




A Systematic Review of Application Progress on Machine Learning-Based Natural Language Processing in Breast Cancer over the Past 5 Years


Abstract
1. Introduction
Contributions
- We have summarized a comprehensive NLP pipeline for applications in breast cancer;
- We have produced a detailed introduction to the mainstream models of NLP applications in breast cancer;
- We have concluded the challenges of applications of NLP in breast cancer;
- We have presented the future trends of NLP in breast cancer.
2. Theoretical Foundation
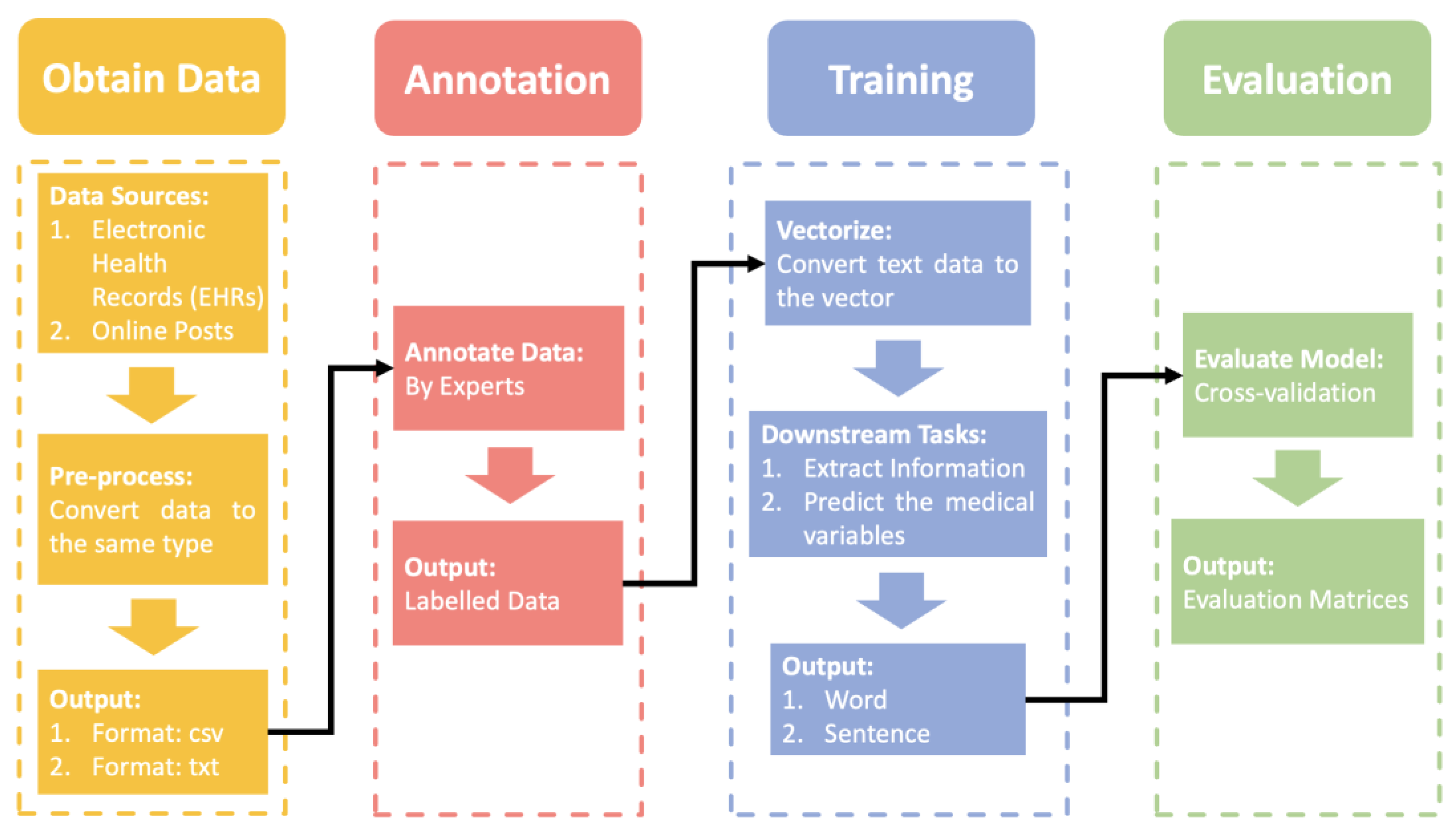
NLP Pipeline
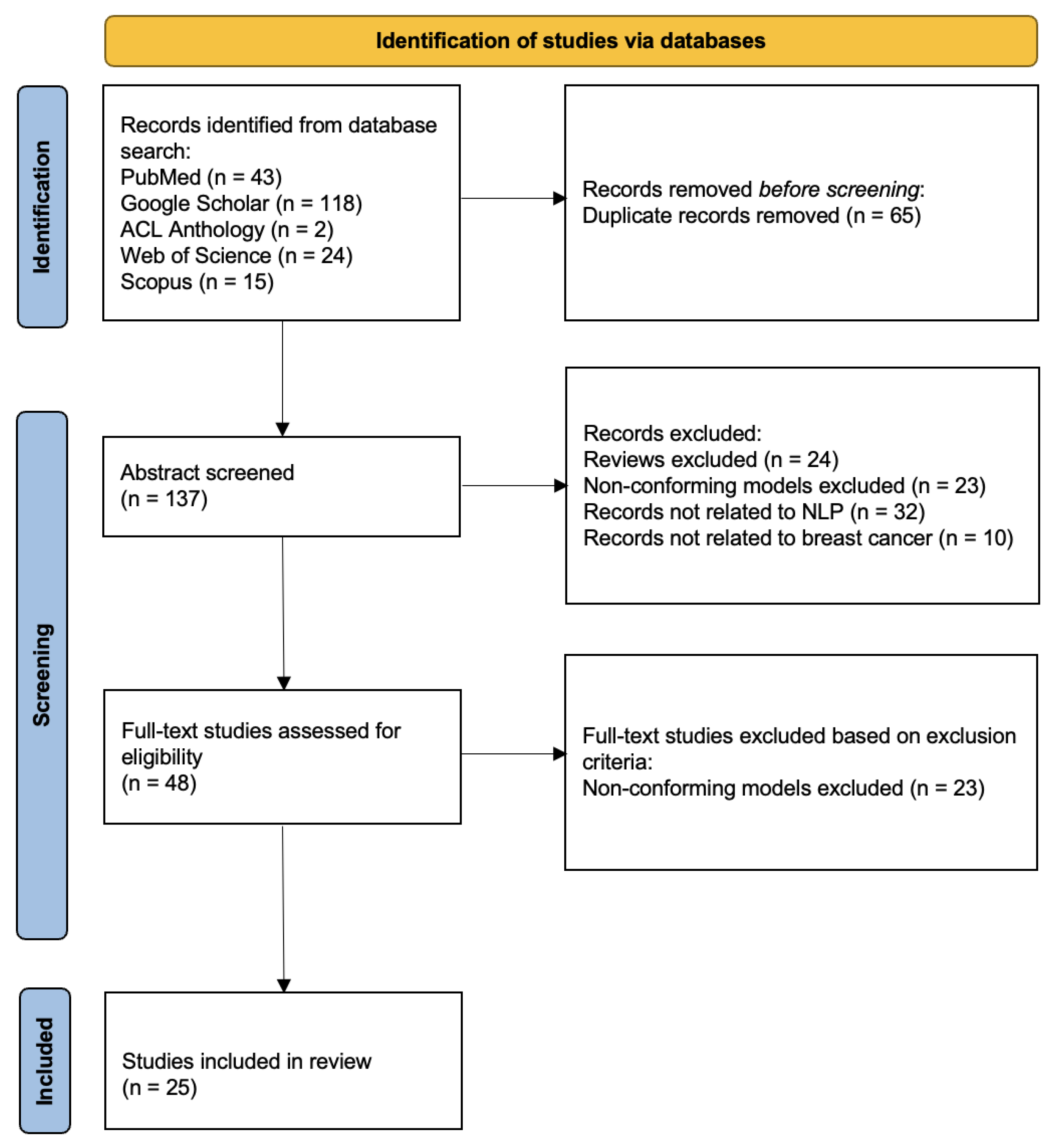
3. Materials and Methods
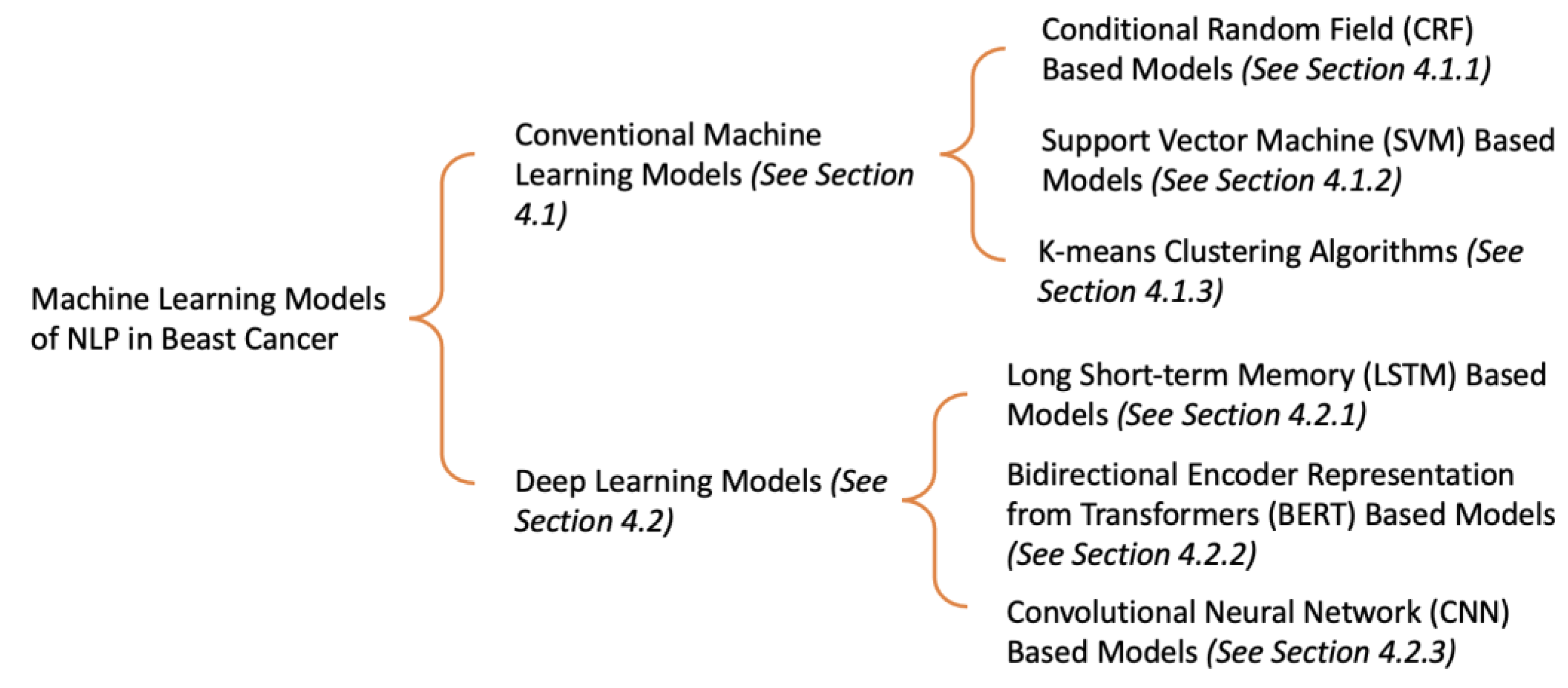
4. Results
4.1. Conventional Machine Learning Models
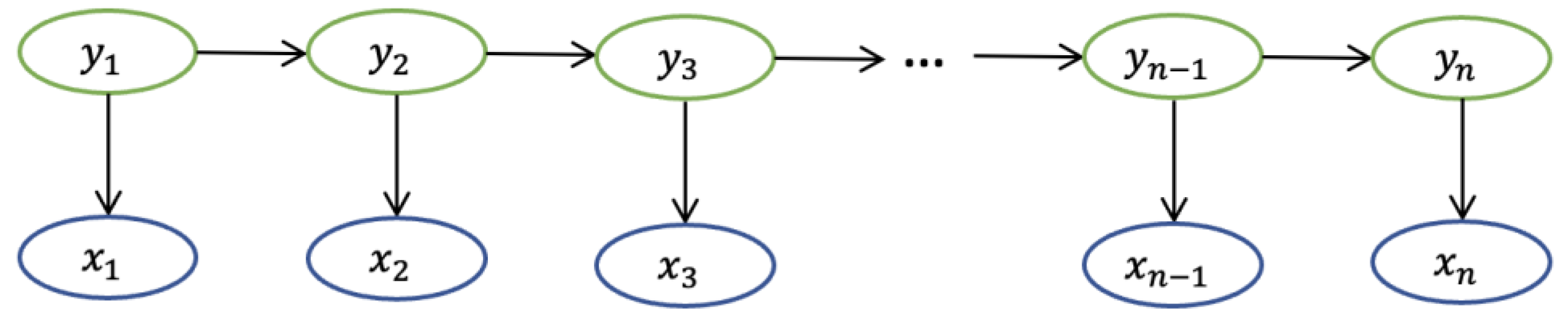
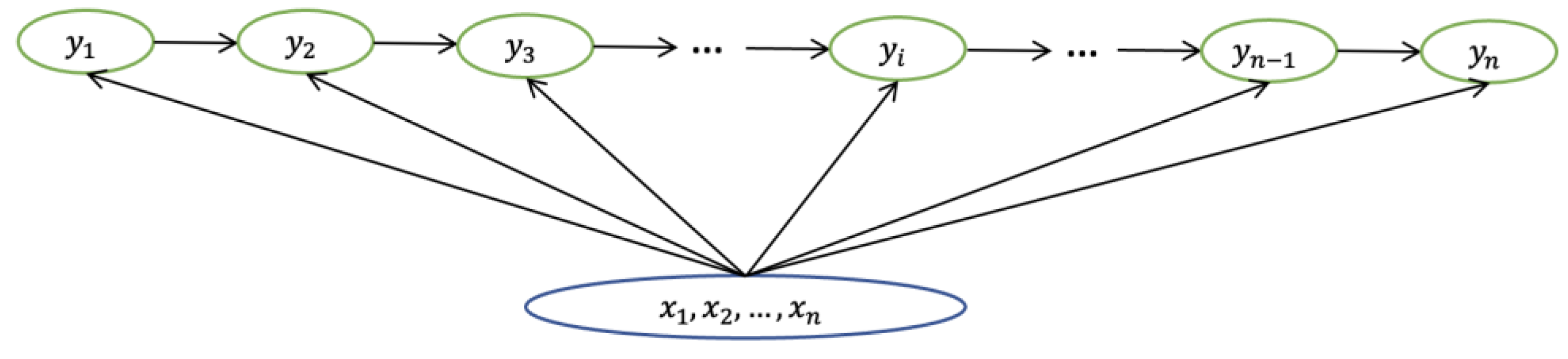
4.1.1. CRF
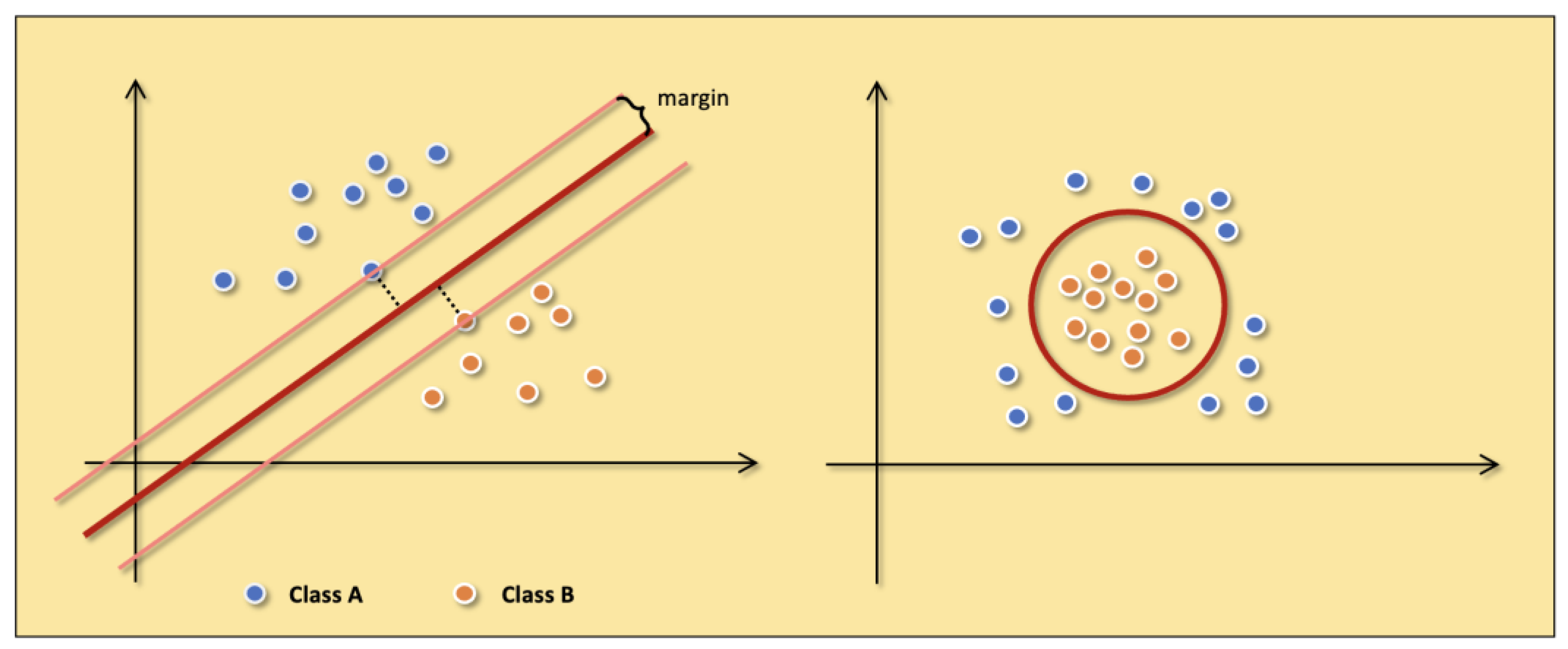
4.1.2. SVM
4.1.3. K-means
4.2. Deep Learning Models
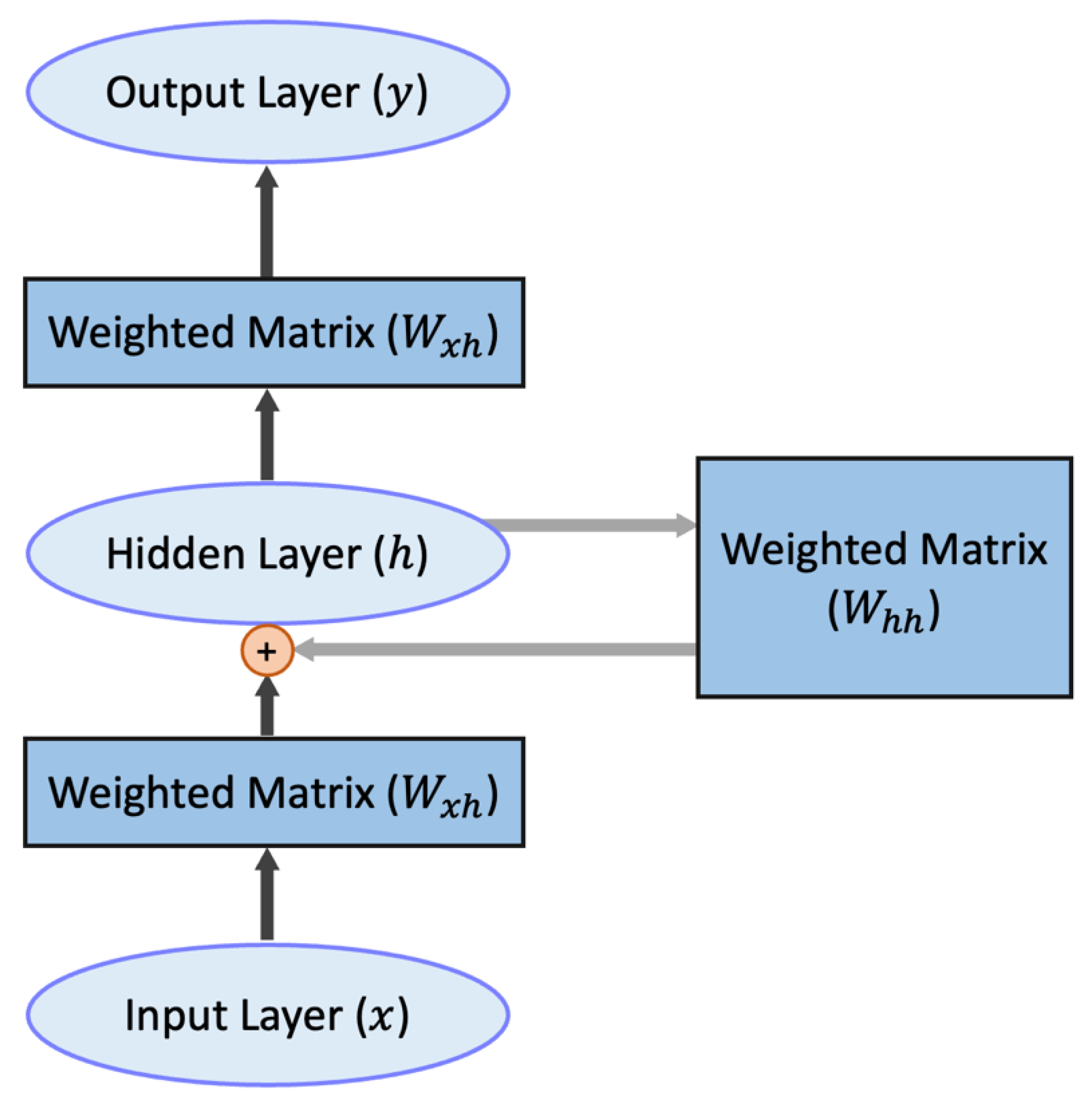
4.2.1. LSTM
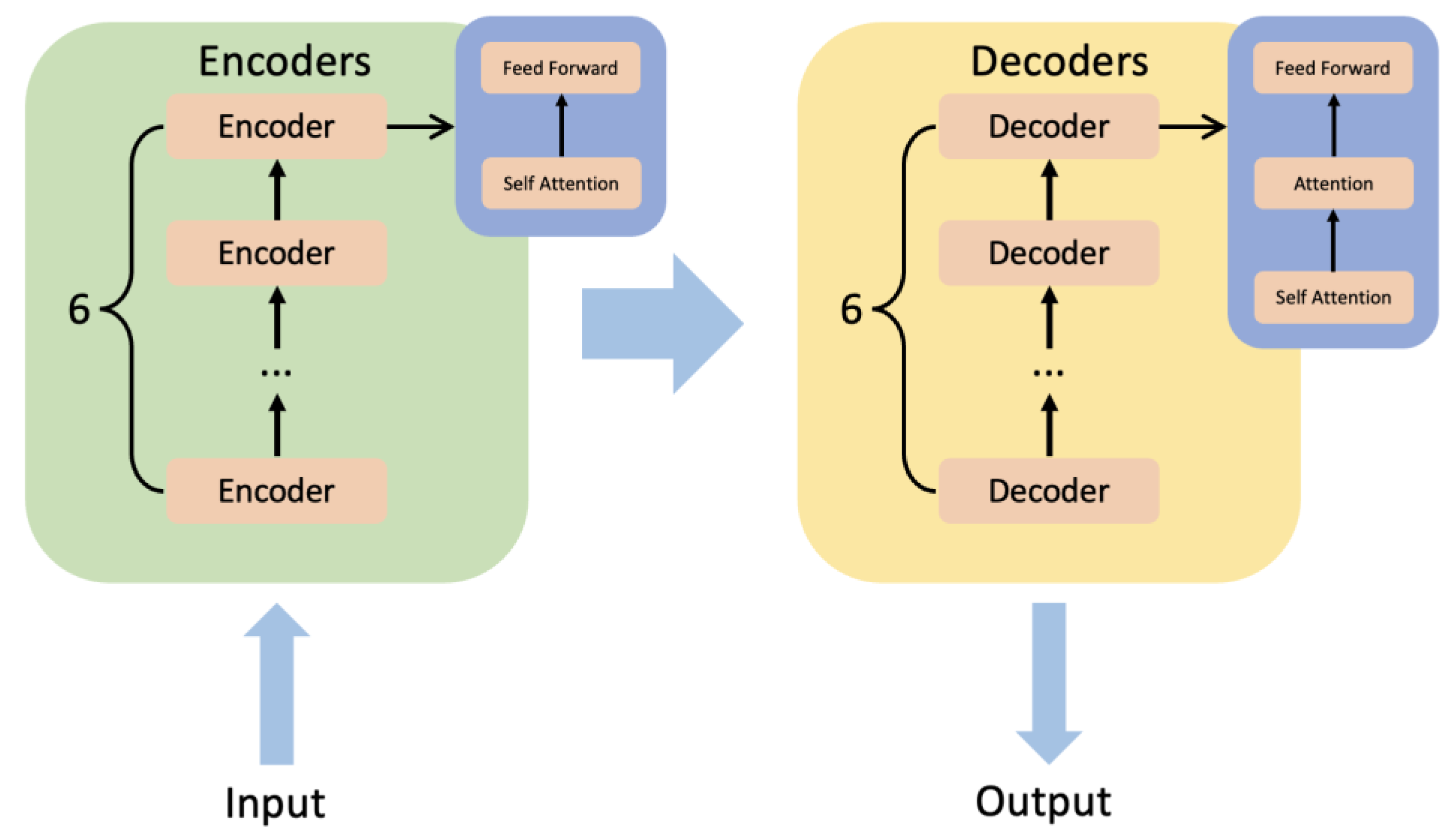
4.2.2. BERT
4.2.3. CNN
5. Discussion
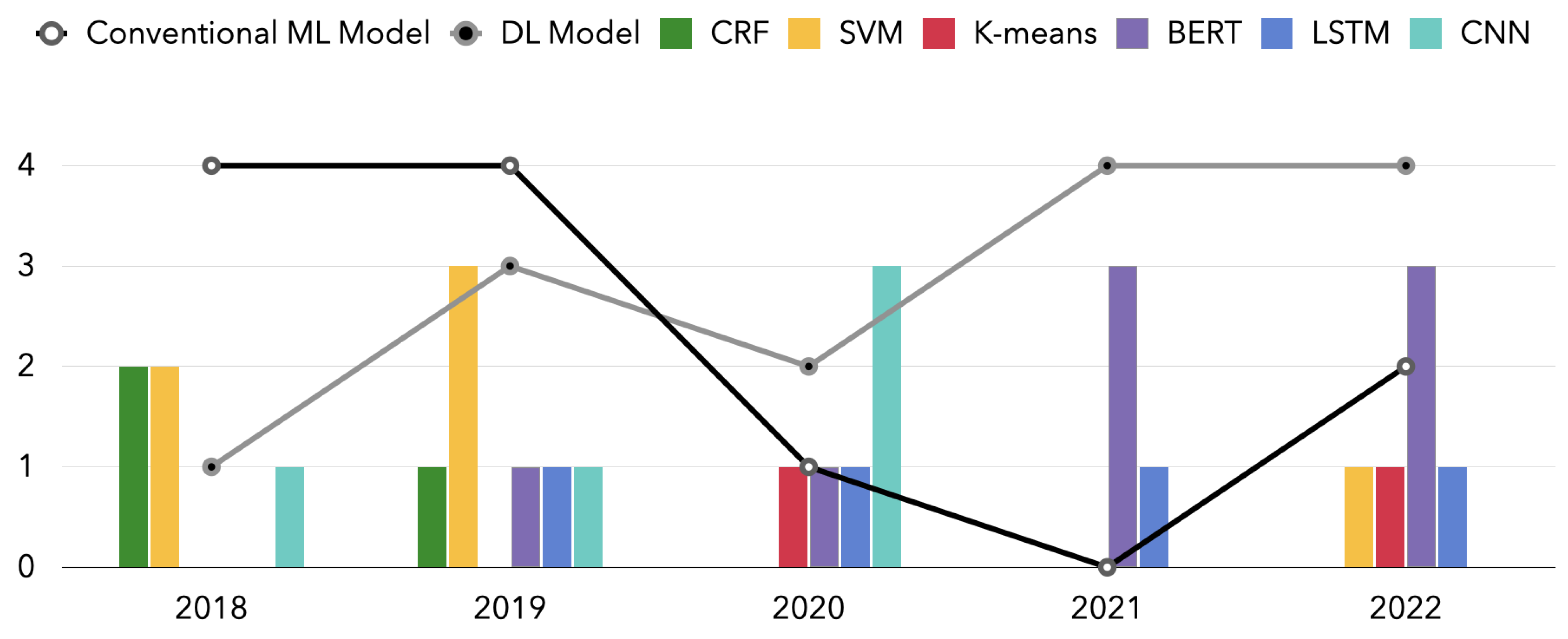
5.1. Models over the Years
5.2. Dataset Information
5.3. Challenges
5.4. Future Directions
5.4.1. Semi-Supervised Learning
5.4.2. Active Learning
5.4.3. Transfer Learning
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bray, F.; Ferlay, J.; Soerjomataram, I.; Siegel, R.L.; Torre, L.A.; Jemal, A. Global Cancer Statistics 2018: GLOBOCAN Estimates of Incidence and Mortality Worldwide for 36 Cancers in 185 Countries. CA Cancer J. Clin. 2018, 68, 394–424. [Google Scholar] [CrossRef] [PubMed]
- Allahqoli, L.; Mazidimoradi, A.; Momenimovahed, Z.; Rahmani, A.; Hakimi, S.; Tiznobaik, A.; Gharacheh, M.; Salehiniya, H.; Babaey, F.; Alkatout, I. The Global Incidence, Mortality, and Burden of Breast Cancer in 2019: Correlation with Smoking, Drinking, and Drug Use. Front. Oncol. 2022, 12, 921015. [Google Scholar] [CrossRef] [PubMed]
- Giaquinto, A.N.; Sung, H.; Miller, K.D.; Kramer, J.L.; Newman, L.A.; Minihan, A.; Jemal, A.; Siegel, R.L. Breast Cancer Statistics, 2022. CA Cancer J. Clin. 2022, 72, 524–541. [Google Scholar] [CrossRef] [PubMed]
- Franceschini, G.; Mason, E.J.; Orlandi, A.; D’Archi, S.; Sanchez, A.M.; Masetti, R. How Will Artificial Intelligence Impact Breast Cancer Research Efficiency? Expert Rev. Anticancer Ther. 2021, 21, 1067–1070. [Google Scholar] [CrossRef]
- Chahal, A.; Gulia, P. Machine Learning and Deep Learning. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 4910–4914. [Google Scholar] [CrossRef]
- Mitchell, T.; Buchanan, B.; DeJong, G.; Dietterich, T.; Rosenbloom, P.; Waibel, A. Machine Learning. Annu. Rev. Comput. Sci. 1990, 4, 417–433. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Rajkomar, A.; Dean, J.; Kohane, I. Machine Learning in Medicine. New Engl. J. Med. 2019, 380, 1347–1358. [Google Scholar] [CrossRef]
- Tang, R.; Ouyang, L.; Li, C.; He, Y.; Griffin, M.; Taghian, A.; Smith, B.; Yala, A.; Barzilay, R.; Hughes, K. Machine Learning to Parse Breast Pathology Reports in Chinese. Breast Cancer Res. Treat 2018, 169, 243–250. [Google Scholar] [CrossRef]
- Watanabe, T.; Yada, S.; Aramaki, E.; Yajima, H.; Kizaki, H.; Hori, S. Extracting Multiple Worries from Breast Cancer Patient Blogs Using Multilabel Classification with the Natural Language Processing Model Bidirectional Encoder Representations from Transformers: Infodemiology Study of Blogs. JMIR Cancer 2022, 8, e37840. [Google Scholar] [CrossRef]
- Han, C.; Rundo, L.; Murao, K.; Nemoto, T.; Nakayama, H. Bridging the Gap between AI and Healthcare Sides: Towards Developing Clinically Relevant AI-Powered Diagnosis Systems. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Neos Marmaras, Greece, 5–7 June 2020; pp. 320–333. [Google Scholar]
- Wang, J.; Deng, H.; Liu, B.; Hu, A.; Liang, J.; Fan, L.; Zheng, X.; Wang, T.; Lei, J. Systematic Evaluation of Research Progress on Natural Language Processing in Medicine over the Past 20 Years: Bibliometric Study on PubMed. J. Med. Internet Res. 2020, 22, e16816. [Google Scholar] [CrossRef] [PubMed]
- Datta, S.; Bernstam, E.V.; Roberts, K. A Frame Semantic Overview of NLP-Based Information Extraction for Cancer-Related EHR Notes. J. Biomed. Inform. 2019, 100, 103301. [Google Scholar] [CrossRef]
- Savova, G.K.; Danciu, I.; Alamudun, F.; Miller, T.; Lin, C.; Bitterman, D.S.; Tourassi, G.; Warner, J.L. Use of Natural Language Processing to Extract Clinical Cancer Phenotypes from Electronic Medical RecordsNatural Language Processing for Cancer Phenotypes from EMRs. Cancer Res. 2019, 79, 5463–5470. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Zhang, Y.; Weng, Y.; Wang, B.; Li, Z. Natural Language Processing Applications for Computer-Aided Diagnosis in Oncology. Diagnostics 2023, 13, 286. [Google Scholar] [CrossRef] [PubMed]
- Kreimeyer, K.; Foster, M.; Pandey, A.; Arya, N.; Halford, G.; Jones, S.F.; Forshee, R.; Walderhaug, M.; Botsis, T. Natural Language Processing Systems for Capturing and Standardizing Unstructured Clinical Information: A Systematic Review. J. Biomed. Inform. 2017, 73, 14–29. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Zhang, Y.; Jin, R.; Zhou, Z.-H. Understanding Bag-of-Words Model: A Statistical Framework. Int. J. Mach. Learn. Cybern. 2010, 1, 43–52. [Google Scholar] [CrossRef]
- Lafferty, J.; McCallum, A.; Pereira, F.C.N. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the 18th International Conference on Machine Learning 2001 (ICML 2001), Williamstown, MA, USA, 28 June–1 July 2001. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-Means Clustering Algorithm. J. R. Stat. Soc. Ser. C Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- O’Shea, K.; Nash, R. An Introduction to Convolutional Neural Networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Gagniuc, P.A. Markov Chains: From Theory to Implementation and Experimentation; John Wiley & Sons: Hoboken, NJ, USA, 2017; ISBN 1119387558. [Google Scholar]
- Pathak, S.; van Rossen, J.; Vijlbrief, O.; Geerdink, J.; Seifert, C.; van Keulen, M. Post-Structuring Radiology Reports of Breast Cancer Patients for Clinical Quality Assurance. IEEE ACM Trans. Comput. Biol. Bioinform. 2019, 17, 1883–1894. [Google Scholar] [CrossRef] [PubMed]
- Forsyth, A.W.; Barzilay, R.; Hughes, K.S.; Lui, D.; Lorenz, K.A.; Enzinger, A.; Tulsky, J.A.; Lindvall, C. Machine Learning Methods to Extract Documentation of Breast Cancer Symptoms from Electronic Health Records. J. Pain Symptom Manag. 2018, 55, 1492–1499. [Google Scholar] [CrossRef]
- Ferroni, P.; Zanzotto, F.M.; Riondino, S.; Scarpato, N.; Guadagni, F.; Roselli, M. Breast Cancer Prognosis Using a Machine Learning Approach. Cancers 2019, 11, 328. [Google Scholar] [CrossRef]
- Alfian, G.; Syafrudin, M.; Fahrurrozi, I.; Fitriyani, N.L.; Atmaji, F.T.D.; Widodo, T.; Bahiyah, N.; Benes, F.; Rhee, J. Predicting Breast Cancer from Risk Factors Using SVM and Extra-Trees-Based Feature Selection Method. Computers 2022, 11, 136. [Google Scholar] [CrossRef]
- Zexian, Z.; Ankita, R.; Xiaoyu, L.; Sasa, E.; Susan, C.; Seema, K.; Yuan, L. Using Clinical Narratives and Structured Data to Identify Distant Recurrences in Breast Cancer. In Proceedings of the 2018 IEEE International Conference on Healthcare Informatics (ICHI), New York City, NY, USA, 4–7 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 44–52. [Google Scholar]
- Aronson, A.R. Metamap: Mapping Text to the Umls Metathesaurus. Bethesda MD NLM NIH DHHS 2006, 1, 26. [Google Scholar]
- Carrillo-de-Albornoz, J.; Aker, A.; Kurtic, E.; Plaza, L. Beyond Opinion Classification: Extracting Facts, Opinions and Experiences from Health Forums. PLoS ONE 2019, 14, e0209961. [Google Scholar] [CrossRef]
- Zeng, Z.; Espino, S.; Roy, A.; Li, X.; Khan, S.A.; Clare, S.E.; Jiang, X.; Neapolitan, R.; Luo, Y. Using Natural Language Processing and Machine Learning to Identify Breast Cancer Local Recurrence. BMC Bioinform. 2018, 19, 65–74. [Google Scholar] [CrossRef]
- Huang, W.-T.; Hung, H.-H.; Kao, Y.-W.; Ou, S.-C.; Lin, Y.-C.; Cheng, W.-Z.; Yen, Z.-R.; Li, J.; Chen, M.; Shia, B.-C. Application of Neural Network and Cluster Analyses to Differentiate TCM Patterns in Patients with Breast Cancer. Front. Pharmacol. 2020, 11, 670. [Google Scholar] [CrossRef]
- Boukobza, A.; Wack, M.; Neuraz, A.; Geromin, D.; Badoual, C.; Bats, A.-S.; Burgun, A.; Koual, M.; Tsopra, R. Determining the Set of Items to Include in Breast Operative Reports, Using Clustering Algorithms on Retrospective Data Extracted from Clinical DataWarehouse. In Advances in Informatics, Management and Technology in Healthcare; IOS Press: Amsterdam, The Netherlands, 2022; pp. 45–48. [Google Scholar]
- Elman, J.L. Finding Structure in Time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Maktapwong, P.; Siriphornphokha, P.; Tubglam, S.; Imsombut, A. Message Classification for Breast Cancer Chatbot Using Bidirectional LSTM. In Proceedings of the 2022 37th International Technical Conference on Circuits/Systems, Computers and Communications (ITC-CSCC), Phuket, Thailand, 5–8 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 434–437. [Google Scholar]
- Zhang, X.; Zhang, Y.; Zhang, Q.; Ren, Y.; Qiu, T.; Ma, J.; Sun, Q. Extracting Comprehensive Clinical Information for Breast Cancer Using Deep Learning Methods. Int. J. Med. Inform. 2019, 132, 103985. [Google Scholar] [CrossRef] [PubMed]
- Sanyal, J.; Tariq, A.; Kurian, A.W.; Rubin, D.; Banerjee, I. Weakly Supervised Temporal Model for Prediction of Breast Cancer Distant Recurrence. Sci. Rep. 2021, 11, 9461. [Google Scholar] [CrossRef]
- Magna, A.A.R.; Allende-Cid, H.; Taramasco, C.; Becerra, C.; Figueroa, R.L. Application of Machine Learning and Word Embeddings in the Classification of Cancer Diagnosis Using Patient Anamnesis. IEEE Access 2020, 8, 106198–106213. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Kuling, G.; Curpen, B.; Martel, A.L. BI-RADS BERT and Using Section Segmentation to Understand Radiology Reports. J. Imaging 2022, 8, 131. [Google Scholar] [CrossRef]
- Solarte-Pabón, O.; Torrente, M.; Garcia-Barragán, A.; Provencio, M.; Menasalvas, E.; Robles, V. Deep Learning to Extract Breast Cancer Diagnosis Concepts. In Proceedings of the 2022 IEEE 35th International Symposium on Computer-Based Medical Systems (CBMS), Shenzhen, China, 21–22 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 13–18. [Google Scholar]
- Zhou, S.; Wang, L.; Wang, N.; Liu, H.; Zhang, R. CancerBERT: A BERT Model for Extracting Breast Cancer Phenotypes from Electronic Health Records. arXiv 2021, arXiv:2108.11303. [Google Scholar]
- Kumar, A.; Kamal, O.; Mazumdar, S. Phoenix@ SMM4H Task-8: Adversities Make Ordinary Models Do Extraordinary Things. NAACL-HLT 2021 2021, 2021, 112–114. [Google Scholar]
- Peng, Y.; Yan, S.; Lu, Z. Transfer Learning in Biomedical Natural Language Processing: An Evaluation of BERT and ELMo on Ten Benchmarking Datasets. arXiv 2019, arXiv:1906.05474. [Google Scholar]
- Chen, D.; Zhong, K.; He, J. BDCN: Semantic Embedding Self-Explanatory Breast Diagnostic Capsules Network. In Proceedings of the China National Conference on Chinese Computational Linguistics, Hohhot, China, 13–15 August 2021; Springer: Cham, Switzerland, 2021; pp. 419–433. [Google Scholar]
- Al-Garadi, M.A.; Yang, Y.-C.; Lakamana, S.; Lin, J.; Li, S.; Xie, A.; Hogg-Bremer, W.; Torres, M.; Banerjee, I.; Sarker, A. Automatic Breast Cancer Cohort Detection from Social Media for Studying Factors Affecting Patient-Centered Outcomes. In Proceedings of the International Conference on Artificial Intelligence in Medicine, Minneapolis, MN, USA, 25–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 100–110. [Google Scholar]
- Saib, W.; Sengeh, D.; Dlamini, G.; Singh, E. Hierarchical Deep Learning Ensemble to Automate the Classification of Breast Cancer Pathology Reports by Icd-o Topography. arXiv 2020, arXiv:2008.12571. [Google Scholar]
- Clark, E.M.; James, T.; Jones, C.A.; Alapati, A.; Ukandu, P.; Danforth, C.M.; Dodds, P.S. A Sentiment Analysis of Breast Cancer Treatment Experiences and Healthcare Perceptions across Twitter. arXiv 2018, arXiv:1805.09959. [Google Scholar]
- Zhao, B. Clinical Data Extraction and Normalization of Cyrillic Electronic Health Records via Deep-Learning Natural Language Processing. JCO Clinical Cancer Informatics 2019, 3, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Li, Y.; Khan, S.A.; Luo, Y. Prediction of Breast Cancer Distant Recurrence Using Natural Language Processing and Knowledge-Guided Convolutional Neural Network. Artif. Intell. Med. 2020, 110, 101977. [Google Scholar] [CrossRef] [PubMed]
- Yao, L.; Mao, C.; Luo, Y. Clinical Text Classification with Rule-Based Features and Knowledge-Guided Convolutional Neural Networks. BMC Med. Inform. Decis. Mak. 2019, 19, 31–39. [Google Scholar] [CrossRef] [PubMed]
- Breast Cancer Dataset. Available online: https://archive.ics.uci.edu/ml/datasets/breast+cancer+coimbra (accessed on 15 January 2023).
- Mediaid Corporation. Life Palette. Available online: https://lifepalette.jp (accessed on 15 January 2023).
- Twitter. Available online: https://twitter.com/iamfireprhoof/status/1570039829378875392 (accessed on 15 January 2023).
- MedHelp. Available online: http://www.medhelp.org (accessed on 15 January 2023).
- Weber, S.C.; Seto, T.; Olson, C.; Kenkare, P.; Kurian, A.W.; Das, A.K. Oncoshare: Lessons Learned from Building an Integrated Multi-Institutional Database for Comparative Effectiveness Research. AMIA Annu. Symp. Proc. 2012, 2012, 970–978. [Google Scholar]
- Uzuner, Ö.; Stubbs, A. Practical Applications for Natural Language Processing in Clinical Research: The 2014 I2b2/UTHealth Shared Tasks. J. Biomed. Inform. 2015, 58, S1. [Google Scholar] [CrossRef] [PubMed]
- Johnson, A.E.W.; Pollard, T.J.; Shen, L.; Lehman, L.H.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Anthony Celi, L.; Mark, R.G. MIMIC-III, a Freely Accessible Critical Care Database. Sci. Data 2016, 3, 160035. [Google Scholar] [CrossRef]
- EDiseases Dataset. Available online: https://zenodo.org/record/1479354#.y8p4kexby3i (accessed on 15 January 2023).
- Goldberg, S.I.; Niemierko, A.; Turchin, A. Analysis of Data Errors in Clinical Research Databases. AMIA Annu. Symp. Proc. 2008, 2008, 242. [Google Scholar]
- Chapelle, O.; Chi, M.; Zien, A. A Continuation Method for Semi-Supervised SVMs. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 185–192. [Google Scholar]
- Settles, B. Active Learning Literature Survey; University of Wisconsin-Madison: Madison, WI, USA, 2009. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A Survey of Transfer Learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model-Related Words | Technique-Related Words | Cancer-Related Words |
|---|---|---|
| AI/ML/DL/Machine Learning/Deep Learning/Artificial Intelligence | NLP/Natural Language Processing | Breast Cancer/Breast Oncology |
| Advantages | Disadvantages |
|---|---|
| Suitable for handling serial data | Low performance ceiling |
| Cheap training environment | |
| Can be a component for improving LSTM |
| Advantages | Disadvantages |
|---|---|
| Can be applied in small sample datasets | Time consuming in large scale datasets |
| Not overly influenced by dimensionality of samples |
| Advantages | Disadvantages |
|---|---|
| Easy to understand | Sensitive to outliers |
| Good clustering | Not suitable for classes with unbalanced sample classes |
| Low complexity | Not suitable for overly discrete classes |
| Not suitable for multiple-label tasks |
| Advantages | Disadvantages |
|---|---|
| Suitable for handling serial data | Cannot be processed in parallel |
| The training process still contains gradient problems. | |
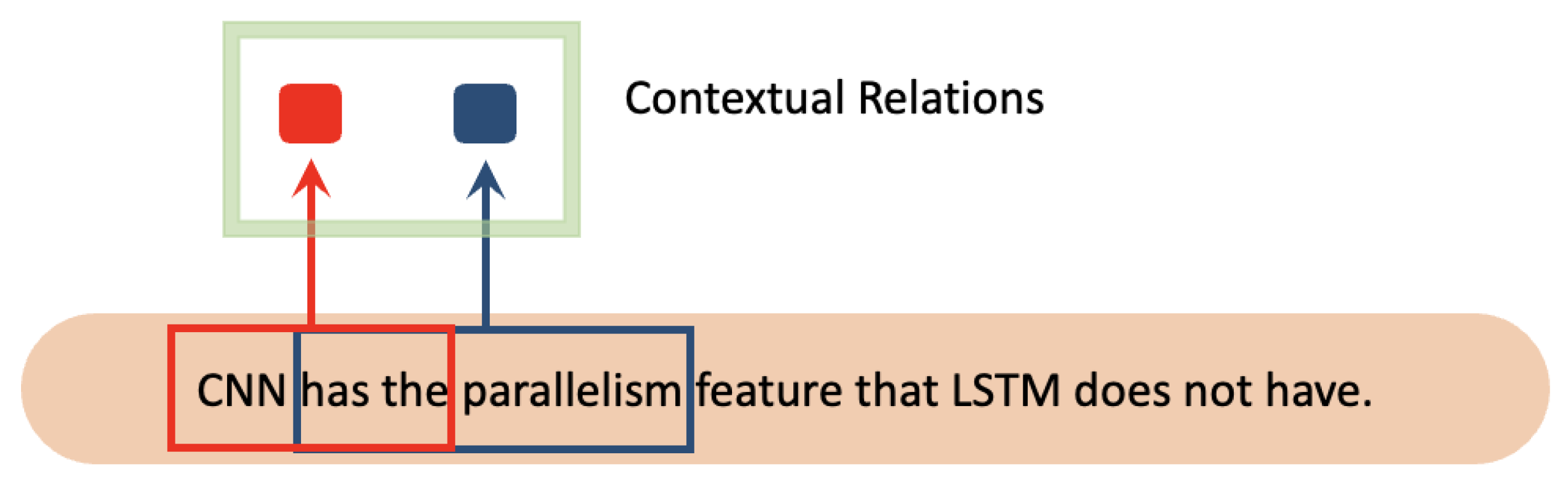
| Can only learn the contextual relationship of feature |
| Advantages | Disadvantages |
|---|---|
| Can extract contextual relationships of long sequences | The pre-trainig and fine-tuning phases of task are not exactly matched |
| Advantages | Disadvantages |
|---|---|
| Computational efficiency and fast training speed | Not good at long distance capture features |
| Reference | Year | Type | Size |
|---|---|---|---|
| [42] | 2022 | Private | Pre-training: 155,000 breast radiology report, Fine-tuning: 900 breast radiology report |
| [43] | 2022 | Private | Lung cancer corpus: 14,000 sentences Breast cancer corpus: 200 sentences |
| [29] | 2022 | Public | 116 subjects |
| [10] | 2022 | Public | 2272 breast cancer posts |
| [37] | 2022 | Private | 1139 messages |
| [35] | 2022 | Private | 14,105 sentences |
| [44] | 2021 | Private | Pre-training: 4,543,184 clinical notes and 1,278,805 pathology reports, Fine-tuning: 9685 sentences |
| [45] | 2021 | Public | 5019 tweets |
| [47] | 2021 | Private | 2857 mammography data |
| [39] | 2021 | Public | 892,550 clinical notes |
| [34] | 2020 | Public | 2738 records |
| [40] | 2020 | Public and Private | Private: 49,475 records, Pulic: 61,464 records |
| [48] | 2020 | Public | 5019 tweets |
| [52] | 2020 | Private | 6447 patients |
| [32] | 2019 | Public | 479 posts |
| [28] | 2019 | Private | 454 patients |
| [26] | 2019 | Private | For heading and content identification: 180 reports, For automatic structuring: 108 reports |
| [38] | 2019 | Private | 8473 sentences |
| [51] | 2019 | Private | 2246 records |
| [9] | 2018 | Private | 2026 breast pathology reports |
| [27] | 2018 | Private | 10,000 sentences |
| [49] | 2018 | Private | 2201 breast cancer pathology reports |
| [33] | 2018 | Private | 701 subjects |
| [50] | 2018 | Public | 1000 tweets |
| [30] | 2018 | Private | 1995 subjects |
| Dataset | Link | Reference |
|---|---|---|
| Breast Cancer Coimbra Dataset | https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Coimbra (accessed on 15 January 2023) | [54] |
| Blog Articles on Life Palette | https://lifepalette.jp | [55] |
| Tweets from Twitter | https://twitter.com/iamfireprhoof/status/1570039829378875392 (an example of tweets) (accessed on 15 January 2023) | [56] |
| Text from MedHelp | http://www.medhelp.org (accessed on 15 January 2023) | [57] |
| Oncoshare Breast Cancer Database | https://med.stanford.edu/oncoshare.html (accessed on 15 January 2023) | [58] |
| I2B2 NLP Research Database | https://www.i2b2.org/NLP/DataSets/Main.php (accessed on 15 January 2023) | [59] |
| MIMIC-III Critical Care Database | https://github.com/MIT-LCP/mimic-code (accessed on 15 January 2023) | [60] |
| eDiseases Dataset | https://zenodo.org/record/1479354#.Y8P4kexBy3I (accessed on 15 January 2023) | [61] |
| China Medical University Hospital (CMUH) database | / | [34] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Weng, Y.; Zhang, Y.; Wang, B. A Systematic Review of Application Progress on Machine Learning-Based Natural Language Processing in Breast Cancer over the Past 5 Years. Diagnostics 2023, 13, 537. https://doi.org/10.3390/diagnostics13030537
Li C, Weng Y, Zhang Y, Wang B. A Systematic Review of Application Progress on Machine Learning-Based Natural Language Processing in Breast Cancer over the Past 5 Years. Diagnostics. 2023; 13(3):537. https://doi.org/10.3390/diagnostics13030537
Chicago/Turabian StyleLi, Chengtai, Ying Weng, Yiming Zhang, and Boding Wang. 2023. "A Systematic Review of Application Progress on Machine Learning-Based Natural Language Processing in Breast Cancer over the Past 5 Years" Diagnostics 13, no. 3: 537. https://doi.org/10.3390/diagnostics13030537
APA StyleLi, C., Weng, Y., Zhang, Y., & Wang, B. (2023). A Systematic Review of Application Progress on Machine Learning-Based Natural Language Processing in Breast Cancer over the Past 5 Years. Diagnostics, 13(3), 537. https://doi.org/10.3390/diagnostics13030537