1. Introduction
Eye-tracking is an increasingly popular methodology across various applications. What captivates numerous researchers is its time-efficiency, cost-effectiveness, reliability, objectiveness, quantifiability, easiness to conduct, non-invasiveness, and accessibility. By leveraging techniques such as shape-based, appearance-based, feature-based, and hybrid methods, eye-tracking technologies capture and analyse the movements of key ocular components, including the pupil, cornea, sclera, iris, and retina [
1,
2,
3]. These movements rely on the physiological mechanism controlled by the central nervous system, involving the brainstem, cerebellum, basal ganglia, and cerebral cortex [
4]. Consequently, eye-tracking measurements provide a valuable window into brain function and cognitive processes.
Eye movements are categorised into four basic types: saccades, smooth pursuit movements, vergence movements, and vestibulo-ocular movements [
5]. Even during fixation, the eye was not completely still due to fixational eye movements, which are composed of three main kinds of smaller movements: microsaccades, drift, and tremor [
6]. Microsaccades and drifts have an average size of approximately 6′ arc, with drifts exhibiting an average velocity of about 1′ arc per second [
7]. These eye movements can influence each other and, sometimes, occur simultaneously. For example, in Miki and Hirata’s study [
8], microsaccades were observed in parallel with the ongoing vestibulo-ocular reflex. Among the aforementioned eye features, saccades and fixations are commonly analysed in eye-tracking studies [
9], although pursuit and pupil dilation are also frequently investigated [
10,
11,
12].
A systematic literature review has summarised the eye-tracking methods for enhancing productivity and reading abilities [
13], categorising studies into four areas: general eye metrics and tracking, comprehension measurement, attention measurement, and typography and typesetting. Notably, the eye metrics such as fixation duration, saccade velocity, and blink rates have been linked to reading behaviours including speed reading and mind-wandering. Although findings across studies have limited generalizability, the integration of machine learning with eye-tracking technologies has shown promising potential in understanding reading behaviour, attention, and cognitive workload.
1.1. Eye-Tracking in Healthcare
Eye-tracking has demonstrated significant potential in healthcare applications, particularly in telemedicine [
6], assistive technologies (e.g., wheelchair control [
14]), and the assessment of neurological and vestibular disorders such as acute-onset vertigo [
15]. It has been used to evaluate memory in conditions such as Amyotrophic Lateral Sclerosis (ALS) and late stages of Alzheimer’s Disease (AD), without relying on intact verbal or motor functions, which may not prevail or be reliable in patients of late stages. By minimising the need for complex instructions or decision-making, eye-tracking provides an accessible means of evaluation [
9].
Eye-tracking features have been identified as potential biomarkers for multiple neurodegenerative disorders. For instance, impaired convergence is observed in Parkinson’s disease (PD) [
16], while atypical saccades characterise preclinical and early-stage Huntington’s disease [
17,
18]. Neurological abnormalities could also be detected in long COVID patients. García Cena et al. proved that long COVID patients were affected by altered latency for centrally directed saccades, impaired memory-guided saccades, and increased latencies for antisaccades [
19].
1.2. Challenges and Limitations
Despite these promising applications, there are still concerns and challenges. The experimental constraints and demands of certain tasks can lead to changes in microsaccade behaviour, potentially producing responses that do not occur in natural conditions. For example, Mergenthaler and Engbert observed more microsaccades in the fixation task than the naturalistic scene viewing task, suggesting those responses might be task-specific [
20]. However, in real-world settings, human behaviour will involve a range of different tasks (with both fixation and free viewing present), resulting in a combination of different types of eye movements. This highlights the difficulty of replicating experimental conditions outside controlled laboratory settings with the use of special eye-tracking equipment.
Therefore, barriers to the widespread adoption of these examinations in daily life or at home require patients to visit a clinic or laboratory for eye-tracking assessments. Moreover, the expensive price and high-calibration requirements, which need specific training, present further obstacles [
6,
21,
22,
23]. While some methods are accurate and effective, they often require skilled professionals to operate, making the process laborious and time-consuming [
24].
To address these limitations, researchers have explored the use of consumer-grade electronic devices like smartphones, video recorders, laptops, and tablets. However, these approaches introduce new challenges, particularly regarding head stabilisation, which significantly affects tracking accuracy. Solutions such as external head restraints and head-mounted equipment have been proposed to mitigate these issues [
6,
21,
25]. Another solution is to use some indicators (e.g., a sticker) to represent the head movement and then subtract it from the eye movement [
22].
1.3. State of the Art
Eye-tracking is sometimes combined with functional magnetic resonance imaging (fMRI) to investigate neurological deficits [
26,
27]. Compared to fMRI, one of the advantages of automated eye feature evaluation is its ability to simultaneously collect multiple measures during the same session and obtain different information for specific analysis and diagnosis [
9]. High-frame-rate cameras further enhance detection capabilities, revealing some covert saccades that are difficult to see with the naked eye.
In order to collect and synthesise the available evidence, in a chapter of ‘Eye Movement Research’, Hutton [
28] introduced the range of eye-tracking technologies currently available. There are two common tests to measure eye movement: video recording (video-oculography or VOG) and electromyography (electro-oculography or EOG). The less common approaches are through limbus reflection, Dual Purkinje Image (DPI), and scleral search coils, but they will not be discussed in detail here.
EOG uses a pair of electrode patches and measures the activity of two cranial nerves, which, respectively, connect the brain with the inner ear and the eye muscles. VOG uses a camera to record the eye movements and calibrate the accuracy. According to Corinna Underwood [
29], there is a general consensus that the accuracy of directly measuring eye movements is higher than indirectly measuring movements via eye muscle motion. Hutton further highlights that EOG’s primary drawback is its susceptibility to spatial inaccuracies due to drift artefacts over time, caused by impedance changes in the electrodes [
28]. While most studies favour VOG over EOG, there is insufficient evidence to conclusively recommend one method over the other. VOG, though more precise, is relatively expensive and requires the eyes to remain open. Meanwhile, using EOG requires careful consideration in practice as certain medications (e.g., sedatives) or medical electrical equipment (e.g., cardiac pacemakers) would affect or interfere with the electromyography function [
29].
VOG systems require head stability due to vestibulo-ocular movements that cause involuntary eye motion (to maintain the gaze fixation on a location, the head motion would cause the eye movement in the opposite direction [
6]). Solutions to this issue fall into two categories: stationary VOG, where the camera remains fixed and external supports such as chin rests stabilise the head, and mobile VOG, where the camera moves with the head (e.g., in wearable eye-tracking glasses). Mobile VOG is generally better suited for real-world tasks, whereas stationary VOG is typically used in research settings that require specific stimuli. However, the need for mobile VOG to be lightweight and wearable imposes limitations on its specifications. As a result, its data quality, sampling rates, and spatial resolution are generally lower than those of high-specification stationary VOG systems [
28].
Infrared-based eye-tracking, known as infrared oculography (IOG), is a common VOG method that tracks corneal reflection and the pupil centre [
9,
30,
31]. Under infrared illumination, the pupil appears as a comparatively dark circle compared to the rest of the eye (e.g., the iris and sclera) [
28]. However, this approach assumes that the pupils dilate and constrict symmetrically around their centre, which is not always accurate under varying luminance conditions according to Wildenmann et al. [
32]. Consequently, researchers continue to explore alternative methods that do not rely on infrared illumination.
Table 1 provides a comparative analysis of different eye-tracking technologies, including fMRI, VOG, and EOG, highlighting their respective advantages and limitations [
6,
9,
28,
29].
1.4. Deep Learning Methods and Hardware Limitations
Deep learning, particularly convolutional neural network (CNN) methods, has become a popular approach in modern eye-tracking research due to its capacity to learn direct mappings from raw facial and ocular images to gaze coordinates. These methods have been greatly accelerated by the availability of large-scale gaze datasets (GazeCapture [
33] and MPIIGaze [
34]) and the outstanding performance of CNNs in computer vision tasks.
Several CNN architectures have been explored in the literature. Early approaches include different CNN structures such as LeNet-based [
35], AlexNet-based [
36], VGGNet-based [
34], and ResNet18-based [
37] and ResNet50-based [
38] models. Among notable CNN-based models, the iTracker model by Krafka et al. [
33] used facial and eye images to predict gaze with high accuracy and was trained using the GazeCapture dataset. Valliappan et al. [
39] demonstrated the feasibility of smartphone-based gaze tracking. Their proposed multi-layer feed-forward CNN achieved a gaze estimation accuracy of 0.6–1°, which is comparable to commercial solutions such as Tobii Pro Glasses.
Despite their effectiveness, these models typically demand a high computational burden, which limits their applicability for real-time deployment on mobile devices. They often require CPUs and GPUs with high cost and power consumption. Due to hardware limitations such as constrained computational power, limited battery life, and network bandwidth, deep learning models are not well suited for low-resource settings and edge computing, particularly on standard smartphone devices.
To address these limitations, several lightweight CNN architectures have been proposed, such as SqueezeNet [
40] and ShuffleNet [
41]. Notably, MobileNet [
42] and MobileNet-V2 [
43] employ depthwise convolutions to significantly reduce parameter count and computational cost while maintaining reasonable accuracy. When combined with edge computing platforms such as the Raspberry Pi, Google Coral USB Accelerator, and NVIDIA Jetson TX2, this direction appears promising.
However, these lightweight models are typically only suitable for gaze estimation on specific smartphone models with relatively high hardware specifications, even with support from mobile-optimised frameworks such as TensorFlow Lite (TFLite) and PyTorch Mobile. While this may become increasingly viable with ongoing advancements in smartphone technology and reductions in device cost, such solutions are not yet feasible in low-resource settings. In these contexts, a traditional processing algorithm embedded within the smartphone may offer a more accessible and practical solution. Ultimately, the choice reflects a trade-off between the required accuracy for the research question and the limitations of the target hardware.
1.5. Smartphone-Based Eye-Tracking
Modern smartphones present an excellent opportunity for accessible and cost-effective eye-tracking. Equipped with high-resolution cameras and increasing on-device processing power, they are well-suited for edge computing, i.e., bringing the computation closer to the devices where data is gathered rather than cloud computing. This allows smartphones to function as both data acquisition and processing units, enabling real-time analysis, reducing latency, and preserving user privacy, which are particularly valuable in medical diagnostics. Their internet connectivity further supports remote deployment and monitoring when needed. Previous research has demonstrated the feasibility of using smartphones as an alternative to commercial-grade equipment for pupillometry [
23]. Their affordability, ease of use, and resilience to power supply make them an attractive solution for large-scale, low-resource applications.
One challenge with smartphone-based tracking is its small screen size, which can restrict visual stimulus presentation. Many researchers have addressed this by incorporating external displays. For instance, Azami et al. [
44] used an Apple iPad display and an Apple iPhone camera to record eye movements in ataxia and PD participants. After comparing different machine learning methods, they decided to use principal components analysis (PCA) and linear support vector machine (SVM), achieving 78% accuracy in distinguishing individuals with and without oculomotor dysmetria. Similarly, before switching to tablets, Lai et al. [
21] initially designed their experiment based on a laptop display and an iPhone 6 camera. The iTracker-face algorithm can estimate mean saccade latency with a precision of less than 10 ms error. However, they did not report gaze accuracy. One exception is the study by Valliappan et al. [
39], using a smartphone (Pixel 2 XL) as both a display and camera on healthy subjects.
While there is a wide variety of equipment and algorithms, few studies integrate eye-tracking with edge computing. Gunawardena et al. [
45] found only one study (by Otoom et al. [
46]) that combined edge computing with eye-tracking. As for the accuracy, Molina-Cantero et al. [
47] reviewed 40 studies on visible-light eye-tracking using a low-cost camera, reporting an average visual angle accuracy of 2.69 degrees. Among these, only a subset achieved errors below 2.3 degrees, including the studies by Yang et al. [
48], Hammal et al. [
49], Liu et al. [
50,
51], Valenti et al. [
52], Jankó and Hajder [
53], Wojke et al. [
54], Cheng et al. [
55], and Jariwala et al. [
56].
1.6. Contribution
Given the gap between the considerable potential of smartphones and the lack of edge computing solutions in eye-tracking, the proposed algorithm aims to introduce a lightweight alternative to conventional resource-demanding deep learning neural networks. As highlighted in the literature review, this cross-modal, smartphone-based approach is computationally efficient. Its low requirements make it especially suitable for smartphones and its compatibility with edge computing supports deployment in low-resource settings, where conventional systems are impractical or unavailable.
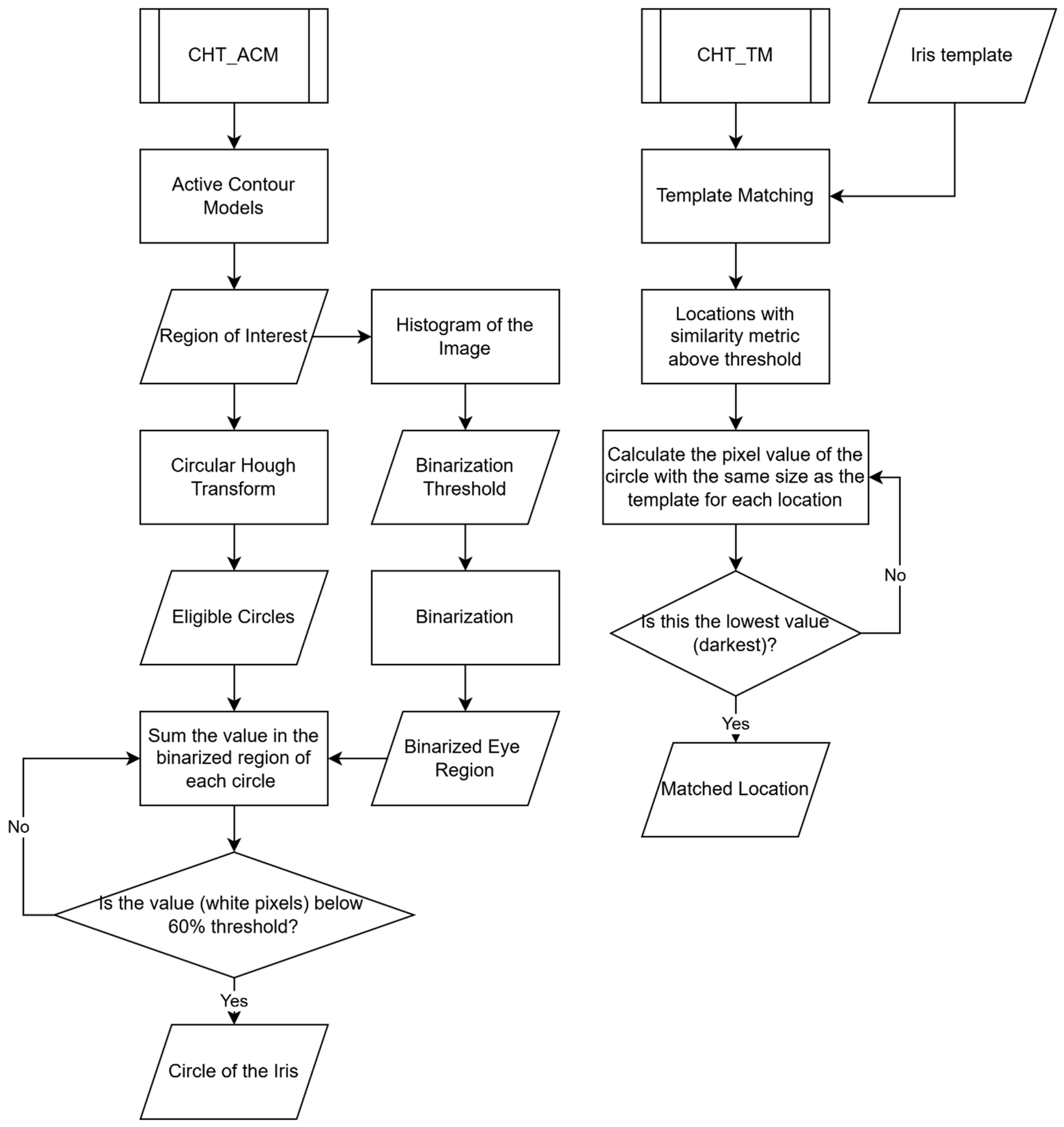
Although most studies would unintentionally mix the concept of eye-tracking and gaze estimation, it is important to distinguish between these two methods. Eye-tracking involves analysing visual information from images or frames in VOG, focusing on identifying facial landmarks, the eye region, and the pupil centre. In contrast, gaze estimation further requires stimulus calibration, head orientation detection, and gaze angle calculation. This article aims to develop a stationary VOG application that prioritises eye-tracking over gaze tracking, utilising smartphone cameras as an alternative to infrared-based systems.
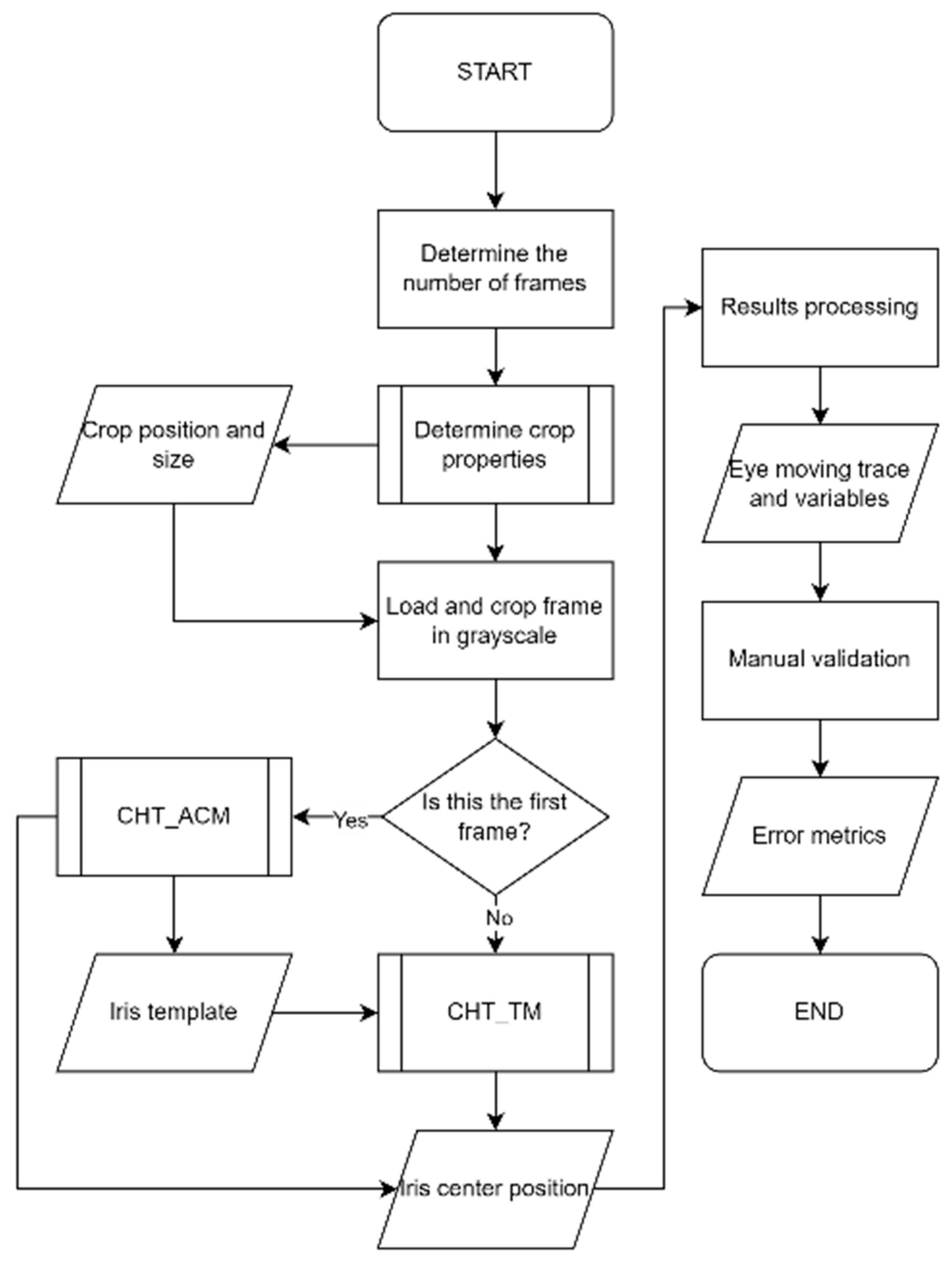
This study evaluates the performance of two eye-tracking algorithms—Circular Hough Transform plus Active Contour Models (CHT_ACM) and Circular Hough Transform Template Matching (CHT_TM)—in tracking the iris, particularly in neurodegenerative conditions. The findings will inform the second phase of the study, aimed at developing a novel gaze estimation software that is based on images acquired in the visible-light spectrum and will be validated against a commercial infrared eye tracker.
Modern eye trackers in gaming (e.g., Tobii Eye Tracker 5 [
57] or Gazepoint 3 Eye Tracker [
58]) achieve an optimistic performance in gaze tracking with unconstrained head movements. However, in line with the United Nations’ Sustainable Development Goal 3 (Good Health and Wellbeing) and the principle of frugal innovation, this study aims to develop a cost-effective, smartphone-based eye-tracking solution that eliminates the need for additional accessories, thereby improving accessibility in low-resource settings. This study further contributes to the ongoing development of smartphone-based eye-tracking, paving the way for wider adoption in both clinical and non-clinical settings.
4. Discussion
This study was aimed at developing and validating an effective eye-tracking algorithm to be used on visible-light images captured by a smartphone camera, in order to unlock more affordable and user-friendly technologies for eye-tracking. Two algorithms, named CHT_TM and CHT_ACM, were compared in terms of performance and computational efficiency. The selection of these algorithms was based on their potential to enhance accuracy and speed without increasing resource consumption.
Comprehensively, CHT_TM demonstrated improved runtime and superior performance in vertical eye movement tracking (y axis), although CHT_ACM outperformed it in horizontal tracking (x axis) in two out of four tasks. Whether it was CHT_ACM or CHT_TM, larger errors were consistently observed along the y axis, as seen in
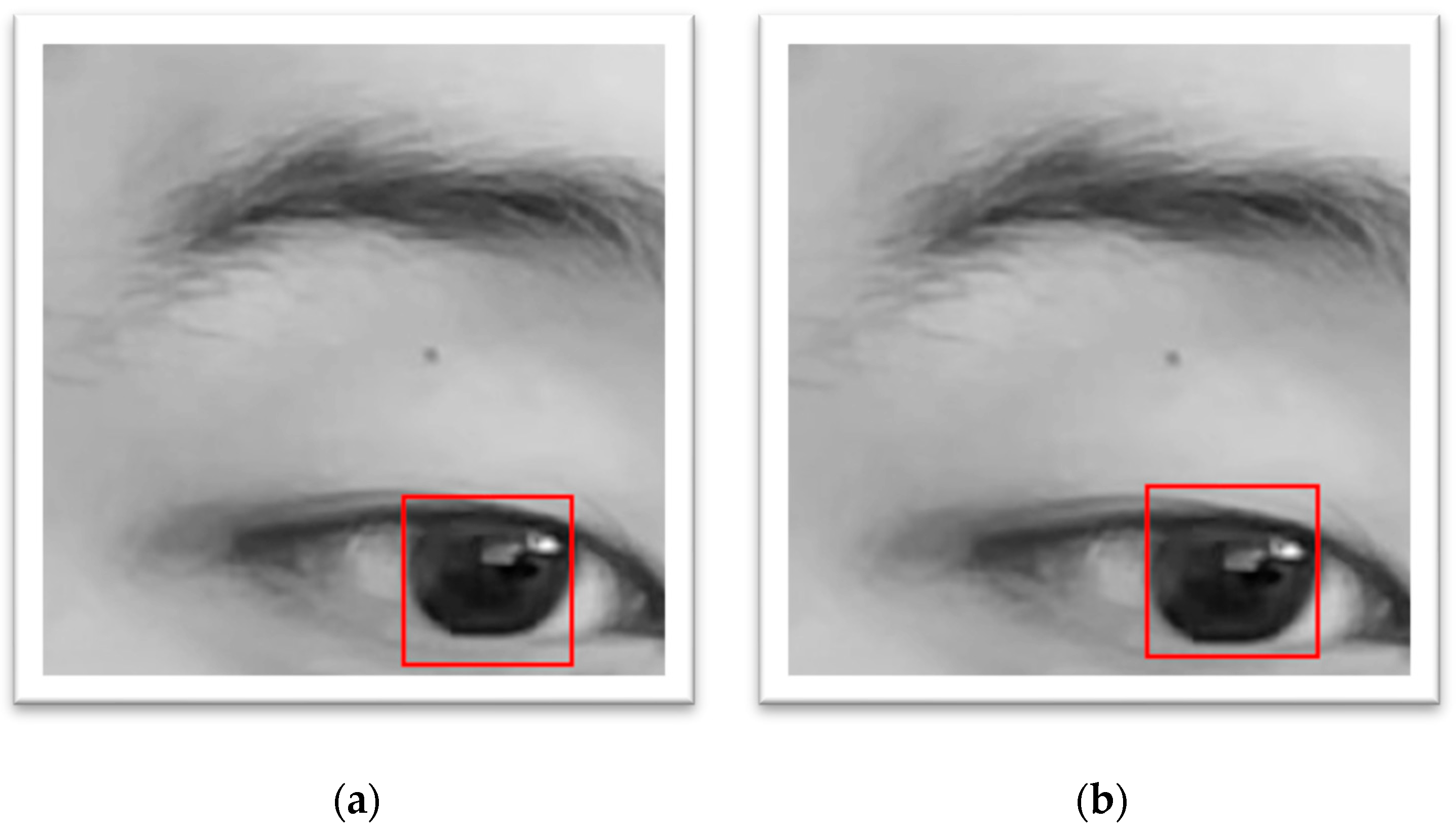
Table 2. This can be attributed to the anatomical reality that the upper and lower regions of the iris are more likely to be covered by the eyelids, especially during upward or downward gaze, or when participants are fatigued and the eyes are half-closed. This introduces inaccuracies in iris centre detection.
From the results comparing with/without-fingers conditions, using the fingers to open the eyelid seems to improve accuracy in most cases. This supports the hypothesis that using fingers can help the algorithm diminish the error of non-intact iris as the eyelid is no longer covering the iris. While CHT_TM performed better along the x axis even without finger assistance, the benefit of finger usage was more significant on the y axis, where eyelid interference is typically greater on the upper edge or the lower edge. Despite this, the use of fingers was reported as uncomfortable for participants and is therefore not advisable in future studies. Alternative non-invasive strategies or postprocessing solutions are recommended.
Task-wise, the circular task produced the largest errors, suggesting that the primary challenge lay in the instability of the task rather than the algorithm itself. CHT_ACM remains less accurate than CHT_TM. As the mean absolute errors of both CHT_ACM and CHT_TM were on the pixel level, these errors were overall very small, also when taking into account the limits of the system for manual measurements with a precision of 0.5 pixels. Fixation tasks, being the most stable, resulted in the lowest tracking errors for both algorithms, which means there was no drastic head movement during the experiment. CHT_TM was better at tracking the fixation task on the y axis. Interestingly, CHT_TM improved x axis tracking in the horizontal task, likely due to its robustness in recognising elliptical iris shapes during lateral gaze. In contrast, CHT_ACM retained an advantage on the x axis for the fixation task. CHT_TM performed more reliably across tasks, especially in preventing tracking loss.
Comparing subjects with different iris colour, the algorithm showed the best performance in subjects with dark iris colour. Nonetheless, both algorithms produced pixel-level errors across all subjects, with CHT_TM consistently outperforming CHT_ACM. This indicates that the iris colour would influence the accuracy of both algorithms simultaneously, especially on the x axis.
No notable differences were found between the fast and the slow experiment.
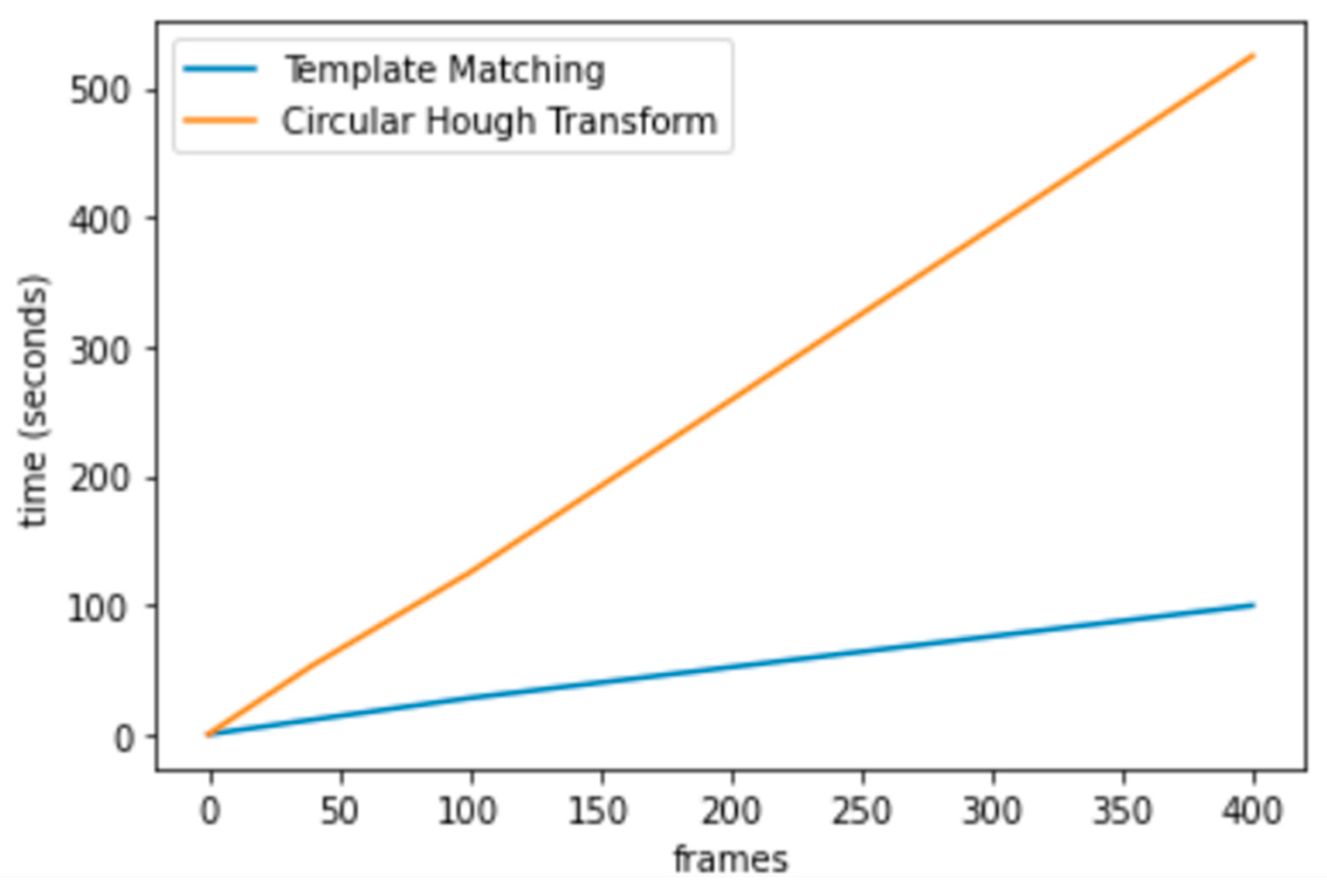
Despite minor differences in error rates, it is noteworthy that both algorithms achieved high accuracy, with an average error of just 1.7 pixels (1.2%) across 19 videos. These results underscore the feasibility of both methods for reliable iris centre detection. However, the most significant difference lay in computational performance, with CHT_TM offering faster processing times.
Comparing the proposed method with existing smartphone-based approaches proved challenging due to a lack of validated benchmarks and methodological transparency in the literature. Many studies fail to disclose algorithmic details and rely instead on vague references to platforms like OpenCV or ARKit, thereby hindering reproducibility. In contrast, this study prioritises transparency and reproducibility by making both the data and algorithms publicly available.
Some may question the absence of machine learning or deep learning in this work, especially given their strong performance in image analysis tasks. However, the lack of a suitable public dataset, particularly one containing data from neurodegenerative patients, prevented the use of AI-based models. The mismatch between public eye-tracking datasets and cognitive experiment settings makes it difficult to adopt or adapt open-access datasets, considering the final goal of distinguishing patients and healthy subjects.
Public datasets are typically based on static stimuli and short-duration recordings, and are primarily designed to optimise gaze point accuracy. In contrast, cognitive experiments involve dynamic, goal-directed, task-specific stimuli, capture temporal dependencies in sequential data, and focus on variables linked to cognitive processes such as attention, memory, and response inhibition. Moreover, datasets collected in clinical or cognitive contexts are smaller due to stricter requirements and limited participant availability. These datasets are also subject to privacy and ethical regulations, which restrict data sharing and limit opportunities for large-scale model training. Additionally, variations in experimental conditions such as viewing distance, screen size, inter-subject variability (patients vs. controls), and ambient lighting hinder experimental reproducibility and limit the transferability of pre-trained models. In fact, data collection from patients would still be inevitable, but replicating the same experiment settings as the used public dataset would remain challenging as explained above.
Additionally, using AI trained on different hardware and image conditions (e.g., infrared cameras) would compromise compatibility with the smartphone-based set-up employed here. For instance, the structure of this algorithm is inspired by and is similar to the one proposed by Zhang et al. [
65]. However, they used a CNN to condense the video and their data was collected from a portable infrared video goggle instead of the smartphone intended in this paper. Not only is the video grayscale but also the distance from the camera to the eye is different, making it impossible to use their data in this experiment or to develop the same algorithm based on varied data.
Beyond data limitations, deploying AI models on smartphones presents practical challenges. Deep learning methods typically require powerful processors or graphics processing units (GPUs) designed for computer systems, which is not the best fit for smartphones. In this case, it is necessary to upload the video data to the cloud server and use cloud computing. This reliance introduces new issues such as internet connectivity (not always available in rural areas or within low-resource settings), delayed response times, and potential data privacy risks (identifiable data like face videos). In contrast, a self-contained, built-in algorithm avoids these complications and better serves low-resource environments.
Nonetheless, AI remains a promising avenue for future work. Studies have shown a similar or even better performance with a CNN using the front-facing camera of Pixel 2 XL phone [
39] or the RealSense digital camera [
66] than a commercial eye tracker. Once a sufficiently large and diverse dataset is collected, including both healthy individuals and patients, AI models could be trained to refine or replace parts of the current algorithm. Such models could automate pre-processing or minimise tracking errors through learned feature extraction.
The future plan for this study is to develop a refined experimental protocol in collaboration with medical professionals, followed by validation against a commercial infrared eye tracker. Then, experiments can be carried out at hospital level on patients affected by neurodegenerative conditions. The ultimate goal is to design a smartphone-compatible eye-tracking toolkit and AI-based system for the early screening of neurodegenerative diseases.
Limitations
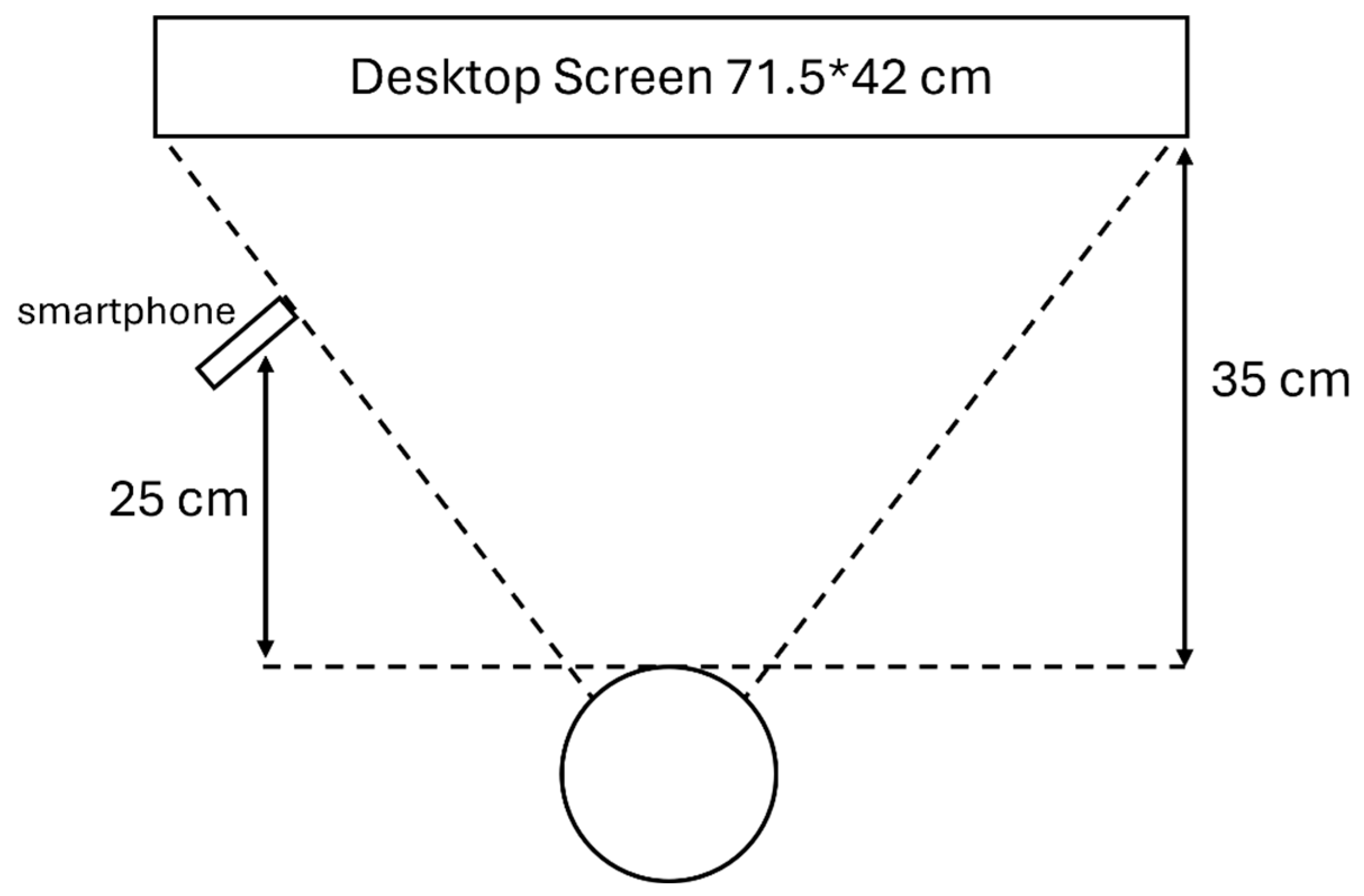
One limitation of the current protocol is the visible trace of the target during the task (see
Figure 1), which allows participants to predict the target’s trajectory. As a result, their eye movements may precede rather than follow the target. Additionally, the absence of a headrest introduces variability due to head movement, which can compromise signal quality. To address this, future studies will explore the feasibility of using a sticker placed in a fixed location as a reference point to track and compensate for head motion, allowing reconstruction of more accurate eye movement data.
Although the study aligns with the principle of frugal innovation and avoids using additional apparatus, a tripod was used as a temporary substitute for a user’s hand or arm. One thing worth noticing is the differences in participant height, which can affect the camera angle towards the eye and may contribute to varying errors among subjects.
Another limitation is the small sample size, as this pilot study was primarily intended to demonstrate feasibility. Manual validation was used to assess the algorithm’s performance. This method, while effective for small datasets, lacks the efficiency and scalability of automated validation methods. This limits the generalizability of the results and the potential for large-scale application.
At this stage, comparisons were made between algorithm outputs and manual annotations of actual eye movement centres, rather than estimated gaze points. Each video was relatively short and did not include significant head movement, so the ROI of the eye was manually cropped and fixed at a constant image coordinate. Consequently, all movement was referenced to the same top-left corner of the cropped ROI (coordinate [0, 0]).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}