
Innovation in Hyperinsulinemia Diagnostics with ANN-L(atin square) Models



Abstract
:1. Introduction
2. Related Work
2.1. Naïve Bayes
2.2. Decision Tree
2.3. Random Forest
2.4. Artificial Neural Networks
3. Methodology
3.1. Naïve Bayes
3.2. Decision Tree
- max_depth: setting up the maximum depth in trees;
- min_samples_split: minimum samples a node must contain to be available for a split;
- min_samples_leaf: this controls the number of examples a terminal leaf node can have;
- max_features: the number of features to consider when looking for the best split;
- min_impurity_decrease: for controlling the amount of impurity, i.e., to define which splits are available.
3.3. Random Forest
- n_estimators: the number of trees in the forest;
- max_features: the number of features to consider when looking for the best split;
- max_depth: the maximum depth of a tree;
- criterion: the function to measure the quality of a split.
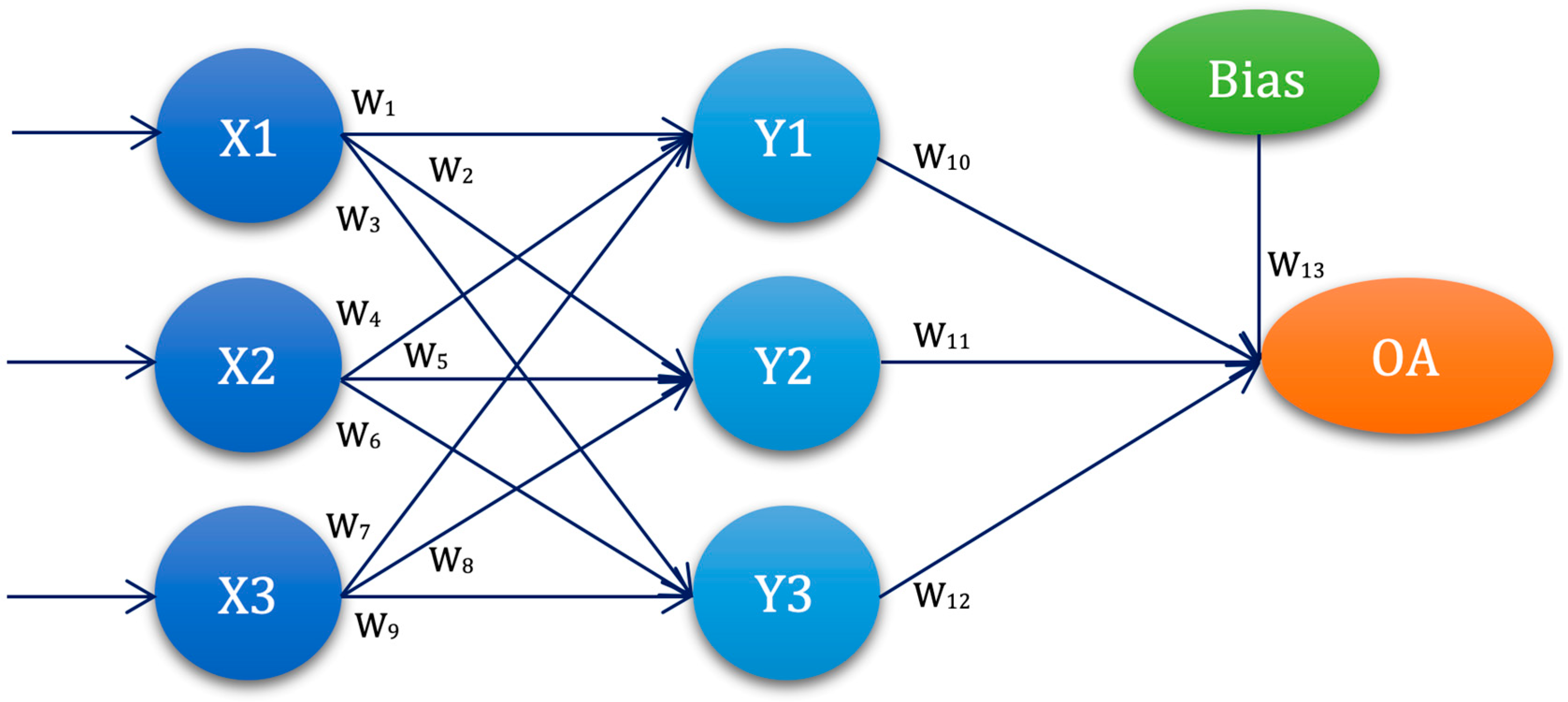
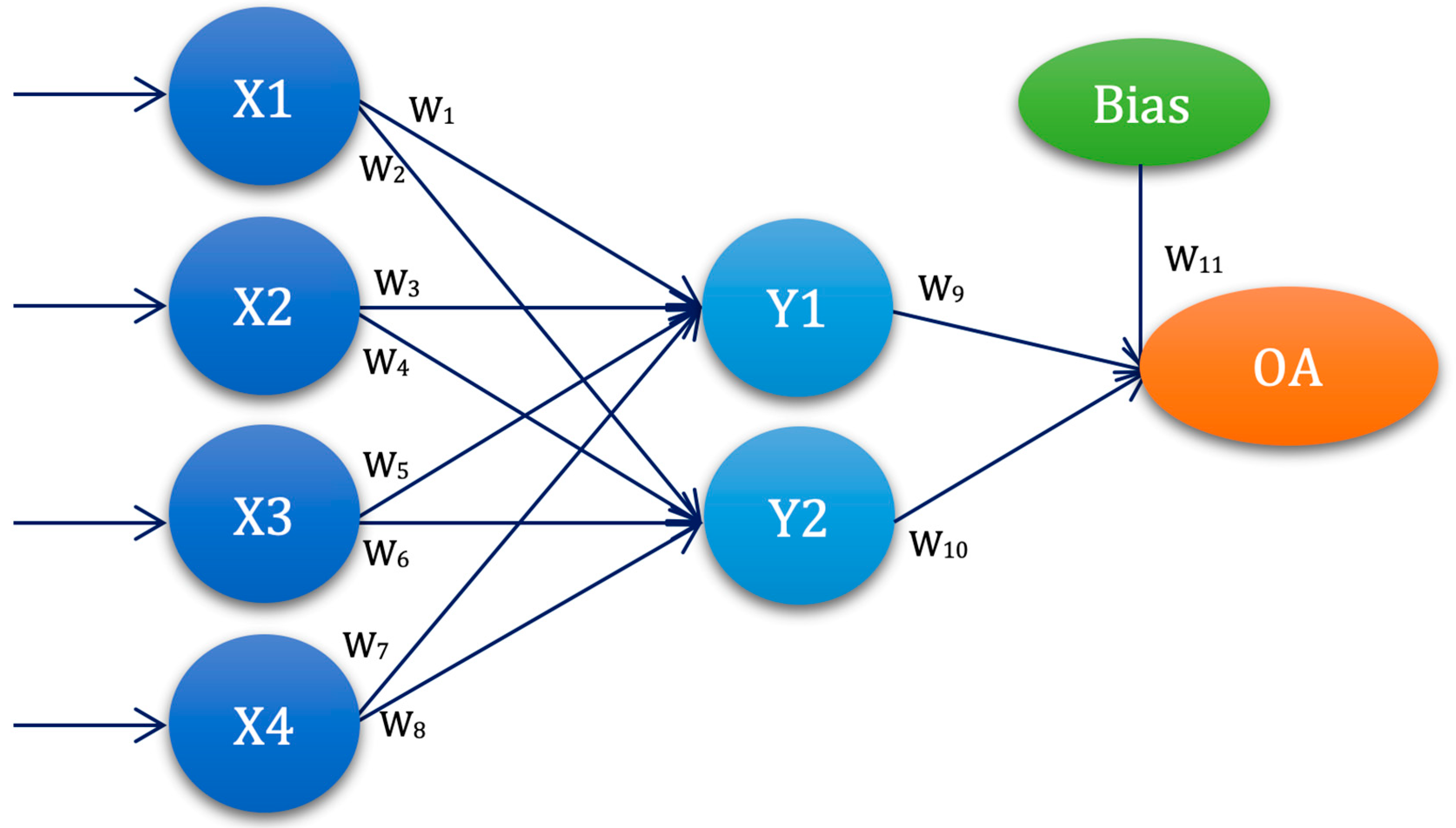
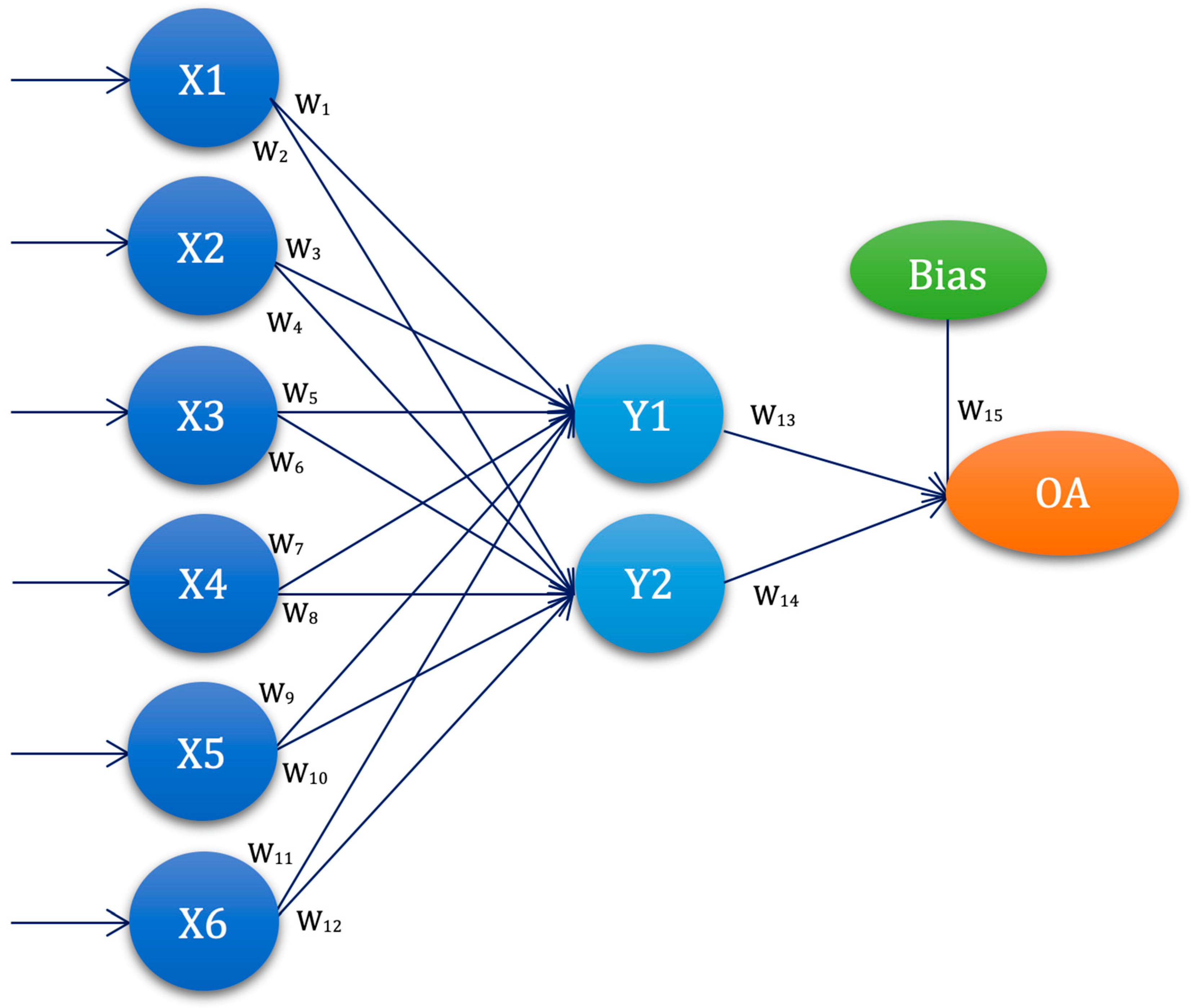
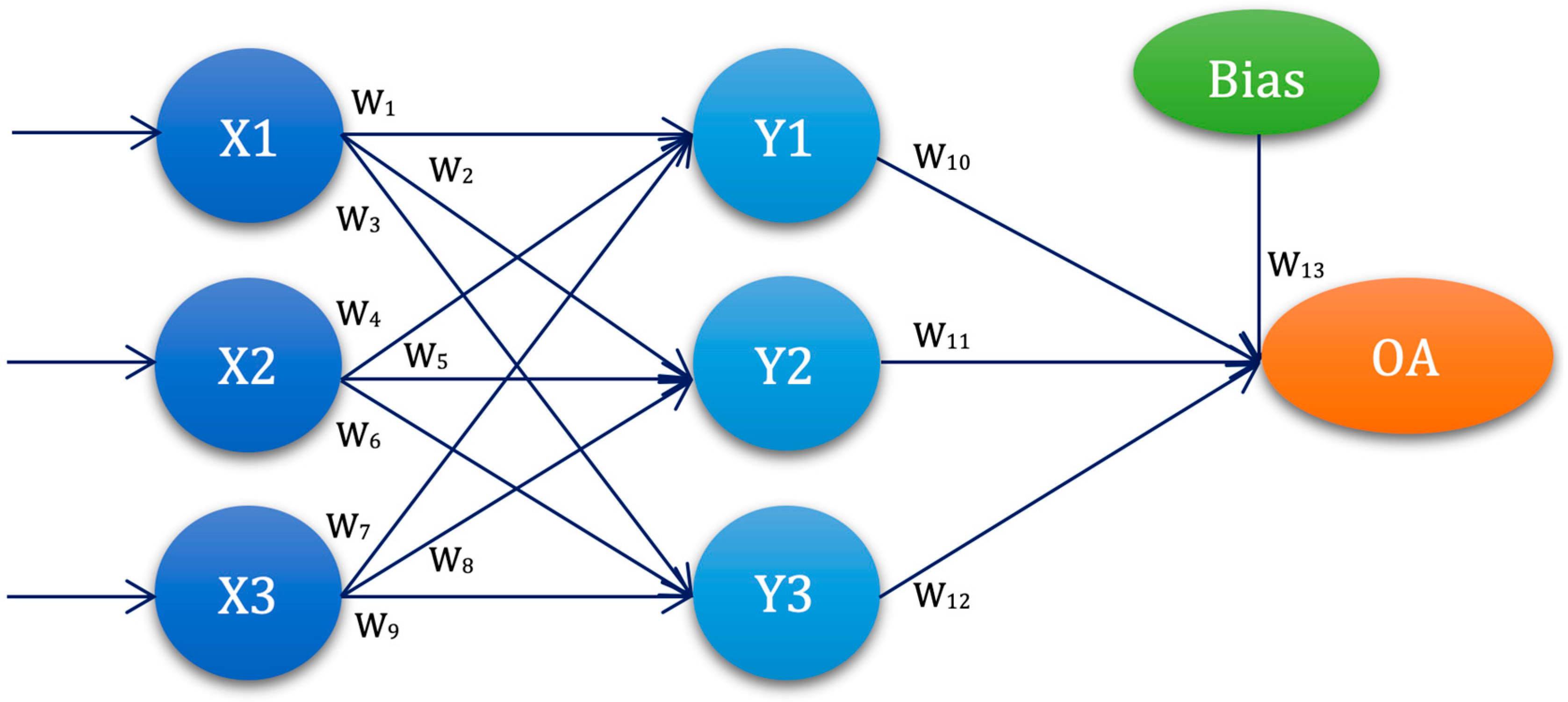
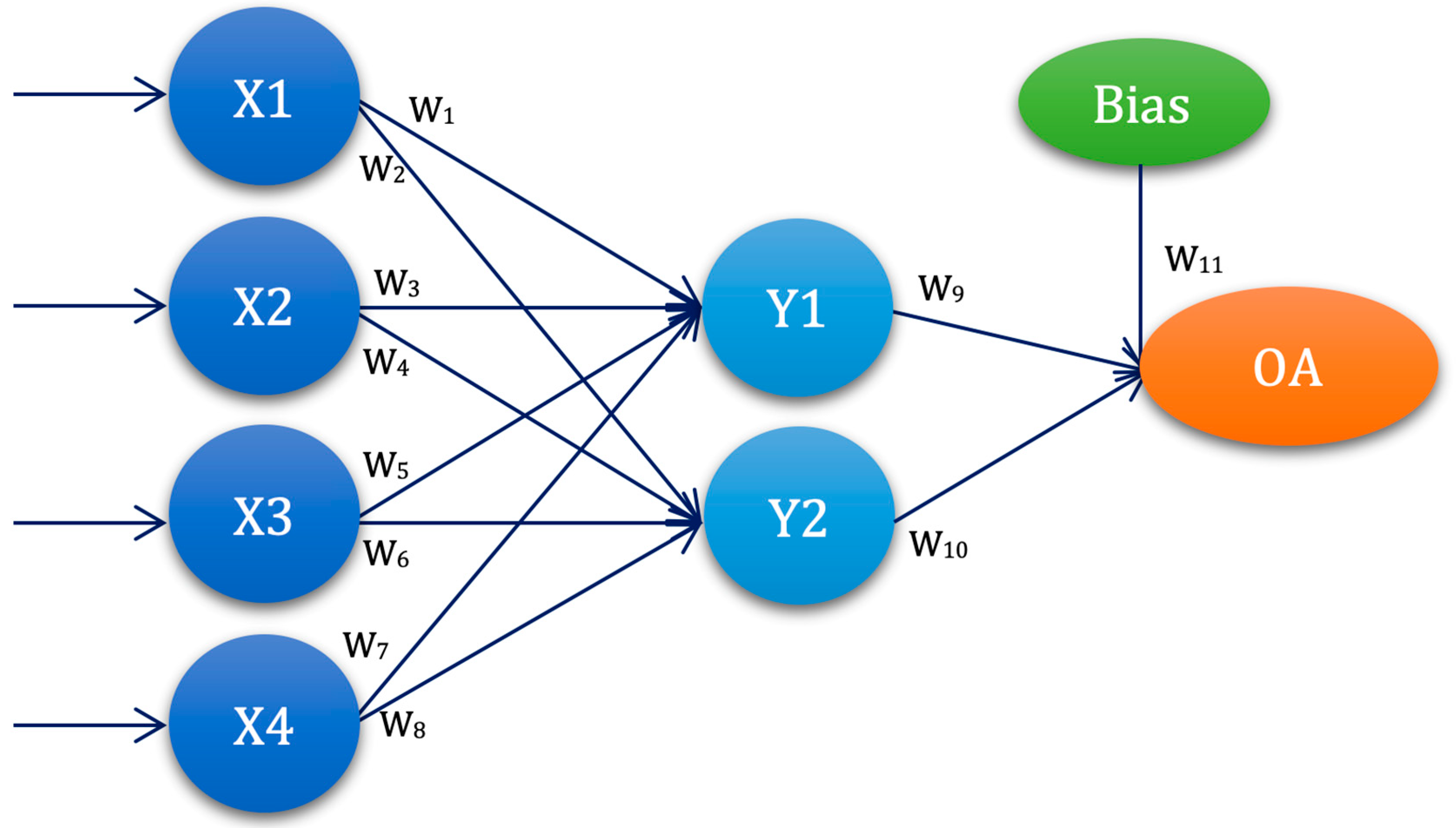
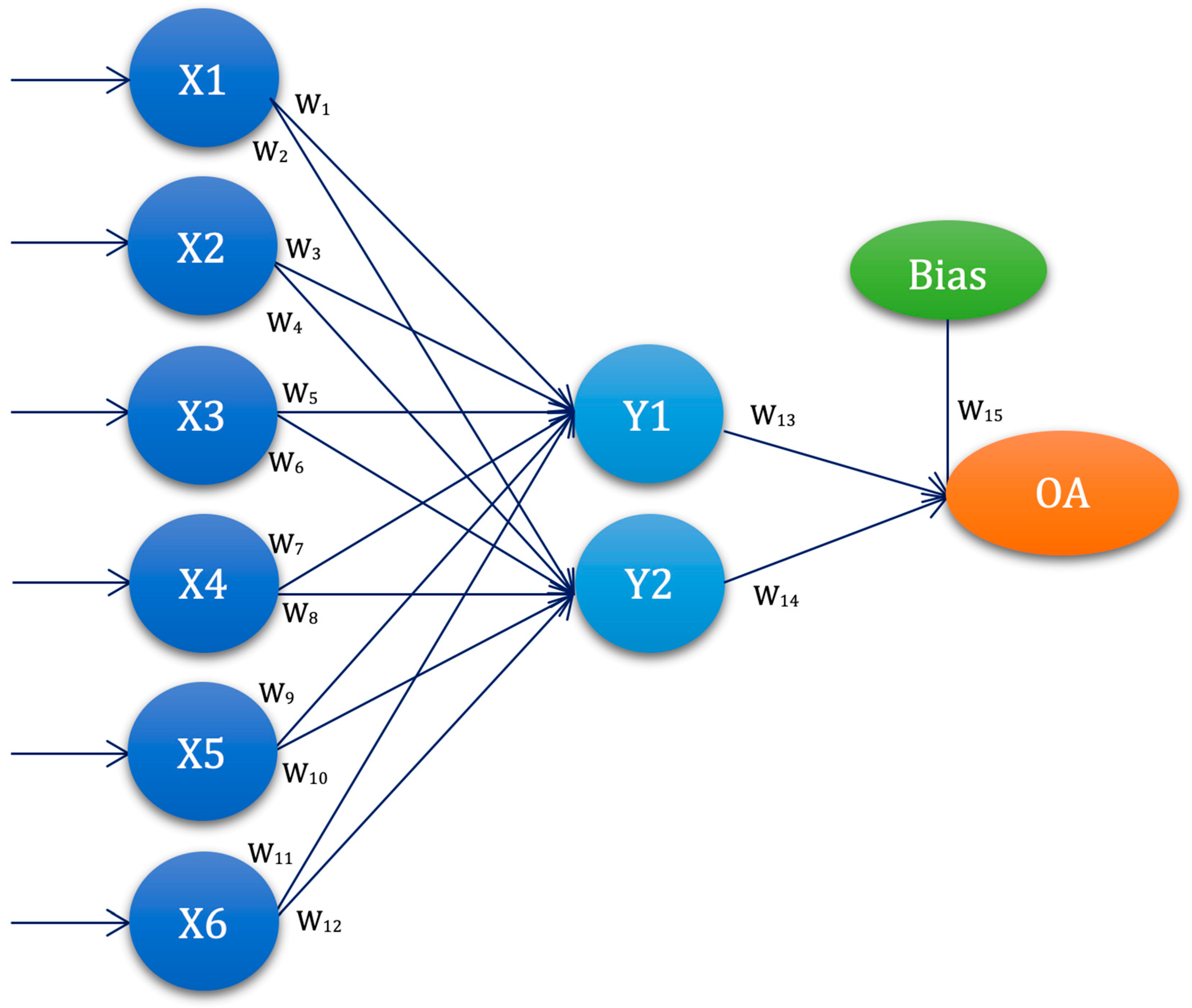
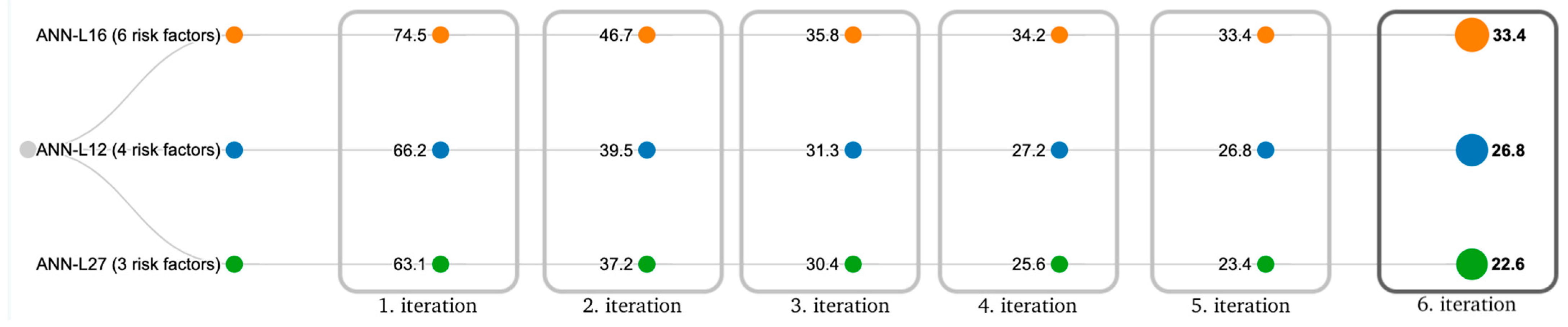
3.4. Experimental Setup—ANN-L(atin) Squares
L2W1 = cost10 + cost11 +…+ cost18
L3W1 = cost19 + cost20 +…+ cost27
…
L1W13 = cost1 + cost5 +…+ cost26
L2W13 = cost2 + cost6 +…+ cost27
L3W13 = cost3 + cost4 +…+ cost25
if cost(i) = ∑MRE(ANN-L27(i))
3.5. Dataset Description
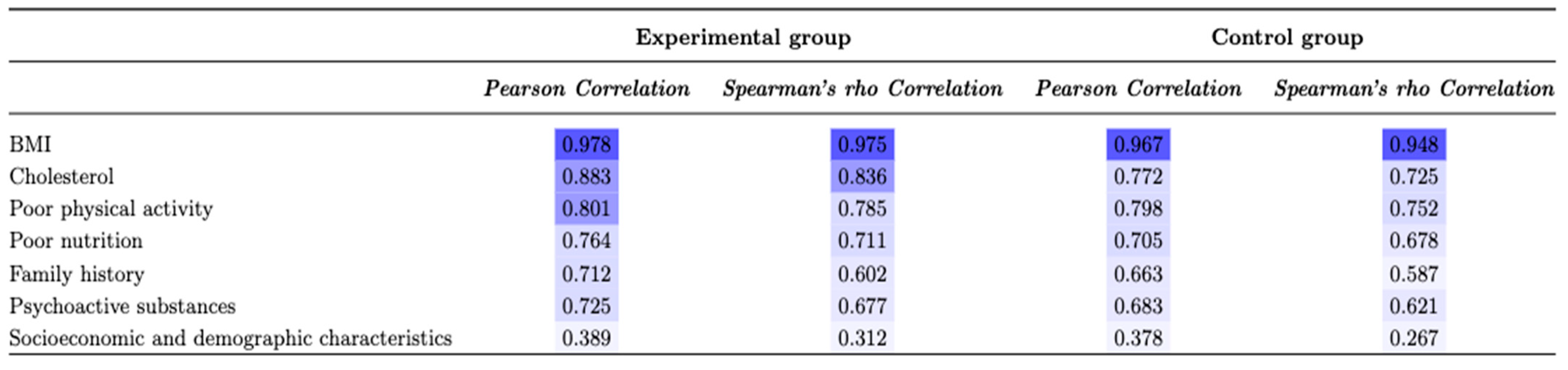
3.6. Statistical Analysis
4. Results
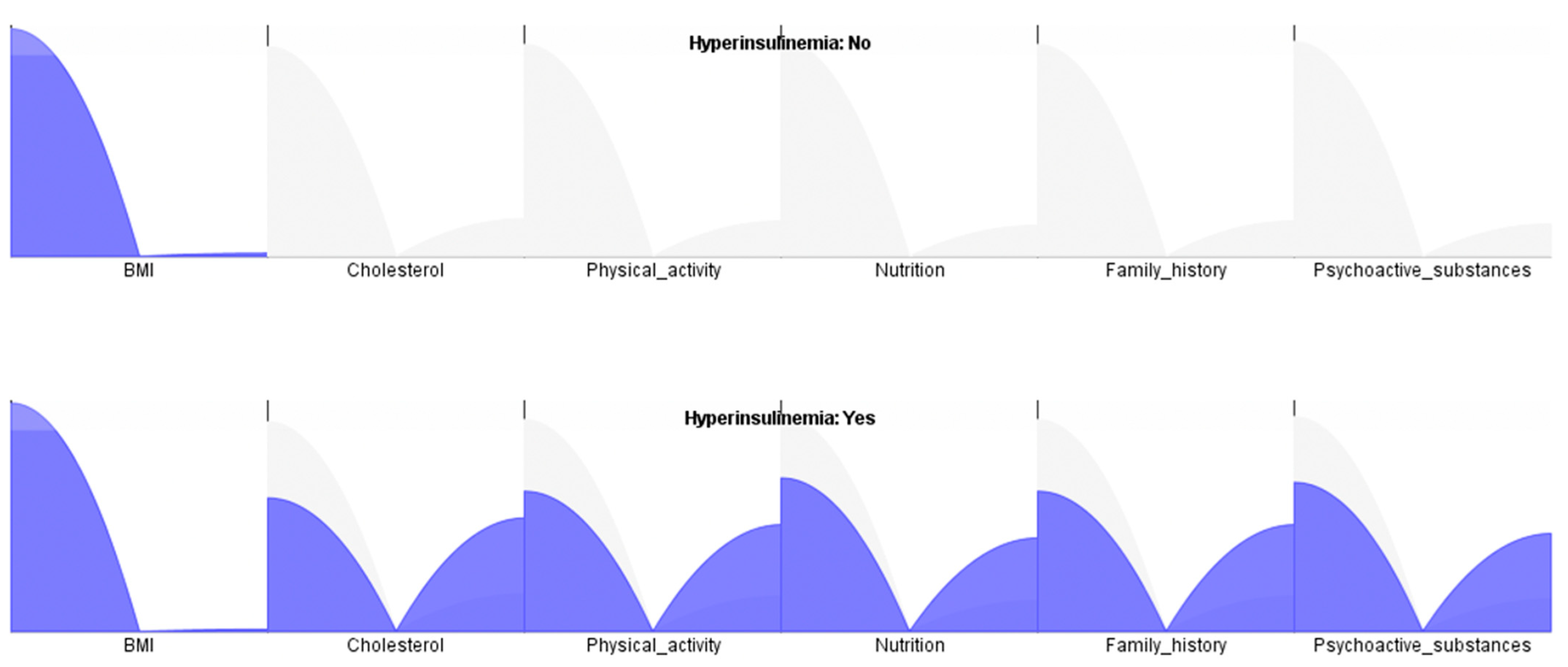
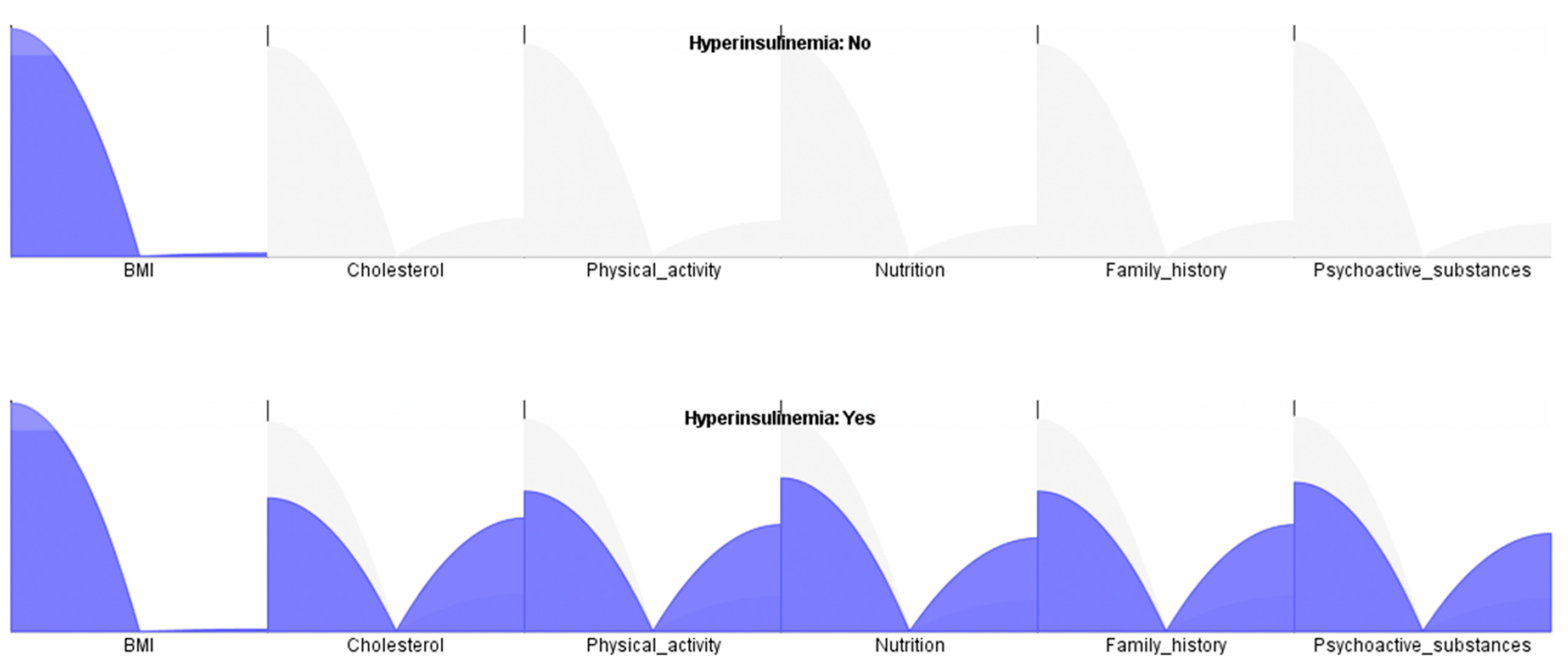
4.1. Factorial Analysis
4.2. Naïve Bayes, Decision Tree, and Random Forest
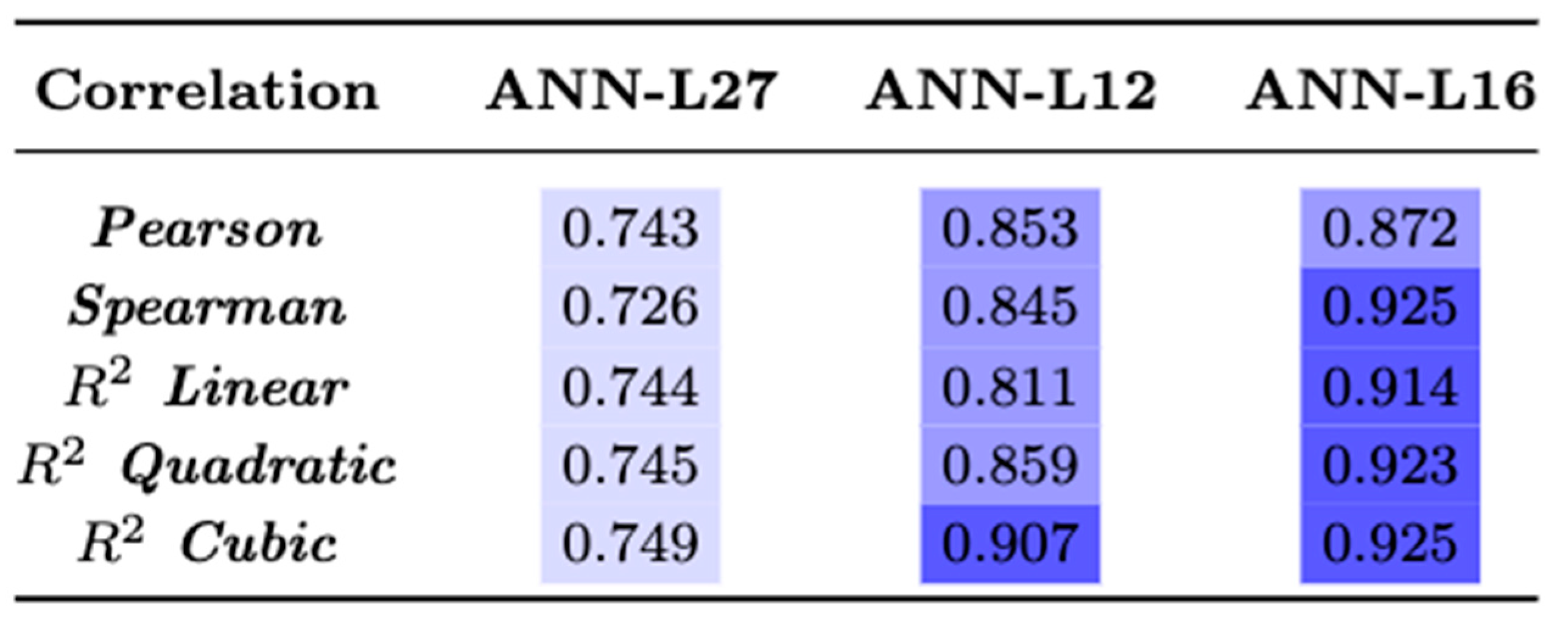
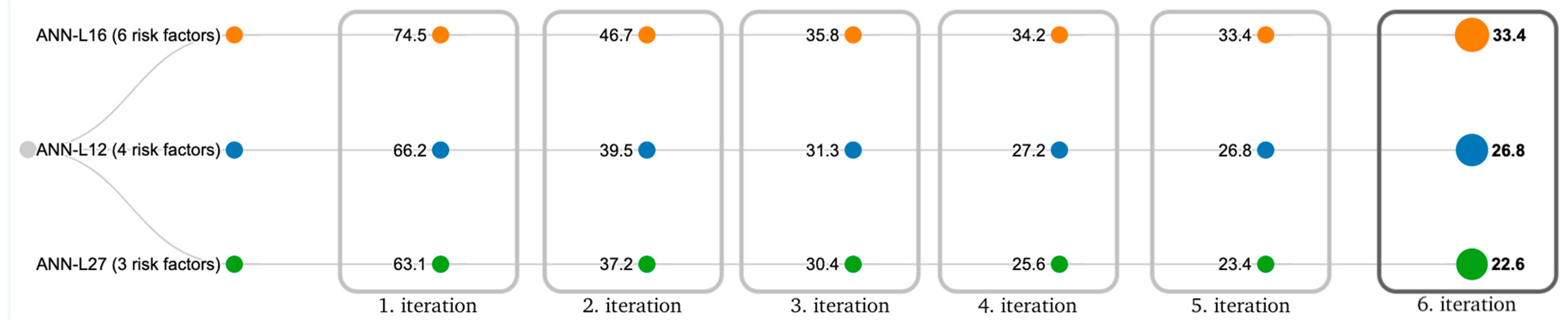
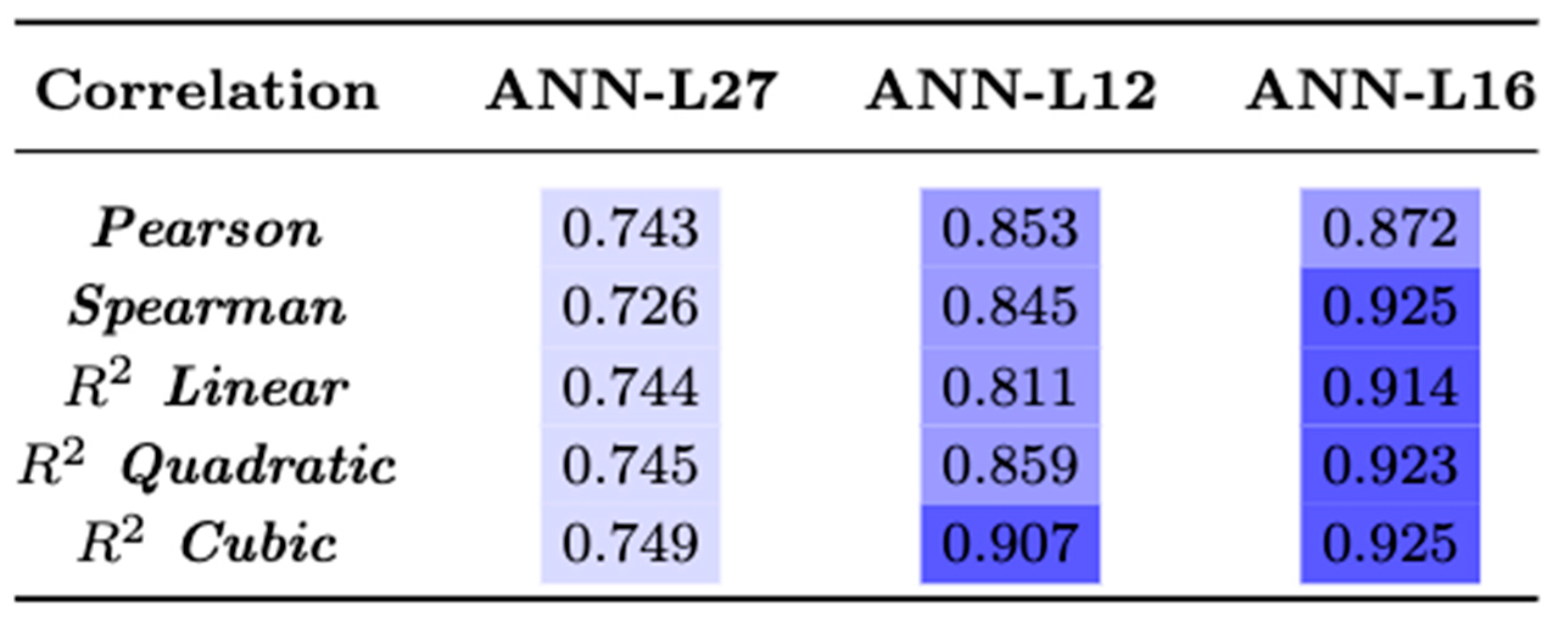
4.3. ANN Based on Taguchi’s Orthogonal Vector Plans (ANN-L)
4.4. Comparative Analysis of the Models
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hong, S.; Han, K.; Park, C.-Y. The triglyceride glucose index is a simple and low-cost marker associated with atherosclerotic cardiovascular disease: A population-based study. BMC Med. 2020, 18, 361. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, H.; Huang, W. Endogenous hyperinsulinemic hypoglycemia: Case series and literature review. Endocrine 2022, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Guemes, M.; Rahman, S.A.; Kapoor, R.R.; Flanagan, S.; Houghton, J.A.L.; Misra, S.; Oliver, N.; Dattani, M.T.; Shah, P. Hyperinsulinemic hypoglycemia in children and adolescents: Recent advances in understanding of pathophysiology and management. Rev. Endocr. Metab. Disord. 2020, 21, 577–597. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, Z.-D.; Hui, P.-P.; Zhang, W.; Zeng, Q.; Zhang, L.; Liu, M.; Yan, J.; Wu, Y.-J.; Sang, Y.-M. Analysis of clinical and genetic characteristics of Chinese children with congenital hyperinsulinemia that is spontaneously relieved. Endocrine 2021, 72, 116–123. [Google Scholar] [CrossRef] [PubMed]
- Jarosinski, M.A.; Dhayalan, B.; Rege, N.; Chatterjee, D.; Weiss, M.A. ‘Smart’ insulin-delivery technologies and intrinsic glucose-responsive insulin analogues. Diabetologia 2021, 64, 1016–1029. [Google Scholar] [CrossRef]
- Mason, I.C.; Qian, J.; Adler, G.K.; Scheer, F.A.J.L. Impact of circadian disruption on glucose metabolism: Implications for type 2 diabetes. Diabetologia 2020, 63, 462–472. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Castillo-López, M.G.; Fernandez, M.F.; Sforza, N.; Barbás, N.C.; Pattin, F.; Mendez, G.; Ogresta, F.; Gondolesi, I.; Schelotto, P.B.; Musso, C.; et al. Hyperinsulinemic hypoglycemia in adolescents: Case report and systematic review. Clin. Diabetes Endocrinol. 2022, 8, 3. [Google Scholar] [CrossRef]
- Korkmaz, F.N.; Canpolat, A.G.; Güllü, S. Determination of insulin-related lipohypertrophy frequency and risk factors in patients with diabetes. Endocrinol. Diabetes Nutr. 2022, 69, 354–361. [Google Scholar] [CrossRef]
- Saleh, M.; Kim, J.Y.; March, C.; Gebara, N.; Arslanian, S. Youth prediabetes and type 2 diabetes: Risk factors and prevalence of dysglycaemia. Pediatr. Obes. 2021, 17, e12841. [Google Scholar] [CrossRef]
- Chen, C.; Zhou, C.; Liu, S.; Jiao, X.; Wang, X.; Zhang, Y.; Yu, X. Association between Suboptimal 25-Hydroxyvitamin D Status and Overweight/Obesity in Infants: A Prospective Cohort Study in China. Nutrients 2022, 14, 4897. [Google Scholar] [CrossRef]
- Qian, E.A.L.; Zhang, F.; Yin, M.; Lei, Q. Cancer metabolism and dietary interventions. Cancer Biol. Med. 2021, 19, 163–174. [Google Scholar] [CrossRef] [PubMed]
- Heresa, S.J.; Evangeline, D.J. Classification of Diabetes Milletus Using Naive Bayes Algorithm. In Intelligence in Big Data Technologies—Beyond the Hype; Peter, J.D., Fernandes, S.L., Alavi, A.H., Eds.; Springer: Singapore, 2021; pp. 401–412. [Google Scholar]
- Jackins, V.; Vimal, S.; Kaliappan, M.; Lee, M.Y. AI-based smart prediction of clinical disease using random forest classifier and Naive Bayes. J. Supercomput. 2020, 77, 5198–5219. [Google Scholar] [CrossRef]
- Mansour, N.A.; Saleh, A.I.; Badawy, M.; Ali, H.A. Accurate detection of Covid-19 patients based on Feature Correlated Naïve Bayes (FCNB) classification strategy. J. Ambient. Intell. Humaniz. Comput. 2021, 13, 41–73. [Google Scholar] [CrossRef] [PubMed]
- Badriyah, T.; Savitri, N.A.; Sa’adah, U.; Syarif, I. Application of Naive Bayes Method for IUGR (Intra Uterine Growth Restriction) Diagnosis on The Pregnancy. In Proceedings of the 2020 International Conference on Electrical, Communication, and Computer Engineering (ICECCE), Istanbul, Turkey, 12–13 June 2020; pp. 1–4. [Google Scholar]
- Ain, K.; Hidayati, H.B.; Nastiti, O.A. Expert System for Stroke Classification Using Naive Bayes Classifier and Certainty Factor as Diagnosis Supporting Device. J. Phys. Conf. Ser. 2020, 1445, 012026. [Google Scholar] [CrossRef]
- Azad, C.; Bhushan, B.; Sharma, R.; Shankar, A.; Singh, K.K.; Khamparia, A. Prediction model using SMOTE, genetic algorithm and decision tree (PMSGD) for classification of diabetes mellitus. Multimed. Syst. 2022, 28, 1289–1307. [Google Scholar] [CrossRef]
- Pathak, A.K.; Valan, J.A. A Predictive Model for Heart Disease Diagnosis Using Fuzzy Logic and Decision Tree. In Smart Computing Paradigms: New Progresses and Challenges; Springer: Berlin/Heidelberg, Germany, 2020; pp. 131–140. [Google Scholar]
- Silahtaroğlu, G.; Yılmaztürk, N. Data analysis in health and big data: A machine learning medical diagnosis model based on patients’ complaints. Commun. Stat.-Theory Methods 2019, 50, 1547–1556. [Google Scholar] [CrossRef]
- Yadav, D.C.; Pal, S. Prediction of thyroid disease using decision tree ensemble method. Hum.-Intell. Syst. Integr. 2020, 2, 89–95. [Google Scholar] [CrossRef] [Green Version]
- Chowdhury, A.R.; Chatterjee, T.; Banerjee, S. A Random Forest classifier-based approach in the detection of abnormalities in the retina. Med. Biol. Eng. Comput. 2018, 57, 193–203. [Google Scholar] [CrossRef]
- Kaur, P.; Kumar, R.; Kumar, M. A healthcare monitoring system using random forest and internet of things (IoT). Multimed. Tools Appl. 2019, 78, 19905–19916. [Google Scholar] [CrossRef]
- Devika, R.; Avilala, S.V.; Subramaniyaswamy, V. Comparative Study of Classifier for Chronic Kidney Disease Prediction Using Naive Bayes, KNN and Random Forest. In Proceedings of the 2019 3rd International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 27–29 March 2019; pp. 679–684. [Google Scholar]
- Benbelkacem, S.; Atmani, B. Random Forests for Diabetes Diagnosis. In Proceedings of the 2019 International Conference on Computer and Information Sciences (ICCIS), Aljouf, Saudi Arabia, 3–4 April 2019; pp. 1–4. [Google Scholar]
- Wang, S.; Wang, Y.; Wang, D.; Yin, Y.; Wang, Y.; Jin, Y. An improved random forest-based rule extraction method for breast cancer diagnosis. Appl. Soft Comput. 2020, 86, 105941. [Google Scholar] [CrossRef]
- Subudhi, A.; Dash, M.; Sabut, S. Automated segmentation and classification of brain stroke using expectation-maximization and random forest classifier. Biocybern. Biomed. Eng. 2020, 40, 277–289. [Google Scholar] [CrossRef]
- Marques, G.; Agarwal, D.; Díez, I.D.L.T. Automated medical diagnosis of COVID-19 through EfficientNet convolutional neural network. Appl. Soft Comput. 2020, 96, 106691. [Google Scholar] [CrossRef] [PubMed]
- Ma, F.; Sun, T.; Liu, L.; Jing, H. Detection and diagnosis of chronic kidney disease using deep learning-based heterogeneous modified artificial neural network. Futur. Gener. Comput. Syst. 2020, 111, 17–26. [Google Scholar] [CrossRef]
- Desai, M.; Shah, M. An anatomization on breast cancer detection and diagnosis employing multi-layer perceptron neural network (MLP) and Convolutional neural network (CNN). Clin. eHealth 2020, 4, 1–11. [Google Scholar] [CrossRef]
- Yu, H.; Yang, L.T.; Zhang, Q.; Armstrong, D.; Deen, M.J. Convolutional neural networks for medical image analysis: State-of-the-art, comparisons, improvement and perspectives. Neurocomputing 2021, 444, 92–110. [Google Scholar] [CrossRef]
- Dey, S.; Wasif, S.; Tonmoy, D.S.; Sultana, S.; Sarkar, J.; Dey, M. Comparative Study of Support Vector Machine and Naive Bayes Classifier for Sentiment Analysis on Amazon Product Reviews. In Proceedings of the 2020 International Conference on Contemporary Computing and Applications (IC3A), Lucknow, India, 5–7 February 2020; pp. 217–220. [Google Scholar]
- Shehab, M.; Abualigah, L.; Shambour, Q.; Abu-Hashem, M.A.; Shambour, M.K.Y.; Alsalibi, A.I.; Gandomi, A.H. Machine learning in medical applications: A review of state-of-the-art methods. Comput. Biol. Med. 2022, 145, 105458. [Google Scholar] [CrossRef]
- Wickramasinghe, I.; Kalutarage, H. Naive Bayes: Applications, variations and vulnerabilities: A review of literature with code snippets for implementation. Soft Comput. 2021, 25, 2277–2293. [Google Scholar] [CrossRef]
- Bhavani, T.T.; Rao, M.K.; Reddy, A.M. Network Intrusion Detection System Using Random Forest and Decision Tree Machine Learning Techniques. In Proceedings of the First International Conference on Sustainable Technologies for Computational Intelligence, Jaipur, India, 29–30 March 2019; pp. 637–643. [Google Scholar]
- Dansana, D.; Kumar, R.; Bhattacharjee, A.; Hemanth, D.J.; Gupta, D.; Khanna, A.; Castillo, O. Early diagnosis of COVID-19-affected patients based on X-ray and computed tomography images using deep learning algorithm. Soft Comput. 2020, 1–9. [Google Scholar] [CrossRef]
- Calzavara, S.; Lucchese, C.; Tolomei, G.; Abebe, S.A.; Orlando, S. Treant: Training evasion-aware decision trees. Data Min. Knowl. Discov. 2020, 34, 1390–1420. [Google Scholar] [CrossRef]
- Yoon, J. Forecasting of Real GDP Growth Using Machine Learning Models: Gradient Boosting and Random Forest Approach. Comput. Econ. 2021, 57, 247–265. [Google Scholar] [CrossRef]
- Palimkar, P.; Shaw, R.N.; Ghosh, A. Machine Learning Technique to Prognosis Diabetes Disease: Random Forest Classifier Approach. In Advanced Computing and Intelligent Technologies; Springer: Berlin/Heidelberg, Germany, 2022; pp. 219–244. [Google Scholar]
- Chen, T.; Zhu, L.; Niu, R.-Q.; Trinder, C.J.; Peng, L.; Lei, T. Mapping landslide susceptibility at the Three Gorges Reservoir, China, using gradient boosting decision tree, random forest and information value models. J. Mt. Sci. 2020, 17, 670–685. [Google Scholar] [CrossRef]
- Rankovic, N.; Rankovic, D.; Ivanovic, M.; Lazic, L. Improved Effort and Cost Estimation Model Using Artificial Neural Networks and Taguchi Method with Different Activation Functions. Entropy 2021, 23, 854. [Google Scholar] [CrossRef] [PubMed]
- Rankovic, N.; Rankovic, D.; Ivanovic, M.; Lazic, L. A New Approach to Software Effort Estimation Using Different Artificial Neural Network Architectures and Taguchi Orthogonal Arrays. IEEE Access 2021, 9, 26926–26936. [Google Scholar] [CrossRef]
- Rankovic, N.; Rankovic, D.; Ivanovic, M.; Lazic, L. Influence of input values on the prediction model error using artificial neural network based on Taguchi’s orthogonal array. Concurr. Comput. Pract. Exp. 2022, 34, e6831. [Google Scholar] [CrossRef]
- Rankovic, N.; Rankovic, D.; Ivanovic, M.; Lazic, L. A Novel UCP Model Based on Artificial Neural Networks and Orthogonal Arrays. Appl. Sci. 2021, 11, 8799. [Google Scholar] [CrossRef]
- Ranković, N.; Ranković, D.; Ivanović, M.; Lazić, L. Artificial Neural Network Architecture and Orthogonal Arrays in Estimation of Software Projects Efforts. In Proceedings of the 2021 International Conference on Innovations in intelligent Systems and Applications (INISTA), Kocaeli, Turkey, 25–27 August 2021; pp. 1–6. [Google Scholar]
- Rankovic, N.; Rankovic, D.; Ivanovic, M.; Lazic, L. COSMIC FP method in software development estimation using artificial neural networks based on orthogonal arrays. Connect. Sci. 2021, 34, 185–204. [Google Scholar] [CrossRef]
- Rankovic, D.; Rankovic, N.; Ivanovic, M.; Lazic, L. The Generalization of Selection of an Appropriate Artificial Neural Network to Assess the Effort and Costs of Software Projects. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Hersonissos, Greece, 17–20 June 2022; pp. 420–431. [Google Scholar]
- Thomas, D.D.; Corkey, B.E.; Istfan, N.W.; Apovian, C.M. Hyperinsulinemia: An Early Indicator of Metabolic Dysfunction. J. Endocr. Soc. 2019, 3, 1727–1747. [Google Scholar] [CrossRef]
- Lawson, L.M.; Hamner, K.; Oligbo, M. Feasibility of the Children’s Health Questionnaire for Measuring Outcomes of Recreational Therapy Interventions in Autism Populations. Ther. Recreat. J. 2021, 55, 249–263. [Google Scholar] [CrossRef]
- Pothirat, C.; Chaiwong, W.; Liwsrisakun, C.; Phetsuk, N.; Theerakittikul, T.; Choomuang, W.; Chanayart, P. Reliability of the Thai version of the International Physical Activity Questionnaire Short Form in chronic obstructive pulmonary disease. J. Bodyw. Mov. Ther. 2021, 27, 55–59. [Google Scholar] [CrossRef]
- Bajorek, K.; Martin, M.; Palumbo, J.S.; Tarango, C.; Mullins, E.S.; Luchtman-Jones, L. Do Family History Questions Improve the Predictive Value of a Standardized Pediatric Bleeding Assessment Tool? Blood 2021, 138, 2111. [Google Scholar] [CrossRef]
- Putri, B.D.; Handayani, N.S.; Ekayafita, S.Z.; Lestari, A.D. The Indonesian Version of SF-36 Questionnaire: Validity and Reliability Testing in Indonesian Healthcare Workers Who Handle Infectious Diseases. Indian J. Forensic Med. Toxicol. 2021, 15, 2114–2121. [Google Scholar] [CrossRef]
- Madeira, I.R.; Carvalho, C.N.M.; Gazolla, F.M.; Matos, H.J.; de Borges, M.A.; Bordallo, M.A.N. Cut-off point for Homeostatic Model Assessment for Insulin Resistance (HOMA-IR) index established from Receiver Operating Characteristic (ROC) curve in the detection of metabolic syndrome in overweight pre-pubertal children. Arq. Bras. Endocrinol. Metabol. 2008, 52, 1466–1473. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ottwell, R.; Cook, C.; Greiner, B.; Hoang, N.; Beswick, T.; Hartwell, M. Lifestyle behaviors and sun exposure among individuals diagnosed with skin cancer: A cross-sectional analysis of 2018 BRFSS data. J. Cancer Surviv. 2021, 15, 792–798. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ANN-L27 | W1 | W2 | W3 | W4 | W5 | W6 | W7 | W8 | W9 | W10 | W11 | W12 | W13 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ANN1 | L1 | L1 | L1 | L1 | L1 | L1 | L1 | L1 | L1 | L1 | L1 | L1 | L1 |
| ANN2 | L1 | L1 | L1 | L1 | L2 | L2 | L2 | L2 | L2 | L2 | L2 | L2 | L2 |
| ANN3 | L1 | L1 | L1 | L1 | L3 | L3 | L3 | L3 | L3 | L3 | L3 | L3 | L3 |
| ANN4 | L1 | L2 | L2 | L2 | L1 | L1 | L1 | L2 | L2 | L2 | L3 | L3 | L3 |
| ANN5 | L1 | L2 | L2 | L2 | L2 | L2 | L2 | L3 | L3 | L3 | L1 | L1 | L1 |
| ANN6 | L1 | L2 | L2 | L2 | L1 | L1 | L1 | L3 | L3 | L3 | L2 | L2 | L2 |
| ANN7 | L1 | L3 | L3 | L3 | L1 | L1 | L1 | L3 | L3 | L3 | L2 | L2 | L2 |
| ANN8 | L1 | L3 | L3 | L3 | L2 | L2 | L2 | L1 | L1 | L1 | L3 | L3 | L3 |
| ANN9 | L1 | L3 | L3 | L3 | L3 | L3 | L3 | L2 | L2 | L2 | L1 | L1 | L1 |
| ANN10 | L2 | L1 | L2 | L3 | L1 | L2 | L3 | L1 | L2 | L3 | L1 | L2 | L3 |
| ANN11 | L2 | L1 | L2 | L3 | L2 | L3 | L1 | L2 | L3 | L1 | L2 | L3 | L1 |
| ANN12 | L2 | L1 | L2 | L3 | L3 | L1 | L2 | L3 | L1 | L2 | L3 | L1 | L2 |
| ANN13 | L2 | L2 | L3 | L1 | L1 | L2 | L3 | L2 | L3 | L1 | L3 | L1 | L2 |
| ANN14 | L2 | L2 | L3 | L1 | L2 | L3 | L1 | L3 | L1 | L2 | L1 | L2 | L3 |
| ANN15 | L2 | L2 | L3 | L1 | L3 | L1 | L2 | L1 | L2 | L3 | L2 | L3 | L1 |
| ANN16 | L2 | L3 | L1 | L2 | L1 | L2 | L3 | L3 | L1 | L2 | L2 | L3 | L1 |
| ANN17 | L2 | L3 | L1 | L2 | L2 | L3 | L1 | L1 | L2 | L3 | L3 | L1 | L2 |
| ANN18 | L2 | L3 | L1 | L2 | L3 | L1 | L2 | L2 | L3 | L1 | L1 | L2 | L3 |
| ANN19 | L3 | L1 | L3 | L2 | L1 | L3 | L2 | L1 | L3 | L2 | L1 | L3 | L2 |
| ANN20 | L3 | L1 | L3 | L2 | L2 | L1 | L3 | L2 | L1 | L3 | L2 | L1 | L3 |
| ANN21 | L3 | L1 | L3 | L2 | L3 | L2 | L1 | L3 | L2 | L1 | L3 | L2 | L1 |
| ANN22 | L3 | L2 | L1 | L3 | L1 | L3 | L2 | L2 | L1 | L3 | L3 | L2 | L1 |
| ANN23 | L3 | L2 | L1 | L3 | L2 | L1 | L3 | L3 | L2 | L1 | L1 | L3 | L2 |
| ANN24 | L3 | L2 | L1 | L3 | L3 | L2 | L1 | L1 | L3 | L2 | L2 | L1 | L3 |
| ANN25 | L3 | L3 | L2 | L1 | L1 | L3 | L2 | L3 | L2 | L1 | L2 | L1 | L3 |
| ANN26 | L3 | L3 | L2 | L1 | L2 | L1 | L3 | L1 | L3 | L2 | L3 | L2 | L1 |
| ANN27 | L3 | L3 | L2 | L1 | L3 | L2 | L1 | L2 | L1 | L3 | L1 | L3 | L2 |
| ANN-L12 | W1 | W2 | W3 | W4 | W5 | W6 | W7 | W8 | W9 | W10 | W11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ANN1 | L1 | L1 | L1 | L1 | L1 | L1 | L1 | L1 | L1 | L1 | L1 |
| ANN2 | L1 | L1 | L1 | L1 | L1 | L2 | L2 | L2 | L2 | L2 | L2 |
| ANN3 | L1 | L1 | L2 | L2 | L2 | L1 | L1 | L1 | L2 | L2 | L2 |
| ANN4 | L1 | L2 | L1 | L2 | L2 | L1 | L2 | L2 | L1 | L1 | L2 |
| ANN5 | L1 | L2 | L2 | L1 | L2 | L2 | L1 | L2 | L1 | L2 | L1 |
| ANN6 | L1 | L2 | L2 | L2 | L1 | L2 | L2 | L1 | L2 | L1 | L1 |
| ANN7 | L2 | L1 | L2 | L2 | L1 | L1 | L2 | L2 | L1 | L2 | L1 |
| ANN8 | L2 | L1 | L2 | L1 | L2 | L2 | L2 | L1 | L1 | L1 | L2 |
| ANN9 | L2 | L1 | L1 | L2 | L2 | L2 | L1 | L2 | L2 | L1 | L1 |
| ANN10 | L2 | L2 | L2 | L1 | L1 | L1 | L1 | L2 | L2 | L1 | L2 |
| ANN11 | L2 | L2 | L1 | L2 | L1 | L2 | L1 | L1 | L1 | L2 | L2 |
| ANN12 | L2 | L2 | L1 | L1 | L2 | L1 | L2 | L1 | L2 | L2 | L1 |
| ANN-L16 | W1 | W2 | W3 | W4 | W5 | W6 | W7 | W8 | W9 | W10 | W11 | W12 | W13 | W14 | W15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ANN1 | L1 | L1 | L1 | L1 | L1 | L1 | L1 | L1 | L1 | L1 | L1 | L1 | L1 | L1 | L1 |
| ANN2 | L1 | L1 | L1 | L1 | L1 | L1 | L1 | L2 | L2 | L2 | L2 | L2 | L2 | L2 | L2 |
| ANN3 | L1 | L1 | L1 | L2 | L2 | L2 | L2 | L1 | L1 | L1 | L1 | L2 | L2 | L2 | L2 |
| ANN4 | L1 | L1 | L1 | L1 | L2 | L2 | L2 | L2 | L2 | L2 | L2 | L1 | L1 | L1 | L1 |
| ANN5 | L1 | L2 | L2 | L1 | L1 | L2 | L2 | L1 | L1 | L2 | L2 | L1 | L1 | L2 | L2 |
| ANN6 | L1 | L2 | L2 | L1 | L1 | L2 | L2 | L2 | L2 | L1 | L1 | L2 | L2 | L1 | L1 |
| ANN7 | L1 | L2 | L2 | L2 | L2 | L1 | L1 | L1 | L1 | L2 | L2 | L2 | L2 | L1 | L1 |
| ANN8 | L1 | L2 | L2 | L2 | L2 | L1 | L1 | L2 | L2 | L1 | L1 | L1 | L1 | L2 | L2 |
| ANN9 | L2 | L1 | L2 | L1 | L2 | L1 | L2 | L1 | L2 | L1 | L2 | L1 | L2 | L1 | L2 |
| ANN10 | L2 | L1 | L2 | L1 | L2 | L1 | L2 | L2 | L1 | L2 | L1 | L2 | L1 | L2 | L1 |
| ANN11 | L2 | L1 | L2 | L2 | L1 | L2 | L1 | L1 | L2 | L1 | L2 | L2 | L1 | L2 | L1 |
| ANN12 | L2 | L1 | L2 | L2 | L1 | L2 | L1 | L2 | L1 | L2 | L1 | L1 | L2 | L1 | L2 |
| ANN13 | L2 | L2 | L1 | L1 | L2 | L2 | L1 | L1 | L2 | L2 | L1 | L1 | L2 | L2 | L1 |
| ANN14 | L2 | L2 | L1 | L1 | L2 | L2 | L1 | L2 | L1 | L1 | L2 | L2 | L1 | L1 | L2 |
| ANN15 | L2 | L2 | L1 | L2 | L1 | L1 | L2 | L1 | L2 | L2 | L1 | L2 | L1 | L1 | L2 |
| ANN16 | L2 | L2 | L1 | L2 | L1 | L1 | L2 | L2 | L1 | L1 | L2 | L1 | L2 | L2 | L1 |
| Sample Structure | ||||
|---|---|---|---|---|
| Experimental Group | Control Group | |||
| Gender | Number | Percentage(%) | Number | Percentage(%) |
| male | 108 | 48.2 | 228 | 50.9 |
| female | 116 | 51.8 | 220 | 49.1 |
| Total | 224 | 100.0 | 448 | 100.0 |
| Age | Number | Percentage(%) | Number | Percentage(%) |
| 12–14 | 108 | 48.2 | 228 | 50.9 |
| 14–17 | 116 | 51.8 | 220 | 49.1 |
| Total | 224 | 100.0 | 448 | 100.0 |
| Region | Number | Percentage(%) | Number | Percentage(%) |
| Kolubara district | 224 | 100.0 | 448 | 100.0 |
| OGTT | Experimental Group | Control Group | Student t Test | p |
|---|---|---|---|---|
| Glucose in 0 min (mmol/L) | ± 1.1 | ± 0.9 | 2.026 | 0.026 * |
| Glucose in 30 min (mmol/L) | ± 1.3 | ± | 2.844 | 0.006 * |
| Glucose in 60 min (mmol/L) | ± 1.4 | ± 1.2 | 5.124 | 0.000 * |
| Glucose in 90 min (mmol/L) | ± 1.3 | ± 1.3 | 2.895 | 0.008 * |
| Glucose in 120 min (mmol/L) | ± | ± | 2.387 | 0.017 * |
| Insuline in 0 min (μIU/mL) | ± | ± | 7.264 | 0.000 * |
| Insuline in 30 min (μIU/mL) | ± | ± | 118.371 | 0.000 * |
| Insuline in 60 min (μIU/mL) | ± | ± | 84.625 | 0.000 * |
| Insuline in 90 min (μIU/mL) | ± | ± | 81.814 | 0.000 * |
| Insuline in 120 min (μIU/mL) | ± | ± | 6.078 | 0.000 * |
| HOMA-IR | ± | ± | 4.680 | 0.000 * |
| Gender | Experimental Group | Control Group | Kruskal–Wallis H | p | ||
|---|---|---|---|---|---|---|
| Male | Female | Male | Female | |||
| Leukocytes WBC | ± 2.7 | ± 3.5 | ± 2.4 | ± 3.3 | 13.322 | 0.001 * |
| Erythrocytes RBC | ± 1.5 | ± 2.1 | ± 2.5 | ± 2.6 | 10.956 | 0.004 * |
| Hemoglobin Hgb | ± 5 | ± 7 | ± 5 | ± 4 | 5.735 | 0.017 * |
| Hematocrit Htc | ± 0.6 | ± 0.9 | ± 0.5 | ± 0.7 | 4.725 | 0.030 * |
| MCV | ± 10.3 | ± 11.7 | ± 12.2 | ± 9.4 | 0.997 | 0.318 |
| MCH | ± 3.3 | ± 4.5 | ± | ± 3.6 | 2.735 | 0.098 |
| MCHC | ± 17.6 | ± 18.9 | ± 12.3 | ± 15.7 | 0.525 | 0.769 |
| RDW | ± 2.7 | ± 3.1 | ± 2.8 | ± 3.6 | 1.925 | 0.165 |
| Platelets PLT | ± 67.2 | ± 84.4 | ± 58.3 | ± 62.4 | 12.023 | 0.003 * |
| Segmented | ± 6.8 | ± 7.9 | ± | ± 7.5 | 0.752 | 0.386 |
| MID | ± 1.5 | ± 2.4 | ± 1.4 | ± 1.9 | 0.851 | 0.356 |
| Lymphocytes | ± 3.3 | ± 3.8 | ± 3.1 | ± 3.5 | 3.847 | 0.043 * |
| Sedimentation | ± 2.2 | ± 2.5 | ± 1.8 | ± 2.4 | 4.205 | 0.036 * |
| CRP | ± 5.3 | ± 6.7 | ± 4.2 | ± 77.9 | 149.599 | 0.000 * |
| Glucose | ± 1.6 | ± 2.6 | ± 1.3 | ± 1.8 | 4.829 | 0.024 * |
| Cholesterol | ± 4.2 | ± 5.4 | ± 3.6 | ± 4.4 | 87.774 | 0.000 * |
| HDL Cholesterol | ± 0.5 | ± 0.7 | ± 0.6 | ± 0.6 | 73.497 | 0.000 * |
| LDL Cholesterol | ± 1.2 | ± 1.7 | ± 1.3 | ± 1.5 | 55.961 | 0.000 * |
| Triglycerides | ± 2.8 | ± 3.4 | ± 2.6 | ± 3.3 | 23.980 | 0.000 * |
| Urea | ± 3.2 | ± 4.3 | ± 2.5 | ± 3.6 | 5.024 | 0.018 * |
| Creatinine | ± 11.5 | ± 14.3 | ± 9.6 | ± 10.0 | 4.527 | 0.027 * |
| Proteins total | ± 3.5 | ± 4.4 | ± 3.2 | ± 3.3 | 8.323 | 0.007 * |
| Bilirubin total | ± 4.3 | ± 5.2 | ± 3.8 | ± 4.1 | 6.024 | 0.016 * |
| AST(SGOT) | ± 3.2 | ± 3.9 | ± 2.8 | ± 3.1 | 4.418 | 0.023 * |
| ALT(SGPT) | ± 4.5 | ± 5.7 | ± 3.6 | ± 4.2 | 6.134 | 0.019 * |
| Sodium | ± 14.2 | ± 16.3 | ± 11.5 | ± 13.8 | 4.324 | 0.031 * |
| Potassium | ± 1.4 | ± 1.9 | ± 1.2 | ± 1.3 | 5.235 | 0.024 * |
| Chlorides | ± 9 | ± 13 | ± 9 | ± 11 | 7.456 | 0.012 * |
| Parameters | Mean ± SD N(%) | Mean ± SD N(%) | ANOVA | p |
|---|---|---|---|---|
| Body height | ± | ± | 2.841 | 0.032 * |
| Body weight | ± | 56.4 ± | 3.269 | 0.005 * |
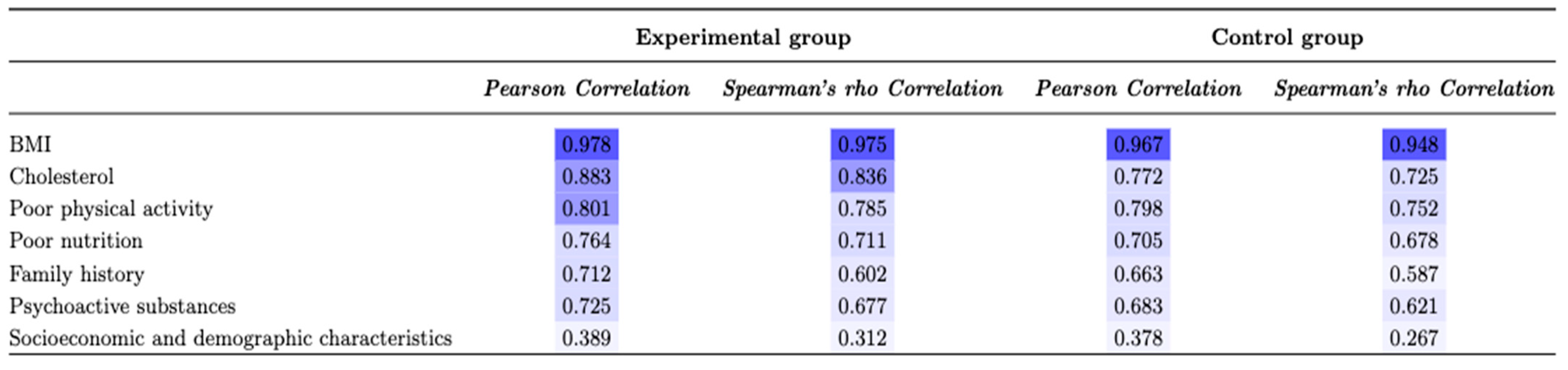
| BMI | ± | ± | 3.841 | 0.003 * |
| Cholesterol | 87 (77.7) | 129 (57.6) | 8.645 | 0.000 * |
| Poor physical activity | 78 (69.6) | 136 (60.7) | 2.0158 | 0.021 * |
| Poor nutrition | 65 (58.0) | 102 (45.6) | 3.040 | 0.020 * |
| Family history | 55 (49.1) | 93 (41.5) | 4.335 | 0.027 * |
| Psychoactive substances | 43 (38.4) | 78 (34.8) | 2.013 | 0.031 * |
| Socioeconomic and demographic characteristics | 27 (24.1) | 51 (22.8) | 1.492 | 0.221 |
| Self-assessment of one’s own health condition | 55 (49.1) | 123 (54.9) | 3.812 | 0.018 * |
| Risk Factors | Factorial Analysis | ANN-L | Naïve Bayes | Decision Tree | Random Forest |
|---|---|---|---|---|---|
| BMI | 35.8 | 33.4 | 32.7 | 32.8 | 33.5 |
| High Cholesterol | 15.3 | 16.6 | 16.7 | 16.6 | 16.9 |
| Poor physical activity | 14.1 | 14.5 | 14.8 | 14.6 | 13.6 |
| Poor Nutrition | 12.0 | 11.8 | 11.3 | 11.6 | 11.2 |
| Family history | 9.0 | 8.9 | 9.0 | 10.2 | 9.1 |
| Psychoactive substances | 7.2 | 8.0 | 8.8 | 7.4 | 9.0 |
| Other factors | 6.7 | 6.8 | 6.7 | 6.8 | 6.7 |
| MMRE | 1.3% | 0.5% | 0.9% | 1.1% | 0.8% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rankovic, N.; Rankovic, D.; Lukic, I. Innovation in Hyperinsulinemia Diagnostics with ANN-L(atin square) Models. Diagnostics 2023, 13, 798. https://doi.org/10.3390/diagnostics13040798
Rankovic N, Rankovic D, Lukic I. Innovation in Hyperinsulinemia Diagnostics with ANN-L(atin square) Models. Diagnostics. 2023; 13(4):798. https://doi.org/10.3390/diagnostics13040798
Chicago/Turabian StyleRankovic, Nevena, Dragica Rankovic, and Igor Lukic. 2023. "Innovation in Hyperinsulinemia Diagnostics with ANN-L(atin square) Models" Diagnostics 13, no. 4: 798. https://doi.org/10.3390/diagnostics13040798
APA StyleRankovic, N., Rankovic, D., & Lukic, I. (2023). Innovation in Hyperinsulinemia Diagnostics with ANN-L(atin square) Models. Diagnostics, 13(4), 798. https://doi.org/10.3390/diagnostics13040798