
Comparing ChatGPT 4.0’s Performance in Interpreting Thyroid Nodule Ultrasound Reports Using ACR-TI-RADS 2017: Analysis Across Different Levels of Ultrasound User Experience
 , and
, and 
Abstract
1. Introduction
2. Materials and Methods
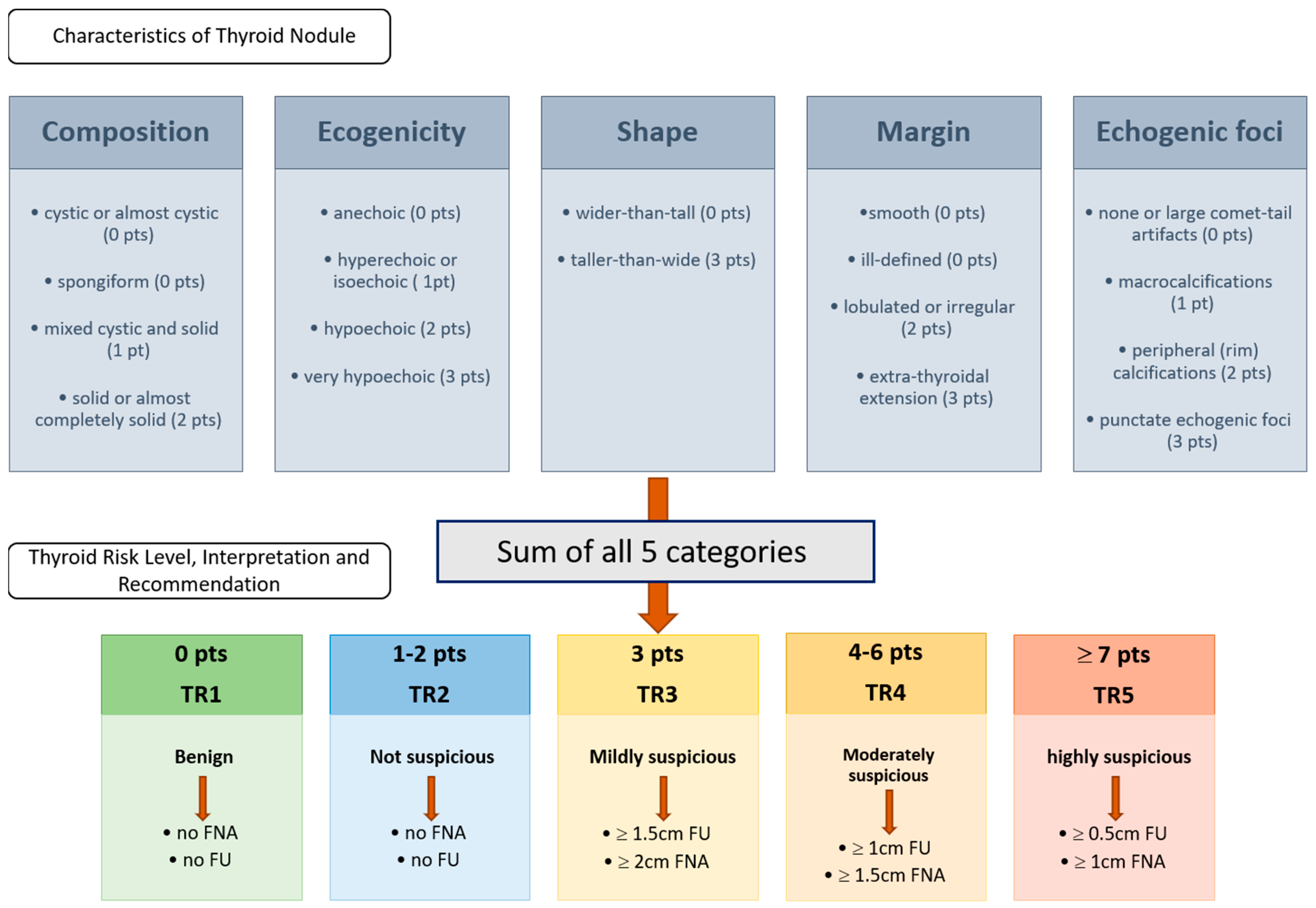
2.1. ACR-TIRADS Criteria of 2017 and US Reports
2.2. Rating
2.3. ChatGPT 4.0 Intervention
- 1.
- Composition
- Cystic or almost completely cystic (0 points)
- Spongiform (0 points)
- Mixed cystic and solid (1 point)
- Solid or almost completely solid (2 points)
- 2.
- Echogenicity
- Anechoic (0 points)
- Hyperechoic or isoechoic (1 point)
- Hypoechoic (2 points)
- Very hypoechoic (3 points)
- 3.
- Shape
- Wider-than-tall (0 points)
- Taller-than-wide (3 points)
- 4.
- Margin
- Smooth (0 points)
- Ill-defined (0 points)
- Lobulated or irregular (2 points)
- Extra-thyroidal extension (3 points)
- 5.
- Echogenic Foci
- None or large comet-tail artifacts (0 points)
- Macrocalcifications (1 point)
- Peripheral (rim) calcifications (2 points)
- Punctate echogenic foci (3 points)
- TR1: Benign (0 points)
- TR2: Not suspicious (2 points or less)
- TR3: Mildly suspicious (3 points)
- bigger than or exactly 1.5 cm follow-up
- bigger than or exactly 2.5 cm FNA
- TR4: Moderately suspicious (4–6 points)
- bigger than or exactly 1.0 cm follow-up
- bigger than or exactly 1.5 cm FNA
- TR5: Highly suspicious (7 points or more)
- bigger than or exactly 0.5 cm follow-up
- bigger than or exactly 1.0 cm FNA
2.4. Data Collection and Analysis
2.5. Statistical Analysis
3. Results
3.1. Intrarater Reliability of ChatGPT 4.0
3.2. Interrater Reliability Between Group of Experts and ChatGPT 4.0
3.3. Interrater Reliability Between Group of Experts and Medical Student
3.4. Diagnostic Performance of ChatGPT 4.0 and Inexperienced US User
3.5. Chat GPT 4.0’s Analysis of US Report with Explicit Instruction Containing the Description of the ACR-TI-RADS Criteria of 2017
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Russell, M.D.; Orloff, L.A. Ultrasonography of the Thyroid, Parathyroids, and Beyond. HNO 2022, 70, 333–344. [Google Scholar] [CrossRef] [PubMed]
- Smith, T.; Kaufman, C.S. Ultrasound Guided Thyroid Biopsy. Tech. Vasc. Interv. Radiol. 2021, 24, 100768. [Google Scholar] [CrossRef] [PubMed]
- Hamill, C.; Ellis, P.; Johnston, P.C. Ultrasound for the Assessment of Thyroid Nodules: An Overview for Non-Radiologists. Br. J. Hosp. Med. 2022, 83, 1–7. [Google Scholar] [CrossRef]
- Liu, C.H.; Hsu, S.Y.; Wang, C.P. Ultrasound Examinations of the Head and Neck—From the Beginning to Now. J. Med. Ultrasound 2020, 28, 5–6. [Google Scholar] [CrossRef]
- Ludwig, M.; Ludwig, B.; Mikula, A.; Biernat, S.; Rudnicki, J.; Kaliszewski, K. The Use of Artificial Intelligence in the Diagnosis and Classification of Thyroid Nodules: An Update. Cancers 2023, 15, 708. [Google Scholar] [CrossRef]
- Radzina, M.; Ratniece, M.; Putrins, D.S.; Saule, L.; Cantisani, V. Performance of Contrast-Enhanced Ultrasound in Thyroid Nodules: Review of Current State and Future Perspectives. Cancers 2021, 13, 5469. [Google Scholar] [CrossRef] [PubMed]
- Horvath, E.; Majlis, S.; Rossi, R.; Franco, C.; Niedmann, J.P.; Castro, A.; Dominguez, M. An Ultrasonogram Reporting System for Thyroid Nodules Stratifying Cancer Risk for Clinical Management. J. Clin. Endocrinol. Metab. 2009, 94, 1748–1751. [Google Scholar] [CrossRef]
- Tessler, F.N.; Middleton, W.D.; Grant, E.G.; Hoang, J.K.; Berland, L.L.; Teefey, S.A.; Cronan, J.J.; Beland, M.D.; Desser, T.S.; Frates, M.C.; et al. Acr Thyroid Imaging, Reporting and Data System (Ti-Rads): White Paper of the Acr Ti-Rads Committee. J. Am. Coll. Radiol. 2017, 14, 587–595. [Google Scholar] [CrossRef]
- Velez-Florez, M.C.; Dougherty, S.; Ginader, A.; Hailu, T.; Bodo, N.; Poznick, L.; Retrouvey, M.; Reid, J.R.; Gokli, A. Hands-on Ultrasound Training for Radiology Residents: The Impact of an Ultrasound Scanning Curriculum. Acad. Radiol. 2023, 30, 2059–2066. [Google Scholar] [CrossRef]
- Recker, F.; Schafer, V.S.; Holzgreve, W.; Brossart, P.; Petzinna, S. Development and Implementation of a Comprehensive Ultrasound Curriculum for Medical Students: The Bonn Internship Point-of-Care-Ultrasound Curriculum (Bi-Pocus). Front. Med. 2023, 10, 1072326. [Google Scholar] [CrossRef]
- Weimer, J.M.; Widmer, N.; Strelow, K.U.; Hopf, P.; Buggenhagen, H.; Dirks, K.; Kunzel, J.; Borner, N.; Weimer, A.M.; Lorenz, L.A.; et al. Long-Term Effectiveness and Sustainability of Integrating Peer-Assisted Ultrasound Courses into Medical School-A Prospective Study. Tomography 2023, 9, 1315–1328. [Google Scholar] [CrossRef] [PubMed]
- Marini, T.J.; Oppenheimer, D.C.; Baran, T.M.; Rubens, D.J.; Toscano, M.; Drennan, K.; Garra, B.; Miele, F.R.; Garra, G.; Noone, S.J.; et al. New Ultrasound Telediagnostic System for Low-Resource Areas: Pilot Results from Peru. J. Ultrasound Med. 2021, 40, 583–595. [Google Scholar] [CrossRef]
- Goodman, R.S.; Patrinely, J.R., Jr.; Osterman, T.; Wheless, L.; Johnson, D.B. On the Cusp: Considering the Impact of Artificial Intelligence Language Models in Healthcare. Med 2023, 4, 139–140. [Google Scholar] [CrossRef] [PubMed]
- Wojcik, S.; Rulkiewicz, A.; Pruszczyk, P.; Lisik, W.; Pobozy, M.; Domienik-Karlowicz, J. Beyond Chatgpt: What Does Gpt-4 Add to Healthcare? The Dawn of a New Era. Cardiol. J. 2023, 30, 1018–1025. [Google Scholar] [CrossRef]
- Zaboli, A.; Brigo, F.; Sibilio, S.; Mian, M.; Turcato, G. Human Intelligence Versus Chat-Gpt: Who Performs Better in Correctly Classifying Patients in Triage? Am. J. Emerg. Med. 2024, 79, 44–47. [Google Scholar] [CrossRef] [PubMed]
- Kung, T.H.; Cheatham, M.; Medenilla, A.; Sillos, C.; De Leon, L.; Elepano, C.; Madriaga, M.; Aggabao, R.; Diaz-Candido, G.; Maningo, J.; et al. Performance of Chatgpt on Usmle: Potential for AI-Assisted Medical Education Using Large Language Models. PLoS Digit. Health 2023, 2, e0000198. [Google Scholar] [CrossRef]
- Namsena, P.; Songsaeng, D.; Keatmanee, C.; Klabwong, S.; Kunapinun, A.; Soodchuen, S.; Tarathipayakul, T.; Tanasoontrarat, W.; Ekpanyapong, M.; Dailey, M.N. Diagnostic Performance of Artificial Intelligence in Interpreting Thyroid Nodules on Ultrasound Images: A Multicenter Retrospective Study. Quant. Imaging Med. Surg. 2024, 14, 3676–3694. [Google Scholar] [CrossRef]
- Li, Y.; Liu, Y.; Xiao, J.; Yan, L.; Yang, Z.; Li, X.; Zhang, M.; Luo, Y. Clinical Value of Artificial Intelligence in Thyroid Ultrasound: A Prospective Study from the Real World. Eur. Radiol. 2023, 33, 4513–4523. [Google Scholar] [CrossRef]
- Guo, S.; Li, R.; Li, G.; Chen, W.; Huang, J.; He, L.; Ma, Y.; Wang, L.; Zheng, H.; Tian, C.; et al. Comparing Chatgpt’s and Surgeon’s Responses to Thyroid-Related Questions from Patients. J. Clin. Endocrinol. Metab. 2024, 110, e841–e850. [Google Scholar] [CrossRef]
- Sanderson, K. Gpt-4 is Here: What Scientists Think. Nature 2023, 615, 773. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The Measurement of Observer Agreement for Categorical Data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S. Gpt-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Goodman, R.S.; Patrinely, J.R.; Stone, C.A., Jr.; Zimmerman, E.; Donald, R.R.; Chang, S.S.; Berkowitz, S.T.; Finn, A.P.; Jahangir, E.; Scoville, E.A.; et al. Accuracy and Reliability of Chatbot Responses to Physician Questions. JAMA Netw. Open 2023, 6, e2336483. [Google Scholar] [CrossRef] [PubMed]
- Qu, R.W.; Qureshi, U.; Petersen, G.; Lee, S.C. Diagnostic and Management Applications of Chatgpt in Structured Otolaryngology Clinical Scenarios. OTO Open 2023, 7, e67. [Google Scholar] [CrossRef] [PubMed]
- Amedu, C.; Ohene-Botwe, B. Harnessing the Benefits of Chatgpt for Radiography Education: A Discussion Paper. Radiography 2024, 30, 209–216. [Google Scholar] [CrossRef] [PubMed]
- Brennan, L.; Balakumar, R.; Bennett, W. The Role of Chatgpt in Enhancing Ent Surgical Training—A Trainees’ Perspective. J. Laryngol. Otol. 2023, 138, 480–486. [Google Scholar] [CrossRef]
- Riestra-Ayora, J.; Vaduva, C.; Esteban-Sanchez, J.; Garrote-Garrote, M.; Fernandez-Navarro, C.; Sanchez-Rodriguez, C.; Martin-Sanz, E. Chatgpt as an Information Tool in Rhinology. Can We Trust Each Other Today? Eur. Arch. Otorhinolaryngol. 2024, 281, 3253–3259. [Google Scholar] [CrossRef]
- Mago, J.; Sharma, M. The Potential Usefulness of Chatgpt in Oral and Maxillofacial Radiology. Cureus 2023, 15, e42133. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, X.; Cao, X.; Huang, C.; Liu, E.; Qian, S.; Liu, X.; Wu, Y.; Dong, F.; Qiu, C.W.; et al. Artificial Intelligence: A Powerful Paradigm for Scientific Research. Innovation 2021, 2, 100179. [Google Scholar] [CrossRef]
- Olawade, D.B.; David-Olawade, A.C.; Wada, O.Z.; Asaolu, A.J.; Adereni, T.; Ling, J. Artificial Intelligence in Healthcare Delivery: Prospects and Pitfalls. J. Med. Surg. Public Health 2024, 3, 100108. [Google Scholar] [CrossRef]
- Hong, M.J.; Lee, Y.H.; Kim, J.H.; Na, D.G.; You, S.H.; Shin, J.E.; Kim, S.K.; Yang, K.S.; Korean Society of Thyroid, R. Orientation of the Ultrasound Probe to Identify the Taller-Than-Wide Sign of Thyroid Malignancy: A Registry-Based Study with the Thyroid Imaging Network of Korea. Ultrasonography 2023, 42, 111–120. [Google Scholar] [CrossRef] [PubMed]
- Trimboli, P.; Colombo, A.; Gamarra, E.; Ruinelli, L.; Leoncini, A. Performance of Computer Scientists in the Assessment of Thyroid Nodules Using Tirads Lexicons. J. Endocrinol. Investig. 2024. [Google Scholar] [CrossRef] [PubMed]
- Xia, S.; Hua, Q.; Mei, Z.; Xu, W.; Lai, L.; Wei, M.; Qin, Y.; Luo, L.; Wang, C.; Huo, S.; et al. Clinical Application Potential of Large Language Model: A Study Based on Thyroid Nodules. Endocrine 2025, 87, 206–213. [Google Scholar] [CrossRef] [PubMed]
- Bhandari, A.; Scott, L.; Weilbach, M.; Marwah, R.; Lasocki, A. Assessment of Artificial Intelligence (AI) Reporting Methodology in Glioma Mri Studies Using the Checklist for Ai in Medical Imaging (Claim). Neuroradiology 2023, 65, 907–913. [Google Scholar] [CrossRef] [PubMed]
- Shrestha, N.; Shen, Z.; Zaidat, B.; Duey, A.H.; Tang, J.E.; Ahmed, W.; Hoang, T.; Restrepo Mejia, M.; Rajjoub, R.; Markowitz, J.S.; et al. Performance of Chatgpt on Nass Clinical Guidelines for the Diagnosis and Treatment of Low Back Pain: A Comparison Study. Spine 2024, 49, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Kadi, G.; Aslaner, M.A. Exploring Chatgpt’s Abilities in Medical Article Writing and Peer Review. Croat. Med. J. 2024, 65, 93–100. [Google Scholar] [CrossRef]
- Wang, L.; Wan, Z.; Ni, C.; Song, Q.; Li, Y.; Clayton, E.W.; Malin, B.A.; Yin, Z. A Systematic Review of Chatgpt and Other Conversational Large Language Models in Healthcare. medRxiv 2024. [Google Scholar] [CrossRef]
- Ullah, E.; Parwani, A.; Baig, M.M.; Singh, R. Challenges and Barriers of Using Large Language Models (Llm) Such as Chatgpt for Diagnostic Medicine with a Focus on Digital Pathology—A Recent Scoping Review. Diagn. Pathol. 2024, 19, 43. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Zhang, Z.; Traverso, A.; Dekker, A.; Qian, L.; Sun, P. Assessing the Role of Gpt-4 in Thyroid Ultrasound Diagnosis and Treatment Recommendations: Enhancing Interpretability with a Chain of Thought Approach. Quant. Imaging Med. Surg. 2024, 14, 1602–1615. [Google Scholar] [CrossRef]
- Wildman-Tobriner, B.; Taghi-Zadeh, E.; Mazurowski, M.A. Artificial Intelligence (Ai) Tools for Thyroid Nodules on Ultrasound, from the Ajr Special Series on Ai Applications. AJR Am. J. Roentgenol. 2022, 219, 547–554. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Cohen’s Kappa | Strength of Agreement | p-Value | |
|---|---|---|---|
| ACR-TI-RADS-Score | 0.380 | Poor | <0.001 |
| TR | 0.509 | Moderate | <0.001 |
| FNA | 0.653 | Substantial | <0.001 |
| Follow-Up | 0.588 | Moderate | <0.001 |
| Composition | 0.413 | Moderate | <0.001 |
| Echogenicity | 0.677 | Substantial | <0.001 |
| Shape | - | - | - |
| Margins | 0.685 | Substantial | <0.001 |
| Echogenic foci | 0.907 | Almost perfect | <0.001 |
| Cohen’s Kappa | Strength of Agreement | p-Value | Accuracy | ||||
|---|---|---|---|---|---|---|---|
| I | II | I | II | I and II | I | II | |
| ACR-Score | 0.474 | 0.492 | Moderate | Moderate | <0.001 | 53% | 54% |
| TR | 0.499 | 0.402 | Moderate | Moderate | <0.001 | 60% | 51% |
| FNA | 0.573 | 0.444 | Moderate | Moderate | <0.001 | 81% | 74% |
| Follow-Up | 0.400 | 0.334 | Moderate | Poor | <0.001 | 71% | 67% |
| Composition | 0.440 | 0.933 | Moderate | Almost perfect | <0.001 | 66% | 97% |
| Echogenicity | 0.953 | 0.68 | Almost perfect | Almost perfect | <0.001 | 97% | 78% |
| Shape | - | - | - | - | - | 79% | 79% |
| Margins | 0.922 | 0.665 | Almost perfect | Substantial | <0.001 | 97% | 86% |
| Echogenic foci | 0.880 | 0.911 | Almost perfect | Almost perfect | <0.001 | 96% | 96% |
| Cohen’s Kappa κ | Strength of Agreement | p-Value | Accuracy | |
|---|---|---|---|---|
| ACR-Score | 0.909 | Almost perfect | <0.001 | 92% |
| TR | 0.933 | Almost perfect | <0.001 | 95% |
| FNA | 0.958 | Almost perfect | <0.001 | 98% |
| Follow-Up | 0.940 | Almost perfect | <0.001 | 97% |
| Composition | 0.933 | Almost perfect | <0.001 | 97% |
| Echogenicity | 0.922 | Almost perfect | <0.001 | 95% |
| Shape | 0.970 | Almost perfect | <0.001 | 99% |
| Margins | 1 | Almost perfect | <0.001 | 100% |
| Echogenic foci | 0.971 | Almost perfect | <0.001 | 99% |
| Sensitivity | Specificity | PPV | NPV | χ2 | p-Value | |
|---|---|---|---|---|---|---|
| FNA | ||||||
| ChatGPT-I | 61% | 94% | 85% | 79% | χ2 (1) = 34.952 | <0.001 |
| ChatGPT-II | 55% | 87% | 72% | 76% | χ2 (1) = 20.532 | <0.001 |
| Student | 97% | 98% | 97% | 98% | χ2 (1) = 91.691 | <0.001 |
| Follow-Up | ||||||
| ChatGPT-I | 96% | 43% | 65% | 91% | χ2 (1) = 21.830 | <0.001 |
| ChatGPT-II | 98% | 34% | 63% | 94% | χ2 (1) = 18.254 | <0.001 |
| Student | 98% | 96% | 96% | 98% | χ2 (1) = 88.341 | <0.001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wakonig, K.M.; Barisch, S.; Kozarzewski, L.; Dommerich, S.; Lerchbaumer, M.H. Comparing ChatGPT 4.0’s Performance in Interpreting Thyroid Nodule Ultrasound Reports Using ACR-TI-RADS 2017: Analysis Across Different Levels of Ultrasound User Experience. Diagnostics 2025, 15, 635. https://doi.org/10.3390/diagnostics15050635
Wakonig KM, Barisch S, Kozarzewski L, Dommerich S, Lerchbaumer MH. Comparing ChatGPT 4.0’s Performance in Interpreting Thyroid Nodule Ultrasound Reports Using ACR-TI-RADS 2017: Analysis Across Different Levels of Ultrasound User Experience. Diagnostics. 2025; 15(5):635. https://doi.org/10.3390/diagnostics15050635
Chicago/Turabian StyleWakonig, Katharina Margherita, Simon Barisch, Leonard Kozarzewski, Steffen Dommerich, and Markus Herbert Lerchbaumer. 2025. "Comparing ChatGPT 4.0’s Performance in Interpreting Thyroid Nodule Ultrasound Reports Using ACR-TI-RADS 2017: Analysis Across Different Levels of Ultrasound User Experience" Diagnostics 15, no. 5: 635. https://doi.org/10.3390/diagnostics15050635
APA StyleWakonig, K. M., Barisch, S., Kozarzewski, L., Dommerich, S., & Lerchbaumer, M. H. (2025). Comparing ChatGPT 4.0’s Performance in Interpreting Thyroid Nodule Ultrasound Reports Using ACR-TI-RADS 2017: Analysis Across Different Levels of Ultrasound User Experience. Diagnostics, 15(5), 635. https://doi.org/10.3390/diagnostics15050635