1. Introduction
Major and dramatic changes in the development of nations, economies, cultures, and the environment, as well as an enhancement of the standard of living, have resulted from breakthroughs in science and technology throughout the past century. However, these technological advances have had unintended consequences, including shifts and disruptions in people’s daily routines, the natural world, cultural practices, and societal and economic structures. Because of this, the population is more susceptible to various internal and external risk factors, any one of which may in turn generate pathological states that may ultimately lead to diseases. Infection with pathogenic bacteria, free radicals, carcinogens, toxic chemicals, pollutants, and genetic abnormalities are only some of the many risk factors that might contribute to the onset of these conditions [
1]. Changes in way of life, nutrition, and exercise, as well as inactivity, have all been linked to the rise of metabolic illnesses [
2]. The aforementioned risk factors may have contributed to the development of diseases such as metabolic syndrome, cardiovascular disorders, diabetes mellitus, cerebrovascular diseases, food-borne diseases, infectious diseases, and cancer [
3]. Therefore, focusing on health indicators is an attractive opportunity to explore the health state of individual and population subjects in relation to biochemical changes in the body.
Central obesity, high blood pressure, high blood sugar, and abnormal lipid profiles are the four main components of metabolic syndrome (MetS) [
4]. It is important to note that rapid economic growth, an aging population, changes in lifestyle, and obesity are all contributing to the rising prevalence of MetS. The global prevalence of MetS is estimated to be between 20 and 25% [
5]. MetS has been linked to an elevated danger of developing diabetes, heart disease, cancer, and mortality [
6]. MetS poses a growing clinical and public health burden all over the world [
7]. That is why it is crucial to implement effective measures to prevent and manage the spread of MetS. Data mining of medical checkup data can help identify patients at high risk of MetS at an early stage, advancing the timing of disease prevention and control from the later stages of disease development to the earlier stages of disease development. Preventing and controlling MetS requires the development of risk prediction models using data from physical examinations. Models for predicting the likelihood of a disease occurring are called disease risk prediction models [
8]. These models are developed to identify those at high risk for a certain disease so that preventative or early intervention measures can be taken. Therefore, it is of considerable practical importance to build a MetS risk prediction model so that at-risk individuals can be identified and treated as soon as possible. Factors such as sex, age, and family history [
9], as well as modifiable factors such as diet, physical activity level, and blood pressure [
10] contribute to the onset and progression of MetS [
11]. Modifiable risk factors are those that can, in theory, be altered. The best way to prevent and manage metabolic syndrome is to identify and address the underlying causes of the condition. However, identifying risk factors for MetS is complicated by interactions between risk factors [
12]. In order to successfully deal with complex interactions between variables, machine learning, which is algorithm-based data analysis technology, is equipped with potent data analysis skills. These considerations led to the development of a machine-learning-based risk prediction model for MetS in this study.
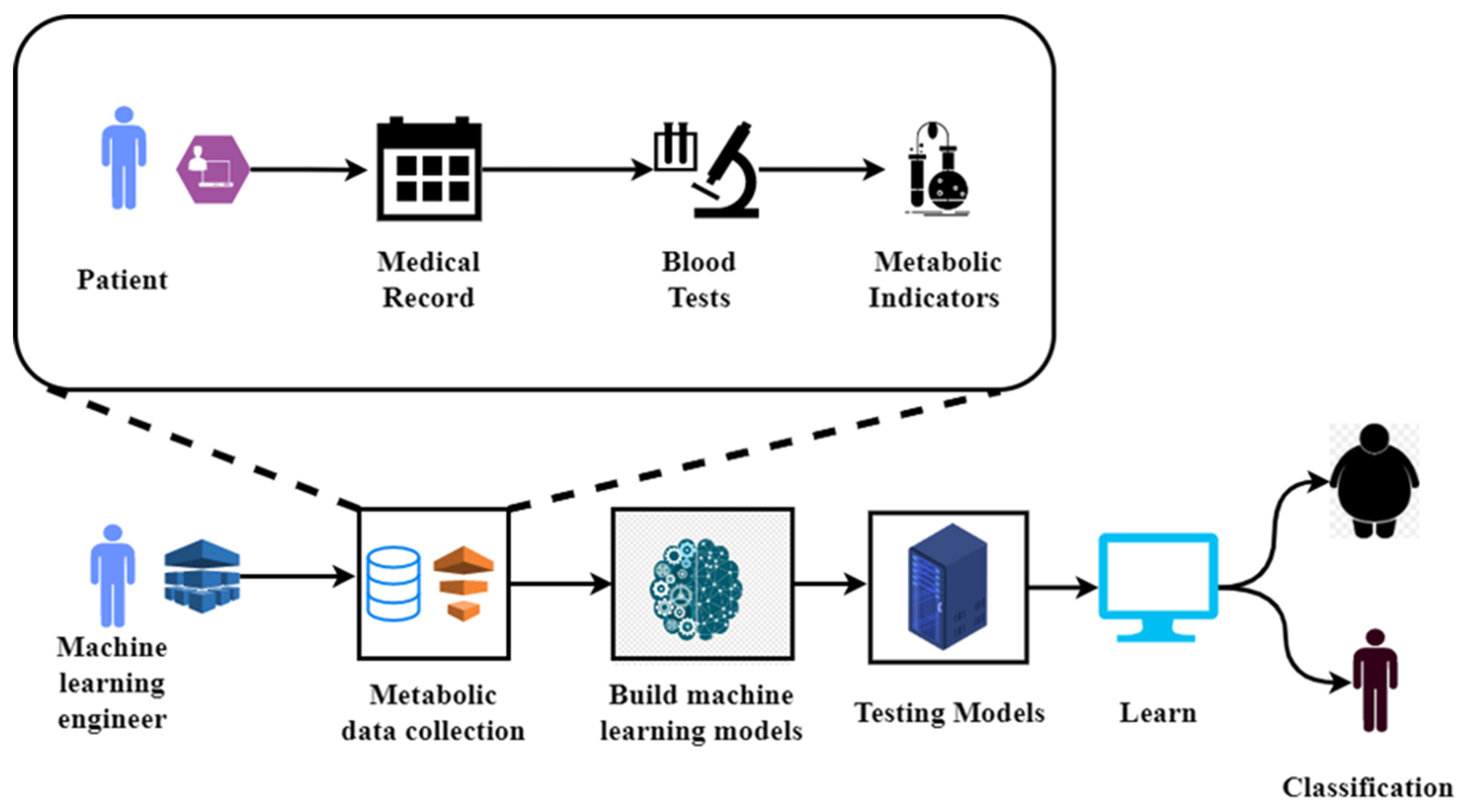
Figure 1 illustrates the metabolic syndrome diagnosis using machine learning [
13].
In this paper, to establish a simple and practical risk prediction model for MetS, we built different machine learning models, based on easily available indicators such as demographic characteristics, anthropometric indicators, living habits, and family history of the subjects and then used a SHAP tool to explain and visualize the model. The interpretable MetS risk prediction model can help uncover risk factors, identify high-risk individuals, and provide methodological references for the prevention and control of MetS.
The key contributions are as follows: (1) Comparing the performance of numerous ancient and new statistical, bagging, and boosting machine learning models; (2) using the synthetic minority oversampling technique (SMOTE) as a data-augmentation strategy to solve the problem of unbalanced classes and avoid bias in machine learning models; (3) using multiple metaheuristics algorithms for feature selection to highlight the metabolic indicators with the best discriminative potential for machine learning models; (4) following feature selection, the Shapley additive explanations (SHAP) method is used to analyze machine learning model results and highlight the most significant metabolic indicators.
The rest of the paper is organized as follows:
Section 2 focuses on relevant studies in the field.
Section 3 illustrates the proposed methodology, data gathered, classifiers used, and metaheuristics methods, whereas
Section 4 shows the statistical measures used for model assessment as well as the hyperparameter tuning process. Moreover,
Section 5 discusses the experimental findings and SHAP’s explanations of machine learning models. Lastly,
Section 6 concludes the study and suggests next directions.
2. Research Background and Related Works
In the field of metabolic syndrome data prediction and classification, a lot of new study methods, including experimental, investigative, empirical, and comparative research techniques, have been developed lately. Today, because of the availability of a large number of data sets that detail a variety of medical examinations, medical information, as well as the symptoms and indicators of particular diseases, has become an aid in the process of predicting diseases in their early stages. Metabolic syndrome is a prime example of this. The authors of [
14] proposed a novel framework for the classification of metabolic data. This new framework makes use of random forests, C 4.5 classifiers, and JRip classifiers. They used a dataset that included information on the lifestyles and blood tests of 2942 patients living in Mexico City. In addition, Chi-squared was used as a feature selection approach in order to exclude irrelevant aspects of the data. According to the results, triglycerides, HDL cholesterol, and waist circumference are some of the greatest indicators of whether or not someone has metabolic syndrome. Regardless of the circumstances, the best results were obtained from random forests. The study in [
15] utilizes clinical and genetic data from a Korean community that does not have an excessively overweight population. A framework was created with the use of the WEKA tool to simplify the employment of five different machine learning classifiers. These classifiers are known as naive Bayes, random forests, decision trees, neural networks, and support vector machines. They used data from a total of 10,349 different people. A few examples of the clinical variables that are discussed in the dataset are triglyceride levels, high-density lipoprotein cholesterol levels, and alcohol intake. In comparison to the other approaches, naive Bayes was successful in obtaining the largest area under the curve (0.69).
Using deep learning: In [
16], a study of metabolic syndrome scores was proposed, and as part of that research, a dataset was offered that described the health of 3577 students in Birjand. The levels of glucose and triglycerides in the blood taken first thing in the morning are two blood tests that may be used as indicators. The distribution of the data, on the other hand, mandated the use of the synthetic minority oversampling technique for the purpose of achieving data parity. A linear discriminant analysis model was used in the process of feature extraction. The CART classifier outperforms neural networks and support vector machines in terms of four statistical metrics; however, these other two methods are more common. The prediction models, on the other hand, came to the conclusion that the most discriminating factors are waist circumference and high-density lipoprotein. In [
17], a dataset consisting of 67,730 Chinese patients who had had a medical examination was used to evaluate the performance of random forest, XGBoost, and stacking classifiers. There were 32 predictors of physical medical tests, blood tests, and ages included in the information that was acquired. However, by employing cross-validation with 10 folds and the area under the curve metric, according to the statistics, XGBoost had the most area under the curve (93%) of any algorithm. In addition, the shapely additive explanation (SHAP) was used in the data to determine the relevance of the attributes. The fasting triglyceride level, abdominal obesity, and body mass index were shown to be the most significant indicators by the SHAP analysis for metabolic data prediction.
The study in [
18] evaluates a dataset that describes medical information and tests for 17,182 patients using six of the most effective machine learning classifiers, including logistic regression, extreme gradient boosting, K-nearest neighbors, light gradient boosting, decision trees, and linear analysis. However, three statistical criteria were utilized to evaluate the models. Light gradient boosting exceeded the others, with an area under the curve of 86%. Furthermore, SHAP analysis revealed that waist circumference, triglycerides, and HDL-cholesterol had the strongest discriminative power for predicting metabolic data. In [
19], decision trees and support vector machines were tested on an Isfahan cohort study dataset. The dataset described 16 metabolic syndrome indicators. However, for data balance, the synthetic minority oversampling technique was used. The WEKA tool and three statistical metrics were used in the experiment. According to the results, the support vector machine outperforms decision trees by 75% in terms of accuracy.
Using one-dimensional neural networks and eight additional machine learning classifiers: A study was conducted in [
20] to evaluate a dataset that describes the lifestyles, medical information, and blood tests of 1991 middle-aged Korean patients. The dataset described several metabolic syndrome indicators such as age, smoking status, sleep time, and waist circumference. However, SMOTE was utilized for data balance. In addition, an area under the curve measure was utilized to evaluate the models. When compared to others, the findings demonstrate that XGBoost has the greatest performance, with an AUC of 85%. Furthermore, waist-to-hip ratio and BMI were shown to be the most important indicators for metabolic prediction. The study in [
21] collected a dataset of 39,134 Chinese metabolic syndrome patients. The data set contained information on 19 different diagnostic tests, including alkaline phosphatase, prior diabetes, uric acid, and eosinophil percentage. The developed framework, on the other hand, assessed the employment of logistic regression, random forest, and extreme gradient boosting classifiers. Recursive feature elimination was also employed to select features. With an accuracy of 99.7%, XGBoost surpassed the others. In addition, the LIME library was utilized to display the significance of features. Fasting triglycerides, central adiposity, and systolic blood pressure were shown to be the most significant indications.
Using gradient boosted trees and logistic regression: In [
22], an experimental study was conducted to investigate the usage of a Japanese metabolic syndrome dataset. The health insurance union data covered certain patients’ demographics and medical examinations, such as high-density lipoprotein cholesterol, anemia, and smoking. However, the proposed machine learning classifiers were fine-tuned. The area under the curve measure was also employed to evaluate the models. The findings, on the other hand, show that gradient-boosted trees performed best, with an AUC of 89.4%. Furthermore, other metabolic indicators, such as diastolic and systolic blood pressure, were shown to have no impact. The study in [
23] was carried out in order to investigate the use of metabolic data from 5646 patients in Bangkok. On the other hand, in order to evaluate how well the random forest classifier worked, four different statistical methods were used. Additionally, ten-fold cross-validation and principal component analysis were carried out on the data. The research indicates that random forest had the best accuracy, coming in at 98.11%. Furthermore, it was shown that the triglyceride level was the single most important feature.
Table 1 summarizes the related research in terms of data gathered, machine learning classifiers employed, and key metabolic syndrome indicators. However, in comparison to prior contributions, in this paper, we compare the performance of ten statistical, boosting, and bagging machine learning classifiers on a metabolic syndrome dataset that includes 29 separate diagnostic procedures and medical tests. We also utilize five metaheuristic algorithms for feature selection, as well as SMOTE for data balance. Furthermore, we apply the Shapley additive explanations tool to explain the outputs of machine learning models at different data observation samples.
5. Metabolic Data Classification Experimental Results and Model Explanations
The next section discusses the experimental findings that were obtained by using the framework that was devised. In this investigation, five different metaheuristics algorithms for feature selection were carried out.
Table 4 demonstrates the fine-tuning that was performed on the proposed metaheuristic algorithms. There are a total of six hyperparameters that required adjustment: chaotic type (µ), number of iterations (β), heuristic rate (η), number of generations (α), crossover function probability (ϓ), and mutation probability (Ψ). The selected features have been shown to have the greatest discriminative power for prediction models that make use of metaheuristics methods.
Figure 3 shows the total number of selected features utilizing metaheuristics. For clarity, we found that subject age, gene a, gene b, gene c, gene d, breathing rate, high blood pressure, high triglyceride, comprehensive metabolic panel test results, maternal pregnancy record, premature delivery, per MCL quantity of white blood cells, maternal abortion count, and reduced HDL were among the most informative features and indicators for metabolic syndrome based on metaheuristics performance.
The testing accuracy results of several classifiers that were evaluated on the metabolic syndrome dataset using metaheuristic approaches are shown in
Table 5. The data, taken as a whole, show an increase in accuracy. Using the genetic and bat algorithms, however, the KNNs classifier outperforms others with a 94.4% accuracy rate. To be clear, this is due to the KNNs algorithm performing better with fewer features, and so the number of features was lowered following the feature selection process utilizing metaheuristics techniques. Another explanation is that KNNs is a distance-based and sluggish algorithm by nature, therefore it outperforms others in the evaluation stage owing to data distribution and training, which is not surprising. On the other hand, the performance of boosting ensemble-based classifiers was superior to that of statistics and bagging classifiers. It was found that the GB, SGB, and CatBoost classifiers had the highest improvement in results, with an average accuracy range increase of between 33% and 35%. This was established by comparing the new findings to the pure results. However, this is not surprising given the fact that boosting-based classifiers decrease bias by increasing variance. In contrast to boosting classifiers, the logistic regression classifier exhibited a 15% gain in accuracy. This is because logistic regression is a linear model, but metabolic data distribution has nonlinear decision boundaries. Additionally, in order to determine which metaheuristic algorithms provided the best results, the average testing accuracy was computed. Notably, the genetic algorithm and the bat optimizer were superior to other methods, since they had an average testing accuracy of 78.1%. In addition, it was discovered that the classifiers KNNs, DTs, GB, SGB, and CatBoost represented significant results when comparing precision and recall, as is shown in
Table 6 and
Table 7. However, by calculating the average value of precision and recall, it was found that particle swarm optimization, firefly algorithm, and ant colony optimizer had the highest outcome improvement, with an average value of 80% for precision and 79% for recall.
Table 8 shows the findings of employing AUC to evaluate the effectiveness of the classifier. However, it is noteworthy that RFs, GB, SGB, and CatBoost classifiers exhibited the best performance, with an AUC of 96.9% as the highest result.
For the purpose of this study, we made use of the SHAP library to explain the results of machine learning models. On the other hand, the bee swarm plot was used to demonstrate the most discriminative metabolic syndrome indicators in comparison to the prediction models.
Figure 4 shows the most informative features determined by DTs, KNNs, GB, CatBoost, and SGB with the use of the optimizers PSO, FA, and ANT. These classifiers demonstrated the most significant increase in terms of testing accuracy, precision, recall, and area under the curve (AUC). Nonetheless, we found that the comprehensive metabolic panel test, the quantity of MCL white blood cells, the subject’s age, high blood pressure, and breathing rate were the most important metabolic indicators via SHAP.
Furthermore, when comparing the importance ranking of features from one classifier to another, it is worth noting that these rankings may differ depending on the feature selection methods utilized and the process of tweaking their hyperparameters. Nonetheless, in this study, we investigated the application of SMOTE as a data-augmentation strategy that minimizes the sensitivity of classifiers to new data samples. As a result, our goal was to build accurate classification models that are as stable as possible. However, another restriction is that we highlighted other significant variables that might give sufficient and effective metabolic indicators, such as body mass index and waist circumference, that did not exist in the dataset employed.
Figure 5 shows a SHAP analysis of KNNs performance that was accomplished using genetic and bat optimizers. KNNs achieved a score of 94.4% accuracy throughout testing, which was higher than any other classifier. Nevertheless, in order to explain the results of the model, we make use of two different SHAP plots: the global force plot, which shows model outcomes over a variety of data observations, and the local force plot, which illustrates model outcomes across a single data observation. In spite of this, we chose two observations from the data at random, 200 and 700, to investigate which metabolic indicators are the most significant. Subject age of 9, maternal abortion count, per MCL quantity of white blood cells of 3.569, and previous maternal pregnancy record indicators have a positive impact and contribution to the KNNs classifier, according to the SHAP analysis of KNNs, which was based on the SHAP base value of 0.939. On the other hand, the KNNs classifier was used in the bee swarm plot, which presents an illustration of the most important features overall. The variables that were found to have the highest feature values were age, the quantity of white blood cells per MCL, a comprehensive metabolic panel, the number of maternal abortions, and the breathing rate.
To go further for medical considerations, first we filtered metabolic indicators using a straightforward, methodical technique that consisted of two main stages: choosing features using metaheuristics algorithms and then interpreting them using the SHAP tool.
Figure 6 shows the intersection of the most significant common features selected using five metaheuristic algorithms and a set of the most important features rated as having the highest discriminating power using SHAP using a Venn diagram. However, based on common features selected by the suggested approaches, such as age, hypertension, white blood cell count, comprehensive medical tests, and raised respiratory rate, it can be inferred that machine learning models obtain the highest accuracy in prediction and classification. However, medical considerations must be taken into account to explain why these qualities were chosen. Therefore, we aim in this study to take medical considerations into account.
For medical considerations, we discuss the ranking of top-importance features as determined by SHAP values below. It should also be noted that the top five most important metabolic indicators are the patient’s age, comprehensive metabolic panel blood tests, per MCL quantity of white blood cells, breathing rate, and high blood pressure. However, when it comes to patient age, we found that the patient’s risk of developing metabolic syndrome increases with age. Seven years of research published in [
45] found that the likelihood of having metabolic syndrome has increased since the 1990s. People above the age of 50 were more likely to be obese than those younger. It is also worth mentioning that as people become older, some disorders emerge that have a high likelihood of producing metabolic syndromes, such as insulin resistance, the development and advent of heart disease, and vascular diseases. These disorders, which worsen with age, have been linked to the development of metabolic syndrome [
46]. Therefore, it may be argued that age plays a significant influence in predicting whether or not an individual is impacted by metabolic disease. However, when it comes to comprehensive metabolic panel blood testing, we found that it covers glucose, a type of sugar that the body needs for energy, and that a high glucose rate may indicate a risk of developing metabolic disease. It also includes measures for carbon dioxide, potassium, chloride, triglyceride levels, and cholesterol. Comprehensive metabolic blood tests have identified these as the most common metabolic syndrome criteria [
47]. Furthermore, triglyceride and cholesterol levels were defined as features in the utilized dataset. As a result, based on data distribution, they provide a strong indicator of the significance of the whole metabolic blood test characteristic. As a result, it was evaluated as the first and third most important indication according to the majority of classifiers.
Furthermore, we found that due to their influence on the body’s immunity, white blood cells are one of the first lines of defense in the body. As a result, the higher the number of white blood cells, the stronger the body’s resistance to diseases, and vice versa. Nonetheless, the studies in [
48,
49] emphasize a relationship between white blood cells and metabolic syndrome. Additionally, they noticed a correlation between white blood cells and other tests, such as high blood pressure, which was identified as another crucial metabolic indication using machine learning algorithms in this study. Some other measurements related to the number of white blood cells are insulin, triglycerides, and body mass index. Therefore, it can be concluded that people with metabolic syndrome have more white blood cells, in addition to some observations on the high levels of some proteins such as C-reactive [
50]. The metabolic syndrome, on the other hand, is heavily influenced by breathing rate. Increasing the rate of breathing raises the body’s metabolism, which enhances the body’s ability to burn extra fat and vice versa.
For high blood pressure, which is also known as hypertension, it was found by prior studies that there is a strong correlation between blood pressure and metabolic syndrome [
51], particularly in the case of severe hypertension. It is stressed, however, that increasing body mass and weight causes a rise in blood pressure. It is also correlated to other tests such as heart pulse rate, where an overweight person’s heart pulse rate rises to allow blood to circulate to the body, which raises blood pressure. However, it should be noted that some studies found that the relationship between high blood pressure and metabolism is still not fully understood, and therefore they found that the body’s insulin resistance and visceral obesity scale are classified as risks leading to high blood pressure in metabolic syndrome [
52]. As a result, machine learning algorithms recognized high blood pressure as one of the most significant metabolic indicators, owing to its strong association with other data such as pulse rate.
To summarize and highlight the proposed methodology’s state of the art in comparison to prior methods, the goal of this work is to highlight the highest indices of discriminative metabolism by interpreting machine learning models using the SHAP approach. Other research revealed significant metabolite indicators that must be considered when developing effective prediction models using feature selection approaches. However, this is not enough to explain all predicted values generated using machine learning models. Therefore, by obtaining the average predictive values for the collection of predicted indicators and evaluating the performance of classifiers at certain samples, we may achieve a reasonable degree of interpretation to understand the reasons behind machine learning models’ preference for some features over others. Furthermore, earlier research has concentrated on the application of a variety of specialized types of machine learning models. However, in this study, we investigated and compared the application of ten machine learning classifiers from all classes, including statistical, bagging, and boosting, to build and find the most accurate models for data classification.
Moreover, when compared to prior studies, we applied data augmentation approaches such as SMOTE to lower the degree of sensitivity of machine learning models to future data. Additionally, it has the advantage of not copying data records when compared to other data resampling methods; instead, it generates synthetic data samples, in addition to the examination of the use of natural-derived algorithms such as metaheuristics, which is regarded as one of the contemporary ways of selecting attributes when compared to other methods such as filter and wrappers techniques. However, we noted that the majority of prior research concentrated on the usage of certain data quality in a given region and culture. As a result, the goal of this study was to employ a dataset that focuses on metabolism at the public level without regard to culture or geography.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}