
Accurately Identifying Cerebroarterial Stenosis from Angiography Reports Using Natural Language Processing Approaches

 ,
,  ,
,
Abstract
:1. Introduction
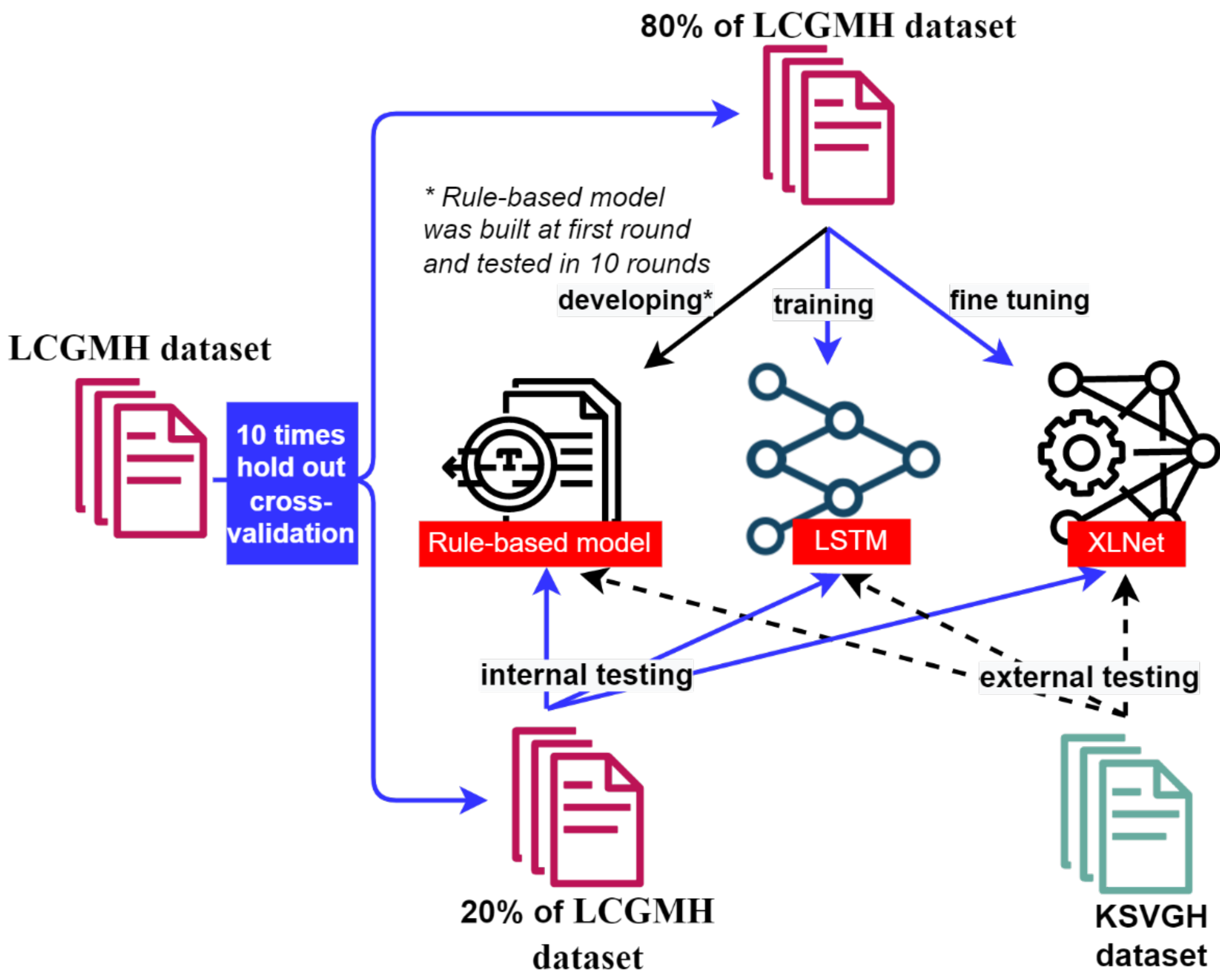
2. Materials and Methods
2.1. Data Collection and Preprocessing
2.2. Stenosis Identification Models
2.2.1. Rule-Based NLP Model
2.2.2. Long Short-Term Memory Model
2.2.3. XLNet Model
2.3. NLP Model Assessments
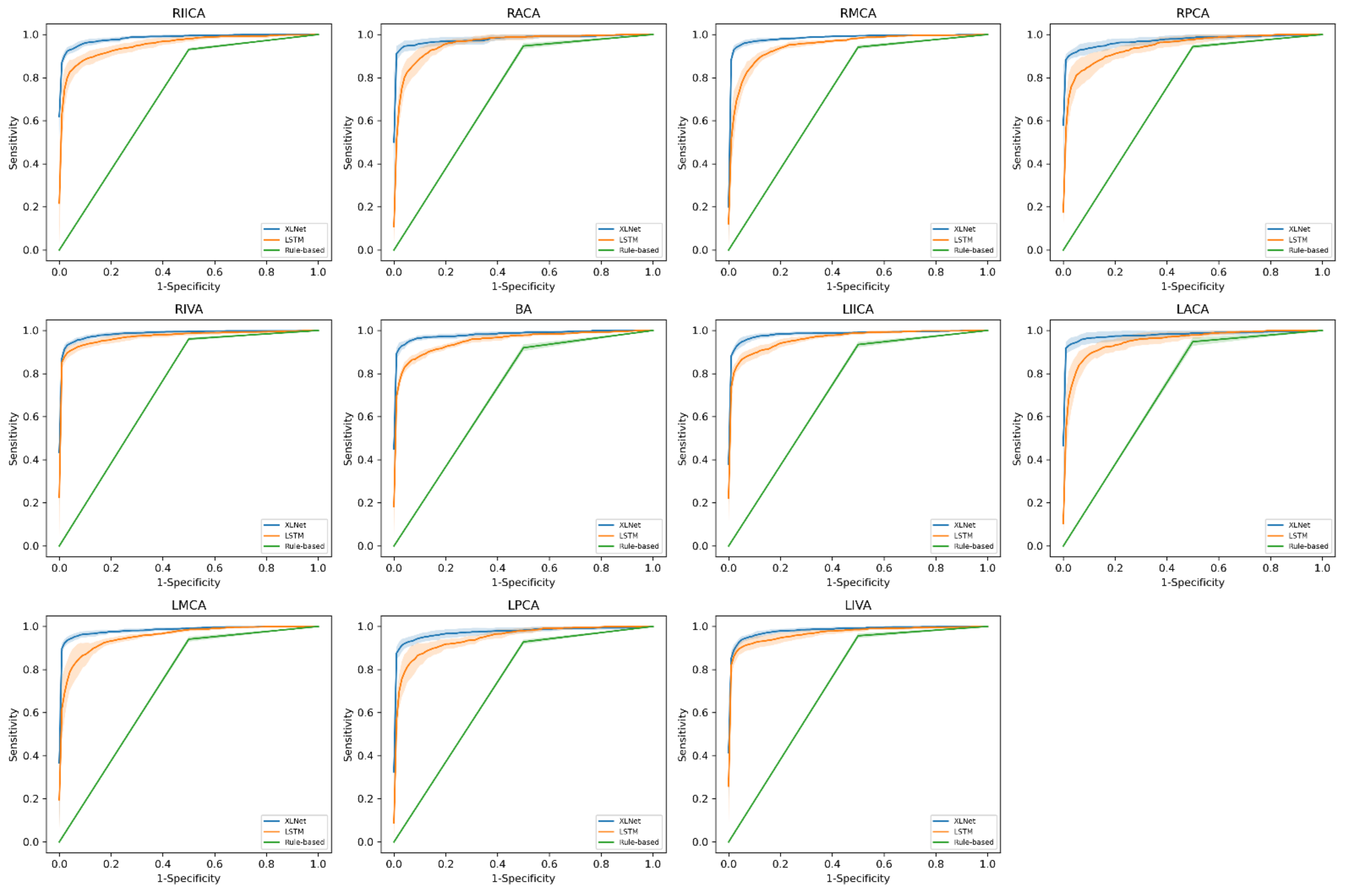
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Holmstedt, C.A.; Turan, T.N.; Chimowitz, M.I. Atherosclerotic intracranial arterial stenosis: Risk factors, diagnosis, and treatment. Lancet Neurol. 2013, 12, 1106–1114. [Google Scholar] [CrossRef] [Green Version]
- Wong, L.K. Global burden of intracranial atherosclerosis. Int. J. Stroke 2006, 1, 158–159. [Google Scholar] [CrossRef] [PubMed]
- Leng, X.; Hurford, R.; Feng, X.; Chan, K.L.; Wolters, F.J.; Li, L.; Soo, Y.O.; Wong, K.S.L.; Mok, V.C.; Leung, T.W. Intracranial arterial stenosis in Caucasian versus Chinese patients with TIA and minor stroke: Two contemporaneous cohorts and a systematic review. J. Neurol. Neurosurg. Psychiatry 2021, 92, 590–597. [Google Scholar] [CrossRef] [PubMed]
- Suri, M.F.K.; Johnston, S.C. Epidemiology of intracranial stenosis. J. Neuroimaging 2009, 19, 11S–16S. [Google Scholar] [CrossRef]
- Chen, H.-X.; Wang, L.-J.; Yang, Y.; Yue, F.-X.; Chen, L.-M.; Xing, Y.-Q. The prevalence of intracranial stenosis in patients at low and moderate risk of stroke. Ther. Adv. Neurol. Disord. 2019, 12, 1756286419869532. [Google Scholar] [CrossRef] [Green Version]
- Hurford, R.; Wolters, F.J.; Li, L.; Lau, K.K.; Küker, W.; Rothwell, P.M.; Cohort, O.V.S.P. Prevalence, predictors, and prognosis of symptomatic intracranial stenosis in patients with transient ischaemic attack or minor stroke: A population-based cohort study. Lancet Neurol. 2020, 19, 413–421. [Google Scholar] [CrossRef]
- Kong, H.-J. Managing unstructured big data in healthcare system. Healthc. Inform. Res. 2019, 25, 1–2. [Google Scholar] [CrossRef]
- Pons, E.; Braun, L.M.; Hunink, M.M.; Kors, J.A. Natural language processing in radiology: A systematic review. Radiology 2016, 279, 329–343. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Mehrabi, S.; Sohn, S.; Atkinson, E.; Amin, S.; Liu, H. Automatic Extraction of Major Osteoporotic Fractures from Radiology Reports using Natural Language Processing. In Proceedings of the 2018 IEEE International Conference on Healthcare Informatics Workshop (ICHI-W), New York, NY, USA, 4–7 June 2018; pp. 64–65. [Google Scholar]
- Chen, M.C.; Ball, R.L.; Yang, L.; Moradzadeh, N.; Chapman, B.E.; Larson, D.B.; Langlotz, C.P.; Amrhein, T.J.; Lungren, M.P. Deep learning to classify radiology free-text reports. Radiology 2018, 286, 845–852. [Google Scholar] [CrossRef]
- Garla, V.; Taylor, C.; Brandt, C. Semi-supervised clinical text classification with Laplacian SVMs: An application to cancer case management. J. Biomed. Inform. 2013, 46, 869–875. [Google Scholar] [CrossRef] [Green Version]
- Moneta, G.L.; Edwards, J.M.; Chitwood, R.W.; Taylor, L.M., Jr.; Lee, R.W.; Cummings, C.A.; Porter, J.M. Correlation of North American Symptomatic Carotid Endarterectomy Trial (NASCET) angiographic definition of 70% to 99% internal carotid artery stenosis with duplex scanning. J. Vasc. Surg. 1993, 17, 152–159. [Google Scholar] [CrossRef] [Green Version]
- Kang, N.; Singh, B.; Afzal, Z.; van Mulligen, E.M.; Kors, J.A. Using rule-based natural language processing to improve disease normalization in biomedical text. J. Am. Med. Inform. Assoc. 2013, 20, 876–881. [Google Scholar] [CrossRef] [Green Version]
- Solti, I.; Cooke, C.R.; Xia, F.; Wurfel, M.M. Automated classification of radiology reports for acute lung injury: Comparison of keyword and machine learning based natural language processing approaches. In Proceedings of the 2009 IEEE International Conference on Bioinformatics and Biomedicine Workshop, Washington, DC, USA, 1–4 November 2009; pp. 314–319. [Google Scholar]
- Lakhani, P.; Kim, W.; Langlotz, C.P. Automated detection of critical results in radiology reports. J. Digit. Imaging 2012, 25, 30–36. [Google Scholar] [CrossRef] [Green Version]
- Sohn, S.; Ye, Z.; Liu, H.; Chute, C.G.; Kullo, I.J. Identifying abdominal aortic aneurysm cases and controls using natural language processing of radiology reports. AMIA Summits Transl. Sci. Proc. 2013, 2013, 249. [Google Scholar]
- Yogatama, D.; Dyer, C.; Ling, W.; Blunsom, P. Generative and discriminative text classification with recurrent neural networks. arXiv 2017, arXiv:1703.01898. [Google Scholar]
- Keras: Deep Learning for Python 7 April 2021. Available online: https://github.com/fchollet/keras (accessed on 23 January 2022).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Processing Syst. 2019, 2019, 5754–5764. [Google Scholar]
- Zhu, Y.; Kiros, R.; Zemel, R.; Salakhutdinov, R.; Urtasun, R.; Torralba, A.; Fidler, S. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Parker, R.; Graff, D.; Kong, J.; Chen, K.; Maeda, K. English Gigaword, 5th ed.; Linguistic Data Consortium: Philadelphia, PA, USA, 2011. [Google Scholar]
- Clueweb09 Data Set [Internet]. 2009. Available online: https://lemurproject.org/clueweb09/ (accessed on 23 January 2022).
- Common Crawl. Available online: https://commoncrawl.org/ (accessed on 23 January 2022).
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M. Huggingface’s transformers: State-of-the-art natural language processing. ArXiv 2019, arXiv:abs/1910.03771. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Huhdanpaa, H.T.; Tan, W.K.; Rundell, S.D.; Suri, P.; Chokshi, F.H.; Comstock, B.A.; Heagerty, P.J.; James, K.T.; Avins, A.L.; Nedeljkovic, S.S. Using natural language processing of free-text radiology reports to identify type 1 modic endplate changes. J. Digit. Imaging 2018, 31, 84–90. [Google Scholar] [CrossRef] [PubMed]
- Quiñonero-Candela, J.; Sugiyama, M.; Lawrence, N.D.; Schwaighofer, A. Dataset Shift in Machine Learning; Mit Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Hadsell, R.; Rao, D.; Rusu, A.A.; Pascanu, R. Embracing change: Continual learning in deep neural networks. Trends Cogn. Sci. 2020, 24, 1028–1040. [Google Scholar] [CrossRef]
- Zaib, M.; Sheng, Q.Z.; Emma Zhang, W. A short survey of pre-trained language models for conversational AI-a new age in NLP. In Proceedings of the Australasian Computer Science Week Multiconference, Melbourne, VIC, Australia, 4–6 February 2020; pp. 1–4. [Google Scholar]
- Qiu, X.; Sun, T.; Xu, Y.; Shao, Y.; Dai, N.; Huang, X. Pre-trained models for natural language processing: A survey. Sci. China Technol. Sci. 2020, 63, 1872–1897. [Google Scholar] [CrossRef]
- Li, Z.; Wallace, E.; Shen, S.; Lin, K.; Keutzer, K.; Klein, D.; Gonzalez, J.E. Train large, then compress: Rethinking model size for efficient training and inference of transformers. arXiv 2020, arXiv:2002.11794. [Google Scholar]
- Wu, X.; Zhao, Y.; Radev, D.; Malhotra, A. Identification of patients with carotid stenosis using natural language processing. Eur. Radiol. 2020, 30, 4125–4133. [Google Scholar] [CrossRef]
- Drozdov, I.; Forbes, D.; Szubert, B.; Hall, M.; Carlin, C.; Lowe, D.J. Supervised and unsupervised language modelling in Chest X-Ray radiological reports. PLoS ONE 2020, 15, e0229963. [Google Scholar]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2020, 36, 1234–1240. [Google Scholar] [CrossRef]
- Huang, K.; Altosaar, J.; Ranganath, R. Clinicalbert: Modeling clinical notes and predicting hospital readmission. arXiv 2019, arXiv:1904.05342. [Google Scholar]
- Alsentzer, E.; Murphy, J.R.; Boag, W.; Weng, W.-H.; Jin, D.; Naumann, T.; McDermott, M. Publicly available clinical BERT embeddings. arXiv 2019, arXiv:1904.03323. [Google Scholar]
- Huang, K.; Singh, A.; Chen, S.; Moseley, E.T.; Deng, C.-y.; George, N.; Lindvall, C. Clinical XLNet: Modeling Sequential Clinical Notes and Predicting Prolonged Mechanical Ventilation. arXiv 2019, arXiv:1912.11975. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
| Internal Dataset (n = 9614) | External Dataset (n = 315) | |
|---|---|---|
| RIICA (%) | 740 (7.7) | 12 (3.8) |
| RACA (%) | 416 (4.3) | 2 (0.6) |
| RMCA (%) | 967 (10.1) | 13 (4.1) |
| RPCA (%) | 491 (5.1) | 6 (1.9) |
| RIVA (%) | 1052 (10.9) | 2 (0.6) |
| BA (%) | 554 (5.8) | 9 (2.9) |
| LIICA (%) | 735 (7.6) | 4 (1.3) |
| LACA (%) | 407 (4.2) | 4 (1.3) |
| LMCA (%) | 1005 (10.5) | 10 (3.2) |
| LPCA (%) | 547 (5.7) | 3 (1.0) |
| LIVA (%) | 943 (9.8) | 2 (0.6) |
| Internal Testing Dataset (n = 1922) | External Testing Dataset (n = 315) | |||||
|---|---|---|---|---|---|---|
| Cerebral Artery (Prevalence in Internal/External Dataset) % | Rule-Based Model | LSTM | XLNet | Rule-Based Model | LSTM | XLNet |
| RIICA (7.7/3.8) | 0.93 ± 0.01 | 0.95 ± 0.01 | 0.98 ± 0.00 | 0.71 | 0.76 ± 0.10 | 0.91 ± 0.11 |
| RACA (4.3/0.6) | 0.95 ± 0.01 | 0.96 ± 0.01 | 0.98 ± 0.01 | 0.50 | 0.73 ± 0.16 | 0.93 ± 0.01 |
| RMCA (10.1/4.1) | 0.94 ± 0.01 | 0.95 ± 0.01 | 0.99 ± 0.00 | 0.58 | 0.77 ± 0.10 | 0.97 ± 0.02 |
| RPCA (5.1/1.9) | 0.94 ± 0.01 | 0.95 ± 0.02 | 0.97 ± 0.01 | 0.50 | 0.58 ± 0.18 | 0.90 ± 0.06 |
| RIVA (10.9/0.6) | 0.96 ± 0.01 | 0.97 ± 0.01 | 0.99 ± 0.00 | 0.75 | 0.55 ± 0.19 | 0.99 ± 0.03 |
| BA (5.8/2.9) | 0.92 ± 0.02 | 0.95 ± 0.01 | 0.98 ± 0.01 | 0.83 | 0.47 ± 0.08 | 0.84 ± 0.04 |
| LIICA (7.6/1.3) | 0.93 ± 0.01 | 0.96 ± 0.01 | 0.98 ± 0.01 | 0.75 | 0.78 ± 0.07 | 0.93 ± 0.08 |
| LACA (4.2/1.3) | 0.95 ± 0.02 | 0.95 ± 0.01 | 0.98 ± 0.01 | 0.75 | 0.70 ± 0.15 | 0.99 ± 0.01 |
| LMCA (10.5/3.2) | 0.94 ± 0.01 | 0.95 ± 0.01 | 0.98 ± 0.00 | 0.50 | 0.80 ± 0.10 | 0.98 ± 0.01 |
| LPCA (5.7/1.0) | 0.93 ± 0.01 | 0.95 ± 0.02 | 0.98 ± 0.01 | 0.50 | 0.61 ± 0.14 | 0.79 ± 0.12 |
| LIVA (9.8/0.6) | 0.95 ± 0.01 | 0.97 ± 0.01 | 0.98 ± 0.00 | 0.50 | 0.65 ± 0.08 | 0.92 ± 0.09 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, C.-H.; Hsu, K.-C.; Liang, C.-K.; Lee, T.-H.; Shih, C.-S.; Fann, Y.C. Accurately Identifying Cerebroarterial Stenosis from Angiography Reports Using Natural Language Processing Approaches. Diagnostics 2022, 12, 1882. https://doi.org/10.3390/diagnostics12081882
Lin C-H, Hsu K-C, Liang C-K, Lee T-H, Shih C-S, Fann YC. Accurately Identifying Cerebroarterial Stenosis from Angiography Reports Using Natural Language Processing Approaches. Diagnostics. 2022; 12(8):1882. https://doi.org/10.3390/diagnostics12081882
Chicago/Turabian StyleLin, Ching-Heng, Kai-Cheng Hsu, Chih-Kuang Liang, Tsong-Hai Lee, Ching-Sen Shih, and Yang C. Fann. 2022. "Accurately Identifying Cerebroarterial Stenosis from Angiography Reports Using Natural Language Processing Approaches" Diagnostics 12, no. 8: 1882. https://doi.org/10.3390/diagnostics12081882
APA StyleLin, C.-H., Hsu, K.-C., Liang, C.-K., Lee, T.-H., Shih, C.-S., & Fann, Y. C. (2022). Accurately Identifying Cerebroarterial Stenosis from Angiography Reports Using Natural Language Processing Approaches. Diagnostics, 12(8), 1882. https://doi.org/10.3390/diagnostics12081882