
Using Machine Learning Techniques to Predict MACE in Very Young Acute Coronary Syndrome Patients

 , ,
, ,  and
and
Abstract
:1. Introduction
2. Materials and Methods
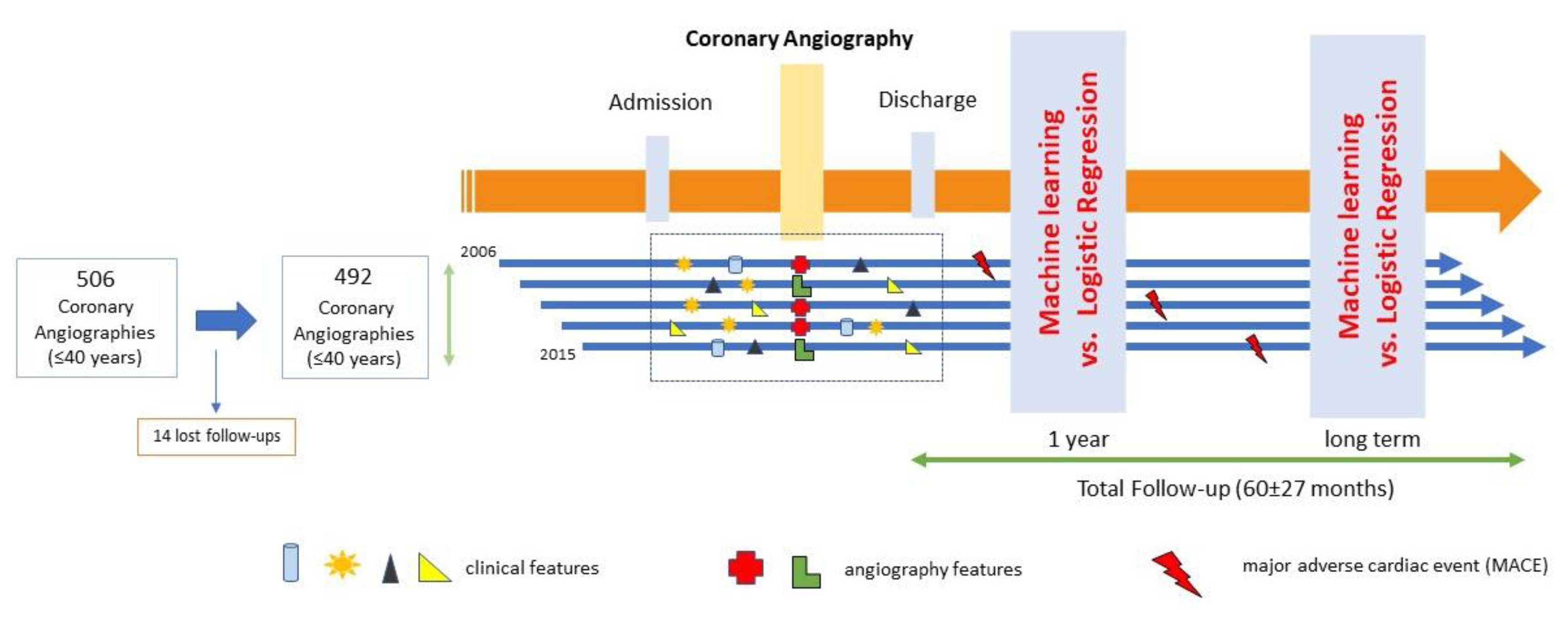
2.1. Study Population
2.2. Study Outcomes
2.3. Machine Learning Model Derivation
2.4. Logistic Regression Model Comparison
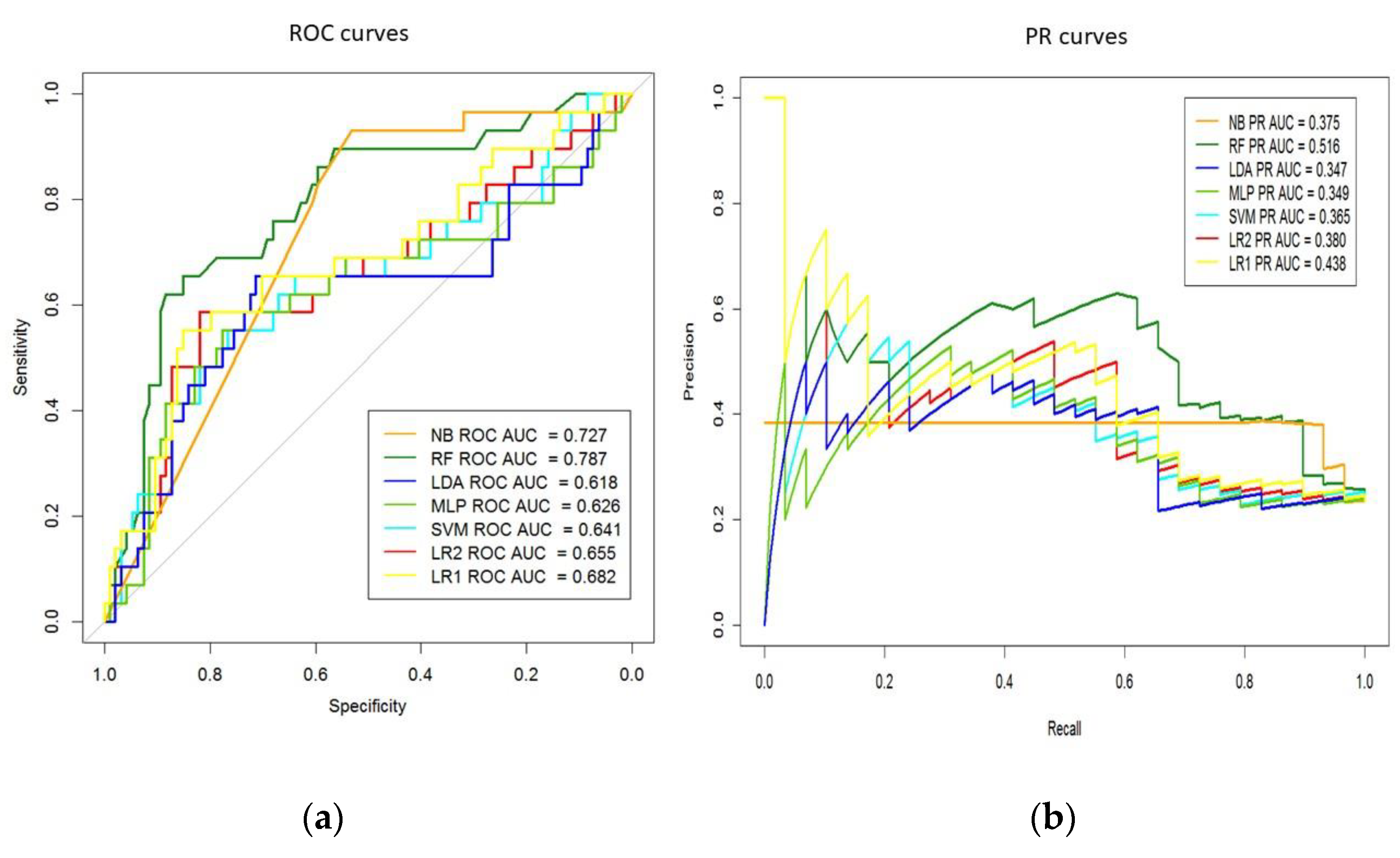
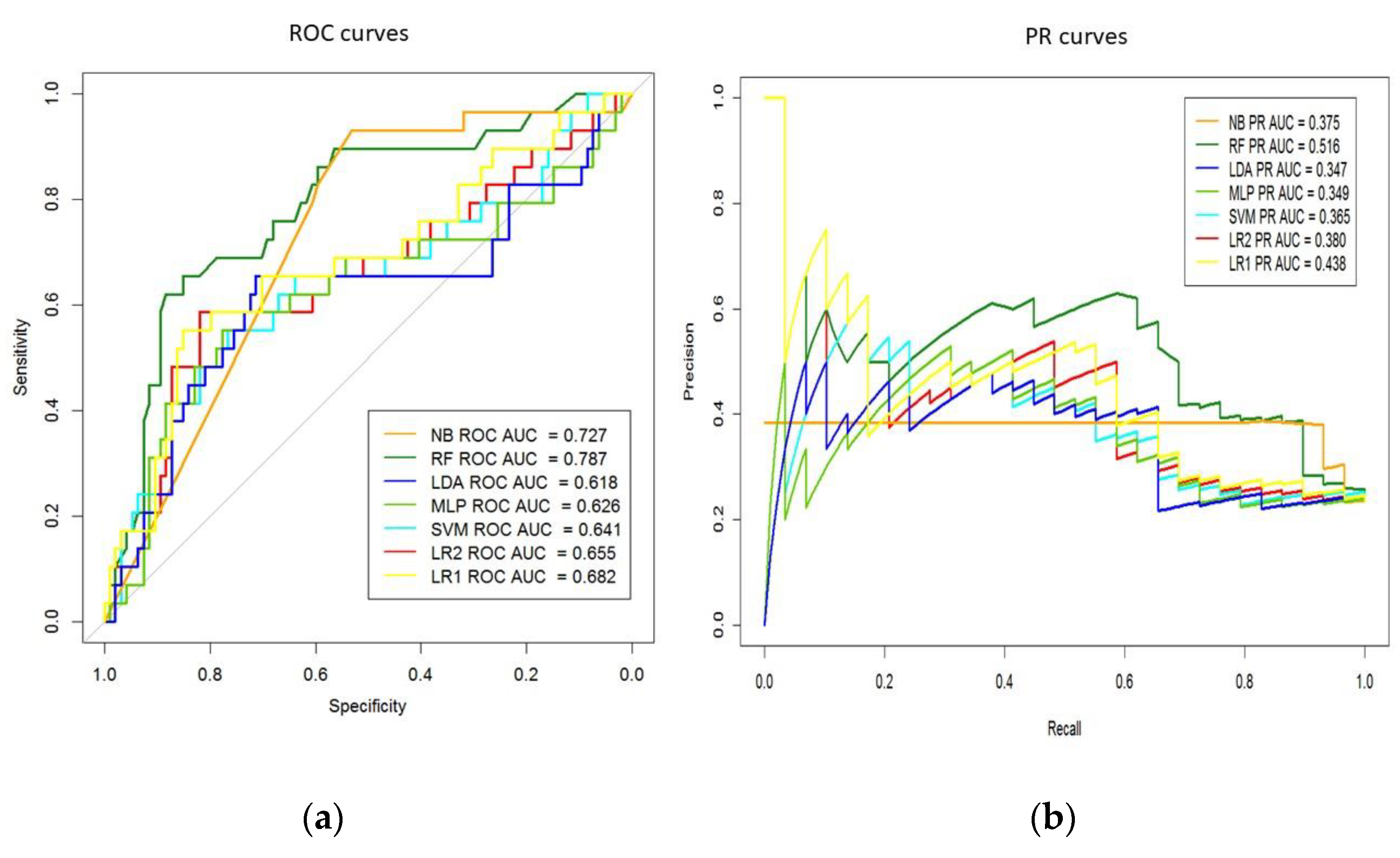
3. Results
3.1. MACE Prediction Models Long-Term Follow-Up
3.2. MACE Prediction Models 1-Year Follow-Up
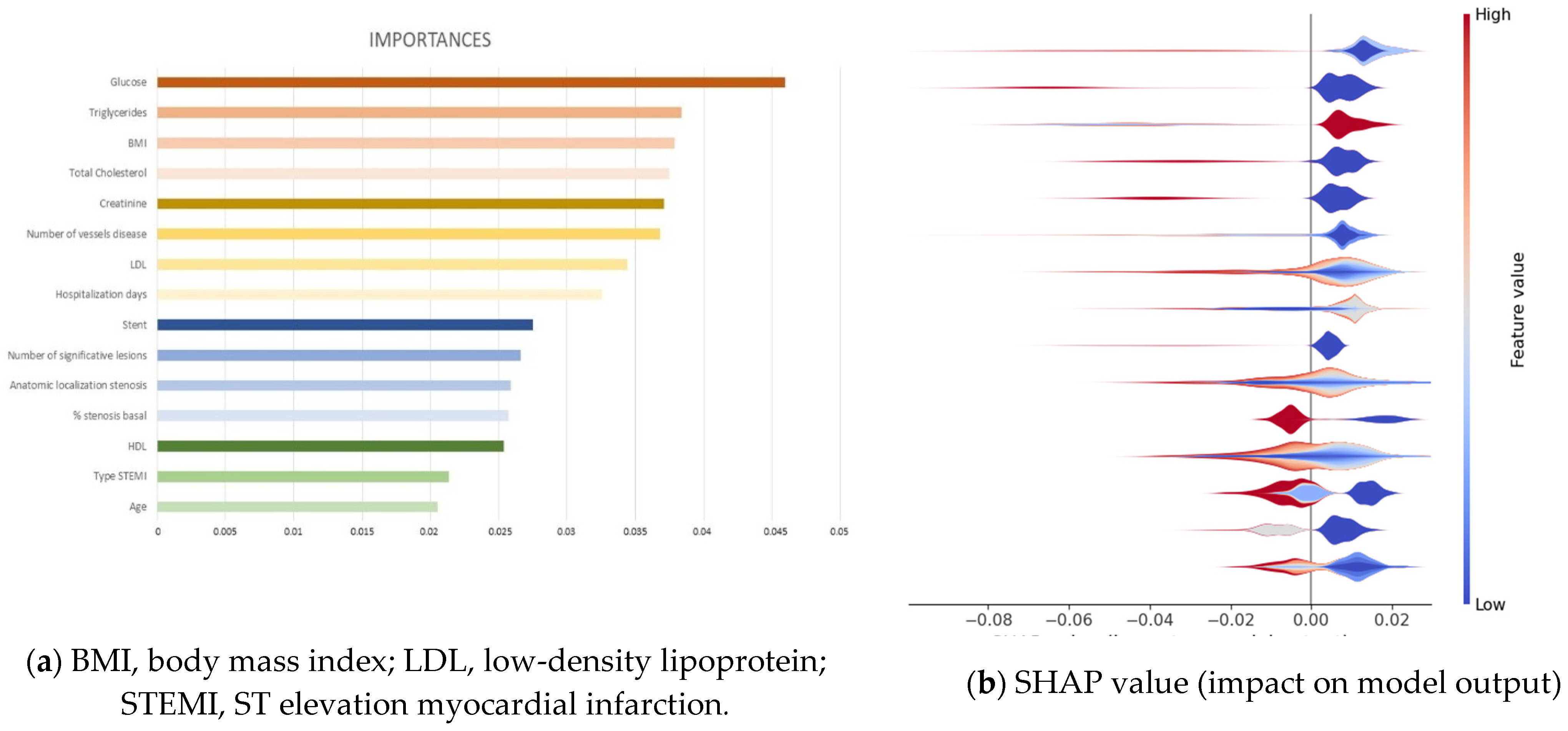
3.3. Extraction of Variables’ Importance and Model Explainability
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| LR2 | NB | LDA | RF | MLP | SVM | LR1 | |
|---|---|---|---|---|---|---|---|
| K = 0 | 0.91 | 0.39 | 0.73 | 0.82 | 0.91 | 0.91 | 0.82 |
| K = 1 | 0.86 | 0.55 | 0.82 | 0.82 | 0.82 | 0.77 | 0.77 |
| K = 2 | 0.77 | 0.32 | 0.73 | 0.90 | 0.80 | 0.70 | 0.90 |
| K = 3 | 1.00 | 0.65 | 0.50 | 0.95 | 0.90 | 0.95 | 1.00 |
| K = 4 | 0.95 | 1.00 | 0.95 | 0.90 | 0.90 | 1.00 | 0.95 |
| K = 5 | 0.70 | 0.20 | 0.80 | 0.50 | 0.65 | 0.70 | 0.75 |
| K = 6 | 0.95 | 0.95 | 0.50 | 0.95 | 1.00 | 0.85 | 1.00 |
| K = 7 | 0.25 | 0.00 | 0.00 | 0.80 | 0.55 | 0.20 | 0.70 |
| K = 8 | 0.80 | 0.35 | 0.65 | 0.70 | 0.70 | 0.75 | 0.75 |
| K = 9 | 0.85 | 0.75 | 0.73 | 0.55 | 0.90 | 0.95 | 0.80 |
References
- Ferreira-Gonza, I. The Epidemiology of Coronary Heart Disease. Rev Española Cardiol. 2014, 67, 139–144. [Google Scholar]
- Meirhaeghe, A.; Montaye, M.; Biasch, K.; Kai, S.H.Y.; Moitry, M.; Amouyel, P.; Ferrières, J.; Dallongeville, J. Coronary heart disease incidence still decreased between 2006 and 2014 in France, except in young age groups: Results from the French MONICA registries. Eur. J. Prev. Cardiol. 2020, 27, 1178–1186. [Google Scholar] [CrossRef]
- Andersson, C.; Vasan, R.S. Epidemiology of cardiovascular disease in young individuals. Nat. Rev. Cardiol. 2017, 15, 230–240. [Google Scholar] [CrossRef]
- Page, R.L., 2nd; Ghushchyan, V.; Gifford, B.; Read, R.A.; Raut, M.; Crivera, C.; Naim, A.B.; Damaraju, C.V.; Nair, K.V. The economic burden of acute coronary syndromes for employees and their dependents: Medical and productivity costs. J. Occup. Environ. Med. 2013, 55, 761–767. [Google Scholar] [CrossRef]
- Rallidis, L.S.; Gialeraki, A.; Triantafyllis, A.S.; Tsirebolos, G.; Liakos, G.; Moutsatsou, P.; Iliodromitis, E. Characteristics and Long-Term Prognosis of Patients ≤35 Years of Age with ST Segment Elevation Myocardial Infarction and “Normal or Near Normal” Coronary Arteries. Am. J. Cardiol. 2017, 120, 740–746. [Google Scholar] [CrossRef]
- Loria, C.M.; Liu, K.; Lewis, C.E.; Hulley, S.B.; Sidney, S.; Schreiner, P.J.; Williams, O.D.; Bild, D.E.; Detrano, R. Early Adult Risk Factor Levels and Subsequent Coronary Artery Calcification: The CARDIA Study. J. Am. Coll. Cardiol. 2007, 49, 2013–2020. [Google Scholar] [CrossRef] [Green Version]
- DeFilippis, A.P.; Young, R.; Carrubba, C.J.; McEvoy, M.J.W.; Budoff, M.J.; Blumenthal, R.S.; Kronmal, R.A.; McClelland, R.L.; Nasir, K.; Blaha, M.J. An Analysis of Calibration and Discrimination Among Multiple Cardiovascular Risk Scores in a Modern Multiethnic Cohort. Ann. Intern. Med. 2015, 162, 266–275. [Google Scholar] [CrossRef] [Green Version]
- Vera, E.; Lázaro, R.; Gramero, S.; Sánchez, D.; Planelles, M. Factores de riesgo cardiovascular en adultos jóvenes de un centro penitenciario. Rev. Esp. Salud. Publica 2018, 92, 1–12. [Google Scholar]
- van Loon, J.E.; de Maat, M.P.M.; Deckers, J.W.; van Domburg, R.T.; Leebeek, F.W.G. Prognostic markers in young patients with premature coronary heart disease. Atherosclerosis 2012, 224, 213–217. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Leviner, D.B.; Witberg, G.; Sharon, A.; Boulos, Y.; Barsheshet, A.; Sharoni, E.; Spiegelstein, D.; Vaknin-Assa, H.; Aravot, D.; Kornowski, R.; et al. Long-term Outcomes of Contemporary Coronary Revascularization by Percutaneous Coronary Intervention or Coronary Artery Bypass Grafting in Young Adults. Isr. Med. Assoc. J. IMAJ 2019, 12, 817–822. [Google Scholar]
- Rallidis, L.S.; Pavlakis, G. The fundamental importance of smoking cessation in those with premature ST-segment elevation acute myocardial infarction. Curr. Opin. Cardiol. 2016, 31, 531–536. [Google Scholar] [CrossRef] [PubMed]
- Tibaut, M.; Caprnda, M.; Kubatka, P.; Sinkovič, A.; Valentova, V.; Filipova, S.; Gazdikova, K.; Gaspar, L.; Mozos, I.; Egom, E.E.; et al. Markers of Atherosclerosis: Part 1—Serological Markers. Heart Lung Circ. 2019, 28, 667–677. [Google Scholar] [CrossRef]
- Tibaut, M.; Caprnda, M.; Kubatka, P.; Sinkovič, A.; Valentova, V.; Filipova, S.; Gazdikova, K.; Gaspar, L.; Mozos, I.; Egom, E.E.; et al. Markers of Atherosclerosis: Part 2—Genetic and Imaging Markers. Heart Lung Circ. 2019, 28, 678–689. [Google Scholar] [CrossRef] [PubMed]
- Huang, Z.; Chan, T.-M.; Dong, W. MACE prediction of acute coronary syndrome via boosted resampling classification using electronic medical records. J. Biomed. Informatics 2017, 66, 161–170. [Google Scholar] [CrossRef] [PubMed]
- Dorado-Díaz, P.I.; Sampedro-Gómez, J.; Vicente-Palacios, V.; Sánchez, P.L. Applications of Artificial Intelligence in Cardiology. The Future is Already Here. Rev. Esp. Cardiol. 2019, 72, 1065–1075. [Google Scholar] [CrossRef]
- Gomes, B.; Pilz, M.; Reich, C.; Leuschner, F.; Konstandin, M.; Katus, H.A.; Meder, B. Machine learning-based risk prediction of intrahospital clinical outcomes in patients undergoing TAVI. Clin. Res. Cardiol. 2020, 110, 343–356. [Google Scholar] [CrossRef]
- Ling, P.; Rong, X.; Hao, G.; Dong, Y. Shrank Support Vector Clustering. Proc. Int. Jt. Conf. Neural Netw. 2014, 452–459. [Google Scholar] [CrossRef]
- Breiman, L. ST4_Method_Random_Forest. Mach Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Rennie, J.D.M.; Shih, L.; Teevan, J.; Karger, D. Tackling the Poor Assumptions of Naive Bayes Text Classifiers. Proc. Twent. Int. Conf. Mach. Learn. 2003, 2, 616–623. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning Data Mining, Inference, and Prediction. Math. Intell. 1988, 27, 83–85. [Google Scholar]
- Delong, E.R.; Delong, D.M.; Clarke-Pearson, D.L. Comparing the Areas under Two or More Correlated Receiver Operating Characteristic Curves: A Nonparametric Approach. Biometrics 1988, 44, 837–845. [Google Scholar] [CrossRef] [PubMed]
- Sampedro-Gómez, J.; Dorado-Díaz, P.I.; Vicente-Palacios, V.; Sánchez-Puente, A.; Jiménez-Navarro, M.; Roman, J.A.S.; Galindo-Villardón, P.; Sanchez, P.L.; Fernández-Avilés, F. Machine Learning to Predict Stent Restenosis Based on Daily Demographic, Clinical, and Angiographic Characteristics. Can. J. Cardiol. 2020, 36, 1624–1632. [Google Scholar] [CrossRef] [PubMed]
- Saito, T.; Rehmsmeier, M. The Precision-Recall Plot Is More Informative than the ROC Plot When Evaluating Binary Classifiers on Imbalanced Datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- RCT. R: A Language and Environment for Statistical Computing; R Found Stat Comput Vienna: Vienna, Austria, 2021. [Google Scholar]
- Stevenson, M.; Nunes, T.; Heuer, C.; Marshall, J.; Sanchez, J.; Thornton, R.; Reiczigel, J.; Robison-Cox, J.; Sebastiani, P.; Solymos, P.; et al. epiR: Tools for the Analysis of Epidemiological Data. 2020. Available online: https://fvas.unimelb.edu.au/research/groups/veterinary-epidemiology-melbourne (accessed on 26 December 2021).
- Robin, X.; Turck, N.; Hainard, A.; Tiberti, N.; Lisacek, F.; Sanchez, J.-C.; Müller, M. pROC: An open-source package for R and S+ to analyze and compare ROC curves. BMC Bioinform. 2011, 12, 77. [Google Scholar] [CrossRef]
- Grau, J.; Grosse, I.; Keilwagen, J. PRROC: Computing and visualizing precision-recall and receiver operating characteristic curves in R. Bioinformatics 2015, 31, 2595–2597. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Du-bourg, V.; et al. Scikit-learn: Machine Learning in Python. J Mach Learn Res. 2011, 12, 2825–2830. [Google Scholar]
- González-Nóvoa, J.A.; Busto, L.; Rodríguez-Andina, J.J.; Fariña, J.; Segura, M.; Gómez, V.; Vila, D.; Veiga, C. Using Explainable Machine Learning to Improve Intensive Care Unit Alarm Systems. Sensors 2021, 21, 7125. [Google Scholar] [CrossRef]
- Al-Mallah, M.H.; Elshawi, R.; Ahmed, A.M.; Qureshi, W.T.; Brawner, C.A.; Blaha, M.J.; Ahmed, H.M.; Ehrman, J.K.; Keteyian, S.J.; Sakr, S. Using Machine Learning to Define the Association between Cardiorespiratory Fitness and All-Cause Mortality (from the Henry Ford Exercise Testing Project). Am. J. Cardiol. 2017, 120, 2078–2084. [Google Scholar] [CrossRef]
- Zack, C.J.; Senecal, C.; Kinar, Y.; Metzger, Y.; Bar-Sinai, Y.; Widmer, R.J.; Lennon, R.; Singh, M.; Bell, M.R.; Lerman, A.; et al. Leveraging Machine Learning Techniques to Forecast Patient Prognosis After Percutaneous Coronary Intervention. JACC Cardiovasc. Interv. 2019, 12, 1304–1311. [Google Scholar] [CrossRef]
- Mortazavi, B.J.; Downing, N.S.; Bucholz, E.M.; Dharmarajan, K.; Manhapra, A.; Li, S.-X.; Negahban, S.N.; Krumholz, H.M. Analysis of Machine Learning Techniques for Heart Failure Readmissions. Circ. Cardiovasc. Qual. Outcomes 2016, 9, 629–640. [Google Scholar] [CrossRef] [Green Version]

| Variables | Overall (n = 492) |
|---|---|
| Women | 60 (12.2%) |
| Follow-up time (months) | 60 ± 27 |
| Body mass index | 28 ± 5 |
| Hypertension | 113 (23.0%) |
| Diabetes mellitus | 43 (8.7%) |
| Smoking | 381 (77.4%) |
| Dyslipidemia | 217 (44.1%) |
| Family history of CAD 1 | 132 (26.8%) |
| Previous revascularization | 62 (12.6%) |
| Cocaine | 52 (10.6%) |
| Alcohol abuse | 52 (10.5%) |
| Cannabis | 56 (11.4%) |
| Peripheral artery disease | 7(1.4%) |
| Congestive heart failure | 3 (0.6%) |
| Previous stroke | 3 (0.6%) |
| Atrial fibrillation | 3 (0.6%) |
| Renal failure | 27 (5.5%) |
| Depression | 44 (8.9%) |
| Total cholesterol (mg/dL) | 194 ± 53 |
| LDL-cholesterol (mg/dL) | 124 ± 48 |
| HDL-cholesterol (mg/dL) | 39 ± 11 |
| Triglycerides (mg/dL) | 162 ± 114 |
| Creatinine (mg/dL) | 1.28 ± 1.8 |
| Glucose (mg/dL) | 107 ± 44 |
| LVEF 2 (%) | 55 ± 9 |
| Hospitalization days | 6 ± 7 |
| CLS | AUC (95% CI) | p-Value | Sensitivity (95% CI) | Specificity (95% CI) | Accuracy (95% CI) | Precision (95% CI) |
|---|---|---|---|---|---|---|
| Prediction Ability Long-Term Follow-Up | ||||||
| LR2 | 0.66 (0.53–0.78) | --- | 0.59 (0.39–0.76) | 0.79 (0.69–0.86) | 0.74 (0.65–0.81) | 0.46 (0.29–0.63) |
| NB | 0.73 (0.64–0.81) | 0.193 | 0.97 (0.82–0.99) | 0.03 (0.01–0.09) | 0.25 (0.18–0.34) | 0.23 (0.16–0.32) |
| LDA | 0.62 (0.48–0.75) | 0.167 | 0.55 (0.36–0.74) | 0.74 (0.64–0.83) | 0.70 (0.61–0.78) | 0.40 (0.25–0.57) |
| RF | 0.79 (0.69–0.88) | 0.021 | 0.69 (0.49–0.85) | 0.70 (0.60–0.79) | 0.70 (0.61–0.78) | 0.42 (0.28–0.57) |
| MLP | 0.63 (0.49–0.76) | 0.143 | 0.48 (0.29–0.67) | 0.82 (0.73–0.89) | 0.74 (0.65–0.81) | 0.45 (0.27–0.64) |
| SVM | 0.64 (0.51–0.77) | 0.689 | 0.38 (0.21–0.58) | 0.85 (0.76–0.92) | 0.74 (0.65–0.81) | 0.44 (0.24–0.65) |
| LR1 | 0.68 (0.56–0.80) | 0.009 | 0.59 (0.39–0.76) | 0.80 (0.70–0.87) | 0.74 (0.66–0.82) | 0.47 (0.30–0.64) |
| CLS | AUC (95% CI) | p-Value | Sensitivity (95% CI) | Specificity (95% CI) | Accuracy (95% CI) | Precision (95% CI) |
|---|---|---|---|---|---|---|
| Prediction Ability One-Year Follow-Up | ||||||
| LR2 | 0.50 (0.33–0.66) | --- | 0.25 (0.073–0.52) | 0.81 (0.73–0.88) | 0.74 (0.65–0.81) | 0.17 (0.05–0.38) |
| NB | 0.47 (0.33–0.60) | 0.741 | 0.75 (0.48–0.93) | 0.06 (0.02–0.12) | 0.15 (0.09–0.22) | 0.11 (0.06–0.18) |
| LDA | 0.49 (0.31–0.67) | 0.970 | 0.37 (0.15–0.66) | 0.78 (0.69–0.86) | 0.73 (0.64–0.80) | 0.21 (0.08–0.40) |
| RF | 0.80 (0.71–0.89) | <0.001 | 0.75 (0.48–0.93) | 0.72 (0.62–0.80) | 0.72 (0.64–0.80) | 0.29 (0.16–0.45) |
| MLP | 0.56 (0.40–0.71) | 0.159 | 0.25 (0.07–0.52) | 0.84 (0.75–0.90) | 0.76 (0.68–0.84) | 0.19 (0.05–0.42) |
| SVM | 0.45 (0.28–0.62) | 0.271 | 0.06 (0.00–0.30) | 0.87 (0.79–0.93) | 0.76 (0.68–0.84) | 0.07 (0.00–0.32) |
| LR1 | 0.61 (0.45–0.78) | 0.066 | 0.56 (0.30–0.80) | 0.52 (0.42–0.62) | 0.53 (0.44–0.62) | 0.15 (0.07–0.27) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Juan-Salvadores, P.; Veiga, C.; Jiménez Díaz, V.A.; Guitián González, A.; Iglesia Carreño, C.; Martínez Reglero, C.; Baz Alonso, J.A.; Caamaño Isorna, F.; Romo, A.I. Using Machine Learning Techniques to Predict MACE in Very Young Acute Coronary Syndrome Patients. Diagnostics 2022, 12, 422. https://doi.org/10.3390/diagnostics12020422
Juan-Salvadores P, Veiga C, Jiménez Díaz VA, Guitián González A, Iglesia Carreño C, Martínez Reglero C, Baz Alonso JA, Caamaño Isorna F, Romo AI. Using Machine Learning Techniques to Predict MACE in Very Young Acute Coronary Syndrome Patients. Diagnostics. 2022; 12(2):422. https://doi.org/10.3390/diagnostics12020422
Chicago/Turabian StyleJuan-Salvadores, Pablo, Cesar Veiga, Víctor Alfonso Jiménez Díaz, Alba Guitián González, Cristina Iglesia Carreño, Cristina Martínez Reglero, José Antonio Baz Alonso, Francisco Caamaño Isorna, and Andrés Iñiguez Romo. 2022. "Using Machine Learning Techniques to Predict MACE in Very Young Acute Coronary Syndrome Patients" Diagnostics 12, no. 2: 422. https://doi.org/10.3390/diagnostics12020422
APA StyleJuan-Salvadores, P., Veiga, C., Jiménez Díaz, V. A., Guitián González, A., Iglesia Carreño, C., Martínez Reglero, C., Baz Alonso, J. A., Caamaño Isorna, F., & Romo, A. I. (2022). Using Machine Learning Techniques to Predict MACE in Very Young Acute Coronary Syndrome Patients. Diagnostics, 12(2), 422. https://doi.org/10.3390/diagnostics12020422