1. Introduction
The inability to move the facial muscles on one or both sides is known as facial palsy or facial paralysis. This inability can be generated from nerve damage due to trauma, congenital conditions, or diseases like stroke, brain tumor, or Bell’s palsy. Patients with facial palsy exhibit problems with speaking, blinking, swallowing saliva, eating, or communicating through natural facial expressions because of a noticeable drooping of facial capabilities. In general, the diagnosis by a clinician relies on a visual inspection of the patient’s facial symmetry. The examination of facial palsy requires specific medical training to produce a diagnosis, and it could vary from practitioner to practitioner. This is a reason why, in recent years, automatic approaches based on computer vision and artificial intelligence have been emerging to provide an objective evaluation of the paralysis.
The wide variety of methodologies working with facial palsy found in the literature can be divided according to their primary task. For example, if the intention is to perform a binary classification to discriminate between healthy or unhealthy subjects (i.e., to detect facial palsy), or to perform a multi-class classification (i.e., to evaluate the level of paralysis). Automatic approaches based on computer vision and artificial intelligence that seek to detect facial palsy include the works in [
1,
2,
3,
4,
5,
6]. Binary classification can be performed with an objective other than detecting facial paralysis; for example, identifying the type of facial palsy that a patient suffers, as Barbosa et al. did in [
2] when seeking to discriminate between peripheral palsy or central palsy.
Automatic approaches aiming to assess the severity of facial palsy require a scale to measure the nerve damage. Those well-known scales are the House-Brackmann (HB), Sunnybrook, Yanagihara, FNGS 2.0, and eFACE. In detail, the grading scales split the facial nerve damage into a series of discrete levels according to some strict measures. Those measures are related to the symmetry of the face while displaying a neutral expression or showing a set of voluntary facial muscle movements; they are also associated with secondary features such as synkinesis [
7]. Some authors, to start testing their algorithms, split the level of facial palsy into fewer degrees, for example: healthy, low, and high degrees of paralysis; and later report their findings [
8,
9,
10].
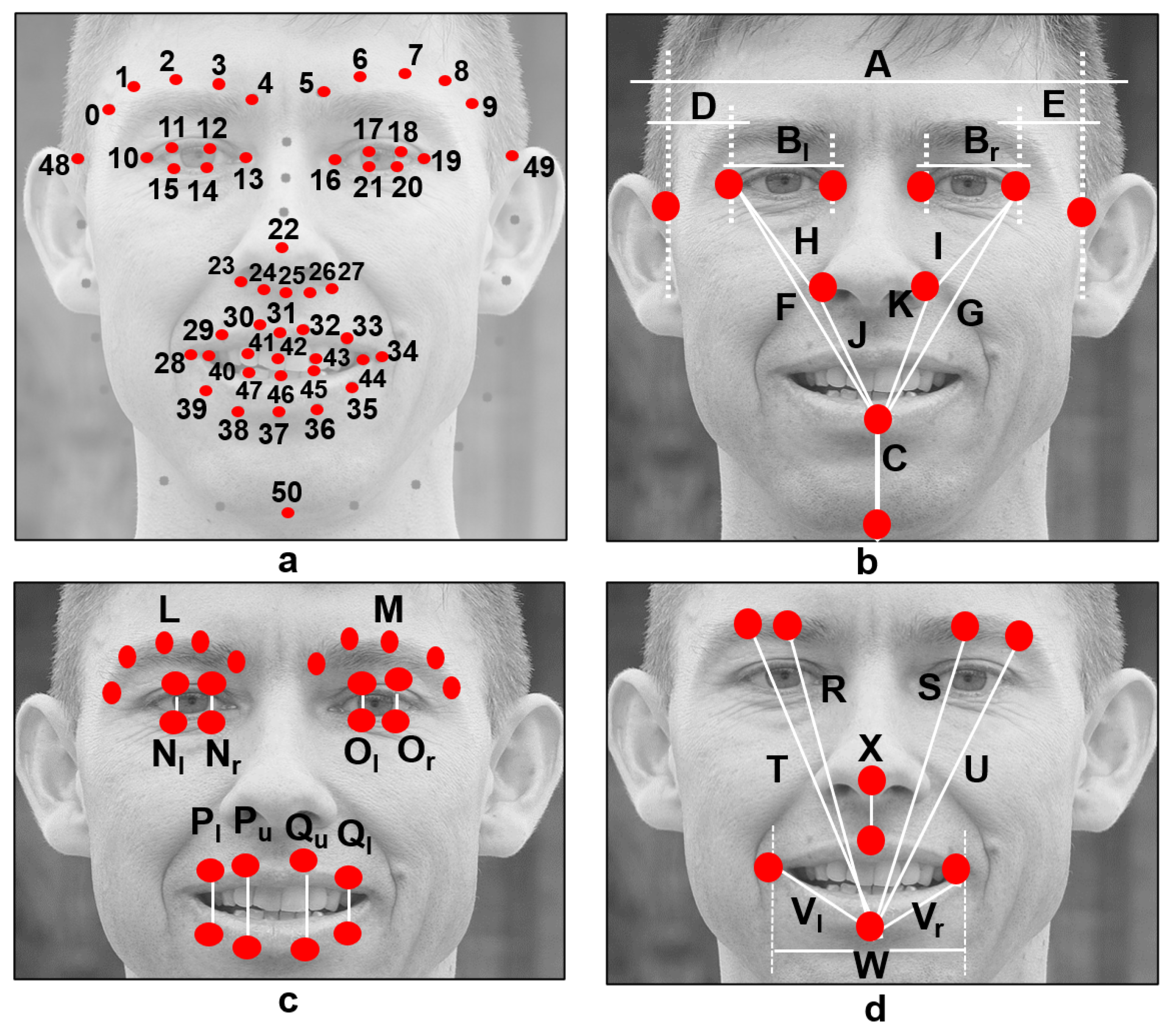
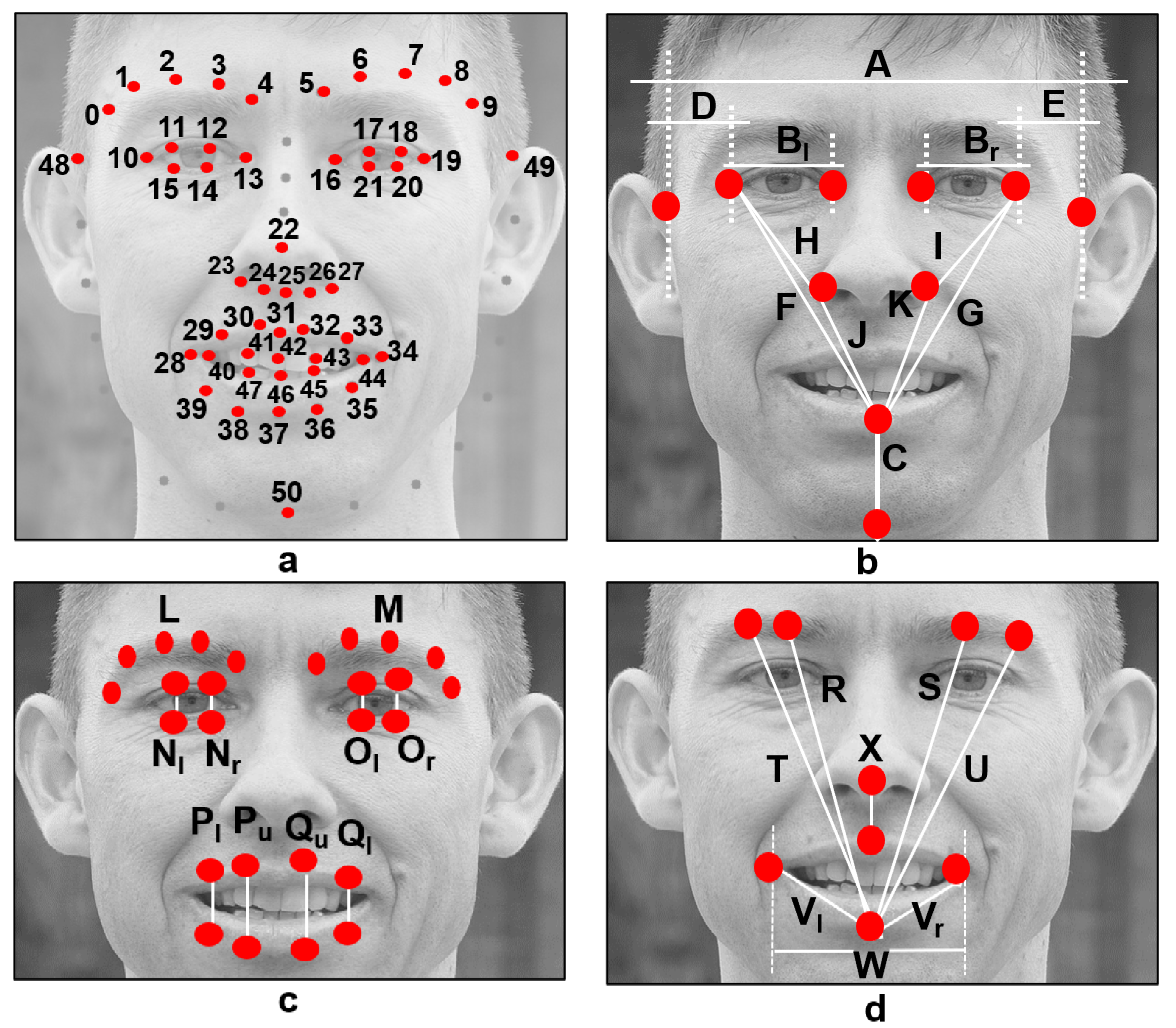
Usually, automatic approaches are designed through handcrafted features and classifiers. Using a similar method, this research focuses on features computed from facial landmarks. As facial landmarks, we refer to the key points extracted using facial models on a face previously detected on an image. Many facial models (often referred to as shape predictors) are publicly available and can locate facial landmarks. Matthews and Baker introduced a 68-point facial model in [
11], which is widely known and employed in the facial analysis field. However, few implementations fail in predicting those key points from persons who have facial palsy because the model was trained using imagery from healthy persons [
12,
13,
14]. Recently, some authors have been working on improving the available shape predictors to extract facial landmarks in palsy patients accurately. Particularly relevant to our research is the model developed and released by Guarin et al. [
15], which was trained using imagery of palsy patients.
The methodologies in [
2,
13,
14,
16] are based on handcrafted features extracted from facial landmarks and the use of a wide variety of classifiers. The asymmetry of the face is a core trait in those methodologies to diagnose facial palsy. Additionally, we wish to emphasize that the detection of facial paralysis was performed on proprietary databases with patients suffering from diverse levels of paralysis. To our knowledge those databases are unavailable to the research community, thus, a direct comparison of the performance is not possible. Some methodologies operate on specific facial gestures [
13] and others require a set of movements to output a result [
2,
14,
16]. Our proposed methodology is also based on handcrafted features, and they do not depend on a specific facial gesture to perform a classification task.
Diverse neural network structures have been applied to solve a variety of problems in the medical field [
6,
17,
18,
19,
20,
21,
22,
23,
24]. Particularly, there are a few methodologies working with deep neural networks to evaluate facial palsy (e.g., [
8,
10,
25,
26,
27,
28]). Deep learning methods can improve the facial palsy detection rate, but their efficiency is limited by insufficient data and class imbalance, according to [
28]. These methods automatically learn discriminative features, meaning that they do not compute handcrafted features but perform some pre-processing steps before training and evaluating the network. Due to the enormous amount of required data, geometric and color transformations, cropping, and resizing of the images are needed to increase the number of samples.
The methodologies in [
10,
26,
28] are evaluated using the same facial palsy database; however, their experimental settings drastically differ in the testing method: leave-one-out protocol in [
26], five-fold cross-validation in [
10], and ten times repetitions in [
28]. With this in mind, circumspect evaluations must be made when comparing performance. Both Hsu et al. [
26] and Abayomi-Alli et al. [
28] based their approach on well-known pre-trained networks with thousands of images. Particularly, Abayomi-Alli et al. extract 1000 deep features from a network’s final layer, and those are fed to a classifier. Our proposed methodology requires a simpler classifier structure with few features and samples to perform a classification task.
The analysis of the human face in terms of symmetry/asymmetry is not a new topic, and there is plenty of literature about it [
29,
30]. We talk about the symmetry of a person’s face knowing that we all are asymmetric. In other words, facial asymmetry responds to the fact that the left and right sides of our face showing no movement or while performing an expression are not identical. This asymmetry can be the result of various factors, including anatomical, neurological, physiological, pathological, psychological, and socio-cultural variables [
29]. Usually, the growth and development of bones, nerves, and muscles should not produce new asymmetries.
We assume in this research that healthy faces have quite an identical left and right sides with a neutral expression, while the affected ones do not, allowing us to characterize the face of a palsy patient. In other words, a threshold value can be obtained using machine learning algorithms to determine to what extent the facial asymmetry is expected and where it is considered an unhealthy condition.
Our previous work in [
6] introduced a system to detect facial palsy using 29 handcrafted geometrical features and a classifier based on neural networks. The objective was to classify face images into healthy and unhealthy regarding the severity of facial paralysis. There, the methodology operates on the assumption that facial paralysis can be characterized by locating levels of asymmetry in the face; if found, then it is said that the subject suffers from paralysis. The algorithm was evaluated in two different databases, obtaining a performance of 94.06% correct classification for the first database and 97.22% on the second one.
In this research, we also take the following perspectives in analyzing facial palsy. Some methodologies work with specific regions of the face (e.g., the mouth, the eyes, the forehead), and others extract helpful information from the entire face. Some approaches require a set of specific gestures to operate, and few need only one image to output a result. Finally, some methodologies perform binary discrimination between healthy and unhealthy subjects, and others evaluate different levels of paralysis based on a predefined clinical scale.
In this paper, we show that the framework introduced in [
6] is independent of the facial gesture displayed by the person and that only one image is sufficient to output a result. We also show that our approach can perform multi-class classification tasks, and that the assessment of facial paralysis is possible with partial occlusions of the face if the analysis is executed on certain regions of the face. A performance analysis using four different classifiers is elaborated attaining excellent results to corroborate our features’ validity in a wide range of situations.
The main contributions of this work are: (1) a methodology to design classifiers based on easy-to-compute features that do not require a set of facial gestures to output a result, (2) a framework to analyze facial palsy using information extracted from the entire face or from specific facial regions (the eyes or the mouth), (3) a performance analysis using four different classifiers with excellent results which could provide orientation in selecting the best classification approach, and (4) evaluations on publicly available databases.
The rest of this paper is organized as follows.
Section 2 introduces the proposed methodology.
Section 3 describes the databases employed in this research and introduces the experiments, findings, and discussion. Finally, concluding remarks are provided in
Section 4.
3. Results and Discussion
A few methodologies in the literature look to assess facial paralysis in an image. Then, it seems relevant to mention that collaborating with the research community has been complicated due to the unavailability of public databases, mainly because of the need of preserving the patient’s privacy. This scenario encouraged us to evaluate our system on a database that is publicly available. As stated previously, this research seeks to expand our previous methodology to perform the tasks of detection and assessment of facial palsy regions. In this work, three experiments were executed to evaluate the performance of four different classification methods. The results and findings are discussed in the following paragraphs.
Comments on the database where images of palsy patients were extracted are given now. The YouTube Facial Palsy (YFP) database is an image collection provided by Hsu et al. [
9]. The YFP database is a compilation of 32 videos from 21 patients obtained from YouTube; 10 additional patients in a second release were included. The patient talks to the camera in each video, and the facial expression variation across time is recorded. Each video was converted into an image sequence at 6 FPS, yielding almost 3000 images. Three independent clinicians labeled the palsy regions in each frame; the junction of the independently cropped areas is considered the ground truth. The authors also provided additional labels to classify the intensity exhibited in each palsy region. It is our understanding that the authors in [
9] determined these intensity labels; they did not declare that the intensity label was approved by a clinician, which could lead to discrepancies in the classification results among methodologies. The YFP is available upon request at [
36].
The Extended Cohn-Kanade (CK+) database distribution, a well-known database in the research community to prototype and benchmark systems for the automated detection of facial expression [
37], was also employed. The CK+ database collects 593 sequences across 123 subjects, close to 10,800 images, and all sequences go from a neutral face to a peak expression. The CK+ database is included in this work, with the YFP database, to make our methodology robust against expression variation as suggested in [
9,
10]. The unhealthy samples came from the YFP database and the healthy subjects from the CK+.
Widely known evaluation metrics are computed to measure the performance of each classifier. These are accuracy, recall (or true positive rate), precision, F1 score, true negative rate, false negative rate, and false positive rate which are calculated according to Equations (
6)–(
12), respectively.
where
TP is short for true positives,
TN for true negatives,
FP for false positives, and
FN for false negatives.
The 5-fold cross-validation protocol was adopted to test the model accuracy for each classification task. Such protocol allows us to test on unseen samples, reducing the possibility of over-fitting to previously seen ones. This cross-validation strategy splits the data set into five subsets. Every subset is preserved as validation data, and the other four are used as training data, ensuring that the test data is untouched in each experiment occurrence. The experiment is repeated five times, where each subset has the same probability for validation. The accumulation of correct classified samples measures the performance.
3.1. Palsy Region Detection
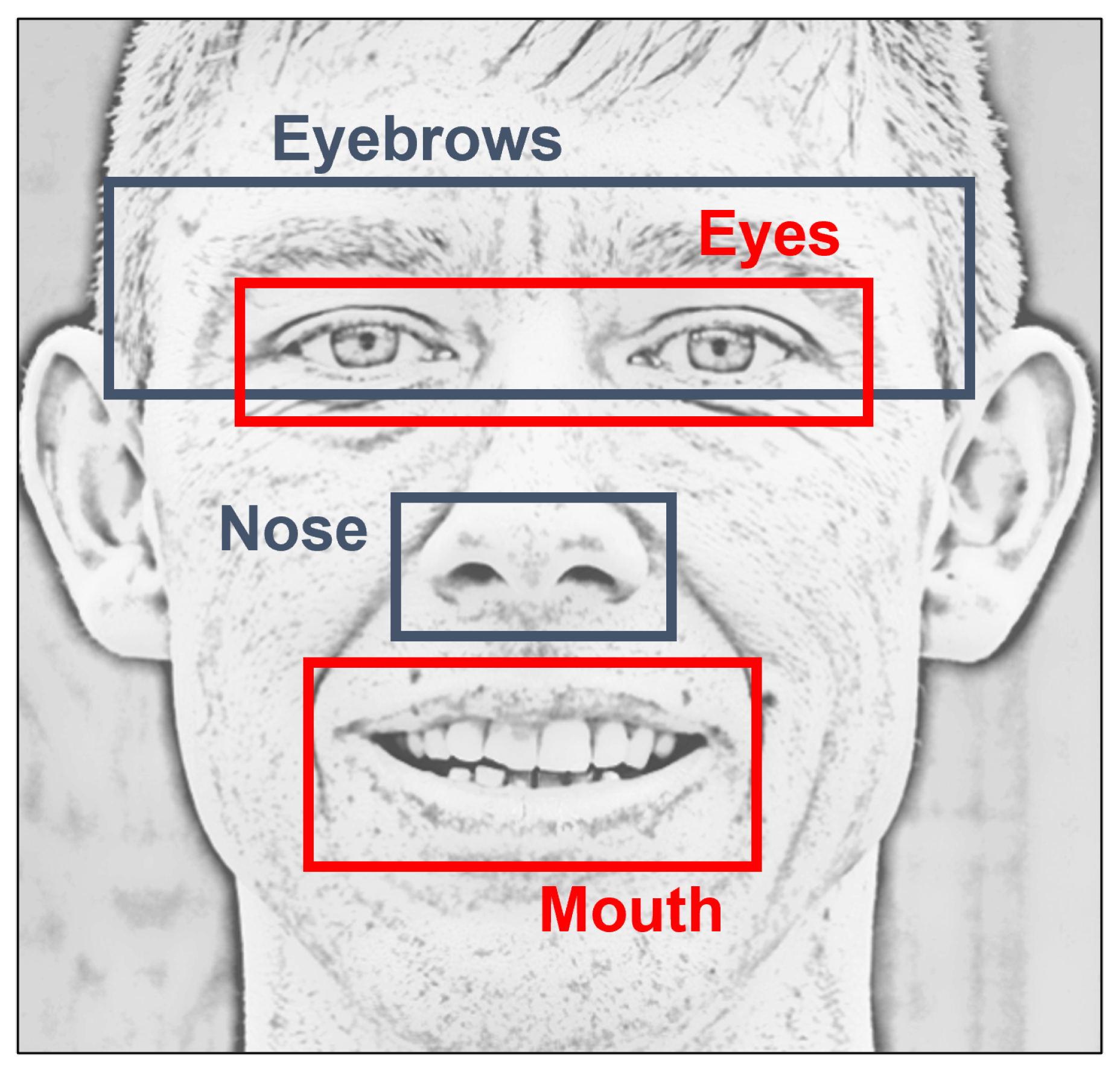
The first experiments are focused on detecting facial palsy, in other words, on classifying the input data as healthy or unhealthy. It is called palsy region detection because those particular algorithms analyze specific facial regions. Here, the experiments evaluate our methodology using regional information, but our initial proposal is to inspect the whole face using our symmetry features. Three tests were performed: (1) the detection of palsy using 29 features, (2) the detection of palsy in the eyes, and (3) the detection of palsy in the mouth. As described earlier, the regional information for the eyes correspond to features named as Eyebrows, Eyes, Nose, and Combined (only
f23 and
f25–
f27) in
Table 1. Similarly, the regional information for the mouth corresponds to all features, except those named as Eyebrows and Eyes features in
Table 1.
In general, the data set is composed of 19 palsy patients and 19 healthy subjects. The palsy patients are subjects 1, 5, 6, 7, 11, 12, 13, 14, 15, 19, 20, 21, 23, 24, 25, 28, 29, 30, and 31 from the YFP database. Patients with less than 20 images and patients with facial occlusions were excluded. The healthy subjects belong to the S022, S026, S028, S034, S042, S046, S050, S054, S057, S102, S105, S124, S130, S131, S132, S133, S134, S135, and S136 folders in the CK+ collection.
The data set for the first experiment comprises 20 images from each of the 38 participants (760 images in total); this arrangement is expected to have the same amount of healthy and palsy samples, making it a balanced data set for the experiment. Notice that the healthy subjects are labeled as class 0 and the palsy subjects as class 1. For this experiment, the classifiers were configured as described in
Table 3. The experiment using 5-fold cross-validation was repeated 10 times, and the average performance is shown in
Table 4, for the three tests.
Great results are obtained for the MLP and SVM classifiers, and , respectively. Few samples were required during the training phase compared to other approaches that required thousands of images to output a label. Good results are also reached using only regional features, in the eye and the mouth, and , respectively. Still, the entire face analysis is better than focusing on a single region when discriminating between healthy and unhealthy subjects.
The confusion matrix of this experiment using the entire face and SVM is depicted in
Figure 4a, and the system’s average accuracy is
, recall
, precision
and F1-score
. The confusion matrix analyzing the eyes with SVM is depicted in
Figure 4b, and the system’s average accuracy is
, recall
, precision
and F1-score
. Finally, the confusion matrix analyzing the eyes with MLP is depicted in
Figure 4c, and the system’s average accuracy is
, recall
, precision
and F1-score
.
Additional performance results for the experiments are provided on
Table 5. For our methodology, the true negative rate (TNR) reflects the number of healthy subjects detected as normal participants; while the true positive rate (TPR) shows the number of palsy patients detected as unhealthy subjects. Great results are achieved using the SVM classifier:
and
for the face,
and
for the eyes. On the other hand, the false negative and false positive rates are expected to be as lower as possible because both of them represent a wrong diagnosis. Good results are obtained for this metric:
and
for the face,
and
for the eyes. Similarly, good results are reached for the mouth using the MLP classifier,
and
of true detection rates; and
and
of false detection rates.
Although out of the scope of this work, those scores using either the eye or mouth information lead us to believe that we can use these features to detect facial palsy on images with partial occlusions. If face detection is achieved and landmarks are predicted adequately, an analysis to detect facial palsy might be possible. In other words, our analysis allows us to determine to what extent regional information is needed to diagnose the severity of the lesion with satisfactory results.
3.2. Prediction of Two Palsy Levels
The second experiment seeks to distinguish between two levels of facial palsy. As stated by Hsu et al. [
9], these levels are slight (or low-intensity) and strong (or high-intensity) facial palsy. The authors provided labels for the mouth and the eyes regions; there might be a case where the intensity is not the same for both regions, then a separate analysis is required. The data set is composed of 19 patients from the YFP database and is now divided into class
(low-intensity) and class
(high-intensity). After preliminary tests, it was found that 40 images per patient were adequate to train the classifier, but for those who did not have enough images, only 20 were employed. To improve the learning process, a data augmentation was performed as suggested in [
1,
16]. This process consisted of rotating in two opposite directions the palsy images to increase the amount of available data. This augmentation also allows us to verify that the algorithm is invariant to rotation, as stated in
Section 2.1. This experiment is divided into two tests (1) using the 29 proposed features and (2) using regional information (19 features for the eyes and 15 features for the mouth).
The data distribution for this experiment is described in
Table 6. There, to evaluate the level of paralysis in the eyes, 208 low-intensity and 472 high-intensity images are included. After data augmentation, the data set is formed by 624 low-intensity and 1416 high-intensity samples (2040 images in total). Similarly, to evaluate the level of paralysis in the mouth, 141 low-intensity and 539 high-intensity images are included. After data augmentation, the data set is formed by 423 low-intensity and 1617 high-intensity samples (2040 images in total).
For the first test, the configuration of the classifiers is described in
Table 7. A 5-fold cross-validation was performed and repeated 10 times, and the average performance is shown in
Table 8 for both regions. Great results are obtained assessing the eyes region, up to
using SVM. Similarly, good results are reached for the mouth area,
. In this task, the KNN classifier reached better results than the MLP for both cases. Still, the proposed MLP yielded good results using few samples, compared to other published deep learning approaches that require thousands of images and complex neural network structures.
For the second test, the configuration of the classifiers is described in
Table 9. Again a 5-fold cross-validation repeated 10 times was performed, and the average performance is shown in
Table 10 for both regions using fewer features. It was expected a lower performance because the information feed to the classifiers was decreased; still, good performance (more than
) was achieved using SVM. A slight increase in performance is observed when using the information from the mouth region. This evaluation leads us to believe that a classification of the palsy intensity is possible to a certain degree, in partial occlusions of the face.
3.3. Prediction of Three Palsy Levels
The goal of assessing the severity of the lesion is to determine how diminished the facial nerve function is. It can be evaluated once the palsy has been detected or evaluated at the same time. For the third experiment, the intensity labels provided by Hsu et al. [
9] were also used. As previously mentioned, the authors offer labels for the mouth and the eyes’ regions independently, and there might be a case where the intensity label is not the same for both regions. The data set is now divided into class
(healthy), class
(slight palsy or low-intensity), and class
(strong palsy or high-intensity). In
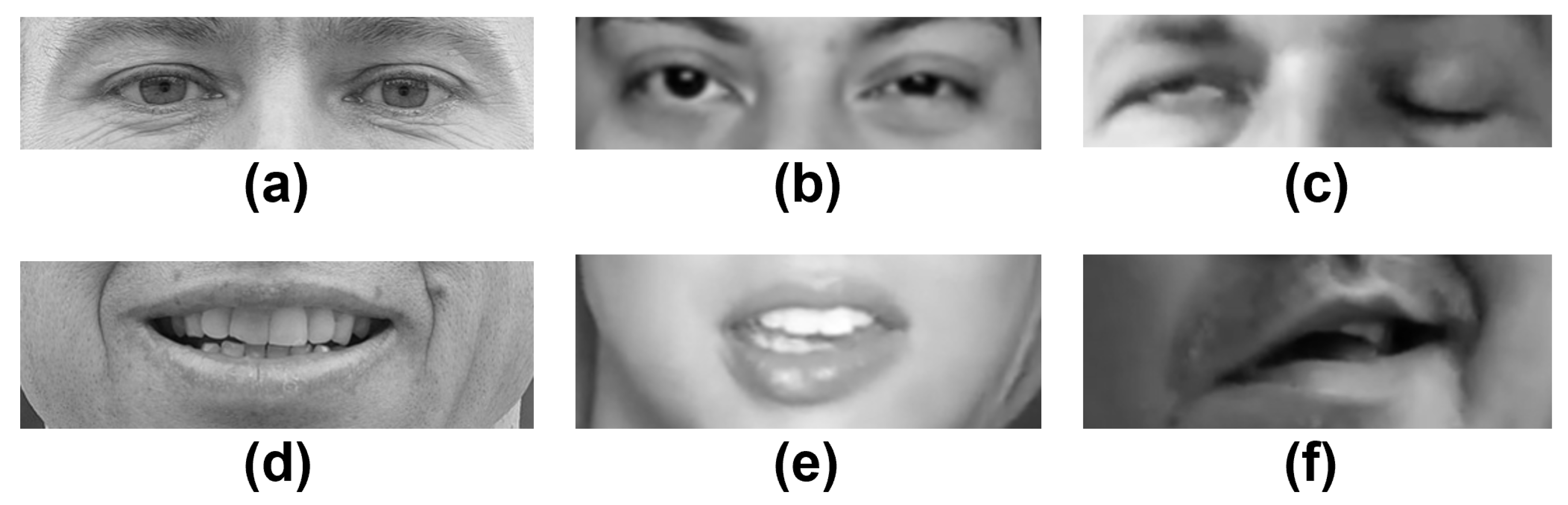
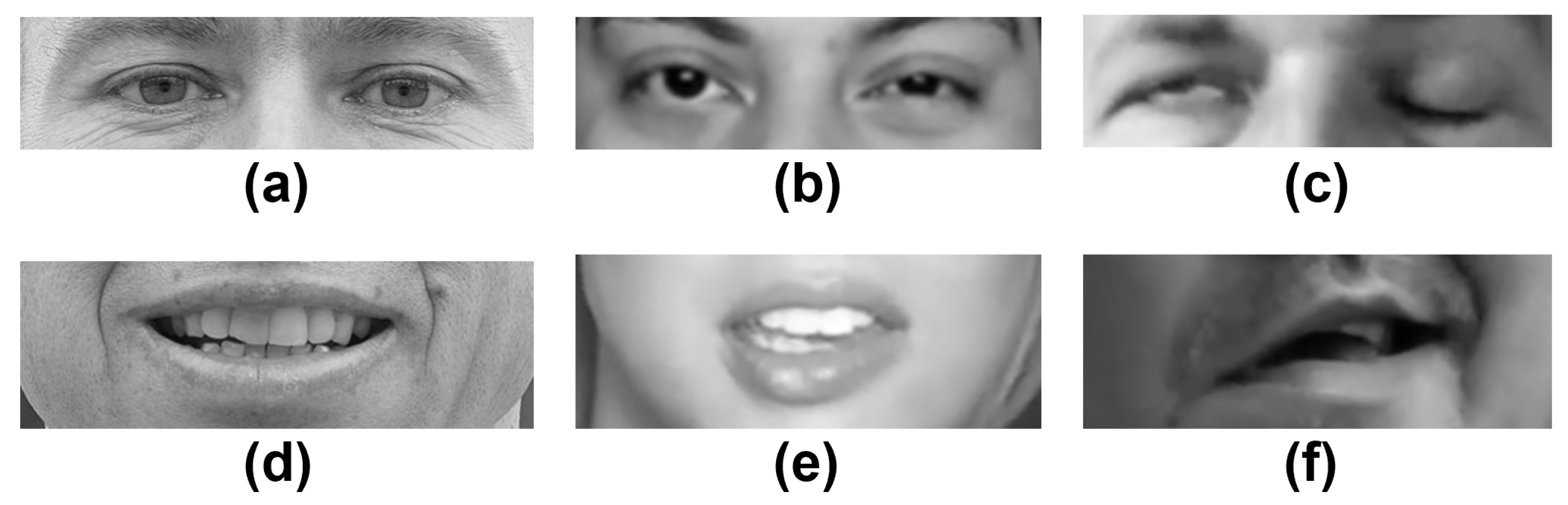
Figure 5, a sample of healthy subjects and patients who have facial palsy is introduced. Specifically, the images show the two facial palsy regions that are of interest in this work: the eyes and mouth.
This experiment is also divided into two tests (1) using the 29 proposed features and (2) using regional information (19 features for the eyes and 15 features for the mouth). The data set is composed of 19 patients from the YFP database and 19 participants from the CK+ database. In this case, 40 images per subject were used; for those who did not have enough images, only 20 were employed. Once more, the same data augmentation process was performed to provide enough information to the classifiers, increasing the amount of data and verifying that the methodology is rotation invariant.
The data distribution is described in
Table 11. For the eyes’ region, 740 healthy, 208 low-intensity, and 472 high-intensity samples are included; it is easy to observe that the classes are unbalanced and that there are few examples for the class
. After augmenting the samples, 4260 images compose the training set with 2220 healthy, 624 low-intensity, and 1416 high-intensity samples. For the mouth region, 740 healthy samples, 141 low-intensity, and 539 high-intensity samples are included; again, there are fewer examples for the class
. After augmenting the samples, 4260 images compose the training set with 2220 healthy, 423 low-intensity, and 1617 high-intensity samples. In both tests, the classes remained unbalanced, but after several evaluations, this data distribution provided the best results.
The configuration of the classifiers is described in
Table 12. The experiment using 5-fold cross-validation was repeated 10 times, and the average performance is shown in
Table 13, for both regions. Great results are obtained assessing the eyes region, up to
using SVM. Similarly, good results are reached for the mouth area,
. In both cases, the proposed MLP yielded similar results using few samples, compared to other deep learning strategies that require thousands of samples and complex neural network structures.
For the second test, the configuration of the classifiers is described in
Table 14. Again a 5-fold cross-validation was performed and repeated 10 times, and the average performance is shown in
Table 15 for both regions using fewer features. It was expected a lower performance because the information fed to the classifiers was decreased; still, good performance, 92.08% and 93.95% were achieved using SVM. Once more, this evaluation leads us to believe that a classification of the palsy intensity is possible to a certain degree, in partial occlusions of the face.
4. Conclusions
A methodology to assess facial paralysis in an image was proposed. It is assumed that facial palsy can be interpreted as a problem of asymmetry levels between the elements of the face, particularly the eyebrows, eyes, and mouth. The proposed assessment system consists of 29 facial symmetry features extracted from predicted landmarks and a classifier that provides a label as an output. Four different classifiers were evaluated in three experiments to validate our methodology. Those experiments seek to detect facial palsy, discriminate among two levels of the palsy, and assess the lesion’s severity among three levels of palsy. The best results were achieved using SVM, but a similar performance with a slight decrease is obtained using the multi-layer perceptron approach. After the evaluations, it was found that dividing the face into specific regions is convenient to detect and assess the paralysis with fewer features. This feature reduction leads us to believe that the analysis of facial paralysis is possible with partial occlusions of the face, as long as face detection is achieved, and landmarks are predicted adequately.
To validate the proposed methodology, tests were performed on publicly available image databases, the YouTube Facial Palsy (YFP) with 21 participants with facial palsy, and the CK+ with 123 healthy subjects. In the first classification task, binary discrimination between healthy and unhealthy subjects, the proposed system achieved the highest accuracy of 95.61% after evaluating using the 5-fold cross-validation protocol. In a second task, a binary classification to detect the intensity of the facial palsy (low-intensity vs. high-intensity), the system achieved the highest accuracy of 95.05% in the eyes and 93.29% in the mouth region. Finally, in a third task to classify the severity of the damage (healthy, low-intensity, and high-intensity), the system achieved the highest accuracy of 95.58% for the eyes and 94.44% for the mouth.
It has been noted that evaluating facial paralysis using symmetry/asymmetry values is risky because the human face is not identical concerning its left and right sides. Then, to thoroughly verify the usefulness of our algorithm in clinical practice, a much larger sample of healthy controls with different degrees of facial asymmetry (not caused by facial palsy) is needed. Achieving this monumental task would require a specific database of healthy participants (i.e., showing no facial palsy of any kind) and a multidisciplinary team of experts to design a grading scale of healthy asymmetry, to calculate how asymmetric is the subject’s face according to it, and to label each participant’s image manually. To the best of our knowledge, no such data set is available for the research community.
Future work would include additional evaluations on available databases, with annotated data, of palsy patients and healthy controls. The design of a mobile application to diagnose facial palsy at home is also desirable to improve the rate of early diagnosis. Furthermore, developing an application to easily monitor the treatment and improvement of the patient would represent a milestone.
To conclude, the accomplished results show that the proposed methodology to design classifiers can be adapted to other data sets with outstanding results. It is a methodology that is easy to replicate compared to the other complex systems and achieves similar results for detecting and evaluating facial paralysis. Finally, the proposed classifiers require fewer samples in the training stage compared to different approaches based on deep neural networks. The code to compute the 29 facial symmetry features and the trained models are available upon request; notice that the image databases must be requested from the rightful owners at [
36,
37].







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}