Version]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Blood Routine Test | General Chemistry | Tumor Marker |
|---|---|---|
| Neutrophil ratio | Albumin | Carbohydrate antigen 72-4 |
| Thrombocytocrit | Indirect bilirubin | Alpha-fetoprotein |
| Hematocrit | Uric acid | Carbohydrate antigen 19-9 |
| Mean corpuscular hemoglubin | Nutrium | Menopause |
| Lymphocyte | Total protein | Carbohydrate antigen 125 |
| Platelet distribution width | Alanine aminotransderase | Carcinoembryonic antigen |
| Mean corpuscular volume | Total bilirubin | Age |
| Platelet count | Blood urea nitrogen | Human epididymic protein 4 |
| Hemoglobin | Magnesium | |
| Eosinophil ratio | Glucose | |
| Mean platelet volume | Creatinine | |
| Basophil cell count | Phosphorus | |
| Red blood cell count | Globulin | |
| Mononuclear cell count | Gama glutamyl tranferasey | |
| Red blood cell distribution width | Alkaline phosphates | |
| Basophil cell ratios | Kalium | |
| Direct bilirubin | ||
| Carban dioxide-combining power | ||
| Chlorine | ||
| Aspartate aminotransferase | ||
| Anion gap |
| Abbreviation | Biomarkers | Type | Unit | Mean ± SD | 95% CI | p | |
|---|---|---|---|---|---|---|---|
| BOT | OC | ||||||
| MPV | Mean platelet volume | full blood | fL | (−0.48, 0.25) | 0.55 | ||
| BASO# | Basophil cell count | full blood | /L | (−0.006, 0.002) | 0.28 | ||
| PHOS | Phosphorus | serum | mmol/L | (−0.05, 0.03) | 0.67 | ||
| GLU | Glucose | serum | mmol/L | (0.18, 0.69) | <0.01 | ||
| CA72-4 | Carbohydrate antigen 72-4 | serum | U/mL | (2.18, 8.01) | <0.01 | ||
| K | Kalium | serum | mmol/L | (−0.4, −1.17) | 0.92 | ||
| AST | Aspartate aminotransferase | serum | u/L | (1.87, 5.32) | <0.01 | ||
| BASO% | Basophil cell ratio | full blood | % | (−0.15, −0.001) | 0.05 | ||
| Mg | Magnesium | serum | mmol/L | (−0.03, 0.02) | 0.78 | ||
| CL | Chlorine | serum | mmol/L | (−0.05, 1.07) | 0.6 | ||
| CEA | Carcinoembryonic antigen | serum | ng/mL | (1.55, 5.98) | <0.01 | ||
| EO# | Eosinophil count | full blood | /L | (−0.03, 0.003) | 0.13 | ||
| CA19-9 | Carbohydrate antigen 19-9 | serum | U/mL | (15.48, 66.01) | <0.01 | ||
| ALB | Albumin | serum | g/L | (−5.29, −3.1) | <0.01 | ||
| IBIL | Indirect bilirubin | serum | umol/L | (−1.77, −0.57) | <0.01 | ||
| GGT | Gama glutamyl transferase | serum | u/L | (−0.85, 6.68) | 0.13 | ||
| MCH | Mean corpuscular hemoglobin | full blood | Pg | (−1.39, −0.32) | <0.01 | ||
| GLO | Globulin | serum | g/L | (0.83, 2.68) | <0.01 | ||
| ALT | Alanine aminotransferase | serum | u/L | (−2.44, 2.23) | 0.93 | ||
| DBIL | Direct bilirubin | serum | umol/L | (−0.74, −0.15) | <0.01 | ||
| RDW | Red blood cell distribution width | full blood | % | (−0.13, 0.62) | 0.2 | ||
| PDW | Platelet distribution width | full blood | % | (−1.46, −0.21) | <0.01 | ||
| CREA | Creatinine | serum | umol/L | (−4.23, 0.7) | 0.16 | ||
| AFP | Alpha-fetoprotein | serum | ng/mL | (−2.28, 37.66) | 0.08 | ||
| HGB | Hemoglobin | full blood | g/L | (−9.35, −2.93) | <0.01 | ||
| Na | Natrium | serum | mmol/L | (0.22, 1.42) | <0.01 | ||
| HE4 | Human epididymis protein 4 | serum | pmol/L | (202.8, 347.34) | <0.01 | ||
| LYM# | Lymphocyte count | full blood | /L | (−0.4, −0.17) | <0.01 | ||
| CA125 | Carbohydrate antigen 125 | serum | U/mL | (449.57, 751.81) | <0.01 | ||
| BUN | Blood urea nitrogen | serum | mmol/L | (−0.28, 0.26) | 0.94 | ||
| LYM% | Lymphocyte ratio | full blood | % | (−8.61, −4.46) | <0.01 | ||
| Ca | Calcium | serum | mmol/L | (−0.21, −0.06) | <0.01 | ||
| AG | Anion gap | serum | mmol/L | (−0.75, 1.08) | 0.73 | ||
| MONO# | Mononuclear cell count | full blood | /L | (−0.03, 0.78) | <0.01 | ||
| PLT | Platelet count | full blood | /L | (32.06, 70,74) | <0.01 | ||
| NEU | Neutrophil ratio | full blood | % | (5.16, 9.09) | <0.01 | ||
| EO% | Eosinophil ratio | full blood | /L | (−0.48, −0.004) | 0.05 | ||
| TP | Total protein | serum | g/L | (−4.29, −1.29) | <0.01 | ||
| UA | Uric acid | serum | mol/L | (−9.46, 19.45) | 0.5 | ||
| RBC | Red blood cell count | full blood | /L | (−0.19, 0.005) | 0.06 | ||
| PCT | Thrombocytocrit | full blood | L/L | (0.02,0.06) | <0.01 | ||
| CO2CP | Carban dioxide-combining power | serum | mmol/L | (−0.05, 1.07) | 0.08 | ||
| TBIL | Total bilirubin | serum | mol/L | (−2.46, −0.77) | <0.01 | ||
| HCT | Hematocrit | full blood | L/L | (−0.02, −0.002) | 0.02 | ||
| MONO% | Monocyte ratio | full blood | % | (−0.03, 0.78) | 0.07 | ||
| MCV | Mean corpuscular volume | full blood | fL | (−1.82, 0.72) | 0.4 | ||
| ALP | Alkaline phosphatase | serum | u/L | (9.56, 27.59) | <0.01 | ||
| Dataset | Model | Accuracy | Precision | Recall | F1-Score | AUC | Log Loss |
|---|---|---|---|---|---|---|---|
| Blood Samples | RF | 0.81 | 0.76 | 0.92 | 0.82 | 0.78 | 7.6 |
| SVM | 0.81 | 0.77 | 0.89 | 0.82 | 0.78 | 7.8 | |
| DT | 0.81 | 0.83 | 0.78 | 0.81 | 0.81 | 6.71 | |
| XGBoost | 0.81 | 0.78 | 0.86 | 0.82 | 0.77 | 7.6 | |
| LR | 0.80 | 0.79 | 0.81 | 0.80 | 0.78 | 7.6 | |
| GBM | 0.82 | 0.82 | 0.84 | 0.83 | 0.82 | 6.23 | |
| LGBM | 0.82 | 0.80 | 0.86 | 0.83 | 0.82 | 6.2 | |
| General Chemistry | RF | 0.81 | 0.80 | 0.83 | 0.82 | 0.80 | 6.71 |
| SVM | 0.80 | 0.76 | 0.90 | 0.81 | 0.79 | 7.11 | |
| DT | 0.68 | 0.70 | 0.68 | 0.69 | 0.68 | 11.03 | |
| XGBoost | 0.76 | 0.76 | 0.78 | 0.78 | 0.77 | 8.15 | |
| LR | 0.80 | 0.75 | 0.89 | 0.82 | 0.79 | 7.11 | |
| GBM | 0.75 | 0.76 | 0.76 | 0.76 | 0.75 | 8.63 | |
| LGBM | 0.75 | 0.87 | 0.82 | 0.84 | 0.76 | 7.11 | |
| OC Marker | RF | 0.86 | 0.80 | 0.97 | 0.87 | 0.86 | 4.79 |
| SVM | 0.85 | 0.80 | 0.95 | 0.86 | 0.84 | 5.27 | |
| DT | 0.85 | 0.81 | 0.92 | 0.86 | 0.85 | 5.2 | |
| XGBoost | 0.86 | 0.80 | 0.97 | 0.86 | 0.86 | 4.79 | |
| LR | 0.83 | 0.80 | 0.92 | 0.85 | 0.83 | 5.7 | |
| GBM | 0.85 | 0.80 | 0.95 | 0.86 | 0.84 | 5.27 | |
| LGBM | 0.85 | 0.80 | 0.95 | 0.86 | 0.84 | 5.27 | |
| Combined | RF | 0.88 | 0.83 | 0.95 | 0.89 | 0.87 | 4.31 |
| SVM | 0.81 | 0.77 | 0.89 | 0.83 | 0.80 | 6.71 | |
| DT | 0.78 | 0.78 | 0.78 | 0.78 | 0.78 | 7.6 | |
| XGBoost | 0.86 | 0.82 | 0.95 | 0.86 | 0.86 | 4.79 | |
| LR | 0.82 | 0.79 | 0.89 | 0.84 | 0.82 | 6.23 | |
| GBM | 0.88 | 0.83 | 0.95 | 0.89 | 0.87 | 4.31 | |
| LGBM | 0.88 | 0.85 | 0.92 | 0.88 | 0.87 | 4.31 |
| Dataset | Model | Accuracy | Precision | Recall | F-1 Score | AUC | Log-Loss |
|---|---|---|---|---|---|---|---|
| Blood Samples | RF | 0.86 | 0.82 | 1 | 0.9 | 0.81 | 4.71 |
| SVM | 0.81 | 0.77 | 1 | 0.88 | 0.75 | 6.28 | |
| DT | 0.77 | 0.8 | 0.86 | 0.83 | 0.74 | 7.85 | |
| XGBoost | 0.77 | 0.8 | 0.86 | 0.83 | 0.74 | 7.85 | |
| LR | 0.82 | 0.78 | 1 | 0.88 | 0.75 | 6.28 | |
| GBM | 0.73 | 0.72 | 0.73 | 0.72 | 0.68 | 9.42 | |
| LGBM | 0.64 | 0.64 | 1 | 0.78 | 0.5 | 12.56 | |
| General Chemistry | RF | 0.77 | 0.76 | 0.93 | 0.84 | 0.71 | 7.85 |
| SVM | 0.77 | 0.76 | 0.93 | 0.84 | 0.71 | 7.85 | |
| DT | 0.59 | 0.67 | 0.71 | 0.69 | 0.54 | 14.13 | |
| XGBoost | 0.73 | 0.75 | 0.86 | 0.8 | 0.68 | 9.42 | |
| LR | 0.77 | 0.76 | 0.93 | 0.84 | 0.71 | 7.85 | |
| GBM | 0.73 | 0.72 | 0.73 | 0.72 | 0.68 | 9.42 | |
| LGBM | 0.64 | 0.64 | 1 | 0.78 | 0.5 | 12.56 | |
| OC Marker | RF | 0.91 | 1 | 0.86 | 0.92 | 0.93 | 3.14 |
| SVM | 0.82 | 0.92 | 0.79 | 0.85 | 0.83 | 6.28 | |
| DT | 0.59 | 1 | 0.36 | 0.53 | 0.68 | 14.13 | |
| XGBoost | 0.68 | 1 | 0.5 | 0.67 | 0.75 | 10.99 | |
| LR | 0.82 | 0.92 | 0.79 | 0.85 | 0.83 | 6.28 | |
| GBM | 0.81 | 0.84 | 0.82 | 0.82 | 0.83 | 6.28 | |
| LGBM | 0.64 | 0.64 | 1 | 0.78 | 0.5 | 12.56 | |
| Combined | RF | 0.86 | 0.87 | 0.93 | 0.9 | 0.84 | 4.71 |
| SVM | 0.64 | 0.8 | 0.57 | 0.67 | 0.66 | 12.56 | |
| DT | 0.68 | 1 | 0.5 | 0.67 | 0.75 | 10.99 | |
| XGBoost | 0.86 | 1 | 0.79 | 0.88 | 0.89 | 4.71 | |
| LR | 0.86 | 0.82 | 1 | 0.9 | 0.81 | 4.71 | |
| GBM | 0.86 | 0.87 | 0.86 | 0.87 | 0.87 | 4.71 | |
| LGBM | 0.64 | 0.64 | 1 | 0.78 | 0.5 | 12.56 |
| References | Dataset | Classifiers | Accuracy | Sensitivity | AUC |
|---|---|---|---|---|---|
| [5] | Clinical data (349 patients with 49 features) | DT | 0.87 | 0.82 | - |
| [12] | Clinical data (202 patients with 32 features) | XGBoost | 0.80 | - | - |
| [29] | Image data (348 patients) | SVM, ELM | 0.87 | 0.87 | 0.89 |
| Proposed | Clicnical data (349 patients with 49 features) | RF, GBM, LGBM | 0.88 | 0.97 | 0.87 |
| Proposed | Clicnical data (106 patients with OC marker features) | RF | 0.91 | 0.86 | 0.93 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahamad, M.M.; Aktar, S.; Uddin, M.J.; Rahman, T.; Alyami, S.A.; Al-Ashhab, S.; Akhdar, H.F.; Azad, A.; Moni, M.A. Early-Stage Detection of Ovarian Cancer Based on Clinical Data Using Machine Learning Approaches. J. Pers. Med. 2022, 12, 1211. https://doi.org/10.3390/jpm12081211
Ahamad MM, Aktar S, Uddin MJ, Rahman T, Alyami SA, Al-Ashhab S, Akhdar HF, Azad A, Moni MA. Early-Stage Detection of Ovarian Cancer Based on Clinical Data Using Machine Learning Approaches. Journal of Personalized Medicine. 2022; 12(8):1211. https://doi.org/10.3390/jpm12081211
Chicago/Turabian StyleAhamad, Md. Martuza, Sakifa Aktar, Md. Jamal Uddin, Tasnia Rahman, Salem A. Alyami, Samer Al-Ashhab, Hanan Fawaz Akhdar, AKM Azad, and Mohammad Ali Moni. 2022. "Early-Stage Detection of Ovarian Cancer Based on Clinical Data Using Machine Learning Approaches" Journal of Personalized Medicine 12, no. 8: 1211. https://doi.org/10.3390/jpm12081211
APA StyleAhamad, M. M., Aktar, S., Uddin, M. J., Rahman, T., Alyami, S. A., Al-Ashhab, S., Akhdar, H. F., Azad, A., & Moni, M. A. (2022). Early-Stage Detection of Ovarian Cancer Based on Clinical Data Using Machine Learning Approaches. Journal of Personalized Medicine, 12(8), 1211. https://doi.org/10.3390/jpm12081211