

Evaluating the Utility of a Large Language Model in Answering Common Patients’ Gastrointestinal Health-Related Questions: Are We There Yet?


Abstract
1. Introduction
2. Methods
Statistical Analysis
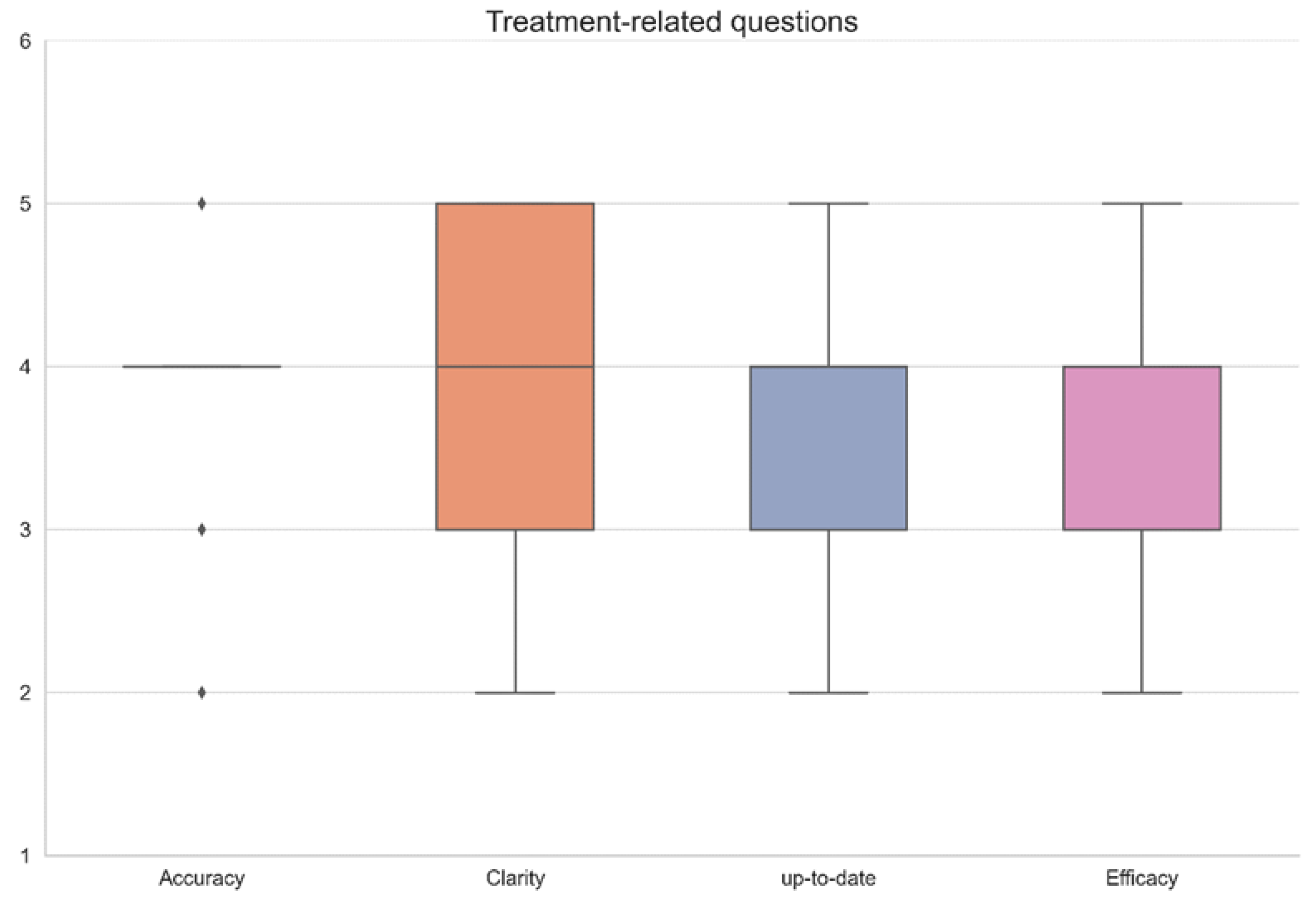
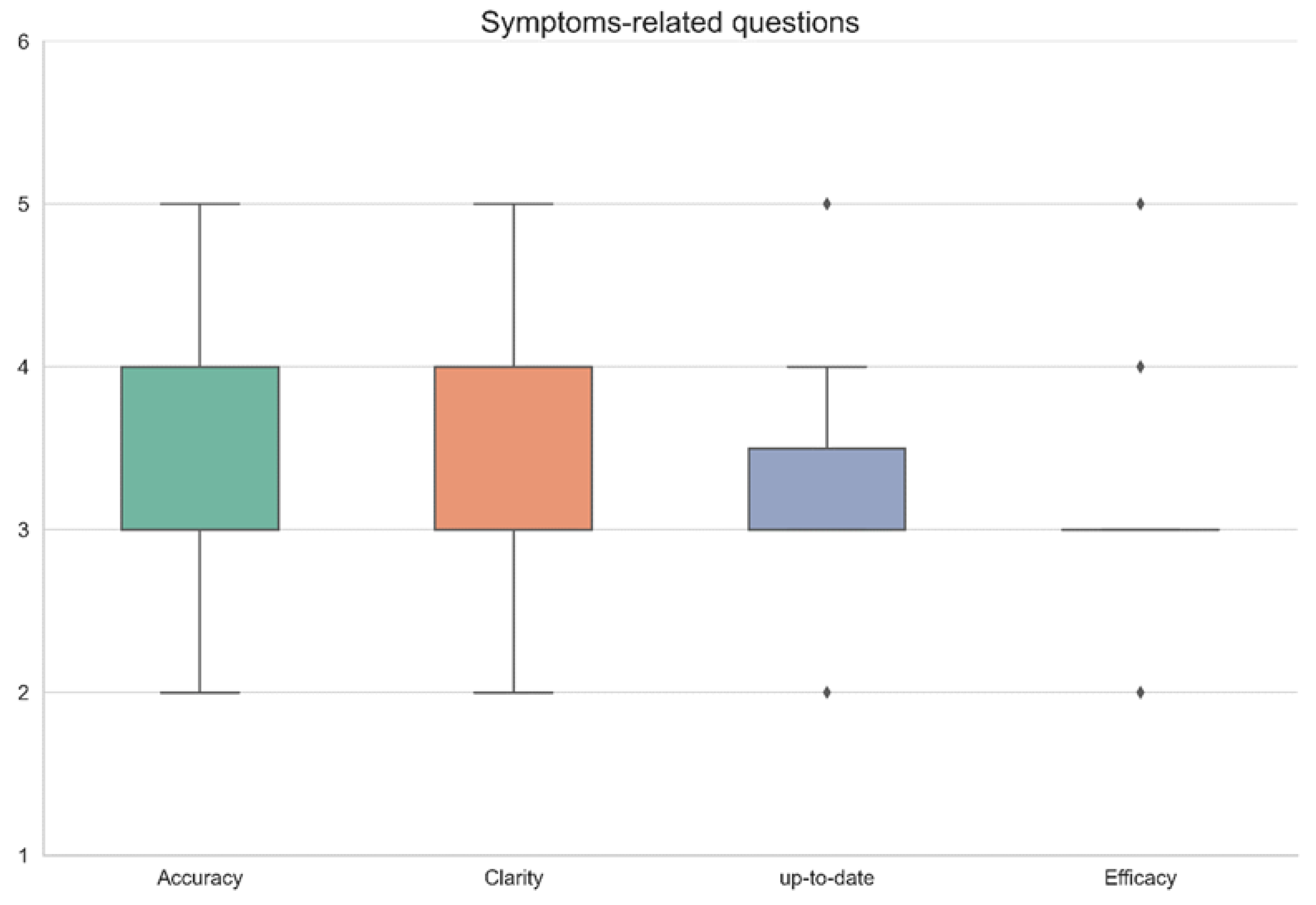
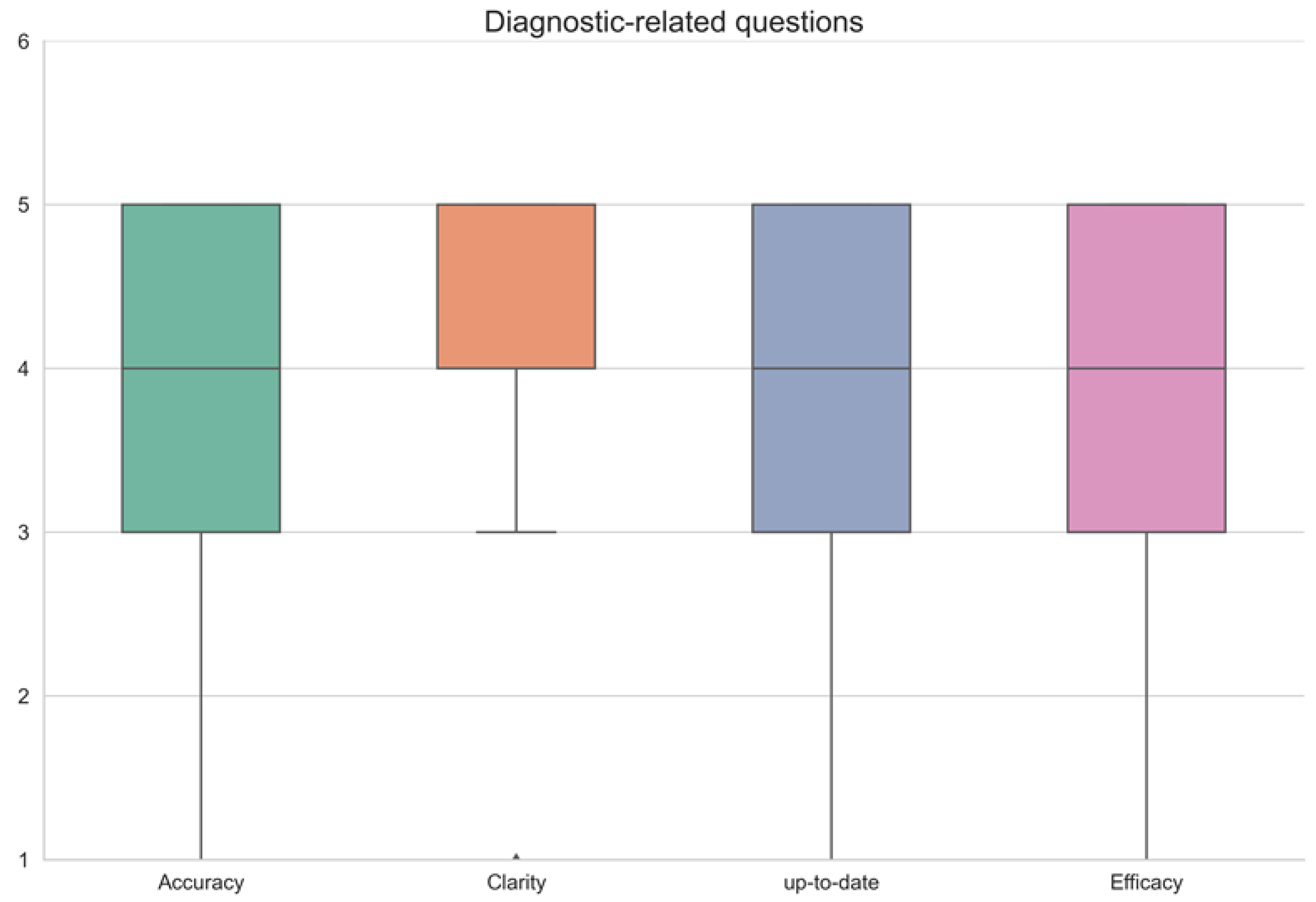
3. Results
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Seifert, B.; Rubin, G.; de Wit, N.; Lionis, C.; Hall, N.; Hungin, P.; Jones, R.; Palka, M.; Mendive, J. The management of common gastrointestinal disorders in general practice: A survey by the European Society for Primary Care Gastroenterology (ESPCG) in six European countries. Dig. Liver Dis. 2008, 40, 659–666. [Google Scholar] [CrossRef] [PubMed]
- Holtedahl, K.; Vedsted, P.; Borgquist, L.; Donker, G.A.; Buntinx, F.; Weller, D.; Braaten, T.; Hjertholm, P.; Månsson, J.; Strandberg, E.L.; et al. Abdominal symptoms in general practice: Frequency, cancer suspicions raised, and actions taken by GPs in six European countries. Cohort study with prospective registration of cancer. Heliyon 2017, 3, e00328. [Google Scholar] [CrossRef] [PubMed]
- Available online: https://openai.com/blog/chatgpt/ (accessed on 1 March 2023).
- Lee, H.; Kang, J.; Yeo, J. Medical Specialty Recommendations by an Artificial Intelligence Chatbot on a Smartphone: Development and Deployment. J. Med. Internet Res. 2021, 23, e27460. [Google Scholar] [CrossRef] [PubMed]
- Montenegro, J.L.Z.; da Costa, C.A.; Righi, R.D.R. Survey of conversational agents in health. Expert Syst. Appl. 2019, 129, 56–67. [Google Scholar] [CrossRef]
- Palanica, A.; Flaschner, P.; Thommandram, A.; Li, M.; Fossat, Y. Physicians’ Perceptions of Chatbots in Health Care: Cross-Sectional Web-Based Survey. J. Med. Internet Res. 2019, 21, e12887. [Google Scholar] [CrossRef] [PubMed]
- Milne-Ives, M.; de Cock, C.; Lim, E.; Shehadeh, M.H.; de Pennington, N.; Mole, G.; Normando, E.; Meinert, E. The Effectiveness of Artificial Intelligence Conversational Agents in Health Care: Systematic Review. J. Med. Internet Res. 2020, 22, e20346. [Google Scholar] [CrossRef] [PubMed]
- Available online: https://www.bloomberg.com/news/articles/2022-12-07/openai-chatbot-so-good-it-can-fool-humans-even-when-it-s-wrong (accessed on 1 March 2023).
- Turing, A.M. Computing Machinery and Intelligence. In Mind; New Series; Oxford University Press on Behalf of the Mind Association: Oxford, UK, 1950; Volume 59, pp. 433–460. [Google Scholar]
- Vayena, E.; Blasimme, A.; Cohen, I.G. Machine learning in medicine: Addressing ethical challenges. PLoS Med. 2018, 15, e1002689. [Google Scholar] [CrossRef] [PubMed]
- Powell, J. Trust Me, I’m a Chatbot: How Artificial Intelligence in Health Care Fails the Turing Test. J. Med. Internet Res. 2019, 21, e16222. [Google Scholar] [CrossRef] [PubMed]
- Lahat, A.; Shachar, E.; Avidan, B.; Shatz, Z.; Glicksberg, B.S.; Klang, E. Evaluating the use of large language model in identifying top research questions ingastroenterology. Sci. Rep. 2023, 13, 4164. [Google Scholar] [CrossRef] [PubMed]
- Ge, J.; Lai, J.C. Artificial intelligence-based text generators in hepatology: ChatGPT isjust the beginning. Hepatol. Commun. 2023, 7, e0097. [Google Scholar] [CrossRef] [PubMed]
- Lahat, A.; Klang, E. Can advanced technologies help address the global increase in demand for specialized medical care and improve telehealth services? J. Telemed. Telecare 2023, 1357633X231155520. [Google Scholar] [CrossRef] [PubMed]
- Hirosawa, T.; Harada, Y.; Yokose, M.; Sakamoto, T.; Kawamura, R.; Shimizu, T. Diagnostic Accuracy of Differential-Diagnosis Lists Generated by Generative Pretrained Transformer 3 Chatbot for Clinical Vignettes with Common Chief Complaints: A Pilot Study. Int. J. Environ. Res. Public Health 2023, 20, 3378. [Google Scholar] [CrossRef] [PubMed]
- Eysenbach, G. The Role of ChatGPT, Generative Language Models, and Artificial Intelligence in Medical Education: A Conversation with ChatGPT and a Call for Papers. JMIR Med. Educ. 2023, 9, e46885. [Google Scholar] [CrossRef] [PubMed]
- Rasmussen, M.L.R.; Larsen, A.C.; Subhi, Y.; Potapenko, I. Artificial intelligence-based ChatGPT chatbot responses for patient and parent questions on vernal keratoconjunctivitis. Graefe’s Arch. Clin. Exp. Ophthalmol. 2023. [Google Scholar] [CrossRef] [PubMed]
- Samaan, J.S.; Yeo, Y.H.; Rajeev, N.; Hawley, L.; Abel, S.; Ng, W.H.; Srinivasan, N.; Park, J.; Burch, M.; Watson, R.; et al. Assessing the Accuracy of Responses by the Language Model ChatGPT to Questions Regarding Bariatric Surgery. Obes. Surg. 2023, 33, 1790–1796. [Google Scholar] [CrossRef] [PubMed]
- Xie, Y.; Seth, I.; Hunter-Smith, D.J.; Rozen, W.M.; Ross, R.; Lee, M. Aesthetic Surgery Advice and Counseling from Artificial Intelligence: A Rhinoplasty Consultation with ChatGPT. Aesthetic Plast Surg. 2023. [Google Scholar] [CrossRef] [PubMed]
- Yeo, Y.H.; Samaan, J.S.; Ng, W.H.; Ting, P.S.; Trivedi, H.; Vipani, A.; Ayoub, W.; Yang, J.D.; Liran, O.; Spiegel, B.; et al. Assessing the performance of ChatGPT in answering questions regarding cirrhosis and hepatocellular carcinoma. Clin. Mol. Hepatol. 2023. [Google Scholar] [CrossRef] [PubMed]
- Johnson, S.B.; King, A.J.; Warner, E.L.; Aneja, S.; Kann, B.H.; Bylund, C.L. Using ChatGPT to evaluate cancer myths and misconceptions: Artificial intelligence and cancer information. JNCI Cancer Spectr. 2023, 7, pkad015. [Google Scholar] [CrossRef] [PubMed]
- Johnson, D.; Goodman, R.; Patrinely, J.; Stone, C.; Zimmerman, E.; Donald, R.; Chang, S.; Berkowitz, S.; Finn, A.; Jahangir, E.; et al. Assessing the Accuracy and Reliability of AI-Generated Medical Responses: An Evaluation of the Chat-GPT Model. Res. Sq. 2023; preprint. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Question No. | Accuracy | Clarity | Up-to-Date | Efficacy | Remarks |
|---|---|---|---|---|---|
| 1 | 3 | 2 | 3 | 3 | |
| 2 | 3 | 4 | 3 | 3 | |
| 3 | 4 | 3 | 4 | 3 | |
| 4 | 4 | 4 | 4 | 3 | |
| 5 | 4 | 4 | 3 | 2 | |
| 6 | 5 | 5 | 4 | 4 | |
| 7 | 4 | 4 | 3 | 2 | |
| 8 | 4 | 4 | 3 | 2 | |
| 9 | 4 | 3 | 4 | 3 | |
| 10 | 5 | 5 | 4 | 4 | |
| 11 | 4 | 4 | 4 | 3 | |
| 12 | 4 | 4 | 3 | 3 | |
| 13 | 3 | 3 | 3 | 2 | |
| 14 | 4 | 3 | 4 | 3 | |
| 15 | 2 | 4 | 2 | 2 | |
| 16 | 4 | 3 | 4 | 4 | |
| 17 | 4 | 3 | 4 | 3 | |
| 18 | 4 | 5 | 5 | 4 | |
| 19 | 3 | 3 | 2 | 2 | |
| 20 | 3 | 4 | 4 | 3 | |
| 21 | 2 | 3 | 2 | 2 | |
| 22 | 4 | 4 | 4 | 5 | |
| 23 | 4 | 2 | 3 | 2 | |
| 24 | 3 | 4 | 3 | 3 | |
| 25 | 4 | 4 | 5 | 4 | |
| 26 | 4 | 5 | 5 | 4 | |
| 27 | 5 | 5 | 4 | 4 | |
| 28 | 4 | 5 | 5 | 4 | |
| 29 | 4 | 5 | 4 | 4 | |
| 30 | 5 | 4 | 5 | 5 | |
| 31 | 4 | 5 | 4 | 4 | |
| 32 | 4 | 5 | 4 | 3 | |
| 33 | 5 | 5 | 5 | 5 | |
| 34 | 4 | 3 | 4 | 3 | |
| 35 | 5 | 4 | 4 | 4 | |
| 36 | 3 | 3 | 4 | 3 | |
| 37 | 2 | 3 | 2 | 2 | |
| 38 | 4 | 3 | 4 | 3 | |
| 39 | 5 | 4 | 5 | 5 | |
| 40 | 4 | 5 | 4 | 4 | |
| 41 | 5 | 5 | 5 | 5 | |
| 42 | 4 | 4 | 5 | 4 | |
| Average ± SD | 3.9 ± 0.8 | 3.9 ± 0.9 | 3.8 ± 0.9 | 3.3 ± 0.9 | |
| Median (IQR) | 4 (4–4) | 4 (3–5) | 4 (3–4) | 3 (3–4) |
| Question No. | Accuracy | Clarity | Up-to-Date | Efficacy | Remarks |
|---|---|---|---|---|---|
| 1 | 3 | 4 | 3 | 3 | |
| 2 | 5 | 5 | 5 | 5 | |
| 3 | 3 | 4 | 3 | 3 | |
| 4 | 3 | 4 | 3 | 3 | |
| 5 | 3 | 4 | 3 | 3 | |
| 6 | 3 | 3 | 3 | 3 | |
| 7 | 4 | 4 | 4 | 4 | |
| 8 | 3 | 4 | 3 | 3 | |
| 9 | 3 | 4 | 3 | 3 | |
| 10 | 4 | 4 | 4 | 4 | |
| 11 | 3 | 3 | 3 | 3 | |
| 12 | 3 | 3 | 3 | 3 | |
| 13 | 2 | 3 | 2 | 2 | |
| 14 | 3 | 2 | 3 | 2 | |
| 15 | 4 | 4 | 4 | 3 | |
| 16 | 3 | 4 | 3 | 3 | |
| 17 | 3 | 4 | 3 | 3 | |
| 18 | 4 | 4 | 3 | 3 | |
| 19 | 3 | 3 | 3 | 3 | |
| 20 | 3 | 4 | 3 | 3 | |
| 21 | 5 | 3 | 4 | 4 | |
| 22 | 3 | 4 | 3 | 3 | |
| 23 | 5 | 5 | 5 | 5 | |
| Average ± SD | 3.4 ± 0.8 | 3.7 ±0.7 | 3.3 ± 0.7 | 3.2 ± 0.7 | |
| Median (IQR) | 3 (3–4) | 4 (3–4) | 3 (3–3.5) | 3 (3–3) |
| Question No. | Accuracy | Clarity | Up-to-Date | Efficacy | Remarks |
|---|---|---|---|---|---|
| 1 | 5 | 5 | 5 | 5 | |
| 2 | 5 | 4 | 4 | 3 | |
| 3 | 4 | 5 | 5 | 5 | |
| 4 | 4 | 5 | 5 | 4 | |
| 5 | 5 | 4 | 5 | 4 | |
| 6 | 5 | 4 | 4 | 5 | |
| 7 | 0 | 0 | 0 | 0 | Not found |
| 8 | 5 | 4 | 5 | 4 | |
| 9 | 1 | 1 | 1 | 1 | Mistake |
| 10 | 5 | 5 | 5 | 5 | |
| 11 | 5 | 5 | 5 | 5 | |
| 12 | 4 | 5 | 4 | 4 | |
| 13 | 5 | 5 | 5 | 5 | |
| 14 | 5 | 5 | 5 | 4 | |
| 15 | 5 | 5 | 5 | 5 | |
| 16 | 5 | 4 | 5 | 4 | |
| 17 | 5 | 4 | 5 | 4 | |
| 18 | 4 | 4 | 5 | 4 | |
| 19 | 5 | 4 | 5 | 4 | |
| 20 | 4 | 5 | 4 | 4 | |
| 21 | 5 | 3 | 3 | 3 | Asks info |
| 22 | 5 | 5 | 5 | 5 | |
| 23 | 0 | 0 | 0 | 0 | Not found |
| 24 | 5 | 5 | 5 | 5 | |
| 25 | 3 | 4 | 4 | 3 | |
| 26 | 3 | 4 | 4 | 3 | |
| 27 | 4 | 4 | 4 | 4 | |
| 28 | 5 | 5 | 5 | 5 | |
| 29 | 5 | 5 | 5 | 5 | |
| 30 | 3 | 4 | 3 | 3 | |
| 31 | 5 | 5 | 5 | 5 | |
| 32 | 4 | 5 | 5 | 4 | |
| 33 | 3 | 4 | 4 | 3 | |
| 34 | 5 | 5 | 4 | 5 | |
| 35 | 5 | 5 | 5 | 5 | |
| 36 | 1 | 1 | 1 | 1 | Mistake |
| 37 | 0 | 0 | 0 | 0 | Not found |
| 38 | 0 | 0 | 0 | 0 | Not found |
| 39 | 3 | 4 | 3 | 3 | |
| 40 | 4 | 5 | 4 | 4 | |
| 41 | 0 | 0 | 0 | 0 | Not found |
| 42 | 0 | 0 | 0 | 0 | Not found |
| 43 | 3 | 5 | 0 | 2 | |
| 44 | 5 | 5 | 4 | 5 | |
| 45 | 4 | 5 | 4 | 4 | |
| Average ± SD | 3.7 ± 1.7 | 3.8 ± 1.7 | 3.6 ± 1.8 | 3.5 ± 1.7 | |
| Median (IQR) | 4 (3–5) | 4 (4–5) | 4 (3–5) | 4 (3–5) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lahat, A.; Shachar, E.; Avidan, B.; Glicksberg, B.; Klang, E. Evaluating the Utility of a Large Language Model in Answering Common Patients’ Gastrointestinal Health-Related Questions: Are We There Yet? Diagnostics 2023, 13, 1950. https://doi.org/10.3390/diagnostics13111950
Lahat A, Shachar E, Avidan B, Glicksberg B, Klang E. Evaluating the Utility of a Large Language Model in Answering Common Patients’ Gastrointestinal Health-Related Questions: Are We There Yet? Diagnostics. 2023; 13(11):1950. https://doi.org/10.3390/diagnostics13111950
Chicago/Turabian StyleLahat, Adi, Eyal Shachar, Benjamin Avidan, Benjamin Glicksberg, and Eyal Klang. 2023. "Evaluating the Utility of a Large Language Model in Answering Common Patients’ Gastrointestinal Health-Related Questions: Are We There Yet?" Diagnostics 13, no. 11: 1950. https://doi.org/10.3390/diagnostics13111950
APA StyleLahat, A., Shachar, E., Avidan, B., Glicksberg, B., & Klang, E. (2023). Evaluating the Utility of a Large Language Model in Answering Common Patients’ Gastrointestinal Health-Related Questions: Are We There Yet? Diagnostics, 13(11), 1950. https://doi.org/10.3390/diagnostics13111950