
Machine Learning Models Cannot Replace Screening Colonoscopy for the Prediction of Advanced Colorectal Adenoma

 ,
,  , , and
, , and
Abstract
1. Introduction
2. Materials and Methods
2.1. Population and Study Design
2.2. Colonoscopy
2.3. Machine Learning Model Development and Evaluation
2.4. Statistical Analyses
3. Results
3.1. Patient Characteristics
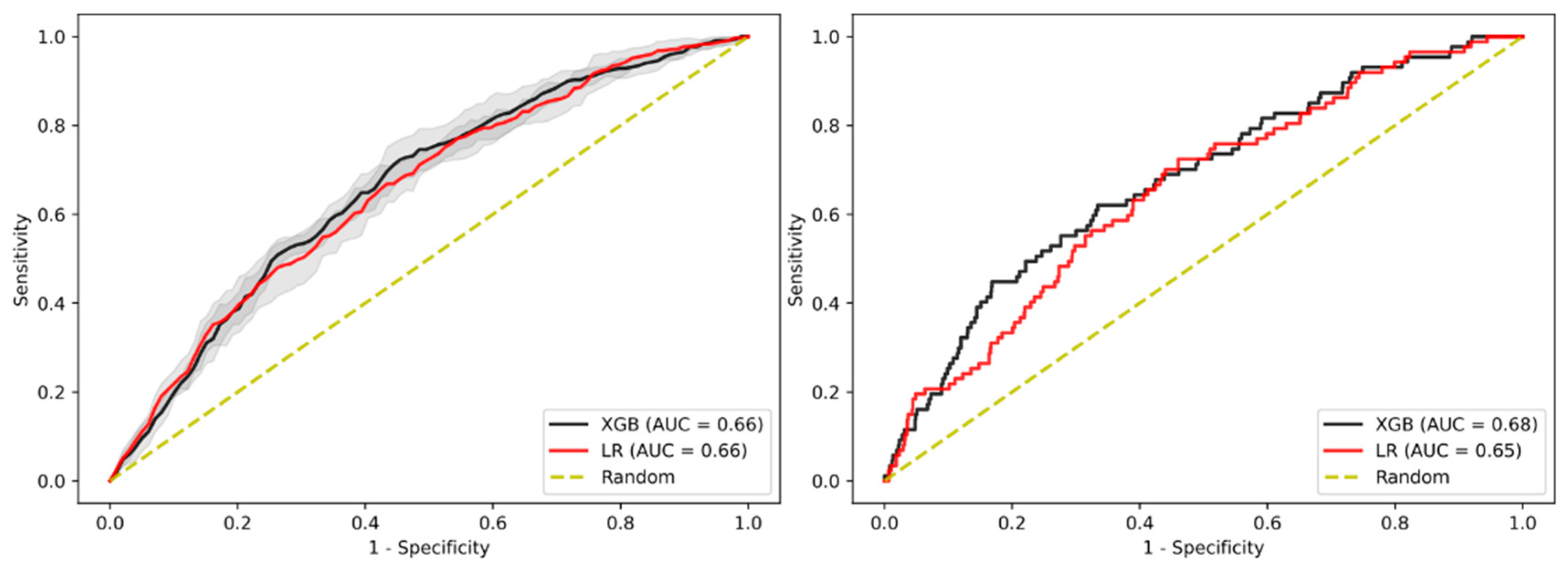
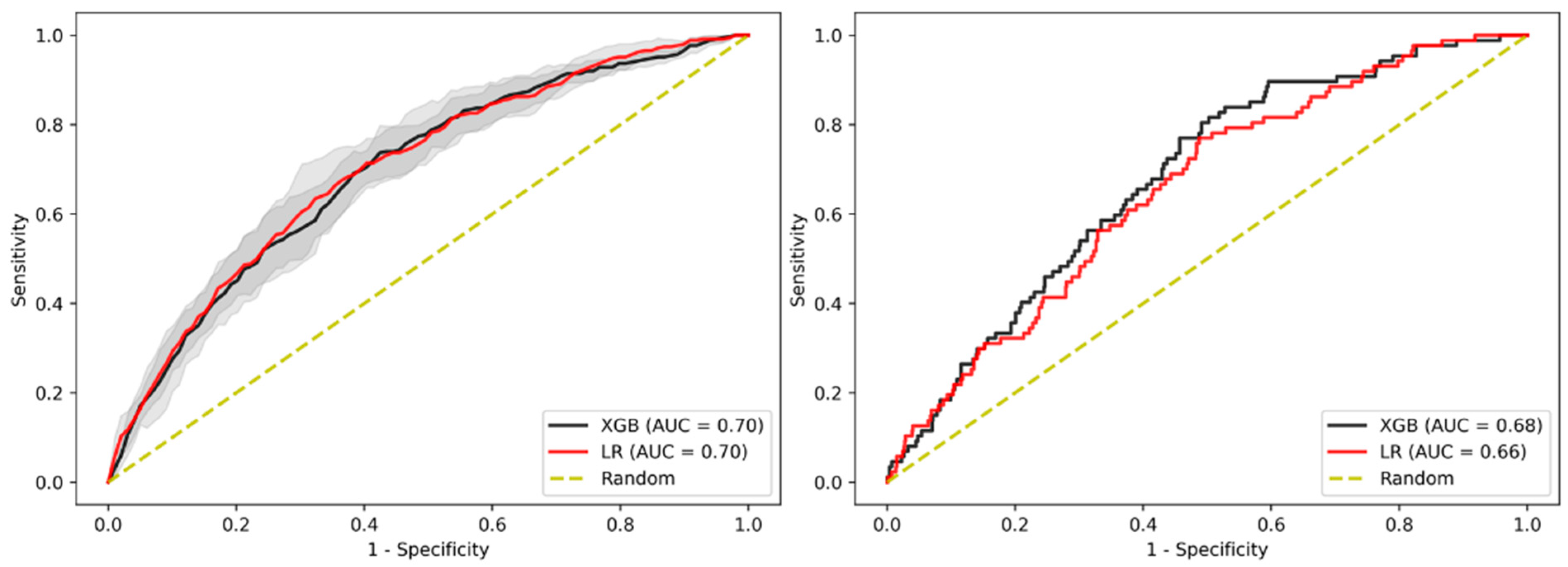
3.2. Prediction of Advanced Adenoma Based on Machine Learning Models
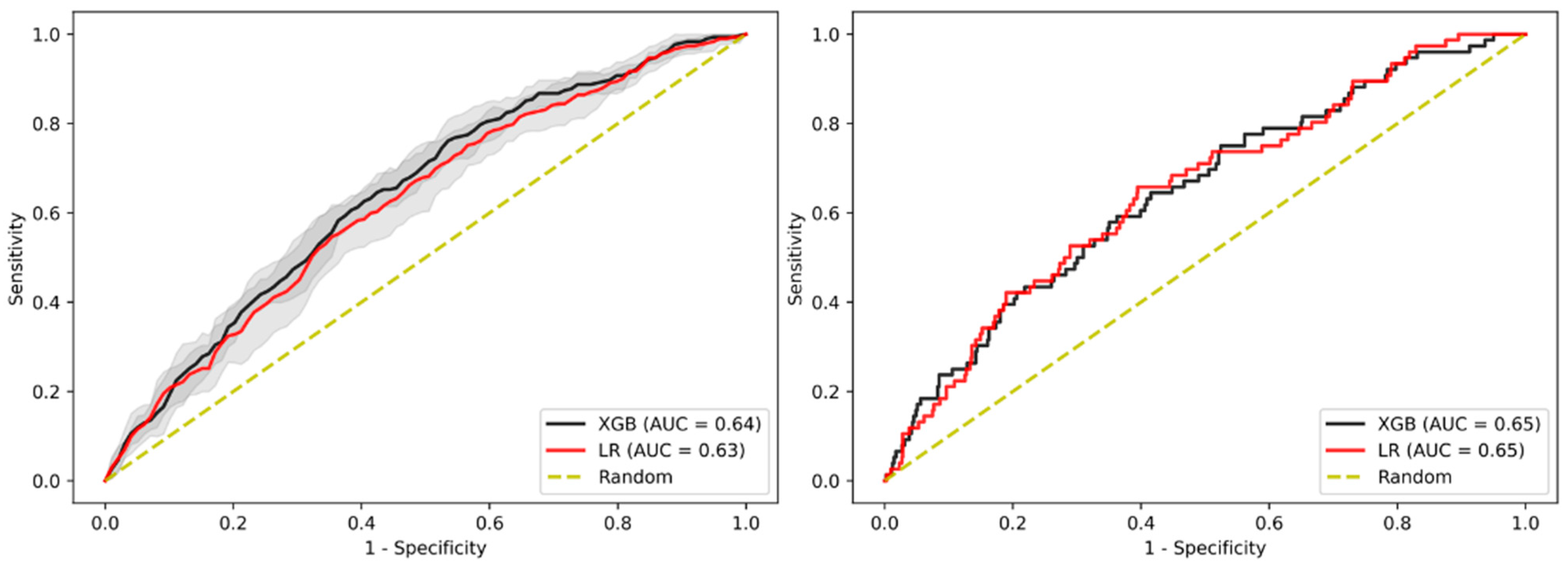
3.3. Sensitivity Analysis Using Only Established Risk Modifiers
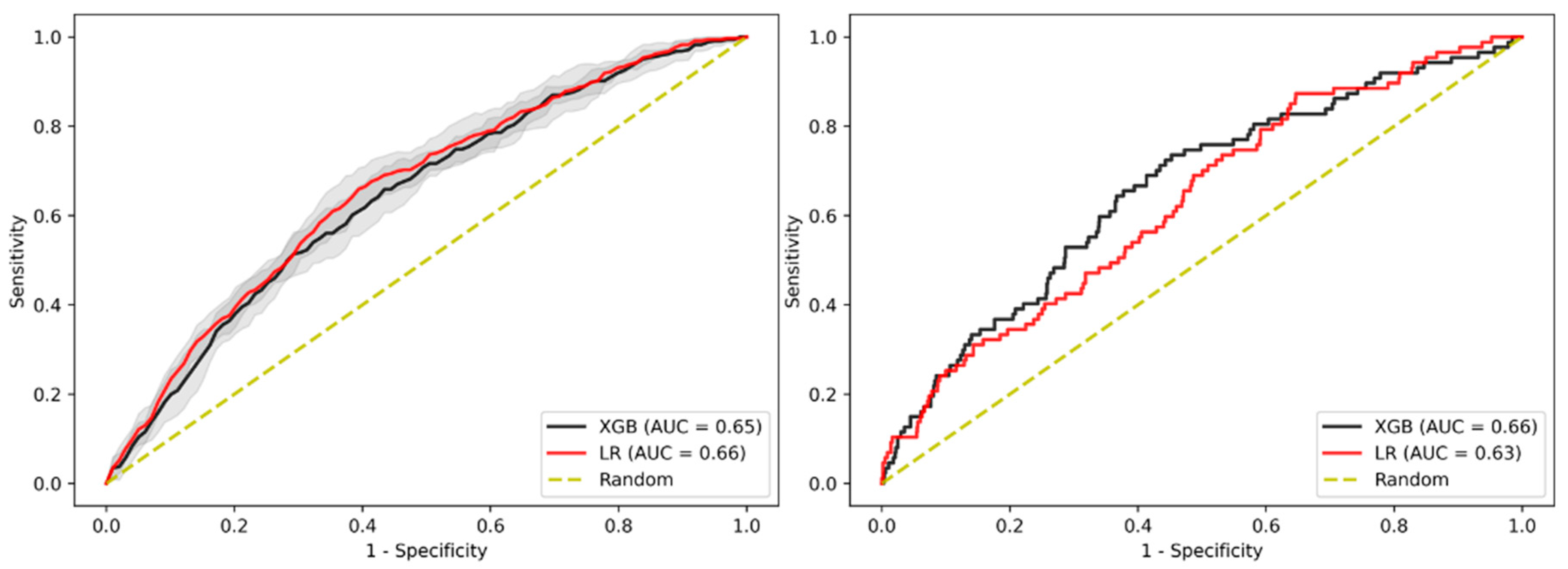
3.4. Sensitivity Analysis on Patients without Family History
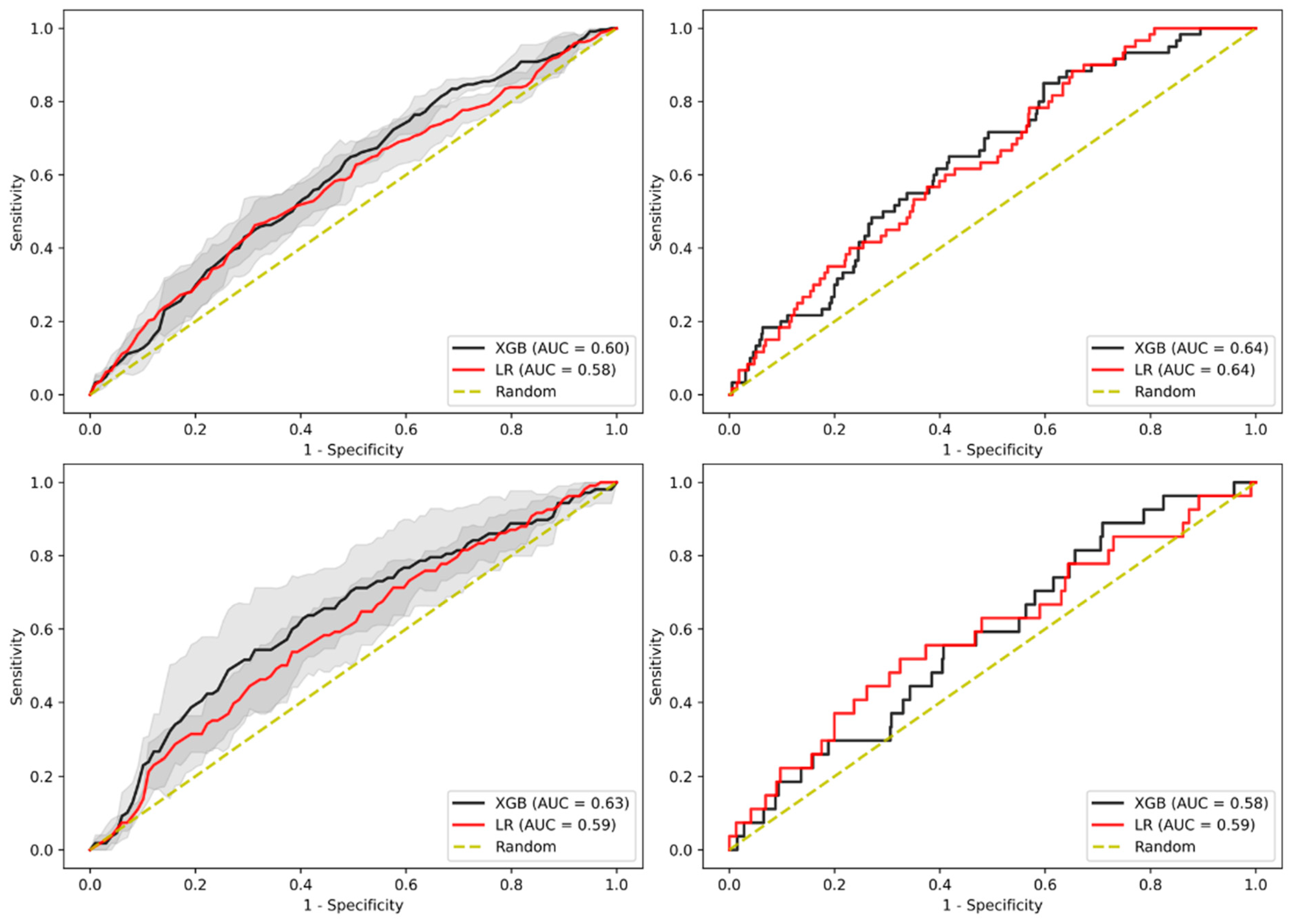
3.5. Sensitivity Analysis on Age
3.6. Sensitivity Analysis on Gender
3.7. Sensitivity Analysis on Sub-Cohort with Advanced Adenomas Only
3.8. Imputation Method
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Arnold, M.; Sierra, M.S.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global patterns and trends in colorectal cancer incidence and mortality. Gut 2017, 66, 683–691. [Google Scholar] [CrossRef] [PubMed]
- Bénard, F.; Barkun, A.N.; Martel, M.; Von Renteln, D. Systematic review of colorectal cancer screening guidelines for average-risk adults: Summarizing the current global recommendations. World J. Gastroenterol. 2018, 24, 124–138. [Google Scholar] [CrossRef]
- von Karsa, L.; Patnick, J.; Segnan, N.; Atkin, W.; Halloran, S.; Saito, H.; Sauvaget, C.; Scharpantgen, A.; Schmiegel, W.; Senore, C.; et al. European guidelines for quality assurance in colorectal cancer screening and diagnosis: Overview and introduction to the full supplement publication. Endoscopy 2013, 45, 51–59. [Google Scholar] [PubMed]
- Benson, V.S.; Atkin, W.S.; Green, J.; Nadel, M.R.; Patnick, J.; Smith, R.A.; Villain, P.; on behalf of the International Colorectal Cancer Screening Network. Toward standardizing and reporting colorectal cancer screening indicators on an international level: The international colorectal cancer screening network. Int. J. Cancer 2012, 130, 2961–2973. [Google Scholar] [CrossRef] [PubMed]
- Peng, L.; Weigl, K.; Boakye, D.; Brenner, H. Risk Scores for Predicting Advanced Colorectal Neoplasia in the Average-risk Population: A Systematic Review and Meta-analysis. Am. J. Gastroenterol. 2018, 113, 1788–1800. [Google Scholar] [CrossRef] [PubMed]
- Peng, L.; Balavarca, Y.; Weigl, K.; Hoffmeister, M.; Brenner, H. Head-to-Head Comparison of the Performance of 17 Risk Models for Predicting Presence of Advanced Neoplasms in Colorectal Cancer Screening. Am. J. Gastroenterol. 2019, 114, 1520–1530. [Google Scholar] [CrossRef]
- Smith, T.; Muller, D.; Moons, K.G.M.; Cross, A.J.; Johansson, M.; Ferrari, P.; Fagherazzi, G.; Peeters, P.H.M.; Severi, G.; Hüsing, A.; et al. Comparison of prognostic models to predict the occurrence of colorectal cancer in asymptomatic individuals: A systematic literature review and external validation in the EPIC and UK Biobank prospective cohort studies. Gut 2018, 68, 672–683. [Google Scholar] [CrossRef]
- Usher-Smith, J.; Harshfield, A.; Saunders, C.; Sharp, S.J.; Emery, J.; Walter, F.; Muir, K.; Griffin, S.J. External validation of risk prediction models for incident colorectal cancer using UK Biobank. Br. J. Cancer 2018, 118, 750–759. [Google Scholar] [CrossRef]
- Wernly, B.; Mamandipoor, B.; Baldia, P.; Jung, C.; Osmani, V. Machine learning predicts mortality in septic patients using only routinely available ABG variables: A multi-centre evaluation. Int. J. Med. Inform. 2021, 145, 104312. [Google Scholar] [CrossRef]
- Goecks, J.; Jalili, V.; Heiser, L.M.; Gray, J.W. How Machine Learning Will Transform Biomedicine. Cell 2020, 181, 92–101. [Google Scholar] [CrossRef]
- Semmler, G.; Bachmayer, S.; Wernly, S.; Wernly, B.; Niederseer, D.; Huber-Schönauer, U.; Stickel, F.; Aigner, E.; Datz, C. Nut consumption and the prevalence and severity of non-alcoholic fatty liver disease. PLoS ONE 2020, 15, e0244514. [Google Scholar] [CrossRef]
- Brenner, H.; Hoffmeister, M.; Stegmaier, C.; Brenner, G.; Altenhofen, L.; Haug, U. Risk of progression of advanced adenomas to colorectal cancer by age and sex: Estimates based on 840 149 screening colonoscopies. Gut 2007, 56, 1585–1589. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; Association for Computing Machinery: San Francisco, CA, USA, 2016; pp. 785–794. [Google Scholar]
- Waldmann, E.; Heinze, G.; Ferlitsch, A.; Gessi, I.; Sallinger, D.; Jeschek, P.; Britto-Arias, M.; Salzl, P.; Fasching, E.; Jilma, B.; et al. Risk factors cannot explain the higher prevalence rates of precancerous colorectal lesions in men. Br. J. Cancer 2016, 115, 1421–1429. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Wernly, S.; Wernly, B.; Semmler, G.; Bachmayer, S.; Niederseer, D.; Stickel, F.; Huber-Schönauer, U.; Aigner, E.; Datz, C. A sex-specific propensity-adjusted analysis of colonic adenoma detection rates in a screening cohort. Sci. Rep. 2021, 11, 17785. [Google Scholar] [CrossRef]
- Doubeni, C.A.; Corley, D.A.; Quinn, V.P.; Jensen, C.D.; Zauber, A.G.; Goodman, M.; Johnson, J.R.; Mehta, S.J.; Becerra, T.A.; Zhao, W.K.; et al. Effectiveness of screening colonoscopy in reducing the risk of death from right and left colon cancer: A large community-based study. Gut 2018, 67, 291–298. [Google Scholar] [CrossRef] [PubMed]
- Ran, T.; Cheng, C.-Y.; Misselwitz, B.; Brenner, H.; Ubels, J.; Schlander, M. Cost-Effectiveness of Colorectal Cancer Screening Strategies—A Systematic Review. Clin. Gastroenterol. Hepatol. 2019, 17, 1969–1981.e15. [Google Scholar] [CrossRef]
- Nishihara, R.; Wu, K.; Lochhead, P.; Morikawa, T.; Liao, X.; Qian, Z.R.; Inamura, K.; Kim, S.A.; Kuchiba, A.; Yamauchi, M.; et al. Long-Term Colorectal-Cancer Incidence and Mortality after Lower Endoscopy. N. Engl. J. Med. 2013, 369, 1095–1105. [Google Scholar] [CrossRef] [PubMed]
- Lin, J.S.; Piper, M.A.; Perdue, L.A.; Rutter, C.M.; Webber, E.M.; O’Connor, E.; Smith, N.; Whitlock, E.P. Screening for Colorectal Cancer: Updated Evidence Report and Systematic Review for the US Preventive Services Task Force. JAMA 2016, 315, 2576–2594. [Google Scholar] [CrossRef] [PubMed]
- Jones, R.M.; Devers, K.J.; Kuzel, A.J.; Woolf, S.H. Patient-Reported Barriers to Colorectal Cancer Screening: A Mixed-Methods Analysis. Am. J. Prev. Med. 2010, 38, 508–516. [Google Scholar] [CrossRef]
- Ferlitsch, M.; Reinhart, K.; Pramhas, S.; Wiener, C.; Gal, O.; Bannert, C.; Hassler, M.; Kozbial, K.; Dunkler, D.; Trauner, M.; et al. Sex-Specific Prevalence of Adenomas, Advanced Adenomas, and Colorectal Cancer in Individuals Undergoing Screening Colonoscopy. JAMA 2011, 306, 1352–1358. [Google Scholar] [CrossRef]
- Ladabaum, U.; Mannalithara, A.; Meester, R.G.; Gupta, S.; Schoen, R.E. Cost-Effectiveness and National Effects of Initiating Colorectal Cancer Screening for Average-Risk Persons at Age 45 Years Instead of 50 Years. Gastroenterology 2019, 157, 137–148. [Google Scholar] [CrossRef]
- Choi, K.S.; Lee, H.-Y.; Jun, J.K.; Shin, A.; Park, E.-C. Adherence to follow-up after a positive fecal occult blood test in an organized colorectal cancer screening program in Korea, 2004-2008. J. Gastroenterol. Hepatol. 2012, 27, 1070–1077. [Google Scholar] [CrossRef]
- Thomas, M.; Sakoda, L.C.; Hoffmeister, M.; Rosenthal, E.A.; Lee, J.K.; van Duijnhoven, F.J.; Platz, E.A.; Wu, A.H.; Dampier, C.H.; de la Chapelle, A.; et al. Genome-wide Modeling of Polygenic Risk Score in Colorectal Cancer Risk. Am. J. Hum. Genet. 2020, 107, 432–444. [Google Scholar] [CrossRef]
- Werner, S.; Krause, F.; Rolny, V.; Strobl, M.; Morgenstern, D.; Datz, C.; Chen, H.; Brenner, H. Evaluation of a 5-Marker Blood Test for Colorectal Cancer Early Detection in a Colorectal Cancer Screening Setting. Clin. Cancer Res. 2016, 22, 1725–1733. [Google Scholar] [CrossRef]
- Niehous, K.; Wan, N.; White, B.; Kannan, A.; Gafni, E.; Liu, T.-Y.; Haque, I.; Putcha, G. Early Stage Colorectal Cancer Detection Using Artificial Intelligence and Whole-Genome Sequencing of Cell-Free DNA in a Retrospective Cohort of 1040 Patients. Am. J. Gastroenterol. 2018, 113, S169. [Google Scholar] [CrossRef]
- Ternes, D.; Karta, J.; Tsenkova, M.; Wilmes, P.; Haan, S.; Letellier, E. Microbiome in Colorectal Cancer: How to Get from Meta-omics to Mechanism? Trends Microbiol. 2020, 28, 401–423. [Google Scholar] [CrossRef] [PubMed]
- Aleksandrova, K.; Reichmann, R.; Kaaks, R.; Jenab, M.; Bueno-De-Mesquita, H.B.; Dahm, C.C.; Eriksen, A.K.; Tjønneland, A.; Artaud, F.; Boutron-Ruault, M.-C.; et al. Development and validation of a lifestyle-based model for colorectal cancer risk prediction: The LiFeCRC score. BMC Med. 2021, 19, 1. [Google Scholar] [CrossRef]
- Click, B.; Pinsky, P.F.; Hickey, T.; Doroudi, M.; Schoen, R.E. Association of Colonoscopy Adenoma Findings With Long-term Colorectal Cancer Incidence. JAMA 2018, 319, 2021–2031. [Google Scholar] [CrossRef] [PubMed]
- Khera, R.; Haimovich, J.; Hurley, N.C.; McNamara, R.; Spertus, J.A.; Desai, N.; Rumsfeld, J.S.; Masoudi, F.A.; Huang, C.; Normand, S.-L.; et al. Use of Machine Learning Models to Predict Death After Acute Myocardial Infarction. JAMA Cardiol. 2021, 6, 633. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Overall, n = 5862 |
|---|---|
| Age, years | 58.7 ± 9.7 |
| Sex | |
| Male | 2811 (48.0%) |
| Female | 3051 (52.0% |
| Obesity | 1404 (24.0%) |
| BMI, kg/m² | 27.2 ± 4.7 |
| Metabolic syndrome 1 | 2095 (39.1%) |
| Hypertension | 3272 (55.8%) |
| Systolic BP, mmHg | 133 ± 19 |
| DM | 871 (14.9%) |
| Fatty liver disease 2 | 2613 (44.8%) |
| Ever/Current smoker | 2898 (49.4%) |
| First degree relative with history of CRC | 659 (11.2%) |
| Any HP | 1737 (29.6%) |
| Any adenoma | 1884 (32.1%) |
| Any AA | 437 (7.5%) |
| CRC | 45 (0.8%) |
| Advanced lesion 3 | 462 (7.9%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Semmler, G.; Wernly, S.; Wernly, B.; Mamandipoor, B.; Bachmayer, S.; Semmler, L.; Aigner, E.; Datz, C.; Osmani, V. Machine Learning Models Cannot Replace Screening Colonoscopy for the Prediction of Advanced Colorectal Adenoma. J. Pers. Med. 2021, 11, 981. https://doi.org/10.3390/jpm11100981
Semmler G, Wernly S, Wernly B, Mamandipoor B, Bachmayer S, Semmler L, Aigner E, Datz C, Osmani V. Machine Learning Models Cannot Replace Screening Colonoscopy for the Prediction of Advanced Colorectal Adenoma. Journal of Personalized Medicine. 2021; 11(10):981. https://doi.org/10.3390/jpm11100981
Chicago/Turabian StyleSemmler, Georg, Sarah Wernly, Bernhard Wernly, Behrooz Mamandipoor, Sebastian Bachmayer, Lorenz Semmler, Elmar Aigner, Christian Datz, and Venet Osmani. 2021. "Machine Learning Models Cannot Replace Screening Colonoscopy for the Prediction of Advanced Colorectal Adenoma" Journal of Personalized Medicine 11, no. 10: 981. https://doi.org/10.3390/jpm11100981
APA StyleSemmler, G., Wernly, S., Wernly, B., Mamandipoor, B., Bachmayer, S., Semmler, L., Aigner, E., Datz, C., & Osmani, V. (2021). Machine Learning Models Cannot Replace Screening Colonoscopy for the Prediction of Advanced Colorectal Adenoma. Journal of Personalized Medicine, 11(10), 981. https://doi.org/10.3390/jpm11100981