
Implementation of Privacy and Security for a Genomic Information System Based on Standards


Abstract
:1. Introduction
1.1. ISO/IEC 23092 (Genomic Information Representation)
1.2. Global Alliance for Genomics and Health (GA4GH)
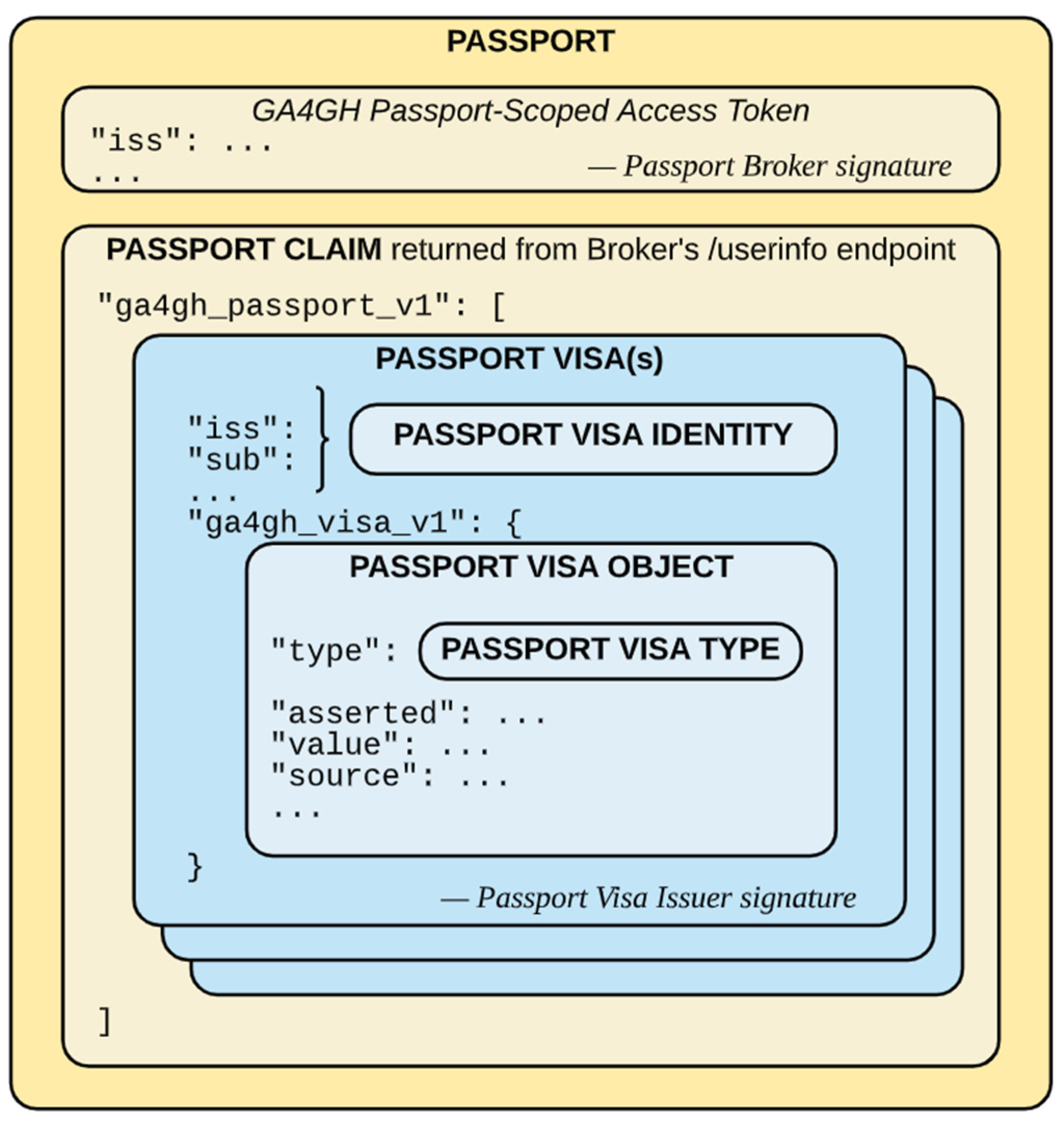
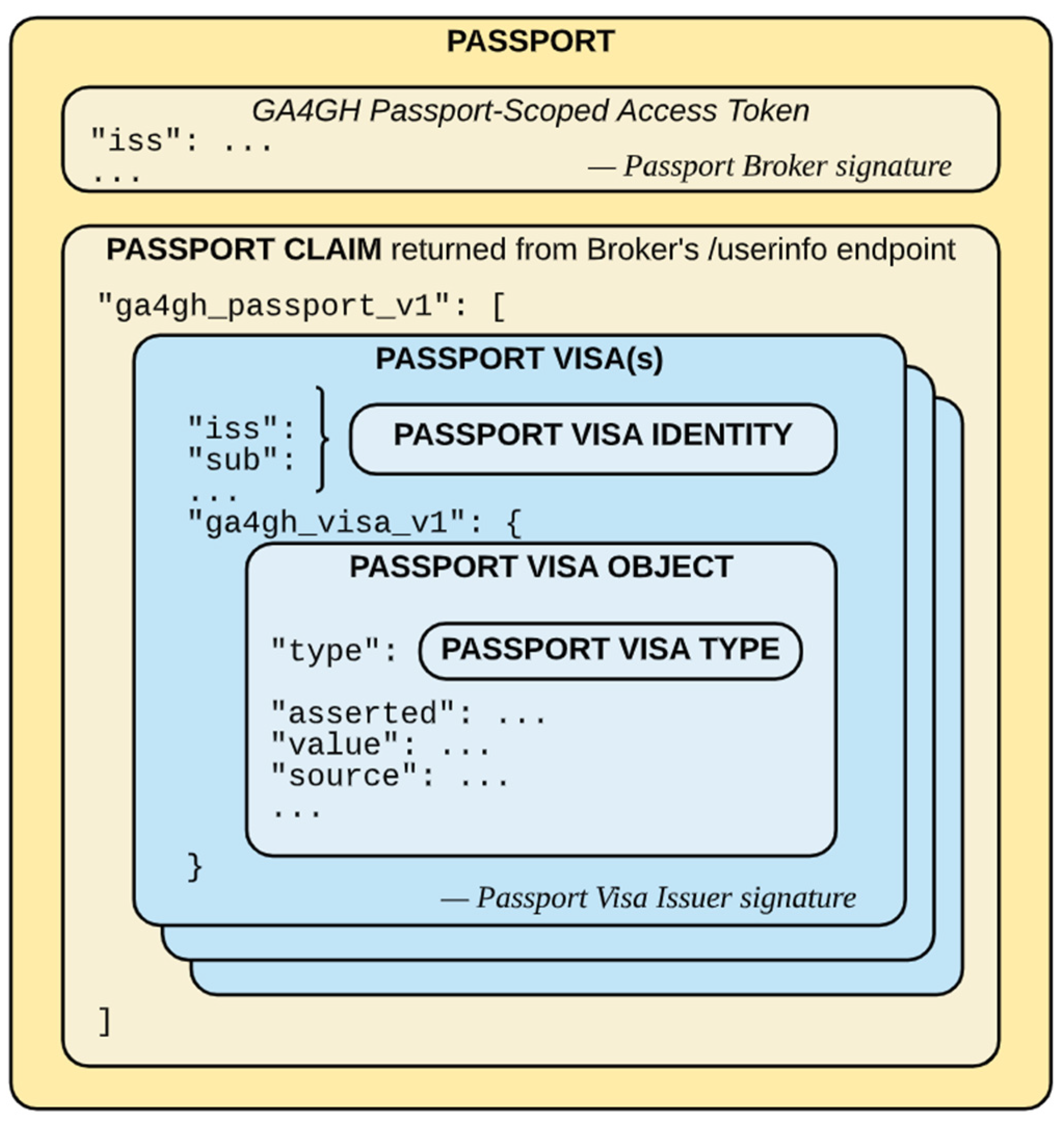
1.2.1. GA4GH Passports
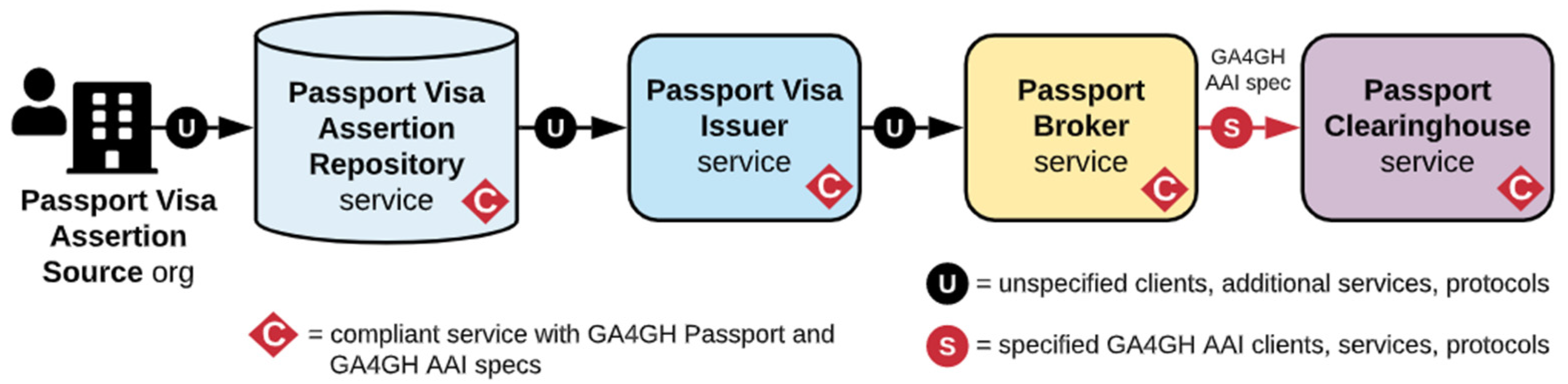
1.2.2. GA4GH Authorization and Authentication Infrastructure (AAI)
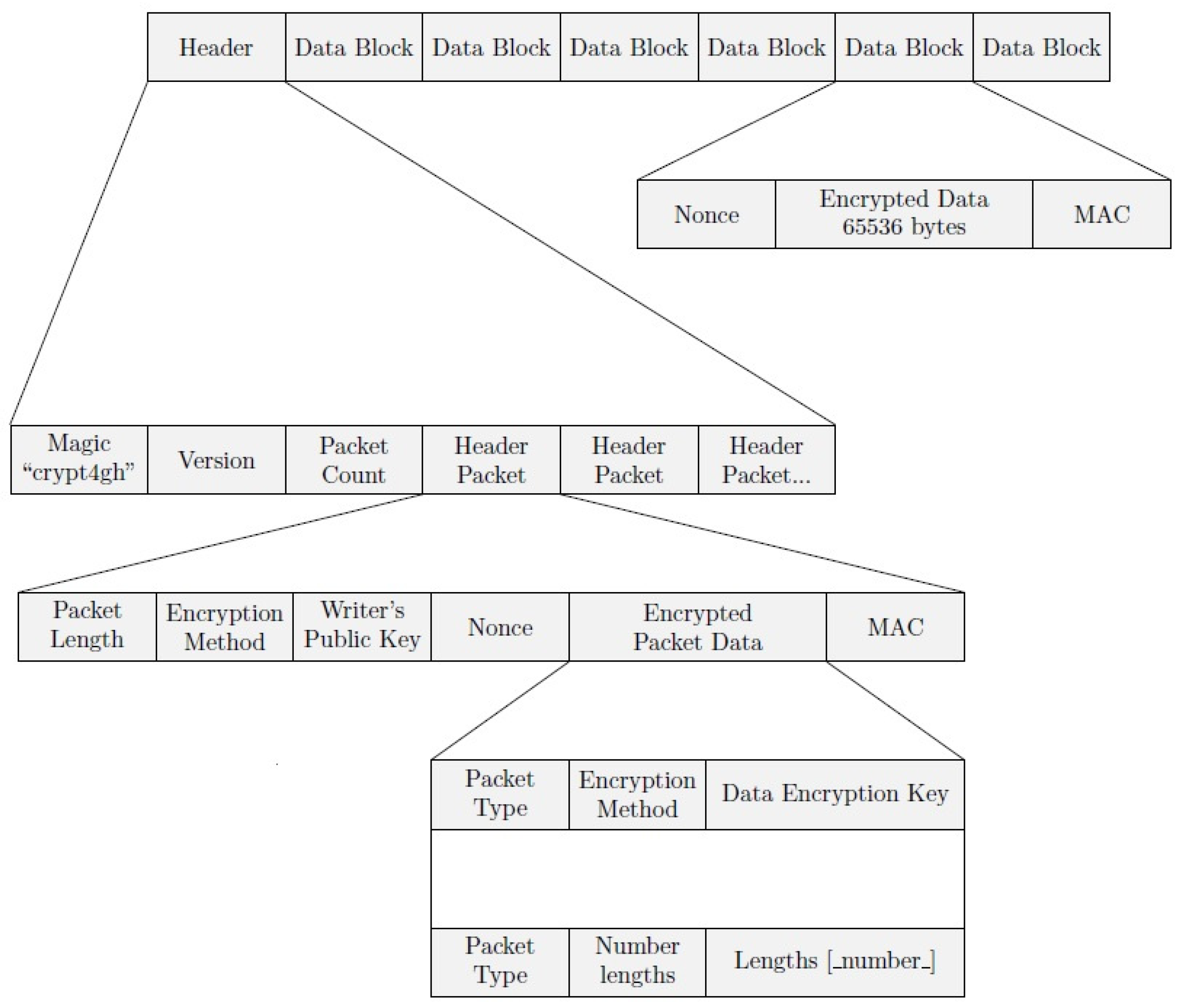
1.2.3. Crypt4GH File Format
2. Materials and Methods
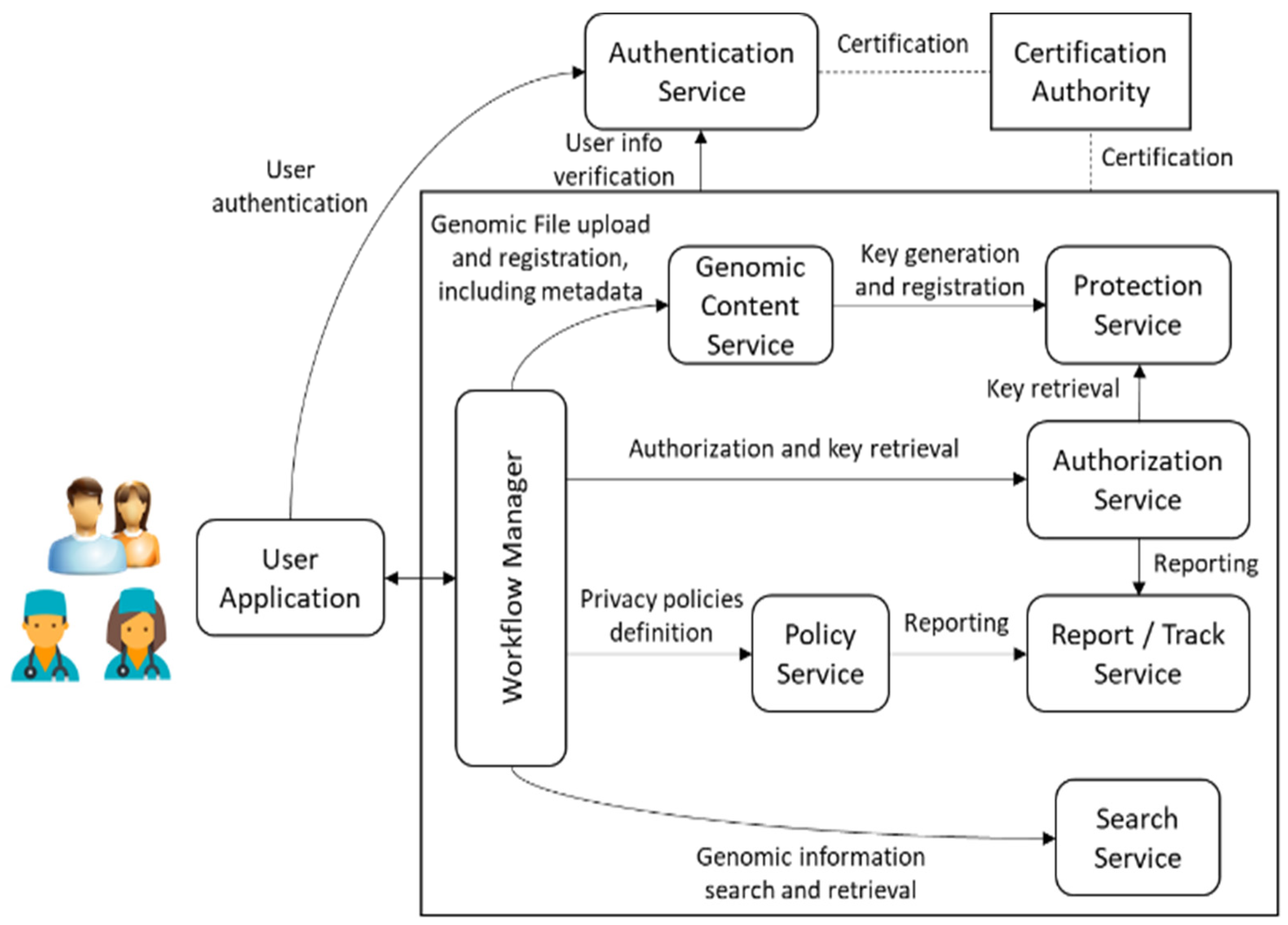
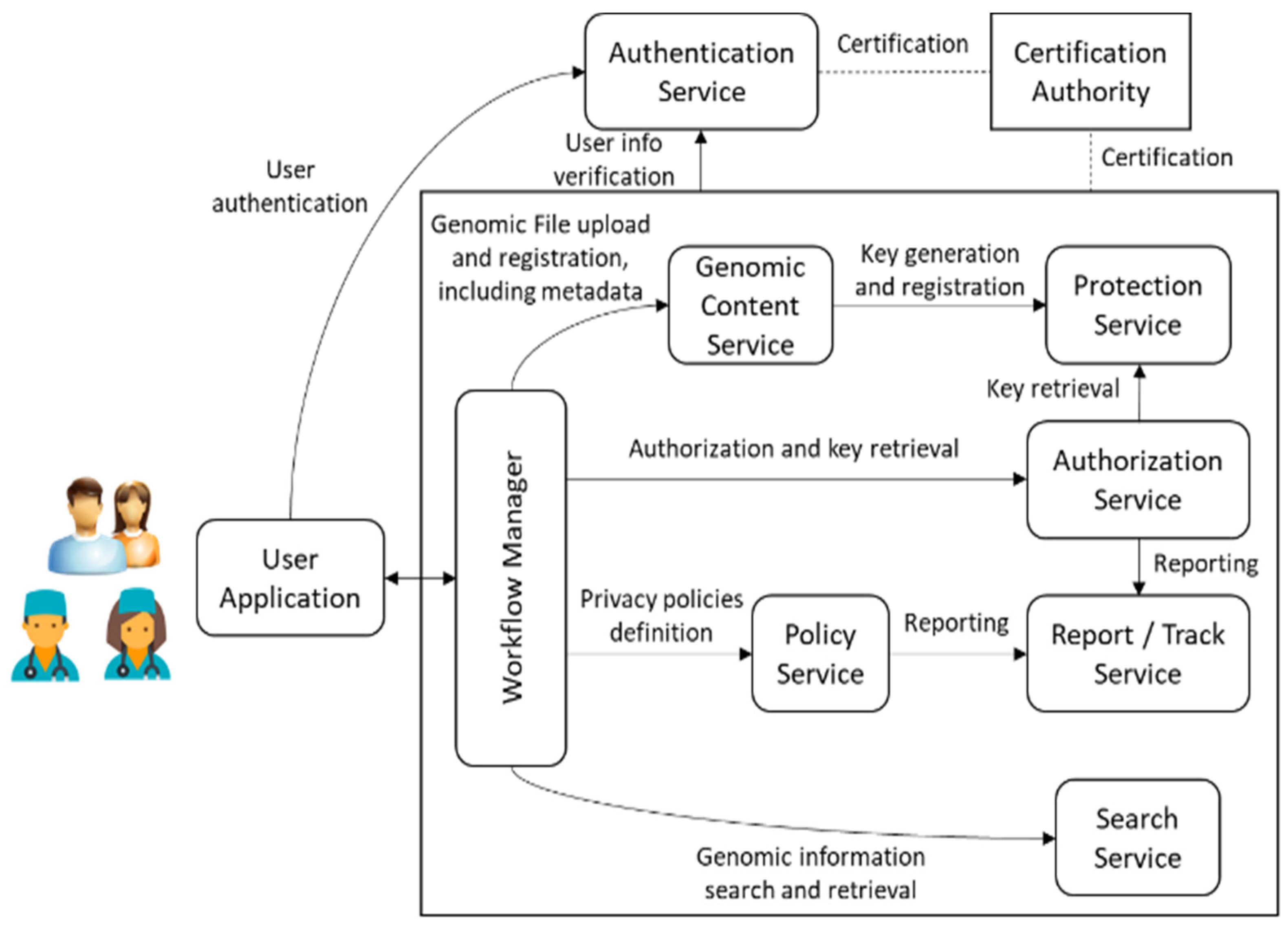
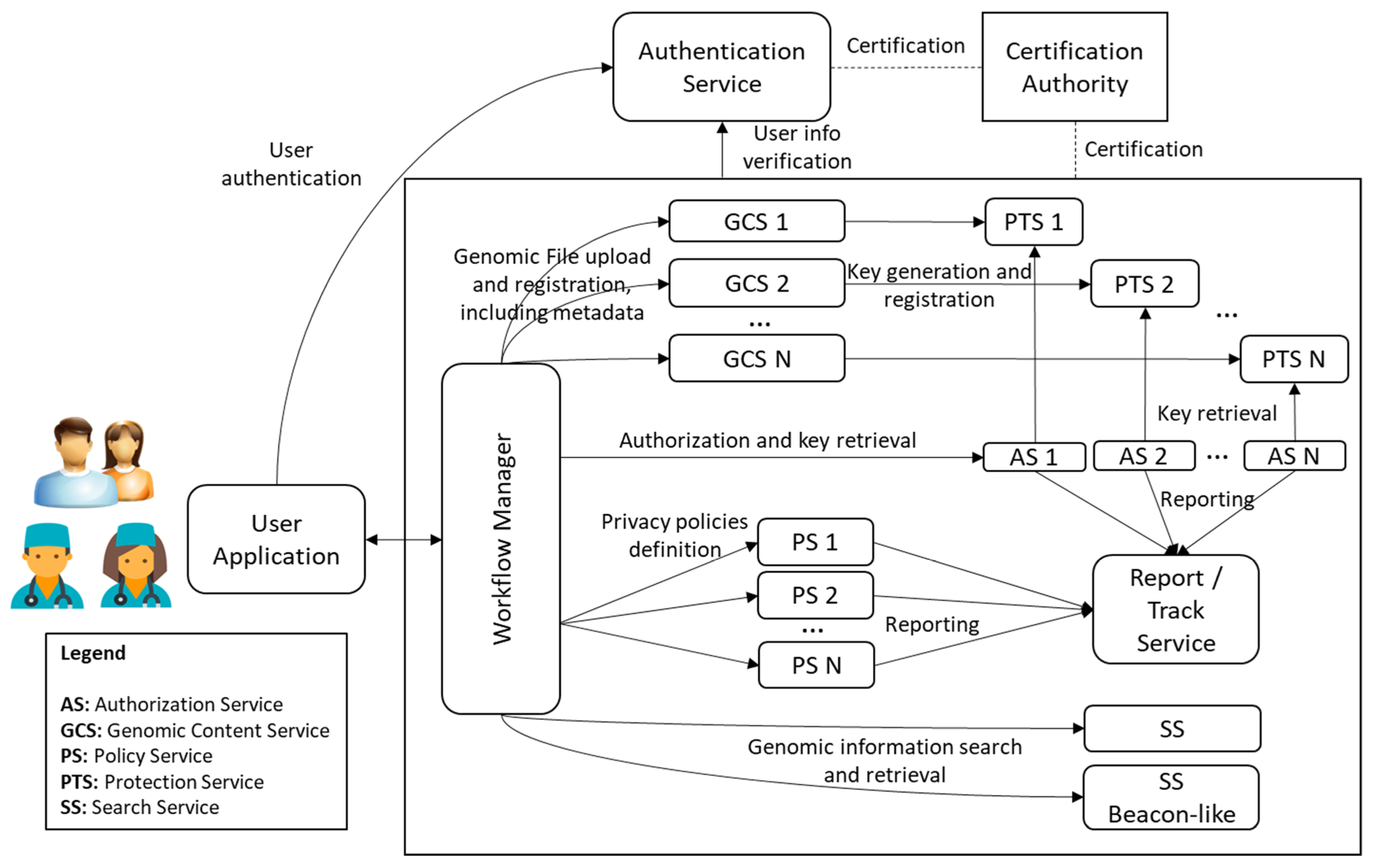
2.1. Genomic Information and Protection Management System (GIPAMS)
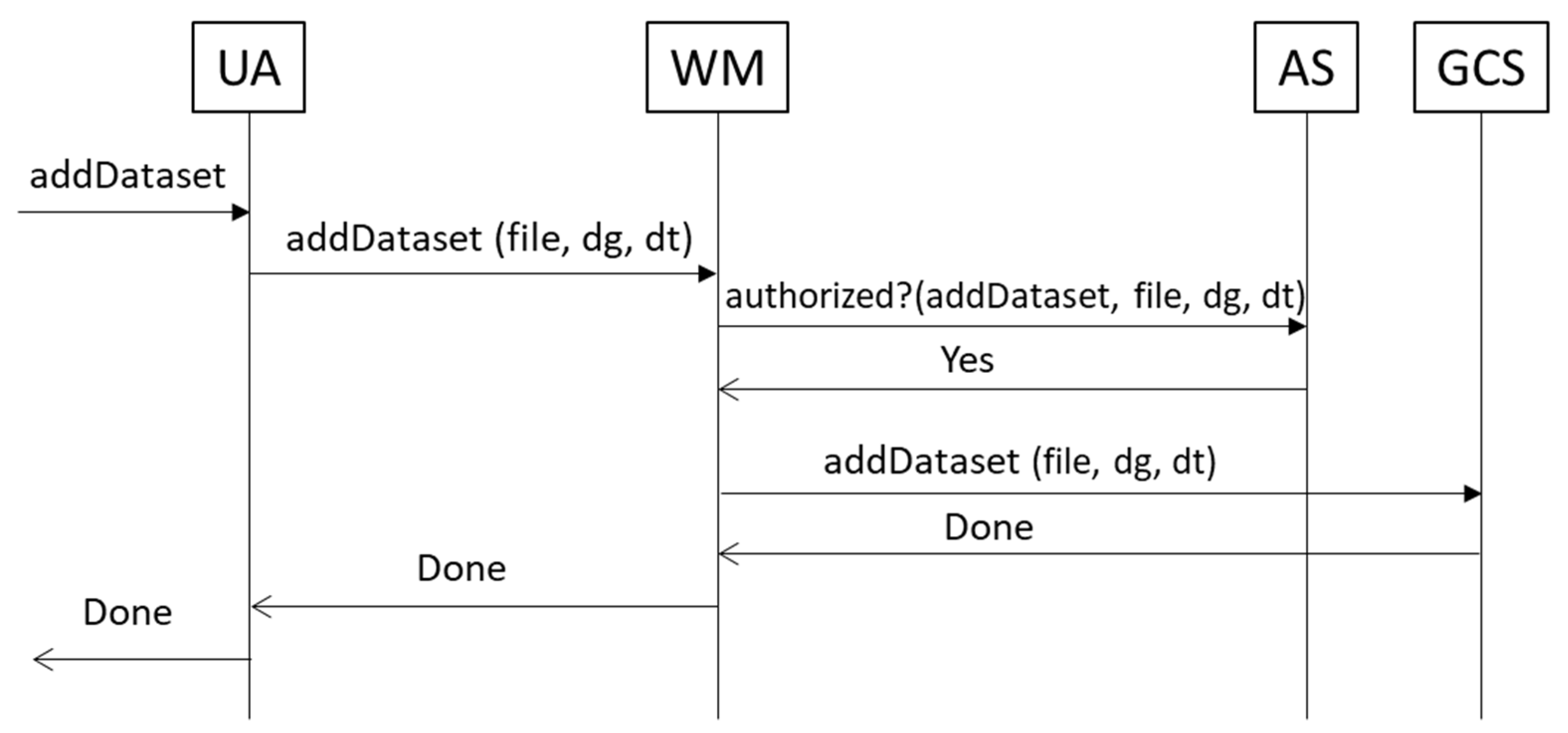
- User Application (UA): Access point to the whole system. It sends all requests to the Workflow Manager, which redirects to the corresponding module based on the action requested by the user. An access token is required, which is provided by the Authentication Service. Communication between this application and the rest of the architecture is performed through a secure channel. It is currently implemented as a web application but it could be a desktop application or even a mobile application.
- Workflow Manager (WM): Intermediate module that acts as a unique entry point to the system to facilitate interactions with the other modules, making them transparent to the final user. Before redirecting to the module in charge of an operation coming from the User Application, it checks if this operation is authorized using the information inside the access token.
- Genomic Content Service (GCS): Module in charge of genomic archives management, both in reading and writing operations. In case genomic data has to be protected (encrypted or signed), it may connect with the Protection Service to obtain the required keys. It also manages metadata storage.
- Authorization Service (AS): Module which validates authorization rules. It is currently based on WSO2 Balana [36]. Authorization requests are usually sent from the Workflow Manager responding to user actions, but other modules may also interact with it to request the authorization of internal operations.
- Search Service (SS): Module which performs searches over genomic information (especially metadata). In order to provide extra filtering features, it uses a relational database where metadata fields are stored. It must be checked by means of authorization rules so that the returned results can be seen by the user requesting them.
- Policy Service (PS): Module in charge of the creation of the authorization rules. In the current version of this module, which makes use of eXtensible Access Control Markup Language (XACML) [37], they are organized into XACML policies and rules.
- Protection Service (PTS): Module which creates protection information metadata associated with genomic information. It applies the defined mechanisms (i.e., encryption, signature, etc.) to the corresponding genomic data or metadata.
- Report/Track Service (RTS): Module in charge of reporting the operations implemented in the system, especially those not authorized. It helps in keeping track of illegal/unusual operations that may indicate an attempt to attack the system.
- Certification Authority (CA): This is not a real module of the system, but something required for its proper functioning. It provides the certificates needed to establish secure connections between the different system components.
2.2. ISO/IEC 23092 Relationship with GIPAMS
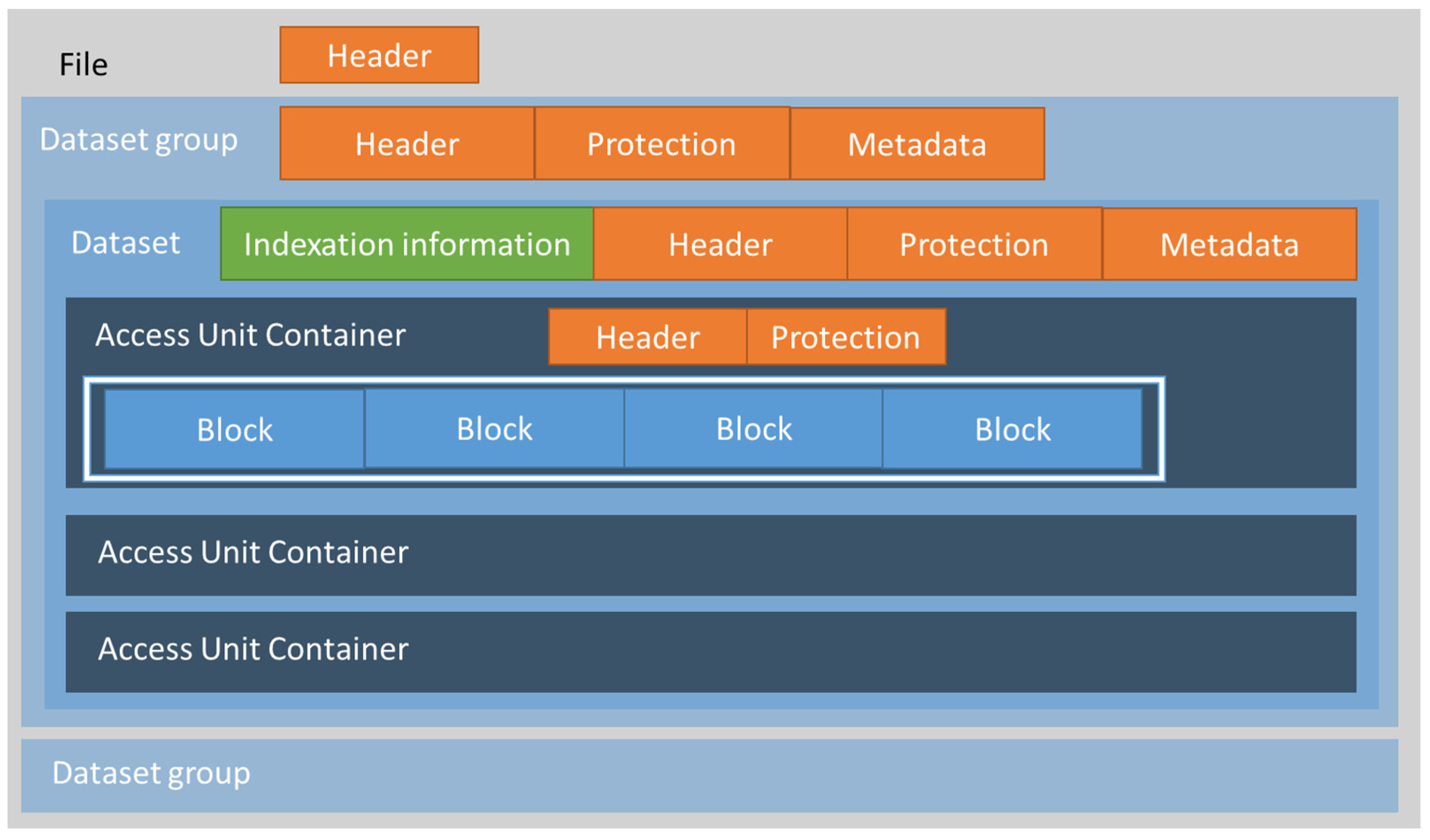
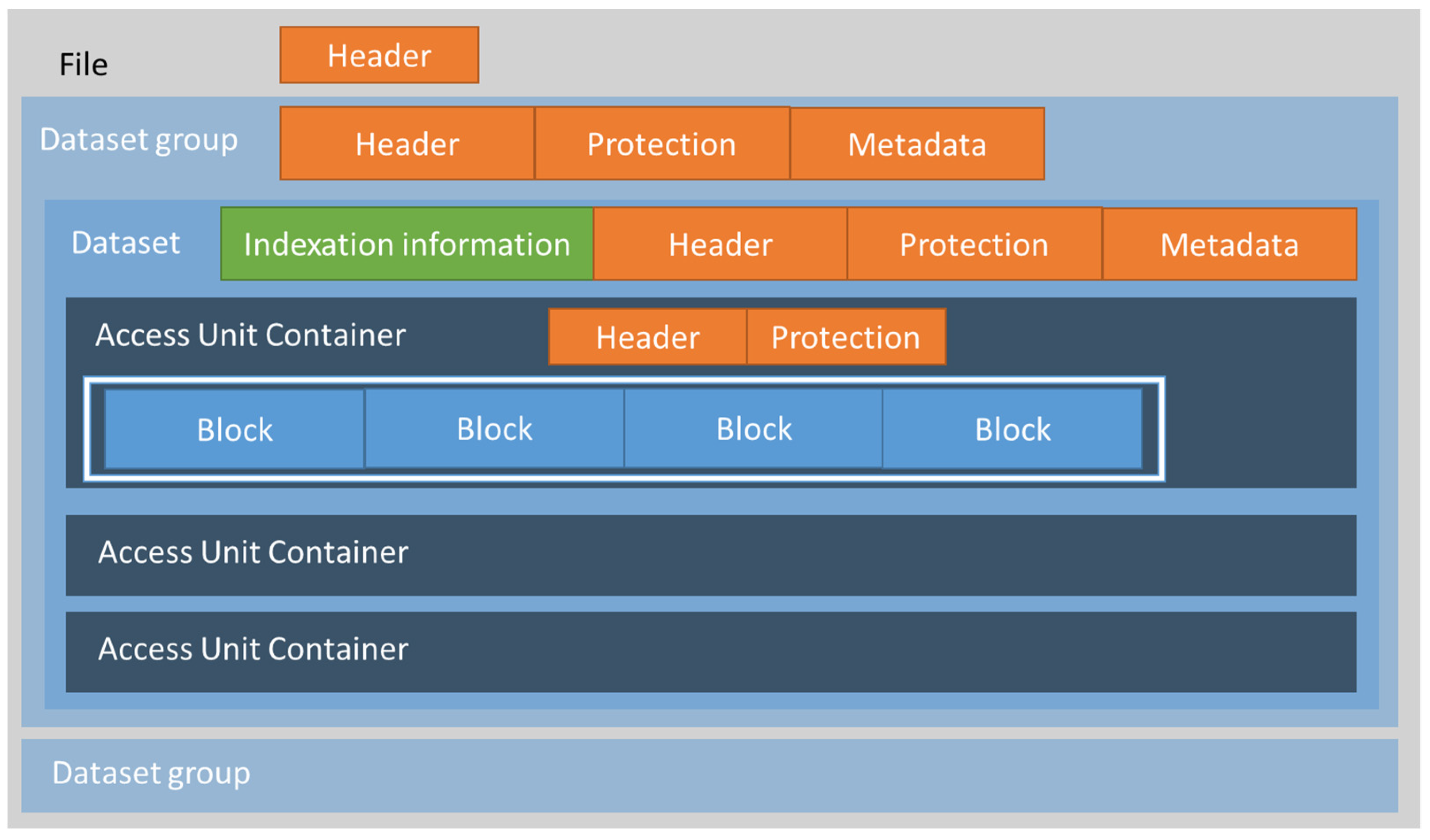
- Hierarchical organization of the genomic information thanks to the file structure defined in the standard [16].
- Compression of genomic information, by means of standardized compression algorithms [18].
- Metadata at different levels of the hierarchy using the corresponding metadata box at the information level it applies, such as file, dataset group, dataset or access unit [18].
- Privacy rules used for access control on both genomic data and metadata, are stored in the corresponding protection box at the information level and apply to dataset groups or datasets [18]. This structure is described in Section 2.3.
- Encryption and protection mechanisms both for genomic data and metadata, stored in the corresponding protection box at the information level it applies to, with dataset groups, datasets or access units [18].
- Integrity by means of digital signatures, which can be applied to genomic data and metadata, stored in the corresponding protection box at the information level it applies to, including dataset groups, datasets or access units [18].
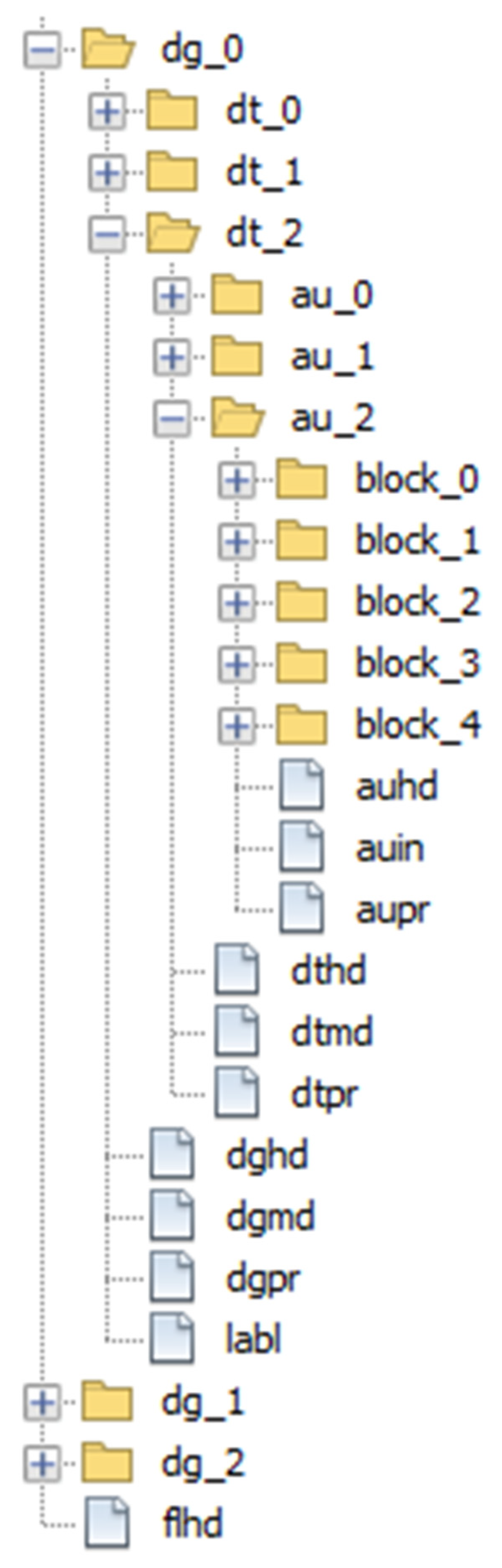
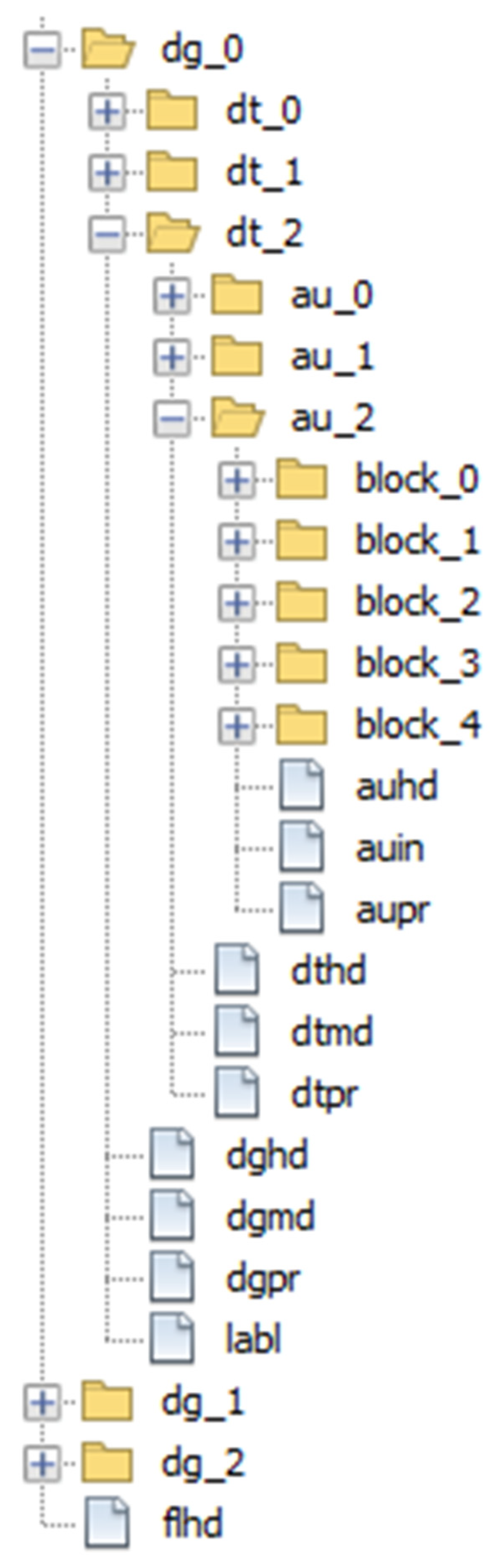
2.3. ISO/IEC 23092 File Structure
2.4. ISO/IEC 23092 Metadata
2.5. ISO/IEC 23092 Privacy Rules
- Who is able to access to the genomic information (user roles or individuals);
- Wat information can be accessed (the complete file, a chromosome, etc.);
- When it can be accessed;
- With which purpose (genetic analysis, anonymized study, etc.) it can be accessed;
- Whether the data provider has to be informed when information is accessed; and
- Which specific permission is provided.
- Under an emergency situation.
- For a read count of 5000.
- Without multiple alignments.
- For reference sequence equal to 4, considering a range between 40,810,027 and 41,216,714, with both extremes included.
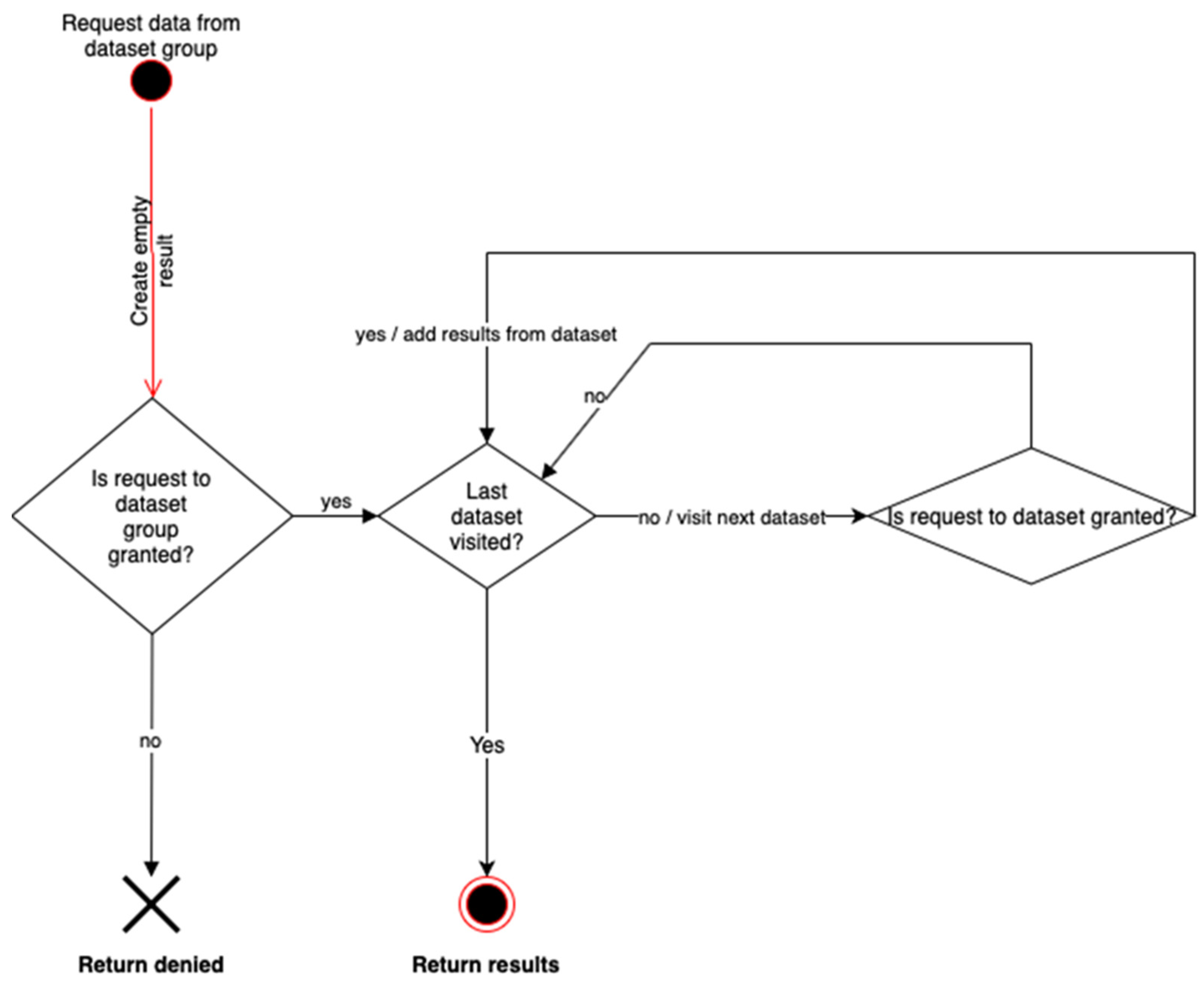
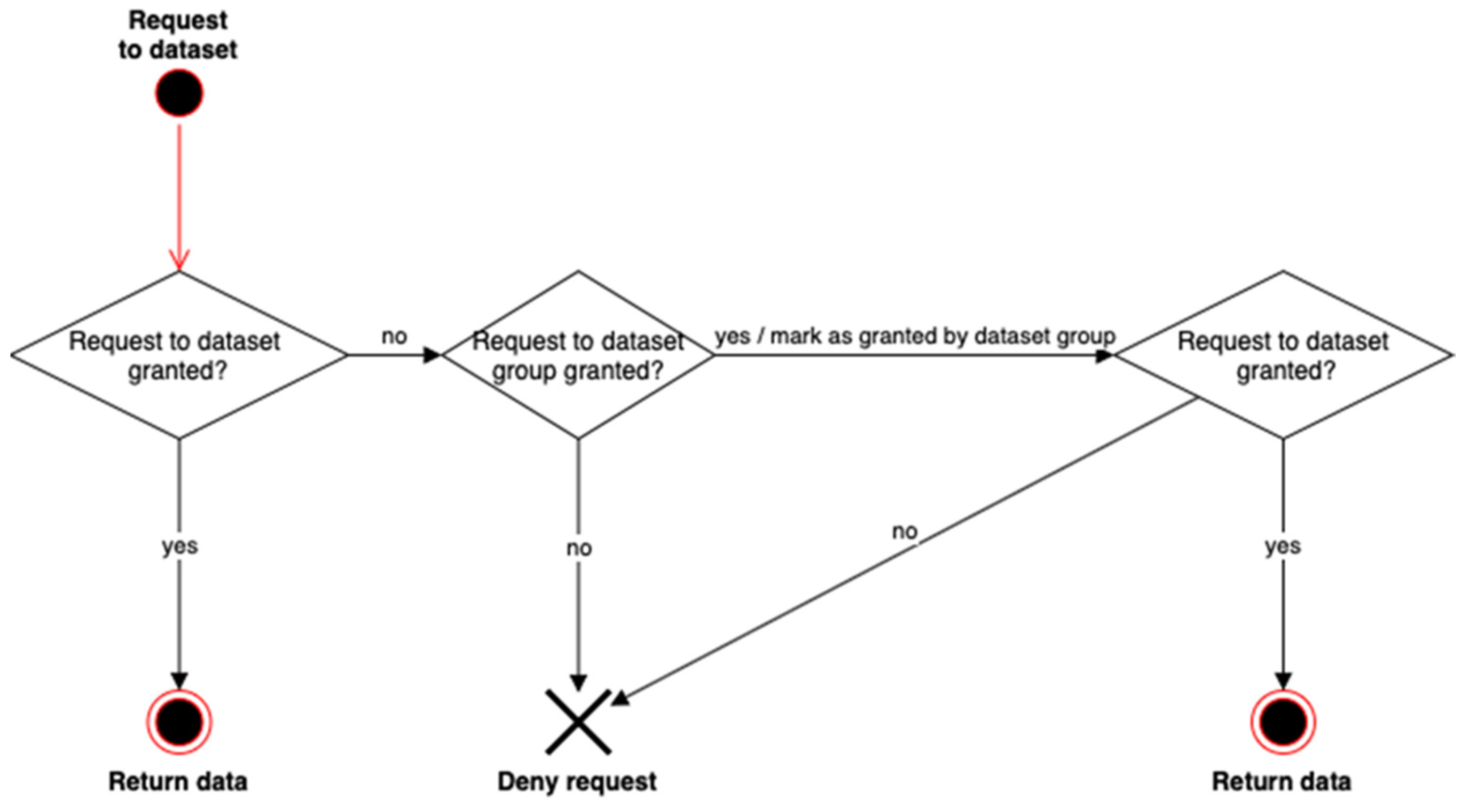
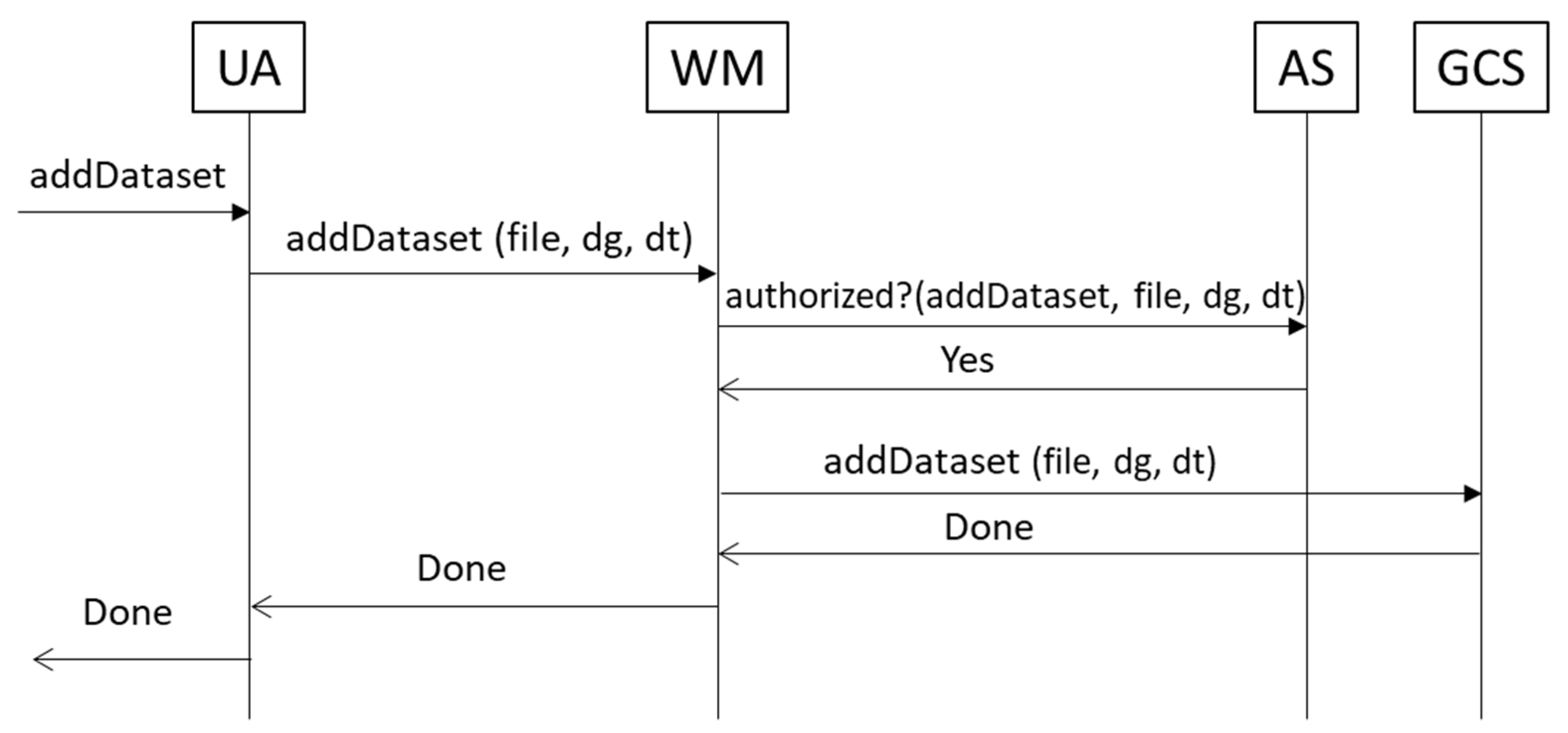
2.6. Authorization Based on ISO/IEC 23092 Hierarchy
3. Results
3.1. File Structure Implementation
3.2. Modules Implementation
4. Discussion
4.1. Alternatives for GIPAMS Modules Implementation Using Other Standards
4.2. Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Delgado, J.; Llorente, S.; Reig, G. Implementation of privacy and security for a genomic information system. In pHealth 2021—Proceedings of the 18th International Conference on Wearable Micro and Nano Technologies for Personalized Health—Genoa, Italy, 8–10 November 2021; Blobel, B., Giacomini, M., Eds.; Studies in Health Technology and Informatics Series; IOS Press: Amsterdam, The Netherlands, 2021; Volume 285, pp. 253–258. Available online: https://ebooks.iospress.nl/doi/10.3233/SHTI210609 (accessed on 8 February 2022).
- ISO/IEC 23092; Information Technology—Genomic Information Representation. ISO/IEC: Geneva, Switzerland, 2020. Available online: https://www.mpeg.org/standards/MPEG-G/ (accessed on 8 February 2022).
- Voges, J.; Hernaez, M.; Mattavelli, M.; Ostermann, J. An Introduction to MPEG-G: The First Open ISO/IEC Standard for the Compression and Exchange of Genomic Sequencing Data. Proc. IEEE 2021, 109, 1607–1622. [Google Scholar] [CrossRef]
- Global Alliance for Genomics and Health (GA4GH). Available online: https://www.ga4gh.org/ (accessed on 8 February 2022).
- GA4GH, GA4GH File Encryption Standard. Available online: https://www.ga4gh.org/wp-content/uploads/crypt4gh.pdf (accessed on 8 February 2022).
- GA4GH, GA4GH Passports and the Authorization and Authentication Infrastructure. Available online: https://www.ga4gh.org/ga4gh-passports/ (accessed on 8 February 2022).
- GA4GH, GA4GH Passport. Available online: https://github.com/ga4gh-duri/ga4gh-duri.github.io/blob/master/researcher_ids/ga4gh_passport_v1.md (accessed on 8 February 2022).
- GA4GH, Introduction to the GA4GH Authentication and Authorization Infrastructure (AAI). Available online: https://github.com/ga4gh/data-security/tree/master/AAI (accessed on 8 February 2022).
- GA4GH, Introduction to the GA4GH Authentication and Authorization Infrastructure (AAI) OpenID Connect Profile. Available online: https://github.com/ga4gh/data-security/blob/master/AAI/AAIConnectProfile.md (accessed on 10 March 2022).
- Li, H.; Handsaker, B.; Wysoker, A.; Fennel, T.; Ruan, J.; Homer, N.; Marth, G.; Abecasis, G. The sequence alignment/map format and samtools. Bioinformatics 2009, 25, 2078–2079. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hsi-Yang Fritz, M.; Leinonen, R.; Cochrane, G.; Birney, E. Efficient storage of high throughput DNA sequencing data using reference-based compression. Genome Res. 2011, 21, 734–740. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Delgado, J.; Llorente, S.; Naro, D. Adding Security and Privacy to Genomic Information Representation. In ICT for Health Science Research; Shabo, A., Madsen, I., Prokosch, H.-U., Häyrinen, K., Wolf, K.-H., Martin-Sanchez, F., Löbe, M., Deserno, T.M., Eds.; Studies in Health Technology and Informatics; IOS Press: Amsterdam, The Netherlands, 2019; Volume 258, pp. 75–79. Available online: http://ebooks.iospress.nl/publication/51356 (accessed on 8 February 2022).
- Delgado, J.; Llorente, S.; Naro, D. Protecting privacy of genomic information. In Informatics for Health: Connected Citizen-Led Wellness and Population Health; Randell, R., Cornet, R., McCowan, C., Peek, N., Scott, P.J., Eds.; Studies in Health Technology and Informatics; IOS Press: Amsterdam, The Netherlands, 2017; Volume 235, pp. 318–322. Available online: http://ebooks.iospress.nl/volumearticle/46354 (accessed on 8 February 2022).
- Delgado, J. Privacy, metadata and APIs in compressed genomic information: The MPEG-G case. In Proceedings of the GA4GH & MPEG Genome Compression Workshop, Basel, Switzerland, 3 October 2018; Available online: https://drive.google.com/file/d/14Y7qK5TmRM5b_5_F5x8UZfwJX3tDS11d/view?usp=sharing (accessed on 8 February 2022).
- Cavoukian. Privacy by Design. Available online: https://www.ipc.on.ca/wp-content/uploads/resources/7foundationalprinciples.pdf (accessed on 8 February 2022).
- ISO/IEC 23092-1; Information Technology—Genomic Information Representation—Part 1: Transport and Storage of Genomic Information. 3rd ed. ISO/IEC: Geneva, Switzerland, 2020. Available online: https://www.iso.org/standard/83526.html (accessed on 8 February 2022).
- ISO/IEC 23092-2; Information Technology—Genomic Information Representation—Part 2: Coding of Genomic Information. 3rd ed. ISO/IEC: Geneva, Switzerland, 2020. Available online: https://www.iso.org/standard/83527.html (accessed on 8 February 2022).
- ISO/IEC 23092-3; Information Technology—Genomic Information Representation—Part 3: Metadata and Application Programming Interfaces (APIs). 2nd ed. ISO/IEC: Geneva, Switzerland, 2020. Available online: https://www.iso.org/standard/82725.html (accessed on 8 February 2022).
- ISO/IEC 23092-4; Information Technology—Genomic Information Representation—Part 4: Reference Software. 1st ed. ISO/IEC: Geneva, Switzerland, 2020. Available online: https://www.iso.org/standard/75859.html (accessed on 8 February 2022).
- ISO/IEC 23092-5; Information Technology—Genomic Information Representation—Part 5: Conformance. 1st ed. ISO/IEC: Geneva, Switzerland, 2020. Available online: https://www.iso.org/standard/73668.html (accessed on 8 February 2022).
- ISO/IEC 23092-6; Information Technology—Genomic Information Representation—Part 6: Coding of Genomic Annotations. 1st ed. ISO/IEC: Geneva, Switzerland, under development. Available online: https://www.iso.org/standard/78478.html (accessed on 8 February 2022).
- Naro, D.; Delgado, J.; Llorente., S. Reversible fingerprinting for genomic information. Multimed. Tools Appl. 2020, 79, 8161–8180. [Google Scholar] [CrossRef]
- W3C. Extensible Markup Language (XML), version 1.1. 2nd ed. W3C: Cambridge, MA, USA. Available online: https://www.w3.org/TR/xml11/(accessed on 8 February 2022).
- Naro, D. Security Strategies in Genomic Files. Ph.D. Thesis, Polytechnic University of Catalonia, Barcelona, Spain, 2020. Available online: http://hdl.handle.net/10803/669108 (accessed on 8 February 2022).
- Htsget Retrieval API; spec v1.2.0; GA4GH: Toronto, ON, Canada, 2019; Available online: http://samtools.github.io/hts-specs/htsget.html (accessed on 8 February 2022).
- Kelleher, J.; Lin, M.; Albach, C.H.; Birney, E.; Davies, R.; Gourtovaia, M.; Glazer, D.; Gonzalez, C.Y.; Jackson, D.K.; Kemp, A.; et al. Htsget: A protocol for securely streaming genomic data. Bioinformatics 2019, 35, 119–121. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- IETF. The JavaScript Object Notation (JSON) Data Interchange Format; IETF: Fremont, CA, USA, 2017; Available online: https://datatracker.ietf.org/doc/html/rfc8259 (accessed on 8 February 2022).
- IETF. The OAuth 2.0 Authorization Framework; IETF: Fremont, CA, USA, 2012; Available online: https://datatracker.ietf.org/doc/html/rfc6749 (accessed on 8 February 2022).
- OpenID Foundation. OpenID Connect. Available online: https://openid.net/connect/ (accessed on 8 March 2022).
- Llorente, S. GIPAMS v1; GitHub: San Francisco, CA, USA, 2022; Available online: https://github.com/silvia-llorente/gipams-v1 (accessed on 8 March 2022).
- Llorente, S.; Rodriguez, E.; Delgado, J.; Torres-Padrosa, V. Standards-based architectures for content management. IEEE Multimed. 2012, 20, 62–72. [Google Scholar] [CrossRef]
- IETF. JSON Web Token (JWT). Available online: https://datatracker.ietf.org/doc/html/rfc7519 (accessed on 8 February 2022).
- Keycloak. Open Source Identity and Access Management. Available online: https://www.keycloak.org/ (accessed on 8 February 2022).
- FusionAuth. Available online: https://fusionauth.io/ (accessed on 8 February 2022).
- Gluu. Available online: https://gluu.org/ (accessed on 8 February 2022).
- WSO2. WSO2 Balana. Available online: https://github.com/wso2/balana (accessed on 8 February 2022).
- OASIS. eXtensible Access Control Markup Language (XACML), v3.0; OASIS: Woburn, MA, USA, 2017. Available online: http://docs.oasis-open.org/xacml/3.0/errata01/os/xacml-3.0-core-spec-errata01-os-complete.html(accessed on 8 February 2022).
- European Genome-Phenome Archive (EGA). Available online: https://ega-archive.org/ (accessed on 8 February 2022).
- National Center for Biotechnology Information (NCBI). Available online: https://www.ncbi.nlm.nih.gov/ (accessed on 8 February 2022).
- OASIS. Available online: https://www.oasis-open.org/ (accessed on 8 February 2022).
- Chowdhury, B.; Garai, G. A review on multiple sequence alignment from the perspective of genetic algorithm. Genomics 2017, 109, 419–431. [Google Scholar] [CrossRef] [PubMed]
- Oracle, Oracle Java. Available online: https://www.oracle.com/java/ (accessed on 14 February 2022).
- Oracle, Java 2 Platform Enterprise Edition (J2EE). Available online: https://www.oracle.com/java/technologies/appmodel.html (accessed on 21 February 2022).
- Nginx. Nginx Reverse Proxy. Available online: https://www.nginx.com/ (accessed on 16 February 2022).
- MySQL. MySQL Relational Database. Available online: https://www.mysql.com/ (accessed on 16 February 2022).
- Fielding, R.T. Architectural Styles and the Design of Network-based Software Architectures. Dissertation Thesis, University of California, Irvine, CA, USA, 2000. Available online: https://www.ics.uci.edu/~fielding/pubs/dissertation/fielding_dissertation.pdf (accessed on 17 February 2022).
- GA4GH. GA4GH Beacon Project. Available online: https://beacon-project.io/ (accessed on 8 February 2022).
- Delgado, J.; Llorente, S. Privacy provision in eHealth using external services. In Digital Healthcare Empowering Europeans; Cornet, R., Stoicu-Tivadar, L., Hörbst, A., Calderón, C.L.P., Andersen, S.K., Hercigonja-Szekeres, M., Eds.; Studies in Health Technology and Informatics; IOS Press: Amsterdam, The Netherlands, 2015; Volume 210, pp. 823–827. Available online: https://ebooks.iospress.nl/publication/39463 (accessed on 8 March 2022).
- Delgado, J.; Llorente, S.; Pamies, M.; Vilalta, J. Security and Privacy in a DACS. In Exploring Complexity in Health: An Interdisciplinary Systems Approach; Hoerbst, A., Hackl, W.O., de Keizer, N., Prokosch, H.-U., Hercigonja-Szekeres, M., de Lusignan, S., Eds.; Studies in Health Technology and Informatics; IOS Press: Amsterdam, The Netherlands, 2016; Volume 228, pp. 122–126. Available online: https://ebooks.iospress.nl/publication/44584 (accessed on 8 March 2022).
- GA4GH. Data Use Ontology (DUO). Available online: https://github.com/EBISPOT/DUO (accessed on 10 March 2022).
- GA4GH. GA4GH Data Privacy and Security Policy. Available online: https://www.ga4gh.org/wp-content/uploads/GA4GH-Data-Privacy-and-Security-Policy_FINAL-August-2019_wPolicyVersions.pdf (accessed on 8 February 2022).
- ISO/IEC 21000-15:2006; Information Technology—Multimedia Framework (MPEG-21)—Part 15: Event Reporting. ISO/IEC: Geneva, Switzerland, 2006. Available online: https://www.iso.org/standard/41837.html (accessed on 8 February 2022).
- Jacobsen, J.O.B.; Baudis, M.; Baynam, G.S.; Beckmann, J.S.; Beltran, S.; Callahan, T.J.; Chute, C.G.; Courtot, M.; Danis, D.; Elemento, O.; et al. The GA4GH Phenopacket schema: A computable representation of clinical data for precision medicine. medRxiv, 2021; preprint. Available online: https://www.medrxiv.org/content/10.1101/2021.11.27.21266944v1(accessed on 8 February 2022).
- ISO/TC 215/SC 1. ISO/DIS 4454; Genomics Informatics—Phenopackets. ISO/IEC: Geneva, Switzerland, under development. Available online: https://www.iso.org/standard/79991.html (accessed on 8 February 2022).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MPEG-G Field | EGA Field |
|---|---|
| Title | Study-STUDY_TITLE |
| Type | Study-STUDY_TYPE |
| Abstract | Study-STUDY_ABSTRACT |
| ProjectCentre | Study-CENTER_PROJECT_NAME |
| Description | Study-STUDY_DESCRIPTION |
| Sample-TaxonId | Assembly-TAXON_ID |
| Sample-Title | Assembly-TITLE |
| MPEG-G Field | NCBI Field |
|---|---|
| Title | BioProject-Title |
| Type | BioProject-ProjectTypeSubmission |
| Abstract | Non existent |
| ProjectCentre | BioProject-Organization |
| Description | BioProject-Description |
| Sample-TaxonId | BioSample-TAXON_ID |
| Sample-Title | BioSample-TITLE |
| Attribute Extension | NCBI Field |
|---|---|
| StudyDesign | BioSample-Attribute-study design |
| BodySite | BioSample-Attribute-body site |
| AnalyteType | BioSample-Attribute-analyte type |
| IsTumor | BioSample-Attribute-is tumor |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Llorente, S.; Delgado, J. Implementation of Privacy and Security for a Genomic Information System Based on Standards. J. Pers. Med. 2022, 12, 915. https://doi.org/10.3390/jpm12060915
Llorente S, Delgado J. Implementation of Privacy and Security for a Genomic Information System Based on Standards. Journal of Personalized Medicine. 2022; 12(6):915. https://doi.org/10.3390/jpm12060915
Chicago/Turabian StyleLlorente, Silvia, and Jaime Delgado. 2022. "Implementation of Privacy and Security for a Genomic Information System Based on Standards" Journal of Personalized Medicine 12, no. 6: 915. https://doi.org/10.3390/jpm12060915
APA StyleLlorente, S., & Delgado, J. (2022). Implementation of Privacy and Security for a Genomic Information System Based on Standards. Journal of Personalized Medicine, 12(6), 915. https://doi.org/10.3390/jpm12060915