
Prediction of Fatty Liver Disease in a Chinese Population Using Machine-Learning Algorithms


Abstract
1. Introduction
2. Materials and Methods
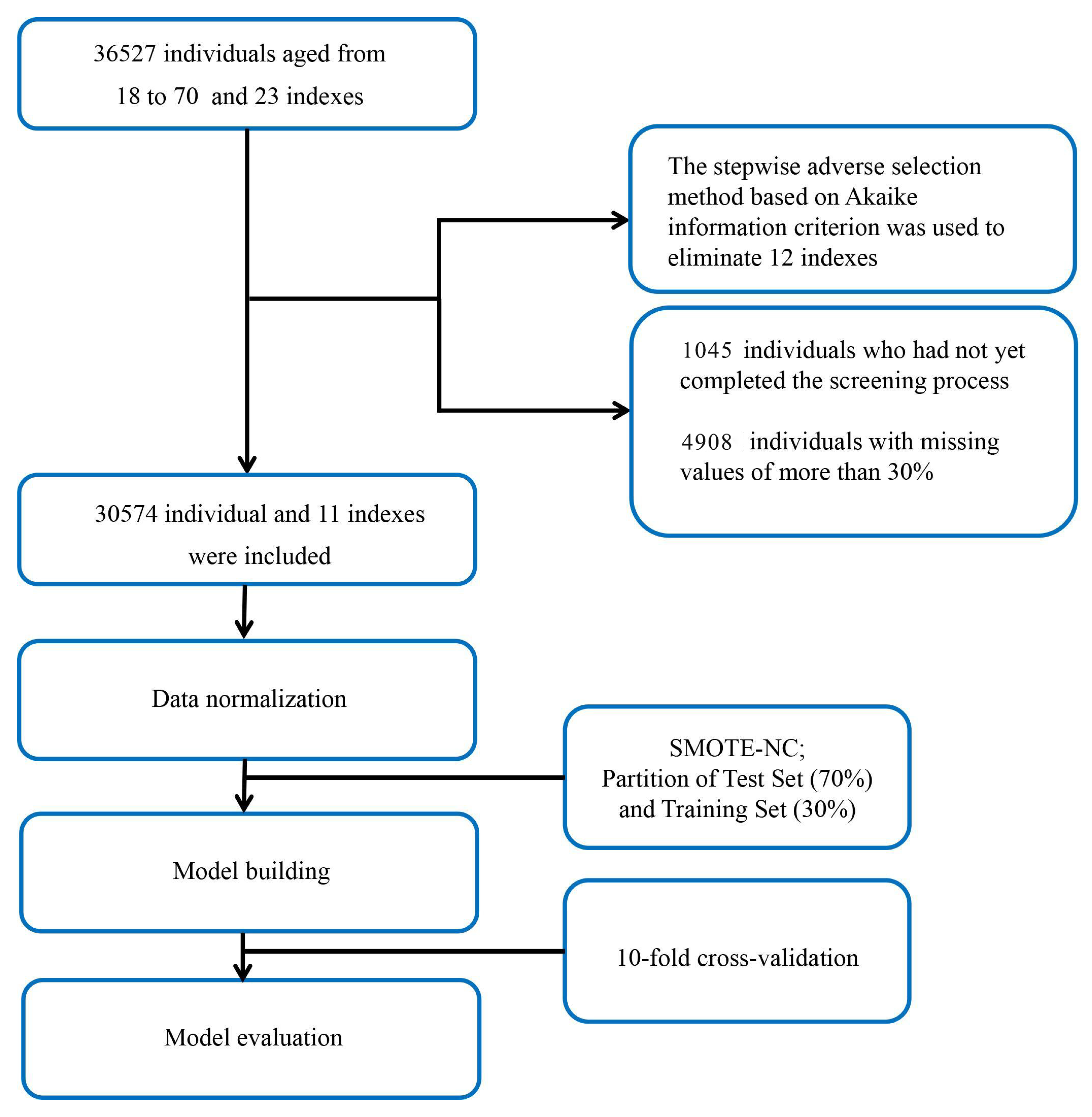
2.1. Study Data
2.2. Data Processing
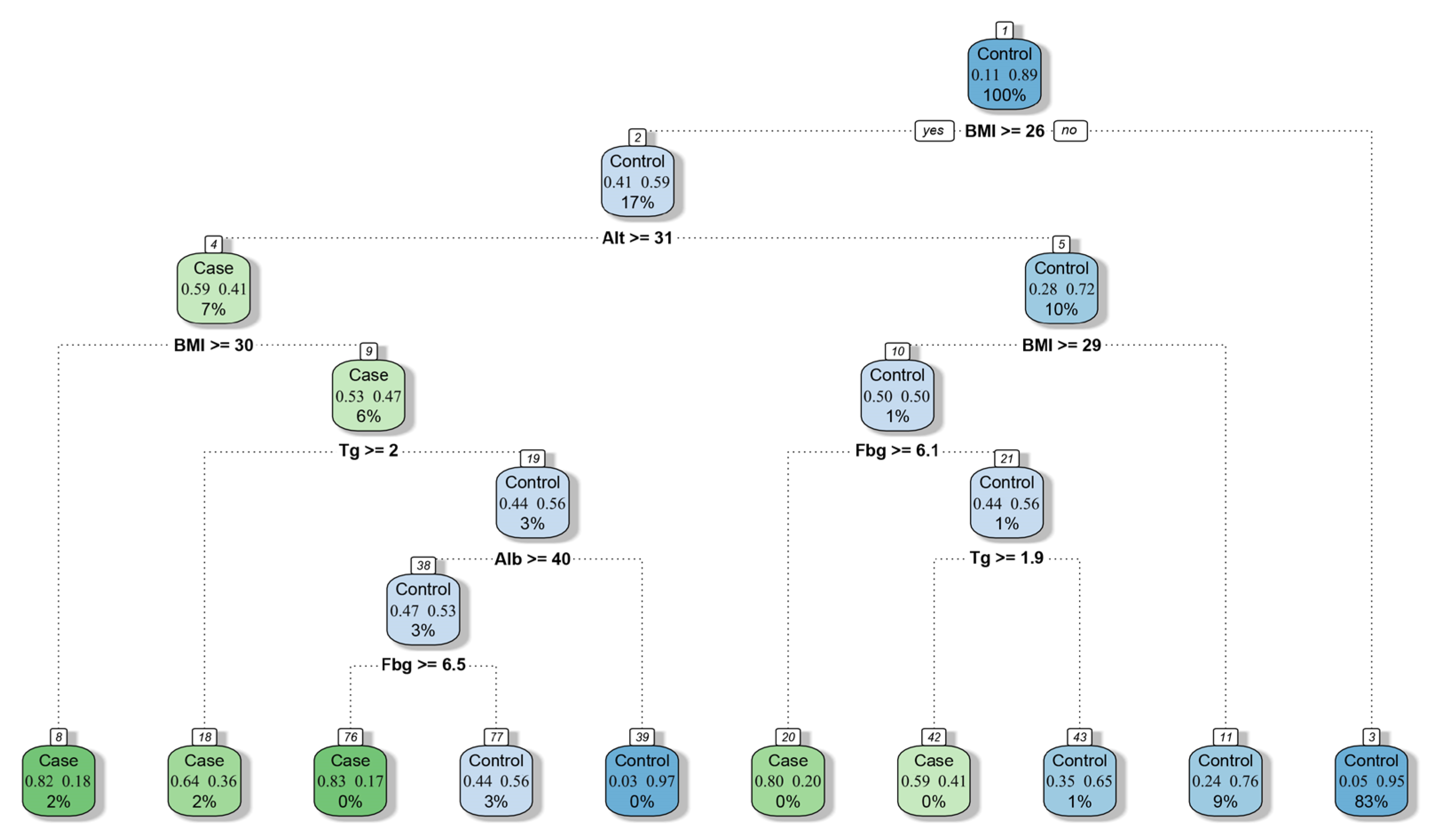
2.3. Establishment of the Model
2.4. Model Performance Assessment
3. Results
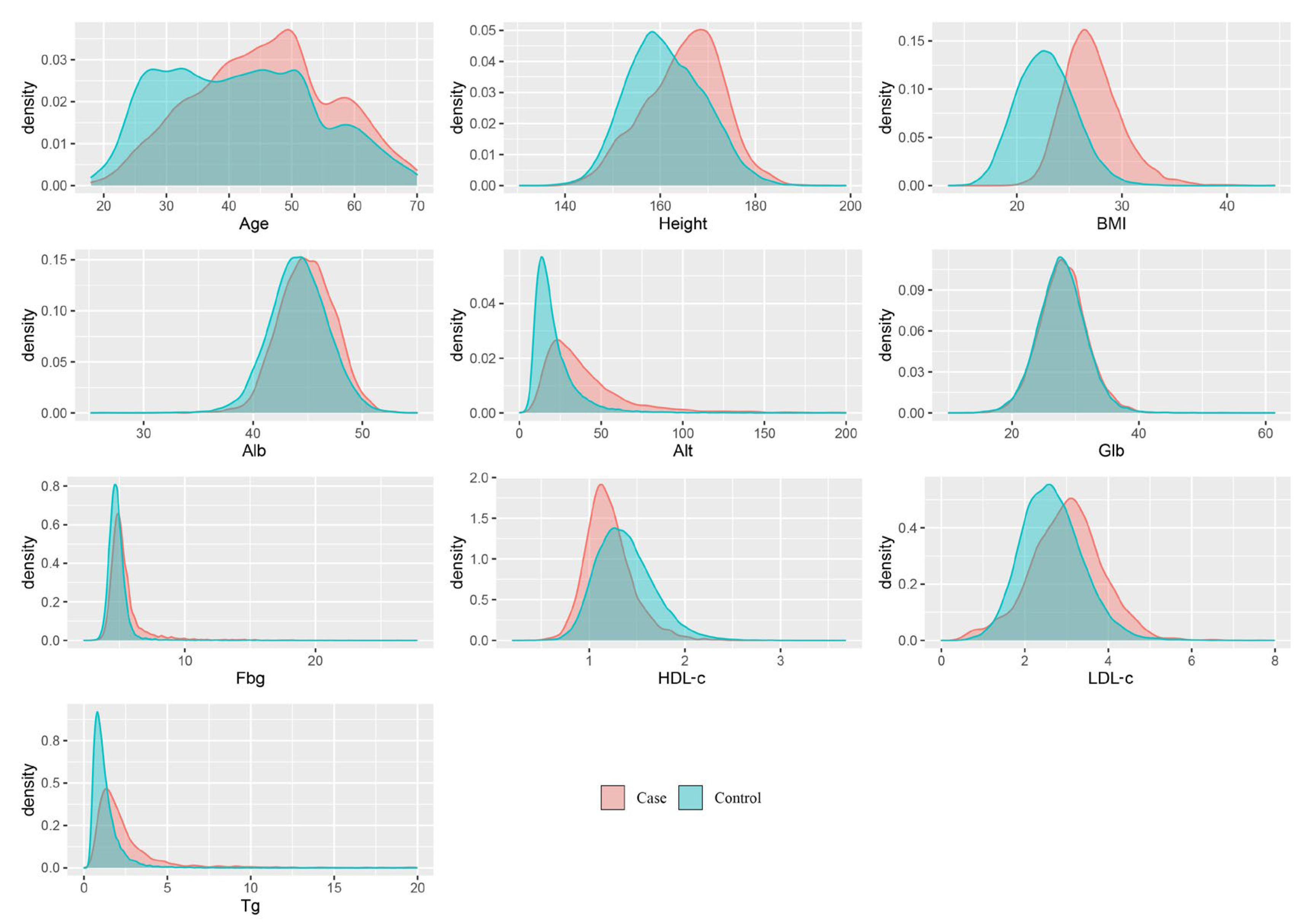
3.1. Features of Participants
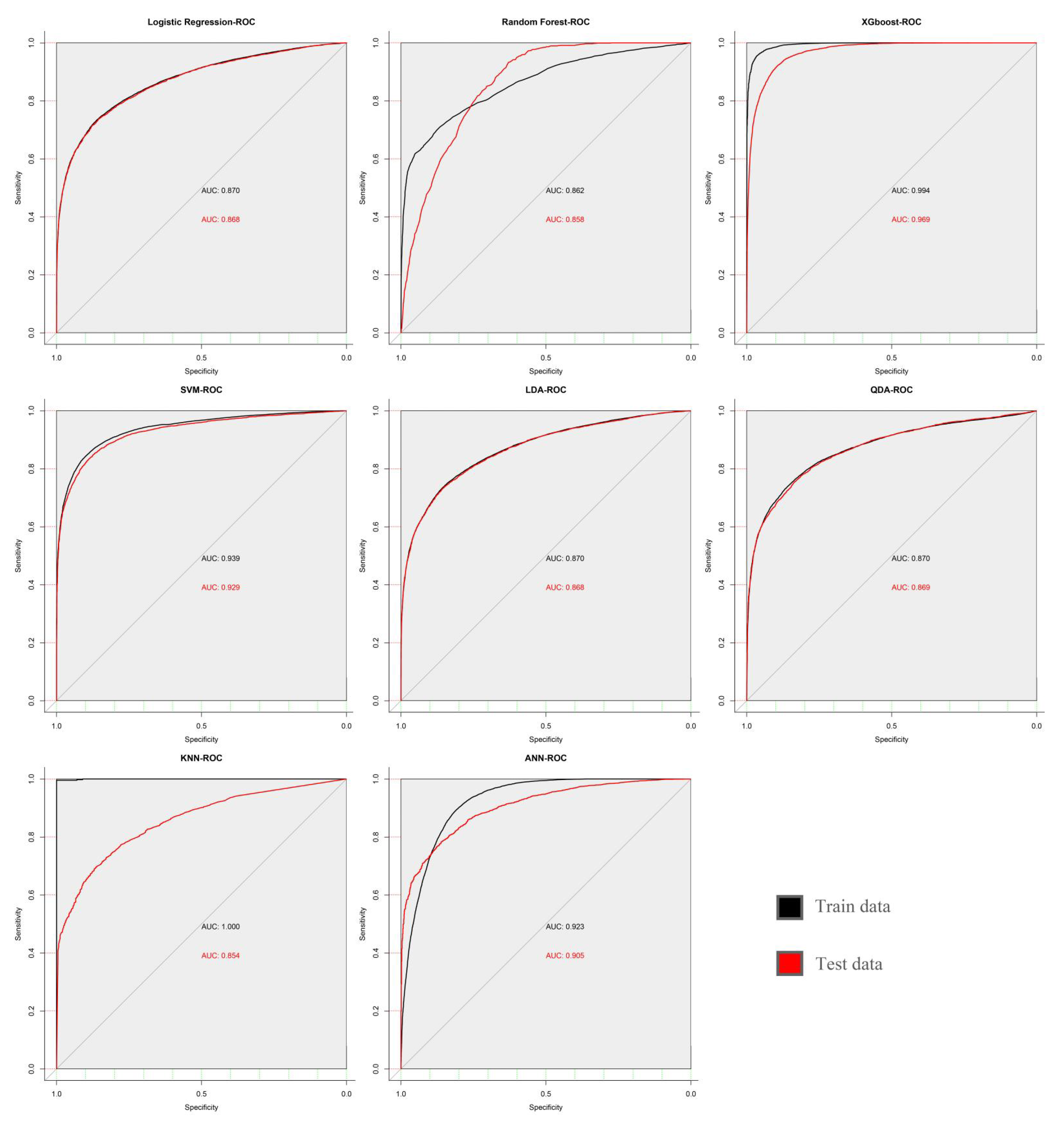
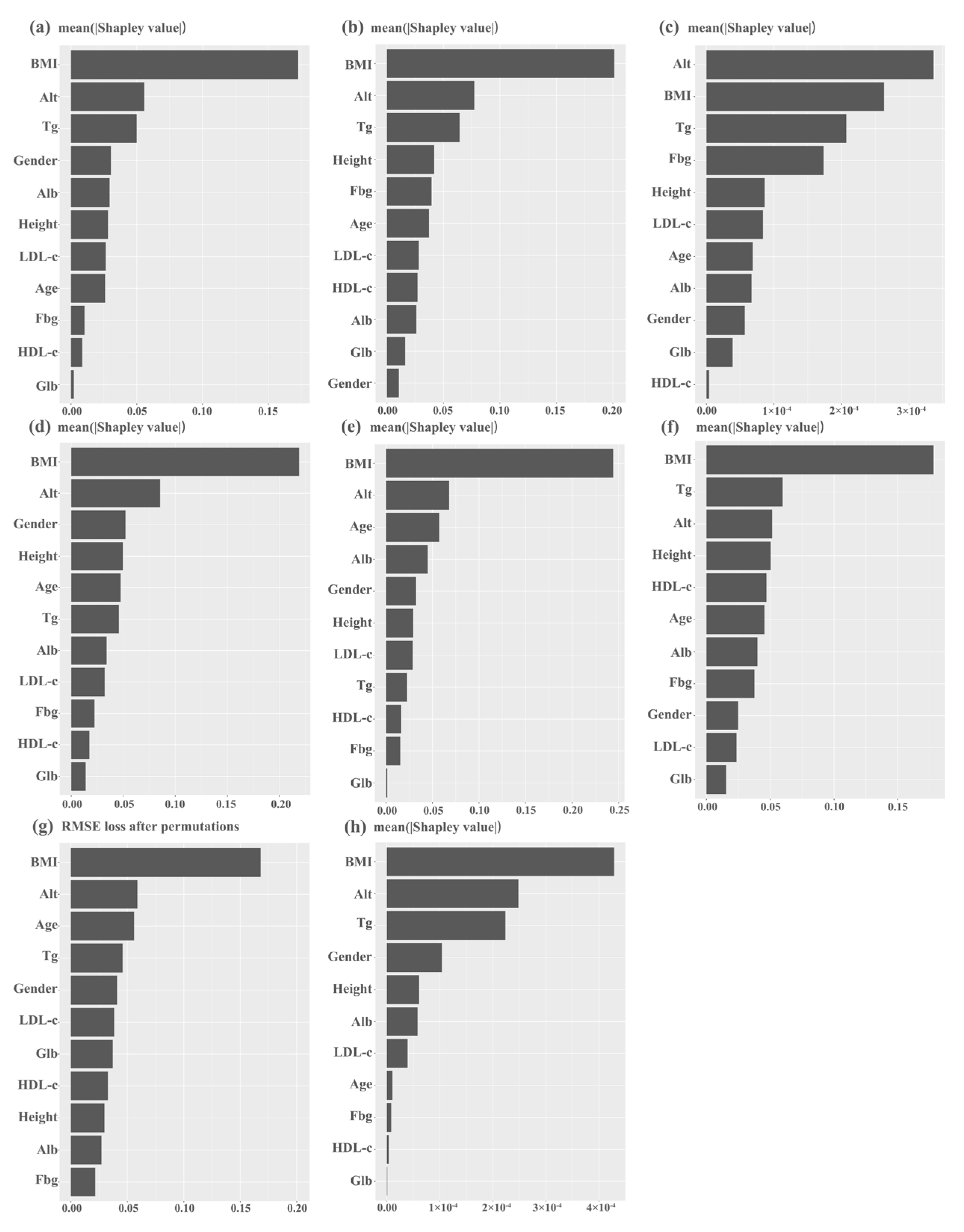
3.2. Model Performance
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Powell, E.E.; Wong, V.W.; Rinella, M. Non-alcoholic fatty liver disease. Lancet 2021, 397, 2212–2224. [Google Scholar] [CrossRef]
- Younossi, Z.; Anstee, Q.M.; Marietti, M.; Hardy, T.; Henry, L.; Eslam, M.; George, J.; Bugianesi, E. Global burden of NAFLD and NASH: Trends, predictions, risk factors and prevention. Nat. Rev. Gastroenterol. Hepatol. 2018, 15, 11–20. [Google Scholar] [CrossRef] [PubMed]
- Kasper, P.; Martin, A.; Lang, S.; Kütting, F.; Goeser, T.; Demir, M.; Steffen, H.M. NAFLD and cardiovascular diseases: A clinical review. Clin. Res. Cardiol. 2021, 110, 921–937. [Google Scholar] [CrossRef] [PubMed]
- Polyzos, S.A.; Kountouras, J.; Mantzoros, C.S. Obesity and nonalcoholic fatty liver disease: From pathophysiology to therapeutics. Metabolism 2019, 92, 82–97. [Google Scholar] [CrossRef] [PubMed]
- Alqahtani, S.A.; Schattenberg, J.M. NAFLD in the Elderly. Clin. Interv. Aging 2021, 16, 1633–1649. [Google Scholar] [CrossRef]
- Younossi, Z.M.; Golabi, P.; de Avila, L.; Paik, J.M.; Srishord, M.; Fukui, N.; Qiu, Y.; Burns, L.; Afendy, A.; Nader, F. The global epidemiology of NAFLD and NASH in patients with type 2 diabetes: A systematic review and meta-analysis. J. Hepatol. 2019, 71, 793–801. [Google Scholar] [CrossRef]
- Ciardullo, S.; Ballabeni, C.; Trevisan, R.; Perseghin, G. Liver Stiffness, Albuminuria and Chronic Kidney Disease in Patients with NAFLD: A Systematic Review and Meta-Analysis. Biomolecules 2022, 12, 105. [Google Scholar] [CrossRef]
- Eslam, M.; Sarin, S.K.; Wong, V.W.; Fan, J.G.; Kawaguchi, T.; Ahn, S.H.; Zheng, M.H.; Shiha, G.; Yilmaz, Y.; Gani, R.; et al. The Asian Pacific Association for the Study of the Liver clinical practice guidelines for the diagnosis and management of metabolic associated fatty liver disease. Hepatol. Int. 2020, 14, 889–919. [Google Scholar] [CrossRef]
- Chalasani, N.; Younossi, Z.; Lavine, J.E.; Charlton, M.; Cusi, K.; Rinella, M.; Harrison, S.A.; Brunt, E.M.; Sanyal, A.J. The diagnosis and management of nonalcoholic fatty liver disease: Practice guidance from the American Association for the Study of Liver Diseases. Hepatology 2018, 67, 328–357. [Google Scholar] [CrossRef]
- Das, A.; Connell, M.; Khetarpal, S. Digital image analysis of ultrasound images using machine learning to diagnose pediatric nonalcoholic fatty liver disease. Clin. Imaging 2021, 77, 62–68. [Google Scholar] [CrossRef]
- Acharya, U.R.; Raghavendra, U.; Fujita, H.; Hagiwara, Y.; Koh, J.E.; Jen Hong, T.; Sudarshan, V.K.; Vijayananthan, A.; Yeong, C.H.; Gudigar, A.; et al. Automated characterization of fatty liver disease and cirrhosis using curvelet transform and entropy features extracted from ultrasound images. Comput. Biol. Med. 2016, 79, 250–258. [Google Scholar] [CrossRef]
- Fan, J.G.; Jia, J.D.; Li, Y.M.; Wang, B.Y.; Lu, L.G.; Shi, J.P.; Chan, L.Y. Guidelines for the diagnosis and management of nonalcoholic fatty liver disease: Update 2010: (published in Chinese on Chinese Journal of Hepatology 2010, 18, 163–166). J. Dig. Dis. 2011, 12, 38–44. [Google Scholar] [CrossRef] [PubMed]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Sakamoto, Y.; Ishiguro, M.; Kitagawa, G. Akaike Information Criterion Statistics; D. Reidel Publishing Company: Dordrecht, The Netherlands, 1986; Volume 81, p. 26853. [Google Scholar]
- Nwanosike, E.M.; Conway, B.R.; Merchant, H.A.; Hasan, S.S. Potential applications and performance of machine learning techniques and algorithms in clinical practice: A systematic review. Int. J. Med. Inform. 2022, 159, 104679. [Google Scholar] [CrossRef]
- Turki, T.; Wang, J.T.L. Clinical intelligence: New machine learning techniques for predicting clinical drug response. Comput. Biol. Med. 2019, 107, 302–322. [Google Scholar] [CrossRef]
- Mancini, A.; Vito, L.; Marcelli, E.; Piangerelli, M.; De Leone, R.; Pucciarelli, S.; Merelli, E. Machine learning models predicting multidrug resistant urinary tract infections using “DsaaS”. BMC Bioinform. 2020, 21, 347. [Google Scholar] [CrossRef]
- Williams, C.D.; Stengel, J.; Asike, M.I.; Torres, D.M.; Shaw, J.; Contreras, M.; Landt, C.L.; Harrison, S.A. Prevalence of nonalcoholic fatty liver disease and nonalcoholic steatohepatitis among a largely middle-aged population utilizing ultrasound and liver biopsy: A prospective study. Gastroenterology 2011, 140, 124–131. [Google Scholar] [CrossRef] [PubMed]
- Bellentani, S.; Saccoccio, G.; Masutti, F.; Crocè, L.S.; Brandi, G.; Sasso, F.; Cristanini, G.; Tiribelli, C. Prevalence of and risk factors for hepatic steatosis in Northern Italy. Ann. Intern. Med. 2000, 132, 112–117. [Google Scholar] [CrossRef] [PubMed]
- Männistö, V.T.; Simonen, M.; Soininen, P.; Tiainen, M.; Kangas, A.J.; Kaminska, D.; Venesmaa, S.; Käkelä, P.; Kärjä, V.; Gylling, H.; et al. Lipoprotein subclass metabolism in nonalcoholic steatohepatitis. J. Lipid Res. 2014, 55, 2676–2684. [Google Scholar] [CrossRef]
- DeFilippis, A.P.; Blaha, M.J.; Martin, S.S.; Reed, R.M.; Jones, S.R.; Nasir, K.; Blumenthal, R.S.; Budoff, M.J. Nonalcoholic fatty liver disease and serum lipoproteins: The Multi-Ethnic Study of Atherosclerosis. Atherosclerosis 2013, 227, 429–436. [Google Scholar] [CrossRef]
- Heeren, J.; Scheja, L. Metabolic-associated fatty liver disease and lipoprotein metabolism. Mol. Metab. 2021, 50, 101238. [Google Scholar] [CrossRef]
- Gao, X.; Fan, J.G. Diagnosis and management of non-alcoholic fatty liver disease and related metabolic disorders: Consensus statement from the Study Group of Liver and Metabolism, Chinese Society of Endocrinology. J. Diabetes 2013, 5, 406–415. [Google Scholar] [CrossRef] [PubMed]
- Seko, Y.; Sumida, Y.; Tanaka, S.; Mori, K.; Taketani, H.; Ishiba, H.; Hara, T.; Okajima, A.; Yamaguchi, K.; Moriguchi, M.; et al. Serum alanine aminotransferase predicts the histological course of non-alcoholic steatohepatitis in Japanese patients. Hepatol. Res. 2015, 45, E53–E61. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.Y.; Lin, C.Y.; Yen, H.H.; Su, P.Y.; Zeng, Y.H.; Huang, S.P.; Liu, I.L. Machine-Learning Algorithm for Predicting Fatty Liver Disease in a Taiwanese Population. J. Pers. Med. 2022, 12, 1026. [Google Scholar] [CrossRef]
- Pei, X.; Deng, Q.; Liu, Z.; Yan, X.; Sun, W. Machine Learning Algorithms for Predicting Fatty Liver Disease. Ann. Nutr. Metab. 2021, 77, 38–45. [Google Scholar] [CrossRef] [PubMed]
- Younossi, Z.M.; Loomba, R.; Anstee, Q.M.; Rinella, M.E.; Bugianesi, E.; Marchesini, G.; Neuschwander-Tetri, B.A.; Serfaty, L.; Negro, F.; Caldwell, S.H.; et al. Diagnostic modalities for nonalcoholic fatty liver disease, nonalcoholic steatohepatitis, and associated fibrosis. Hepatology 2018, 68, 349–360. [Google Scholar] [CrossRef] [PubMed]
- Hassoun, S.; Bruckmann, C.; Ciardullo, S.; Perseghin, G.; Di Gaudio, F.; Broccolo, F. Setting up of a machine learning algorithm for the identification of severe liver fibrosis profile in the general US population cohort. Int. J. Med. Inform. 2023, 170, 104932. [Google Scholar] [CrossRef]
- Lemmer, P.; Manka, P.; Best, J.; Kahraman, A.; Kälsch, J.; Vilchez-Vargas, R.; Link, A.; Chiang, H.; Gerken, G.; Canbay, A.; et al. Effects of Moderate Alcohol Consumption in Non-Alcoholic Fatty Liver Disease. J. Clin. Med. 2022, 11, 890. [Google Scholar] [CrossRef]
- Jarvis, H.; O’Keefe, H.; Craig, D.; Stow, D.; Hanratty, B.; Anstee, Q.M. Does moderate alcohol consumption accelerate the progression of liver disease in NAFLD? A systematic review and narrative synthesis. BMJ Open 2022, 12, e049767. [Google Scholar] [CrossRef]
- Andrade, R.J.; Aithal, G.P.; Björnsson, E.S.; Kaplowitz, N.; Kullak-Ublick, G.A.; Larrey, D.; Karlsen, T.H.; European Association for the Study of the Liver. EASL Clinical Practice Guidelines: Drug-induced liver injury. J. Hepatol. 2019, 70, 1222–1261. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Data | Variable | Description |
|---|---|---|
| Demographics Data | Gender | Gender of the participant |
| Age | Age in years at screening | |
| Examination Data | Height | Height of the participant |
| Weight | Weight of the participant | |
| BMI | Body Mass Index | |
| Sp | Systolic pressure | |
| Dp | Diastolic pressure | |
| Laboratory Data | TC | Total cholesterol |
| Tg | Triglyceride | |
| LDL-c | Low-density lipoprotein cholesterol | |
| HDL-c | High-density lipoprotein cholesterol | |
| Fbg | Fasting blood glucose | |
| Alb | Albumin | |
| Glb | Globulin | |
| Tp | Total protein | |
| DBil | Direct Bilirubin | |
| TBil | Total bilirubin | |
| Tba | Total bile acid | |
| ALT | Alanine aminotransferase | |
| AST | Aspartate aminotransferase | |
| BUN | Blood urea nitrogen | |
| Cr | Creatinine | |
| UA | Uric acid |
| Variable | Deviance | AIC |
|---|---|---|
| BMI | 16,005 | 16,043 |
| Alt | 13,589 | 13,627 |
| Tg | 13,425 | 13,463 |
| Fbg | 13,356 | 13,394 |
| Alb | 13,263 | 13,301 |
| Age | 13,260 | 13,298 |
| Ldl-c | 13,237 | 13,275 |
| Age | 13,228 | 13,266 |
| Glb | 13,211 | 13,249 |
| Alb | 13,202 | 13,240 |
| Hdl-c | 13,187 | 13,225 |
| Characteristic | Case (N = 3474 1) | Control (N = 27,100 1) | p-Value 2 |
|---|---|---|---|
| Height | 165.0 (8.1) | 161.3 (8.0) | <0.001 |
| Age | 45.7 (10.9) | 41.7 (12.0) | <0.001 |
| Gender | <0.001 | ||
| Female | 823 (23.7%) | 15,501 (57.2%) | |
| Male | 2651 (76.3%) | 11,599 (42.8%) | |
| BMI | 27.2 (2.8) | 22.8 (2.8) | <0.001 |
| Alb | 44.9 (2.6) | 44.2 (2.7) | <0.001 |
| ALT | 40.7 (30.3) | 22.2 (26.1) | <0.001 |
| Glb | 28.1 (3.7) | 27.9 (3.8) | <0.001 |
| Fbg | 5.5 (1.8) | 4.9 (1.0) | <0.001 |
| HDL-c | 1.2 (0.3) | 1.4 (0.3) | <0.001 |
| LDL-c | 3.0 (0.9) | 2.7 (0.7) | <0.001 |
| Tg | 2.5 (2.7) | 1.3 (1.1) | <0.001 |
| 1 Mean (SD); n (%) | |||
| 2 Welch Two Sample t-test; Fisher’s exact test | |||
| Accuracy | Sen | Spe | Ppv | Npv | AUC | Kappa | |
|---|---|---|---|---|---|---|---|
| XGBoost | 0.8977 | 0.9247 | 0.889 | 0.7272 | 0.9736 | 0.969 | 0.745 |
| SVM | 0.8586 | 0.8589 | 0.8959 | 0.8251 | 0.8213 | 0.929 | 0.7177 |
| ANN | 0.8116 | 0.9019 | 0.7827 | 0.5704 | 0.9614 | 0.913 | 0.5716 |
| LR | 0.7926 | 0.8565 | 0.7354 | 0.7439 | 0.851 | 0.868 | 0.5873 |
| LDA | 0.7903 | 0.8513 | 0.7356 | 0.7429 | 0.8465 | 0.868 | 0.5825 |
| QDA | 0.7887 | 0.8602 | 0.7245 | 0.737 | 0.8524 | 0.869 | 0.5797 |
| KNN | 0.7536 | 0.7543 | 0.7535 | 0.2817 | 0.9599 | 0.854 | 0.2933 |
| RF | 0.7322 | 0.83493 | 0.71907 | 0.27584 | 0.97142 | 0.858 | 0.2941 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Weng, S.; Hu, D.; Chen, J.; Yang, Y.; Peng, D. Prediction of Fatty Liver Disease in a Chinese Population Using Machine-Learning Algorithms. Diagnostics 2023, 13, 1168. https://doi.org/10.3390/diagnostics13061168
Weng S, Hu D, Chen J, Yang Y, Peng D. Prediction of Fatty Liver Disease in a Chinese Population Using Machine-Learning Algorithms. Diagnostics. 2023; 13(6):1168. https://doi.org/10.3390/diagnostics13061168
Chicago/Turabian StyleWeng, Shuwei, Die Hu, Jin Chen, Yanyi Yang, and Daoquan Peng. 2023. "Prediction of Fatty Liver Disease in a Chinese Population Using Machine-Learning Algorithms" Diagnostics 13, no. 6: 1168. https://doi.org/10.3390/diagnostics13061168
APA StyleWeng, S., Hu, D., Chen, J., Yang, Y., & Peng, D. (2023). Prediction of Fatty Liver Disease in a Chinese Population Using Machine-Learning Algorithms. Diagnostics, 13(6), 1168. https://doi.org/10.3390/diagnostics13061168