4.3. Performance Assessment of the Proposed Model
The multi-cancer dataset includes the oral tumor dataset. The oral tumor dataset was divided as follows: 70% was designated for the training set (6998 HIs), 15% was designated for the test set (1501 HIs), and 15% was designated for the validation set (1501 HIs). We conducted two experiments which focused on applying transfer learning by pre-training five DL models. In the first experiment, we employed the LRT for our training process. The second experiment involved the implementation of a constant LR algorithm. In both experiments, we engaged in the transfer learning process.
The transfer learning process has two stages. In stage one, we initiated supervised pre-training of various DL models, specifically EfficientNet-B3, EfficientNet-B1, EfficientNet-B2, DenseNet169, and InceptionV3, using the ImageNet dataset. In stage two, we refined these models further by utilizing the training set from the oral tumor dataset. After completing each experiment, we evaluated the performance of the five DL models by applying metrics based on Equations (1)–(7).
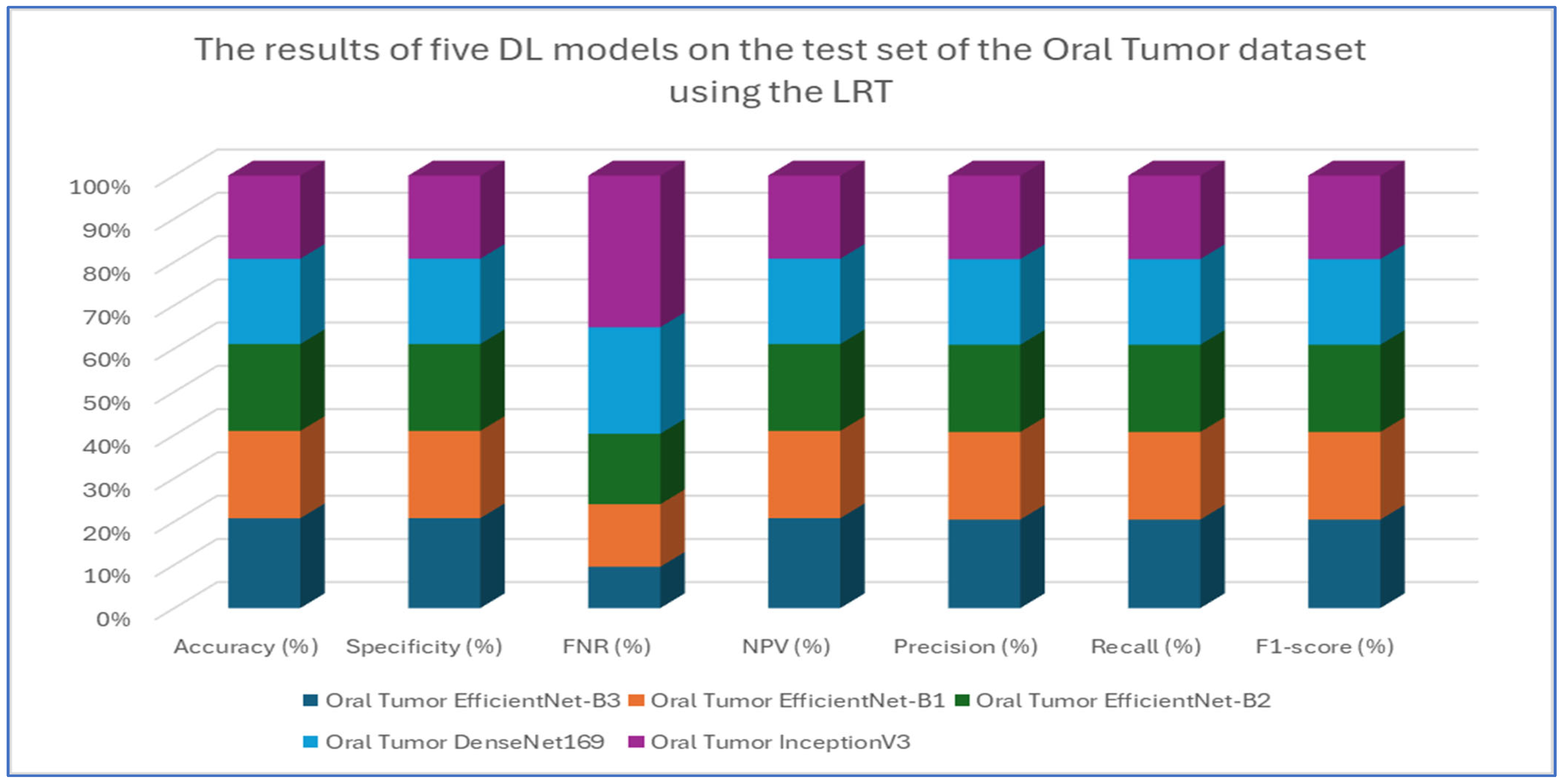
The results from the first experiment involving EfficientNet-B3, EfficientNet-B1, EfficientNet-B2, DenseNet169, and InceptionV3 on the oral tumor test set are summarized in
Table 3 and
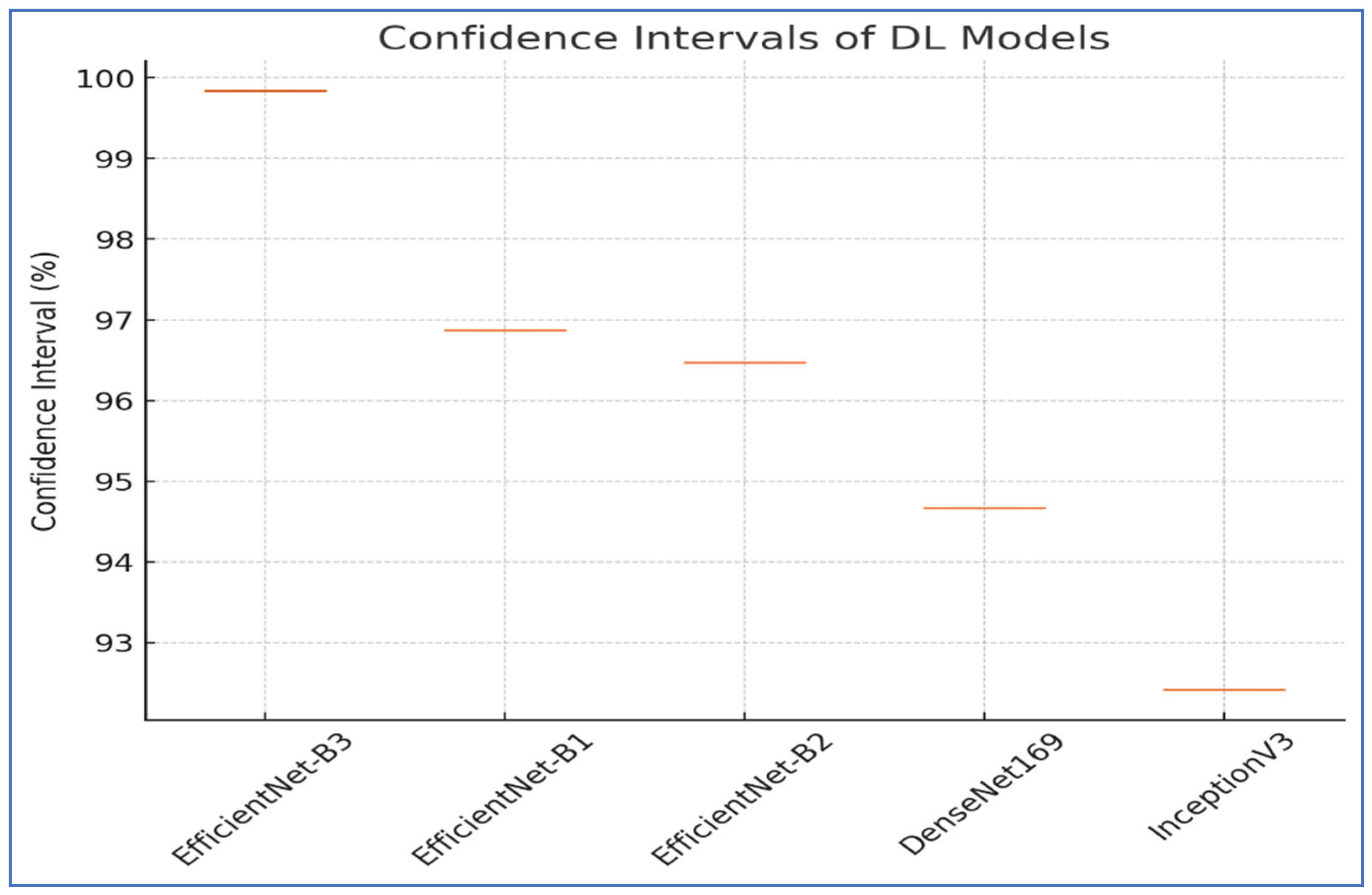
Figure 8. Among the models evaluated, EfficientNet-B3 achieved the highest performance metrics on the oral tumor dataset, with an accuracy of 99.84%, specificity and NPV of 99.92%, and a recall and F1-score of 97.93%. Its precision was notably high at 97.94%, while the FNR was minimal at 2.07%, establishing it as the leading model for this dataset. The high recall and low FNR indicate EfficientNet-B3’s effectiveness in identifying TP cases, thus reducing the likelihood of missed detections. This low FNR makes EfficientNet-B3 particularly suitable for clinical applications, where failing to detect a tumor can have serious implications.
EfficientNet-B1 showed slightly better performance than EfficientNet-B2, with an accuracy of 96.87% compared to 96.47%, and a lower FNR of 3.13% versus 3.53%. This suggests that the increased capacity of EfficientNet-B3, achieved through compound scaling in depth, width, and resolution, likely played a significant role in its superior performance.
In contrast, DenseNet169 and InceptionV3 performed less effectively than the EfficientNet variants, with DenseNet169 achieving an accuracy of 94.67% and InceptionV3 recording the lowest accuracy at 92.41%. The higher FNR of InceptionV3 at 7.59% points to its challenges in capturing essential tumor features compared to the more advanced architectures. The consistent drop in performance from EfficientNet-B3 to InceptionV3 highlights the importance of architectural improvements over time. For example, EfficientNet’s implementation of compound scaling and optimized convolutional blocks has likely improved feature extraction efficiency, while InceptionV3’s reliance on multi-branch inception modules, though innovative at its inception, may not have been as effective for the complexities of the oral tumor dataset.
In conclusion, this analysis underscores the superiority of EfficientNet-B3 in oral tumor detection, while older models, like InceptionV3, faced challenges in addressing contemporary medical imaging tasks. The findings emphasize the significance of advancing neural network designs that prioritize both accuracy and computational efficiency for real-world applications.
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8 presents class-wise evaluation metrics for the five DL models on the test set of the oral tumor dataset that contains two classes, namely OSCC and normal. The evaluation results shown in
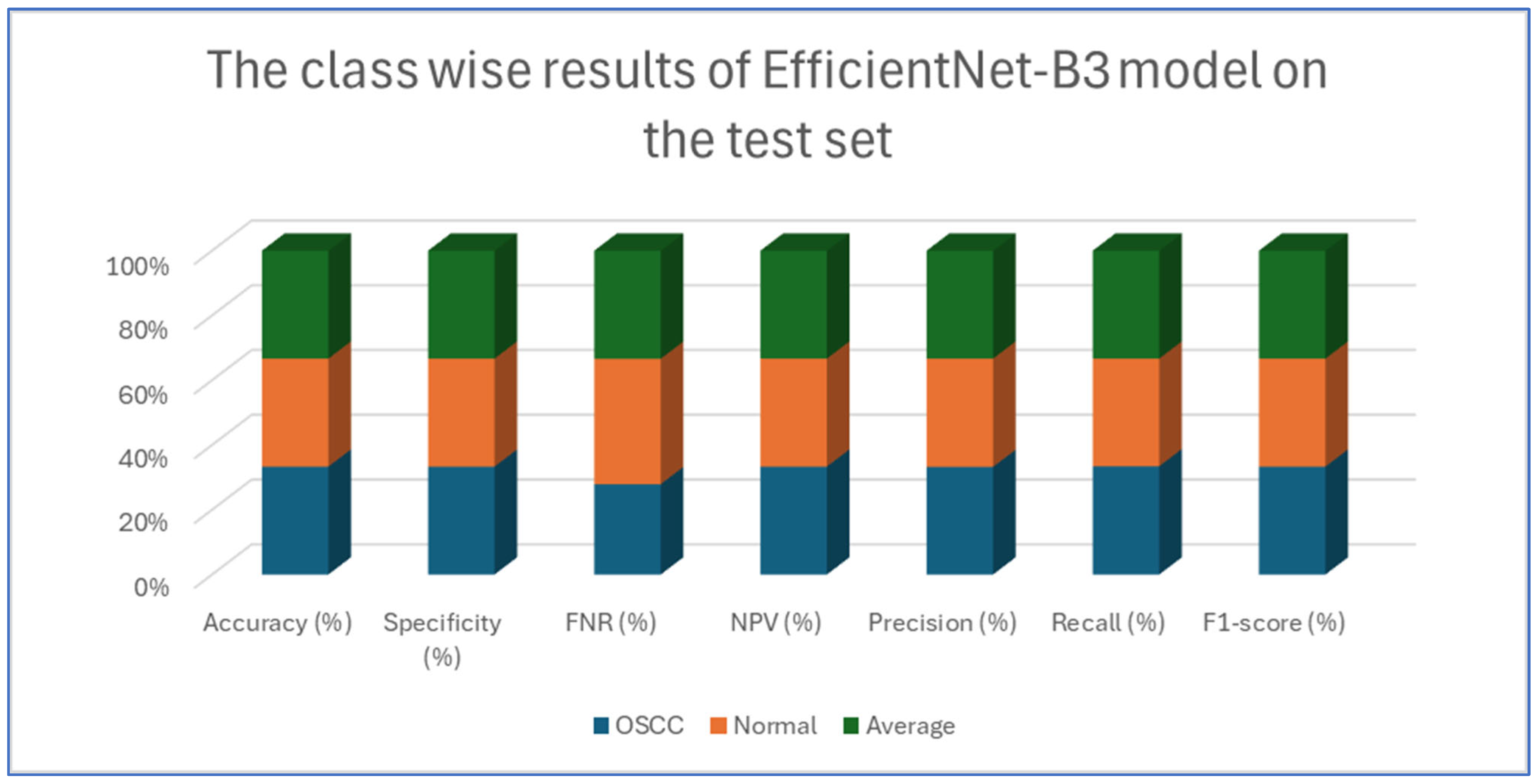
Table 4 and
Figure 9 illustrate the performance of the EfficientNet-B3 model in distinguishing between OSCC and normal cases from the dataset. For the OSCC class, the model achieved an accuracy of 99.84%, a specificity of 99.90%, and an FNR of 1.73%. The NPV was 99.93%, showcasing the model’s ability to accurately predict the absence of OSCC, while its precision, recall, and F1-score were 97.62%, 98.27%, and 97.94%, respectively. For the normal class, the model achieved the same accuracy of 99.84%, a specificity of 99.93%, and an FNR of 2.40%. The NPV was 99.90%, with precision, recall, and F1-score recorded at 98.26%, 97.60%, and 97.93%, respectively.
On average across both classes, the model demonstrated a 99.84% accuracy, a specificity of 99.92%, an FNR of 2.07%, an NPV of 99.92%, and both precision and recall scores as well as F1-score at 97.93%. These results highlight the model’s strong capability to reliably detect both OSCC and normal tissues, with minimal FNs, making it a valuable tool for diagnostic applications.
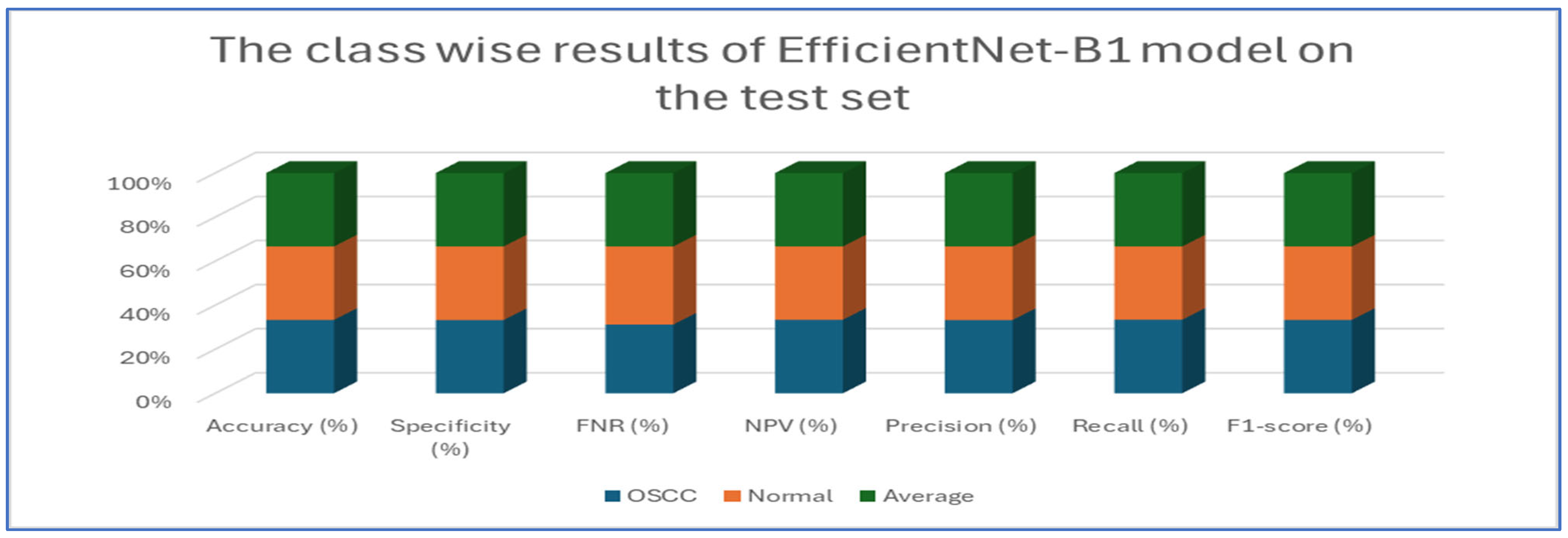
Table 5 and
Figure 10 present the performance of the EfficientNet-B1 model when applied to two classes, namely OSCC and normal. For the OSCC class, the model achieved an accuracy of 96.87%, a specificity of 96.67%, and an FNR of 2.93%. The NPV was recorded at 97.05%, with a precision of 96.68%, a recall of 97.07%, and an F1-score of 96.88%. In the case of the normal class, the model maintained the same overall accuracy of 96.87% but demonstrated a slightly higher specificity at 97.07% and an FNR of 3.33%. The NPV for this class was 96.68%, while the precision was 97.05%, the recall was 96.67%, and the F1-score was 96.86%. The average performance across both classes was summarized with values of 96.87% for accuracy, specificity, precision, recall, and F1-score, while the average FNR was 3.13% and the average NPV was 96.87%.
Overall, the analysis indicated that the EfficientNet-B1 model exhibited consistent and balanced performance across the OSCC and normal classes, maintaining high accuracy and robust performance metrics throughout.
Table 6 and
Figure 11 provide an evaluation of the EfficientNet-B2 model across two classes—OSCC and normal—as well as their averaged metrics. The analysis showed that for the OSCC class, the model achieved an accuracy of 96.47%, with a specificity of 96.27% and an FNR of 3.33%. In addition, the NPV was 96.65%, the precision was 96.29%, the recall reached 96.67%, and the F1-score was 96.48%. For the normal class, the model maintained the same overall accuracy of 96.47%, while the specificity improved slightly to 96.67%. However, the FNR increased slightly to 3.73%. The NPV for this class was 96.29%, and the precision and recall were 96.65% and 96.27%, respectively, which resulted in an F1-score of 96.46%.
This analysis demonstrates that the model performed robustly and consistently across both categories, maintaining high accuracy and balanced performance metrics.
Table 7 and
Figure 12 present the performance metrics for the DenseNet169 model applied to a dataset containing OSCC (oral squamous cell carcinoma) and normal samples. For the OSCC class, the model achieved an accuracy of 94.67%. It exhibited a high specificity of 96.13% and maintained a low FNR of 6.79%. The NPV was calculated at 93.39%, while precision reached 96.02%. The recall was slightly lower at 93.21%, resulting in an F1-score of 94.59%. In the case of the normal class, the model also achieved an accuracy of 94.67%. However, the specificity for this class was lower at 93.21%, and the FNR was reduced to 3.87%. The NPV improved to 96.02%, and the precision was noted to be 93.39%. Conversely, the recall increased to 96.13%, leading to a slightly higher F1-score of 94.74%.
Overall, the analysis indicates that the DenseNet169 model performed consistently across both classes. It demonstrated a strong balance between recall and precision, as evidenced by the similar F1-scores. These results suggest that the model effectively distinguished between OSCC and normal cases, showcasing robust and reliable diagnostic capabilities.
Table 8 and
Figure 13 present an analysis of the InceptionV3 model’s performance on a dataset containing two classes, namely OSCC and normal. For the OSCC class, the model achieved an accuracy of 92.41%, a specificity of 92.67%, an FNR of 7.86%, and an NPV of 92.18%. The precision was 92.64%, the recall was 92.14%, and the F1-score was 92.39%. For
the normal class, the model also reached an accuracy of 92.41%, but the specificity was slightly lower at 92.14%, while the FNR was 7.33% and the NPV was 92.64%. The precision and recall for the normal class were 92.18% and 92.67%, respectively, and the F1-score was 92.42%.
The analysis indicates that the InceptionV3 model performed consistently well across both classes, with only minor variations between the OSCC and normal classes. The balanced metrics suggest that the model achieved reliable performance on the dataset.
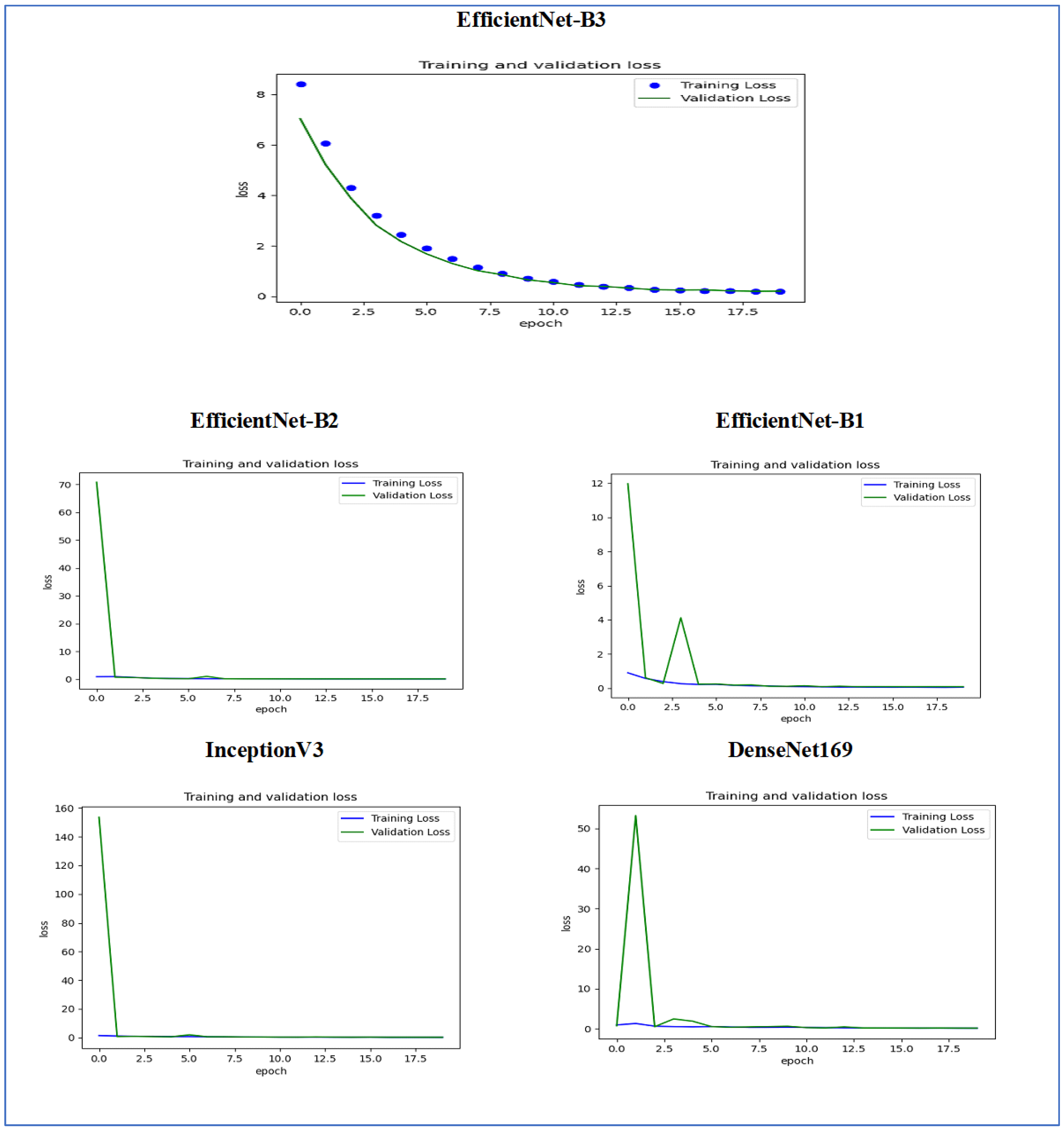
Figure 14 illustrates the training and validation loss of the five DL models when evaluated on the test set of the oral tumor dataset through the LRT. For EfficientNet-B3, the training loss, represented by the blue dots, started at a high point of approximately 9 and rapidly decreased during the initial epochs, showcasing the model’s quick learning capability. Similarly, the validation loss, shown by the green line, also experienced a significant initial decline, mirroring the trend of the training loss. As the training progressed over the epochs, both training and validation losses stabilized and approached low values near zero. This convergence suggested that the model achieved a steady state with minimal error. Additionally, the close correspondence between the training and validation losses in the later epochs indicated that overfitting was not a major issue for this model.
For EfficientNet-B1, the training loss began at a higher value and demonstrated a steady decline as the number of epochs increased. This trend indicates that the model was effectively learning and enhancing its performance on the training data. In contrast, the validation loss also started higher but displayed a more variable pattern compared to the training loss. This fluctuation suggests that although the model was generalized to some degree, there were instances where it had difficulty with the validation data, potentially indicating overfitting or the need for further tuning. By the conclusion of 17.5 epochs, both the training and validation losses had decreased. However, the validation loss was still slightly higher than the training loss, which is a common occurrence in many machine learning scenarios. Overall, while the model made progress in reducing loss, there is likely room for additional optimization to achieve improved generalization.
For EfficientNet-B2, the training loss consistently decreased over the epochs, indicating that the model was effectively learning from the training data. The validation loss also showed a decline over time but displayed more fluctuations compared to the training loss. This variability suggests that the model’s performance on the validation data was less stable, which could indicate potential issues, such as overfitting or a need for further tuning of hyperparameters. By the final epoch, both the training and validation losses had decreased; however, the validation loss remained higher than the training loss. This is a common observation in model training. Overall, the trend shows that the model improved its performance, but there may be further opportunities to enhance its generalization capabilities.
For DenseNet169, the training loss started at a higher value and showed a steady decline throughout the epochs, indicating that the model was effectively learning and improving its performance on the training data. In contrast, the validation loss also began high but displayed more fluctuations compared to the training loss. These fluctuations suggest that the model’s performance on the validation data was less stable, which could indicate potential overfitting or the need for further optimization. By the end of the 17.5 epochs, both the training and validation losses had decreased. However, the validation loss remained higher than the training loss, which is a common occurrence in many training scenarios. Overall, the model showed progress in reducing loss, but there may have been opportunities to enhance its generalization on the validation data.
For InceptionV3, the training loss initially started at a higher value and showed a steady downward trend as the number of epochs increased. This indicates that the model was successfully learning and enhancing its performance on the training data. The validation loss also began at a higher value but displayed greater variability compared to the training loss. This variability suggests that the model’s performance on the validation data was less consistent, which could indicate issues, such as overfitting or the need for additional tuning. By the conclusion of 17.5 epochs, both the training and validation losses had decreased. However, it is important to note that the validation loss remained higher than the training loss, a common occurrence in many machine learning scenarios. Overall, the model showed progress in reducing loss, but there may still be opportunities for further optimization to improve generalization on the validation data.
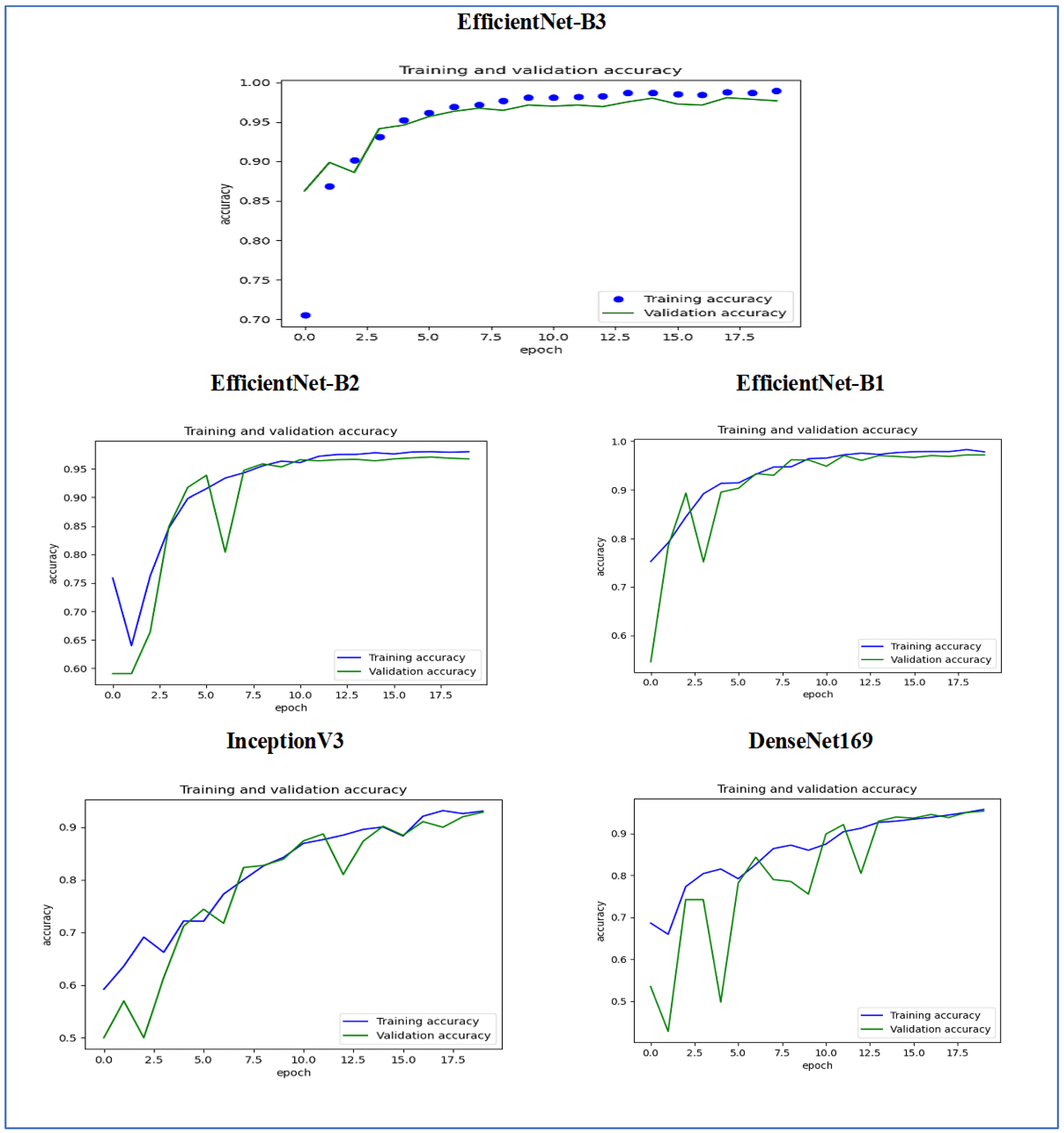
Figure 15 illustrates the training and validation accuracy of the five DL models when evaluated on the test set of the oral tumor dataset through the LRT. For EfficientNet-B3, the training accuracy increased rapidly in the early epochs and eventually plateaued at around 1.0. This indicates that the model successfully acquired knowledge from the training data. In a similar fashion, the validation accuracy showed an initial upward trend but stabilized at a slightly lower level than the training accuracy. Despite experiencing some minor variations, the general trend demonstrated a steady increase. Thus, the model was effectively generalizing to new, unseen data.
For EfficientNet-B1, the training accuracy consistently increased with each epoch, demonstrating that the model was effectively learning and enhancing its performance on the training dataset. The validation accuracy also rose over time; however, it showed some fluctuations, indicating that the model’s performance on the validation dataset was not as stable as on the training dataset. These fluctuations may suggest possible overfitting or the necessity for additional hyperparameter tuning. By the conclusion of 17.5 epochs, both training and validation accuracies had improved. Nonetheless, the validation accuracy remained slightly lower than the training accuracy, which is a common occurrence in many training scenarios. Overall, the model exhibited progress in accuracy improvements, but there may have been opportunities to further enhance its generalization on the validation dataset.
For EfficientNet-B2, the training accuracy consistently increased as the epochs progressed, indicating effective learning and improvement in performance on the training data. The validation accuracy also showed an upward trend, but with some fluctuations, suggesting that the model’s performance on the validation data was less stable compared to the training data. These fluctuations may indicate potential overfitting or a need for further hyperparameter tuning. By the end of 17.5 epochs, both the training and validation accuracies had improved, but the validation accuracy remained slightly lower than the training accuracy, which is common in many training scenarios. Overall, the model demonstrated progress in enhancing accuracy, but there may have been opportunities to further improve its generalization on the validation data.
For DenseNet169, the training accuracy started at a lower level and showed a consistent increase, rising from approximately 0.5 to 0.9 by the final epoch. This steady improvement indicated that the model was effectively learning patterns from the training data. The validation accuracy also increased overall but exhibited noticeable fluctuations during certain epochs, particularly between 5.0 and 12.5 epochs. These variations suggested instability in the model’s ability to generalize to unseen data, potentially due to overfitting or inconsistencies within the validation dataset. Despite these fluctuations, the validation accuracy reached a higher value by the end of the training period, although it remained slightly lower than the training accuracy. By the end of 17.5 epochs, the gap between training and validation accuracy had narrowed but still persisted, which is a common sign of mild overfitting. The model demonstrated strong learning capabilities on the training data, but it may have benefited from additional regularization techniques or early stopping to improve validation performance. Overall, the observed trends reflect successful learning while also highlighting opportunities for further optimization to enhance generalization.
For InceptionV3, the training accuracy began at approximately 0.5 and increased steadily, reaching a peak of 0.9 by the final epoch. This upward trajectory indicated that the model learned effectively from the training data, refining its predictions over time. The validation accuracy also improved overall, starting at a similar initial value but exhibiting fluctuations during intermediate epochs (e.g., between 5.0 and 12.5 epochs). These oscillations suggested variability in the model’s generalization performance, potentially due to overfitting or inconsistencies in the validation dataset. Despite these variations, the validation accuracy trended upward, ending close to training accuracy but slightly lagging behind. By the final epoch (17.5), the gap between training and validation accuracy had narrowed, though a small discrepancy persisted. This pattern aligned with typical training dynamics, where the model prioritizes fitting the training data but may struggle to generalize perfectly to unseen examples. The results implied that while the model achieved strong performance, additional regularization (e.g., dropout or weight decay) or early stopping might have further stabilized validation accuracy. Overall, the training process succeeded in improving model performance, but opportunities remained to enhance robustness on validation data.
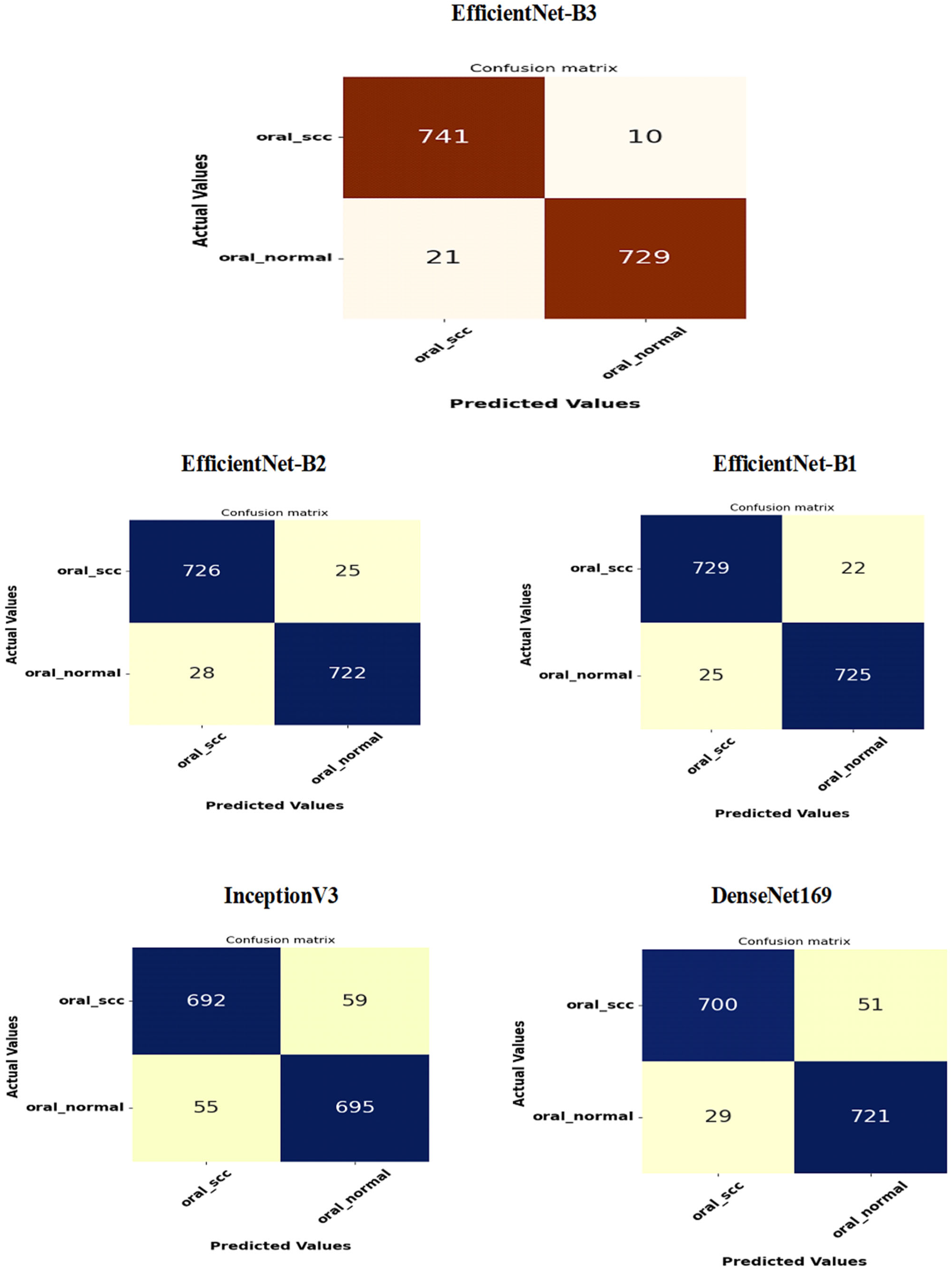
Figure 16 presents the confusion matrices for the five DL models, which were assessed across the test set of the oral tumor dataset utilizing the LRT. For EfficientNet-B3, the test set consists of 1501 HIs. The class distribution includes 750 HIs labeled as normal and 751 HIs labeled as OSCC. The EfficientNet-B3 model exhibited high accuracy, with the majority of its predictions being correct. It showed exceptional performance for the OSCC class, achieving an accuracy of 98.6%, with nearly all instances accurately classified. The model also performed well for the normal class, resulting in a few misclassifications and an accuracy of 97.2%. Overall, the EfficientNet-B3 model displayed strong capabilities in classifying oral cancer images into the OSCC and normal categories.
The EfficientNet-B1 model successfully classified 729 instances of the SCC class and 725 instances of the normal class. This resulted in an impressive overall performance, achieving an accuracy of 96.87%, along with balanced precision and recall for the SCC class. However, the model misclassified 22 SCC samples as normal and 25 normal samples as SCC. In a clinical context, the 22 missed SCC cases (FNs) could potentially delay critical treatment, while the 25 FPs might lead to unnecessary interventions. Overall, the model exhibited high accuracy with a relatively low number of misclassifications, demonstrating strong predictive capability for the task at hand.
The EfficientNet-B2 model demonstrated impressive overall performance with an accuracy of 96.47%. It achieved a well-balanced precision and recall for the SCC class. However, it misclassified 25 FNs, where SCC cases were incorrectly identified as normal. Additionally, there were 28 FPs, where normal cases were misclassified as SCC. In a clinical setting, the 25 missed SCC cases (FNs) could result in delays in critical treatment, while the 28 FPs could lead to unnecessary medical interventions.
The DenseNet169 model exhibited strong overall performance with an accuracy of 94.67%. However, it showed a slightly lower recall for the SCC class when compared to its precision. Specifically, the model recorded 51 FNs, where the SCC cases were incorrectly classified as normal, and 29 FPs, where the normal cases were misclassified as SCC. In a clinical setting, the 51 missed SCC cases (FNs) could potentially delay essential treatment, while the 29 FPs could result in unnecessary medical interventions. While the model demonstrated reasonable generalization capabilities, it had a higher rate of FNs than previous models.
The InceptionV3 model achieved a moderate overall performance with an accuracy of 92.40%. It exhibited balanced precision and recall for the SCC class. However, the analysis revealed 59 FNs, where SCC cases were incorrectly classified as normal, and 55 FPs, where normal cases were misclassified as SCC. In a clinical setting, the 59 missed SCC cases (FNs) could result in delays in critical treatment, while the 55 false alarms (FPs) could lead to unnecessary interventions. Overall, the model demonstrated acceptable generalization; however, it exhibited a higher rate of FNs and FPs compared to previous models.
The results from the second experiment, which implemented a constant LR using EfficientNet-B3 on the oral tumor test set, are summarized in
Table 9 and
Figure 17. The EfficientNet-B3 model achieved an overall accuracy of 83.08%. For the OSCC class, the model demonstrated a specificity of 87.20% and an FNR of 21.04%. The NPV was recorded at 80.54%, while precision and recall were 86.07% and 78.96%, respectively. The F1-score for this class reached 82.36%.
In the normal class, the model attained a specificity of 78.96% and an FNR of 12.80%. The NPV was 86.07%, with precision and recall at 80.54% and 87.20%, respectively. The F1-score for this class was slightly higher at 83.74%.
On average, the model exhibited balanced performance across all metrics, with an overall accuracy, specificity, and recall of 83.08%, an FNR of 16.92%, and both NPV and precision at 83.30%. The final F1-score for the model was 83.05%, indicating consistent predictive capability across both classes.
A comparative analysis of the EfficientNet-B3 model performance using the LRT and a fixed LR was presented in
Table 10.
Figure 18 shows the trends of training and validation loss over several epochs for the EfficientNet-B3 model. At the beginning, the validation loss was very high, indicating that the model made significant errors in its early stages. However, it decreased rapidly within the first few epochs, demonstrating that the model quickly learned important patterns in the data. Throughout the remaining epochs, both training and validation losses stayed low, though there were occasional fluctuations in the validation loss, which suggested some instability in generalization. Notably, around the 5th and 12th epochs, there were spikes in the validation loss, indicating potential overfitting or sensitivity to specific batches of validation data. By the later epochs, both losses converged to relatively stable values, showing that the model reached a balanced state with minimal error. Overall, the model displayed effective learning behavior, despite the spikes in validation loss.
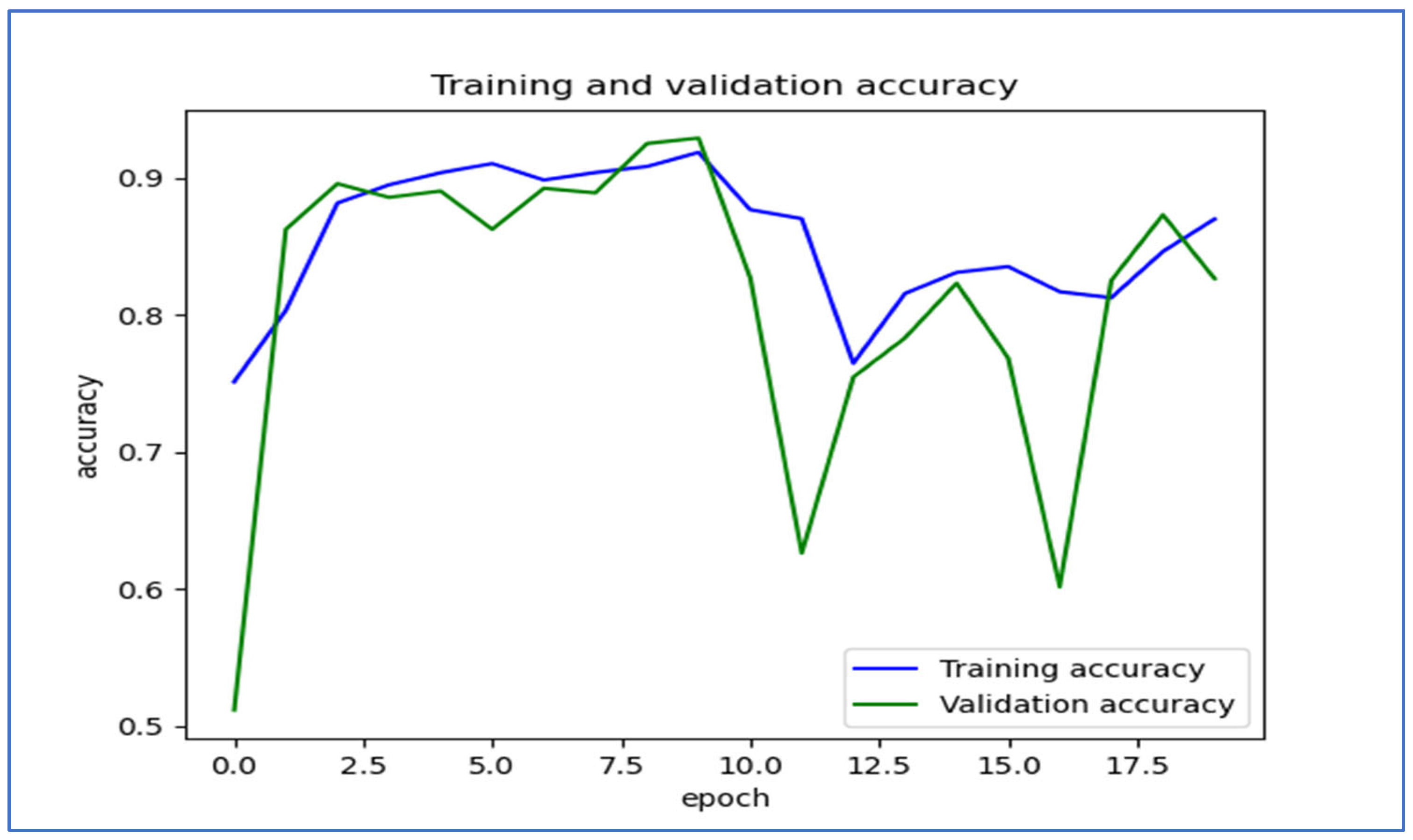
Figure 19 shows the trends in training and validation accuracy over multiple epochs for the EfficientNet-B3 model. At first, both training and validation accuracy increased quickly, indicating effective learning by the model. Around the fifth epoch, the validation accuracy showed slight fluctuations, while the training accuracy remained stable and high. After about the 10th epoch, there were significant drops in validation accuracy, which suggested potential overfitting; the model performed well on the training set but had difficulty generalizing new data. Despite these fluctuations, both accuracies recovered somewhat, with training accuracy stabilizing above 80% and validation accuracy following a similar trend. Overall, the model displayed a strong learning capability, but the variations in validation accuracy suggested sensitivity to the validation dataset.
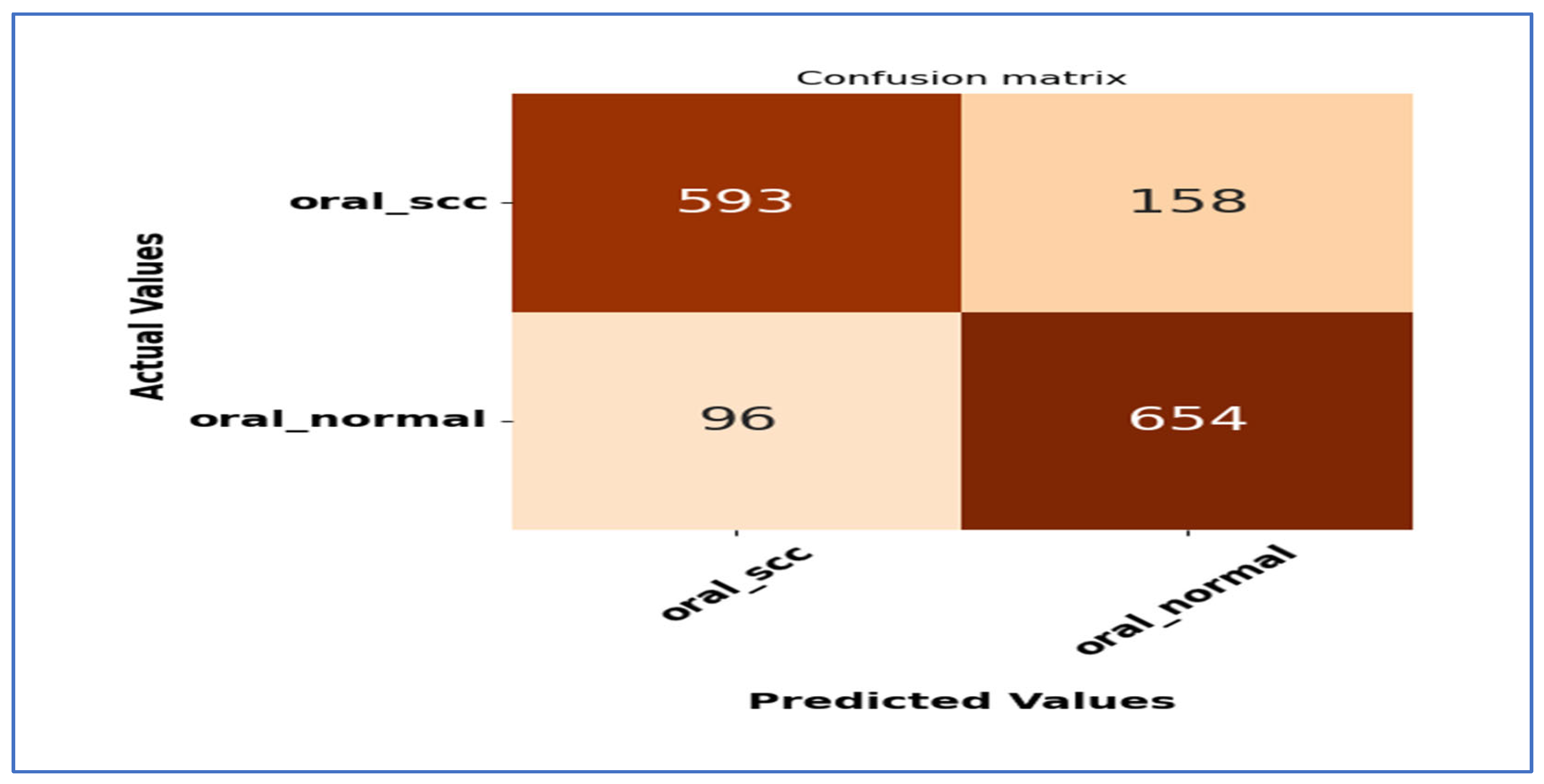
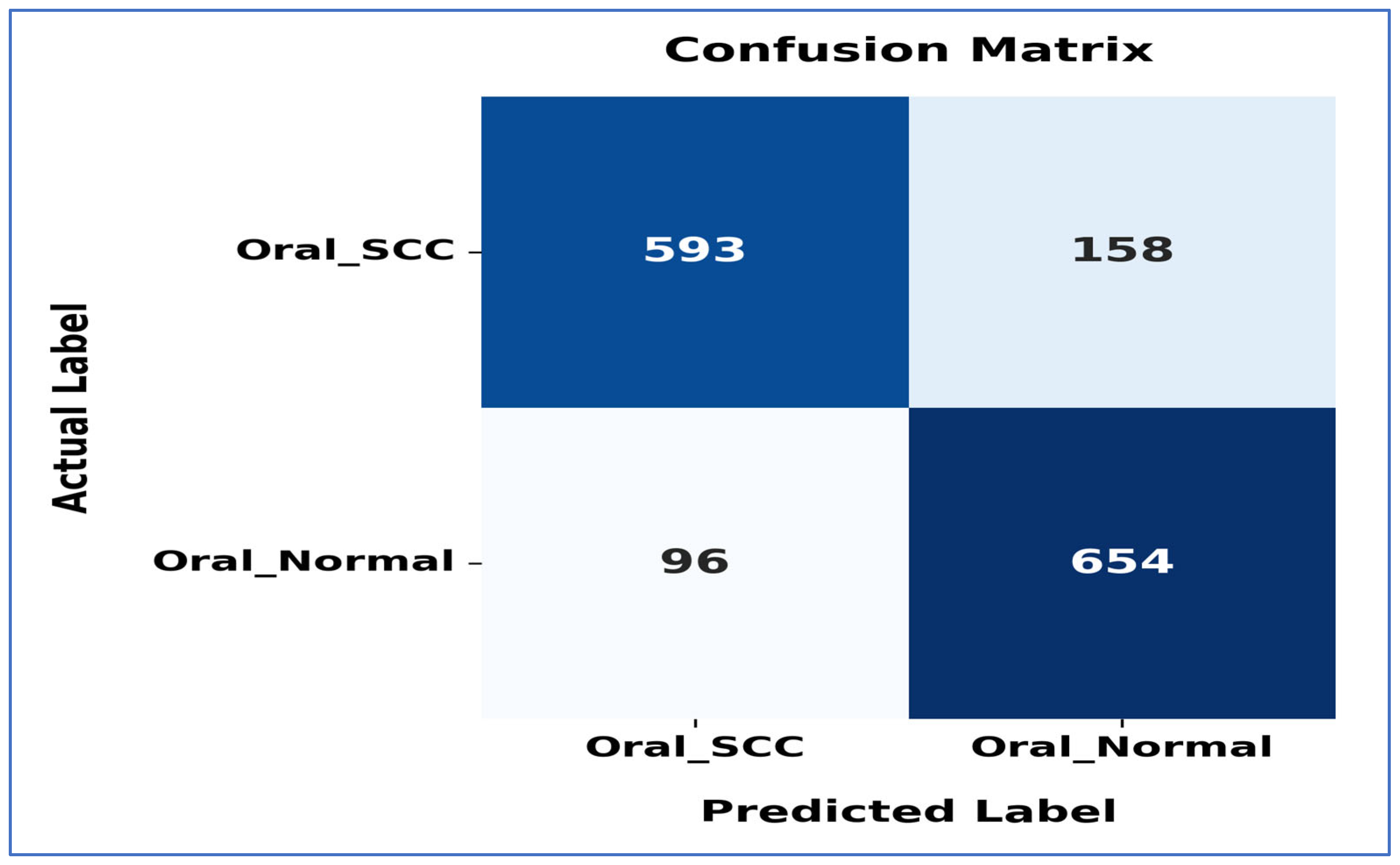
Figure 20 shows the confusion matrix for the EfficientNet-B3 model. This matrix illustrates how well the EfficientNet-B3 model performed in distinguishing between SCC and normal cases. The model accurately classified 593 instances of the SCC class and 654 instances of the normal class. However, it misidentified 158 SCC samples as normal and 96 normal samples as SCC.
The model exhibited a higher number of FNs for the SCC class, indicating that some cancerous cases were mistakenly identified as normal. This misclassification could have serious consequences in a medical context, as failing to identify positive cases may delay diagnosis and treatment. Despite these errors, the model demonstrated reasonable performance in predicting both classes accurately, though further optimization could enhance its sensitivity to SCC cases.
4.5. Ablation Study
An ablation study in DL is a detailed examination that assesses the significance and effect of various components or techniques within a model’s structure or training process. This approach involves deliberately removing or altering specific parts of the model to gauge their impact on overall performance. For example, in a complex CNN, an ablation study may include disabling certain layers, eliminating data preprocessing steps, or adjusting hyperparameters to see how these modifications influence metrics, like accuracy, precision, or recall.
The main objective of an ablation study is to uncover which features or design choices are vital for achieving optimal results. It assists researchers and practitioners in pinpointing unnecessary or less impactful components, improving computational efficiency, and enhancing the interpretability of models. In DL applications, such as image classification, natural language processing, or object detection, typical ablation studies might evaluate the effects of different activation functions, feature extraction layers, or attention mechanisms. For instance, removing a dropout layer from a model can demonstrate its role in mitigating overfitting.
Ablation studies are crucial for validating design choices and informing future enhancements. By offering empirical evidence regarding a model’s internal dependencies, they support the development of more robust, efficient, and understandable AI systems. The findings from these studies are often showcased in research papers through comparative tables or graphs that illustrate performance variations when certain elements are removed, making them an essential resource for furthering deep learning research and refining complex models [
48].
In our research, we performed an ablation study by altering the optimizers utilized in our experiments. We began with the Adam optimizer, setting the LR to 0.0001. The outcomes demonstrated an impressive accuracy of 99.84%. Subsequently, we repeated the experiments using the Adam optimizer along with two additional optimizers, namely stochastic gradient descent (SGD) and the adaptive gradient algorithm (Adagrad). We assessed the accuracy for each class within the oral tumor dataset of the multi-cancer dataset. Additionally, we calculated the average accuracy across the two classes from the oral tumor dataset. The results, showcasing the accuracy of EfficientNet-B3 with the LRT for the three optimizers, are summarized and presented in
Table 12.
Table 12 presents an analysis of the EfficientNet-B3 model’s performance on the test set of the Oral Tumor dataset using the Adagrad optimizer. For the OSCC category, the model achieved an accuracy of 98.09%, a specificity of 99.09%, and an FNR of 26.93%. The NPV was 98.92%, while precision, recall, and F1-score were 76.32%, 73.07%, and 74.66%, respectively.
In the case of normal samples, the model’s accuracy was 98.03%, with a specificity of 98.93% and an FNR of 24.50%. The NPV reached 99.02%, while precision, recall, and F1-score were 73.92%, 75.50%, and 74.70%, respectively.
Overall, across both classes, the model recorded an average accuracy of 98.06%, a specificity of 99.01%, an FNR of 25.72%, and an NPV of 98.97%. The average precision, recall, and F1-score were 75.12%, 74.28%, and 74.68%, respectively. This thorough evaluation indicates that while the model shows high accuracy and specificity, the relatively higher FNR and moderate precision and recall values highlight areas for improvement, particularly in reducing misclassification of positive cases and enhancing detection sensitivity.
Table 12 displays the performance metrics of the EfficientNet-B3 model in detecting OSCC as well as normal tissues using the SGD optimizer. For OSCC detection, the model achieved an accuracy of 98.27%, specificity of 99.12%, and an FNR of 23.07%. The NPV was 99.08%, while the precision, recall, and F1-score were 77.76%, 76.93%, and 77.35%, respectively.
In the classification of normal tissues, the model exhibited comparable performance, achieving an accuracy of 98.22%, specificity of 99.09%, and an FNR of 23.57%. The NPV was 99.06%, with precision, recall, and F1-score values of 77.05%, 76.43%, and 76.74%, respectively.
When considering the average performance across both OSCC and normal tissues, the model demonstrated an overall accuracy of 98.24%, specificity of 99.10%, and an FNR of 23.32%. The average NPV was 99.07%, while the precision, recall, and F1-score averaged 77.40%, 76.68%, and 77.04%, respectively. This analysis reveals that although the model achieved high accuracy and specificity, the metrics for recall and precision indicate that there is still potential for improvement, especially in reducing the FN rate and enhancing the balance between precision and recall.
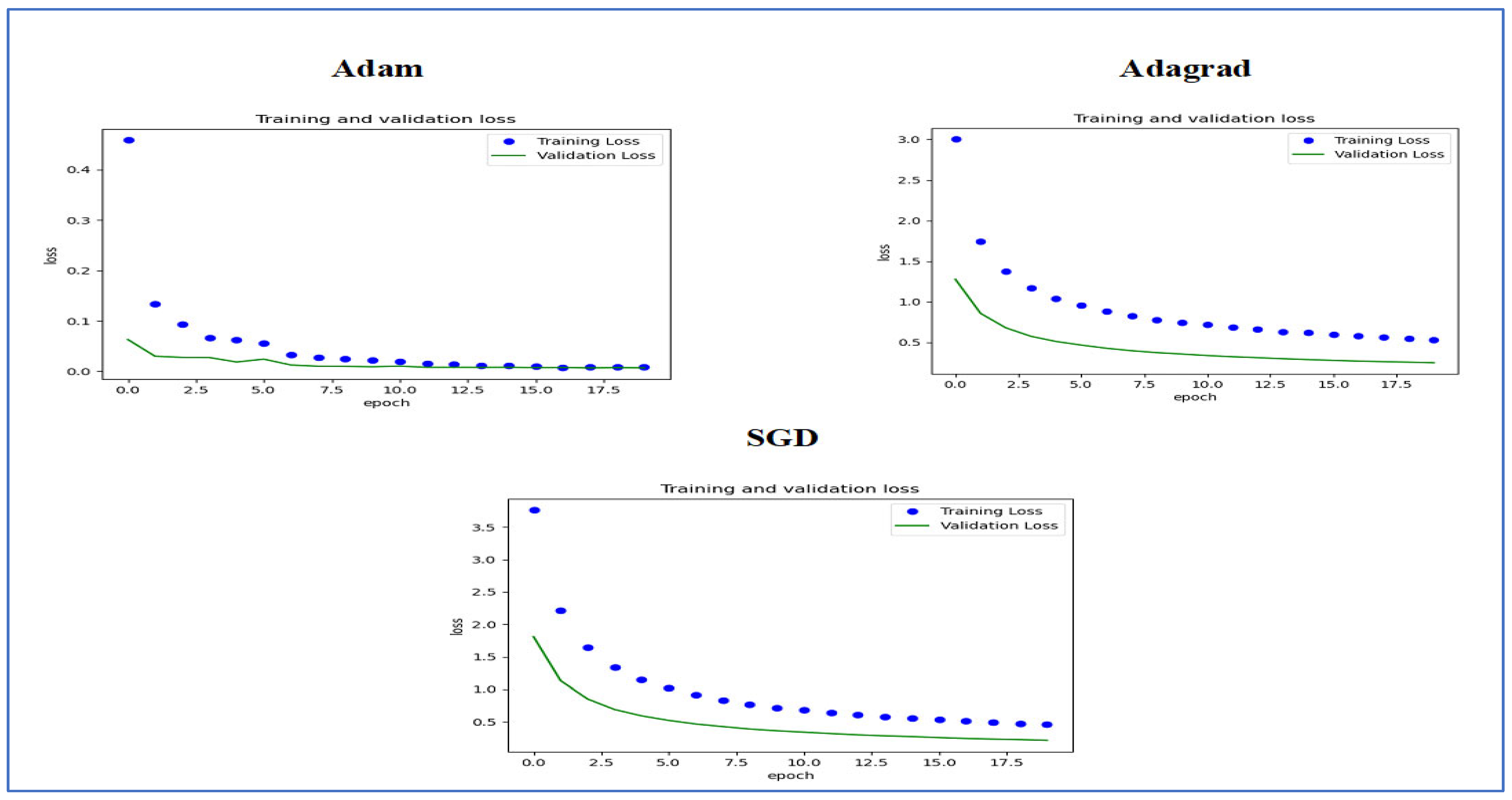
Figure 22 presents the training and validation loss curves for three optimization algorithms, namely Adam, Adagrad, and SGD. Each graph shows how the loss values evolved over 20 epochs for both the training and validation sets.
In the Adam optimizer graph, the training loss decreased consistently, beginning with a high initial value and converging quickly within the first few epochs. The validation loss exhibited a similar pattern, stabilizing with minimal deviation from the training loss, which indicates effective generalization performance.
The Adagrad optimizer displayed a slower initial decrease in training loss compared to Adam. Nevertheless, it also achieved convergence throughout the training epochs, albeit with a slightly higher final loss. The validation loss showed a comparable downward trend but remained slightly above that of Adam.
For the SGD optimizer, both training and validation loss started at higher values than the other optimizers. The decrease in loss was more gradual; despite notable improvements, the final loss was still higher than those recorded with Adam and Adagrad. The difference between training and validation loss was more significant, suggesting possible issues with overfitting or less efficient learning.
In summary, the Adam optimizer exhibited the best performance in reducing loss and achieving stable training and validation curves, followed by Adagrad. SGD demonstrated slower convergence and relatively higher losses, highlighting the performance differences among these optimizers for the training and validation sets used.
Figure 23 shows the training and validation accuracy over 18 epochs for the EfficientNet-B3 model, which was utilized to classify two categories using the LRT method and three different optimizers, namely Adam, Adagrad, and SGD.
For the Adam optimizer, the training accuracy increased rapidly at first and then stabilized around 1.0, indicating effective learning. The validation accuracy also rose initially but leveled off slightly lower than the training accuracy. The model exhibited strong performance on both training and validation data.
For the Adagrad optimizer, the training accuracy quickly stabilized around 0.8, with the validation accuracy following a similar trend and plateauing at a slightly lower level. The small gap between training and validation accuracy suggested minimal signs of overfitting, indicating that the model generalizes well to new data.
For the SGD optimizer, the training accuracy stabilized around 0.85, while the validation accuracy plateaued slightly lower. The slight gap between the two accuracy curves hinted at a potential for minor overfitting, although the model still demonstrated strong generalization to new data. Overall, it showed solid performance on both training and validation datasets. In conclusion, all optimizers resulted in strong model performance with minimal overfitting, making the model a suitable candidate for deployment.
4.6. Comparing the Results with the State-of-the-Art
OSCC is the sixth most common cancer worldwide, and its incidence is increasing. The diagnosis of OSCC mainly relies on HIs, but this approach can be time-consuming, costly, and requires specialized skills. Manual diagnosis often results in inaccuracies and inconsistencies, underscoring the critical need for automated and reliable diagnostic methods to improve early detection and treatment outcomes.
The previously mentioned research used a fixed LR, while our proposed model implemented the LRT to overcome the limitations of a fixed LR. The LRT dynamically adjusts the LR during training based on various factors, such as gradient magnitudes, loss convergence, and training progress. This flexibility allows the model to navigate complex optimization landscapes more efficiently. By adapting the LR in real time, the LRT facilitates faster convergence, accelerating progress during the initial training phases and reducing oscillations or overshooting as optimization approaches convergence. Consequently, our proposed model achieved higher accuracy compared to the current state-of-the-art approaches in this field.
We carried out an experiment that examined the use of transfer learning by pre-training the models EfficientNet-B1, EfficientNet-B2, EfficientNet-B3, DenseNet169, and InceptionV3. This was achieved using the multi-cancer dataset, which includes the oral tumor dataset. The dataset is organized as follows: 70% of the data is used for the training set (6998 histopathological images or HIs), while 15% is allocated for the test set (1501 HIs), and the remaining 15% is set aside for the validation set (1501 HIs).
During the first stage of transfer learning, we performed supervised pre-training on these five DL models using the ImageNet dataset. In the subsequent stage, we improved the models further by using the training set of the oral tumor dataset. When tested on the oral tumor dataset, the model showed excellent results, achieving an accuracy of 99.84% and a specificity of 99.92%, along with other strong performance metrics. These results suggest that the model could simplify the diagnostic process, reduce costs, and improve patient outcomes in clinical environments.
Table 13 and
Table 14, along with
Figure 24, provide a comparative analysis of different methods for detecting OSCC tumors, focusing on their accuracy and the datasets used. Shetty, S.K. et al. [
3] implemented the DPODTL-OSC3 model, achieving an accuracy of 97.28% on the oral tumor dataset. Nagarajan, B. et al. [
17] used a modified gorilla troops optimizer, reaching an accuracy of 95%. Ahmed, I.A. et al. [
34] employed fused CNNs, which yielded the highest accuracy of 99.3%. Das, M. et al. [
14] adopted a CNN-based model, reporting an accuracy of 97.82%. Panigrahi, S. et al. [
35] utilized a DCNN model, achieving an accuracy of 96.6%. Fati, S.M. et al. [
36] who combined hybrid features from AlexNet, DWT, LBP, FCH, and GLCM in an ANN model, achieved an accuracy of 99.1%. Afify, H.M. et al. [
37] integrated ResNet-101 and EfficientNet-B0 with Grad-CAM, with ResNet-101 achieving 100% accuracy at 100× magnification, and EfficientNet-B0 reaching 95.65% at 400× magnification. Albalawi, E. et al. [
38] applied EfficientNet-B3, resulting in an accuracy of 99%.
Furthermore, Badawy, M. et al. [
8] combined AO, GTO, and DenseNet201, recording accuracies of 99.25% with AO and 97.27% with GTO. Ananthakrishnan, B. et al. [
39] combined CNN with a RF classifier, reporting an impressive accuracy of 99.65%.
Lastly, the proposed model using EfficientNet-B3 and LRT demonstrated exceptional performance with an accuracy of 99.84% at magnifications of both 100× and 400×, making it one of the top-performing methods for oral tumor classification on the same dataset.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}