
Computational Intelligence-Based Stuttering Detection: A Systematic Review

 , , and
, , and
Abstract
:1. Introduction
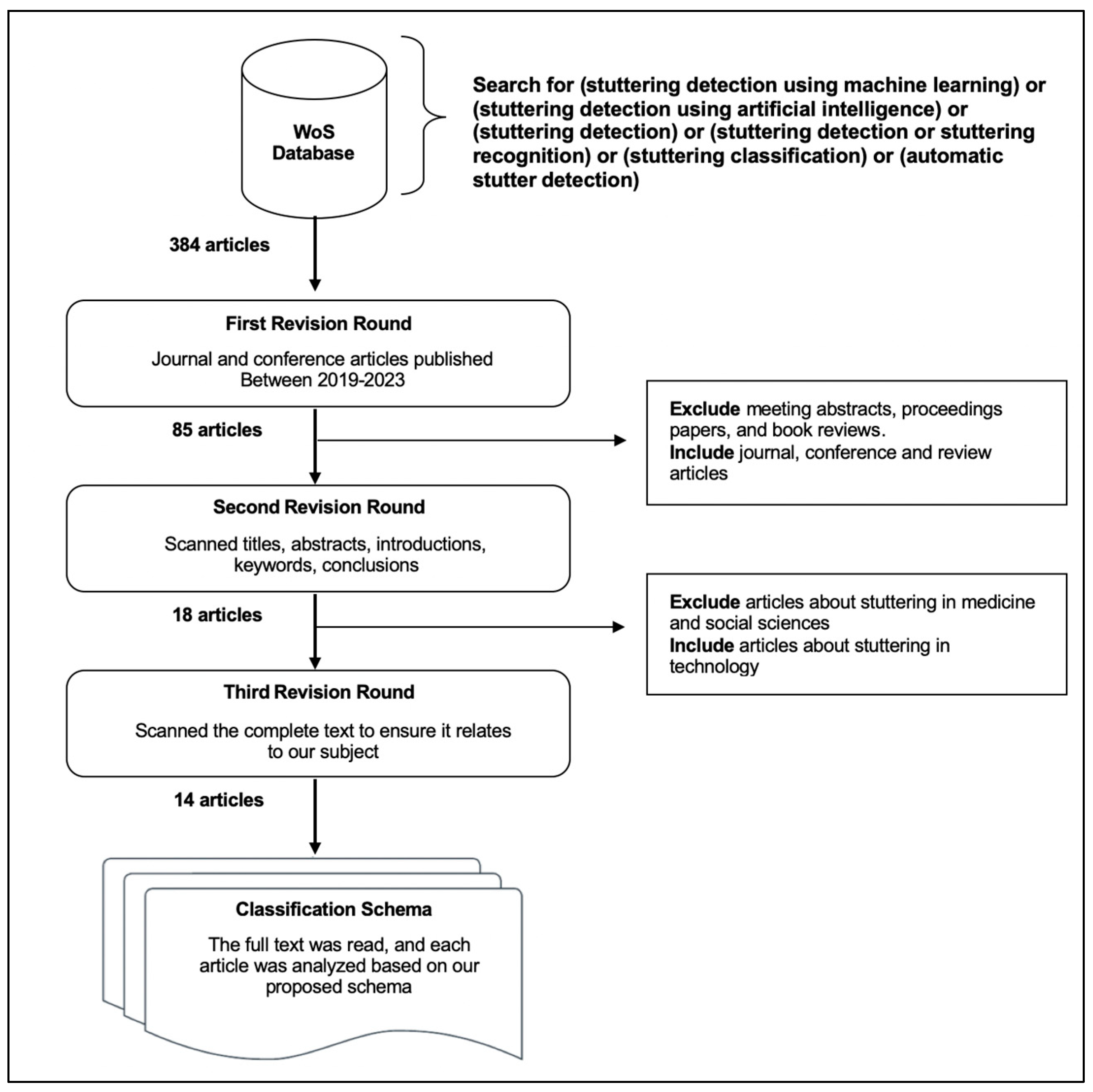
2. Research Methodology
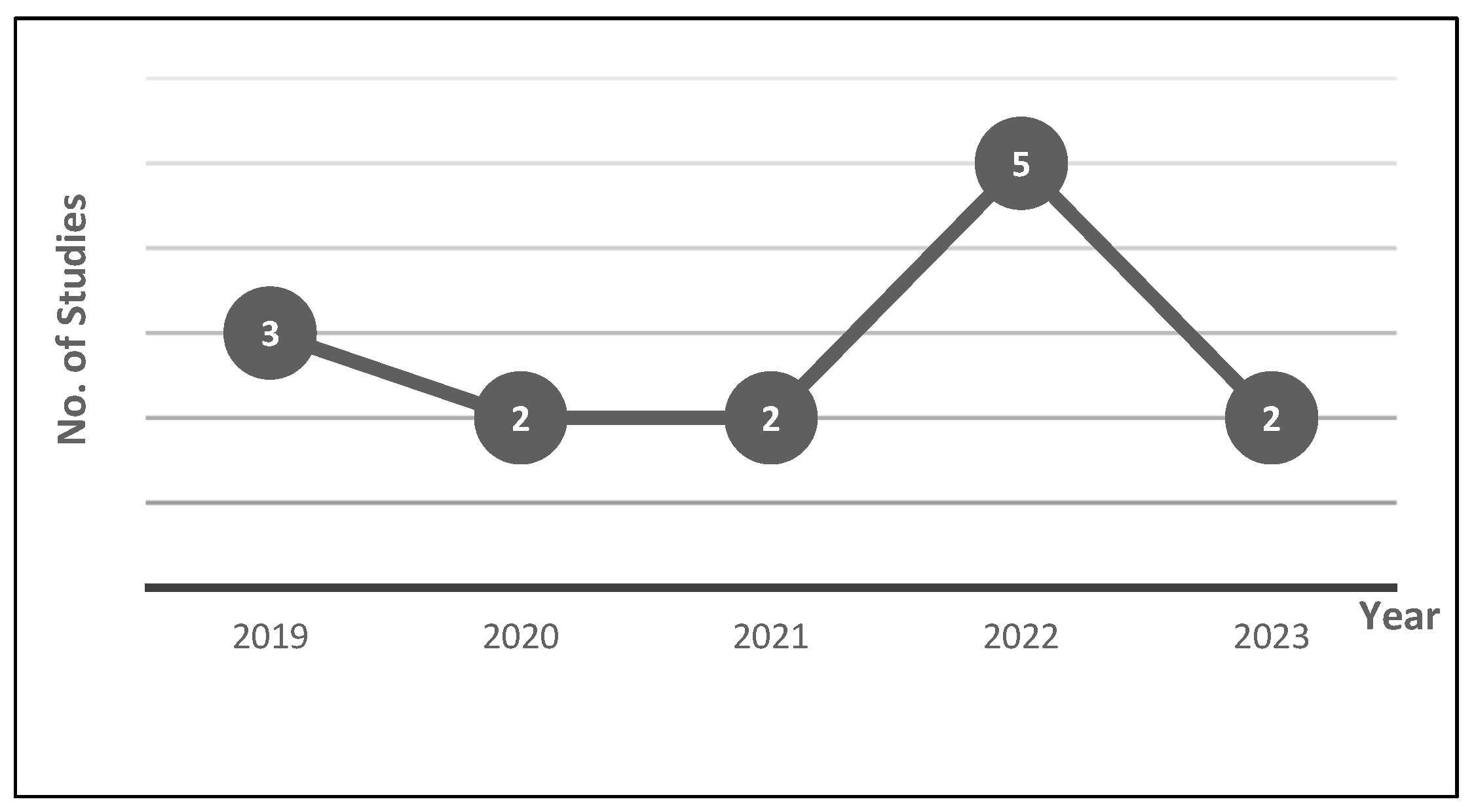
3. Results
3.1. Datasets
3.2. Classified Stuttering Type
3.3. Feature-Extraction Approach
3.4. Classifier Selection
3.5. Preformance Evaluation
4. Discussion
4.1. Challenges
4.2. Future Directions
4.2.1. Multiclass Learning
4.2.2. Classifier Improvements
4.2.3. Model Generalization and Optimization
4.2.4. Dataset Improvement
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Etchell, A.C.; Civier, O.; Ballard, K.J.; Sowman, P.F. A Systematic Literature Review of Neuroimaging Research on Developmental Stuttering between 1995 and 2016. J. Fluen. Disord. 2018, 55, 6–45. [Google Scholar] [CrossRef] [PubMed]
- Guitar, B. Stuttering: An Integrated Approach to Its Nature and Treatment; Lippincott Williams & Wilkins: Philadelphia, PA, USA, 2013; ISBN 978-1-4963-4612-4. [Google Scholar]
- FAQ. Available online: https://www.stutteringhelp.org/faq (accessed on 8 August 2023).
- What Is Stuttering? Diagnosis & Treatment|NIDCD. Available online: https://www.nidcd.nih.gov/health/stuttering (accessed on 8 August 2023).
- Craig, A.; Blumgart, E.; Tran, Y. The Impact of Stuttering on the Quality of Life in Adults Who Stutter. J. Fluen. Disord. 2009, 34, 61–71. [Google Scholar] [CrossRef]
- Sheikh, S.A.; Sahidullah, M.; Hirsch, F.; Ouni, S. Advancing Stuttering Detection via Data Augmentation, Class-Balanced Loss and Multi-Contextual Deep Learning. IEEE J. Biomed. Health Inform. 2023, 27, 2553–2564. [Google Scholar] [CrossRef]
- Korinek, A.; Schindler, M.; Stiglitz, J. Technological Progress, Artificial Intelligence, and Inclusive Growth; IMF Working Paper no. 2021/166; International Monetary Fund: Washington, DC, USA, 2021. [Google Scholar]
- Sheikh, S.A.; Sahidullah, M.; Hirsch, F.; Ouni, S. D-Machine Learning for Stuttering Identification: Review, Challenges and Future Directions. Neurocomputing 2022, 514, 385–402. [Google Scholar] [CrossRef]
- Barrett, L.; Hu, J.; Howell, P. Systematic Review of Machine Learning Approaches for Detecting Developmental Stuttering. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 1160–1172. [Google Scholar] [CrossRef]
- Document Search—Web of Science Core Collection. Available online: https://www-webofscience-com.sdl.idm.oclc.org/wos/woscc/basic-search (accessed on 8 August 2023).
- Howell, P.; Davis, S.; Bartrip, J. The UCLASS Archive of Stuttered Speech. J. Speech Lang. Hear. Res. 2009, 52, 556–569. [Google Scholar] [CrossRef]
- Lea, C.; Mitra, V.; Joshi, A.; Kajarekar, S.; Bigham, J.P. SEP-28k: A Dataset for Stuttering Event Detection from Podcasts with People Who Stutter. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6 June 2021; pp. 6798–6802. [Google Scholar]
- FluencyBank. Available online: https://fluency.talkbank.org/ (accessed on 13 September 2023).
- Kourkounakis, T.; Hajavi, A.; Etemad, A. FluentNet: End-to-End Detection of Stuttered Speech Disfluencies With Deep Learning. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 2986–2999. [Google Scholar] [CrossRef]
- Nagrani, A.; Chung, J.S.; Zisserman, A. VoxCeleb: A Large-Scale Speaker Identification Dataset. arXiv 2017, arXiv:1706.08612. [Google Scholar]
- Manjula, G.; Shivakumar, M.; Geetha, Y.V. Adaptive Optimization Based Neural Network for Classification of Stuttered Speech. In Proceedings of the 3rd International Conference on Cryptography, Security and Privacy, Kuala Lumpur, Malaysia, 19 January 2019; pp. 93–98. [Google Scholar]
- Pravin, S.C.; Palanivelan, M. Regularized Deep LSTM Autoencoder for Phonological Deviation Assessment. Int. J. Patt. Recogn. Artif. Intell. 2021, 35, 2152002. [Google Scholar] [CrossRef]
- Asci, F.; Marsili, L.; Suppa, A.; Saggio, G.; Michetti, E.; Di Leo, P.; Patera, M.; Longo, L.; Ruoppolo, G.; Del Gado, F.; et al. Acoustic Analysis in Stuttering: A Machine-Learning Study. Front. Neurol. 2023, 14, 1169707. [Google Scholar] [CrossRef] [PubMed]
- Alharbi, S.; Hasan, M.; Simons, A.J.H.; Brumfitt, S.; Green, P. Sequence Labeling to Detect Stuttering Events in Read Speech. Comput. Speech Lang. 2020, 62, 101052. [Google Scholar] [CrossRef]
- Kourkounakis, T.; Hajavi, A.; Etemad, A. Detecting Multiple Speech Disfluencies Using a Deep Residual Network with Bidirectional Long Short-Term Memory; IEEE: Barcelona, Spain, 2020; p. 6093. [Google Scholar]
- Gupta, S.; Shukla, R.S.; Shukla, R.K.; Verma, R. Deep Learning Bidirectional LSTM Based Detection of Prolongation and Repetition in Stuttered Speech Using Weighted MFCC. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 345–356. [Google Scholar] [CrossRef]
- Sheikh, S.A.; Sahidullah, M.; Hirsch, F.; Ouni, S. StutterNet: Stuttering Detection Using Time Delay Neural Network. In 2021 29th European Signal Processing Conference (EUSIPCO); IEEE: Dublin, Ireland, 2021; pp. 426–430. [Google Scholar]
- Jouaiti, M.; Dautenhahn, K. Dysfluency Classification in Stuttered Speech Using Deep Learning for Real-Time Applications. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 6482–6486. [Google Scholar]
- Al-Banna, A.-K.; Edirisinghe, E.; Fang, H. Stuttering Detection Using Atrous Convolutional Neural Networks. In Proceedings of the 2022 13th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 21–23 June 2022; pp. 252–256. [Google Scholar]
- Sheikh, S.A.; Sahidullah, M.; Hirsch, F.; Ouni, S. Introducing ECAPA-TDNN and Wav2Vec2.0 Embeddings to Stuttering Detection. arXiv 2022, arXiv:2204.01564. [Google Scholar] [CrossRef]
- Prabhu, Y.; Seliya, N. A CNN-Based Automated Stuttering Identification System. In Proceedings of the 2022 21st IEEE International Conference on Machine Learning and Applications (ICMLA), Nassau, Bahamas, 12–14 December 2022; pp. 1601–1605. [Google Scholar]
- Filipowicz, P.; Kostek, B. D-Rediscovering Automatic Detection of Stuttering and Its Subclasses through Machine Learning—The Impact of Changing Deep Model Architecture and Amount of Data in the Training Set. Appl. Sci. 2023, 13, 6192. [Google Scholar] [CrossRef]
- Automatic Speaker Recognition Using MFCC and Artificial Neural Network. Available online: https://www.researchgate.net/publication/338006282_Automatic_Speaker_Recognition_using_MFCC_and_Artificial_Neural_Network?enrichId=rgreq-4822a0f9838aa087ae99ea77c2ec27ce-XXX&enrichSource=Y292ZXJQYWdlOzMzODAwNjI4MjtBUzo4NTA1MDQxNDU5NzczNTVAMTU3OTc4NzM5ODY0MA==&el=1_x_3&_esc=publicationCoverPdf (accessed on 7 November 2023).
- Ancilin, J.; Milton, A. Improved Speech Emotion Recognition with Mel Frequency Magnitude Coefficient. Appl. Acoust. 2021, 179, 108046. [Google Scholar] [CrossRef]
- Constantino, C.D.; Leslie, P.; Quesal, R.W.; Yaruss, J.S. A Preliminary Investigation of Daily Variability of Stuttering in Adults. J. Commun. Disord. 2016, 60, 39–50. [Google Scholar] [CrossRef] [PubMed]
- Jackson, E.S.; Yaruss, J.S.; Quesal, R.W.; Terranova, V.; Whalen, D.H. Responses of Adults Who Stutter to the Anticipation of Stuttering. J. Fluen. Disord. 2015, 45, 38–51. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
| Dataset | Classes | Description |
|---|---|---|
| UCLASS (2009) [11] | Interjection, sound repetition, part-word repetition, word repetition, phrase repetition, prolongation, and no stutter | The University College London’s Archive of Stuttered Speech (UCLASS) is a widely used dataset in stuttering research. It includes monologs, conversations, and readings, totaling 457 audio recordings. Although small, UCLASS is offered in two releases by UCL’s Department of Psychology and Language Sciences. Notably, UCLASS3 release 1 contains 138 monolog samples, namely 120 and 18 from male and female participants, respectively, from 81 individuals who stutter, aged 5–47 years. Conversely, release 2 contains a total of 318 monologs, reading, and conversation samples from 160 speakers suffering from stuttering, aged 5–20 years, with samples from 279 male and 39 female participants. Transcriptions, including orthographic versions, are available for some recordings, making them suitable for stutter labeling. |
| VoxCeleb (2017) [15] | The dataset does not have classes in the traditional sense, as it is more focused on identifying and verifying individual speakers | It is developed by the VGG, Department of Engineering Science, University of Oxford, UK. It is a large-scale dataset designed for speaker-recognition and verification tasks. It contains a vast collection of speech segments extracted from celebrity interviews, talk shows, and online videos. This dataset covers a diverse set of speakers and is widely employed in research that is related to speaker recognition, speaker diarization, and voice biometrics. |
| SEP-28k (2021) [12] | Prolongations, repetitions, blocks, interjections, and instances of fluent speech | Comprising a total of 28,177 samples, the SEP-28k dataset stands as the first publicly available annotated dataset to include stuttering labels. These labels encompass various disfluencies, such as prolongations, repetitions, blocks, interjections, and instances of fluent speech without disfluencies. Alongside these, the dataset covers nondisfluent labels such as natural pauses, unintelligible speech, uncertain segments, periods of no speech, poor audio quality, and even musical content. |
| FluencyBank (2021) [13] | Individuals who stutter (IWS) and individuals who do not stutter (IWN) | The FluencyBank dataset is a collection of audio recordings of people who stutter. It was created by researchers from the United States and Canada and contains over 1000 h of recordings from 300 speakers. The dataset is divided into two parts, namely research and teaching. The research data are password-protected, and the teaching data are open-access. The teaching data include audio recordings of 10 speakers who stutter, transcripts, and annotations of stuttering disfluencies. The dataset is valuable for researchers and clinicians studying stuttering. |
| LibriStutter (2021) [14] | Sound, word, and phrase repetitions; prolongations; and interjections. | The LibriStutter dataset is a corpus of audio recordings of speech with synthesized stutters. It was created by the Speech and Language Processing group at Queen’s University in Canada. The dataset contains 100 h of audio recordings of 10 speakers, each of whom stutters differently. The stutters were synthesized via a technique known as the hidden Markov model. It is a valuable resource for researchers who are developing automatic speech-recognition (ASR) systems for people who stutter. The dataset can also be used to train models for detecting and classifying different types of stutters. |
| Type | Definition | Example |
|---|---|---|
| Repetition | Repeating a sound, syllable, or word multiple times. | “I-I-I want to go to the park.” |
| Prolongation | Extending or elongating sounds or syllables within words. | “Sssssend me that email, please.” |
| Block | Temporary interruption or cessation of speech flow. | “I can’t... go to the... park tonight.” |
| Interjection | Spontaneous and abrupt interruption in speech with short exclamations. | “Um, I don’t know the answer.” |
| Sound repetitions | Repeating individual sounds within a word. | “Th-th-that movie was great.” |
| Part-word repetitions | Repetition of part of a word, usually a syllable or sound. | “Can-c-c-come over later?” |
| Word repetitions | Repeating entire words within a sentence. | “I like pizza, pizza, pizza.” |
| Phrase repetitions | Repeating phrases or groups of words. | “He said, “he said it too.” |
| Syllable repetition | Repeating a syllable within a word. | “But-b-but I want to go.” |
| Revision | Rewording or revising a sentence during speech to avoid stuttering. | “I’ll take the, um, the bus.” |
| Method | No. of Studies | Ref. |
|---|---|---|
| Mel frequency cepstral coefficient (MFCC) | 6 | Sheikh et al., 2023 [6] Manjula et al., 2019 [16] Sheikh et al., 2021 [22] Jouaiti and Dautenhahn, 2022 [23] Sheikh et al., 2022 [25] Filipowicz and Kostek, 2023 [27] |
| Weighted MFCC (WMFCC) | 1 | Gupta et al., 2020 [21] |
| Spectrograms | 3 | Kourkounakis et al., 2020 [20] Al-Banna et al., 2022 [24] Prabhu and Seliya, 2022 [26] |
| Phonation features | 1 | Pravin and Palanivelan, 2021 [17] |
| Ngram | 1 | Alharbi et al., 2020 [19] |
| Character-based features | 1 | Alharbi et al., 2020 [19] |
| Utterance-based features | 1 | Alharbi et al., 2020 [19] |
| Acoustic analysis of voice recordings | 1 | Asci et al., 2023 [18] |
| Word distance features | 1 | Alharbi et al., 2020 [19] |
| Phoneme features | 2 | Sheikh et al., 2023 [6] Sheikh et al., 2022 [25] |
| Squeeze-and-excitation (SE) residual networks | 1 | Kourkounakis et al., 2021 [14] |
| Bidirectional long short-term memory (BLSTM) layers | 1 | Kourkounakis et al., 2021 [14] |
| Speaker embeddings from the ECAPA-TDNN model | 1 | Sheikh et al., 2022 [25] |
| Contextual embeddings from the Wav2Vec2.0 model | 1 | Sheikh et al., 2022 [25] |
| Pitch-determining feature | 1 | Filipowicz and Kostek, 2023 [27] |
| Two-dimensional speech representations | 1 | Filipowicz and Kostek, 2023 [27] |
| Method | Ref. |
|---|---|
| Artificial neural network (ANN) | Manjula et al., 2019 [16] Sheikh et al., 2022 [25] |
| K-nearest neighbor (KNN) | Sheikh et al., 2022 [25] Filipowicz and Kostek, 2023 [27] |
| Gaussian back-end | Sheikh et al., 2022 [25] |
| Support vector machine (SVM) | Asci et al., 2023 [18] Filipowicz and Kostek, 2023 [27] |
| Bidirectional long short-term memory (BLSTM) | Pravin and Palanivelan, 2021 [17] Asci et al., 2023 [18] Alharbi et al., 2020 [19] Gupta et al., 2020 [21] |
| Convolutional neural networks (CNNs) | Kourkounakis et al., 2020 [20] Prabhu et al., 2022 [26] |
| Two-dimensional atrous convolutional network | Al-Banna et al., 2022 [24] |
| Conditional random fields (CRF) | Alharbi et al., 2020 [19] |
| ResNet18 | Filipowicz and Kostek, 2023 [27] |
| ResNetBiLstm | Filipowicz and Kostek, 2023 [27] |
| Wav2Vec2 | Filipowicz and Kostek, 2023 [27] |
| Deep LSTM autoencoder (DLAE) | Pravin and Palanivelan, 2021 [17] |
| FluentNet | Kourkounakis et al., 2021 [14] |
| StutterNet | Sheikh et al., 2023 [6] Sheikh et al., 2021 [22] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alnashwan, R.; Alhakbani, N.; Al-Nafjan, A.; Almudhi, A.; Al-Nuwaiser, W. Computational Intelligence-Based Stuttering Detection: A Systematic Review. Diagnostics 2023, 13, 3537. https://doi.org/10.3390/diagnostics13233537
Alnashwan R, Alhakbani N, Al-Nafjan A, Almudhi A, Al-Nuwaiser W. Computational Intelligence-Based Stuttering Detection: A Systematic Review. Diagnostics. 2023; 13(23):3537. https://doi.org/10.3390/diagnostics13233537
Chicago/Turabian StyleAlnashwan, Raghad, Noura Alhakbani, Abeer Al-Nafjan, Abdulaziz Almudhi, and Waleed Al-Nuwaiser. 2023. "Computational Intelligence-Based Stuttering Detection: A Systematic Review" Diagnostics 13, no. 23: 3537. https://doi.org/10.3390/diagnostics13233537
APA StyleAlnashwan, R., Alhakbani, N., Al-Nafjan, A., Almudhi, A., & Al-Nuwaiser, W. (2023). Computational Intelligence-Based Stuttering Detection: A Systematic Review. Diagnostics, 13(23), 3537. https://doi.org/10.3390/diagnostics13233537