
Machine Learning for Online Automatic Prediction of Common Disease Attributes Using Never-Ending Image Learner

 ,
,  ,
,  , ,
, ,
Abstract
1. Introduction
- Introduces machine-learning-assisted automatic prediction from multiple images using multiple-instance learning;
- Stores data as per the isotropic positioning for deeper storage of images and their data;
- Uses Never-Ending Image Learner to predict disease factors;
- Uses structural risk minimization to select from finite image data;
- Shows how machine-learning-enabled M-theory with virtual sensing can be used to predict real-time images.
- Forming the “Never Ending Image Learner” for predicting the disease factors
- Forming the “Structural risk minimization” for selecting from finite data images.
- Machine Learning Enabled M-Theory with Virtual sensing for predicting the real-time images
2. Related Work
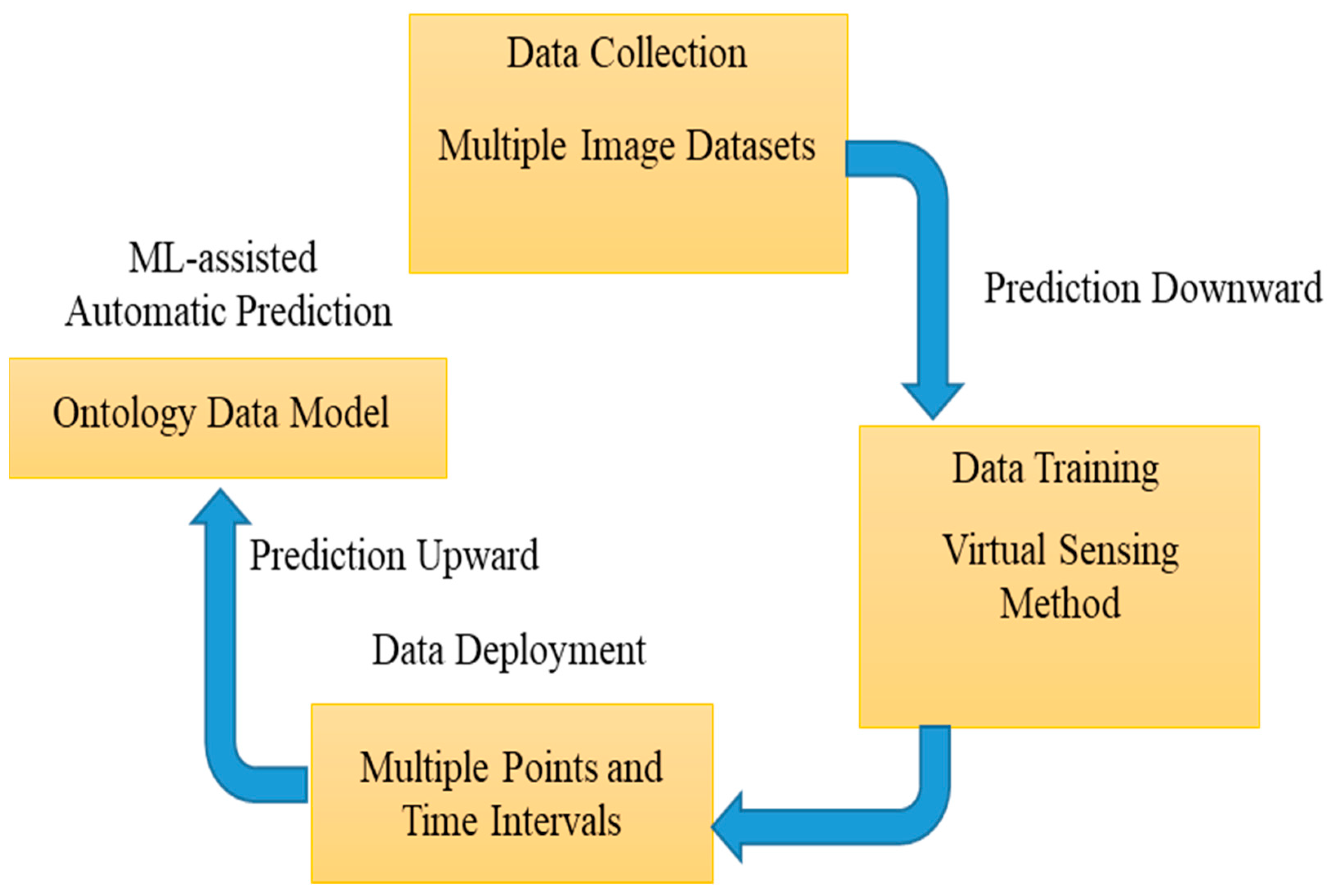
3. Methods
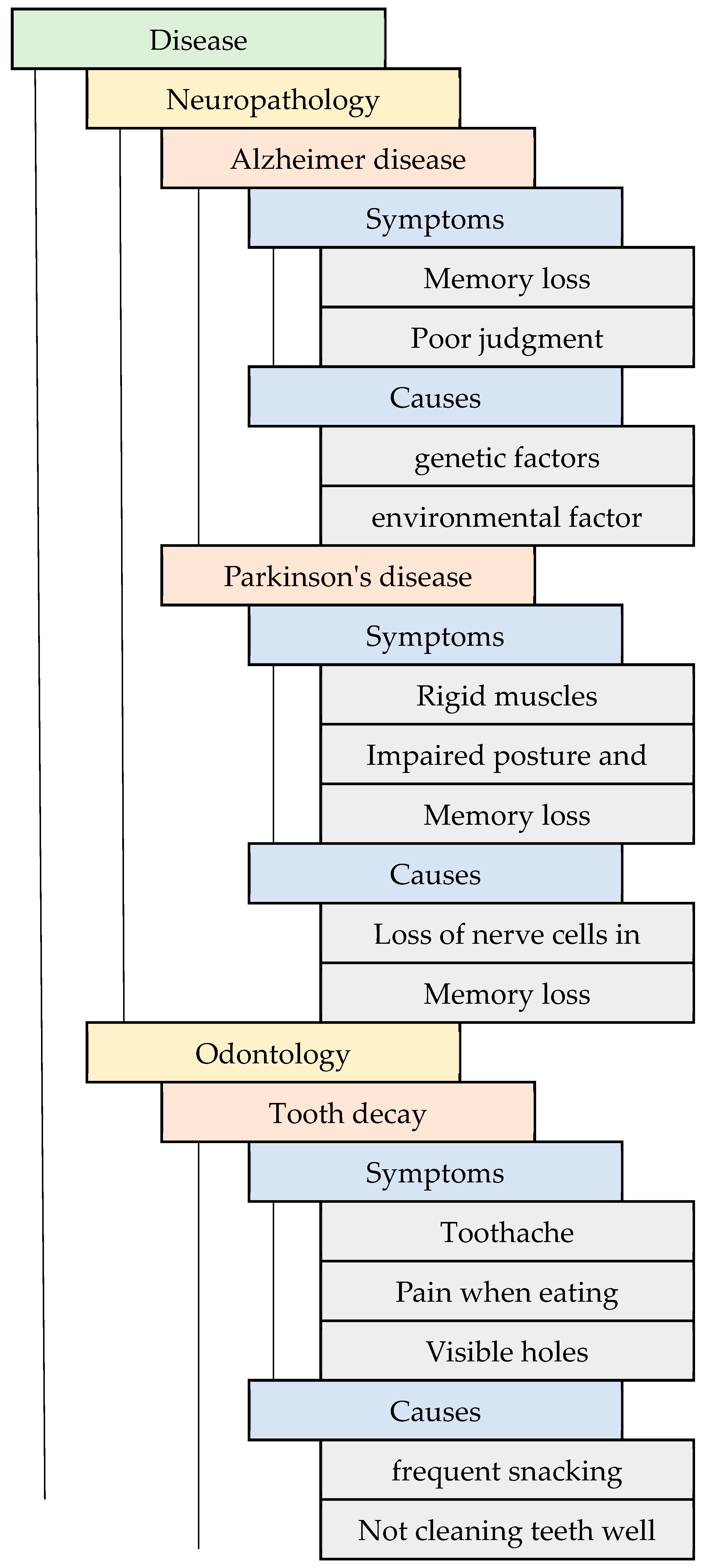
3.1. Ontology Mapping for Healthcare
3.2. ML-Assisted Automatic Prediction
| Algorithm 1. Automatic prediction from the dataset. |
| input; dataset output; prediction of attributes for each disease data i for each attribute a remove → a for each disease data (i, t) MIN = 0 for each disease data (i, k) & (k≠t) MIN = MIN + S (k, t) if (MIN < low_Thold) low_Thold = MIN end if end for end for for each disease data (i, t) MAX = 0 for each disease data (i, k) & (k≠t) MAX = MAX + S (k, t) if (MAX > high_Thold) high_Thold = MAX add → a Ts = 0 end if end for end for for each (i, t) & (a≠t) Ts = Ts + S (a, t) end for if (Ts > high_Thold) predict disease data (i, a) else if (Ts > low_Thold) interpolated S = interpolate (Ts, low_Thold, high_Thold) end if if (interpolated S > cut-off) predict disease data (i, a) end if end for end for |
3.3. Isotropic Positioning
| Algorithm 2. Isotropic positioning. |
| input; d-distribution ⊂RN, V-vector for Vϵ d if (EVVT = ID) if (uniform distribution over ID) V of an orthogonal set ← isotropic end if end if for all b RN if (k ϵ RN) if(|k| = 1) & (β > 0) end if end if end for end for return, Isotropic position for storing data |
3.4. Structural Risk Minimization
| Algorithm 3. Working principles of structural risk minimization. |
| input; image data—{(a1, b1)…, (at, bt)}, f(a)-function, E(f) = expected risk function, generate expected risk function E(f) = for unknown problem find empirical risk function E(f) ← Eemp(f) Eemp(f) = 1/t for nonnegative set if (0 ≤ Q (b, f(a)) ≤ Y) P ← 1− η else if (Q (b, f(a)) ≤ Y) E(f) Eemp(f) + end if ← 2(ln n-ln η)/L if L/d large Eemp(f) ← small E(f) ← small end if end for end for return, minimization of structural risk |
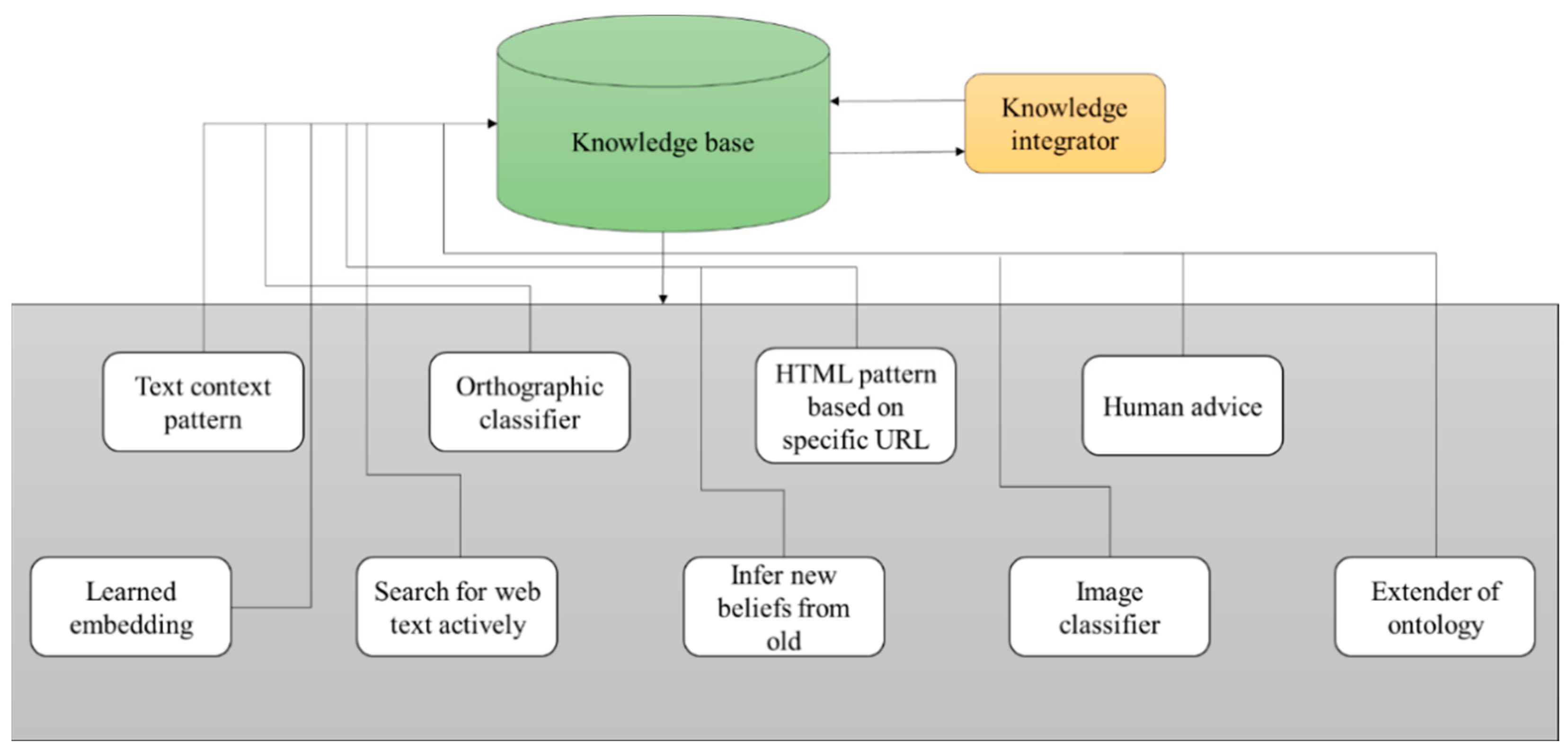
3.5. NEL (Never-Ending Learning)
| Algorithm 4. Never-Ending Image Learner for image prediction. |
| input; an ontology-O output; trusted instances for each group share initial image data for k = 1, 2… for each group ϵ O extract new image data filter patients train data classifiers assess the patient using a trained classifier promote highest-confidence patient end for Share items end for for each class if X mutually exclusive with Y Y ← negative instance of image end if if (Y(X) ← X) Y ← trusted item end if if (co-occur ← two trusted patterns) & (co-occur ← any –Ve pattern in the same web) NELL then filters out end if end for |
| Algorithm 5. Automatic online prediction of common disease attributes. |
| generate database-DB = {symptom, time, intensity, organ name, duration} create a tag for symptom user input as word for each user word separate each word check each word in DB if (word → found) put relevant array else if (word → not found) Search symptoms and reference tag if (reference word → found) move to the relevant decision else put relative attributes and continue end if end if end for return, prediction of common disease attribute |
- 6.
- Synonym parent tree
- 7.
- Symptom reference tag
- 8.
- Relevant attribute array
4. Experimental Results and Discussion
4.1. Overall Accuracy
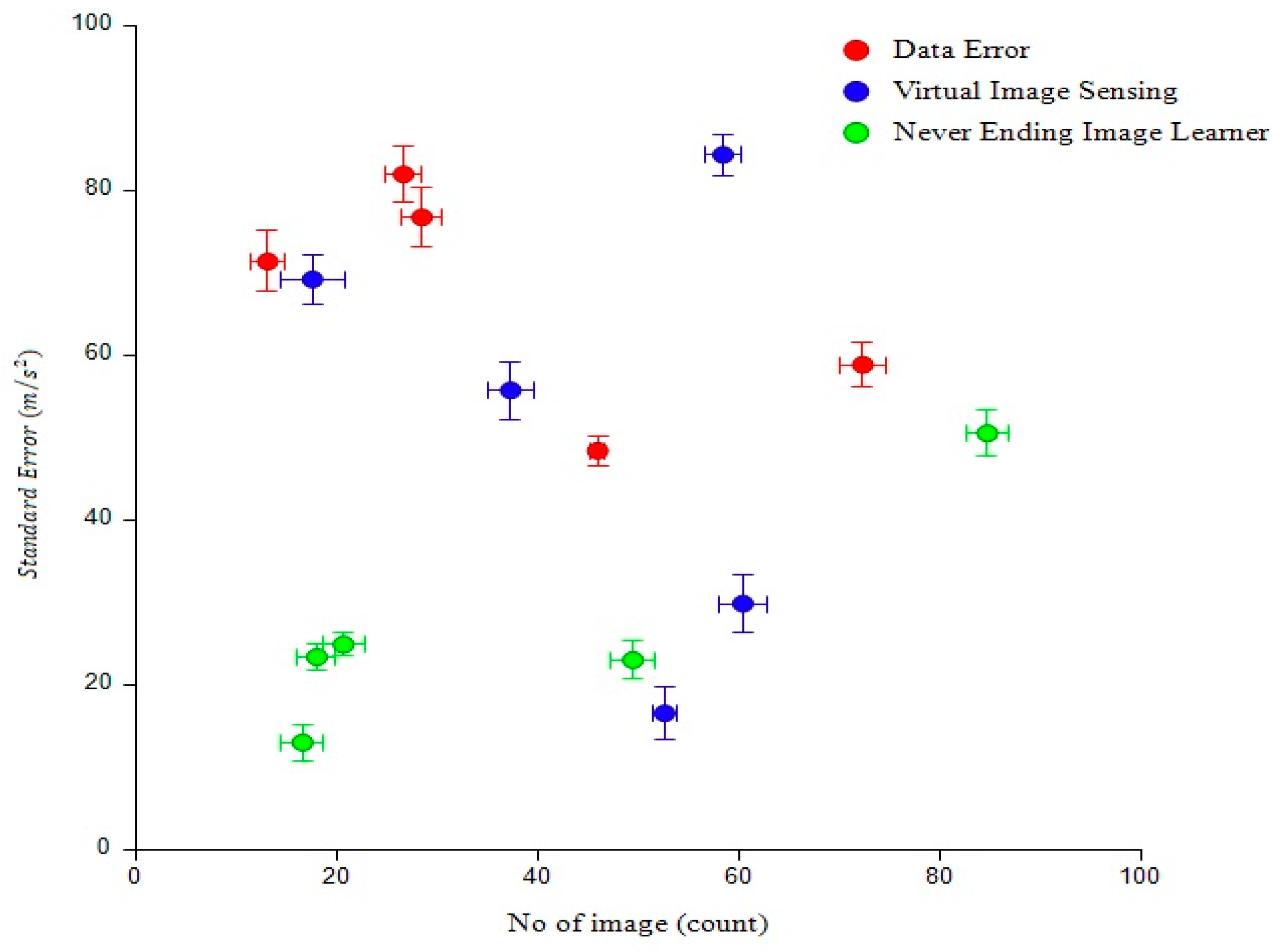
4.2. The Standard Error
4.3. Time Duration and Normalized Frequency
4.4. Predictions of Intelligent Analysis of Disease Factors
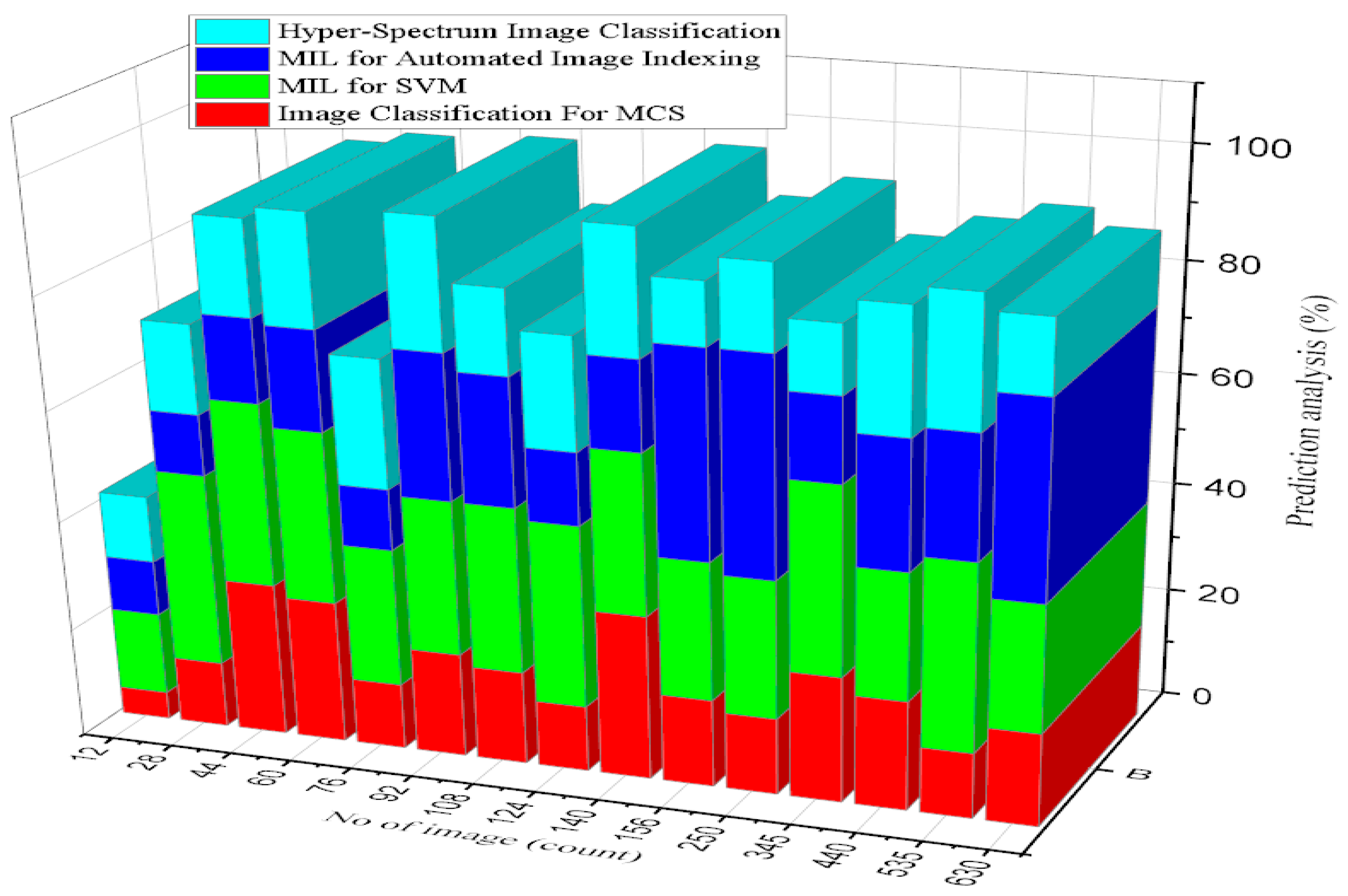
4.5. Image Classification for Prediction Functions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kumar, N.; Narayan Das, N.; Gupta, D.; Gupta, K.; Bindra, J. Efficient automated disease diagnosis using machine learning models. J. Healthc. Eng. 2021, 2021, 9983652. [Google Scholar] [CrossRef] [PubMed]
- Hossain, M.; Laskar, M.; Rahman, T. Automated Disease Prediction System (ADPS): A User Input-Based Reliable Architecture for Disease Prediction. Doctoral Dissertation, Department of Computer Science and Engineering, Islamic University of Technology, Gazipur, Bangladesh, 2015. [Google Scholar]
- Marcos-Zambrano, L.J.; Karaduzovic-Hadziabdic, K.; Turukalo, T.L.; Przymus, P.; Trajkovik, V.; Aasmets, O.; Berland, M.; Gruca, A.; Hasic, J.; Hron, K.; et al. Applications of machine learning in human microbiome studies: A review on feature selection, biomarker identification, disease prediction, and treatment. Front. Microbiol. 2021, 12, 313. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Shrivastava, A.; Gupta, A. Neil: Extracting visual knowledge from web data. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 2–8 December 2013; pp. 1409–1416. [Google Scholar]
- Abdel Hameed, M.; Hassaballah, M.; Hosney, M.E.; Alqahtani, A. An AI-Enabled Internet of Things Based Autism Care System for Improving Cognitive Ability of Children with Autism Spectrum Disorders. Comput. Intell. Neurosci. 2022, 2022, 2247675. [Google Scholar] [CrossRef] [PubMed]
- Houssein, E.H.; Ibrahim, I.E.; Hassaballah, M.; Wazery, Y.M. Integration of Machine Learning and Optimization Techniques for Cardiac Health Recognition. In Integrating Meta-Heuristics and Machine Learning for Real-World Optimization Problems; Springer: Cham, Switzerland, 2022; pp. 121–148. [Google Scholar]
- Narin, A.; Kaya, C.; Pamuk, Z. Automatic detection of coronavirus disease (COVID-19) using X-ray images and deep convolutional neural networks. Pattern Anal. Appl. 2021, 24, 1207–1220. [Google Scholar] [CrossRef] [PubMed]
- Shafiee, N.; Dadar, M.; Ducharme, S.; Collins, D.L.; for the Alzheimer’s Disease Neuroimaging Initiative. Automatic Prediction of Cognitive and Functional Decline Can Significantly Decrease the Number of Subjects Required for Clinical Trials in Early Alzheimer’s Disease. J. Alzheimer’s Dis. 2021, 84, 1071–1078. [Google Scholar] [CrossRef]
- Makroum, M.A.; Adda, M.; Bouzouane, A.; Ibrahim, H. Machine Learning and Smart Devices for Diabetes Management: Systematic Review. Sensors 2022, 22, 1843. [Google Scholar] [CrossRef]
- Nancy, A.A.; Ravindran, D.; Raj Vincent, P.D.; Srinivasan, K.; Gutierrez Reina, D. Iot-cloud-based smart healthcare monitoring system for heart disease prediction via deep learning. Electronics 2022, 11, 2292. [Google Scholar] [CrossRef]
- Allimuthu, U.; Mahalakshmi, K. Intelligent route discovery towards rushing attacks in ad hoc wireless networks. J. Ambient. Intell. Humaniz. Comput. 2022, 13, 921–960. [Google Scholar] [CrossRef]
- Dileep, P.; Rao, K.N.; Bodapati, P.; Gokuruboyina, S.; Peddi, R.; Grover, A.; Sheetal, A. An automatic heart disease prediction using cluster-based bi-directional LSTM (C-BiLSTM) algorithm. Neural Comput. Appl. 2022, 1–14. [Google Scholar] [CrossRef]
- Pičulin, M.; Smole, T.; Žunkovič, B.; Kokalj, E.; Robnik-Šikonja, M.; Kukar, M.; Fotiadis, D.I.; Pezoulas, V.C.; Tachos, N.S.; Barlocco, F.; et al. Disease progression of hypertrophic cardiomyopathy: Modeling using machine learning. JMIR Med. Inform. 2022, 10, e30483. [Google Scholar] [CrossRef]
- Shastri, S.; Kour, P.; Kumar, S.; Singh, K.; Mansotra, V. GBoost: A novel Grading-AdaBoost ensemble approach for automatic identification of erythemato-squamous disease. Int. J. Inf. Technol. 2021, 13, 959–971. [Google Scholar] [CrossRef]
- Tang, Z.; Xie, H.; Du, C.; Liu, Y.; Khalaf, O.I.; Allimuthu, U.K. Machine Learning Assisted Energy Optimization in Smart Grid for Smart City Applications. J. Interconnect. Netw. 2022, 28, 2144006. [Google Scholar] [CrossRef]
- Dwivedi, R.; Mehrotra, D.; Chandra, S. Potential of Internet of Medical Things (IoMT) applications in building a smart healthcare system: A systematic review. J. Oral Biol. Craniofacial Res. 2021, 12, 302–318. [Google Scholar] [CrossRef] [PubMed]
- Arumugam, S.; Subramani, S.B. Enhancing the web image search results through direct and indirect relevance model. In AIP Conference Proceedings; AIP Publishing LLC.: Melville, NY, USA, 2022; Volume 2424, p. 050002. [Google Scholar]
- Gillmann, C.; Pajor, G.; Ramadori, P.; Albers, P.; Mons, U.; Steindorf, K.; Kentner, S.; Baumann, M. Solving problems is smart, preventing them is wise: Lessons learned from the 2nd International DKFZ Conference on Cancer Prevention. Int. J. Cancer 2021, 148, 3086–3096. [Google Scholar] [CrossRef] [PubMed]
- Yu, L.; Chen, H.; Dou, Q.; Qin, J.; Heng, P.A. Integrating online and offline three-dimensional deep learning for automated polyp detection in colonoscopy videos. IEEE J. Biomed. Health Inform. 2016, 21, 65–75. [Google Scholar] [CrossRef] [PubMed]
- El-Hasnony, I.M.; Elzeki, O.M.; Alshehri, A.; Salem, H. Multi-label active learning-based machine learning model for heart disease prediction. Sensors 2022, 22, 1184. [Google Scholar] [CrossRef]
- Jayakumar, L.; Dumka, A. A Timeline Optimization Approach of Green Requirement Engineering Framework for Efficient Categorized Natural Language Documents in Non-Functional Requirements. Int. J. Bus. Anal. IJBAN 2021, 8, 21–37. [Google Scholar]
- Pang, H.; Zheng, Z.; Zhen, T.; Sharma, A. Smart farming: An approach for disease detection implementing IoT and image processing. Int. J. Agric. Environ. Inf. Syst. IJAEIS 2021, 12, 55–67. [Google Scholar] [CrossRef]
- Pramanik, P.K.P.; Upadhyaya, B.K.; Pal, S.; Pal, T. Internet of things, smart sensors, and pervasive systems: Enabling connected and pervasive healthcare. Healthc. Data Anal. Manag. 2019, 1–58. [Google Scholar]
- Joshi, R.C.; Kaushik, M.; Dutta, M.K.; Srivastava, A.; Choudhary, N. VirLeafNet: Automatic analysis and viral disease diagnosis using deep-learning in Vigna mungo plant. Ecol. Inform. 2021, 61, 101197. [Google Scholar] [CrossRef]
- Giannakopoulou, K.M.; Roussaki, I.; Demestichas, K. Internet of Things Technologies and Machine Learning Methods for Parkinson’s Disease Diagnosis, Monitoring and Management: A Systematic Review. Sensors 2022, 22, 1799. [Google Scholar] [CrossRef] [PubMed]
- Dhaka, V.S.; Meena, S.V.; Rani, G.; Sinwar, D.; Ijaz, M.F.; Woźniak, M. A survey of deep convolutional neural networks applied for prediction of plant leaf diseases. Sensors 2021, 21, 4749. [Google Scholar] [CrossRef]
- Jain, D.; Mishra, A.K.; Das, S.K. Machine learning-based automatic prediction of Parkinson’s Disease using speech features. In Proceedings of International Conference on Artificial Intelligence and Applications; Springer: Singapore, 2021; pp. 351–362. [Google Scholar]
- Muhammad, G.; Alshehri, F.; Karray, F.; El Saddik, A.; Alsulaiman, M.; Falk, T.H. A comprehensive survey on multimodal medical signals fusion for smart healthcare systems. Inf. Fusion 2021, 76, 355–375. [Google Scholar] [CrossRef]
- Tuli, S.; Basumatary, N.; Gill, S.S.; Kahani, M.; Arya, R.C.; Wander, G.S.; Buyya, R. HealthFog: An ensemble deep learning based Smart Healthcare System for Automatic Diagnosis of Heart Diseases in integrated IoT and fog computing environments. Future Gener. Comput. Syst. 2020, 104, 187–200. [Google Scholar] [CrossRef]
- Ting, D.S.; Lin, H.; Ruamviboonsuk, P.; Wong, T.Y.; Sim, D.A. Artificial intelligence, the internet of things, and virtual clinics: Ophthalmology at the digital translation forefront. Lancet Digit. Health 2020, 2, 8–9. [Google Scholar] [CrossRef]
- Jaki, S.; De Smedt, T.; Gwóźdź, M.; Panchal, R.; Rossa, A.; De Pauw, G. Online hatred of women in the Incels. me forum: Linguistic analysis and automatic detection. J. Lang. Aggress. Confl. 2019, 7, 240–268. [Google Scholar] [CrossRef]
- Lee, E.J.; Park, S.J. A Preference-Driven Smart Home Service for the Elderly’s Biophilic Experience. Sensors 2021, 21, 5108. [Google Scholar] [CrossRef]
- Mbunge, E.; Akinnuwesi, B.; Fashoto, S.G.; Metfula, A.S.; Mashwama, P. A critical review of emerging technologies for tackling COVID-19 pandemic. Hum. Behav. Emerg. Technol. 2021, 3, 25–39. [Google Scholar] [CrossRef]
- Mohanta, B.; Das, P.; Patnaik, S. Healthcare 5.0: A paradigm shift in digital healthcare system using Artificial Intelligence, IOT and 5G Communication. In Proceedings of the 2019 International Conference on Applied Machine Learning (ICAML), Bhubaneswar, India, 25–26 May 2019; pp. 191–196. [Google Scholar]
- Tang, N. Motion image detection algorithm for juvenile obesity based on video surveillance and internet of things. Microprocess. Microsyst. 2021, 81, 103788. [Google Scholar] [CrossRef]
- Allimuthu, U. Efficient Mobile Ad Hoc Route Maintenance Against Social Distances Using Attacker Detection Automation. Mob. Netw. Appl. 2022, 1–32. [Google Scholar] [CrossRef]
- Elansary, I.; Darwish, A.; Hassanien, A.E. The future scope of internet of things for monitoring and prediction of COVID-19 patients. In Digital Transformation and Emerging Technologies for Fighting COVID-19 Pandemic: Innovative Approaches; Springer: Cham, Switzerland, 2021; pp. 235–247. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SI No. | Disease | Symptoms |
|---|---|---|
| 1 | Alzheimer’s | Memory loss |
| Poor judgment | ||
| Confusion | ||
| 2 | Parkinson’s | Poor judgment |
| Trouble speaking | ||
| 3 | Stroke | Slowed movement |
| Trouble speaking |
| Automatic Online Prediction Analysis | Image-Sensing Accuracy Clustering Analysis | ||
|---|---|---|---|
| Sample Images (Count) | Image-Sensing Accuracy (%) | No Image Sample (Count) | Image-Sensing Accuracy (%) |
| 25 | 66.7 | 10 | 66.6 |
| 58 | 76.5 | 28 | 59.09 |
| 70 | 78.05 | 46 | 56.25 |
| 85 | 78.21 | 64 | 54.76 |
| 150 | 77.22 | 64 | 53.84 |
| 235 | 80.67 | 64 | 53.22 |
| 286 | 80.32 | 64 | 52.7 |
| 350 | 83.1 | 136 | 52.43 |
| 400 | 86.6 | 154 | 52.17 |
| 500 | 88.3 | 172 | 51.96 |
| 650 | 85.6 | 190 | 51.78 |
| 725 | 87.9 | 208 | 55.5 |
| 815 | 92.8 | 226 | 59.4 |
| 900 | 95.6 | 244 | 60.78 |
| 950 | 97.8 | 262 | 65.34 |
| No. of Image Samples (Count) | Standard Deviation | Data Sample Count | Error STD (m/s2) |
|---|---|---|---|
| 15 | 3.93 | 1 | 3.93 |
| 28 | 4.15 | 3 | 1.38 |
| 41 | 4.37 | 9 | 0.48 |
| 54 | 4.59 | 13 | 0.35 |
| 67 | 4.81 | 17 | 0.28 |
| 80 | 5.03 | 21 | 2.56 |
| 93 | 5.25 | 25 | 1.21 |
| 150 | 5.47 | 29 | 1.18 |
| 175 | 5.69 | 33 | 1.17 |
| 250 | 5.91 | 37 | 2.15 |
| 300 | 6.13 | 41 | 3.14 |
| 450 | 6.35 | 45 | 0.14 |
| 475 | 6.57 | 49 | 2.13 |
| 500 | 6.79 | 53 | 1.12 |
| 650 | 7.01 | 57 | 3.12 |
| Time Duration (d) | No. of Image Samples (Count) | Normalized frequency (f) |
|---|---|---|
| 0.67 | 5 | 0.23 |
| 1.56 | 18 | 0.058 |
| 2.45 | 31 | 0.032 |
| 3.34 | 44 | 0.028 |
| 4.23 | 57 | 0.0189 |
| 5.12 | 70 | 0.981 |
| 6.01 | 83 | 0.125 |
| 6.9 | 96 | 0.523 |
| 7.79 | 109 | 0.125 |
| 8.68 | 122 | 0.523 |
| 9.57 | 135 | 0.921 |
| 10.46 | 148 | 1.319 |
| 11.35 | 161 | 1.717 |
| 12.24 | 174 | 2.115 |
| 12.43 | 187 | 2.513 |
| No. of Image Samples (Count) | Prediction Analysis (%) | No. of Image Samples (Count) | Prediction Analysis (%) |
|---|---|---|---|
| 12 | 56.7 | 250 | 65.4 |
| 28 | 58.9 | 345 | 68.2 |
| 44 | 61.1 | 440 | 71 |
| 60 | 63.3 | 535 | 73.8 |
| 76 | 65.5 | 630 | 76.6 |
| 92 | 67.7 | 725 | 79.4 |
| 108 | 69.9 | 820 | 82.2 |
| 124 | 72.1 | 915 | 85 |
| 140 | 74.3 | 950 | 87.8 |
| 156 | 76.5 | 1000 | 90.6 |
| Image Classification | Prediction Function | Image Classification | Prediction Function |
|---|---|---|---|
| 2 | 45.3 | 135 | 56.8 |
| 11 | 47.9 | 150 | 57.2 |
| 20 | 50.5 | 165 | 57.6 |
| 29 | 53.1 | 180 | 58 |
| 38 | 55.7 | 195 | 58.4 |
| 47 | 58.3 | 210 | 58.8 |
| 56 | 60.9 | 225 | 59.2 |
| 65 | 63.5 | 240 | 59.6 |
| 74 | 66.1 | 255 | 60 |
| 83 | 68.7 | 270 | 60.4 |
| 92 | 71.3 | 285 | 60.8 |
| 101 | 73.9 | 300 | 61.2 |
| 110 | 76.5 | 315 | 61.6 |
| 119 | 79.1 | 330 | 62 |
| 128 | 81.7 | 345 | 62.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rajesh, E.; Basheer, S.; Dhanaraj, R.K.; Yadav, S.; Kadry, S.; Khan, M.A.; Kim, Y.J.; Cha, J.-H. Machine Learning for Online Automatic Prediction of Common Disease Attributes Using Never-Ending Image Learner. Diagnostics 2023, 13, 95. https://doi.org/10.3390/diagnostics13010095
Rajesh E, Basheer S, Dhanaraj RK, Yadav S, Kadry S, Khan MA, Kim YJ, Cha J-H. Machine Learning for Online Automatic Prediction of Common Disease Attributes Using Never-Ending Image Learner. Diagnostics. 2023; 13(1):95. https://doi.org/10.3390/diagnostics13010095
Chicago/Turabian StyleRajesh, E., Shajahan Basheer, Rajesh Kumar Dhanaraj, Soni Yadav, Seifedine Kadry, Muhammad Attique Khan, Ye Jin Kim, and Jae-Hyuk Cha. 2023. "Machine Learning for Online Automatic Prediction of Common Disease Attributes Using Never-Ending Image Learner" Diagnostics 13, no. 1: 95. https://doi.org/10.3390/diagnostics13010095
APA StyleRajesh, E., Basheer, S., Dhanaraj, R. K., Yadav, S., Kadry, S., Khan, M. A., Kim, Y. J., & Cha, J.-H. (2023). Machine Learning for Online Automatic Prediction of Common Disease Attributes Using Never-Ending Image Learner. Diagnostics, 13(1), 95. https://doi.org/10.3390/diagnostics13010095