
Lumbar Spine Computed Tomography to Magnetic Resonance Imaging Synthesis Using Generative Adversarial Network: Visual Turing Test

 , , , and
, , , and
Abstract
:1. Introduction
2. Material and Methods
2.1. Ethics Statement
2.2. Data Preparation for Training and Test
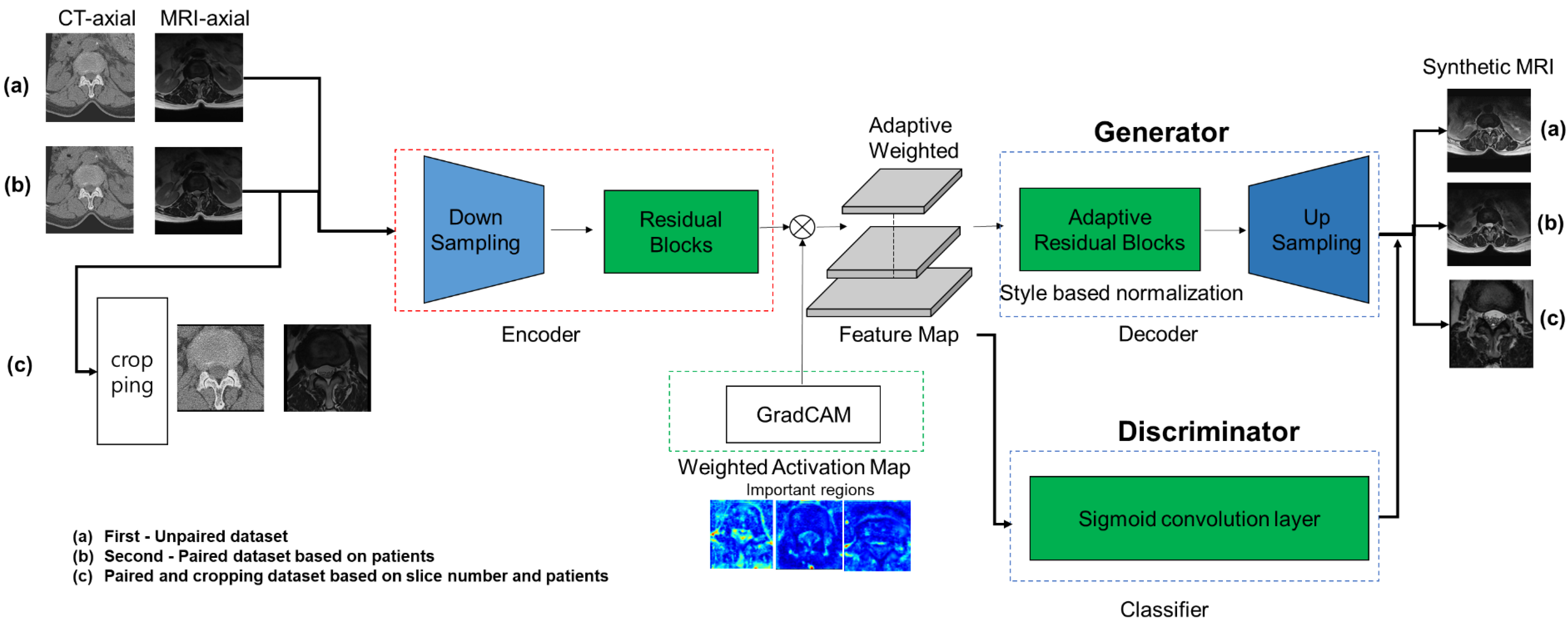
2.3. Training the GAN to Generate Lumbar MR Images from CT Images
3. Deep Learning Framework
4. General Architecture
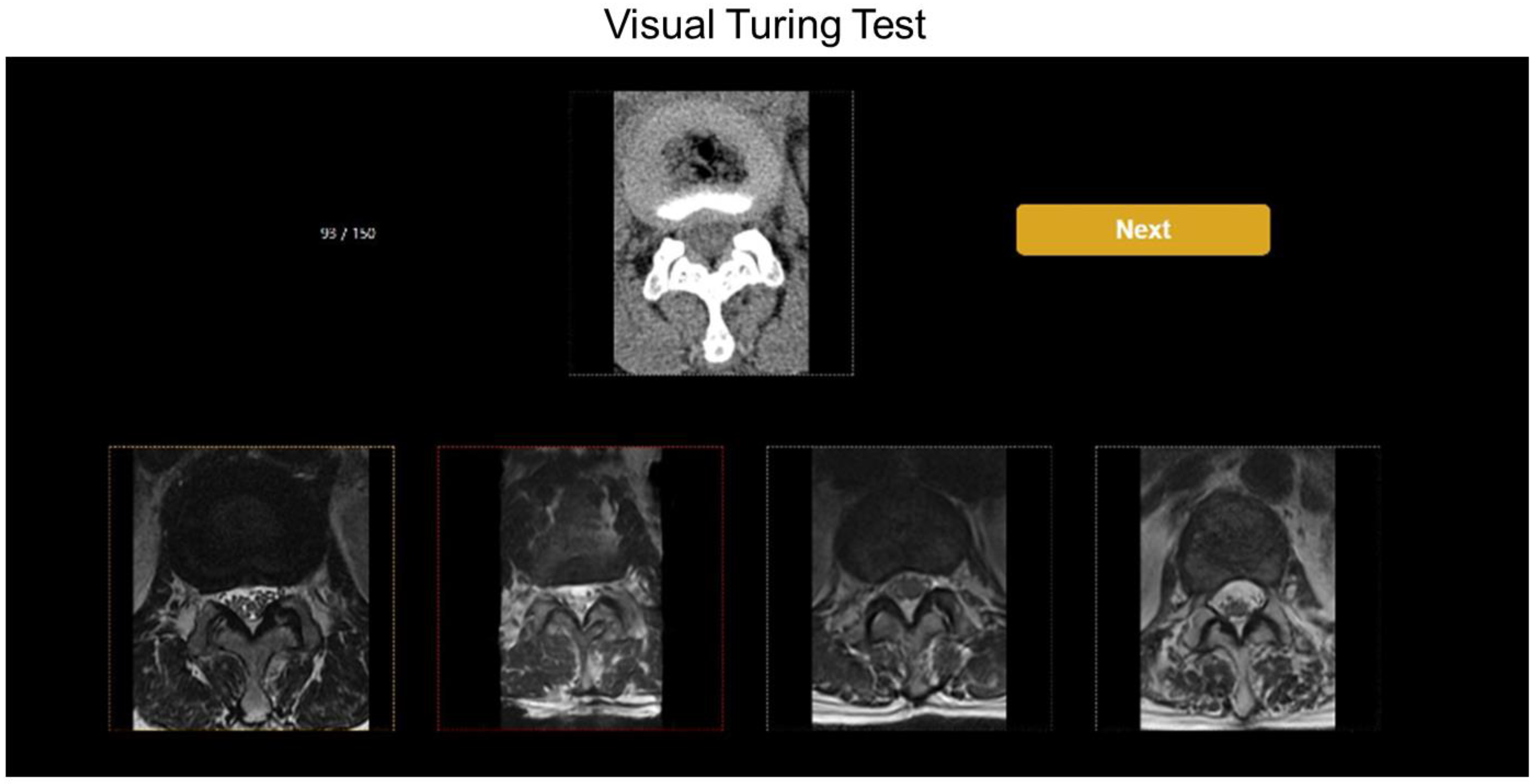
5. Visual Turing Test
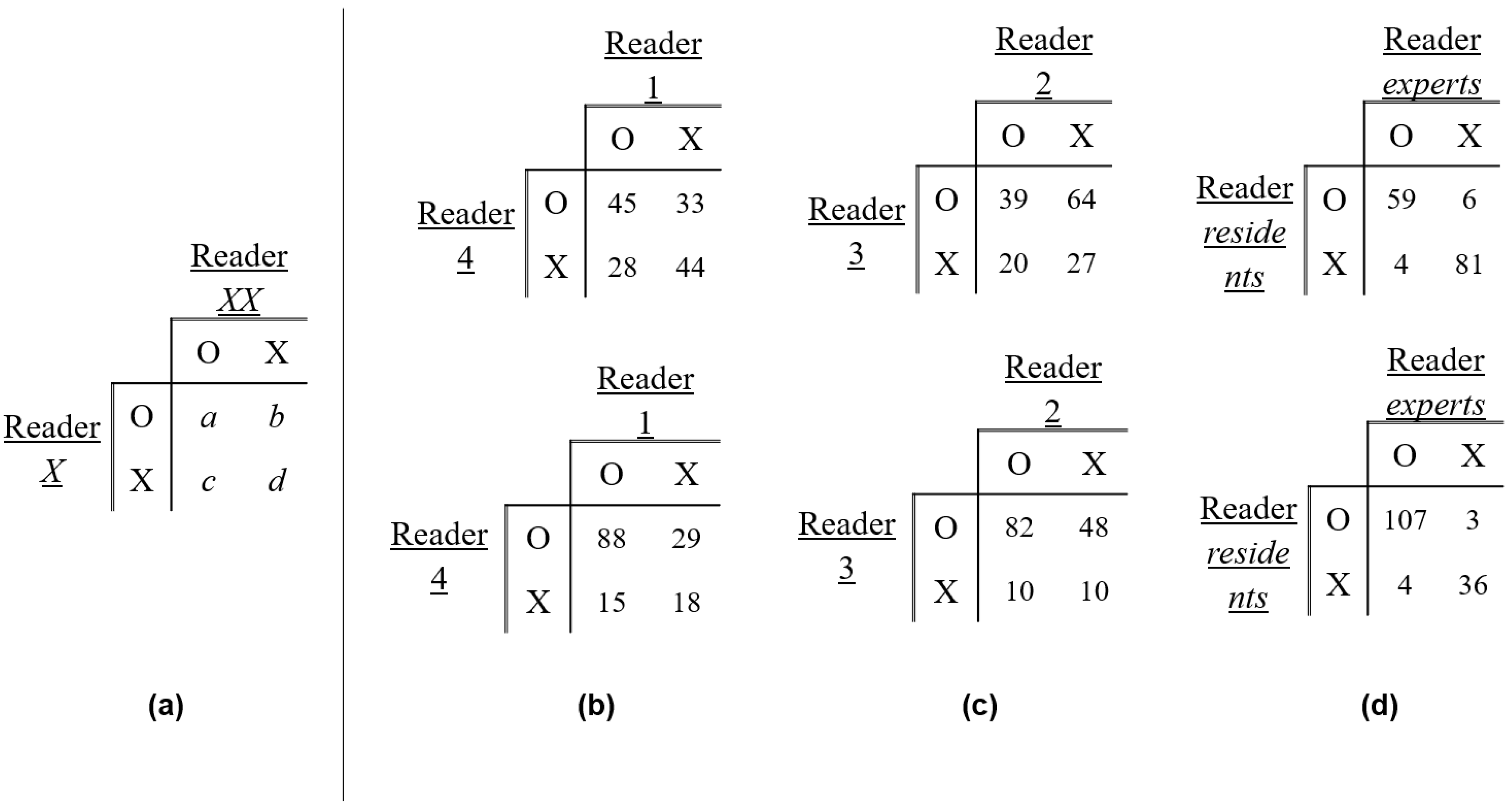
6. Statistical Analyses
7. Results
7.1. Accuracy of Identifying the True Images
7.2. Comparisons of Training Methods for Generating Synthetic MR Images
7.3. Evaluations between the Expert and Resident Reader Groups
7.4. Evaluations of PSNR and SSIM among the Three Algorithms
8. Discussion
8.1. The Research of Other Algorithms and GAN
8.2. The Present Study for Conversion from CT and MR Images
8.3. The Limitations of Our Study
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chartrand, G.; Cheng, P.M.; Vorontsov, E.; Drozdzal, M.; Turcotte, S.; Pal, C.J.; Kadoury, S.; Tang, A. Deep Learning: A Primer for Radiologists. RadioGraphics 2017, 37, 2113–2131. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jo, Y.J.; Bae, K.M.; Park, J.Y. Research trends of generative adversarial networks and image generation and translation. Electron. Telecommun. Trends 2020, 35, 91–102. [Google Scholar]
- Bi, L.; Kim, J.; Kumar, A.; Feng, D.; Fulham, M. Synthesis of positron emission tomography (PET) images via multi-channel generative adversarial networks (GANs). In Molecular Imaging, Reconstruction and Analysis of Moving Body Organs, and Stroke imaging and Treatment; Cardoso, M.J., Arbel, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2017; pp. 43–51. [Google Scholar]
- Nie, D.; Trullo, R.; Lian, J.; Petitjean, C.; Ruan, S.; Wang, Q.; Shen, D. Medical Image Synthesis with Context-Aware Generative Adversarial Networks. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2017; Volume 10435, pp. 417–425. [Google Scholar]
- Jin, C.-B.; Kim, H.; Liu, M.; Han, I.H.; Lee, J.I.; Lee, J.H.; Joo, S.; Park, E.; Ahn, Y.S.; Cui, X. DC2Anet: Generating Lumbar Spine MR Images from CT Scan Data Based on Semi-Supervised Learning. Appl. Sci. 2019, 9, 2521. [Google Scholar] [CrossRef] [Green Version]
- Park, H.Y.; Bae, H.-J.; Hong, G.-S.; Kim, M.; Yun, J.; Park, S.; Chung, W.J.; Kim, N. Realistic High-Resolution Body Computed Tomography Image Synthesis by Using Progressive Growing Generative Adversarial Network: Visual Turing Test. JMIR Med. Inform. 2021, 9, e23328. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Kim, M.; Kang, H.; Lee, K. U-gat-it: Unsupervised generative attentional networks with adaptive layer-instance normalization for image-to-image translation. arXiv 2019, arXiv:1907.10830. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the 16th IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Park, T.; Efros, A.A.; Zhang, R.; Zhu, J.-Y. Contrastive Learning for Unpaired Image-to-Image Translation. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 319–345. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bartlett, J.W.; Frost, C. Reliability, repeatability and reproducibility: Analysis of measurement errors in continuous variables. Ultrasound Obstet. Gynecol. 2008, 31, 466–475. [Google Scholar] [CrossRef] [PubMed]
- Kong, K.A. Statistical Methods: Reliability Assessment and Method Comparison. Ewha Med. J. 2017, 40, 9–16. [Google Scholar] [CrossRef] [Green Version]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to discover cross-domain relations with generative adversarial networks. In International Conference on Machine Learning; PMLR: London, UK, 2017; pp. 1857–1865. [Google Scholar]
- Hsu, S.-H.; Cao, Y.; Huang, K.; Feng, M.; Balter, J.M. Investigation of a method for generating synthetic CT models from MRI scans of the head and neck for radiation therapy. Phys. Med. Biol. 2013, 58, 8419–8435. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zheng, W.; Kim, J.P.; Kadbi, M.; Movsas, B.; Chetty, I.J.; Glide-Hurst, C.K. Magnetic Resonance–Based Automatic Air Segmentation for Generation of Synthetic Computed Tomography Scans in the Head Region. Int. J. Radiat. Oncol. 2015, 93, 497–506. [Google Scholar] [CrossRef] [PubMed]
- Kapanen, M.; Tenhunen, M. T1/T2*-weighted MRI provides clinically relevant pseudo-CT density data for the pelvic bones in MRI-only based radiotherapy treatment planning. Acta Oncol. 2013, 52, 612–618. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Jin, C.-B.; Kim, H.; Liu, M.; Jung, W.; Joo, S.; Park, E.; Ahn, Y.S.; Han, I.H.; Lee, J.I.; Cui, X. Deep CT to MR Synthesis Using Paired and Unpaired Data. Sensors 2019, 19, 2361. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wolterink, J.M.; Dinkla, A.M.; Savenije, M.H.; Seevinck, P.R.; van den Berg, C.A.; Išgum, I. Deep MR to CT synthesis using unpaired data. In Simulation and Synthesis in Medical Imaging. SASHIMI 2017. Lecture Notes in Computer Science; Tsaftaris, S., Gooya, A., Frangi, A., Prince, J., Eds.; Springer: Cham, Switzerland, 2017; Volume 10557, pp. 14–23. [Google Scholar]
- Lee, J.H.; Han, I.H.; Kim, D.H.; Yu, S.; Lee, I.S.; Song, Y.S.; Joo, S.; Jin, C.-B.; Kim, H. Spine Computed Tomography to Magnetic Resonance Image Synthesis Using Generative Adversarial Networks: A Preliminary Study. J. Korean Neurosurg. Soc. 2020, 63, 386–396. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chuquicusma, M.J.M.; Hussein, S.; Burt, J.; Bagci, U. How to fool radiologists with generative adversarial networks? a visual turing test for lung cancer diagnosis. In Proceedings of the IEEE 15th International Symposium on Biomedical Imaging, Washington, DC, USA, 4–7 April 2018. [Google Scholar]
- Han, C.; Hayashi, H.; Rundo, L.; Araki, R.; Shimoda, W.; Muramatsu, S.; Furukawa, Y.; Mauri, G.; Nakayama, H. GAN-based synthetic brain MR image generation. In Proceedings of the IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 734–738. [Google Scholar]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training (with Tuning) | Test (VTT) | ||
|---|---|---|---|
| Patients | 285 | 59 | |
| CT slices | Unsupervised training Semi-supervised training | 40,173 | 150 CT axial images |
| Supervised training | 4629 | ||
| Level-L1–2 | 812 | 32 | |
| Level-L2–3 | 891 | 33 | |
| Level-L3–4 | 1048 | 33 | |
| Level-L4–5 | 1035 | 31 | |
| Level-L5–S1 | 843 | 21 | |
| MRI slices | Unsupervised training Semi-supervised training | 9622 | 150 true and 450 synthetic MR axial images |
| Supervised training | 3566 | ||
| Level-L1–2 | 558 | 32 + 96 | |
| Level-L2–3 | 650 | 33 + 99 | |
| Level-L3–4 | 788 | 33 + 99 | |
| Level-L4–5 | 800 | 31 + 93 | |
| Level-L5–S1 | 770 | 21 + 63 | |
| Age (years) | |||
| Male | 63.18 ± 16.47 | 68.56 ± 4.24 | |
| Female | 68.08 ± 15.46 | 69.66 ± 7.07 | |
| Sex | |||
| Male | 129 | 18 | |
| Female | 156 | 41 | |
| Visual Turing Test | p-Value | |||||||
|---|---|---|---|---|---|---|---|---|
| Total | Level 1–2 | Level 2–3 | Level 3–4 | Level 4–5 | Level 5–S1 | |||
| Reader 1 | first | 51.3% (77/150) | 40.6% (13/32) | 51.5% (17/33) | 66.7% (22/33) | 58.1% (18/31) | 33.3% (7/21) | reference |
| first + second | 78.0% (117/150) | 81.3% (26/32) | 75.8% (25/33) | 87.9% (29/33) | 77.4% (24/31) | 61.9% (13/21) | reference | |
| Reader 2 | first | 38.7% (58/150) | 46.9% (15/32) | 39.4% (13/33) | 42.4% (14/33) | 32.3% (10/31) | 28.6% (6/21) | 0.2497 |
| first + second | 62.0% (93/150) | 78.1% (25/32) | 60.6% (20/33) | 69.7% (23/33) | 58.1% (18/31) | 41.6% (10/21) | 0.2178 | |
| Reader 3 | first | 69.3% (104/150) | 59.4% (19/32) | 66.7% (22/33) | 78.8% (26/33) | 67.7% (21/31) | 76.2% (16/21) | 0.1190 |
| first + second | 84.0% (130/150) | 81.3% (26/32) | 81.8% (27/33) | 87.9% (29/33) | 90.3% (28/31) | 95.2% (20.21) | 0.4396 | |
| Reader 4 | first | 48.7% (73/150) | 65.6% (21/32) | 51.5% (17/33) | 39.4% (13/33) | 41.9% (13/31) | 42.9% (9/21) | 0.8125 |
| first + second | 70.7% (114/150) | 81.3% (26/32) | 78.8% (26/33) | 60.6% (20/33) | 67.7% (21/31) | 61.9% (13/21) | 0.9671 | |
| Total | first | 52.0% (312/600) | 53.1% (68/128) | 52.3% (69/132) | 56.8% (75/132) | 50.0% (62/124) | 45.2% (38/84) | - |
| first + second | 74.3% (446/600) | 78.1% (100/128) | 74.2% (98/132) | 76.5% (101/132) | 73.4% (91/124) | 66.7% (56/84) | - | |
| Deep Learning Algorithm | ||||
|---|---|---|---|---|
| Unsupervised | Semi-Supervised | Supervised | ||
| Reader 1 | first | 10 | 25 | 38 |
| first + second | 45 | 66 | 72 | |
| Reader 2 | first | 38 | 28 | 26 |
| first + second | 77 | 72 | 58 | |
| Reader 3 | first | 1 | 13 | 32 |
| first + second | 26 | 52 | 92 | |
| Reader 4 | first | 31 | 24 | 22 |
| first + second | 72 | 64 | 58 | |
| Total | first | 80/600 (13.3%) | 90/600 (15.0%) | 118/600 (19.7%) |
| first + second | 220/600 (36.7%) | 254/600 (42.3%) | 280/600 (46.7%) | |
| PPA (%) | CPPA (%) | K | ||
|---|---|---|---|---|
| Two expert radiologists | first | 59.6 | 42.5 | 0.187 |
| first + second | 80.0 | 66.7 | 0.258 | |
| Two resident radiologists | first | 48.2 | 31.7 | −0.389 |
| first + second | 66.1 | 58.6 | 0.072 | |
| Expert radiologists versus Resident radiologists | first | 92.2 | 85.5 | 0.845 |
| first + second | 96.8 | 93.9 | 0.880 |
| PSNR | SSIM | ||
|---|---|---|---|
| First method: Unsupervised learning | Level 1–2 | 16.062 ± 1.347 | 0.538 ± 0.060 |
| Level 2–3 | 15.678 ± 1.647 | 0.526 ± 0.067 | |
| Level 3–4 | 15.772 ±1.352 | 0.507 ± 0.062 | |
| Level 4–5 | 14.844 ± 1.350 | 0.465 ± 0.068 | |
| Level 5–S1 | 14.033 ± 1.258 | 0.412 ± 0.064 | |
| Total | 15.278 ± 0.830 | 0.490 ± 0.051 | |
| Second method: Semi-supervised learning | Level 1–2 | 16.234 ± 1.964 | 0.529 ± 0.069 |
| Level 2–3 | 16.149 ± 2.020 | 0.515 ± 0.073 | |
| Level 3–4 | 15.708 ±1.824 | 0.492 ± 0.069 | |
| Level 4–5 | 14.670 ± 1.729 | 0.448 ± 0.075 | |
| Level 5–S1 | 13.836 ± 1.865 | 0.398 ± 0.079 | |
| Total | 15.319 ± 1.037 | 0.479 ± 0.048 | |
| Second method: Semi-supervised learning | Level 1–2 | 16.554 ± 1.203 | 0.557 ± 0.094 |
| Level 2–3 | 16.732 ± 1.395 | 0.553 ± 0.102 | |
| Level 3–4 | 16.560 ±1.116 | 0.544 ± 0.084 | |
| Level 4–5 | 15.863 ± 1.449 | 0.521 ± 0.087 | |
| Level 5–S1 | 14.228 ± 1.341 | 0.455 ± 0.076 | |
| Total | 15.987 ± 1.039 | 0.518 ± 0.042 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, K.-T.; Cho, Y.; Kang, C.H.; Ahn, K.-S.; Lee, H.; Kim, J.; Hong, S.J.; Kim, B.H.; Shim, E. Lumbar Spine Computed Tomography to Magnetic Resonance Imaging Synthesis Using Generative Adversarial Network: Visual Turing Test. Diagnostics 2022, 12, 530. https://doi.org/10.3390/diagnostics12020530
Hong K-T, Cho Y, Kang CH, Ahn K-S, Lee H, Kim J, Hong SJ, Kim BH, Shim E. Lumbar Spine Computed Tomography to Magnetic Resonance Imaging Synthesis Using Generative Adversarial Network: Visual Turing Test. Diagnostics. 2022; 12(2):530. https://doi.org/10.3390/diagnostics12020530
Chicago/Turabian StyleHong, Ki-Taek, Yongwon Cho, Chang Ho Kang, Kyung-Sik Ahn, Heegon Lee, Joohui Kim, Suk Joo Hong, Baek Hyun Kim, and Euddeum Shim. 2022. "Lumbar Spine Computed Tomography to Magnetic Resonance Imaging Synthesis Using Generative Adversarial Network: Visual Turing Test" Diagnostics 12, no. 2: 530. https://doi.org/10.3390/diagnostics12020530
APA StyleHong, K.-T., Cho, Y., Kang, C. H., Ahn, K.-S., Lee, H., Kim, J., Hong, S. J., Kim, B. H., & Shim, E. (2022). Lumbar Spine Computed Tomography to Magnetic Resonance Imaging Synthesis Using Generative Adversarial Network: Visual Turing Test. Diagnostics, 12(2), 530. https://doi.org/10.3390/diagnostics12020530