

Turkish Chest X-Ray Report Generation Model Using the Swin Enhanced Yield Transformer (Model-SEY) Framework



Abstract
1. Introduction
2. Materials and Methods
2.1. Turkish Chest X-Ray Images Medical Report Generation Dataset
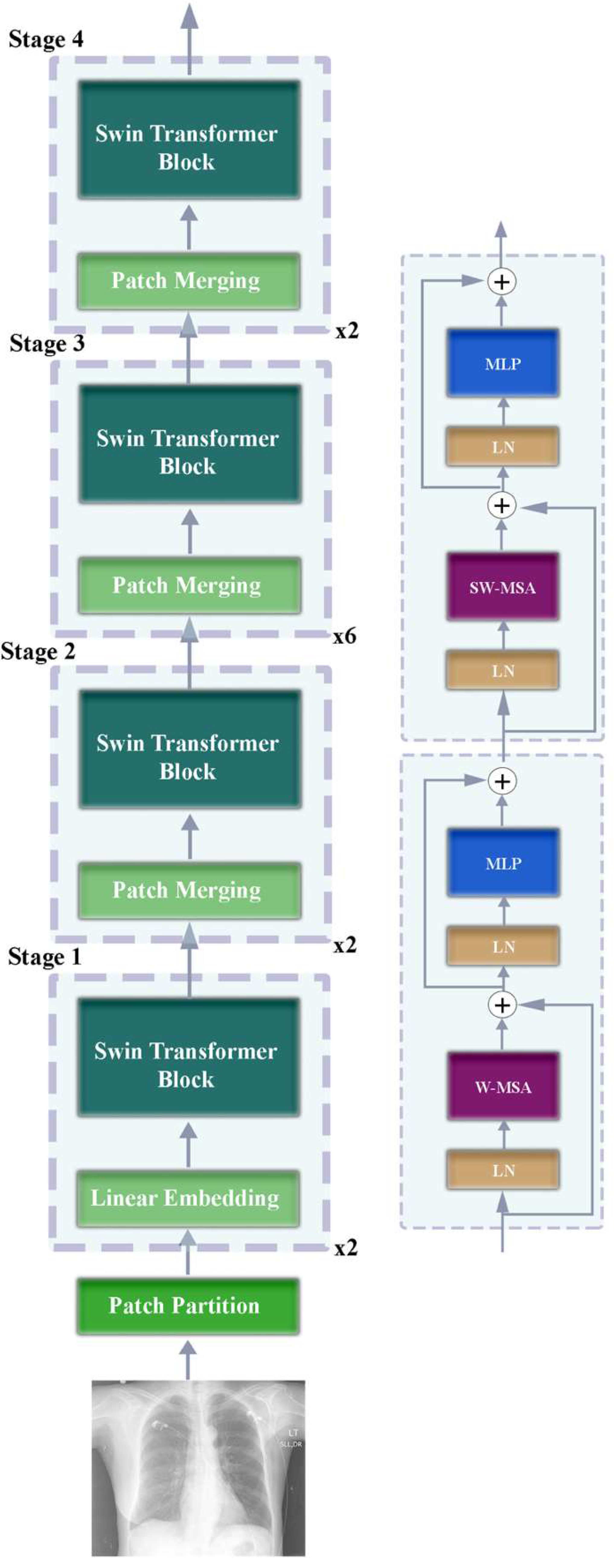
2.2. Swin Transformer
2.3. Generative Pre-Training Transformer
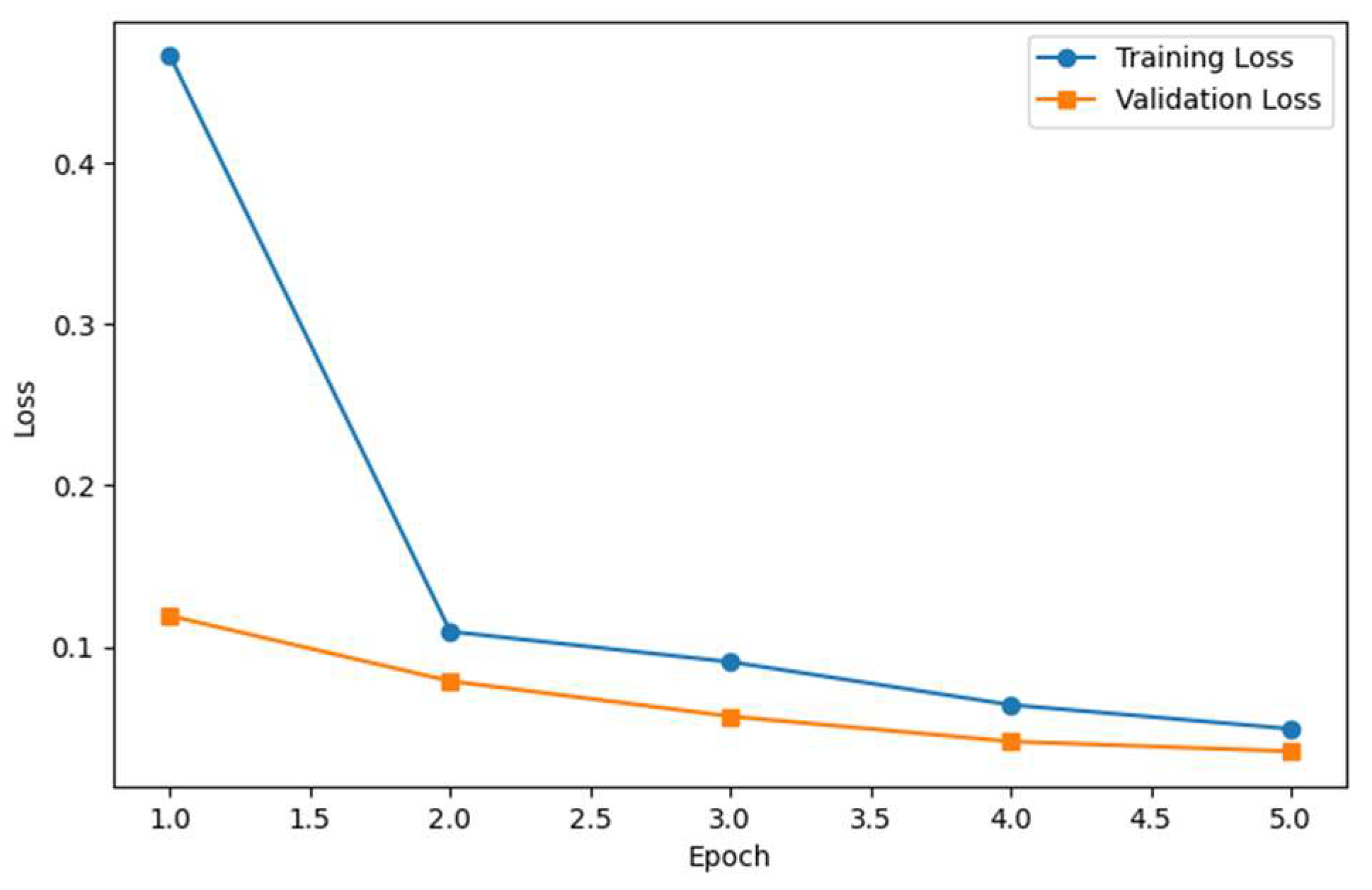
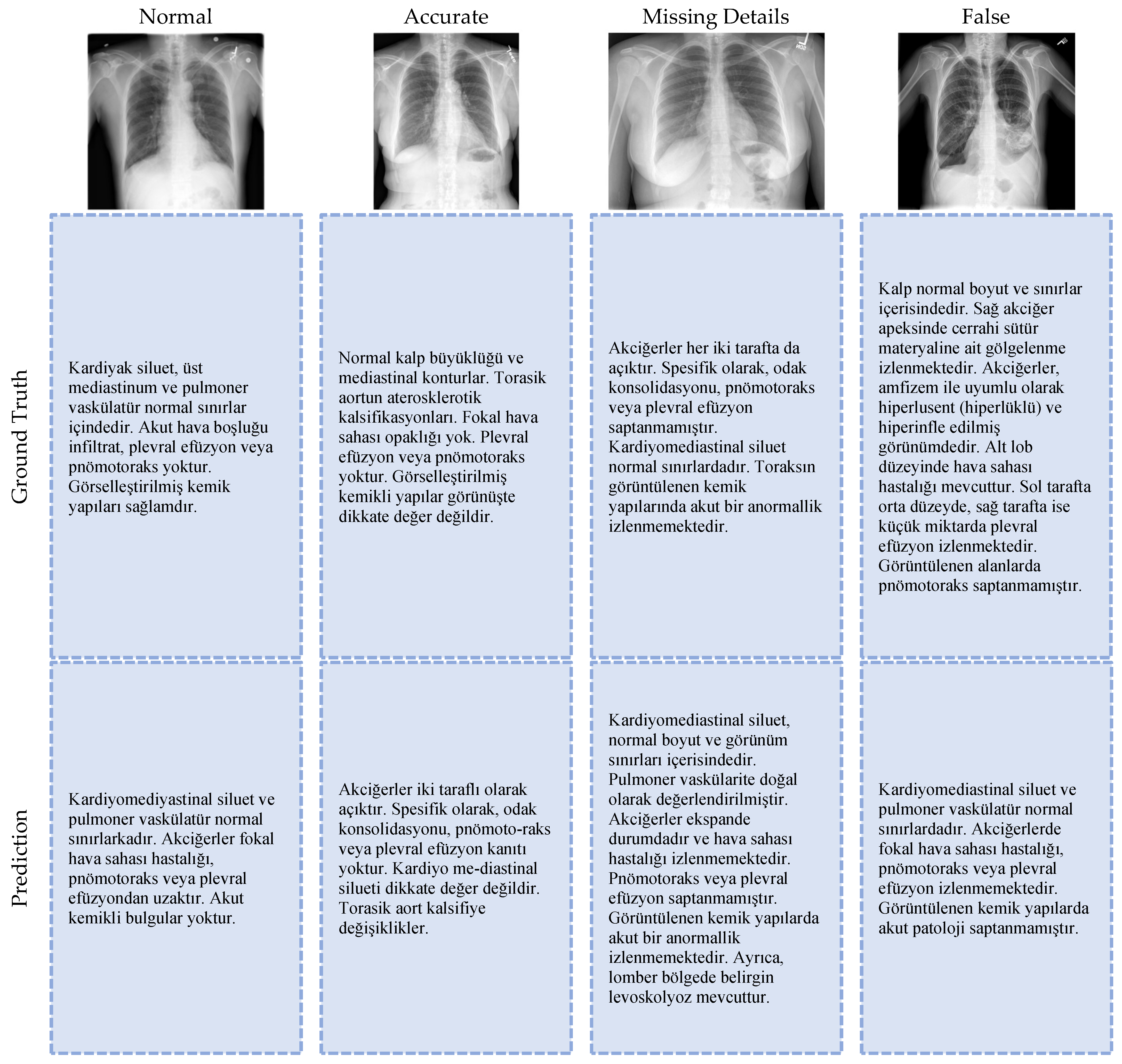
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Navuduri, A.; Kulkarni, S. Generation of Medical Reports from Chest X-Ray Images Using Multi Modal Learning Approach. Ind. J. Sci. Technol. 2023, 16, 2703–2708. [Google Scholar] [CrossRef]
- Tsaniya, H.; Fatichah, C.; Suciati, N. Automatic Radiology Report Generator Using Transformer With Contrast-Based Image Enhancement. IEEE Access 2024, 12, 25429–25442. [Google Scholar] [CrossRef]
- Ucan, S.; Ucan, M.; Kaya, M. Deep Learning Based Approach with EfficientNet and SE Block Attention Mechanism for Multiclass Alzheimer’s Disease Detection. In Proceedings of the 2023 4th International Conference on Data Analytics for Business and Industry (ICDABI), Online, 25–26 October 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 285–289. [Google Scholar]
- Sahin, M.E.; Ulutas, H.; Yuce, E.; Erkoc, M.F. Detection and Classification of COVID-19 by Using Faster R-CNN and Mask R-CNN on CT Images. Neural Comput. Appl. 2023, 35, 13597–13611. [Google Scholar] [CrossRef] [PubMed]
- Jiang, H.; Diao, Z.; Shi, T.; Zhou, Y.; Wang, F.; Hu, W.; Zhu, X.; Luo, S.; Tong, G.; Yao, Y.-D. A Review of Deep Learning-Based Multiple-Lesion Recognition from Medical Images: Classification, Detection and Segmentation. Comput. Biol. Med. 2023, 157, 106726. [Google Scholar] [CrossRef] [PubMed]
- Ulutas, H.; Sahin, M.E.; Karakus, M.O. Application of a Novel Deep Learning Technique Using CT Images for COVID-19 Diagnosis on Embedded Systems. Alex. Eng. J. 2023, 74, 345–358. [Google Scholar] [CrossRef]
- Dovganich, A.A.; Khvostikov, A.V.; Pchelintsev, Y.A.; Krylov, A.A.; Ding, Y.; Farias, M.C.Q. Automatic Out-of-Distribution Detection Methods for Improving the Deep Learning Classification of Pulmonary X-Ray Images. J. Image Graph. 2022, 10, 56–63. [Google Scholar] [CrossRef]
- Uysal, E. Statistical Performance Evaluation of the Deep Learning Architectures Over Body Fluid Cytology Images. IEEE Access 2025, 13, 82540–82553. [Google Scholar] [CrossRef]
- Ataş, İ. Comparison of Deep Convolution and Least Squares GANs for Diabetic Retinopathy Image Synthesis. Neural Comput. Appl. 2023, 35, 14431–14448. [Google Scholar] [CrossRef]
- Ucan, M.; Kaya, B.; Kaya, M. Generating Medical Reports With a Novel Deep Learning Architecture. Int. J. Imaging Syst. Technol. 2025, 35, e70062. [Google Scholar] [CrossRef]
- Ahmed, S.B.; Solis-Oba, R.; Ilie, L. Explainable-AI in Automated Medical Report Generation Using Chest X-Ray Images. Appl. Sci. 2022, 12, 11750. [Google Scholar] [CrossRef]
- Shaikh, Z.; Bharti, J. Transformer-Based Chest X-Ray Report Generation Model. In International Conference on Soft Computing and Signal Processing; Springer: Singapore, 2024; pp. 227–236. [Google Scholar]
- Lin, Z.; Zhang, D.; Shi, D.; Xu, R.; Tao, Q.; Wu, L.; He, M.; Ge, Z. Contrastive Pre-Training and Linear Interaction Attention-Based Transformer for Universal Medical Reports Generation. J. Biomed. Inf. 2023, 138, 104281. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Peng, Y.; Lu, L.; Lu, Z.; Summers, R.M. TieNet: Text-Image Embedding Network for Common Thorax Disease Classification and Reporting in Chest X-Rays. arXiv 2018, arXiv:1801.04334. [Google Scholar] [CrossRef]
- Liu, G.; Hsu, T.-M.H.; McDermott, M.; Boag, W.; Weng, W.-H.; Szolovits, P.; Ghassemi, M. Clinically Accurate Chest X-Ray Report Generation. In Proceedings of the 4th Machine Learning for Healthcare Conference, Ann Arbor, MI, USA, 9–10 August 2019; Doshi-Velez, F., Fackler, J., Jung, K., Kale, D., Ranganath, R., Wallace, B., Wiens, J., Eds.; PMLR. MLR Press: Philadelphia, PA, USA, 2019; Volume 106, pp. 249–269. [Google Scholar]
- Alfarghaly, O.; Khaled, R.; Elkorany, A.; Helal, M.; Fahmy, A. Automated Radiology Report Generation Using Conditioned Transformers. Inf. Med. Unlocked 2021, 24, 100557. [Google Scholar] [CrossRef]
- Ucan, M.; Kaya, B.; Kaya, M.; Alhajj, R. Medical Report Generation from Medical Images Using Vision Transformer and Bart Deep Learning Architectures. In International Conference on Advances in Social Networks Analysis and Mining; Springer: Cham, Switzerland, 2025; pp. 257–267. [Google Scholar]
- Unal, M.E.; Citamak, B.; Yagcioglu, S.; Erdem, A.; Erdem, E.; Cinbis, N.I.; Cakici, R. TasvirEt: A Benchmark Dataset for Automatic Turkish Description Generation from Images. In Proceedings of the 2016 24th Signal Processing and Communication Application Conference (SIU), Zonguldak, Turkey, 16–19 May 2016; pp. 1977–1980. [Google Scholar]
- Yildiz, S.; Memiş, A.; Varli, S. TRCaptionNet: A Novel and Accurate Deep Turkish Image Captioning Model with Vision Transformer Based Image Encoders and Deep Linguistic Text Decoders. Turk. J. Electr. Eng. Comput. Sci. 2023, 31, 1079–1098. [Google Scholar] [CrossRef]
- Demner-Fushman, D.; Kohli, M.D.; Rosenman, M.B.; Shooshan, S.E.; Rodriguez, L.; Antani, S.; Thoma, G.R.; McDonald, C.J. Preparing a Collection of Radiology Examinations for Distribution and Retrieval. J. Am. Med. Inform. Assoc. 2016, 23, 304–310. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Üzen, H.; Firat, H.; Atila, O.; Şengür, A. Swin Transformer-Based Fork Architecture for Automated Breast Tumor Classification. Expert Syst. Appl. 2024, 256, 125009. [Google Scholar] [CrossRef]
- Vuran, S.; Ucan, M.; Akin, M.; Kaya, M. Multi-Classification of Skin Lesion Images Including Mpox Disease Using Transformer-Based Deep Learning Architectures. Diagnostics 2025, 15, 374. [Google Scholar] [CrossRef] [PubMed]
- Ferdous, G.J.; Sathi, K.A.; Hossain, M.A.; Dewan, M.A.A. SPT-Swin: A Shifted Patch Tokenization Swin Transformer for Image Classification. IEEE Access 2024, 12, 117617–117626. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models Are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 8. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. OpenAI Blog 2018. Available online: https://www.mikecaptain.com/resources/pdf/GPT-1.pdf (accessed on 14 July 2025).
- Kesgin, H.T.; Yuce, M.K.; Dogan, E.; Uzun, M.E.; Uz, A.; Seyrek, H.E.; Zeer, A.; Amasyali, M.F. Introducing CosmosGPT: Monolingual Training for Turkish Language Models. In Proceedings of the 2024 International Conference on INnovations in Intelligent SysTems and Applications (INISTA), Craiova, Romania, 4–6 September 2024; pp. 1–6. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Nicolson, A.; Dowling, J.; Koopman, B. Improving Chest X-Ray Report Generation by Leveraging Warm Starting. Artif. Intell. Med. 2023, 144, 102633. [Google Scholar] [CrossRef] [PubMed]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and Tell: A Neural Image Caption Generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Configuration |
|---|---|
| Learning rate (LR) | 5 × 10−5 |
| Optimizer | AdamW |
| Weight decay | 0.01 |
| Number of epochs | 5 |
| Activation function | GELU |
| Batch size | 8 |
| Word Overlap Evaluation Metric | Value | Value (%) |
|---|---|---|
| BLEU-1 | 0.6412 | 64.12 |
| BLEU-2 | 0.5335 | 53.35 |
| BLEU-3 | 0.4395 | 43.95 |
| BLEU-4 | 0.3716 | 37.16 |
| ROUGE | 0.2240 | 22.40 |
| Method | Year | Target Language | Encoder | Decoder | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | ROUGE |
|---|---|---|---|---|---|---|---|---|---|
| CNN-RNN [30] | 2015 | English | CNN | RNN | 0.316 | 0.211 | 0.140 | 0.095 | 0.267 |
| VSGRU [16] | 2021 | English | DenseNet | GRU | 0.347 | 0.221 | 0.156 | 0.116 | 0.251 |
| CDGPT2 [16] | 2021 | English | DenseNet | GPT | 0.387 | 0.245 | 0.166 | 0.111 | 0.289 |
| TieNet [14] | 2018 | English | CNN | LSTM | 0.286 | 0.159 | 0.103 | 0.073 | 0.226 |
| Gamma Enhancement [2] | 2024 | English | DenseNet | BERT | 0.363 | 0.371 | 0.388 | 0.412 | - |
| Vi-Ba [17] | 2024 | English | Vision Transformer | BART | - | - | - | 0.150 | 0.274 |
| CNN/RNN and Greedy Search [1] | 2023 | English | CNN | RNN | 0.592 | 0.422 | 0.298 | 0.205 | - |
| G-CNX [10] | 2025 | English | ConvNeXt | GRU | 0.6544 | 0.5035 | 0.3682 | 0.2766 | 0.4277 |
| (Our) Model-SEY | 2025 | Turkish | Swin Transformer | CosmosGPT | 0.6412 | 0.5335 | 0.4395 | 0.3716 | 0.2240 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ucan, M.; Kaya, B.; Kaya, M. Turkish Chest X-Ray Report Generation Model Using the Swin Enhanced Yield Transformer (Model-SEY) Framework. Diagnostics 2025, 15, 1805. https://doi.org/10.3390/diagnostics15141805
Ucan M, Kaya B, Kaya M. Turkish Chest X-Ray Report Generation Model Using the Swin Enhanced Yield Transformer (Model-SEY) Framework. Diagnostics. 2025; 15(14):1805. https://doi.org/10.3390/diagnostics15141805
Chicago/Turabian StyleUcan, Murat, Buket Kaya, and Mehmet Kaya. 2025. "Turkish Chest X-Ray Report Generation Model Using the Swin Enhanced Yield Transformer (Model-SEY) Framework" Diagnostics 15, no. 14: 1805. https://doi.org/10.3390/diagnostics15141805
APA StyleUcan, M., Kaya, B., & Kaya, M. (2025). Turkish Chest X-Ray Report Generation Model Using the Swin Enhanced Yield Transformer (Model-SEY) Framework. Diagnostics, 15(14), 1805. https://doi.org/10.3390/diagnostics15141805