

Applications of Artificial Intelligence in Thrombocytopenia

 , , , , , ,
, , , , , ,  ,
,
Abstract
1. Introduction
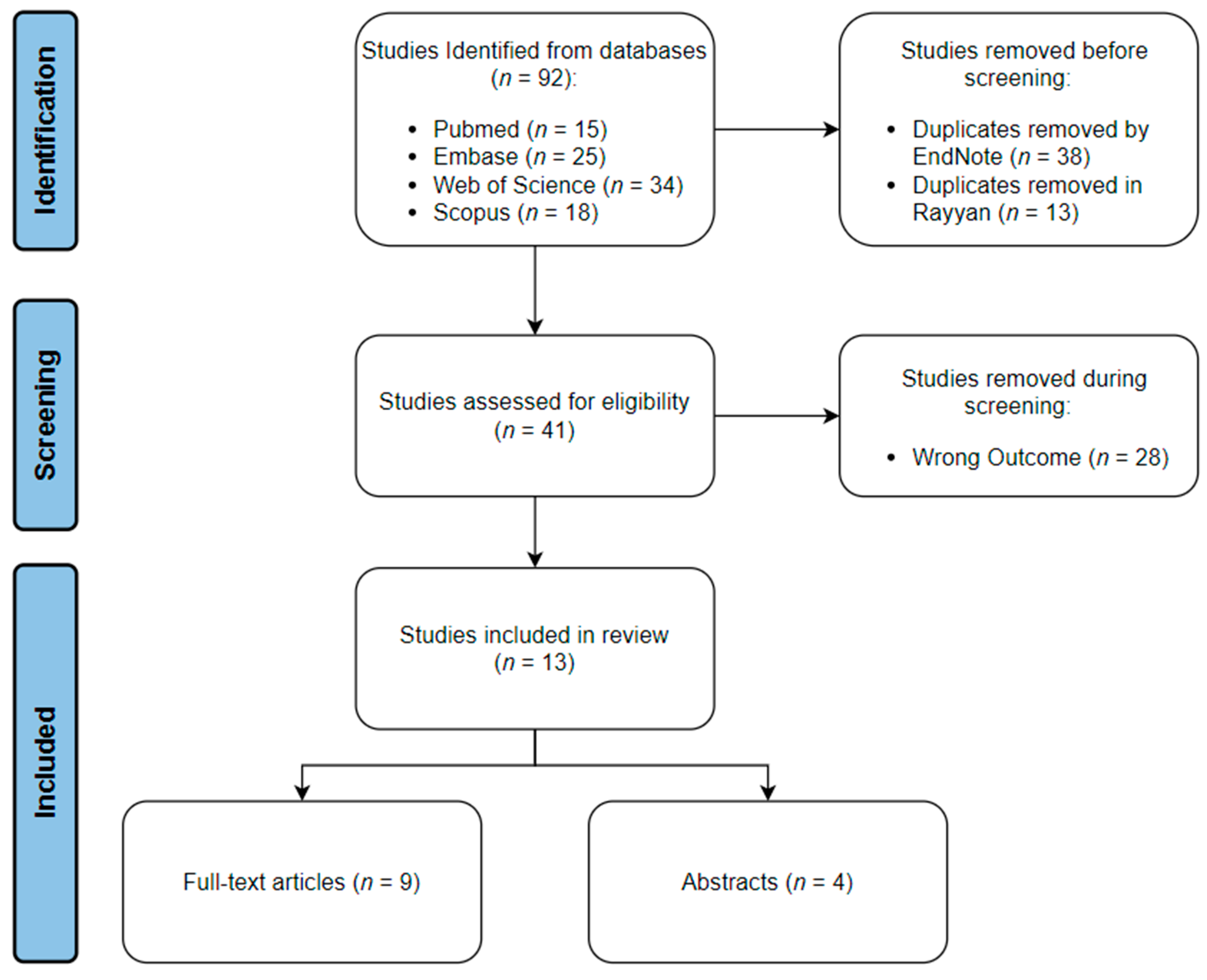
2. Materials and Methods
3. Results
3.1. Sepsis Associated Thrombocytopenia
3.1.1. Diagnosis
3.1.2. Prognosis
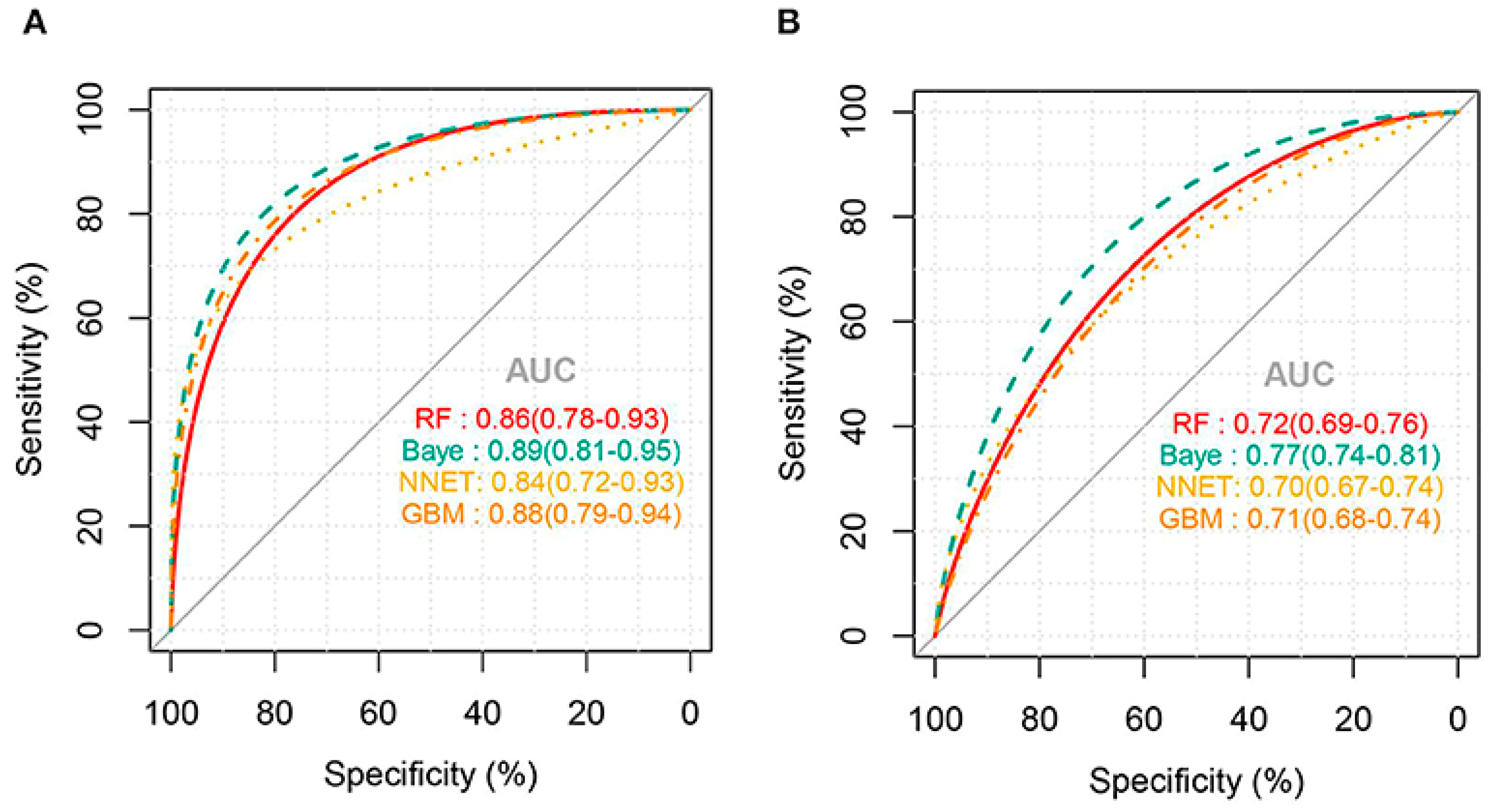
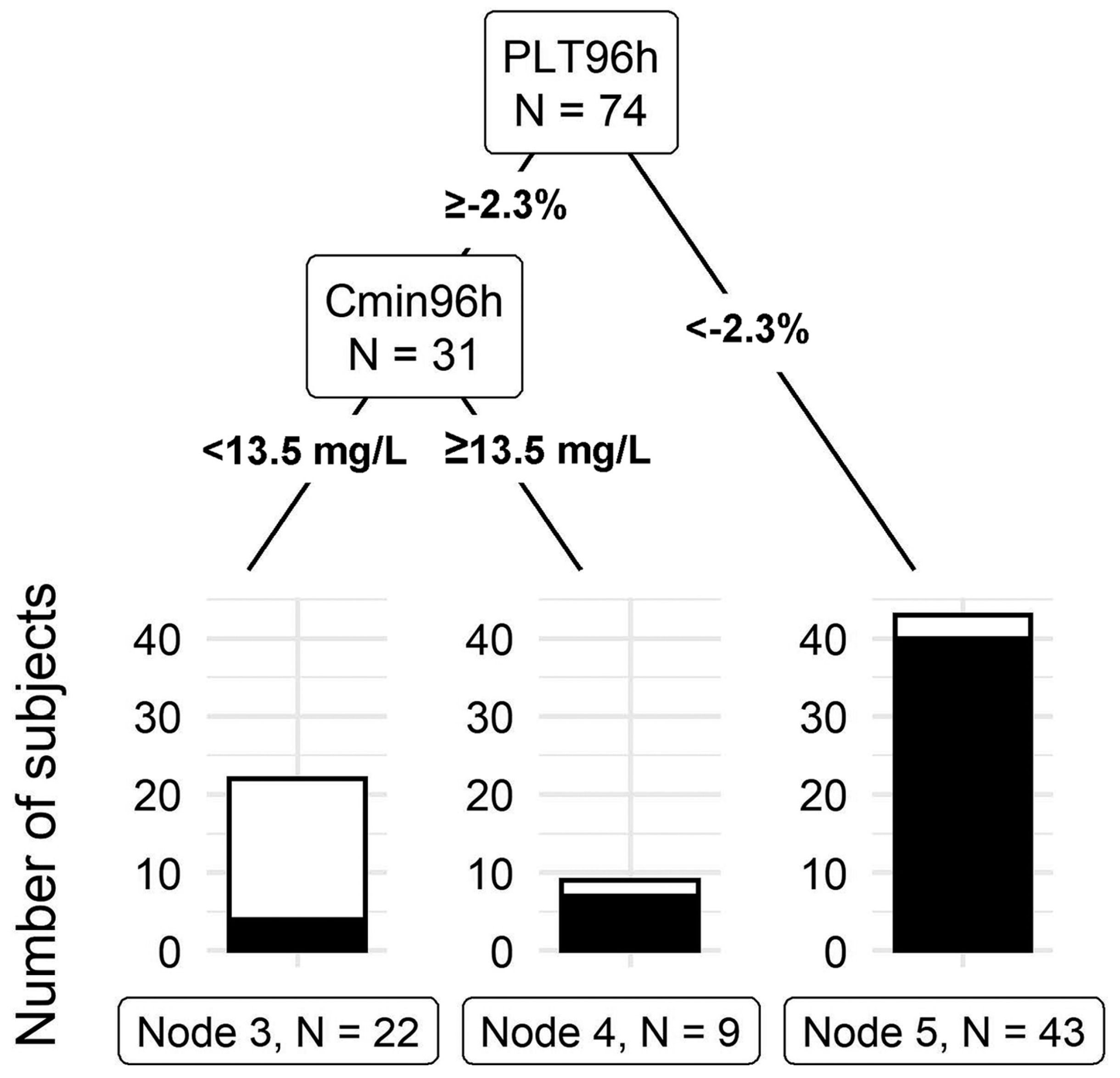
3.2. Drug-Induced Immune Thrombocytopenia
3.2.1. Diagnosis of DITP
3.2.2. Predicting Drugs Causing DITP
3.3. Hospital Acquired Thrombocytopenia
3.4. Immune Thrombocytopenia
3.4.1. Diagnosis
3.4.2. Prognosis
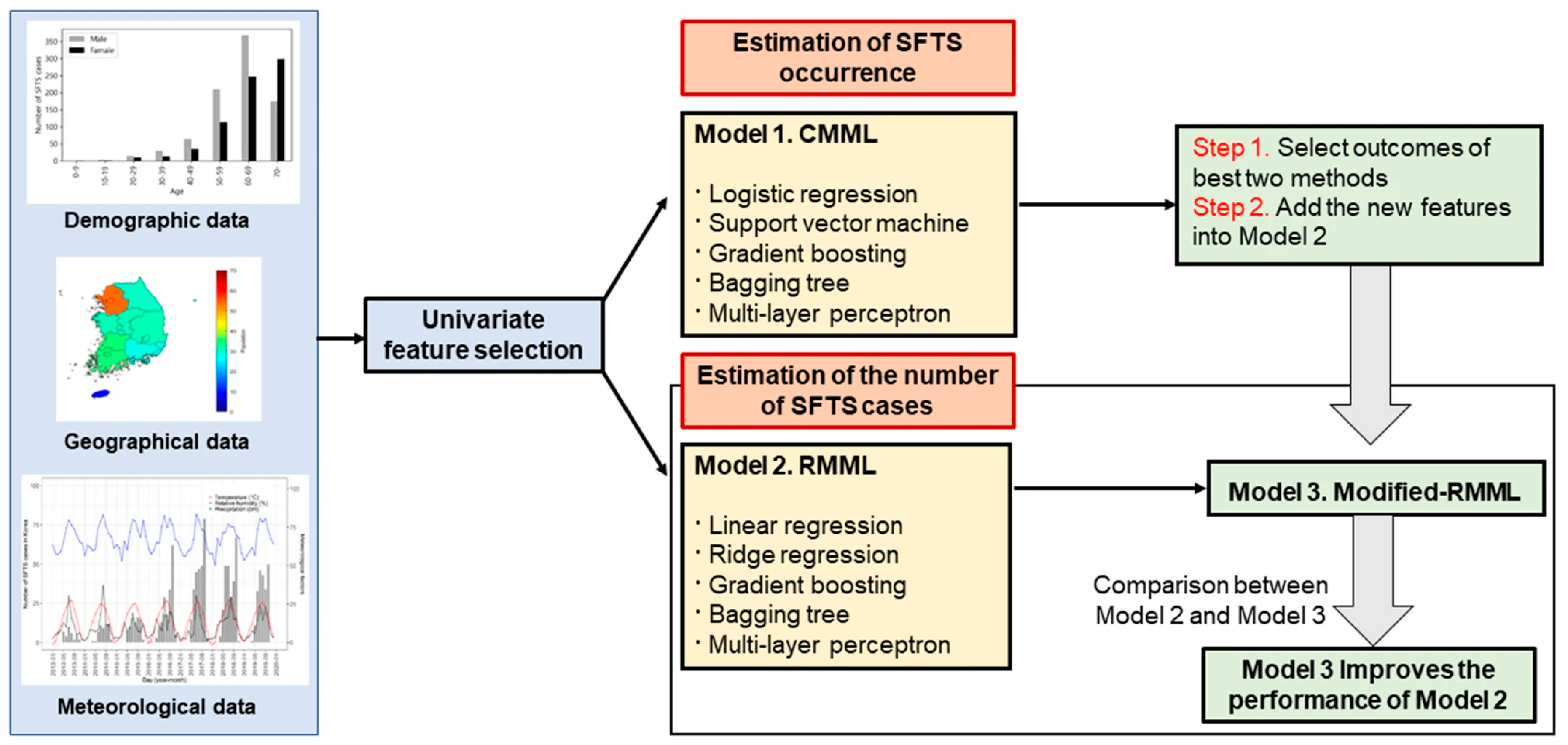
3.5. Severe Fever with Thrombocytopenia
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Audia, S.; Mahevas, M.; Nivet, M.; Ouandji, S.; Ciudad, M.; Bonnotte, B. Immune Thrombocytopenia: Recent Advances in Pathogenesis and Treatments. Hemasphere 2021, 5, e574. [Google Scholar] [CrossRef] [PubMed]
- Provan, D.; Semple, J.W. Recent advances in the mechanisms and treatment of immune thrombocytopenia. EBioMedicine 2022, 76, 103820. [Google Scholar] [CrossRef] [PubMed]
- Santoshi, R.K.; Patel, R.; Patel, N.S.; Bansro, V.; Chhabra, G. A Comprehensive Review of Thrombocytopenia with a Spotlight on Intensive Care Patients. Cureus 2022, 14, e27718. [Google Scholar] [CrossRef] [PubMed]
- Amisha; Malik, P.; Pathania, M.; Rathaur, V.K. Overview of artificial intelligence in medicine. J. Fam. Med. Prim. Care 2019, 8, 2328–2331. [Google Scholar] [CrossRef]
- Mani, V.; Ghonge, M.M.; Chaitanya, N.K.; Pal, O.; Sharma, M.; Mohan, S.; Ahmadian, A. A new blockchain and fog computing model for blood pressure medical sensor data storage. Comput. Electr. Eng. 2022, 102, 108202. [Google Scholar] [CrossRef]
- Zhao, C.; Xiang, S.; Wang, Y.; Cai, Z.; Shen, J.; Zhou, S.; Zhao, D.; Su, W.; Guo, S.; Li, S. Context-aware network fusing transformer and V-Net for semi-supervised segmentation of 3D left atrium. Expert Syst. Appl. 2023, 214, 119105. [Google Scholar] [CrossRef]
- Iwendi, C.; Huescas, C.G.Y.; Chakraborty, C.; Mohan, S. COVID-19 health analysis and prediction using machine learning algorithms for Mexico and Brazil patients. J. Exp. Theor. Artif. Intell. 2022, 1–21. [Google Scholar] [CrossRef]
- Nichols, J.A.; Herbert Chan, H.W.; Baker, M.A.B. Machine learning: Applications of artificial intelligence to imaging and diagnosis. Biophys. Rev. 2019, 11, 111–118. [Google Scholar] [CrossRef]
- Kumar, Y.; Koul, A.; Singla, R.; Ijaz, M.F. Artificial intelligence in disease diagnosis: A systematic literature review, synthesizing framework and future research agenda. J. Ambient. Intell. Hum. Comput. 2022, 1–28. [Google Scholar] [CrossRef]
- Clark, J.M.; Sanders, S.; Carter, M.; Honeyman, D.; Cleo, G.; Auld, Y.; Booth, D.; Condron, P.; Dalais, C.; Bateup, S.; et al. Improving the translation of search strategies using the Polyglot Search Translator: A randomized controlled trial. J. Med. Libr. Assoc. 2020, 108, 195–207. [Google Scholar] [CrossRef]
- Jiang, X.; Wang, Y.; Pan, Y.; Zhang, W. Prediction Models for Sepsis-Associated Thrombocytopenia Risk in Intensive Care Units Based on a Machine Learning Algorithm. Front. Med. 2022, 9, 837382. [Google Scholar] [CrossRef] [PubMed]
- Ling, J.; Liao, T.; Wu, Y.; Wang, Z.; Jin, H.; Lu, F.; Fang, M. Predictive value of red blood cell distribution width in septic shock patients with thrombocytopenia: A retrospective study using machine learning. J. Clin. Lab. Anal. 2021, 35, e24053. [Google Scholar] [CrossRef]
- Takahashi, S.; Tsuji, Y.; Kasai, H.; Ogami, C.; Kawasuji, H.; Yamamoto, Y.; To, H. Classification Tree Analysis Based On Machine Learning for Predicting Linezolid-Induced Thrombocytopenia. J. Pharm. Sci. 2021, 110, 2295–2300. [Google Scholar] [CrossRef]
- Maray, I.; Rodríguez-Ferreras, A.; Álvarez-Asteinza, C.; Alaguero-Calero, M.; Valledor, P.; Fernández, J. Linezolid induced thrombocytopenia in critically ill patients: Risk factors and development of a machine learning-based prediction model. J. Infect. Chemother. Off. J. Jpn. Soc. Chemother. 2022, 28, 1249–1254. [Google Scholar] [CrossRef]
- Nilius, H.; Cuker, A.; Haug, S.; Nakas, C.; Studt, J.D.; Tsakiris, D.A.; Greinacher, A.; Mendez, A.; Schmidt, A.; Wuillemin, W.A.; et al. A machine-learning model for reducing misdiagnosis in heparin-induced thrombocytopenia: A prospective, multicenter, observational study. EClinicalMedicine 2023, 55, 101745. [Google Scholar] [CrossRef]
- Wang, B.; Tan, X.; Guo, J.; Xiao, T.; Jiao, Y.; Zhao, J.; Wu, J.; Wang, Y. Drug-Induced Immune Thrombocytopenia Toxicity Prediction Based on Machine Learning. Pharmaceutics 2022, 14, 943. [Google Scholar] [CrossRef]
- Cheng, Y.; Chen, C.; Yang, J.; Yang, H.; Fu, M.; Zhong, X.; Wang, B.; He, M.; Hu, Z.; Zhang, Z.; et al. Using Machine Learning Algorithms to Predict Hospital Acquired Thrombocytopenia after Operation in the Intensive Care Unit: A Retrospective Cohort Study. Diagnostics 2021, 11, 1614. [Google Scholar] [CrossRef]
- Miao, D.; Dai, K.; Zhao, G.P.; Li, X.L.; Shi, W.Q.; Zhang, J.S.; Yang, Y.; Liu, W.; Fang, L.Q. Mapping the global potential transmission hotspots for severe fever with thrombocytopenia syndrome by machine learning methods. Emerg. Microbes Infect. 2020, 9, 817–826. [Google Scholar] [CrossRef]
- Cho, G.; Lee, S.; Lee, H. Estimating severe fever with thrombocytopenia syndrome transmission using machine learning methods in South Korea. Sci. Rep. 2021, 11, 21831. [Google Scholar] [CrossRef] [PubMed]
- Singer, M.; Deutschman, C.S.; Seymour, C.W.; Shankar-Hari, M.; Annane, D.; Bauer, M.; Bellomo, R.; Bernard, G.R.; Chiche, J.D.; Coopersmith, C.M.; et al. The Third International Consensus Definitions for Sepsis and Septic Shock (Sepsis-3). JAMA 2016, 315, 801–810. [Google Scholar] [CrossRef] [PubMed]
- Vardon-Bounes, F.; Ruiz, S.; Gratacap, M.P.; Garcia, C.; Payrastre, B.; Minville, V. Platelets Are Critical Key Players in Sepsis. Int. J. Mol. Sci. 2019, 20, 3494. [Google Scholar] [CrossRef] [PubMed]
- Mavrommatis, A.C.; Theodoridis, T.; Orfanidou, A.; Roussos, C.; Christopoulou-Kokkinou, V.; Zakynthinos, S. Coagulation system and platelets are fully activated in uncomplicated sepsis. Crit. Care Med. 2000, 28, 451–457. [Google Scholar] [CrossRef] [PubMed]
- Vanderschueren, S.; De Weerdt, A.; Malbrain, M.; Vankersschaever, D.; Frans, E.; Wilmer, A.; Bobbaers, H. Thrombocytopenia and prognosis in intensive care. Crit. Care Med. 2000, 28, 1871–1876. [Google Scholar] [CrossRef]
- Syed, M.; Syed, S.; Sexton, K.; Syeda, H.B.; Garza, M.; Zozus, M.; Syed, F.; Begum, S.; Syed, A.U.; Sanford, J.; et al. Application of Machine Learning in Intensive Care Unit (ICU) Settings Using MIMIC Dataset: Systematic Review. Informatics 2021, 8, 16. [Google Scholar] [CrossRef]
- Gutierrez, G. Artificial Intelligence in the Intensive Care Unit. Crit. Care 2020, 24, 101. [Google Scholar] [CrossRef] [PubMed]
- Jones, A.E.; Trzeciak, S.; Kline, J.A. The Sequential Organ Failure Assessment score for predicting outcome in patients with severe sepsis and evidence of hypoperfusion at the time of emergency department presentation. Crit. Care Med. 2009, 37, 1649–1654. [Google Scholar] [CrossRef]
- Zhou, W.; Fan, C.; He, S.; Chen, Y.; Xie, C. Impact of Platelet Transfusion Thresholds on Outcomes of Patients with Sepsis: Analysis of the MIMIC-IV Database. Shock 2022, 57, 486–493. [Google Scholar] [CrossRef]
- Johnson, A.E.; Pollard, T.J.; Shen, L.; Lehman, L.W.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Celi, L.A.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 160035. [Google Scholar] [CrossRef]
- Ellingsen, T.S.; Lappegard, J.; Skjelbakken, T.; Braekkan, S.K.; Hansen, J.B. Impact of red cell distribution width on future risk of cancer and all-cause mortality among cancer patients—The Tromso Study. Haematologica 2015, 100, e387–e389. [Google Scholar] [CrossRef]
- Liu, S.; Wang, P.; Shen, P.P.; Zhou, J.H. Predictive Values of Red Blood Cell Distribution Width in Assessing Severity of Chronic Heart Failure. Med. Sci. Monit. 2016, 22, 2119–2125. [Google Scholar] [CrossRef]
- Felker, G.M.; Allen, L.A.; Pocock, S.J.; Shaw, L.K.; McMurray, J.J.; Pfeffer, M.A.; Swedberg, K.; Wang, D.; Yusuf, S.; Michelson, E.L.; et al. Red cell distribution width as a novel prognostic marker in heart failure: Data from the CHARM Program and the Duke Databank. J. Am. Coll. Cardiol. 2007, 50, 40–47. [Google Scholar] [CrossRef]
- Jandial, A.; Kumar, S.; Bhalla, A.; Sharma, N.; Varma, N.; Varma, S. Elevated Red Cell Distribution Width as a Prognostic Marker in Severe Sepsis: A Prospective Observational Study. Indian J. Crit. Care Med. 2017, 21, 552–562. [Google Scholar] [CrossRef]
- Wang, A.Y.; Ma, H.P.; Kao, W.F.; Tsai, S.H.; Chang, C.K. Red blood cell distribution width is associated with mortality in elderly patients with sepsis. Am. J. Emerg. Med. 2018, 36, 949–953. [Google Scholar] [CrossRef] [PubMed]
- Jo, Y.H.; Kim, K.; Lee, J.H.; Kang, C.; Kim, T.; Park, H.M.; Kang, K.W.; Kim, J.; Rhee, J.E. Red cell distribution width is a prognostic factor in severe sepsis and septic shock. Am. J. Emerg. Med. 2013, 31, 545–548. [Google Scholar] [CrossRef] [PubMed]
- Aster, R.H.; Curtis, B.R.; McFarland, J.G.; Bougie, D.W. Drug-induced immune thrombocytopenia: Pathogenesis, diagnosis, and management. J. Thromb. Haemost. 2009, 7, 911–918. [Google Scholar] [CrossRef] [PubMed]
- Curtis, B.R. Drug-induced immune thrombocytopenia: Incidence, clinical features, laboratory testing, and pathogenic mechanisms. Immunohematology 2014, 30, 55–65. [Google Scholar] [CrossRef]
- George, J.N.; Aster, R.H. Drug-induced thrombocytopenia: Pathogenesis, evaluation, and management. Hematol. Am. Soc. Hematol. Educ. Program 2009, 153–158. [Google Scholar] [CrossRef] [PubMed]
- Vayne, C.; Guery, E.A.; Rollin, J.; Baglo, T.; Petermann, R.; Gruel, Y. Pathophysiology and Diagnosis of Drug-Induced Immune Thrombocytopenia. J. Clin. Med. 2020, 9, 2212. [Google Scholar] [CrossRef]
- Arnold, D.M.; Curtis, B.R.; Bakchoul, T. Platelet Immunology Scientific Subcommittee of the International Society on, T.; Hemostasis. Recommendations for standardization of laboratory testing for drug-induced immune thrombocytopenia: Communication from the SSC of the ISTH. J. Thromb. Haemost. 2015, 13, 676–678. [Google Scholar] [CrossRef]
- Arnold, D.M.; Kukaswadia, S.; Nazi, I.; Esmail, A.; Dewar, L.; Smith, J.W.; Warkentin, T.E.; Kelton, J.G. A systematic evaluation of laboratory testing for drug-induced immune thrombocytopenia. J. Thromb. Haemost. 2013, 11, 169–176. [Google Scholar] [CrossRef]
- Bakchoul, T.; Marini, I. Drug-associated thrombocytopenia. Hematol. Am. Soc. Hematol. Educ. Program 2018, 2018, 576–583. [Google Scholar] [CrossRef] [PubMed]
- Tajima, M.; Kato, Y.; Matsumoto, J.; Hirosawa, I.; Suzuki, M.; Takashio, Y.; Yamamoto, M.; Nishi, Y.; Yamada, H. Linezolid-Induced Thrombocytopenia Is Caused by Suppression of Platelet Production via Phosphorylation of Myosin Light Chain 2. Biol. Pharm. Bull. 2016, 39, 1846–1851. [Google Scholar] [CrossRef] [PubMed]
- Natsumoto, B.; Yokota, K.; Omata, F.; Furukawa, K. Risk factors for linezolid-associated thrombocytopenia in adult patients. Infection 2014, 42, 1007–1012. [Google Scholar] [CrossRef] [PubMed]
- Attassi, K.; Hershberger, E.; Alam, R.; Zervos, M.J. Thrombocytopenia associated with linezolid therapy. Clin. Infect Dis. 2002, 34, 695–698. [Google Scholar] [CrossRef]
- Hogan, M.; Berger, J.S. Heparin-induced thrombocytopenia (HIT): Review of incidence, diagnosis, and management. Vasc. Med. 2020, 25, 160–173. [Google Scholar] [CrossRef]
- Burnett, A.E.; Bowles, H.; Borrego, M.E.; Montoya, T.N.; Garcia, D.A.; Mahan, C. Heparin-induced thrombocytopenia: Reducing misdiagnosis via collaboration between an inpatient anticoagulation pharmacy service and hospital reference laboratory. J. Thromb. Thrombolysis 2016, 42, 471–478. [Google Scholar] [CrossRef]
- McMahon, C.M.; Tanhehco, Y.C.; Cuker, A. Inappropriate documentation of heparin allergy in the medical record because of misdiagnosis of heparin-induced thrombocytopenia: Frequency and consequences. J. Thromb. Haemost. 2017, 15, 370–374. [Google Scholar] [CrossRef]
- Mitta, A.; Curtis, B.R.; Reese, J.A.; George, J.N. Drug-induced thrombocytopenia: 2019 Update of clinical and laboratory data. Am. J. Hematol. 2019, 94, E76–E78. [Google Scholar] [CrossRef]
- Wong, R.S.M.; Yavasoglu, I.; Yassin, M.A.; Tarkun, P.; Yoon, S.S.; Wei, X.; Elghandour, A.; Angchaisuksiri, P.; Ozcan, M.A.; Yang, R.; et al. Eltrombopag in patients with chronic immune thrombocytopenia in Asia-Pacific, Middle East, and Turkey: Final analysis of CITE. Blood Adv. 2022. ahead of print. [Google Scholar] [CrossRef]
- Zainal, A.; Salama, A.; Alweis, R. Immune thrombocytopenic purpura. J. Community Hosp. Intern Med. Perspect. 2019, 9, 59–61. [Google Scholar] [CrossRef]
- Swinkels, M.; Rijkers, M.; Voorberg, J.; Vidarsson, G.; Leebeek, F.W.G.; Jansen, A.J.G. Emerging Concepts in Immune Thrombocytopenia. Front. Immunol. 2018, 9, 880. [Google Scholar] [CrossRef] [PubMed]
- Justiz Vaillant, A.A.; Gupta, N. ITP-Immune Thrombocytopenic Purpura. In StatPearls; StatPearls Publishing: Treasure Island, FL, USA, 2022. [Google Scholar]
- Abdelmahmuod, E.A.; Ali, E.; Ahmed, M.A.; Yassin, M.A. Eltrombopag and its beneficial role in management of ulcerative Colitis associated with ITP as an upfront therapy case report. Clin. Case Rep. 2021, 9, 1416–1419. [Google Scholar] [CrossRef] [PubMed]
- Kim, T.O.; MacMath, D.; Pettit, R.W.; Kirk, S.E.; Grimes, A.B.; Gilbert, M.M.; Powers, J.M.; Despotovic, J.M. Predicting Chronic Immune Thrombocytopenia in Pediatric Patients at Disease Presentation: Leveraging Clinical and Laboratory Characteristics Via Machine Learning Models. Blood 2021, 138, 1023. [Google Scholar] [CrossRef]
- An, Z.Y.; Wu, Y.J.; Huang, R.B.; Zhou, H.; Huang, Q.S.; Fu, H.X.; Jiang, Q.; Jiang, H.; Lu, J.; Huang, X.J.; et al. Personalized machine-learning-based prediction for critical immune thrombocytopenia bleeds: A nationwide data study. HemaSphere 2022, 6, 2905–2906. [Google Scholar] [CrossRef]
- Zhang, X.H.; Chong, S.; Zhao, P.; Huang, R.B.; Zhou, H.; Zhang, J.N.; Huang, Q.S.; Fu, H.X.; Jiang, Q.; Jiang, H.; et al. Machine-learning-based mortality prediction of ich in adults with itp: A nationwide representative multicentre study. HemaSphere 2022, 6, 2900–2901. [Google Scholar] [CrossRef]
- Liu, F.Q.; Chen, Q.; Qu, Q.; Sun, X.; Huang, Q.S.; He, Y.; Zhu, X.; Wang, C.; Fu, H.X.; Li, Y.Y.; et al. Machine-learning model for resistance/relapse prediction in immune thrombocytopenia using gut microbiota and function signatures. Blood 2021, 138, 18. [Google Scholar] [CrossRef]
- Jiang, X.L.; Zhang, S.; Jiang, M.; Bi, Z.Q.; Liang, M.F.; Ding, S.J.; Wang, S.W.; Liu, J.Y.; Zhou, S.Q.; Zhang, X.M.; et al. A cluster of person-to-person transmission cases caused by SFTS virus in Penglai, China. Clin. Microbiol. Infect 2015, 21, 274–279. [Google Scholar] [CrossRef]
- Wu, Y.X.; Yang, X.; Leng, Y.; Li, J.C.; Yuan, L.; Wang, Z.; Fan, X.J.; Yuan, C.; Liu, W.; Li, H. Human-to-human transmission of severe fever with thrombocytopenia syndrome virus through potential ocular exposure to infectious blood. Int. J. Infect Dis. 2022, 123, 80–83. [Google Scholar] [CrossRef]
- Kim, W.Y.; Choi, W.; Park, S.W.; Wang, E.B.; Lee, W.J.; Jee, Y.; Lim, K.S.; Lee, H.J.; Kim, S.M.; Lee, S.O.; et al. Nosocomial transmission of severe fever with thrombocytopenia syndrome in Korea. Clin. Infect Dis. 2015, 60, 1681–1683. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Q.; Hu, W.; Wu, J.; Wang, Y.; Mei, L.; Walker, D.H.; Ren, J.; Wang, Y.; Yu, X.J. Person-to-person transmission of severe fever with thrombocytopenia syndrome virus. Vector Borne Zoonotic Dis. 2012, 12, 156–160. [Google Scholar] [CrossRef]
- Casel, M.A.; Park, S.J.; Choi, Y.K. Severe fever with thrombocytopenia syndrome virus: Emerging novel phlebovirus and their control strategy. Exp. Mol. Med. 2021, 53, 713–722. [Google Scholar] [CrossRef]
- Dese, K.; Raj, H.; Ayana, G.; Yemane, T.; Adissu, W.; Krishnamoorthy, J.; Kwa, T. Accurate Machine-Learning-Based classification of Leukemia from Blood Smear Images. Clin. Lymphoma Myeloma Leuk. 2021, 21, e903–e914. [Google Scholar] [CrossRef] [PubMed]
- Cerrato, T.R. Use of artificial intelligence to improve access to initial leukemia diagnosis in low-and middleincome countries. J. Clin. Oncol. 2020, 38, e14117. [Google Scholar] [CrossRef]
- Cruz-Roa, A.; Gilmore, H.; Basavanhally, A.; Feldman, M.; Ganesan, S.; Shih, N.N.C.; Tomaszewski, J.; Gonzalez, F.A.; Madabhushi, A. Accurate and reproducible invasive breast cancer detection in whole-slide images: A Deep Learning approach for quantifying tumor extent. Sci. Rep. 2017, 7, 46450. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Kohlberger, T.; Norouzi, M.; Dahl, G.E.; Smith, J.L.; Mohtashamian, A.; Olson, N.; Peng, L.H.; Hipp, J.D.; Stumpe, M.C. Artificial Intelligence-Based Breast Cancer Nodal Metastasis Detection: Insights Into the Black Box for Pathologists. Arch. Pathol. Lab. Med. 2019, 143, 859–868. [Google Scholar] [CrossRef] [PubMed]
- Ehteshami Bejnordi, B.; Veta, M.; Johannes van Diest, P.; van Ginneken, B.; Karssemeijer, N.; Litjens, G.; van der Laak, J.; Hermsen, M.; Manson, Q.F.; Balkenhol, M.; et al. Diagnostic Assessment of Deep Learning Algorithms for Detection of Lymph Node Metastases in Women with Breast Cancer. JAMA 2017, 318, 2199–2210. [Google Scholar] [CrossRef]
- Hosseini, M.; Powell, M.; Collins, J.; Callahan-Flintoft, C.; Jones, W.; Bowman, H.; Wyble, B. I tried a bunch of things: The dangers of unexpected overfitting in classification of brain data. Neurosci. Biobehav. Rev. 2020, 119, 456–467. [Google Scholar] [CrossRef]
- Coiera, E. On algorithms, machines, and medicine. Lancet Oncol. 2019, 20, 166–167. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study (Year) | Outcome | Advantages | Disadvantages |
|---|---|---|---|
| Jiang, X., et al. (2022) [11] | Predicting SAT and severe SAT |
|
|
| Ling, J., et al. (2021) [12] | Predicting the 28-day mortality risk in patients with SAT |
|
|
| Takahashi, S., et al. (2021) [13] | Predicting LAT in patients taking linezolid treatment |
|
|
| Marray, L., et al. (2022) [14] | Predicting LAT in ICU patients started on linezolid treatment |
|
|
| Nilius, H., et al. (2022) [15] | Diagnosing HIT based on clinical and laboratory data |
|
|
| Wang, B., et al. (2022) [16] | Distinguishing DITP toxicants from non-toxicants |
|
|
| Cheng, Y., et al. (2021) [17] | Prediction of HAT risk in patients following surgery |
|
|
| Miao, D., et al. (2020) [18] | Mapping global potential hotspots for SFTS Transmission |
|
|
| Cho, G., S. Lee, and H. Lee (2021) [19] | Mapping SFTS Virus Transmission in South Korea |
|
|
| Study (Year) | Outcomes | Best Models | Validation | AUC | ACC | SEN | SPE |
|---|---|---|---|---|---|---|---|
| Jiang, X., et al. (2022) [11] | Predicting Thrombocytopenia | NNET | Internal | 0.79 | NR | NR | NR |
| External | 0.72 | 0.68 | NR | 0.71 | |||
| Predicting Severe Thrombocytopenia | Bayes | Internal | 0.89 | NR | NR | NR | |
| External | 0.77 | 0.68 | NR | 0.62 | |||
| Ling, J., et al. (2021) [12] | Prognosis of SAT | XGBoost based on RDW | Internal | 0.646 | NR | 0.70 | 57 |
| Takahashi, S., et al. (2021) [13] | Predicting LAT | CART | Internal | NR | NR | 0.922 | 0.783 |
| Maray, I., et al. (2022) [14] | Predicting LAT | LogR Model 1 | Internal | 0.89 | 0.79 | 0.71 | 0.80 |
| LogR Model 2 | Internal | 0.88 | 0.79 | 0.71 | 0.80 | ||
| Nilius, H., et al. (2022) [15] | Diagnosing DIT using ELISA | SVM | Internal | 0.985 | NR | 0.89 | 0.95 |
| Diagnosing DIT using CLIA | XGBoost | Internal | 0.989 | NR | 0.96 | 0.95 | |
| Diagnosing DIT using PaGIA | SVM | Internal | 0.991 | NR | 1.00 | 0.95 | |
| Wang, B., et al. (2022) [16] | Predicting DITP toxicity of drugs | k-NN based on RDMD-PubChem | Internal | 0.628 | 0.627 | 0.69 | 0.566 |
| External | 0.769 | 0.756 | 0.833 | 0.704 | |||
| Cheng, Y., et al. (2021) [17] | Predicting HAT following surgery | RF | Internal | 0.834 | NR | 0.793 | 0.791 |
| GB | Internal | 0.829 | NR | 0.736 | 0.737 | ||
| Miao, D., et al. (2020) [18] | Predicting Potential transmission of SFTS | BRT | Internal | 0.893 | NR | NR | NR |
| Cho, G., S. Lee, and H. Lee (2021) [19] | Predicting SFTS Occurrence | GB | Internal | 0.986 | NR | NR | NR |
| BT | Internal | 1.00 | NR | NR | NR |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elshoeibi, A.M.; Ferih, K.; Elsabagh, A.A.; Elsayed, B.; Elhadary, M.; Marashi, M.; Wali, Y.; Al-Rasheed, M.; Al-Khabori, M.; Osman, H.; et al. Applications of Artificial Intelligence in Thrombocytopenia. Diagnostics 2023, 13, 1060. https://doi.org/10.3390/diagnostics13061060
Elshoeibi AM, Ferih K, Elsabagh AA, Elsayed B, Elhadary M, Marashi M, Wali Y, Al-Rasheed M, Al-Khabori M, Osman H, et al. Applications of Artificial Intelligence in Thrombocytopenia. Diagnostics. 2023; 13(6):1060. https://doi.org/10.3390/diagnostics13061060
Chicago/Turabian StyleElshoeibi, Amgad M., Khaled Ferih, Ahmed Adel Elsabagh, Basel Elsayed, Mohamed Elhadary, Mahmoud Marashi, Yasser Wali, Mona Al-Rasheed, Murtadha Al-Khabori, Hani Osman, and et al. 2023. "Applications of Artificial Intelligence in Thrombocytopenia" Diagnostics 13, no. 6: 1060. https://doi.org/10.3390/diagnostics13061060
APA StyleElshoeibi, A. M., Ferih, K., Elsabagh, A. A., Elsayed, B., Elhadary, M., Marashi, M., Wali, Y., Al-Rasheed, M., Al-Khabori, M., Osman, H., & Yassin, M. (2023). Applications of Artificial Intelligence in Thrombocytopenia. Diagnostics, 13(6), 1060. https://doi.org/10.3390/diagnostics13061060