Framework for the Development of Data-Driven Mamdani-Type Fuzzy Clinical Decision Support Systems

 ,
,
Abstract
:1. Introduction
| Attribute number | Domain |
| 1. Clump Thickness—CT | 1–10 |
| 2. Uniformity of Cell Size—UCSi | 1–10 |
| 3. Uniformity of Cell Shape—UCSh | 1–10 |
| 4. Marginal Adhesion—MA | 1–10 |
| 5. Single Epithelial Cell Size—SECS | 1–10 |
| 6. Bare Nuclei—BN | 1–10 |
| 7. Bland Chromatin—BC | 1–10 |
| 8. Normal Nucleoli—NN | 1–10 |
| 9. Mitoses—Mi | 1–10 |
| 10. Class: | (2 for benign 4 for malignant) |
- None of the feature extraction methods were applied before the cluster’s analysis.
- None of the machine learning algorithms was used or applied.
- Clustering was the unique data mining technique that we used.
- We present a novel method for knowledge discovery through an easy extraction of the knowledge database and knowledge rule base for the development of Mamdani-type Fuzzy Inference systems.
- Using clustering and pivot tables in classification problems allows knowledge discovery through patterns’ recognition. These two tools can increase the likelihood of reducing input variables (feature extraction), which simplifies the decision-making process.
- The use of the two tools could be considered a deep machine learning algorithm.
- All the algorithms were tested in real-world problem datasets (Appendix A, Appendix B, Appendix C, Appendix D, Appendix E, Appendix F, Appendix G and Appendix H).
2. Theoretical Background
2.1. Fuzzy Sets Theory
2.1.1. The Mamdani-Type Fuzzy Model
2.1.2. The Sugeno-Type Fuzzy Model
2.2. Decision Support Systems (DSS)
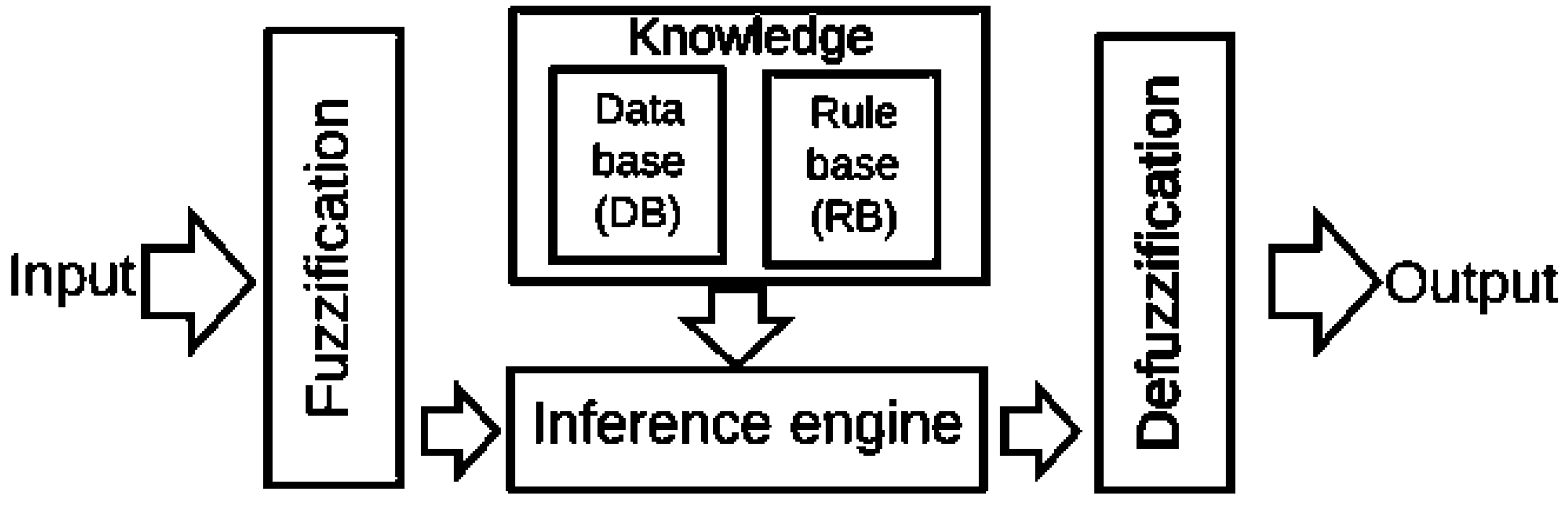
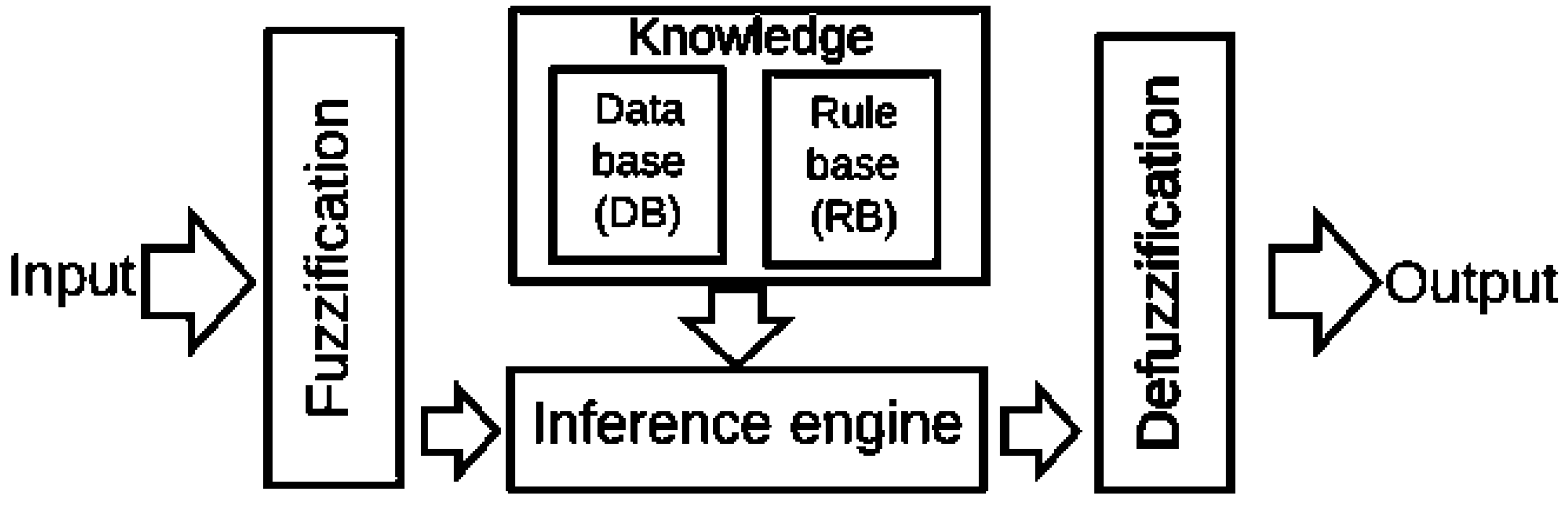
Decision Support Systems’ Components
2.3. Fuzzy Sets Theory in Clinical Decision Support Systems
2.4. Clustering Approach
2.4.1. K-Means Clusters
2.4.2. Hierarchical—Ward Method
2.4.3. Nearest Neighbor
2.4.4. Pivot or Pivot Tables
3. Materials and Methods
4. Case Studies
4.1. Step 1. Identifying the Datasets
4.2. Data Preparation (Crisp Inputs)
4.3. Reviewing Existing Models
4.4. Evaluating the Number of the Optimal Clusters
4.5. Setting the Number of the Clusters (Minimum and Maximum)
4.6. Random Permutations
4.7. Cluster Analysis (Fuzzification Process)
4.8. Sampling: Cross-Validation
4.9. Pivot Tables
4.9.1. Combining Different Cluster Datasets
4.9.2. Setting the Fuzzy Rules for each Variable
4.10. Elaborating the Data-Driven Mamdani-Type Fuzzy Decision Support System (Inference Engine)
4.11. Evaluating the Fuzzy Inference System Performance (Defuzzification and Crisp Outputs)
4.11.1. Classification Accuracy
4.11.2. Sensitivity
4.11.3. Specificity
4.11.4. F-Measure
4.11.5. Area under the Curve
- Between 0.90–1.00 = excellent classification;
- between 0.80–0.90 = good classification;
- between 0.70–0.80 = fair classification;
- between 0.60–0.70 = poor classification;
- between 0.50–0.60 = failure.
5. Experimental Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Pseudo-Code for the Implementation of the Fuzzification Function
| function [KnowledgeDataBase, totalmatrix, ranges, MFs] = Fuzzification (matrix, cluster_method, numinputs, numoutputs) |
| numvariables = numinputs+numoutputs; |
| maxnumrows = 0; |
| for i = 1: numvariables |
| rowssize(i) = unique(matrix(:,i),’rows’,’stable’);%pivot tables |
| if rowssize > maxnumrows |
| maxnumrows = rowssize(i); |
| end |
| end |
| if maxnumrows > 20 |
| maxnumrows = round(sqrt(maxnurows,0)); |
| end |
| for i = 1: numvariables |
| if rowssize(i) > maxnumrows |
| optimaly = round(sqrt(rowssize(i),0)); |
| rowssize(i) = optimaly; |
| else |
| optimaly = rowssize(i); |
| end |
| if cluster_method == ‘Ward’ |
| clustering = clusterdata(matrix(:,i),’linkage’,’ward’,optimaly);%here we apply clustering methods |
| else |
| clustering = kmeans(matrix(:,i),optimaly); |
| end |
| totalmatrix = [matrix clustering]; |
| [ranges,knowledgeDataBase,MFs] = knowledgeDB(maxnumrows,matrix(:,i),clustering,i); |
| end |
| end |
Appendix B. Pseudo-Code for the Implementation of KnowledgeDB Function
| function [ranges,knowledgeDataBase,MFs] = knowledgeDB (maxnumrows,matrix,clustering,i) |
| calculate maximum from clustering; |
| for j = 1: maximum |
| k = find(clustering == j); |
| aA = matrix(k); |
| calculate min from aA; %this value is representing the value of b in the MF. |
| calculate max from aA; %this value is representing the value of c in the MF. |
| end |
| if min from aA == max from aA |
| MF(i) = ‘trimf’; |
| calculate the point_a. Point_c is the same value of max from aA or min from aA. |
| else |
| MF(i) = ‘trapmf’; |
| calculate the point_a and point_d for the Membership function. |
| end |
| knowledgeDataBase = [point_a Min(aA) Max(aA) point_d]; |
| ranges = [min(aA) max(aA)]; |
| MFs = MF; |
| end |
| end |
Appendix C. Pseudo-Code for the Implementation of KnowledgeRB Function
| function [knowledgeRuleBase] = knowledgeRB(round,training, validation,testing,numvarinputs) |
| for a = 2:numvarinputs percent, it could be the same numvarinputs if you work with the same number of input variables. |
| numvars = a; |
| n = 1:1:numvarinputs; |
| combinations = nchoosek(n,numvars); |
| for i = 1:size(combinations,1) |
| for j = 1:size(combinations,2) |
| clustersinputsindices(i,j) = combinations(i,j) *2; |
| end |
| end |
| calculate the clustersoutputsindices; |
| for i = 1:size(combinations,1) |
| [RuleBaseInputs,ia,ic] = unique(training(:,clustersinputsindices(i,:)),’rows’,’sorted’); %pivot tables |
| RuleBaseOutputs = training(ia,clustersoutputsindices(i,:)); |
| RuleBase = [RuleBaseInputs RuleBaseOutputs]; |
| weightsandconnections = ones(size(RuleBase,1),2); |
| [knowledgeRuleBase] = [RuleBase weightsandconnections]; |
| InferenceEngineandDefuzzification(combination,trainingdata,validationdata,testdata,knowledgeRuleBase,indicesinputs,indicesoutputs); |
| end |
| end |
| end |
Appendix D. Pseudo-Code for the Implementation of Fuzzification Sampling Function
| function [trainingdataset,validationdataset,testingdataset,trainingdata,validationdata,testdata,knowledgeRuleBase] = fuzzyfication_sampling(totalmatrix) |
| read the percentage for training; |
| read the percentage for validation; |
| read the percentage for testing subsets; |
| read the iterations number; |
| calculate the number of variables; |
| for i = 1: iterations number |
| for j = 1: number of variables |
| [training, validation,testing ] = divide randomly the complete dataset with the chosen percentages. |
| end |
| [knowledgeRuleBase] = knowledgeRB(i,training, validation,testing,numvarinputs); |
| end |
| end |
Appendix E. Pseudo-Code for the Implementation of CrispOutputs Function
| function [performance] = CrispOutputs(fis,trainingdata,validationdata,testingdata,indicesinputs,indicesoutputs,combination); |
| inputtrainingdata = trainingdata(:,indicesinputs(combination,:)); |
| outputsdata = trainingdata(:,indicesoutputs(combination,:)); |
| fisoutputstrainingdata = evaluate the performance with the inputtrainingdata variable. |
| calculate correlation coefficient (regression) using outputsdata and fisoutputtrainingdata; |
| calculate the square of the correlation coefficient (R2) |
| inputvalidationdata = validationdata(:,indicesinputs(combination,:)); |
| outputsdata = validationdata(:,indicesoutputs(combination,:)); |
| fisoutputsvalidationdata = evaluate the performance with the inputvalidationdata variable. |
| calculate correlation coefficient (regression) using outputsdata and fisoutputvalidationdata; |
| calculate the square of the correlation coefficient (R2) |
| inputtestingdata = testingdata(:,indicesinputs(combination,:)); |
| outputsdata = testingdata(:,indicesoutputs(combination,:)); |
| fisoutputstestingdata = evaluate the performance with the inputtestingdata variable. |
| calculate correlation coefficient (regression) using outputsdata and fisoutputtestingdata; |
| calculate the square of the correlation coefficient (R2); |
| Calculate the total performance using the complete dataset (training, validation, and testing). |
| Calculate correlation coefficient (regression) using totaloutputsdata and fisoutputtotaldata. |
| Calculate the square of the correlation coefficient (R2). |
| performance = [R2_total,R2_training,R2_validation,R2_testing]; |
| end |
Appendix F. Pseudo-Code for the Implementation of InferenceEngineandDefuzzification Function
| function InferenceEngineandDefuzzification(combination,trainingdata,validationdata,testdata,knowledgeRuleBase,indicesinputs,indicesoutputs) |
| fis = newfis(put the fis file name); |
| define the defuzzification method; |
| for i = 1: size(indicesinputs,2) |
| put input variable name; |
| assign ranges for the input variables; |
| for j = 1: inputs(indicesinputs(combination,i) |
| put name to the membership function for the input variable |
| put type to the membership function for the input variable |
| if type == ‘trapmf’ |
| put parameters = knowledgeDataBase(j,:,indicesinputs(combination,i)); |
| else |
| put parameters = knowledgeDataBase(j,[1,2,4],indicesinputs(combination,i)); |
| end |
| end |
| end |
| for i = 1: size(indicesoutputs,2) |
| put output variable name; |
| assign ranges for the output variables; |
| for j = 1: inputs(indicesoutputs(combination,i) |
| put name to the membership function for the output variable |
| put type to the membership function for the output variable |
| if type == ‘trapmf’ |
| put parameters = knowledgeDataBase(j,:,indicesoutputs(combination,i)); |
| else |
| put parameters = knowledgeDataBase(j,[1,2,4],indicesoutputs(combination,i)); |
| end |
| end |
| end |
| for m = 1: size(knowledgeRuleBase,1) |
| put antecedents; |
| put consequents; |
| put weights; |
| put connections; |
| end |
| namevars = concatenate(‘Vars_’,indicesinputs(combination,:)); |
| [performances(:,:,combination)] = CrispOutputs(fis,trainingdata,validationdata,testingdata,indicesinputs,indicesoutputs,combination); |
| namefis = concatenate(performances(:,:,combination),’#_vars’,size(indicesinputs,2),’_’,namevars); |
| save the fis file: ‘*.fis’ with the namefis variable; |
| save the variables: ‘*.mat’ with the namefis variable; |
| end |
Appendix G. Pseudo-Code for the Implementation of Show Results Function
| function ShowResults(numinputs,numoutputs,fisbiggerR2,subsetdata,indicesinputsdata,indicesoutputsdata) |
| inputsdata = subsetdata(:,indicesinputsdata); |
| outputsdata = subsetdata(:,indicesoutputsdata); |
| fisoutputsdata = evaluate the performance with the inputsdata variable. |
| make a confusion matrix between outputsdata and fisoutputdata; |
| show the matrix confusion; |
| make a table with the input and output variables (observed and predicted); |
| save the table; |
| end |
Appendix H. Pseudo-Code for the Implementation of Fuzzification cross Validation Function
| function [trainingdataset,validationdataset,testingdataset,trainingdata,validationdata,testdata,knowledgeRuleBase] = fuzzyfication_Cross_Validation(totalmatrix,kfolds,partition_method) |
| CVO = cvpartition(totalmatrix(:,end-1,end); |
| for i = 1: CVO.NumTestSets |
| trIndx = CVO.training(i); |
| teIndx = CVO.test(i); |
| trainingdataset = []; |
| trainingdata = []; |
| validationdataset = []; |
| validationdata = []; |
| testingdataset = []; |
| testingdata = []; |
| for j = 1: number of variables |
| trainingdataset(:,:,j) = totalmatrix(trIndx,:,j); |
| trainingdata (:,:,j) = trainingdataset(:,1,j); |
| validationdataset(:,:,j) = totalmatrices(teIndx,:,j); |
| validationdata(:,:,j) = validationdataset(:,1,j); |
| end |
| reshape trainingdata; |
| reshape validationdata; |
| [knowledgeRuleBase] = knowledgeRB(i,trainingdata, validationdata,testingdata,numvarinputs); |
| end |
| end |
Appendix I. Pseudo-Code for the Implementation of the Main Function
| function Main() |
| read inputs; |
| numinputs = sizeInputs; |
| read outputs; |
| numoutputs = sizeOutputs; |
| read cluster_method; |
| matrix = [inputs outputs]; |
| read data partition method; |
| [knowledgeDataBase,ranges] = Fuzzification(matrix,cluster_method,numinputs,numoutputs); |
| Case data partition method == random sampling: |
| [trainingdataset,validationdataset,testingdataset,trainingdata,validationdata,testdata,knowledgeRuleBase] = fuzzyfication_sampling(totalmatrix); |
| Case data partition method == cross validation: |
| read partition method; |
| read kfolds; |
| [trainingdataset,validationdataset,testingdataset,trainingdata,validationdata,testdata,knowledgeRuleBase] = fuzzyfication_sampling(totalmatrix,kfolds,partition method); |
| for each subset |
| ShowResults(numinputs,numoutputs,fisbiggerR2,subsetdata,indicesinputs,indicesoutputs); |
| end |
| end |
Appendix J. Links for Downloading the Implemented Fuzzy Inference Systems for Each Dataset
| https://drive.google.com/open?id=1J1i57dxTQlqJdqR--fqirG3iaNgQwW7n for Coimbra Breast Cancer Dataset (random sampling and cross validation). |
| https://drive.google.com/open?id=1FKOfcEmpHPyiF-OH97FIzGsgyzzKWTsV for Wisconsin Breast cancer dataset (random sampling and cross validation). |
| https://drive.google.com/file/d/15HBZe-20thQAgwSUVxIggQO-P6FnmNyv/view?usp=sharing for the cesarean section dataset (random sampling and cross validation). |
| https://drive.google.com/file/d/1jVm7fqNiSZvHh1Poi5XKzLwFRUTSaJsi/view?usp=sharing for the cryotherapy dataset (random sampling and cross validation). |
| https://drive.google.com/file/d/1E-BldqrIfy-8oRRX9PE35dqvVnHeboRh/view?usp=sharing for the immunotherapy dataset (random sampling and cross validation). |
| https://drive.google.com/file/d/1oTTVn5a5lClmh5oKm6ClI5TuVIsG73cf/view?usp=sharing for testing the implemented datasets. |
References
- Schuh, C.; de Bruin, J.S.; Seeling, W. Clinical decision support systems at the vienna general hospital using arden syntax: Design, implementation, and integration. Artif. Intell. Med. 2018, 92, 24–33. [Google Scholar] [CrossRef]
- Yassin, N.I.R.; Omran, S.; El Houby, E.M.F.; Allam, H. Machine learning techniques for breast cancer computer aided diagnosis using different image modalities: A systematic review. Comput. Methods Programs Biomed. 2018, 156, 25–45. [Google Scholar] [CrossRef]
- Shen, D.; Wu, G.; Suk, H.-I. Deep learning in medical image analysis. Annu. Rev. Biomed. Eng. 2017, 19, 221–248. [Google Scholar] [CrossRef]
- Ahmadi, H.; Gholamzadeh, M.; Shahmoradi, L.; Nilashi, M.; Rashvand, P. Diseases diagnosis using fuzzy logic methods: A systematic and meta-analysis review. Comput. Methods Programs Biomed. 2018, 161, 145–172. [Google Scholar] [CrossRef]
- Pota, M.; Esposito, M.; De Pietro, G. Designing rule-based fuzzy systems for classification in medicine. Knowl. Based Syst. 2017, 124, 105–132. [Google Scholar] [CrossRef]
- Liu, K.; Kang, G.; Zhang, N.; Hou, B. Breast cancer classification based on fully-connected layer first convolutional neural networks. IEEE Access 2018, 6, 23722–23732. [Google Scholar] [CrossRef]
- Shahnaz, C.; Hossain, J.; Fattah, S.A.; Ghosh, S.; Khan, A.I. Efficient approaches for accuracy improvement of breast cancer classification using wisconsin database. In Proceedings of the 2017 IEEE Region 10 Humanitarian Technology Conference (R10-HTC), Dhaka, Bangladesh, 21–23 December 2017; pp. 792–797. [Google Scholar]
- Hoo-Chang, S.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep convolutional neural networks for computer-aided detection: Cnn architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar]
- Zemouri, R.; Omri, N.; Devalland, C.; Arnould, L.; Morello, B.; Zerhouni, N.; Fnaiech, F. Breast cancer diagnosis based on joint variable selection and constructive deep neural network. In Proceedings of the 2018 IEEE 4th Middle East Conference on Biomedical Engineering (MECBME), Tunis, Tunisia, 28–30 March 2018. [Google Scholar]
- Karthik, S.; Srinivasa Perumal, R.; Chandra Mouli, P.V.S.S.R. Breast cancer classification using deep neural networks. In Knowledge Computing and Its Applications: Knowledge Manipulation and Processing Techniques: Volume 1; Margret Anouncia, S., Wiil, U.K., Eds.; Springer: Singapore, 2018; pp. 227–241. [Google Scholar]
- Abdel-Zaher, A.M.; Eldeib, A.M. Breast cancer classification using deep belief networks. Expert Syst. Appl. 2016, 46, 139–144. [Google Scholar] [CrossRef]
- Nivaashini, M.; Soundariya, R.S. Deep boltzmann machine based breast cancer risk detection for healthcare systems. Int. J. Pure Appl. Math. 2018, 119, 581–590. [Google Scholar]
- Abdulllah, M.; Alshehri, W.; Alamri, S.; Almutairi, N. A review of automated decision support system. J. Fundam. Appl. Sci. 2018, 10, 252–257. [Google Scholar]
- Turban, E.; Aronson, J.E.; Liang, T.-P. Decision Support Systems and Intelligent Systems, 7th ed.; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 2004. [Google Scholar]
- Nguyen, T.; Khosravi, A.; Creighton, D.; Nahavandi, S. Medical data classification using interval type-2 fuzzy logic system and wavelets. Appl. Soft Comput. 2015, 30, 812–822. [Google Scholar] [CrossRef]
- Cheruku, R.; Edla, D.R.; Kuppili, V.; Dharavath, R. Rst-batminer: A fuzzy rule miner integrating rough set feature selection and bat optimization for detection of diabetes disease. Appl. Soft Comput. 2018, 67, 764–780. [Google Scholar] [CrossRef]
- Patrício, M.; Pereira, J.; Crisóstomo, J.; Matafome, P.; Gomes, M.; Seiça, R.; Caramelo, F. Using resistin, glucose, age and bmi to predict the presence of breast cancer. BMC Cancer 2018, 18, 29. [Google Scholar] [CrossRef]
- Uzun, R.; Isler, Y.; Toksan, M. Use of support vector machines to predict the success of wart treatment methods. In Proceedings of the 2018 Innovations in Intelligent Systems and Applications Conference (ASYU), Adana, Turkey, 4–6 October 2018; pp. 1–4. [Google Scholar]
- Khozeimeh, F.; Alizadehsani, R.; Roshanzamir, M.; Khosravi, A.; Layegh, P.; Nahavandi, S. An expert system for selecting wart treatment method. Comput. Biol. Med. 2017, 81, 167–175. [Google Scholar] [CrossRef]
- Khozeimeh, F.; Jabbari Azad, F.; Mahboubi Oskouei, Y.; Jafari, M.; Tehranian, S.; Alizadehsani, R.; Layegh, P. Intralesional immunotherapy compared to cryotherapy in the treatment of warts. Int. J. Dermatol. 2017, 56, 474–478. [Google Scholar] [CrossRef] [PubMed]
- Khatri, S.; Arora, D.; Kumar, A. Enhancing decision tree classification accuracy through genetically programmed attributes for wart treatment method identification. Procedia Comput. Sci. 2018, 132, 1685–1694. [Google Scholar] [CrossRef]
- Jain, R.; Sawhney, R.; Mathur, P. Feature selection for cryotherapy and immunotherapy treatment methods based on gravitational search algorithm. In Proceedings of the 2018 International Conference on Current Trends towards Converging Technologies (ICCTCT), Coimbatore, India, 1–3 March 2018; pp. 1–7. [Google Scholar]
- Nugroho, H.W.; Adji, T.B.; Setiawan, N.A. Random forest weighting based feature selection for c4. 5 algorithm on wart treatment selection method. Int. J. Adv. Sci. Eng. Inf. Technol. 2018, 8, 1858–1863. [Google Scholar] [CrossRef]
- Basarslan, M.S.; Kayaalp, F. A hybrid classification example in the diagnosis of skin disease with cryotherapy and immunotherapy treatment. In Proceedings of the 2018 2nd International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Ankara, Turkey, 19–21 October 2018; pp. 1–5. [Google Scholar]
- Akben, S.B. Predicting the success of wart treatment methods using decision tree based fuzzy informative images. Biocybern. Biomed. Eng. 2018, 38, 819–827. [Google Scholar] [CrossRef]
- Onan, A. A fuzzy-rough nearest neighbor classifier combined with consistency-based subset evaluation and instance selection for automated diagnosis of breast cancer. Expert Syst. Appl. 2015, 42, 6844–6852. [Google Scholar] [CrossRef]
- Gayathri, B.M.; Sumathi, C.P. Mamdani fuzzy inference system for breast cancer risk detection. In Proceedings of the 2015 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC), Madurai, India, 10–12 December 2015; pp. 1–6. [Google Scholar]
- American Cancer Society. Cancer Facts & Figures 2018; American Cancer Society Inc.: Atlanta, NW, USA, 2018; p. 76. [Google Scholar]
- Hernández-Julio, Y.F.; Hernández, H.M.; Guzmán, J.D.C.; Nieto-Bernal, W.; Díaz, R.R.G.; Ferraz, P.P. Fuzzy knowledge discovery and decision-making through clustering and dynamic tables: Application in medicine. In Information Technology and Systems. Icits 2019. Advances in Intelligent Systems and Computing; Rocha, Á., Ferrás, C., Paredes, M., Eds.; Springer: Quito, Ecuador, 2019; Volume 918, pp. 122–130. [Google Scholar]
- Polat, K.; Sentürk, U. A novel ml approach to prediction of breast cancer: Combining of mad normalization, kmc based feature weighting and adaboostm1 classifier. In Proceedings of the 2018 2nd International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Ankara, Turkey, 19–21 October 2018; pp. 1–4. [Google Scholar]
- Al Aboud, A.M.; Nigam, P.K. Wart (Plantar, Verruca Vulgaris, Verrucae). Available online: https://www.ncbi.nlm.nih.gov/books/NBK431047/ (accessed on 15 March 2019).
- World Health Organization—WHO. Who Statement on Caesarean Section Rates. Available online: https://apps.who.int/iris/bitstream/handle/10665/161442/WHO_RHR_15.02_eng.pdf;jsessionid=A7558FC224C8FFA233F16CB6C15EA20C?sequence=1 (accessed on 14 March 2019).
- National Center for Health Statistics. Cesarean Delivery Rate by State; Statistics, N.C.f.H., Ed.; Center for Disease Control and Prevention: Clifton Road Atlanta, GA, USA, 2019; p. 1.
- Gharehchopogh, F.S.; Mohammadi, P.; Hakimi, P. Application of decision tree algorithm for data mining in healthcare operations: A case study. Int. J. Comput. Appl. 2012, 52. [Google Scholar] [CrossRef]
- Amin, M.; Ali, A. Performance Evaluation of Supervised Machine Learning Classifiers for Predicting Healthcare Operational Decisions; Wavy AI Research Foundation: Lahore, Pakistan, 2018. [Google Scholar]
- Hayat, M.A. Breast cancer: An introduction. In Methods of Cancer Diagnosis, Therapy and Prognosis: Breast Carcinoma; Hayat, M.A., Ed.; Springer: Dordrecht, The Netherlands, 2008; pp. 1–3. [Google Scholar]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Riza, L.S.; Bergmeir, C.N.; Herrera, F.; Benítez Sánchez, J.M. Frbs: Fuzzy Rule-Based Systems For Classification and Regression in R. J. Stat. Softw. 2015, 65, 4181. [Google Scholar] [CrossRef]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning—i. Inf. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- Mohammadpour, R.A.; Abedi, S.M.; Bagheri, S.; Ghaemian, A. Fuzzy rule-based classification system for assessing coronary artery disease. Comput. Math. Methods Med. 2015, 2015. [Google Scholar] [CrossRef]
- Kim, M.W.; Ryu, J.W. Optimized Fuzzy Classification Using Genetic Algorithm; Springer: Berlin/Heidelberg, Germany, 2005; pp. 392–401. [Google Scholar]
- Mamdani, E.H.; Assilian, S. An experiment in linguistic synthesis with a fuzzy logic controller. Int.J. Man Mach. Stud. 1975, 7, 1–13. [Google Scholar] [CrossRef]
- Takagi, T.; Sugeno, M. Fuzzy identification of systems and its applications to modeling and control. IEEE Trans. Syst. Man Cybern. 1985, SMC-15, 116–132. [Google Scholar] [CrossRef]
- Babuška, R. Fuzzy Modeling for Control; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 12. [Google Scholar]
- De Barros, L.C.; Bassanezi, R.C. Tópicos de Lógica Fuzzy E Biomatemática; Grupo de Biomatemática, Instituto de Matemática, Estatística e Computação Científica (IMECC), Universidade Estadual de Campinas (UNICAMP): Campinas, Brazil, 2010. [Google Scholar]
- Blej, M.; Azizi, M. Comparison of mamdani-type and sugeno-type fuzzy inference systems for fuzzy real time scheduling. Int. J. Appl. Eng. Res. 2016, 11, 11071–11075. [Google Scholar]
- Wang, L.-X.; Mendel, J.M. Generating fuzzy rules by learning from examples. IEEE Trans. Syst. Man Cybern. 1992, 22, 1414–1427. [Google Scholar] [CrossRef]
- Hernández-Julio, Y.F.; Yanagi, T.; de Fátima Ávila Pires, M.; Aurélio Lopes, M.; Ribeiro de Lima, R. Models for prediction of physiological responses of holstein dairy cows. Appl. Artif. Intell. 2014, 28, 766–792. [Google Scholar] [CrossRef]
- Ferraz, P.F.P.; Yanagi Junior, T.; Hernández Julio, Y.F.; Castro, J.d.O.; Gates, R.S.; Reis, G.M.; Campos, A.T. Predicting chick body mass by artificial intelligence-based models. Pesq. Agrop. Bras. 2014, 49, 559–568. [Google Scholar] [CrossRef]
- Chiu, S. Method and software for extracting fuzzy classification rules by subtractive clustering. In Proceedings of the Fuzzy Information Processing Society, 1996. NAFIPS., 1996 Biennial Conference of the North American, Berkeley, CA, USA, 19–22 June 1996; pp. 461–465. [Google Scholar]
- Ferraz, P.F.; Yanagi Junior, T.; Hernandez-Julio, Y.F.; Ferraz, G.A.; Silva, M.A.; Damasceno, F.A. Genetic fuzzy system for prediction of respiratory rate of chicks subject to thermal challenges. Rev. Bras. Eng. Agríc. E Ambient. 2018, 22, 412–417. [Google Scholar] [CrossRef]
- Hamam, A.; Georganas, N.D. A comparison of mamdani and sugeno fuzzy inference systems for evaluating the quality of experience of hapto-audio-visual applications. In Proceedings of the IEEE International Workshop on Haptic Audio visual Environments and Games, Ottawa, ON, Canada, 18–19 October 2008; pp. 87–92. [Google Scholar]
- Paul, A.K.; Shill, P.C.; Rabin, M.R.I.; Kundu, A.; Akhand, M.A.H. Fuzzy membership function generation using dms-pso for the diagnosis of heart disease. In Proceedings of the 2015 18th International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 21–23 December 2015; pp. 456–461. [Google Scholar]
- Romero-Córdoba, R.; Olivas, J.Á.; Romero, F.P.; Alonso-Gómez, F. Clinical Decision Support System for the Diagnosis and Treatment of Fuzzy Diseases; Springer International Publishing: Cham, Switzerland, 2015; pp. 128–138. [Google Scholar]
- D’Acierno, A.; Esposito, M.; De Pietro, G. An extensible six-step methodology to automatically generate fuzzy dsss for diagnostic applications. BMC Bioinform. 2013, 14, S4. [Google Scholar] [CrossRef]
- Romero-Córdoba, R.; Olivas, J.A.; Romero, F.P.; Alonso-Gonzalez, F.; Serrano-Guerrero, J. An application of fuzzy prototypes to the diagnosis and treatment of fuzzy diseases. Int. J. Intell. Syst. 2017, 32, 194–210. [Google Scholar] [CrossRef]
- Nazari, S.; Fallah, M.; Kazemipoor, H.; Salehipour, A. A fuzzy inference-fuzzy analytic hierarchy process-based clinical decision support system for diagnosis of heart diseases. Expert Syst. Appl. 2018, 95, 261–271. [Google Scholar] [CrossRef]
- Dabre, K.R.; Lopes, H.R.; D’monte, S.S. Intelligent decision support system for smart agriculture. In Proceedings of the 2018 International Conference on Smart City and Emerging Technology (ICSCET), Mumbai, India, 5 January 2018; pp. 1–6. [Google Scholar]
- Kukar, M.; Vračar, P.; Košir, D.; Pevec, D.; Bosnić, Z. Agrodss: A decision support system for agriculture and farming. Comput. Electron. Agric. 2018, in press. [Google Scholar]
- Ignatius, J.; Hatami-Marbini, A.; Rahman, A.; Dhamotharan, L.; Khoshnevis, P. A fuzzy decision support system for credit scoring. Neural Comput. Appl. 2018, 29, 921–937. [Google Scholar] [CrossRef]
- Centobelli, P.; Cerchione, R.; Esposito, E. Aligning enterprise knowledge and knowledge management systems to improve efficiency and effectiveness performance: A three-dimensional fuzzy-based decision support system. Expert Syst. Appl. 2018, 91, 107–126. [Google Scholar] [CrossRef]
- Serrano-Silva, Y.O.; Villuendas-Rey, Y.; Yáñez-Márquez, C. Automatic feature weighting for improving financial decision support systems. Decis. Support Syst. 2018, 107, 78–87. [Google Scholar] [CrossRef]
- Al Nahyan, M.T.; Hawas, Y.E.; Raza, M.; Aljassmi, H.; Maraqa, M.A.; Basheerudeen, B.; Mohammad, M.S. A fuzzy-based decision support system for ranking the delivery methods of mega projects. Int. J. Manag. Proj. Bus. 2018, 11, 122–143. [Google Scholar] [CrossRef]
- Hajek, P.; Olej, V. Interval-valued intuitionistic fuzzy inference system for supporting corporate financial decisions. In Proceedings of the 2018 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–7. [Google Scholar]
- Akcay, C.; Manisali, E. Fuzzy decision support model for the selection of contractor in construction works. Rev. Constr. J. Constr. 2018, 17, 258–266. [Google Scholar]
- Sugiyarti, E.; Jasmi, K.A.; Basiron, B.; Huda, M.; Shankar, K.; Maseleno, A. Decision support system of scholarship grantee selection using data mining. Int. J. Pure Appl. Math. 2018, 119, 2239–2249. [Google Scholar]
- Manivannan, P.; Devi, P.I. Dengue fever prediction using k-means clustering algorithm. In Proceedings of the 2017 IEEE International Conference on Intelligent Techniques in Control, Optimization and Signal Processing (INCOS), Srivilliputhur, India, 23–25 March 2017; pp. 1–5. [Google Scholar]
- Fan, C.; Xiao, K.; Xiu, B.; Lv, G. A fuzzy clustering algorithm to detect criminals without prior information. In Proceedings of the 2014 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Beijing, China, 17–20 August 2014; pp. 238–243. [Google Scholar]
- Malhat, M.G.; El-Sisi, A.B. Parallel ward clustering for chemical compounds using opencl. In Proceedings of the 2015 Tenth International Conference on Computer Engineering & Systems (ICCES), Cairo, Egypt, 23–24 December 2015; pp. 23–27. [Google Scholar]
- Leach, A.R.; Gillet, V.J. An Introduction to Chemoinformatics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Gunanto, S.G.; Hariadi, M.; Yuniarno, E.M. Feature-points nearest neighbor clustering on 3d face models. In Proceedings of the 2016 4th International Conference on Cyber and IT Service Management, Bandung, Indonesia, 26–27 April 2016; pp. 1–5. [Google Scholar]
- Bhatia, N. Survey of nearest neighbor techniques. arXiv 2010, preprint. arXiv:1007.0085. [Google Scholar]
- Microsoft. Información general sobre tablas dinámicas y gráficos dinámicos. Available online: https://support.office.com/es-es/article/informaci%C3%B3n-general-sobre-tablas-din%C3%A1micas-y-gr%C3%A1ficos-din%C3%A1micos-527c8fa3-02c0-445a-a2db-7794676bce96 (accessed on 28 November 2019).
- Dan, N. Excel Pivot Tables: Easy Practical Guide for Everyone; CreateSpace Independent Publishing Platform: Scottsdale Valley, CA, USA, 2018; p. 88. [Google Scholar]
- Palit, A.K.; Popovic, D. Computational Intelligence in Time Series Forecasting: Theory and Engineering Applications; Springer: London, UK, 2006. [Google Scholar]
- Cavalcante, R.C.; Brasileiro, R.C.; Souza, V.L.F.; Nobrega, J.P.; Oliveira, A.L.I. Computational intelligence and financial markets: A survey and future directions. Expert Syst. Appl. 2016, 55, 194–211. [Google Scholar] [CrossRef]
- Lee, M.-C. Using support vector machine with a hybrid feature selection method to the stock trend prediction. Expert Syst. Appl. 2009, 36, 10896–10904. [Google Scholar] [CrossRef]
- Lin, F.; Liang, D.; Yeh, C.-C.; Huang, J.-C. Novel feature selection methods to financial distress prediction. Expert Syst. Appl. 2014, 41, 2472–2483. [Google Scholar] [CrossRef]
- Kao, L.-J.; Chiu, C.-C.; Lu, C.-J.; Yang, J.-L. Integration of nonlinear independent component analysis and support vector regression for stock price forecasting. Neurocomputing 2013, 99, 534–542. [Google Scholar] [CrossRef]
- Tsinaslanidis, P.E.; Kugiumtzis, D. A prediction scheme using perceptually important points and dynamic time warping. Expert Syst. Appl. 2014, 41, 6848–6860. [Google Scholar] [CrossRef]
- Aghabozorgi, S.; Teh, Y.W. Stock market co-movement assessment using a three-phase clustering method. Expert Syst. Appl. 2014, 41, 1301–1314. [Google Scholar] [CrossRef]
- Hernández-Julio, Y.F.; Prieto-Guevara, M.J.; Nieto-Bernal, W.; Jiménez-Velásquez, C.; Ruíz-Guzmán, J. Fuzzy knowledge discovery and decision-making through clustering and dynamic tables: Application to bioengineering. In Fuzzy Systems and Data Mining Iv; Tallón-Ballesteros, A.J., Li, K., Eds.; IOS Press: Bangkok, Thailand, 2018; Volume 309, pp. 480–487. [Google Scholar]
- The MathWorks Inc. Design and Simulate Fuzzy Logic Systems; The MathWorks Inc.: Natick, MA, USA, 2017. [Google Scholar]
- Moreno Velo, F.J.; Baturone, I.; Sánchez-Solano, S.; Barriga, Á. Xfuzzy 3.0: A development environment for fuzzy systems. In International Conference in Fuzzy Logic and Technology (EUSFLAT 2001); European Society for Fuzzy Logic and Technology: Leicester, UK, 2001. [Google Scholar]
- Nahrstaedt, H.; Urzua Grez, J. Sciflt is a Fuzzy Logic Toolbox for Scilab; 0.4.7; Scilab.org, 2014. [Google Scholar]
- Ali, F.; Islam, S.M.R.; Kwak, D.; Khan, P.; Ullah, N.; Yoo, S.-j.; Kwak, K.S. Type-2 fuzzy ontology–aided recommendation systems for iot–based healthcare. Comput. Commun. 2018, 119, 138–155. [Google Scholar] [CrossRef]
- Dua, D.; Karra Taniskidou, E. Uci Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml (accessed on 15 March 2019).
- Bache, K.; Lichman, M. Uci Machine Learning Repository; University of California, School of Information and Computer Science: Irvine, CA, USA, 2013. [Google Scholar]
- Mangasarian, O.L. Cancer diagnosis via linear programming. SIAM News 1990, 23, 1–18. [Google Scholar]
- Hernández-Julio, Y.F.; Yanagi Junior, T.; Ávila Pires, M.F.; Aurélio Lopes, M.; Ribeiro de Lima, R. Fuzzy system to predict physiological responses of holstein cows in southeastern brazil. Rev. Col. Cienc. Pecu. 2015, 28, 42–53. [Google Scholar]
- Tanaka, K. An introduction to Fuzzy Logic for Practical Applications, 1st ed.; Springer: New York, NY, USA, 1996. [Google Scholar]
- Sivanandam, S.; Sumathi, S.; Deepa, S. Introduction to Fuzzy Logic Using Matlab; Springer: Berlin/Heidelberg, Germany, 2007; Volume 1. [Google Scholar]
- Gorunescu, F. Data mining: Concepts, Models and Techniques, 1 ed.; Springer: Berlin/Heidlberg, Germany, 2011; Volume 12. [Google Scholar]
- Thungrut, W.; Wattanapongsakorn, N. Diabetes classification with fuzzy genetic algorithm. In Recent Advances in Information and Communication Technology 2018. Ic2it 2018. Advances in Intelligent Systems and Computing; Unger, H., Sodsee, S., Meesad, P., Eds.; Springer: Cham, Switzerland, 2018; Volume 769, pp. 107–114. [Google Scholar]
- Verma, D.; Mishra, N. Analysis and prediction of breast cancer and diabetes disease datasets using data mining classification techniques. In Proceedings of the 2017 International Conference on Intelligent Sustainable Systems (ICISS), Tirupur, Tamilnadu, India, 7–8 December 2017; pp. 533–538. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, B.P.; Tay, W.; Chui, C. Robust biometric recognition from palm depth images for gloved hands. IEEE Trans. Hum. Mach. Syst. 2015, 45, 799–804. [Google Scholar] [CrossRef]

{kind=link}
| Feature | Attribute | Patients | Controls | p-Value |
|---|---|---|---|---|
| 1 | Age (years) | 53.0 (23.0) | 65 (33.2) | 0.479 |
| 2 | BMI (kg/m2) | 27 (4.6) | 28.3 (5.4) | 0.202 |
| 3 | Glucose (mg/dL) | 105.6 (26.6) | 88.2 (10.2) | <0.001 |
| 4 | Insulin (µU/mL) | 12.5 (12.3) | 6.9 (4.9) | 0.027 |
| 5 | HOMA | 3.6 (4.6) | 1.6 (1.2) | 0.003 |
| 6 | Leptin (ng/mL) | 26.6 (19.2) | 26.6 (19.3) | 0.949 |
| 7 | Adiponectin (µg/mL) | 10.1 (6.2) | 10.3 (7.6) | 0.767 |
| 8 | Resistin (ng/mL) | 17.3 (12.6) | 11.6 (11.4) | 0.002 |
| 9 | MCP-1 (pg/dL) | 563 (384) | 499.7 (292.2) | 0.504 |
| Immunotherapy | |||
|---|---|---|---|
| Feature | Attribute | Type | Values |
| 1 | Sex | Numeric | 41 male and 49 females |
| 2 | Age | Numeric | 15–56 |
| 3 | Time elapsed before treatment (months) | Numeric | 0–12 |
| 4 | Number of warts | Numeric | 1–19 |
| 5 | Type of warts (count) | Numeric | 47 common, 22 plantar, and 21 both |
| 6 | Surface area (mm2) | Numeric | 6–900 |
| 7 | Induration diameter of initial test (mm) | Numeric | 5–70 |
| 8 | Response to treatment | Nominal | Yes or no |
| Cryotherapy | |||
| 1 | Sex | Numeric | 47 male and 43 females |
| 2 | Age | Numeric | 15–67 |
| 3 | Time elapsed before treatment (months) | Numeric | 0–12 |
| 4 | Number of warts | Numeric | 1–12 |
| 5 | Type of warts (count) | Numeric | 54 common, 09 plantar, and 27 both |
| 6 | Surface area (mm2) | Numeric | 4–750 |
| 7 | Response to treatment | Nominal | Yes or no |
| DDMTFCDSS Activity Steps | Activity Description |
|---|---|
| Identifying the problems and evaluating the complexity of the specific domain | |
| 1. To identify the dataset. | This stage is related to identifying the source of the collected data to make the fuzzy inference system. These data usually belong to experiments that seek to observe the behavior of some dependent variables through the interaction of independent variables. Generally, the first variables are known as output variables and the second are known as input variables. This section describes the context and the adopted methodology to obtain the database that will serve as an input to work with the other framework components. |
| 2. Data Preparation (Crisp inputs). | This step, according to the methodology proposed by Palit and Popovic [75] and modified by Cavalcante et al. [76], means that the data stored in multiple data sources (Spreadsheets, Data Bases—DBs, Comma-Separated Values—CSV, Enterprise Resource Planning—ERP, Customer Relationship Managers—CRM, Material Requirements Planning—MRP, among others) must be pre-processed [76]. The first part of this phase is to define the input and output variables that will be used for modeling. The pre-processing is a procedure where datasets (input(s) and output(s)) are prepared to be processed by the data mining technique (clusters) and the computational intelligence (fuzzy system). For doing that, in the literature, some pre-processing mechanisms used to improve the prediction or classification performance, among these, we can found Feature selection [77], Feature Extraction [78], de-noising, outlier detection [79], Time series segmentation [80], and Clustering [81]. Datasets must be normalized and structured. This can be done with the help of spreadsheet software like Microsoft Excel® among others. |
| 3. Reviewing existing models. | In this stage, an academic and scientific search of the different works related to the problem is carried out. For this, different indexed databases such as Scopus, Science Direct, Web of Science, Scielo, Google Scholar, ACM, etc. are used. |
| DDMTFCDSS Activity Steps | Activity Description |
|---|---|
| 4. Evaluating the optimal number of clusters. | This stage pretends to find the optimal number of clusters for each one of the input and output variables. It determines a reference pivot number for adding or removing groups depending on whether you want to reduce or increase the number of fuzzy sets for each variable. This cluster number will indicate the same amount of fuzzy sets for the selected variable. If the variables are input, then you can determine the number of rules that the fuzzy system will have through the interaction between them. If the variables are output, then the number of the cluster will be the number of the fuzzy set that will have that variable, but it will not affect the rule set number. For the reasons above, it is important to have this optimal value of clusters, because it will give us an initial idea of how many rules and how many fuzzy sets we must have at maximum for each variable.To determine the optimal number of clusters, for each variable (input and output(s)), we applied pivot tables to establish the maximum number of clusters that could have each one. The pivot table makes a unique table (without repetitions of values). If the optimal number of clusters mentioned above is greater than 20, it is recommended to calculate the square root of this value and take that value as the optimal number of clusters. The recommended minimum number of clusters is two (2)—Appendix A. |
| 5. Setting a number of clusters (minimum and maximum) according to the previous evaluation. | Determining the optimal number of clusters, we can have an idea of how many fuzzy sets and the number of rules we can have for the construction of the fuzzy system. Based on that optimal number of clusters, we can establish a range (minimum and maximum) in which the result of the previous section is within it. For example: If the result of the previous step threw five (5) clusters for the first input variable, we could set the range between minimum two (2) and maximum five (5). This is done to see the possibilities of reducing the number of clusters that can directly affect the number of rules or, on the contrary, see if the performance with a higher number of rules can be improved. For this case, the principal idea is to optimize the effectiveness of the established fuzzy system with a reduced rules number—Appendix A. |
| DDMTCDSS Activity Steps | Activity Description |
|---|---|
| Begin Iterative Design and Development of Data-Driven Clinical Decision Support Systems | |
| 6. Random permutations | This stage allows us to make random permutations into the selected dataset(s). This is made to avoid the same input and output(s) order and could be chosen different classes or attributes at the moment for choosing the two or three subsets for training, validation, and test through random sampling or cross-validation processes. |
| Knowledge Database Creation | |
| 7. Cluster analysis: fuzzification process. | At this stage, the main idea is to classify the data values of the respective input and output variables, according to the criteria set out in the previous section. For the individual analyses, it is recommended to use at least one of the two types of algorithms recognized in the academic and scientific field. Non-hierarchical (K-means) and hierarchical clusters (nearest neighbor and the Ward method) can be used to evaluate the performance of each one of the algorithms through the next phase of the methodology—Appendix A. Depending on each variable, these results (clusters) could change for each case. The result of this stage is the knowledge representation or knowledge base for the fuzzy inference systems because the clusters represent the number of fuzzy sets (input and output range values or membership functions). See Appendix B. |
| 8. Sampling: Cross-validation datasets. | This stage seeks to randomly divide the dataset into two or three sub-sets. The framework proposes two kinds of data partition. The first one consists of random sampling. The user can select two or three subsets (training, validation, and testing). Generally, the percentage for each one, could be: 70:30:0; 70:20:10; 70:15:15; 70:10:20, etc. The user chooses this percentage. See Appendix D. The user also chose the number of repetitions that want to have, for example, if the problem has three input variables. The recommendation is to make at least three repetitions, which increases the possibility of finding an optimal combination of the sets formed by the clusters by avoiding some set(s) outside of the learning process. The results of the two or three selected subsets are saved into a multidimensional array with the divided datasets. The second option for data partition is through the Cross Validation process. In this option, the dataset is randomly partitioned into k equal sized partitions (by default is 10 —the users can change this value). One partition is used for testing the performance of the system, whereas the rest of the partitions is used for the training process. This procedure is repeated k times to use each partition as a test subset exactly one time. In the end, a mean accuracy of the individual results is consolidated. All two processes are automatized. See Appendix H. |
| Pivot Tables: Feature Selection and Knowledge Rulebase Creation. | |
| 9. Pivot tables | Knowing the number of the optimal clusters to each variable, we can calculate the rules number that the fuzzy system can have through the interaction between the input variables—Rulebase. According to Hernández-Julio, Hernández, Guzmán, Nieto-Bernal, Díaz, and Ferraz [29] and Hernández-Julio, et al. [82], this stage looks for a combination that allows capable results without having to reach the maximum number of input variables—Feature extraction. Doing this, it is guaranteed that the fuzzy system will be optimized in the number of variables (minimum) and the number of fuzzy sets for each variable, mainly in the output variables—knowledge discovery. In this phase, the following sub-phases are done (Table 4)—Appendix A and Appendix C. |
| DDMTFCDSS Activity Steps | Activity Description |
|---|---|
| 9.1 Combining different input variable cluster datasets. | The objective in this stage is to make combinations between input variables clusters datasets generated in the previous step, to find the best performance. For doing this, we can use the command nchoosek from any matrices laboratory software—Appendix C. |
| 9.2 Establishing the fuzzy rules. | This section is based on the previous one. If the operations carried out with the use of the pivot tables find one or several combinations that guarantee good results (not clusters overlapping or minimum differences between the values), it proceeds to make the rules base of the fuzzy system. This is done by the recommendations of the previous section (using the command Unique). The rules will be easily detectable. To see an example refers to the case studies—Appendix C. |
| Data Driven Mamdani-Type Fuzzy Clinical Decision Support System | |
| 10. Elaborating the Decision Support System based on a fuzzy set theory (Inference engine). | This stage refers to the implementation in specific software for the elaboration of fuzzy model systems such as Matlab® [83], Xfuzzy® [84], sciFLT® [85], and more. For doing this, until the moment, we must have, through the current framework, the following elements: definition of the linguistic variables, the rules set, the sets number, and the membership function values of each variable. In this step, the modeler must know the environment of the software platform to work with each of the elements previously mentioned. The recommendation for this stage is that the modeler may need to manually adjust the values of the sets suggested by the methodology, until achieving the desired values (Appendix F). |
| 11. Evaluating the fuzzy inference system performance (defuzzification and Crisp Outputs). | This stage aims to measure the designed and implemented system performance until this moment. For doing this, we must use the evaluation functions of each specific program and realize the simulations with the observed data and with the mean values of these or the test data subset (Appendix E). In this case, the recommendation is to try to perform the simulation and get the results in a table format, where you can realize some statistical calculations that allow us to evaluate the model’s performance. As part of the recommendation, for regression problems, within the calculations carried out by the system for each output variable, there are the following statistical indexes: absolute deviation, standard deviation, percentage error, a graph of coefficient of Correlation R, and a calculation of the coefficient of determination R2 (see Appendix E and Appendix G). Other statistical values can be calculated. However, they could be made in a spreadsheet with the results of the output variables observed and those predicted by the system. These calculations can be: standard error, Root Mean Square error (RMSE), regression coefficients (slopes), intercepts, and more. If the obtained model’s results suggest that the system has a good or excellent performance, the modeling process is finished, changes are saved, and the results are shown. For classification problems, the system’s performance evaluation could be measured through the following metrics: The Classification accuracy (ACC), sensitivity, specificity, Function Measure, Area under the curve, and Kappa statistics. These evaluation metrics are explained in detail in Reference [26] and Reference [86] with their respective formulae. |
| End of Iterative Process | |
| 12. Communication. | This stage refers to the paper or documentation preparation. In this case, the modeler may show the results through a user manual or an academic and scientific journal article. If the main aim is to publish a journal article, the target population must be researchers or practitioners within the interest domain. |
| Inputs | Output | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| CT | UCSi | UCSh | MA | SECS | BN * | BC | NN | MI | ||
| Wisconsin Breast Cancer | ||||||||||
| Rows Number | 10 | 10 | 10 | 10 | 10 | 11 | 10 | 10 | 10 | 2 |
| Rounded Square root | 10 | 10 | 10 | 10 | 10 | 11 | 10 | 10 | 10 | - |
| Coimbra Breast Cancer | ||||||||||
| Age | BMI | Glucose | Insulin | HOMA | Leptin | Adiponectin | Resistin | MCP-1 | ||
| Rows Number | 51 | 110 | 50 | 113 | 116 | 116 | 115 | 116 | 113 | 2 |
| Rounded Square root | 7 | 10 | 7 | 11 | 11 | 11 | 11 | 11 | 11 | - |
| Inp_Var 1 | Inp_Var 2 | Inp_Var 3 | Inp_Var 4 | Inp_Var 5 | Out_Var |
|---|---|---|---|---|---|
| 1 | 2 | 3 | 2 | 1 | 2 |
| 2 | 2 | 2 | 3 | 1 | 2 |
| 3 | 4 | 3 | 1 | 2 | 2 |
| 4 | 4 | 1 | 3 | 1 | 1 |
| 4 | 4 | 3 | 2 | 2 | 1 |
| 5 | 4 | 1 | 2 | 2 | 1 |
| 6 | 3 | 2 | 2 | 2 | 2 |
| References | DDFCDSS—This Work | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Main Aspects | [29] | [11] | [10] | [9] | [94] | [6] | [26] | [95] | Five Variables (RS) | Five Variables (CV) | |
| Num of Variables | 3 | 9 | - | 6 | 9 | 9 | 7 | 3 | 5 | 5 | |
| Num of Rules or Hidden neurons/technique | 39/FIS | DBN/4:2 | DNN | DNN | SMO | FCLF and CNN | FRNN | WT and IT2FLS | 192/DDFCDSS | 233/DDFCDSS | |
| Performance | Accuracy (%): | 98.57% | 99.68% | 98.62% | 96.2%:96.6% | 72.70% | 98.71% | 99.72% | 97.88% | 99.28% | 99.40% |
| Sensitivity: | 0.9793 | 1.000 | - | - | - | 0.976 | 1.000 | 0.9850 | 0.9836 | 0.988 | |
| Specificity: | 0.9891 | 0.9947 | - | - | - | 0.9943 | 0.9947 | 0.9650 | 0.9978 | 0.998 | |
| F-Measure: | 0.9793 | - | - | - | 0.71 | - | 0.9970 | - | 0.9897 | 0.992 | |
| Area under curve: | 0.9901 | - | - | - | 0.63 | 0.9816 | 1.000 | 0.9750 | 0.9936 | 0.995 | |
| Kappa statistics: | 0.9683 | - | - | - | - | - | 0.9943 | - | 0.9842 | 0.987 | |
| Main Aspects | Reference [17] | Reference [30] | DDFCDSS—This Work | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| CV | RS | |||||||||
| Number of Variables | V1:V2 | V1:V3 | V1:4 | V1-V5 | V1:V6 | V1:V9 | V1:V8 | V2,V3,V6,V8,V9 | V1:V9 | |
| Number of Rules or Hidden neurons/technique | SVM | AdaBoostM1 and MAD | 97 | 81 | ||||||
| Performance | Accuracy (%): | - | - | - | - | - | - | 91.37 | 95.9% | 94.0% |
| Sensitivity: | 0.81:0.86 | 0.87:0.92 | 0.82:0.88 | 0.84:0.9 | 0.81:0.86 | 0.75:0.81 | - | 0.937 | 0.901 | |
| Specificity: | 0.7:0.76 | 0.78:0.83 | 0.84:0.9 | 0.81:0.87 | 0.8:0.86 | 0.78:0.84 | - | 0.992 | 1.000 | |
| F-Measure: | - | - | - | - | - | - | 0.914 | 0.964 | 0.948 | |
| Area under curve: | 0.76:0.81 | 0.82:0.86 | 0.87:0.91 | 0.86:0.9 | 0.83:0.88 | 0.81:0.85 | 0.938 | 0.957 | 0.933 | |
| Kappa statistics: | - | - | - | - | - | - | 82.76% | 0.917 | 87.6% | |
| Precision: | - | - | - | - | - | - | 0.919 | 0.994 | 1.000 | |
| Recall: | - | - | - | - | - | - | 0.914 | 0.937 | 0.901 | |
| Main Aspects | References | This Work | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| [19] | [24] | [18] | [22] | [23] | [25] | [21] | RS | CV | |||
| Number of Variables | 4 | 3 | 6 * | 6 | 3/Merged dataset | 3 | 2 | 6 | 4 | 4 | |
| Number of Rules or Hidden neurons/technique | ANFIS | NB, C4.5, DT, LR, K-NN | SVM | RF, BGSA + RF | C4.5 + RFFW | DT | J48, J48 + GA | 46/DDFCDSS | 52/DDFCDS | ||
| Performance | Accuracy (%): | 80% | 95.40% | 85.46% | 94.81% | 87.22% | 93.33% | 94.4% | 93.3% | 100.0% | 100% |
| Sensitivity: | 0,820 | 0.976 | 0.474 | - | 0.805 | 0.885 | - | 0.989 | 1.000 | 1.000 | |
| Specificity: | 0,770 | - | 0.958 | - | 0.908 | 0.980 | - | 0.130 | 1.000 | 1.000 | |
| F-Measure: | - | 0.933 | - | - | 0.799 | 0.919 | - | 0.989 | 1.000 | 1.000 | |
| Area under curve: | - | - | - | - | 0.830 | 0.617 | - | 0.988 | 1.000 | 1.000 | |
| Kappa statistics: | - | - | - | - | - | - | - | 0.977 | 1.000 | 1.000 | |
| Precision: | - | 0.937 | - | - | - | - | - | 0.989 | 1.000 | 1.000 | |
| Recall: | - | - | - | - | - | - | - | 0.989 | 1.000 | 1.000 | |
| Main Aspects | References | This Work | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| [19] | [24] | [18] | [22] | [23] | [25] | [21] | RS | CV | |||
| Number of Input Variables | 3 | 3 | 6 | 6 | 3/Merged dataset | 3 | 2 | 7 | 3 | 5 | |
| Number of Rules or Hidden Neurons/Technique | ANFIS | NB, C4.5, DT, LR, K-NN | SVM | RF, BGSA + RF | C4.5 + RFFW | DT | J48, J48 + GA | 57/DDFCDSS | 78/DDFCDSS | ||
| Performance | Accuracy (%): | 83.33% | 84% | 85.46% | 88.14% | 87.22% | 84.44% | 90% | 96.66% | 97.8% | 97.8% |
| Sensitivity: | 0.870 | 0.832 | 0.474 | - | 0.805 | 0.55 | - | 0.967 | 0.986 | 0.973 | |
| Specificity: | 0.710 | - | 0.958 | - | 0.908 | 0.9143 | - | 0.086 | 0.947 | 1.000 | |
| F-Measure: | - | 0.851 | - | 0.799 | 0.611 | - | 0.966 | 0.986 | 0.986 | ||
| Area under curve: | - | - | - | 0.830 | 0.707 | - | 0.972 | 0.966 | 0.947 | ||
| Kappa statistics: | - | - | - | - | - | - | 0.898 | 0.933 | 0.93 | ||
| Precision: | - | 0.901 | - | - | - | - | 0.966 | 0.986 | 1.000 | ||
| Recall: | - | - | - | - | - | - | 0.967 | 0.986 | 0.973 | ||
| Main Aspects | References | This Work | |||
|---|---|---|---|---|---|
| [34] | [35] | RS | CV | ||
| Number of Input Variables | 5 | 5 | 5 | 5 | |
| Number of Rules or Hidden neurons/technique | C4.5 DT/31 and 21 leaves nodes | k-nearest neighbors and Random forest | 74/DDFCDSS | 67/DDFCDSS | |
| Performance | Accuracy (%): | 86.25% | 95%:95% | 95% | 93.4% |
| Sensitivity: | 0.8630 | 0.95:0.95 | 1.0000 | 0.934 | |
| Specificity: | 0.1090 | 0.037:0.052 | 0.8947 | 0.934 | |
| F-Measure: | 0.9460 | - | 0.9545 | 0.943 | |
| Area under the curve: | - | 0.995:0.994 | 0.9565 | 0.93 | |
| Kappa statistics: | 0.7281 | 0.8992:0.8977 | 0.8992 | 0.864 | |
| Precision: | 0.8860 | 0.955:0.950 | 0.9130 | 0.952 | |
| Recall: | 0.8630 | - | 1.0000 | 0.934 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hernández-Julio, Y.F.; Prieto-Guevara, M.J.; Nieto-Bernal, W.; Meriño-Fuentes, I.; Guerrero-Avendaño, A. Framework for the Development of Data-Driven Mamdani-Type Fuzzy Clinical Decision Support Systems. Diagnostics 2019, 9, 52. https://doi.org/10.3390/diagnostics9020052
Hernández-Julio YF, Prieto-Guevara MJ, Nieto-Bernal W, Meriño-Fuentes I, Guerrero-Avendaño A. Framework for the Development of Data-Driven Mamdani-Type Fuzzy Clinical Decision Support Systems. Diagnostics. 2019; 9(2):52. https://doi.org/10.3390/diagnostics9020052
Chicago/Turabian StyleHernández-Julio, Yamid Fabián, Martha Janeth Prieto-Guevara, Wilson Nieto-Bernal, Inés Meriño-Fuentes, and Alexander Guerrero-Avendaño. 2019. "Framework for the Development of Data-Driven Mamdani-Type Fuzzy Clinical Decision Support Systems" Diagnostics 9, no. 2: 52. https://doi.org/10.3390/diagnostics9020052
APA StyleHernández-Julio, Y. F., Prieto-Guevara, M. J., Nieto-Bernal, W., Meriño-Fuentes, I., & Guerrero-Avendaño, A. (2019). Framework for the Development of Data-Driven Mamdani-Type Fuzzy Clinical Decision Support Systems. Diagnostics, 9(2), 52. https://doi.org/10.3390/diagnostics9020052