
Accurate and Reliable Classification of Unstructured Reports on Their Diagnostic Goal Using BERT Models

 , , , and
, , , and
Abstract
1. Introduction
2. Related Work
2.1. Natural Language Processing and Language Models
2.2. Dutch BERT Models
2.3. Explainable AI
2.4. Natural Language Processing on Radiology Reports
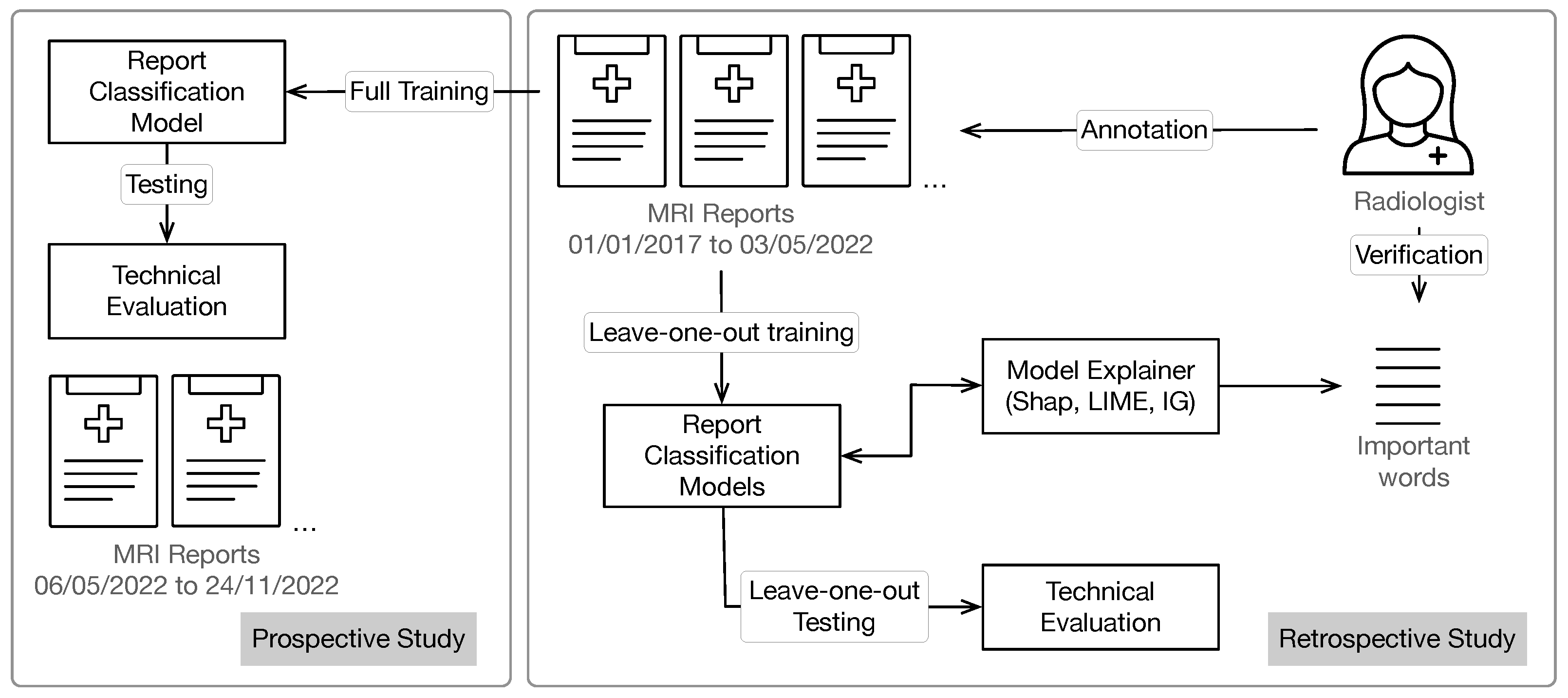
3. Dataset and Preprocessing
- Ambiguity:
- Both, classes 1 and 2 are correct (2 reports).
- Exception:
- This report is an exception (3 reports). Patient is pregnant, patient switched hospital, or standard protocol was not followed.
- Exclusion:
- This report should not be in the dataset. The patient is not a MS patient, or the report is not about an MRI scan related to their MS (3 reports).
4. Experimental Setup
4.1. Machine Learning Models
4.2. Model Explanations
4.3. Evaluation and Verification with Domain Knowledge
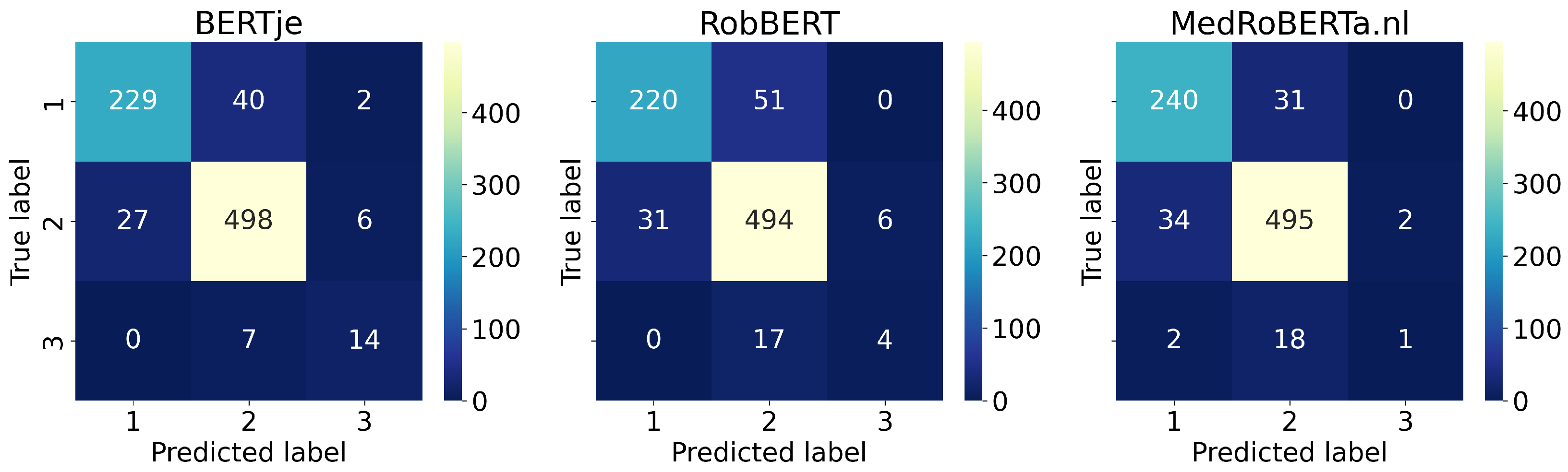
5. Results
5.1. Technical Evaluation
5.2. Model Explanations
5.3. Verification with Domain Knowledge
5.4. Prospective Study
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Example Reports

{kind=link}
{kind=link}
| Example A: Label 1, correctly classified as label 1 by BERTje | |
|---|---|
| Klinische gegevens: migraine aanvallen en visuskl afwk cerebraal ?? Verslag: Onvolledig onderzoek aangezien patiënt voortijdig het onderzoek wou staken. Derhalve alleen sagittale T1, axiale T2 en T2 TIRM sequentie. Ter correlatie de CT van 11/05/2015. Hersenstam, pons, mesencephalon normaal. Cerebellum zonder afwijkingen. Basale kernen en thalami zonder afwijkingen. Witte stof en de grijze stof normaal. Normale sella en suprasellaire regio. Ventrikel-systeem, basale cisternen en sulci normaal. Flow-voids zonder afwijkingen. Conclusie: Voor zover te beoordelen bij incompleet onderzoek normaal aspekt van het brein. | Clinical data: migraine attacks and visuskl impairment cerebral ?? Report: Incomplete study as patient wanted to stop the study prematurely. Therefore only sagittal T1, axial T2 and T2 TIRM sequence. For correlation, the CT of 11/05/2015. Brain stem, pons, mesencephalon normal. Cerebellum without abnormalities. Basal nuclei and thalami without abnormalities. White matter and gray matter normal. Normal sella and suprasellar region. Ventricular system, basal cisterns and sulci normal. Flow-voids without anomalies. Conclusion: As far as can be judged by incomplete examination, normal aspect of the brain. |
| Example B: Label 1, misclassified as label 2 by BERTje | |
| Klinische gegevens: VG: Witte stof afwijkingen. Controle, toename, aankleuring? Verslag: Vergeleken met 23/12/2016. Volgens nieuw MS protocol, direct na i.v. gadolinium. Het aantal en locatie van de witte stof afwijkingen is ten opzichte van 23/12/2016 niet wezenlijk veranderd. Er zijn geen aankleurende laesies, geen actieve MS plaques. Ook in het cervicale myelum zijn geen aankleurende MS plaques. Er is geen aanwijzing voor secundair corticaal weefselverlies. Slanke centrale en perifere liquorruimten en normale windingen. Geen verstoring van bloedhersenbarrière. Geen andere nevenbevindingen. Conclusie: Geen aanwijzing voor toename van witte stof afwijkingen ten opzichte van 2016 maar ook niet ten opzichte van 2014. Geen aankleurende plaques en geen atrofie. | Clinical data: VG: White matter abnormalities. Control, increase, enhancement ? Report: Compared to 23/12/2016. According to new MS protocol, immediately after i.v. gadolinium. The number and location of the white matter abnormalities has not changed significantly compared to 23/12/2016. There are no coloring lesions, no active MS plaques. There are also no coloring MS plaques in the cervical myelum. There is no evidence of secondary cortical tissue loss. Slim central and peripheral liquorspaces and normal convolutions. No disruption of blood brain barrier. No other incidental findings. Conclusion: No indication of an increase in white matter abnormalities compared to 2016, but also not compared to 2014. No coloring plaques and no atrophy. |
| Example C: Label 2, correctly classified as label 2 by BERTje | |
|---|---|
| Klinische gegevens: controle RR MS ziekte activiteit Verslag: Bekende meervoudige periventriculaire, juxtacorticale en infratentoriële laesies. Ongewijzigd sinds april 2012. Geen aankleuring. Geen relevant volumeverlies van het hersenparenchym. Normaal aspekt van de weke delen van aangezicht en de ossale structuren. Geen gebieden met abnormale susceptibiliteitsartefacten. Lichte inflammatoire kenmerken van de neusbijholten. Conclusie: Stabiel beeld. | Clinical data: control RR MS disease activity Report: Known multiple periventricular, juxtacortical, and infratentorial lesions. Unchanged since April 2012. No coloring. No relevant volume loss of the brain parenchyma. Normal aspect of the soft tissues of the face and the osseous structures. No areas of abnormal susceptibility artifacts. Mild inflammatory features of the paranasal sinuses. Conclusion: Stable image. |
| Example D: Label 2, misclassified as label 1 by BERTje | |
| Klinische gegevens: Pijn en verminderde kracht in rechterlichaamshelft; bekend met MS .aankleurende laesie? Verslag: MRI hersenen met contrast: Geen vergelijkend onderzoek mogelijk. Het hersenparenchym vertoont een periventriculaire witte stoflaesie frontopariëtale overgang linker hemisfeer en een laesie ventraal in het stamgebied paramediaan rechts. Beide laesies kleuren niet aan. Postcontrast geen pathologische aankleuringen met name niet van de witte stoflaesie. Ventrikelsystemen licht symmetrisch verwijd. Flow-void in de grote intracraniële vaten. In de parasellaire regio, brughoekregio en cervico-occipitale overgang geen bijzonderheden. Geen focale diffusierestrictie. Geen susceptibiliteitsartefacten verdacht voor oude bloedingen. Conclusie: Een ovoïde niet-aankleurende periventriculaire witte stoflaesie rechterhemisfeer en een kleine (witte stof) laesie paramediaan links in het stamgebied. Beeld passend bij demyelinisatie plaques. | Clinical data: Pain and reduced strength in right half of the body; familiar with MS .coloring lesion? Report: MRI brain with contrast: No comparative study possible. The brain parenchyma shows a periventricular white matter lesion frontoparietal junction left hemisphere and a lesion ventrally in the trunk region paramedian right. Both lesions do not stain. Postcontrast no pathological enhancements especially not of the white matter lesion. Ventricular systems slightly symmetrically dilated. Flow-void in the great intracranial vessels. No abnormalities in the parasellar region, bridge angle region and cervico-occipital junction. No focal diffusion restriction. No susceptibility artifacts suspected of old bleeding. Conclusion: An ovoid non-coloring periventricular white matter lesion right hemisphere and a small (white matter) paramedian lesion in the left trunk region. Image matching demyelination plaques. |
| Only the Important Words | Without the Important Words | |||||||
|---|---|---|---|---|---|---|---|---|
| Example | Ground Truth | Unchanged Report | LIME | SHAP | IG | LIME | SHAP | IG |
| A | 1 | 1 | 1 | 1 | 2 | 1 | 1 | 1 |
| B | 1 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| C | 2 | 2 | 2 | 2 | 2 | 1 | 2 | 2 |
| D | 2 | 1 | 1 | 1 | 2 | 2 | 2 | 1 |
| E | 3 | 3 | 3 | 3 | 3 | 2 | 2 | 2 |
| F | 3 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| Example E: Label 3, correctly classified as label 3 by BERTje | |
|---|---|
| Klinische gegevens: controle scan na start Natalizumab. PML? Nieuwe afwijkingen? Verslag: Bekende MS. Ten opzichte van het meest recente onderzoek van 22/08/2014 is er een evidente afname van het oedeem rondom de witte stoflaesies, vrijwel op alle niveaus. Witte stoflaesies lijken ook iets afgenomen in volume. Er is nu geen aankleuring meer na i.v. gadolinium. Er zijn geen nieuwe witte stof laesies bijgekomen. Kleine fusiforme laesie tegen de falx aangelegen aan de linkerzijde occipitaal berust waarschijnlijk op een klein falx meningeoom zie rondom IMA 61 van serie 7 en rondom IMA 65 van serie 7. Er is conform eerder lichte verwijding van centrale liquorruimten. Perifere liquorruimten zijn nog normaal. Geen aanwijzingen voor doorgemaakte microbloedingen op de SWI. Geen diffusierestrictie op de DWI. Conclusie: Evidente afname van het perifocale oedeem rondom de laesies op het vorig onderzoek. De bekende MS laesies kleuren op huidig onderzoek niet aan. Er zijn geen nieuwe witte stoflaesies. Evidente verbetering van het beeld. Mogelijk een klein falx meningeoompje links occipitaal. | Clinical data: control scan after starting Natalizumab. PML? New deviations? Report: Known MS. Compared to the most recent study of 22/08/2014, there is an evident decrease in the edema around the white matter lesions, almost at all levels. White matter lesions also appear to be slightly reduced in volume. There is now no more coloring after i.v. gadolinium. There were no new white matter lesions. Small fusiform lesion adjacent to the falx on the left occipital side probably due to a small falx meningioma see surrounding IMA 61 of series 7 and around IMA 65 of series 7. As before, there is slight dilation of central liquor spaces. Peripheral liquorspaces are normal. No evidence of prior microbleeds on the SWI. No diffusion restriction on the DWI. Conclusion: Evident reduction of the perifocal edema around the lesions on the previous examination. The known MS lesions do not match current study. There are no new white matter lesions. Obvious improvement of the image. Possibly a small falx meningioma left occipital. |
| Example F: Label 3, misclassified as label 2 by BERTje | |
| Klinische gegevens: RRMS, sinds mei Tysabri. Toename krachtsvermindering en coordinatie rechter lichaamshelft. Toename slikken en micite klachten. Nieuwe laesies? PML? Verslag: MRI hersenen met contrast: Een vergelijkend onderzoek d.d. 30/04/2012. Het hersenparenchym vertoont multifocale witte stoflaesies subcorticaal en periventriculair rechterhemisfeer meer dan de linker. Drietal hyperintense subcorticaal gelegen witte stoflaesies frontopariëtaal rechts ten opzichte van het vorig onderzoek nieuwvorming. De twee laesies zijn zichtbaar in serie 6 coupe 77. Postcontrast kleuren deze drie laesies aan. De overige oude witte stoflaesies kleuren niet aan. Geen susceptibiliteitsartefacten verdacht voor oude bloedingen. Geen focale diffusierestrictie. Ventrikelsystemen symmetrisch normaal. Flow-void in de grote intracraniële vaten. De orbita links duidelijker dan rechts vertonen focaal afwijkend signaal in de nervus opticus. Postcontrast wat dubieuze aankleuring. De sinus maxillaris rechts vertoont een retentiecyste met daarin mogelijk een kleine poliep. Conclusie. Patiënte bekend met MS. Beide hemisferen rechts meer dan links vertonen witte stoflaesies subcorticaal dan wel periventriculair. Thans aanwijzingen voor drietal nieuw aankleurende witte stoflaesies frontopariëtaal rechts. Afwijkend signaal in de nervus opticus links duidelijker dan rechts passend bij een neuritis opticus. Geen duidelijk beeld van PML. | Clinical data: RRMS, since May Tysabri. Increase in strength reduction and coordination in the right half of the body. Increase in swallowing and micturition complaints. New lesions? PML? Report: MRI brain with contrast: A comparative study dated 30/04/2012. The brain parenchyma shows multifocal white matter lesions subcortical and periventricular right hemisphere more than the left. Three hyperintense subcortical white matter lesions frontoparietal to the right neoplasm compared to the previous examination. The two lesions are visible in series 6 slice 77. Post contrast stains these three lesions. The other old white matter lesions do not stain. No susceptibility artifacts suspected of old bleeding. No focal diffusion restriction. Ventricular systems symmetrically normal. Flow void in the great intracranial vessels. The orbits on the left are more pronounced than on the right, showing focally aberrant signal in the optic nerve. Post-contrast some dubious coloring. The maxillary sinus on the right shows a retention cyst possibly containing a small polyp. Conclusion. Patient familiar with MS. Both hemispheres on the right more than on the left show subcortical or periventricular white matter lesions. Currently there are indications for three new enlarging white matter lesions right frontoparietal. Abnormal signal in the optic nerve on the left more clearly than on the right consistent with an optic neuritis. No clear picture of PML. |
References
- Centraal Bureau voor de Statistiek. Zorguitgaven; Kerncijfers; Centraal Bureau voor de Statistiek: Hague, The Netherland, 2022. [Google Scholar]
- Langlotz, C.P. Structured Radiology Reporting: Are We There Yet? Radiology 2009, 253, 23–25. [Google Scholar] [CrossRef]
- Ashfaq, H.A.; Lester, C.A.; Ballouz, D.; Errickson, J.; Woodward, M.A. Medication Accuracy in Electronic Health Records for Microbial Keratitis. JAMA Ophthalmol. 2019, 137, 929–931. [Google Scholar] [CrossRef]
- Hernandez-Boussard, T.; Tamang, S.; Blayney, D.; Brooks, J.; Shah, N. New Paradigms for Patient-Centered Outcomes Research in Electronic Medical Records. eGEMs 2016, 4, 1231. [Google Scholar] [CrossRef]
- Payne, T.H.; Zhao, L.P.; Le, C.; Wilcox, P.; Yi, T.; Hinshaw, J.; Hussey, D.; Kostrinsky-Thomas, A.; Hale, M.; Brimm, J.; et al. Electronic health records contain dispersed risk factor information that could be used to prevent breast and ovarian cancer. J. Am. Med Inform. Assoc. JAMIA 2020, 27, 1443–1449. [Google Scholar] [CrossRef]
- Gotz, D.; Borland, D. Data-Driven Healthcare: Challenges and Opportunities for Interactive Visualization. IEEE Comput. Graph. Appl. 2016, 36, 90–96. [Google Scholar] [CrossRef]
- Džuganová, B. Medical language—A unique linguistic phenomenon. JAHR-Eur. J. Bioeth. 2019, 10, 129–145. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar] [CrossRef]
- Ramos, J.E. Using TF-IDF to Determine Word Relevance in Document Queries. Proc. First Instr. Conf. Mach. Learn. 2003, 242, 29–48. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Radford, A.; Narasimhan, K. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 12 October 2022).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv 2019, arXiv:1906.08237. [Google Scholar]
- Haley, C. This is a BERT. Now there are several of them. Can they generalize to novel words? In Proceedings of the Third BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP, Online, 20 November 2020; pp. 333–341. [Google Scholar] [CrossRef]
- de Vries, W.; van Cranenburgh, A.; Bisazza, A.; Caselli, T.; Noord, G.v.; Nissim, M. BERTje: A Dutch BERT Model. arXiv 2019, arXiv:1912.09582. [Google Scholar]
- Nozza, D.; Bianchi, F.; Hovy, D. What the [MASK]? Making Sense of Language-Specific BERT Models. arXiv 2020, arXiv:2003.02912. [Google Scholar]
- Brandsen, A. Language Resources by TMR. 2019. Available online: http://textdata.nl (accessed on 10 October 2022).
- Delobelle, P.; Winters, T.; Berendt, B. RobBERT: A Dutch RoBERTa-based Language Model. arXiv 2020, arXiv:2001.06286. [Google Scholar]
- Oostdijk, N.; Reynaert, M.; Hoste, V.; Schuurman, I. The Construction of a 500-Million-Word Reference Corpus of Contemporary Written Dutch. In Essential Speech and Language Technology for Dutch: Results by the STEVIN Programme; Spyns, P., Odijk, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 219–247. [Google Scholar] [CrossRef]
- Ortiz Suárez, P.J.; Sagot, B.; Romary, L. Asynchronous Pipeline for Processing Huge Corpora on Medium to Low Resource Infrastructures. In Proceedings of the 7th Workshop on the Challenges in the Management of Large Corpora (CMLC-7), Cardiff, UK, 22 July 2019; Bański, P., Barbaresi, A., Biber, H., Breiteneder, E., Clematide, S., Kupietz, M., Lüngen, H., Iliadi, C., Eds.; Leibniz-Institut für Deutsche Sprache: Mannheim, Germany, 2019. [Google Scholar] [CrossRef]
- de Vries, W.; van Cranenburgh, A.; Bisazza, A.; Caselli, T.; Noord, G.v.; Nissim, M. BERTje: A Dutch BERT Model (GitHub). 2021. Available online: https://github.com/wietsedv/bertje (accessed on 10 October 2022).
- Delobelle, P.; Winters, T.; Berendt, B. RobBERTje: A Distilled Dutch BERT Model. Comput. Linguist. Neth. J. 2021, 11, 125–140. [Google Scholar]
- Beltagy, I.; Lo, K.; Cohan, A. SciBERT: A Pretrained Language Model for Scientific Text. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 3615–3620. [Google Scholar] [CrossRef]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2019, 36, 1234–1240. [Google Scholar] [CrossRef]
- Brandsen, A.; Verberne, S.; Lambers, K.; Wansleeben, M. Can BERT Dig It? Named Entity Recognition for Information Retrieval in the Archaeology Domain. J. Comput. Cult. Herit. 2022, 15, 1–18. [Google Scholar] [CrossRef]
- De Kruijf, G. Training a Dutch (+English) BERT Model Applicable for the Legal Domain. 2022. Available online: https://www.ru.nl/publish/pages/769526/gerwin_de_kruijf.pdf (accessed on 14 October 2022).
- Verkijk, S.; Vossen, P. MedRoBERTa.nl: A Language Model for Dutch Electronic Health Records. Comput. Linguist. Neth. J. 2021, 11, 141–159. [Google Scholar]
- Islam, M.U.; Mozaharul Mottalib, M.; Hassan, M.; Alam, Z.I.; Zobaed, S.M.; Fazle Rabby, M. The Past, Present, and Prospective Future of XAI: A Comprehensive Review. In Explainable Artificial Intelligence for Cyber Security: Next Generation Artificial Intelligence; Ahmed, M., Islam, S.R., Anwar, A., Moustafa, N., Pathan, A.S.K., Eds.; Studies in Computational Intelligence; Springer International Publishing: Cham, Switzerland, 2022; pp. 1–29. [Google Scholar] [CrossRef]
- Danilevsky, M.; Qian, K.; Aharonov, R.; Katsis, Y.; Kawas, B.; Sen, P. A Survey of the State of Explainable AI for Natural Language Processing. arXiv 2020, arXiv:2010.00711. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic Attribution for Deep Networks. arXiv 2017, arXiv:1703.01365. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. arXiv 2016, arXiv:1602.04938. [Google Scholar]
- Lundberg, S.M.; Lee, S. A unified approach to interpreting model predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Gorinski, P.J.; Wu, H.; Grover, C.; Tobin, R.; Talbot, C.; Whalley, H.; Sudlow, C.; Whiteley, W.; Alex, B. Named Entity Recognition for Electronic Health Records: A Comparison of Rule-based and Machine Learning Approaches. arXiv 2019, arXiv:1903.03985. [Google Scholar]
- Noorbakhsh-Sabet, N.; Tsivgoulis, G.; Shahjouei, S.; Hu, Y.; Goyal, N.; Alexandrov, A.V.; Zand, R. Racial Difference in Cerebral Microbleed Burden Among a Patient Population in the Mid-South United States. J. Stroke Cerebrovasc. Dis. 2018, 27, 2657–2661. [Google Scholar] [CrossRef]
- Kim, C.; Zhu, V.; Obeid, J.; Lenert, L. Natural language processing and machine learning algorithm to identify brain MRI reports with acute ischemic stroke. PLoS ONE 2019, 14, e0212778. [Google Scholar] [CrossRef]
- Garg, R.; Oh, E.; Naidech, A.; Kording, K.; Prabhakaran, S. Automating Ischemic Stroke Subtype Classification Using Machine Learning and Natural Language Processing. J. Stroke Cerebrovasc. Dis. 2019, 28, 2045–2051. [Google Scholar] [CrossRef]
- Fu, S.; Leung, L.Y.; Wang, Y.; Raulli, A.O.; Kallmes, D.F.; Kinsman, K.A.; Nelson, K.B.; Clark, M.S.; Luetmer, P.H.; Kingsbury, P.R.; et al. Natural Language Processing for the Identification of Silent Brain Infarcts From Neuroimaging Reports. JMIR Med. Inf. 2019, 7, e12109. [Google Scholar] [CrossRef]
- Galbusera, F.; Cina, A.; Bassani, T.; Panico, M.; Sconfienza, L.M. Automatic Diagnosis of Spinal Disorders on Radiographic Images: Leveraging Existing Unstructured Datasets with Natural Language Processing. Glob. Spine J. 2021, 21925682211026910. [Google Scholar] [CrossRef]
- Wood, D.A.; Kafiabadi, S.; Al Busaidi, A.; Guilhem, E.L.; Lynch, J.; Townend, M.K.; Montvila, A.; Kiik, M.; Siddiqui, J.; Gadapa, N.; et al. Deep learning to automate the labelling of head MRI datasets for computer vision applications. Eur. Radiol. 2022, 32, 725–736. [Google Scholar] [CrossRef]
- Davis, M.F.; Sriram, S.; Bush, W.S.; Denny, J.C.; Haines, J.L. Automated extraction of clinical traits of multiple sclerosis in electronic medical records. J. Am. Med. Inform. Assoc. 2013, 20, e334–e340. [Google Scholar] [CrossRef]
- Li, I.; Pan, J.; Goldwasser, J.; Verma, N.; Wong, W.P.; Nuzumlalı, M.Y.; Rosand, B.; Li, Y.; Zhang, M.; Chang, D.; et al. Neural Natural Language Processing for Unstructured Data in Electronic Health Records: A Review. arXiv 2021, arXiv:2107.02975. [Google Scholar] [CrossRef]
- Costa, A.D.; Denkovski, S.; Malyska, M.; Moon, S.Y.; Rufino, B.; Yang, Z.; Killian, T.; Ghassemi, M. Multiple Sclerosis Severity Classification From Clinical Text. arXiv 2020, arXiv:2010.15316. [Google Scholar]
- Wattjes, M.P.; Ciccarelli, O.; Reich, D.S.; Banwell, B.; Stefano, N.D.; Enzinger, C.; Fazekas, F.; Filippi, M.; Frederiksen, J.; Gasperini, C.; et al. 2021 MAGNIMS–CMSC–NAIMS consensus recommendations on the use of MRI in patients with multiple sclerosis. Lancet Neurol. 2021, 20, 653–670. [Google Scholar] [CrossRef] [PubMed]
- Lau, J.H.; Baldwin, T. An Empirical Evaluation of doc2vec with Practical Insights into Document Embedding Generation. arXiv 2016, arXiv:1607.05368. [Google Scholar]
- Tunstall, L.; von Werra, L.; Wolf, T. Natural Language Processing with Transformers: Building Language Applications with Hugging Face; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2022. [Google Scholar]
- Nauta, M.; Trienes, J.; Pathak, S.; Nguyen, E.; Peters, M.; Schmitt, Y.; Schlötterer, J.; van Keulen, M.; Seifert, C. From Anecdotal Evidence to Quantitative Evaluation Methods: A Systematic Review on Evaluating Explainable AI. arXiv 2023, arXiv:2201.08164. [Google Scholar] [CrossRef]
- Bobicev, V.; Sokolova, M. Inter-Annotator Agreement in Sentiment Analysis: Machine Learning Perspective. In Proceedings of the International Conference Recent Advances in Natural Language Processing, RANLP 2017, Varna, Bulgaria, 2–8 September 2017; pp. 97–102. [Google Scholar] [CrossRef]
- Trienes, J.; Trieschnigg, D.; Seifert, C.; Hiemstra, D. Comparing Rule-based, Feature-based and Deep Neural Methods for De-identification of Dutch Medical Records. arXiv 2020, arXiv:2001.05714. [Google Scholar]


| Label | Description | Reports |
|---|---|---|
| Diagnosis | For initial diagnosis, or to create a (new) baseline | 271 |
| Progression | Progression or monitoring medication effect | 531 |
| Monitoring | Monitoring on secondary complications (mostly PML) | 21 |
| Accuracy | Precision | Recall | F1 | |
|---|---|---|---|---|
| TF-IDF | ||||
| +LR | 0.89 | 0.92 | 0.78 | 0.83 |
| +RF | 0.86 | 0.91 | 0.60 | 0.63 |
| +SVM | 0.85 | 0.89 | 0.63 | 0.67 |
| doc2vec | ||||
| +LR | 0.82 | 0.63 | 0.65 | 0.64 |
| +RF | 0.78 | 0.68 | 0.57 | 0.61 |
| +SVM | 0.82 | 0.67 | 0.64 | 0.66 |
| BERTje | ||||
| +LR | 0.84 | 0.71 | 0.65 | 0.67 |
| +RF | 0.81 | 0.55 | 0.52 | 0.53 |
| +SVM | 0.82 | 0.65 | 0.65 | 0.65 |
| end-to-end | 0.90 | 0.81 | 0.82 | 0.82 |
| RobBERT | ||||
| +LR | 0.86 | 0.78 | 0.79 | 0.79 |
| +RF | 0.84 | 0.56 | 0.55 | 0.55 |
| +SVM | 0.79 | 0.63 | 0.81 | 0.66 |
| end-to-end | 0.87 | 0.72 | 0.64 | 0.67 |
| MedRoBERTa.nl | ||||
| +LR | 0.80 | 0.59 | 0.60 | 0.60 |
| +RF | 0.83 | 0.88 | 0.56 | 0.57 |
| +SVM | 0.80 | 0.62 | 0.71 | 0.64 |
| end-to-end | 0.89 | 0.70 | 0.62 | 0.63 |
| Majority Baseline | 0.65 | 0.22 | 0.33 | 0.26 |
| BERTje | SHAP | LIME | IG |
|---|---|---|---|
| full report | no selection: 0.90 | ||
| only important words | 0.89 | 0.76 | 0.69 |
| without important words | 0.87 | 0.75 | 0.73 |
| RobBERT | SHAP | LIME | IG |
| full report | no selection: 0.87 | ||
| only important words | 0.87 | 0.80 | 0.68 |
| without important words | 0.87 | 0.80 | 0.73 |
| MedRoBERTa.nl | SHAP | LIME | IG |
| full report | no selection: 0.89 | ||
| only important words | 0.90 | 0.83 | 0.74 |
| without important words | 0.88 | 0.83 | 0.80 |
| BERTje | SHAP | LIME | IG |
|---|---|---|---|
| valid | 0.53 ± 0.26 | 0.47 ± 0.29 | 0.22 ± 0.18 |
| perhaps valid | 0.03 ± 0.08 | 0.07 ± 0.13 | 0.06 ± 0.11 |
| unknown | 0.35 ± 0.27 | 0.30 ± 0.28 | 0.32 ± 0.21 |
| invalid: other | 0.04 ± 0.08 | 0.10 ± 0.17 | 0.08 ± 0.13 |
| invalid: wrong | 0.05 ± 0.09 | 0.06 ± 0.11 | 0.32 ± 0.17 |
| RobBERT | SHAP | LIME | IG |
| valid | 0.49 ± 0.26 | 0.47 ± 0.26 | 0.26 ± 0.24 |
| perhaps valid | 0.02 ± 0.07 | 0.05 ± 0.10 | 0.03 ± 0.09 |
| unknown | 0.33 ± 0.28 | 0.27 ± 0.25 | 0.62 ± 0.26 |
| invalid: other | 0.11 ± 0.16 | 0.15 ± 0.16 | 0.04 ± 0.10 |
| invalid: wrong | 0.04 ± 0.09 | 0.07 ± 0.12 | 0.05 ± 0.10 |
| MedRoBERTa.nl | SHAP | LIME | IG |
| valid | 0.36 ± 0.25 | 0.37 ± 0.25 | 0.23 ± 0.20 |
| perhaps valid | 0.02 ± 0.07 | 0.03 ± 0.06 | 0.01 ± 0.05 |
| unknown | 0.46 ± 0.28 | 0.41 ± 0.26 | 0.53 ± 0.28 |
| invalid: other | 0.08 ± 0.13 | 0.12 ± 0.16 | 0.12 ± 0.18 |
| invalid: wrong | 0.07 ± 0.11 | 0.07 ± 0.13 | 0.11 ± 0.15 |
| Dataset | Set Type | Type of Reports | ||
|---|---|---|---|---|
| Diagnosis | Progression | Monitoring | ||
| Train (Original) | 271 | 531 | 21 | |
| Test (New) | 19 | 101 | 0 | |
| Results (BERTje) | Metrics | |||
| Accuracy | Precision | Recall | F1-Score | |
| 0.92 | 0.95 | 0.92 | 0.93 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rietberg, M.T.; Nguyen, V.B.; Geerdink, J.; Vijlbrief, O.; Seifert, C. Accurate and Reliable Classification of Unstructured Reports on Their Diagnostic Goal Using BERT Models. Diagnostics 2023, 13, 1251. https://doi.org/10.3390/diagnostics13071251
Rietberg MT, Nguyen VB, Geerdink J, Vijlbrief O, Seifert C. Accurate and Reliable Classification of Unstructured Reports on Their Diagnostic Goal Using BERT Models. Diagnostics. 2023; 13(7):1251. https://doi.org/10.3390/diagnostics13071251
Chicago/Turabian StyleRietberg, Max Tigo, Van Bach Nguyen, Jeroen Geerdink, Onno Vijlbrief, and Christin Seifert. 2023. "Accurate and Reliable Classification of Unstructured Reports on Their Diagnostic Goal Using BERT Models" Diagnostics 13, no. 7: 1251. https://doi.org/10.3390/diagnostics13071251
APA StyleRietberg, M. T., Nguyen, V. B., Geerdink, J., Vijlbrief, O., & Seifert, C. (2023). Accurate and Reliable Classification of Unstructured Reports on Their Diagnostic Goal Using BERT Models. Diagnostics, 13(7), 1251. https://doi.org/10.3390/diagnostics13071251