
Machine Learning-Based Non-Invasive Prediction of Metabolic Dysfunction-Associated Steatohepatitis in Obese Patients: A Retrospective Study


Abstract
1. Introduction
2. Materials and Methods
2.1. Study Design and Participants
2.2. Liver Pathology
2.3. Statistical Analysis
2.4. Machine Learning Data Processing
3. Results
3.1. Patient Characteristics
3.2. Univariate and Multivariate Analyses
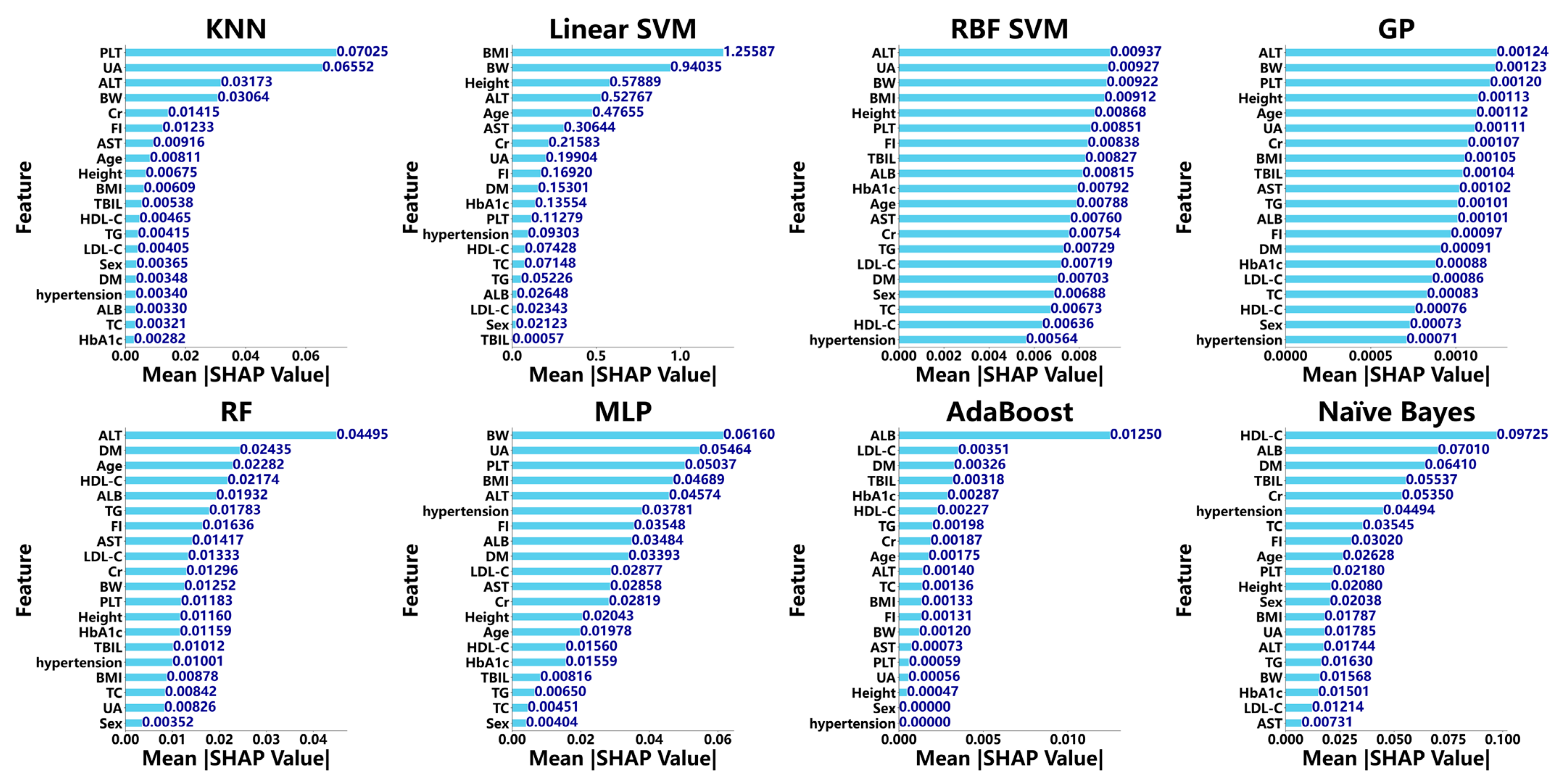
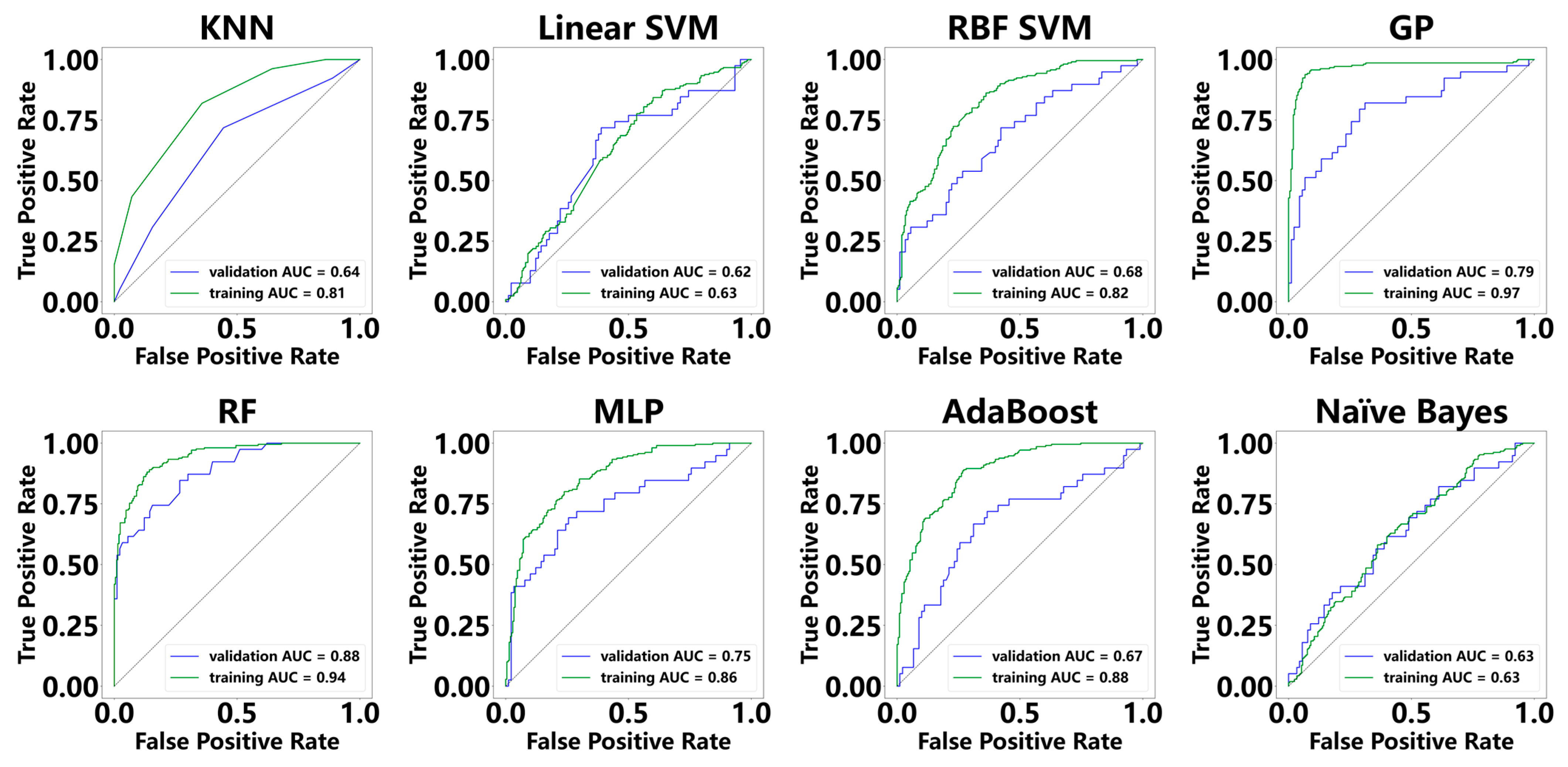
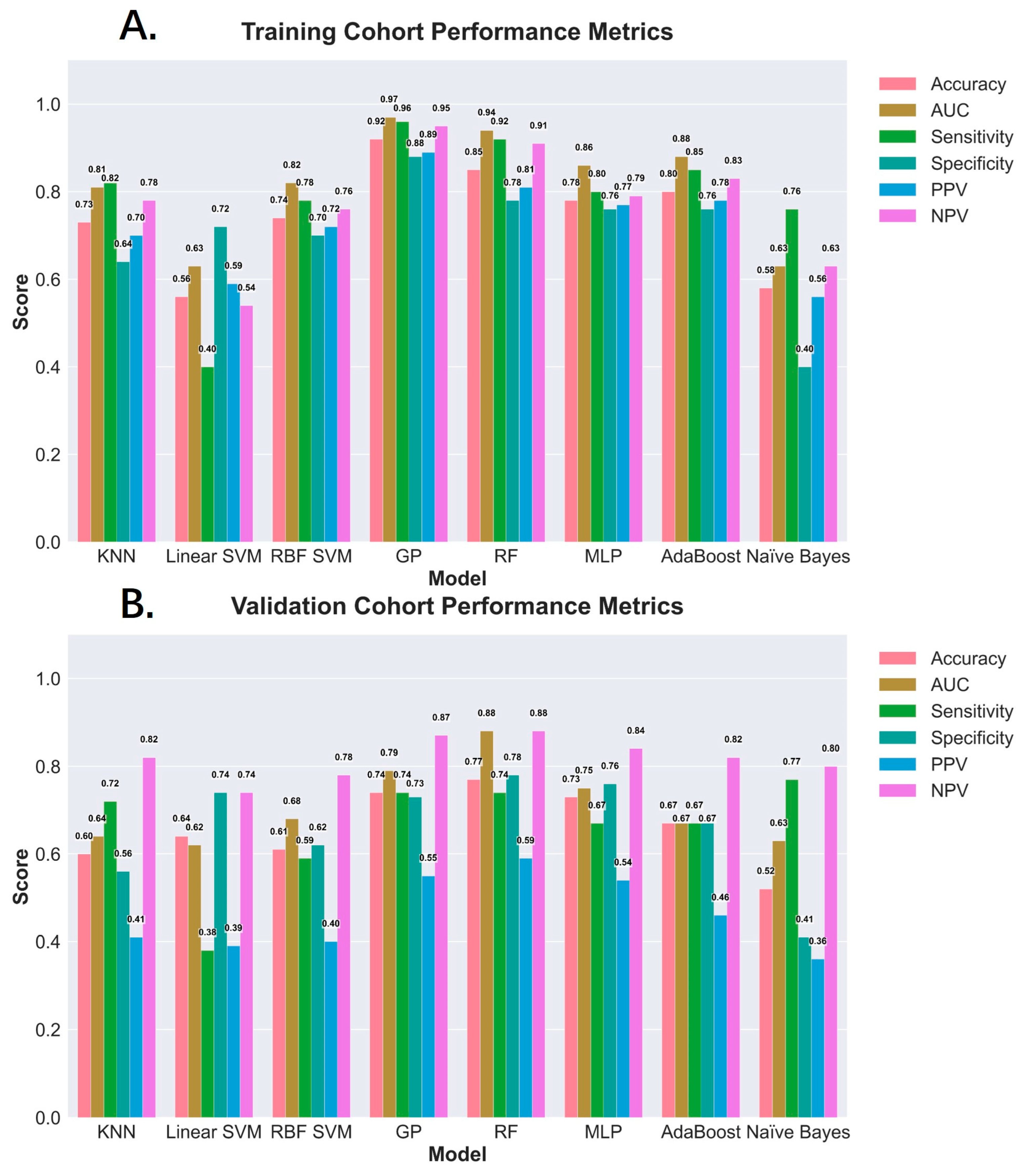
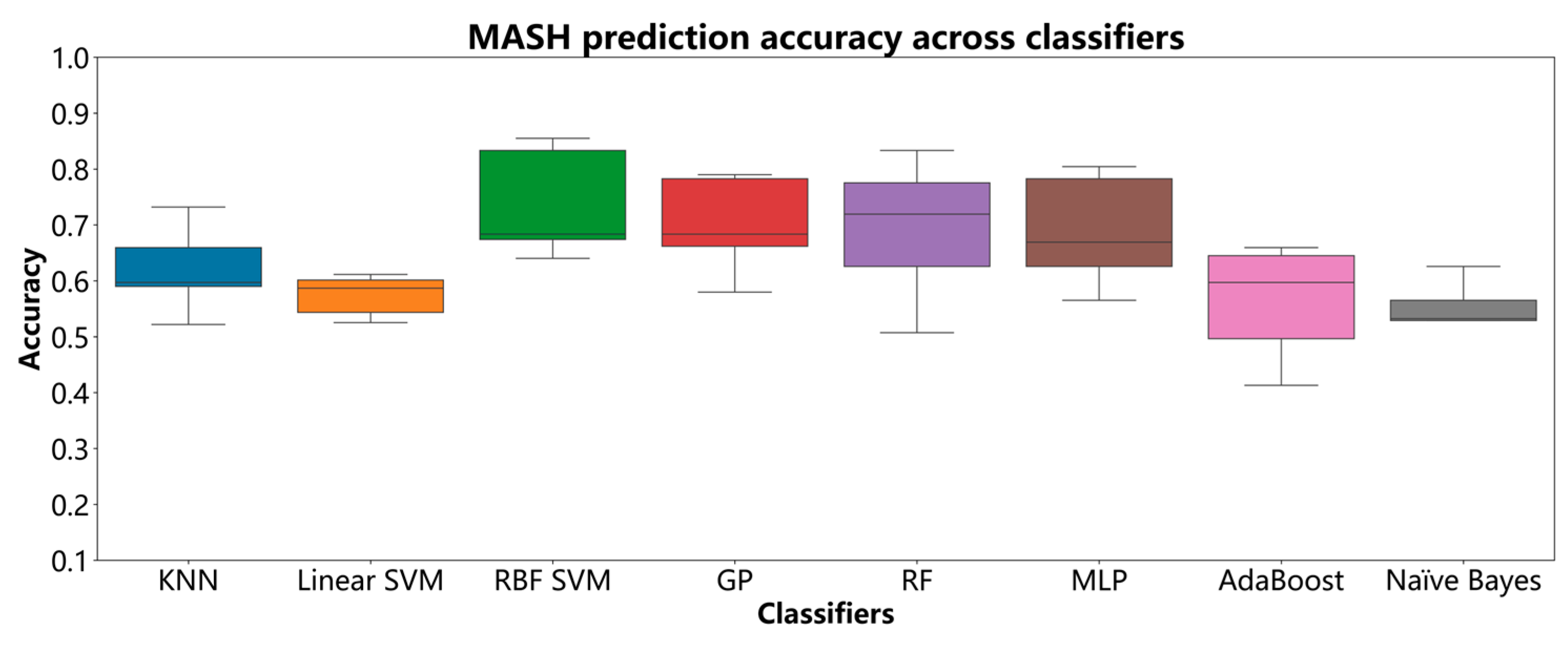
3.3. Diagnostic Performance of ML Models for MASH
3.4. Transaminase Performance in Diagnosing MASH
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ML | Machine learning |
| MASH | Metabolic dysfunction-associated steatohepatitis |
| SHAP | SHapley Additive exPlanations |
| AUC | Area under the curve |
| MAFLD | Metabolic dysfunction-associated fatty liver disease |
| NAFLD | Non-alcoholic fatty liver disease |
| NASH | Non-alcoholic steatohepatitis |
| FIB-4 | Fibrosis-4 |
| RF | Random forest |
| HCC | Hepatocellular carcinoma |
| KNNs | K-nearest neighbors |
| Linear SVM | Linear support vector machine |
| MLP | Multilayer perceptron |
| AdaBoost | Adaptive boosting |
| DM | Diabetes mellitus |
| BMI | Body Mass Index |
| ALT | Alanine aminotransferase |
| ALB | Albumin |
| HDL-C | High-density lipoprotein cholesterol |
| LDL-C | Low-density lipoprotein cholesterol |
| PLT | Platelet count |
| TG | Triglycerides |
| TC | Triglyceride |
| PPV | Positive predictive value |
| NPV | Negative predictive value |
References
- Younossi, Z.M.; Koenig, A.B.; Abdelatif, D.; Fazel, Y.; Henry, L.; Wymer, M. Global epidemiology of nonalcoholic fatty liver disease-Meta-analytic assessment of prevalence, incidence, and outcomes. Hepatology 2016, 64, 73–84. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Zhou, F.; Wang, W.; Zhang, X.-J.; Ji, Y.X.; Zhang, P.; She, Z.G.; Zhu, L.; Cai, J.; Li, H. Epidemiological Features of NAFLD from 1999 to 2018 in China. Hepatology 2020, 71, 1851–1864. [Google Scholar] [CrossRef]
- Rinella, M.E. Nonalcoholic fatty liver disease: A systematic review. JAMA 2015, 313, 2263–2273. [Google Scholar] [CrossRef]
- Hashimoto, E.; Tokushige, K. Prevalence, gender, ethnic variations, and prognosis of NASH. J. Gastroenterol. 2011, 46 (Suppl. S1), 63–69. [Google Scholar] [CrossRef] [PubMed]
- Eslam, M.; Sanyal, A.J.; George, J. MAFLD: A Consensus-Driven Proposed Nomenclature for Metabolic Associated Fatty Liver Disease. Gastroenterology 2020, 158, 1999–2014.e1991. [Google Scholar] [CrossRef]
- Chalasani, N.; Younossi, Z.; Lavine, J.E.; Charlton, M.; Cusi, K.; Rinella, M.; Harrison, S.A.; Brunt, E.M.; Sanyal, A.J. The diagnosis and management of nonalcoholic fatty liver disease: Practice guidance from the American Association for the Study of Liver Diseases. Hepatology 2018, 67, 328–357. [Google Scholar] [CrossRef]
- Di Mauro, S.; Scamporrino, A.; Filippello, A.; Di Pino, A.; Scicali, R.; Malaguarnera, R.; Purrello, F.; Piro, S. Clinical and Molecular Biomarkers for Diagnosis and Staging of NAFLD. Int. J. Mol. Sci. 2021, 22, 1905. [Google Scholar] [CrossRef] [PubMed]
- Sumida, Y.; Nakajima, A.; Itoh, Y. Limitations of liver biopsy and non-invasive diagnostic tests for the diagnosis of nonalcoholic fatty liver disease/nonalcoholic steatohepatitis. World J. Gastroenterol. 2014, 20, 475–485. [Google Scholar] [CrossRef]
- Sterling, R.K.; Lissen, E.; Clumeck, N.; Sola, R.; Correa, M.C.; Montaner, J.; Mark, S.S.; Torriani, F.J.; Dieterich, D.T.; Thomas, D.L.; et al. Development of a simple noninvasive index to predict significant fibrosis in patients with HIV/HCV coinfection. Hepatology 2006, 43, 1317–1325. [Google Scholar] [CrossRef]
- Angulo, P.; Hui, J.M.; Marchesini, G.; Bugianesi, E.; George, J.; Farrell, G.C.; Enders, F.; Saksena, S.; Burt, A.D.; Bida, J.P.; et al. The NAFLD fibrosis score: A noninvasive system that identifies liver fibrosis in patients with NAFLD. Hepatology 2007, 45, 846–854. [Google Scholar] [CrossRef]
- Schreiner, A.D.; Livingston, S.; Zhang, J.; Gebregziabher, M.; Marsden, J.; Koch, D.G.; Petz, C.A.; Durkalski-Mauldin, V.L.; Mauldin, P.D.; Moran, W.P. Identifying Patients at Risk for Fibrosis in a Primary Care NAFLD Cohort. J. Clin. Gastroenterol. 2023, 57, 89–96. [Google Scholar] [CrossRef] [PubMed]
- Basile, A.O.; Verma, A.; Tang, L.A.; Serper, M.; Scanga, A.; Farrell, A.; Destin, B.; Carr, R.M.; Anyanwu-Ofili, A.; Rajagopal, G.; et al. Rapid identification and phenotyping of nonalcoholic fatty liver disease patients using a machine-based approach in diverse healthcare systems. Clin. Transl. Sci. 2025, 18, e70105. [Google Scholar] [CrossRef] [PubMed]
- Strnad, P.; Canbay, A.; Kälsch, J.; Neumann, U.; Rau, M.; Hohenester, S.; Baba, H.A.; Rust, C.; Geier, A.; Heider, D.; et al. Non-invasive assessment of NAFLD as systemic disease—A machine learning perspective. PLoS ONE 2019, 14, e0214436. [Google Scholar] [CrossRef]
- Chang, D.; Truong, E.; Mena, E.A.; Pacheco, F.; Wong, M.; Guindi, M.; Todo, T.T.; Noureddin, N.; Ayoub, W.; Yang, J.D.; et al. Machine learning models are superior to noninvasive tests in identifying clinically significant stages of NAFLD and NAFLD-related cirrhosis. Hepatology 2023, 77, 546–557. [Google Scholar] [CrossRef]
- Newsome, P.N.; Sasso, M.; Deeks, J.J.; Paredes, A.; Boursier, J.; Chan, W.-K.; Yilmaz, Y.; Czernichow, S.; Zheng, M.-H.; Wong, V.W.-S.; et al. FibroScan-AST (FAST) score for the non-invasive identification of patients with non-alcoholic steatohepatitis with significant activity and fibrosis: A prospective derivation and global validation study. Lancet Gastroenterol. Hepatol. 2020, 5, 362–373. [Google Scholar] [CrossRef]
- Yang, Y.; Liu, J.; Sun, C.; Shi, Y.; Hsing, J.C.; Kamya, A.; Keller, C.A.; Antil, N.; Rubin, D.; Wang, H.; et al. Nonalcoholic fatty liver disease (NAFLD) detection and deep learning in a Chinese community-based population. Eur. Radiol. 2023, 33, 5894–5906. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Sun, Y.; Xiao, L.; Long, W.; Wang, G.; Cui, J.; Ren, J. Quantum and complex-valued hybrid networks for multi-principal element alloys phase prediction. iScience 2025, 28, 111582. [Google Scholar] [CrossRef]
- Plé, T.; Adjoua, O.; Lagardère, L.; Piquemal, J.P. FeNNol: An efficient and flexible library for building force-field-enhanced neural network potentials. J. Chem. Phys. 2024, 161, 042502. [Google Scholar] [CrossRef]
- Hrizi, O.; Gasmi, K.; Ben Ltaifa, I.; Alshammari, H.; Karamti, H.; Krichen, M.; Ben Ammar, L.; Mahmood, M.A. Tuberculosis Disease Diagnosis Based on an Optimized Machine Learning Model. J. Healthc. Eng. 2022, 2022, 8950243. [Google Scholar] [CrossRef]
- Nwanosike, E.M.; Conway, B.R.; Merchant, H.A.; Hasan, S.S. Potential applications and performance of machine learning techniques and algorithms in clinical practice: A systematic review. Int. J. Med. Inform. 2022, 159, 104679. [Google Scholar] [CrossRef]
- Rubinger, L.; Gazendam, A.; Ekhtiari, S.; Bhandari, M. Machine learning and artificial intelligence in research and healthcare. Injury 2023, 54 (Suppl. S3), S69–S73. [Google Scholar] [CrossRef] [PubMed]
- Kleiner, D.E.; Brunt, E.M.; Van Natta, M.; Behling, C.; Contos, M.J.; Cummings, O.W.; Ferrell, L.D.; Liu, Y.C.; Torbenson, M.S.; Unalp-Arida, A.; et al. Design and validation of a histological scoring system for nonalcoholic fatty liver disease. Hepatology 2005, 41, 1313–1321. [Google Scholar] [CrossRef]
- Zhang, Z. Introduction to machine learning: K-nearest neighbors. Ann. Transl. Med. 2016, 4, 218. [Google Scholar] [CrossRef] [PubMed]
- Srisuradetchai, P.; Suksrikran, K. Random kernel k-nearest neighbors regression. Front. Big Data 2024, 7, 1402384. [Google Scholar] [CrossRef]
- Chauhan, V.K.; Dahiya, K.; Sharma, A. Problem formulations and solvers in linear SVM: A review. Artif. Intell. Rev. 2019, 52, 803–855. [Google Scholar] [CrossRef]
- Prasad, S.V.S.; Savithiri, T.S.; Krishna, V.M. Performance Evaluation of Svm Kernels on Multispectral Liss III Data for Object Classification. Int. J. Smart Sens. Intell. Syst. 2017, 10, 863–878. [Google Scholar] [CrossRef]
- Gurugubelli, S.; Chepuri, S.P. Gaussian Processes for Edge Flow Prediction with Active Learning. In Proceedings of the 2023 57th Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 29 October–1 November 2023; pp. 809–813. [Google Scholar]
- Schulz, E.; Speekenbrink, M.; Krause, A. A tutorial on Gaussian process regression: Modelling, exploring, and exploiting functions. J. Math. Psychol. 2016, 85, 1–16. [Google Scholar] [CrossRef]
- Karabadji, N.E.I.; Korba, A.A.; Assi, A.; Seridi-Bouchelaghem, H.; Aridhi, S.; Dhifli, W. Accuracy and diversity-aware multi-objective approach for random forest construction. Expert Syst. Appl. 2023, 225, 120138. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Alsmadi, M.K.S.; Omar, K.; Noah, S.A.M. Back Propagation Algorithm: The Best Algorithm Among the Multi-layer Perceptron Algorithm. Int. J. Comput. Sci. Netw. Secur. 2009, 9, 378–383. [Google Scholar]
- Sheng, W.; Liu, Y.; Söffker, D. A novel adaptive boosting algorithm with distance-based weighted least square support vector machine and filter factor for carbon fiber reinforced polymer multi-damage classification. Struct. Health Monit. 2022, 22, 1273–1289. [Google Scholar] [CrossRef]
- Yang, F.-J. An Implementation of Naive Bayes Classifier. In Proceedings of the 2018 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 12–14 December 2018; pp. 301–306. [Google Scholar] [CrossRef]
- Rinella, M.E.; Neuschwander-Tetri, B.A.; Siddiqui, M.S.; Abdelmalek, M.F.; Caldwell, S.; Barb, D.; Kleiner, D.E.; Loomba, R. AASLD Practice Guidance on the clinical assessment and management of nonalcoholic fatty liver disease. Hepatology 2023, 77, 1797–1835. [Google Scholar] [CrossRef]
- Li, M.; Liu, Y.; Jin, L.; Zeng, N.; Wang, L.; Zhao, K.; Lv, H.; Zhang, M.; Xu, W.; Zhang, P.; et al. Metabolic Features of Individuals with Obesity Referred for Bariatric and Metabolic Surgery: A Cohort Study. Obes. Surg. 2019, 29, 3966–3977. [Google Scholar] [CrossRef] [PubMed]
- Schmitz, S.M.; Storms, S.; Koch, A.; Stier, C.; Kroh, A.; Rheinwalt, K.P.; Schipper, S.; Hamesch, K.; Ulmer, T.F.; Neumann, U.P.; et al. Insulin Resistance Is the Main Characteristic of Metabolically Unhealthy Obesity (MUO) Associated with NASH in Patients Undergoing Bariatric Surgery. Biomedicines 2023, 11, 1595. [Google Scholar] [CrossRef]
- Kwak, M.; Mehaffey, J.H.; Hawkins, R.B.; Hsu, A.; Schirmer, B.; Hallowell, P.T. Bariatric surgery is associated with reduction in non-alcoholic steatohepatitis and hepatocellular carcinoma: A propensity matched analysis. Am. J. Surg. 2020, 219, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Praveenraj, P.; Gomes, R.M.; Kumar, S.; Karthikeyan, P.; Shankar, A.; Parthasarathi, R.; Senthilnathan, P.; Rajapandian, S.; Palanivelu, C. Prevalence and Predictors of Non-Alcoholic Fatty Liver Disease in Morbidly Obese South Indian Patients Undergoing Bariatric Surgery. Obes. Surg. 2015, 25, 2078–2087. [Google Scholar] [CrossRef]
- Harrison, S.A.; Bedossa, P.; Guy, C.D.; Schattenberg, J.M.; Loomba, R.; Taub, R.; Labriola, D.; Moussa, S.E.; Neff, G.W.; Rinella, M.E.; et al. A Phase 3, Randomized, Controlled Trial of Resmetirom in NASH with Liver Fibrosis. N. Engl. J. Med. 2024, 390, 497–509. [Google Scholar] [CrossRef]
- Younossi, Z.M.; Loomba, R.; Anstee, Q.M.; Rinella, M.E.; Bugianesi, E.; Marchesini, G.; Neuschwander-Tetri, B.A.; Serfaty, L.; Negro, F.; Caldwell, S.H.; et al. Diagnostic modalities for nonalcoholic fatty liver disease, nonalcoholic steatohepatitis, and associated fibrosis. Hepatology 2018, 68, 349–360. [Google Scholar] [CrossRef]
- Poynard, T.; Ratziu, V.; Charlotte, F.; Messous, D.; Munteanu, M.; Imbert-Bismut, F.; Massard, J.; Bonyhay, L.; Tahiri, M.; Thabut, D.; et al. Diagnostic value of biochemical markers (NashTest) for the prediction of non alcoholo steato hepatitis in patients with non-alcoholic fatty liver disease. BMC Gastroenterol. 2006, 6, 34. [Google Scholar] [CrossRef]
- Chandra Kumar, C.V.; Skantha, R.; Chan, W.K. Non-invasive assessment of metabolic dysfunction-associated fatty liver disease. Ther. Adv. Endocrinol. Metab. 2022, 13, 20420188221139614. [Google Scholar] [CrossRef]
- Åsberg, A.; Løfblad, L.; Hov, G.G. The likelihood ratios of FIB-4-values for diagnosing advanced liver fibrosis in patients with NAFLD. Clin. Chem. Lab. Med. (CCLM) 2023, 61, e233–e234. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Westphal, M.; Vali, Y.; Boursier, J.; Petta, S.; Ostroff, R.; Alexander, L.; Chen, Y.; Fournier, C.; Geier, A.; et al. Machine learning algorithm improves the detection of NASH (NAS-based) and at-risk NASH: A development and validation study. Hepatology 2023, 78, 258–271. [Google Scholar] [CrossRef] [PubMed]
- Docherty, M.; Tietz, A.; Regnier, S.; Balp, M.; Capkun, G.; Loeffler, J.; Pedrosa, M.; Schattenberg, J. 1487-P: Increased Identification of NASH among Diabetic and Nondiabetic Patients through Machine Learning in Real-World Settings. Diabetes 2020, 69, 1487. [Google Scholar] [CrossRef]
- Yasar, O.; Long, P.; Harder, B.; Marshall, H.; Bhasin, S.; Lee, S.; Delegge, M.; Roy, S.; Doyle, O.; Leavitt, N.; et al. Machine learning using longitudinal prescription and medical claims for the detection of non-alcoholic steatohepatitis (NASH). BMJ Health Care Inform. 2022, 29, e100510. [Google Scholar] [CrossRef]
- Eslam, M.; Newsome, P.N.; Sarin, S.K.; Anstee, Q.M.; Targher, G.; Romero-Gomez, M.; Zelber-Sagi, S.; Wai-Sun Wong, V.; Dufour, J.F.; Schattenberg, J.M.; et al. A new definition for metabolic dysfunction-associated fatty liver disease: An international expert consensus statement. J. Hepatol. 2020, 73, 202–209. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | Training Cohort (n = 390) | Validation Cohort (n = 168) |
|---|---|---|
| Male | 152 (39.0%) | 70 (41.7%) |
| Age (years) | 34.0 (28.0–41.0) | 34.0 (27.8–40.3) |
| Body weight (kg) | 110.0 (95.0–127.8) | 114.0 (96.7–130.4) |
| Height (cm) | 168.0 (162.5–174.0) | 168.5 (164.0–175.0) |
| Body mass index (kg/m2) | 39.0 (34.6–43.4) | 39.8 (34.8–44.8) |
| Diabetes mellitus | 148 (37.9%) | 55 (32.7%) |
| Hypertension | 153 (39.2%) | 64 (38.1%) |
| Platelet count (×109/L) | 260.0 (220.0–303.0) | 277 (235.5–310.5) |
| Alanine transaminase (U/L) | 37.0 (22.0–57.8) | 39.0 (22.8–63.0) |
| Aspartate transaminase (U/L) | 24.0 (16.0–33.0) | 25.0 (18.0–34.0) |
| Total bilirubin (µmol/L) | 12.3 (9.7–15.3) | 12.9 (9.5–16.0) |
| Albumin (g/L) | 43.6 (41.7–45) | 43.6 (42.0–45.0) |
| Uric acid (µmol/L) | 421.0 (352.0–491.5) | 435.0 (356.0–503.3) |
| Total cholesterol (mmol/L) | 4.9 (4.3–5.4) | 4.9 (4.4–5.4) |
| Triglyceride (mmol/L) | 1.8 (1.3–2.5) | 1.9 (1.3–2.4) |
| High-density lipoprotein cholesterol (mmol/L) | 1.0 (0.8–1.1) | 1.0 (0.8–1.1) |
| Low-density lipoprotein cholesterol (mmol/L) | 3.1 (2.6–3.5) | 3.1 (2.7–3.6) |
| Creatinine (μmol/L) | 55.7 (47.6–65.6) | 58.7 (48.4–66.0) |
| Glycosylated hemoglobin (%) | 6.1 (5.6–6.8) | 6.2 (5.6–6.7) |
| Fasting insulin (pmol/mL) | 23.5 (15.4–30.1) | 24.1 (17.2–29.1) |
| Grade of steatosis | ||
| Grade 0 | 36 (9.2%) | 21 (12.5) |
| Grade 1 | 157 (40.3%) | 66 (39.3%) |
| Grade 2 | 125 (32.1%) | 44 (26.2%) |
| Grade 3 | 72 (18.4%) | 37 (22.0%) |
| MASH: Yes | 245 (62.8%) | 67 (39.9%) |
| MASH: No | 145 (37.2%) | 101 (60.1%) |
| Fibrosis stage | ||
| F0 | 309 (79.2%) | 126 (75.0%) |
| F1 | 58 (14.9%) | 35 (20.8%) |
| F2 | 8 (2.0%) | 3 (1.8%) |
| F3 | 12 (3.1%) | 3 (1.8%) |
| F4 | 3 (0.8) | 1 (0.6%) |
| Variables | OR (95% CI) | p-Value |
|---|---|---|
| Hypertension | 1.55 (1.06–2.27) | 0.025 |
| Diabetes mellitus | 1.78 (1.21–2.62) | 0.004 |
| Body weight | 1.23 (1.02–1.48) | 0.028 |
| Body mass index | 1.24 (1.03–1.50) | 0.021 |
| Alanine aminotransferase | 1.51 (1.25–1.84) | <0.001 |
| Aspartate aminotransferase | 1.43 (1.18–1.73) | <0.001 |
| Albumin | 1.27 (1.05–1.54) | 0.012 |
| Triglycerides | 1.27 (1.06–1.54) | 0.011 |
| Fasting insulin | 1.37 (1.13–1.65) | 0.001 |
| High-density lipoprotein cholesterol | 0.82 (0.67–0.99) | 0.038 |
| Steatosis grade | 2.03 (1.62–2.53) | <0.001 |
| Fibrosis stage | 3.72 (2.47–5.60) | <0.001 |
| Sex | 0.78 (0.53–1.14) | 0.205 |
| Age | 0.98 (0.81–1.18) | 0.819 |
| Height | 1.10 (0.91–1.32) | 0.314 |
| Platelet count | 1.09 (0.91–1.31) | 0.365 |
| Total bilirubin | 0.99 (0.82–1.19) | 0.928 |
| Uric acid | 1.12 (0.93–1.34) | 0.244 |
| Total cholesterol | 1.11 (0.92–1.34) | 0.269 |
| Low-density lipoprotein cholesterol | 1.13 (0.93–1.36) | 0.212 |
| Creatinine | 1.01 (0.84–1.21) | 0.954 |
| Glycated hemoglobin | 1.14 (0.95–1.37) | 0.156 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Zhang, B.; Cheng, Y.; Jia, Y.; Zhou, B. Machine Learning-Based Non-Invasive Prediction of Metabolic Dysfunction-Associated Steatohepatitis in Obese Patients: A Retrospective Study. Diagnostics 2025, 15, 1096. https://doi.org/10.3390/diagnostics15091096
Chen J, Zhang B, Cheng Y, Jia Y, Zhou B. Machine Learning-Based Non-Invasive Prediction of Metabolic Dysfunction-Associated Steatohepatitis in Obese Patients: A Retrospective Study. Diagnostics. 2025; 15(9):1096. https://doi.org/10.3390/diagnostics15091096
Chicago/Turabian StyleChen, Jie, Bo Zhang, Yong Cheng, Yuanchen Jia, and Biao Zhou. 2025. "Machine Learning-Based Non-Invasive Prediction of Metabolic Dysfunction-Associated Steatohepatitis in Obese Patients: A Retrospective Study" Diagnostics 15, no. 9: 1096. https://doi.org/10.3390/diagnostics15091096
APA StyleChen, J., Zhang, B., Cheng, Y., Jia, Y., & Zhou, B. (2025). Machine Learning-Based Non-Invasive Prediction of Metabolic Dysfunction-Associated Steatohepatitis in Obese Patients: A Retrospective Study. Diagnostics, 15(9), 1096. https://doi.org/10.3390/diagnostics15091096