
Cost-Effectiveness of Screening Algorithms for Familial Hypercholesterolaemia in Primary Care

 , , ,
, , , 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Population
2.2. Interventions and Comparator
2.3. Study Design
2.4. Model Inputs
2.5. Costs
2.6. Analytical Strategy
2.7. Sensitivity Analyses
2.8. Patient and Public Involvement
3. Results
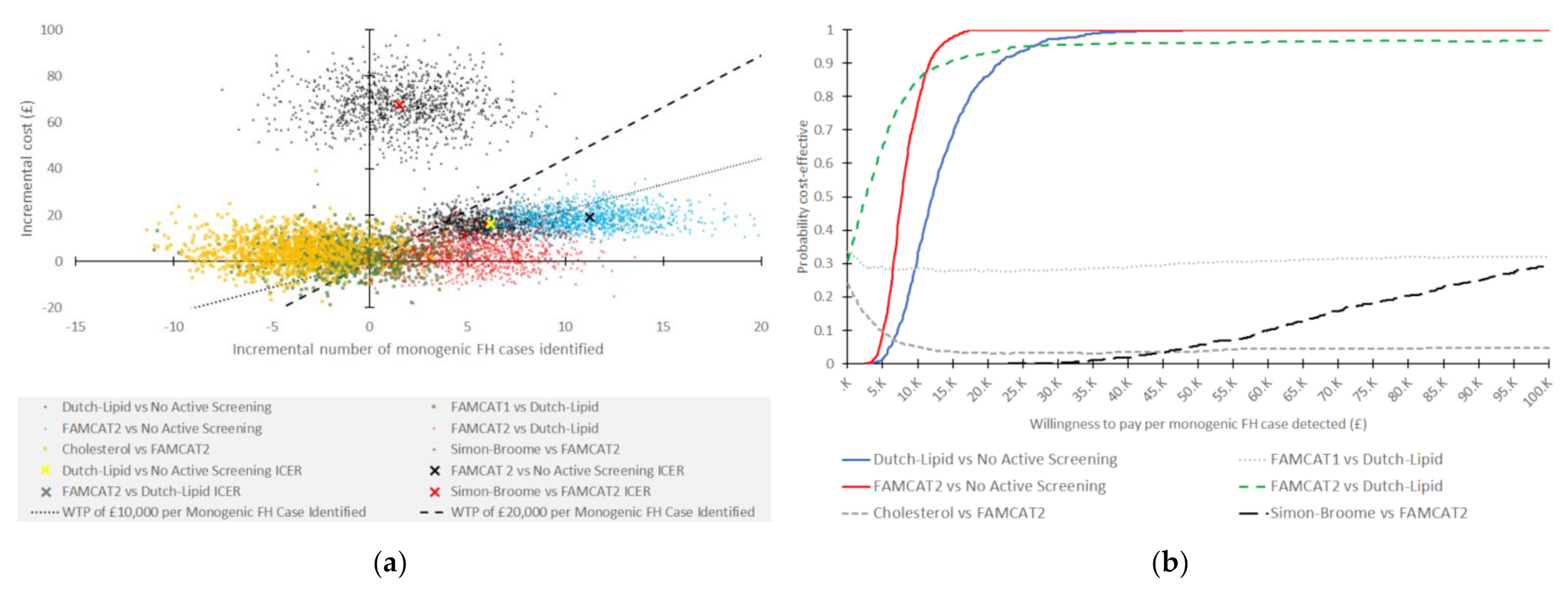
3.1. Probabilistic Sensitivity Analysis
3.2. One-Way Sensitivity Analysis
3.3. Scenario Analysis
4. Discussion
4.1. Strengths
4.2. Limitations
4.3. In Context with Other Work
4.4. Implications for Policy
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sharifi, M.; Futema, M.; Nair, D.; Humphries, S.E. Genetic Architecture of Familial Hypercholesterolaemia. Curr. Cardiol. Rep. 2017, 19, 44. [Google Scholar] [CrossRef] [PubMed]
- Scientific Steering Committee on behalf of the Simon Broome Register Group. Risk of fatal coronary heart disease in familial hypercholesterolaemia. BMJ 1991, 303, 893–896. [Google Scholar] [CrossRef] [PubMed]
- Neil, H.A.; Huxley, R.R.; Hawkins, M.M.; Durrington, P.N.; Betteridge, D.J.; Humphries, S.E. Comparison of the risk of fatal coronary heart disease in treated xanthomatous and non-xanthomatous heterozygous familial hypercholesterolaemia: A prospective registry study. Atherosclerosis 2003, 170, 73–78. [Google Scholar] [CrossRef]
- National Institute for Health and Care Excellence. Familial Hypercholesterolaemia: Identification and Management: Clinical Guideline [CG71]; National Institute for Health and Care Excellence: London, UK, 2019. [Google Scholar]
- Iyen, B.; Qureshi, N.; Weng, S.; Roderick, P.; Kai, J.; Capps, N.; Durrington, P.N.; McDowell, I.F.; Soran, H.; Neil, A.; et al. Sex differences in cardiovascular morbidity associated with familial hypercholesterolaemia: A retrospective cohort study of the UK Simon Broome register linked to national hospital records. Atherosclerosis 2020, 315, 131–137. [Google Scholar] [CrossRef] [PubMed]
- Humphries, S.E.; Cooper, J.A.; Seed, M.; Capps, N.; Durrington, P.N.; Jones, B.; McDowell, I.F.W.; Soran, H.; Neil, H.A.W. Coronary heart disease mortality in treated familial hypercholesterolaemia: Update of the UK Simon Broome FH register. Atherosclerosis 2018, 274, 41–46. [Google Scholar] [CrossRef]
- Wald, D.S.; Bestwick, J.P.; Morris, J.K.; Whyte, K.; Jenkins, L.; Wald, N.J. Child–Parent Familial Hypercholesterolemia Screening in Primary Care. N. Engl. J. Med. 2016, 375, 1628–1637. [Google Scholar] [CrossRef]
- National Health Service. The NHS Long Term Plan; National Health Service: London, UK, 2019. [Google Scholar]
- Maynard, A. Rationing health care: An exploration. Health Policy 1999, 49, 5–11. [Google Scholar] [CrossRef]
- Crosland, P.; Maconachie, R.; Buckner, S.; McGuire, H.; Humphries, S.E.; Qureshi, N. Cost-utility analysis of searching electronic health records and cascade testing to identify and diagnose familial hypercholesterolaemia in England and Wales. Atherosclerosis 2018, 275, 80–87. [Google Scholar] [CrossRef]
- Hendricks-Sturrup, R.M.; Lu, C.Y. Understanding Implementation Challenges to Genetic Testing for Familial Hypercholesterolemia in the United States. J. Pers. Med. 2019, 9, 9. [Google Scholar] [CrossRef]
- Qureshi, N.; Akyea, R.K.; Dutton, B.; Leonardi-Bee, J.; Humphries, S.E.; Weng, S.; Kai, J. Comparing the performance of the novel FAMCAT algorithms and established case-finding criteria for familial hypercholesterolaemia in primary care. Open Heart 2021, 8, e001752. [Google Scholar] [CrossRef]
- Roberts, M.; Russell, L.B.; Paltiel, A.D.; Chambers, M.; McEwan, P.; Krahn, M. Conceptualizing a model: A report of the ISPOR-SMDM Modeling Good Research Practices Task Force-2. Med. Decis. Mak. Int. J. Soc. Med. Decis. Mak. 2012, 32, 678–689. [Google Scholar] [CrossRef] [PubMed]
- Caro, J.J.; Briggs, A.H.; Siebert, U.; Kuntz, K.M. Modeling good research practices--overview: A report of the ISPOR-SMDM Modeling Good Research Practices Task Force-1. Med. Decis. Mak. Int. J. Soc. Med. Decis. Mak. 2012, 32, 667–677. [Google Scholar] [CrossRef] [PubMed]
- Weinstein, M.C.; O’Brien, B.; Hornberger, J.; Jackson, J.; Johannesson, M.; McCabe, C.; Luce, B.R. Principles of good practice for decision analytic modeling in health-care evaluation: Report of the ISPOR Task Force on Good Research Practices—Modeling Studies. Value Health 2003, 6, 9–17. [Google Scholar] [CrossRef] [PubMed]
- Husereau, D.; Drummond, M.; Petrou, S.; Carswell, C.; Moher, D.; Greenberg, D.; Augustovski, F.; Briggs, A.H.; Mauskopf, J.; Loder, E. Consolidated Health Economic Evaluation Reporting Standards (CHEERS)—Explanation and Elaboration: A Report of the ISPOR Health Economic Evaluation Publication Guidelines Good Reporting Practices Task Force. Value Health 2013, 16, 231–250. [Google Scholar] [CrossRef] [PubMed]
- Qureshi, N.; Akyea, R.K.; Dutton, B.; Humphries, S.E.; Abdul Hamid, H.; Condon, L.; Weng, S.F.; Kai, J. Case-finding and genetic testing for familial hypercholesterolaemia in primary care. Heart 2021, 107, 1928–1930. [Google Scholar] [CrossRef]
- Mach, F.; Baigent, C.; Catapano, A.L.; Koskinas, K.C.; Casula, M.; Badimon, L.; Chapman, M.J.; De Backer, G.G.; Delgado, V.; Ference, B.A.; et al. 2019 ESC/EAS Guidelines for the management of dyslipidaemias: Lipid modification to reduce cardiovascular risk: The Task Force for the management of dyslipidaemias of the European Society of Cardiology (ESC) and European Atherosclerosis Society (EAS). Eur. Heart J. 2019, 41, 111–188. [Google Scholar] [CrossRef]
- Weng, S.; Kai, J.; Akyea, R.; Qureshi, N. Detection of familial hypercholesterolaemia: External validation of the FAMCAT clinical case-finding algorithm to identify patients in primary care. Lancet Public Health 2019, 4, e256–e264. [Google Scholar] [CrossRef]
- Brennan, A.; Chick, S.E.; Davies, R. A taxonomy of model structures for economic evaluation of health technologies. Health Econ. 2006, 15, 1295–1310. [Google Scholar] [CrossRef]
- Drummond, M.F.; Sculpher, M.J.; Torrance, G.W.; O’Brien, B.J.; Stoddart, G.L. Methods for the Economic Evaluation of Health Care Programmes, 3rd ed.; Oxford University Press: Oxford, UK, 2005. [Google Scholar]
- Briggs, A.; Sculpher, M.J.; Claxton, K. Decision Modelling for Health Economic Evaluation, 1st ed.; Oxford University Press: Oxford, UK, 2006. [Google Scholar]
- Ausvet. Confidence Limits for a Proportion. Available online: https://epitools.ausvet.com.au/ciproportion (accessed on 13 April 2021).
- Haralambos, K.; Humphries, S.E.; Whitmore, J.; Datta, D.; Cather, M.; Miedzybrodzka, Z.; Breen, J.; Gritzmacher, L.; Hamlen, A.; Potter, A.; et al. Familial hypercholesterolaemia (fh) genetic testing in the UK. Atheroscler. Suppl. 2018, 34, e4. [Google Scholar] [CrossRef]
- Duell, P.B.; Gidding, S.S.; Andersen, R.L.; Knickelbine, T.; Anderson, L.; Gianos, E.; Shrader, P.; Kindt, I.; O’Brien, E.C.; McCann, D.; et al. Longitudinal low density lipoprotein cholesterol goal achievement and cardiovascular outcomes among adult patients with familial hypercholesterolemia: The CASCADE FH registry. Atherosclerosis 2019, 289, 85–93. [Google Scholar] [CrossRef]
- Kerr, M.; Pears, R.; Miedzybrodzka, Z.; Haralambos, K.; Cather, M.; Watson, M.; Humphries, S.E. Cost effectiveness of cascade testing for familial hypercholesterolaemia, based on data from familial hypercholesterolaemia services in the UK. Eur. Heart J. 2017, 38, 1832–1839. [Google Scholar] [CrossRef] [PubMed]
- Knowles, J.W.; Rader, D.J.; Khoury, M.J. Cascade Screening for Familial Hypercholesterolemia and the Use of Genetic Testing. JAMA 2017, 318, 381–382. [Google Scholar] [CrossRef] [PubMed]
- Nherera, L.; Marks, D.; Minhas, R.; Thorogood, M.; Humphries, S.E. Probabilistic cost-effectiveness analysis of cascade screening for familial hypercholesterolaemia using alternative diagnostic and identification strategies. Heart 2011, 97, 1175–1181. [Google Scholar] [CrossRef] [PubMed]
- Qureshi, N.; Weng, S.; Tranter, J.; El-Kadiki, A.; Kai, J. Feasibility of improving identification of familial hypercholesterolaemia in general practice: Intervention development study. BMJ Open 2016, 6, e011734. [Google Scholar] [CrossRef]
- Claxton, K.; Martin, S.; Soares, M.; Rice, N.; Spackman, E.; Hinde, S.; Devlin, N.; Smith, P.C.; Sculpher, M. Methods for the estimation of the National Institute for Health and Care Excellence cost-effectiveness threshold. Health Technol. Assess. 2015, 19, 5–6. [Google Scholar] [CrossRef]
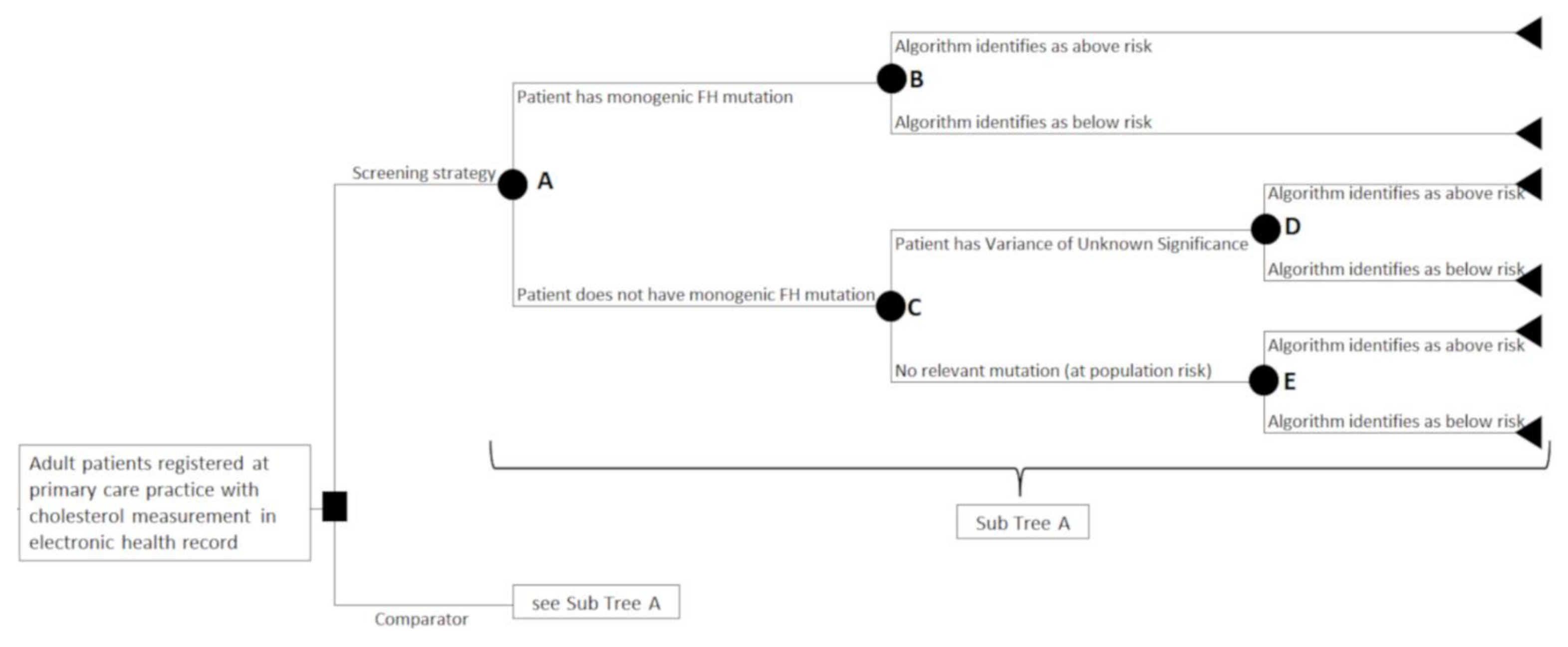

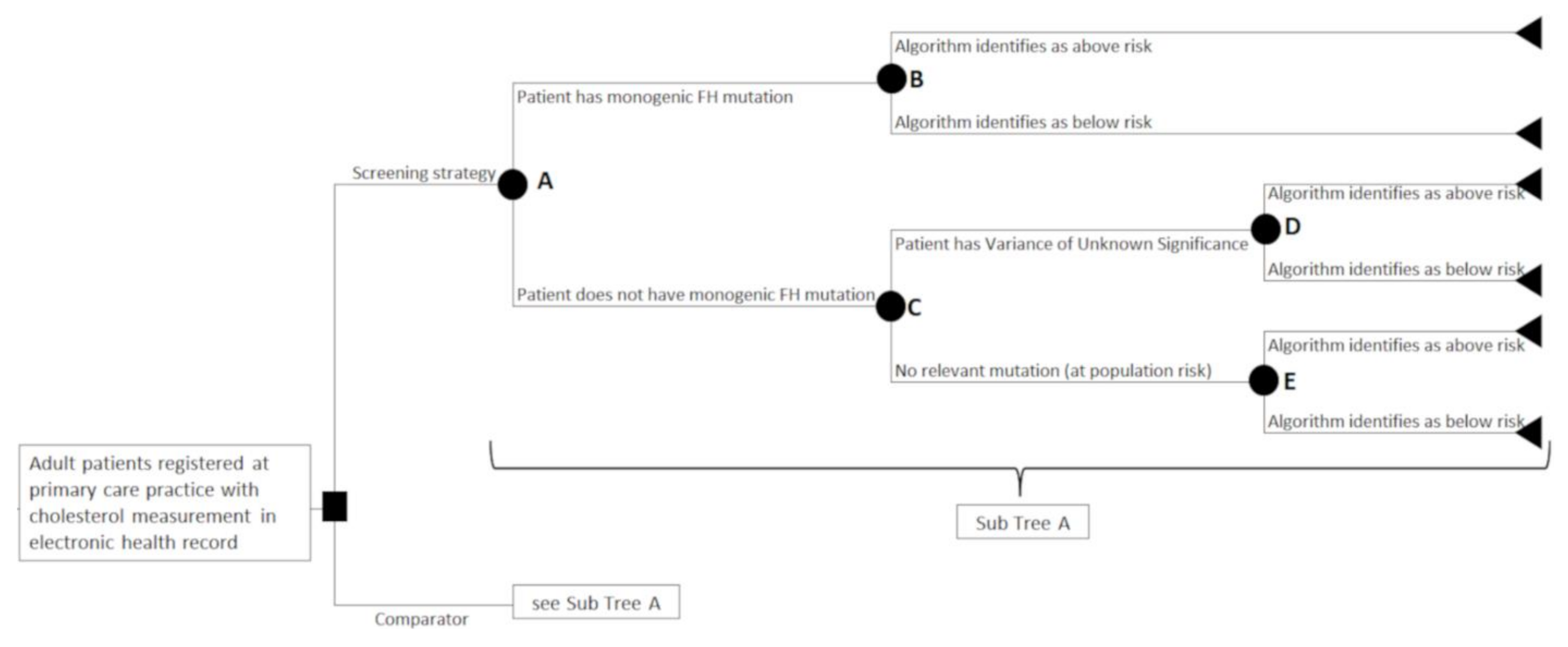{kind=link}
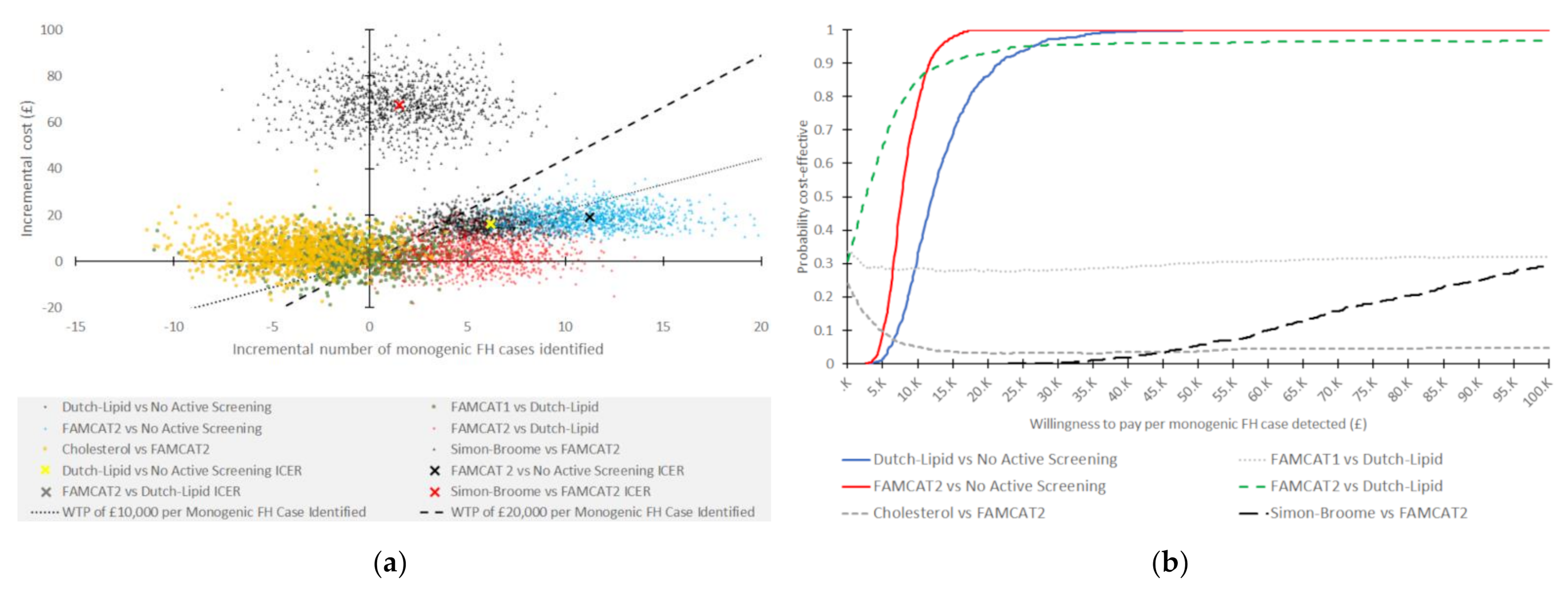{kind=link}
| Name of Intervention | Action | Requirements to Run Case-Finding Criteria |
|---|---|---|
| No active, systematic screening of electronic health records | Patient electronic health records are not screened for possible markers of FH | None |
| Cholesterol 1 [4] | Search electronic health records for individuals who are either (i) younger than 30 years old with a total cholesterol concentration greater than 7.5 mmol/L, or (ii) 30 years or older with a total cholesterol concentration greater than 9.0 mmol/L. Current approach as recommended by NICE [4] | Most recent LDL-cholesterol concentration level |
| Dutch Lipid Clinic Network 1 [4] | Points-based criteria. Points awarded on the basis of symptoms, cholesterol levels, family history of illness, and/or DNA test. Patients are scored, with a score of eight or greater having definite FH, and a score of five or greater as possible FH. | Untreated LCL-C recorded, family history of premature coronary and/or vascular disease, first-degree relative with known LDL-cholesterol above 95th percentile, tendinous xanthomata and/or arcus cornealis, clinical history of premature coronary artery disease, cerebral, or peripheral vascular disease |
| Simon Broome Criteria 1 [4] | Category-based criteria based on a patient’s cholesterol levels, family history of premature CHD or high cholesterol, and/or DNA test. Patients are either coded as definite or probable FH. | Age, total cholesterol, LDL cholesterol, tendon xanthomas in patient, first- or second-degree relative, DNA-based evidence of a functional LDLR, PCSK9, and APOB mutation, family history of premature CVD events, family history of extremely high cholesterol. |
| Familial Hypercholesterolaemia Case Identification Tool version 1 (FAMCAT1) 1 [12] | A multivariate logistic regression model, consisting of nine diagnostic indicators stratified by gender. Age, cholesterol levels, and triglycerides are categorised. Algorithm identifies patients at increased risk of FH. | Gender, total cholesterol or LDL-cholesterol, age during cholesterol measurement, triglycerides, lipid-lowering drug usage, family history of FH, family history of CHD, family history of raised cholesterol, diabetes, and chronic kidney disease. |
| Familial Hypercholesterolaemia Case Identification Tool version 2 (FAMCAT2) 1 [12] | An updated FAMCAT1 algorithm, with re-estimated regression equations using continuous variables for total cholesterol, LDL-cholesterol, triglycerides, and age. Algorithm identifies patients at increased risk of FH. | As above |
| Intervention | Expected Total Cost per Patient (GBP; 2018/2019) | Number of FH Cases Identified | Number of Genetic Tests to Fine One FH Case | Incremental Cost (GBP) 1 | Incremental Number of FH Cases Identified | Incremental Cost per Additional FH Case Identified (GBP; 2018/2019) | Notes |
|---|---|---|---|---|---|---|---|
| No active screening | £0 | 0 | - | - | - | - | |
| Dutch Lipid | £16.12 | 6 | 35 | 16.12 | 6.18 | 11,734 | Versus no active screening, extendedly dominated 3 by FAMCAT 2 |
| FAMCAT1 | £18.51 | 5 | 49 | 2.39 | −1.03 | Dominated 2 | Dominated by Dutch Lipid |
| FAMCAT2 | £19.02 | 11 | 23 | 19.02 | 11.33 | 7552 | Versus no active screening |
| Cholesterol | £23.63 | 7 | 46 | 4.61 | −4.12 | Dominated 2 | Dominated by FAMCAT2 |
| Simon Broome | £87.28 | 13 | 102 | 68.26 | 1.49 | 206,431 | Versus FAMCAT 2 |
| Screening Algorithm | Expected Total Cost per Patient (GBP) Mean (95% CI) | Number of FH Cases Identified Mean (95% CI) | Number of Genetic Tests Required to Identify One Patient with Monogenic FH Mean (95% CI) | Incremental Cost (GBP) Mean (95% CI) | Incremental Number of FH Cases Identified Mean (95% CI) | Incremental Cost per Additional FH Case Identified (GBP) Mean (95% CI) |
|---|---|---|---|---|---|---|
| No active screening | 0 (0-0) | 0 (0-0) | 0 (0-0) | - | - | - |
| Dutch Lipid | 16.32 (9.16–25.80) | 6 (3–11) | 40 (14–93) | 16.32 (9.16–25.80) 1 | 6 (3–11) 1 | 13,528 (5395–31,086) 1 |
| FAMCAT1 | 19.00 (10.91–29.02) | 5 (2–9) | 60 (22–150) | 2.69 (−9.30–15.01) 2 | −1 (−6–4) 2 | 2946 (−138,736–123,755) 2 |
| FAMCAT2 | 19.23 (11.59–28.75) | 11 (7–17) | 24 (11–46) | 19.23 (11.59–28.75) 1 | 11 (7–17) 1 | 8111 (4088–14,865) 1 |
| 2.91 (−8.91–14.52) 2 | 5 (0–10) 2 | 6118 (−22,023–32,018) 2 | ||||
| Cholesterol | 23.83 (15.37–34.32) | 7 (4–12) | 51 (23–103) | 4.61 (−7.82–17.44) 3 | −4 (−9–1) 3 | −16,589 (−56,929–50,116) 3 |
| Simon Broome | 86.92 (70.95–104.80) | 13 (7–19) | 109 (66–188) | 67.70 (48.47–87.22) 3 | 2 (−5–7) 3 | 74,059 (−1,113,172–1,697,142) 3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jones, M.; Akyea, R.K.; Payne, K.; Humphries, S.E.; Abdul-Hamid, H.; Weng, S.; Qureshi, N. Cost-Effectiveness of Screening Algorithms for Familial Hypercholesterolaemia in Primary Care. J. Pers. Med. 2022, 12, 330. https://doi.org/10.3390/jpm12030330
Jones M, Akyea RK, Payne K, Humphries SE, Abdul-Hamid H, Weng S, Qureshi N. Cost-Effectiveness of Screening Algorithms for Familial Hypercholesterolaemia in Primary Care. Journal of Personalized Medicine. 2022; 12(3):330. https://doi.org/10.3390/jpm12030330
Chicago/Turabian StyleJones, Matthew, Ralph K. Akyea, Katherine Payne, Steve E. Humphries, Hasidah Abdul-Hamid, Stephen Weng, and Nadeem Qureshi. 2022. "Cost-Effectiveness of Screening Algorithms for Familial Hypercholesterolaemia in Primary Care" Journal of Personalized Medicine 12, no. 3: 330. https://doi.org/10.3390/jpm12030330
APA StyleJones, M., Akyea, R. K., Payne, K., Humphries, S. E., Abdul-Hamid, H., Weng, S., & Qureshi, N. (2022). Cost-Effectiveness of Screening Algorithms for Familial Hypercholesterolaemia in Primary Care. Journal of Personalized Medicine, 12(3), 330. https://doi.org/10.3390/jpm12030330