
Breast Cancer Mammograms Classification Using Deep Neural Network and Entropy-Controlled Whale Optimization Algorithm


Abstract
:1. Introduction
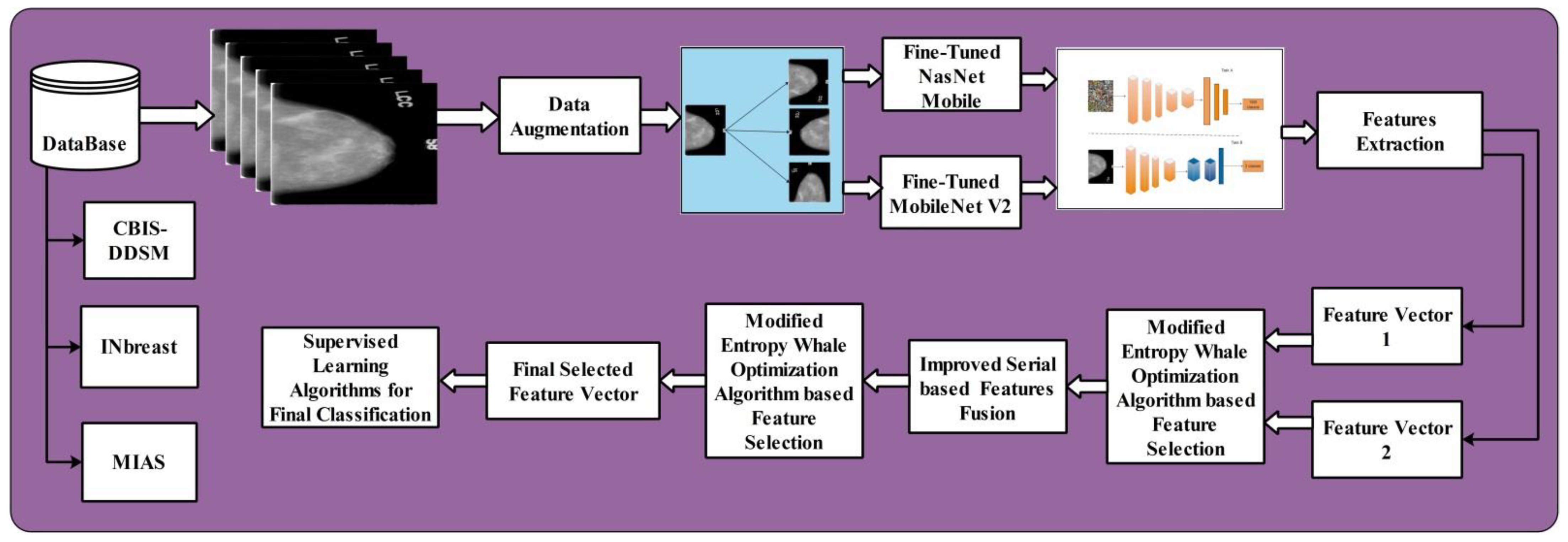
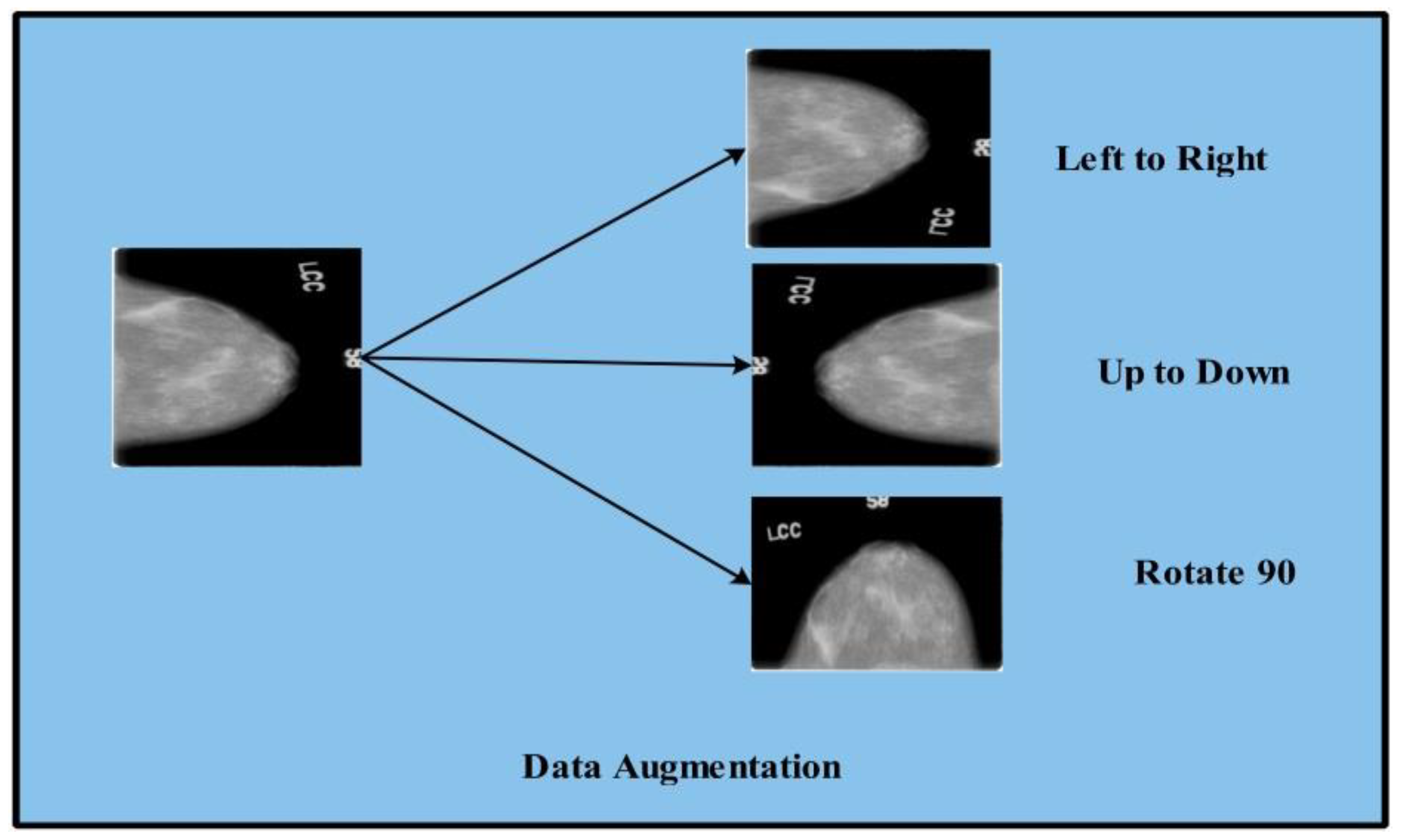
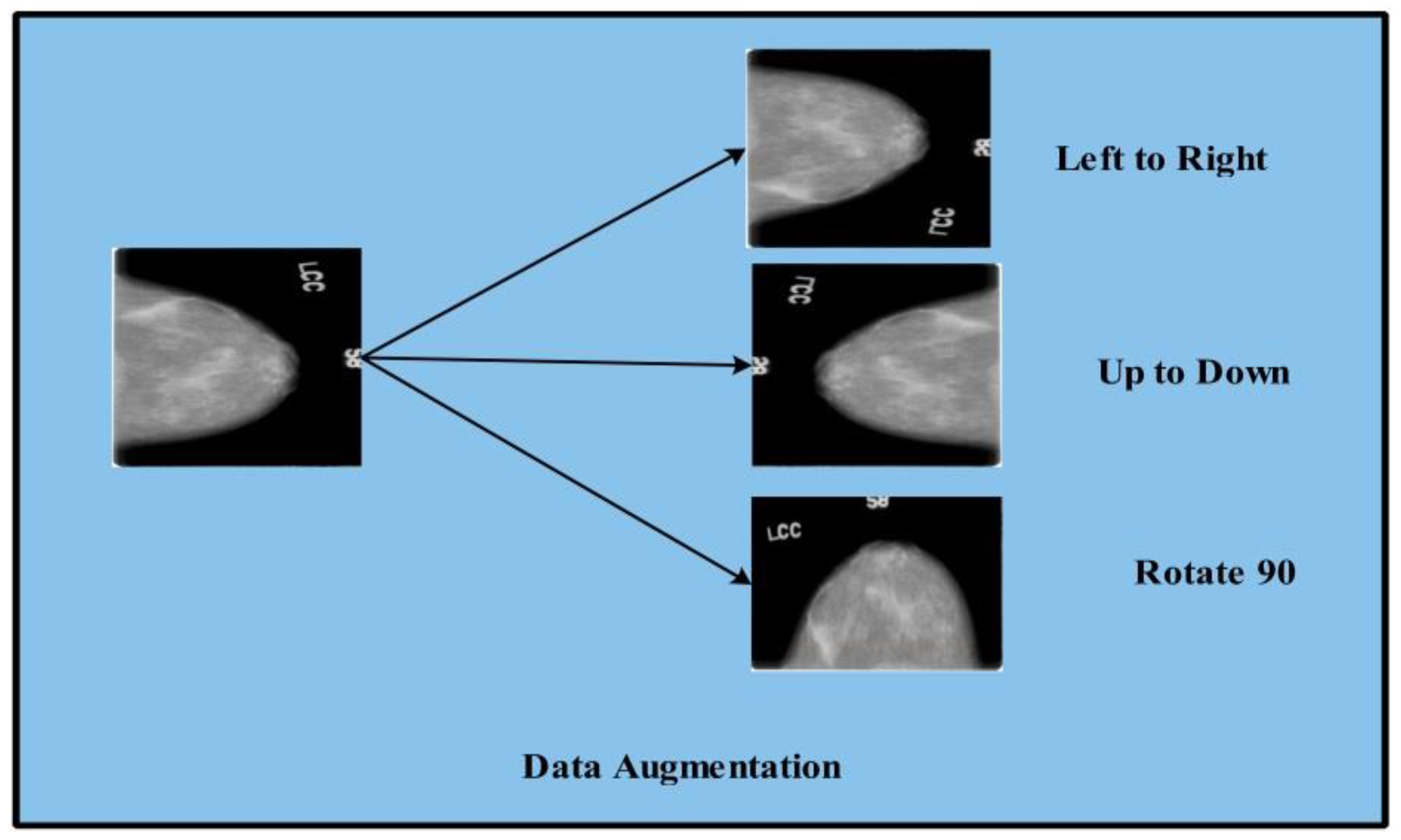
- Data augmentation is performed using three mathematical formulas: horizontal shift, vertical shift, and rotation 90.
- Two deep learning pre-trained models are fine-tuned such as Nasnet mobile andMobilenetV2 and deep features are extracted from the middle layer (average pool) instead of the FC layer.
- We proposed a Modified Entropy-controlled Whale Optimization Algorithm for optimal feature selection and reducing the computational cost.
- We fused the optimal deep learning features using a serial-based threshold approach.
Literature Review
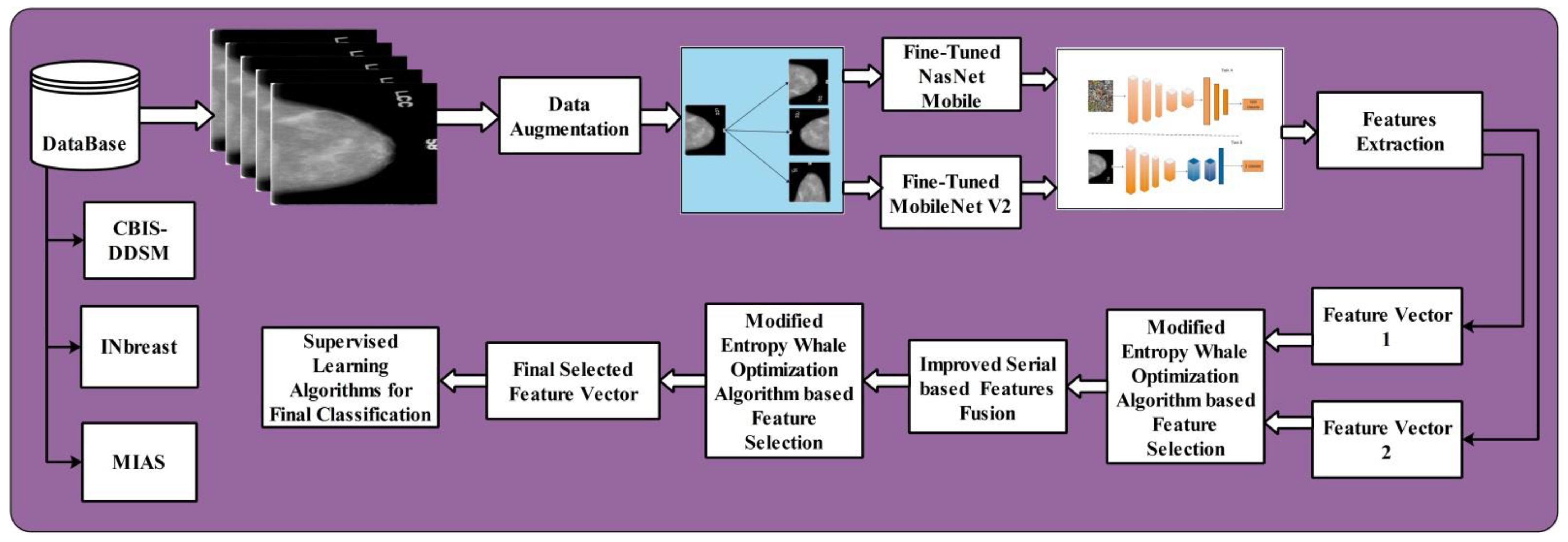
2. Methods and Materials
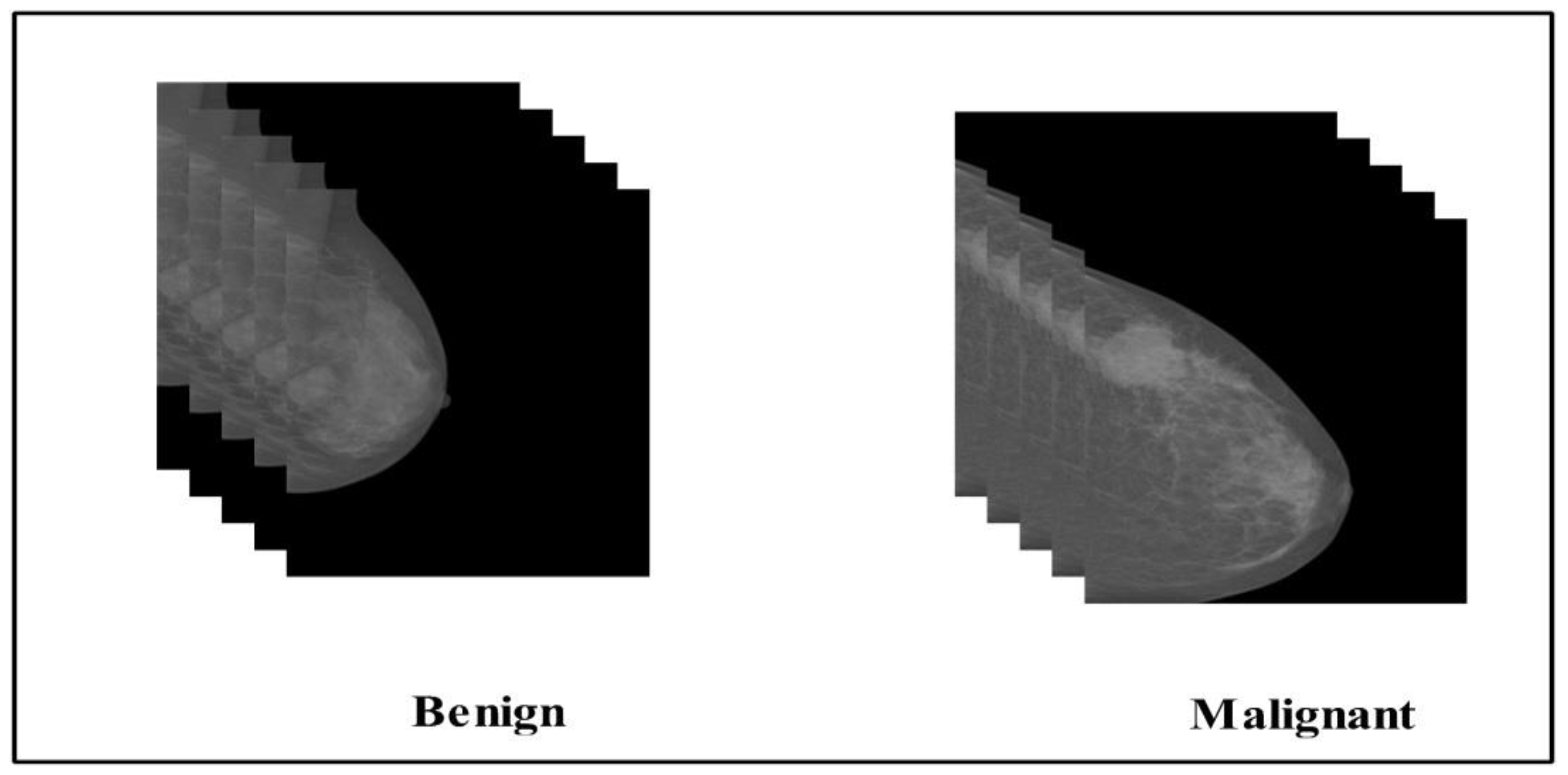
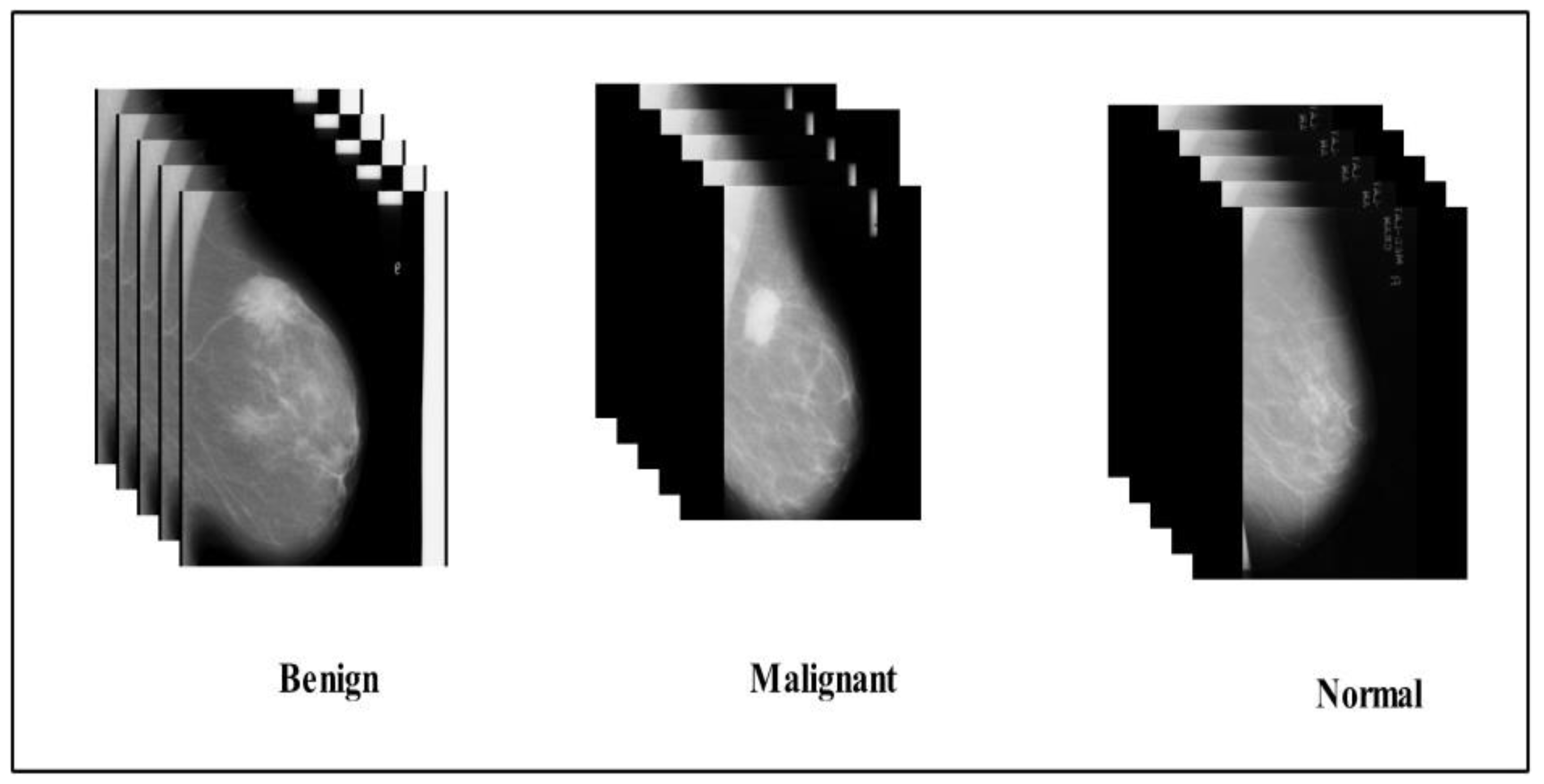
2.1. Datasets
2.2. Data Augmentation
| Algorithm 1: Data Augmentation |
| While (i = 1 to target object) Step 1: Input read Step 2: Flip Left to right Step 3: Flip-up to down Step 4: Rotate image to Step 5: Image write step 2 Step 6: Image write step 3 Step 7: Image write Step 4 End |
2.3. Convolutional Neural Network
2.4. Fine-Tuned MobilenetV2
2.5. Fine-Tuned Nasnet Mobile
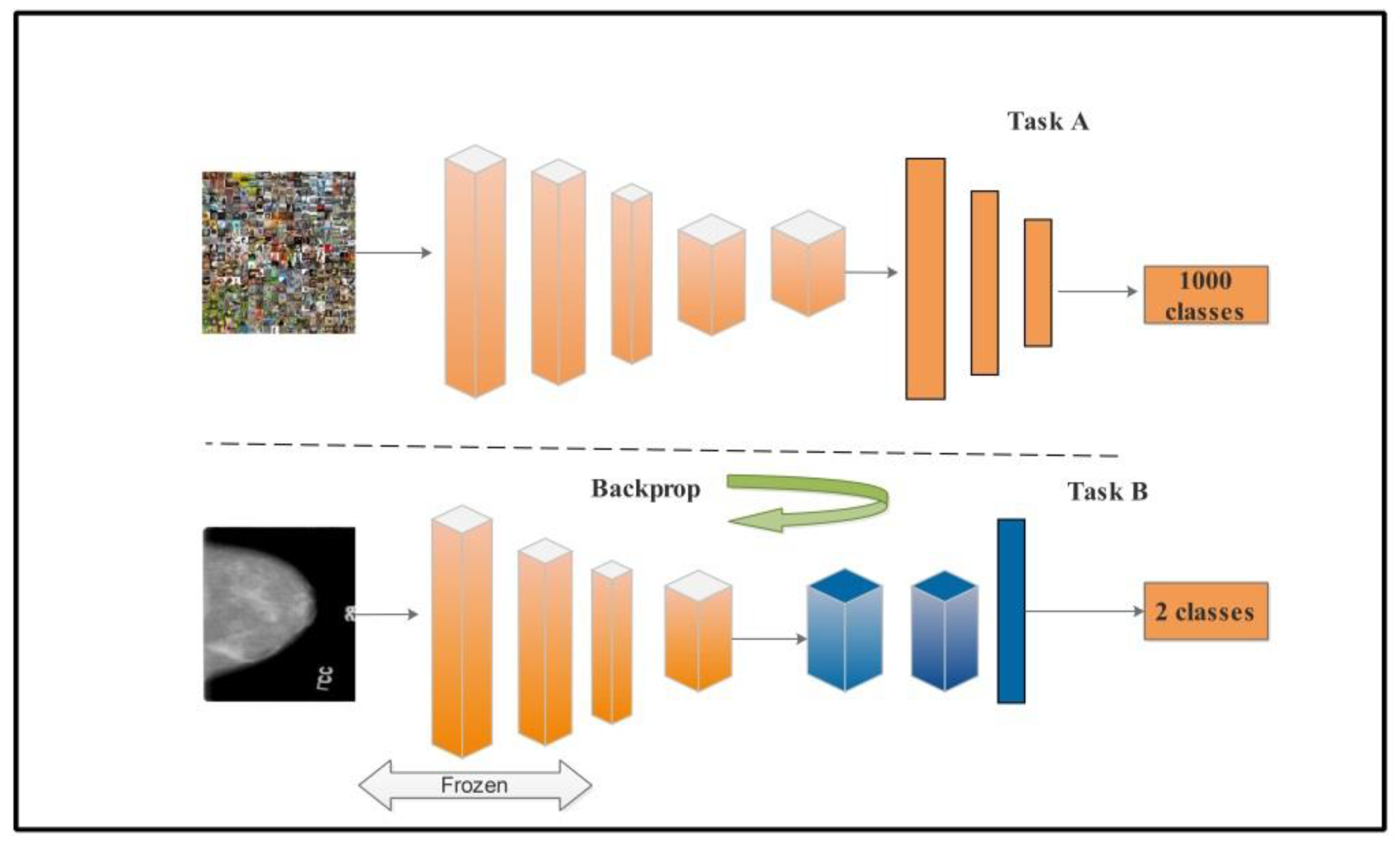
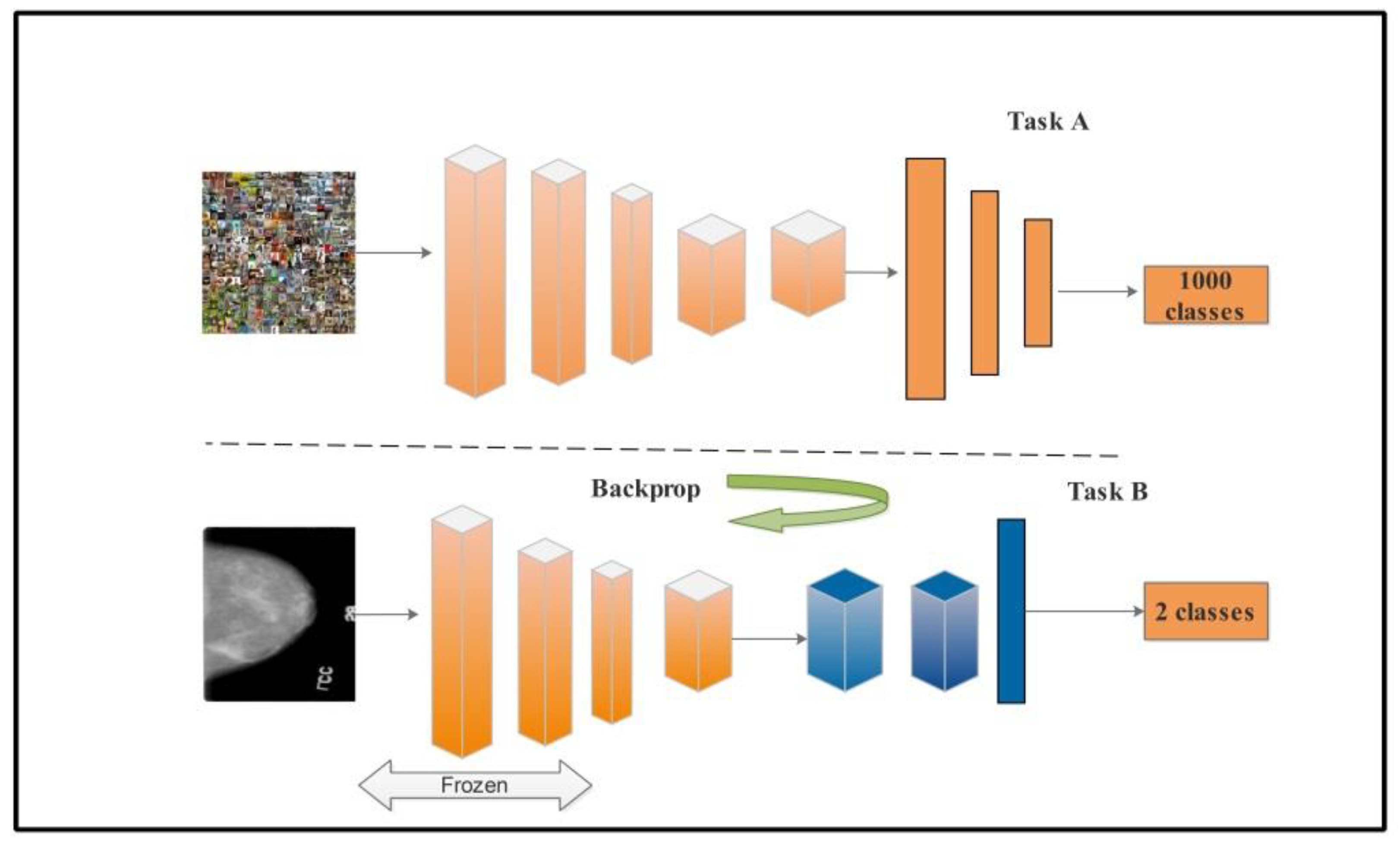
2.6. Transfer Learning
2.7. Whale Optimization Algorithm (WOA)
2.7.1. Modified Entropy Whale Optimization Algorithm (MEWOA)
2.7.2. Linear Increasing Probability
2.7.3. Adaptive Social Learning Strategy
2.7.4. Morlet Wavelet Mutation
| Algorithm 2: Modified Entropy Whale Optimization Algorithm. |
| Start Parameters to initialize MEWOA such as a, , e, t, PN, , The initial population randomly generates G Assess each whale’s individual fitness values, , search individual best c = 1 While ( Update according to Equation (6), compute the neighborhood of whale, for each search individual according to Equations (8)–(11) If ( update the whale individual by using Equation (12); Else If Use Equation (13); Else Use Equation (14); End if End if End for Fix boundaries of the whale individuals that go beyond. Evaluate individual whale fitness values; Update the global best solution. End while Output the best search individual ; End |
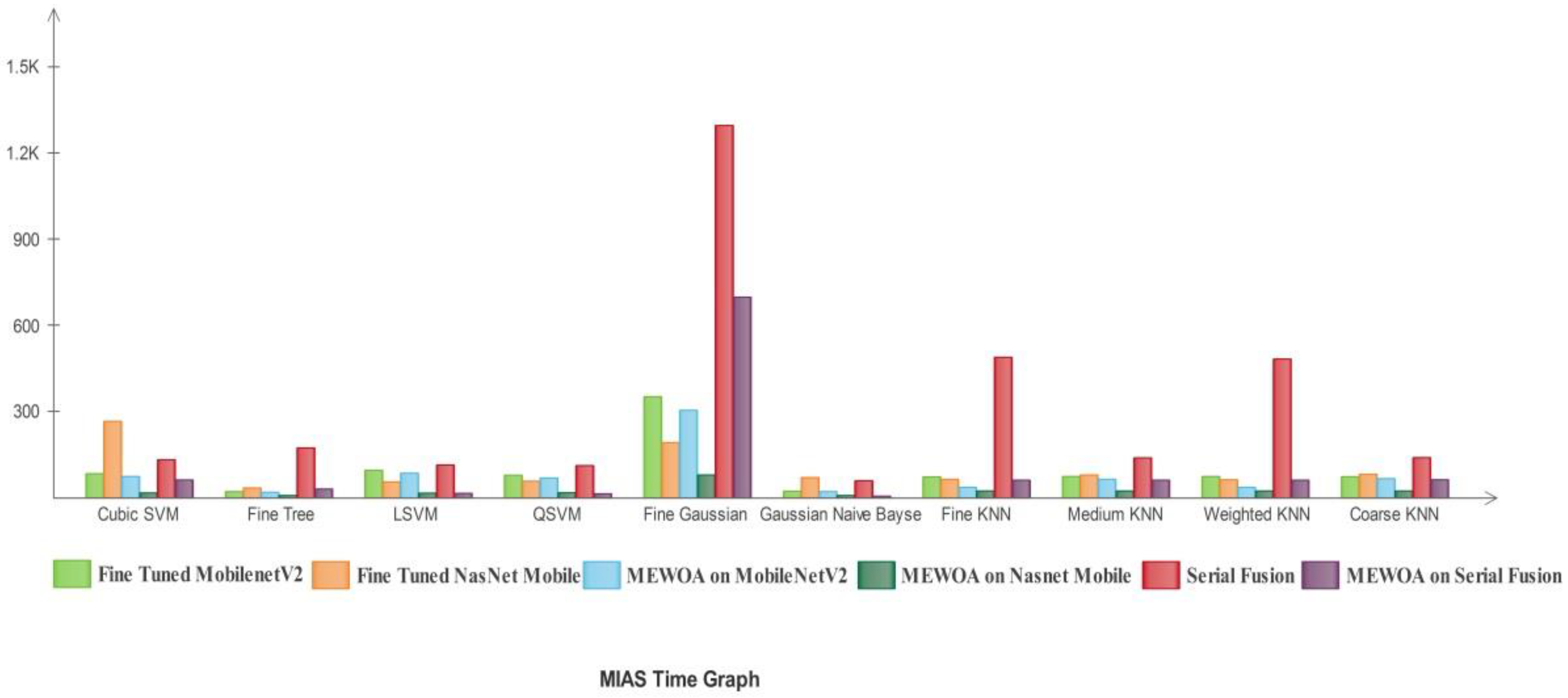
3. Results
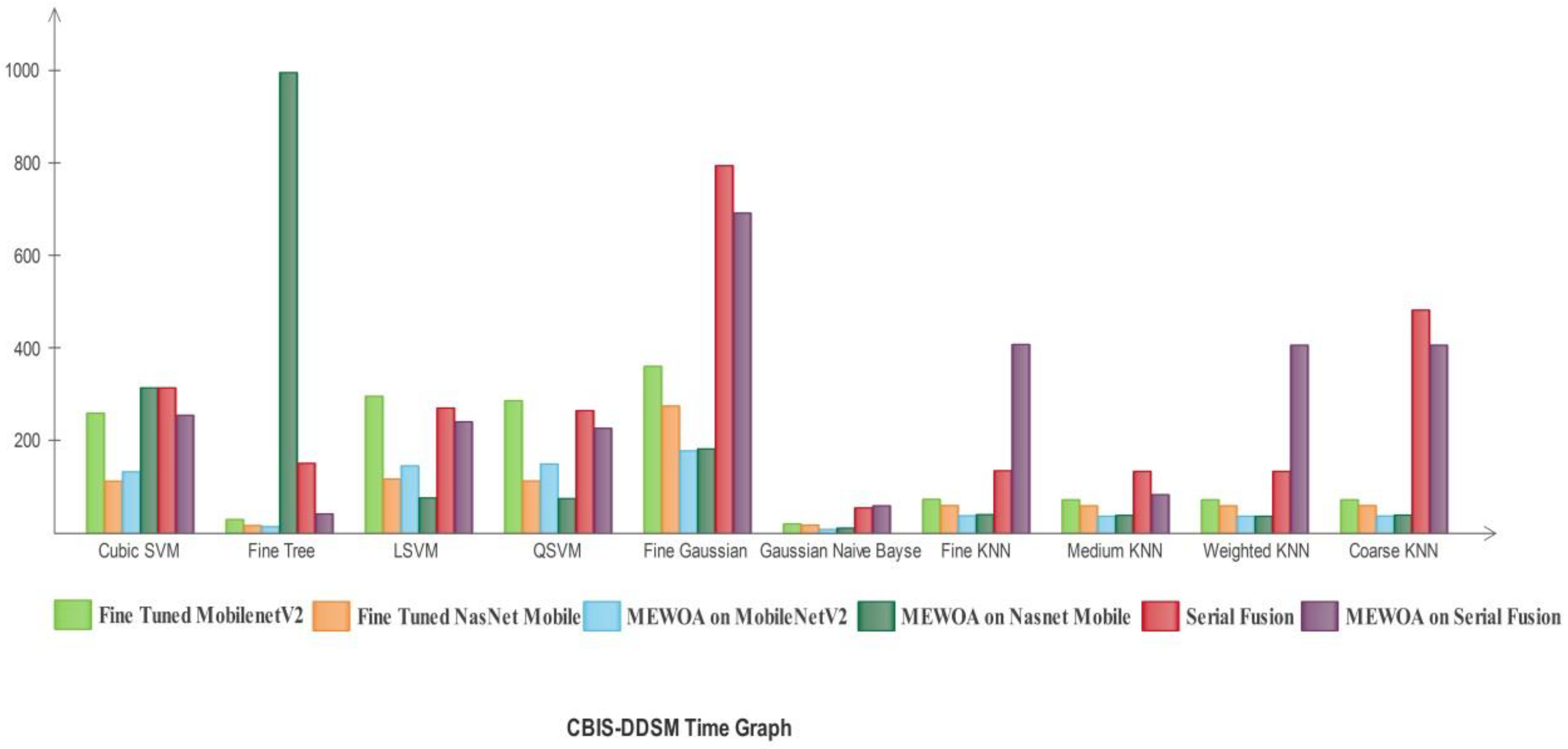
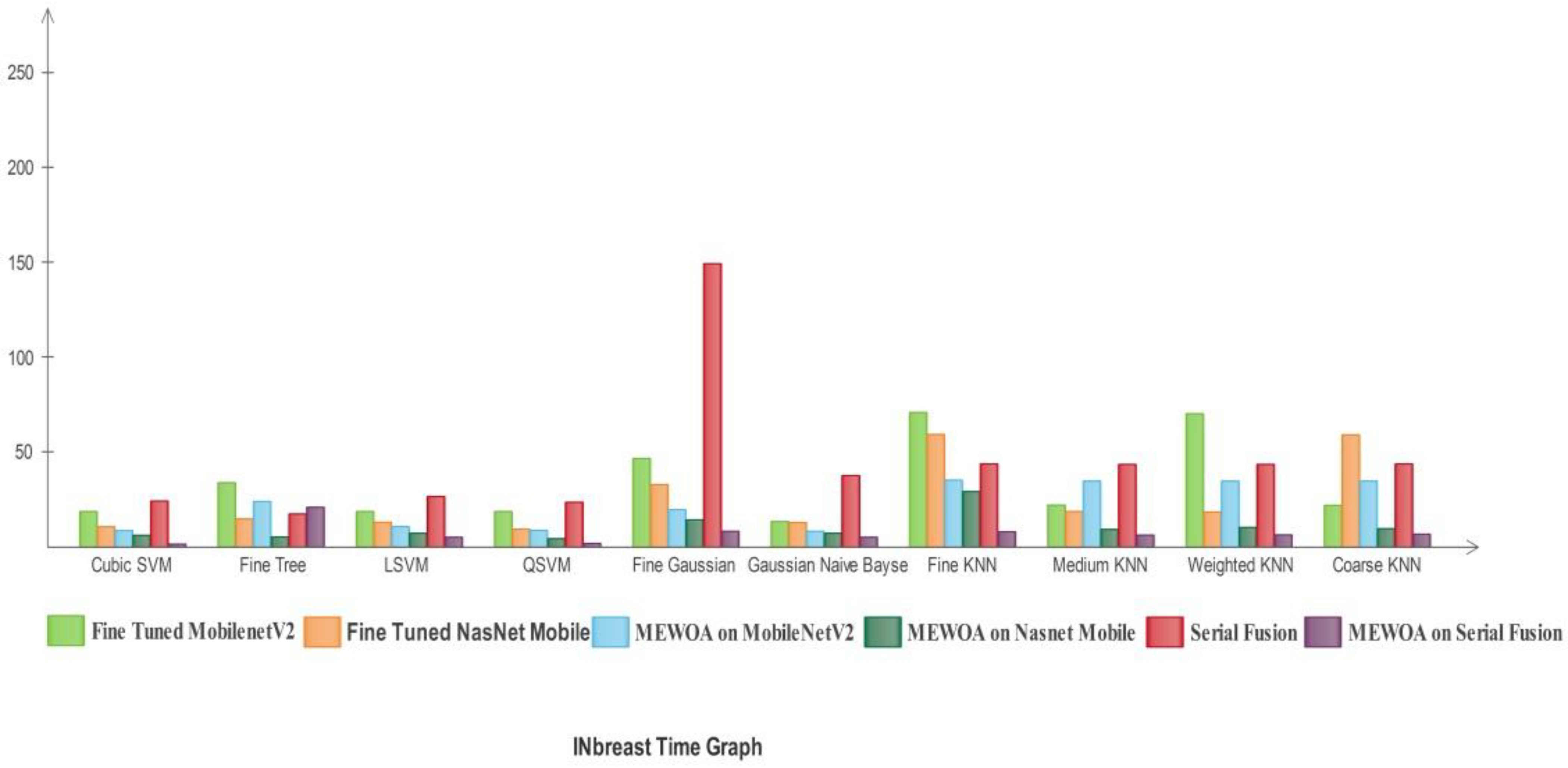
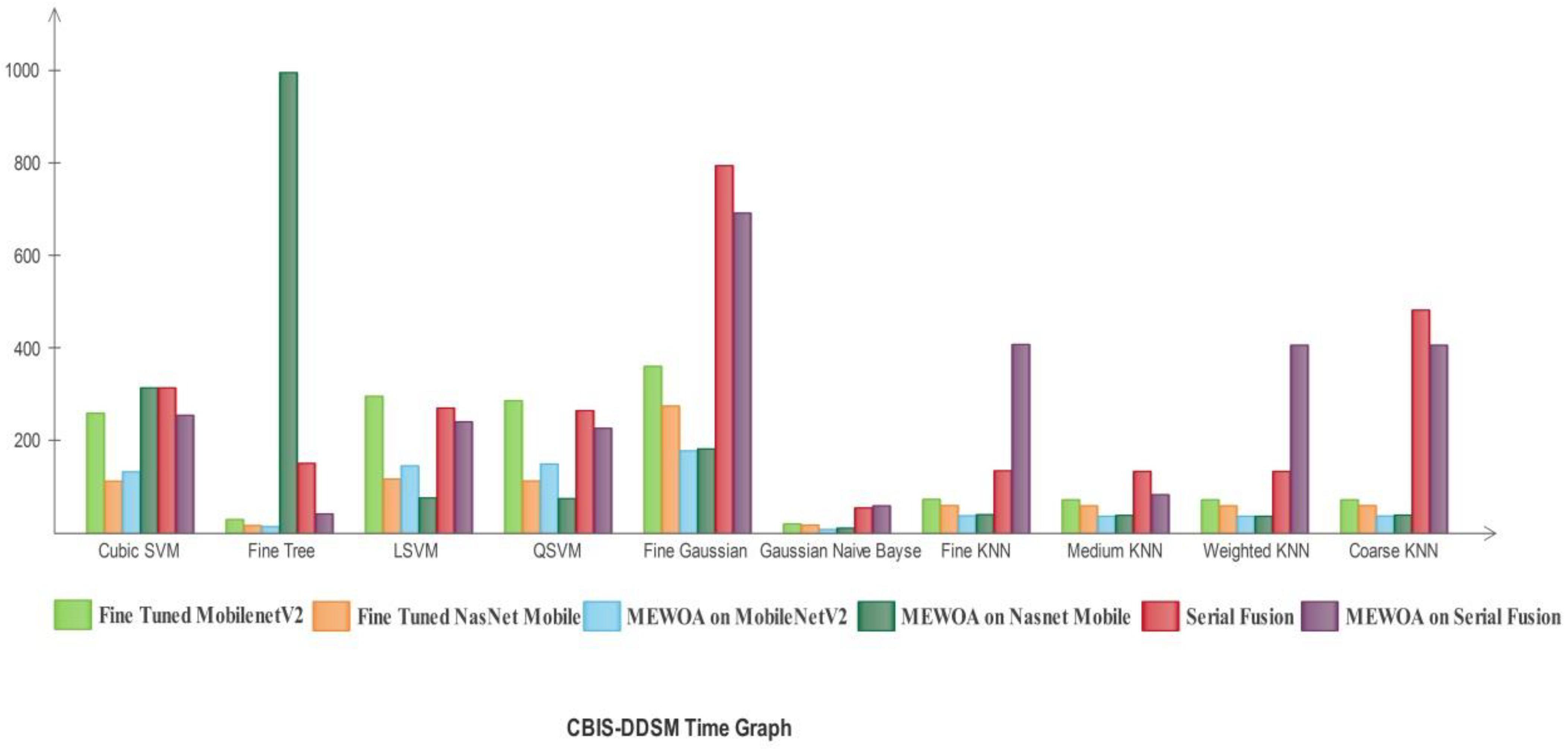
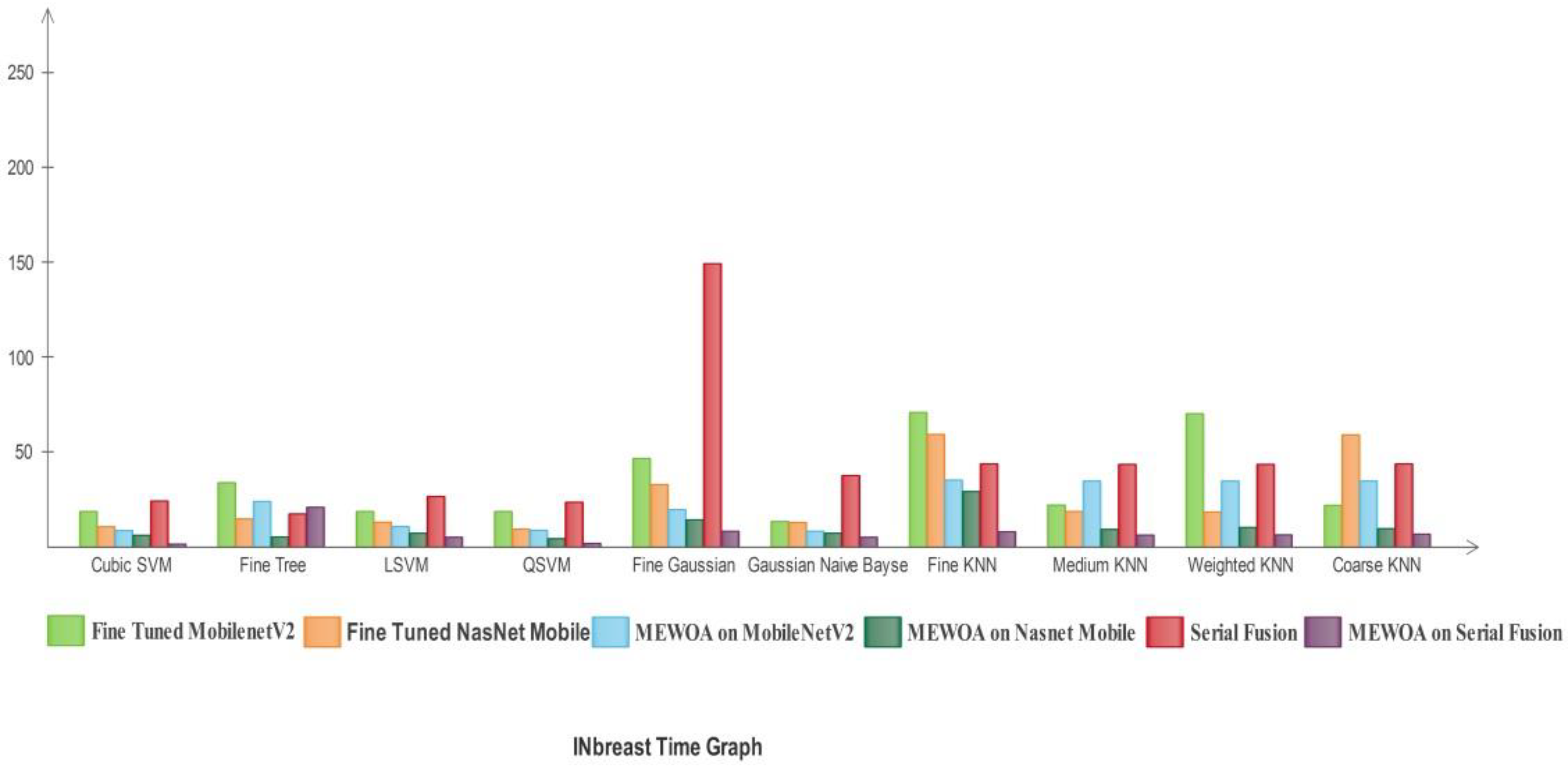
3.1. Experimental Results
- Several experiments are conducted to validate the proposed method.
- Classification using Fine-tuned MobilenetV2 deep features.
- Classification using Fine-tuned Nasnet Mobile deep features.
- Classification using MEWOA on Fine-tuned MobilenetV2 deep features.
- Classification using MEWOA on Fine-tuned Nasnet Mobile deep features.
- Classification using serial-based non-redundant fusion approach.
- Classification using MEWOA on fused features.
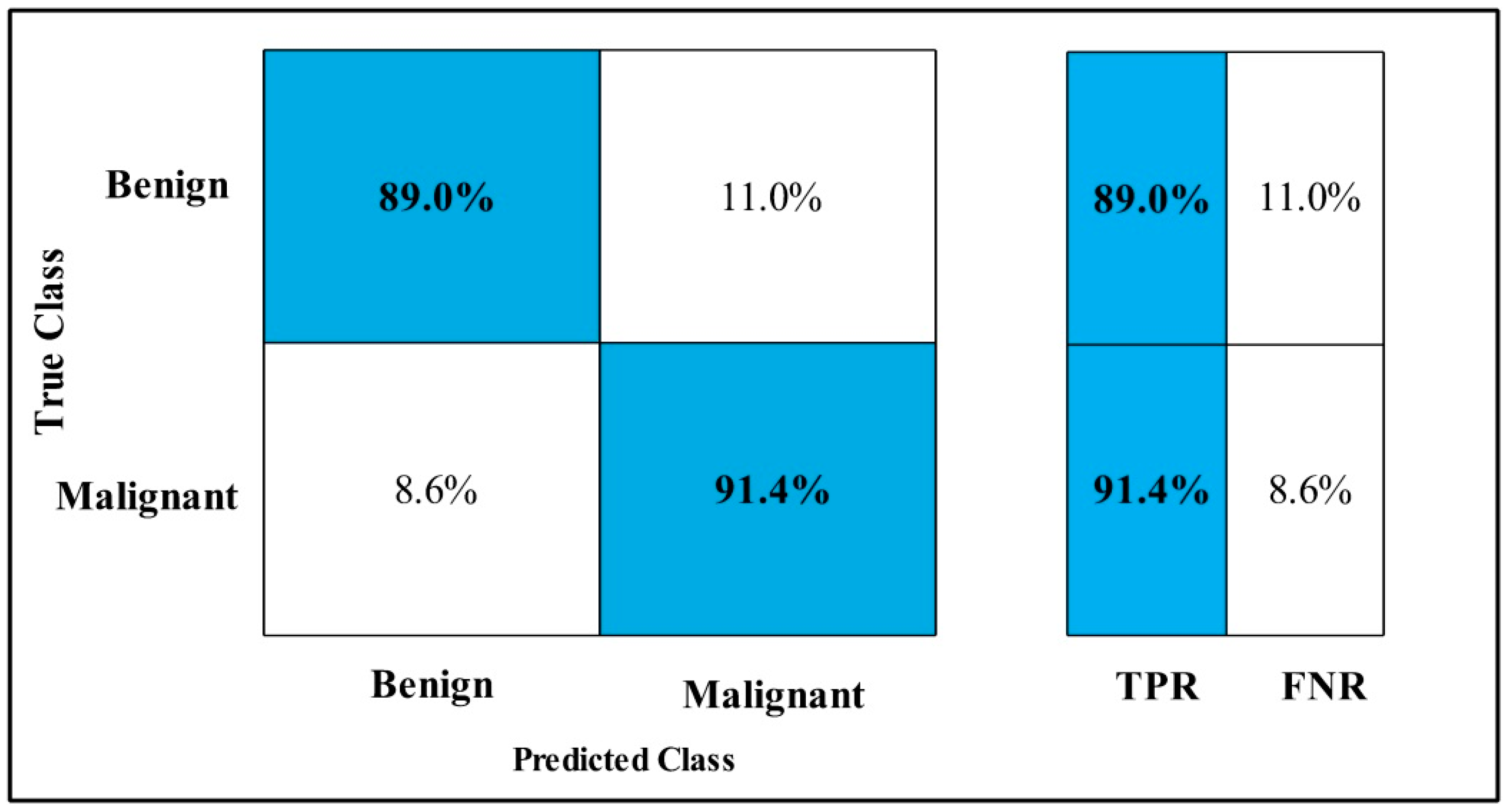
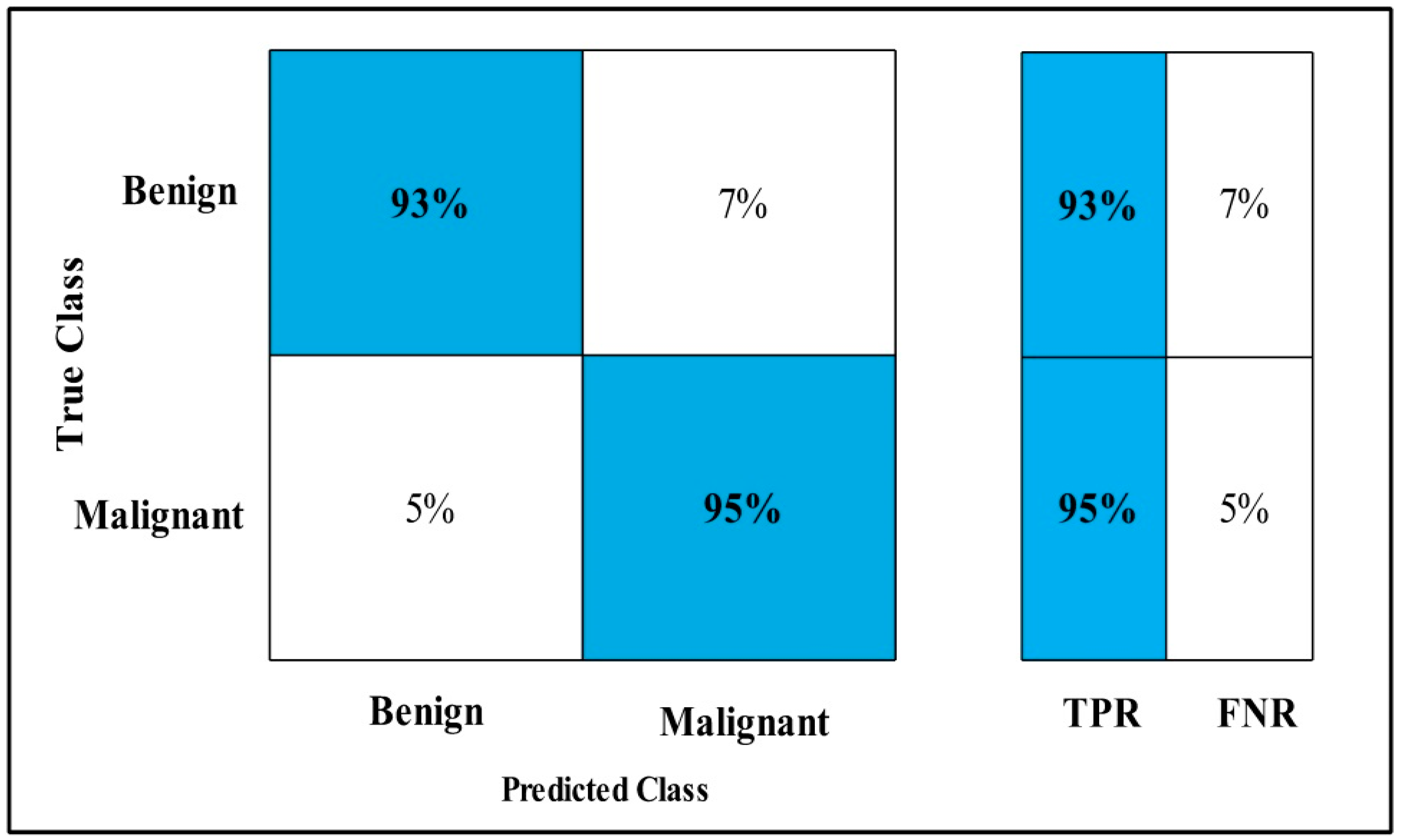
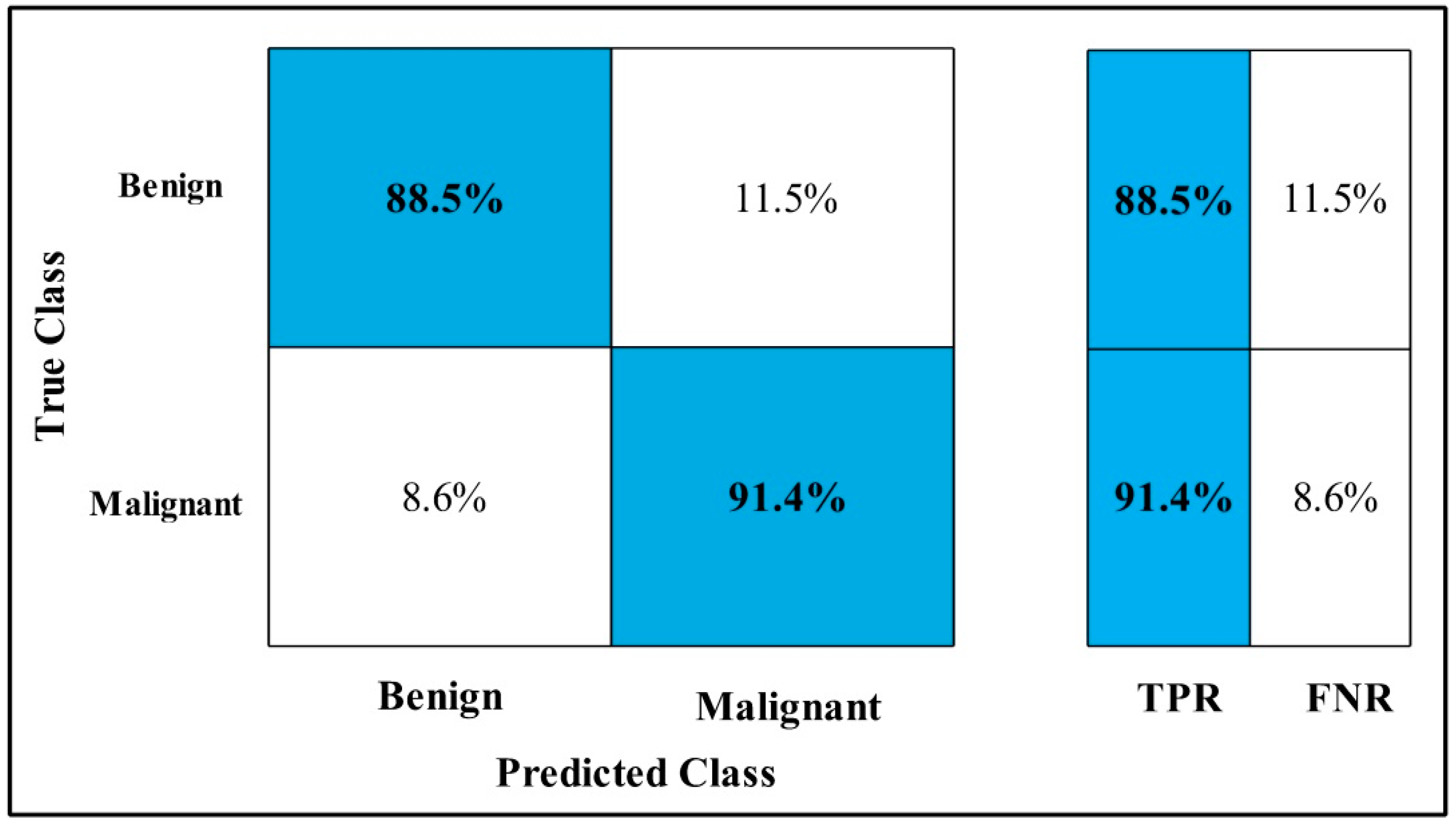
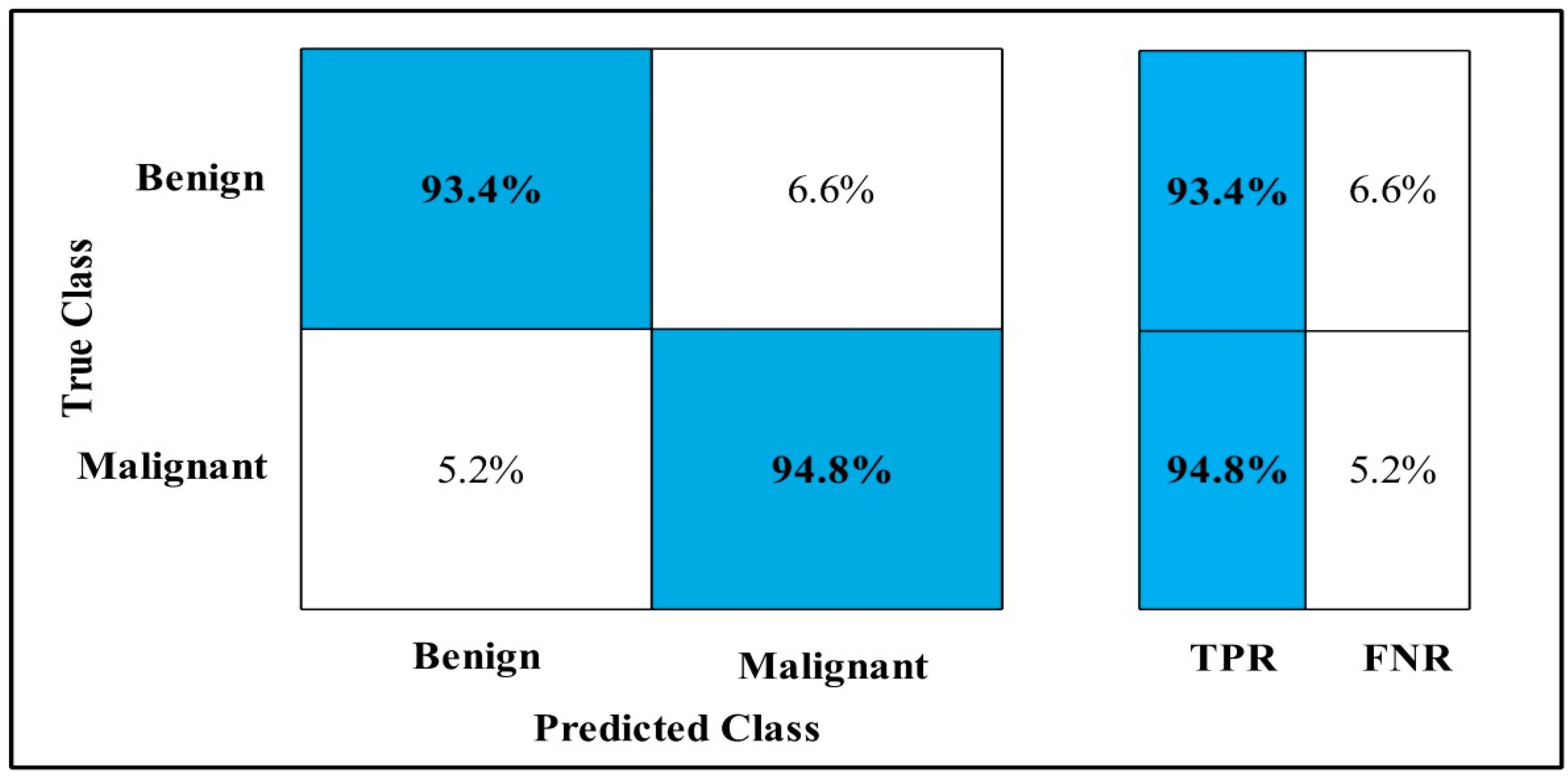
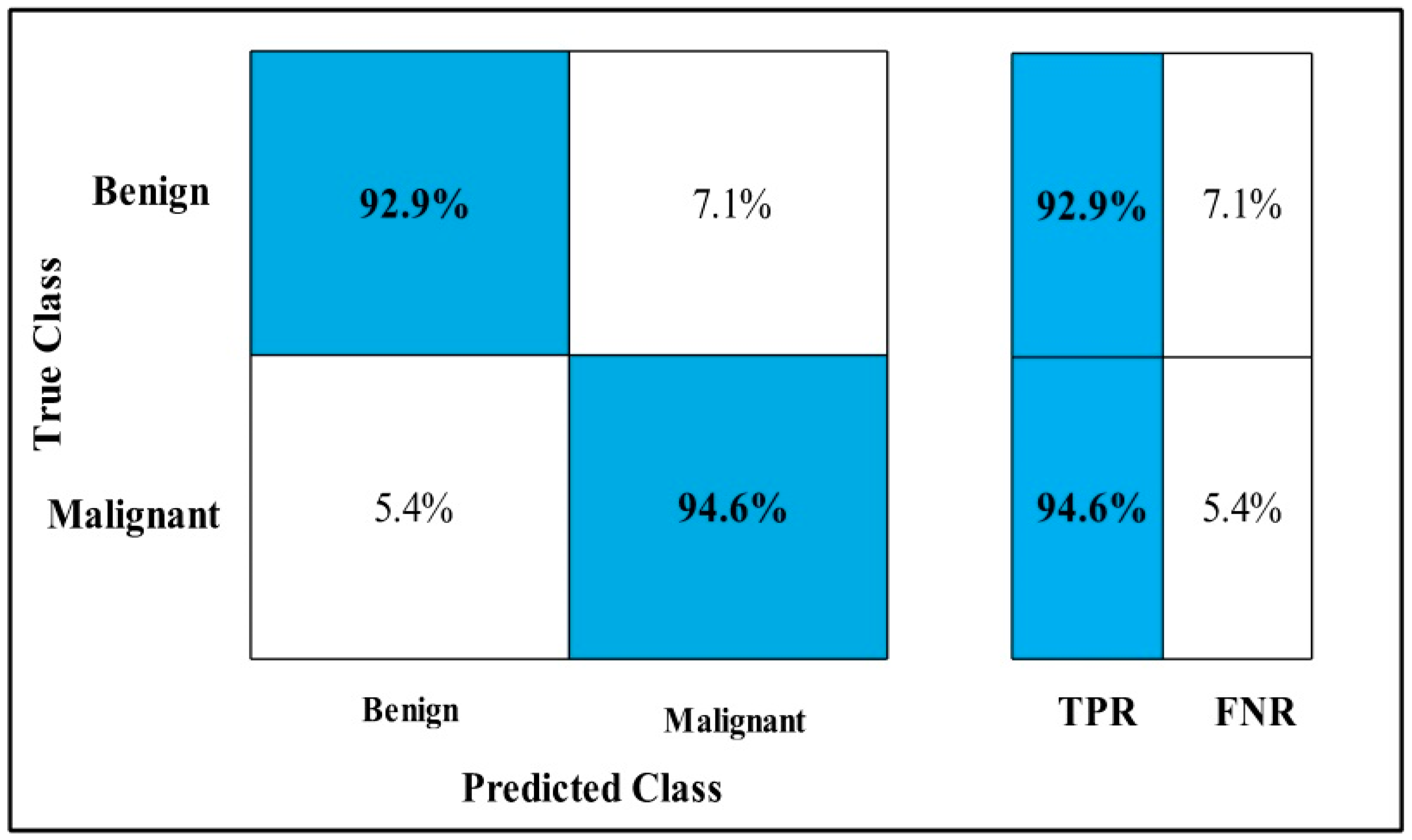
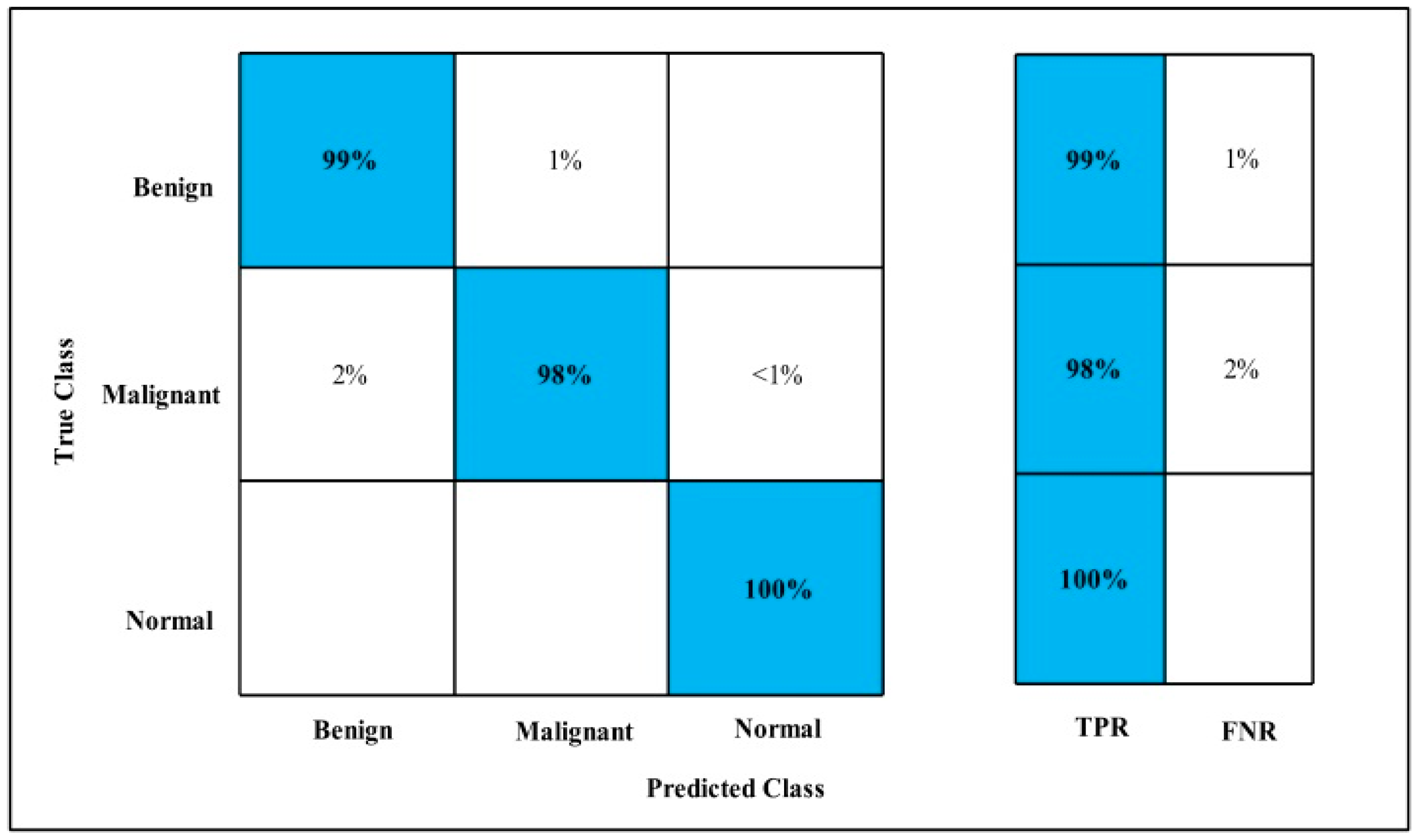
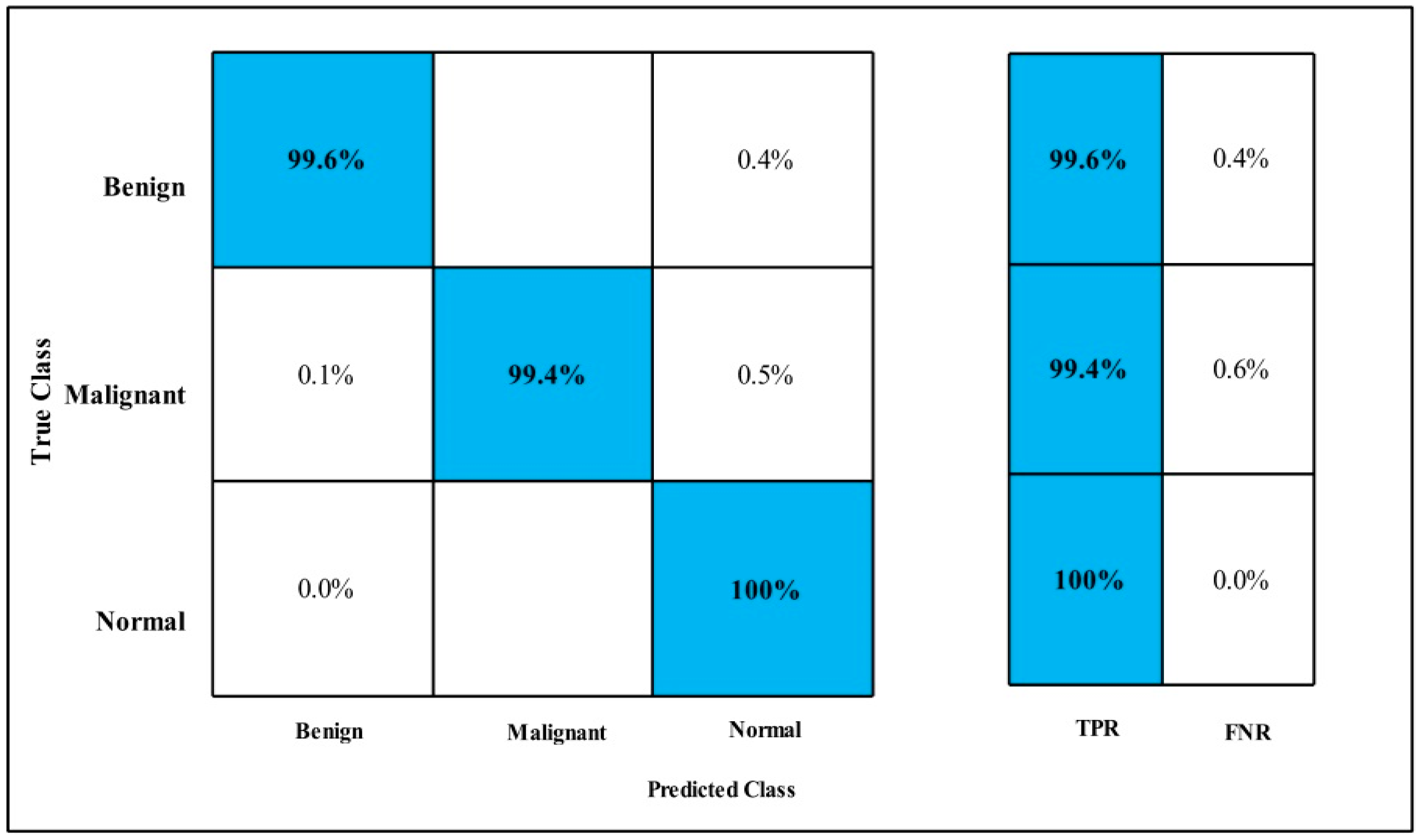
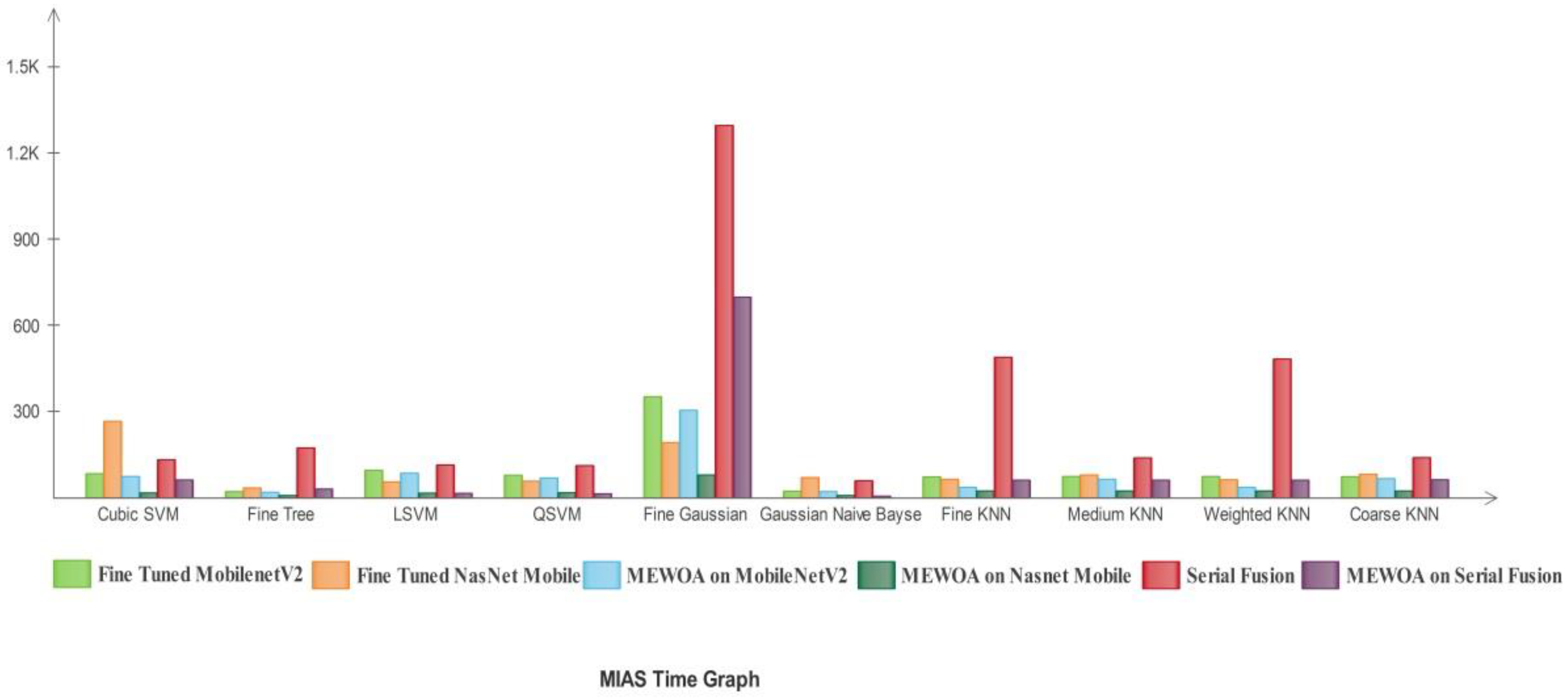
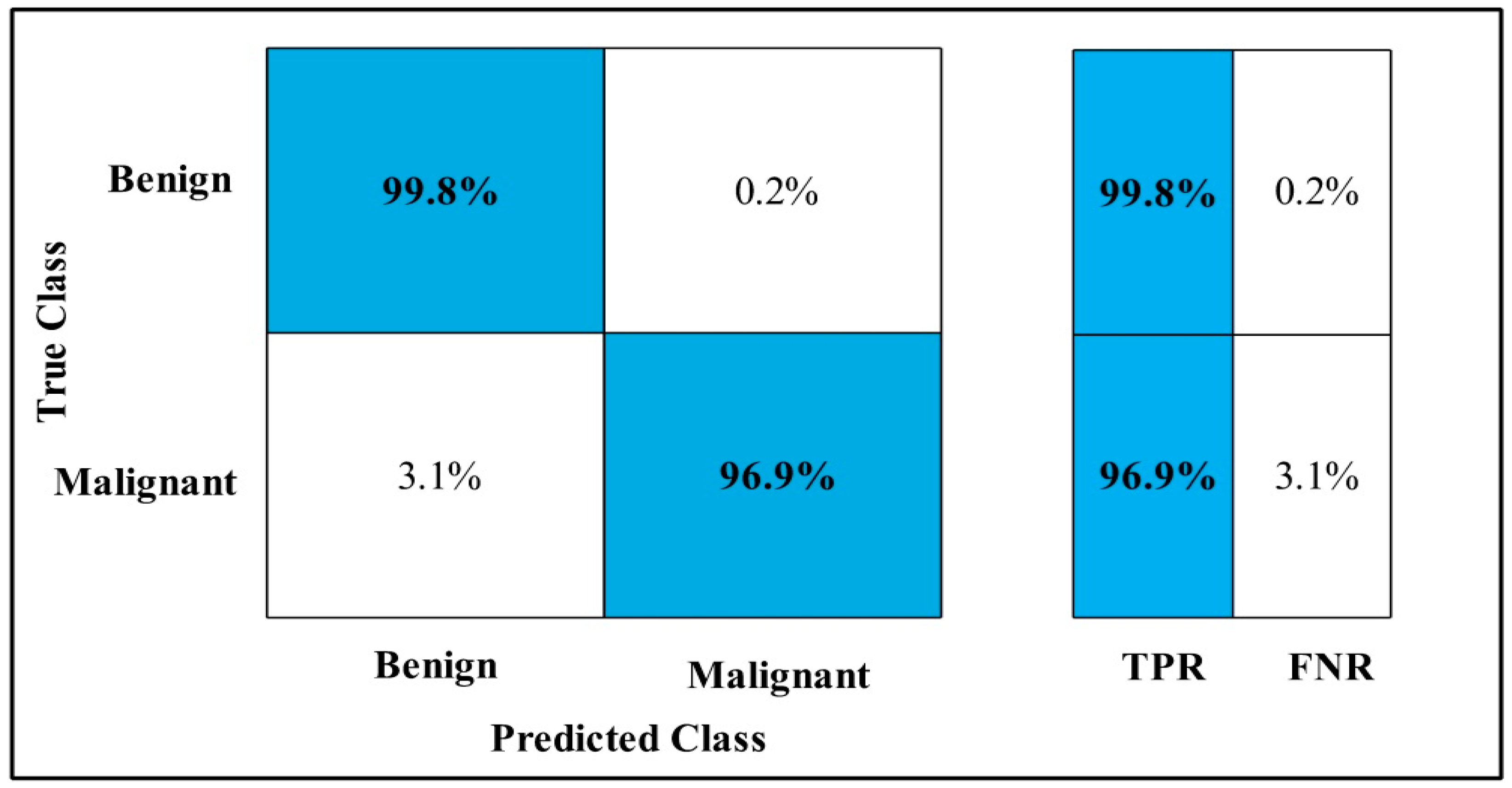
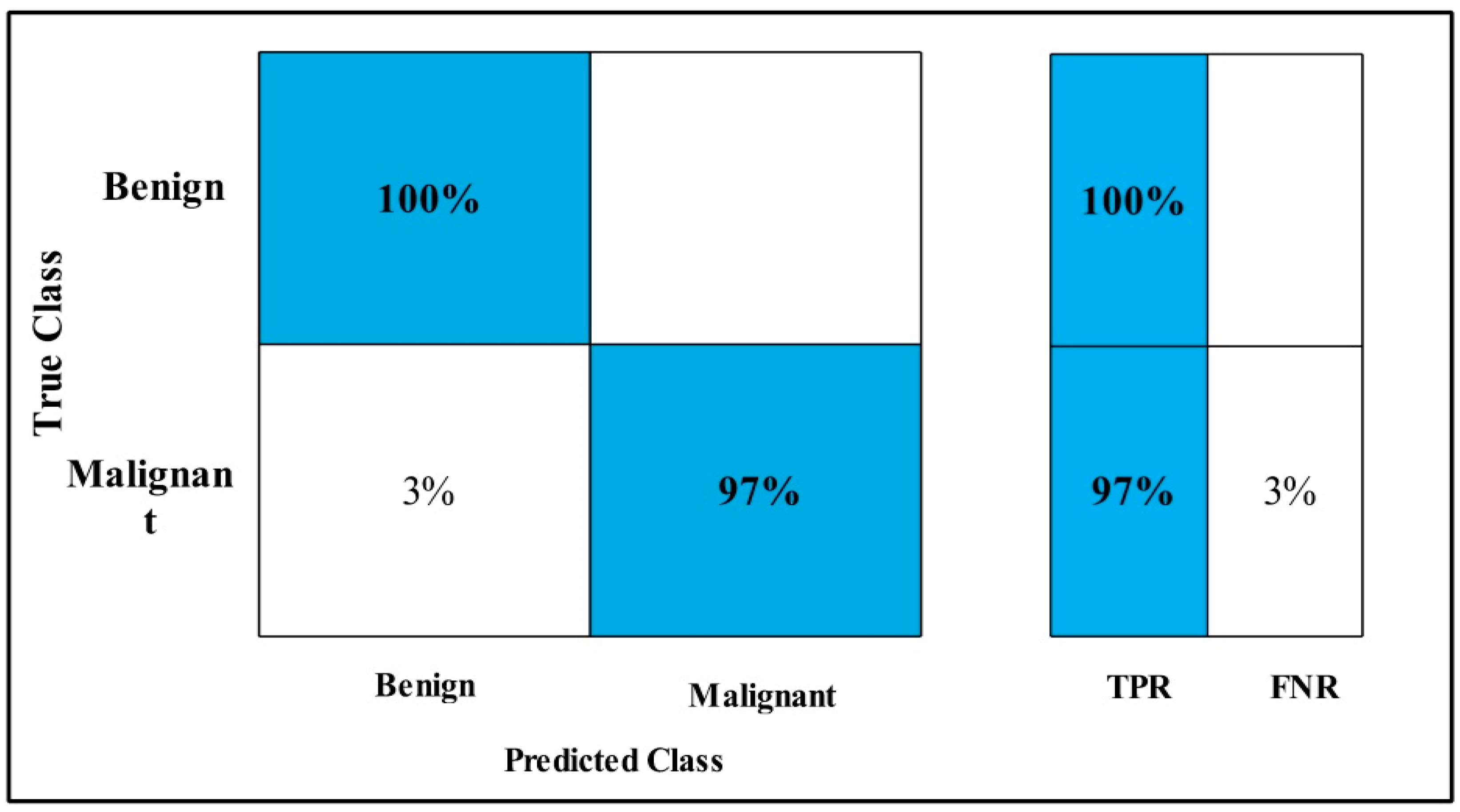
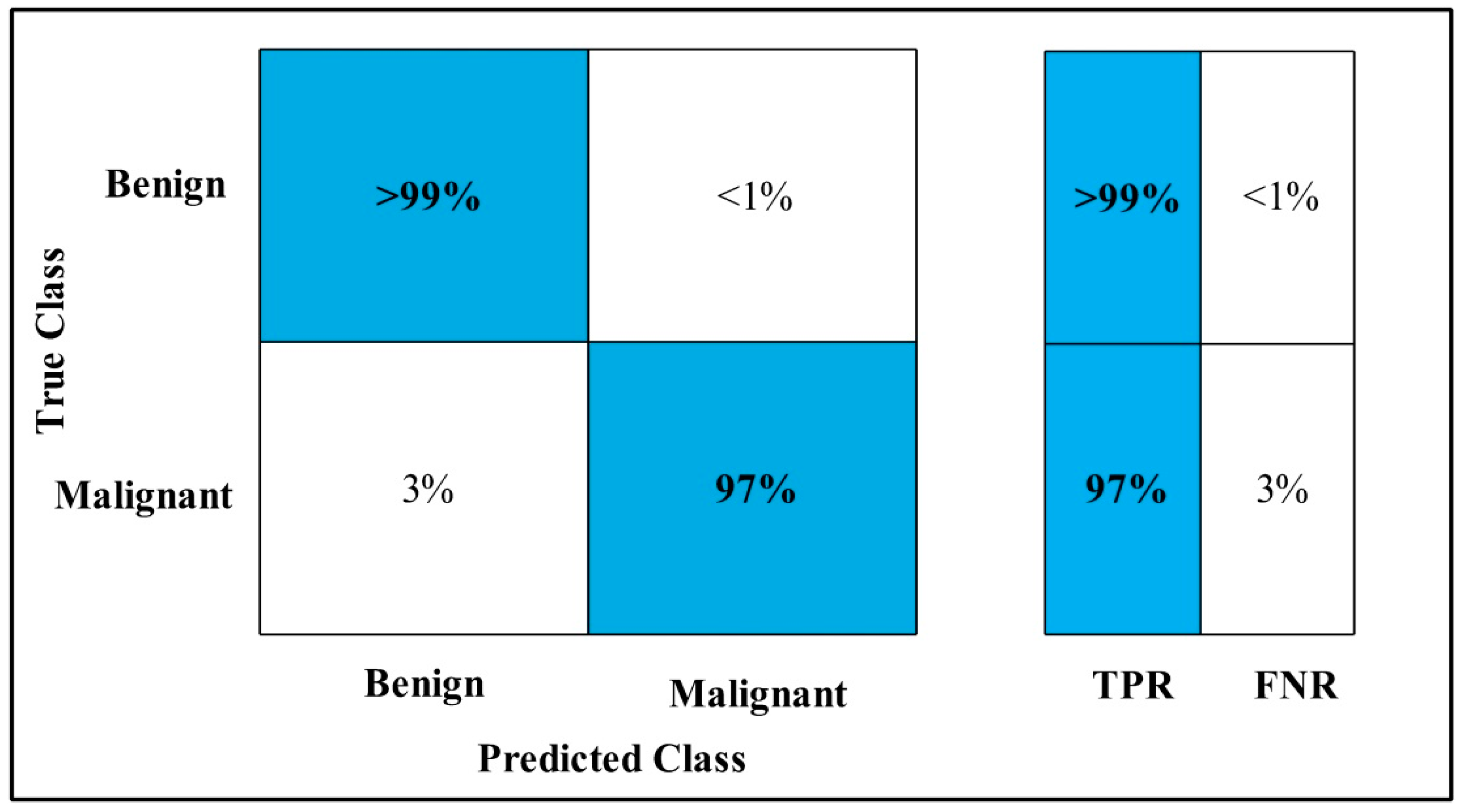
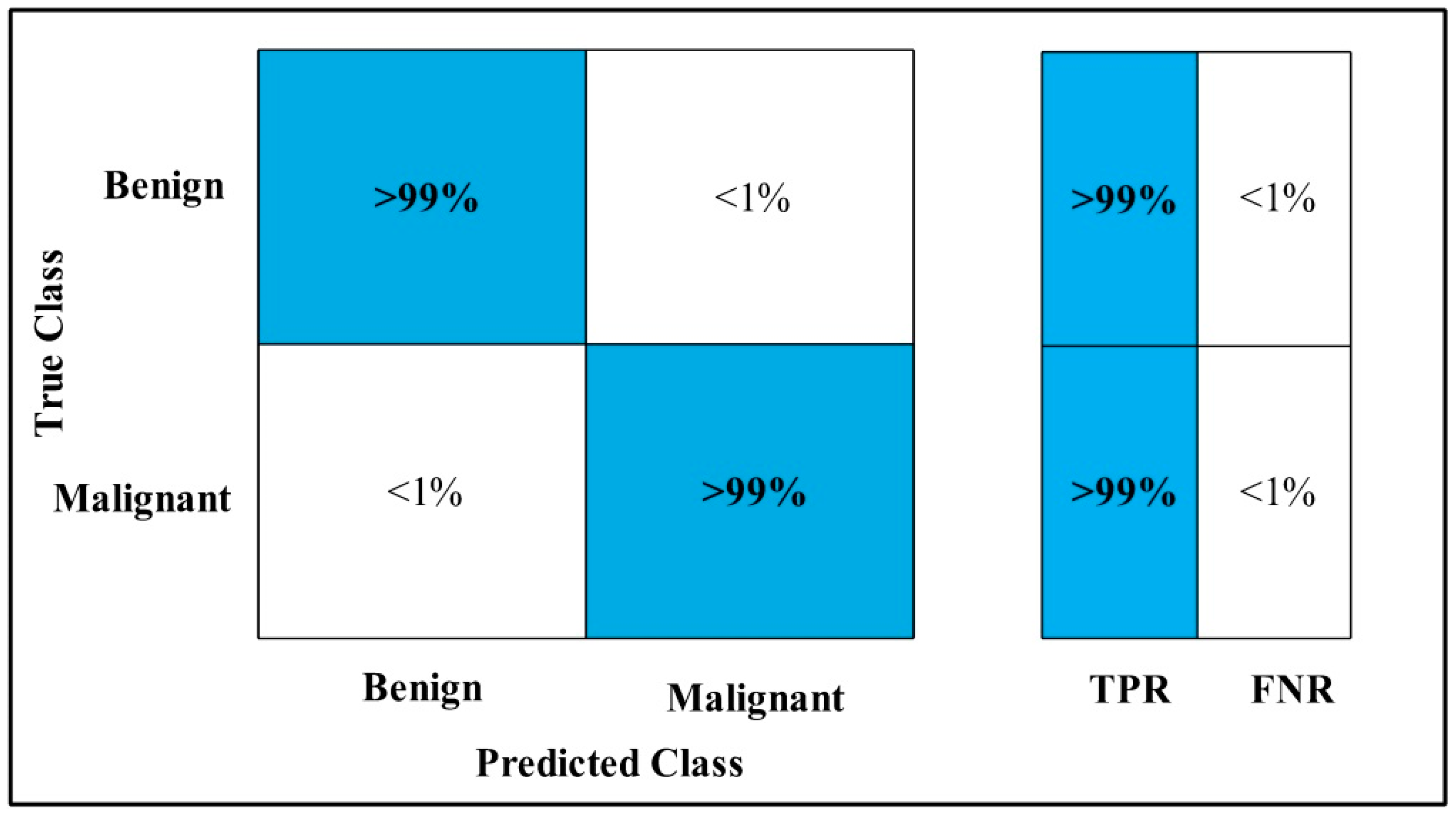
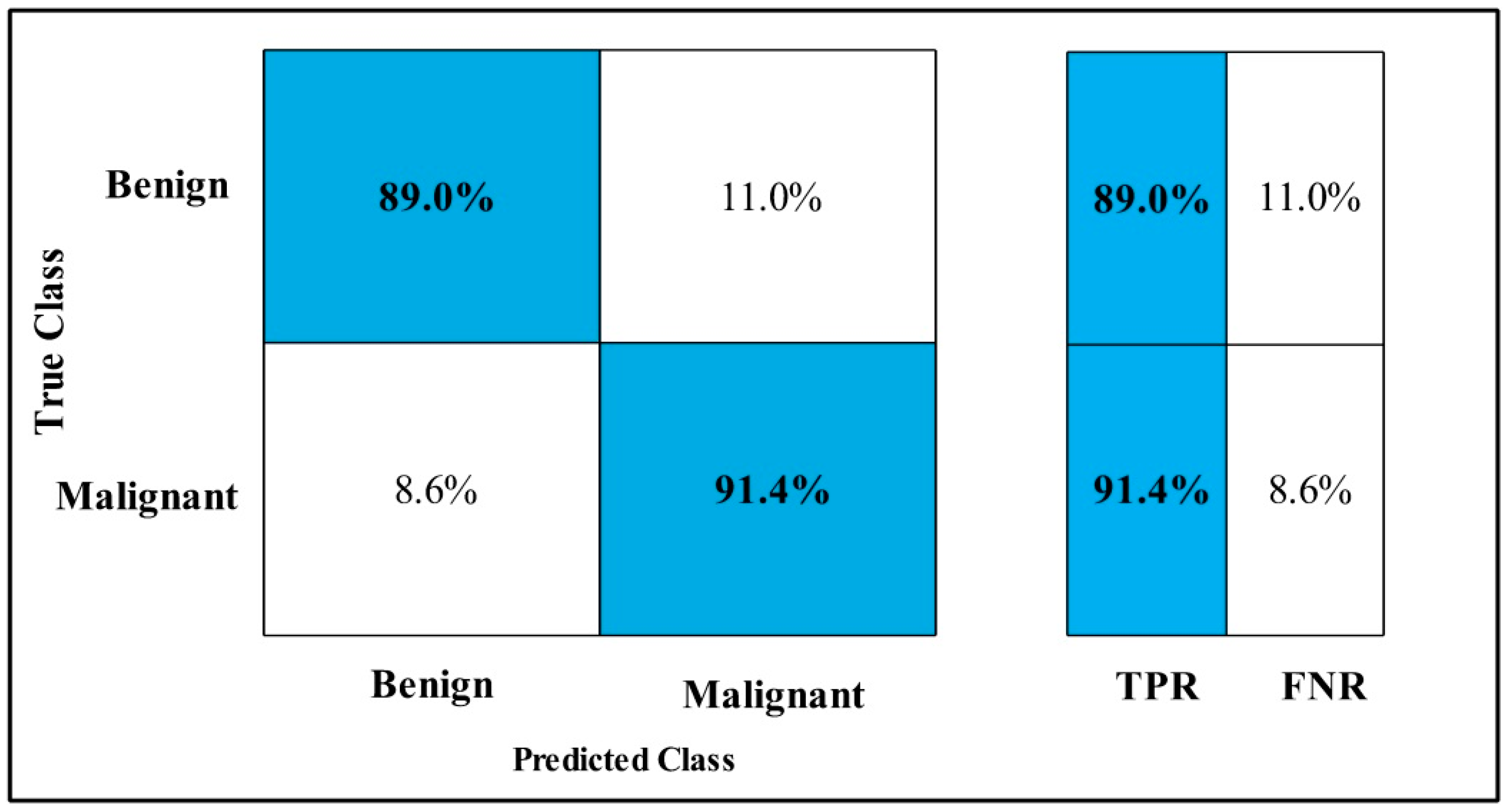
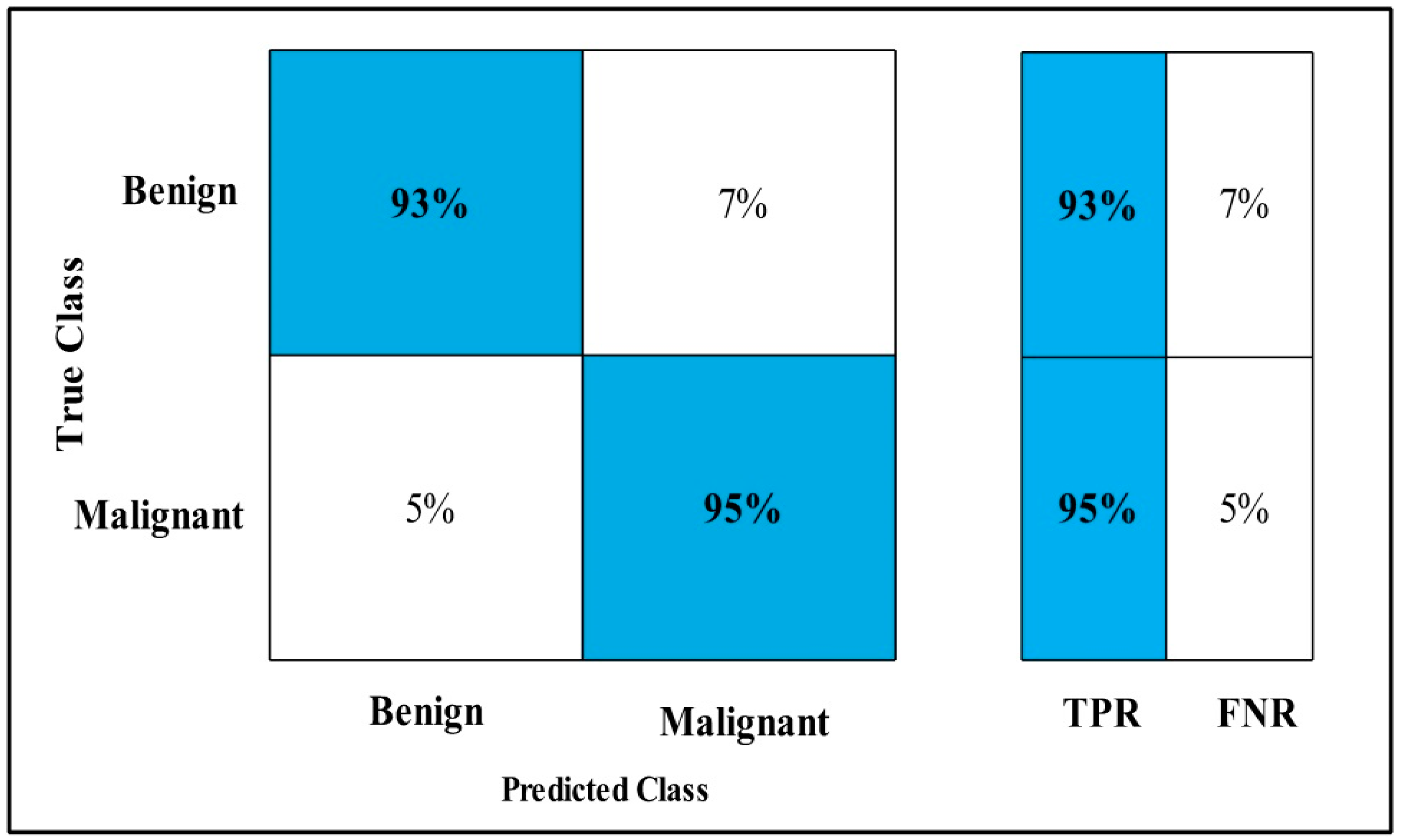
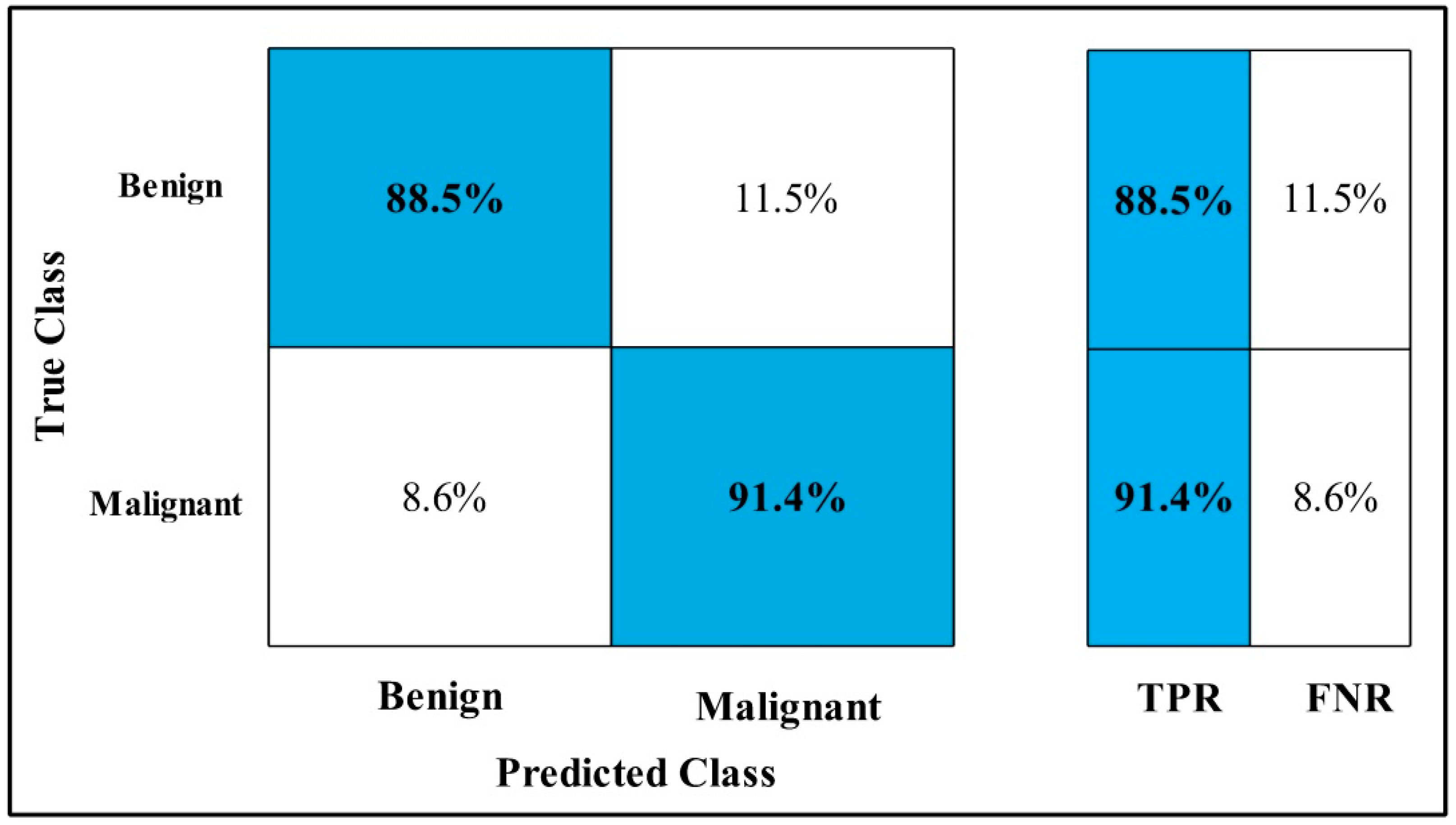
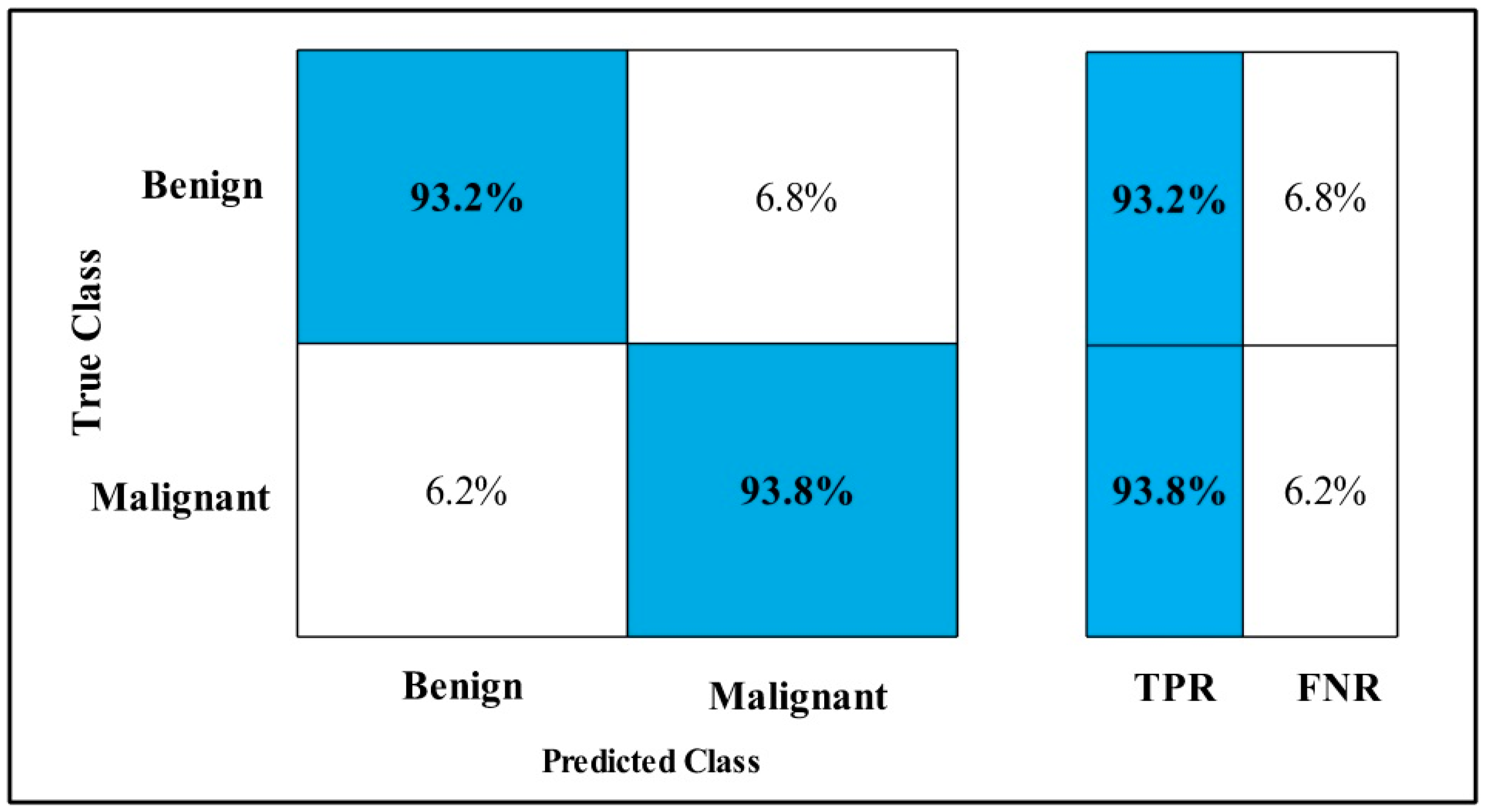
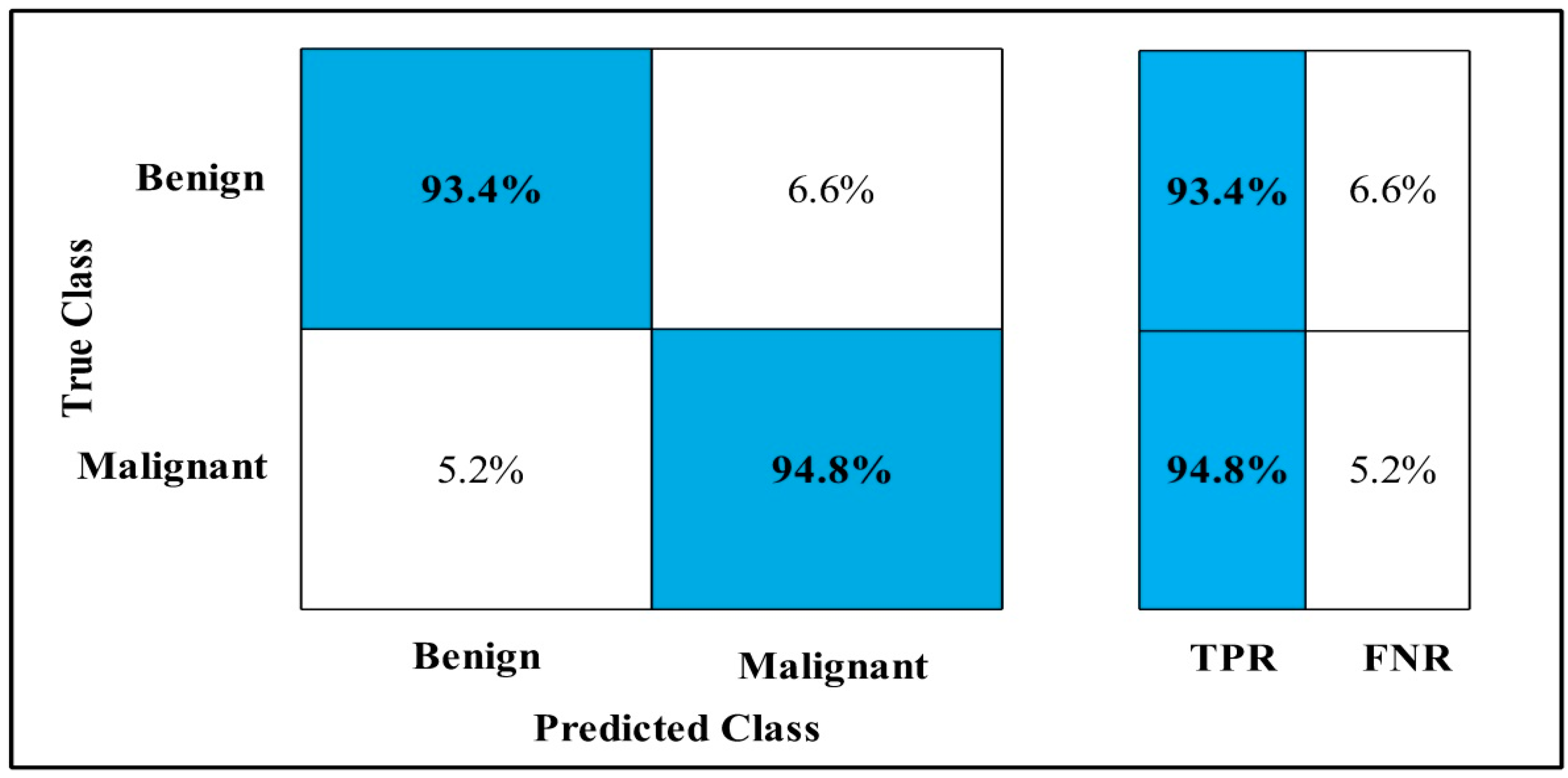
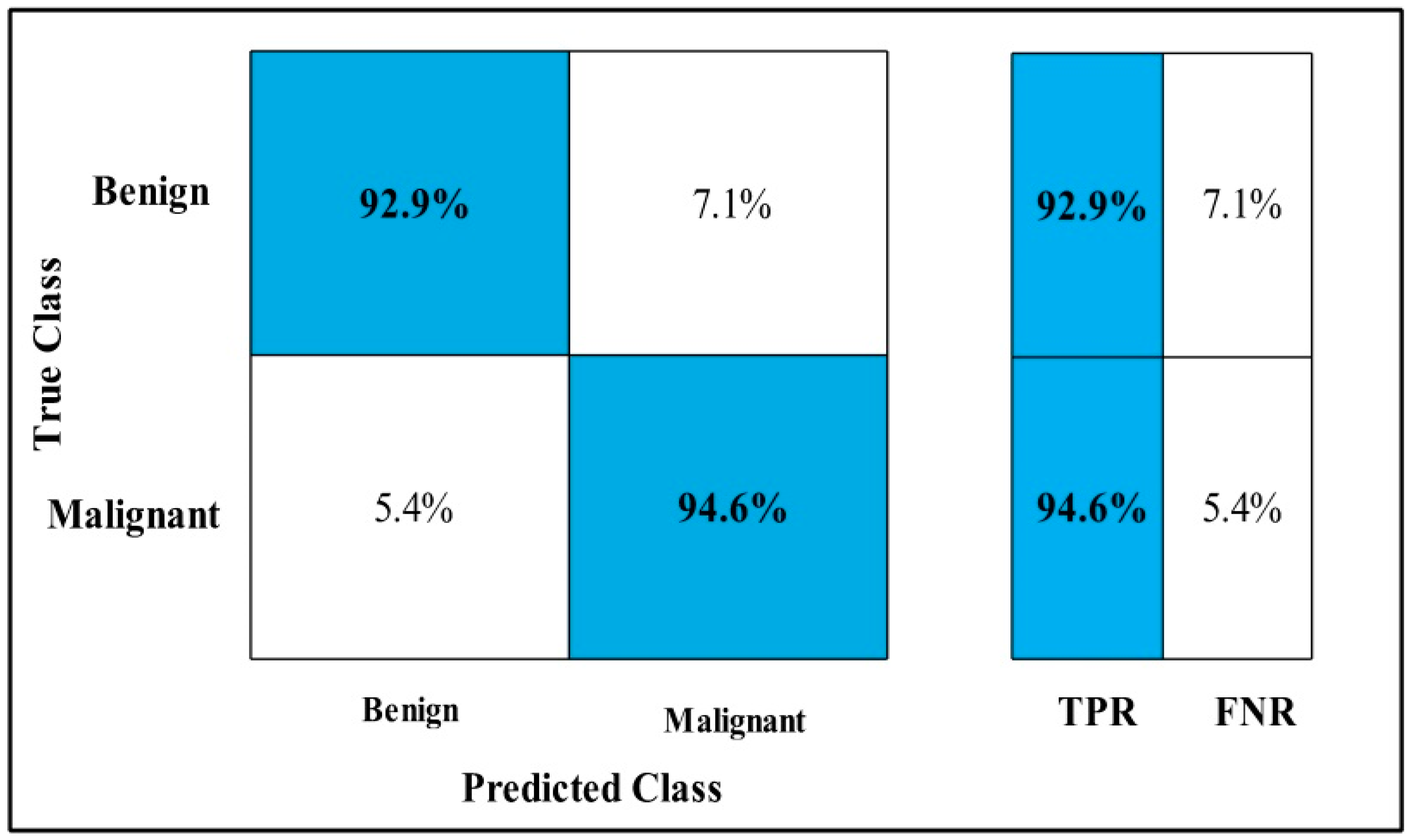
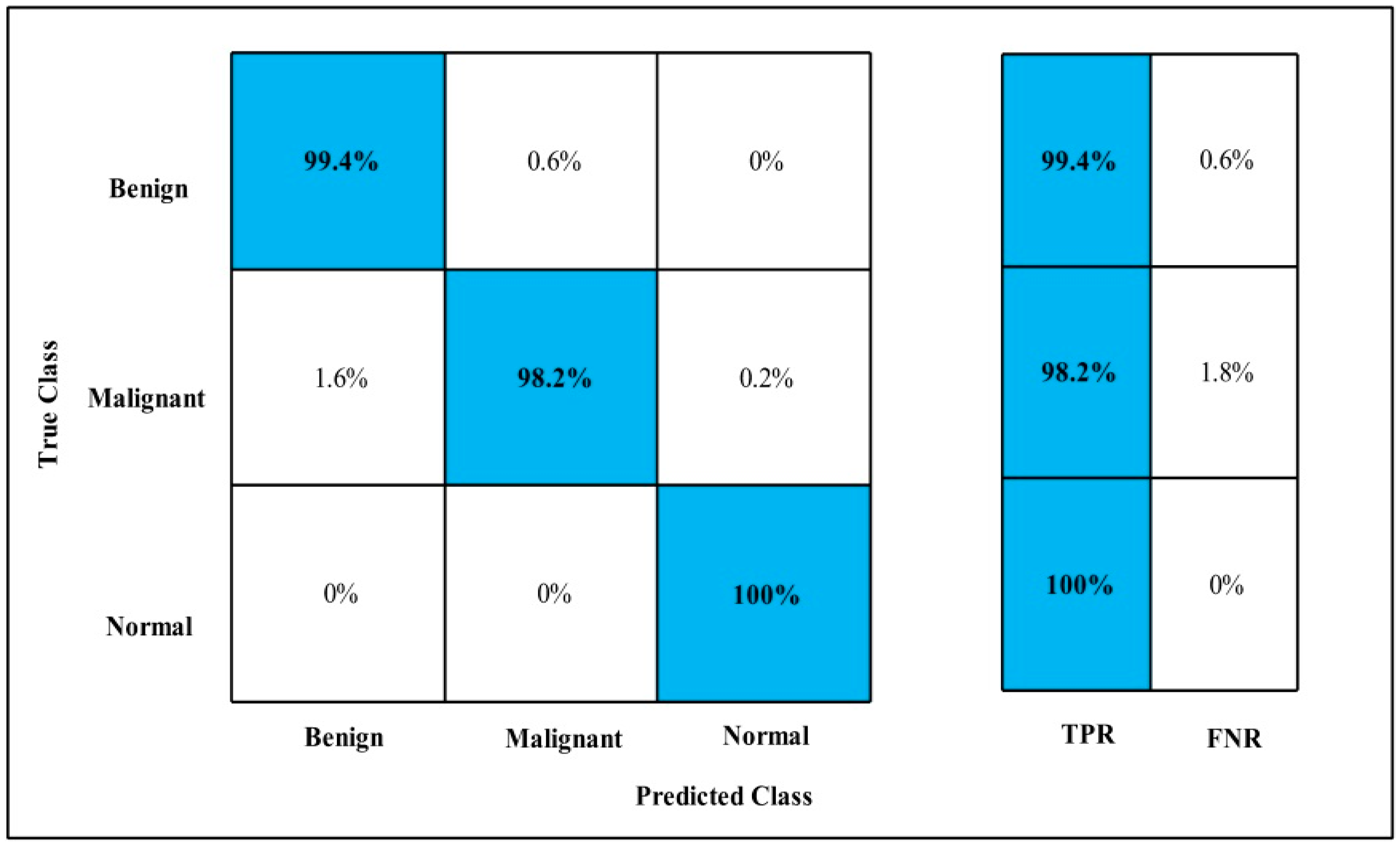
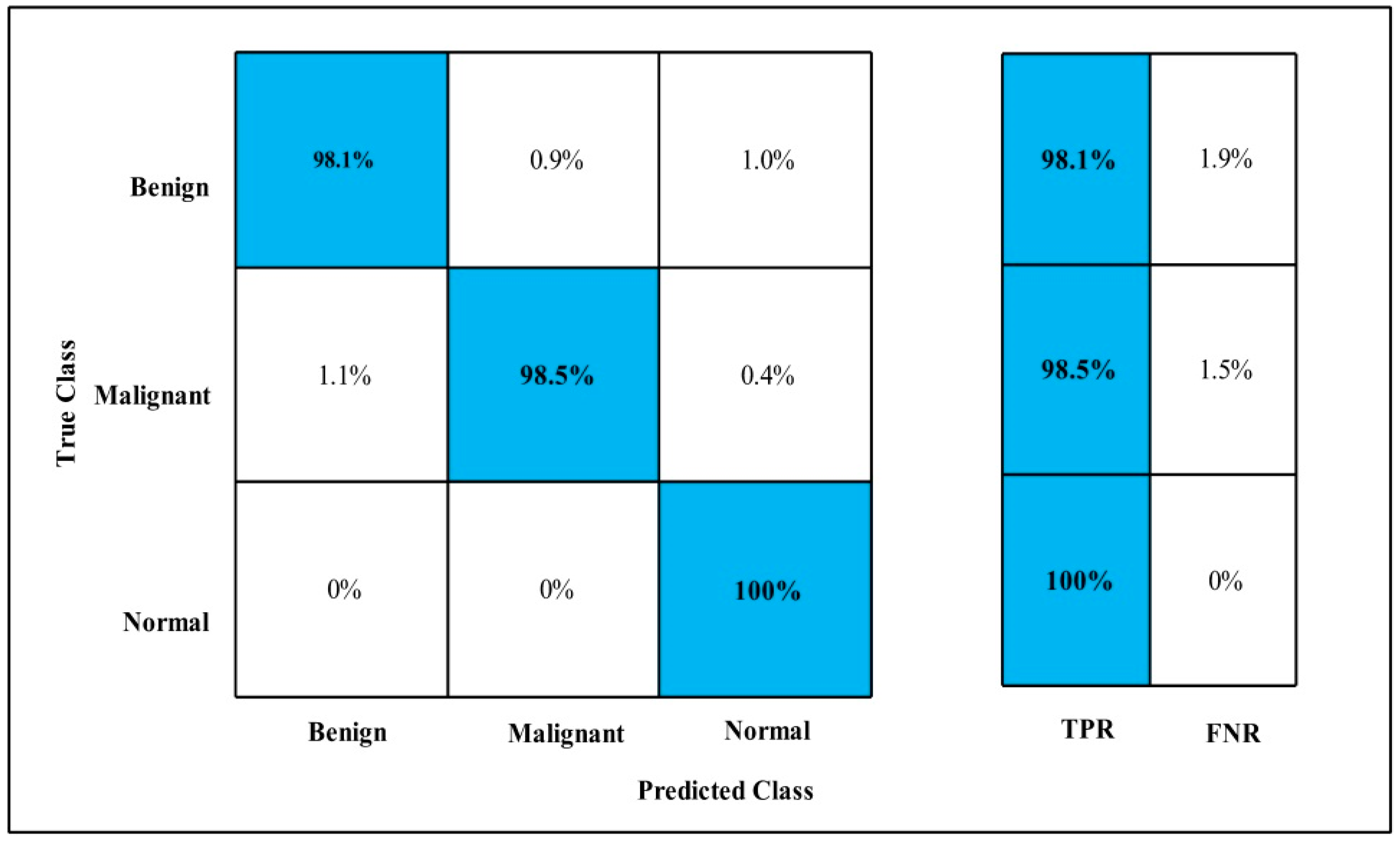
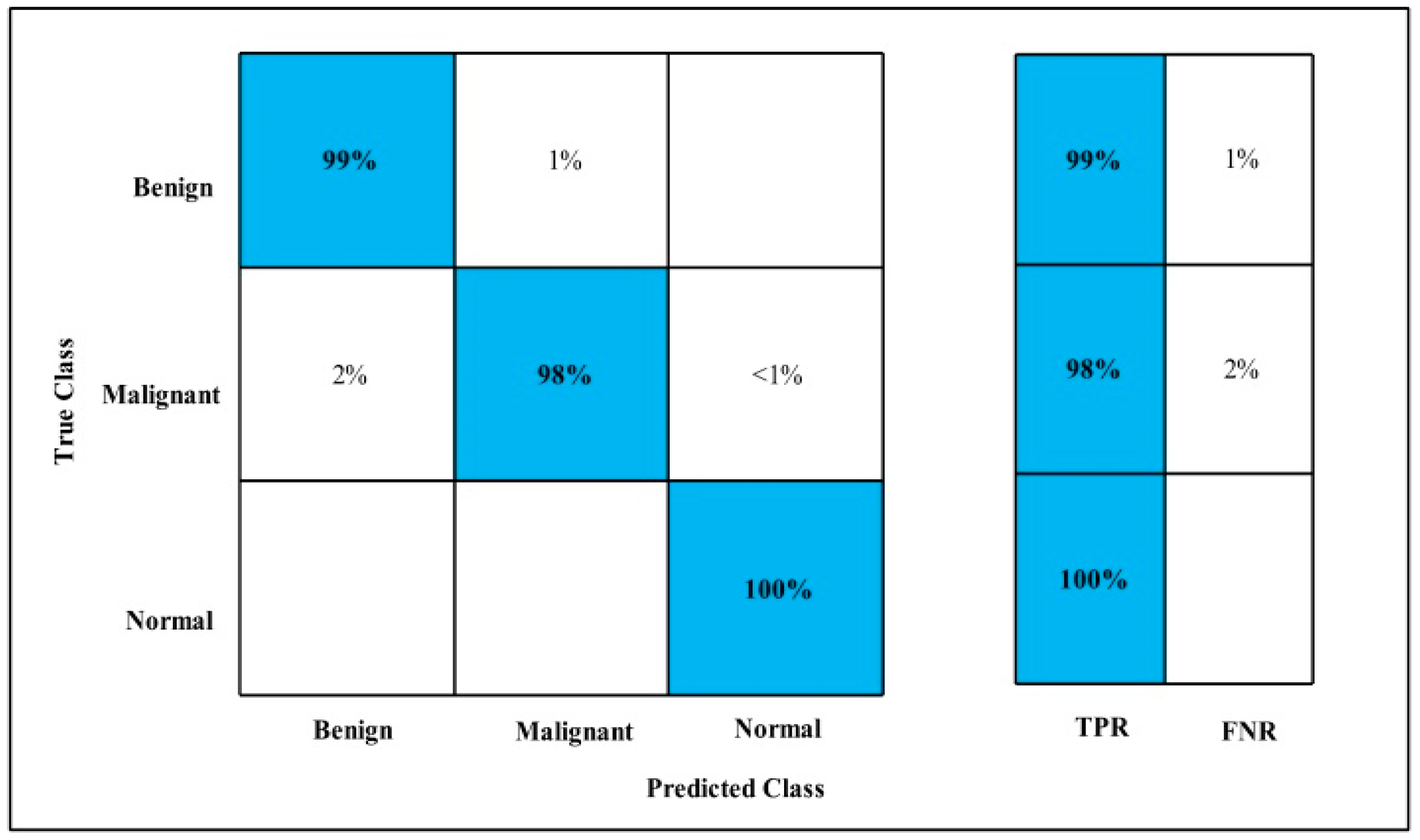
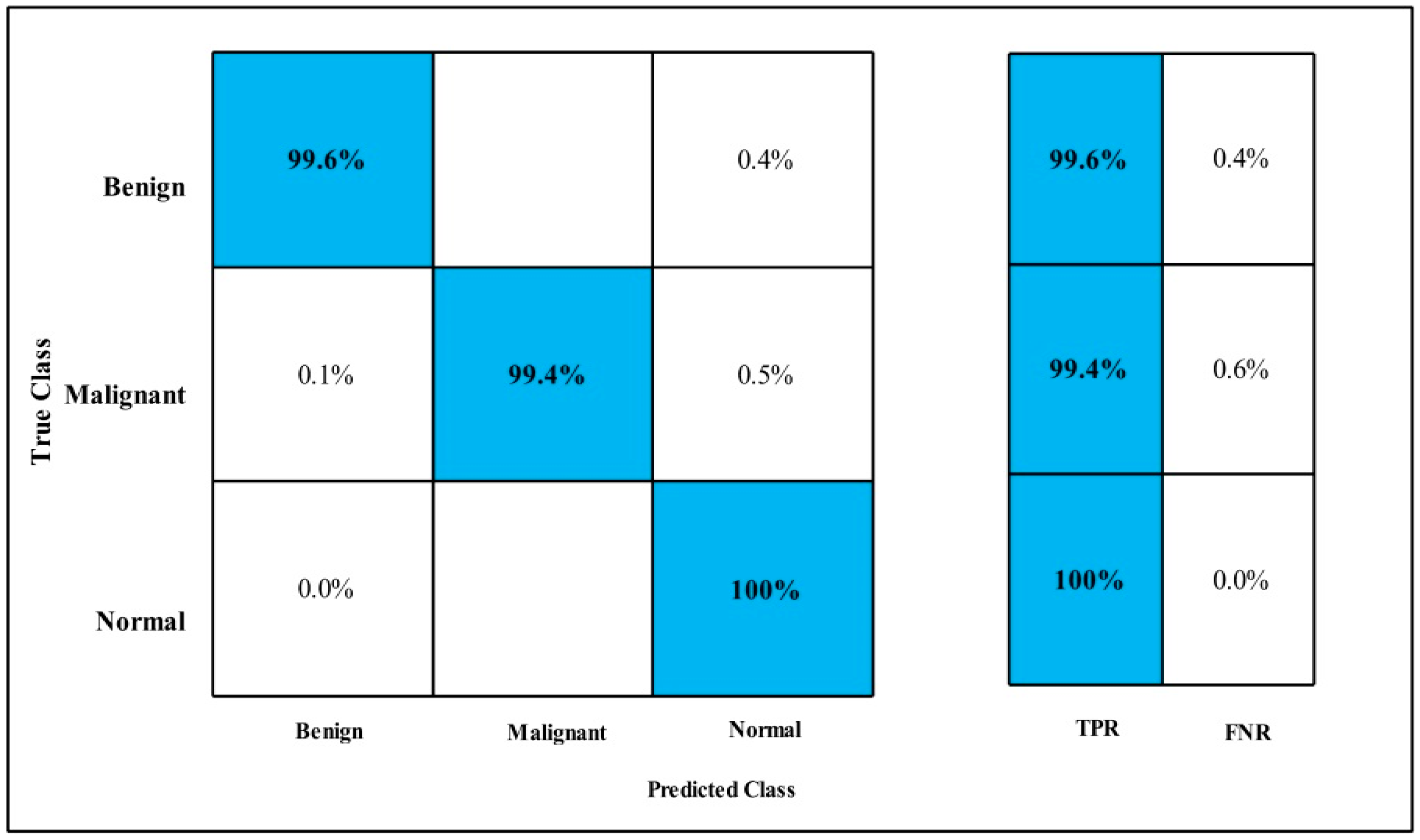
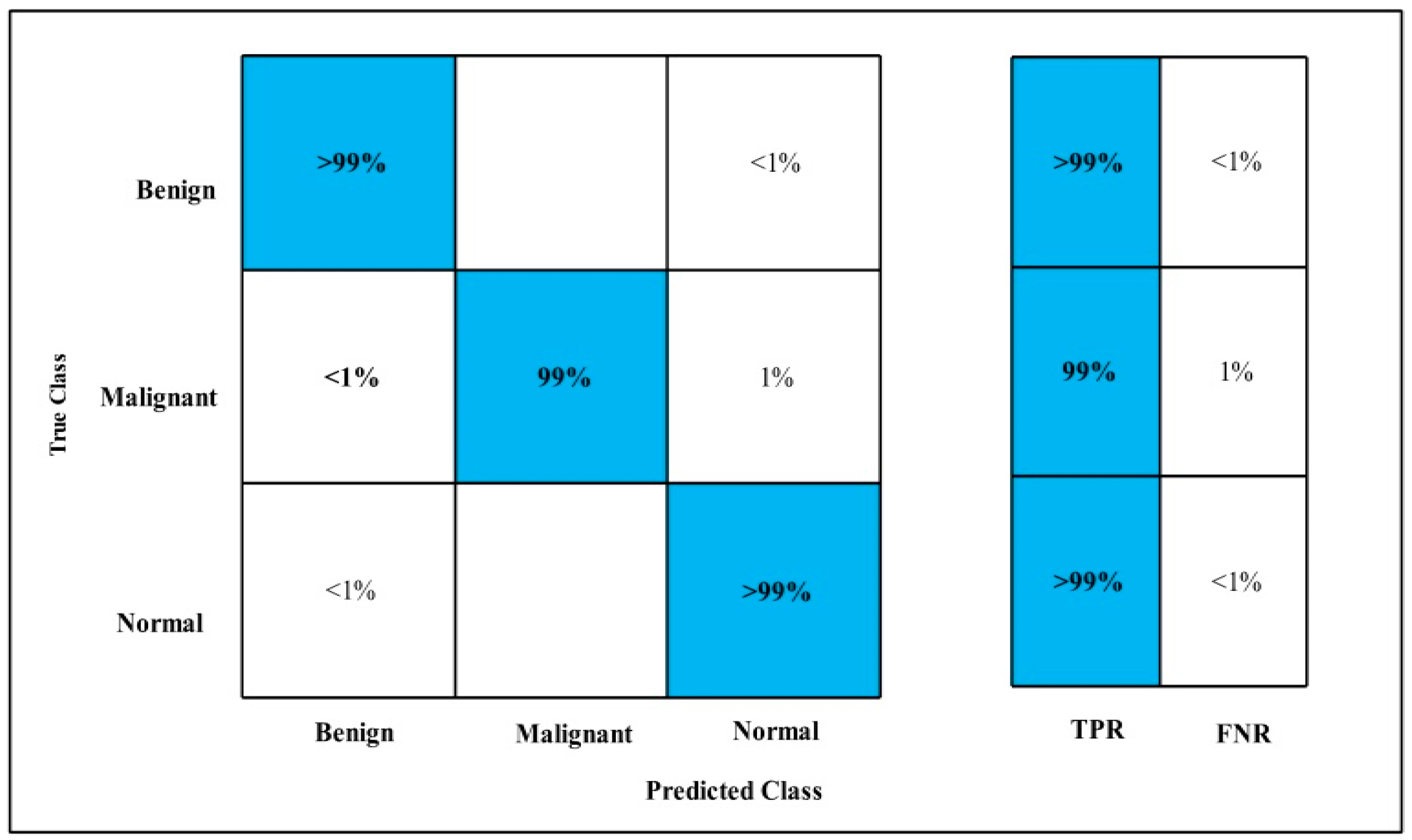
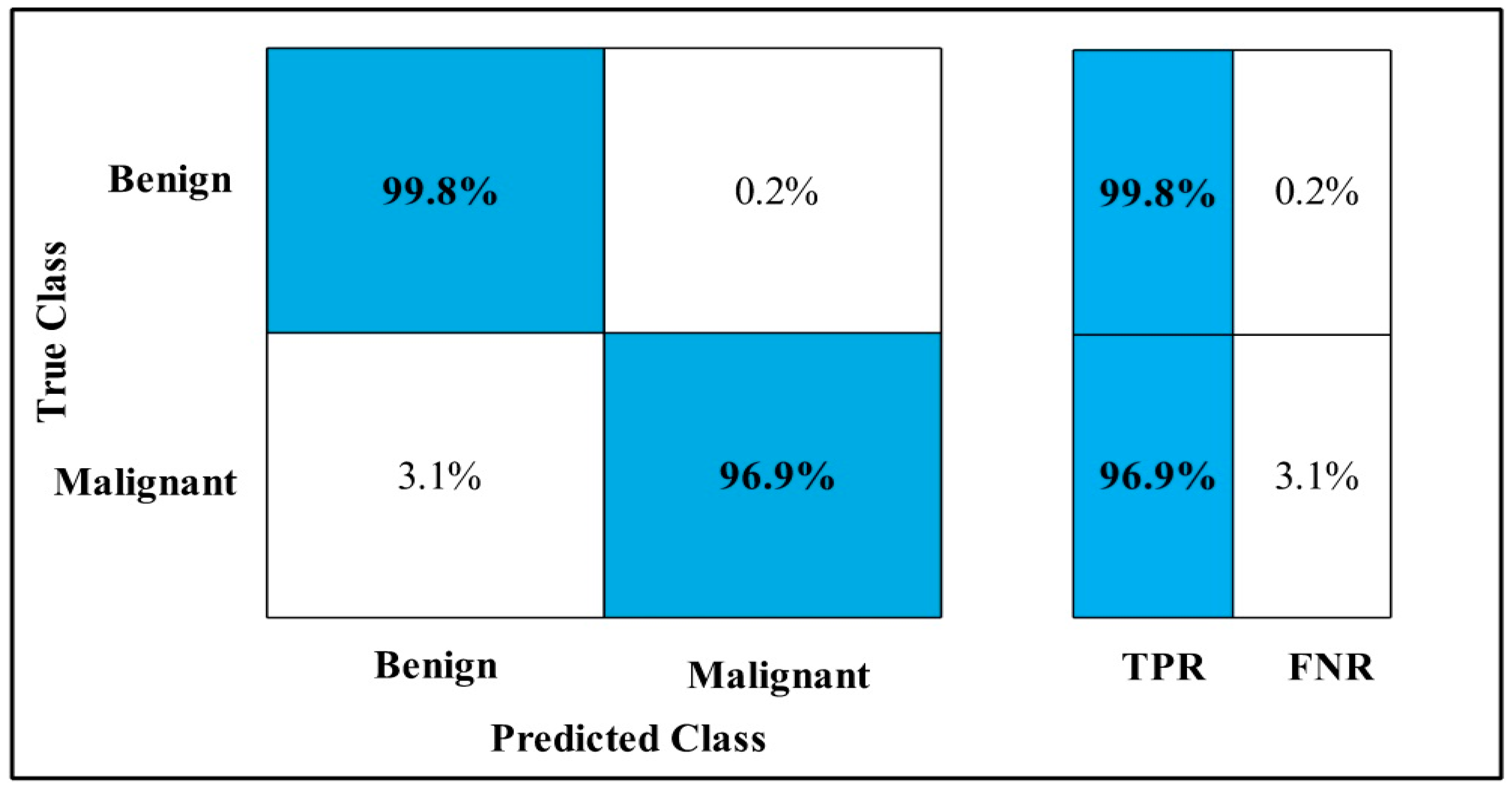
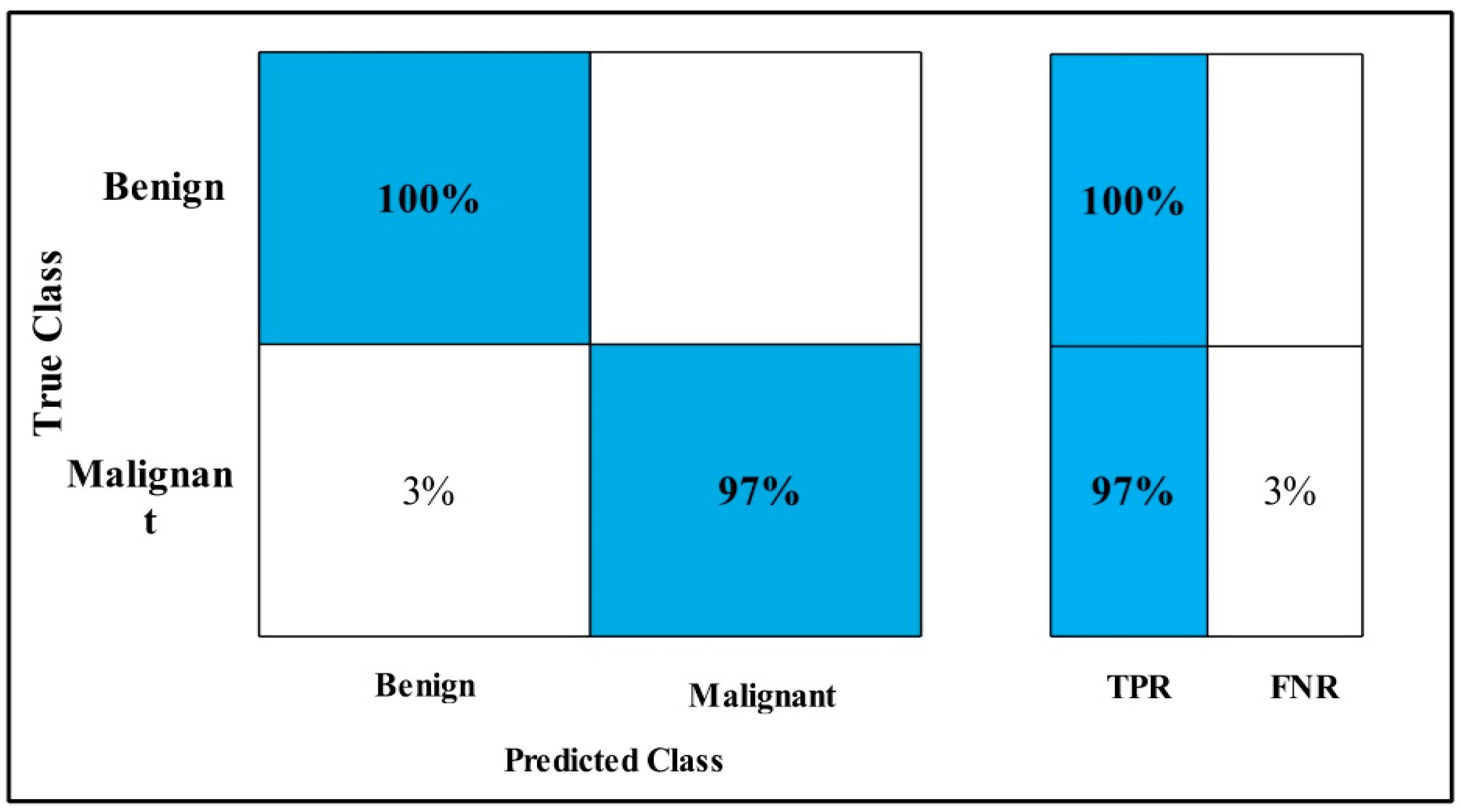
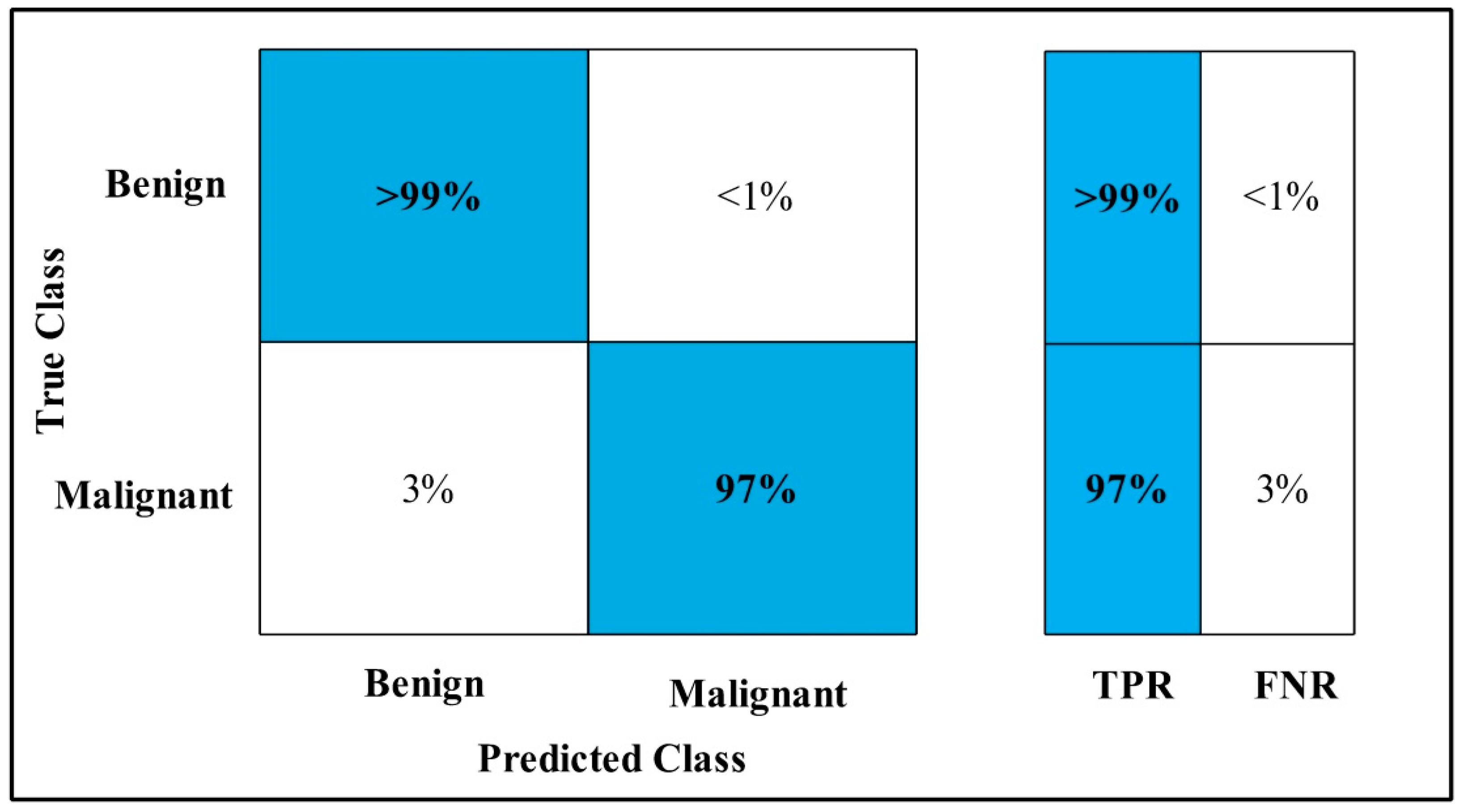
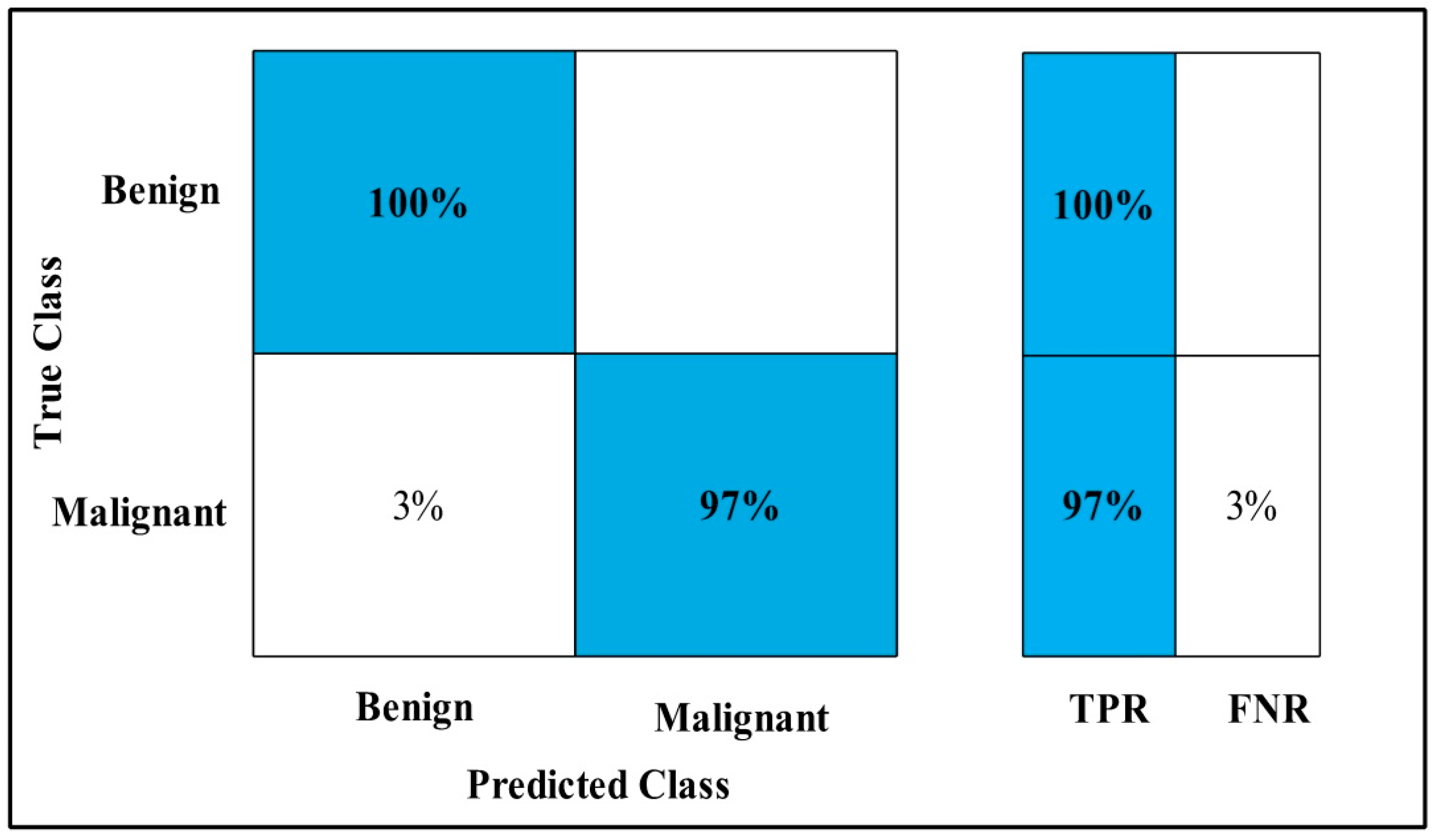
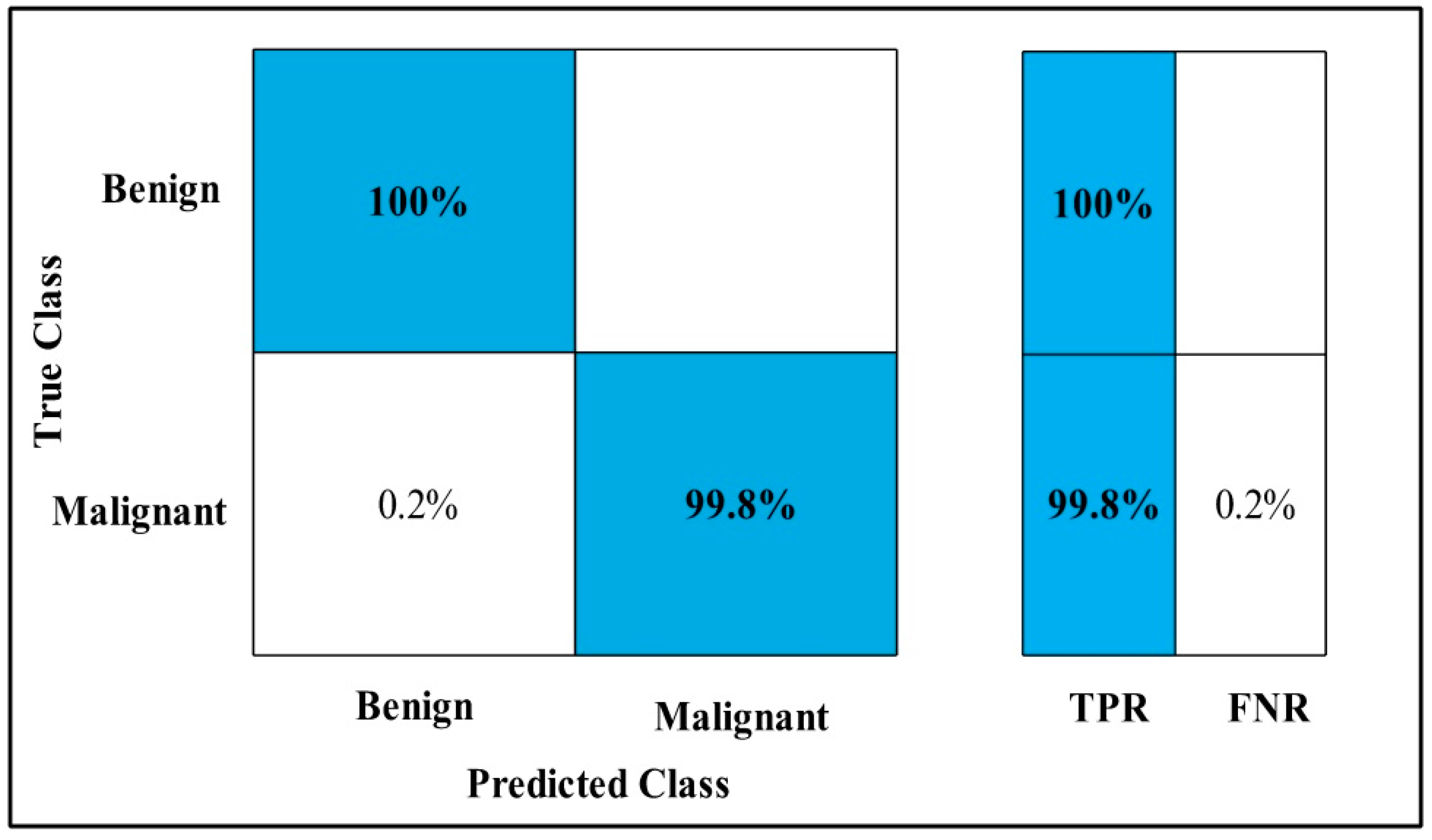
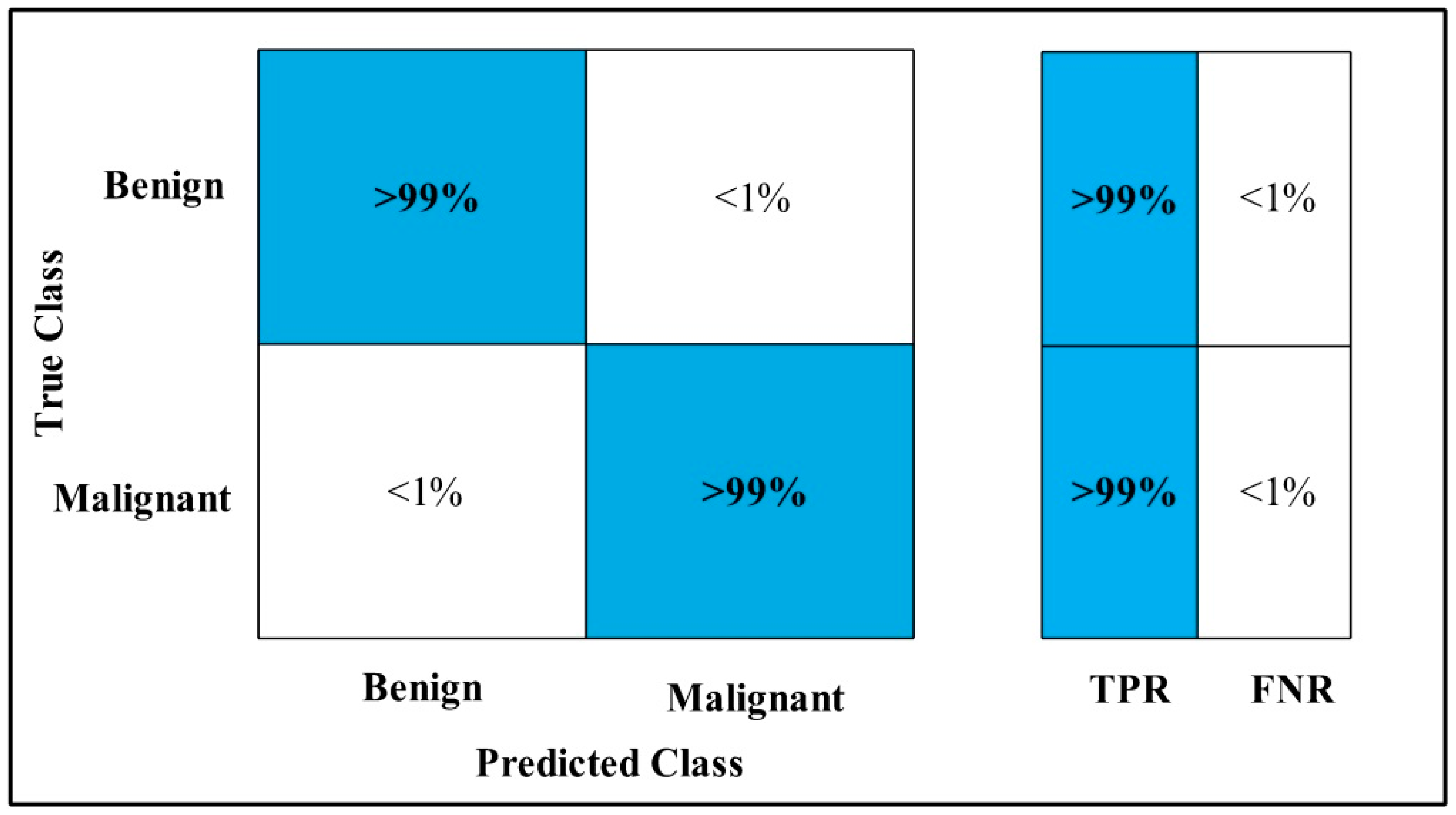
3.2. Classification Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sharma, G.N.; Dave, R.; Sanadya, J.; Sharma, P.; Sharma, K. Various types and management of breast cancer: An overview. J. Adv. Pharm. Technol. Res. 2010, 1, 109. [Google Scholar]
- Ekpo, E.U.; Alakhras, M.; Brennan, P. Errors in mammography cannot be solved through technology alone. Asian Pac. J. Cancer Prev. APJCP 2018, 19, 291. [Google Scholar]
- Lauby-Secretan, B.; Scoccianti, C.; Loomis, D.; Benbrahim-Tallaa, L.; Bouvard, V.; Bianchini, F.; Straif, K. Breast-cancer screening—Viewpoint of the IARC Working Group. N. Engl. J. Med. 2015, 372, 2353–2358. [Google Scholar] [CrossRef] [Green Version]
- Khan, M.A.; Ashraf, I.; Alhaisoni, M.; Damaševičius, R.; Scherer, R.; Rehman, A.; Bukhari, S.A.C. Multimodal brain tumor classification using deep learning and robust feature selection: A machine learning application for radiologists. Diagnostics 2020, 10, 565. [Google Scholar] [CrossRef] [PubMed]
- Khan, M.A.; Sharif, M.; Akram, T.; Damaševičius, R.; Maskeliūnas, R. Skin lesion segmentation and multiclass classification using deep learning features and improved moth flame optimization. Diagnostics 2021, 11, 811. [Google Scholar] [CrossRef]
- Zahoor, S.; Lali, I.U.; Khan, M.A.; Javed, K.; Mehmood, W. Breast cancer detection and classification using traditional computer vision techniques: A comprehensive review. Curr. Med. Imaging 2020, 16, 1187–1200. [Google Scholar] [CrossRef]
- Coolen, A.M.; Voogd, A.C.; Strobbe, L.J.; Louwman, M.W.; Tjan-Heijnen, V.C.; Duijm, L.E. Impact of the second reader on screening outcome at blinded double reading of digital screening mammograms. Br. J. Cancer 2018, 119, 503–507. [Google Scholar] [CrossRef]
- Jung, N.Y.; Kang, B.J.; Kim, H.S.; Cha, E.S.; Lee, J.H.; Park, C.S.; Whang, I.Y.; Kim, S.H.; An, Y.Y.; Choi, J.J. Who could benefit the most from using a computer-aided detection system in full-field digital mammography? World J. Surg. Oncol. 2014, 12, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Freer, T.W.; Ulissey, M.J. Screening mammography with computer-aided detection: Prospective study of 12,860 patients in a community breast center. Radiology 2001, 220, 781–786. [Google Scholar] [CrossRef]
- Warren Burhenne, L.J.; Wood, S.A.; D’Orsi, C.J.; Feig, S.A.; Kopans, D.B.; O’Shaughnessy, K.F.; Sickles, E.A.; Tabar, L.; Vyborny, C.J.; Castellino, R.A. Potential contribution of computer-aided detection to the sensitivity of screening mammography. Radiology 2000, 215, 554–562. [Google Scholar] [CrossRef]
- Saleem, F.; Khan, M.A.; Alhaisoni, M.; Tariq, U.; Armghan, A.; Alenezi, F.; Choi, J.-I.; Kadry, S. Human gait recognition: A single stream optimal deep learning features fusion. Sensors 2021, 21, 7584. [Google Scholar] [CrossRef]
- Khan, S.; Khan, M.A.; Alhaisoni, M.; Tariq, U.; Yong, H.-S.; Armghan, A.; Allenzi, F. Human Action Recognition: Paradigm of Best Deep Learning Features Selection and Serial Based Extended Fusion. Sensors 2021, 21, 7941. [Google Scholar] [CrossRef]
- Khan, M.A.; Alhaisoni, M.; Tariq, U.; Hussain, N.; Majid, A.; Damaševičius, R.; Maskeliunas, R. COVID-19 Case Recognition from Chest CT Images by Deep Learning, Entropy-Controlled Firefly Optimization, and Parallel Feature Fusion. Sensors 2021, 21, 7286. [Google Scholar] [CrossRef]
- Azhar, I.; Sharif, M.; Raza, M.; Khan, M.A.; Yong, H.-S. A Decision Support System for Face Sketch Synthesis Using Deep Learning and Artificial Intelligence. Sensors 2021, 21, 8178. [Google Scholar] [CrossRef]
- Chai, J.; Zeng, H.; Li, A.; Ngai, E.W. Deep learning in computer vision: A critical review of emerging techniques and application scenarios. Mach. Learn. Appl. 2021, 6, 100134. [Google Scholar] [CrossRef]
- Khan, M.A.; Rajinikanth, V.; Satapathy, S.C.; Taniar, D.; Mohanty, J.R.; Tariq, U.; Damasevicius, R. VGG19 Network Assisted Joint Segmentation and Classification of Lung Nodules in CT Images. Diagnostics 2021, 11, 2208. [Google Scholar] [CrossRef]
- Nawaz, M.; Nazir, T.; Masood, M.; Mehmood, A.; Mahum, R.; Khan, M.A.; Kadry, S.; Thinnukool, O. Analysis of brain MRI images using improved cornernet approach. Diagnostics 2021, 11, 1856. [Google Scholar] [CrossRef]
- Ragab, D.A.; Sharkas, M.; Marshall, S.; Ren, J. Breast cancer detection using deep convolutional neural networks and support vector machines. PeerJ 2019, 7, e6201. [Google Scholar] [CrossRef]
- Suzuki, S.; Zhang, X.; Homma, N.; Ichiji, K.; Sugita, N.; Kawasumi, Y.; Ishibashi, T.; Yoshizawa, M. Mass detection using deep convolutional neural network for mammographic computer-aided diagnosis. In Proceedings of the 2016 55th Annual Conference of the Society of Instrument and Control Engineers of Japan (SICE), Tsukuba, Japan, 20–23 September 2016; p. 1382. [Google Scholar]
- Sharma, S.; Khanna, P. Computer-aided diagnosis of malignant mammograms using Zernike moments and SVM. J. Digit. Imaging 2015, 28, 77–90. [Google Scholar] [CrossRef]
- Shen, L.; Margolies, L.R.; Rothstein, J.H.; Fluder, E.; McBride, R.; Sieh, W. Deep learning to improve breast cancer detection on screening mammography. Sci. Rep. 2019, 9, 1–12. [Google Scholar] [CrossRef]
- Falconi, L.G.; Perez, M.; Aguilar, W.G.; Conci, A. Transfer learning and fine tuning in breast mammogram abnormalities classification on CBIS-DDSM database. Adv. Sci. Technol. Eng. Syst. 2020, 5, 154–165. [Google Scholar] [CrossRef] [Green Version]
- Khan, H.N.; Shahid, A.R.; Raza, B.; Dar, A.H.; Alquhayz, H. Multi-view feature fusion based four views model for mammogram classification using convolutional neural network. IEEE Access 2019, 7, 165724–165733. [Google Scholar] [CrossRef]
- Ansar, W.; Shahid, A.R.; Raza, B.; Dar, A.H. Breast cancer detection and localization using mobilenet based transfer learning for mammograms. In Proceedings of the International Symposium on Intelligent Computing Systems, Sharjah, United Arab Emirates, 18–19 March 2020; Springer: Cham, Switzerland, 2020; pp. 11–21. [Google Scholar]
- Chakraborty, J.; Midya, A.; Rabidas, R. Computer-aided detection and diagnosis of mammographic masses using multi-resolution analysis of oriented tissue patterns. Expert Syst. Appl. 2018, 99, 168–179. [Google Scholar] [CrossRef]
- Lbachir, I.A.; Daoudi, I.; Tallal, S. Automatic computer-aided diagnosis system for mass detection and classification in mammography. Multimed. Tools Appl. 2021, 80, 9493–9525. [Google Scholar] [CrossRef]
- Aminikhanghahi, S.; Shin, S.; Wang, W.; Jeon, S.I.; Son, S.H. A new fuzzy Gaussian mixture model (FGMM) based algorithm for mammography tumor image classification. Multimed. Tools Appl. 2017, 76, 10191–10205. [Google Scholar] [CrossRef]
- Al-Antari, M.A.; Al-Masni, M.A.; Choi, M.-T.; Han, S.-M.; Kim, T.-S. A fully integrated computer-aided diagnosis system for digital X-ray mammograms via deep learning detection, segmentation, and classification. Int. J. Med. Inform. 2018, 117, 44–54. [Google Scholar] [CrossRef]
- Khamparia, A.; Bharati, S.; Podder, P.; Gupta, D.; Khanna, A.; Phung, T.K.; Thanh, D.N. Diagnosis of breast cancer based on modern mammography using hybrid transfer learning. Multidimens. Syst. Signal Process. 2021, 32, 747–765. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, Y.; Zhao, G.; Man, P.; Lin, Y.; Wang, M. A novel algorithm for breast mass classification in digital mammography based on feature fusion. J. Healthc. Eng. 2020, 2020, 8860011. [Google Scholar] [CrossRef]
- Ridhi, A.; Rai, P.K.; Balasubramanian, R. Deep feature-based automatic classification of mammograms. Med. Biol. Eng. Comput. 2020, 58, 1199–1211. [Google Scholar]
- Dhungel, N.; Carneiro, G.; Bradley, A.P. A deep learning approach for the analysis of masses in mammograms with minimal user intervention. Med. Image Anal. 2017, 37, 114–128. [Google Scholar] [CrossRef] [Green Version]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Gardezi, S.J.S.; Elazab, A.; Lei, B.; Wang, T. Breast cancer detection and diagnosis using mammographic data: Systematic review. J. Med. Internet Res. 2019, 21, e14464. [Google Scholar] [CrossRef] [Green Version]
- Abbas, A.; Abdelsamea, M.M.; Gaber, M.M. Detrac: Transfer learning of class decomposed medical images in convolutional neural networks. IEEE Access 2020, 8, 74901–74913. [Google Scholar] [CrossRef]
- Al-Antari, M.A.; Han, S.-M.; Kim, T.-S. Evaluation of deep learning detection and classification towards a computer-aided diagnosis of breast lesions in digital X-ray mammograms. Comput. Methods Programs Biomed. 2020, 196, 105584. [Google Scholar] [CrossRef]
- Ribli, D.; Horváth, A.; Unger, Z.; Pollner, P.; Csabai, I. Detecting and classifying lesions in mammograms with deep learning. Sci. Rep. 2018, 8, 1–7. [Google Scholar] [CrossRef] [Green Version]
- Agnes, S.A.; Anitha, J.; Pandian, S.I.A.; Peter, J.D. Classification of mammogram images using multiscale all convolutional neural network (MA-CNN). J. Med. Syst. 2020, 44, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Dhungel, N.; Carneiro, G.; Bradley, A.P. The automated learning of deep features for breast mass classification from mammograms. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Athens, Greece, 17–21 October 2016; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Jagtap, A.D.; Kawaguchi, K.; Karniadakis, G.E. Adaptive activation functions accelerate convergence in deep and physics-informed neural networks. J. Comput. Phys. 2020, 404, 109136. [Google Scholar] [CrossRef] [Green Version]
- Jagtap, A.D.; Kawaguchi, K.; Karniadakis, G.E. Locally adaptive activation functions with slope recovery for deep and physics-informed neural networks. Proc. R. Soc. A 2020, 476, 20200334. [Google Scholar] [CrossRef]
- Jagtap, A.D.; Shin, Y.; Kawaguchi, K.; Karniadakis, G.E. Deep Kronecker neural networks: A general framework for neural networks with adaptive activation functions. arXiv 2021, arXiv:2105.09513. [Google Scholar] [CrossRef]
- Lee, R.S.; Gimenez, F.; Hoogi, A.; Rubin, D. Curated breast imaging subset of DDSM. Cancer Imaging Arch. 2016, 8, 2016. [Google Scholar]
- Moreira, I.C.; Amaral, I.; Domingues, I.; Cardoso, A.; Cardoso, M.J.; Cardoso, J.S. Inbreast: Toward a full-field digital mammographic database. Acad. Radiol. 2012, 19, 236–248. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hou, X.; Bai, Y.; Xie, Y.; Li, Y. Mass segmentation for whole mammograms via attentive multi-task learning framework. Phys. Med. Biol. 2021, 66, 105015. [Google Scholar] [CrossRef] [PubMed]
- Attique Khan, M.; Sharif, M.; Akram, T.; Kadry, S.; Hsu, C.H. A two-stream deep neural network-based intelligent system for complex skin cancer types classification. Int. J. Intell. Syst. 2021, 1–29. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8697–8710. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef] [Green Version]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Guo, W.; Liu, T.; Dai, F.; Xu, P. An improved whale optimization algorithm for forecasting water resources demand. Appl. Soft Comput. 2020, 86, 105925. [Google Scholar] [CrossRef]
- El Houby, E.M.; Yassin, N.I. Malignant and nonmalignant classification of breast lesions in mammograms using convolutional neural networks. Biomed. Signal Process. Control 2021, 70, 102954. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, R.; Yuan, T.; Jiang, Z.; Huang, S.; Wu, J.; Hua, J.; Niu, Z.; Ji, D. DE-Ada*: A novel model for breast mass classification using cross-modal pathological semantic mining and organic integration of multi-feature fusions. Inf. Sci. 2020, 539, 461–486. [Google Scholar] [CrossRef]
- Tsochatzidis, L.; Costaridou, L.; Pratikakis, I. Deep learning for breast cancer diagnosis from mammograms—A comparative study. J. Imaging 2019, 5, 37. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shams, S.; Platania, R.; Zhang, J.; Kim, J.; Lee, K.; Park, S.J. Deep generative breast cancer screening and diagnosis. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; Springer: Cham, Switzerland, 2018; pp. 859–867. [Google Scholar]
- Chakravarthy, S.S.; Rajaguru, H. Automatic Detection and Classification of Mammograms Using Improved Extreme Learning Machine with Deep Learning. IRBM 2021, 43, 49–61. [Google Scholar] [CrossRef]
- Shayma’a, A.H.; Sayed, M.S.; Abdalla, M.I.; Rashwan, M.A. Breast cancer masses classification using deep convolutional neural networks and transfer learning. Multimed. Tools Appl. 2020, 79, 30735–30768. [Google Scholar]
- Kaur, P.; Singh, G.; Kaur, P. Intellectual detection and validation of automated mammogram breast cancer images by multi-class SVM using deep learning classification. Inform. Med. Unlocked 2019, 16, 100151. [Google Scholar] [CrossRef]
- Ting, F.F.; Tan, Y.J.; Sim, K.S. Convolutional neural network improvement for breast cancer classification. Expert Syst. Appl. 2019, 120, 103–115. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Total Images | Classes | Augmented Images |
|---|---|---|---|
| CBIS-DDSM | 1696 | 2 | 14,328 |
| INbreast | 108 | 2 | 7200 |
| MIAS | 300 | 3 | 14,400 |
| Model | Sensitivity (%) | Precision (%) | F1-Score (%) | AUC | FPR | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|
| Cubic SVM | 90.20 | 90.25 | 90.22 | 0.96 | 0.100 | 90.3 | 260.13 |
| Fine Tree | 72.25 | 72.50 | 72.34 | 0.78 | 0.275 | 72.6 | 30.13 |
| LSVM | 77.45 | 77.55 | 77.49 | 0.85 | 0.225 | 77.6 | 296.91 |
| QSVM | 85.85 | 85.95 | 85.89 | 0.93 | 0.140 | 86.0 | 287.09 |
| FG-SVM | 84.20 | 88.50 | 86.29 | 0.94 | 0.155 | 85.2 | 361.36 |
| GN-Bayes | 71.65 | 71.55 | 71.59 | 0.78 | 0.285 | 71.5 | 20.43 |
| FKNN | 87.05 | 86.90 | 86.97 | 0.87 | 0.130 | 87.0 | 73.68 |
| MKNN | 69.75 | 70.05 | 69.89 | 0.77 | 0.305 | 69.2 | 73.00 |
| WKNN | 88.25 | 88.10 | 88.17 | 0.96 | 0.120 | 88.2 | 72.92 |
| Co-KNN | 67.45 | 67.50 | 67.47 | 0.75 | 0.325 | 67.1 | 72.90 |
| Models | Sensitivity (%) | Precision (%) | F1-Score (%) | AUC | FPR | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|
| Cubic SVM | 94.00 | 94.00 | 94.00 | 0.98 | 0.060 | 93.9 | 112.96 |
| Fine Tree | 89.50 | 90.00 | 89.74 | 0.93 | 0.105 | 89.8 | 16.91 |
| LSVM | 89.50 | 89.50 | 89.50 | 0.96 | 0.105 | 89.4 | 117.51 |
| QSVM | 92.50 | 92.00 | 92.24 | 0.98 | 0.075 | 92.4 | 113.75 |
| FG-SVM | 84.00 | 87.50 | 85.71 | 0.95 | 0.160 | 84.6 | 275.70 |
| GN-Bayes | 84.50 | 84.50 | 84.50 | 0.86 | 0.155 | 84.0 | 18.27 |
| FKNN | 93.00 | 93.00 | 93.00 | 0.93 | 0.010 | 92.9 | 60.35 |
| MKNN | 87.00 | 86.50 | 86.74 | 0.94 | 0.130 | 86.5 | 60.00 |
| WKNN | 94.00 | 93.50 | 93.74 | 0.98 | 0.060 | 93.6 | 59.90 |
| Co-KNN | 86.50 | 86.50 | 86.50 | 0.94 | 0.135 | 86.4 | 60.19 |
| Models | Sensitivity (%) | Precision (%) | F1-Score (%) | AUC | FPR | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|
| Cubic SVM | 89.95 | 90.05 | 89.99 | 0.96 | 0.105 | 90.0 | 132.98 |
| Fine Tree | 70.20 | 70.25 | 70.22 | 0.76 | 0.300 | 70.4 | 14.83 |
| LSVM | 75.45 | 75.55 | 75.49 | 0.83 | 0.245 | 75.7 | 146.36 |
| QSVM | 85.15 | 85.25 | 85.19 | 0.92 | 0.150 | 85.3 | 150.17 |
| FG-SVM | 83.45 | 88.05 | 85.68 | 0.94 | 0.165 | 84.5 | 178.98 |
| GN-Bayes | 70.60 | 70.50 | 70.54 | 0.78 | 0.295 | 70.5 | 8.70 |
| FKNN | 86.75 | 86.60 | 86.67 | 0.87 | 0.130 | 86.7 | 37.96 |
| MKNN | 69.40 | 69.55 | 69.47 | 0.77 | 0.305 | 68.9 | 37.01 |
| WKNN | 87.40 | 87.35 | 87.37 | 0.96 | 0.125 | 87.4 | 37.38 |
| Co-KNN | 67.30 | 67.25 | 67.27 | 0.74 | 0.330 | 67.3 | 37.49 |
| Models | Sensitivity (%) | Precision (%) | F1-Score (%) | AUC | FPR | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|
| Cubic SVM | 93.50 | 93.45 | 93.47 | 0.98 | 0.065 | 93.5 | 73.24 |
| Fine Tree | 88.95 | 88.95 | 88.95 | 0.92 | 0.110 | 89.0 | 996.56 |
| LSVM | 89.15 | 89.25 | 89.19 | 0.96 | 0.110 | 89.3 | 77.09 |
| QSVM | 92.25 | 92.35 | 92.30 | 0.97 | 0.080 | 92.3 | 75.26 |
| FG-SVM | 84.25 | 87.60 | 85.89 | 0.95 | 0.160 | 85.1 | 182.78 |
| GN-Bayes | 84.20 | 84.45 | 84.32 | 0.86 | 0.160 | 83.7 | 11.57 |
| FKNN | 92.65 | 92.50 | 92.57 | 0.93 | 0.075 | 92.6 | 40.46 |
| MKNN | 86.60 | 86.40 | 86.49 | 0.94 | 0.135 | 86.4 | 39.42 |
| WKNN | 93.50 | 93.45 | 93.47 | 0.98 | 0.065 | 93.5 | 42.39 |
| Co-KNN | 86.10 | 86.00 | 86.04 | 0.94 | 0.140 | 86.1 | 39.88 |
| Models | Sensitivity (%) | Precision (%) | F1-Score (%) | AUC | FPR | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|
| Cubic SVM | 94.10 | 94.10 | 94.10 | 0.99 | 0.060 | 94.1 | 314.97 |
| Fine Tree | 88.60 | 88.65 | 88.62 | 0.91 | 0.115 | 88.7 | 151.53 |
| LSVM | 92.05 | 92.05 | 92.05 | 0.98 | 0.080 | 92.1 | 271.30 |
| QSVM | 93.00 | 93.05 | 93.02 | 0.98 | 0.070 | 93.0 | 265.45 |
| FG-SVM | 50.65 | 76.85 | 61.05 | 0.72 | 0.495 | 54.0 | 795.29 |
| GN-Bayes | 85.85 | 86.30 | 86.07 | 0.87 | 0.145 | 85.5 | 55.16 |
| FKNN | 92.80 | 92.60 | 92.69 | 0.93 | 0.075 | 92.6 | 135.51 |
| MKNN | 89.35 | 89.20 | 89.27 | 0.96 | 0.105 | 89.2 | 134.29 |
| WKNN | 92.10 | 92.00 | 92.04 | 0.98 | 0.080 | 92.1 | 134.09 |
| Co-KNN | 88.60 | 88.45 | 88.52 | 0.96 | 0.150 | 88.5 | 483.34 |
| Models | Sensitivity (%) | Precision (%) | F1-Score (%) | AUC | FPR | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|
| Cubic SVM | 93.75 | 93.80 | 93.77 | 0.98 | 0.120 | 93.8 | 255.84 |
| Fine Tree | 87.90 | 87.95 | 87.92 | 0.90 | 0.120 | 88.0 | 42.42 |
| LSVM | 91.75 | 91.80 | 91.77 | 0.98 | 0.080 | 91.8 | 241.52 |
| QSVM | 92.90 | 92.95 | 92.92 | 0.98 | 0.510 | 93.0 | 227.28 |
| FG-SVM | 50.70 | 76.85 | 61.09 | 0.69 | 0.450 | 54.0 | 692.97 |
| GN-Bayes | 85.95 | 86.00 | 85.97 | 0.88 | 0.140 | 85.5 | 59.89 |
| FKNN | 92.50 | 92.45 | 92.47 | 0.93 | 0.075 | 92.5 | 408.99 |
| MKNN | 88.50 | 88.40 | 88.44 | 0.96 | 0.115 | 88.2 | 83.916 |
| WKNN | 92.20 | 91.75 | 91.97 | 0.98 | 0.085 | 91.8 | 407.35 |
| Co-KNN | 88.60 | 88.45 | 88.52 | 0.96 | 0.115 | 88.5 | 407.14 |
| Models | Sensitivity (%) | Precision (%) | F1-Score (%) | AUC | FPR | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|
| Cubic SVM | 98.73 | 99.10 | 98.91 | 1.00 | 0.003 | 99.4 | 85.29 |
| Fine Tree | 79.73 | 86.03 | 82.76 | 0.91 | 0.933 | 88.9 | 22.82 |
| LSVM | 96.86 | 98.20 | 97.52 | 1.00 | 0.013 | 98.4 | 97.40 |
| QSVM | 98.50 | 98.96 | 98.72 | 1.00 | 0.003 | 99.3 | 79.88 |
| FG-SVM | 96.03 | 98.63 | 97.31 | 1.00 | 0.016 | 98.2 | 353.67 |
| GN-Bayes | 89.03 | 81.43 | 85.06 | 0.97 | 0.060 | 88.5 | 24.15 |
| FKNN | 98.90 | 98.93 | 98.91 | 1.00 | 0.000 | 99.4 | 73.83 |
| MKNN | 88.23 | 89.90 | 89.05 | 0.99 | 0.053 | 92.6 | 75.73 |
| WKNN | 97.70 | 98.26 | 97.97 | 1.00 | 0.006 | 98.8 | 75.39 |
| Co-KNN | 52.06 | 88.40 | 65.52 | 0.96 | 0.236 | 77.9 | 74.30 |
| Models | Sensitivity (%) | Precision (%) | F1-Score (%) | AUC | FPR | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|
| Cubic SVM | 99.03 | 99.13 | 99.08 | 1.00 | 0.000 | 99.6 | 267.43 |
| Fine Tree | 98.33 | 98.30 | 98.31 | 1.00 | 0.006 | 99.1 | 35.18 |
| LSVM | 97.13 | 98.60 | 97.86 | 1.00 | 0.020 | 98.7 | 56.34 |
| QSVM | 98.06 | 98.86 | 98.46 | 1.00 | 0.006 | 99.1 | 58.91 |
| FG-SVM | 95.83 | 98.56 | 97.17 | 1.00 | 0.016 | 98.2 | 193.88 |
| GN-Bayes | 96.00 | 91.00 | 93.43 | 0.98 | 0.020 | 95.4 | 71.71 |
| FKNN | 99.03 | 99.33 | 99.18 | 1.00 | 0.000 | 99.6 | 85.83 |
| MKNN | 97.63 | 98.03 | 97.83 | 1.00 | 0.010 | 98.7 | 80.99 |
| WKNN | 99.20 | 99.30 | 99.24 | 1.00 | 0.000 | 99.7 | 81.45 |
| Co-KNN | 96.20 | 97.8 | 96.99 | 1.00 | 0.01 | 98.1 | 82.53 |
| Models | Sensitivity (%) | Precision (%) | F1-Score (%) | AUC | FPR | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|
| Cubic SVM | 98.87 | 98.16 | 99.01 | 1.00 | 0.000 | 99.4 | 75.49 |
| Fine Tree | 80.00 | 86.56 | 83.15 | 0.91 | 0.093 | 89.1 | 20.09 |
| LSVM | 96.77 | 98.16 | 97.46 | 1.00 | 0.016 | 98.3 | 86.78 |
| QSVM | 98.73 | 99.06 | 98.89 | 1.00 | 0.000 | 99.4 | 69.90 |
| FG-SVM | 95.77 | 98.66 | 97.19 | 0.99 | 0.016 | 98.1 | 305.64 |
| GN-Bayes | 89.40 | 81.80 | 85.43 | 0.96 | 0.056 | 88.9 | 22.38 |
| FKNN | 98.77 | 98.83 | 98.79 | 0.99 | 0.006 | 99.3 | 65.81 |
| MKNN | 88.40 | 89.50 | 88.94 | 0.98 | 0.056 | 92.4 | 65.34 |
| WKNN | 97.80 | 98.40 | 98.09 | 1.00 | 0.006 | 98.9 | 64.05 |
| Co-KNN | 51.30 | 88.30 | 64.89 | 0.96 | 0.240 | 77.6 | 67.94 |
| Models | Sensitivity (%) | Precision (%) | F1-Score (%) | AUC | FPR | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|
| CSVM | 99.00 | 99.00 | 99.00 | 1.00 | 0.000 | 99.6 | 18.35 |
| Fine Tree | 97.66 | 98.00 | 97.83 | 1.00 | 0.003 | 98.9 | 9.40 |
| LSVM | 97.00 | 99.00 | 97.98 | 1.00 | 0.010 | 98.8 | 17.49 |
| QSVM | 98.00 | 99.00 | 98.49 | 1.00 | 0.006 | 99.1 | 18.92 |
| FG-SVM | 96.00 | 98.66 | 97.31 | 1.00 | 0.016 | 98.2 | 80.55 |
| GN-Bayes | 95.00 | 90.00 | 92.43 | 0.97 | 0.023 | 94.9 | 9.06 |
| FKNN | 98.66 | 98.66 | 98.66 | 0.99 | 0.000 | 99.6 | 25.15 |
| MKNN | 97.33 | 97.66 | 97.49 | 1.00 | 0.010 | 98.5 | 24.62 |
| WKNN | 99.00 | 99.00 | 99.00 | 1.00 | 0.000 | 99.7 | 24.70 |
| Co-KNN | 95.66 | 98.00 | 96.81 | 1.00 | 0.013 | 98.1 | 25.10 |
| Models | Sensitivity (%) | Precision (%) | F1-Score (%) | AUC | FPR | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|
| Cubic SVM | 99.66 | 99.86 | 99.73 | 1.00 | 0.003 | 99.8 | 133.46 |
| Fine Tree | 98.00 | 98.00 | 98.00 | 0.98 | 0.006 | 98.9 | 175.03 |
| LSVM | 99.20 | 99.73 | 99.46 | 1.00 | 0.006 | 99.6 | 115.46 |
| QSVM | 99.66 | 99.90 | 99.78 | 1.00 | 0.000 | 99.8 | 113.38 |
| FG-SVM | 47.33 | 91.60 | 62.05 | 0.83 | 0.260 | 76.2 | 1276.20 |
| GN-Bayes | 97.23 | 92.70 | 94.91 | 0.98 | 0.016 | 96.4 | 60.06 |
| FKNN | 99.16 | 98.96 | 99.06 | 0.99 | 0.003 | 99.4 | 490.17 |
| MKNN | 98.33 | 99.00 | 98.66 | 1.00 | 0.020 | 99.3 | 140.46 |
| WKNN | 98.76 | 99.46 | 99.11 | 1.00 | 0.003 | 99.4 | 484.52 |
| Co-KNN | 96.60 | 98.30 | 97.44 | 1.00 | 0.010 | 98.7 | 141.04 |
| Models | Sensitivity (%) | Precision (%) | F1-Score (%) | AUC | FPR | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|
| Cubic SVM | 99.00 | 99.33 | 99.16 | 1.00 | 0.000 | 99.8 | 63.28 |
| Fine Tree | 97.20 | 97.10 | 97.14 | 0.99 | 0.013 | 98.2 | 31.91 |
| LSVM | 98.76 | 99.16 | 98.96 | 1.00 | 0.000 | 99.3 | 16.55 |
| QSVM | 99.43 | 99.70 | 99.56 | 1.00 | 0.000 | 99.7 | 15.37 |
| FG-SVM | 47.60 | 91.60 | 62.64 | 0.78 | 0.260 | 76.3 | 699.49 |
| GN-Bayes | 96.00 | 91.66 | 93.78 | 0.98 | 0.020 | 95.7 | 7.09 |
| FKNN | 99.20 | 99.20 | 99.20 | 0.99 | 0.003 | 99.5 | 62.45 |
| MKNN | 98.30 | 98.53 | 98.41 | 1.00 | 0.006 | 98.9 | 62.35 |
| WKNN | 98.83 | 99.40 | 99.11 | 1.00 | 0.003 | 99.4 | 62.49 |
| Co-KNN | 96.46 | 98.03 | 97.24 | 1.00 | 0.013 | 98.2 | 63.85 |
| Models | Sensitivity (%) | Precision (%) | F1-Score (%) | AUC | FPR | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|
| Cubic SVM | 98.20 | 98.15 | 98.17 | 0.99 | 0.020 | 98.1 | 18.89 |
| Fine Tree | 97.85 | 97.75 | 97.79 | 0.99 | 0.020 | 97.8 | 34.00 |
| LSVM | 98.35 | 98.25 | 98.29 | 1.00 | 0.015 | 98.3 | 18.80 |
| QSVM | 98.25 | 98.20 | 98.22 | 0.99 | 0.015 | 98.2 | 16.11 |
| FG-SVM | 97.65 | 97.60 | 97.62 | 0.98 | 0.025 | 97.6 | 46.86 |
| GN-Bayes | 94.85 | 94.80 | 94.82 | 0.97 | 0.050 | 94.8 | 13.53 |
| FKNN | 98.30 | 98.20 | 98.24 | 0.98 | 0.015 | 98.2 | 71.07 |
| MKNN | 95.30 | 95.25 | 95.27 | 1.00 | 0.065 | 95.1 | 22.20 |
| WKNN | 98.05 | 98.00 | 98.02 | 1.00 | 0.020 | 98.0 | 70.38 |
| Co-KNN | 92.70 | 92.80 | 92.74 | 0.99 | 0.075 | 92.4 | 22.05 |
| Models | Sensitivity (%) | Precision (%) | F1-Score (%) | AUC | FPR | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|
| Cubic SVM | 98.50 | 98.50 | 98.50 | 1.00 | 0.0150 | 98.6 | 10.85 |
| Fine Tree | 98.50 | 98.50 | 98.50 | 1.00 | 0.0150 | 98.3 | 14.92 |
| LSVM | 98.50 | 98.50 | 98.50 | 1.00 | 0.0150 | 98.6 | 13.23 |
| QSVM | 98.50 | 98.50 | 98.50 | 1.00 | 0.0150 | 98.6 | 9.54 |
| FG-SVM | 98.50 | 98.00 | 98.24 | 0.99 | 0.0150 | 98.2 | 33.00 |
| GN-Bayes | 98.00 | 98.00 | 98.00 | 0.99 | 0.0150 | 98.4 | 13.07 |
| FKNN | 98.50 | 98.50 | 98.50 | 0.99 | 0.0150 | 98.6 | 59.50 |
| MKNN | 98.00 | 98.00 | 98.00 | 1.00 | 0.0150 | 98.4 | 18.79 |
| WKNN | 98.50 | 98.00 | 98.25 | 1.00 | 0.0150 | 98.4 | 18.53 |
| Co-KNN | 98.00 | 98.00 | 98.00 | 1.00 | 0.020 | 98.1 | 59.31 |
| Models | Sensitivity (%) | Precision (%) | F1-Score (%) | AUC | FPR | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|
| Cubic SVM | 98 | 98 | 98 | 0.99 | 0.02 | 98.1 | 8.77 |
| Fine Tree | 98 | 98 | 98 | 1.00 | 0.02 | 97.8 | 24.05 |
| LSVM | 98 | 98 | 98 | 1.00 | 0.02 | 98.1 | 10.92 |
| QSVM | 98 | 98 | 98 | 0.99 | 0.015 | 98.2 | 8.86 |
| FG-SVM | 97.5 | 97.5 | 97.5 | 0.98 | 0.025 | 97.8 | 19.83 |
| GN-Bayes | 94 | 94 | 94 | 0.97 | 0.06 | 94.0 | 8.44 |
| FKNN | 98 | 98 | 98 | 0.98 | 0.015 | 98.3 | 35.41 |
| MKNN | 94.5 | 94.5 | 94.5 | 1.00 | 0.055 | 94.2 | 34.88 |
| WKNN | 98 | 98 | 98 | 1.00 | 0.02 | 98.2 | 34.86 |
| Co-KNN | 93.5 | 93.5 | 93.5 | 0.98 | 0.065 | 93.4 | 34.89 |
| Models | Sensitivity (%) | Precision (%) | F1-Score (%) | AUC | FPR | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|
| Cubic SVM | 98.50 | 98.50 | 98.50 | 1.00 | 0.0150 | 98.6 | 6.24 |
| Fine Tree | 98.50 | 98.50 | 98.50 | 1.00 | 0.0150 | 98.4 | 5.44 |
| LSVM | 98.50 | 98.50 | 98.50 | 1.00 | 0.0150 | 98.6 | 7.47 |
| QSVM | 98.50 | 98.50 | 98.50 | 1.00 | 0.0150 | 98.6 | 4.55 |
| FG-SVM | 98.50 | 98.00 | 98.24 | 0.99 | 0.0150 | 98.2 | 14.49 |
| GN-Bayes | 98.00 | 98.00 | 98.00 | 0.99 | 0.0150 | 98.4 | 7.47 |
| FKNN | 98.50 | 98.50 | 98.50 | 0.99 | 0.0150 | 98.6 | 29.35 |
| MKNN | 98.50 | 98.40 | 98.44 | 1.00 | 0.0150 | 98.4 | 9.47 |
| WKNN | 98.50 | 98.50 | 98.50 | 1.00 | 0.0150 | 98.5 | 10.47 |
| Co-KNN | 98.00 | 97.50 | 97.74 | 1.00 | 0.0200 | 97.8 | 9.75 |
| Models | Sensitivity (%) | Precision (%) | F1-Score (%) | AUC | FPR | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|
| Cubic SVM | 99.90 | 99.90 | 99.90 | 1.00 | 0.000 | 99.9 | 23.04 |
| Fine Tree | 99.00 | 99.0 | 99.00 | 0.99 | 0.010 | 98.8 | 17.63 |
| LSVM | 99.50 | 99.50 | 99.50 | 1.00 | 0.000 | 99.8 | 26.72 |
| QSVM | 99.50 | 99.50 | 99.50 | 1.00 | 0.000 | 99.8 | 23.68 |
| FG-SVM | 52.65 | 76.95 | 62.52 | 0.76 | 0.475 | 55.0 | 149.5 |
| GN-Bayes | 99.00 | 99.00 | 99.00 | 0.99 | 0.010 | 99.1 | 37.75 |
| FKNN | 99.00 | 99.00 | 99.00 | 1.00 | 0.000 | 99.6 | 44.00 |
| MKNN | 99.00 | 99.00 | 99.00 | 1.00 | 0.010 | 98.9 | 43.68 |
| WKNN | 99.50 | 99.50 | 99.50 | 1.00 | 0.005 | 99.5 | 43.64 |
| Co-KNN | 98.50 | 98.50 | 98.50 | 1.00 | 0.015 | 98.5 | 43.93 |
| Models | Sensitivity (%) | Precision (%) | F1-Score (%) | AUC | FPR | Accuracy (%) | Time |
|---|---|---|---|---|---|---|---|
| Cubic SVM | 99.00 | 99.10 | 99.10 | 1.00 | 0.010 | 99.1 | 1.61 |
| Fine Tree | 98.50 | 98.50 | 98.50 | 0.99 | 0.015 | 98.6 | 21.07 |
| LSVM | 99.00 | 99.00 | 99.00 | 1.00 | 0.005 | 99.6 | 5.30 |
| QSVM | 99.00 | 99.00 | 99.00 | 1.00 | 0.000 | 99.6 | 1.99 |
| FG-SVM | 52.50 | 77.00 | 62.43 | 0.78 | 0.475 | 54.9 | 8.40 |
| GN-Bayes | 98.00 | 98.50 | 98.24 | 1.00 | 0.020 | 98.2 | 5.33 |
| FKNN | 99.00 | 99.00 | 99.00 | 0.99 | 0.010 | 99.4 | 8.16 |
| MKNN | 99.00 | 99.00 | 99.00 | 1.00 | 0.005 | 99.4 | 6.43 |
| WKNN | 99.00 | 99.00 | 99.00 | 1.00 | 0.000 | 99.7 | 6.57 |
| Co-KNN | 99.00 | 99.00 | 99.00 | 1.00 | 0.005 | 99.4 | 6.95 |
| References | Year | Method | Images | Sensitivity (%) | Precision (%) | F1-Score (%) | AUC (%) | Accuracy (%) |
|---|---|---|---|---|---|---|---|---|
| [59] | 2021 | CNN | 1592 | 92.31 | 90.00 | 91.76 | 0.92 | 91.2 |
| [24] | 2020 | Nasnet, MobileNet, VGG, Resnet, Xception | 1696 | _____ | ______ | 85.0 | 0.84 | 84.4 |
| [26] | 2020 | MobilenetV1, MobilenetV2 | 1696 | ______ | 70.00 | 76.00 | ______ | 74.5 |
| [60] | 2020 | DE-Ada* | _____ | ______ | ______ | ______ | 92.19 | 87.05 |
| [23] | 2019 | VGG, Residual Network | _____ | 86.10 | 80.10 | ______ | 0.91 | ______ |
| [61] | 2019 | DCNN, Alexnet | 1696 | ______ | ______ | ______ | 0.80 | 75.0 |
| [62] | 2018 | Deep GeneRAtive Multitask | _____ | ______ | ______ | ______ | 88.4 | 89 |
| Proposed Method | 2021 | MobilenetV2, Nasnet Mobile, MEWOM | 1696 | 93.75 | 93.80 | 93.77 | 0.98 | 93.8 |
| References | Year | Method | Images | Sensitivity (%) | Precision (%) | F1-Score (%) | AUC (%) | Accuracy (%) |
|---|---|---|---|---|---|---|---|---|
| [63] | 2021 | ResNet-18, (ICS-ELM) | 322 | ______ | ______ | ______ | _____ | 98.13 |
| [59] | 2021 | CNN | 322 | 92.72 | 94.12 | 93.58 | 0.94 | 93.39 |
| [64] | 2020 | AlexNet, GoogleNet | 68 | 100, 80 | 97.37, 94.74 | 98.3, 85.71 | 0.98, 0.94 | 98.53, 88.24 |
| [40] | 2019 | (MA-CNN) | 322 | 96.00 | ______ | ______ | 0.99 | 96.47 |
| [65] | 2019 | DCNN, MSVM | 322 | ______ | ______ | ______ | 0.99 | 96.90 |
| [66] | 2019 | Convolutional Neural Network Improvement (CNNI-BCC) | ______ | 89.47 | 90.71 | ______ | 0.90 | 90.50 |
| Proposed Method | 2021 | Mobilenet V2 & NasNet Mobile, MEWOA | 300 | 99.00 | 99.33 | 99.16 | 1.00 | 99.80 |
| References | Year | Method | Images | Sensitivity (%) | Precision (%) | F1-Score (%) | AUC (%) | Accuracy (%) |
|---|---|---|---|---|---|---|---|---|
| [63] | 2021 | ResNet-18, (ICS-ELM) | 179 | ______ | ______ | ______ | _____ | 98.26 |
| [59] | 2021 | CNN | 387 | 94.83 | 91.23 | 93.22 | 0.94 | 93.04 |
| [38] | 2020 | Inception ResNet V2 | 107 | ______ | ______ | ______ | 0.95 | 95.32 |
| [60] | 2020 | De-ada* | ______ | ______ | ______ | ______ | 92.65 | 87.93 |
| [34] | 2017 | Transfer learning, Random Forest | 108 | 98.0 | 70.0 | ______ | _____ | 90.0 |
| Proposed Method | 2021 | Fine-tuned MobilenetV2, Nasnet, MEWOM | 108 | 99.0 | 99.0 | 99.0 | 1.00 | 99.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zahoor, S.; Shoaib, U.; Lali, I.U. Breast Cancer Mammograms Classification Using Deep Neural Network and Entropy-Controlled Whale Optimization Algorithm. Diagnostics 2022, 12, 557. https://doi.org/10.3390/diagnostics12020557
Zahoor S, Shoaib U, Lali IU. Breast Cancer Mammograms Classification Using Deep Neural Network and Entropy-Controlled Whale Optimization Algorithm. Diagnostics. 2022; 12(2):557. https://doi.org/10.3390/diagnostics12020557
Chicago/Turabian StyleZahoor, Saliha, Umar Shoaib, and Ikram Ullah Lali. 2022. "Breast Cancer Mammograms Classification Using Deep Neural Network and Entropy-Controlled Whale Optimization Algorithm" Diagnostics 12, no. 2: 557. https://doi.org/10.3390/diagnostics12020557
APA StyleZahoor, S., Shoaib, U., & Lali, I. U. (2022). Breast Cancer Mammograms Classification Using Deep Neural Network and Entropy-Controlled Whale Optimization Algorithm. Diagnostics, 12(2), 557. https://doi.org/10.3390/diagnostics12020557