
Multitask Learning for Mental Health: Depression, Anxiety, Stress (DAS) Using Wearables



Abstract
1. Introduction
- RQ1: What are the underlying biomarkers of mental well-being, considering factors such as stress, anxiety, and depression?
- RQ2: Are these biomarkers in line with conventional psychological studies?
- RQ3: Do time-based versions of conventional algorithms lead to improved prediction performance in the context of mental health?
- RQ4: Do further methodologies such as MTL on top of time-based models improve the final performance?
2. Background and Related Work
2.1. Motivation for Depression, Anxiety, Stress (DAS)
2.2. Mental Health
2.3. Time-Based and Multitask Learning for Mental Health
3. Methodology
3.1. Motivation for Methodologies
3.1.1. Time-Based Modeling
3.1.2. Multitask Learning
3.2. Dataset
3.2.1. Sensing Streams
3.2.2. Predictors
3.2.3. Target Values
- DepressionDepression is a pervasive mental health condition marked by persistent and deep-seated feelings of sadness, hopelessness, and diminished interest or pleasure in once-enjoyable activities, leading to substantial impairment in daily functioning and overall quality of life [1,21]. NetHealth contains two different survey responses for depression such as ‘CES-D’ https://www.apa.org/pi/about/publications/caregivers/practice-settings/assessment/tools/depression-scale (accessed on 17 January 2024) and ‘BDI’ https://www.apa.org/pi/about/publications/caregivers/practice-settings/assessment/tools/beck-depression (accessed on 17 January 2024). Additionally, we have continuous scores ranging from 0 to 60 for CES-D and from 0 to 63 for BDI, with higher scores indicating greater depressive symptoms. For CES-D, there is also a grouped version ranging from 0 to 1, representing not depressed and depressed. For BDI, the grouped version ranges from 0 to 3, representing minimal, mild, moderate, and severe levels of depression. Throughout the study, we employed the BDI with its corresponding classification levels.
- AnxietyAnxiety is a prolonged state of excessive worry and fear about future events, characterized by heightened alertness and unease; while it can be a normal response to stress, overwhelming and impairing forms may indicate an anxiety disorder [1,22]. Similar to depression values, NetHealth also contains two different survey responses for anxiety: ‘STAI’ https://www.apa.org/pi/about/publications/caregivers/practice-settings/assessment/tools/trait-state (accessed on 17 January 2024) and ‘BAI’ https://en.wikipedia.org/wiki/Beck_Depression_Inventory (accessed on 17 January 2024). We have continuous scores ranging from 20 to 80 for STAI and from 0 to 63 for BAI, where higher scores indicate greater anxiety. STAI has a grouped version ranging from 0 to 1, representing not anxious and anxious, respectively. On the other hand, BAI ranges from 0 to 2, representing low, moderate, and severe anxiety levels. In the scope of this study, we utilized the BAI with its corresponding levels.
- StressStress is a physiological and psychological response to perceived threats, encompassing external and internal stressors, triggering the body’s “fight or flight” response; while acute stress can be adaptive, chronic stress, persisting over time, can negatively impact both physical and mental health, contributing to conditions like anxiety and depression [1,23]. In NetHealth, we have only ‘PSS’ https://www.das.nh.gov/wellness/docs/percieved%20stress%20scale.pdf (accessed on 17 January 2024). We are only provided with its Likert-scale version ranging from 0 to 4, corresponding to never through very often. Given the absence of alternative options for the stress target, we utilized a class-based scale for the entire study. We made choices regarding the survey and value types for other target variables (raw continuous value or classes) by aligning them with the response type available for stress. This decision was made to ensure coherence among target variables despite the differing class scale ranges.
3.3. Missing Data
3.4. Data Preprocessing for Time-Based Methods
3.5. Models and Evaluation Metrics
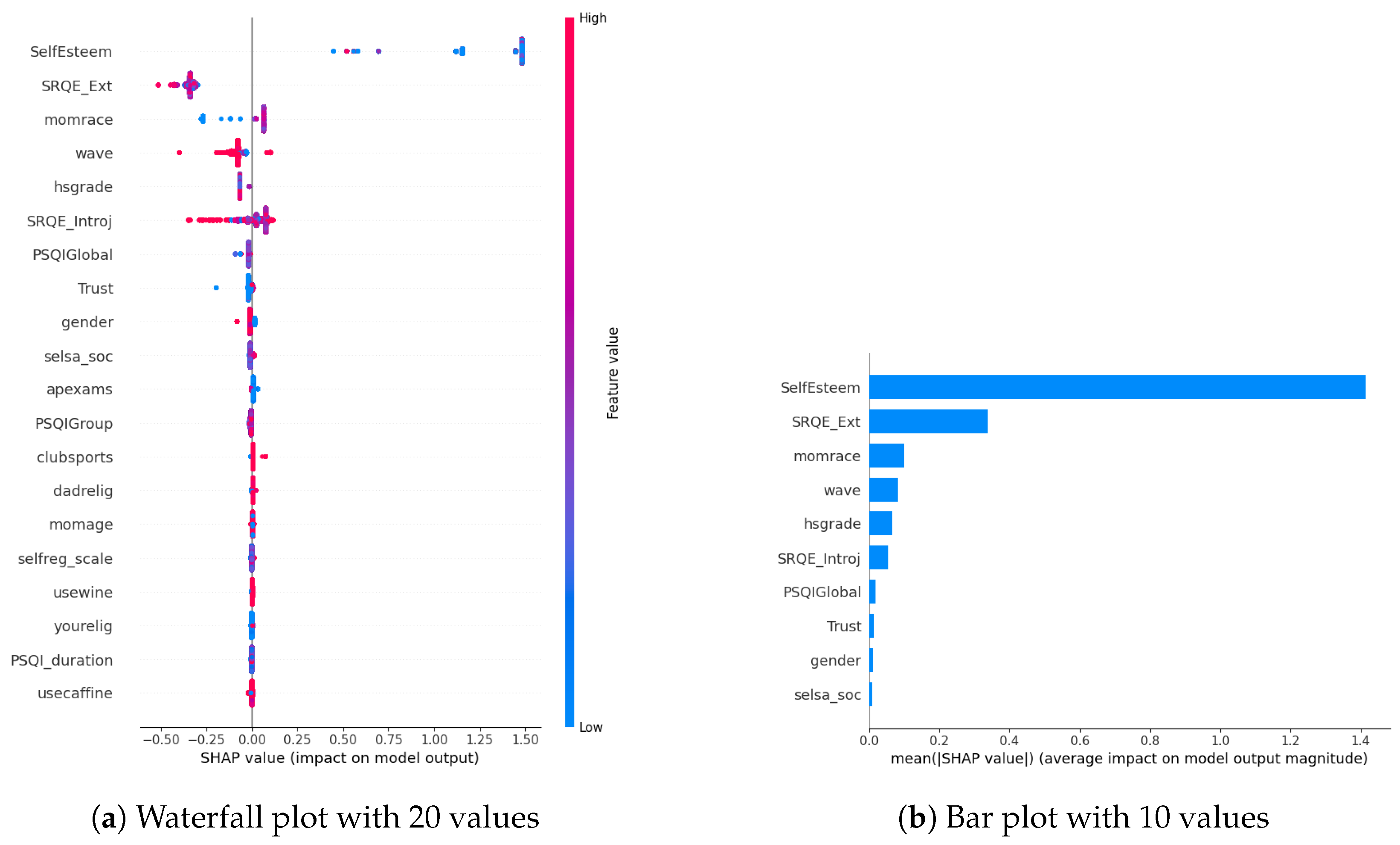
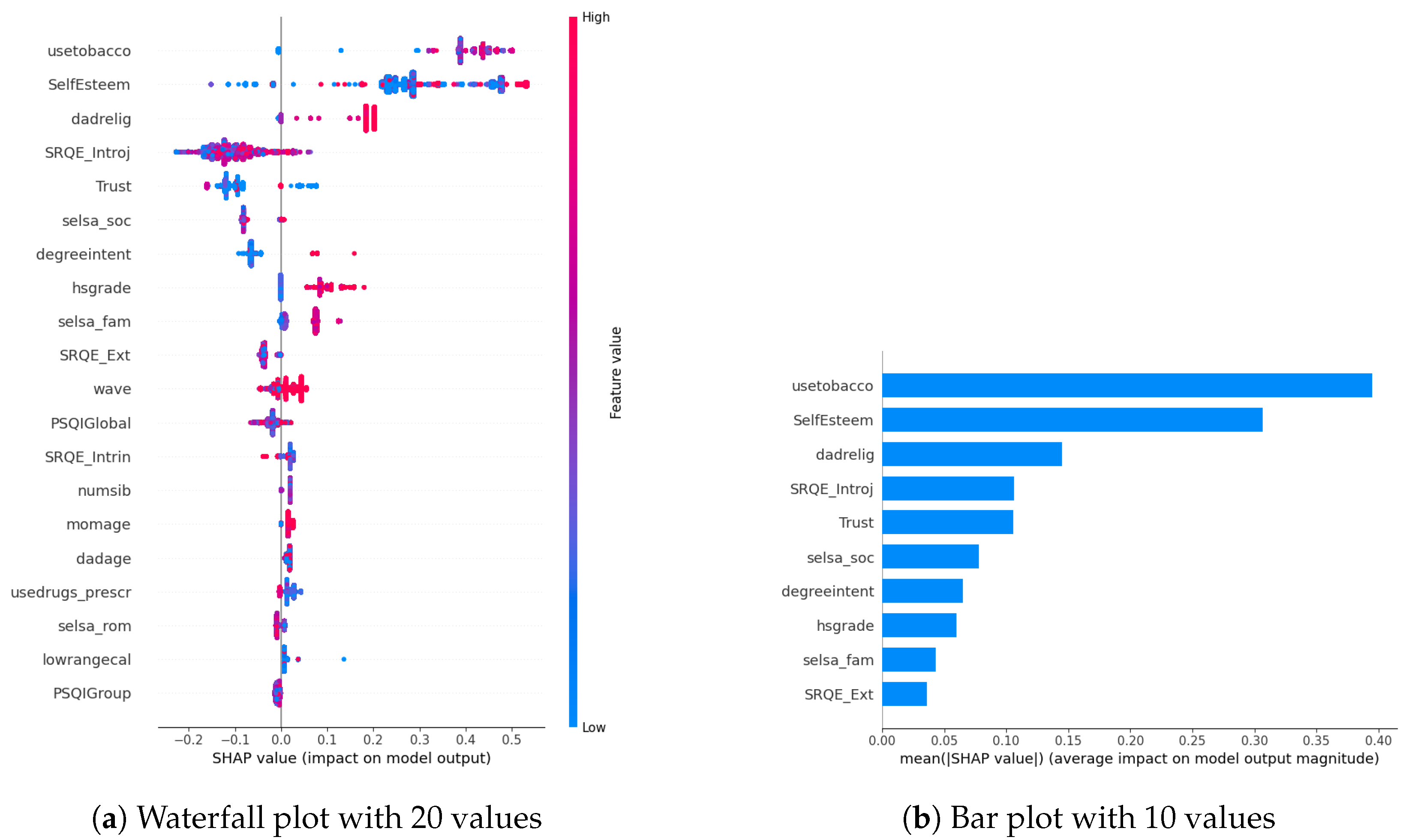
4. Quantification of Biomarkers Related to DAS
Biomarkers Related to DAS via Only Wearable Parameters
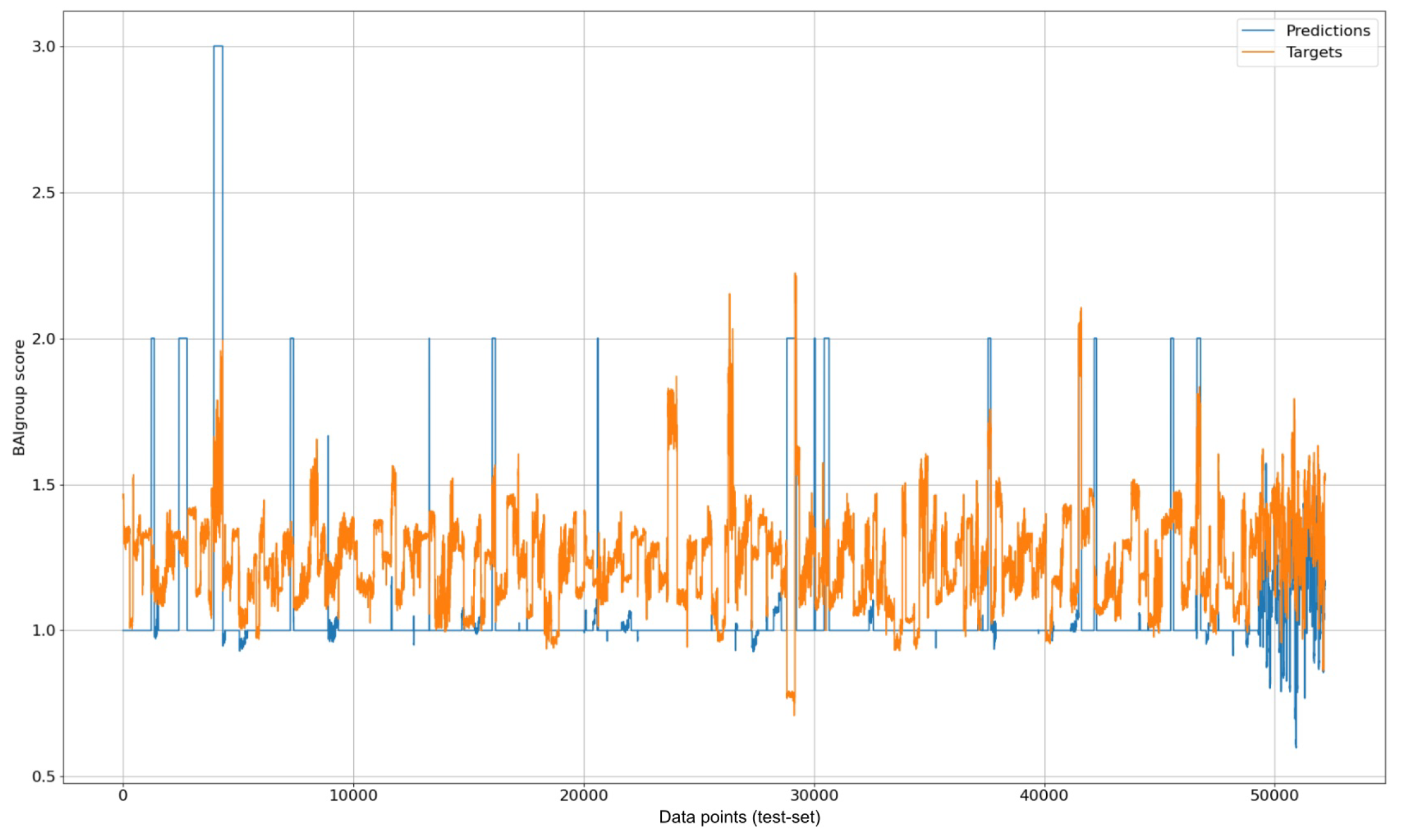
5. Conventional, Multitask, Time-Based, and Multitask Time-Based DAS Predictions
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Hyperparameters |
|---|---|
| RF-Depression | (‘max depth’, 5), (‘min samples leaf’, 1), (‘min samples split’, 2), (‘n estimators’, 10) |
| RF-Anxiety | (‘max depth’, 5), (‘min samples leaf’, 2), (‘min samples split’, 3), (‘n estimators’, 6) |
| RF-Stress | (‘max depth’, 4), (‘min samples leaf’, 1), (‘min samples split’, 10), (‘n estimators’, 5) |
| XGBoost-Depression | (‘alpha’, 1), (‘colsample bytree’, 0.7333635223098999), (‘gamma’, 1), (‘learning rate’, 0.058336569586572316), |
| (‘max depth’, 8), (‘min child weight’, 3), (‘n estimators’, 82), (‘subsample’, 0.641372976280757) | |
| XGBoost-Anxiety | (‘alpha’, 0), (‘colsample bytree’, 0.510066209080432), (‘gamma’, 0), (‘learning rate’, 0.04359820016477877), |
| (‘max depth’, 7), (‘min child weight’, 8), (‘n estimators’, 70), (‘subsample’, 0.9080823751699505) | |
| XGBoost-Stress | (‘alpha’, 0), (‘colsample bytree’, 1.0), (‘gamma’, 0), (‘learning rate’, 0.2993), (‘max depth’, 3), (‘min child weight’, 6), |
| (‘n estimators’, 157), (‘subsample’, 0.5) | |
| LSTM | 25 layered LSTM with epochs 10, batch size 72, Adam optimizer with learning rate 0.001, hyperbolic tangent as an activation function, |
| MAE as a loss function | |
| RF-MTL | (‘max depth’, 6), (‘min samples leaf’, 1), (‘min samples split’, 6), (‘n estimators’, 5) |
| XGBoost-MTL | (‘alpha’, 0), (‘colsample bytree’, 0.8530567994101286), (‘gamma’, 1), (‘learning rate’, 0.07023334252979543), (‘max depth’, 4), |
| (‘min child weight’, 7), (‘n estimators’, 124), (‘subsample’, 0.9930831348301362) | |
| LSTM-MTL | 32 layered LSTM with epochs 10, batch size 8, Adam optimizer with learning rate 0.001, hyperbolic tangent as an activation function, |
| MAE as a loss function |
References
- Lovibond, P.F.; Lovibond, S.H. The structure of negative emotional states: Comparison of the Depression Anxiety Stress Scales (DASS) with the Beck Depression and Anxiety Inventories. Behav. Res. Ther. 1995, 33, 335–343. [Google Scholar] [CrossRef]
- Gomes, N.; Pato, M.; Lourenço, A.R.; Datia, N. A Survey on Wearable Sensors for Mental Health Monitoring. Sensors 2023, 23, 1330. [Google Scholar] [CrossRef] [PubMed]
- Graham, S.; Depp, C.; Lee, E.E.; Nebeker, C.; Tu, X.; Kim, H.C.; Jeste, D.V. Artificial intelligence for mental health and mental illnesses: An overview. Curr. Psychiatry Rep. 2019, 21, 116. [Google Scholar] [CrossRef] [PubMed]
- Bond, R.R.; Mulvenna, M.D.; Potts, C.; O’Neill, S.; Ennis, E.; Torous, J. Digital transformation of mental health services. NPJ Ment. Health Res. 2023, 2, 13. [Google Scholar] [CrossRef]
- Purta, R.; Mattingly, S.; Song, L.; Lizardo, O.; Hachen, D.; Poellabauer, C.; Striegel, A. Experiences measuring sleep and physical activity patterns across a large college cohort with fitbits. In Proceedings of the 2016 ACM International Symposium on Wearable Computers, Heidelberg, Germany, 12–16 September 2016; pp. 28–35. [Google Scholar]
- Zhang, Y.; Yang, Q. An overview of multi-task learning. Natl. Sci. Rev. 2018, 5, 30–43. [Google Scholar] [CrossRef]
- Chung, J.; Teo, J. Mental health prediction using machine learning: Taxonomy, applications, and challenges. Appl. Comput. Intell. Soft Comput. 2022, 2022, 9970363. [Google Scholar] [CrossRef]
- Coutts, L.V.; Plans, D.; Brown, A.W.; Collomosse, J. Deep learning with wearable based heart rate variability for prediction of mental and general health. J. Biomed. Inform. 2020, 112, 103610. [Google Scholar] [CrossRef] [PubMed]
- Garriga, R.; Mas, J.; Abraha, S.; Nolan, J.; Harrison, O.; Tadros, G.; Matic, A. Machine learning model to predict mental health crises from electronic health records. Nat. Med. 2022, 28, 1240–1248. [Google Scholar] [CrossRef]
- Saylam, B.; İncel, Ö.D. Quantifying Digital Biomarkers for Well-Being: Stress, Anxiety, Positive and Negative Affect via Wearable Devices and Their Time-Based Predictions. Sensors 2023, 23, 8987. [Google Scholar] [CrossRef]
- Tateyama, N.; Fukui, R.; Warisawa, S. Mood Prediction Based on Calendar Events Using Multitask Learning. IEEE Access 2022, 10, 79747–79759. [Google Scholar] [CrossRef]
- Taylor, S.; Jaques, N.; Nosakhare, E.; Sano, A.; Picard, R. Personalized multitask learning for predicting tomorrow’s mood, stress, and health. IEEE Trans. Affect. Comput. 2017, 11, 200–213. [Google Scholar] [CrossRef] [PubMed]
- Yang, K.; Wang, C.; Gu, Y.; Sarsenbayeva, Z.; Tag, B.; Dingler, T.; Wadley, G.; Goncalves, J. Behavioral and physiological signals-based deep multimodal approach for mobile emotion recognition. IEEE Trans. Affect. Comput. 2021, 14, 1082–1097. [Google Scholar] [CrossRef]
- la Barrera, U.D.; Flavia, A.; Monserrat, C.; Inmaculada, M.C.; José-Antonio, G.G. Using ecological momentary assessment and machine learning techniques to predict depressive symptoms in emerging adults. Psychiatry Res. 2024, 332, 115710. [Google Scholar] [CrossRef] [PubMed]
- Kaushik, S.; Choudhury, A.; Sheron, P.K.; Dasgupta, N.; Natarajan, S.; Pickett, L.A.; Dutt, V. AI in healthcare: Time-series forecasting using statistical, neural, and ensemble architectures. Front. Big Data 2020, 3, 4. [Google Scholar] [CrossRef] [PubMed]
- Seng, K.P.; Ang, L.M.; Peter, E.; Mmonyi, A. Machine Learning and AI Technologies for Smart Wearables. Electronics 2023, 12, 1509. [Google Scholar] [CrossRef]
- Evgeniou, T.; Pontil, M. Regularized multi–task learning. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 109–117. [Google Scholar]
- Ruder, S. An overview of multi-task learning in deep neural networks. arXiv 2017, arXiv:1706.05098. [Google Scholar]
- Saylam, B.; Ekmekci, E.Y.; Altunoğlu, E.; Incel, O.D. Academic Performance Relation with Behavioral Trends and Personal Characteristics: Wearable Device Perspective. In Proceedings of the Information Society Multiconference, Ljubljana, Slovenia, 10–14 October 2022; pp. 35–39. [Google Scholar]
- Akin, A.; Çetin, B. The Depression Anxiety and Stress Scale (DASS): The study of validity and reliability. Kuram Uygulamada Egit. Bilim. 2007, 7, 260. [Google Scholar]
- Conejero, I.; Olié, E.; Calati, R.; Ducasse, D.; Courtet, P. Psychological pain, depression, and suicide: Recent evidences and future directions. Curr. Psychiatry Rep. 2018, 20, 1–9. [Google Scholar] [CrossRef]
- Abend, R.; Bajaj, M.A.; Coppersmith, D.D.; Kircanski, K.; Haller, S.P.; Cardinale, E.M.; Salum, G.A.; Wiers, R.W.; Salemink, E.; Pettit, J.W.; et al. A computational network perspective on pediatric anxiety symptoms. Psychol. Med. 2021, 51, 1752–1762. [Google Scholar] [CrossRef]
- Fink, G. Stress: Definition and history. Stress Sci. Neuroendocrinol. 2010, 3, 3–14. [Google Scholar]
- Raghunathan, T.E.; Lepkowski, J.M.; Van Hoewyk, J.; Solenberger, P. A multivariate technique for multiply imputing missing values using a sequence of regression models. Surv. Methodol. 2001, 27, 85–96. [Google Scholar]
- Xu, D.; Shi, Y.; Tsang, I.W.; Ong, Y.S.; Gong, C.; Shen, X. Survey on multi-output learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 2409–2429. [Google Scholar] [CrossRef]
- Taelman, J.; Vandeput, S.; Spaepen, A.; Van Huffel, S. Influence of mental stress on heart rate and heart rate variability. In Proceedings of the 4th European Conference of the International Federation for Medical and Biological Engineering: ECIFMBE 2008, Antwerp, Belgium, 23–27 November 2008; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1366–1369. [Google Scholar]
- Shwartz-Ziv, R.; Armon, A. Tabular data: Deep learning is not all you need. Inf. Fusion 2022, 81, 84–90. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 1–10. [Google Scholar]
- Shekhawat, N.; Jain, K. Relationship of Self-Regulation with Mental Health Among Boy and Girl Adolescents. Int. J. Indian Psychol. 2022, 10, 463–467. [Google Scholar]
- Scott, A.J.; Webb, T.L.; Martyn-St James, M.; Rowse, G.; Weich, S. Improving sleep quality leads to better mental health: A meta-analysis of randomised controlled trials. Sleep Med. Rev. 2021, 60, 101556. [Google Scholar] [CrossRef] [PubMed]
- Billah, M.A.; Akhtar, S.; Khan, M.N. Loneliness and trust issues reshape mental stress of expatriates during early COVID-19: A structural equation modelling approach. BMC Psychol. 2023, 11, 140. [Google Scholar] [CrossRef] [PubMed]



| Dataset | Measured Values |
|---|---|
| Wearable data (Activity) | complypercent (percent minutes using Fitbit), meanrate (mean heart rate), sdrate (st. dev. heart rate), steps, floors, sedentaryminutes, lightlyactiveminutes, fairlyactiveminutes, veryactiveminutes, lowrangemins, fatburnmins, cardiomins, peakmins, lowrangecal, fatburncal, cardiocal, peakcal |
| Wearable data (Sleep) | timetobed (time went to bed), timeoutofbed (time out of bed), bedtimedur (minutues in bed in minutes), minstofallasleep (minutes to fall asleep), minsafterwakeup (minutes in bed after waking), minsasleep (minutes asleep), minsawake (minutes awake during sleep period), Efficiency (minsasleep/(minsasleep + minsawake)) |
| Survey data (Bad habits) | usetobacco (used tobacco), usebeer (drank beer), usewine (drank wine or liquor), usedrugs (used rec drugs like marij. or cocaine), usedrugs_prescr (used presc. drugs not prescribed), usecaffine (drank caffenated drinks) |
| Survey data (BigFive/Personal inventory) | Extraversion, Agreeableness, Conscientiousness, Neuroticism, Openness |
| Survey data (Education) | hs (high school type), hssex (high school sex composition), hsgrade (high school average grade), apexams (# of hs ap exams), degreeintent (highest intended degree), hrswork (paid hours senior year), ndfirst (Notre Dame first choice of applied colleges?) |
| Survey data (Exercise) | hsclubrc (club activities), exercise (excersise), clubsports (play club, intramural or rec sports), varsitysports (play varsity sports), swimming (swim), Dieting (special type of diet), PhysicalDisability (physical disability) |
| Survey data (Health) | SelfEsteem (on the whole, I am satisfied with myself), Trust (most people can be trusted), SRQE_Ext (external self-regulation (exercise)), SRQE_Introj (introjective self-regulation (exercise)), SRQE_Ident(identified self-regulation (exercise), SelfEff_exercise_scale (when i am feeling tired), SelfEff_diet_scale (self_efficacy score (diet items)), selfreg_scale (i have trouble making plans to help me reach my goals) |
| Survey data (Origin) | momdec (is your mother deceased?), momusa (was mother born outside usa?), daddec (is your dad deceased?), dadusa (was your dad born outside usa?), living together or divorced/living apart), dadage (father’s age), momage (mom’s age), numsib (number of siblings), birthorder (which # in birth order are you?), parentincome (parent’s total income last year), parenteduc (combined parent education), momrace (mother’s race), dadrace (father’s race), momrelig (mother’s religious preference), dadrelig (father’s religious preference), yourelig (your religious prefence) |
| Survey data (Personal info) | selsa_rom (romantic loneliness), selsa_fam (family loneliness), selsa_soc (social loneliness) |
| Survey data (Sex) | gender |
| Survey data (Sleep) | PSQI_duration (computed time in bed), PSQIGlobal (PSQI total score), PSQIGroup (PSQI two categories), MEQTotal (MEQ (chronotype) score - high score morning person), MEQGroup (MEQ (chronotype) groups) |
| Type | Method | Depression | Anxiety | Stress | |
|---|---|---|---|---|---|
| Baseline | RF | 1.1804 | 0.1277 | 0.2742 | |
| XGBoost | 1.1537 | 0.1588 | 0.2722 | ||
| LSTM | 1.7342 | 0.1487 | 0.5199 | ||
| Multitask | RF | 1.1600 | 0.1348 | 0.2794 | |
| XGBoost | 1.1771 | 0.1347 | 0.2798 | ||
| LSTM | 1.7181 | 0.2584 | 0.6029 | ||
| Time-based baseline (1 day look-up) | 1 day look back | RF | 0.0198 | 0.0047 | 0.0314 |
| XGBoost | 0.0433 | 0.0060 | 0.0264 | ||
| LSTM | 0.0379 | 0.0221 | 0.0653 | ||
| 7 days look back | RF | 0.0198 | 0.0036 | 0.0230 | |
| XGBoost | 0.0361 | 0.0060 | 0.0278 | ||
| LSTM | 0.0373 | 0.0178 | 0.0646 | ||
| 15 days look back | RF | 0.0194 | 0.0047 | 0.0228 | |
| XGBoost | 0.0399 | 0.0072 | 0.0289 | ||
| LSTM | 0.0424 | 0.0134 | 0.0703 | ||
| 1 month look back | RF | 0.0198 | 0.0047 | 0.0233 | |
| XGBoost | 0.0433 | 0.0059 | 0.0292 | ||
| LSTM | 0.0462 | 0.0220 | 0.0741 | ||
| 1 semester look back | RF | 0.0234 | 0.0048 | 0.0220 | |
| XGBoost | 0.0371 | 0.0059 | 0.0270 | ||
| LSTM | 0.0738 | 0.0286 | 0.0792 | ||
| Time-based multitask | RF | 0.0049 | 0.0131 | 0.0166 | |
| XGBoost | 0.0070 | 0.0083 | 0.0091 | ||
| LSTM | 0.0319 | 0.0352 | 0.0381 |
| Type | Time | Details | Method | Depression | Anxiety | Stress |
|---|---|---|---|---|---|---|
| Time-based | 7 days lookup | 7 days look back | RF | 0.0528 | 0.0105 | 0.0436 |
| XGBoost | 0.1324 | 0.0190 | 0.0455 | |||
| LSTM | 0.0392 | 0.0109 | 0.0704 | |||
| 15 days look back | RF | 0.0563 | 0.0114 | 0.0397 | ||
| XGBoost | 0.1339 | 0.0200 | 0.0426 | |||
| LSTM | 0.0492 | 0.0188 | 0.0739 | |||
| 1 month look back | RF | 0.0535 | 0.0097 | 0.0442 | ||
| XGBoost | 0.1298 | 0.0187 | 0.0448 | |||
| LSTM | 0.0389 | 0.0150 | 0.0721 | |||
| 1 semester look back | RF | 0.0774 | 0.0097 | 0.0407 | ||
| XGBoost | 0.1305 | 0.0182 | 0.0426 | |||
| LSTM | 0.0993 | 0.0322 | 0.1508 | |||
| 15 days lookup | 15 days look back | RF | 0.1082 | 0.0192 | 0.0618 | |
| XGBoost | 0.2426 | 0.0368 | 0.0648 | |||
| LSTM | 0.0905 | 0.0142 | 0.0759 | |||
| 1 month look back | RF | 0.1091 | 0.0185 | 0.0662 | ||
| XGBoost | 0.2409 | 0.0359 | 0.0691 | |||
| LSTM | 0.0608 | 0.0281 | 0.1524 | |||
| 1 semester look back | RF | 0.1430 | 0.0196 | 0.0670 | ||
| XGBoost | 0.2394 | 0.0355 | 0.0641 | |||
| LSTM | 0.1265 | 0.0353 | 0.1074 | |||
| 1 month lookup | 1 month look back | RF | 0.1955 | 0.0314 | 0.1055 | |
| XGBoost | 0.4281 | 0.0644 | 0.1009 | |||
| LSTM | 0.0838 | 0.0361 | 0.0794 | |||
| 1 semester look back | RF | 0.2581 | 0.0322 | 0.1113 | ||
| XGBoost | 0.4279 | 0.0640 | 0.0974 | |||
| LSTM | 0.2443 | 0.0586 | 0.1596 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saylam, B.; İncel, Ö.D. Multitask Learning for Mental Health: Depression, Anxiety, Stress (DAS) Using Wearables. Diagnostics 2024, 14, 501. https://doi.org/10.3390/diagnostics14050501
Saylam B, İncel ÖD. Multitask Learning for Mental Health: Depression, Anxiety, Stress (DAS) Using Wearables. Diagnostics. 2024; 14(5):501. https://doi.org/10.3390/diagnostics14050501
Chicago/Turabian StyleSaylam, Berrenur, and Özlem Durmaz İncel. 2024. "Multitask Learning for Mental Health: Depression, Anxiety, Stress (DAS) Using Wearables" Diagnostics 14, no. 5: 501. https://doi.org/10.3390/diagnostics14050501
APA StyleSaylam, B., & İncel, Ö. D. (2024). Multitask Learning for Mental Health: Depression, Anxiety, Stress (DAS) Using Wearables. Diagnostics, 14(5), 501. https://doi.org/10.3390/diagnostics14050501