
Evaluation of the Performance of a YOLOv10-Based Deep Learning Model for Tooth Detection and Numbering on Panoramic Radiographs of Patients in the Mixed Dentition Period


Abstract
1. Introduction
2. Materials and Methods
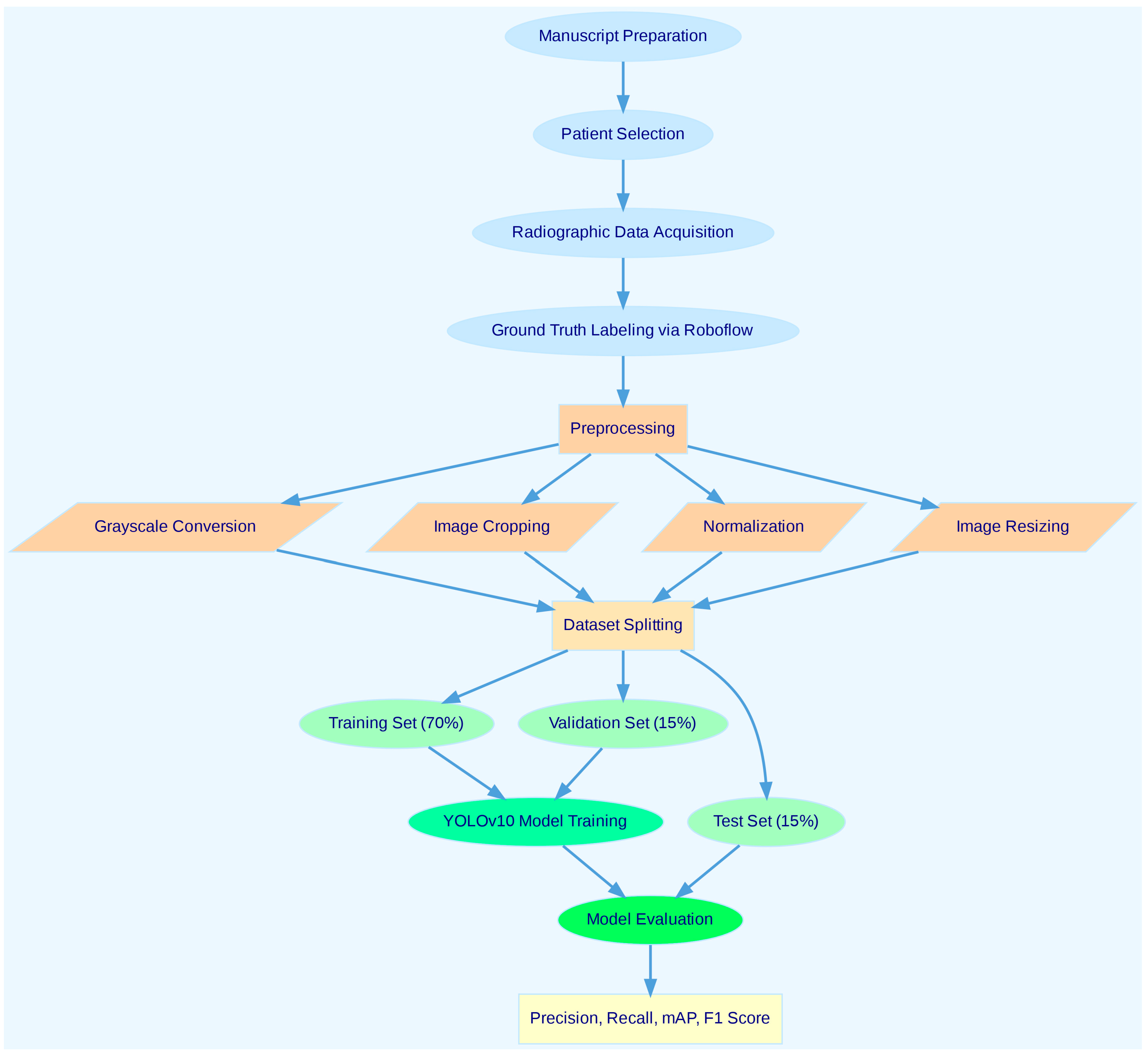
2.1. Overview of the Study Workflow
2.2. Patient Selection
2.3. Radiographic Dataset
2.4. Ground Truth Labeling
2.5. YOLOv10
2.5.1. Analysis of the YOLOv10 Architecture
2.5.2. Key Features of YOLOv10
2.6. Preprocessing
- Grayscale image loading: Although panoramic radiographs are typically acquired in grayscale, all images were explicitly converted to a single-channel grayscale format during preprocessing. This step was undertaken to ensure uniformity across the dataset by eliminating potential inconsistencies in image format or metadata, which might arise due to differences in file handling or storage protocols.
- Image cropping: Specific regions of the images were cropped to focus solely on important areas. This approach eliminated distracting elements, allowing the model to work with only the necessary data during the training process.
- Contrast enhancement: The contrast of the images was increased to make the details more prominent. This process enabled the model to learn important features better in low-contrast images.
- Normalization: Pixel values were normalized to the (0, 1) range. Normalization helped achieve more consistent results by reducing the impact of brightness and contrast variations across images.
- Image resizing: Images were resized to 640 × 640 pixels. This standardized sizing ensured consistency in the model’s inputs and eliminated data mismatches during the training process.
2.7. Dataset Splitting
- Training set: 70% of the total dataset, comprising 140 images, was used to train the YOLOv10 DLM. This portion was allocated to allow the model to learn various object features and improve its overall performance.
- Test set: 15% of the dataset, consisting of 30 images, was set aside for independent testing of the model. This portion was used to assess the model’s performance on real-world data and evaluate its accuracy.
- Validation set: The validation set, comprising 15% of the dataset, was used to fine-tune the model’s hyperparameters and monitor performance. During training, validation metrics such as precision, recall, and loss values were evaluated at each epoch to assess the model’s ability to generalize to unseen data. Early stopping was implemented to halt training if no improvement was observed in validation loss for 10 consecutive epochs, thereby minimizing the risk of overfitting. The validation set was independent of both the training and test datasets, ensuring unbiased evaluation of the model.
2.8. YOLOv10 Model Training
2.8.1. Training Process and Parameters
- model: Set to ‘None’, meaning that no specific model file was designated. In this case, a default model configuration file or a pretrained model was not used.
- data: Specified as ‘None’, indicating that no configuration file for dataset to be used in training was defined.
2.8.2. Training Duration and Early Stopping
- epochs: Training was set to a total of 200 epochs, meaning the model was trained on the 70% training subset 200 times. This iterative process allowed the model to optimize its parameters by repeatedly learning from the training data.
- time: Set to ‘None’, indicating that no maximum training time was restricted. Training was completed based on the specified number of epochs.
- patience: Early stopping was applied if no improvement was observed for 10 consecutive epochs. This aimed to prevent the model from overfitting.
2.8.3. Batch and Image Size
- batch: The batch size used during training was set to 16. This represents the number of samples processed by the model at each step, which affects processing speed.
- imgsz: The image size was set to 640 pixels, meaning that all training images would be resized to this dimension.
2.8.4. Saving and Caching
- save: Set to ‘True’, indicating that the model would be saved during training.
- save period: Set to ‘−1’, meaning the model would not be saved at the end of each epoch.
- cache: Set to ‘False’, indicating that the dataset would not be cached in memory.
2.8.5. Optimization and Other Parameters
- optimizer: Set to ‘Auto’, meaning that the most suitable optimization method was automatically selected based on model performance.
- cos_lr: Set to ‘False’, meaning that a cosine curve scheduler was not applied to the learning rate.
- amp: Set to ‘True’, indicating that Automatic Mixed Precision training was enabled to enhance computational efficiency.
- fraction: The entire dataset (1.0) was used for training.
- freeze: Set to ‘None’, meaning that no layers of the model were frozen, and all layers were trained.
2.9. Metrics of Model Performance
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DLM | Deep learning model |
| PR | Panoramic radiograph |
| AI | Artificial intelligence |
| ML | Machine learning |
| YOLO | You Only Look Once |
| DL | Deep learning |
| CNN | Convolutional neural network |
| CLAIM | Checklist for Artificial Intelligence in Medical Imaging |
| STARD | Standards for the Reporting of Diagnostic Accuracy Studies |
| FDI | Fédération Dentaire Internationale |
| NMS | Non-maximum suppression |
| CSPNet | Cross Stage Partial Network |
| PAN | Path Aggregation Network |
| IoU | Intersection over Union |
References
- Shah, N.; Bansal, N.; Logani, A. Recent advances in imaging technologies in dentistry. World J. Radiol. 2014, 6, 794–807. [Google Scholar] [CrossRef]
- Angelopoulos, C.; Bedard, A.; Katz, J.O.; Karamanis, S.; Parissis, N. Digital panoramic radiography: An overview. Semin. Orthod. 2004, 10, 194–203. [Google Scholar] [CrossRef]
- Bumann, E.E.; Al-Qarni, S.; Chandrashekar, G.; Sabzian, R.; Bohaty, B.; Lee, Y. A novel collaborative learning model for mixed dentition and fillings segmentation in panoramic radiographs. J. Dent. 2024, 140, 104779. [Google Scholar] [CrossRef]
- Jacobs, R.; Quirynen, M. Dental cone beam computed tomography: Justification for use in planning oral implant placement. Periodontology 2000 2014, 66, 203–213. [Google Scholar] [CrossRef] [PubMed]
- Beser, B.; Reis, T.; Berber, M.N.; Topaloglu, E.; Gungor, E.; Kılıc, M.C.; Duman, S.; Çelik, Ö.; Kuran, A.; Bayrakdar, I.S. YOLO-V5 based deep learning approach for tooth detection and segmentation on pediatric panoramic radiographs in mixed dentition. BMC Med. Imaging 2024, 24, 172. [Google Scholar] [CrossRef]
- Leite, A.F.; Gerven, A.V.; Willems, H.; Beznik, T.; Lahoud, P.; Gaêta-Araujo, H.; Vranckx, M.; Jacobs, R. Artificial intelligence-driven novel tool for tooth detection and segmentation on panoramic radiographs. Clin. Oral Investig. 2021, 25, 2257–2267. [Google Scholar] [CrossRef] [PubMed]
- Bağ, İ.; Bilgir, E.; Bayrakdar, I.; Baydar, O.; Atak, F.M.; Çelik, Ö.; Orhan, K. An artificial intelligence study: Automatic description of anatomic landmarks on panoramic radiographs in the pediatric population. BMC Oral Health 2023, 23, 764. [Google Scholar] [CrossRef] [PubMed]
- Heo, M.-S.; Kim, J.-E.; Hwang, J.-J.; Han, S.-S.; Kim, J.-S.; Yi, W.-J.; Park, I.-W. Artificial intelligence in oral and maxillofacial radiology: What is currently possible? Dentomaxillofacial Radiol. 2021, 50, 20200375. [Google Scholar] [CrossRef] [PubMed]
- Kong, H.-J.; Yoo, J.-Y.; Lee, J.-H.; Eom, S.-H.; Kim, J.-H. Performance evaluation of deep learning models for the classification and identification of dental implants. J. Prosthet. Dent. 2023. [Google Scholar] [CrossRef] [PubMed]
- Bonfanti-Gris, M.; Herrera, A.; Paraíso-Medina, S.; Alonso-Calvo, R.; Martínez-Rus, F.; Pradíes, G. Performance evaluation of three versions of a convolutional neural network for object detection and segmentation using a multiclass and reduced panoramic radiograph dataset. J. Dent. 2024, 144, 104891. [Google Scholar] [CrossRef]
- Hussain, M.; Khanam, R. In-Depth Review of YOLOv1 to YOLOv10 Variants for Enhanced Photovoltaic Defect Detection. Solar 2024, 4, 351–386. [Google Scholar] [CrossRef]
- Public Health England (PHE); Faculty of General Dental Practice (UK) (FGDP[UK]). Guidance Notes for Dental Practitioners on the Safe Use of X-Ray Equipment, 2nd ed.; PHE and FGDP(UK): London, UK, 2020. [Google Scholar]
- Lee, J.-H.; Han, S.-S.; Kim, Y.H.; Lee, C.; Kim, I. Application of a fully deep convolutional neural network to the automation of tooth segmentation on panoramic radiographs. Oral Surg. Oral Med. Oral Pathol. Oral Radiol. 2020, 129, 635–642. [Google Scholar] [CrossRef]
- Tuzoff, D.V.; Tuzova, L.N.; Bornstein, M.M.; Krasnov, A.S.; Kharchenko, M.A.; Nikolenko, S.I.; Sveshnikov, M.M.; Bednenko, G.B. Tooth detection and numbering in panoramic radiographs using convolutional neural networks. Dentomaxillofac. Radiol. 2019, 48, 20180051. [Google Scholar] [CrossRef]
- Ong, S.-H.; Kim, H.; Song, J.-S.; Shin, T.J.; Hyun, H.-K.; Jang, K.-T.; Kim, Y.-J. Fully automated deep learning approach to dental development assessment in panoramic radiographs. BMC Oral Health 2024, 24, 426. [Google Scholar] [CrossRef]
- Görürgöz, C.; Orhan, K.; Bayrakdar, I.S.; Çelik, Ö.; Bilgir, E.; Odabaş, A.; Aslan, A.F.; Jagtap, R. Performance of a convolutional neural network algorithm for tooth detection and numbering on periapical radiographs. Dentomaxillofacial Radiol. 2022, 51, 20210246. [Google Scholar] [CrossRef]
- Jang, T.J.; Kim, K.C.; Cho, H.C.; Seo, J.K. A Fully Automated Method for 3D Individual Tooth Identification and Segmentation in Dental CBCT. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6562–6568. [Google Scholar] [CrossRef]
- Sadr, S.; Rokhshad, R.; Daghighi, Y.; Golkar, M.; Kheybari, F.T.; Gorjinejad, F.; Kojori, A.M.; Rahimirad, P.; Shobeiri, P.; Mahdian, M.; et al. Deep learning for tooth identification and numbering on dental radiography: A systematic review and meta-analysis. Dentomaxillofacial Radiol. 2023, 53, 5–21. [Google Scholar] [CrossRef]
- Ahn, Y.; Hwang, J.J.; Jung, Y.-H.; Jeong, T.; Shin, J. Automated Mesiodens Classification System Using Deep Learning on Panoramic Radiographs of Children. Diagnostics 2021, 11, 1477. [Google Scholar] [CrossRef]
- Mine, Y.; Iwamoto, Y.; Okazaki, S.; Nakamura, K.; Takeda, S.; Peng, T.; Mitsuhata, C.; Kakimoto, N.; Kozai, K.; Murayama, T. Detecting the presence of supernumerary teeth during the early mixed dentition stage using deep learning algorithms: A pilot study. Int. J. Paediatr. Dent. 2022, 32, 678–685. [Google Scholar] [CrossRef]
- Ha, E.-G.; Jeon, K.J.; Kim, Y.H.; Kim, J.-Y.; Han, S.-S. Automatic detection of mesiodens on panoramic radiographs using artificial intelligence. Sci. Rep. 2021, 11, 23061. [Google Scholar] [CrossRef]
- Kaya, E.; Gunec, H.G.; Aydin, K.C.; Urkmez, E.S.; Duranay, R.; Ates, H.F. A deep learning approach to permanent tooth germ detection on pediatric panoramic radiographs. Imaging Sci. Dent. 2022, 52, 275–281. [Google Scholar] [CrossRef]
- Kaya, E.; Gunec, H.G.; Gokyay, S.S.; Kutal, S.; Gulum, S.; Ates, H.F. Proposing a CNN Method for Primary and Permanent Tooth Detection and Enumeration on Pediatric Dental Radiographs. J. Clin. Pediatr. Dent. 2022, 46, 293–298. [Google Scholar] [CrossRef]
- Putra, R.H.; Astuti, E.R.; Putri, D.K.; Widiasri, M.; Laksanti, P.A.M.; Majidah, H.; Yoda, N. Automated permanent tooth detection and numbering on panoramic radiograph using a deep learning approach. Oral Surg. Oral Med. Oral Pathol. Oral Radiol. 2023, 137, 537–544. [Google Scholar] [CrossRef]
- Bilgir, E.; Bayrakdar, I.Ş.; Çelik, Ö.; Orhan, K.; Akkoca, F.; Sağlam, H.; Odabaş, A.; Aslan, A.F.; Ozcetin, C.; Kıllı, M.; et al. An artifıcial ıntelligence approach to automatic tooth detection and numbering in panoramic radiographs. BMC Med. Imaging 2021, 21, 124. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tooth No. | Precision (P) | Recall (R) | mAP50 | mAP50-95 | F1 Score |
|---|---|---|---|---|---|
| 11 | 0.964 | 1.000 | 0.995 | 0.779 | 0.982 |
| 12 | 0.995 | 0.897 | 0.977 | 0.673 | 0.943 |
| 13 | 0.908 | 1.000 | 0.993 | 0.783 | 0.951 |
| 14 | 0.966 | 0.958 | 0.992 | 0.733 | 0.962 |
| 15 | 0.962 | 1.000 | 0.995 | 0.731 | 0.980 |
| 16 | 0.839 | 1.000 | 0.986 | 0.840 | 0.913 |
| 17 | 0.979 | 1.000 | 0.995 | 0.822 | 0.989 |
| 18 | 0.793 | 1.000 | 0.978 | 0.752 | 0.885 |
| 21 | 0.967 | 0.933 | 0.990 | 0.736 | 0.950 |
| 22 | 0.993 | 0.933 | 0.990 | 0.744 | 0.962 |
| 23 | 0.959 | 0.967 | 0.993 | 0.767 | 0.963 |
| 24 | 0.967 | 0.974 | 0.994 | 0.720 | 0.971 |
| 25 | 0.966 | 0.947 | 0.987 | 0.687 | 0.956 |
| 26 | 0.829 | 0.967 | 0.980 | 0.856 | 0.893 |
| 27 | 0.907 | 0.978 | 0.988 | 0.790 | 0.941 |
| 28 | 1.000 | 0.938 | 0.995 | 0.726 | 0.968 |
| 31 | 0.936 | 0.970 | 0.993 | 0.760 | 0.953 |
| 32 | 0.977 | 1.000 | 0.995 | 0.781 | 0.988 |
| 33 | 0.994 | 0.900 | 0.984 | 0.812 | 0.944 |
| 34 | 1.000 | 0.938 | 0.995 | 0.769 | 0.968 |
| 35 | 0.965 | 0.921 | 0.989 | 0.800 | 0.943 |
| 36 | 0.880 | 0.975 | 0.991 | 0.889 | 0.925 |
| 37 | 0.786 | 1.000 | 0.968 | 0.804 | 0.880 |
| 38 | 0.967 | 0.900 | 0.908 | 0.652 | 0.932 |
| 41 | 0.932 | 1.000 | 0.983 | 0.729 | 0.965 |
| 42 | 0.986 | 0.933 | 0.986 | 0.722 | 0.959 |
| 43 | 0.871 | 1.000 | 0.989 | 0.785 | 0.931 |
| 44 | 0.960 | 1.000 | 0.993 | 0.816 | 0.980 |
| 45 | 0.898 | 0.967 | 0.989 | 0.779 | 0.931 |
| 46 | 0.916 | 1.000 | 0.974 | 0.854 | 0.956 |
| 47 | 0.947 | 1.000 | 0.972 | 0.808 | 0.973 |
| 48 | 0.929 | 0.900 | 0.905 | 0.580 | 0.914 |
| 51 | 0.656 | 0.800 | 0.712 | 0.337 | 0.721 |
| 52 | 0.681 | 0.715 | 0.835 | 0.502 | 0.697 |
| 53 | 0.907 | 0.926 | 0.948 | 0.635 | 0.916 |
| 54 | 0.914 | 0.972 | 0.992 | 0.692 | 0.942 |
| 55 | 0.963 | 0.988 | 0.959 | 0.719 | 0.975 |
| 61 | 0.816 | 0.898 | 0.962 | 0.400 | 0.855 |
| 62 | 0.911 | 1.000 | 0.995 | 0.588 | 0.953 |
| 63 | 0.922 | 0.912 | 0.969 | 0.628 | 0.917 |
| 64 | 0.946 | 0.921 | 0.985 | 0.714 | 0.933 |
| 65 | 0.805 | 0.868 | 0.908 | 0.668 | 0.835 |
| 71 | 0.660 | 1.000 | 0.995 | 0.0995 | 0.795 |
| 72 | 1.000 | 0.675 | 0.984 | 0.492 | 0.806 |
| 73 | 0.941 | 0.960 | 0.972 | 0.705 | 0.950 |
| 74 | 0.799 | 0.865 | 0.940 | 0.696 | 0.830 |
| 75 | 0.975 | 0.963 | 0.991 | 0.770 | 0.969 |
| 81 | 0.450 | 1.000 | 0.995 | 0.597 | 0.621 |
| 82 | 0.871 | 0.751 | 0.926 | 0.444 | 0.807 |
| 83 | 0.892 | 0.760 | 0.900 | 0.621 | 0.821 |
| 84 | 0.886 | 1.000 | 0.965 | 0.731 | 0.940 |
| 85 | 0.863 | 1.000 | 0.936 | 0.688 | 0.926 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peker, R.B.; Kurtoglu, C.O. Evaluation of the Performance of a YOLOv10-Based Deep Learning Model for Tooth Detection and Numbering on Panoramic Radiographs of Patients in the Mixed Dentition Period. Diagnostics 2025, 15, 405. https://doi.org/10.3390/diagnostics15040405
Peker RB, Kurtoglu CO. Evaluation of the Performance of a YOLOv10-Based Deep Learning Model for Tooth Detection and Numbering on Panoramic Radiographs of Patients in the Mixed Dentition Period. Diagnostics. 2025; 15(4):405. https://doi.org/10.3390/diagnostics15040405
Chicago/Turabian StylePeker, Ramazan Berkay, and Celal Oguz Kurtoglu. 2025. "Evaluation of the Performance of a YOLOv10-Based Deep Learning Model for Tooth Detection and Numbering on Panoramic Radiographs of Patients in the Mixed Dentition Period" Diagnostics 15, no. 4: 405. https://doi.org/10.3390/diagnostics15040405
APA StylePeker, R. B., & Kurtoglu, C. O. (2025). Evaluation of the Performance of a YOLOv10-Based Deep Learning Model for Tooth Detection and Numbering on Panoramic Radiographs of Patients in the Mixed Dentition Period. Diagnostics, 15(4), 405. https://doi.org/10.3390/diagnostics15040405