

Advances in Periodontal Diagnostics: Application of MultiModal Language Models in Visual Interpretation of Panoramic Radiographs


Abstract
1. Introduction
- Evaluate the agreement in teeth identification between ChatGPT and dental professionals.
- Evaluate the differences between measurements of remaining bone height (RBH) performed by ChatGPT models.
- Evaluate the agreement in RBH values between ChatGPT and dental professionals.
- Assess the clinical relevance of ChatGPT in dental radiology at its current stage of advancement.
2. Materials and Methods
2.1. Ethics Statement
2.2. Definitions
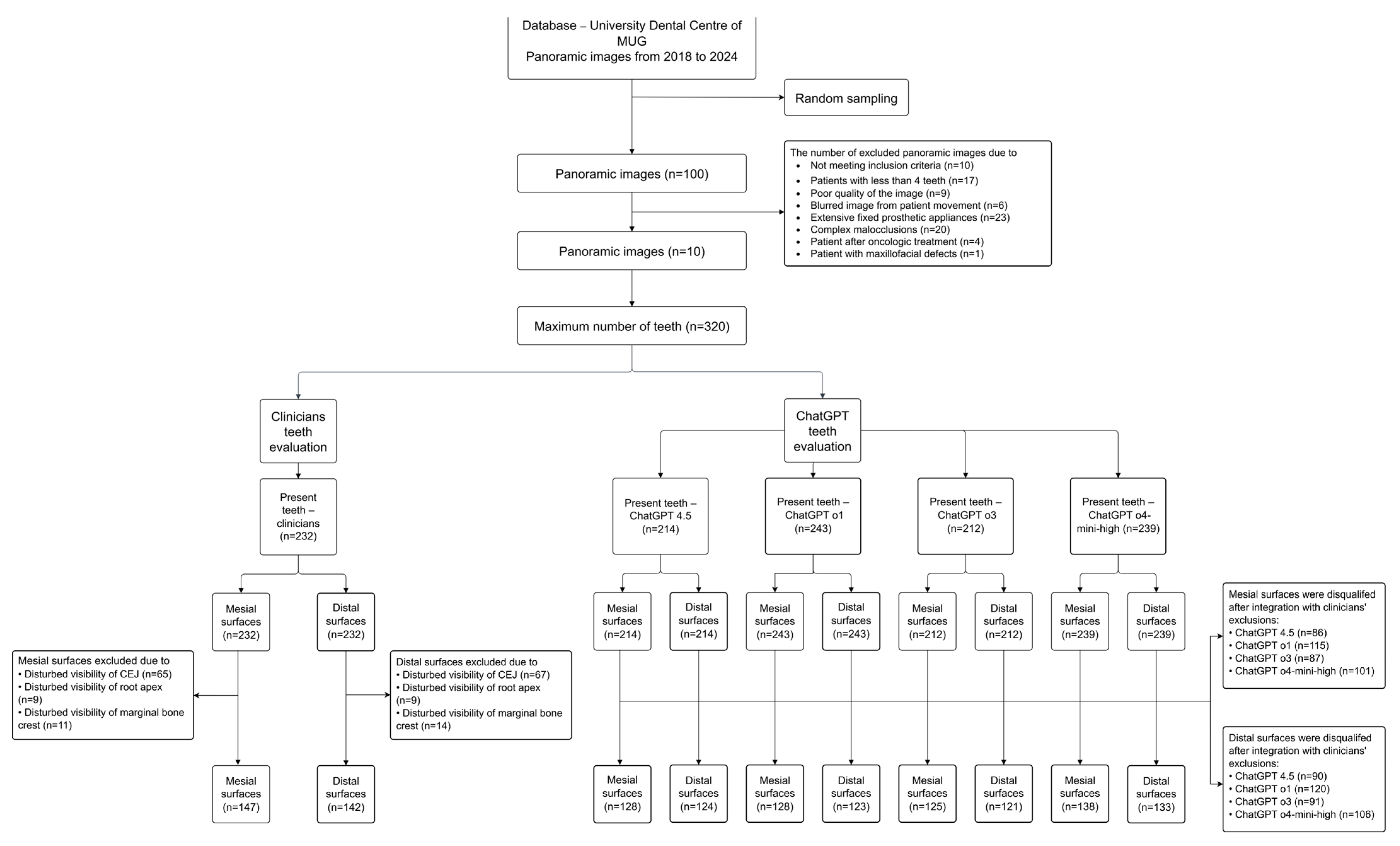
2.3. Source Data and Eligibility Criteria
- Inclusion criteria for panoramic radiographs:
- Panoramic images obtained from adult patients treated for periodontitis at the Department of Periodontal and Oral Mucosa Diseases between 2018 and 2024.
- Exclusion criteria for panoramic radiographs:
- Patients with less than 4 teeth;
- Poor quality of the panoramic image;
- Severely blurred image due to patient movement;
- Extensive fixed prosthetic appliances, including multiple-unit dental bridges;
- Complex malocclusions associated with teeth crowding;
- Patients who had received radiotherapy or resective surgery;
- Patients with abnormalities of the maxillofacial region.
- Exclusion criteria for the approximal surfaces:
- Disturbed visibility of the cemento-enamel junction due to caries, massive restorations and teeth rotation;
- Disturbed visibility of the root apex due to the overlapping of anatomical structures and poor quality of the area covered;
- Disturbed visibility of the marginal bone crest due to the overlapping of anatomical structures.
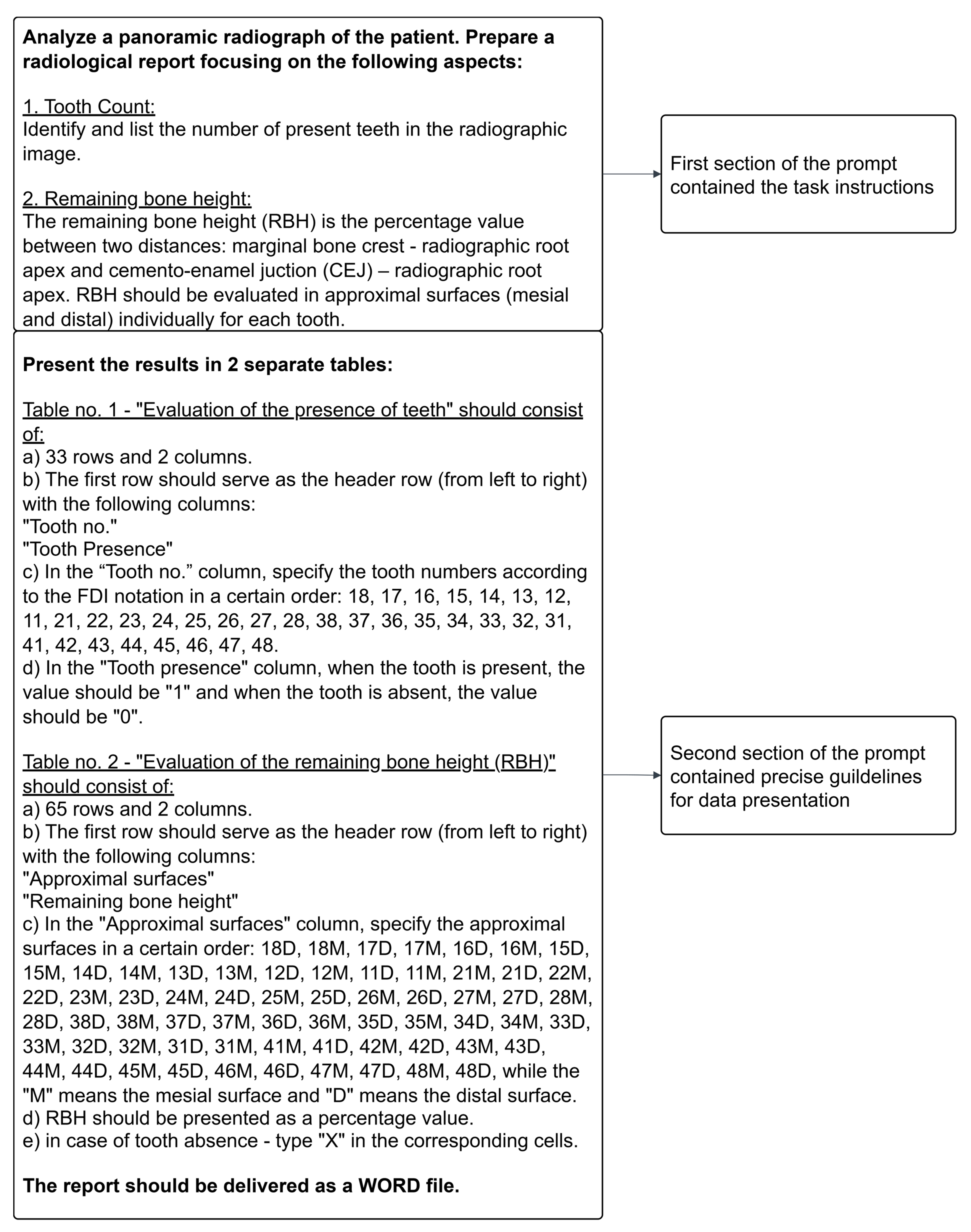
2.4. Tooth Count, Remaining Bone Height (RBH) Measurement and Data Collection
2.4.1. Analysis Conducted by Clinicians
2.4.2. Analysis Conducted by ChatGPT
2.5. Statistical Analysis
3. Results
3.1. Number of Teeth Evaluated by Clinicians and ChatGPT Models
3.2. Intraclass Correlation Coefficient for Remaining Bone Height (RBH) Values Between Clinicians
3.3. Summary of RBH Values for Distal and Mesial Surfaces Evaluated by Clinicians
3.4. Summary of RBH Values for Distal and Mesial Surfaces Evaluated by ChatGPT Models
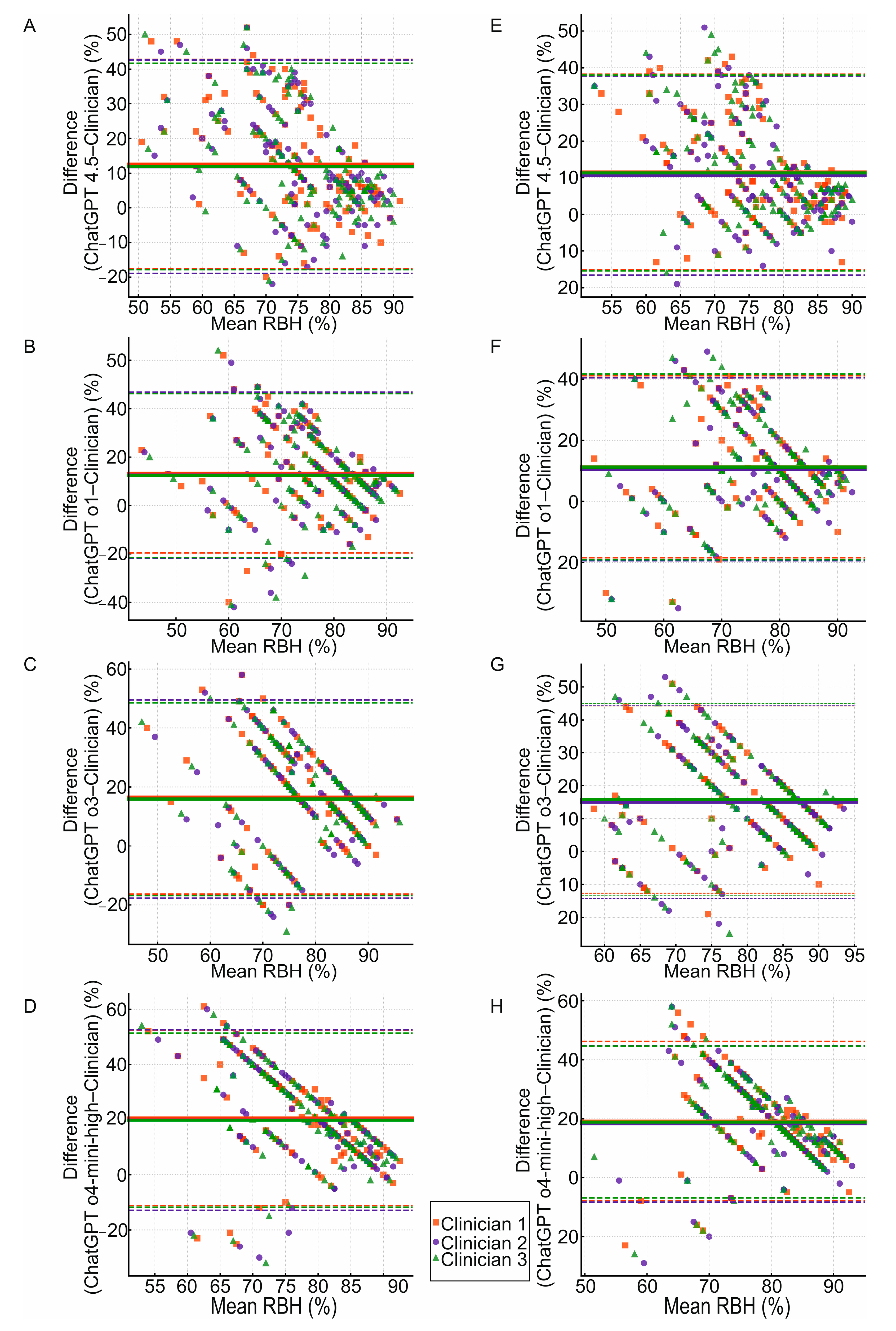
3.5. Agreement Between Clinicians and ChatGPT Models in RBH Measurement for Approximal Surfaces
3.6. Comparison Between ChatGPT Models in RBH Measurement for Approximal Surfaces
4. Discussion
- Panoramic images were used in their original form, even though numerous publications propose various preprocessing methods. Available techniques such as contrast enhancement, filter application, image cropping or image sharpening were not employed.
- We analyzed a limited number of panoramic radiographs due to the variability in image quality and strict exclusion criteria. However, this approach ensured that the results were not influenced by confounding factors and accurately reflected the actual effectiveness of ChatGPT.
- Three dentists participated in the research, while other studies involved a greater number of clinicians, including radiologists.
- There is a lack of comparable data in the existing scientific literature assessing the effectiveness of medical image analysis performed by ChatGPT. Additionally, the OpenAI developers have not provided any reports on the clinical application of ChatGPT models.
- A highly complex prompt may challenge the models’ performance in terms of processing a large set of logically connected words. However, the implementation of precise instructions reduces the risk of hallucinations.
- The risk of hallucinations related to the built-in training database.
5. Conclusions
- In the assessment of tooth counts, the models mainly showed substantial agreement with the clinicians. ChatGPT o4-mini-high showed the highest sensitivity. However, based on the overall evaluation of all the parameters, models 4.5 and o3 proved to be the most reliable. In comparison with various convolutional neural networks, the ChatGPT models achieved similar or lower performances. Currently, transformer models are not recommended for the independent analysis of teeth presence.
- The clinicians’ measurements of the RBH presented excellent consistency, which provided a reliable reference for comparison with the ChatGPT performance.
- The ChatGPT models exhibited significant differences in the assessment of the RBH on the approximal surfaces.
- ChatGPT o1 demonstrated the lowest mean bias in the RBH measurement among the o-series. The lowest mean bias was observed in ChatGPT 4.5 compared with all the other models. The RBH values yielded by all the models fell within wide limits of agreement. This may be clinically relevant in the context of single measurements that could significantly deviate from clinician evaluations.
- A proportional bias was observed across all the ChatGPT models with a higher mean bias associated with a lower mean RBH. This may have clinical implications for the underdiagnosis of periodontal disease.
- ChatGPT 4.5 achieved the highest reliability in both the assessment of tooth counts and the RBH measurement between the ChatGPT models, suggesting its greatest potential for clinical utilization. However, ChatGPT 4.5 remains a preview version of the most advanced generative pre-trained transformer and may undergo substantial reconstruction.
- Convolutional neural networks currently appear to outperform ChatGPT models in the assessment of the alveolar bone level and associated bone loss. However, further studies are needed to compare the effectiveness of both AI models.
- As multimodal language models continue to develop and different calibration methods may be applied, ChatGPT’s potential in assessing panoramic images is increasing. Currently, ChatGPT models demonstrate inadequate agreement with dental professionals in assessing the RBH to serve as a diagnostic tool. Models 4.5 and o3 show potential in tooth count evaluation but are not precise enough for clinical implementation.
- Hardware and environmental costs should be a significant component of the responsible implementation of transformer models in dental diagnostics.
- Multimodal language models are accessible and widely available for various applications. However, in highly specialized fields, such as periodontology, they may pose a risk to individuals who are unable to verify the reliability of the outputs.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| RBH | Remaining bone height |
| CEJ | Cemento-enamel junction |
| LLMs | Large language models |
| ChatGPT | Chat Generative Pre-Trained Transformer |
| CNNs | Convolutional neural networks |
| CBCT | Cone-beam computed tomography |
| LoAs | Limits of agreement |
| PPV | Predictive positive value |
| ICC | Intraclass correlation coefficient |
| Pp | Percentage points |
| RLHF | Reinforcement Learning from Human Feedback |
| SLMs | Small language models |
| RPR | Raw panoramic radiograph |
| O2PR | O2 panoramic radiograph |
| TRPR | Textual report with panoramic radiographs |
| ViT | Visual Transformer |
| GPT-4 | Generative Pre-Trained Transformer-4 |
References
- Kwon, T.; Lamster, I.B.; Levin, L. Current Concepts in the Management of Periodontitis. Int. Dent. J. 2021, 71, 462–476. [Google Scholar] [CrossRef] [PubMed]
- Nascimento, G.G.; Alves-Costa, S.; Romandini, M. Burden of Severe Periodontitis and Edentulism in 2021, with Projections up to 2050: The Global Burden of Disease 2021 Study. J. Periodontal Res. 2024, 59, 823–867. [Google Scholar] [CrossRef] [PubMed]
- Shinjo, T.; Nishimura, F. The Bidirectional Association between Diabetes and Periodontitis, from Basic to Clinical. Jpn. Dent. Sci. Rev. 2024, 60, 15–21. [Google Scholar] [CrossRef] [PubMed]
- Molina, A.; Huck, O.; Herrera, D.; Montero, E. The association between respiratory diseases and periodontitis: A systematic review and meta-analysis. J. Clin. Periodontol. 2023, 50, 842–887. [Google Scholar] [CrossRef] [PubMed]
- Sanz, M.; Del Castillo, A.M.; Jepsen, S.; Gonzalez-Juanatey, J.R.; D’Aiuto, F.; Bouchard, P.; Chapple, I.; Dietrich, T.; Gotsman, I.; Graziani, F.; et al. Periodontitis and cardiovascular diseases: Consensus report. J. Clin. Periodontol. 2020, 47, 268–288. [Google Scholar] [CrossRef] [PubMed]
- Araújo, V.M.A.; Melo, I.M.; Lima, V. Relationship between Periodontitis and Rheumatoid Arthritis: Review of the Literature. Mediat. Inflamm. 2015, 2015, 259074. [Google Scholar] [CrossRef] [PubMed]
- Agarwal, B.; Bizzoca, M.E.; Musella, G.; De Vito, D.; Lo Muzio, L.; Ballini, A.; Cantore, S.; Pisani, F. Tooth Loss in Periodontitis Patients—A Risk Factor for Mild Cognitive Impairment: A Systematic Review and Meta—Analysis. J. Pers. Med. 2024, 14, 953. [Google Scholar] [CrossRef] [PubMed]
- Papapanou, P.N.; Sanz, M.; Buduneli, N.; Dietrich, T.; Feres, M.; Fine, D.H.; Flemmig, T.F.; Garcia, R.; Giannobile, W.V.; Graziani, F.; et al. Periodontitis: Consensus Report of Workgroup 2 of the 2017 World Workshop on the Classification of Periodontal and Peri-Implant Diseases and Conditions. J. Periodontol. 2018, 89, S173–S182. [Google Scholar] [CrossRef] [PubMed]
- Zhao, D.; Zhang, S.; Chen, X.; Liu, W.; Sun, N.; Guo, Y.; Dong, Y.; Mo, A.; Yuan, Q. Evaluation of Periodontitis and Bone Loss in Patients Undergoing Hemodialysis. J. Periodontol. 2014, 85, 1515–1520. [Google Scholar] [CrossRef] [PubMed]
- Rydén, L.; Buhlin, K.; Ekstrand, E.; de Faire, U.; Gustafsson, A.; Holmer, J.; Kjellström, B.; Lindahl, B.; Norhammar, A.; Nygren, Å.; et al. Periodontitis Increases the Risk of a First Myocardial Infarction: A Report from the PAROKRANK Study: A Report from the PAROKRANK Study. Circulation 2016, 133, 576–583. [Google Scholar] [CrossRef] [PubMed]
- Choi, I.G.G.; Cortes, A.R.G.; Arita, E.S.; Georgetti, M.A.P. Comparison of Conventional Imaging Techniques and CBCT for Periodontal Evaluation: A Systematic Review. Imaging Sci. Dent. 2018, 48, 79–86. [Google Scholar] [CrossRef] [PubMed]
- Jacobs, R.; Fontenele, R.C.; Lahoud, P.; Shujaat, S.; Bornstein, M.M. Radiographic Diagnosis of Periodontal Diseases—Current Evidence versus Innovations. Periodontology 2000 2024, 95, 51–69. [Google Scholar] [CrossRef] [PubMed]
- Valappila, N.J.; Beena, V. Panoramic radiography: A review. J. Oral Med. Surg. Pathol. 2016, 1, 21–31. [Google Scholar]
- Liu, Y.; Han, T.; Ma, S.; Zhang, J.; Yang, Y.; Tian, J.; He, H.; Li, A.; He, M.; Liu, Z.; et al. Summary of ChatGPT-Related Research and Perspective towards the Future of Large Language Models. Meta-Radiology 2023, 1, 100017. [Google Scholar] [CrossRef]
- Bhayana, R. Chatbots and Large Language Models in Radiology: A Practical Primer for Clinical and Research Applications. Radiology 2024, 310, e232756. [Google Scholar] [CrossRef] [PubMed]
- Chatterjee, S.; Bhattacharya, M.; Pal, S.; Lee, S.-S.; Chakraborty, C. ChatGPT and Large Language Models in Orthopedics: From Education and Surgery to Research. J. Exp. Orthop. 2023, 10, 128. [Google Scholar] [CrossRef] [PubMed]
- Lewandowski, M.; Kropidłowska, J.; Kvinen, A.; Barańska-Rybak, W. A Systemic Review of Large Language Models and Their Implications in Dermatology. Australas. J. Dermatol. 2025, 66, e202–e208. [Google Scholar] [CrossRef] [PubMed]
- Boonstra, M.J.; Weissenbacher, D.; Moore, J.H.; Gonzalez-Hernandez, G.; Asselbergs, F.W. Artificial Intelligence: Revolutionizing Cardiology with Large Language Models. Eur. Heart J. 2024, 45, 332–345. [Google Scholar] [CrossRef] [PubMed]
- Yang, D.; Wei, J.; Xiao, D.; Wang, S.; Wu, T.; Li, G.; Li, M.; Wang, S.; Chen, J.; Jiang, Y.; et al. PediatricsGPT: Large Language Models as Chinese Medical Assistants for Pediatric Applications. Neural Inf. Process Syst. 2024, 37, 138632–138662. [Google Scholar] [CrossRef]
- Moura, L.; Jones, D.T.; Sheikh, I.S.; Murphy, S.; Kalfin, M.; Kummer, B.R.; Weathers, A.L.; Grinspan, Z.M.; Silsbee, H.M.; Jones, L.K., Jr.; et al. Implications of Large Language Models for Quality and Efficiency of Neurologic Care: Emerging Issues in Neurology: Emerging Issues in Neurology. Neurology 2024, 102, e209497. [Google Scholar] [CrossRef] [PubMed]
- Guevara, M.; Chen, S.; Thomas, S.; Chaunzwa, T.L.; Franco, I.; Kann, B.H.; Moningi, S.; Qian, J.M.; Goldstein, M.; Harper, S.; et al. Large Language Models to Identify Social Determinants of Health in Electronic Health Records. NPJ Digit. Med. 2024, 7, 6. [Google Scholar] [CrossRef] [PubMed]
- de Menezes Torres, L.M.; de Morais, E.F.; Fernandes Almeida, D.R.d.M.; Pagotto, L.E.C.; de Santana Santos, T. The Impact of the Large Language Model ChatGPT in Oral and Maxillofacial Surgery: A Systematic Review. Br. J. Oral Maxillofac. Surg. 2025, 63, 357–362. [Google Scholar] [CrossRef] [PubMed]
- Gupta, B.; Mufti, T.; Sohail, S.S.; Madsen, D.Ø. ChatGPT: A Brief Narrative Review. Cogent Bus. Manag. 2023, 10, 2275851. [Google Scholar] [CrossRef]
- Tastan Eroglu, Z.; Babayigit, O.; Ozkan Sen, D.; Ucan Yarkac, F. Performance of ChatGPT in Classifying Periodontitis According to the 2018 Classification of Periodontal Diseases. Clin. Oral Investig. 2024, 28, 407. [Google Scholar] [CrossRef] [PubMed]
- Alan, R.; Alan, B.M. Utilizing ChatGPT-4 for Providing Information on Periodontal Disease to Patients: A DISCERN Quality Analysis. Cureus 2023, 15, e46213. [Google Scholar] [CrossRef] [PubMed]
- Camlet, A.; Kusiak, A.; Świetlik, D. Application of Conversational AI Models in Decision Making for Clinical Periodontology: Analysis and Predictive Modeling. AI 2025, 6, 3. [Google Scholar] [CrossRef]
- Ossowska, A.; Kusiak, A.; Świetlik, D. Evaluation of the Progression of Periodontitis with the Use of Neural Networks. J. Clin. Med. 2022, 11, 4667. [Google Scholar] [CrossRef] [PubMed]
- Ossowska, A.; Kusiak, A.; Świetlik, D. Progression of Selected Parameters of the Clinical Profile of Patients with Periodontitis Using Kohonen’s Self-Organizing Maps. J. Pers. Med. 2023, 13, 346. [Google Scholar] [CrossRef] [PubMed]
- Graves, D.T.; Li, J.; Cochran, D.L. Inflammation and Uncoupling as Mechanisms of Periodontal Bone Loss. J. Dent. Res. 2011, 90, 143–153. [Google Scholar] [CrossRef] [PubMed]
- Winkler, P.; Dannewitz, B.; Nickles, K.; Petsos, H.; Eickholz, P. Assessment of Periodontitis Grade in Epidemiological Studies Using Interdental Attachment Loss Instead of Radiographic Bone Loss. J. Clin. Periodontol. 2022, 49, 854–861. [Google Scholar] [CrossRef] [PubMed]
- Stødle, I.H.; Koldsland, O.C.; Lukina, P.; Andersen, I.L.; Mjønes, P.; Rønne, E.; Høvik, H.; Ness-Jensen, E.; Verket, A. Undiagnosed Celiac Disease and Periodontal Bone Loss: A Cross-Sectional Radiological Assessment from the HUNT Study. Int. J. Dent. 2024, 2024, 1952244. [Google Scholar] [CrossRef] [PubMed]
- Huang, N.; Shimomura, E.; Yin, G.; Tran, C.; Sato, A.; Steiner, A.; Heibeck, T.; Tam, M.; Fairman, J.; Gibson, F.C., 3rd. Immunization with Cell-Free-Generated Vaccine Protects from Porphyromonas Gingivalis-Induced Alveolar Bone Loss. J. Clin. Periodontol. 2019, 46, 197–205. [Google Scholar] [CrossRef] [PubMed]
- Anbiaee, N.; Pahlavanzadeh, P. Evaluation of Panoramic Radiography Diagnostic Accuracy in the Assessment of Interdental Alveolar Bone Loss Using CBCT. Clin. Exp. Dent. Res. 2024, 10, e70042. [Google Scholar] [CrossRef] [PubMed]
- Amasya, H.; Jaju, P.P.; Ezhov, M.; Gusarev, M.; Atakan, C.; Sanders, A.; Manulius, D.; Golitskya, M.; Shrivastava, K.; Singh, A.; et al. Development and Validation of an Artificial Intelligence Software for Periodontal Bone Loss in Panoramic Imaging. Int. J. Imaging Syst. Technol. 2024, 34, e22973. [Google Scholar] [CrossRef]
- Machado, V.; Proença, L.; Morgado, M.; Mendes, J.J.; Botelho, J. Accuracy of Panoramic Radiograph for Diagnosing Periodontitis Comparing to Clinical Examination. J. Clin. Med. 2020, 9, 2313. [Google Scholar] [CrossRef] [PubMed]
- Salvi, G.E.; Roccuzzo, A.; Imber, J.-C.; Stähli, A.; Klinge, B.; Lang, N.P. Clinical Periodontal Diagnosis. Periodontology 2000 2023. [Google Scholar] [CrossRef] [PubMed]
- Akesson, L.; Håkansson, J.; Rohlin, M. Comparison of Panoramic and Intraoral Radiography and Pocket Probing for the Measurement of the Marginal Bone Level. J. Clin. Periodontol. 1992, 19, 326–332. [Google Scholar] [CrossRef] [PubMed]
- Gedik, R.; Marakoğlu, Í.; Demirer, S. Assessment of Alveolar Bone Levels from Bitewing, Periapical and Panoramic Radiographs in Periodontitis Patients. West Indian Med. J. 2008, 57, 410–413. [Google Scholar] [PubMed]
- Manja, C.D.; Fransiari, M.E. A Comparative Assessment of Alveolar Bone Loss Using Bitewing, Periapical, and Panoramic Radiography. Bali Med. J. 2018, 7, 636–638. [Google Scholar] [CrossRef]
- Kim, T.-S.; Obst, C.; Zehaczek, S.; Geenen, C. Detection of Bone Loss with Different X-Ray Techniques in Periodontal Patients. J. Periodontol. 2008, 79, 1141–1149. [Google Scholar] [CrossRef] [PubMed]
- Venkatesh, E.; Elluru, S.V. Cone Beam Computed Tomography: Basics and Applications in Dentistry. J. Istanb. Univ. Fac. Dent. 2017, 51, S102–S121. [Google Scholar] [CrossRef] [PubMed]
- Takeshita, W.M.; Vessoni Iwaki, L.C.; Da Silva, M.C.; Tonin, R.H. Evaluation of Diagnostic Accuracy of Conventional and Digital Periapical Radiography, Panoramic Radiography, and Cone-Beam Computed Tomography in the Assessment of Alveolar Bone Loss. Contemp. Clin. Dent. 2014, 5, 318–323. [Google Scholar] [CrossRef] [PubMed]
- de Faria Vasconcelos, K.; Evangelista, K.M.; Rodrigues, C.D.; Estrela, C.; de Sousa, T.O.; Silva, M.A.G. Detection of Periodontal Bone Loss Using Cone Beam CT and Intraoral Radiography. Dentomaxillofac. Radiol. 2012, 41, 64–69. [Google Scholar] [CrossRef] [PubMed]
- Christiaens, V.; Pauwels, R.; Mowafey, B.; Jacobs, R. Accuracy of Intra-Oral Radiography and Cone Beam Computed Tomography in the Diagnosis of Buccal Bone Loss. J. Imaging 2023, 9, 164. [Google Scholar] [CrossRef] [PubMed]
- Acar, B.; Kamburoğlu, K. Use of Cone Beam Computed Tomography in Periodontology. World J. Radiol. 2014, 6, 139–147. [Google Scholar] [CrossRef] [PubMed]
- Mandelaris, G.A.; Scheyer, E.T.; Evans, M.; Kim, D.; McAllister, B.; Nevins, M.L.; Rios, H.F.; Sarment, D. American Academy of Periodontology Best Evidence Consensus Statement on Selected Oral Applications for Cone-Beam Computed Tomography. J. Periodontol. 2017, 88, 939–945. [Google Scholar] [CrossRef] [PubMed]
- Persson, R.E.; Tzannetou, S.; Feloutzis, A.G.; Brägger, U.; Persson, G.R.; Lang, N.P. Comparison between Panoramic and Intra-Oral Radiographs for the Assessment of Alveolar Bone Levels in a Periodontal Maintenance Population: Panoramic and Intra-Oral Radiography. J. Clin. Periodontol. 2003, 30, 833–839. [Google Scholar] [CrossRef] [PubMed]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional Neural Networks: An Overview and Application in Radiology. Insights Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef] [PubMed]
- Özçelik, S.T.A.; Üzen, H.; Şengür, A.; Fırat, H.; Türkoğlu, M.; Çelebi, A.; Gül, S.; Sobahi, N.M. Enhanced Panoramic Radiograph-Based Tooth Segmentation and Identification Using an Attention Gate-Based Encoder-Decoder Network. Diagnostics 2024, 14, 2719. [Google Scholar] [CrossRef] [PubMed]
- Rubiu, G.; Bologna, M.; Cellina, M.; Cè, M.; Sala, D.; Pagani, R.; Mattavelli, E.; Fazzini, D.; Ibba, S.; Papa, S.; et al. Teeth Segmentation in Panoramic Dental X-ray Using Mask Regional Convolutional Neural Network. Appl. Sci. 2023, 13, 7947. [Google Scholar] [CrossRef]
- Mohammad, N.; Muad, A.M.; Ahmad, R.; Yusof, M.Y.P.M. Accuracy of Advanced Deep Learning with Tensorflow and Keras for Classifying Teeth Developmental Stages in Digital Panoramic Imaging. BMC Med. Imaging 2022, 22, 66. [Google Scholar] [CrossRef] [PubMed]
- Introducing GPT-4.5. Available online: https://openai.com/index/introducing-gpt-4-5/?utm_source=chatgpt.com (accessed on 30 May 2025).
- Thinking with Images. Available online: https://openai.com/index/thinking-with-images/ (accessed on 30 May 2025).
- Krois, J.; Ekert, T.; Meinhold, L.; Golla, T.; Kharbot, B.; Wittemeier, A.; Dörfer, C.; Schwendicke, F. Deep Learning for the Radiographic Detection of Periodontal Bone Loss. Sci. Rep. 2019, 9, 8495. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.; Dai, F.; Zhu, H.; Yang, H.; Huang, Y.; Jiang, L.; Tang, X.; Deng, L.; Song, L. Deep Learning for the Early Identification of Periodontitis: A Retrospective, Multicentre Study. Clin. Radiol. 2023, 78, e985–e992. [Google Scholar] [CrossRef] [PubMed]
- Xue, T.; Chen, L.; Sun, Q. Deep Learning Method to Automatically Diagnose Periodontal Bone Loss and Periodontitis Stage in Dental Panoramic Radiograph. J. Dent. 2024, 150, 105373. [Google Scholar] [CrossRef] [PubMed]
- Dasanayaka, C.; Dandeniya, K.; Dissanayake, M.B.; Gunasena, C.; Jayasinghe, R. Multimodal AI and Large Language Models for Orthopantomography Radiology Report Generation and Q&A. Appl. Syst. Innov. 2025, 8, 39. [Google Scholar] [CrossRef]
- Silva, B.; Fontinele, J.; Vieira, C.L.Z.; Tavares, J.M.R.S.; Cury, P.R.; Oliveira, L. A holistic approach for classifying dental conditions from textual reports and panoramic radiographs. Med. Image Anal. 2025, 105, 103709. [Google Scholar] [CrossRef] [PubMed]
- Veitz-Keenan, A.; Keenan, J.R. Implant Outcomes Poorer in Patients with History of Periodontal Disease. Evid. Based Dent. 2017, 18, 5. [Google Scholar] [CrossRef] [PubMed]
- Tangsrivimol, J.A.; Darzidehkalani, E.; Virk, H.U.H.; Wang, Z.; Egger, J.; Wang, M.; Hacking, S.; Glicksberg, B.S.; Strauss, M.; Krittanawong, C. Benefits, Limits, and Risks of ChatGPT in Medicine. Front. Artif. Intell. 2025, 8, 1518049. [Google Scholar] [CrossRef] [PubMed]
- Chelli, M.; Descamps, J.; Lavoué, V.; Trojani, C.; Azar, M.; Deckert, M.; Raynier, J.-L.; Clowez, G.; Boileau, P.; Ruetsch-Chelli, C. Hallucination Rates and Reference Accuracy of ChatGPT and Bard for Systematic Reviews: Comparative Analysis. J. Med. Internet Res. 2024, 26, e53164. [Google Scholar] [CrossRef] [PubMed]
- Giuffrè, M.; You, K.; Shung, D.L. Evaluating ChatGPT in Medical Contexts: The Imperative to Guard against Hallucinations and Partial Accuracies. Clin. Gastroenterol. Hepatol. 2024, 22, 1145–1146. [Google Scholar] [CrossRef] [PubMed]
- Aljamaan, F.; Temsah, M.-H.; Altamimi, I.; Al-Eyadhy, A.; Jamal, A.; Alhasan, K.; Mesallam, T.A.; Farahat, M.; Malki, K.H. Reference Hallucination Score for Medical Artificial Intelligence Chatbots: Development and Usability Study. JMIR Med. Inform. 2024, 12, e54345. [Google Scholar] [CrossRef] [PubMed]
- Roustan, D.; Bastardot, F. The Clinicians’ Guide to Large Language Models: A General Perspective with a Focus on Hallucinations. Interact. J. Med. Res. 2025, 14, e59823. [Google Scholar] [CrossRef] [PubMed]
- Tlili, A.; Burgos, D. Ai hallucinations? what about human hallucination?!: Addressing human imperfection is needed for an ethical AI. IJIMAI 2025, 9, 68–71. [Google Scholar] [CrossRef]
- Chen, B.; Zhang, Z.; Langrené, N.; Zhu, S. Unleashing the Potential of Prompt Engineering for Large Language Models. Patterns 2025, 6, 101260. [Google Scholar] [CrossRef] [PubMed]
- Shaji George, A.; Hovan George, A.S.; Gabrio Martin, A.S. The Environmental Impact of AI: A Case Study of Water Consumption by Chat GPT. Partn. Univers. Int. Innov. J. 2023, 1, 97–104. [Google Scholar]
- Khowaja, S.A.; Khuwaja, P.; Dev, K.; Wang, W.; Nkenyereye, L. ChatGPT Needs SPADE (Sustainability, PrivAcy, Digital Divide, and Ethics) Evaluation: A Review. Cognit. Comput. 2024, 16, 2528–2550. [Google Scholar] [CrossRef]
- Yoon, I.; Mun, J.; Min, K.-S. Comparative Study on Energy Consumption of Neural Networks by Scaling of Weight-Memory Energy Versus Computing Energy for Implementing Low-Power Edge Intelligence. Electronics 2025, 14, 2718. [Google Scholar] [CrossRef]
- Irugalbandara, C.; Mahendra, A.; Daynauth, R.; Arachchige, T.K.; Dantanarayana, J.; Flautner, K.; Tang, L.; Kang, Y.; Mars, J. Scaling down to Scale up: A Cost-Benefit Analysis of Replacing OpenAI’s LLM with Open Source SLMs in Production. In Proceedings of the 2024 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Indianapolis, IN, USA, 5–7 May 2024; pp. 280–291. [Google Scholar]
- Lorencin, I.; Tankovic, N.; Etinger, D. Optimizing Healthcare Efficiency with Local Large Language Models. AHFE Int. 2025, 160, 576–584. [Google Scholar]
- Stojkovic, J.; Zhang, C.; Goiri, Í.; Torrellas, J.; Choukse, E. DynamoLLM: Designing LLM Inference Clusters for Performance and Energy Efficiency. In Proceedings of the 2025 IEEE International Symposium on High Performance Computer Architecture (HPCA), Las Vegas, NV, USA, 1–5 March 2025; pp. 1348–1362. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Clinician 1–3 | ChatGPT 4.5 | ChatGPT o1 | ChatGPT o3 | ChatGPT o4-Mini-High |
|---|---|---|---|---|
| 232 (72.5%) | 214 (66.9%) | 243 (75.9%) | 212 (66.3%) | 239 (74.7%) |
| Clinician vs. ChatGPT 4.5 | Clinician vs. ChatGPT o1 | Clinician vs. ChatGPT o3 | Clinician vs. ChatGPT o4-mini-high | |
| Fleiss’ kappa (95% CI) | 0.65 (0.56–0.73) | 0.52 (0.41–0.62) | 0.66 (0.57–0.75) | 0.69 (0.59–0.78) |
| Sensitivity | 85.8% | 89.7% | 85.8% | 93.1% |
| Specificity | 83.0% | 60.2% | 85.2% | 73.9% |
| PPV | 93.0% | 85.6% | 94.0% | 90.4% |
| Approximal Surface | Number of Measurements | ICC (2,1) (95% CI) | ICC (2,3) (95% CI) |
|---|---|---|---|
| Distal | 142 | 0.96 (0.94–0.97) | 0.99 (0.98–0.99) |
| Mesial | 147 | 0.95 (0.93–0.96) | 0.98 (0.98–0.99) |
| Clinician 1 | Clinician 2 | Clinician 3 | p-Value | |
|---|---|---|---|---|
| 0.7853 | ||||
| Mean (SD) | 70.4% (11.6%) | 72.6% (12.4%) | 71.9% (12.8%) | |
| Range | 28.0–85.0% | 31.0–86.0% | 26.0–89.0% | |
| Median (IQR) | 72.0% (16.0%) | 75.0% (18.5%) | 75.5% (15.0%) | |
| 95% CI | [66.2%; 74.6%] | [68.2%; 77.1%] | [67.3%; 76.5%] |
| Clinician 1 | Clinician 2 | Clinician 3 | p-Value | |
|---|---|---|---|---|
| 0.7933 | ||||
| Mean (SD) | 68.8% (9.1%) | 70.7% (9.5%) | 69.7% (9.2%) | |
| Range | 52.0–85.0% | 56.0–87.0% | 54.0–90.0% | |
| Median (IQR) | 69.0% (14.0%) | 73.0% (16.0%) | 71.0% (12.0%) | |
| 95% CI | [65.5%; 72.1%] | [67.2%; 74.2%] | [66.4%; 73.1%] |
| ChatGPT 4.5 | ChatGPT o1 | ChatGPT o3 | ChatGPT o4-Mini-High | p-Value | |
|---|---|---|---|---|---|
| <0.0001 | |||||
| Mean (SD) | 73.7% (6.9%) a,b | 76.7% (15.4%) c,d | 73.0% (12.4%) a,c | 77.0% (10.4%) b,d | a,b,d <0.0001 c 0.0053 |
| Range | 60.0–85.0% | 40.0–90.0% | 60.0–92.0% | 50.0–90.0% | |
| Median (IQR) | 74.0% (10.0%) | 85.0% (20.0%) | 70.0% (25.0%) | 80.0% (5.0%) | |
| 95% CI | [70.9%; 76.6%] | [69.6%; 83.7%] | [67.6%; 78.4%] | [72.9%; 81.2%] |
| ChatGPT 4.5 | ChatGPT o1 | ChatGPT o3 | ChatGPT o4-Mini-High | p-Value | |
|---|---|---|---|---|---|
| <0.0001 | |||||
| Mean (SD) | 74.2% (6.8%) a,b | 75.8% (16.3%) c,d | 74.2% (12.4%) a,c | 78.2% (10.5%) b,d | a,b,d <0.0001 c 0.0002 |
| Range | 55.0–85.0% | 35.0–90.0% | 60.0–92.0% | 45.0–92.0% | |
| Median (IQR) | 75.0% (10.0%) | 85.0% (25.0%) | 70.0% (25.0%) | 80.0% (0.0%) | |
| 95% CI | [71.4%; 77.1%] | [68.1%; 83.4%] | [68.9%; 79.6%] | [74.0%; 82.5%] |
| Clinician | ChatGPT 4.5 Bias (95% CI) | ChatGPT o1 Bias (95% CI) | ChatGPT o3 Bias (95% CI) | ChatGPT o4-Mini-High Bias (95% CI) |
|---|---|---|---|---|
| 1 | +13 pp (−18 pp; +43 pp) | +13 pp (−20 pp; +46 pp) | +17 pp (−16 pp; +50 pp) | +21 pp (−11 pp; +52 pp) |
| 2 | +12 pp (−19 pp; +43 pp) | +13 pp (−22 pp; +47 pp) | +16 pp (−18 pp; +50 pp) | +20 pp (−13 pp; +53 pp) |
| 3 | +12 pp (−18 pp; +42 pp) | +12 pp (−22 pp; +46 pp) | +16 pp (−17 pp; +49 pp) | +20 pp (−12 pp; +51 pp) |
| Clinician | ChatGPT 4.5 Bias (95% CI) | ChatGPT o1 Bias (95% CI) | ChatGPT o3 Bias (95% CI) | ChatGPT o4-Mini-High Bias (95% CI) |
|---|---|---|---|---|
| 1 | +12 pp (−15 pp; +38 pp) | +11 pp (−19 pp; +41 pp) | +16 pp (−13 pp; +44 pp) | +19 pp (−8 pp; +46 pp) |
| 2 | +11 pp (−17 pp; +38 pp) | +11 pp (−19 pp; +40 pp) | +15 pp (−14 pp; +44 pp) | +18 pp (−8 pp; +45 pp) |
| 3 | +11 pp (−15 pp; +38 pp) | +11 pp (−19 pp; +42 pp) | +16 pp (−13 pp; +45 pp) | +19 pp (−7 pp; +45 pp) |
| Model | Bias | LoA Width | Performance |
|---|---|---|---|
| 4.5 | +12 pp | ~60 pp | Lowest bias |
| o1 | +13 pp | ~66 pp | Moderate bias |
| o3 | +16 pp | ~66 pp | Moderate bias |
| o4-mini-high | +20 pp | ~64 pp | Highest bias |
| Model | Bias | LoA Width | Performance |
|---|---|---|---|
| 4.5 | +11 pp | ~54 pp | Lowest bias |
| o1 | +11 pp | ~60 pp | Wider LoA |
| o3 | +15 pp | ~58 pp | Moderate bias |
| o4-mini-high | +19 pp | ~54 pp | Highest bias |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Camlet, A.; Kusiak, A.; Ossowska, A.; Świetlik, D. Advances in Periodontal Diagnostics: Application of MultiModal Language Models in Visual Interpretation of Panoramic Radiographs. Diagnostics 2025, 15, 1851. https://doi.org/10.3390/diagnostics15151851
Camlet A, Kusiak A, Ossowska A, Świetlik D. Advances in Periodontal Diagnostics: Application of MultiModal Language Models in Visual Interpretation of Panoramic Radiographs. Diagnostics. 2025; 15(15):1851. https://doi.org/10.3390/diagnostics15151851
Chicago/Turabian StyleCamlet, Albert, Aida Kusiak, Agata Ossowska, and Dariusz Świetlik. 2025. "Advances in Periodontal Diagnostics: Application of MultiModal Language Models in Visual Interpretation of Panoramic Radiographs" Diagnostics 15, no. 15: 1851. https://doi.org/10.3390/diagnostics15151851
APA StyleCamlet, A., Kusiak, A., Ossowska, A., & Świetlik, D. (2025). Advances in Periodontal Diagnostics: Application of MultiModal Language Models in Visual Interpretation of Panoramic Radiographs. Diagnostics, 15(15), 1851. https://doi.org/10.3390/diagnostics15151851