



DeepBiteNet: A Lightweight Ensemble Framework for Multiclass Bug Bite Classification Using Image-Based Deep Learning

 , and
, and
Abstract
1. Introduction
2. Related Works
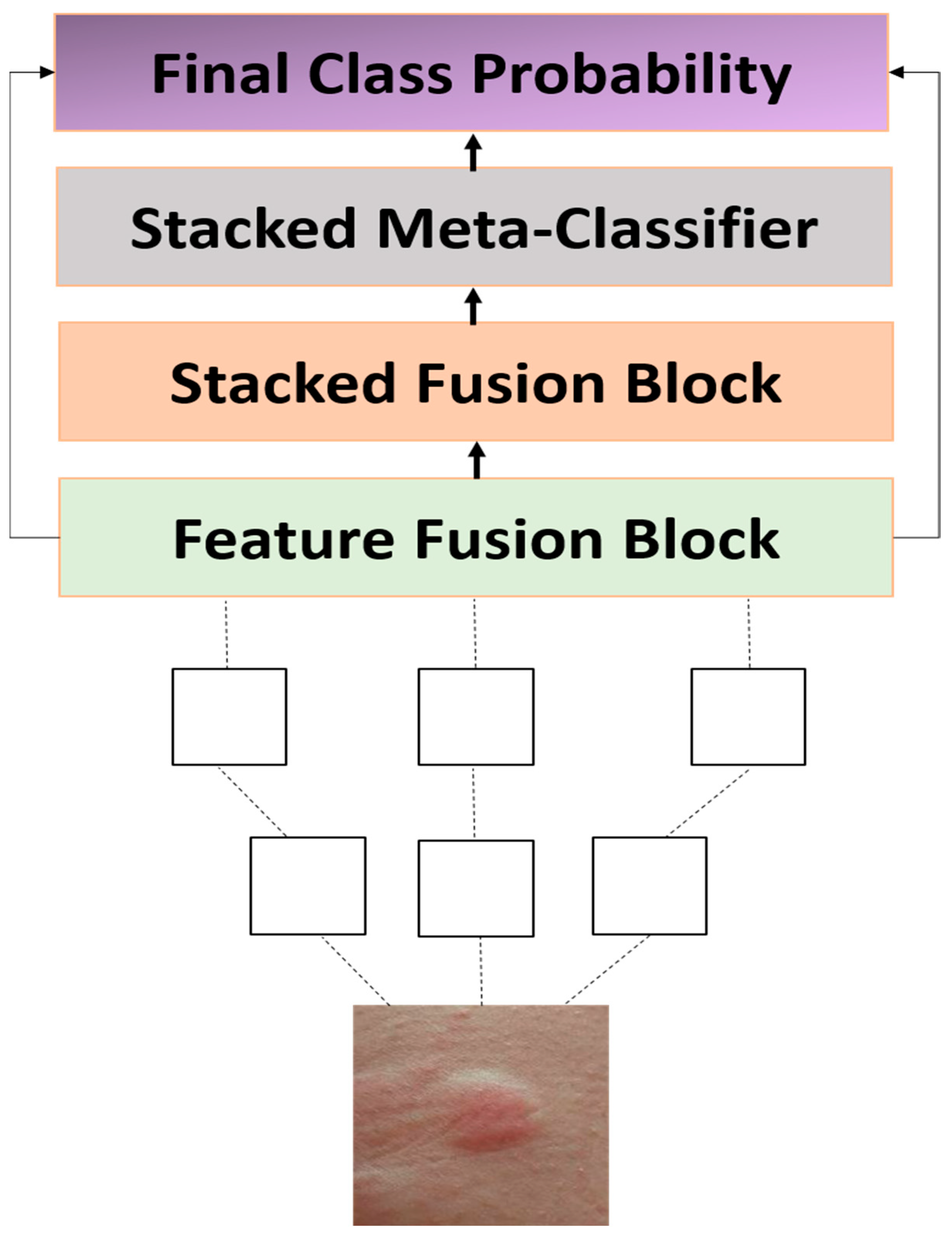
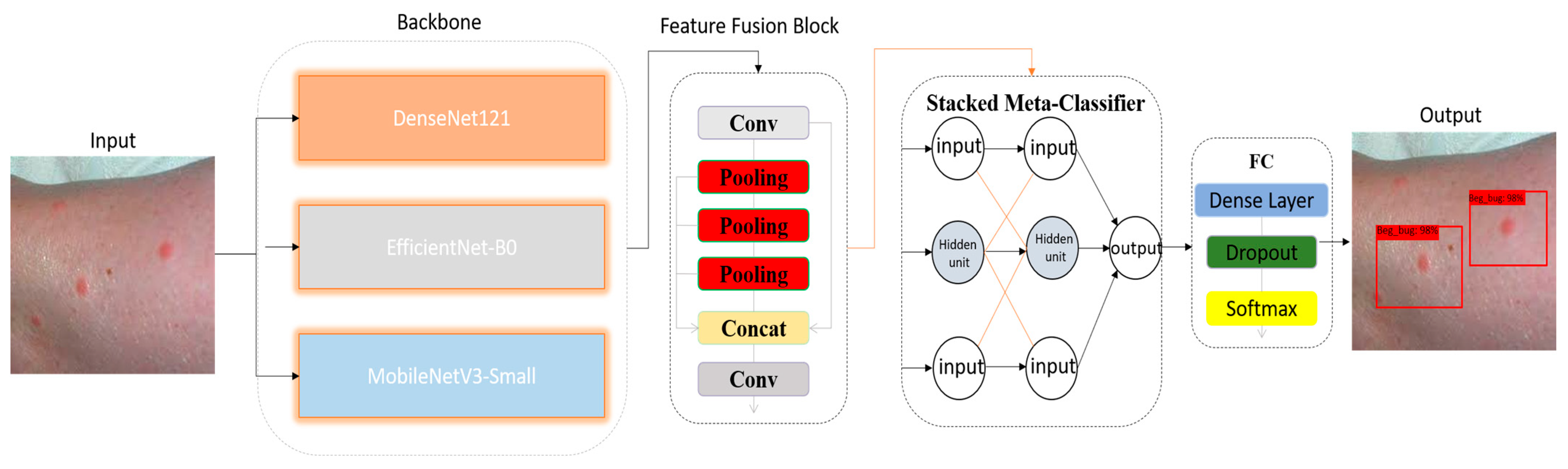
3. Materials and Methods
Training Strategy
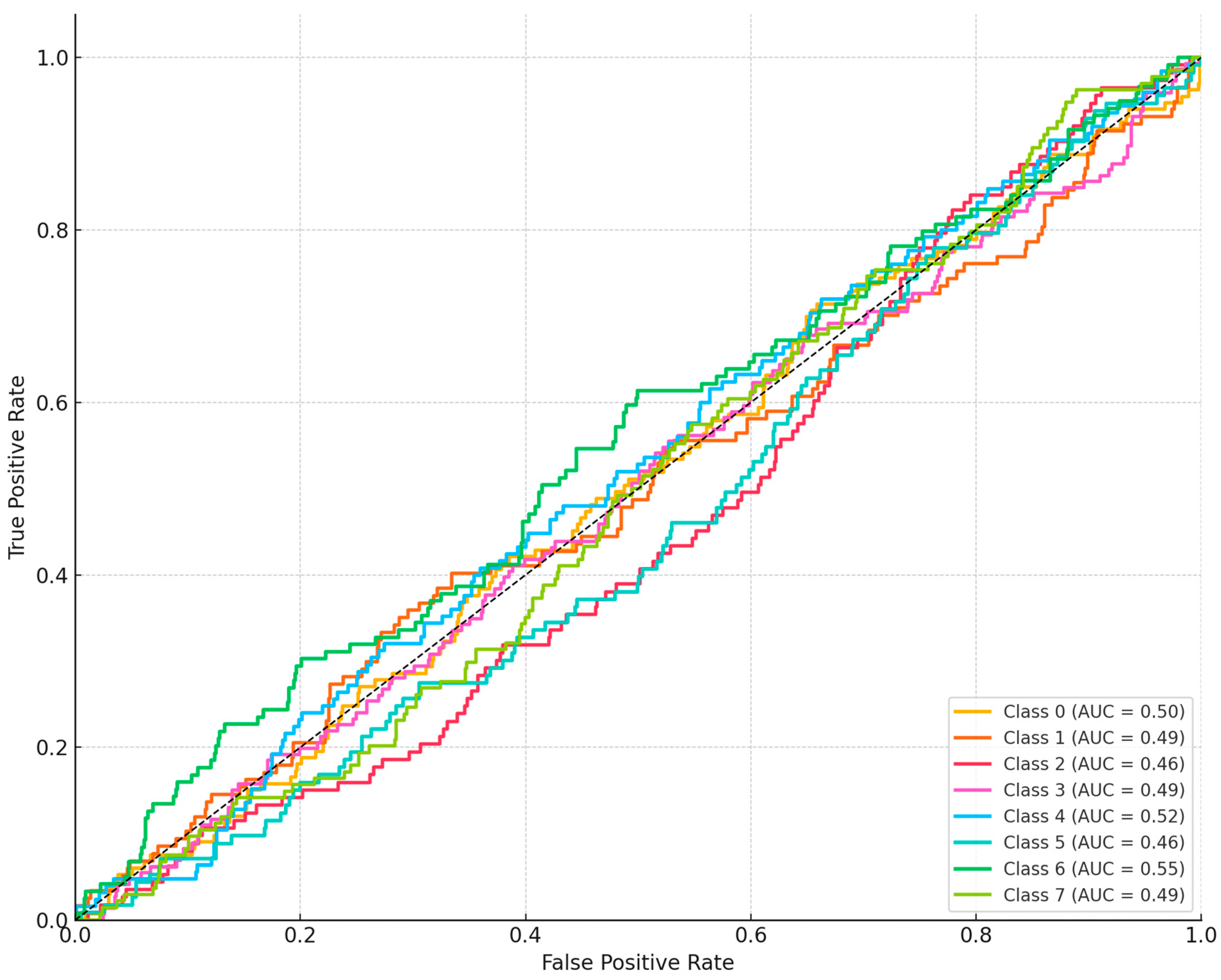
4. Results
Dataset Preprocessing
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ilijoski, B.; Trojachanec Dineva, K.; Tojtovska Ribarski, B.; Petrov, P.; Mladenovska, T.; Trajanoska, M.; Gjorshoska, I.; Lameski, P. Deep Learning methods for bug bite classification: An end-to-end system. Appl. Sci. 2023, 13, 5187. [Google Scholar] [CrossRef]
- Sushma, K.V.N.D.; Pande, S.D. Multiclass Classification of Insect Bites Using Deep Learning Techniques. In Proceedings of the International Conference on Machine Vision and Augmented Intelligence, Patna, India, 24–25 November 2023; Springer Nature: Singapore, 2023; pp. 577–585. [Google Scholar]
- Umirzakova, S.; Muksimova, S.; Baltayev, J.; Cho, Y.I. Force Map-Enhanced Segmentation of a Lightweight Model for the Early Detection of Cervical Cancer. Diagnostics 2025, 15, 513. [Google Scholar] [CrossRef] [PubMed]
- Akshaykrishnan, V.; Sharanya, C.; Abhinav, K.; Aparna, C.K.; Bindu, P.V. A machine learning based insect bite classification. In Proceedings of the 2023 3rd International Conference on Smart Data Intelligence (ICSMDI), Trichy, India, 30–31 March 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 259–264. [Google Scholar]
- Rajak, P.; Ganguly, A.; Adhikary, S.; Bhattacharya, S. Smart technology for mosquito control: Recent developments, challenges, and future prospects. Acta Trop. 2024, 258, 107348. [Google Scholar] [CrossRef] [PubMed]
- Zeledon, E.V.; Baxt, L.A.; Khan, T.A.; Michino, M.; Miller, M.; Huggins, D.J.; Jiang, C.S.; Vosshall, L.B.; Duvall, L.B. Next-generation neuropeptide Y receptor small-molecule agonists inhibit mosquito-biting behavior. Parasites Vectors 2024, 17, 276. [Google Scholar] [CrossRef] [PubMed]
- Nainggolan, P.I.; Efendi, S.; Budiman, M.A.; Lydia, M.S.; Rahmat, R.F.; Bukit, D.S.; Salmah, U.; Indirawati, S.M.; Sulaiman, R. Detection and Classification of Mosquito Larvae Based on Deep Learning Approach. Eng. Lett. 2025, 33, 198–206. [Google Scholar]
- Aggarwal, G.; Goyal, M.K. V2SeqNet: A robust deep learning framework for malaria parasite stage classification in thin smear microscopic images. J. Integr. Sci. Technol. 2025, 13, 1104. [Google Scholar] [CrossRef]
- Muksimova, S.; Umirzakova, S.; Shoraimov, K.; Baltayev, J.; Cho, Y.-I. Novelty Classification Model Use in Reinforcement Learning for Cervical Cancer. Cancers 2024, 16, 3782. [Google Scholar] [CrossRef] [PubMed]
- Zhang, B.; Zhou, X.; Luo, Y.; Zhang, H.; Yang, H.; Ma, J.; Ma, L. Opportunities and challenges: Classification of skin disease based on deep learning. Chin. J. Mech. Eng. 2021, 34, 112. [Google Scholar] [CrossRef]
- Michelerio, A.; Rubatto, M.; Roccuzzo, G.; Coscia, M.; Quaglino, P.; Tomasini, C. Eosinophilic Dermatosis of Hematologic Malignancy: Emerging Evidence for the Role of Insect Bites—A Retrospective Clinico-Pathological Study of 35 Cases. J. Clin. Med. 2024, 13, 2935. [Google Scholar] [CrossRef] [PubMed]
- Amekpor, F.; Mwansa, C.; Benjamin, D.O.; Adedokun, D.A.; Aderonke, T.R.; Kamfechukwu, O.G.; Tripathy, S.; Mehta, V. The Prospects and Challenges of Telemedicine and Digital Health Tools in Enhancing the Timely Reporting and Surveillance of Malaria Cases. J. Health Sci. Med. Res. 2025, 43, 20251167. [Google Scholar] [CrossRef]
- Deniz-Garcia, A.; Fabelo, H.; Rodriguez-Almeida, A.J.; Zamora-Zamorano, G.; Castro-Fernandez, M.; Alberiche Ruano, M.D.P.; Solvoll, T.; Granja, C.; Schopf, T.R.; Callico, G.M.; et al. Quality, usability, and effectiveness of mHealth apps and the role of artificial intelligence: Current scenario and challenges. J. Med. Internet Res. 2023, 25, e44030. [Google Scholar] [CrossRef] [PubMed]
- Verma, N.; Ranvijay; Yadav, D.K. A comprehensive review on step-based skin cancer detection using machine learning and deep learning methods. Arch. Comput. Methods Eng. 2025, 32, 1–54. [Google Scholar] [CrossRef]
- McMullen, E.P.; Al Naser, Y.A.; Maazi, M.; Grewal, R.S.; Abdel Hafeez, D.; Folino, T.R.; Vender, R.B. Predicting psoriasis severity using machine learning: A systematic review. Clin. Exp. Dermatol. 2025, 50, 520–528. [Google Scholar] [CrossRef] [PubMed]
- Asif, S.; Khan, S.U.R.; Amjad, K.; Awais, M. SKINC-NET: An efficient Lightweight Deep Learning Model for Multiclass skin lesion classification in dermoscopic images. Multimed. Tools Appl. 2024, 84, 12531–12557. [Google Scholar] [CrossRef]
- Amin, M.U.; Iqbal, M.M.; Saeed, S.; Hameed, N.; Iqbal, M.J. Skin lesion detection and classification. J. Comput. Biomed. Inform. 2024, 6, 47–54. [Google Scholar]
- Padhy, S.; Dash, S.; Kumar, N.; Singh, S.P.; Kumar, G.; Moral, P. Temporal Integration of ResNet Features with LSTM for Enhanced Skin Lesion Classification. Results Eng. 2025, 25, 104201. [Google Scholar] [CrossRef]
- Bello, A.; Ng, S.C.; Leung, M.F. Skin cancer classification using fine-tuned transfer learning of DENSENET-121. Appl. Sci. 2024, 14, 7707. [Google Scholar] [CrossRef]
- Dillshad, V.; Khan, M.A.; Nazir, M.; Saidani, O.; Alturki, N.; Kadry, S. D2LFS2Net: Multi-class skin lesion diagnosis using deep learning and variance-controlled Marine Predator optimisation: An application for precision medicine. CAAI Trans. Intell. Technol. 2025, 10, 207–222. [Google Scholar] [CrossRef]
- Akhoundi, M.; Sereno, D.; Marteau, A.; Bruel, C.; Izri, A. Who Bites Me? A Tentative Discriminative Key to Diagnose Hematophagous Ectoparasites Biting Using Clinical Manifestations. Diagnostics 2020, 10, 308. [Google Scholar] [CrossRef] [PubMed]
- Singh, S.; Mann, B.K. Insect bite reactions. Indian J. Dermatol. Venereol. Leprol. 2013, 79, 151. [Google Scholar] [CrossRef] [PubMed]
- Vaidyanathan, R.; Feldlaufer, M.F. Bed bug detection: Current technologies and future directions. Am. J. Trop. Med. Hyg. 2013, 88, 619. [Google Scholar] [CrossRef] [PubMed]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Task | Models | Dataset | Mobile-Ready | Accuracy |
|---|---|---|---|---|---|
| Ilijoski et al. (2023) [1] | Bug bite classification | VGG16 + InceptionV3 | Kaggle + curated | No | ~86% |
| Sushma & Pande (2023) [2] | Multiclass bite classification | MobileNetV2 | Self-curated | No | ~76% |
| Akshaykrishnan et al. (2023) [4] | Insect bite classification | CNN + SVM | Custom dataset | No | ~78% |
| Asif et al. (2024) [16] | Lesion classification | SKINC-Net | Dermoscopy | Yes | 83% |
| Amin et al. (2024) [17] | Skin disease | CNNs | Public datasets | No | 86% |
| Class | Number of Images |
|---|---|
| Ant | 239 |
| Bed Bug | 218 |
| Chigger | 213 |
| Flea | 251 |
| Mosquito | 287 |
| Spider | 265 |
| Tick | 206 |
| Unaffected Skin | 253 |
| Total | 1932 |
| Model | Accuracy (%) | Precision | Recall | F1-Score | Params (M) | FLOPs (G) |
|---|---|---|---|---|---|---|
| DeepBiteNet | 84.6 | 0.88 | 0.87 | 0.875 | ~15.8 | ~3.2 |
| DenseNet121 | 78.2 | 0.742 | 0.732 | 0.737 | 7.98 | 2.9 |
| DenseNet169 | 77.9 | 0.757 | 0.747 | 0.752 | 14.15 | 3.4 |
| EfficientNet-B1 | 77.2 | 0.788 | 0.778 | 0.783 | 7.8 | 0.7 |
| EfficientNet-B0 | 76.9 | 0.773 | 0.763 | 0.768 | 5.3 | 0.39 |
| InceptionV3 | 76.3 | 0.665 | 0.655 | 0.66 | 23.9 | 5.7 |
| Xception | 76 | 0.803 | 0.793 | 0.798 | 22.9 | 8.4 |
| ConvNeXt-T | 75.9 | 0.865 | 0.855 | 0.86 | 28.6 | 4.5 |
| MobileNetV3 | 75.4 | 0.727 | 0.717 | 0.722 | 2.5 | 0.07 |
| MobileNetV2 | 75.1 | 0.711 | 0.701 | 0.706 | 3.4 | 0.3 |
| NASNetMobile | 74.6 | 0.819 | 0.809 | 0.814 | 5.3 | 0.6 |
| ResNet50 | 74.5 | 0.65 | 0.64 | 0.645 | 25.6 | 4.1 |
| VGG19 | 73.5 | 0.696 | 0.686 | 0.691 | 143.7 | 19.6 |
| VGG16 | 72.8 | 0.681 | 0.671 | 0.676 | 138.3 | 15.5 |
| ShuffleNet | 71.5 | 0.834 | 0.824 | 0.829 | 1.4 | 0.14 |
| SqueezeNet | 70.8 | 0.849 | 0.839 | 0.844 | 1.2 | 0.24 |
| Class | Precision | Recall | F1-Score |
|---|---|---|---|
| Ant | 0.88 | 0.87 | 0.875 |
| Bed Bug | 0.86 | 0.84 | 0.85 |
| Chigger | 0.83 | 0.82 | 0.825 |
| Flea | 0.89 | 0.90 | 0.895 |
| Mosquito | 0.91 | 0.92 | 0.915 |
| Spider | 0.88 | 0.86 | 0.87 |
| Tick | 0.84 | 0.83 | 0.835 |
| Unaffected Skin | 0.87 | 0.88 | 0.875 |
| Setting | Accuracy (%) | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Without Augmentation | 79.2 | 0.81 | 0.80 | 0.805 |
| With Augmentation | 84.6 | 0.88 | 0.87 | 0.875 |
| Initialization | Accuracy (%) | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Without Pretraining | 78.5 | 0.79 | 0.78 | 0.785 |
| With ImageNet Weights | 84.6 | 0.88 | 0.87 | 0.875 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khasanov, D.; Khujamatov, H.; Shakhnoza, M.; Abdullaev, M.; Toshtemirov, T.; Anarova, S.; Lee, C.; Jeon, H.-S. DeepBiteNet: A Lightweight Ensemble Framework for Multiclass Bug Bite Classification Using Image-Based Deep Learning. Diagnostics 2025, 15, 1841. https://doi.org/10.3390/diagnostics15151841
Khasanov D, Khujamatov H, Shakhnoza M, Abdullaev M, Toshtemirov T, Anarova S, Lee C, Jeon H-S. DeepBiteNet: A Lightweight Ensemble Framework for Multiclass Bug Bite Classification Using Image-Based Deep Learning. Diagnostics. 2025; 15(15):1841. https://doi.org/10.3390/diagnostics15151841
Chicago/Turabian StyleKhasanov, Doston, Halimjon Khujamatov, Muksimova Shakhnoza, Mirjamol Abdullaev, Temur Toshtemirov, Shahzoda Anarova, Cheolwon Lee, and Heung-Seok Jeon. 2025. "DeepBiteNet: A Lightweight Ensemble Framework for Multiclass Bug Bite Classification Using Image-Based Deep Learning" Diagnostics 15, no. 15: 1841. https://doi.org/10.3390/diagnostics15151841
APA StyleKhasanov, D., Khujamatov, H., Shakhnoza, M., Abdullaev, M., Toshtemirov, T., Anarova, S., Lee, C., & Jeon, H.-S. (2025). DeepBiteNet: A Lightweight Ensemble Framework for Multiclass Bug Bite Classification Using Image-Based Deep Learning. Diagnostics, 15(15), 1841. https://doi.org/10.3390/diagnostics15151841