
Impact of Radiologist Experience on AI Annotation Quality in Chest Radiographs: A Comparative Analysis

 , , ,
, , ,  and
and
Abstract
1. Introduction
2. Materials and Methods
2.1. Data Collection
2.2. Segmentation Process
- Anatomical Structures: These were categorized based on their level of difficulty in terms of identification and annotation. The structures included were the left lung (easy), the heart (medium), and the superior vena cava (VCS) (hard).
- Foreign Material: The CVC, if present, was annotated. In many cases, the CVC had to be distinguished from other tube-like foreign material, e.g., dialysis catheters. Twelve of the images showed a misplaced CVC.
- Pulmonary Pathology: Pneumonic opacity was annotated. All participants were aware that all patients in the cohort were treated for pneumonia.
2.3. Statistics
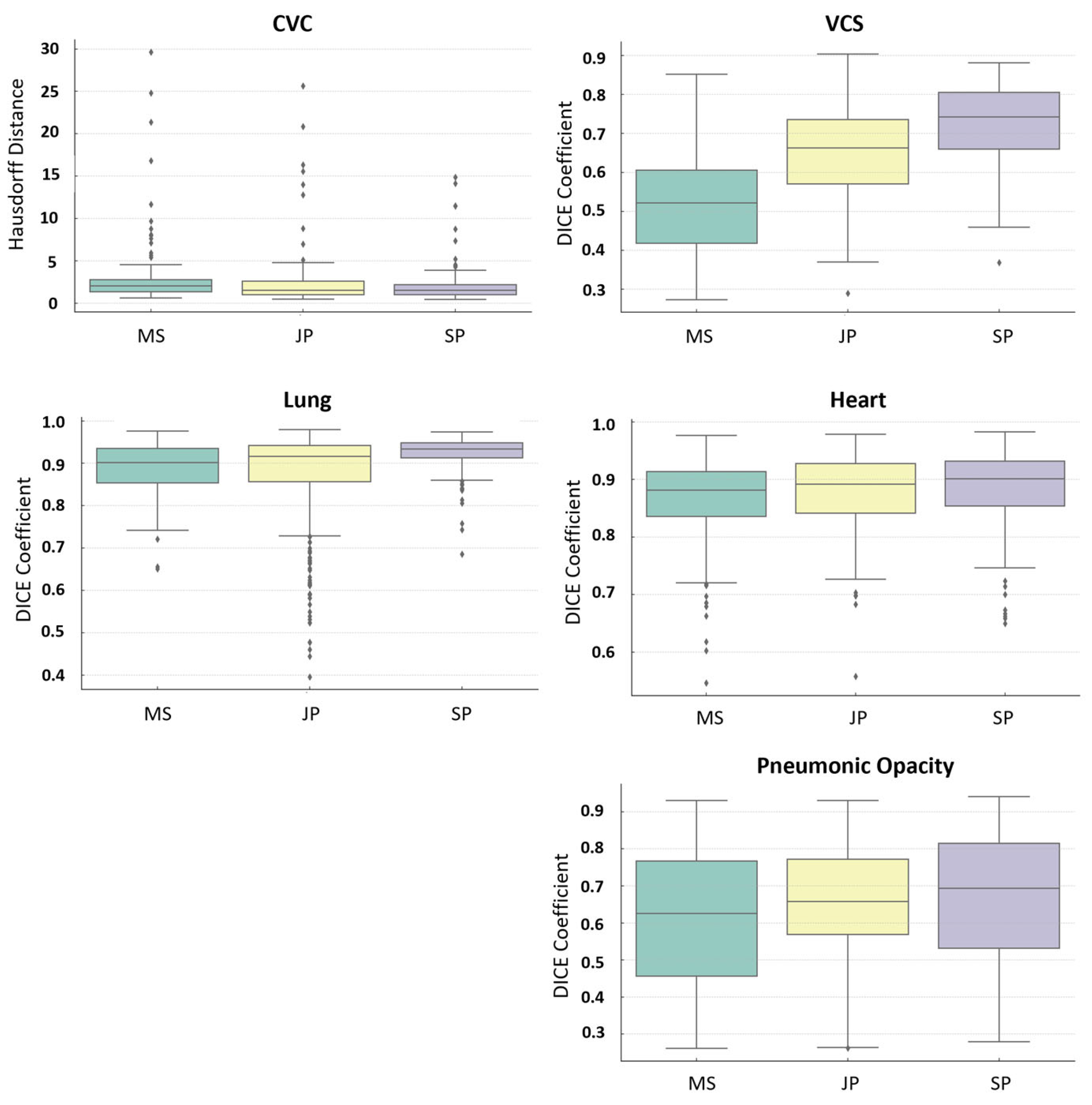
3. Results
- CVC: Significant differences were noted between the group MS and JP, as well as the MS and SP groups.
- VCS: All pairs of groups exhibited significant differences in their annotations.
- Heart Structure: A significant difference was noted only between the MS and SP groups.
- Lung Structure: Significant differences were found between the JP and SP groups, as well as the MS and SP groups.
- Pneumonic Opacity Structure: Significant differences were observed between the MS and JP groups, and the MS and SP groups.
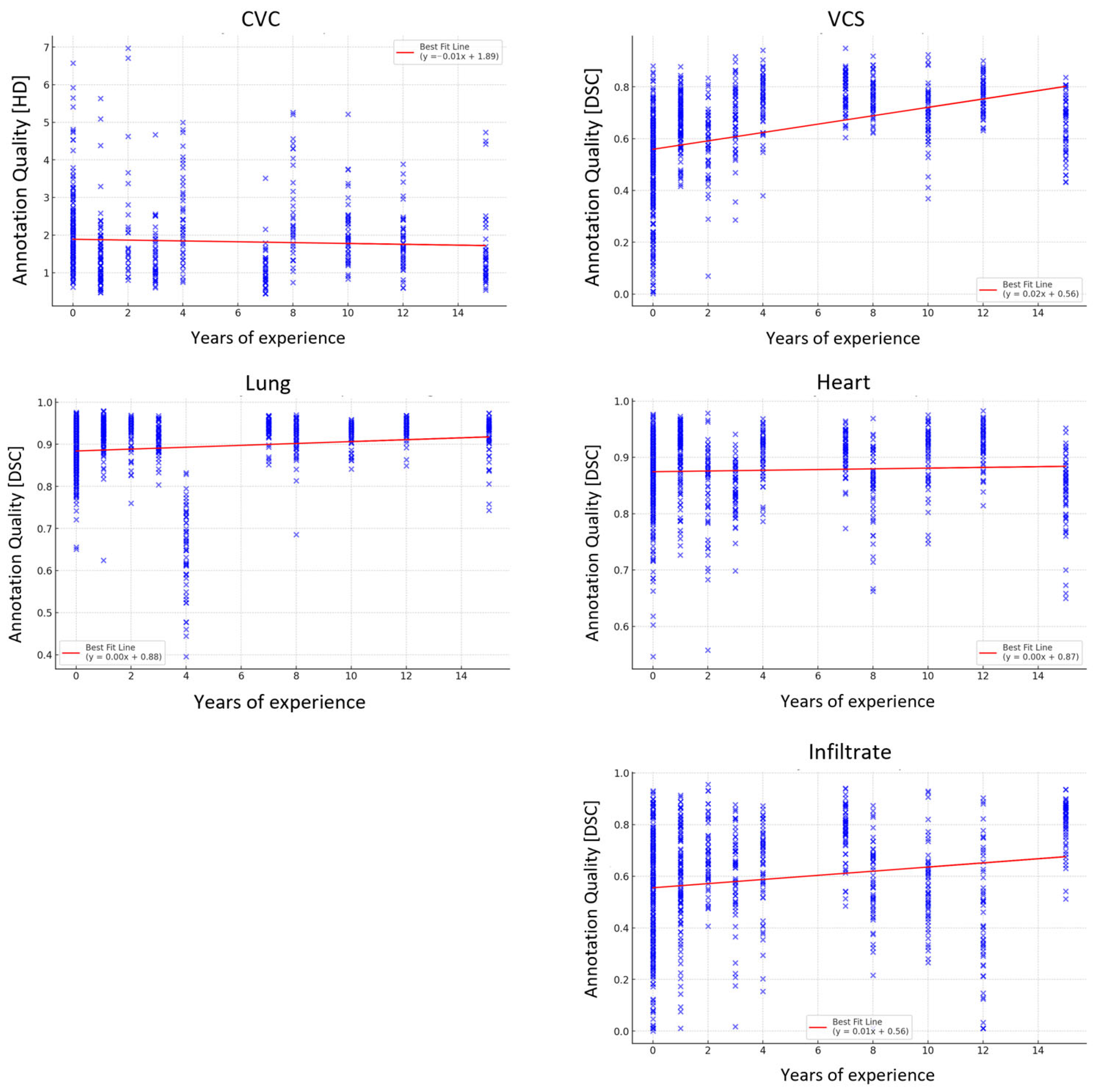
3.1. Correlation and Regression Analysis
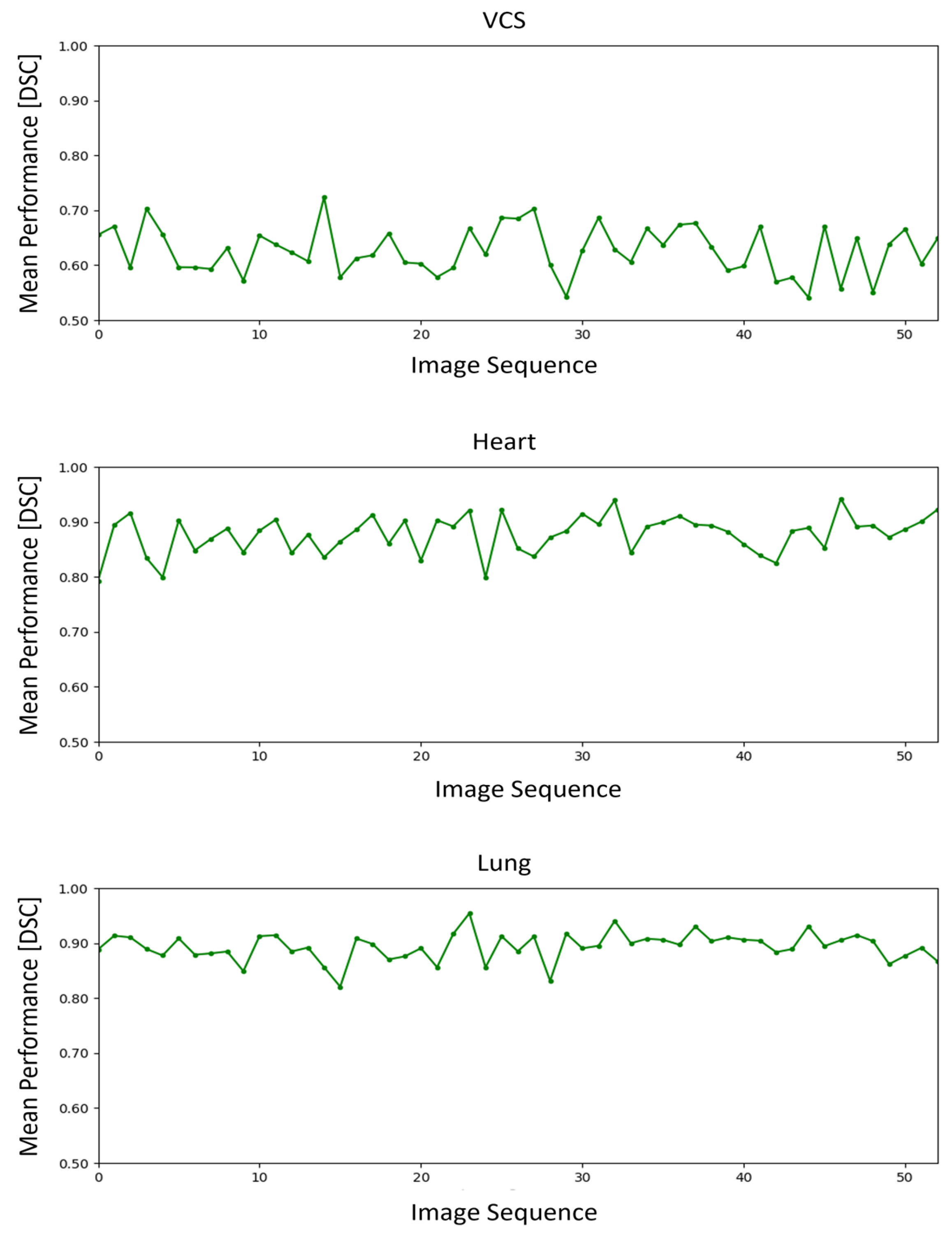
3.2. Time-Series Analysis
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| HD | Hausdorff Distance |
| DSC | Dice Coefficient |
| ICC | Intraclass Correlation Coefficient |
| OLS | Ordinary Least Squares (OLS) |
| VCS | Vena Cava Superior |
| MS | Medical Students |
| JP | Junior Professionals |
| SP | Senior Professionals |
References
- Van Leeuwen, K.G.; De Rooij, M.; Schalekamp, S.; Van Ginneken, B.; Rutten, M.J.C.M. Clinical use of artificial intelligence products for radiology in the Netherlands between 2020 and 2022. Eur. Radiol. 2023, 34, 348–354. [Google Scholar] [CrossRef] [PubMed]
- Van Leeuwen, K.G.; Schalekamp, S.; Rutten, M.J.C.M.; Van Ginneken, B.; De Rooij, M. Artificial intelligence in radiology: 100 commercially available products and their scientific evidence. Eur. Radiol. 2021, 31, 3797–3804. [Google Scholar] [CrossRef] [PubMed]
- Adams, S.J.; Henderson, R.D.E.; Yi, X.; Babyn, P. Artificial Intelligence Solutions for Analysis of X-ray Images. Can. Assoc. Radiol. J. 2021, 72, 60–72. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Peng, L.; Li, T.; Adila, D.; Zaiman, Z.; Melton-Meaux, G.B.; Ingraham, N.E.; Murray, E.; Boley, D.; Switzer, S.; et al. Performance of a Chest Radiograph AI Diagnostic Tool for COVID-19: A Prospective Observational Study. Radiol. Artif. Intell. 2022, 4, e210217. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Rong, R.; Li, Q.; Yang, D.M.; Yao, B.; Luo, D.; Zhang, X.; Zhu, X.; Luo, J.; Liu, Y.; et al. A deep learning-based model for screening and staging pneumoconiosis. Sci. Rep. 2021, 11, 2201. [Google Scholar] [CrossRef] [PubMed]
- Stadler, C.B.; Lindvall, M.; Lundström, C.; Bodén, A.; Lindman, K.; Rose, J.; Treanor, D.; Blomma, J.; Stacke, K.; Pinchaud, N.; et al. Proactive Construction of an Annotated Imaging Database for Artificial Intelligence Training. J. Digit. Imaging 2021, 34, 105–115. [Google Scholar] [CrossRef] [PubMed]
- Rueckel, J.; Huemmer, C.; Fieselmann, A.; Ghesu, F.-C.; Mansoor, A.; Schachtner, B.; Wesp, P.; Trappmann, L.; Munawwar, B.; Ricke, J.; et al. Pneumothorax detection in chest radiographs: Optimizing artificial intelligence system for accuracy and confounding bias reduction using in-image annotations in algorithm training. Eur. Radiol. 2021, 31, 7888–7900. [Google Scholar] [CrossRef] [PubMed]
- Stroeder, J.; Multusch, M.; Berkel, L.; Hansen, L.; Saalbach, A.; Schulz, H.; Heinrich, M.P.; Elser, Y.; Barkhausen, J.; Sieren, M.M. Optimizing Catheter Verification: An Understandable AI Model for Efficient Assessment of Central Venous Catheter Placement in Chest Radiography. Invest. Radiol. 2025, 60, 267–274. [Google Scholar] [CrossRef] [PubMed]
- Bellini, D.; Panvini, N.; Rengo, M.; Vicini, S.; Lichtner, M.; Tieghi, T.; Ippoliti, D.; Giulio, F.; Orlando, E.; Iozzino, M.; et al. Diagnostic accuracy and interobserver variability of CO-RADS in patients with suspected coronavirus disease-2019: A multireader validation study. Eur. Radiol. 2021, 31, 1932–1940. [Google Scholar] [CrossRef] [PubMed]
- Singh, S.P.; Gierada, D.S.; Pinsky, P.; Sanders, C.; Fineberg, N.; Sun, Y.; Lynch, D.; Nath, H. Reader variability in identifying pulmonary nodules on chest radiographs from the national lung screening trial. J. Thorac. Imaging 2012, 27, 249–254. [Google Scholar] [CrossRef] [PubMed]
- Mairhöfer, D.; Laufer, M.; Simon, P.M.; Sieren, M.; Bischof, A.; Käster, T.; Barth, E.; Barkhausen, J.; Martinetz, T. An AI-based Framework for Diagnostic Quality Assessment of Ankle Radiographs. Proc. Mach. Learn. Res. 2021, 143, 484–496. [Google Scholar]
- Sieren, M.M.; Widmann, C.; Weiss, N.; Moltz, J.H.; Link, F.; Wegner, F.; Stahlberg, E.; Horn, M.; Oecherting, T.H.; Goltz, J.P.; et al. Automated segmentation and quantification of the healthy and diseased aorta in CT angiographies using a dedicated deep learning approach. Eur. Radiol. 2022, 32, 690–701. [Google Scholar] [CrossRef] [PubMed]
- Lange, M.; Boddu, P.; Singh, A.; Gross, B.D.; Mei, X.; Liu, Z.; Bernheim, A.; Chung, M.; Huang, M.; Masseaux, J.; et al. Influence of thoracic radiology training on classification of interstitial lung diseases. Clin. Imaging 2023, 97, 14–21. [Google Scholar] [CrossRef] [PubMed]
- Hochhegger, B.; Alves, G.R.T.; Chaves, M.; Moreira, A.L.; Kist, R.; Watte, G.; Moreira, J.S.; Irion, K.L.; Marchiori, E. Interobserver agreement between radiologists and radiology residents and emergency physicians in the detection of PE using CTPA. Clin. Imaging 2014, 38, 445–447. [Google Scholar] [CrossRef] [PubMed]
- Martini, K.; Ottilinger, T.; Serrallach, B.; Markart, S.; Glaser-Gallion, N.; Bluthgen, C.; Leschka, S.; Bauer, R.W.; Wildermuth, S.; Messerli, M. Lung cancer screening with submillisievert chest CT: Potential pitfalls of pulmonary findings in different readers with various experience levels. Eur. J. Radiol. 2019, 121, 108720. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Zhang, C.; Zhou, K.; Gao, S. Chest X-Ray Diagnostic Quality Assessment: How Much Is Pixel-Wise Supervision Needed? IEEE Trans. Med. Imaging 2022, 41, 1711–1723. [Google Scholar] [CrossRef] [PubMed]
- Thelle, A.; Gjerdevik, M.; Grydeland, T.; Skorge, T.D.; Wentzel-Larsen, T.; Bakke, P.S. Pneumothorax size measurements on digital chest radiographs: Intra- and inter- rater reliability. Eur. J. Radiol. 2015, 84, 2038–2043. [Google Scholar] [CrossRef]
- Rajaraman, S.; Sornapudi, S.; Alderson, P.O.; Folio, L.R.; Antani, S.K. Analyzing inter-reader variability affecting deep ensemble learning for COVID-19 detection in chest radiographs. PLoS ONE 2020, 15, e0242301. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Li, C.; Wang, R.; Liu, Z.; Wang, M.; Tan, H.; Wu, Y.; Liu, X.; Sun, H.; Yang, R.; et al. Annotation-efficient deep learning for automatic medical image segmentation. Nat. Commun. 2021, 12, 5915. [Google Scholar] [CrossRef] [PubMed]
- Lekadir, K.; Osuala, R.; Gallin, C.; Lazrak, N.; Kushibar, K.; Tsakou, G.; Aussó, S.; Alberich, L.C.; Marias, K.; Tsiknakis, M. FUTURE-AI: Guiding Principles and Consensus Recommendations for Trustworthy Artificial Intelligence in Medical Imaging. arXiv 2024, arXiv:2109.09658. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Structure | Groups | Mean | Std. Dev. | Min. | 0.25 | Median | 0.75 | Max. | Misses [%] |
|---|---|---|---|---|---|---|---|---|---|
| CVC HD [mm] | MS | 22.43 | 56.96 | 0.62 | 1.48 | 2.26 | 7.82 | 524.18 | 18 |
| JP | 26.39 | 95.17 | 0.47 | 1.04 | 1.63 | 3.34 | 554.16 | 12 | |
| SP | 17.41 | 76.72 | 0.4 | 1.13 | 1.67 | 2.51 | 556.18 | 4 | |
| VCS DICE | MS | 0.48 | 0.20 | 0.0002 | 0.35 | 0.52 | 0.63 | 0.88 | 1.8 |
| JP | 0.67 | 0.13 | 0.069 | 0.60 | 0.68 | 0.76 | 0.94 | 0.4 | |
| SP | 0.73 | 0.10 | 0.368 | 0.68 | 0.74 | 0.80 | 0.95 | 0 | |
| Heart DICE | MS | 0.867 | 0.068 | 0.546 | 0.836 | 0.881 | 0.913 | 0.977 | 0 |
| JP | 0.880 | 0.064 | 0.558 | 0.842 | 0.892 | 0.928 | 0.978 | 0 | |
| SP | 0.885 | 0.064 | 0.650 | 0.854 | 0.901 | 0.932 | 0.983 | 0 | |
| Lung DICE | MS | 0.890 | 0.057 | 0.651 | 0.853 | 0.902 | 0.935 | 0.976 | 0 |
| JP | 0.866 | 0.123 | 0.396 | 0.856 | 0.916 | 0.942 | 0.979 | 0 | |
| SP | 0.925 | 0.038 | 0.685 | 0.913 | 0.934 | 0.948 | 0.974 | 0 | |
| Pneumonic Opacity DICE | MS | 0.516 | 0.246 | 0.00004 | 0.339 | 0.560 | 0.711 | 0.931 | 16.4 |
| JP | 0.621 | 0.181 | 0.010 | 0.524 | 0.647 | 0.748 | 0.956 | 5.2 | |
| SP | 0.631 | 0.211 | 0.010 | 0.503 | 0.660 | 0.806 | 0.941 | 4.8 |
| Structure | Groups | Interreader | Intrareader |
|---|---|---|---|
| CVC HD [mm] | MS | 0.38 | 0.81 |
| JP | 0.41 | 0.84 | |
| SP | 0.61 | 0.87 | |
| VCS DICE | MS | 0.90 | 0.85 |
| JP | 0.86 | 0.80 | |
| SP | 0.85 | 0.82 | |
| Heart DICE | MS | 0.867 | 0.88 |
| JP | 0.880 | 0.88 | |
| SP | 0.885 | 0.91 | |
| Lung DICE | MS | 0.90 | 0.92 |
| JP | 0.92 | 0.94 | |
| SP | 0.98 | 0.93 | |
| Pneumonic Opacity DICE | MS | 0.45 | 0.61 |
| JP | 0.52 | 0.72 | |
| SP | 0.66 | 0.77 |
| Structure | R-Squared | Correlation (Experience) | p-Value | Spearman Coefficient | p-Value |
|---|---|---|---|---|---|
| CVC | 0.001 | n.s. | 0.34 | −0.150 | <0.001 |
| VCS | 0.136 | 0.0120 | <0.05 | 0.545 | <0.001 |
| Heart | 0.015 | 0.0018 | <0.05 | 0.081 | <0.05 |
| Lung | 0.001 | n.s. | 0.89 | 0.180 | <0.001 |
| Pneumonic Opacity | 0.003 | n.s. | 0.12 | 0.173 | <0.001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Multusch, M.M.; Hansen, L.; Heinrich, M.P.; Berkel, L.; Saalbach, A.; Schulz, H.; Wegner, F.; Barkhausen, J.; Sieren, M.M. Impact of Radiologist Experience on AI Annotation Quality in Chest Radiographs: A Comparative Analysis. Diagnostics 2025, 15, 777. https://doi.org/10.3390/diagnostics15060777
Multusch MM, Hansen L, Heinrich MP, Berkel L, Saalbach A, Schulz H, Wegner F, Barkhausen J, Sieren MM. Impact of Radiologist Experience on AI Annotation Quality in Chest Radiographs: A Comparative Analysis. Diagnostics. 2025; 15(6):777. https://doi.org/10.3390/diagnostics15060777
Chicago/Turabian StyleMultusch, Malte Michel, Lasse Hansen, Mattias Paul Heinrich, Lennart Berkel, Axel Saalbach, Heinrich Schulz, Franz Wegner, Joerg Barkhausen, and Malte Maria Sieren. 2025. "Impact of Radiologist Experience on AI Annotation Quality in Chest Radiographs: A Comparative Analysis" Diagnostics 15, no. 6: 777. https://doi.org/10.3390/diagnostics15060777
APA StyleMultusch, M. M., Hansen, L., Heinrich, M. P., Berkel, L., Saalbach, A., Schulz, H., Wegner, F., Barkhausen, J., & Sieren, M. M. (2025). Impact of Radiologist Experience on AI Annotation Quality in Chest Radiographs: A Comparative Analysis. Diagnostics, 15(6), 777. https://doi.org/10.3390/diagnostics15060777