
Optimizing GPT-4 Turbo Diagnostic Accuracy in Neuroradiology through Prompt Engineering and Confidence Thresholds
 , , , , , ,
, , , , , ,
Abstract
1. Introduction
2. Materials and Methods
2.1. Data Collection
2.2. AI Model and Platform
2.3. Prompt Instruction
2.3.1. Role-Playing
2.3.2. Step-by-Step Thinking
2.3.3. Multiple Diagnostic Suggestions
2.3.4. Confidence Assessment
2.4. Evaluation of the Diagnostic Accuracy of GPT-4 Turbo
- Excellent: The top diagnostic suggestion matched the correct diagnosis exactly.
- Good: The correct diagnosis was among the top suggested candidates, indicating a useful but not precise match.
- Insufficient: The correct diagnosis was not listed among the suggested candidates, indicating a failure in the diagnostic process.
3. Results
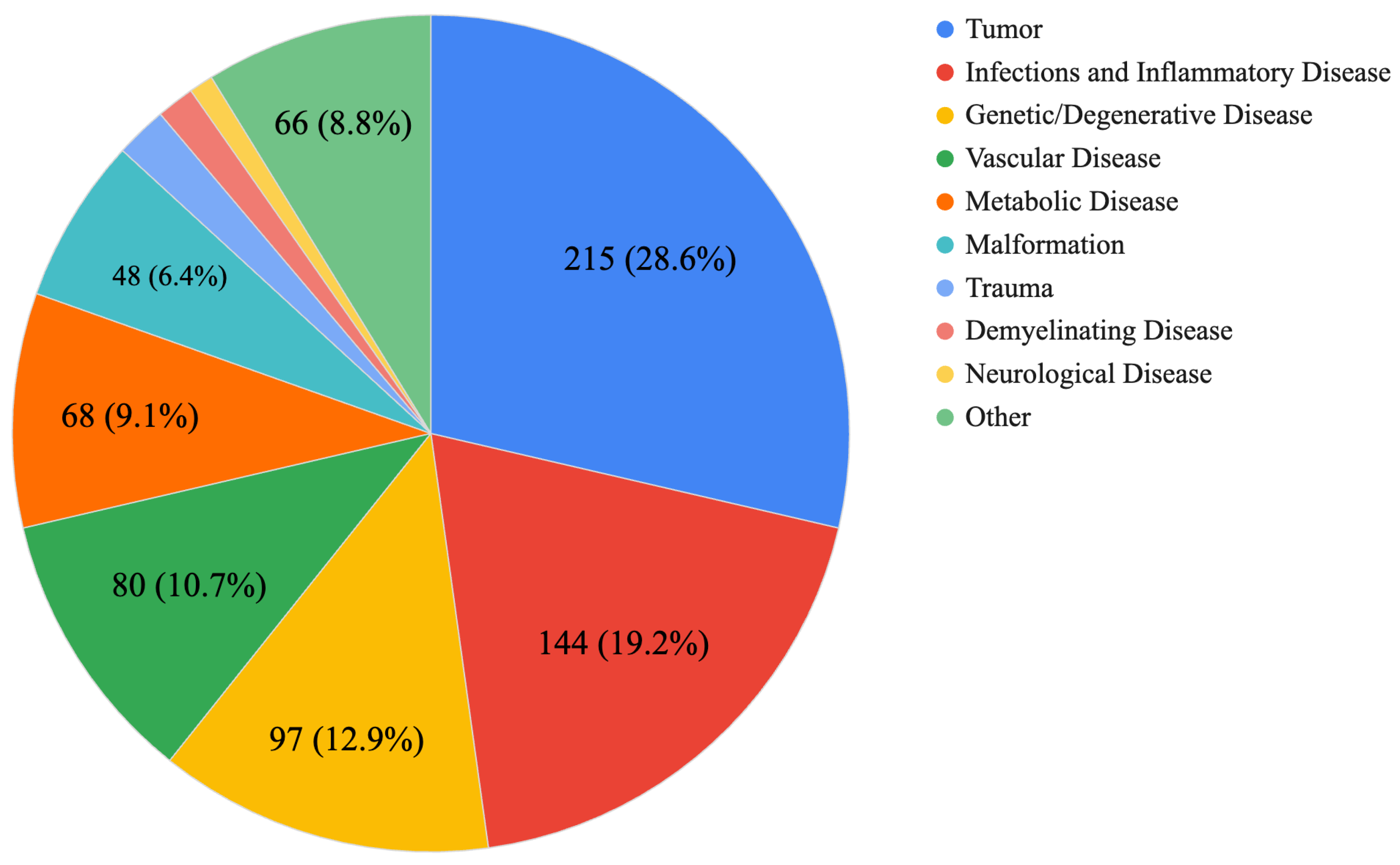
3.1. Case Distribution Analysis
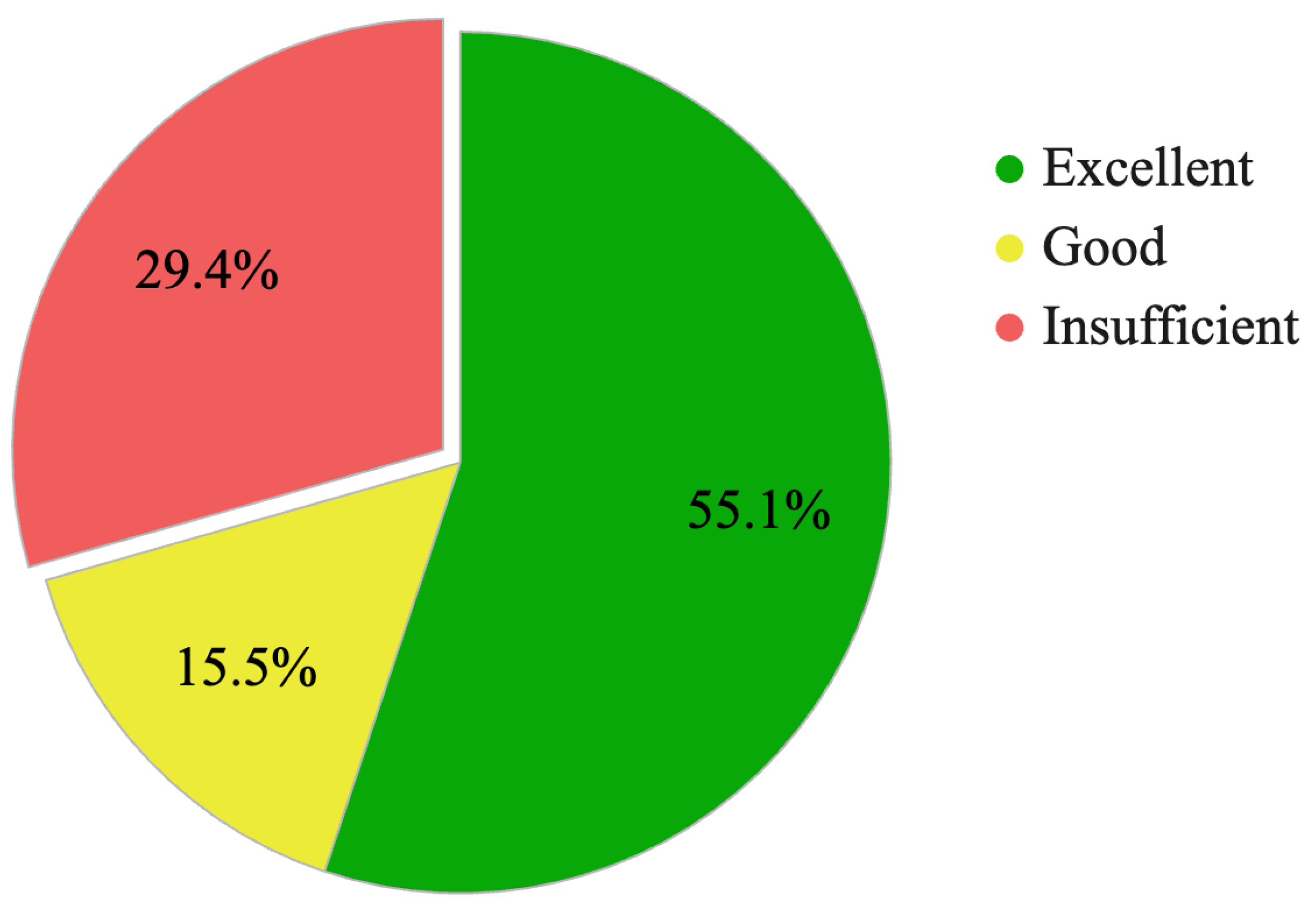
3.2. Diagnostic Performance Overview
3.3. Impact of Confidence Thresholds on Diagnostic Accuracy
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hirosawa, T.; Harada, Y.; Yokose, M.; Sakamoto, T.; Kawamura, R.; Shimizu, T. Diagnostic Accuracy of Differential-Diagnosis Lists Generated by Generative Pretrained Transformer 3 Chatbot for Clinical Vignettes with Common Chief Complaints: A Pilot Study. Int. J. Environ. Res. Public Health 2023, 20, 3378. [Google Scholar] [CrossRef] [PubMed]
- Chen, A.; Chen, D.O.; Tian, L. Benchmarking the Symptom-Checking Capabilities of ChatGPT for a Broad Range of Diseases. J. Am. Med. Inform. Assoc. 2023, ocad245. [Google Scholar] [CrossRef] [PubMed]
- Antaki, F.; Touma, S.; Milad, D.; El-Khoury, J.; Duval, R. Evaluating the Performance of ChatGPT in Ophthalmology: An Analysis of Its Successes and Shortcomings. medRxiv 2023. [Google Scholar] [CrossRef]
- Lallas, A.; Lallas, K.; Tschandl, P.; Kittler, H.; Apalla, Z.; Longo, C.; Argenziano, G. The Dermoscopic Inverse Approach Significantly Improves the Accuracy of Human Readers for Lentigo Maligna Diagnosis. J. Am. Acad. Dermatol. 2021, 84, 381–389. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Yao, Z.; Tasmin, M.; Vashisht, P.; Jang, W.S.; Ouyang, F.; Wang, B.; Berlowitz, D.; Yu, H. Performance of Multimodal GPT-4V on USMLE with Image: Potential for Imaging Diagnostic Support with Explanations. medRxiv 2023. [Google Scholar] [CrossRef]
- Gertz, R.; Bunck, A.; Lennartz, S.; Dratsch, T.; Iuga, A.-I.; Maintz, D.; Kottlors, J. GPT-4 for Automated Determination of Radiological Study and Protocol Based on Radiology Request Forms: A Feasibility Study. Radiology 2023, 307, e230877. [Google Scholar] [CrossRef] [PubMed]
- Biswas, S. ChatGPT and the Future of Medical Writing. Radiology 2023, 30, e223312. [Google Scholar] [CrossRef]
- Bhayana, R.; Bleakney, R.R.; Krishna, S. GPT-4 in Radiology: Improvements in Advanced Reasoning. Radiology 2023, 307, e230987. [Google Scholar] [CrossRef] [PubMed]
- Fink, M.A.; Bischoff, A.; Fink, C.A.; Moll, M.; Kroschke, J.; Dulz, L.; Heußel, C.P.; Kauczor, H.-U.; Weber, T.F. Potential of ChatGPT and GPT-4 for Data Mining of Free-Text CT Reports on Lung Cancer. Radiology 2023, 308, e231362. [Google Scholar] [CrossRef]
- Jiang, S.-T.; Xu, Y.-Y.; Lu, X. ChatGPT in Radiology: Evaluating Proficiencies, Addressing Shortcomings, and Proposing Integrative Approaches for the Future. Radiology 2023, 308, e231335. [Google Scholar] [CrossRef]
- Haver, H.L.; Ambinder, E.B.; Bahl, M.; Oluyemi, E.T.; Jeudy, J.; Yi, P.H. Appropriateness of Breast Cancer Prevention and Screening Recommendations Provided by ChatGPT. Radiology 2023, 307, e230424. [Google Scholar] [CrossRef] [PubMed]
- Jeblick, K.; Schachtner, B.; Dexl, J.; Mittermeier, A.; Stüber, A.T.; Topalis, J.; Weber, T.; Wesp, P.; Sabel, B.O.; Ricke, J.; et al. ChatGPT Makes Medicine Easy to Swallow: An Exploratory Case Study on Simplified Radiology Reports. Eur. Radiol. 2023, 34, 2817–2825. [Google Scholar] [CrossRef] [PubMed]
- Bhayana, R. Chatbots and Large Language Models in Radiology: A Practical Primer for Clinical and Research Applications. Radiology 2024, 310, e232756. [Google Scholar] [CrossRef] [PubMed]
- Bhayana, R.; Krishna, S.; Bleakney, R.R. Performance of ChatGPT on a Radiology Board-Style Examination: Insights into Current Strengths and Limitations. Radiology 2023, 307, e230582. [Google Scholar] [CrossRef] [PubMed]
- Ueda, D.; Mitsuyama, Y.; Takita, H.; Horiuchi, D.; Walston, S.L.; Tatekawa, H.; Miki, Y. Diagnostic Performance of ChatGPT from Patient History and Imaging Findings on the Diagnosis Please Quizzes. Radiology 2023, 308, e231040. [Google Scholar] [CrossRef]
- Kottlors, J.; Bratke, G.; Rauen, P.; Kabbasch, C.; Persigehl, T.; Schlamann, M.; Lennartz, S. Feasibility of Differential Diagnosis Based on Imaging Patterns Using a Large Language Model. Radiology 2023, 308, e231167. [Google Scholar] [CrossRef]
- Horiuchi, D.; Tatekawa, H.; Shimono, T.; Walston, S.L.; Takita, H.; Matsushita, S.; Oura, T.; Mitsuyama, Y.; Miki, Y.; Ueda, D. Accuracy of ChatGPT Generated Diagnosis from Patient’s Medical History and Imaging Findings in Neuroradiology Cases. Neuroradiology 2024, 66, 73–79. [Google Scholar] [CrossRef]
- Suthar, P.P.; Kounsal, A.; Chhetri, L.; Saini, D.; Dua, S.G. Artificial Intelligence (AI) in Radiology: A Deep Dive Into ChatGPT 4.0’s Accuracy with the American Journal of Neuroradiology’s (AJNR) “Case of the Month”. Cureus 2023, 15, e43958. [Google Scholar] [CrossRef] [PubMed]
- Shen, Y.; Heacock, L.; Elias, J.; Hentel, K.D.; Reig, B.; Shih, G.; Moy, L. ChatGPT and Other Large Language Models Are Double-Edged Swords. Radiology 2023, 307, e230163. [Google Scholar] [CrossRef]
- Prompt Engineering—OpenAI API. Available online: https://platform.openai.com/docs/guides/prompt-engineering (accessed on 18 March 2024).
- Case of the Week Diagnoses|American Journal of Neuroradiology. Available online: https://www.ajnr.org/cow/by/diagnosis (accessed on 18 March 2024).
- GPT-4 Turbo in the OpenAI API. Available online: https://help.openai.com/en/articles/8555510-gpt-4-turbo (accessed on 26 May 2024).
- Nori, H.; King, N.; McKinney, S.M.; Carignan, D.; Horvitz, E. Capabilities of GPT-4 on Medical Challenge Problems. arXiv 2023, arXiv:2303.13375. [Google Scholar]
- MD.Ai. Available online: https://www.md.ai/ (accessed on 26 May 2024).
- Ickes, W.; Holloway, R.; Stinson, L.L.; Hoodenpyle, T.G. Self-Monitoring in Social Interaction: The Centrality of Self-Affect. J. Pers. 2006, 74, 659–684. [Google Scholar] [CrossRef] [PubMed]
- Ye, Q.; Axmed, M.; Pryzant, R.; Khani, F. Prompt Engineering a Prompt Engineer. arXiv 2023. [Google Scholar] [CrossRef]
- Sylvester, J.; Reggia, J. Engineering Neural Systems for High-Level Problem Solving. Neural Netw. Off. J. Int. Neural Netw. Soc. 2015, 79, 37–52. [Google Scholar] [CrossRef] [PubMed]
- Scandura, J.M. Algorithm Learning and Problem Solving. J. Exp. Educ. 1966, 34, 1–6. [Google Scholar] [CrossRef]
- Zheng, C.; Liu, Z.; Xie, E.; Li, Z.; Li, Y. Progressive-Hint Prompting Improves Reasoning in Large Language Models. arXiv 2023. [Google Scholar] [CrossRef]
- Huang, J.; Gu, S.; Hou, L.; Wu, Y.; Wang, X.; Yu, H.; Han, J. Large Language Models Can Self-Improve. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; pp. 1051–1068. [Google Scholar] [CrossRef]
- Savage, T.; Nayak, A.; Gallo, R.; Rangan, E.; Chen, J.H. Diagnostic Reasoning Prompts Reveal the Potential for Large Language Model Interpretability in Medicine. NPJ Digit. Med. 2024, 7, 20. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Li, H.; Wang, Y.; Wang, Y. Improving the Reliability of Large Language Models by Leveraging Uncertainty-Aware In-Context Learning. arXiv 2023. [Google Scholar] [CrossRef]
- Wightman, G.P.; Delucia, A.; Dredze, M. Strength in Numbers: Estimating Confidence of Large Language Models by Prompt Agreement. In Proceedings of the 3rd Workshop on Trustworthy Natural Language Processing (TrustNLP 2023), Toronto, ON, Canada, 14 July 2023; pp. 326–362. [Google Scholar] [CrossRef]
- Zhao, T.; Wei, M.; Preston, J.S.; Poon, H. Pareto Optimal Learning for Estimating Large Language Model Errors. arXiv 2023. [Google Scholar] [CrossRef]
- Schuster, T.; Fisch, A.; Gupta, J.; Dehghani, M.; Bahri, D.; Tran, V.Q.; Tay, Y.; Metzler, D. Confident Adaptive Language Modeling. arXiv 2022. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Disease Category | GPT4-Turbo Response Results | Proportion of Total Cases | ||
|---|---|---|---|---|
| Excellent | Good | Insufficient | ||
| Tumor | 0.442 | 0.191 | 0.367 | 0.29 (215) |
| Demyelinating Disease | 0.727 | 0.000 | 0.273 | 0.01 (11) |
| Infections and Inflammatory Disease | 0.535 | 0.153 | 0.313 | 0.19 (144) |
| Vascular Disease | 0.688 | 0.150 | 0.163 | 0.11 (80) |
| Genetic/Degenerative Disease | 0.515 | 0.134 | 0.351 | 0.13 (97) |
| Trauma | 0.667 | 0.267 | 0.067 | 0.02 (15) |
| Metabolic Disease | 0.735 | 0.088 | 0.176 | 0.09 (68) |
| Malformation | 0.563 | 0.229 | 0.208 | 0.06 (48) |
| Neurological Disease | 0.571 | 0.000 | 0.429 | 0.01 (7) |
| Other | 0.576 | 0.106 | 0.318 | 0.09 (66) |
| Total | 0.551 | 0.154 | 0.294 | 1.00 (751) |
| Confidence Threshold | Excellent (%) | Good (%) | Insufficient (%) | Adoption Rate |
|---|---|---|---|---|
| ≥60% | 55.1 | 15.5 | 29.4 | 100% (751/751) |
| ≥70% | 55.3 | 15.5 | 29.2 | 99% (746/751) |
| ≥80% | 57.9 | 15.8 | 26.3 | 92% (689/751) |
| ≥90% | 72.9 | 13.0 | 14.1 | 47% (354/751) |
| 1 | 87.5 | 12.5 | 0.0 | 1% (8/751) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wada, A.; Akashi, T.; Shih, G.; Hagiwara, A.; Nishizawa, M.; Hayakawa, Y.; Kikuta, J.; Shimoji, K.; Sano, K.; Kamagata, K.; et al. Optimizing GPT-4 Turbo Diagnostic Accuracy in Neuroradiology through Prompt Engineering and Confidence Thresholds. Diagnostics 2024, 14, 1541. https://doi.org/10.3390/diagnostics14141541
Wada A, Akashi T, Shih G, Hagiwara A, Nishizawa M, Hayakawa Y, Kikuta J, Shimoji K, Sano K, Kamagata K, et al. Optimizing GPT-4 Turbo Diagnostic Accuracy in Neuroradiology through Prompt Engineering and Confidence Thresholds. Diagnostics. 2024; 14(14):1541. https://doi.org/10.3390/diagnostics14141541
Chicago/Turabian StyleWada, Akihiko, Toshiaki Akashi, George Shih, Akifumi Hagiwara, Mitsuo Nishizawa, Yayoi Hayakawa, Junko Kikuta, Keigo Shimoji, Katsuhiro Sano, Koji Kamagata, and et al. 2024. "Optimizing GPT-4 Turbo Diagnostic Accuracy in Neuroradiology through Prompt Engineering and Confidence Thresholds" Diagnostics 14, no. 14: 1541. https://doi.org/10.3390/diagnostics14141541
APA StyleWada, A., Akashi, T., Shih, G., Hagiwara, A., Nishizawa, M., Hayakawa, Y., Kikuta, J., Shimoji, K., Sano, K., Kamagata, K., Nakanishi, A., & Aoki, S. (2024). Optimizing GPT-4 Turbo Diagnostic Accuracy in Neuroradiology through Prompt Engineering and Confidence Thresholds. Diagnostics, 14(14), 1541. https://doi.org/10.3390/diagnostics14141541