
Enhancing Tip Detection by Pre-Training with Synthetic Data for Ultrasound-Guided Intervention

 ,
,  , and
, and
Abstract
1. Introduction
- Clinical US images have the features of equipment diversity, physician diversity, patient diversity, and tip diversity. Wherein the equipment diversity means that US puncture images are acquired from various grades of US machines from various manufacturers, leading to all kinds of image styles and quality. Physician diversity means US puncture images could have great diversity from scanners with various levels of scanning expertise and experience. Patient diversity denotes that US puncture images of various patients could be also different even for the same organ due to individual differences. Finally, tip diversity refers to the variation in echo characteristics of the tip, which changes with factors such as needle angle, tip material, ultrasound frequency, and the properties of surrounding tissues.
- Expert annotations for tips are quite expensive. To train TipDet and other DL-based tip detectors, tip bounding box annotation for thousands of images is necessary. Moreover, the more and the higher-quality annotations are acquired, the better tip detection performance is expected. However, the labeling process is monotonous, time-consuming, and exhausting, and the cost of hiring highly skilled interventionalists is prohibitive.
- We propose a data synthesis method capable of generating large volumes of US puncture images with substantial clinical diversity, all without the need for expert labeling, thereby significantly reducing the data acquisition costs for training advanced tip detectors.
- Using the proposed method, we generated a large dataset of synthetic US puncture images. Through pretraining with this synthetic data, we further enhanced the performance of the current tip detector, particularly improving its generalization capability, resulting in a new SOTA tip detector, TipDet with synthetic data pre-training (TipDet-SDP).
- To facilitate the research of automatic tip localization for US-guided interventions, we have released part of our research data and tip generation model.
2. Materials and Methods
2.1. Clinical US Image Acquisition
2.2. New Tip Generation with Generative DL
2.2.1. DDPM Training
2.2.2. Tip Generation Through Sampling
- (1)
- Acquire an image patch through sampling from Gaussian noise: ;
- (2)
- Predict the noise added at time step t with ;
- (3)
- Based on Equation (2), acquire the noise-added image at time step t through sampling:where the standard deviation and ;
- (4)
- Repeatedly perform step (3) for T times to acquire , i.e., a generated tip image patch.
2.2.3. Puncture Image Synthesis
2.2.4. Utilization Methods of the Synthetic Data
3. Experimental Results and Discussions
3.1. Experimental Setup
3.1.1. Real US Puncture Dataset
3.1.2. Evaluation Criterion
3.1.3. DDPM Training Setup
3.1.4. Tip Detector Training Setup
3.2. Effectiveness of the Synthetic Puncture Data
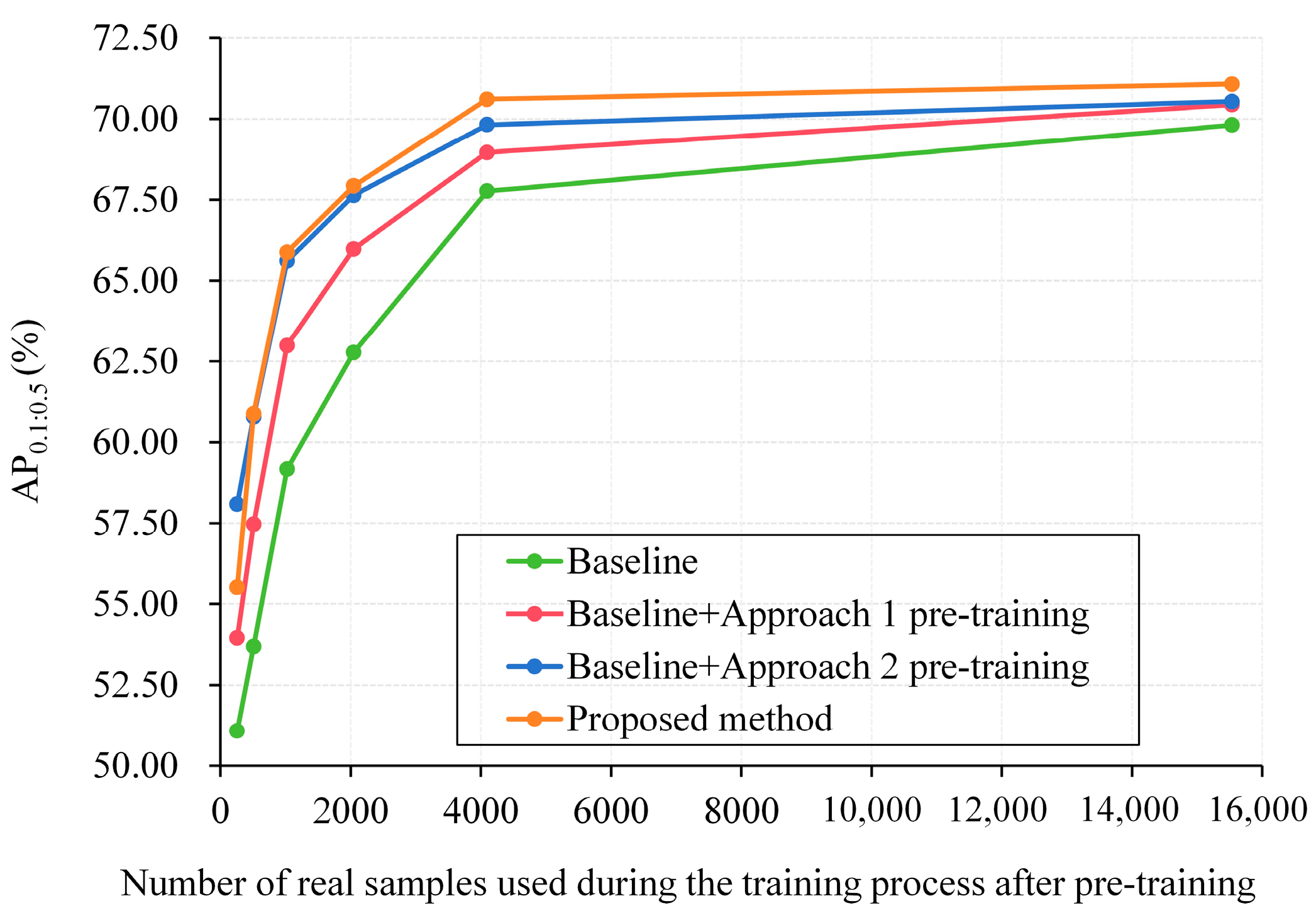
3.2.1. Utilization Method Comparison
3.2.2. Impact of the Number of Fused Tips
3.2.3. Model Generalization
3.2.4. Ablation Study
3.2.5. Turing Test-Style Evaluation by US Physicians
3.2.6. Tip Generation Efficiency and Deployment Feasibility
3.2.7. Enhancing Current Tip Detectors with Synthetic Pre-Training

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tip Detector | AP0.1:0.5 (%) | AP0.2 (%) | AP0.5 (%) | RMSE (Pixels) |
|---|---|---|---|---|
| MEGA-r50 [27] | 70.07 ± 0.25 | 73.27 ± 0.27 | 61.93 ± 0.30 | 12.00 ± 6.95 |
| MEGA-r50-SDP | 71.21 ± 0.22↑1.14 | 74.35 ± 0.25 | 62.94 ± 0.28 | 11.22 ± 6.58 |
| YOLOV-s [28] | 68.67 ± 0.28 | 73.28 ± 0.32 | 57.09 ± 0.35 | 13.73 ± 6.98 |
| YOLOV-s-SDP | 70.25 ± 0.26↑1.58 | 75.38 ± 0.28 | 59.46 ± 0.33 | 11.89 ± 6.64 |
| PTSEFormer-r101 [29] | 77.74 ± 0.20 | 83.03 ± 0.22 | 64.61 ± 0.25 | 9.34 ± 5.40 |
| PTSEFormer-r101-SDP | 78.96 ± 0.17↑1.22 | 84.21 ± 0.24 | 65.73 ± 0.23 | 9.01 ± 5.54 |
| TipDet [15] | 78.72 ± 0.18 | 83.25 ± 0.20 | 66.51 ± 0.23 | 8.71 ± 4.25 |
| TipDet-SDP | 80.48 ± 0.15↑1.76 | 84.77 ± 0.18 | 68.44 ± 0.21 | 7.78 ± 4.10 |
4. Conclusions
5. Limitations and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| SDP | Synthetic data pre-training |
| CUID | Clinical US image dataset of human organs or anatomical regions |
| DDPM | Denoising probabilistic diffusion model |
| GD-T | Generated dataset of tips |
References
- Müller, T.; Braden, B. Ultrasound-guided interventions in the biliary system. Diagnostics 2024, 14, 403. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.C.; Lu, Y.H.; Ting, W.Y. Ultrasound-guided vs. Non-ultrasound-guided femoral artery puncture techniques: A comprehensive systematic review and meta-analysis. Ultrasound J. 2025, 17, 19. [Google Scholar] [CrossRef] [PubMed]
- Qafesha, R.M.; Kashbour, M.; Amro, S.; Hindawi, M.D.; Elbadry, M.; Ghalwash, A.A.; Alnatsheh, Z.; Abdelaziz, M.A.Y.; Eldeeb, H.; Shiha, A.R. Ultrasound-guided thermal ablation versus thyroidectomy in the treatment of benign thyroid nodules: Systematic review and meta analysis. J. Ultrasound Med. 2025, 44, 605–635. [Google Scholar] [CrossRef]
- Grasso, F.; Capasso, A.; Pacella, D.; Borgia, F.; Salomè, S.; Capasso, L.; Raimondi, F. Ultrasound guided catheter tip location in neonates: A prospective cohort study. J. Pediatr. 2022, 244, 86–91. [Google Scholar] [CrossRef]
- Gomaa, S.M.A.; Farouk, M.H.; Ali, A.M. Ultrasound Guided Drainage and Aspiration of Intra-Abdominal Fluid Collections. Benha J. Appl. Sci. 2023, 8, 113–120. [Google Scholar] [CrossRef]
- Che, H.; Qin, J.; Chen, Y.; Ji, Z.; Yan, Y.; Yang, J.; Wang, Q.; Liang, C.; Wu, J. Improving Needle Tip Tracking and Detection in Ultrasound-Based Navigation System Using Deep Learning-Enabled Approach. IEEE J. Biomed. Heal. Inform. 2024, 28, 2930–2942. [Google Scholar] [CrossRef]
- Bernardi, S.; Palermo, A.; Grasso, R.F.; Fabris, B.; Stacul, F.; Cesareo, R. Current status and challenges of US-guided radiofrequency ablation of thyroid nodules in the long term: A systematic review. Cancers 2021, 13, 2746. [Google Scholar] [CrossRef]
- Mwikirize, C.; Nosher, J.L.; Hacihaliloglu, I. Convolution neural networks for real-time needle detection and localization in 2D ultrasound. Int. J. Comput. Assist. Radiol. Surg. 2018, 13, 647–657. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Lin, Y.; Li, Z.; Wang, F.; Cao, Q. Automatic and accurate needle detection in 2D ultrasound during robot-assisted needle insertion process. Int. J. Comput. Assist. Radiol. Surg. 2022, 17, 295–303. [Google Scholar] [CrossRef]
- Beigi, P.; Rohling, R.; Salcudean, T.; Lessoway, V.A.; Ng, G.C. Detection of an invisible needle in ultrasound using a probabilistic SVM and time-domain features. Ultrasonics 2017, 78, 18–22. [Google Scholar] [CrossRef]
- Mwikirize, C.; Kimbowa, A.B.; Imanirakiza, S.; Katumba, A.; Nosher, J.L.; Hacihaliloglu, I. Time-aware deep neural networks for needle tip localization in 2D ultrasound. Int. J. Comput. Assist. Radiol. Surg. 2021, 16, 819–827. [Google Scholar] [CrossRef]
- Amin, Z.T.A.; Maryam, A.J.; Hossein, M.; Mirbagheri, A.; Ahmadian, A. Spatiotemporal analysis of speckle dynamics to track invisible needle in ultrasound sequences using convolutional neural networks: A phantom study. Int. J. Comput. Assist. Radiol. Surg. 2023, 18, 1373–1382. [Google Scholar] [CrossRef]
- Yan, W.; Ding, Q.; Chen, J.; Yan, K.; Tang, R.S.-Y.; Cheng, S.S. Learning-based needle tip tracking in 2D ultrasound by fusing visual tracking and motion prediction. Med. Image Anal. 2023, 88, 102847. [Google Scholar] [CrossRef] [PubMed]
- Wang, R.; Tan, G.; Liu, X. TipDet: A multi-keyframe motion-aware framework for tip detection during ultrasound-guided interventions. Comput. Methods Programs Biomed. 2024, 247, 108109. [Google Scholar] [CrossRef] [PubMed]
- Khosravi, B.; Li, F.; Dapamede, T.; Rouzrokha, P.; Gamblea, C.U.; Trivedic, H.M.; Wylesb, C.C.; Sellergrend, A.B.; Purkayasthae, S.; Ericksona, B.J.; et al. Synthetically enhanced: Unveiling synthetic data’s potential in medical imaging research. EBioMedicine 2024, 104, 105174. [Google Scholar] [CrossRef]
- Wang, J.; Wang, K.; Yu, Y.; Lu, Y.; Xiao, W.; Sun, Z.; Liu, F.; Zou, Z.; Gao, Y.; Yang, L.; et al. Self-improving generative foundation model for synthetic medical image generation and clinical applications. Nat. Med. 2025, 31, 609–617. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Hua, Q.; Jia, X.; Zheng, Y.; Hu, Q.; Bai, B.; Miao, J.; Zhu, L.; Zhang, M.; Tao, R.; et al. Synthetic breast ultrasound images: A study to overcome medical data sharing barriers. Research 2024, 7, 0532. [Google Scholar] [CrossRef]
- Croitoru, F.A.; Hondru, V.; Ionescu, R.T.; Shah, M. Diffusion models in vision: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10850–10869. [Google Scholar] [CrossRef]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Online, 6–12 December 2020; Volume 33, pp. 6840–6851. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Prez, P.; Gangnet, M.; Blake, A. Poisson image editing. ACM Trans. Graph. 2003, 22, 313–318. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Germany, 2014; Volume 8693, pp. 740–755. [Google Scholar]
- Song, J.; Meng, C.; Ermon, S. Denoising diffusion implicit models. arXiv 2020, arXiv:2010.02502. [Google Scholar]
- Jiang, H.; Imran, M.; Zhang, T.; Zhou, Y.; Liang, M.; Gong, K.; Shao, W. Fast-DDPM: Fast denoising diffusion probabilistic models for medical image-to-image generation. IEEE J. Biomed. Health Inform. 2025, 1–11. [Google Scholar] [CrossRef]
- Chen, Y.; Cao, Y.; Hu, H.; Wang, L. Memory enhanced global-local aggregation for video object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10337–10346. [Google Scholar]
- Shi, Y.; Wang, N.; Guo, X. YOLOV: Making still image object detectors great at video object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 2254–2262. [Google Scholar]
- Wang, H.; Tang, J.; Liu, X.; Guan, S.; Xie, R.; Song, L. Ptseformer: Progressive temporal-spatial enhanced transformer towards video object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 732–747. [Google Scholar]
- Li, J.; Yu, Z.; Du, Z.; Zhu, L.; Shen, H.T. A comprehensive survey on source-free domain adaptation. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 5743–5762. [Google Scholar] [CrossRef] [PubMed]
- Fogante, M.; Carboni, N.; Argalia, G. Clinical application of ultra-high frequency ultrasound: Discovering a new imaging frontier. J. Clin. Ultrasound 2022, 50, 817–825. [Google Scholar] [CrossRef] [PubMed]













| Property | Number | Description |
|---|---|---|
| Raw videos | 405 | Mean video lasting time: 27 s, mean frame rate: 23, mean video width: 1108, mean video height: 785 |
| Subject | 20 | Age range: 20–55, mean age: 37, male number: 10, female number: 10 |
| Organs or anatomical region | 20 | Thyroid, carotid artery, heart, kidney, spleen, pancreas, liver, lung, gallbladder, breast, bladder, prostate (uterus), vertebral artery, femoral artery (vein), anterior tibial (posterior tibial) artery, popliteal artery (vein) |
| US physician | 3 | 1 year, 5 years and 10 years of clinical practice |
| US machine | 6 | GE Vivid E95 (General Electric, Chicago, IL, USA), Philips IE33 (Philips, Amsterdam, The Netherlands), Samsung RS80 (Samsung, Suwon, Republic of Korea), Esaote Mylab Class C (Esaote, Genoa, Italy), Supersonic AixPlorer (Supersonic, Aix-en-Provence, France), and SonoStar UProbe C4PL (SonoStar, Guangzhou, China). |
| Pre-Training Dataset | AP0.1:0.5 | AP0.2 | AP0.5 |
|---|---|---|---|
| None * (MSCOCO) | 69.81 | 73.32 | 60.05 |
| CUID-HO-2.5k-T | 66.17 | 68.78 | 59.31 |
| CUID-HO-5k-T | 67.70 | 70.99 | 58.49 |
| CUID-HO-10k-T | 70.71 | 73.51 | 62.09 |
| CUID-HO-25k-T | 70.29 | 73.44 | 61.02 |
| CUID-HO-50k-T | 64.39 | 67.59 | 56.47 |
| Synthetic Dataset in the Merged Dataset | AP0.1:0.5 | AP0.2 | AP0.5 |
|---|---|---|---|
| None * (MSCOCO) | 69.81 | 73.32 | 60.05 |
| CUID-HO-2.5k-T | 67.63 | 71.05 | 58.51 |
| CUID-HO-5k-T | 68.55 | 71.95 | 58.79 |
| CUID-HO-10k-T | 66.73 | 70.26 | 56.13 |
| CUID-HO-25k-T | 62.28 | 65.14 | 54.13 |
| CUID-HO-50k-T | 61.44 | 64.09 | 54.24 |
| US Physician | Generated → Judged Real | Real → Judged Real |
|---|---|---|
| 1 | 65.3% ± 13.20% | 74.0% ± 9.93% |
| 2 | 52.7% ± 11.81% | 64.7% ± 8.22% |
| Average | 59.0% ± 12.51% | 69.4% ± 9.08% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, R.; Wang, J.; Zhao, W.; Liu, X.; Tan, G.; Liu, J.; Wang, Z. Enhancing Tip Detection by Pre-Training with Synthetic Data for Ultrasound-Guided Intervention. Diagnostics 2025, 15, 1926. https://doi.org/10.3390/diagnostics15151926
Wang R, Wang J, Zhao W, Liu X, Tan G, Liu J, Wang Z. Enhancing Tip Detection by Pre-Training with Synthetic Data for Ultrasound-Guided Intervention. Diagnostics. 2025; 15(15):1926. https://doi.org/10.3390/diagnostics15151926
Chicago/Turabian StyleWang, Ruixin, Jinghang Wang, Wei Zhao, Xiaohui Liu, Guoping Tan, Jun Liu, and Zhiyuan Wang. 2025. "Enhancing Tip Detection by Pre-Training with Synthetic Data for Ultrasound-Guided Intervention" Diagnostics 15, no. 15: 1926. https://doi.org/10.3390/diagnostics15151926
APA StyleWang, R., Wang, J., Zhao, W., Liu, X., Tan, G., Liu, J., & Wang, Z. (2025). Enhancing Tip Detection by Pre-Training with Synthetic Data for Ultrasound-Guided Intervention. Diagnostics, 15(15), 1926. https://doi.org/10.3390/diagnostics15151926